
Abstract
With the development of computer vision technologies, manufacturing is now using stereo models for production, and the amount of stereo models generated recently has increased significantly. Thus, a fast and reliable model retrieval algorithm has become important. In this article, we propose a novel view-based stereo-model retrieval algorithm using a modified principal component analysis algorithm. Unlike a traditional principal component analysis that uses the origin of a two-dimensional image, we apply principal component analysis to extract eigenvectors for each stereo model. First, we extract a set of two-dimensional images from different directions of the stereo object. Because each two-dimensional image can be seen as one sample of the stereo object, we utilize principal component analysis to extract the eigenvectors as a dictionary for each stereo object. Then, those eigenvectors are used to rebuild the query. Finally, the reconstruction residual is applied to represent the similarity between the query and the candidate stereo object. Experimentally, the proposed retrieval algorithm has been evaluated using the ETH-80 and ALOI datasets. Experimental results and comparisons with other methods show the effectiveness of the proposed approach that can be used in engineering manufacturing and computer-aided design applications.
Keywords
Introduction
With the rapid development of computer vision technology, computer vision equipment has become more widely used than ever before. The amount of stereo data has increased exponentially in the past decade, and thus, stereo information is easily available; therefore, effective stereo retrieval methods are now required. Stereo models have been widely used in many applications such as engineering manufacturing, computer graphics, computer-aided design, computer vision and image processing.1–2 Compared to two-dimensional (2D) images, stereo models can convey more information about an object. As shown in Figure 1, a stereo image describes multiple views of an object instead of only one. The fast growth of stereo-model archives necessitates the progress of stereo-model retrieval techniques. The purpose of stereo-model retrieval is to provide algorithms that compute similarities between the query and stereo models in the dataset efficiently and effectively. 3 Generally, there are two categories of stereo-model retrieval algorithms: model-based methods and view-based methods. Early studies primarily investigated model-based methods, in which low-level feature-based methods or high-level structure-based methods were used. Low-level feature-based methods utilize geometric moments, 4 surface distributions, 5 volumetric information 6 and surface geometry 7 to describe stereo models. Many low-level features are also based on a 2D image feature, and stereo-model retrieval depends on the low-level feature comparison. Concurrently, high-level structures require stereo models to be available explicitly. 8 Each stereo model must have spatial and structural information, which limits the practical applications of model-based methods.

One example of a stereo object described by multiple views.
View-based methods are the other category of the popular stereo-model retrieval algorithm.9–11 View-based methods represent stereo models by a set of 2D images; this image set shows the stereo object from different views. Thus, these 2D images provide spatial and structure information; however, how to extract features from these 2D images to represent spatial and structure information for each stereo model is a challenge. Zernike moments and Fourier descriptors 12 are typically used to describe each 2D image, and the elevation descriptor (ED) 8 has also been proposed recently. Six elevations are obtained from six different views to describe a given stereo model. Stereo model comparison is then based on the comparison of these six elevations. Recently, Gao et al. 13 proposed a spatial structure circular descriptor (SSCD) method to compare two stereo models. In this method, the stereo model is projected onto a plane, and the comparison between two stereo models is based on matching between the two groups of SSCD images. However, SSCD requires a fully stereo model to generate 2D images in different planes and is thus difficult to implement in practical applications; view-based methods have a highly discriminative property for object representation, and visual analysis plays an important role in multimedia applications. View-based methods have two distinct advantages. First, they do not require explicit virtual model information, which makes the method more applicable in practical applications. Second, image processing has been investigated for many decades; view-based stereo-model analysis methods can benefit from existing image processing technologies.
View-based stereo-model retrieval algorithms compare stereo models using view sets. Images representing a stereo model should consider the spatial information of images. Based on these reasons, we proposed a novel stereo-model retrieval algorithm based on the principal component analysis (PCA) algorithm 14 in this article. In the proposed algorithm, the stereo model includes a set of 2D images. We first extract features from these 2D images and then apply the PCA algorithm to extract eigenvectors for these features. We select these eigenvectors to represent the features of a given stereo model. In the retrieval process, we apply these eigenvectors to rebuild the feature space of the query image and then use reconstruction error to represent the similarity between the query and stereo model: the smaller the error, the higher the similarity between the query and a given stereo model. We use this similarity to retrieve the stereo model in the stereo dataset.
The proposed scheme has two advantages:
We propose to apply the PCA algorithm to extract eigenvectors as the representative features of a stereo model, and eigenvectors can be used for stereo-model retrieval.
We apply these feature eigenvectors to rebuild the query and use reconstruction error as the similarity between two stereo models. This method can fully consider the spatial and structure information of stereo models and guarantee better matching because eigenvectors reserve the majority information of a given stereo model.
This article is organized as follows: section ‘Related work’ briefly reviews the related work; section ‘Proposed stereo-model retrieval method’ introduces how to extract features of 2D images and how to extract eigenvectors for each stereo model; the distance between the query and stereo model is presented in section ‘Similarity between query and stereo model’; experiments are provided in section ‘Experiment and analysis’; and finally, we conclude this article in section ‘Conclusion and future work’.
Related work
In this section, we primarily review related works that have investigated view-based techniques for stereo object retrieval.15–18 In view-based stereo-model retrieval, features are extracted from 2D images. Visual similarities between the different view images from different models are compared with each other to measure the difference of the models. Light Field 19 is a famous view-based shape descriptor that defines the distance between two stereo models as the minimum distance between their 10 corresponding silhouette views. To measure the difference between two silhouette views, the method uses a hybrid image metric 20 that integrates the Zernike moments’ descriptor and Fourier descriptor. The multiple-view descriptor first aligns the model with PCA 14 and then classifies models by comparing the primary, secondary and tertiary views defined by the principle axes.
The salient local visual feature-based retrieval method 21 first renders a set of depth view images for a stereo model and then extracts the multi-scale local features of these views using scale-invariant feature transform (SIFT), 22 which is invariant to translation, scaling and rotation. Finally, it fuses all local features into a histogram using the bag-of-words (BOW) approach, which records visual words of multiple views into a single histogram to represent the feature of a stereo model.
Recently, Gao et al. 13 proposed another view-based descriptor called the SSCD, which can preserve the global spatial structure of stereo models and is invariant to rotation and scaling. In addition, all spatial information of stereo models can be represented by the SSCD without redundancy. Because this method requires a fully stereo model to generate the SSCD, it is difficult to use in practice.
Proposed stereo-model retrieval method
Overview of system
The goal of stereo-model retrieval is to compute the distance between a query and the available stereo models. In the first stage, we need to select a robust feature that can represent the spatial and structure information of a stereo model. We use the Zernike moments descriptor as the feature for each stereo model, which extracts features from each 2D image that can represent the structural information of a given stereo object. Then, the similarity between two models in content-based stereo-model retrieval is performed. Each stereo model includes a set of 2D images; thus, it is difficult to select a matching image between two different stereo models. As a result, we apply PCA to extract eigenvectors for each stereo object to represent the stereo model and use the reconstruction error to calculate the similarity between two models. Finally, this similarity is used to manage the stereo-model retrieval problem. The framework of the proposed stereo-model retrieval algorithm is shown in Figure 2.
