
Abstract
Manufacturing systems involve a huge number of combinatorial problems that must be optimized in an efficient way. One of these problems is related to task scheduling problems. These problems are NP-hard, so most of the complete techniques are not able to obtain an optimal solution in an efficient way. Furthermore, most of real manufacturing problems are dynamic, so the main objective is not only to obtain an optimized solution in terms of makespan, tardiness, and so on but also to obtain a solution able to absorb minor incidences/disruptions presented in any daily process. Most of these industries are also focused on improving the energy efficiency of their industrial processes. In this article, we propose a knowledge-based model to analyse previous incidences occurred in the machines with the aim of modelling the problem to obtain robust and energy-aware solutions. The resultant model (called dual model) will protect the more dynamic and disrupted tasks by assigning buffer times. These buffers will be used to absorb incidences during execution and to reduce the machine rate to minimize energy consumption. This model is solved by a memetic algorithm which combines a genetic algorithm with a local search to obtain robust and energy-aware solutions able to absorb further disruptions. The proposed dual model has been proven to be efficient in terms of energy consumption, robustness and stability in different and well-known benchmarks.
Introduction
Nowadays, many companies and enterprises are focused on improving their benefits to be more competitive in their manufacturing processes. However, there exist other objectives beyond the benefits, such as robustness and sustainability. Manufacturing processes have a huge impact on the environment. Some of them such as chemical, food, refining, paint, or metal industries are highly energy consuming and present a high risk of producing an important amount of waste or pollution. For example, during 2000, about 60% of the US$700 million energy expenditures in 37 US automotive assembly plants are spent in painting processes. 1 In such a context, a 5% reduction in energy consumption may result in a saving of more than half million dollars per year for each plant. Industrial processes are also known to be the major sources of greenhouse gas (GHG) emissions. Statistics has shown that the GHG emitted from the usage of energy sources such as electricity, coal, oil and gas during manufacturing accounts for more than 37% even 50% of the world total GHG. 2
Therefore, the enterprises have started to take steps to reduce GHG emission from their products and services under the mounting pressure stemming from the implementation of the Kyoto Protocol and Copenhagen Accord. Industrial sector has a lot of influence in the environmental impacts, because it represents the sector where more energy is used. The energy consumed in the world in 2011 was 524 quadrillion BTU (British thermal unit) and the energy used by the industrial sector amounts to 51%. 3 So reducing consumption in this sector directly affects the total consumption. Nevertheless, it is still difficult for enterprises to consider renewable sources application and emissions reduction when making manufacturing and operation decisions, especially on the production planning and scheduling problems. 4
During the last few years, many works have been carried out to optimize energy consumption in manufacturing processes based on the machine level and the product level. 5 Besides, from the manufacturing system-level perspective, optimizing the objectives of production scheduling is a feasible and efficient approach for manufacturing companies to decrease energy consumption without any machine or product redesign. Recently, interesting efforts have been performed to investigate production-scheduling problems that take into account energy efficiency.
May et al. 6 addressed a multi-objective scheduling model related to energy consumption and makespan in a job-shop system and obtained a series of different Pareto front solutions based on a green genetic algorithm (GA). Escamilla et al. 7 developed a GA to minimize energy consumption and makespan in an extended version of the job-shop scheduling problem (JSP), where each machine can work at different rates. Mingcheng et al. 8 built a multi-objective optimization (MOO) model involving makespan, processing cost, processing quality and energy consumption for a flexible JSP and designed a modified on-dominant sorting GA to solve it. Liu et al. 9 established a scheduling model that minimized the total non-processing electricity consumption and total weighted tardiness for the JSP. This problem was solved by using a non-dominant sorting GA.
In the literature on dynamic scheduling problems, predictive–reactive scheduling strategies have been widely used in manufacturing systems, where schedules are revised in response to dynamic factors. 10 Most of them consider only efficiency of the schedule like makespan. However, reducing energy consumption in production scheduling considering dynamic factors has been rather limited. Pach et al. 11 proposed a reactive scheduling model based on potential fields in flexible manufacturing systems, which considered three indicators: makespan, energy consumption and the number of resource switches in a dynamic context. Zheng et al. 12 proposed a dynamic shop floor rescheduling approach inspired by a neuroendocrine regulation mechanism.
The JSP represents a problem in which some tasks are assigned to machines with a specific processing time. We work with an extension of JSP where each machine can work at different rates, so each machine has different available processing times and energy consumptions. Thus, if a machine works at higher rate, it consumes more energy but the processing time is reduced. Energy efficiency is a critical parameter to take into account, but also other parameters such as robustness can result in schedule profitability, safety, or simplicity to avoid rescheduling, so robustness and energy efficiency can be considered in many real-life manufacturing problems.
Problem description
Many industrial processes can be represented as a JSP where machines can work at different speeds/rates (JSMS). This problem consists of a set of n jobs
A feasible schedule is composed of a complete assignment of starting times to tasks that satisfies the following constraints:
The tasks of each job are sequentially scheduled.
Each machine can process at most one task at any time.
No preemption is allowed.
The aim of the JSMS problems is to find a feasible schedule that minimizes makespan and energy consumption meanwhile maximizes the robustness of the schedule.
This problem represents an extension of the standard JSP
Robustness and stability
Robustness can be related with many real-world problems. In industry, robustness can be profitable, because if a perturbation appears in the schedule, it remains valid so it is not necessary to reschedule and, therefore, to interrupt the production process. We consider that a system is robust, if it is able to maintain its functionality even though some incidences can appear. In scheduling problems, a solution is robust if it is able to absorb some disruptions without the delay of further tasks.
In real world, problems are very common to leave some gaps/buffers between consecutive tasks of the schedule. Sometimes new gaps appear to satisfy precedence constraints. In JSMS problem, there is the possibility to change the speed of the machines, so increasing the speed of a machine can be enough to recover the incidences (energy-efficient buffer).
In JSMS problem, a solution (S) is robust if given an incidence (I); it only affects to one task, and it is able to be absorbed. In this case, the incidence can be absorbed by an existing gap, or the machine that executes this task can increase the speed to absorb the incidence. Moreover, a gap and an energy-efficient buffer can be joined to absorb incidences. If there is no buffer or it is smaller than the incidence size, the delay of a task is propagated to other tasks, so the solution is not considered robust. Thus, the robustness of a solution can be modelled as:
Thus, a robust solution is a solution that maintains its feasibility over the whole set of expected incidences. If a solution is not robust against a perturbation, it can be considered stable only when it is able to remain valid against incidences with only few changes. 14 Thus, stability is an interest parameter for rescheduling in order to recover the original solution by means of modifying the value of only a few tasks.
