
Abstract
In modern complicated and changing manufacturing environments, unforeseen dynamic events such as machine breakdown or unexpected job arrival make required production resources unpredictable. The scheduling scheme is desired to maintain high stability in dynamic manufacturing environments. To cope with the classic disturbance of machine breakdown, a robust pro-active scheduling scheme is proposed by inserting the repair time into a disjunctive graph for reinforcement learning (IRDRL) in this paper. Firstly, a new mathematical model is developed to predict the machine fault which is assumed to be determined by service time and bearing load. Secondly, a disjunctive graph with breakdown information is designed to express the dynamic scheduling status. Then, an online scheduling framework is built based on the well-trained model through the proximal policy optimization (PPO) algorithm. Finally, compared with the classical methods such as the right-shift strategy and static model of reinforcement learning (RL), the proposed robust pro-active scheduling scheme is verified with high robustness, stability, and short running time.
Keywords
Introduction
In the modern complex and variable manufacturing industry, scheduling plays an essential role in improving efficiency and competitiveness. The job shop scheduling problem (JSSP) has been extensively studied in academia and industry.1–4 Traditionally, it is assumed that all resources in production are deterministic in JSSP. However, various random disturbances will inevitably occur in actual manufacturing,5,6 resulting in reduced productivity and delayed deliveries, etc.
Therefore, as one of the most extensively studied scheduling schemes for dynamical job shop scheduling problems (DJSP),7–9 the robust pro-active scheduling has been researched by many scholars to minimize the impact of disturbances on scheduling scheme stability, which is designed to consider disturbances in advance, and absorb the influence of disturbances during the execution of the scheduling.10,11 To the best knowledge of the authors, most researchers used meta-heuristic algorithms and heuristic rules to solve robust pro-active scheduling schemes. The hybrid local-search algorithm, which is combined with the tabu technique and the simulated-annealing 12 or the genetic algorithm, 13 has been used to address the robust pro-active scheduling in uncertain processing times scenarios. In Xiong et al., 14 the robust scheduling for dual objective optimization with random machine breakdown was tackled by knowledge-based heuristic searching architecture. 14 The genetic algorithm was used to minimize the dispatching risk. 15 With unstable resource availability and time-varying, the variable neighborhood-search-based local-search heuristic was proposed to identify the priority rule for dynamical scheduling. 16
However, on the one hand, relying too much on the problem, the meta-heuristic algorithms or heuristic rules are only effective in specific cases,17–19 and cannot adjust adaptively when there is a deviation between disturbance prediction and reality. In addition, even minor changes require a recalculation since the schemes have weak generalization ability. On the other hand, the single-objective scheduling is usually insufficient for real-world manufacturing that often requires the simultaneous performance of dual or more objectives, which has been studied in academia.20–22
Given the above issues, a robust pro-active for dual-objective scheduling scheme is proposed, where the repair time for unexpected machine breakdown is inserted into a disjunctive graph for reinforcement learning (IRDRL) to enhance the generalization adaptability of the scheduling scheme. The primary work of this paper is as follows. (1) A new practical mathematical model for dual-objective is established, considering the reality of machine wear and breakdown. (2) An adaptive robust pro-active scheduling is proposed by inserting the repair time into a disjunctive graph for reinforcement learning. (3) An online scheduling framework is developed to form the mapping relationship between the manufacturing environment and the optimal scheduling model. (4) Comparisons between IRDRL and other methods are carried out to prove the effectiveness and improvement of the proposed approach.
The remainder of this paper is arranged as follows. A brief review of dynamical scheduling based on RL and mathematical models is given in Section “Literature review.” Section “Problem description and modeling” presents the updated mathematical model of dynamical scheduling with machine breakdown. Section “The online scheduling framework and IRDRL approach for DJSP with machine breakdown” offers the online scheduling framework and the design details of the proposed IRDRL approach. Section “Experiments analysis” shows the results of numerical experiments, which can prove the effectiveness and advancement of the proposed IRDRL approach. Finally, the conclusions and suggested future work are drawn in last section.
Literature review
RL-based dynamical scheduling
In the actual manufacturing process, random job arrivals, machine breakdown, and variable processing time are typical disturbances. Many researchers have applied RL algorithms, such as Q-learning, deep-Q-network (DQN), proximal policy optimization (PPO), and other variants, to the DJSP considering various disturbances. These researches clarified new directions for efficient decision-making under uncertain resource environments, as summarized in Table 1. The general principle of RL-based scheduling is to transform the manufacturing environment into Markov Decision Processes (MDP), 23 extracting the three key elements: state, action, and reward. To present the state of the manufacturing environment, most of the artificial design feature indexes are adopted,24–31 which rely heavily on prior expert knowledge and experience. The state of the manufacturing environment can be inaccurately and incompletely expressed due to artificial factors. Action space is mainly designed as priority rules32,33 or parameter optimization, 34 which don’t meet the desired execution efficiency in action exploration. In addition, some work even generalizes the model developed in the static environment to an uncertain resource environment, 35 lacking the learning process in the dynamic environment.
DJSP with various disturbances based on RL.
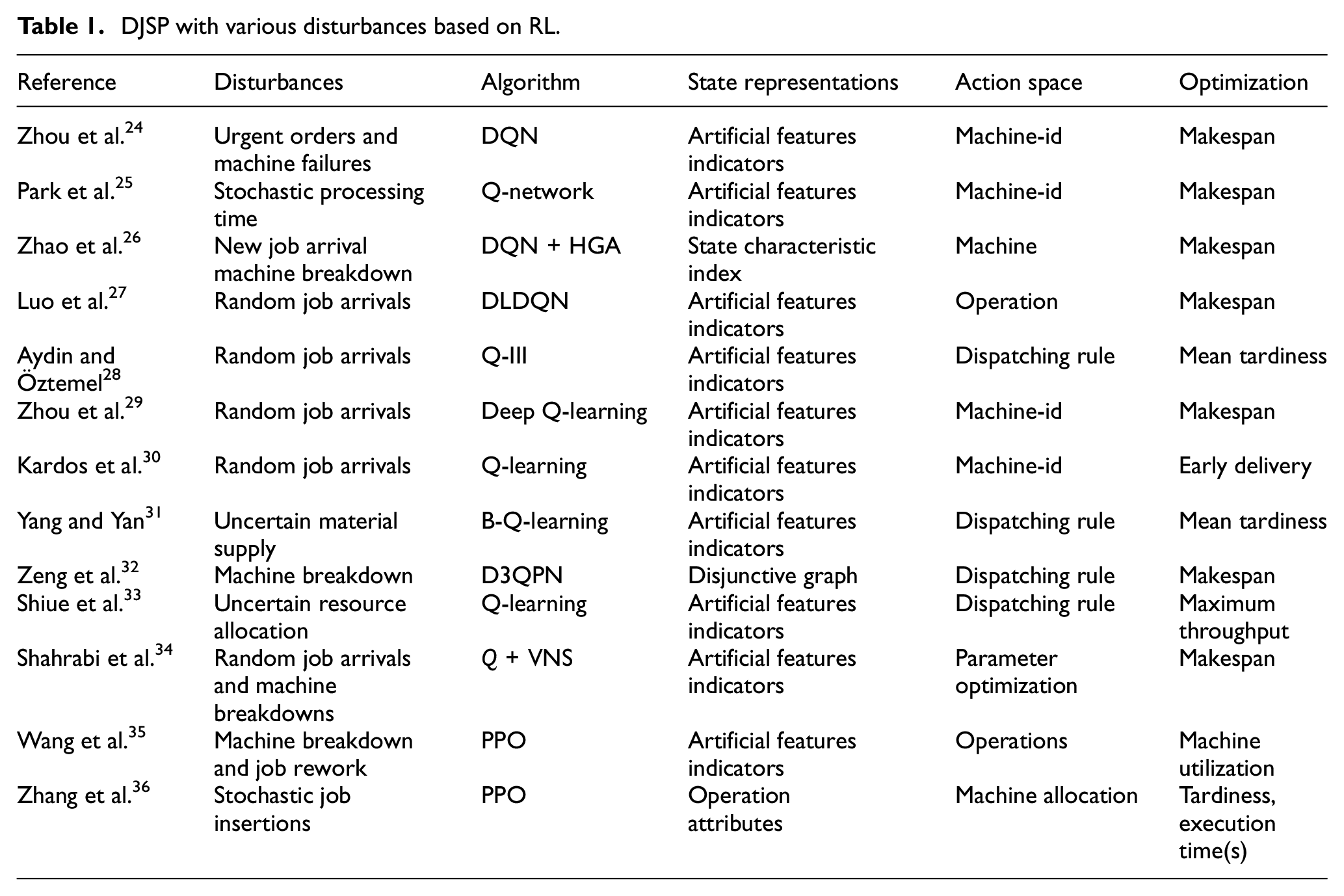
Through the above literature research, it is easy to be inspired on how to solve the dynamical scheduling using RL. However, there are two remaining issues: (1) how to represent the job shop state comprehensively and extract dynamic disturbance features objectively; (2) how to design the action space to improve the action execution. Considering these two issues, a robust pro-active scheduling scheme based on RL with an objective expression of dynamic disturbance is proposed in this paper.
