
Abstract
The generalized module is one of the basic elements of parametric product platform, which can effectively support product variant design and mass customization design. A similarity analysis method for the non-isomorphism generalized module is proposed to support the precise configuration of product’s function, structure, and process. The structure, function, and process information of product modules are extracted from the product lifecycle management/product data management database and converted into eigenvector by range identification. Then, the parameters of different scales in non-isomorphism classes are normalized to eliminate the effect of different dimensions. The similarity measure of function and process information is completed by vector matching. The function equivalence classes and process equivalence classes are obtained using the proposed classification algorithms. The results of similarity analysis can increase the flexibility of product variant, meet the needs of customization, and thus directly support the precise configuration. Finally, the feasibility and effectiveness of the proposed method are verified by a case study of high and middle pressure valves.
Keywords
Introduction
Product module is one of the basic elements for product platform, which plays a very important role in mass customization design. With the increase in product complexity and user personalization demand, the traditional module presents more and more limitations, and it has been difficult to meet the requirements of the market. In many customized mechanical products, the number of modules is large, the working condition is complex, and the series classification characteristic is not obvious. Conventional modular design methods could not better meet the requirement on the variant design of the customized mechanical products. Aiming at the limitation of the traditional modular design, some parametrization methods are introduced to the modular design. Many scholars propose the generalized modular design method, which have been become a research hotspot. Some generalized modules have identical or similar structure, which are called the isomorphism generalized modules. Others are structurally different, which are called the non-isomorphism generalized modules. As the main attribute in generalized module, function information and process information contain a lot of potential similarity rules. These information are very important for product design and manufacture. Most of function information and process information are the same for the isomorphism generalized modules, so they are not discussed in this article. In spite of the differences in the structure of the non-isomorphism generalized modules, the function and process information may also be consistent in different parameter ranges. However, the similarity and its regularity are implicit in a large number of product data. With the application of computer information system (product data management (PDM)/product lifecycle management (PLM)), the enterprise’s product data grow exponentially, which contain advanced management idea and process knowledge. In the process of realizing the strategy of mass customization, it is the key for enterprise how to scientifically analyze and utilize these product data so that it can be quickly converted into the product platform for mass customization. Therefore, a similarity analysis method is proposed for the non-isomorphism generalized module in product platform.
Traditional modular design methods emphasize on the generality, standardization, and serialization of modules. It has been difficult to be applied to the product variant design, especially for customized products with complex structure and no obvious series classification. Therefore, generalized module has been becoming a research hotspot. Xu et al. 1 proposed the design idea of the generalized modular design and established the concept system of generalized modular design. In Gao et al., 2 the concept of generalized module was further expanded. The generalized module was defined as a structure with a specific function, which has the parameterized structural model and interface feature. Zhong et al. 3 systematically studied method of generalized modular design and proved the feasibility of the generalized modular design technology. Gao and Xu 4 discussed the construction technology of the generalized module. The similar feature clustering method and parametric modeling method were used to create the structure mode of generalized module. For the integration of generalized module design information, Suresh, 5 Gordon, 6 Park et al., 7 and David et al. 8 proposed many methods, such as the integration method based on the geometric information of the product structure and module, the integration method based on the product analysis and evaluation information, and the integration method based on the integration model of geometric information and evaluation information. In the aspects of generalized module analysis, Tseng et al. 9 claimed that the core of mass customization design was to use the product family architecture (PFA) to develop product. They thought that the essence of product family design is to fully identify and utilize the similarity in product design and manufacturing process. In order to apply to the product variants, a module hierarchical sharing method was proposed by Gabriel and Yoram. 10 Schuh et al. 11 studied the identification of product structure, module commonality criteria, and modular product platform. Antoine et al. 12 described a general product structure with adaptivity. The dynamic product family structure model was used to polymerize the product variant and highlight their differentiation. Sui et al. 13 proposed the function ontology model for customer demand and function–structure model for product family. A design structure matrix, with great advantages on analyzing the correlation between product system elements, is employed to establish a correlation matrix between components by Yan et al. 14 The semantic relevance, similarity was integrated to mapping hierarchical ontology matching. In the literature, 15 the research on model analysis included inclusion analysis, manufacturability analysis, comparison of parametric model, and so on.
The similarity of the non-isomorphism generalized module is implicit in a large number of product data. It is difficult to be analyzed by general data analysis method. Data mining is the key step of knowledge discovery in database, which can find out the hidden rules or information from large amounts of data. Data mining has been widely used in many fields, such as finance, medicine, biology, and agriculture. 16 In the aspects of data mining on product design and manufacturing, Song and Kusiak 17 applied data mining method to manage the diversity and complexity of product. And these rules extracted from historical sales data could be used to form sub components and configure product. Based on the strategy of assemble to order, a product module mining method was proposed by Tsai et al. 18 The modularity of mass customization product was finally realized by evaluating the overall cost of each module. In addition to the excavation of customer demand, product family model, production processes, and other resources, many researchers have studied the design process, design knowledge, platform support for mass customization, and their mining methods.19,20 Parshutin 21 studied the multi-intelligent data mining system to adapt to enterprise production planning, the main function of which is to analyze the lifecycle information in product demand and transition stage. Elliot 22 proposed a data mining theory and its process framework based on the enterprise resource planning (ERP) system. Massaf et al. 23 discussed a new mining method to analyze the product and process data by analyzing the similarity and differentiation of three-dimensional (3D) product geometric model. Tucker et al. 24 obtained product family using decision tree method, which was verified in engineering design. A data mining algorithm for product relation graph was proposed to analyze the relationship between customer purchasing power and product demand and finally get the association rules. 25 Huang et al. 26 proposed an effective numerical control machining process reuse approach by merging feature similarity assessment and data mining for computer-aided manufacturing models.
In summary, there are some studies on generalized module, module analysis, and product data mining method for mass customization design in recent years, which support strongly the product family planning and new product modeling in product development. The generalized module provides a new approach for the development of mass customization product platform; the successful application of data mining in product design and manufacturing is conducive to the excavation of product and process resources or knowledge. However, most of the existing researches9–15 focus on the similarity and reusability of the product platform elements with the same series or the same structure. The similarity of different structure elements is seldom studied (the non-isomorphism generalized modules may have the same feature in function, process, interface, variation regularity of scale, and so on). The researches on product data mining method are not very sufficient enough,16–25 such as the relative independence of the mining algorithm, the lack of integral mining system for all aspects of mass customization, and the neglect of the standardization of mining results. Due to the lack of more effective theories and methods, lots of resource and knowledge in product data are difficult to express, mine, and discovery. In fact, the implicit information of the non-isomorphism generalized module provides large mining resources. The similarity analysis can support the fast and accurate configuration, optimize the process route, and reduce the manufacturing cost. The similarity analysis method can effectively process and reuse the existing product data and make it quickly converted into the product platform for mass customization.
