
Abstract
The essence of the “ratio data” in cellular manufacturing system has rarely been correctly emphasized since past few decades of research and study. This article is an attempt to deal with cell formation problem which exploits machine utilization percentage and eliminates the “fuzziness” on the subject of ratio data. In the course of this study, a distinctive technique is adopted based on multi-criteria decision technique with significant modifications which is experimented on test data and compared with published methodology. To verify the grouping result, a novel performance measure is proposed and elaborated analytically to establish its superiority and robustness over the earlier efficiency measures published in the past literature of cellular manufacturing system. The novelty of this research remains in eradicating ambiguities on the subject of “ratio data,” imposing appropriate rules while generating the test problems, catering a unique multi-criteria decision technique–based approach and a novel performance measure for the aforesaid problem.
Keywords
Introduction
Cellular manufacturing system (CMS) is a function of group technology (GT), a manufacturing philosophy, which minimizes setup time, lead time, lot sizes, throughput and material handling cost, which further minimizes the level of the work-in-progress (WIP) and finished goods stocks in order to increase the utilization of the machines of the whole system. 1 CMS usually groups dissimilar machines into cells and similar parts into part families. Part families are then assigned to the appropriate cells depending upon their processing requirements which further enhance the total production of the system. This problem is universally known as cell formation problem (CFP) or machine-part grouping problem (MPGP). The very first step of CFP/MPGP is to acquire the near-best solution of the problem which is known as a combinatorial optimization problem which might be having numerous solutions in polynomial time (non-deterministic polynomial (NP)-complete). 2 In the past literature, the CFP/MPGP is presented with a matrix, namely, “machine-part incident matrix” (MPIM) in which all the elements are either 0 or 1 depending upon whether a particular part is being processed or not by a particular machine. This matrix data representation is known as “binary data.” Variations are found in such matrix data representations. If the unit processing time of parts is provided instead of the 1s’, then this is termed as “ratio data” and if the machining sequences of the parts are presented in the matrix, then this is named as “ordinal data.” 3
Binary cell formation is the mostly used problem in the literature of CMS. McCormick et al., 4 Rajagopalan and Batra, 5 King, 6 Chandrasekharan and Rajagopalan, 7 Srinivasan, 8 Dimopoulos and Mort, 9 Xambre and Vilarinho, 10 Durán et al., 11 Sayadi et al. 12 and so on are few of these. However, it is already a proven fact that binary cell formation only indicates the processing requirements, and in realistic production situation, cell formation implies far more than only processing requirements. These are processing time, processing sequence, machine utilization, production volume, available machining hours, machine breakdown time and many more. 13 Yet researchers are working with 0–1 CFP till present time, which is merely significant in practice at present. 14 The usage of ordinal data is being intensified in latest research of CMS.15–18
Ratio data are considered in this research which are proposed by Venugopal and Narendran 3 and being used since then.13,19,20 George et al. 19 have stated that the workload data are usually considered as ratio data in CMS, and an altered machine-part matrix is obtained using this information. The overall processing time of the job could be obtained when the total production volume and the processing time per unit are multiplied. All the “1”s in the incidence matrix are replaced with ratio values. The ratio data are finally obtained in the range of 0–1. However, authors did not particularly mention the procedure to achieve the workload ratio value (fractional figure) from total processing time data. Therefore, all the workload datasets found in the literature of CMS suffer from the lack of consistency which is further elaborated in section “Problem definitions.”
CFPs are primarily based on part coding analysis (PCA) and production flow analysis (PFA) among which PFA is mostly exploited which is based on job routing sheet rather than the shape and geometry of the parts. All the different variants of CFPs are being solved using numerous published methods, which are classified as array-based method, clustering methods, similarity coefficient–based methods, graph partitioning techniques, mathematical programming (MP) approaches and soft computing (SC) methods. 21
Array-based approaches count binary words which are presented by the rows and columns of the 0–1 matrix and adjust them in such a way that these would convert the matrix into another matrix where non-zero elements are diagonally arranged in blocks. To solve the CFPs, the use of rank order clustering (ROC) technique is moderately higher than the other array-based methods. 6 Chandrasekharan and Rajagopalan 7 and King and Nakornchai 22 have modified the ROC technique further to obtain adjusted and enhanced solutions in CMS. Other important array-based methodologies are direct clustering analysis recommended by Chan and Milner 24 and bond energy algorithm introduced by McCormick et al. 4
Generalized clustering approaches are being used in CMS with or without modifications to achieve machine-part cells since past few decades. Clustering methods could be categorized into (1) hierarchical techniques and (2) non-hierarchical techniques primarily. Among these, bond energy algorithm by McCormick et al., 4 ROC by King, 6 modified ROC by Chandrasekharan and Rajagopalan 7 and King and Nakornchai, 22 hierarchical clustering approach by Dimopoulos and Mort, 9 heuristic-based clustering method by Waghodekar and Sahu, 23 direct clustering approach by Chan and Milner, 24 matrix-based clustering approach by Kusiak, 25 non-hierarchical clustering approach by Srinivasan and Narendran, 26 generalized approach by Seifoddini, 27 hierarchical approach based on similarity and distance metrics by Shafer and Rogers 28 and improved method over ROC by Mosier and Taube 29 are the most popular clustering methods which are being widely practiced in CMS.
Similarity coefficient–based approaches are first reported by McAuley. 30 These methods exploit the similarity between two machines and put them in same or different cells based on their composite score of similarity. Some articles depict the reverse technique and compute dissimilarity coefficient scores among machines and put them in cells based on the scores achieved. Prabhakaran et al. 31 stated dissimilarity coefficient for generalized CFPs which practically introduces the operation sequences (ordinal data) and operational time (ratio data) of components. Once the similarity/dissimilarity scores are acquired, some suitable clustering techniques are employed to form a hierarchical tree structure called dendrogram to obtain the cells, and such clustering methods could be based on single linkage clustering analysis (SLCA) by Dimopoulos and Mort 9 or average linkage clustering analysis (ALCA) by Seifoddini and Wolfe. 32
In graph theory–based methods, machines are denoted as vertices (V) and the arcs’ weights (E) represent the machine similarities and the composite structure as G (V, E). Rajagopalan and Batra 5 first recommended the practice of graph theoretic approach to obtain optimal manufacturing cells. Chandrasekharan and Rajagopalan 7 suggested an ideal-seed non-hierarchical clustering approach which utilizes graph theory efficiently in CMS. Ballakur and Steudel 33 offered a graph searching algorithm which selects a pivot machine or part based on a pre-definite norm and forms the cells around the pivots. Minimum spanning tree (MST) for the CFP is used by Srinivasan. 8 An MST of machines could be obtained in first stage and in later stage the part family seeds are spawned using previous MST. A graph theory–based NP-algorithm for optimal cell design termed as vertex-tree graphic matrices is developed by Veeramani and Mani. 34
Various MP methods are successfully practiced in the domain of CMS. Among these, integer linear programming (ILP) is used by Kusiak 25 and Rabbani et al., 35 goal programming (GP) is proposed by Shafer and Rogers, 28 dynamic programming (DP) is practiced by Ballakur and Steudel 33 and linear programming (LP) is introduce by Boctor. 36 Ramabhatta and Nagi 37 proposed some branch-and-bound (B&B) technique to obtain block diagonal formation which minimizes inter-cell material flow considering complementary routings of the parts being processed. MP methods are extremely popular since these tools are highly capable of dealing with the real-life constraints and practical aims for manufacturing firms while obtaining ideal cellular structure on shop-floor. These techniques are two-phase techniques. In the first phase, the objectives and constraints of manufacturing firm are presented in the form of mathematical equations and inequalities, and in the latter phase, the model is solved using an appropriate optimization algorithm/tool.
Lately, the soft computing–based methods became hugely popular for solving the CFPs due to its proven ability of optimizing large and complex data, for example, Tabu search approach,38,39 neural network,40–42 genetic algorithms (GAs),43–49 simulated annealing10,50,51 and other latest nature-inspired algorithms such as particle swarm optimization (PSO), 11 ant algorithm, 52 firefly-inspired algorithm 12 and bacteria foraging algorithm (BFA). 53 These techniques are capable of achieving better solutions; however, these are not reasonably quick in terms of central processing unit (CPU) time. Furthermore, the time complexity becomes higher with the increasing number of jobs and machines for the problem.
In this article, a typical CFP is demonstrated which employs machine utilization percentage as the major criterion of cell design. Thereafter, a novel machine-part ranking technique is adopted which is a multi-criteria decision technique (MCDT) model based on analytical hierarchy process (AHP). This technique is considerably modified using machine utilization percentage as an important factor. This proposed methodology is verified on few datasets and successfully compared with McQueen’s 54 K-means method. To measure the goodness of the obtained solutions, a new performance measure called utilization-based grouping efficiency (UGE) based on machine usage is also proposed, and finally, an analytical study is presented on the UGE to establish its superiority and robustness over other published efficiency measures for ratio data.
The remainder of this article is prepared in the following order. Section “Problem definitions” would discuss the problem considered in this article. Section “AHP-based algorithm” demonstrates the methodology adopted in a systematic manner. Section “Performance measure” reports the detailed discussion on the new grouping measure UGE, section “Results and discussion” portrays the results acquired and analyzes the significance of the aimed approach and section “Conclusion” concludes this study.
Problem definitions
As per the stated ideas, many articles are authored in the domain of CMS, but very few of these particularly addressed the “processing time” or “ratio data” in practical and scientific manner. As it was first demonstrated by Venugopal and Narendran, 3 the proposed problem is re-defined here in the following manner

where tij is the unit processing time (hour/unit) of part j on machine i; 1 ⩽ i ⩽ q and 1 ⩽ j ⩽ p, nj is the production volume of part j, MHi is the available machine hours of machine i, U = [uij] is an (p × q)-machine-component incidence matrix where uij is the percentage utilization of machine i induced by part j.
Conditions imposed

For each part j

Equation (1) generates an MPIM U which is widely recognized as “processing time” matrix. However, the elements (uij) of matrix U do not indicate any absolute values; therefore, these should not be dubbed as “processing time” realistically. These values are percentage values (hours ÷ hours); hence, these are unit-less.
uij expresses the fraction of machine hours of machine i being utilized to produce the total volume of a particular part j on the machine i. Therefore, a novel idiom is adopted in this article, “percentage utilization of machine” or “machine utilization factor,” which is more sensible and relevant than “processing time.”
For that matter two conditions (equations (2) and (3)) are imposed on equation (1).
Condition 1
Equation (2) shows that value of uij is either zero or non-zero depending upon the processing requirement of a particular part j on a particular machine i.
Condition 2
Equation (3) shows that the total percentage utilization of machine i for all parts must not be theoretically larger than 1 because the total utilization (TU) of a machine can never be more than 100%. However, in actual scenario, a particular machine is never being used for all the time as long as the shift runs on shop-floor. Therefore, total machine utilization for a particular machine remains in the range [0.1, 0.9] realistically and equation (3) is modified as