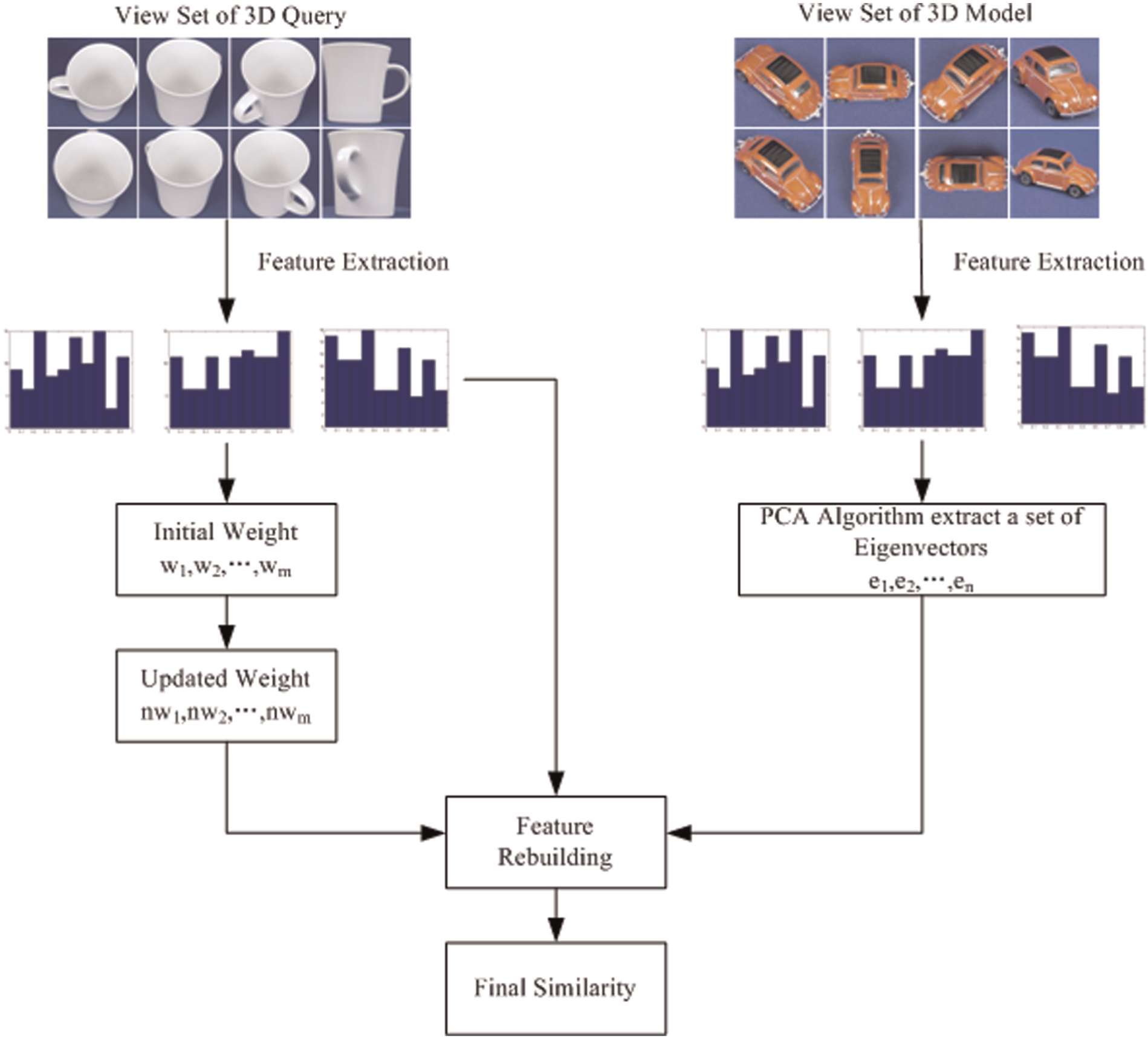
Framework of the stereo object retrieval model.
Feature of stereo models
Each stereo model has a set of 2D images from different directions. Traditionally, many feature algorithms, such as histogram of oriented gradients (HoG), local binary patterns (LBP) and RGB, can be used to analyse 2D images; however, these feature algorithms do not represent the spatial and structure information of a set of 2D images. Thus, 49 coefficients of Zernike moments are used as view features. Zernike moments are robust to image translation, scaling and rotation and have been applied in many studies of stereo-model analysis; they have also been effective in creating 2D view descriptions. In this process, one 49-dimensional (49D) vector feature will be extracted from each 2D image, producing a set of vectors that will represent a given stereo model.
Model reconstruction with PCA
PCA is a popular technique for data compression and has been successfully used as an initial step in many computer vision tasks, including face recognition and object recognition. All traditional PCA algorithms work on the original 2D image. Unlike traditional PCA methods, in this study, we apply PCA to extract eigenvectors in the feature space. Each image in the set of 2D images that describe a stereo model has spatial and structure information, and because it is difficult to define a weight for each 2D image, we utilize features and eigenvectors from the feature space. The formulation of PCA is as follows. Considering a set of m images, each of size r × c, a 49D feature vector is extracted from each image Ii . The mean object of the set is defined by
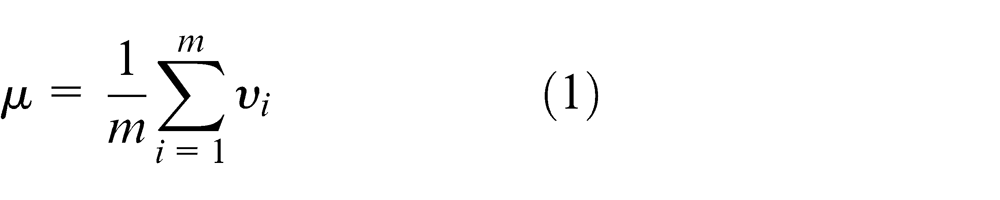
C, the covariance matrix, is given by
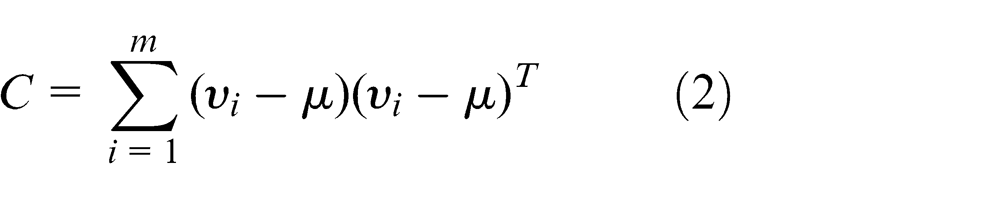
The principal components (PCs) are then the eigenvectors of C. These eigenvectors can be computed in several ways; perhaps the easiest is to solve the generalized eigenvector problem using the QZ algorithm or one of its variants. It is also common to formulate the problem as locating the basis vectors that minimize reconstruction error and then solve the problem using the standard least-squares techniques. In this system, we compute these eigenvectors using the implementation provided by MATLAB, which is based on the QZ algorithm.