Thus, we consider a solution S is
Memetic algorithm (GA* + LS)
In this section, we present a memetic algorithm which combines a GA with a local search (LS). GAs are adaptive methods which may be used to solve optimization problems. 16 They are based on the genetic process of biological organisms. Over many generations, natural populations evolve according to the principle of natural selection. At each generation, every new individual (chromosome) corresponds to a solution, that is, a schedule for the given JSMS instance. Before a GA can be run, a suitable encoding (representation) of the problem must be devised. The essence of a GA is to encode a set of parameters (known as genes) and to join them together to form a string of values (chromosome). A fitness function is also required, which assigns a figure of merit to each encoded solution. The fitness of an individual depends on its chromosome and is evaluated by the fitness function. During the run, parents must be selected for reproduction and recombined to generate offspring. Parents are randomly selected from the population, using a scheme which favours fitter individuals. Having selected two parents, their chromosomes are combined, typically by using crossover and mutation mechanisms to generate better offspring, so they represent better solutions. The process is iterated until a stopping criterion is satisfied.
Chromosome encoding and decoding
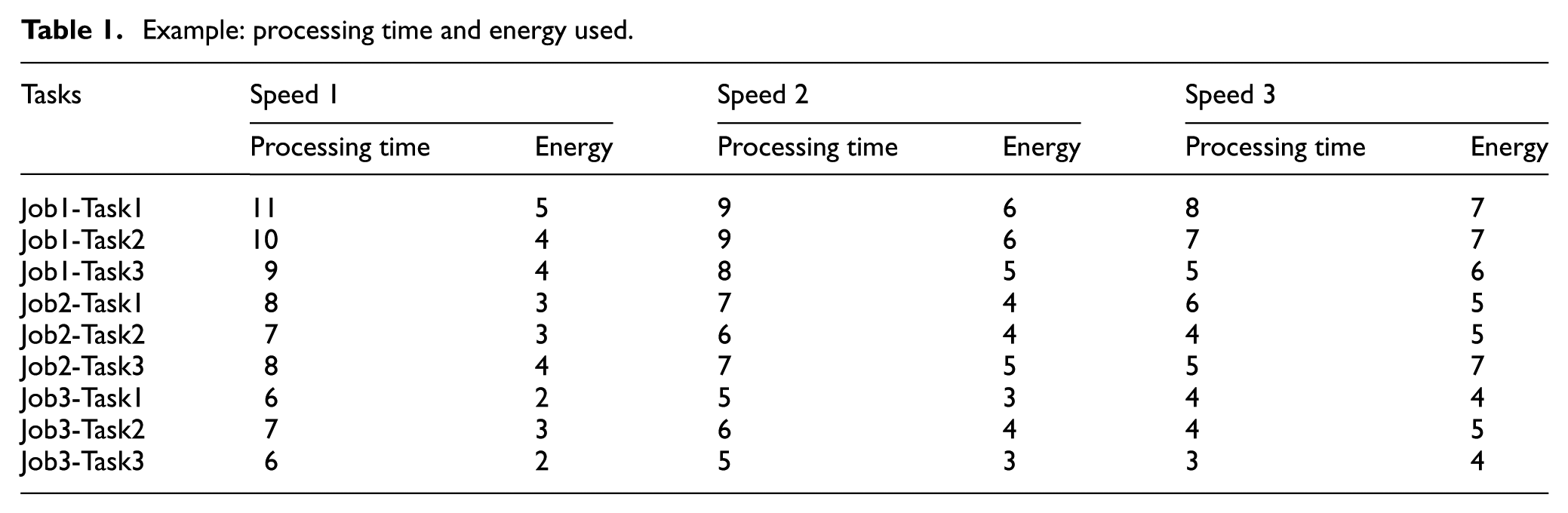
In GAs, each candidate represents a solution in the solution space. The first step to construct a GA is to define an appropriate genetic representation (coding). Table 1 shows an example of the processing time and the energy consumption of a JSMS composed of three jobs, three machines and three tasks per job. A chromosome is a permutation of the set of tasks that represents a tentative ordering to schedule them. The sequence (2 1 1 3 2 3 1 2 3) is a valid chromosome for this example, where each number of the sequence represents the job of the task. The first number ‘2’ represents the first task of the job 2 and it will be executed as soon as possible following the problem constraints. As it was shown in Varela et al.,
17
this encoding has a number of interesting properties for the classic JSP. However, in the JSMS problem, the machine speed of each operation has to be represented. Thus, it is added a value to each task in order to represent the speed of the machine that processes this task. For instance, a valid chromosome could be (2
Example: processing time and energy used.
Initial population and fitness
Each gene represents one task of the problem. The position of each task determines its dispatch order in this genome/solution. The initial chromosomes are obtained following some dispatching rules or by random permutation. We employ six common dispatching rules: shortest processing time (SPT), longest processing time (LPT), job with more load (JML), job with more tasks (JMT), machine with more load (MML) and machine with more tasks (MMT). We also employ a random rule, which select a job randomly from the remaining jobs. The dispatching rule SPT assigns high priority to short tasks, LPT assigns high priority to long tasks, JML assigns high priority to tasks which job has more load, JMT assigns high priority to tasks which job has more tasks, MML assigns high priority to tasks whose machine has more load and MMT assigns high priority to tasks whose machine has more tasks. To create each genome, each dispatching rule can be randomly selected with a probability of 10% and random rule with a probability of 40%. Thus, it obtains variety and diversity in the initial population in order to obtain good solutions. Each dispatching rule assigns a priority to each task. This priority can be based on attributes of the jobs, the machines, or tasks. The machine speed for each gene is generated depending on the value of
In a single objective optimization, there is a single optimal solution. However, in MOO not only one optimal solution but a set of optimal solutions can be identified. This set of optimal solutions composes the Pareto front. Diverse techniques have been developed to solve MOO problems. One of the most well-known methods for solving MOO problems is the normalized weighted additive utility function (NWAUF), where multiple objectives are normalized and added to form a utility function. NWAUF has been implemented in a wide range of MOO applications due to its simplicity and natural ability to identify efficient solutions. Let
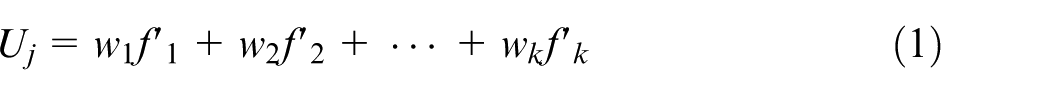
where
The definition of fitness function is just the reciprocal of the objective function value. The objective is to find a solution that minimizes the multi-objective makespan and energy consumption. Following NWAUF rules, the fitness function (2) is created, where the weights assigned to both variables are given by the
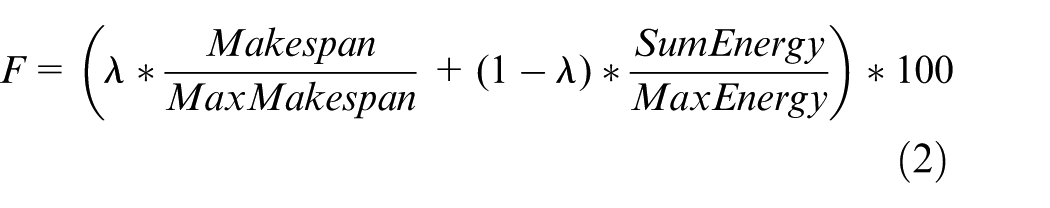
Crossover operator
For chromosome mating, the GA uses the job-based order crossover (JOX) described in Bierwirth. 18 Given two parents, JOX selects a random subset of jobs and copies their genes to the offspring in the same positions as they are in the first parent. Then the remaining genes are taken from the second parent so as they maintain their relative ordering. To clarify how JOX works, let us consider the following two parents in Figure 1 for the example presented in section ‘Example’.