Commonly adopted mathematical model of machine breakdown
As one of the most classic disturbances, machine breakdown has attracted significant attention.37–39 The machine failure probability and repair time are assumed to be same for all machines40,41 in the common modeling of machine breakdown; alternatively, the machine breaks down in order of its load. 42 In fact, the machine failure is related to the machine service, load. etc., and thus it varies from machine to machine. Moreover, it is not necessarily that the machine breaks down only under enormous load, and a minor load can also lead to failure. Considering the above issues, a new practical mathematical model is established in this paper.
Problem description and modeling
Deterministic scheduling
The JSSP has been regarded as a sequential decision-making problem with limited resources. To improve production efficiency, makespan
Notations in the problem description.
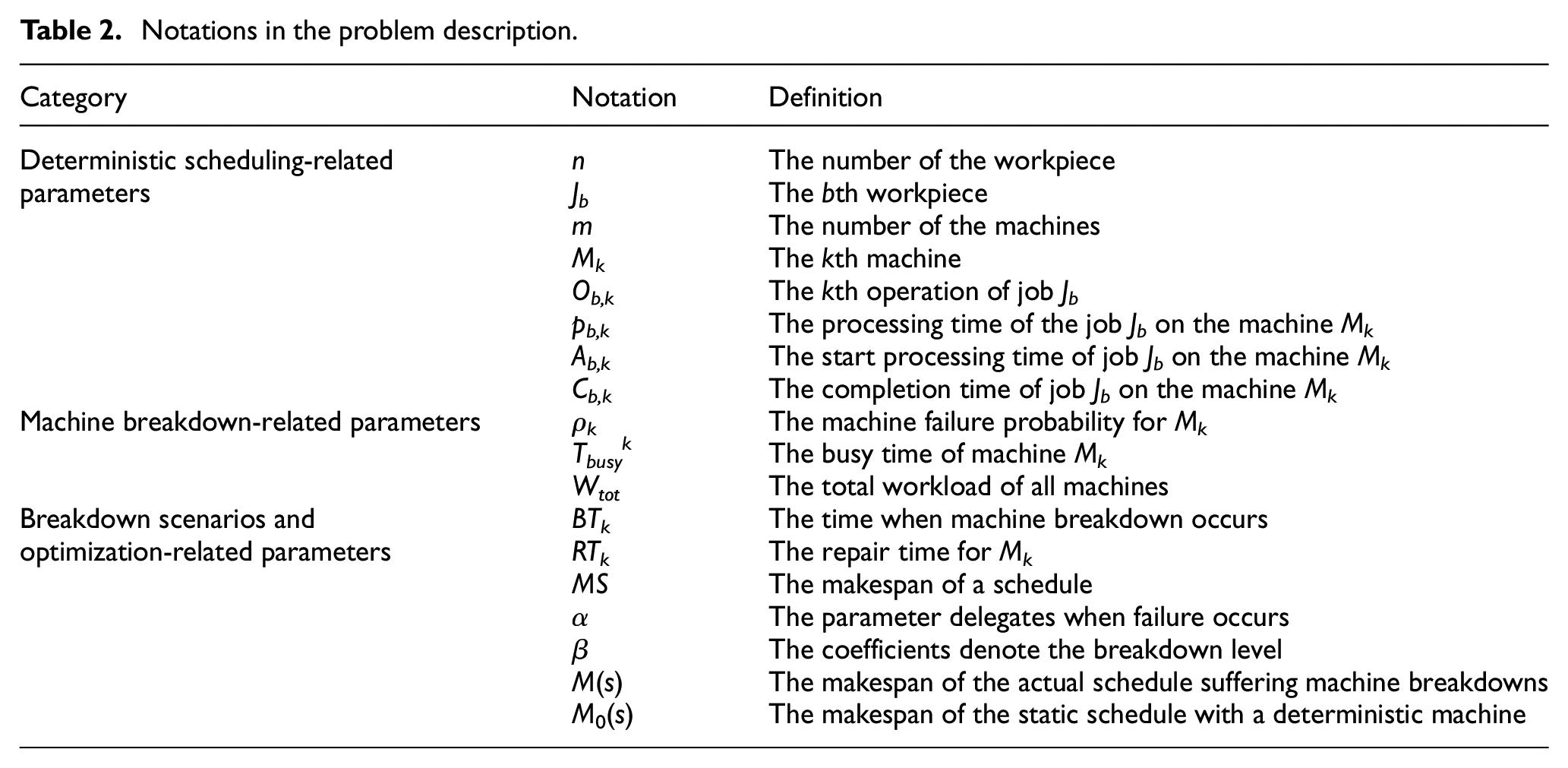
To facilitate the modeling, some assumptions are made as follows: (1) the sequential relationship and processing time of different operations in the same workpiece are known in advance, (2) each machine can process at most one operation at a time, (3) each operation can only be processed on one machine at a time, (4) any operation should be processed continuously without interruption until completion, (5) there is no sequential constraint between processes of different workpieces.
Formulation for machine breakdown
Given that machine failure is related to its load and service time, the new mathematics model is proposed as follows:



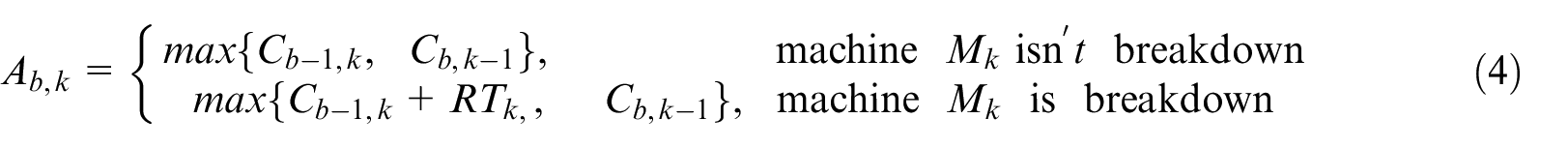
Change in
For a more accurate description of machine disturbances scenarios, the time when machine breakdown occurs and the repair time of the failed machines are defined as the uniform distribution in equations (5) and (6). The problem can be divided into four scenarios as presented in Table 3 as in literature. 43


Machine breakdown scenarios.

Dual-objective optimization for DJSP
The dual-objective optimization problem, including the quality and robustness of the scheduling scheme, is considered synthetically in this paper.
Makespan
As one of the most critical scheduling quality objectives, makespan will be inevitably affected by machine breakdown. It indicates the earliest completion time for all the operations, as shown in equation (7).

Robustness measure
The robustness of the scheduling scheme is defined as the relative stability between the static makespan and the actual makespan under machine breakdowns. The formula is shown in equation (8), suggesting that the higher the value, the stronger robustness.

The online scheduling framework and IRDRL approach for DJSP with machine breakdown
This section proposes an online scheduling framework to avoid time-wasting of recalculation and designs the IRDRL approach of robust pro-active scheduling. As shown in Figure 2, the framework includes four blocks: Env-Block, Training-Block, Model-Block, and Implementation-Block. The operational process is as follows: Env-Block collects production data through the sensor in the job shop, and extracts the current state as the input of Training-Block. Training-Block trains the scheduling model offline by the PPO algorithm. The trained models are verified and saved in the Model-Block. In the Implementation-Block, the suitable model can be invoked in real-time corresponding to the production state. The details of the scheduling framework, including IRDRL approach and scheduling model invocation, are presented as follows.
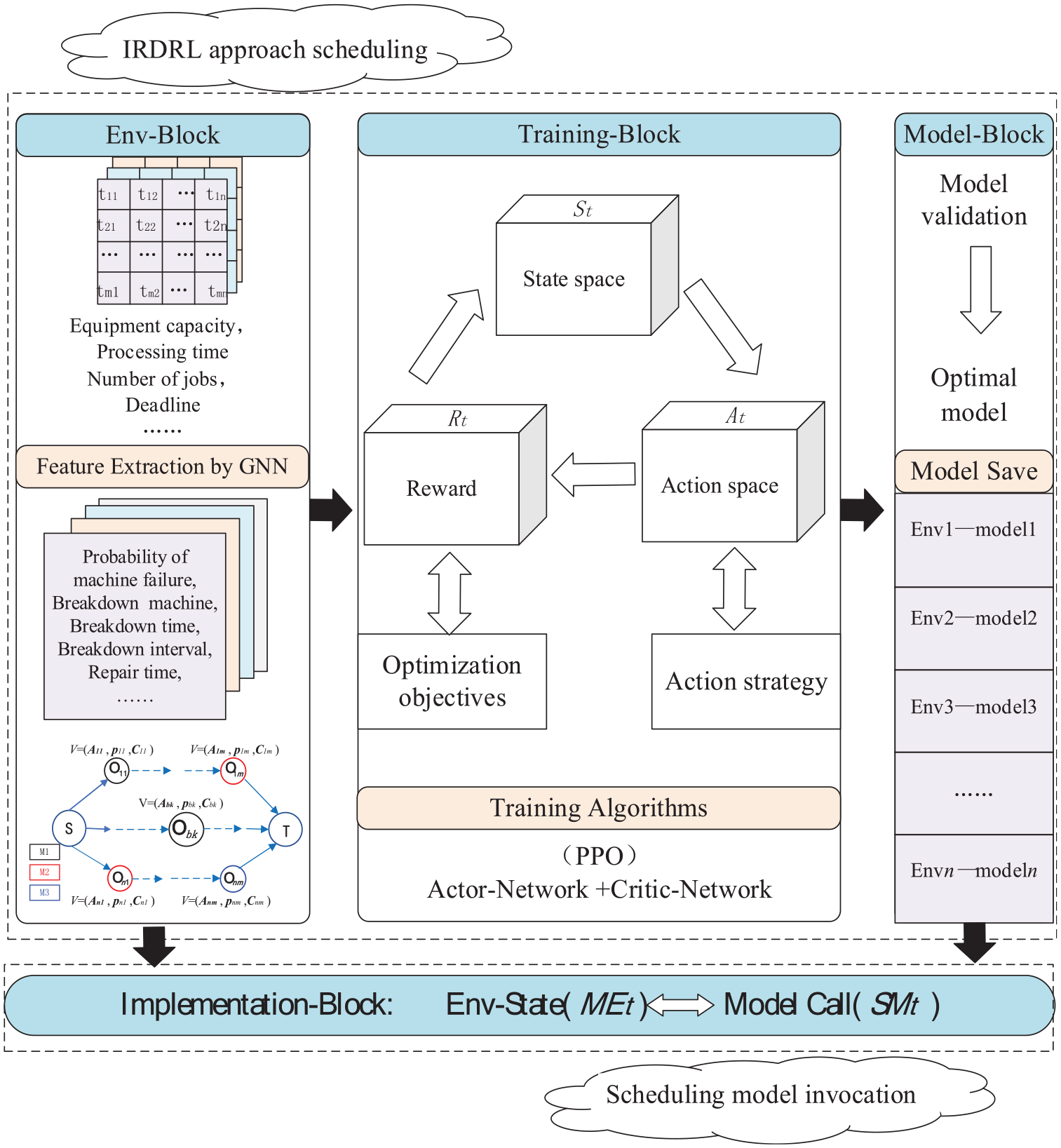
Online scheduling framework for the dynamic environment.
