
Abstract
Bearings are the most widely used mechanical parts in rotating machinery under high load and high rotational speeds. Operating continuously under such harsh conditions, wear and failure are imminent. Developing defects give rise to even-higher vibration and temperature levels. In general, mechanical defects in a machine cause high vibration levels. Therefore, bearing fault identification and early detection enables the maintenance team to repair the problem before it triggers catastrophic failure in the bearing. Machine downtime is thus avoided or minimized. This paper explores the use of Machine Learning (ML) integrated with decision-making techniques to predict possible bearing failures and improve the overall manufacturing operations by applying the correct maintenance actions at the right time. The accuracy of the Predictive Maintenance (PdM) module has been tested on real industrial production datasets. The paper proposes an effective PdM methodology using different ML algorithms to detect failures before they happen and reduce pump downtime. The performance of the tested ML algorithms is based on five performance indicators: accuracy, precision, F-score, recall, and an area under curve (AUC). Experimental results revealed that all tested ML algorithms are successful and effective. Furthermore, decision making with utility theory has been employed to exploit the probability of failures and thus help to perform the appropriate maintenance interventions. This provides a logical framework for decision-makers to identify the optimum action with the maximum expected benefit. As a case study, the model is applied on forwarding pumping stations belonging to the Sewerage Treatment Company (STC), one of the largest sewage stations in Qatar.
Keywords
Introduction
Bearings are essential components of most rotary machines, failure of which contributes to a reduction in the performance of production lines and may eventually lead to the breakdown of these machines. 1 In bearings, most of the faults occur due to wear loss in their elements (i.e. inner race, outer race, and rolling parts) which in general, can dominantly be detected by mechanical noise, temperature, and vibration. 2 Therefore, the most frequently identified problems in bearings can be summarized as the following 3 :
Insufficient or excessive lubricant,
Poor installation of the bearings,
Small bearing clearance or heavy load,
High friction between lip and seal groove,
Improper lubricant type, and
Creep between the fitting surfaces.
However, the unexpected failure of the bearings can be very expensive due to many factors such as loss of production, cost of replacement, and significant damage to other parts of rotating machinery.4–6 Hence, early detection techniques by continuous condition monitoring7–10 have appeared as promising means to avoid catastrophic component failure of the machines by sensing, measuring, and recording the physical variables that collected from the sensor-mediated components11,12 and thereby these data are functionalized according to particular operating conditions. More specifically, when the operating conditions reach a certain critical level, alerting signals are displayed by developed models to apply predictive maintenance (PdM).13,14 Predictive maintenance primarily involves expecting a breakdown of the system to be maintained by detecting early signs of failure to make maintenance jobs more proactive. 15 PdM aims at predicting failure time of a system based on experience, physical laws, and machine learning techniques to replace the faulty components before failure, and as the result minimizing downtime of the systems, reducing the maintenance costs, and improving quality of product. 16
For PdM, a variety of technologies can be used as parts of a comprehensive program including monitoring and diagnostic techniques. These techniques include vibration monitoring,5,17–19 acoustic emission,20,21 thermographic inspection, 22 oil analysis,23,24 Radiographic inspection, 25 shock pulse, 26 ultrasonic leak detectors, 27 performance testing, wear and dimensional measurements, 28 signature analysis, 29 and time and frequency domain.30,31 Among the above techniques, vibration analysis has attracted a great deal of attention as time domain and time-frequency domain for tracking machinery operating conditions which in turn successfully diagnoses the defects and increases the machinery life. In this regard, vibration signals are firstly gathered and processed using vibration analyzers equipped with sensors in the time domain. These signals are then converted into the frequency domain using Fast Fourier Transform (FFT) to extract the frequency signature. The information obtained from the vibration signals has significant advantages in terms of predicting catastrophic failures. 32
The networking of physical devices and computers which assist in collecting and sharing the data is called the Internet of Things (IoT). These devices have formed a gateway to connect to machines and its subcomponents to not only collect the process data and its parameters but also to collect the physical health aspects of the machine such as vibration, pressure, temperature, acoustics, viscosity, flow rate, etc. 33 This information is widely used for early fault detection and identification, health assessment of the machine, and predicting the future state of the machine. Some of this is made possible owing to machine learning (ML) algorithms available through different learning domains. 34 IoT has also been versioned for the application in maintenance, particularly PdM. As reported in references,15,35 the advances in information, communication, and computer technologies, such as IoT and Radio-Frequency Identification RFID, have enabled PdM to be conducted more efficiently with enhanced data collected in a time-efficient manner.
The machine learning model is a mathematical model that generates predictions by finding patterns in the data. ML helps in solving many problems in big data, vision, speech recognition, and robotics.36,37 It can be classified into three types: supervised-, unsupervised-, and reinforced learning. Unlike the first type in which the predictors and response variables are known for building the model, in the second type only observations are known. However, in reinforced learning, the agent learns actions and consequences by interacting with the environment.34,38,39 Supervised ML aims at building a predictive model of the classification of class labels to determine the predictor features. The resulting classifier is then used to assign class labels to the testing dataset where the values of the predictor features are known, but the value of the class label is unknown. As far as this work is concerned, the authors have chosen supervised ML as a prediction model in terms of analyzing the collected data.
Related work
Tian et al. 40 presented a fault detection method of oil pump based on Support Vector Machines (SVM) which its parameters were optimized by genetic algorithm. Associating the ability of strong self-learning with the generalization of SVM, the detection method was truly shown to diagnose the fault in oil pumps by learning the fault information. The real detection results showed that the proposed method was feasible and effective. Samantaray 41 presented a new technique for high impedance fault (HIF) detection in a power distribution network using ensemble decision trees (random forest RF). The process included two stages: the first was estimating the amplitude and phase of harmonic contents in the HIF current signal whereas, in the second stage, the random forest was trained with the amplitude and phase information of the HIF current signal. The results indicate that the proposed method can reliably detect more than 99% HIF in a large power distribution network. Li et al. 42 showed that application of analytical approaches (including correlation analysis, causal analysis, time series analysis, and ML techniques) against both historical and real-time data such as failure data, maintenance action data, inspection schedule data, train type data, and weather data led to failure predicting in the future, thus avoiding service interruptions and increasing network velocity. Kroll et al. 43 presented an approach that used timed-hybrid automata of the machine’s normal behavior for PdM of industrial plants. They have demonstrated that this method has an advantage over a traditional, static limit testing. This advantage is a model of the whole continuous dynamics, which reduces it to separately modeled state vectors. This, in turn, allowed effective anomaly detection by implementing a combined data acquisition and anomaly detection approach, and presented outlook for other applications, such as PdM planning.
Cline et al. 44 demonstrated the potential of ML techniques on enhancing the operations of an Oil and Gas equipment service department. Analyzing significant data sets of individual machine performance resulted in major improvements in the customer’s ability to identify risky assets up to 1 year in advance. Paolanti 45 described the ML architecture for PdM on the base of the Random Forest approach. The system was tested on a real industry example by developing the data collection and data system analysis, applying the ML approach, and comparing it to the simulation tool analysis. Data collection has been done using various sensors, machine programmable logic controllers (PLCs), and communication protocols before being available to Data Analysis Tool on the Azure Cloud architecture. Preliminary results show a proper behavior of the approach to predicting different machine states with high accuracy. Amruthnath and Gupta 34 who have chosen a simple vibration data collected from an exhaust fan and have fit different unsupervised learning algorithms such as Principal component analysis (PCA), T 2 statistic, Hierarchical clustering, K-Means, and Fuzzy C-Means to test its accuracy, performance, and robustness, have eventually proposed a methodology to benchmark different algorithms and choosing the final model. In their study, the T 2 statistic provided more accurate results compared to the Gaussian mixture model (GMM) method. However, Clustering methodology is undoubtedly a better tool in detecting different levels of faults where T 2 statistic would be challenging after certain levels. Strictly speaking, when the cost of machine maintenance is expensive, clustering would be a flexible option where machine health can be monitored continuously until a critical level is reached.