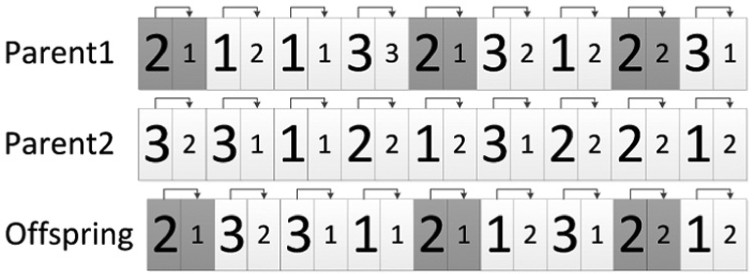
Result of crossover operator between two parents.
If the selected subset of jobs from the first parent just includes the job 2 (dark genes of parent 1 in Figure 1), the generated offspring is showed at the end of Figure 1.
Hence, operator JOX maintains for each machine a subsequence of operations in the same order as they are in parent 1 and the remaining in the same order as they are in parent 2.
The remaining elements of GA are rather conventional. To create a new generation, all chromosomes from the current one are organized into couples which are two mated offspring in accordance with the crossover probability.
Mutation operator
Two offspring generated with crossover operation can also be mutated in accordance the mutation probability. Two positions of the chromosome child are randomly chosen (position ‘a’ and position ‘b’), where ‘a’ must be lower than ‘b’. Values between ‘a’ and ‘b’ are randomly shuffled. Furthermore, in each gene, machine speed values are randomly changed. Finally, tournament replacement among every couple of parents and their offspring is carried out to obtain the next generation.
LS
Conventional GAs can produce good results. However, significant improvements can be obtained by hybridization with other methods. For example hybridization of a GA and an LS algorithm can produce better results because LS algorithms move from solution to solution in the search space by applying local changes. This is possible only if a neighbourhood relation is defined on the search space. An LS is implemented by defining a neighbourhood of each point in the search space as the set of chromosomes reachable by a given transformation rule. Then, a chromosome is replaced by the selected neighbour that satisfies the acceptance criterion. We propose a neighbourhood structure based on the concepts of critical path and critical block.19–21 A critical block is a maximal subsequence of operations of a critical path requiring the same machine. Mattfeld
22
defined the neighbourhood structure
Following the idea of neighbourhood structure
A model for obtaining robust and energy-aware solutions
In this section, we propose a knowledge-based model to obtain robust and energy-aware solutions for the JSP with machines working at different speeds (JSMS).
Most scheduling problems involved in industrial processes are dynamic by nature. These dynamic problems are faced with incidences which generate delays in tasks. In some cases the original solution is recovered in a given time but in other cases the incidence is propagated in cascade so the original solution cannot be valid or recovered. Buffering is used in industrial processes to compensate for variations in the schedule. Changes in supply and demand would be an example of these variations. Think of buffering as a means to ensure that schedule continues to run smoothly despite unforeseen factors, such as machine breakdowns, coming into play. Thus, buffers in industrial processes are usually inserted to keep operations running smoothly. However, the inclusion of buffer in scheduling processes has advantages and disadvantages. The most important advantage of using buffering in scheduling is, when done correctly, its implementation tends to be more robust so, in order to increase production efficiency, reduce overall costs and keep operations running smoothly. However, when done incorrectly, the opposite can be true. For example, if a schedule keeps too much buffer time between all tasks, the makespan increases to remain the obtained solution not feasible in terms of profitability. To maintain an optimal balance, many operators tend to gravitate towards using industrial process strategies in which they use the least amount of buffering necessary to ensure their projected rates.
In this section, we transform the original scheduling model into a dual scheduling model in which some selected tasks are accomplished in a buffer time according to previous problem knowledge. The size of each buffer time assigned to a task is in accordance to the average duration of the previous disruptions generated in this task.
Figure 2 shows the different rates a machine can work for an assigned task Ti: green colour (speed 1) means that the machine works at lowest rate (lowest energy consumption), so the processing time is highest; yellow colour (speed 2) means that the machine works at regular rate, so the processing time is regular; and red colour (speed 3) means that the machine works at highest rate (highest energy consumption), so the processing time is lowest. Thus, the processing time of a task is dependent of the rate the assigned machine works. However, once the scheduling problem is solved and during execution, if an incidence occurs in task Ti, the assigned machine could increase its rate (if it was planned to work at speed 1 or 2) in order to absorb this incidence. Thus, the time interval between a given processing time and the lowest processing time of task Ti can be considered as an energy-efficient buffer.
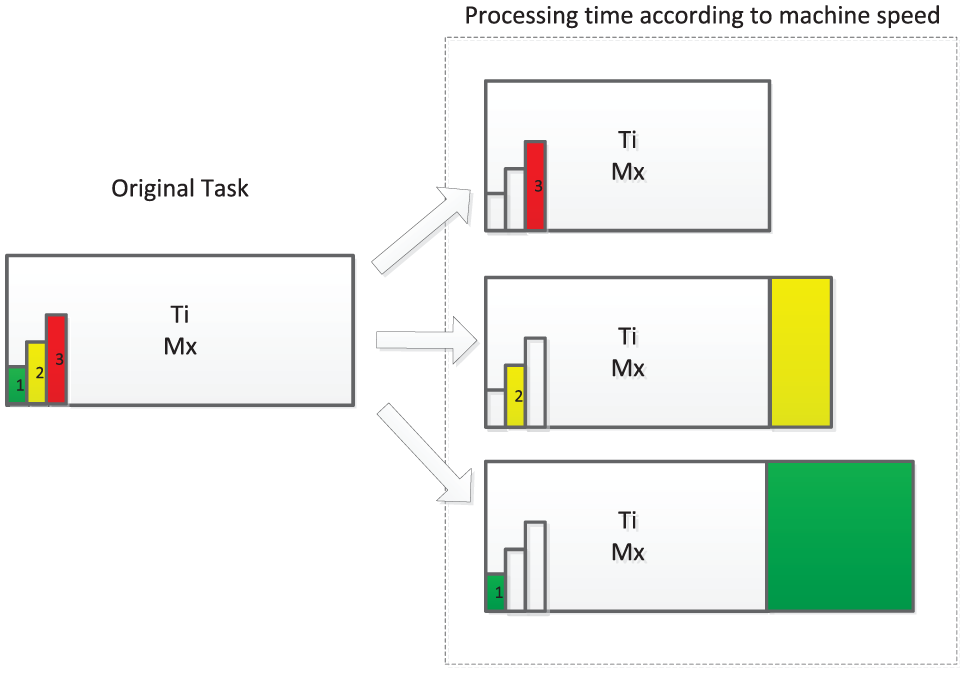
Processing time of a task in a machine working at different rates.