Description of the similarity
In traditional modular design methods, the product modules are series models with the fixed size standards, the focus of which is the generality, standardization, and serialization. The generalized modules of this article are derived from PLM database by data mining. 27 The generalized module is an extension of the traditional module, and it is the carrier of product function, geometric topology structure, and process information. The generalized module is a parameterized model with variant ability, which is driven by the parameters or variables of product structure. In this article, the generalized module is defined as a function of M

where
In this article, the generalized modules which have the same function are called function equivalence class, and the generalized modules which have the same process are called process equivalence class. The similarity analysis is to mine function equivalence class and process equivalence class from the non-isomorphism generalized module. The function equivalence class and process equivalence class are shown in Figure 1. The generalized modules M11, M12, M13, and M14 belong to isomorphism class set
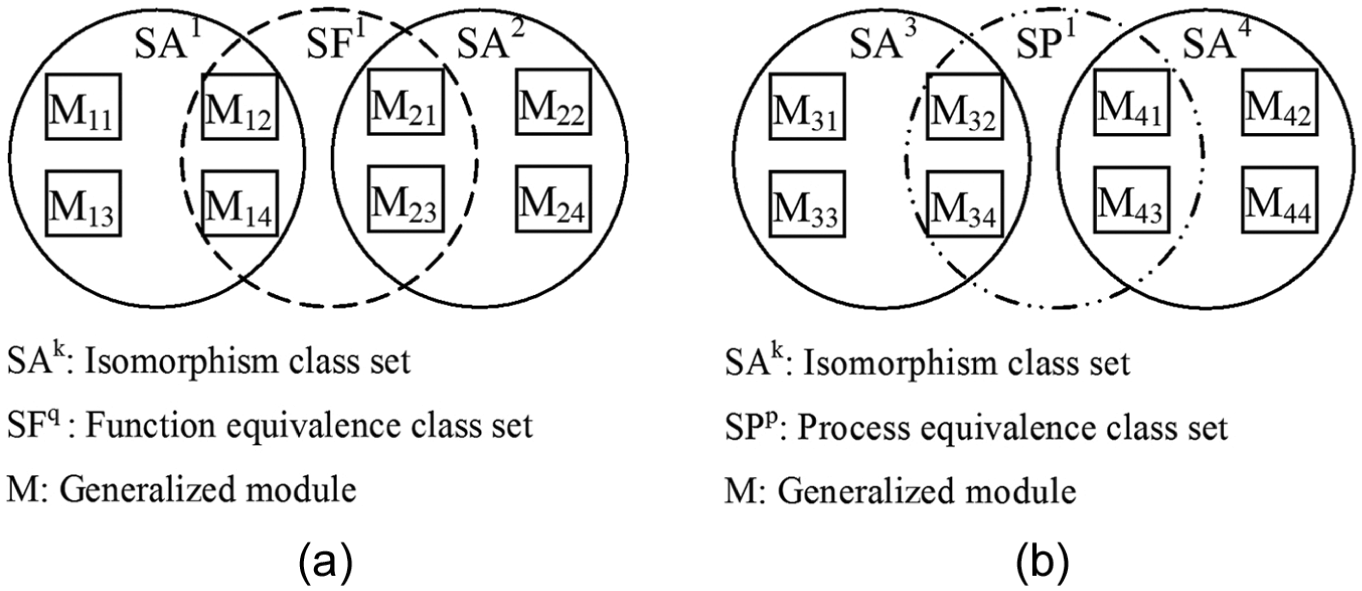
Two models in non-isomorphism class: (a) function equivalence class model and (b) process equivalence class model.
Similarity analysis method
The similarity analysis method includes the procedure of range identification, consistency analysis, vector matching, and equivalence classification. The range of the main characteristic parameters of generalized module is identified to build eigenvector first. Then, the parameters of different scales in non-isomorphism classes are normalized to eliminate the effect of different dimensions. The classification algorithm of function equivalence class and process equivalence class is proposed, which is based on the matching of the main eigenvector. The function information and process information of the generalized module are expressed in matrix, and the similarity of these data is analyzed by vector matching. As a result of the similarity analysis, function equivalence class and process equivalence class are generated by the classification algorithm. The details of this method are discussed as follows.
Range identification
The parameters’ variation range of the generalized module must be identified first before the similarity analysis. There is no comparability for non-isomorphism classes at different scales. The structure, function, and process information are extracted from the PDM/PLM database and transformed into eigenvector. This work includes the following three steps:
Step 1. The geometric information (dimension parameters and their value) of the generalized module is extracted from PDM/PLM database. All the dimension parameters are defined as the structure vector
Step 2. The function information (function codes and parameters’ value) of the generalized module is extracted from PDM/PLM database. All the function codes are defined as the function vector
Step 3. The process information (process codes and parameters’ value) of the generalized module is extracted from PDM/PLM database. All the process codes are defined as the process vector
The scales of the structure parameters may be different; the function codes and the process codes may be non-numerical data. Such problems will be processed in the next section.
Consistency analysis
The diversity of generalized module attributes is caused by the dimensional difference of the main characteristic parameters, which has a great impact on the similarity analysis. So, the values of the main characteristic parameters need to be converted into non-dimensional values. The process of conversion is called consistency analysis. The function vector
For the function vector
For the structure vector
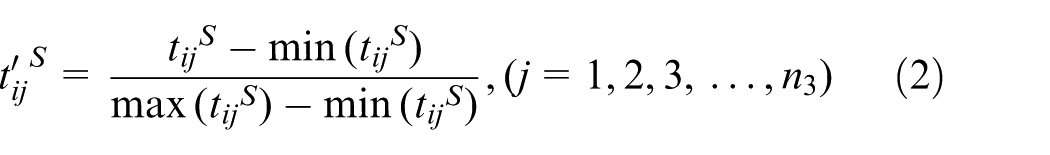
The converted value
Vector matching
The similarity analysis could be transformed into a mathematical problem of the matching of the non-isomorphism main characteristic parameters. In order to classify the non-isomorphism generalized modules into function equivalence classes and process equivalence classes, the function vectors are matched with each other. In the same way, the process vectors are matched with each other.