Recently, Allah Bukhsh et al. 46 employed the ML techniques for the development of PdM models based on decision tree (DT), random forest (RF), and gradient boosted tree (GBT) by using existing data from a railway agency. For the prediction of maintenance need, the GBT model performed most optimally as compared to other methods with 86% accuracy. For maintenance activity type and trigger’s status prediction, the RF model attains an accuracy of 70% and 79% on the held-out test set respectively. They proposed that by collecting more data, specifically for minority classes, the predictive performance of the models can even be further improved. Gutschi et al. 47 presented a data-driven approach for estimating the machine breakdown probability during a specified time interval in the future. The authors described applied data-mining, feature-extraction, and ML methods and concluded that machine failures can be reliably predicted up to 168 h in advance. Xayyasith et al. 48 presented the ML application for PdM of a water cooling system in Nam Ngum-1 (NNG-1) hydropower plant located by using the Classification Learner Application of train model. A 22 classifier types were organized in six major comparable classification algorithms (including Decision Trees, Discriminant Analysis, Support Vector Machines (SVM), Logistic Regression, k-Nearest Neighbors (KNN), and Ensemble Classification), it was shown that the SVM and Decision Trees are better at predicting faults as compared to the other algorithms used in this study.
In the last related work, Nam et al. 49 have applied a data-driven approach to develop a health monitoring and diagnosis framework for a fused deposition modeling process based on a machine learning algorithm. For the data-driven approach, three accelerometers, an acoustic emission sensor, and three thermocouples are installed, and associated data are collected from those sensors and processed to obtain root mean square values. Among various root mean square values, those of acceleration data from the frame were most effective for diagnosing health states of the fused deposition modeling process with the non-linear support vector machine-based model.
The current work which is concerned with the fault detection in bearings components of the forwarding pump stations helps the production managers in planning the maintenance activities, that is technicians and spare part availability. The supervised ML method has been applied in this study where the data fed (mainly temperature and vibration) belong to the labeled type. In this respect, a comparison among four different types of classifiers: decision trees, random forest, and gradient boosted trees as well as support vector machine. This comparison was achieved by utilizing python programming language to investigate which type provides the highest detection accuracy. Since the binary classification output of the applied ML algorithms can generate the pseudo probability of an observation belongs to a class the authors choose to use the utility theory to exploit the probability of failures and thus help to perform correct maintenance actions.
Research methodology
Figure 1 summarizes the research methodology which is based on an integration of an online fault detection algorithm with the decision theory for PdM. As the figure indicates, historical data are used for the offline model training, whereas online data are observed from instantaneous sensor measurement for predicting the process state. The utility theory is finally used for scheduling PdM.
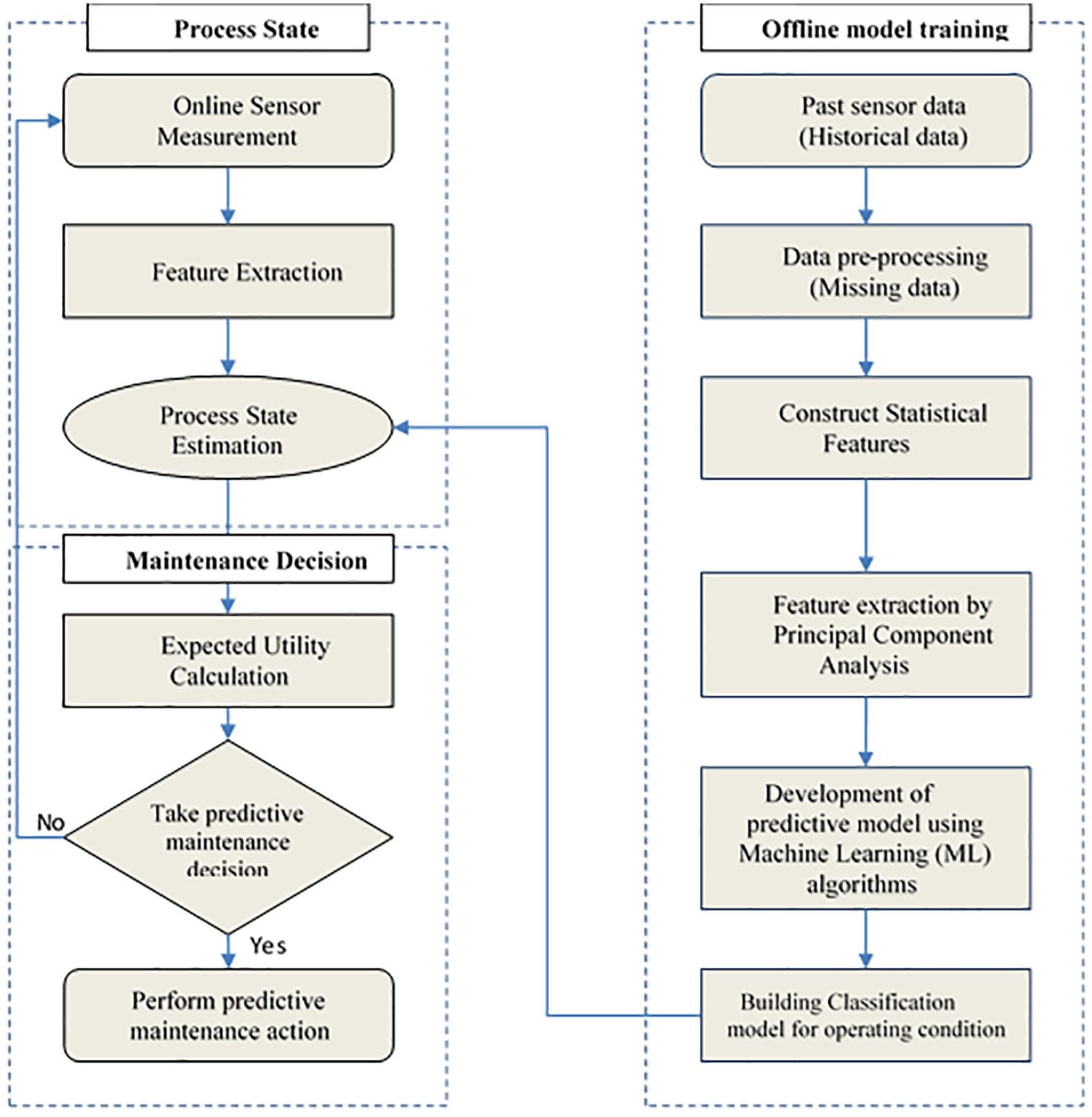
The flow chart of the proposed method for bearing fault prediction model.
The first stage to build the prediction model depends on data acquisition, a process of collecting and storing useful data from the target system to monitor the condition and diagnose the faults. The input for the data acquisition process is vibration signals and temperature readings. These signals are extracted to reduce the dimension of feature space where the reduced features are fed to several types of ML algorithms to classify the operating conditions. Performance comparison among the tested ML algorithms is performed to select the one with the most accurate bearings faults prediction. The selected model is then used to process state estimation for online sensor data measurements after feature extraction. Besides, we utilize utility theory coupled with the probability scores resulted from ML to guide decision-makers on when to implement the maintenance activities in an efficient and cost-effective manner. Therefore, our decision model provides a well-defined framework for the selection of the correct maintenance action. The following sections explain more details of the study main stages.
Offline model training
Several statistical features were extracted to train the ML models that, in turn, generate the final fault predictions. Seven descriptive statistical features for each sensor signal were constructed from the selected dataset of the bearing component: they are mean, skewness, kurtosis, maximum and minimum values representing the upper and lower ends of our data. The standard deviation (SD) and root mean square (RMS) was also included. 6 These statistical features are calculated for each selected attribute (i.e. temperature and vibration) that gained from six different sensors. Among those features, the RMS values are considered the most effective to distinguish the differences between healthy and faulty states. 49
The binary classification is viably used for PdM, being able to estimate whether the equipment will fail over a future period of time. To use the binary classification, it is necessary to identify two types of classes, represented by zero and one. Each class is a record of a unit of time for an asset that conceptually describes the operating conditions, taking into consideration the technical data of the pump design as well as its specifications.