The dual scheduling model is aimed to insert additional buffer times to more dynamic tasks. To this end, the historical data are analysed to determine which tasks must be protected by a buffer time. Due the above advantages and disadvantages of the inclusion of buffer times, only the most dynamic tasks will be selected. Figure 3 shows the dual transformation of a dynamic task Ti. The dual transformation is composed of the following steps:
1. The original task model is composed of the number of tasks within the job (Ti), the assigned machine (Mx) and the different ways this machine can work (see Figure 2).
2. Modelling– if the task Ti is selected among the most dynamic ones, a dual task model
3. Solving– once the dual tasks
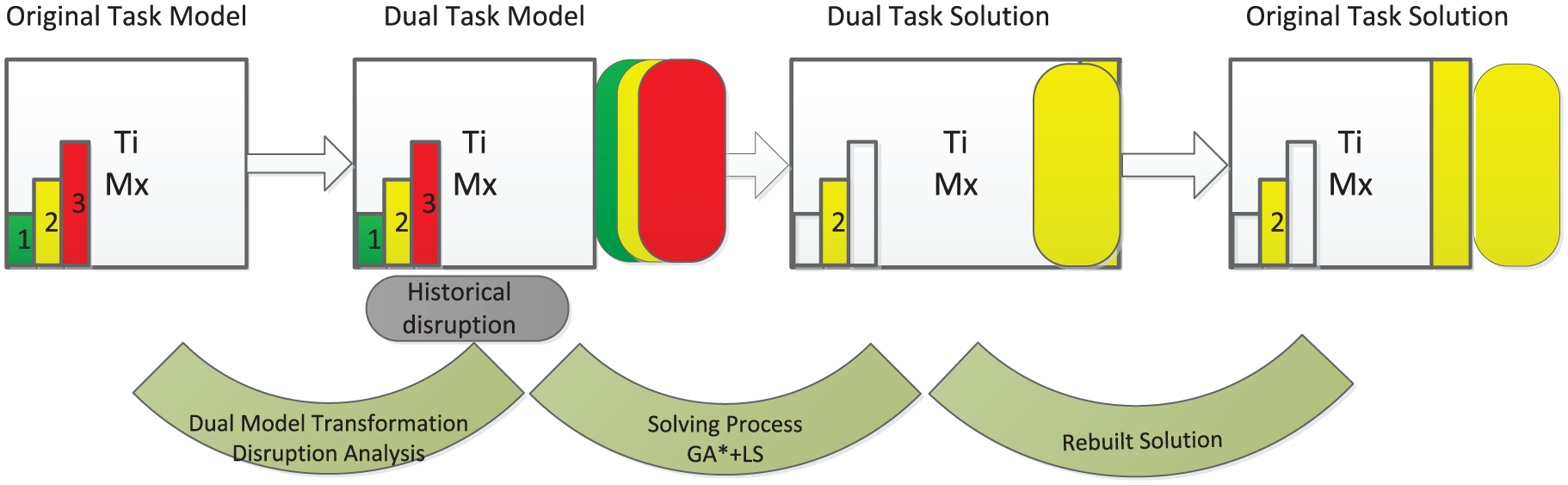
Dual transformation of a scheduling task.
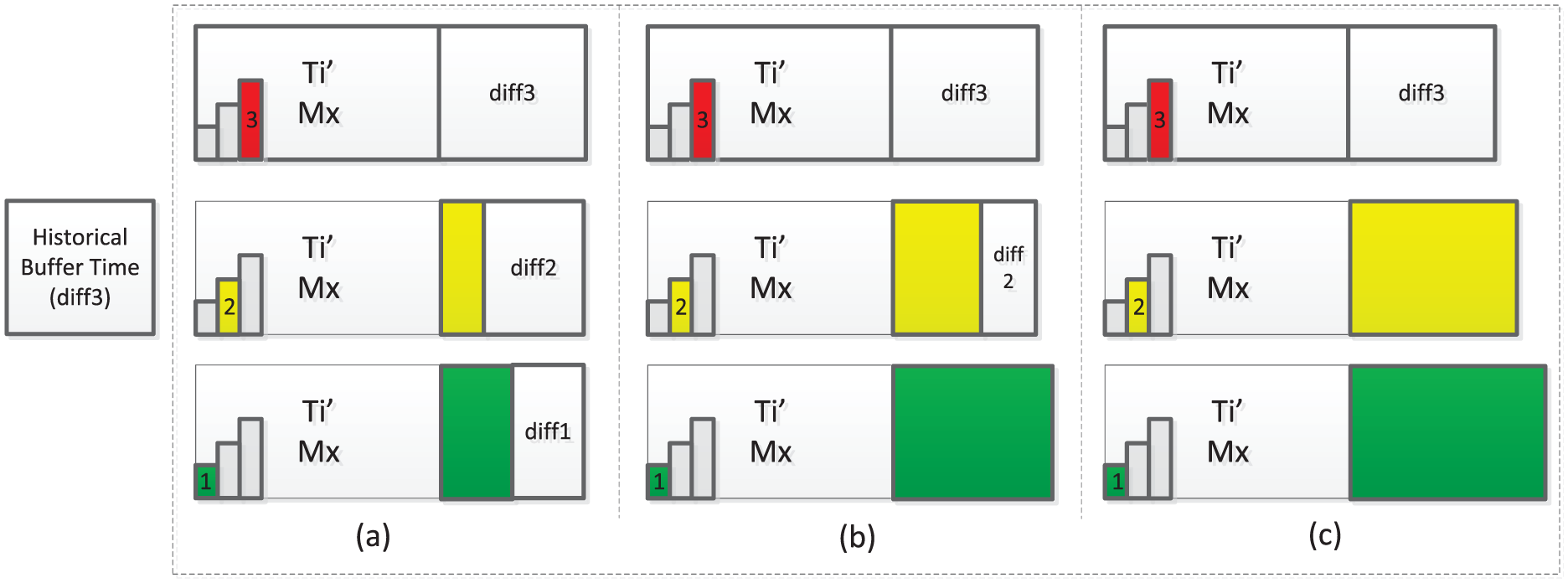
Three different cases for the buffer time assignment.

It must be taken into account that any solver could be applied to the dual model. The selected solver is aimed to assign for each task, its start time, the processing time and the speed that the machine executes each task. Furthermore, the makespan and the energy consumption can be determined by the solver.