The function vectors are extracted to establish the function matrix
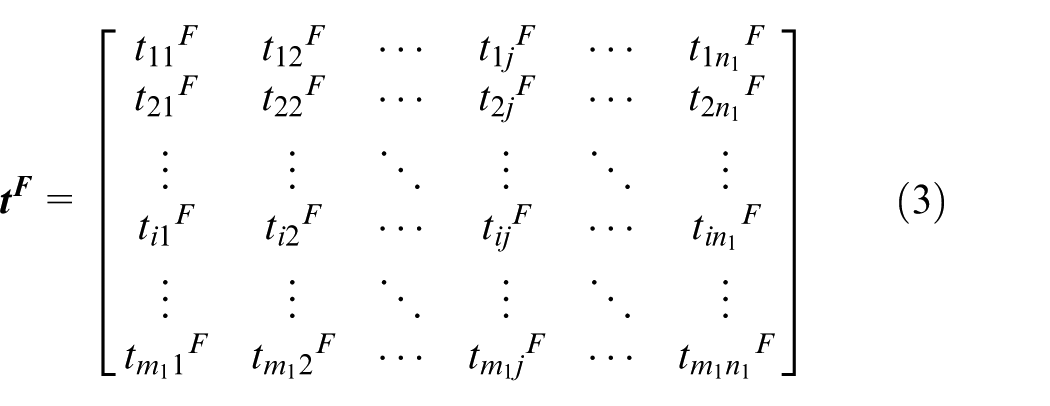
where i represents the serial number of the generalized module, and
The function matrix
Similarly, the process matrix of the non-isomorphism classes is established as follows
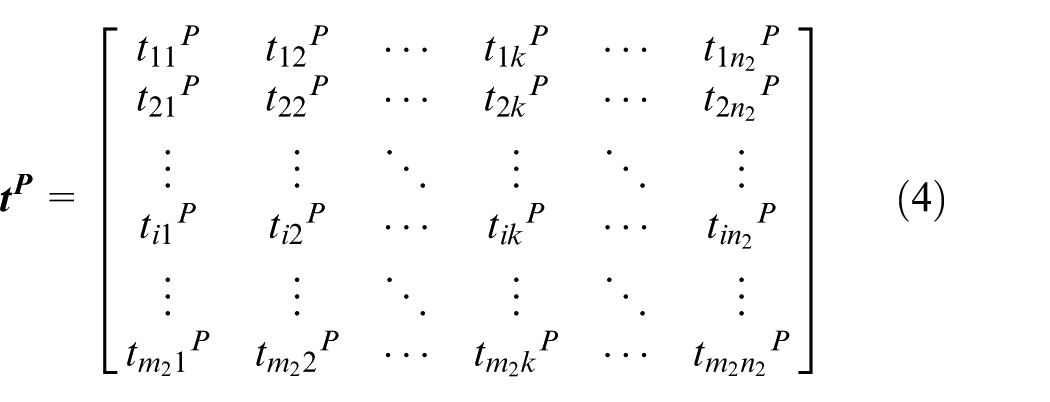
where k represents the serial number of process, and
The process matrix
Equivalence classification
In supervised learning, the purpose of machine learning is to produce a classification function or rule, which is called the classifier. The primary problem of the classification is to establish the classifier of function equivalence class and process equivalence class. According to the data characteristic of the function vector and process vector, the rule induction method is selected to build the classifier. It can be regarded as a rule set named the decision table. The decision table must be ordered; otherwise, the different rules may cross each other. The decision table
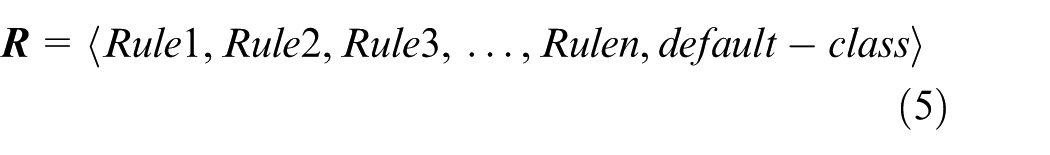
The analysis model of the function equivalence class is shown in Figure 2. The framework of the classification algorithm based on the classifier is shown in Table 1.
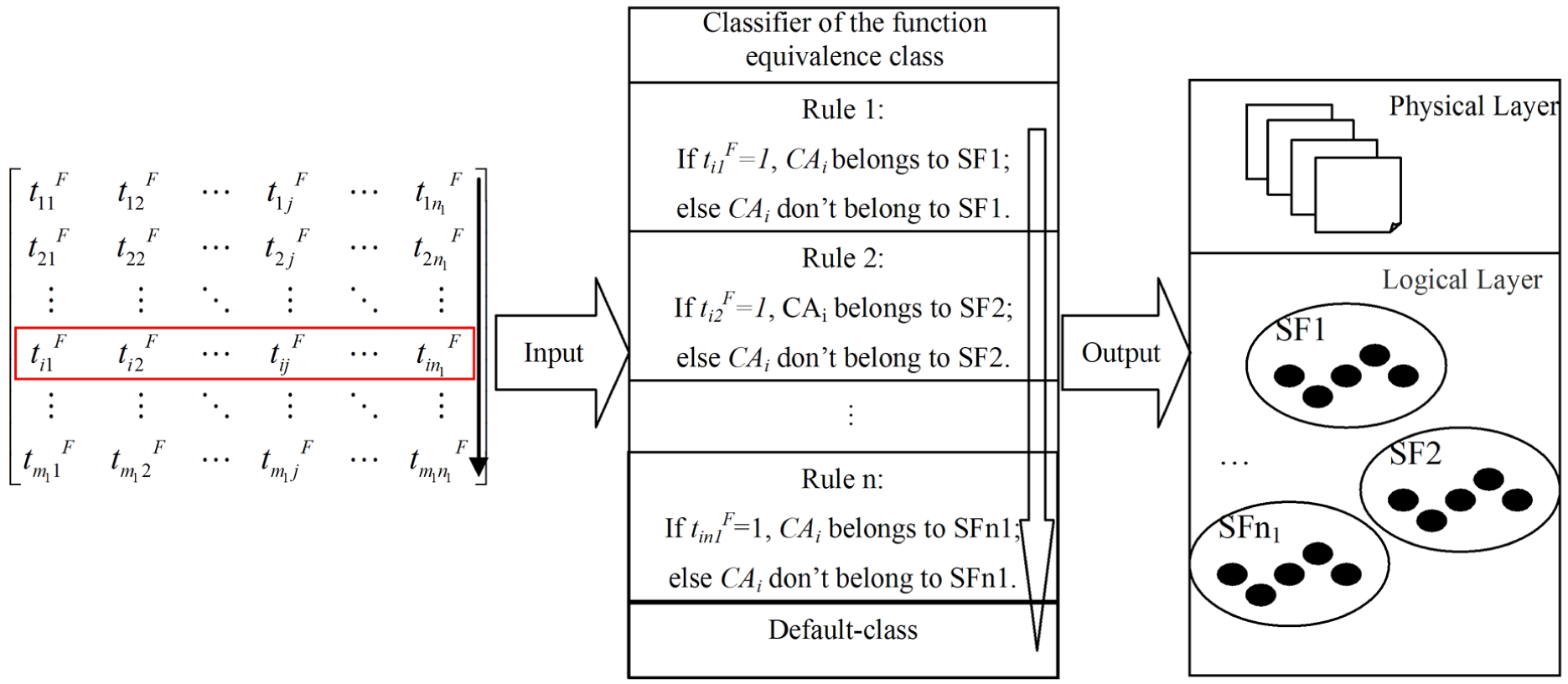
Analysis model of the function equivalence class.
Classification algorithm of the function equivalence class.

In the same way, the analysis model of the process equivalence class is shown in Figure 3, and the framework of the classification algorithm based on the classifier is shown in Table 2.