In the context of the PdM binary classification, the class “1” denotes the faults while the “0” class stands on the normal operation condition. This classification aims to find a model that identifies the condition of which each bearing may fail or work normally in the future. In the present work two different operating conditions have been considered, the first condition was labeled as normal, where no faults were present in the bearings. Whereas the second one is known as fault indication condition (announced when the operating conditions of the bearings, that is temperature or vibration, reach to or go over the critical limit value) are summarized in Table 1.
Selected attribute classification.

Thus, the ML approach applied to temperature and vibration data has mainly focused on finding the relations between normal and critical operation conditions to extract the most likely root causes for bearings faults determination. 50
Temperature measurements help in potential failure estimating which are related to the temperature change in the equipment such as excessive mechanical friction (faulty bearings, inadequate lubrication, fouling in a heat exchanger, and poor electrical connections). While those of vibrations can indicate problems such as wear, imbalance, misalignment, and damage. 51 These measurements contribute to determining the causes of the faults that occur in the bearings mainly due to either temperature and/or vibration. In accordance with the results that came from these observations, expert knowledge of maintainers as well as the maintenance manual of pumping machinery, the right maintenance action can be executed.
ML algorithms
Decision Tree (DT), Random Forest (RF), Gradient Boosting (GB), and Support Vector Machine (SVM) algorithms are used to find the best classifier for the data under study. A brief introduction about ML algorithms is given in the following.
Decision Trees (DT)
In respect of this, Sheng and Rovnyak 52 and Kotsiantis et al. 53 have made an overview of decision trees in which the advantages of the DT in ML have been given. Therefore, the authors of the current paper have chosen the decision tree which is a well-known technique in providing the logic-based rule as well as those of classification by tracing down the nodes and branches in the tree. It, furthermore, turns out the decision tree model that gives good results and, hence, satisfies the accuracy requirement and generates simple logic rules that can be interpreted as straightforwardly by operators.
In respect of the proposed ML classification model, the binary classification (0,1) dependent-decision trees exhibit better tendency in terms of its performance and consequently, the decision/classification can be quickly calculated. 54
Random Forest (RF)
Random Forest, so-called ensemble decision trees, has been used in this work as a classifier algorithm for it gives better predictive results and also operates building multiple decision trees, providing faults detection with higher reliability and accuracy as compared with DT especially when the data are originally expanded.55,56 Furtherly, RF is used to reduce the difference between the actual and predicted values like variance, bias, and noise which is not functionally included in RF.
Gradient Boosted (GB)
Gradient Boosted is an alternative ensemble learning technique that consecutively produces weak tree classifiers in a stage-wise fashion as other boosting algorithms do with a different base model. To implement the GB algorithm for a particular problem, we need to estimate the right size of tree and number of iterations (number of trees) that give the best prediction accuracy. Each iteration is an attempt to reduce the loss function such as cross-entropy or sum of squared errors which implies that the number of iterations should be large enough to minimize the error function. 57 Moreover, boosting algorithms are relatively simple to implement with different model designs. 58
Support Vector Machines (SVM)
Support Vector Machines (SVM) are probably the most popular approach which is primarily used in classification and regression of large sample size owing to their high classification accuracy, even for nonlinear problems and their availability of optimized algorithms for their computation.39,59–61 In this context, the (SVMs) has received great attention in the last years in much research especially in the field of machine condition monitoring and diagnosis. 62
Decision-making theory
Aiming at determining the optimal strategy alternatives, decision making and utility theory have been comprehensively used in the design of manufacturing and production activities.
63
In our case study, there is a list of
Among the possible decisions (
To compute the expected utilities for different decisions, formula (1) is considered for which the probabilities for each event

Case study
Sewerage Treatment Plant treats 245,000 m3 of wastewater on a daily basis which mainly used in irrigation and other non-potable purposes while the sludge from the treatment plant is used as a soil conditioner in the neighboring agricultural fields and as a source of green energy. For these purposes, vertical and single-stage forwarding pumps (TORISHIMA, Korea) are used. The technical specifications of these pumps are driver output: 840 kW, flow capacity: 4738 m3/h, total head: 47 m, speed: 730 rev/min, and frequency: 50 Hz. One of these many pumps is chosen from which the data used for applying ML algorithms, that is vibration and temperature, are collected at each minute, giving a total number of 130,956 data points which corresponds to a period of 3 months. As for the vibration, four accelerometers of sensitivity: 100 mV/g, sensitivity precision: ±5% at 25°C, and acceleration range: 0 to 80 peak were installed along vertical and horizontal directions to pick up the vibration (acceleration) signals created at Driving End (DE) & Non Driving End (NDE) Bearings. Likewise, there are two temperature sensors of type of Resistance Temperature Detectors (RTD)-PT100. These sensors are installed in the same directional mode with a measuring range between −50 and +180°C for DE & NDE Bearing. The schematic of the forwarding pump adopted in our study is depicted in Figure 2. Moreover, a photo of the pumping station and sensor types are shown in Figure 3.
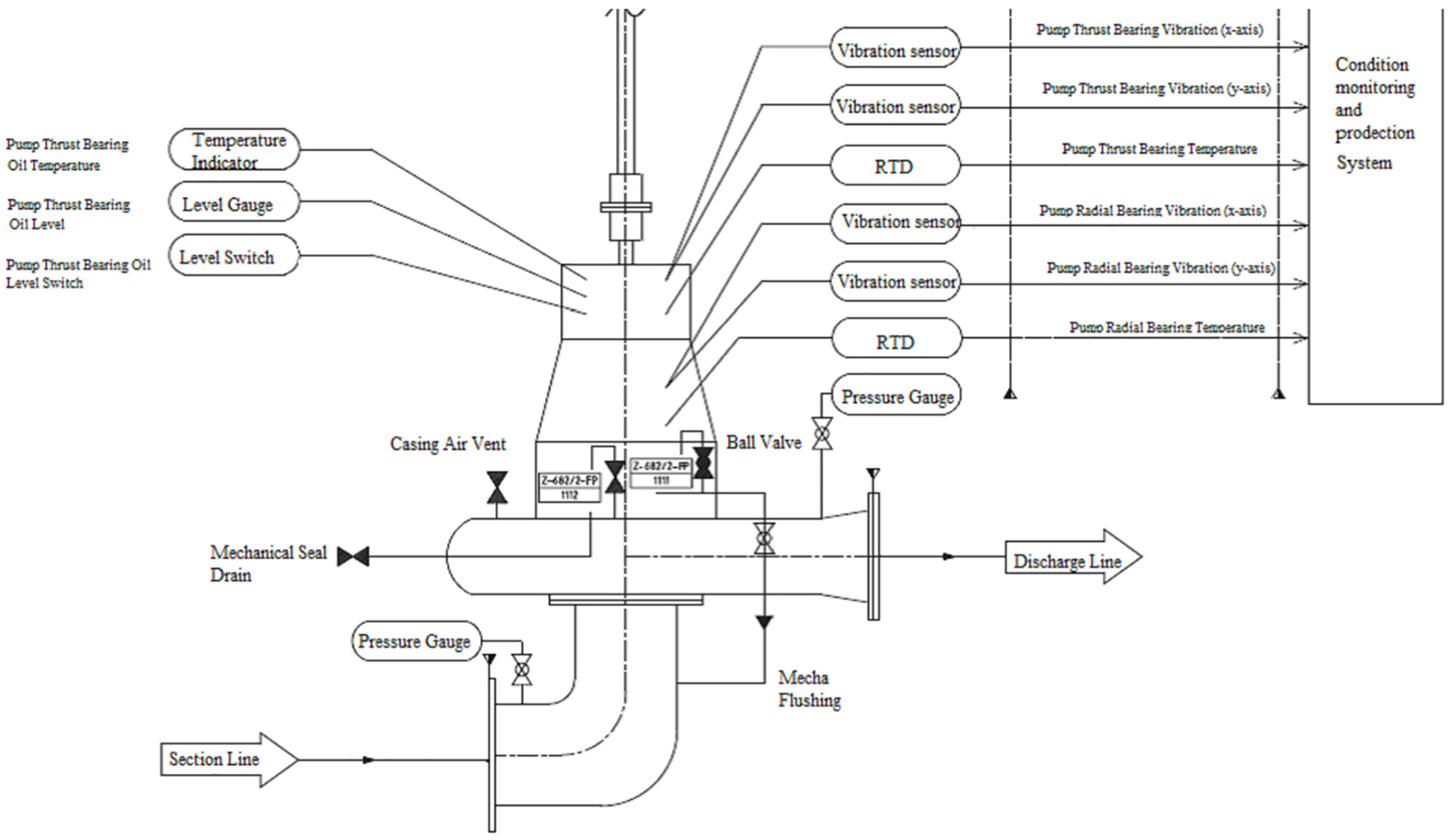
A schematic drawing of the forwarding pump and specific location of the sensors.