4. Rebuilt– once the obtained solutions are generated for the dual scheduling model, they are rebuilt to obtain solutions of the original scheduling model (see Figure 3). Thus, the robustness can be measured by decoupling the buffer times and the energy-efficient buffers generated in the schedule. This rebuilt task is formally presented in Algorithm 2.

Sometimes buffers can be generated close to a buffer time assigned in the dual model. So if the sum of both is higher than the maximum duration of the historical incidence, the speed of the assigned machine can be reduced (if possible) to get a more energy-aware solution with the same degree of robustness.
Example
In this section, a small example is shown to analyse and clarify the proposed model. Table 1 shows the processing time and the energy consumption for each rate/speed that each machine can work. The JSMS is composed of three jobs, three machines and three tasks per job. It must be taken into account that when the speed increases the energy consumption also increases, but the processing time decreases. For this example, 60 incidences were randomly generated. Table 2 shows the distribution of incidences among the most dynamic tasks (Column Nincidences). Only the more dynamic ones are selected to generate a dual model (the three tasks with more incidences, Job1-Task1, Job1-Task2 and Job3-Task1 are presented in Table 2).
Buffer times for most dynamic tasks.
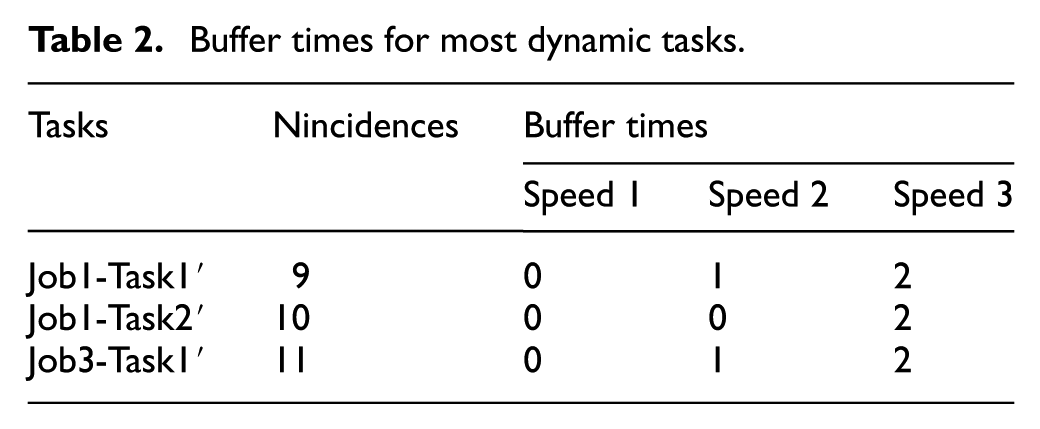
The historical buffer time will be calculated according to the historical disruptions. In this above set of 60 incidences, the average size of the disruption was 2. Thus, Algorithm 1 is executed to each selected dynamic task. The input of the algorithm is composed of the selected task and the average size of disruptions. Finally, the dual task model is obtained. This dual task model is composed of the original tasks with their corresponding processing time and the dual tasks with the original processing times plus the obtained buffer times shown in Table 2.
For example, Job1-Task1′ is a dual dynamic task with a buffer time assignment of type (b) according to Figure 4:
Buffer time at lowest speed is 0: the processing time of the original task at highest speed plus the historical buffer time is not bigger than the processing time at lowest speed.
Buffer time at regular speed is 1: The processing time of the original task at highest speed plus the historical buffer time is 1 unit bigger than the processing time at regular speed.
Buffer time at highest speed is 2: The processing time of the original task is increased with the historical buffer time (2 units).
Thus, the processing time of the dual tasks are updated by adding the calculated buffer times of Table 2. Then, the resultant dual model can be solved. Once the solution has been obtained, the dual tasks must rebuild to obtain the original processing times and their corresponding buffers.
Figure 5 shows the solution (Gantt chart) for the original example and the corresponding solution of the dual model. The assigned values of the processing time for the selected speed are shown in bold in Table 1. The buffer times are shown in grey blocks. The gaps are represented in black blocks. By comparing both solutions it can be observed that the energy consumption is the same and the makespan in the original model is 27 meanwhile in the dual model is 29. However, the solution obtained by the dual model is more robust due to the fact that almost all tasks (except Job2-Task3) are able to absorb incidences up to 2 time units.
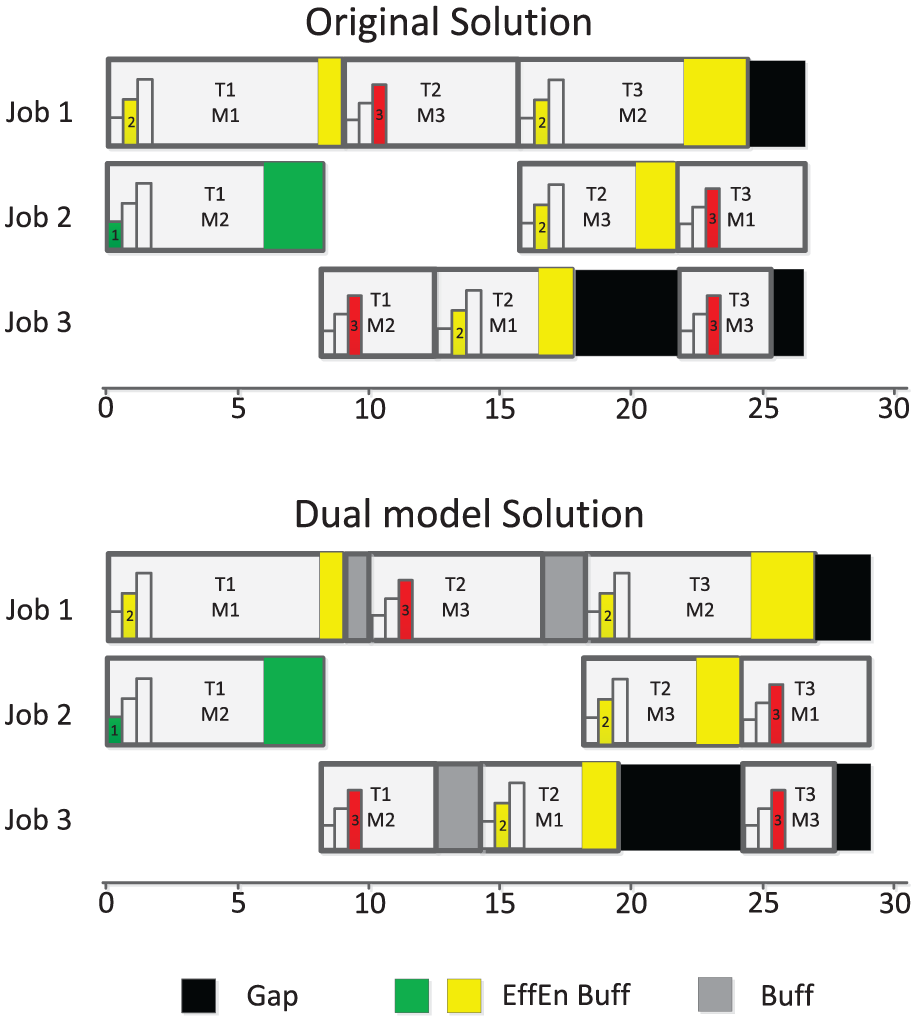
Original solution and dual model solution.