Problem instance
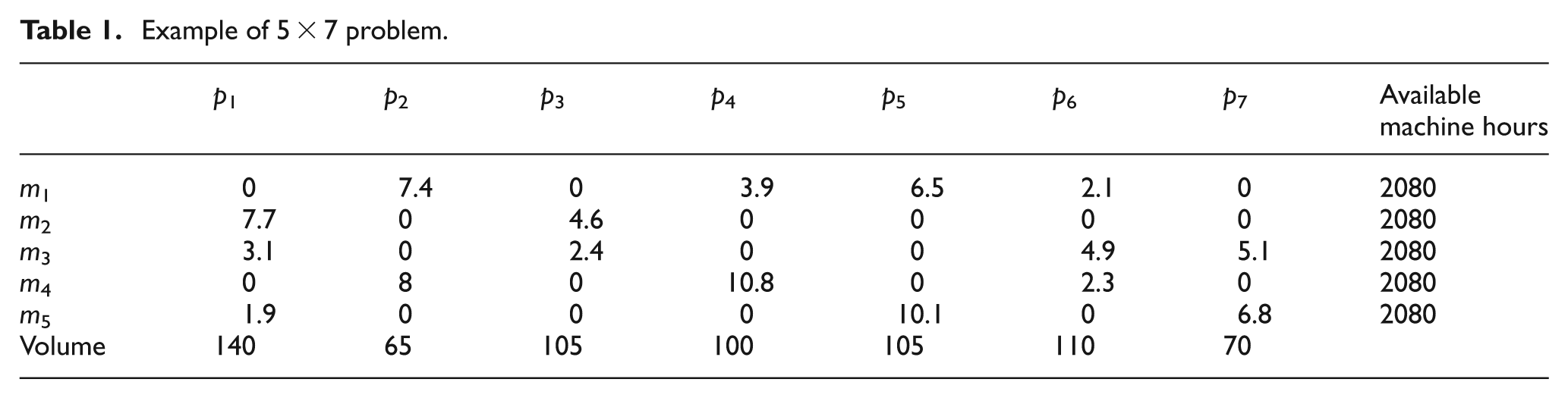
An example of the stated problem is depicted in Table 1 for five machines and seven parts with unit processing time (hour/unit), production volume and available machine hours. Using the stated method, the U matrix is obtained and shown in Table 2 satisfying all conditions.
Example of 5 × 7 problem.
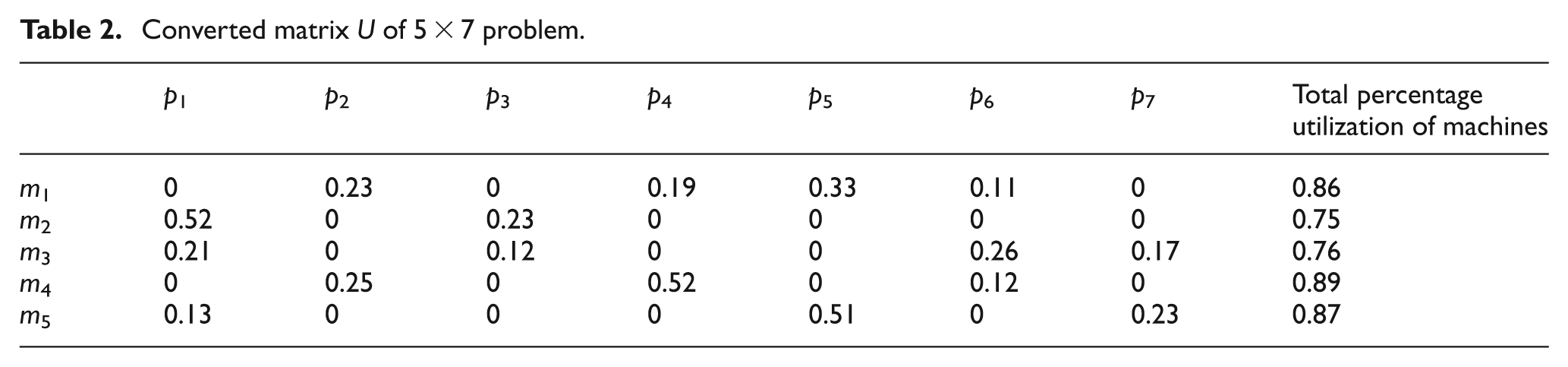
Converted matrix U of 5 × 7 problem.
AHP-based algorithm
The AHP method used in this article is a multi-criteria decision approach (MCDA) which uses hierarchical relations among machines and parts to represent the CFP. AHP allows the decision makers to correspond to the crossing points of various factors in complex and uncertain scenario. In his pioneer work, Saaty 55 stated that the priorities for alternatives are obtained depending upon the viewpoints of the experts in the area of study. Assuming a CFP has q criteria (machines), m1, m2,…, mq, and n alternatives (parts), p1, p2,…, pn, every alternative is assessed relating to the q criteria. The said approach is grounded on the pairwise comparison of alternatives relating to the criteria. These pairwise comparison matrices could be attained (q × q), q is the number of comparing criteria. The adopted AHP algorithm is demonstrated herewith.
Step 1
The relational hierarchy of the 5 × 7 test problem (Table 1) is shown in Figure 1. The problem is dismantled into three levels: 55 The first level reports the primary objective: cell formation, the second level depicts the criteria (machines) and the third level portrays the alternatives (parts) to be compared.
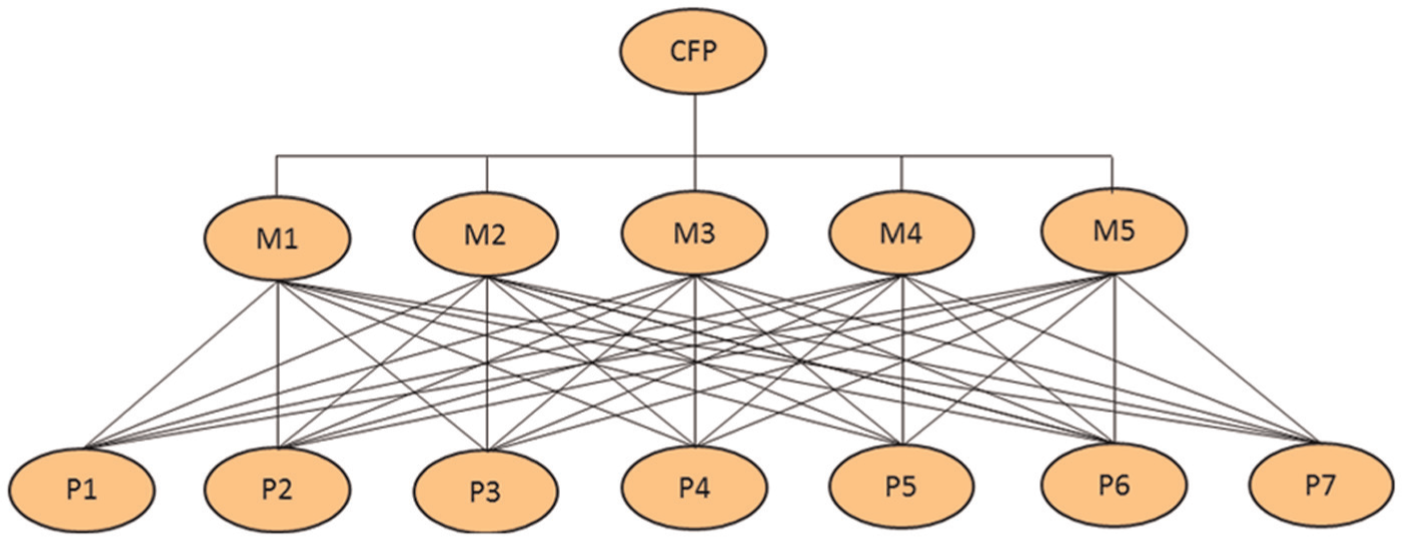
Relational hierarchy of the cell formation problem (CFP).
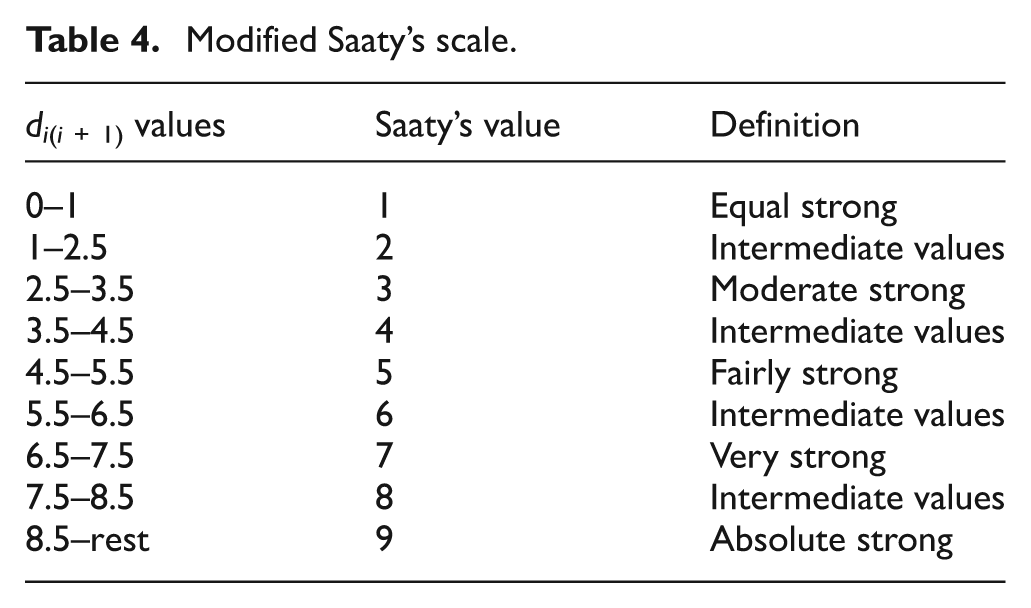
Step 2
The pairwise comparison of each level can be obtained using computing formula provided in equations (5)–(9). To achieve this, a ranking scale is necessary for evaluation of criteria. 55 Saaty’s scale is portrayed in Table 3. To assign these values to the criteria, AHP questionnaire sheet is required on which experts’ opinion could be obtained. This implies that the qualitative factors are being converted into numerical values to ease the computation.
Saaty’s 9-point scale. 55

The abovementioned phenomena cannot be directly adopted for MPGP. Therefore, substantial modification is performed in this article to adopt Saaty’s scale for CFP.
Step 2.1
For each machine i, the total percentage utilization is computed using

These values are listed in the last column of Table 2. According to the proposition of equation (4), these values remain between 0.1 and 0.9.
Step 2.2
The largest and smallest TU values are obtained from Table 2, and the “scaling factor for criteria” (σc) is obtained using equation (6)
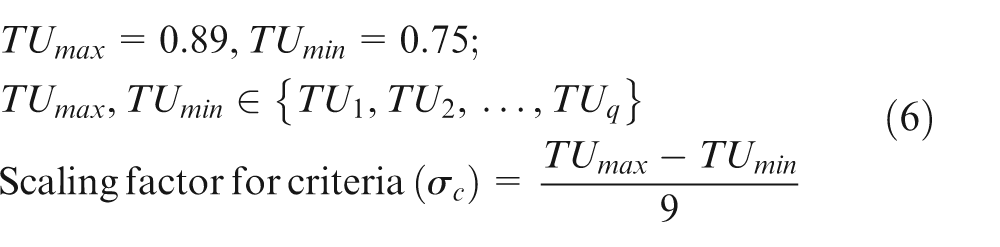
For the example problem considered, the value of scaling factor (σ) is 0.02.
Step 2.3
At this point, the pairwise comparison matrix for criteria (q × q) is believed to be formed. For that matter, each criteria is believed to be compared with another. Here, this comparison is done using equation (7)

di(i + 1) c is the distance between machine i and machine i + 1. This value is mapped with the modified Saaty’s scale suggested in Table 4.
Modified Saaty’s scale.
Thereafter, the pairwise comparison matrix is formed with all the di(i + 1). If the value of di(i + 1) is +ve, that is, machine i has more priority over machine i + 1 and if value of di(i + 1) is −ve, that is, machine i + 1 has more priority over machine i. Using equation (7) and Table 4, the pairwise comparison matrix is obtained and depicted in Figure 2.
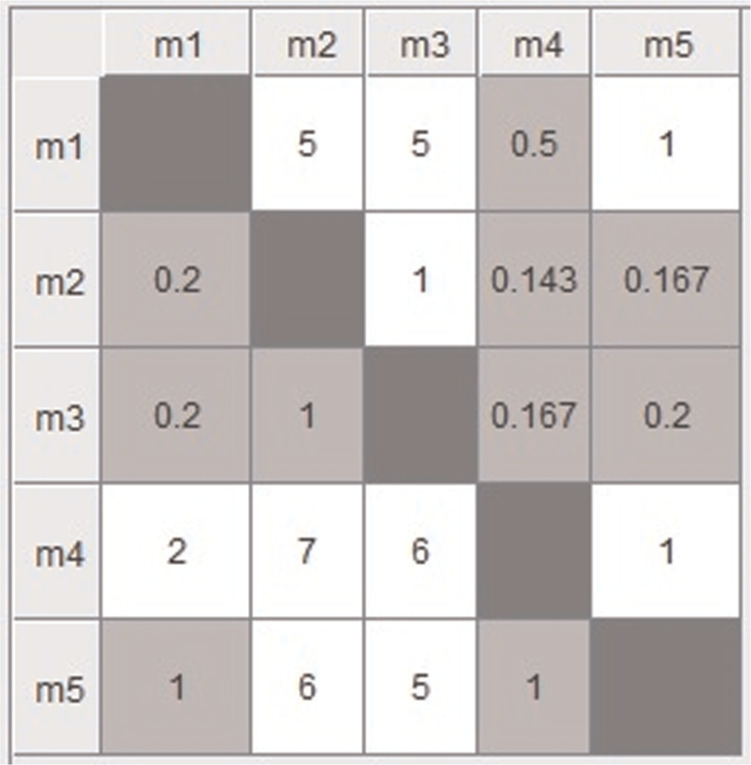
Pairwise comparison matrix of criteria (machines).
Step 3
Calculation of the pairwise comparison matrix for all the alternatives (parts) with respect to each criterion (machine) is performed using a minute modification added with the prior step.
Step 3.1
The largest and smallest uij values are obtained from Table 2 and the scaling factor for alternatives (σa) is obtained using equation (8)
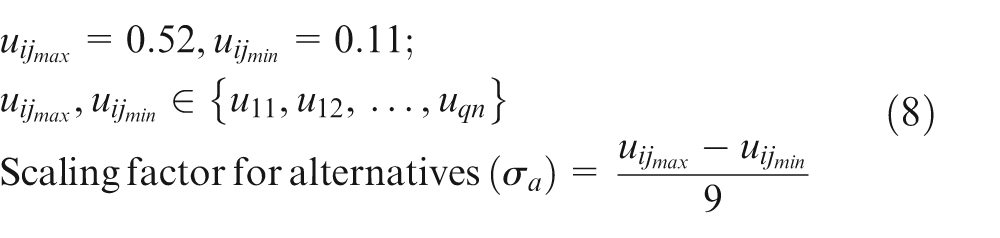
For the example problem considered, the value of scaling factor for alternatives (σa) is 0.05.
Step 3.2
At this point, the pairwise comparison matrices for alternatives (q × q) are believed to be formed. For that matter, each alternative is believed to be compared with another. Here, this comparison is done using equation (9)