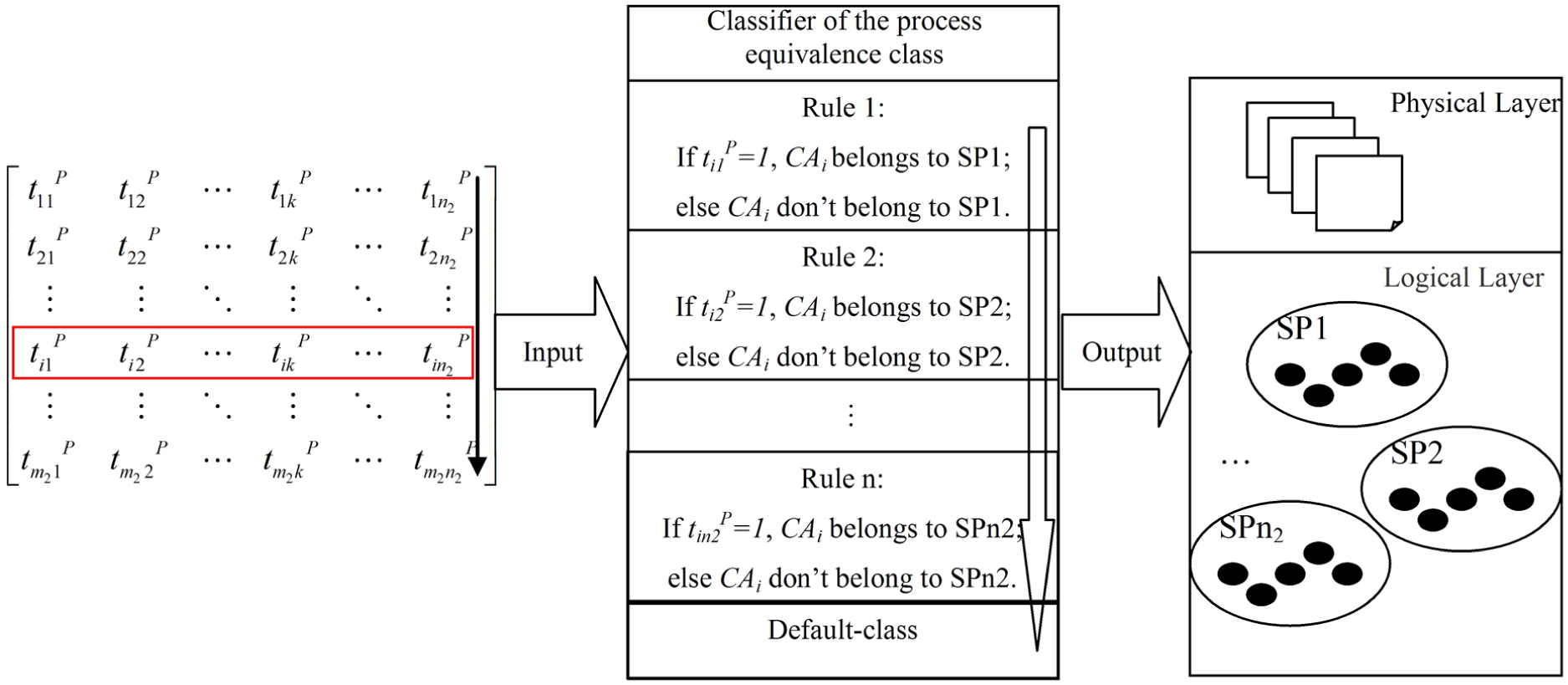
Analysis model of the process equivalence class.
Classification algorithm of the process equivalence class.

The classification of function equivalence classes and process equivalence classes is completed by the above classification algorithm. According to the results, the modules in function equivalence classes have the same or similar function features, and the modules in process equivalence classes have the same or similar process features. The generalized modules in function equivalence class can improve the flexibility of product variant and meet the requirements of customized. The generalized modules in process equivalence class can further optimize the process route, improve the processing efficiency, and reduce the manufacturing cost.
Case study
The high and middle pressure valves are taken as an example to verify the proposed method. The valve bodies of gate valve, stop valve, ball valve, check valve, and control valve belong to different valve products’ series. They are very different in structure, so they are non-isomorphism generalized modules. The structure of the five kinds of valves is shown in Figure 4.
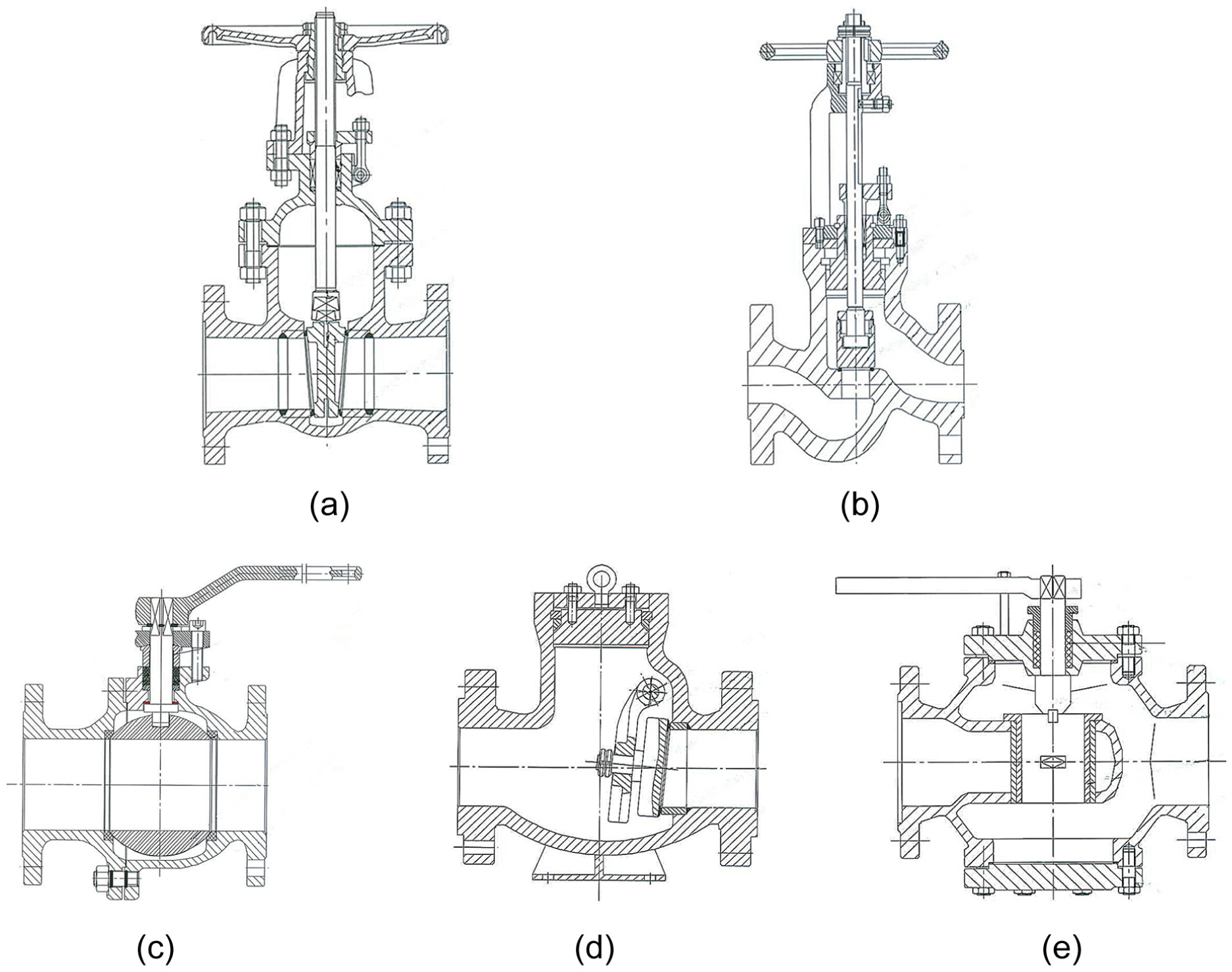
Structure of the five kinds of valves: (a) gate valve, (b) stop valve, (c) ball valve, (d) check valve, and (e) control valve.
The valve data come from the PLM database of a high-pressure and middle valve company. In order to facilitate calculation, a temporary database of the valve generalized modules is established using these data. The similarity analysis is realized on the basis of the temporary database, as shown in Figure 5.