Evaluation
In this section, an evaluation of the proposed dual model is carried out to analyse and compare against the original model for finding robust and energy-aware solutions. As it has been pointed out, a memetic algorithm (GA* + LS) which combines a GA with an LS to solve the JSMS is applied. Furthermore, a comparative study was carried out by changing the value of buffer times to demonstrate that, as the buffer time increases, the robustness and energy efficiency also increase but the makespan decreases. Otherwise, stability is considered and solutions are analysed to know how incidences can be absorbed with the robustness and stable concepts.
Analysis of parameters
To carry out an extensive evaluation, two well-known benchmarks were used: Agnetis benchmarks
23
and Watson benchmarks.
24
In both cases, the instances were classified by the number of jobs
Agnetis instances are classified into two big groups, small and large:
Small: j = 3; m = 3, 5, 7; vmax = 5, 7, 10; p = (1, 10), (1, 50), (1, 100)
Large: j = 3; m = 3; vmax = 20, 25, 30; p = (1, 50), (1, 100), (1, 200)
In Watson instances, the number of jobs
j = 50, 100, 200; m = 20; vmax = 20; p = (1, 100)
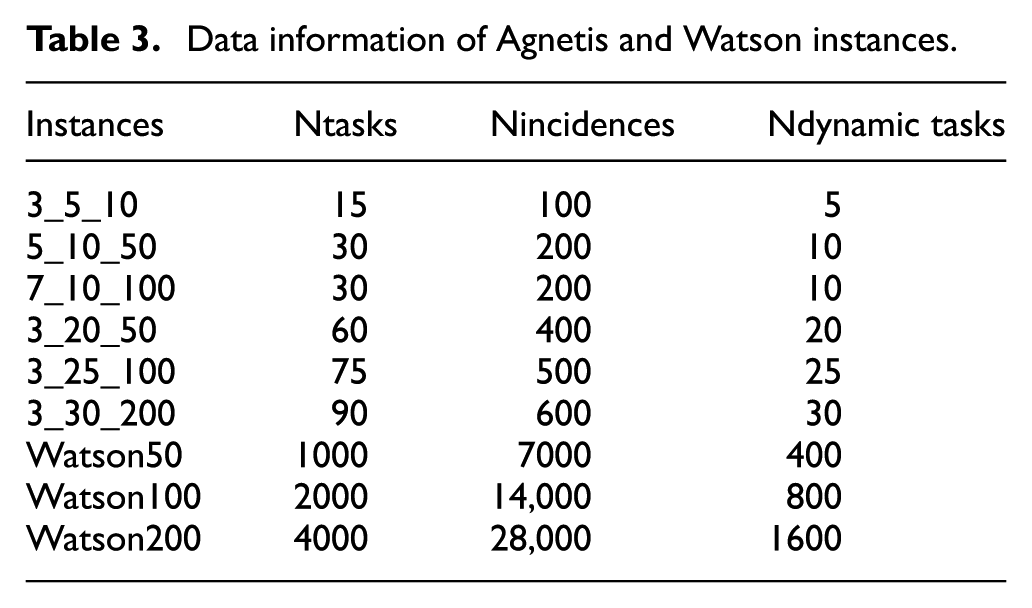
To simulate a historical background of the incidences for the Agnetis and Watson instances, a set of incidences were randomly assigned to tasks. To this end, the number of incidences was always proportional to the total number of tasks. Table 3 shows the analysed instances, the number of tasks, the number of simulated incidences and the number of selected dynamic tasks for the dual model. There must be a proportional relationship among the number of tasks, the number of simulated incidences and the number of selected dynamic tasks. The number of incidences must be significantly higher in order to classify and discriminate the more dynamic tasks. The number of dynamic tasks is also related to the number of tasks. A high number of dynamic tasks will generate a high degree of robustness but a worse makespan. As it was pointed out before, there must be equilibrium between the number of buffers and the optimality in terms of makespan.
Data information of Agnetis and Watson instances.
For each type of problem, 10 instances were evaluated, so the average results are shown in next tables. Original instances were extended as explained in Escamilla et al. 7 New instances and more information can be found in the research group webpage (http://gps.webs.upv.es/jobshop/).