dj(j + 1) a is the distance between part j and part j + 1 for every machine i. This value is mapped with the modified Saaty’s scale suggested in Table 4.
Thereafter, the pairwise comparison matrices are formed with all the dj(j + 1). If the value of dj(j + 1) is +ve, that is, part j has more priority over part j + 1 and if value of dj(j + 1) is −ve, that is, part j + 1 has more priority over part j. Using equation (9) and Table 4, the pairwise comparison matrix for every criterion (machine) is obtained and depicted in Figures 3–7.
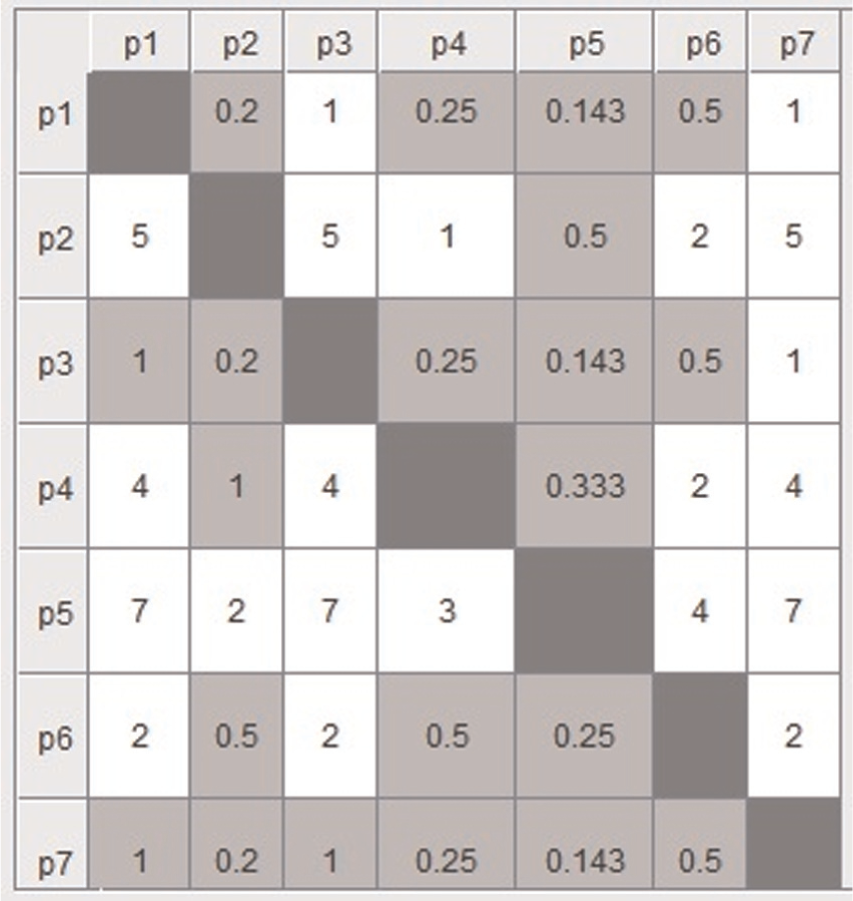
Pairwise comparison matrix of alternatives (parts) for criterion 1 (machine 1).
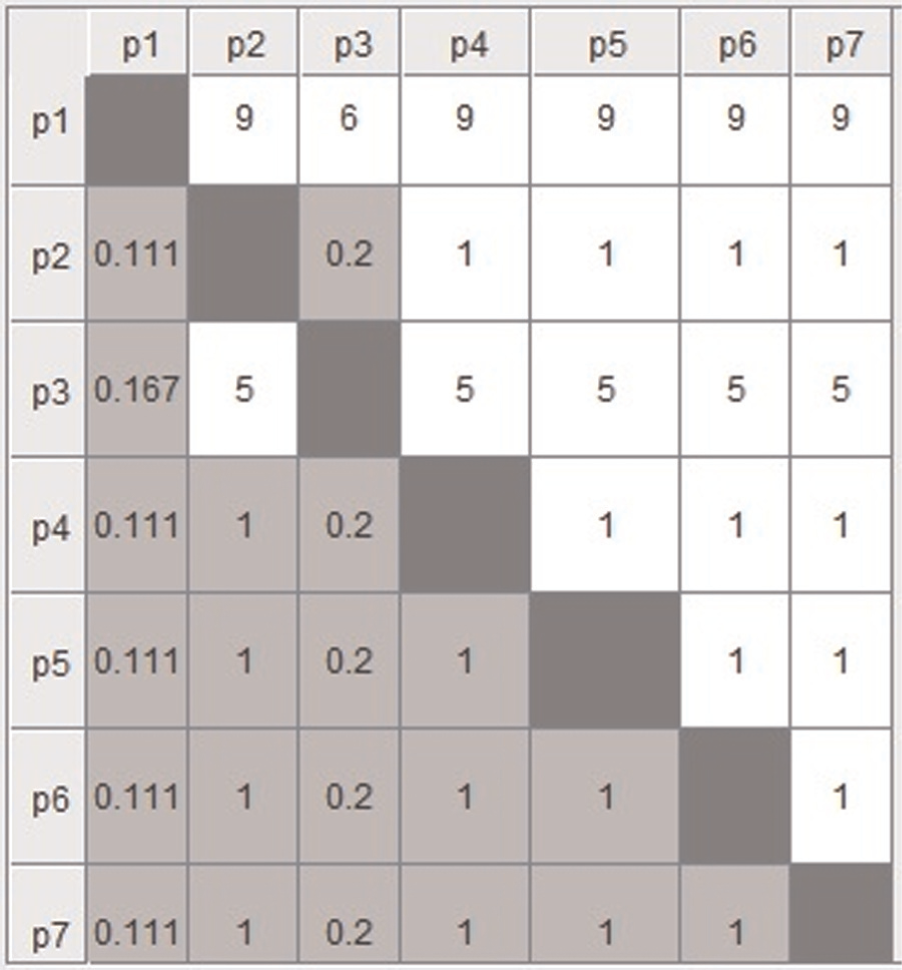
Pairwise comparison matrix of alternatives (parts) for criterion 2 (machine 2).
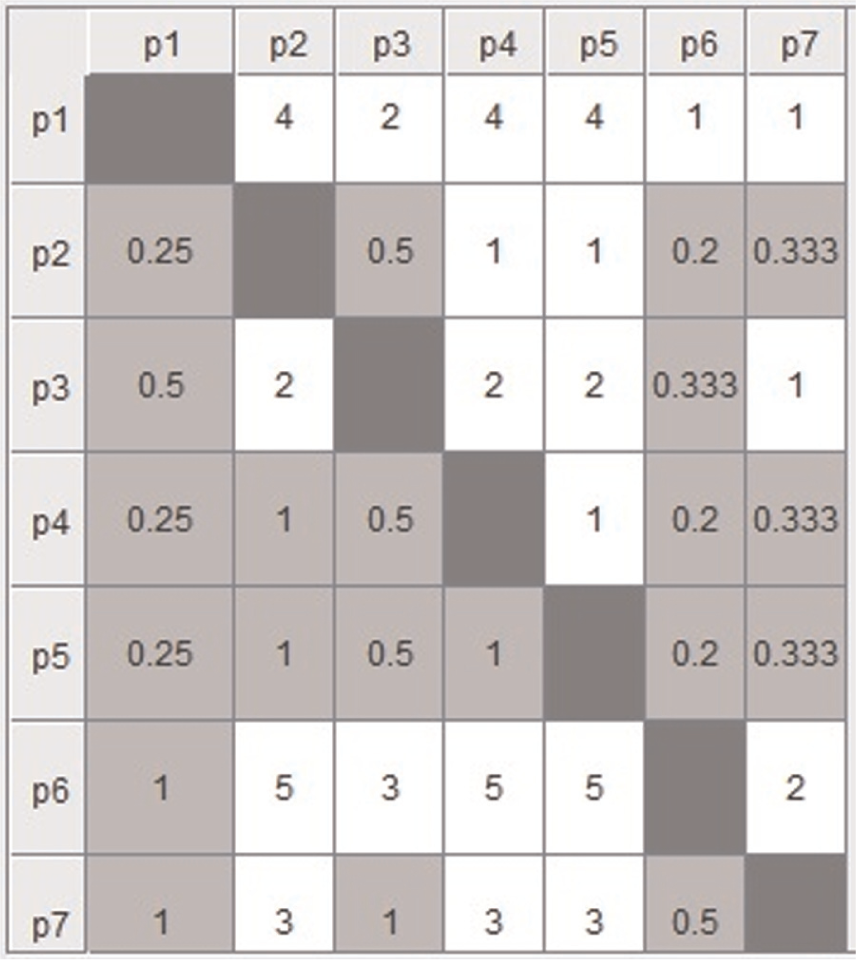
Pairwise comparison matrix of alternatives (parts) for criterion 3 (machine 3).
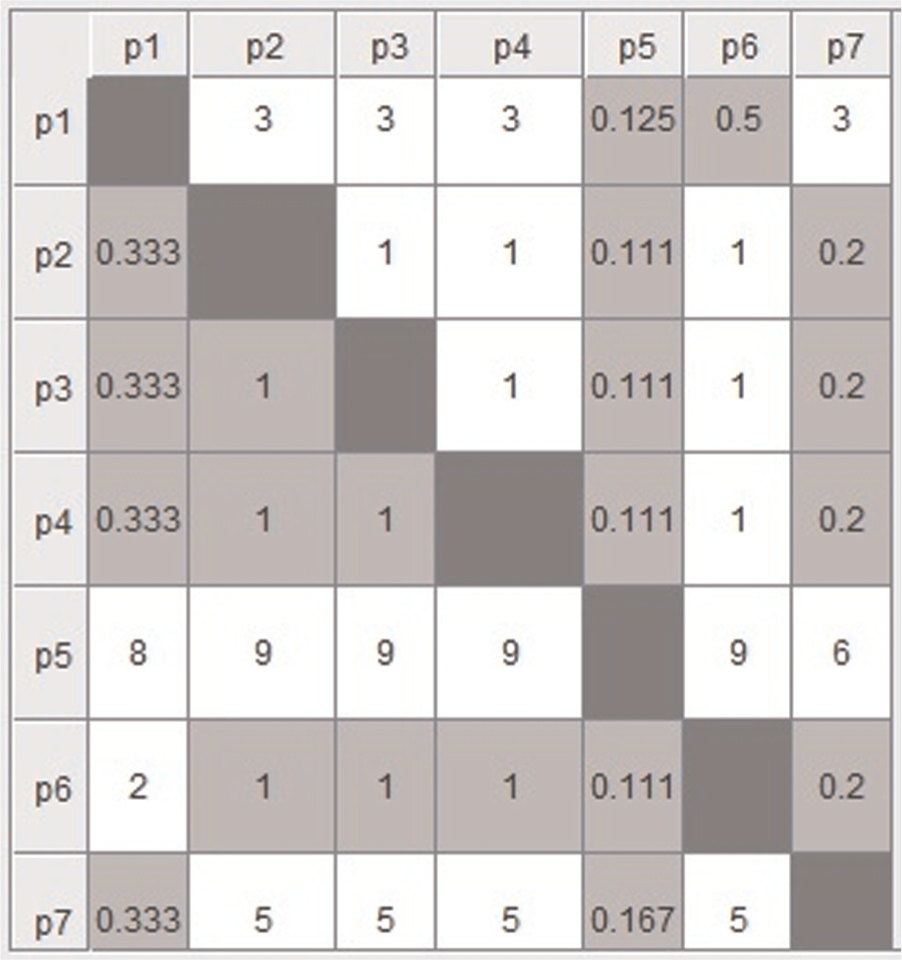
Pairwise comparison matrix of alternatives (parts) for criterion 4 (machine 4).
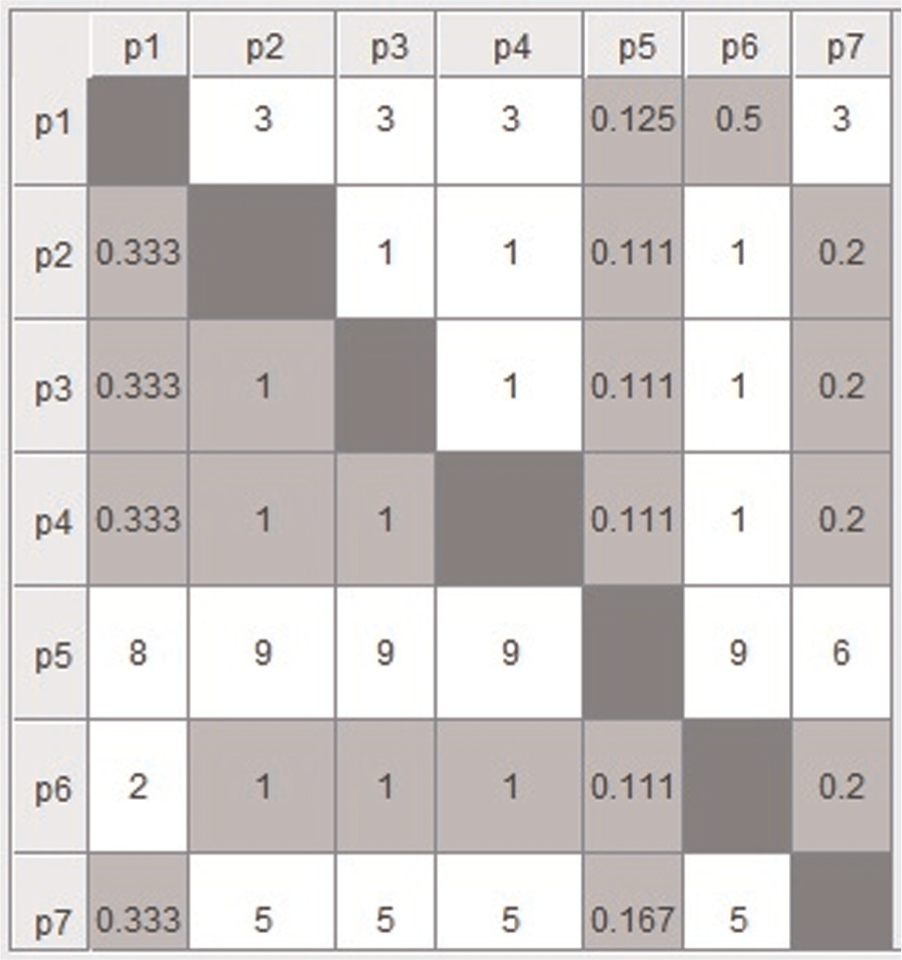
Pairwise comparison matrix of alternatives (parts) for criterion 5 (machine 5).
Step 4
Once all the pairwise comparison matrices are obtained, a generic AHP computing algorithm is applied and the respective relative weights for each matrix is obtained and presented in Tables 5–10.
Weights of the criteria over each other.