The IRDRL approach scheduling for DJSP with machine breakdown
This part mainly introduces the design detail of the IRDRL approach In the Env-Block, a method for status perception and feature extraction with machine breakdown is developed based on graph neural networks (GNN). In the Training-Block, the production process is translated into MDP, and the PPO algorithm is introduced for training the networks. Finally, the well-trained models are validated and saved in the Model-Block.
Perception and feature extraction for machine breakdown in the Env-Block
The production data is collected by the sensor equipment and transmitted into Env-Block to prepare for expressing the dynamical disturbance features of job shop. Different from the artificial feature index designing, the GNN is designed to optimize the transformation of the attributes in the disjunctive graph to extract dynamical disturbance features comprehensively and objectively.
Disjunctive graph for workshop scheduling
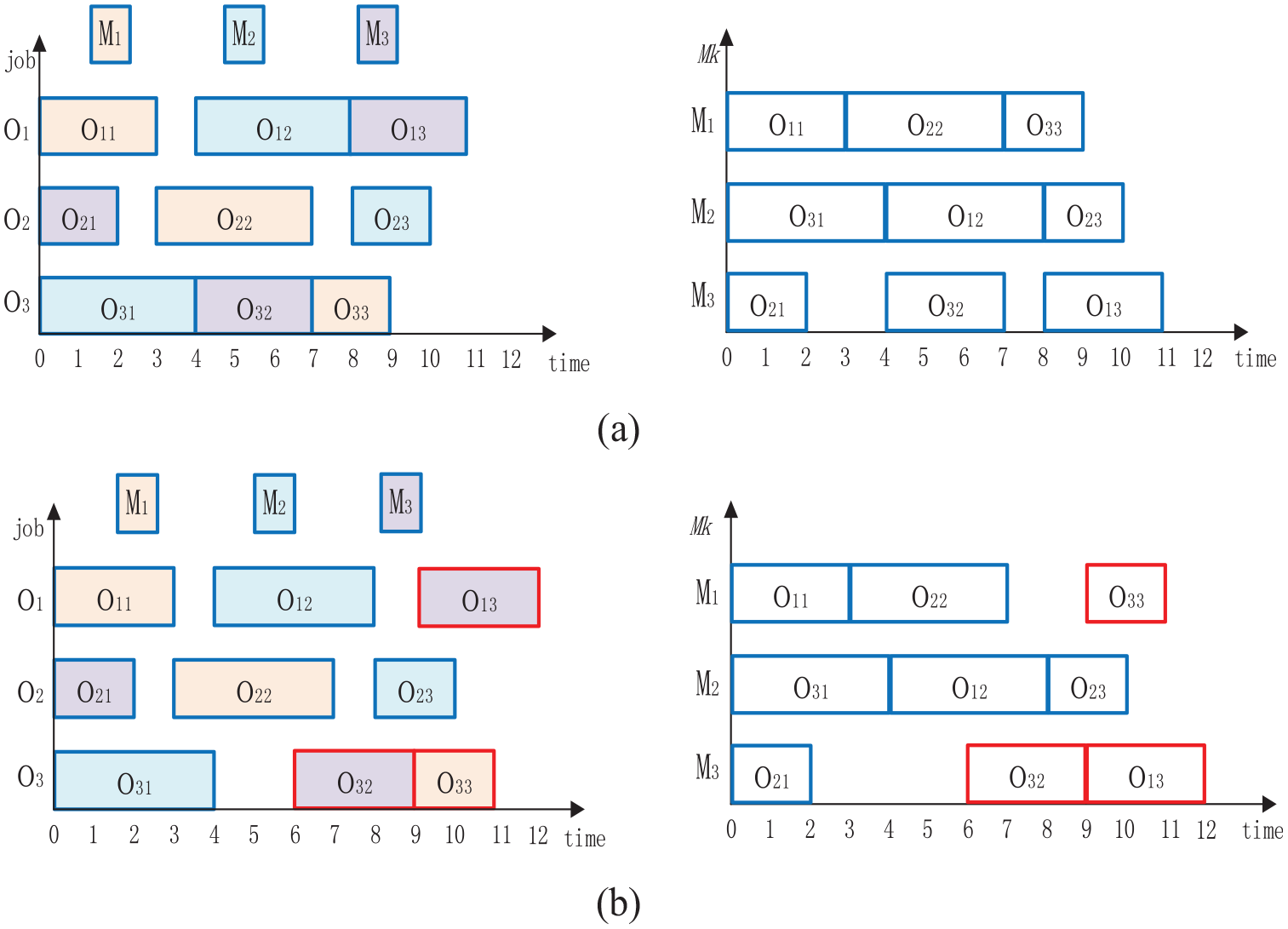
Production scheduling could be represented as a disjunctive graph. The longest distance from the starting node to the end node in the disjunctive graph is the makespan, which is determined by the direction of the disjunction arcs. As shown in Figure 3, the longest distance of strategy A is shorter than B, which means strategy A is superior to B.
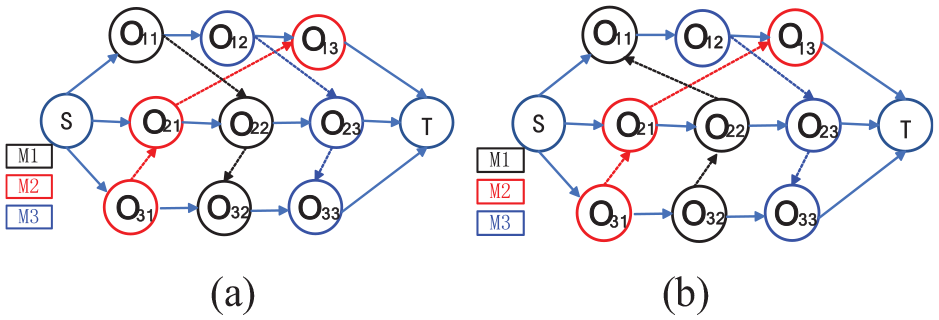
Disjunctive graph for different scheduling strategies: (a) strategy A and (b) strategy B.
Disjunctive graph representation for machine breakdown
The disjunctive graph can express the production scheduling process comprehensively by embedding resource information into nodes.
As described in Section “Formulation for machine breakdown,” machine breakdown affects the completion time
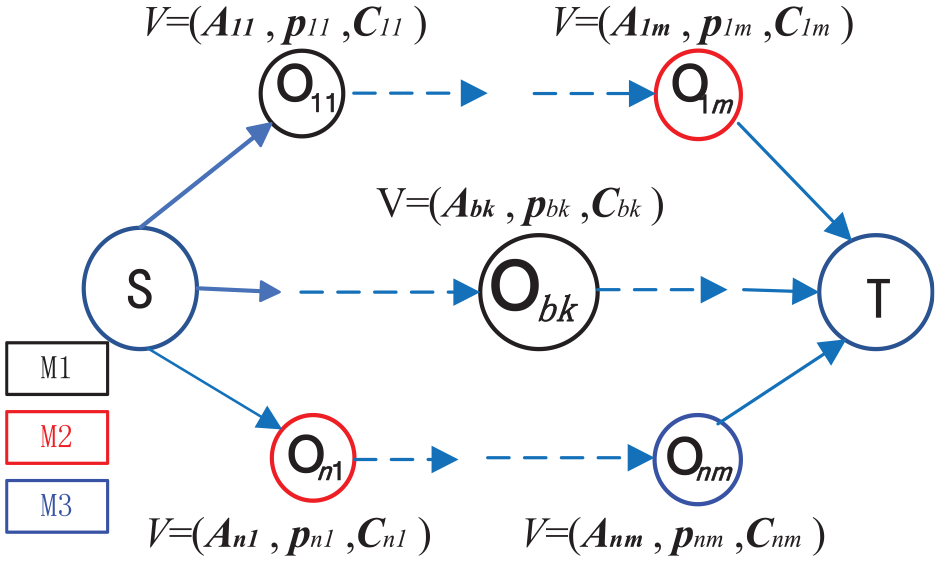
Representation of machine breakdown.