Comparative study
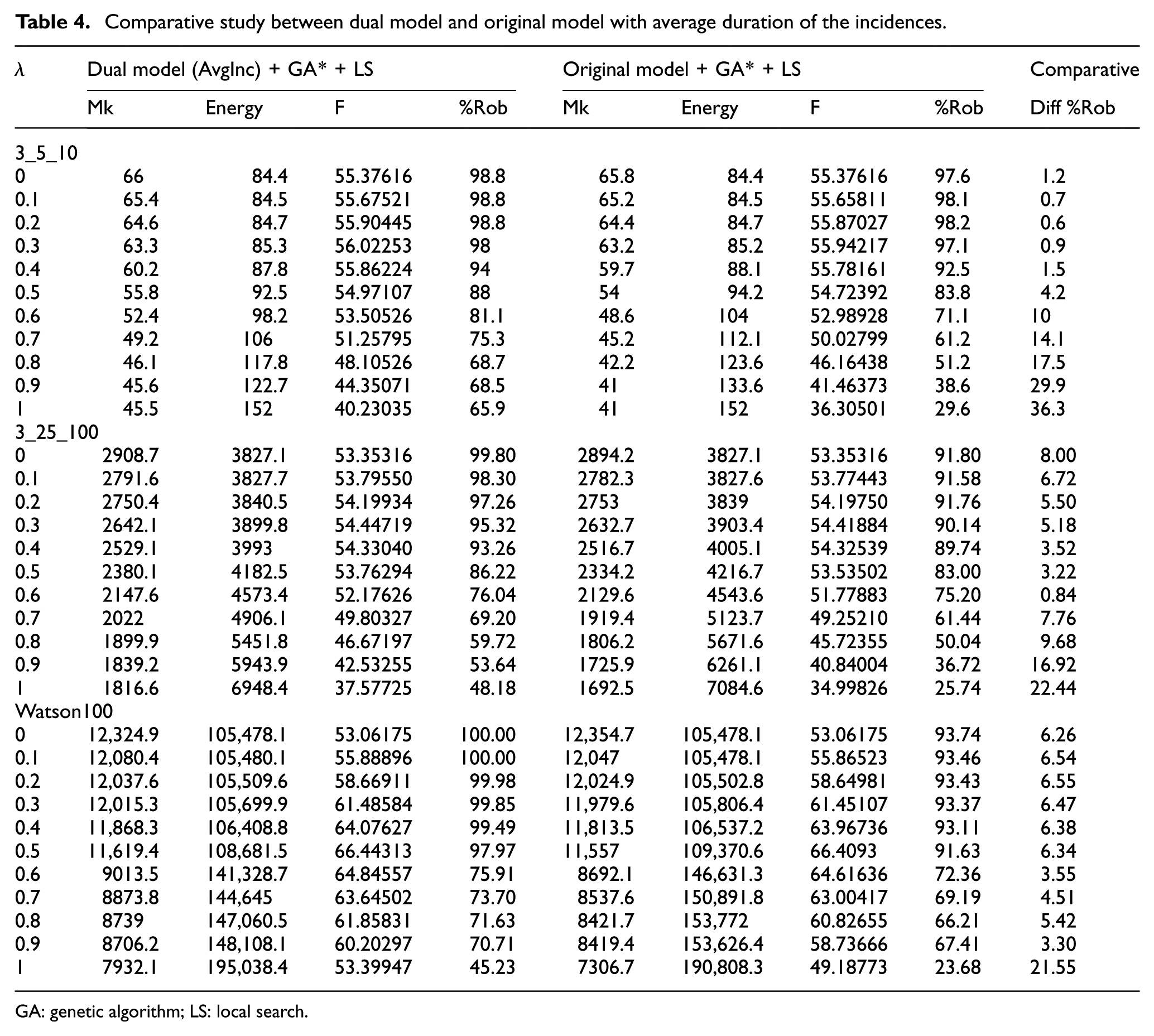
In this section, the behaviour of the dual model is compared against the original model. To this end, both models were executed over the same solver (GA* + LS) to analyse the performance of both models in terms of makespan, energy consumption and robustness. The incidences were randomly generated and assigned to tasks following the relation of Table 3. Once an incidence is assigned to a task, the duration is randomly generated between 1% and 20% of the maximum processing time for that instance. Thus, for instances where processing time was 50, the incidences were assigned a duration between 1 and 10. Table 4 shows the results for the Agnetis instances 3_5_10 and 3_25_100 and Watson100 instances. In all cases, the experiments were made over 10 different instances, so the values of the tables show average results. The values of robustness were also an average over the all incidences, so they are shown in percentage.
Comparative study between dual model and original model with average duration of the incidences.
GA: genetic algorithm; LS: local search.
Table 4 shows the makespan, energy consumption, F value and robustness of both models for different
In general, the solutions obtained by applying the dual model had a worse F value, but on other hand the solutions were more robust. Furthermore, it can be observed in the last column (Diff %Rob) that as the
When only makespan was optimized, makespan was worsened but the robustness was improved.
When only the energy consumption was optimized, the robustness was improved without losing optimality.
When both variables were optimized, makespan was worse but energy consumption had a different behaviour, but robustness was improved.
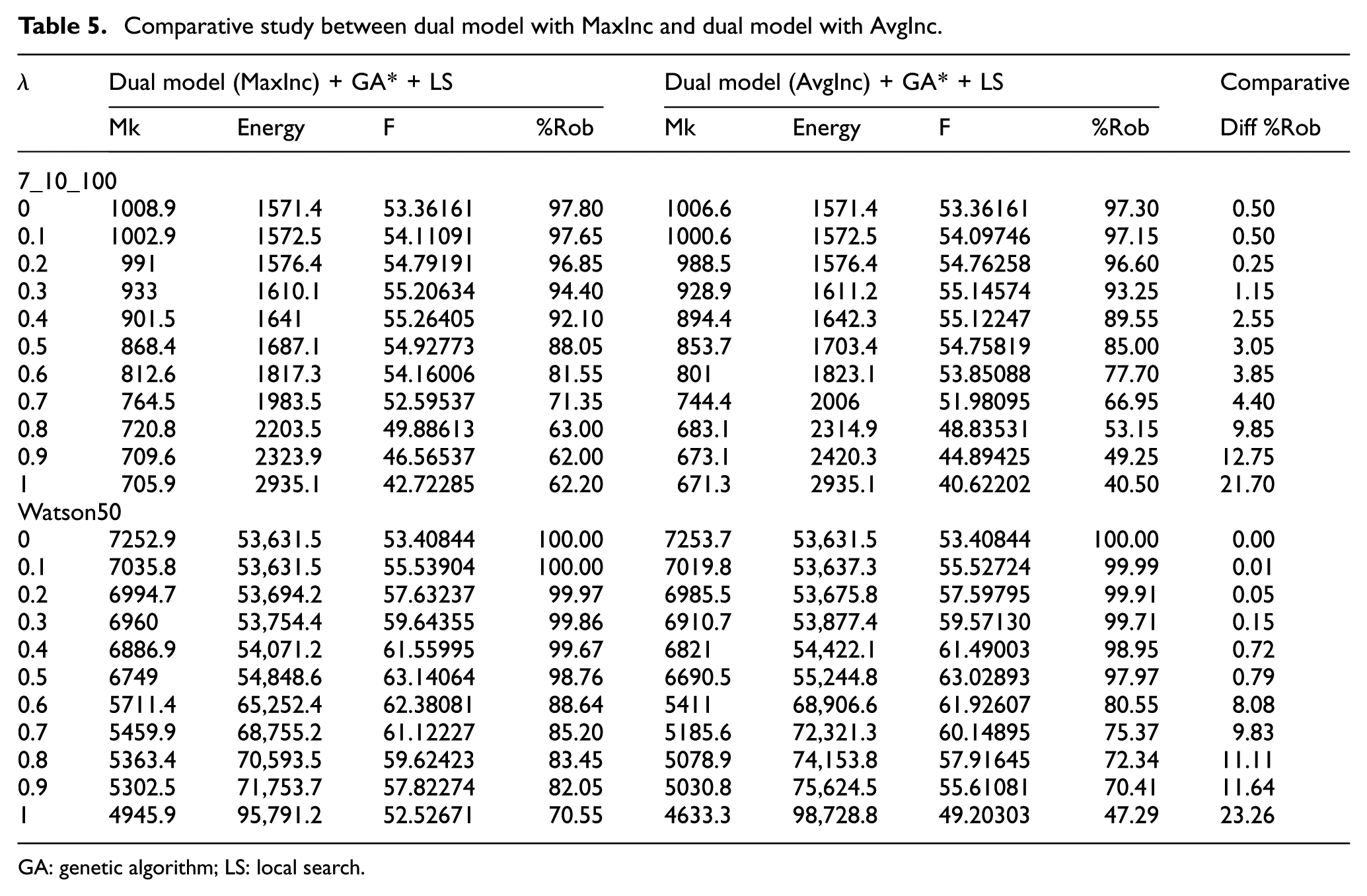
Table 5 shows the results of Agnetis instances 7_10_100 and Watson50 instances to analyse the behaviour of the dual model over the size of the buffer times. To this end, two different buffer time sizes were analysed: buffer times with the maximum duration size of the incidences (MaxInc) and buffer times with the average size of all incidences (AvgInc). This table represents the behaviour of all instances analysed in Table 3 and all instances showed a similar behaviour.