Photographs of the (a) PS70 pumping station, (b) vibration sensor, and (c) temperature sensor.
This paper presents a ML approach using data collected by IoT technology, specifically, by SKF@ptitude observer monitoring which is an expert diagnostics software usually used for pump monitoring system illustrated in Figure 4. It maximizes the rotating equipment performance (REP) via allowing more agile business, delivers greater output, reliability, and optimizes safety. A variety of sensors are installed along with the pumping system components used to measure the data needed as input to the ML. Furthermore, other relevant information is shown in user-friendly displays. Live data, updated every second, and long-term history can easily be displayed in many different formats. In the process overview window, live data and alarm indications are shown in descriptive pictures for pumps. SKF@ptitude observer gives direct measurements of bearing temperature and vibration. Besides, SKF@ptitude observer monitors bearing noise indicating defects that may eventually lead to bearing overheating problems. These recorded measurements are important to protect the machine where the observer gives an alarm if the recorded data exceeds a pre-specified threshold. Such a critical threshold is usually set depending on pump specification and manufacturing standard. For example, when the bearing temperature is greater than 120°, an alarm is triggered and immediately stopping the pump is required. In addition, when undesirable events occur, the software sends an alarm message to the maintenance management department which in turn evaluates the causes of this critical machine condition. However, due to their simplicity, they can only capture imminent overheating and bearing failure accurately. This does not provide enough lead time to perform PdM planning and resource optimization. This highlights the advantage of the current study which integrates the benefits of SKF@ptitude and the ML predictive power to detect the occurrence of abnormal conditions in advance.
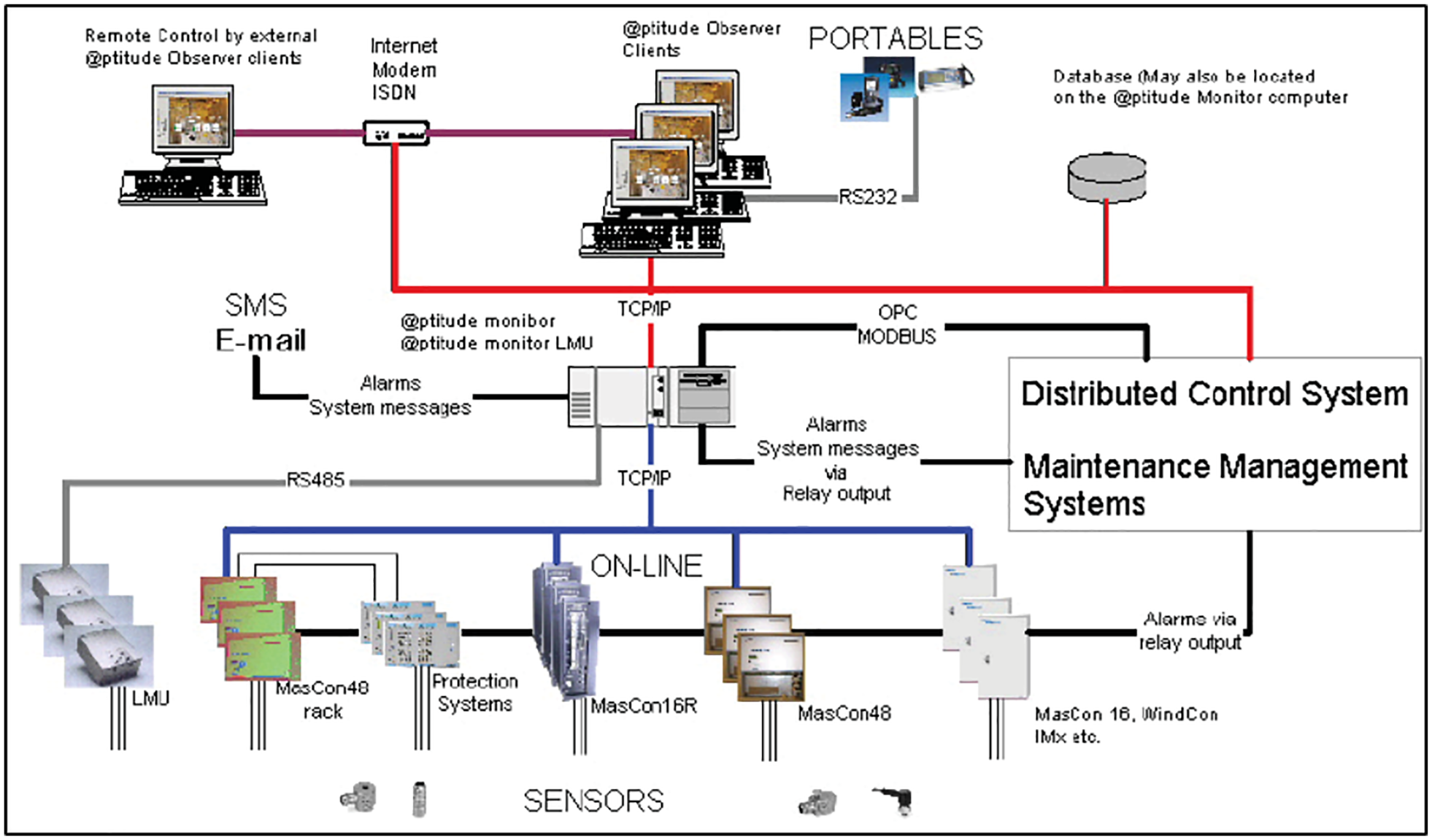
SKF@ptitude observer monitoring system.
Data collection and preprocess
Data collecting is the most important step in applying ML algorithms. As mentioned previously, this work is based on a real data-set collected from several types of sensors that monitor the pumping processes in the sewerage treatment company. The sensor data stream-in at an interval of 1 min, which is equivalent to 1440 rows of data per day, a description of the original data sets as a time series of accelerations and temperature shown in Figure 5. However, as reserved-dataset is not directly suitable to be used in creating a predicting model because it mostly contains noise and missing feature values. Therefore, the second step of data preparation and data preprocessing is applied before feeding it to the ML algorithm in order to convert the raw data into a clean data set and make them more suitable for further analysis.