Feature extraction of the disjunctive graph by GNN
Neighborhood aggregation of the disjunctive graph is defined by equation (9), whose purpose is an aggregate representation of neighborhood node information. 44
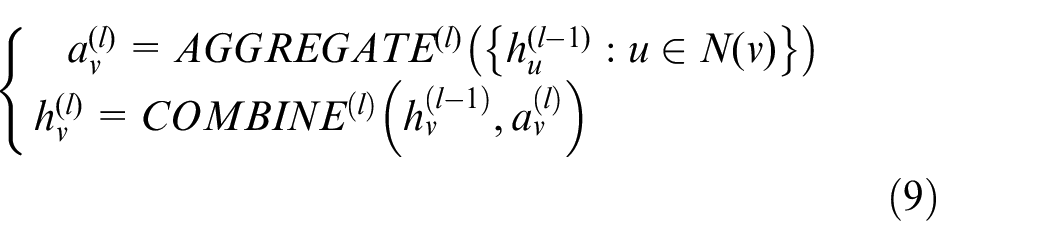
Where,
Combined with the multi-layer perceptron, the iterative update formula for the nodes in the disjunctive graph can be defined as equation (10) as follows 44 :
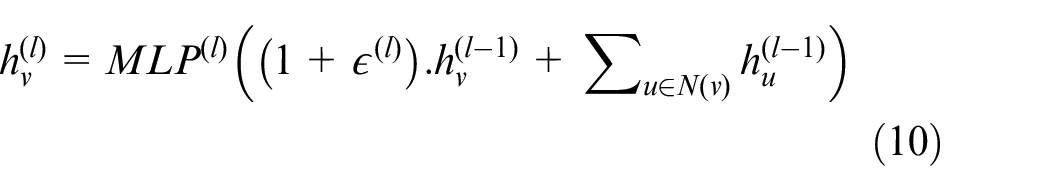
Where,
Whole-map feature extraction of the disjunctive graph, which represents the current status of the manufacturing environment, is read out by the following formula as equation (11).
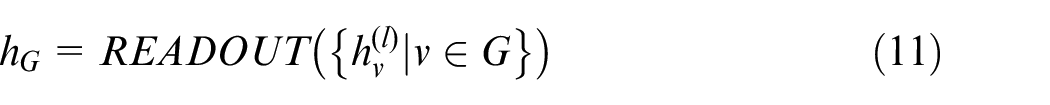
Where,
Markov process modeling and PPO algorithm for training in Training-Block
The agent continuously interacts with the environment to acquire a maximum cumulative reward in the process of RL. Through trial-error and experience accumulation, the reward can guide the agent to explore the best action strategy, as shown in Figure 5. The MDP model has several key elements as follows:
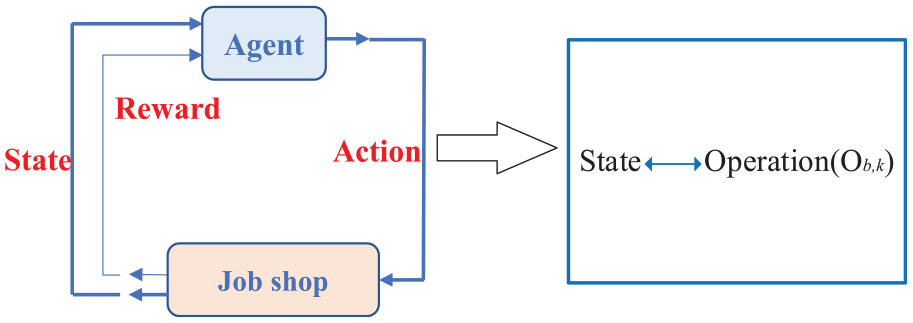
Interaction between the agent and the job shop.
State of the dynamical job shop
In Section “Perception and feature extraction for machine breakdown in the Env-Block,” the scheduling is expressed by a disjunctive graph, and the scheduling resource information is embedded into the feature vector of the node. Each node includes: (1) the processing time
Action space modeling
As the bridge of interaction between the agent and environment, the action is taken by the agent under the current status. In this paper, the operations of the workpieces are designed as a more direct and effective action space. However, it will lead the action space to increase sharply with the rise of scheduling size, resulting in a significant burden of exploration.
To solve this problem, the mark of the completed operation is added to the feature vector. The action space is reduced to the scope of the next operation, which is equal to the number of unfinished jobs currently, as
Reward designing
The instant reward is the feedback that the environment gives to the agent for its action choice. The reward guides the agent toward the direction of the optimal strategy, and the greater the cumulative reward, the more correct the exploration. In this paper, the reward function is defined as equation (12), where

Where,
PPO algorithm for training the network
The PPO is a DRL algorithm based on the actor-critic framework, where the actor network is used for action selection, and the critic network is used to evaluate the decisions made by the actor. The interaction between the actor and critic network can guide the agent to explore in a more promising direction. Therefore, this algorithm is more hopeful to find the optimal JSSP scheme in a large number of shop scheduling solution spaces. To keep network updates stable, it is necessary to limit the scale of each update, as the clip operation adopted by PPO2. As shown in equations (13) and (14), the updated scale is restricted to
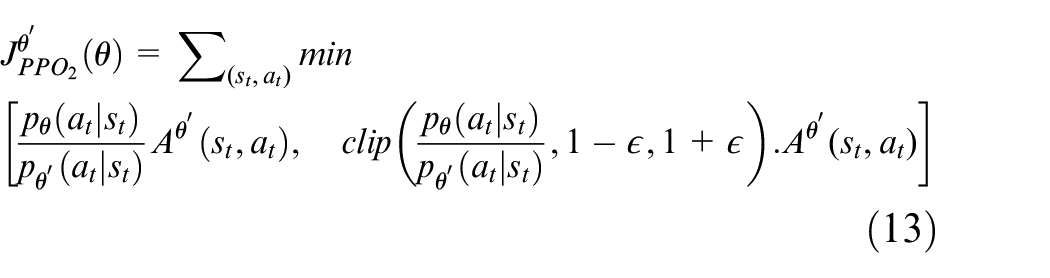
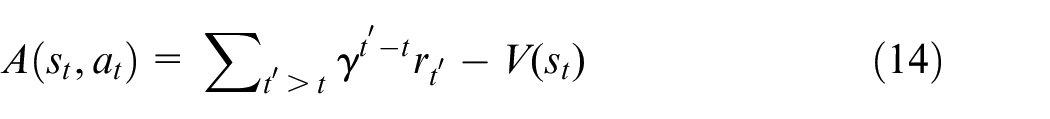
The networks perform excellent convergence performance through training, and represent the mapping relationship between the state (

Model validation and preservation in the Model-Block
The role of the Model-Block is to validate the trained model and save the model with the best performance, constructing a matching relationship between the scheduling environment and the scheduling model.
Scheduling model invocation
The second part of the online framework focuses on the Implementation-Block; the matched model can be invoked and implemented instantly to avoid prolonged downtime waits. A mapping between the manufacturing environment (

The online scheduling framework provides a basis for real-time scheduling for complex and changing manufacturing scenarios.
Experiments analysis
The proposed IRDRL approach is validated with various conditions and parameters. This section successively provides: the parameter settings, the benchmark problem, and the experimental comparison between the proposed method and others.
Parameters setting
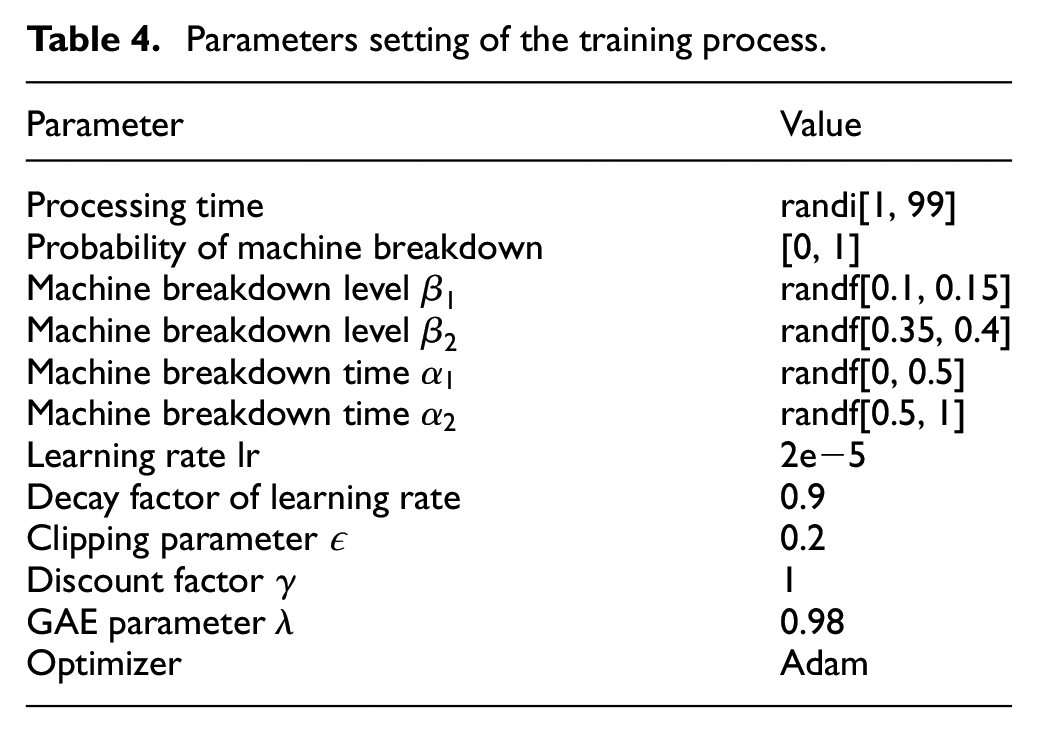
The training process follows the IRDRL approach described in Section “The online scheduling framework and IRDRL approach for DJSP with machine breakdown,” and the processing time of operations in various scales is randomly generated in the range of 1–99. Experimentally, the convergence is achieved when the number of training trajectories is 10,000. The proposed IRDRL approach is coded and implemented in python 3.6 on a PC with Intel Core i7-6700 @ 4.0 GHz CPU, GEFORCE RTX 2080Ti GPU, and 8 GB RAM. All the parameters of the training process are shown in Table 4, which are elaborately set by preliminary experiments. The notations “randi” and “randf” denote the uniform distribution of integers and real numbers, respectively.