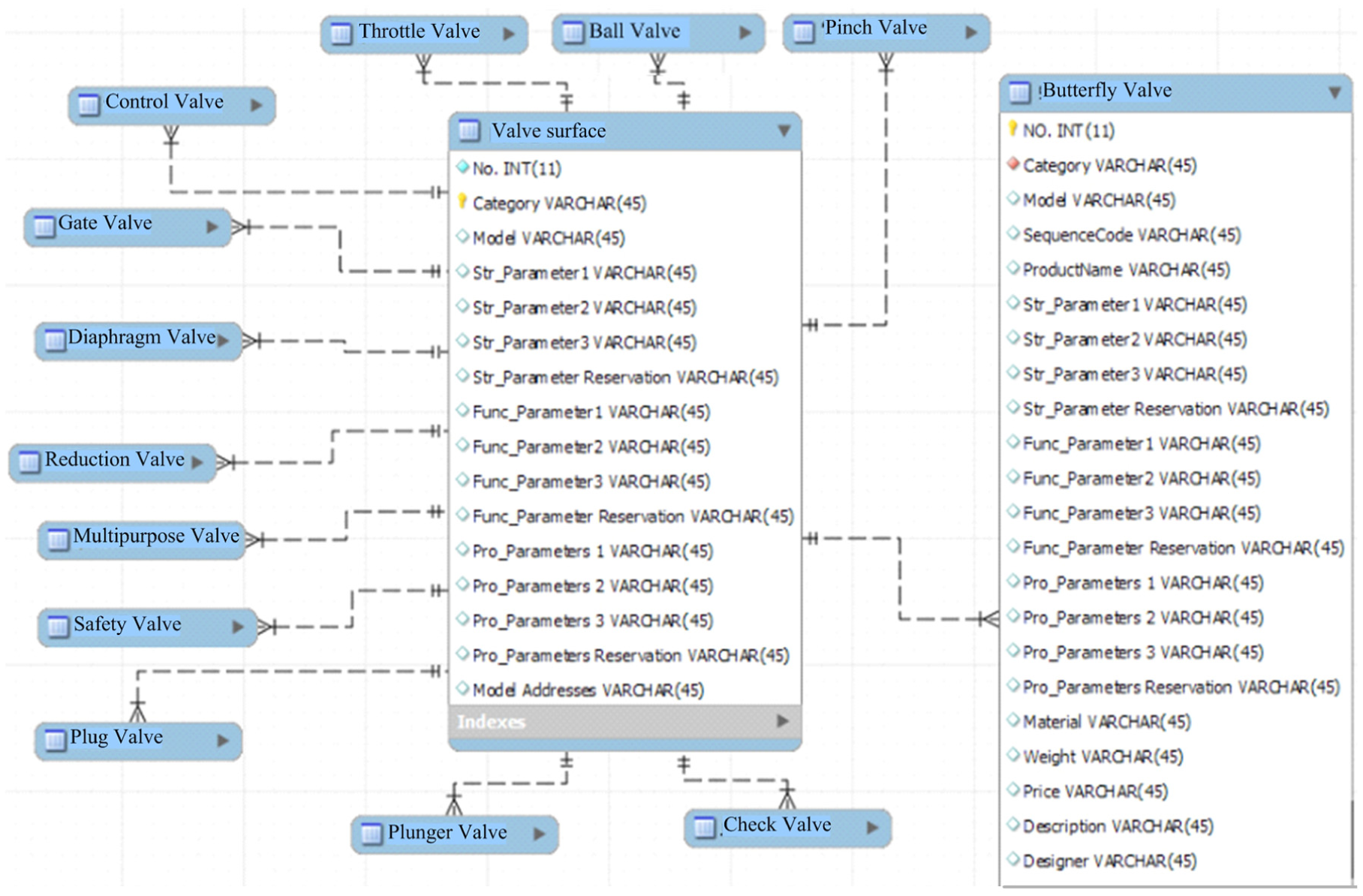
Temporary database of the high and middle pressure valve modules.
Distribution analysis of structure data
The structural data of gate valve body, stop valve body, ball valve body, check valve body, and control valve body (each 10 modules) is extracted from the temporary database to analyze its distribution by consistency analysis. The result is shown in Figure 6. The key dimensions include structural length, external diameter, middle diameter, internal diameter, and valve cavity diameter. It can be seen that each key size is presented as five categories from Figure 6, which means the five types of valve body modules are non-isomorphism class to each other. The distribution of each dimension value is uniform, which shows that the extracted data are representative.
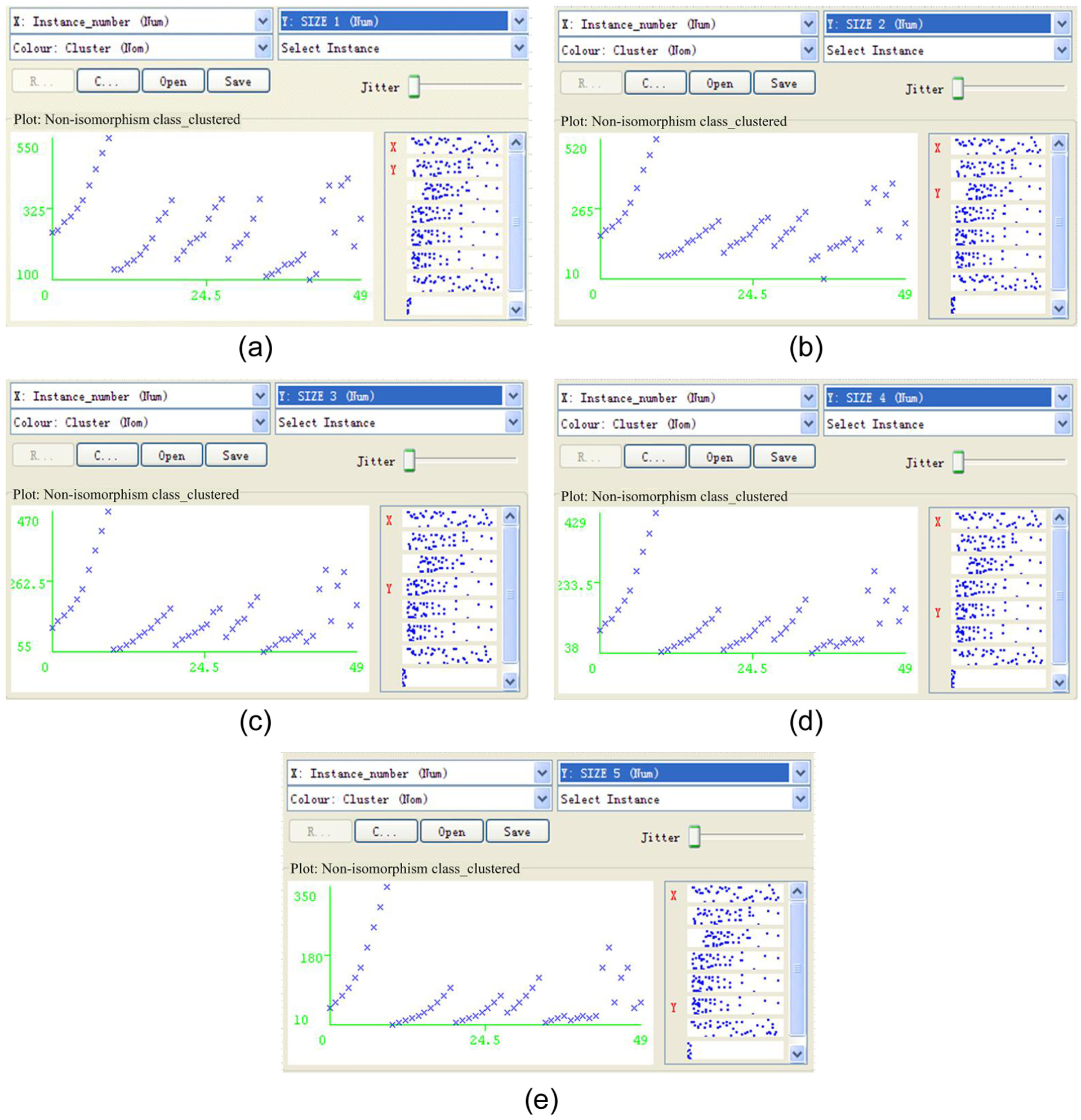
Distribution of the five key dimensions—(a) dimension 1: structural length, (b) dimension 2: external diameter, (c) dimension 3: middle diameter, (d) dimension 4: internal diameter, and (e) dimension 5: valve cavity diameter.