Weights of the alternatives over each other for criterion 1.

Weights of the alternatives over each other for criterion 2.

Weights of the alternatives over each other for criterion 3.

Weights of the alternatives over each other for criterion 4.

Weights of the alternatives over each other for criterion 5.

Hence, the generic AHP algorithm to compute relative weights is stated hereunder as presented by Ghosh et al. 56 Consider [By = λmaxy] where B is the comparison (m × m), where m is the number of criteria; y denotes the Eigenvector (m × 1); and λmax is the Eigenvalue, λmax ∈ ℜ > m.
Eigenvector Y can be obtained using the following algorithm:
1. Initialization:
1.1. matrix B is multiplied with the same to obtained square matrix, that is, B2 = B × B
1.2. Sums of rows of B2 are obtained which is further normalized to find E0.
1.3. Assign B: = B2
2. Main:
2.1. matrix B is multiplied with the same to obtained square matrix, that is, B2 = B × B
2.2. Sums of rows of B2 are obtained which is further normalized to find E1.
2.3. Obtain D = E1 − E0.
2.4. If all the elements of D are near to zero value, assign Y = E1
2.5. else assign B: = B2, assign E0: = E1 and go to Step 2.1.
2.6. STOP.
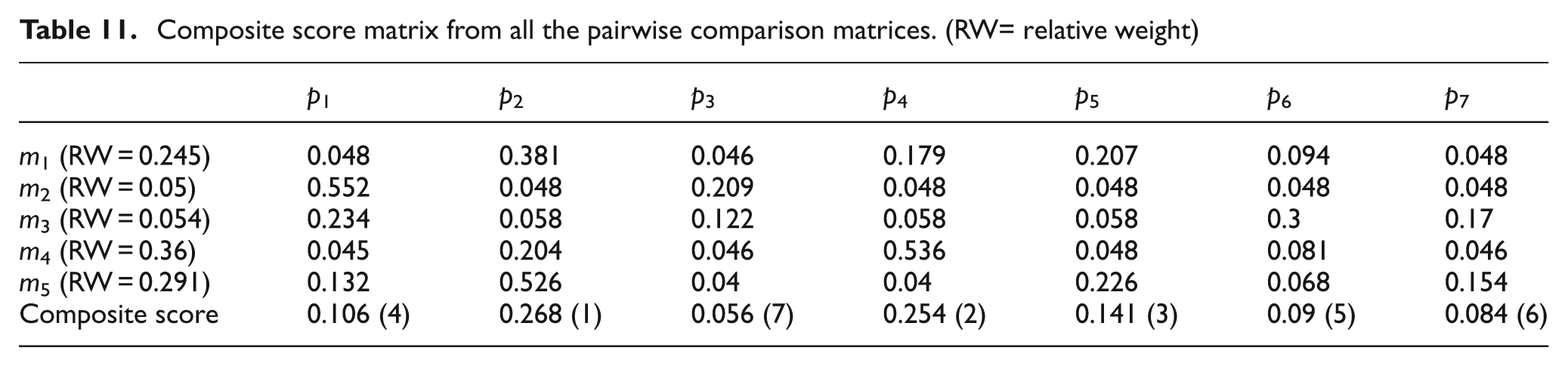
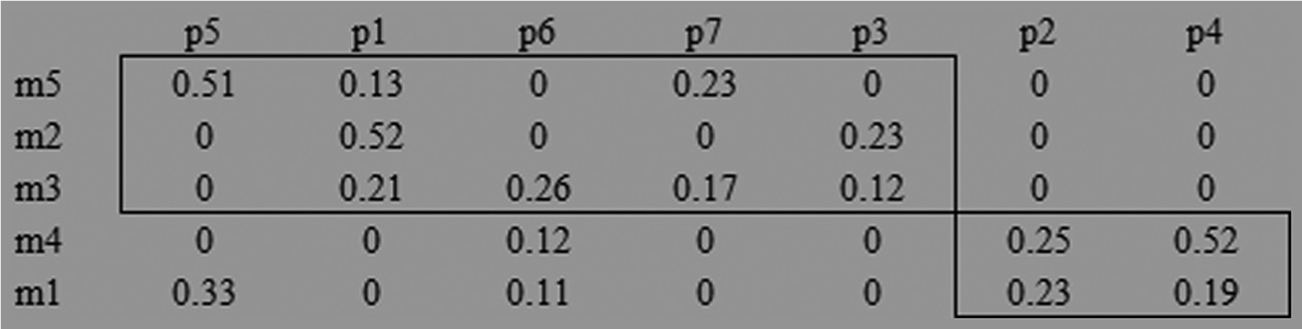
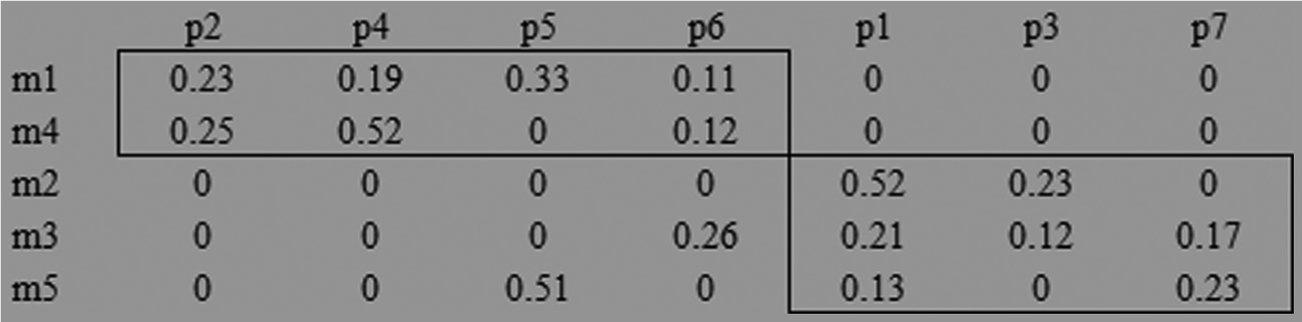
Thereafter, relative weight factor obtained for each criterion and the alternatives are multiplied. Then, the total rating of each alternative is calculated by adding these obtained values (Table 11). Table 11 demonstrates that part 2 is the highest ranked part with composite ranking “1” and composite score “0.268” followed by parts 4, 5, 1, 6, 7 and 3.
Composite score matrix from all the pairwise comparison matrices. (RW= relative weight)
Machine ranking method
Subsequently, the machines are ranked using the identical technique. For that matter, the machines are assigned as alternatives and the parts are assigned as criteria. After the composite score computation, the machine ranks are obtained and demonstrated in Table 12. Table 12 demonstrates that machine 5 (overall ranking is 1 and composite score is 0.28) is the highest ranked machine followed by machines 2, 3, 4 and 1.
Composite scores for all the machines and ranks.

Finalizing the cell formation solution
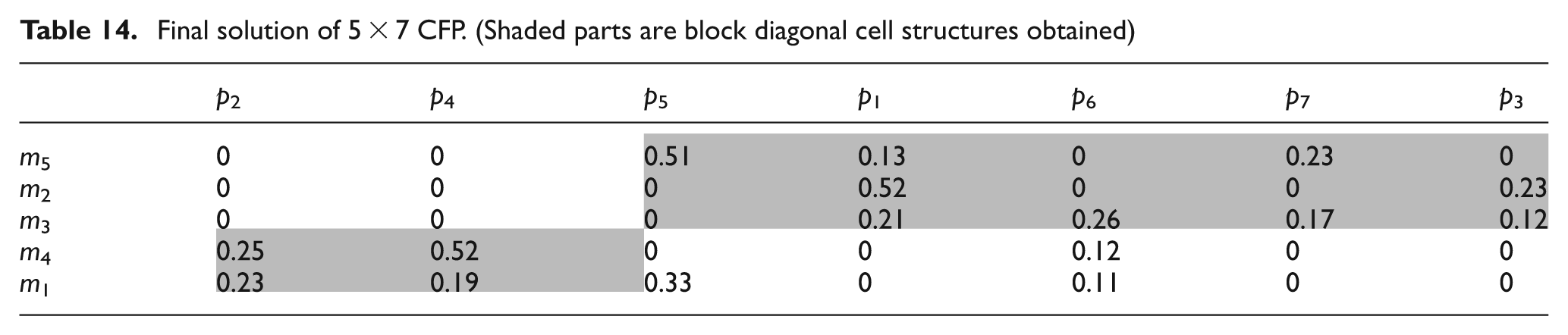
In the final step, the machines and parts of the initial CFP that are obtained in Table 2 are ordered with their ranks obtained from Tables 11 and 12. This newly formed ordered machine-part incidence matrix is portrayed in Table 13. The block diagonal structure which indicates the group of machines and parts in cells can be used to determine the cellular structure. For the present 5 × 7 problem, the block diagonal cellular structure is depicted in Table 14 and the details of the cells are shown in Table 15.
Final solution of 5 × 7 CFP.
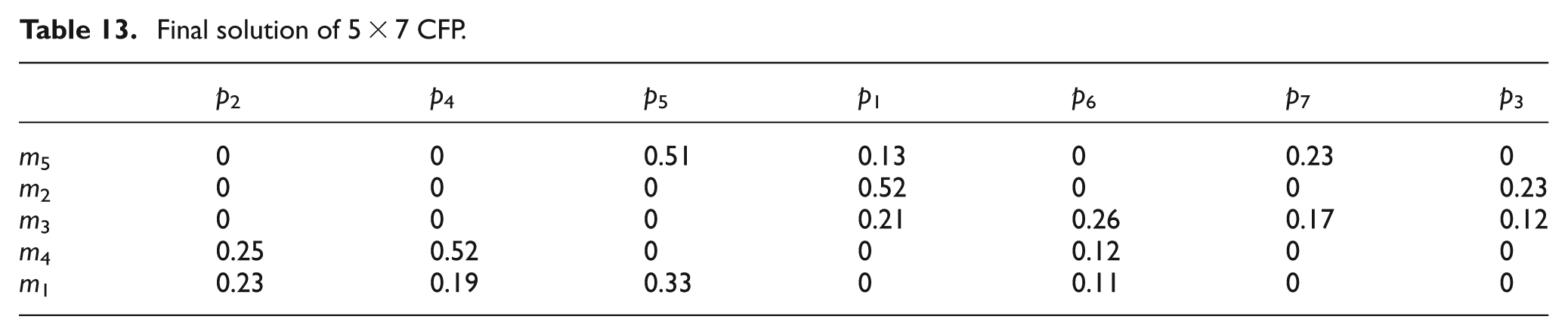
Final solution of 5 × 7 CFP. (Shaded parts are block diagonal cell structures obtained)
Details of cellular configuration.