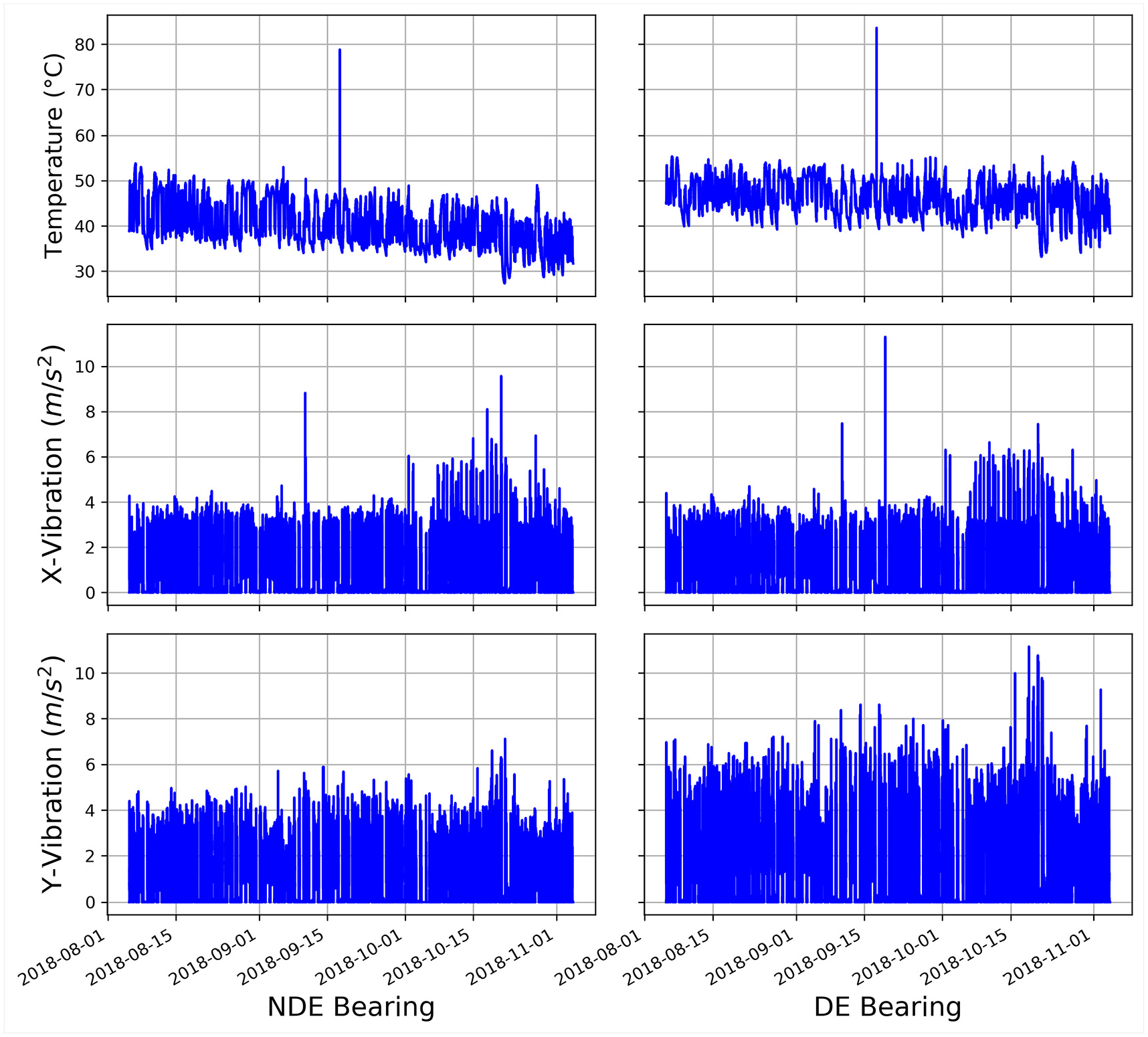
Features of the original data sets.
In this respect, feature extraction is used for data preprocessing that focuses on modifying the data for better fitting in a specific ML method. It also involves reducing the data by generating a smaller set of predictors that seek to capture a majority of the information in the original variables. 39 In this way, the original data are replaced by fewer variables providing a reasonable fidelity.
Dimension reduction
Principal component analysis method, the commonly used feature extraction technique, 67 seeks to find out the correlation nature among statistical features. It is also used to reduce the number of features by not only removing the ones among which the high correlations but also maximizing the variance over a set of instances.
Basing on this unique characteristic, PCA is finally used for the classification of variables and hence early identification of abnormalities in the data structure. 68 In respect of this explanation and according to the available data, a set of 42 statistical features for six attributes listed in Table 2 was reduced to a smaller set of seven uncorrelated final features corresponding to a 95% variance of the original data set.
Selected attributes for bearing prediction.

Figure 6 shows the change of the explained variance ratio of the 42 variables selected for PCA versus the principal component. It is can be seen that seven of these 42 variables have explained 95% of the variance. This means that the seven PCs subspace contains enough information about the variation of the original features which is sufficient to construct the model that can detect the faults in the bearing component
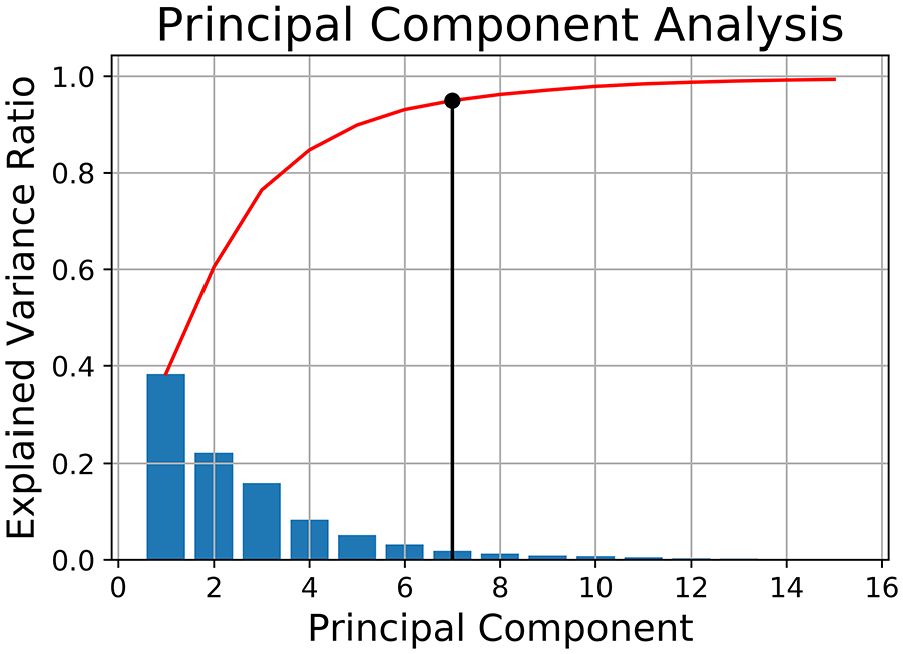
Principal component selection.
Later, the analyzed frame of the target timestamp has been properly sized by a limited-analysis approach. In current work, the time series is split into sub smaller time periods in which the above-described features are extracted from sliding windows with a size of 10 h and a sliding length of 1 h. These strategies could be perform using weekly or monthly time periods depending on the requirements of the PdM. 69
The use of prior time steps to predict the next time step is called the sliding window method. For short, it may be called the window method in some literature. In statistics and time series analysis, this is called a lag or lag method.
A classification model is then generated from the training set while its performance is estimated on the test set. Among the most commonly used methods for evaluating the performance of a classifier by splitting, the original data set into subsets is k-fold cross-validation. In order to build the classifier, a subset is taken from the training set, called as validation set which is used as a test set with which the original training set is learned to tune the model or obtain the parameters associated with the model. 36
In our model, we performed five-fold cross-validation using the original data set. The training set is divided into five equal parts; one of them is used as the validation set whereas the remained ones formed the training set. We have repeated this process five times considering a different part as a validation set at each time and compute the accuracy on the validation data. The final accuracy results are the average of all different validation cycles.
Building classification algorithm
While the process state is used as input for ML algorithms,

where
DT, RF, GB, and SVM are used to determine the best ML technique that will predict process conditions. In DT, the Gini index has a dual function: it is used to find the feature splits the training data that would be the root node of the tree; moreover, it can be used in evaluating the quality of a particular split. 70
The Gini index is defined by:

where
The maximum depth of a tree is set to five to prevent overfitting where max depth gives the maximum depth up to which a tree can grow. 36 In order to achieve the best results in the test data set, we tried values from 2 to 10 for maximum depth parameter so as to cover a wide range of possibilities.
In the RF algorithm, a number of trees (number of iterations) are set to 100 which used the same parameters of splitting decision and the maximum depth of the DT. Using more than 100 models in RF algorithm did not improve the results.
The learning rate is taken as 0.12 and 100 models are built in a GB Algorithm. As the case of RF algorithm; 100 models did not improve the results of GB algorithm. Among the tested learning rates (0.01–0.5), a learning rate of 0.12 gave the best accuracy results for GB.