Establishment of the function matrix and process matrix
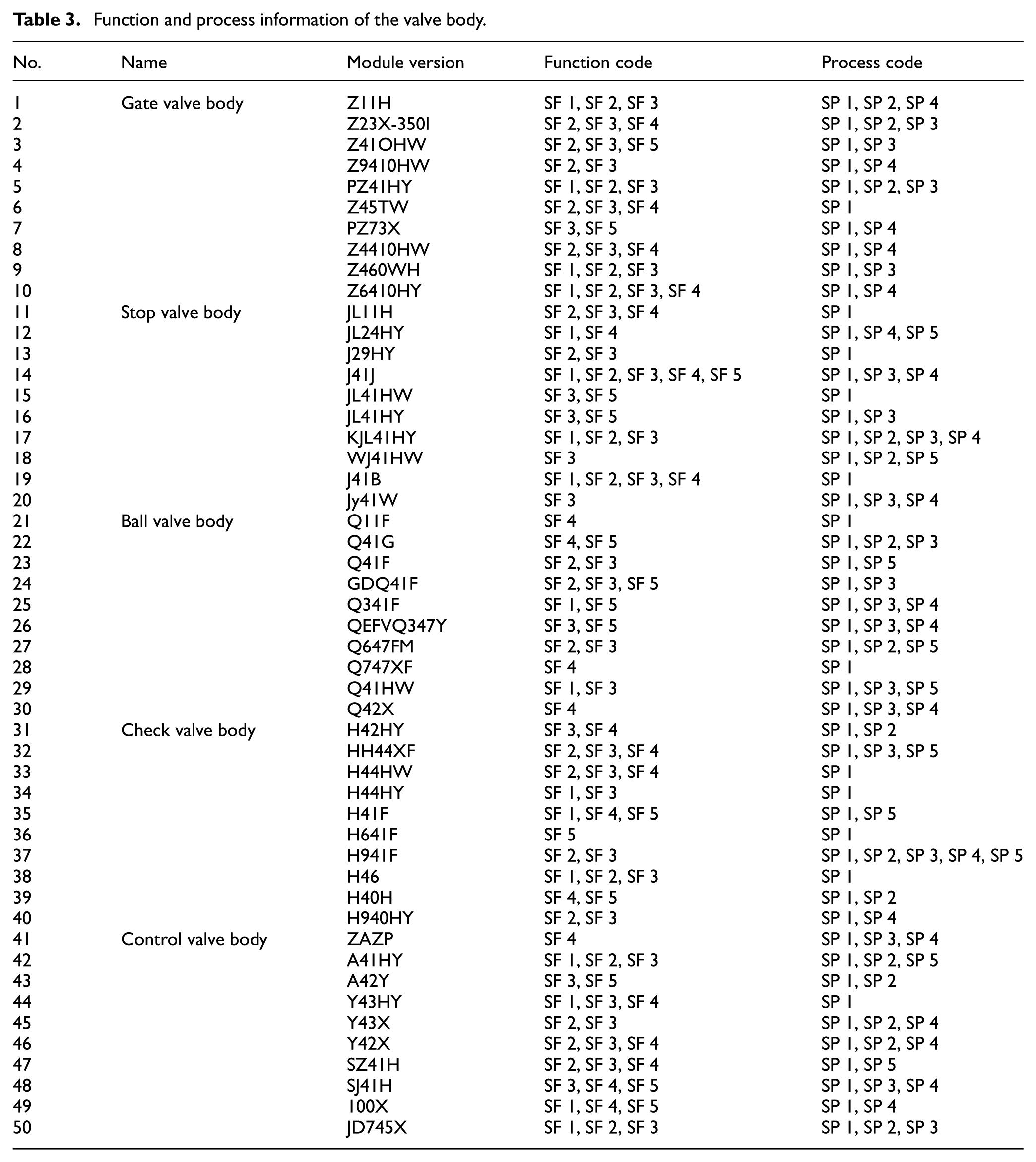
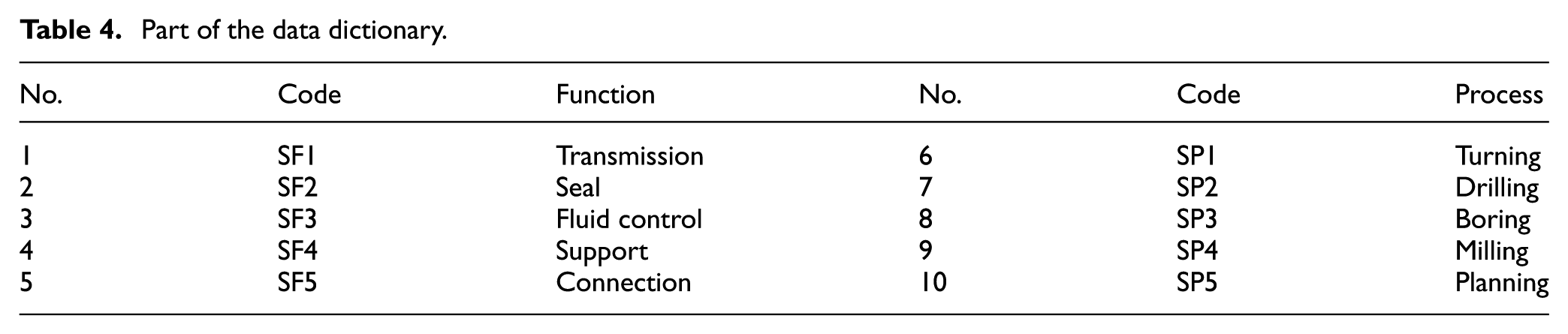
The function and process information of valve body are extracted from the temporary database by range identification of the main characteristic parameters. The frequently used functions include transmission, seal, fluid control, support, and connection. The common processes include turning, drilling, boring, milling, and planning. The extracted data are shown in Tables 3 and 4.
Function and process information of the valve body.
Part of the data dictionary.