Performance measure
According to the past literature, there are two mostly explored measures are grouping efficiency by Chandrasekharan and Rajagopalan 7 and grouping efficacy by Kumar and Chandrasekharan 57 , which are heavily being used to verify the clustering efficiency of machine cells obtained by an appropriate grouping method. However, these two measures do not work with ratio data since these are designed for binary data. Therefore, these measures are incapable to handle CFPs with percentage utilization of machines. Generalized grouping efficacy developed by Zolfaghari and Liang 44 is designed to handle CFPs where ratio data are considered. However, generalized grouping efficacy overlooks the influence of voids in the machine cells, which primarily affects the quality of the solutions obtained for CFPs. For that matter, Ponnambalam et al. 58 proposed another performance measure which suitably deals with ratio data–based CFP and considered exceptional elements and void efficiently. This measure is known as modified grouping efficiency (MGE)
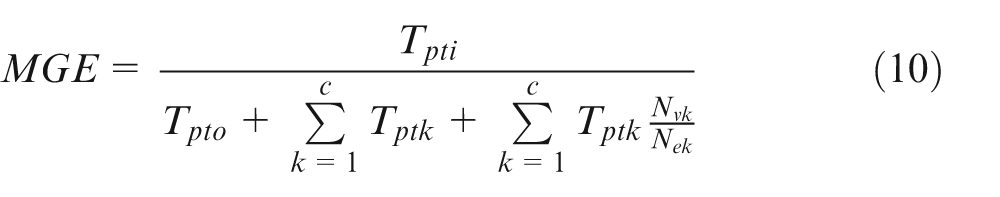
where Tpti is the total processing time inside the cells, Tpto is the total processing time outside the cells, Tptk is the total processing time of cell k, Nvk is the no. of voids in cell k and Nek is the total number of elements in cell k.
However, MGE is capable of checking the effect of the number of exceptional elements only, but it fails to investigate the influence of the numerical values (percentage utilizations) of the exceptional elements. Hence, a novel performance measure for CFP dubbed as UGE has been introduced in this article that competently deals with percentage utilization (ratio data) matrix with all the facts ignored in all the previously published performance measures.
Few rules are believed to be considered while designing an efficient grouping measure for the ratio data–based CFP. These rules are as follows:
Rule 1. The holistic utilization of all the machines in the whole plant is always constant. This numerical figure is substantially significant while designing a performance measure.
Rule 2. Number of voids and exceptional elements should be integrated in the design.
Rule 3. Consideration of utilization of each individual cell is important since presence of voids influences the cumulative in-cell utilizations.
Rule 4. The ratio of the utilization of all the exceptional elements and the total in-cell utilization should be incorporated in design which not only considers the number of exceptional elements but also the utilization (numerical figure) of exceptional elements.
Following all the rules described, the new performance measure UGE is proposed in this article. The UGE is defined using following equation (11)
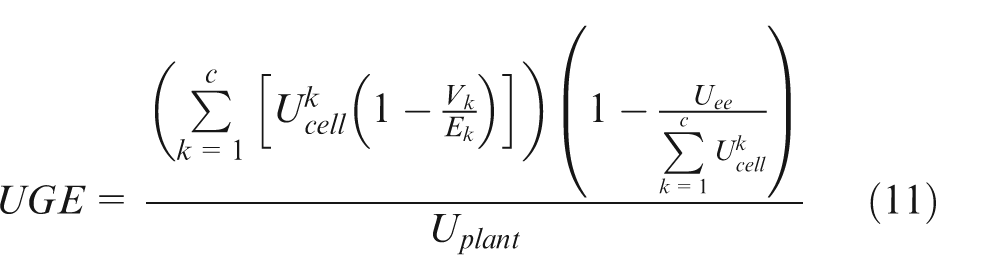