If we sort the eigenvectors by decreasing order of their corresponding eigenvalues, a projection onto the space defined by the first k eigenvectors (1 < k < 49) is optimal with respect to information loss. If P is the matrix whose columns are the first k eigenvectors of C, then the projection of an image feature u into this eigenvector space is given by
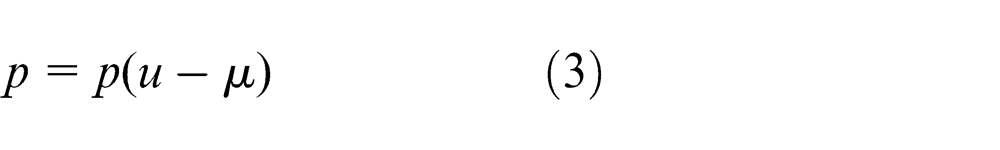
When reconstructing an image feature with the PCA algorithm, the image is projected onto the PCs, and from this projection, we try to recover the original image feature. Thus, the reconstructed image feature
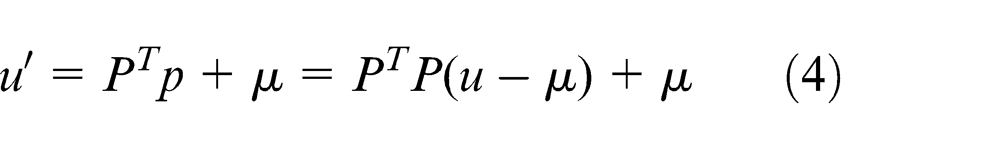
If P is the matrix whose columns are the first k eigenvectors of C, then the projection of an image into this eigenspace is given by
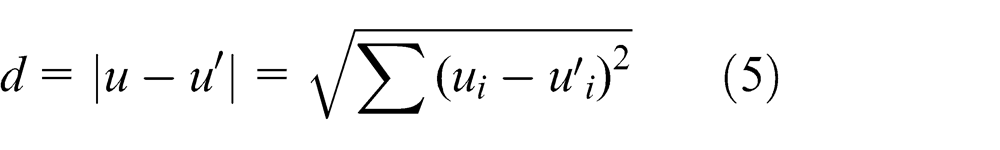
In general, the more PCs we use to obtain the projection, the less information loss we will have; thus, the reconstruction of the image feature will be more accurate. Additionally, the more similar u is to the images used to generate P, the better the reconstruction will be for a fixed number of eigenvectors.
Similarity between query and stereo model
Following the above process, PCA searches for a set of PCs that best describes the distribution of the data being analysed. Therefore, these PCs will better preserve the information of the stereo model. We can apply these PCs to rebuild the 2D image for other stereo models. If two stereo objects belong to the same category, the rebuilding error between the rebuilt image and the origin image will be small. However, each stereo model has a set of 2D images. In the stereo models, it is difficult to define the weight of each 2D image because each 2D image can represent spatial and structure information of the stereo models. In this article, we propose a novel method to define the weight of each query image. The process framework is shown in Figure 2.
In practical applications, people often upload images of one object from different perspectives. As a result, some images will contain more important information than others. These images should be qualified as more important than other images, and thus given more weight when describing the stereo model. Given a set of query views for one stereo model M, the views of M are
First, we define the same weight prvi for each image, where prvi = 1/n. When one image is relatively similar to another image, this image has more information than neighbouring images and should thus have a larger weight than other images. Thus, the relationship among different images can be taken into consideration to help define image weights. During processing, a relevance graph model is constructed to describe the relationship among query images, while each node represents one image, and the edge between two nodes is the relevance r(rv1, rv2 ) between the two query images rv1 and rv2 , which is defined as
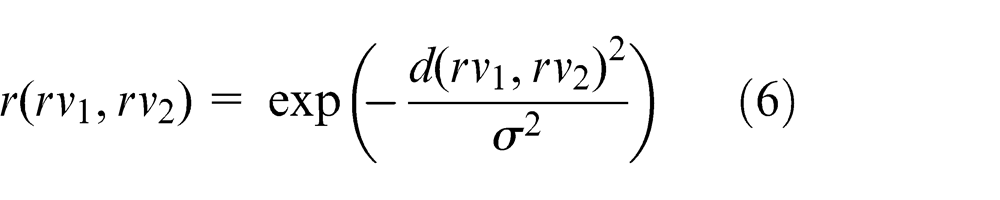
where σ is experimentally selected. Then, we utilize the random walk method to update the weight for each image. The transition probability from rvi to rvj is defined as
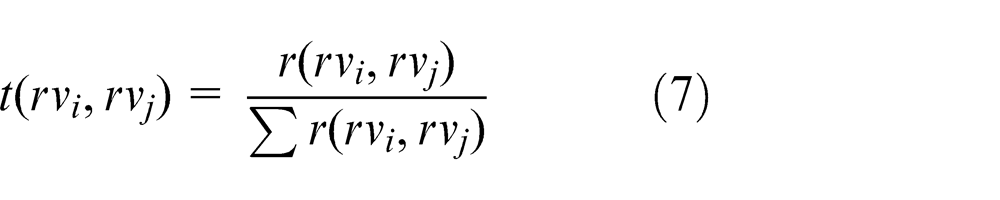
The updating procedure can be formulated by
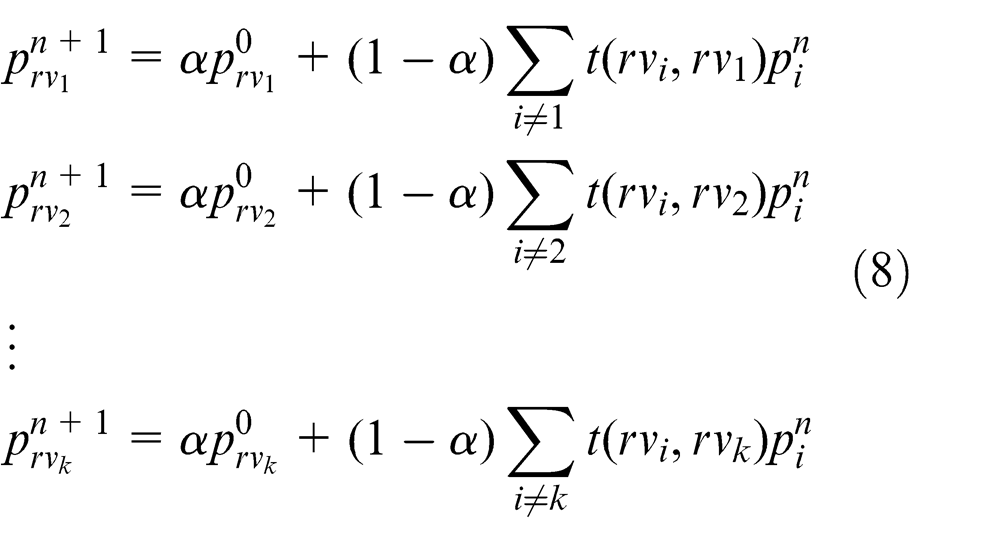
where α is a parameter determining how important the initial weight value is. This procedure can converge after several iterations experimentally. Then, all query images have final weight values. Finally, we apply these weights and the reconstruction error to obtain the final distances between the query and stereo model; this distance is used as the similarity between the query images and stereo model.
Experiment and analysis
In the retrieval process, we assume that each query includes a set of 2D images of the observed object from different perspectives because people often capture a set of views from different perspectives using digital equipment to record the information. For example, one visitor will capture some photos of a landmark building and search this object on the Web using these photos; the photos used in this search are the query. Thus, this problem can be formulated into a stereo-model retrieval problem. Stereo-model retrieval technology is thus developing rapidly. Based on the mentioned assumptions, we design a set of experiments to demonstrate the performance of this method. We randomly selected a set of 2D images as a query from a stereo dataset. The details of the experimental design are shown in the next sections.
Dataset
To evaluate the proposed approach, we conduct experiments using the ETH stereo object dataset and the Amsterdam Library of Object Images (ALOI) object images dataset, which are real-world stereo object multiple views datasets. The ETH dataset contains 80 objects in eight categories. Each object from the ETH dataset includes 41 different views that are spaced evenly over the upper viewing hemisphere, and all positions for cameras are determined by subdividing the faces of an octahedron to the third recursion level. Because there is no stereo-model information in the ETH dataset, we randomly split the 41 views into two multi-view groups for each stereo object. One group of multi-views (including 20 views) is used as the query, and the other group (including 21 views) is used as the testing data. ALOI is a colour image collection of 1000 small objects and also provides multiple real-world views for each object. To capture the images, the camera view angle, illumination angle and illumination colour for each object are systematically varied. For the camera view angle, the camera is rotated in a plane in 5° increments to record 72 views of each object; each object has 72 views from different directions. We randomly split the 72 views into two multi-view groups for each object; one group (including 20 views) is used as the query, and the other group (including 52 views) is sued as the testing data.