Every function and process can be identified by two states, and the numbers 0 and 1 are used to mark the two states. The elements of the obtained matrixes are only numbers 0 and 1, which show they are the same scale. This work is done through a software filter, which transforms the non-numeric attribute value into numbers 0 and 1 as seen in Table 3. As a result, the function matrix and process matrix are shown as follows
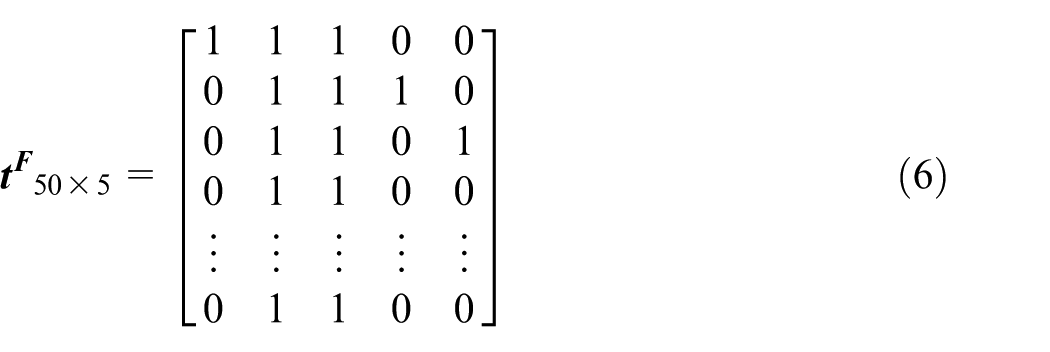
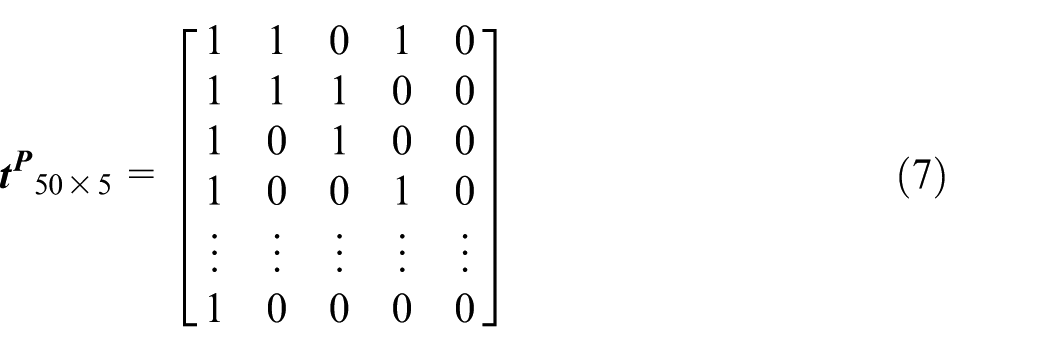
The function or process binary code of each non-isomorphism generalized module can be obtained by equations (6) and (7). For example, the body function code of gate valve Z11H is 11100, which means the valve body of gate valve Z11H has the function of transmission, seal, and fluid control.
Classification
Each row of the matrix
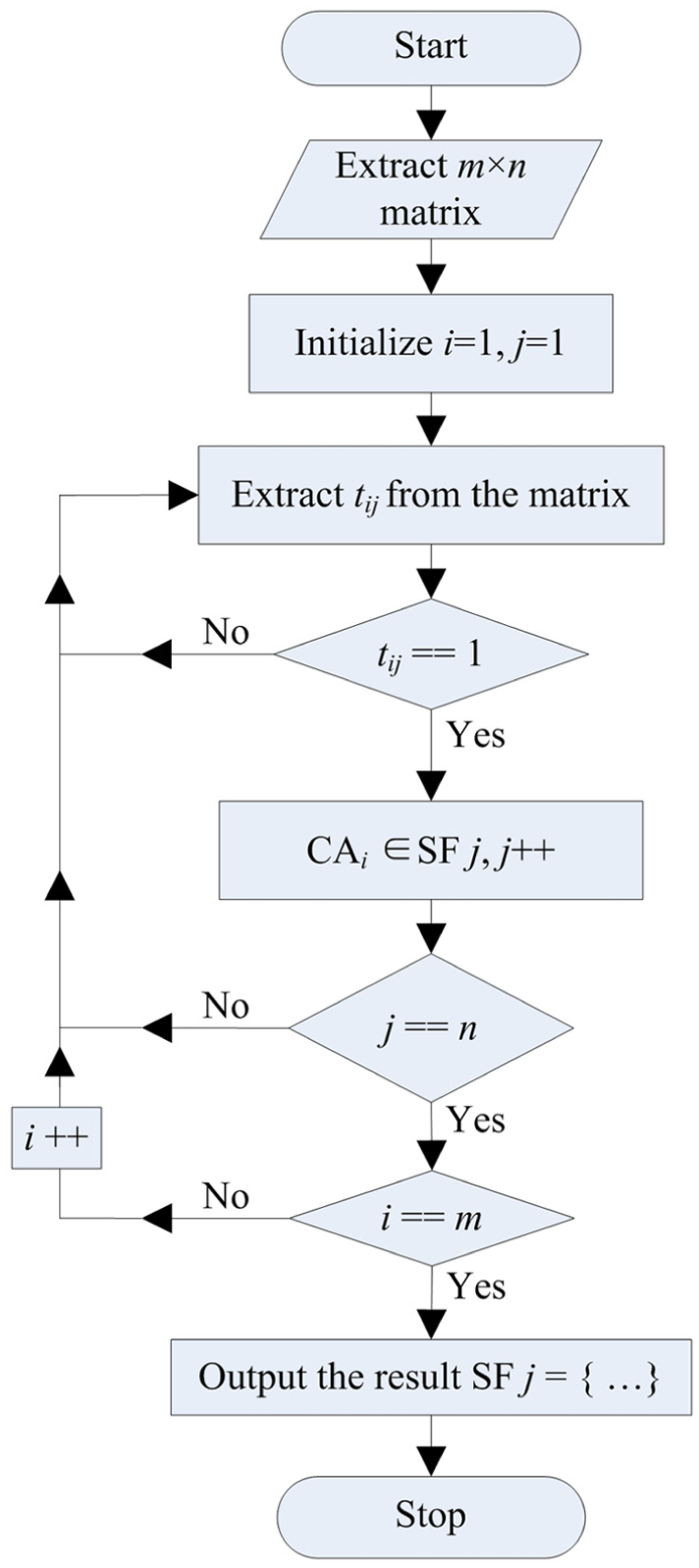
Procedure of classification algorithms.
Results of the similarity analysis
Table 5 is the function equivalence class of the high and middle pressure valves, and Table 6 is the process equivalence class of the high and middle pressure valves.
Results of the function equivalence class.

Results of the process equivalence class.

Analysis and application of the results
SF1 represents the function equivalence class 1 in Table 5, SP1 represents the process equivalence class 1 in Table 6, and CA1–CA50 represents the 50 generalized modules of valve body. It can be seen from Figure 7 that the function equivalence class 1 includes generalized modules CA1, CA5, CA10, CA12, CA14, CA17, CA19, CA25, CA29, CA34, CA35, CA38, CA42, CA44, CA49, and CA50, which means that all the above valve modules have the transmission function. The rest of the function equivalence class and process equivalence class can be introduced in the same way.
In module configuration or variant design, designers can get products’ modules not only from the same product family but also from the different product family by the proposed method. For example, a gate valve body with these functions (e.g. transmission, seal and fluid control) needs to be processed in a personalized order. According to the order, the valve body modules are searched only in the gate valve product family because the modules derived from the other valve product families are considered to have no reference value for different structural products. This design method may have shrunk the search scope and reduce the search accuracy. In fact, the valve body modules from other valve product family may meet the demands of users and also have reference in variant design especially. The proposed method searches the valve body modules from the function equivalence classes SP1, SP2, and SP3 and then finds the modules CA1, CA5, CA10, CA17, CA19, and CA42, all of which have the function of transmission, seal, and fluid control. Finally, the designers can get the valve body module meeting the demands of users by configuration or variant design. The process is shown in Figure 8. The proposed method greatly improves the search accuracy, expands the search scope, and shortens the search time. The results support the fast and precise configuration and variant design in mass customization design.