Comparative study between dual model with MaxInc and dual model with AvgInc.
GA: genetic algorithm; LS: local search.
The dual model with MaxInc had an F value higher than the dual model with AvgInc. However, the robustness value was always higher in the dual model with MaxInc. This is because, as the buffer time of the MaxInc was always bigger than AvgInc, the makespan value was also higher and thus the F value. For example for
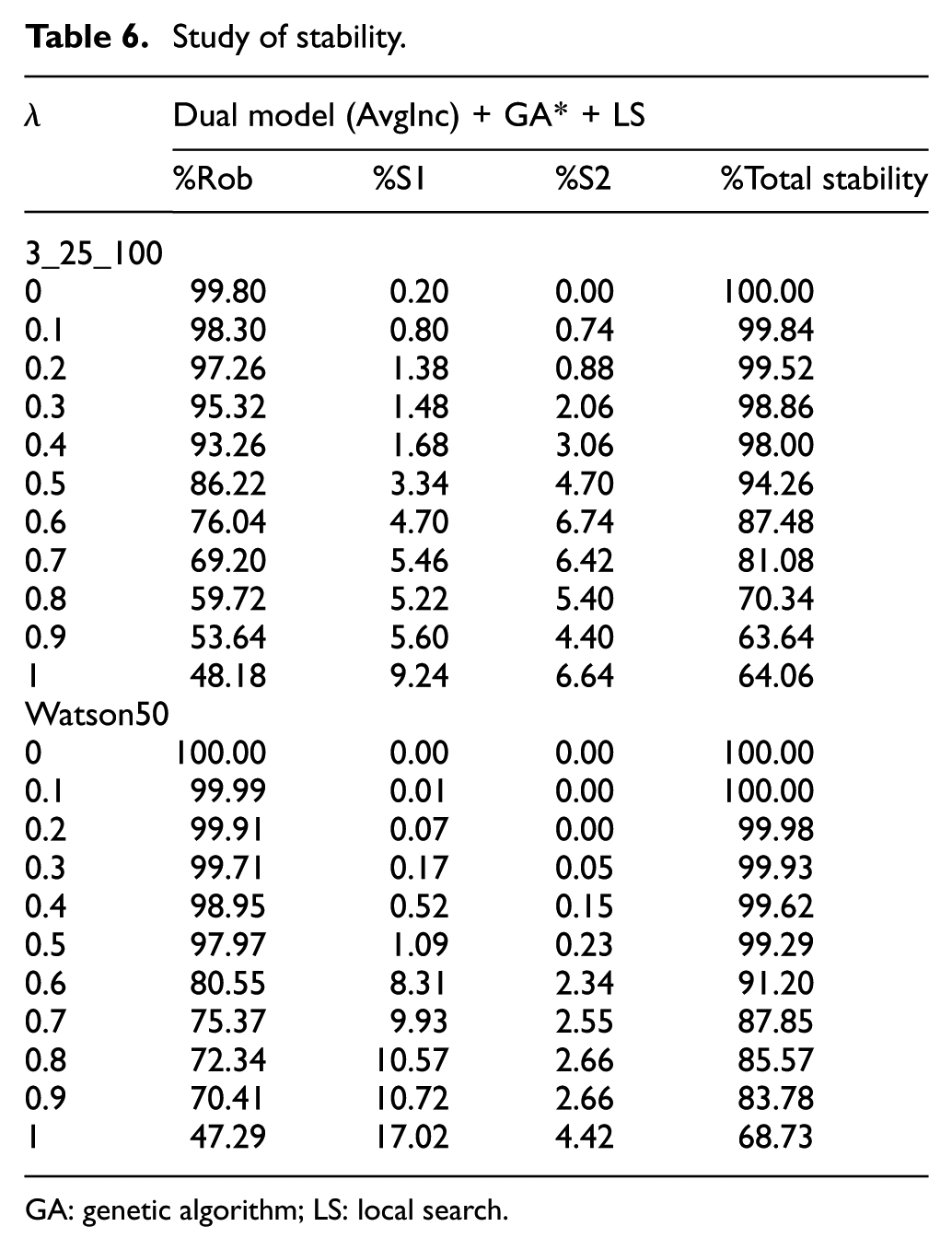
Finally, the stability was analysed for the dual model in both Agnetis and Watson instances. As it was pointed out in section ‘Robustness and stability’, stability is the ability of a solution to recover with only a few changes. Thus, given an incidence in a task Ti, 0-stable is equivalent to robustness, so no further tasks will be affected, meanwhile 1-stable and 2-stable require to change the start time of 1
Table 6 shows the percentage of robustness or 0-stability (%Rob), 1-stability (%S1) and 2-stability (%S2), and the percentage of total stability (%Total Stability) obtained by summing up the three previous parameters for Agnetis instances 3_25_100 and Watson50 instances. The rest of instances presented in Table 3 maintained similar behaviours. It can be observed that robustness or 0-stability (%Rob) had a higher value than 1-stability (%S1) and 2-stability (%S2). This is due to the fact that, the dual model was designed to add buffer times to more dynamic tasks. Thus, given an incidence, the algorithm tried to absorb it by increasing the speed of the machine or by using the assigned buffer time. If the incidence was not able to be absorbed, it was checked whether the incidence could be absorbed by the next task of the same machine or by the next task of the same job. If the incidence can be absorbed by changing only one task (from the same machine or the same job), it is considered a 1-stable solution. However, if both tasks have to be modified, it is considered a 2-stable solution. For both Agnetis and Watson instances, the percentage of total stability was close to 100% for
Study of stability.
GA: genetic algorithm; LS: local search.
Conclusion
Industrial processes involve a large number of task scheduling problems. JSPs where machines can work at different rates/speeds (JSMS) represent a large number of combinatorial problems in industrial processes. In this article, a dual model is proposed to relate optimality criteria with energy consumption and robustness/stability. This model is committed to protect dynamic tasks against further incidences in order to obtain robust and energy-aware solutions. The proposed dual model has been evaluated with a memetic algorithm (GA* + LS) to compare the behaviour against the original model. The result shows that the proposed dual model was able to obtain more robust solutions in all instances and more energy-efficient solutions in most of them. This is due to the fact that the assigned buffer times to some tasks are used to protect them against incidences. Furthermore, if during execution, there is no incidence, the involved machine can use this buffer to work at lower speed, so the energy consumption can be also reduced. The combination of robustness and stability gives the proposal an added value because although an incidence cannot be directly absorbed by the disrupted task, it can be repaired by involving only a small number of tasks. Thus the original solution can be recovered in order to maintain feasible the rest of the obtained schedule.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research has been supported by the Spanish Government under research project TIN2013-46511-C2-1 for the Spanish government and the TETRACOM EU project FP7-ICT-2013-10-No 609491.