Compared methods
Several state-of-the-art methods are selected for comparison. The details about these methods are described as follows:
CCFV. 9 CCFV is a camera-constraint-free view–based stereo object retrieval algorithm. In this method, the author proposed Gaussian models to represent the stereo feature distribution.
BoRW. 23 BoRW applies bag-of-visual-words feature vectors to represent the stereo models. In this method, the SIFT feature is used to describe the 2D images from the stereo model.
OM. 24 The original optimal matching algorithm, OM, uses direct bipartite graph matching, and weight values are not considered.
HAUS. 8 Called the Hausdorff distance method, the maximum distance of a set to the nearest point in another set is calculated using equation (9)
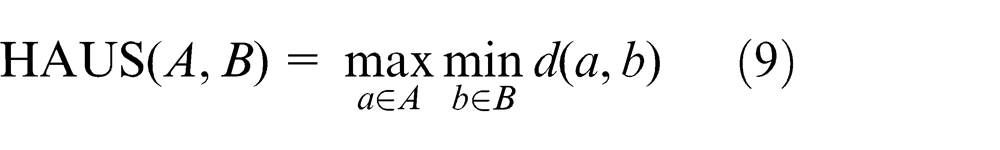
where A, B represent one stereo model that includes a set of 2D images, and a, b represent one 2D image from the stereo model.
Evaluation criteria
The following metrics are used to evaluate the proposed algorithm:9,10
Nearest neighbour (NN). NN is the correct rate of the first retrieved result.
First tier (FT). FT is defined as the recall of the top T results, where T is the number of relevant samples in the dataset.
Second tier (ST). ST is defined as the recall of the top 2T results, where T is the number of relevant samples in the dataset.
Precision-recall curve. 25 The performance of stereo object retrieval is assessed in terms of average recall (AR) and average precision (AP). These terms both range from [0, 1]. A high AR or AP value represents a superior ability to retrieve a relevant stereo model. They are computed as follows
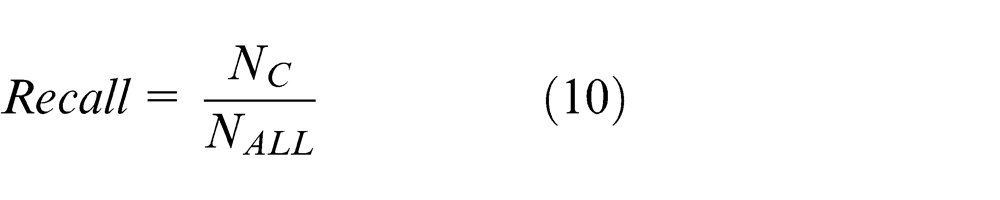
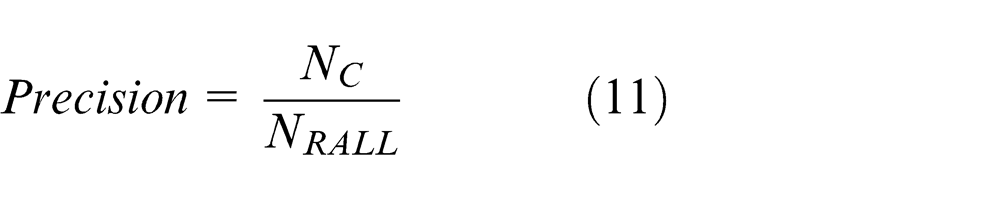
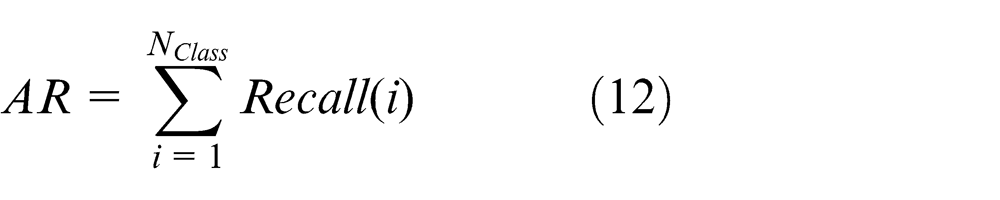
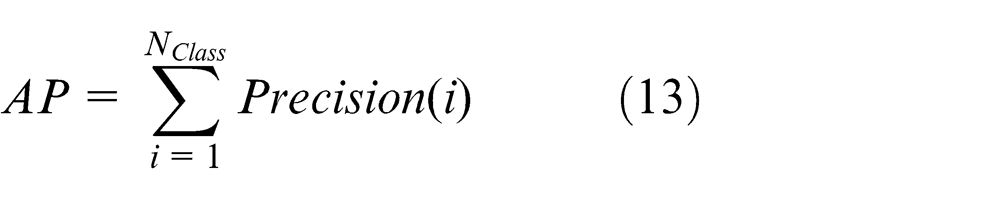
where NC is the number of correctly retrieved objects, NALL is the number of all relevant objects, NRALL is the number of all retrieved objects, Recall(i) is the recall of the ith class, and NClass is the number of stereo-model class. Note that in these experiments, NClass = 21. The precision-recall curve can intuitively show retrieval performance.
Analysis on the query information
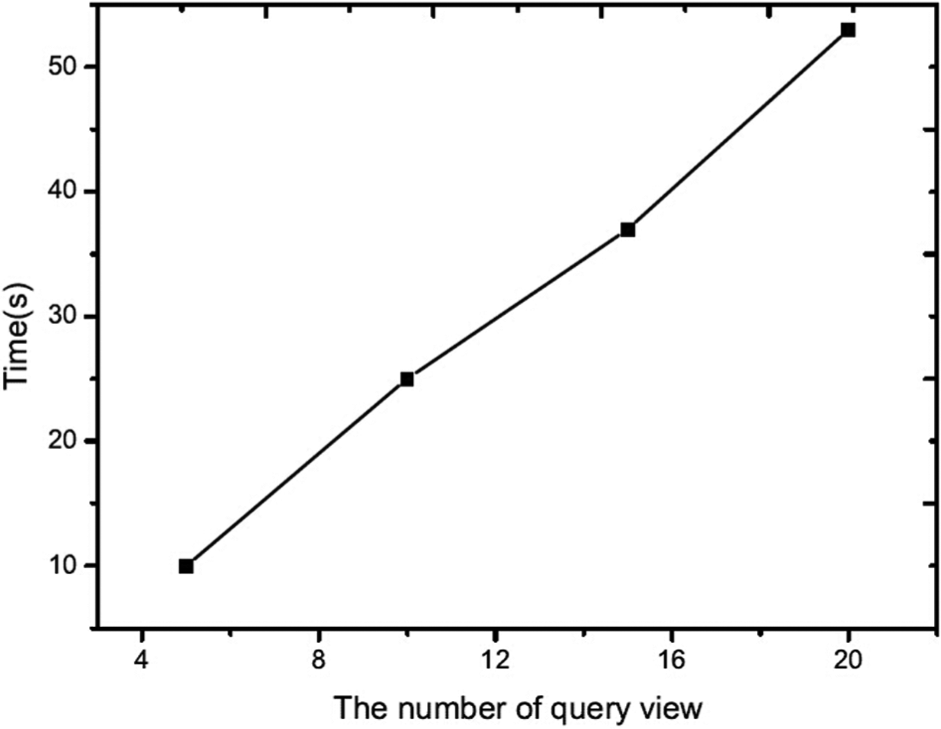
In this section, the influence of different query information on retrieval performance is investigated. Different numbers of query views are sampled from the ETH and ALOI dataset to create query information. The number of query views is selected as 5, 10, 15 and 20. In this experiment, each object in the ETH dataset is used as a testing query. For each group of query information, query views are randomly selected from the views of each query object. The experimental comparison is shown in Figures 3 and 4. The ALOI dataset captures 1000 small objects, which does not provide the category annotation of each object. As a result, we do not evaluate the performance of the proposed algorithm using the first and second tiers. The experimental comparison is shown in Figures 5 and 6. From these results, it is evident that more query views yield better results. More query views provide more spatial and structure information for stereo object retrieval, and thus, better retrieval results are shown. However, the time cost also increases because more queries require more time to determine the similarity between query views and other stereo models, as shown in Figures 7 and 8.