Parameters setting of the training process.
Benchmark problem
There is no standard benchmark problem for training and testing with machine breakdown. The training data is generated randomly, and endowed with dynamic properties by introducing random disturbance. The testing data is divided into two classes. One is randomly generated from the literature
46
as Ex1 consisting of 6 * 6, Ex2 consisting of 10 * 10, Ex3 consisting of 15 * 15, Ex4 consisting of 20 * 20, and Ex5 consisting of 30 * 20. The other is based on the standard benchmark problem, such as ABZ,
47
FT,
48
TA,
49
YN,
50
DMU,
51
and LA.
52
To simulate a dynamic environment with machine breakdown, a series of random factors are embedded into the standard benchmark, including the probability of breakdown
Comparisons experiments
Comparisons with right-shift strategy
Random machine breakdown is inevitable in the actual manufacturing environment. The right-shift strategy has been proposed to deal with machine fault disturbance in job shop scheduling. 53 When the machine fault occurs, the interrupted work presses the pause button and restarts until the faulty machine is repaired and the machine is recovered. The interrupted operation and all other remaining operations are right-shifted by the amount of the repair time.
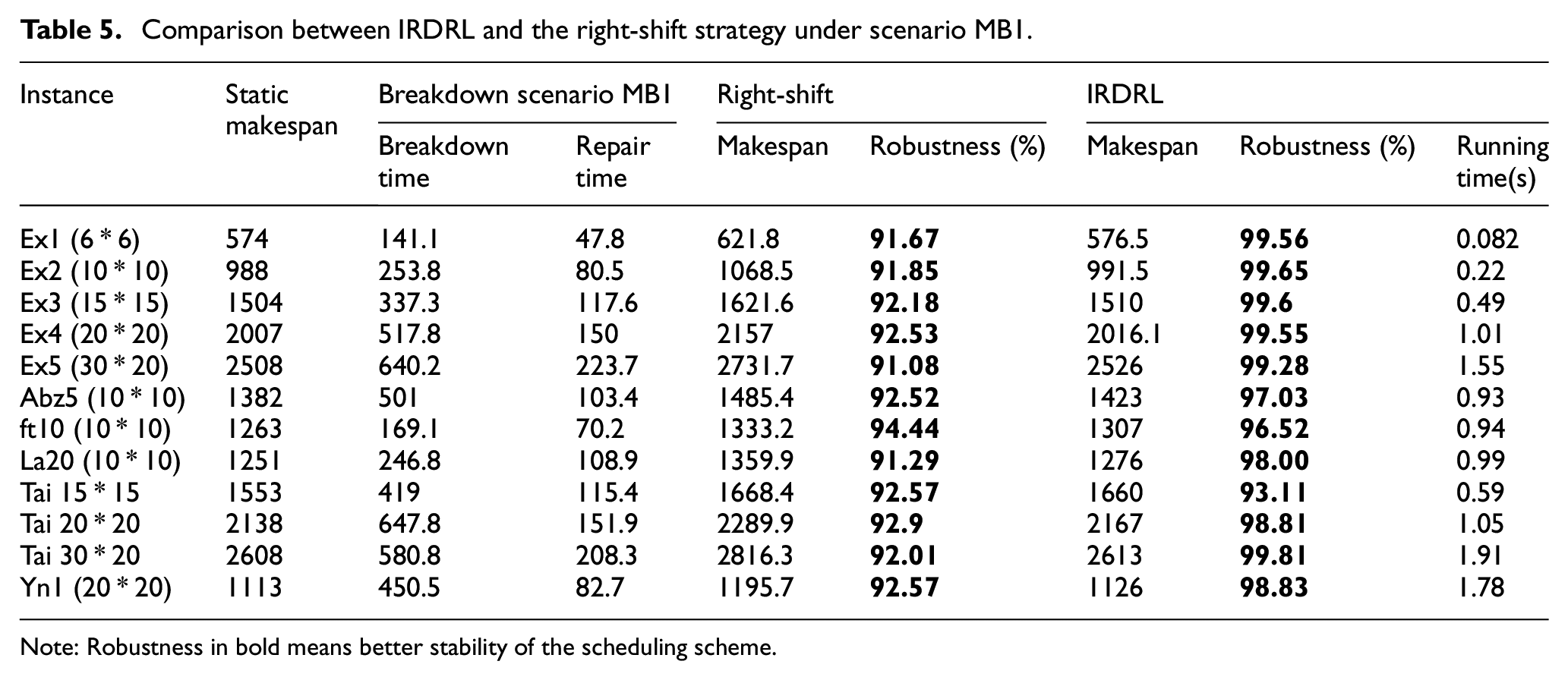
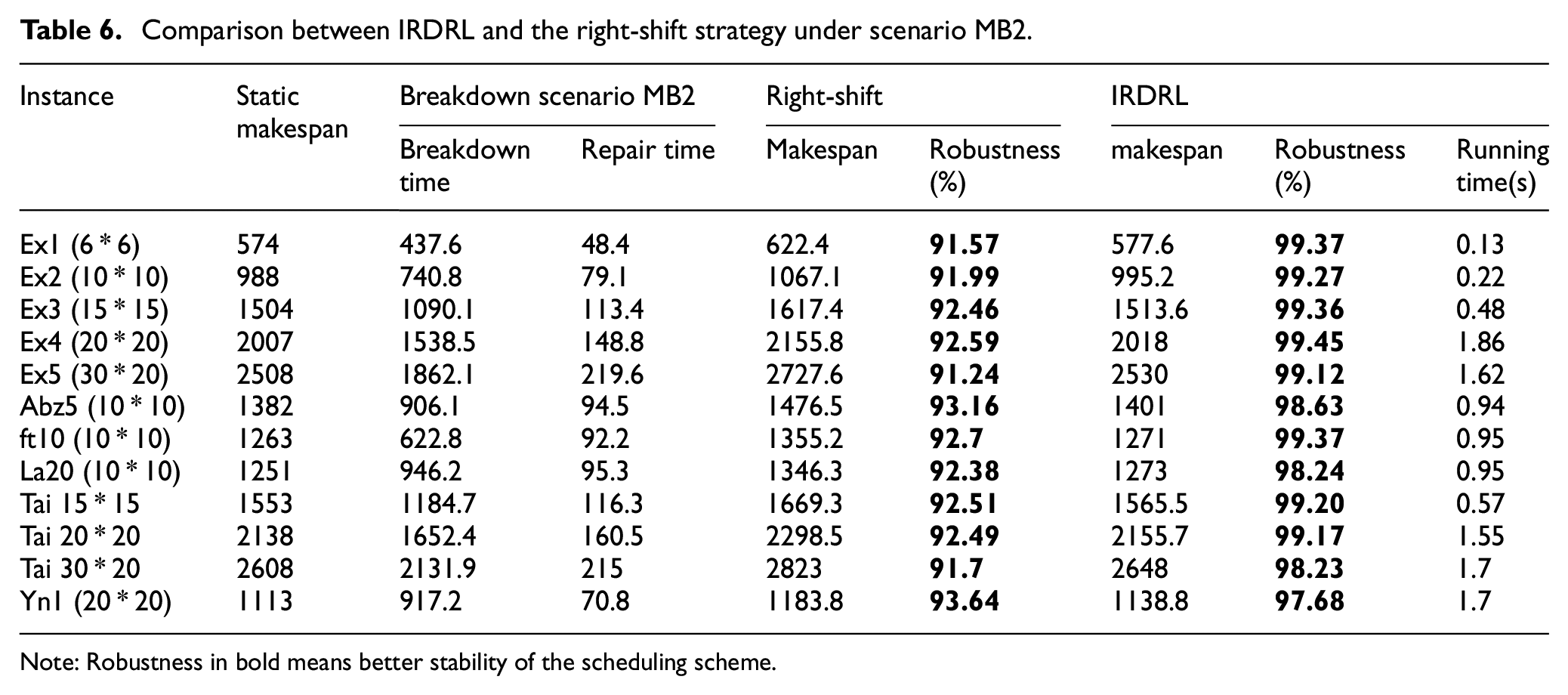
Under all four machine breakdown scenarios, the proposed IRDRL scheduling is compared with the right-shift strategy in terms of makespan and robustness. As shown in Tables 5 to 8, the static makespan can be obtained under the deterministic environment without machine breakdown. When the manufacturing environment is disturbed, the makespan will be extended, disrupting the production schedule. Makespan is expected to remain as stable as possible to ensure the robustness of the scheduling strategy.