For the SVM algorithm, the radial basis kernel function outperforms the kernel functions of linear, polynomial of order two and three and sigmoid function. Another important support vector classifier (SVC) parameter is regularization parameter C changing the regularization parameter affects the shape of the function. While High values of C results in more smooth functions, low values result in more complex functions leading to overfitting problems. In our experiments, we found that the best C value is 1.0. Results of the algorithms are summarized in figures and tables below.
Next, we will fit a classification model in order to predict pump condition using delay (lag) functions need to be created from data sources including timestamps. Lag features are the classical way that time series forecasting problems are transformed into supervised learning problems. The simplest approach is to predict the value at the next time (t+1) given the value at the previous time (t).
The discussion begins with analyzing the numerical and graphical summaries that resulted from applying ML algorithms for the bearings data. For each recorded data, we have predicted the fault occurrence recognized by pump operating conditions for the nine previous hours, Lag 1 through Lag 9. Now we compare the algorithms’ performance across five random train-test splits of the data using classification accuracy. Figure 7 presents the output of accuracy for every nine lags expressed as the probability of correct classification. As the figure indicates, the GB and RF achieved slightly more than 88% mean accuracy in Lag 1, associated with the correct detection of critical bearing conditions before 1 h. On the other hand, SVM and DT respectively resulted in 82.2% and 81.9% mean accuracy giving an initial indication that DT gives the worse accuracy compared with the other three algorithms. A more extensive analysis of the algorithm’s performance is presented later in the Performance Measures section.
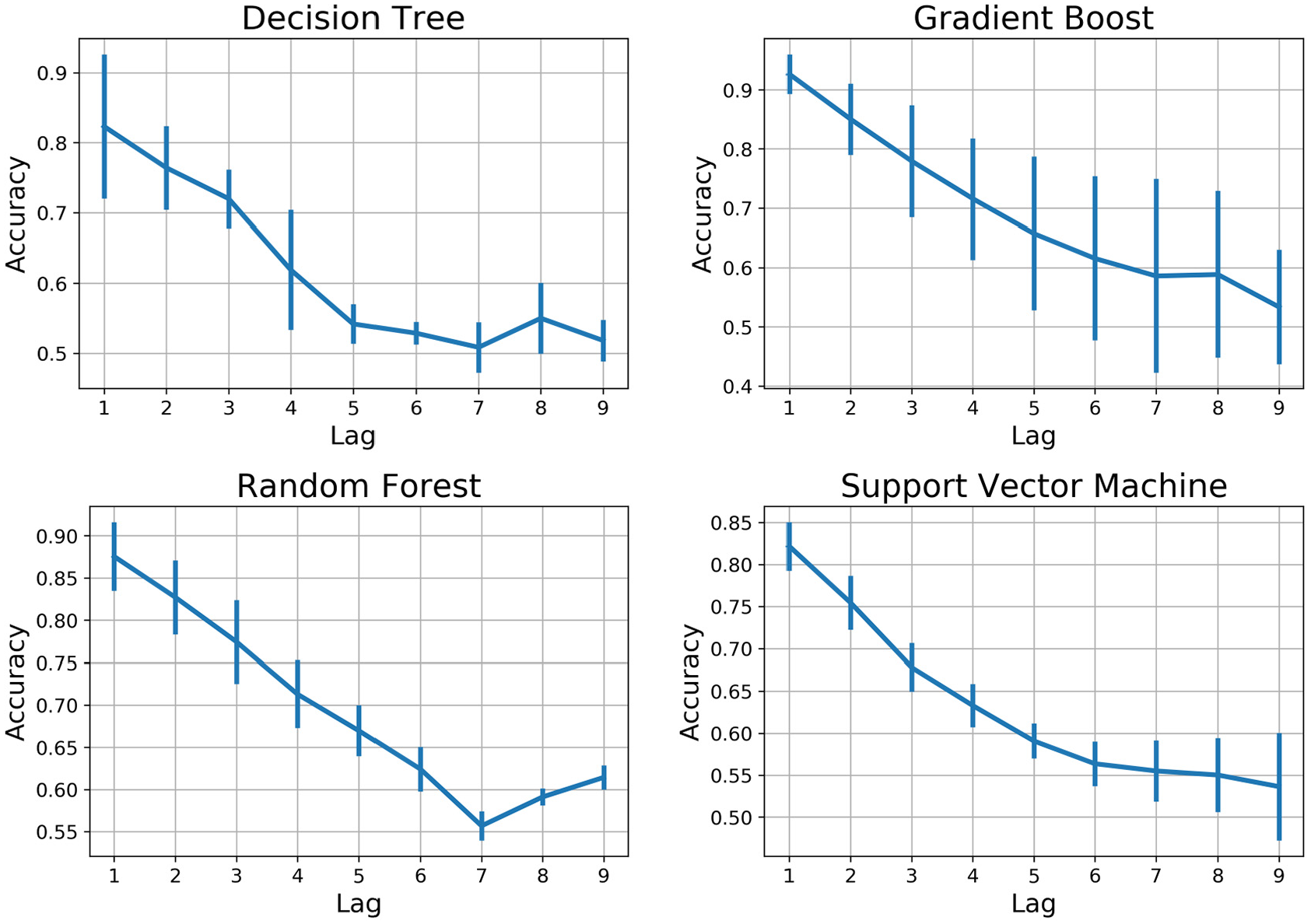
Comparison of ML algorithms performance with respect to their accuracy-lag.
In general, we can see that the prediction accuracy for all models is decreasing significantly with increasing the lag number from one to nine reaching minimum prediction accuracy less than 53% at lag 9. This is a logical consequence since many unexpected circumstances might appear when the prediction took place earlier. Table 3 summarizes the mean and standard deviation (SD) for all ML models for nine lags.
The mean and standard deviation for all ML models for nine lags.
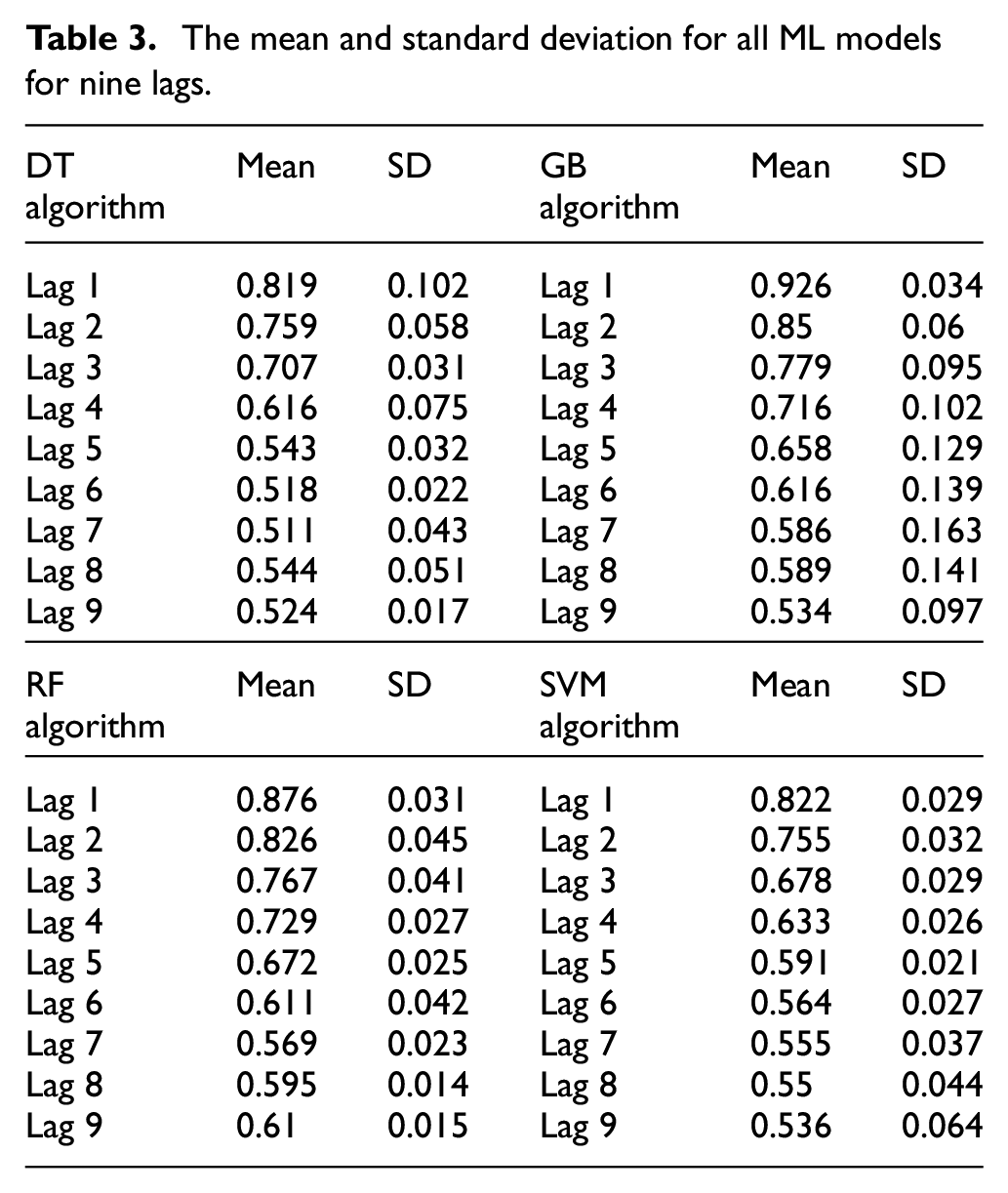
For the purpose of comparing algorithms performance, it is important to consider both mean and SD values. The higher the SD, the less precise is the prediction estimate. For example, although the mean value for GB is better than RF, the SD in RF is less indicating a more precise estimation. To compare the overall performance of both algorithms, a confidence interval may be useful to draw the conclusion.