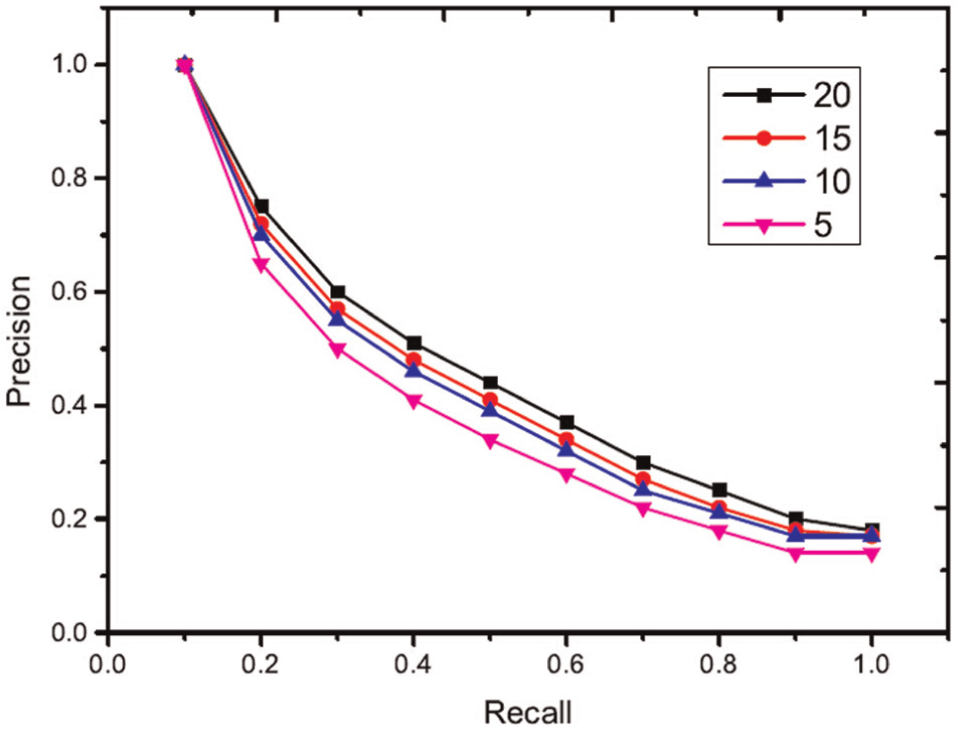
Performance of different numbers of query views (ETH dataset).
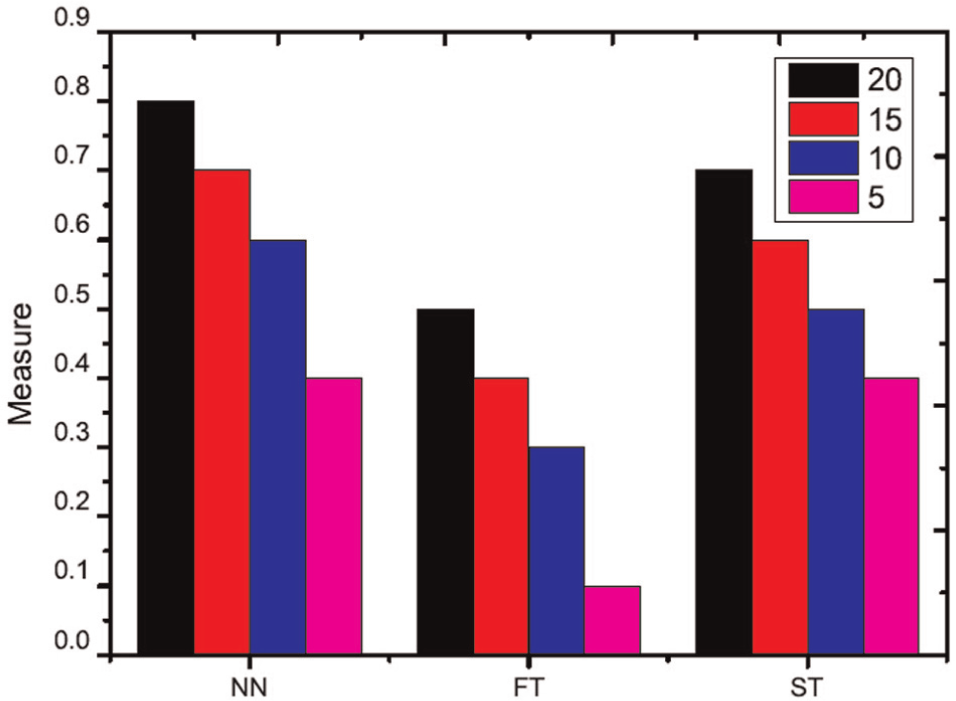
Comparison with other evaluation methods (ETH dataset).
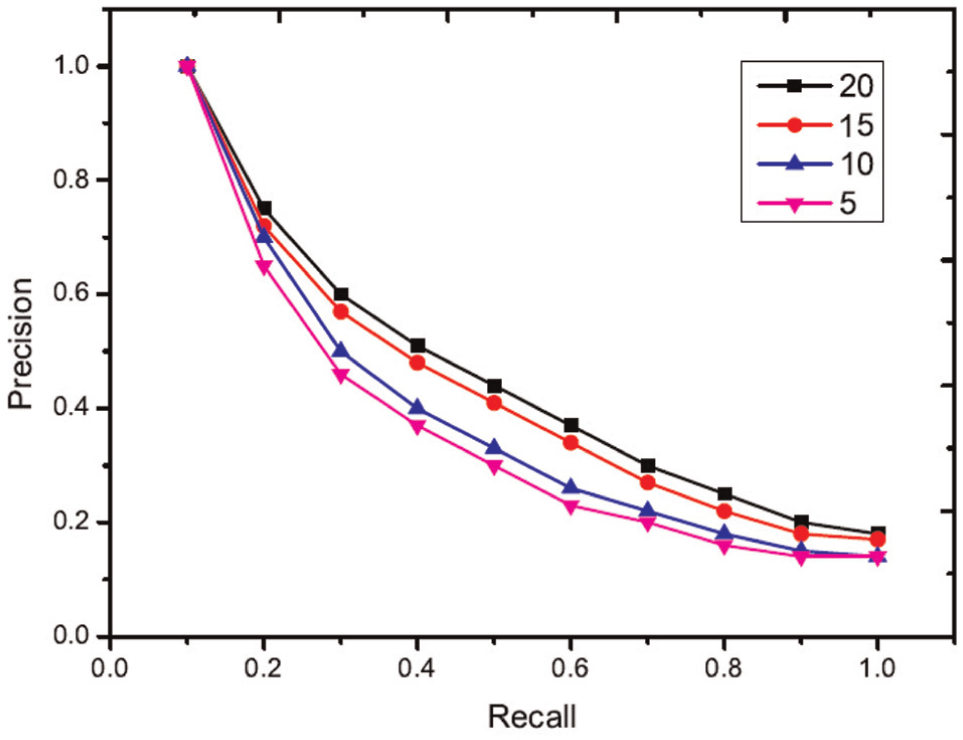
Performance of different numbers of query views (ALOI dataset).