Comparison between IRDRL and the right-shift strategy under scenario MB1.
Note: Robustness in bold means better stability of the scheduling scheme.
Comparison between IRDRL and the right-shift strategy under scenario MB2.
Note: Robustness in bold means better stability of the scheduling scheme.
Comparison between IRDRL and the right-shift strategy under scenario MB3.
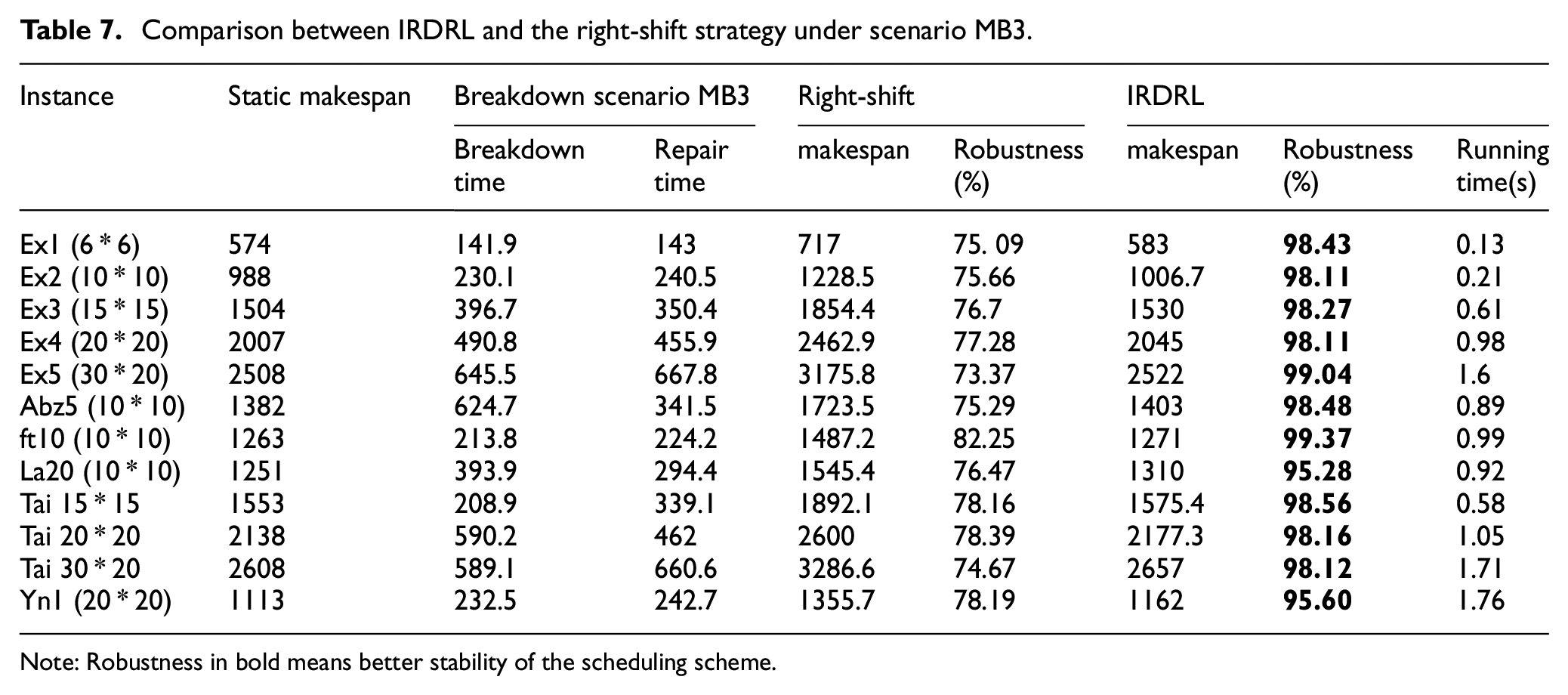
Note: Robustness in bold means better stability of the scheduling scheme.
Comparison between IRDRL and the right-shift strategy under scenario MB4.
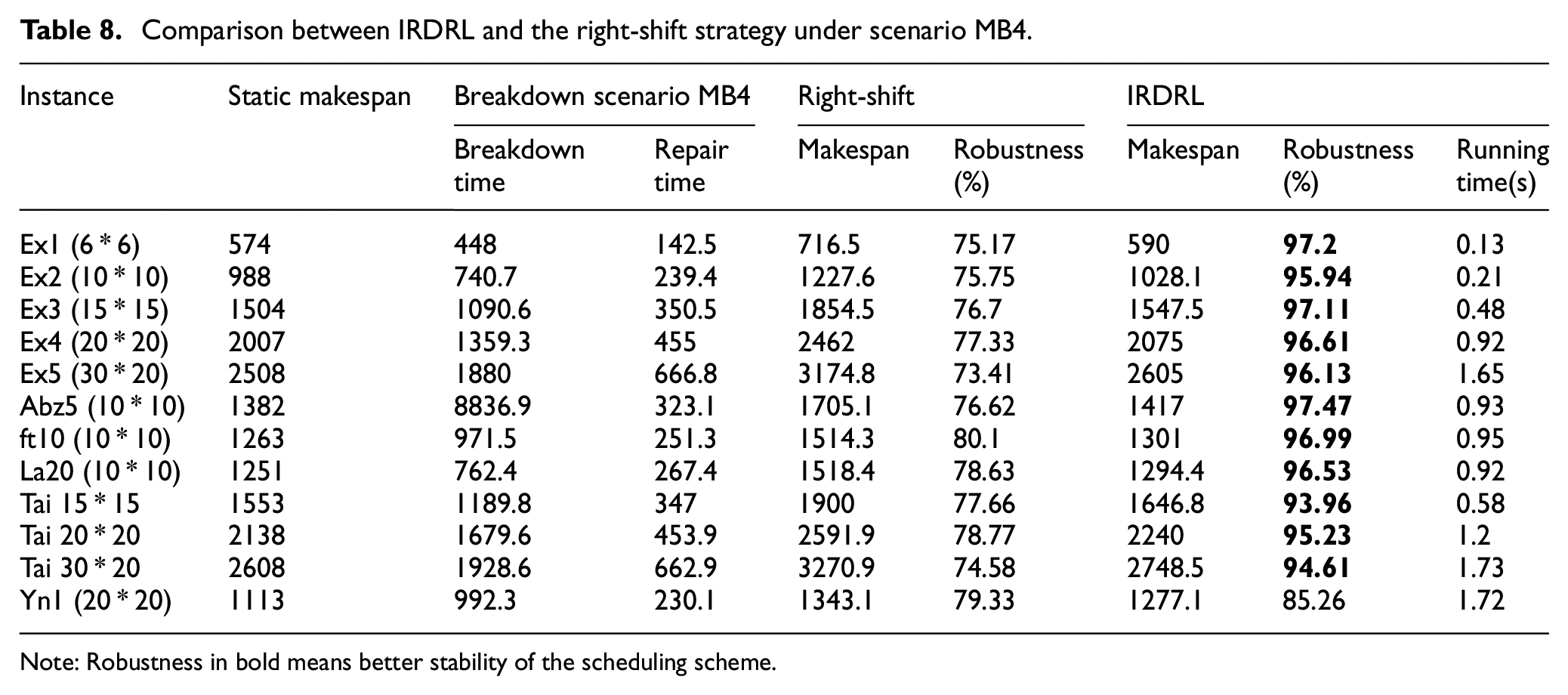
Note: Robustness in bold means better stability of the scheduling scheme.
The experiments in the above Tables 5 and 6 are carried out under scenarios MB1 and MB2. The manufacturing environment for both scenarios is characterized by machine breakdown with minor fault levels in the early or later stage. Machine breakdowns are minor, and repairs can be completed very quickly. The indicators of robustness in bold are overwhelmingly above 90%, indicating the limited impact on the scheduling strategy by the minor machine faults. In Tables 7 and 8, the experiments are carried out under scenarios MB3 and MB4 with high fault levels. The repair time is longer, and the most robustness indicators of the right-shift strategy are 70%–80%, indicating that the disturbance has a significant impact on scheduling. Experiments show that the running time of IRDRL is short enough to ensure the feasibility of real-time scheduling.
From all tables above, the makespan of the right-shift strategy is always longer, and the robustness is always smaller than the IRDRL method, which indicates that the IRDRL scheduling performs better, especially in responding to disturbances with high fault levels. The reason is that the IRDRL agent observes and evaluates the affected and unaffected operations through the disjunctive graph, and adjusts the scheduling scheme dynamically to avoid wasting time during the whole shutdown.
Comparisons with static-model of RL
To further confirm the advantage of the IRDRL scheduling, this part provides a comparison with the previous RL method. The method proposed in reference 35 is to generalize the model produced in the static environment to the dynamic environment. In this paper, the proposed IRDRL approach puts the agent into a dynamic backdrop to learn and accumulate experience. The comparison between the previous static-model and the proposed IRDRL model in terms of makespan and robustness is shown in Figure 6.