Performance measures
Several performance measures are used to compare and evaluate the power of model prediction. As mentioned earlier, four distinct models are developed to predict if the operating condition is critical or normal where the maintenance is performed or delay accordingly. The training results of an application are compared in terms of the predictive performance for the testing accuracy of the classifiers algorithm. In the analysis accuracy (%) is considered as a performance index and is computed as:
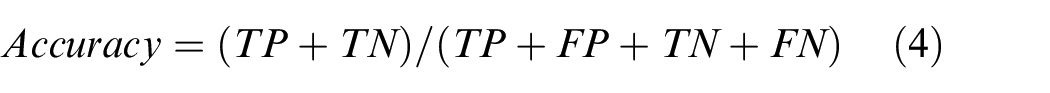
where TP, TN, FP, and FN are true positive, true negative, false positive, and false negative rates, respectively. The accuracy is thus a combination of precision (or positive predictive value) and recall (sensitivity) measures. 71 The precision determines the exactness of the model. It is a ratio of correctly predicted positive instances (TP) to the total positively predicted instances (TP + FP). Precision is represented as:

In contrast, recall provides a measure of the model’s completeness. It is a ratio of a correctly predicted positive instance to the total instance of the positive class (TP + FN) in test data. A recall is calculated as:

Precision represents the model’s performance with respect to false positives, whereas recall represents the performance with respect to false negatives. The F1-score conveys the balance between precision and recall by taking their weighted sum. F1-score is calculated as follows:
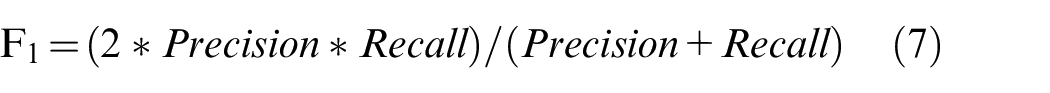
Similar to the accuracy, F1-score performs well with the fairly balanced dataset. Given the performance evaluation measures, the idea is to maximize the TP and TN and minimize the FN and FP. Generally, a reasonable tradeoff between the FP and TN risks is needed for better predictability. In the case of maintenance, however, the false negative (i.e. when the model predicts no need for maintenance, where it is needed) is more critical. Finally, in our experiments, we also compute the receiver operating characteristic curve ROC (a.k.a Area under the curve AUC), which is a measure of the model’s performance based on the tradeoffs between TP and TN rates over all possible risk thresholds between 0% and 100%. In the ML community, a ROC over 0.70 is considered good, and a ROC over 0.80 is very good. 44
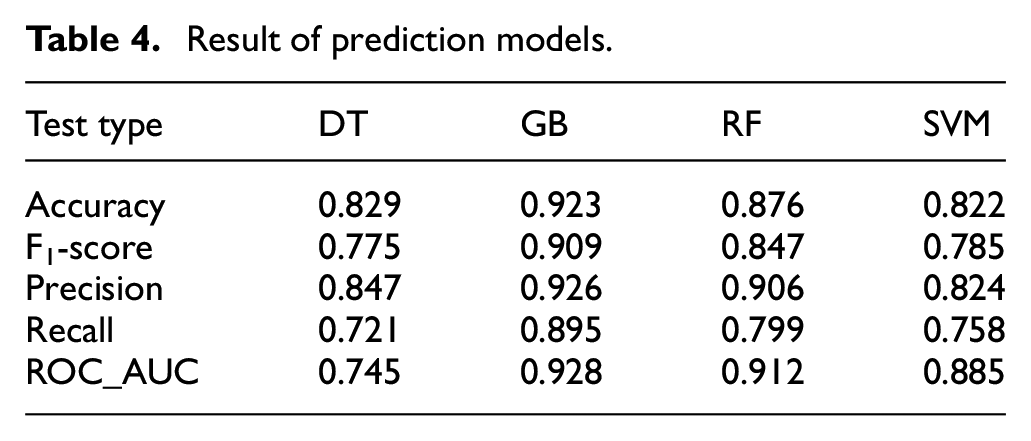
Table 4 shows the model evaluation results tested on a cross-validation dataset. All models show a negligible difference in performance. The GB model performs best in terms of all performance indicators where it reaches an accuracy of 92%; precision of 92.6% has an F-score and Recall of 91% and 89.5%, respectively. This supports our previous conclusion that the GB approach outperforms the other tested ML models. The SVM model, on the other hand, shows the lowest accuracy rate nearly to 82% as such as to the other evaluation criteria. Therefore, GB and RF showed the best performance indicators, with almost identical measures, and are found to outperform the other two models. It is also noteworthy that even with the worst ML model, DT, the AUC measure is considered acceptable (>0.7). ROC curves plots are used in order to evaluate the distinctive ability of the prediction, the GB model exhibits an even higher AUC (92.8%) while the DT model gives a lower AUC (74.5%) as shown in Figure 8 and Table 4.
Result of prediction models.
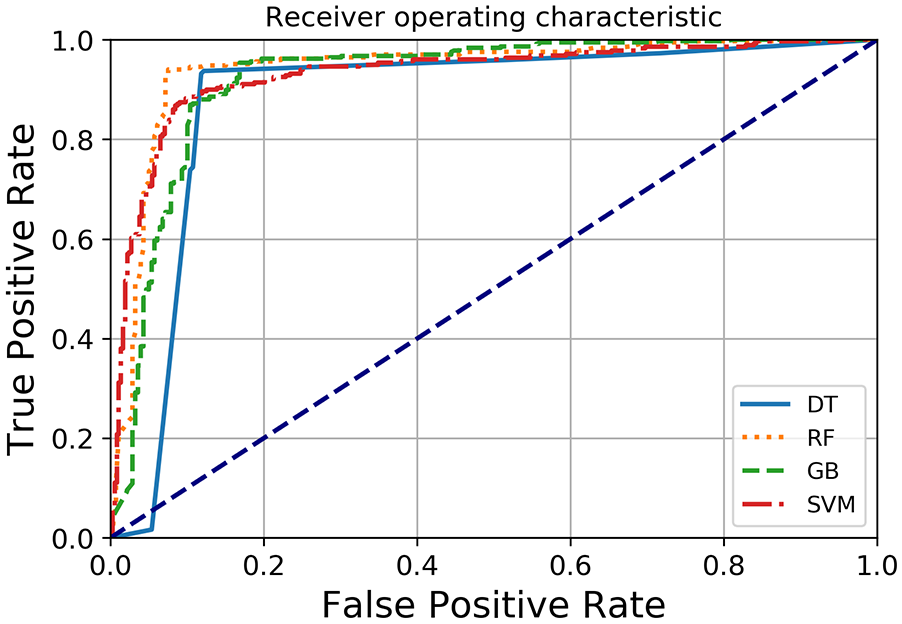
ROC curve of ML algorithms.