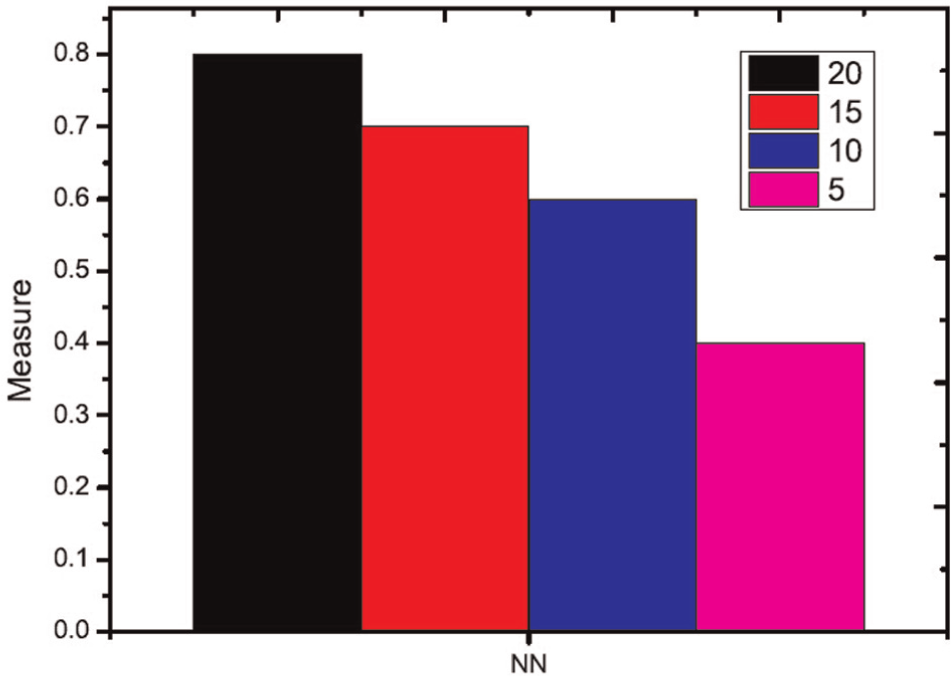
Comparison with other evaluation methods (ALOI dataset).
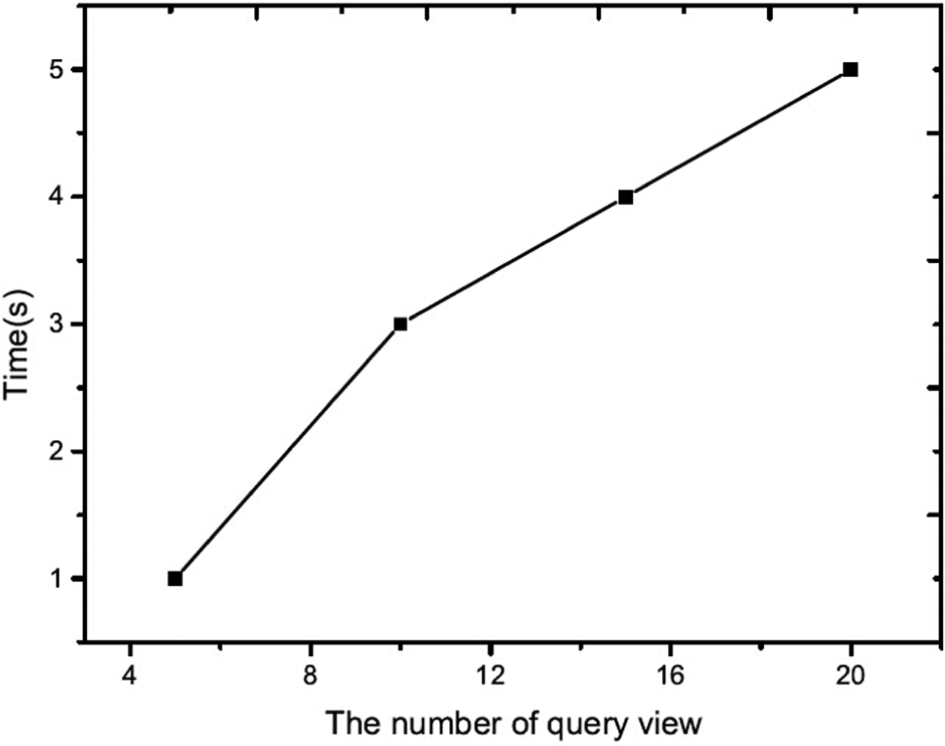
Time cost for different numbers of query views (ETH dataset).
Time cost for different numbers of query views (ALOI dataset).
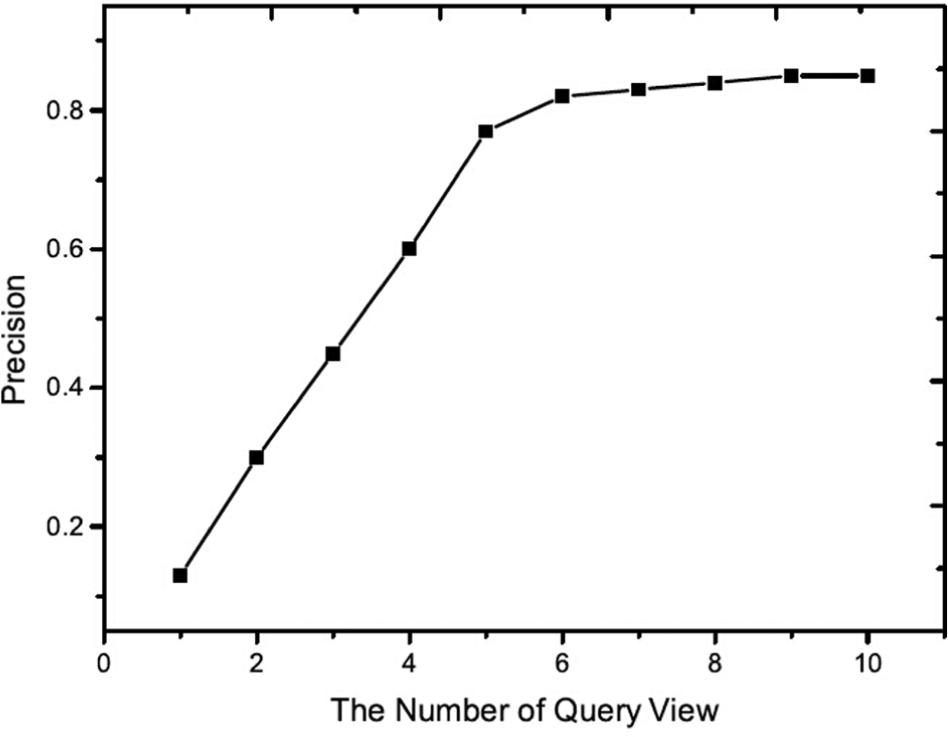
To balance retrieval performance and time cost, we define weights for each query view in the above process. Another experiment is then conducted where we select the top k weight query views. These results are shown in Figures 9 and 10. From these results, with the increase in number of query views, the performance flattens out because the top k query views provide sufficient information for accurate retrieval. Thus, a user uploading 5–7 views will likely obtain good retrieval results. These results also demonstrate the effectiveness of PCA methods.