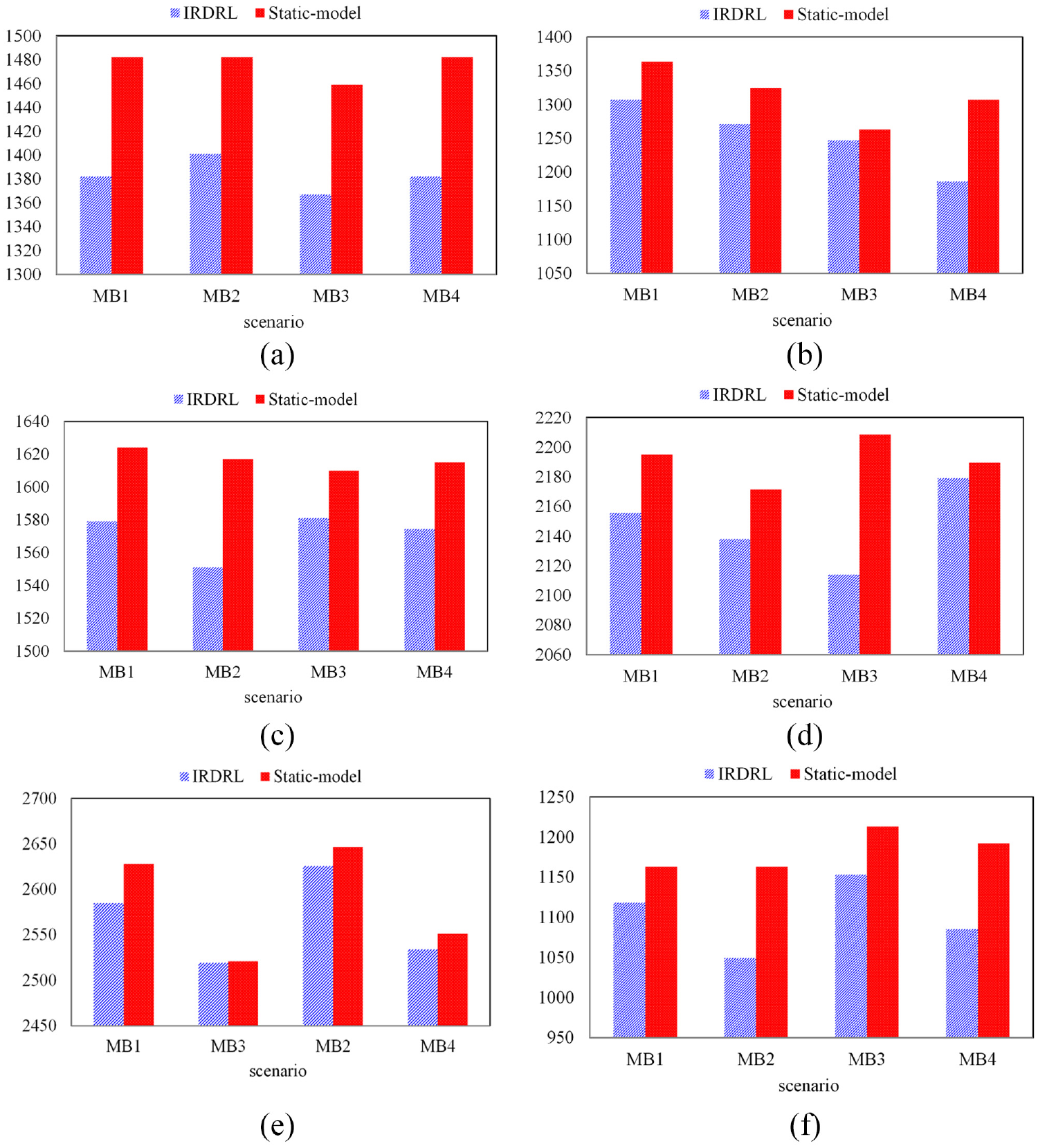
Comparison between the IRDRL model and static-model: (a) Abz5 (6 * 6), (b) ft10 (10 * 10), (c) Tai 15*15, (d) Tai 20 * 20, (e) Tai 30 * 20, and (f) yn1 (20 * 20).
As can be seen, the selected instances cover both large and small scales. The columns of these instances with the static-model are almost always higher than the IRDRL model, which indicates that the static-model has some generalization, but can’t gain the makespan as good as the IRDRL model, verifying the effectiveness and superiority of IRDRL comprehensively.
Generalization of IRDRL approach compared with heuristic
Heuristic methods need recalculation whenever the problem changes, even slightly, which is time-consuming and impractical. Therefore, the purpose of the experiment is to prove the adaption of the IRDRL model.
Generalization of IRDRL model in scheduling scale
In actual manufacturing, the scheduling scale, that is, the number of the workpieces varies from batch to batch. It is expected that a well-trained model can have excellent scheduling performance for a similar scale, especially for large-scale scheduling problems. Therefore, this experiment takes the 30 * 20 model under scenario MB1 as an example, verifying the generalization ability of the 30 * 20 model to other large-scale cases, which are selected from standard benchmark Tai and DMU. The results are shown in Figure 7 and Table 9.
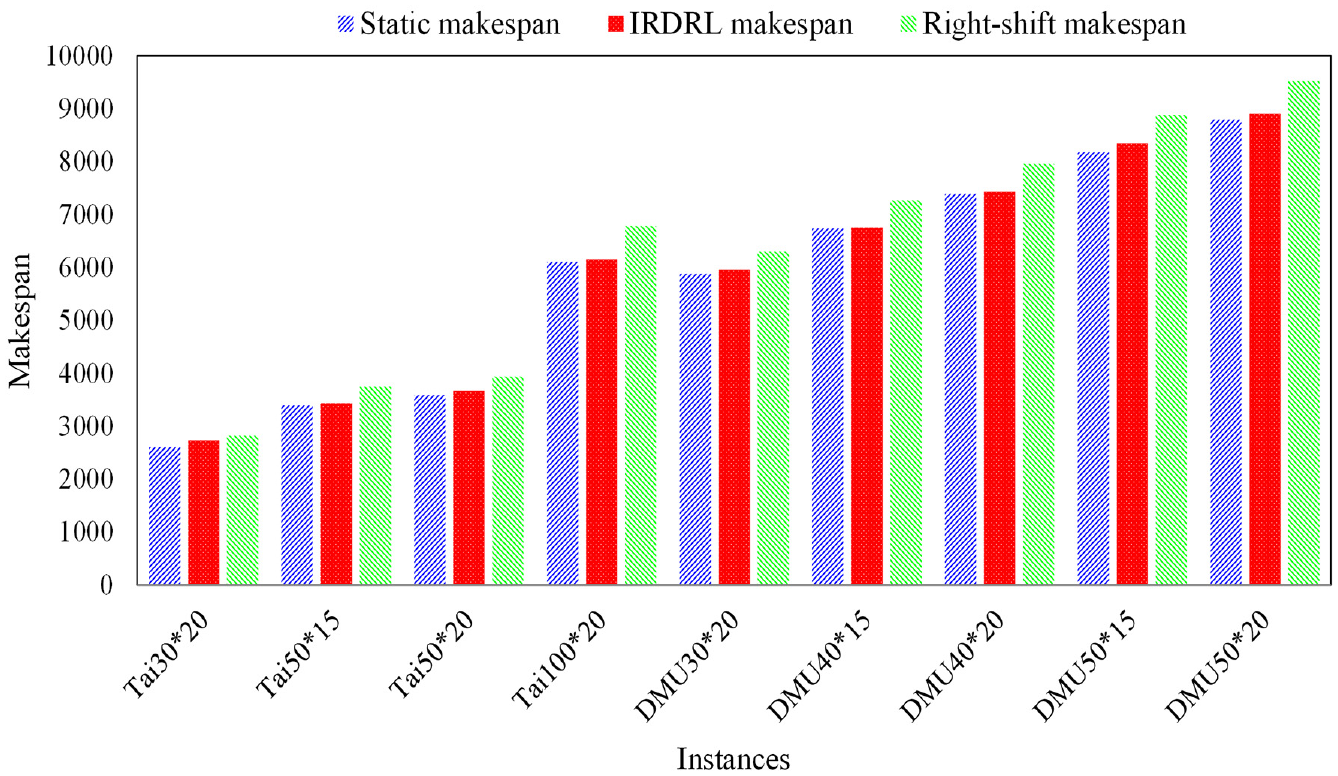
Generalization of the 30 * 20 model in the scheduling scale.
Generalization of the 30 * 20 model in scheduling scale under scenario MB1.