where c is the number of cells, m is the number of parts, p is the number of machines, k is the index of cell {k = 1, 2,…, c}, i is the index of machines {i = 1, 2,…, m}, j is the index of parts {i = 1, 2,…, p},
Due to the qualitative differences among various performance measures, some suitable sensitivity analysis and a qualitative analysis are required 59 to authenticate this newly developed performance measure. Hence, the following discussion would depict the in-depth comparison among UGE and its nearest predecessor MGE. It would also be portrayed that all the facts which are ignored while designing MGE are accomplished in UGE.
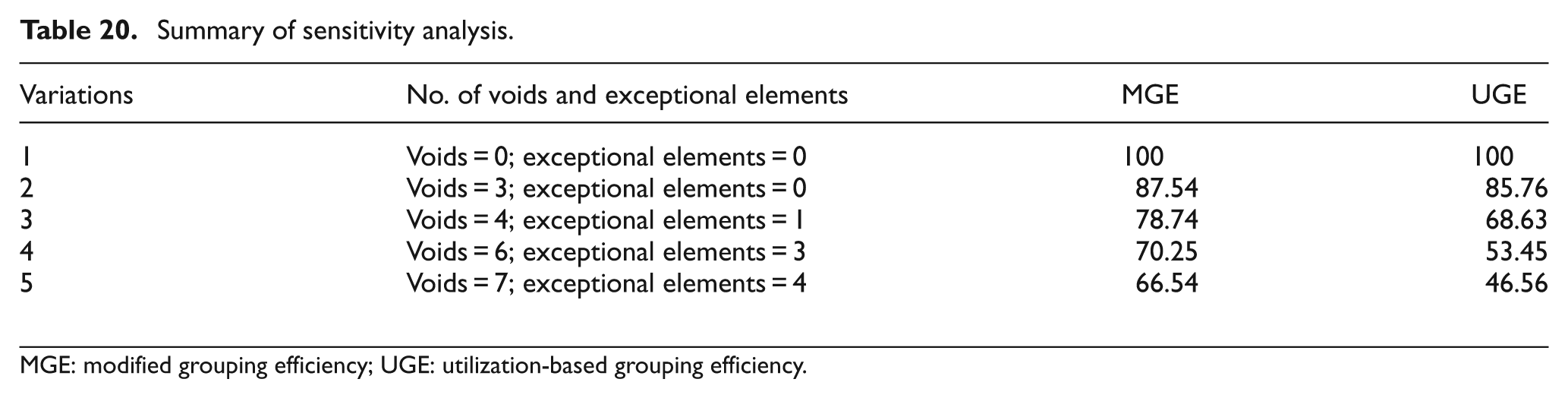
Sensitivity analysis
To assess the sensitivity of UGE and MGE with the variations of datasets and the goodness of block diagonal cell structure obtained in solution matrix, different versions of the 5 × 7 CFP of Table 2 are considered. Deviations from one version to another are restricted to small amount of changes in the number of exceptional elements and their utilization factors.
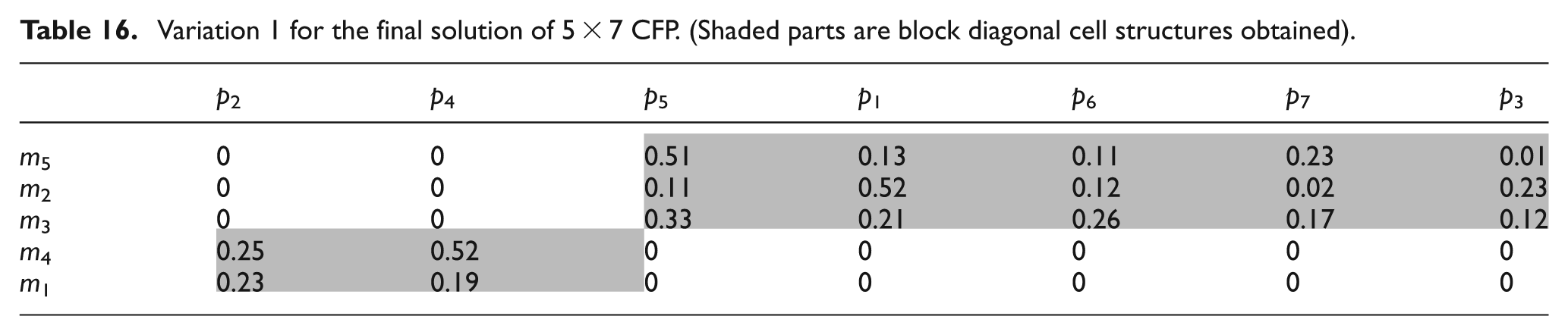
The solution matrix obtained in Table 14 has three exceptional elements and six voids. Variation 1 is shown in Table 16, part 6 is no longer being process through machine 4 and machine 1 rather being processed through machine 2 and machine 5 and part 5 is being processed through machine 3 instead of being processed through machine 1. It is a compact or ideal CFP solution (no exceptional elements and no voids), obtained by replacing all three voids of variation 1 with arbitrary utilization values. As per the norms of efficiency measures, both MGE and UGE show 100% values for this configuration.
Variation 1 for the final solution of 5 × 7 CFP. (Shaded parts are block diagonal cell structures obtained)
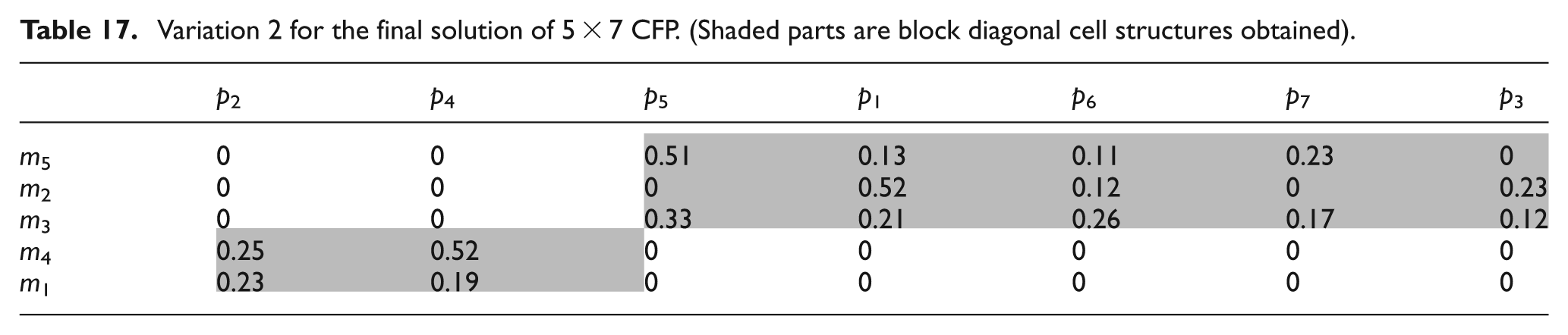
Variation 2 is obtained after small alteration done over solution matrix of Table 14. It is shown in Table 17, part 6 is no longer being process through machine 4 and machine 1 rather being processed through machine 2 and machine 5 and part 5 is being processed through machine 3 instead of being processed through machine 1. In this new configuration, the number of exceptional elements is 0 and number of voids is 3. The computed values of MGE and UGE are 87.54% and 85.76%, respectively.
Variation 2 for the final solution of 5 × 7 CFP. (Shaded parts are block diagonal cell structures obtained)
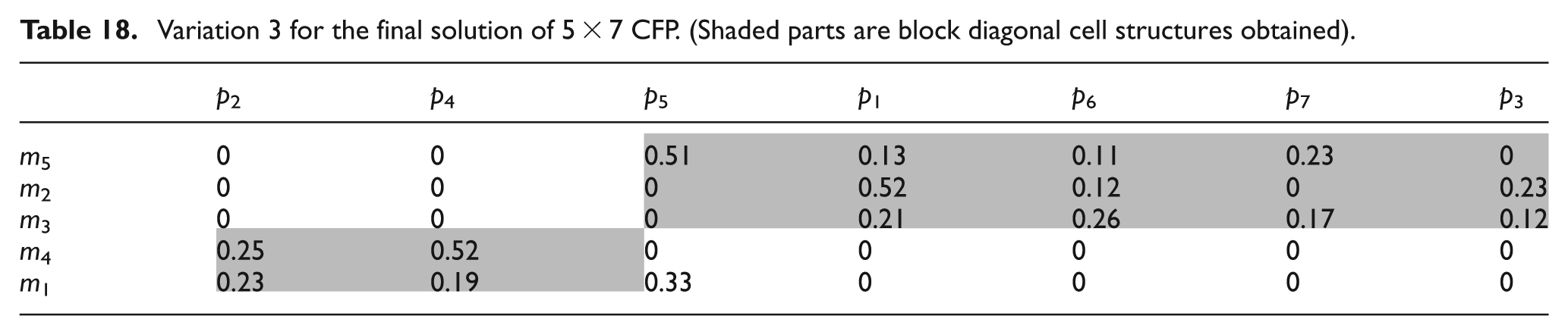
Variation 3 is obtained after a small amount of changes in Table 14 (original solution) and shown in Table 18. Here, part 6 is no longer being process through machine 4 and machine 1 rather being processed through machine 2 and machine 5. In this new configuration, the number of exceptional elements is 1 and number of voids is 4. The computed values of MGE and UGE are 78.74% and 68.63%, respectively.
Variation 3 for the final solution of 5 × 7 CFP. (Shaded parts are block diagonal cell structures obtained)
Variation 4 is the original solution matrix of Table 14 with three exceptional elements and six voids. The computed values of MGE and UGE are 70.25% and 53.45%, respectively.
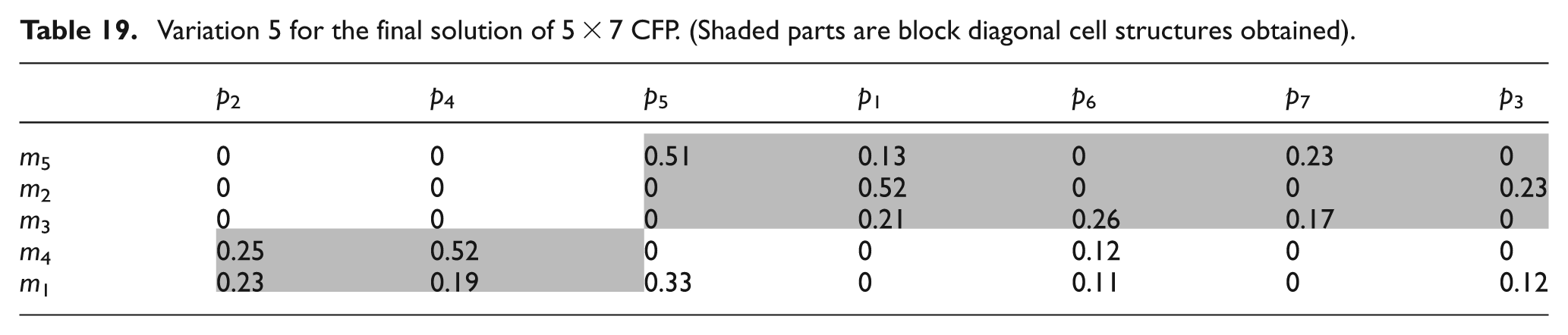
Variation 5 is portrayed in Table 19, where part 3 is no longer being processed through machine 3 rather being processed through machine 1. This configuration gives four exceptional elements and seven voids. The computed values of MGE and UGE are 66.54% and 46.56%, respectively.
Variation 5 for the final solution of 5 × 7 CFP. (Shaded parts are block diagonal cell structures obtained)
This above analysis is briefed down in Table 20 for all the presented variations of cellular configurations.
Summary of sensitivity analysis.
MGE: modified grouping efficiency; UGE: utilization-based grouping efficiency.
The above observations are plotted in Figure 8, which clearly portrays the sensitivity of UGE over MGE for small changes in the same solution. Addition or elimination of one void or exceptional element makes drastic change in the response of UGE. The changes are crisp and clear for UGE over MGE. For a large size and more scattered dataset, these small changes would be hard to visualize in MGE response curve. But due to the design features of UGE, these changes would be significantly prominent in UGE response curve. Therefore, the above analysis shows that the UGE is much sensitive than MGE when the dataset is a sparse matrix and changes in solution are small.
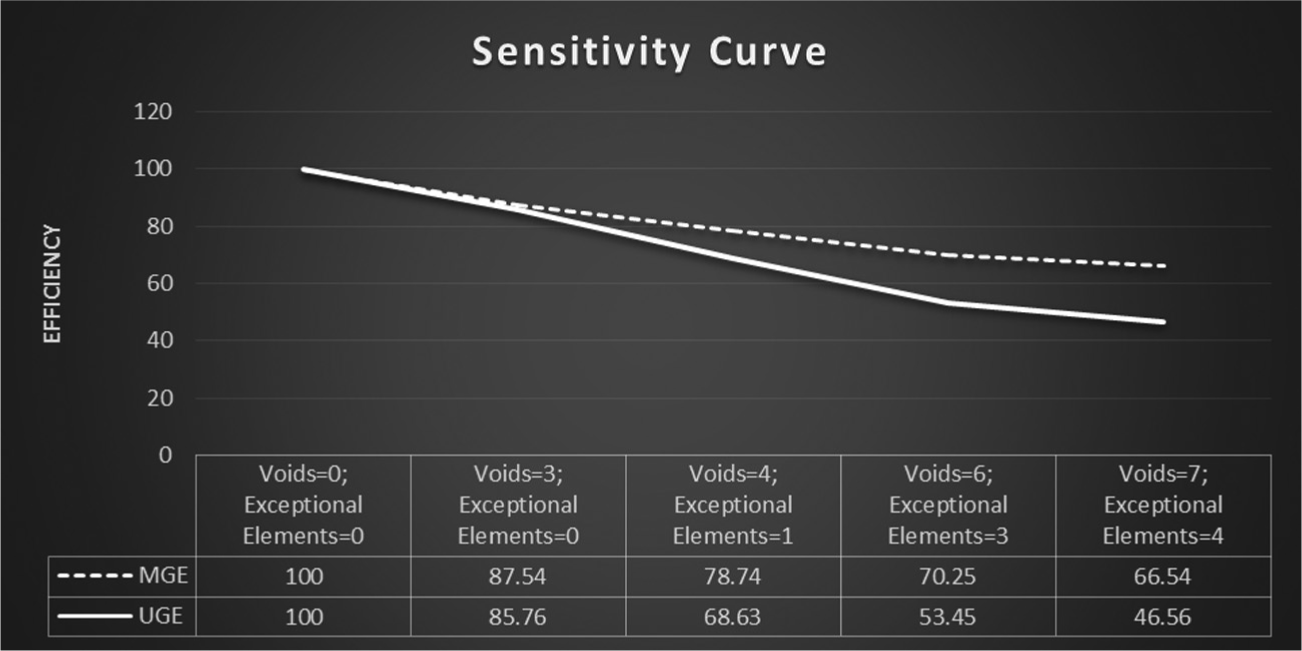
Sensitivity curve obtained from Table 20.
Qualitative analysis