Performance of the top k weight query views (ETH dataset).
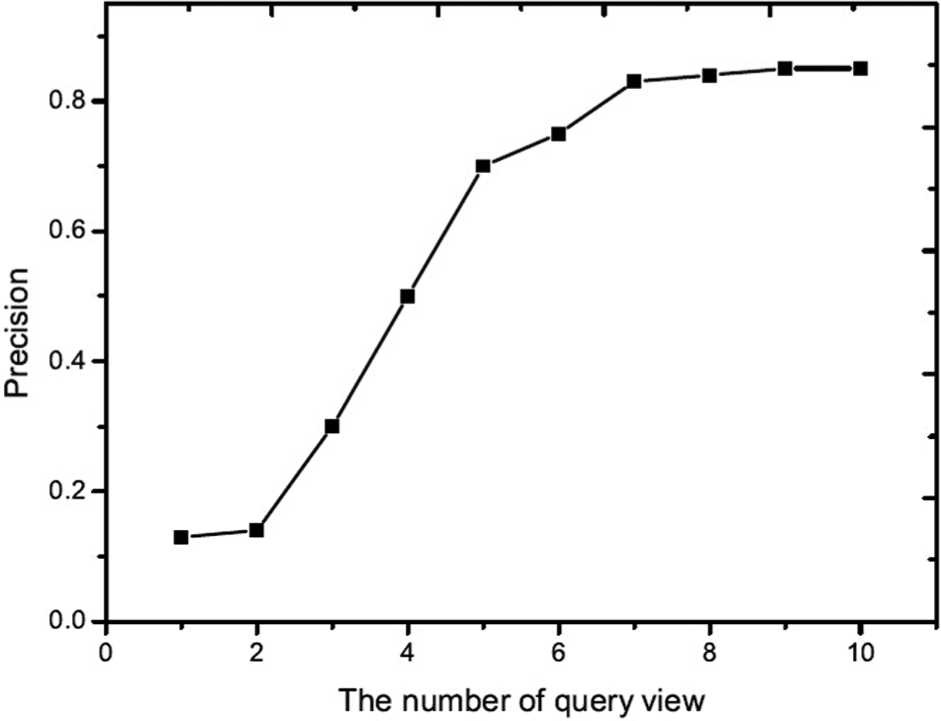
Performance of the top k weight query views (ALOI dataset).
Comparisons with other methods
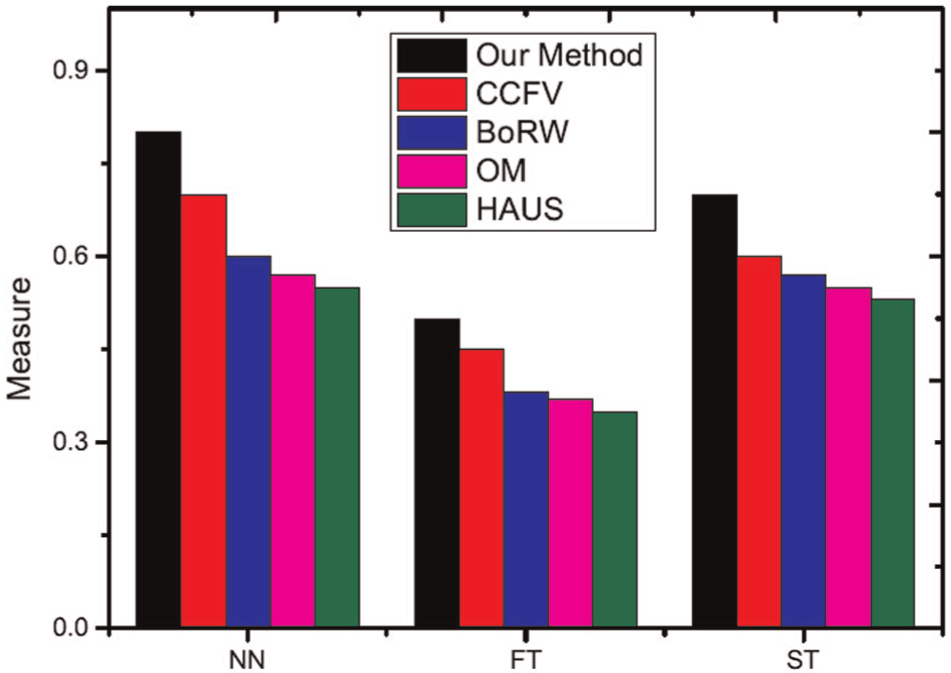
Precision-recall curves of the experimental results are shown in Figures 11 and 12. From these experimental results, the proposed method achieves the best performance using the ETH and ALOI datasets. The first and second tiers are used as performance evaluation metrics. These evaluation results are shown in Figures 13 and 14. The proposed method also shows better performance than other methods. In the experimental results, the HAUS method shows the worst experiment results because it only utilizes features of images to compute the distance but does not consider the matching level among images. Each model has a set of images, and these images typically have redundant information. If we only compute the distance between images and select the maximum distance as the similarity between images, this distance must be influenced by redundant information and does not represent the real distance between two different models. OM is shown to have the second poorest experimental results for the same reason (i.e. redundant information). OM applies bipartite graph matching to solve the matching problem between two different models; however, redundant information affects matching precision. For example, with two different models at certain angles, these two models may have a high similarity. If we recorded this model many times from these certain angles, these images would be redundant information. In the proposed method, the selection of query views can remove this information; however, the OM algorithm does not have this ability. This redundant information thus influences the final matching results and the final similarity between two different models. Thus, the OM algorithm does not show good experimental results. CCFV is a model-based retrieval method that uses Gaussian models to represent the model feature distribution. Its training step is typically long and is thus not suitable for manufacturing. BoRW uses the SIFT feature and BOW to represent the object model. In this article, the feature of an object should be scale and rotation invariant and should also represent the global features of the model. Significantly, SIFT does not have this characteristic. The proposed method applies the random walk method to remove redundant information and uses the reconstruction error to describe the similarity between the query model and the candidate model. Thus, this method produces the best results compared to the other methods studied.
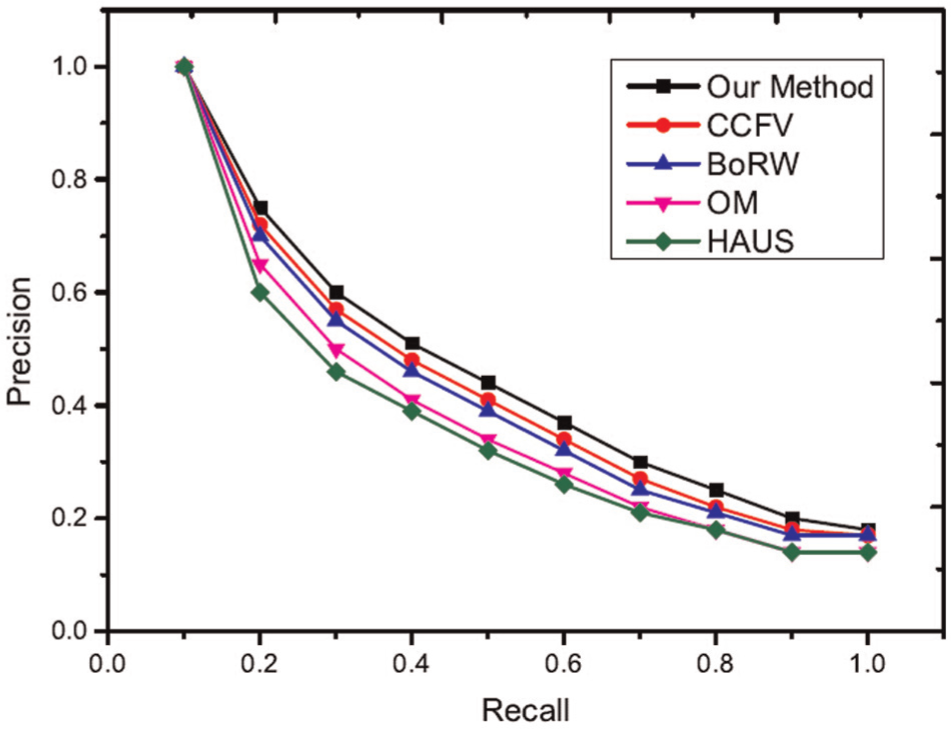
Retrieval performance using different methods (ETH dataset).