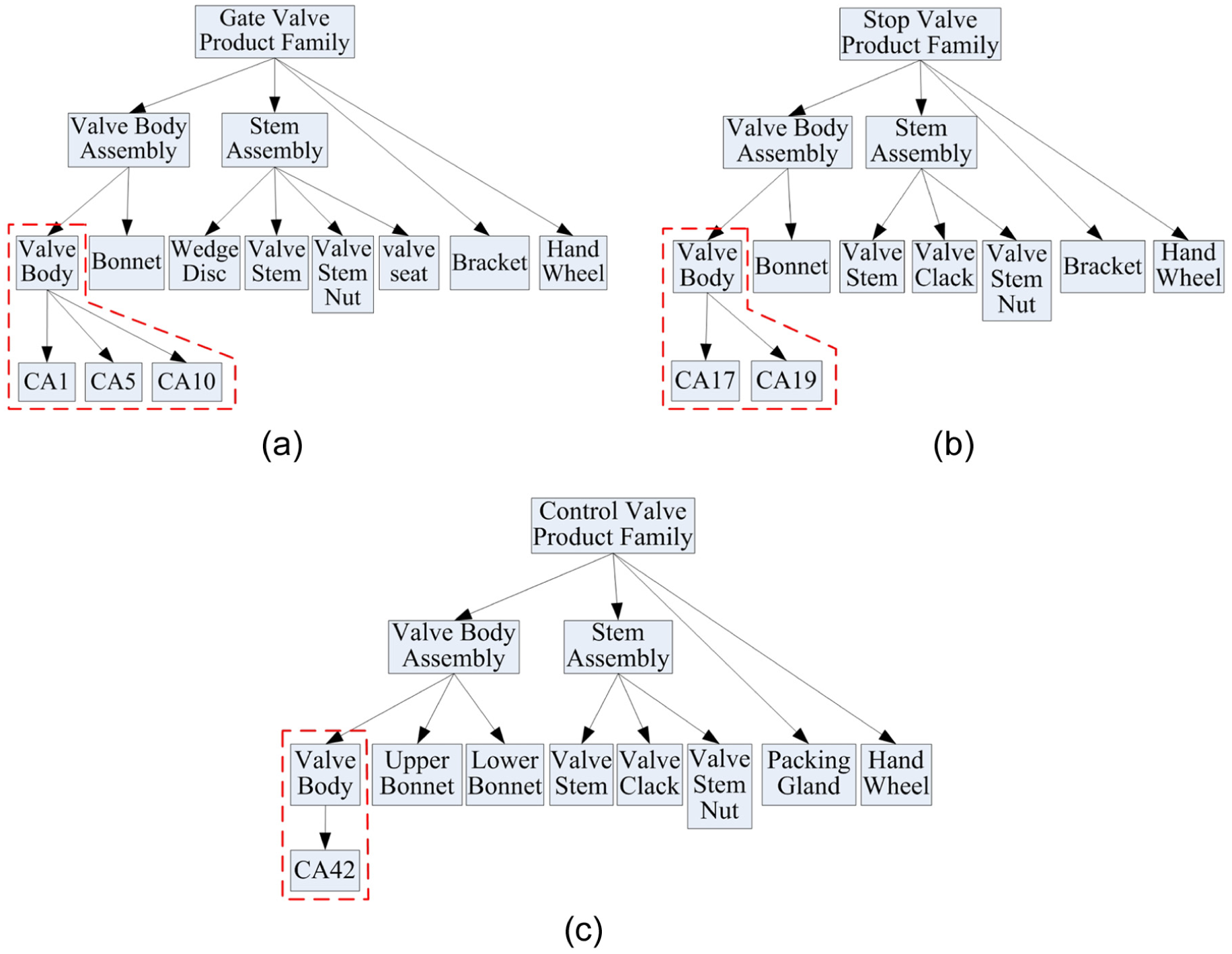
Valve body modules in valve product family: (a) gate valve, (b) stop valve, and (c) control valve.
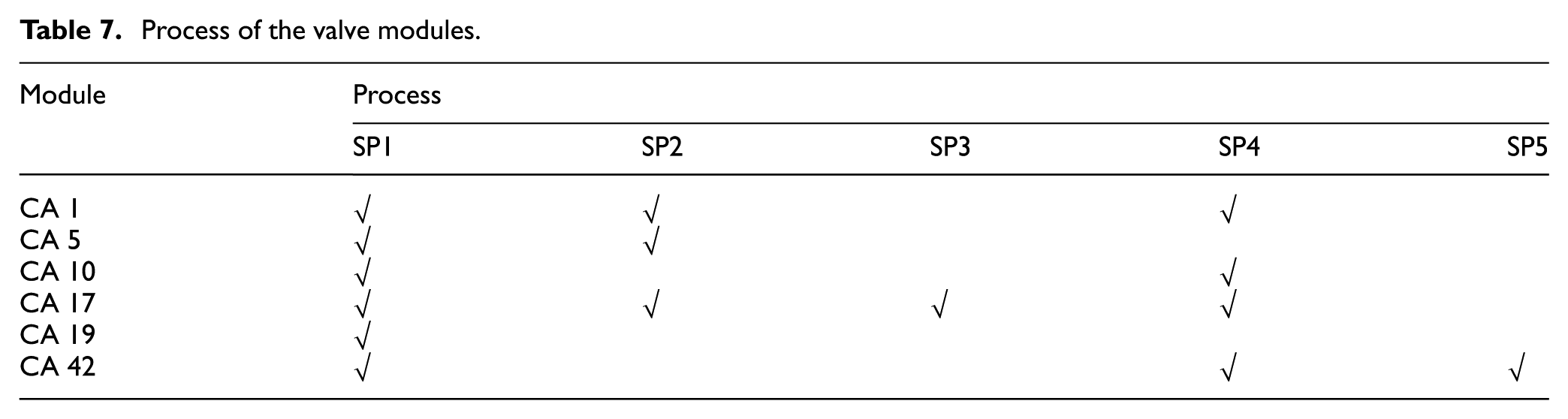
Similarly, there is also some similarity for the process route of the non-isomorphism generalized modules. The generalized modules with the same process are divided into a class by the process equivalence class. It is helpful to optimize the process route, improve the production efficiency, and save the manufacturing cost. For example, in the formulation of the process route of generalized modules CA1, CA5, CA70, CA17, CA19, and CA42, designers can find the modules with the same process from the process equivalence class, and the result is shown in Table 7. The modules with the same process (not affected by the machining sequence) will be processed centrally, which is helpful to optimize further the process route.
Process of the valve modules.
Conclusion
A similarity analysis method is proposed for the non-isomorphism generalized module, which includes range identification, consistency analysis, vector matching, and equivalence classification. Range identification and consistency analysis can effectively overcome the problems of missing data and non-unified dimension. Vector matching realizes the similarity measure of function and process information. The classification algorithms can effectively process the existing product data and convert it into the product platform for mass customization. The similarity analysis method provides a new tool for the establishment and application of the product platform.
The function and process information are stated in matrix by range identification and consistency analysis. Function matrix and process matrix are helpful to mine the hidden function and process rules in large amounts of product data. Finally, the generalized modules with different structures but same function or process are clustered into the function equivalence class or process equivalence class by the proposed method. The similarity analysis increases the flexibility of product variant, meets the needs of customization, and supports the precise configuration.
The generalized modules of gate valve body, stop valve body, ball valve body, check valve body, and control valve body are taken as a case to verify the proposed method. These different valves are divided into two equivalence classes. Designers can get more references of function or process from the valve modules with different structures for product variant design and mass customization design. The results of similarity analysis show that the proposed method is feasible and effective.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by National Natural Science Foundation of China (No. 51275362) and National Science and Technology Major Project (No. 2014ZX04015021).