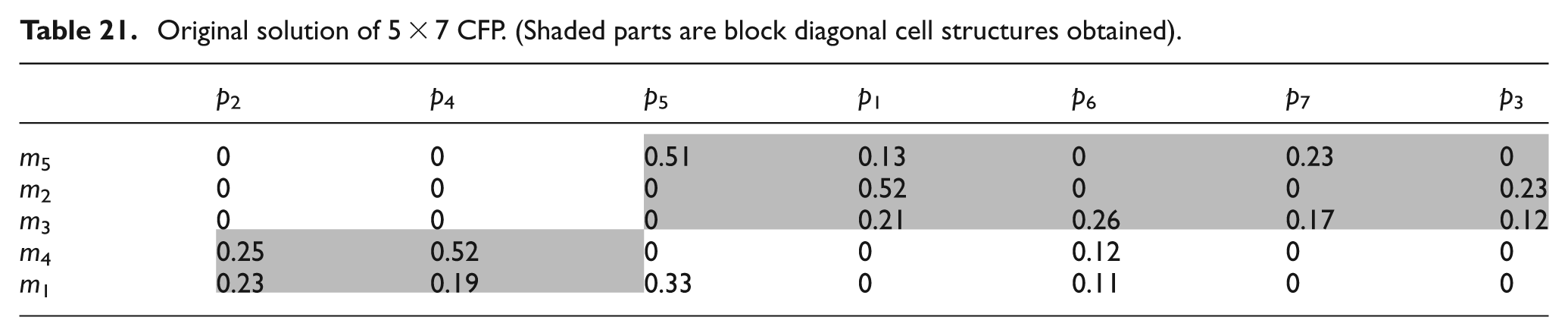
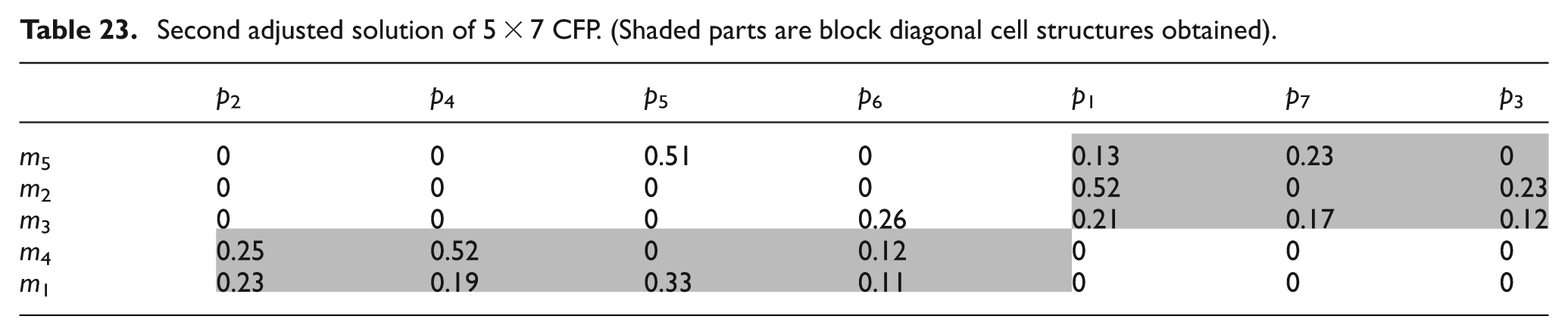
Measuring the solution quality realistically is an essential decisive factor of any performance measure in CMS. Most of the performance measures are solely focused on minimizing exceptional elements and voids. 58 However, this is not the sole objective of a good cellular configuration in practice. Since the CFP considered in this article is based on machine utilizations, the objective of a good cellular configuration is to minimize the TU of exceptional elements along with the number of exceptional elements and voids. To authenticate this observation, the original solution of Table 14 is considered and displayed in Table 21. This solution matrix produces three exceptional elements and six voids. The computed values of MGE and UGE are 70.25% and 53.45%, respectively.
Original solution of 5 × 7 CFP. (Shaded parts are block diagonal cell structures obtained)
In the course of this analysis, this original solution matrix is altered in such a way that the number of exceptional elements and voids is minimized. Therefore, part 6 is moved to cell 1 from cell 2 in first adjusted solution (Table 22) and parts 5 and 6 both are transferred from cell 2 to cell 1 in second adjusted solution (Table 23). It is clearly visible that in the first adjusted solution matrix, the number of exceptional elements is 2 and the number of voids is 4, and for the second adjusted solution matrix, the number of exceptional elements is 2 and the number of voids is 3. Therefore, it can be presumed that the adjusted solutions are better than the original solution and performance measures are believed to attain a better efficiency value for these solutions. The computed values of MGE and UGE are shown in Table 24. This can be distinctly observed that the MGE caters an improved score for both the adjusted solutions while UGE obtains an inferior score for second adjusted solution but shows enhancement in first adjusted solution.
First adjusted solution of 5 × 7 CFP. (Shaded parts are block diagonal cell structures obtained)
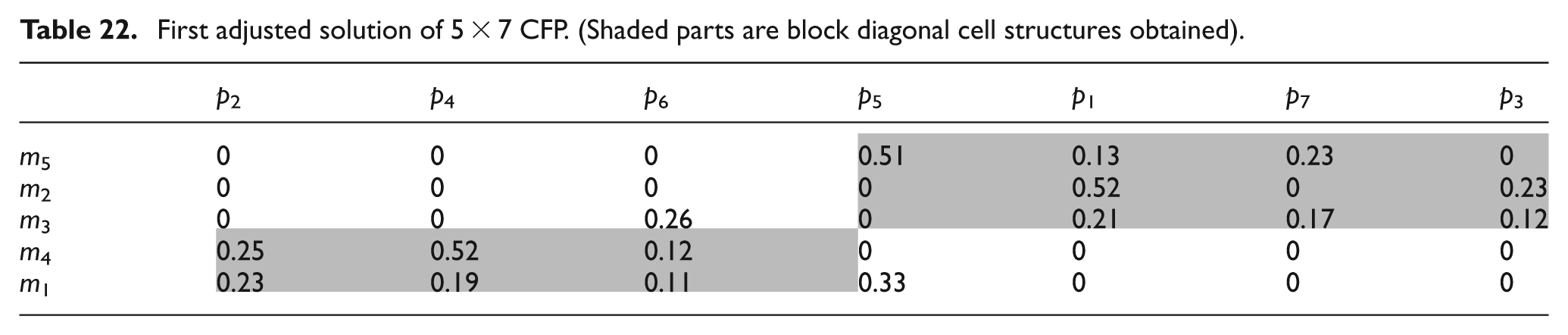
Second adjusted solution of 5 × 7 CFP. (Shaded parts are block diagonal cell structures obtained)
Summary of qualitative analysis.
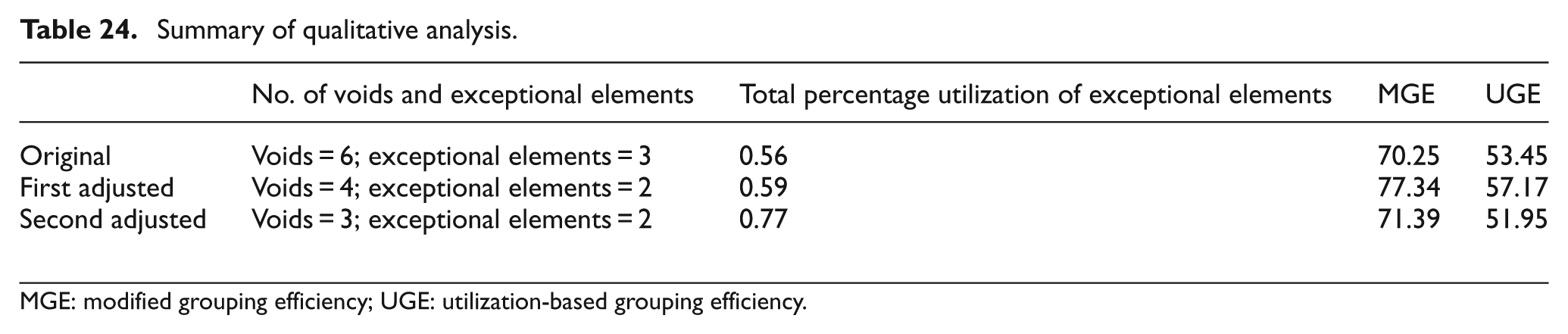
MGE: modified grouping efficiency; UGE: utilization-based grouping efficiency.
This observation illustrates a critical inference; MGE is capable of assessing the solution matrix in terms of number of exceptional elements and voids only but completely fails to realize the total percentage utilization outside of the block diagonal cellular structure. However, the proposed UGE not only focuses on the total percentage utilization of exceptional elements but also keeps track of the number exceptional elements and voids. Therefore, UGE can trade-off between these two issues and assist in achieving best solution so far. Hence, finally, the first adjusted solution can be called a more optimized solution in terms of the quality of solution after observing the behavior of UGE while MGE is incompetent for that matter.
It is concluded that the proposed UGE is shown to be much improved and relevant measure of efficiency for the CFP with “ratio data.” UGE not only improves its score with the reduced number of exceptional elements and void but also it is enhanced with the minimized value of the TU of the exceptional elements which is an important aspect in the real production situation. UGE is also shown to be much sensitive with the variation in data. Small amount of deviations in block diagonal cellular structure can change the UGE score drastically which would be more prominent for large-size sparse matrix.
Results and discussion
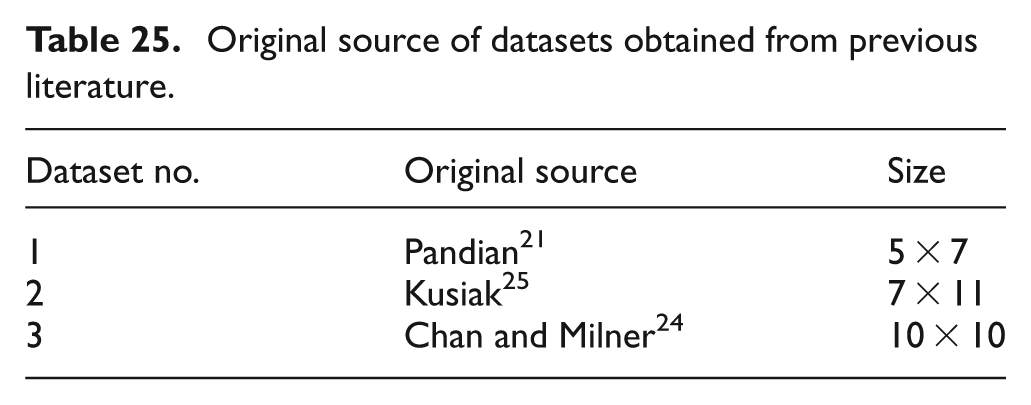
In section “Problem definitions,” it has been observed that obtaining appropriate test problems is one of the trickiest tasks of solving CFP in real time. Merely generating random matrices would be an incompetent method since condition 2 (equation (4)) could get violated. Therefore, this logic would negate the statement by Mahapatra and Pandian: 20 “The real valued matrix is produced by assigning random numbers in the range of 0.5 to 1 as uniformly distributed values by replacing the ones in the incidence matrix and zeros to remain in its same positions” (p. 637). In reality, nearly all the past literature dealt with ratio data in CMS, overlooked condition 2 (equation (4)), which is an essential part while designing the datasets. Therefore, any of the existing datasets from past literature would not be an absolute choice for the CFP considered in this article. However, three existing datasets are considered from published articles which are small to medium in size and displayed in Table 25. All these datasets do not satisfy condition 2 (equation (4)). Hence, these three test problems are adjusted and condition 2 is imposed and made working for the model of CFP considered here.