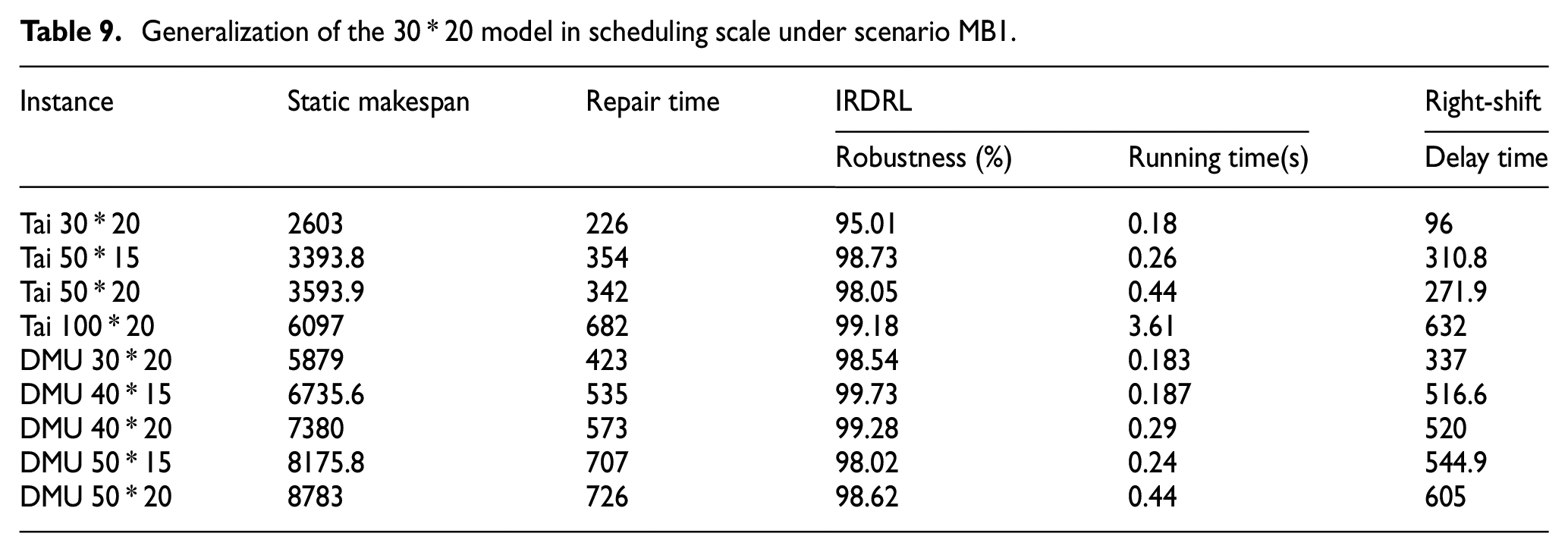
From Figure 7, static makespan is the solution in the determined manufacturing environment, while the IRDRL presents the solutions generalized by the 30 * 20 model for different large-scale cases. The IRDRL of each instance is better than the right-shift strategy. From Table 9, the robustness of all instances is over 90%, proving the excellent generalization ability of IRDRL models. The delay time means the time consumed by right-shift compared with IRDRL. In addition, the running time for each instance is less than 1 s, which contributes to implementing the online scheduling framework.
Generalization of the IRDRL model in similar breakdown scenarios
It is expected that the well-trained model can be used in a similar machine breakdown environment. Therefore, this experiment takes the models under scenario MB1 and scenario MB3 as examples. Models for break level 0.1–0.15 are generalized to the environment break level 0.15–0.25, while models for break level 0.35–0.4 are generalized to break level 0.4–0.5. To prove the generalization of the proposed IRDRL model, the standard benchmarks ranging from small to large are selected, as shown in Table 10. The experimental results shows that the robustness in all scenarios is above 90%, which proves the excellent generalization performance of the IRDRL models. Similarly, the extremely short running time demonstrates the feasibility of calling the model in real-time.
Generalization of the model to the similar break levels.
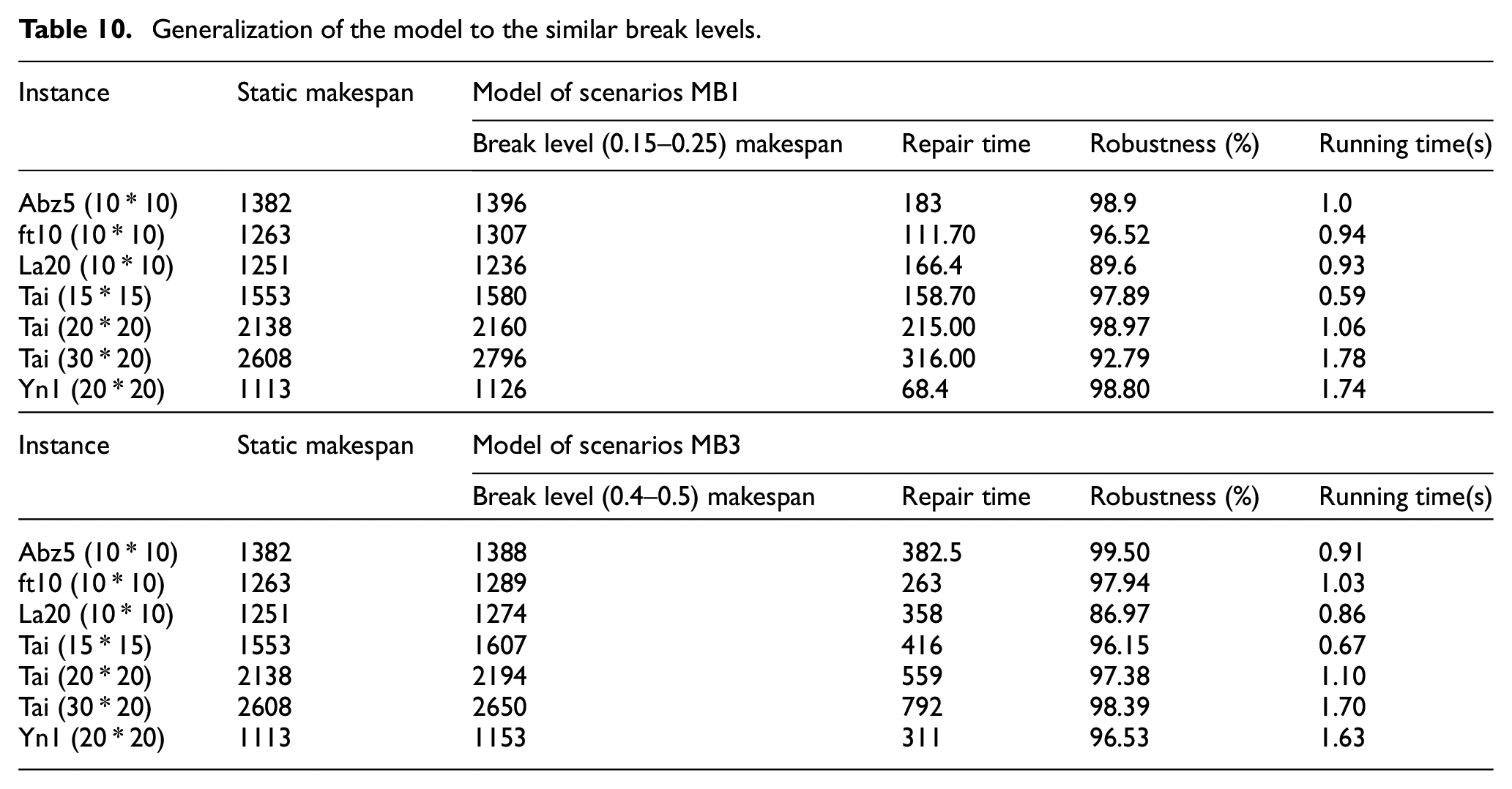
The satisfied generalization performance of the IRDRL model is helpful for the implementation of the online scheduling framework.
Conclusion and future work
In this paper, the IRDRL approach is developed for a dynamic job shop to minimize the makespan and maintain the robustness of the scheduling. The starting time and completion time of operations are inserted into the feature vector of the disjunctive graph to present the machine breakdown status. The optimal dynamic scheduling model is formed through the learning of the agent. Based on the IRDRL model, the online scheduling framework is proposed, which establishes a mapping relationship between the manufacturing environment and the optimal scheduling model.
Numerical experiments are carried out in many instances, including well-known benchmarks and randomly generated instances, to demonstrate the advantage of the proposed approach. An optimal balance between scheduling quality and speed could be achieved, which has proved the feasibility of the online scheduling framework.
Although the proposed approach shows improved performance, some minor factors ignored in this paper need to be considered in future work. (1) In respect of the mathematical model, the possibility of repeated machine failure after repair is ignored, which is a small possibility but cannot be neglected in actual production, and the following research will continue to improve the mathematical model to make it more accurate and realistic to the actual production. (2) In respect of disturbance and job shop scenario, multiple disturbances usually co-exist in actual production, such as uncertain processing times and urgent orders. It is necessary to simultaneously consider this co-existing and coupled disturbance. Meanwhile, the research scenario of the proposed approach should be extended from a job shop to a flexible job shop which is widely used in modern industrial manufacturing. In addition, the research of single job shop can be extended to distributed job shops to meet new production requirements. (3) In respect of optimization objectives, many other objectives in actual production management should be considered in the following research, such as tardiness, machine utilization, cost, etc.
Footnotes
Appendix
Author contributions
The authors declare their contributions to the published paper “Dynamic scheduling for dual-objective job shop with machine breakdown by reinforcement learning” as follows: XG: Investigation, conceptualization, methodology, formal analysis, writing – original draft; YZ: Analysis, writing – review and editing; GY: Data curation, validation, writing – review and editing; AZ: Software visualization, analysis, validation; FT: Resources, supervision. All authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the National Key R&D Program of China (2020YFB1713300), in part by the Natural Science Foundation of China (61863005), in part by the Fundamental Research Funds for the Central Universities under Grant (YWF-22-L-1144).
Availability of data and material
All data generated or analyzed during the current study are included in this article.