Decision making
Once the ML algorithms are tested and the best approach is selected, the utility theory is integrated into our model to plan the maintenance action based on the probability of fault occurrence. Table 5 summarizes the utility matrix u ij expressing the corresponding consequence for taking decision i given event j. Since it is less desirable to continue the machine work when the process is under a critical condition compared with taking a maintenance action when the process is normal, the utility (cost) for consequence u 12 is chosen to be less (higher) than that of u 21 .
Decision table for critical condition prediction.
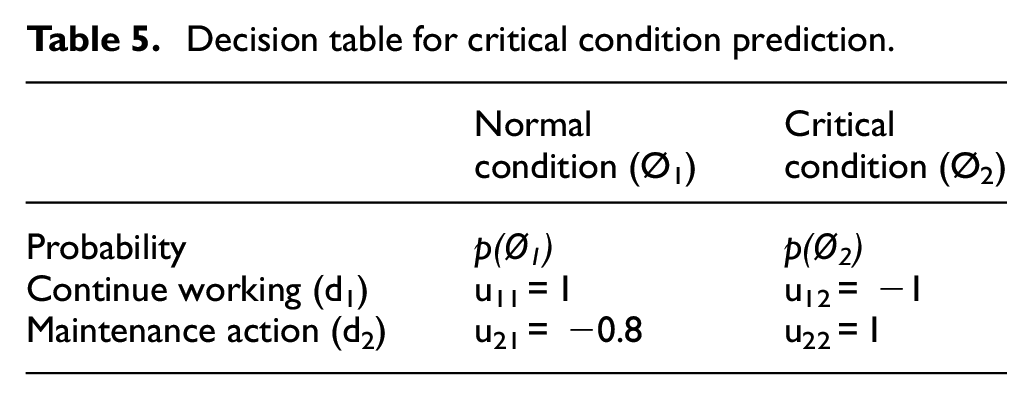
The probability p(Ø) represents how likely event i is to happen given the status of the active features extracted in the offline training phase. There are several approaches to detect these probabilities such as Bayesian networks and neural network algorithms. In this paper, however, we utilize the score resulted from the ML, which is a reflection of the status of all extracted features, and use it as input to the utility theory-based decision making. It is worth noting that the final output of ML is binary 0, 1 classification depending on whether the resulted decimal score is less or greater than 0.5, respectively. However, the decimal score (before binary classification) can be utilized in the application of utility theory as probability of normal and critical conditions.
The choice of the utility value u ij is based on the decision maker’s knowledge of the system under investigation. Obviously, continue working under normal condition and take a maintenance action under critical condition will receive the maximum utility 1. The worst consequence, on the other hand, happens when work continues on a machine under a critical condition which not only produces nonconforming items but also may cause extra damage in the machinery and production system. Therefore, a utility of −1 is selected for such a consequence. The choice of utility value for taking a maintenance action under normal conditions depends on the cost of unnecessary maintenance and its impact on the production flow but in most cases, it is less serious than working under critical conditions. In this study, a value of −0.8 has been arbitrarily chosen for computational illustration.
It is also worthy to mention that the attitude of decision makers toward risk can significantly influence the way utility scores are defined. For example, in situations where the production management seeks to maximize profit through increasing the production volume within short period (risk-seeking approach), an unnecessary maintenance act will be avoided and critical condition signs with relatively small probabilities will be disregarded. On the other hand, risk-averse decision-makers who follow a more conservative approach will be more protective against any risk of machine failure even with low probability and thus will assign higher utility to unnecessary maintenance action.
The current paper provides a general framework for integrating the concept utility theory with ML to improve decision making regarding PdM. Considering maintenance costs including inspection, repair, failure, and replacement costs; as well as decision-makers’ attitude to risks will help to provide an accurate estimate of the expected utility for each decision alternative. We highlight this as a gap for further extension and investigation.
Figure 9 shows the two expected utility curves for d1 and d2. Based on utility maximization rule we should take maintenance action when the expected utility for d2 (maintenance action) becomes larger than d1 (continue working). Thus, the maintenance action time can be identified by the intersection of two expected utility functions.
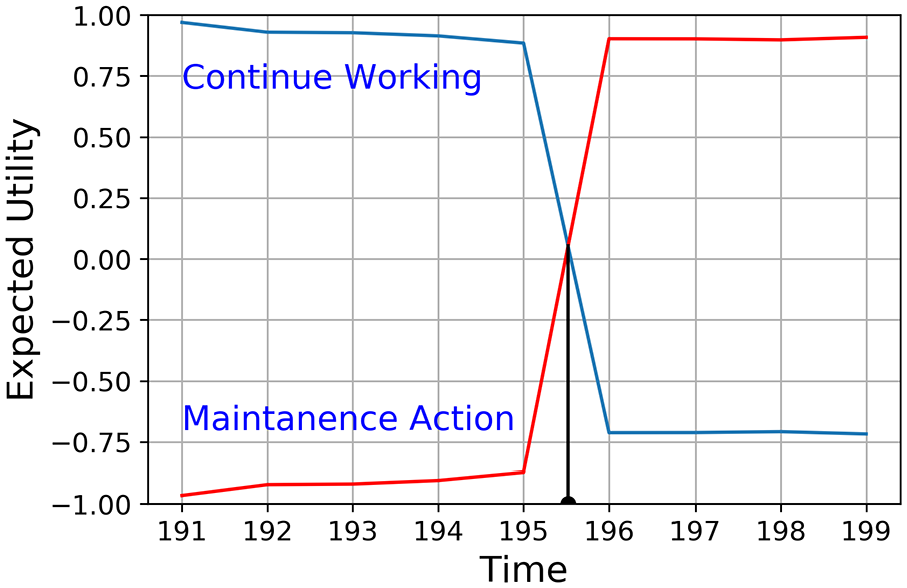
Expected utility for “continue working” and “maintenance action.”
Conclusions and future works
This paper utilizes ML techniques for the development of fault prediction models. Our models are based on estimations taken 1 to 9 h (Lag) in advance that give sufficient time for operators to prepare for inspections. This helps in taking the correct maintenance action on bearing components (e.g. checking the lubricant, cleaning the bearing housing, or preventing overheating) which will in turn increase bearings durability.
The prediction model has been implemented on a real industrial company which provided us with the necessary data collected using an online sensor measurement system. The proposed model has been achieved by training several ML algorithms on the python program. The computational analysis showed that the four ML approaches resulted in acceptable fault detection power. However, among the tested algorithms, GB and RF gave the best performance and accuracy: 92% and 87.6%, respectively. Using ML with the recorded maintenance data demonstrated that PdM could be done and provides good and reliable criteria for the maintenance planned interventions. The model aids operators to easily visualize and monitor the pumping system. Furthermore, while most of the related literature depends on their maintenance action only based on ML results (0, 1 binary classification), the current model is distinguished by its ability to show the probability of critical conditions through the use of utility theory. This helps to avoid false positive alarms and thus reduces the unnecessary maintenance costs. Therefore, this paper significantly contributes to achieving a more trustworthy maintenance management system for different Industrial applications. As a potential area for future research, the proposed fault detection methodology can be extended to include planning of maintenance schedules using a statistical cost minimization approach.
Footnotes
Acknowledgements
Authors of this study are extremely grateful to Sewerage Treatment Company/QATAR, for the provision of various data and information on the machines and equipment. Special thanks are due to Dr Mohanad Al-Ani for his assist. Ministry of Higher Education and Scientific Research of Iraq is gratefully acknowledged for the PhD study program of Raghad Mohammed Khorsheed.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.