Original source of datasets obtained from previous literature.
The first adjusted dataset is the 5 × 7 test problem which is depicted in Table 2 and is also portrayed in Figure 9. Second and third adjusted datasets are displayed in Figures 10 and 11, respectively. The proposed MCDT model based on AHP is used to solve these test problems and obtained results are compared with McQueen’s 54 K-means algorithm successfully.
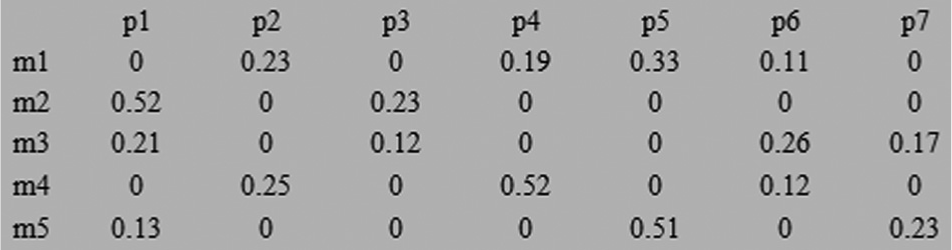
Redesigned dataset of King and Nakornchai 22 (5 × 7).
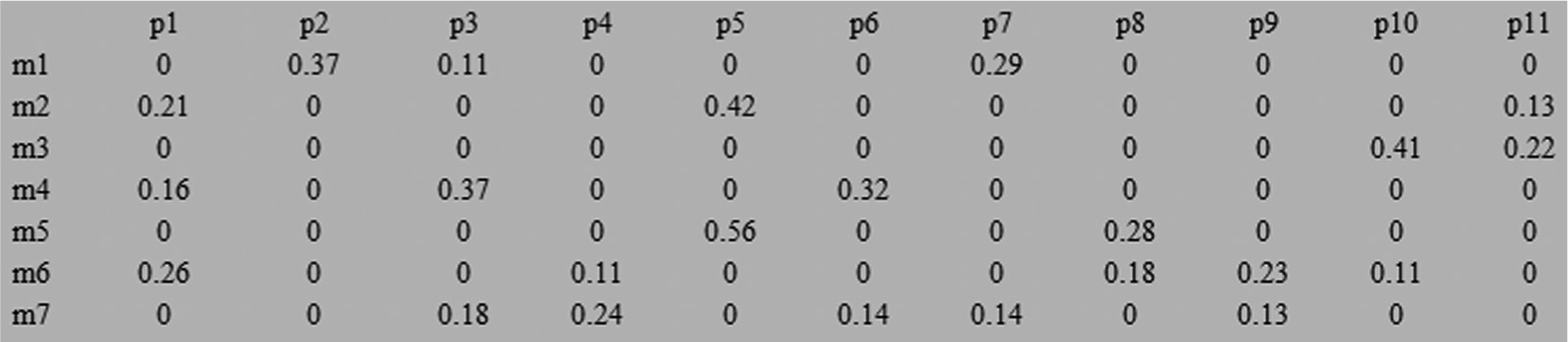
Redesigned dataset of Kusiak 25 (7 × 11).
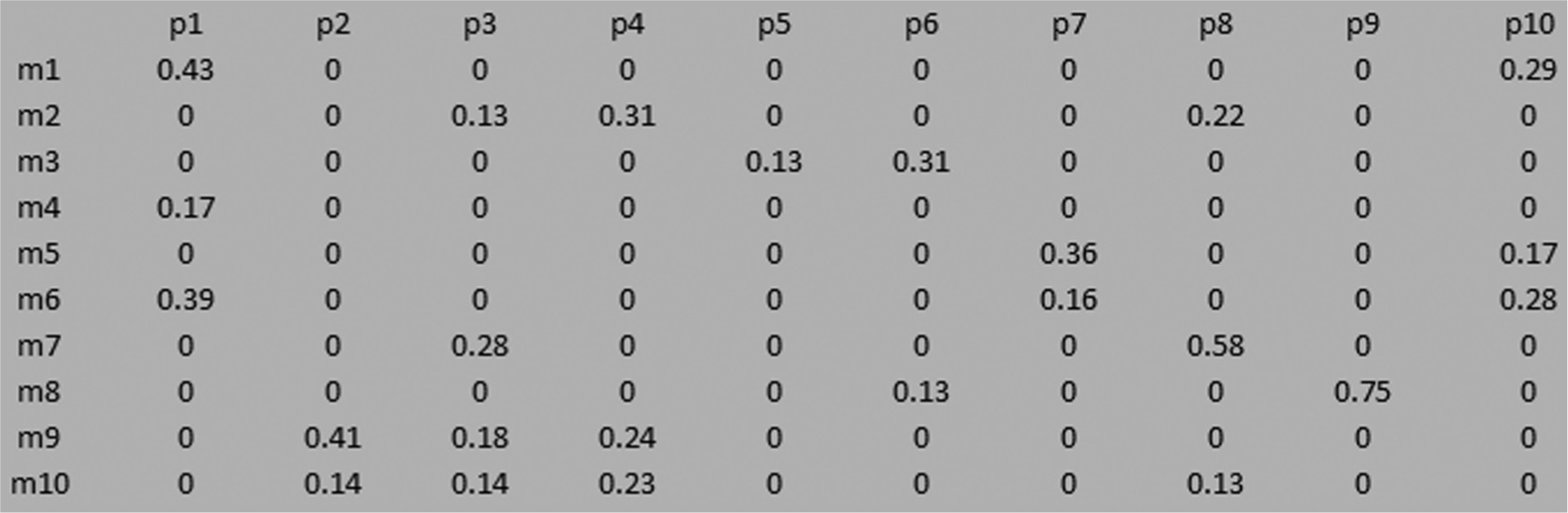
Redesigned dataset of Mosier and Taube 29 (10 × 11).
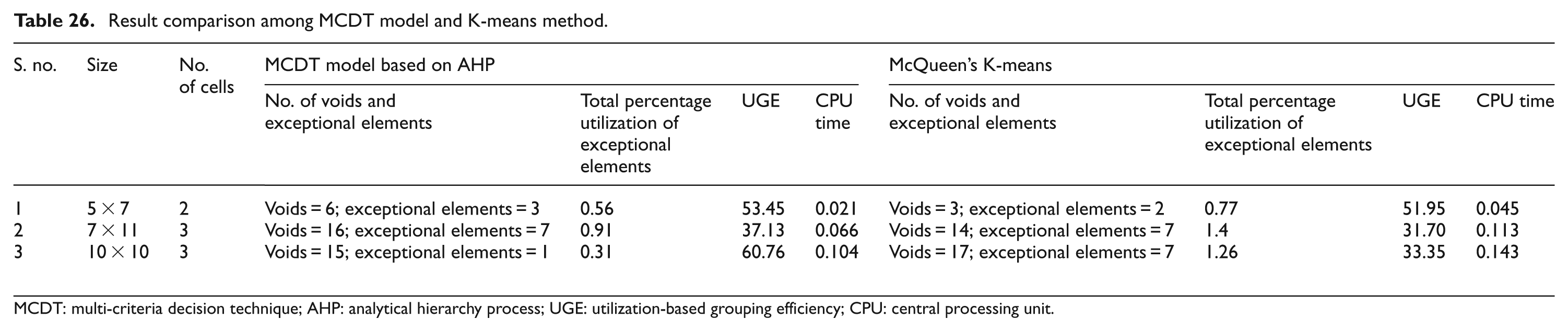
Both the techniques are coded in MATLAB 7.6 and tested on Intel Core i3 Processor with 4 GB RAM. The test problems in the form of matrices are the input to the K-means algorithm and the pairwise comparison matrices are the input to the MCDT model. Comparison results are depicted in Table 26, which demonstrate the competency of the proposed MCDT model based on AHP over K-means algorithm.
Result comparison among MCDT model and K-means method.
MCDT: multi-criteria decision technique; AHP: analytical hierarchy process; UGE: utilization-based grouping efficiency; CPU: central processing unit.
Table 26 shows that MCDT model has the ability to find good solutions for the CFPs. This novel technique not only reduces the exceptional elements and voids but also minimizes the total percentage utilization of exceptional elements and produces improved UGE scores for all the problem instances. This method clearly outperforms the K-means method which is a standing cell formation technique and used heavily in past literatures.3,13,58 MCDT model is also slightly quicker than the K-means method in terms of CPU time. A graphical analysis on the performance of the proposed approach and the improvement in terms of CPU time is presented in Figure 12. All the solution matrices obtained by MCDT model and K-means method are portrayed in Figures 13–18.
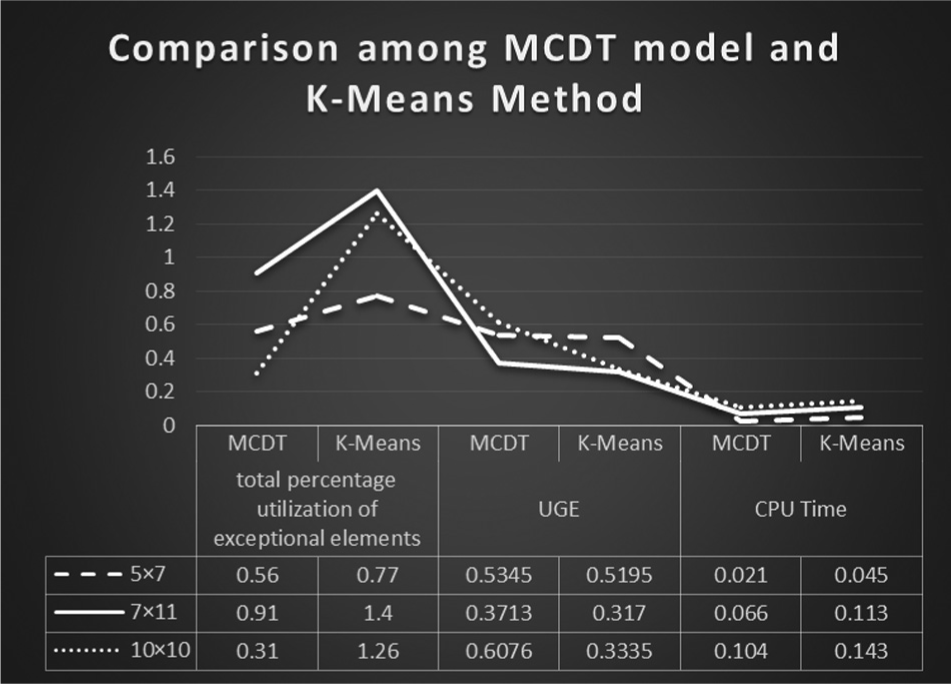
Graphical comparison among MCDT model and K-means methods.
Solution of 5 × 7 CFP by MCDT model.
Solution of 5 × 7 CFP by K-means method.
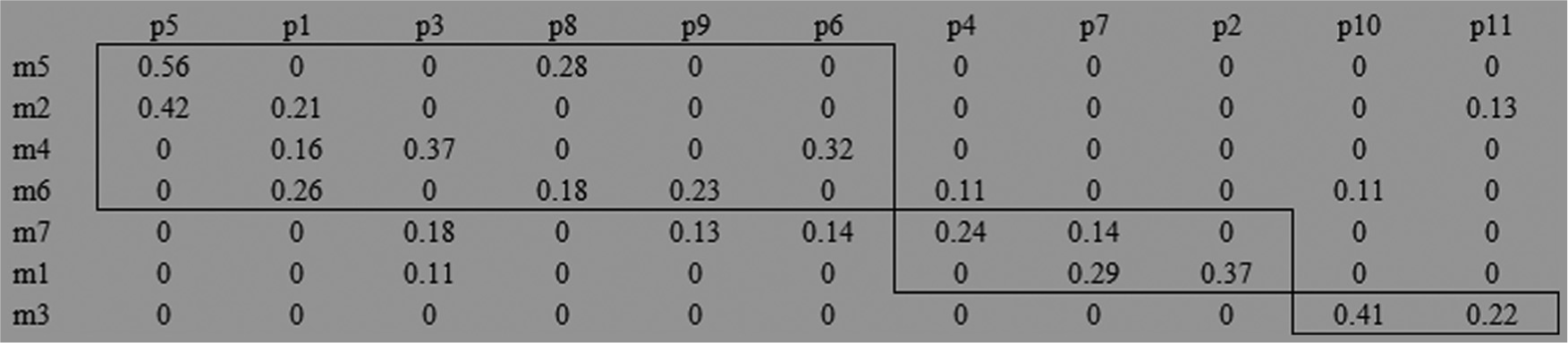
Solution of 7 × 11 CFP by MCDT model.
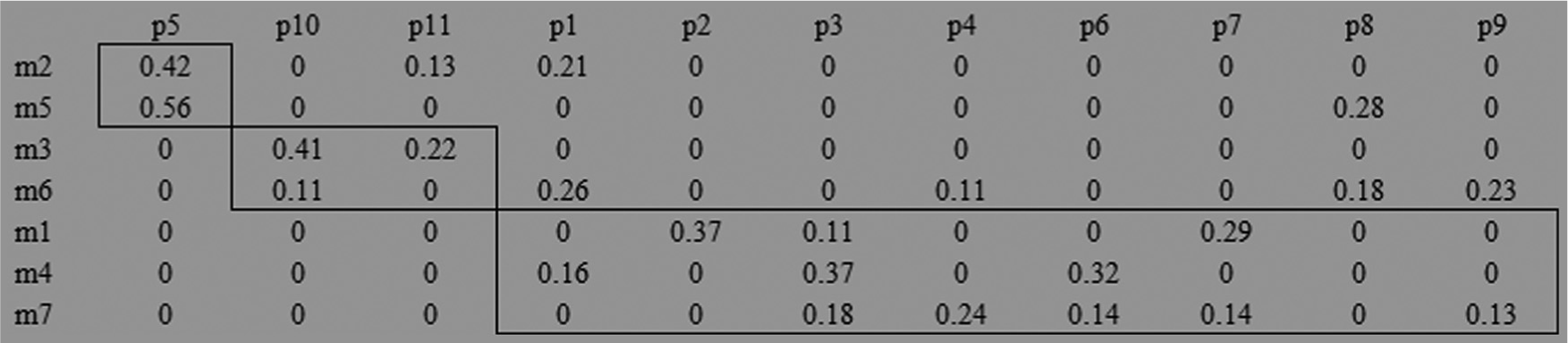
Solution of 7 × 11 CFP by K-means method.
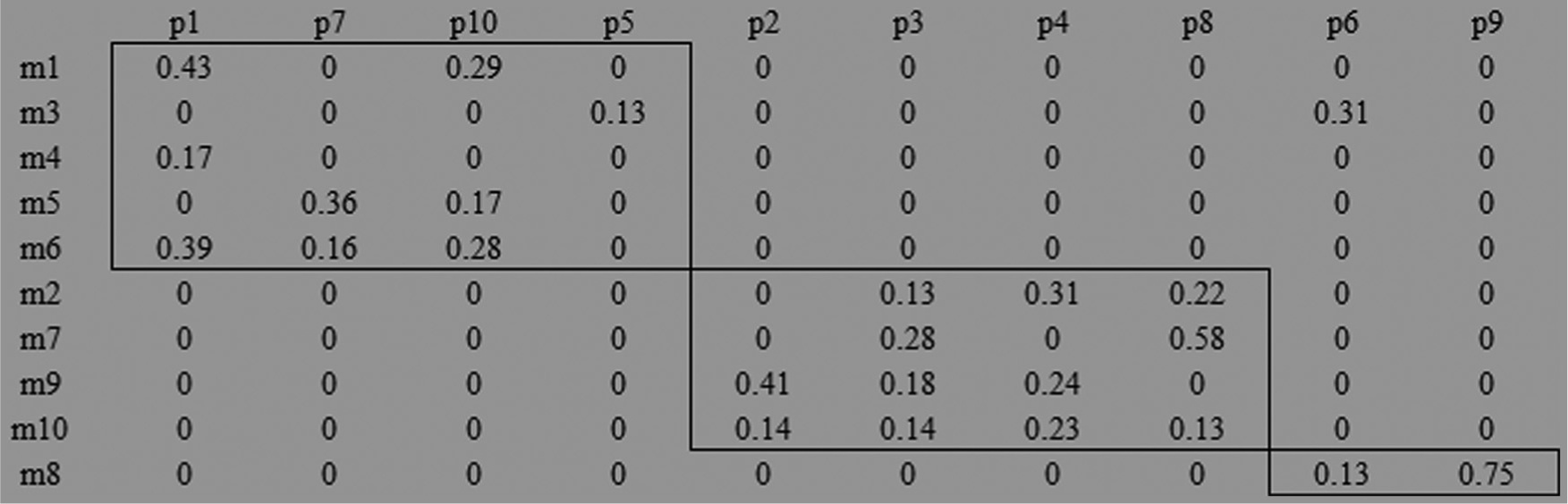
Solution of 10 × 10 CFP by MCDT model.
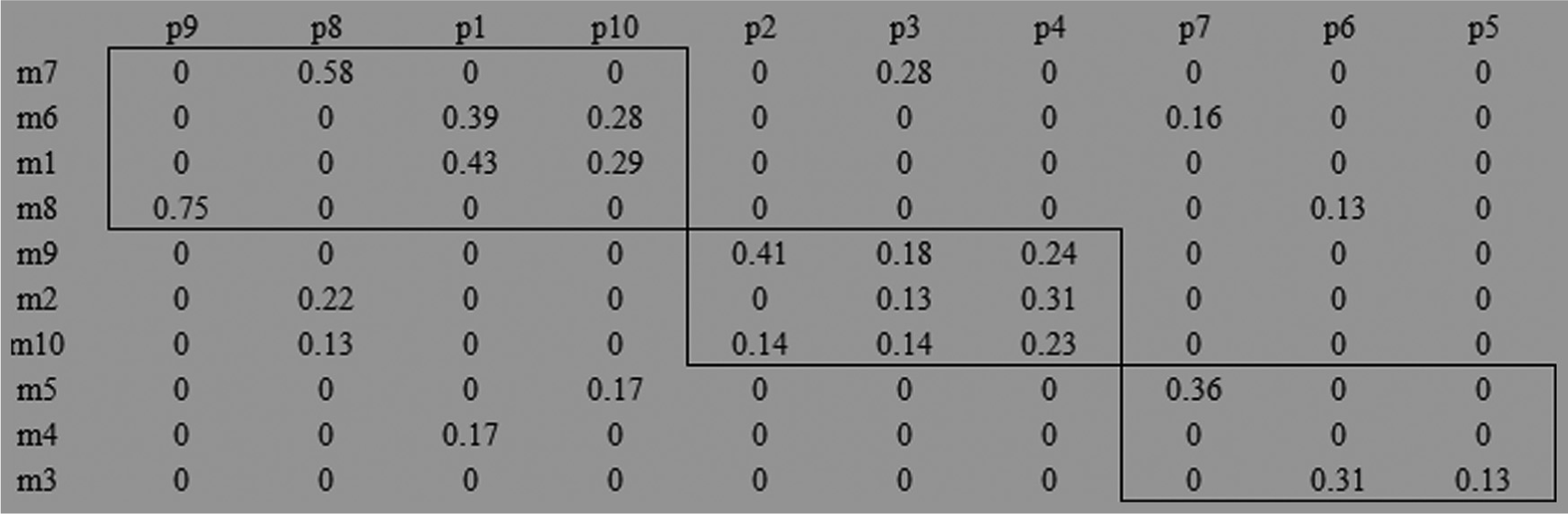
Solution of 10 × 10 CFP by K-means method.
Conclusion
This article is an attempt to put together three novel verdicts for the CFPs in CMS. First, it shows that the “ratio data” is in fact “percentage utilization of machines,” not “processing time.” Therefore, the intention of the researchers observed in past literature, to generate the “processing time”-based test problem with simple random function call, is incorrect. In order to rectify this, the datasets are adjusted scientifically. Thereafter, a novel AHP-based method is proposed as a cell formation technique which utilizes a modified Saaty’s scale which further exploits machine utilization phenomenon conveniently. This article shows that AHP method could be substantially handy while generating quick solutions to the CFPs. Finally, a novel grouping measure called UGE is proposed which is critically analyzed and compared with its nearest predecessor MGE. UGE is displayed to be substantially improved and relevant grouping measure for the “ratio data”-based CFPs. This field of study still has enormous possibilities to be explored. This research could be extended further in many directions such as development of a universal data generation algorithm for the problem considered, development of suitable similarity coefficient based on machine utilization factor, development of mathematical formulation of the problem to manage large datasets and implementation of the model in realistic production shop-floor.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author Tamal Ghosh (IF120670) is thankful to DST-INSPIRE governing body of Department of Science & Technology, Government of India, for the financial support to carry out the doctoral research.