Retrieval performance using different methods (ALOI dataset).
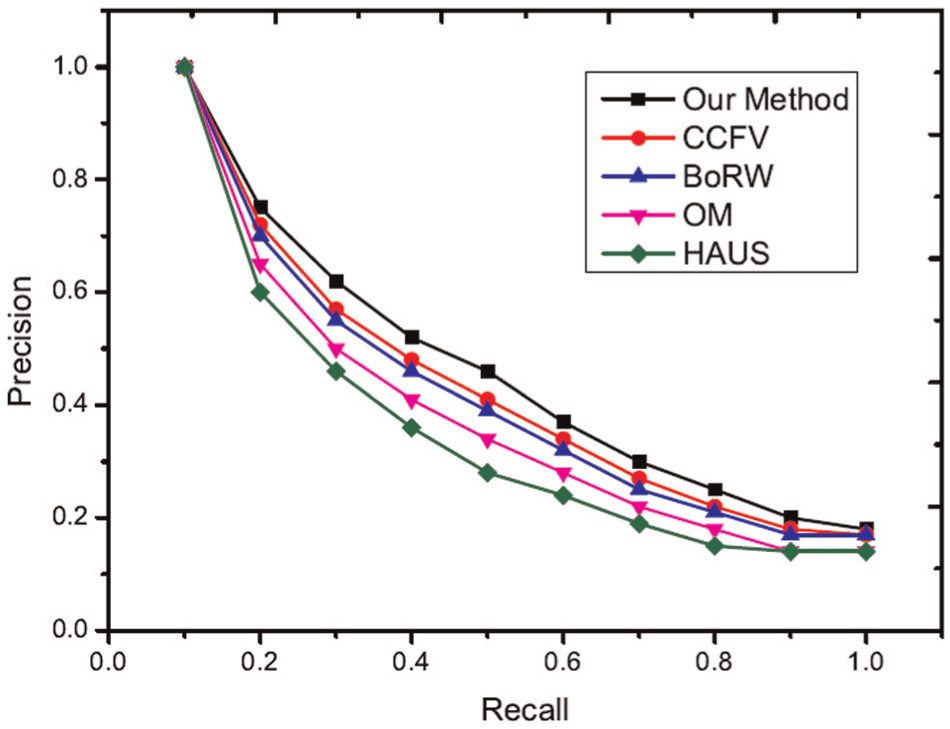
Performance of different methods in other evaluations (ETH dataset).
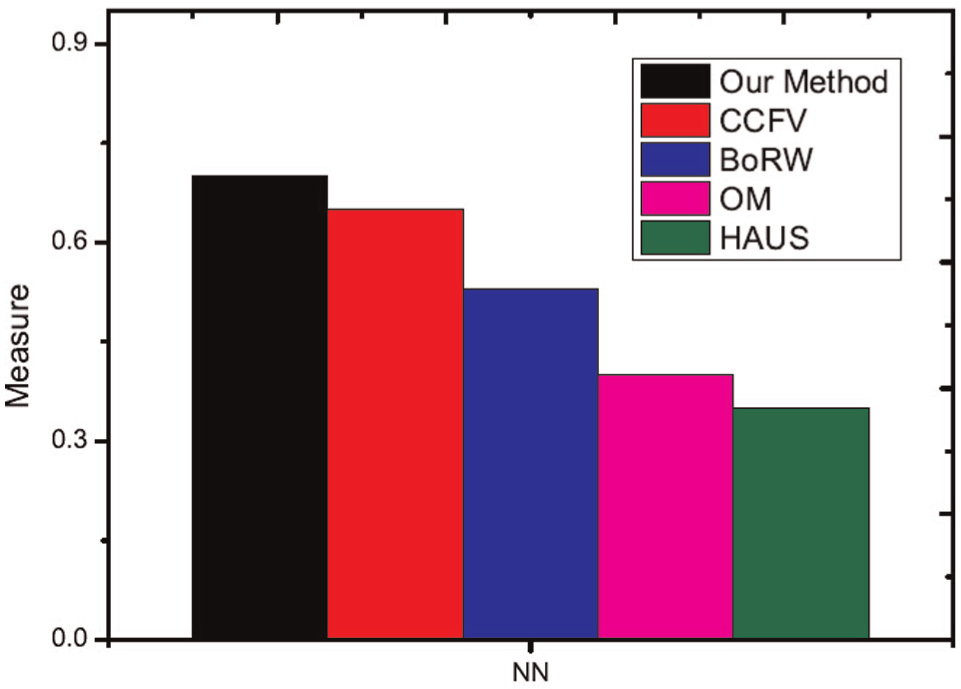
Performance of different methods in other evaluations (ALOI dataset).
To demonstrate the performance of the proposed method, the computation times of different algorithms were investigated. In this experiment, we select one model as a query from each of the ETH and ALOI datasets to compute its similarity to the other stereo models in the respective dataset. Finally, we select the object with the highest similarity as the retrieval result. The experimental results are shown in Figure 15.
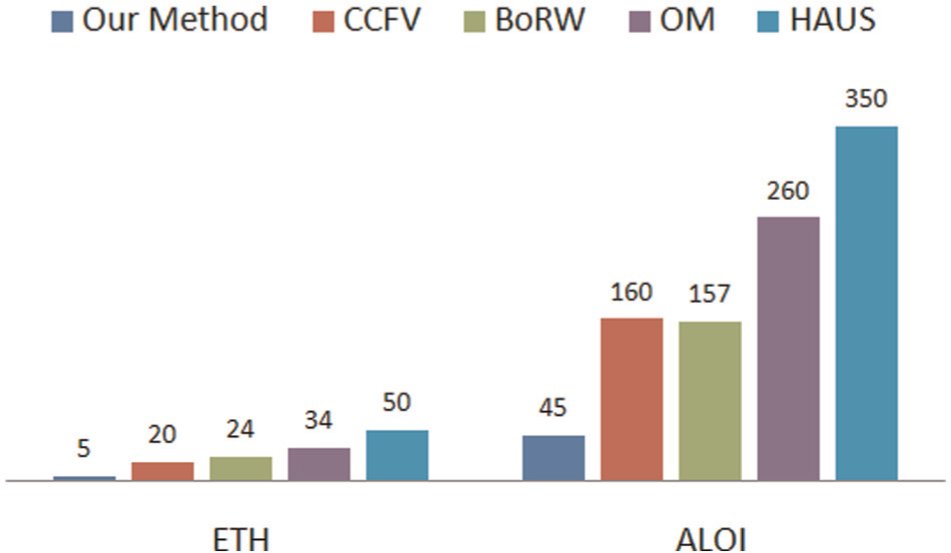
Time cost of different methods using the ETH and ALOI datasets.
Conclusion and future work
In this article, we propose a new stereo object retrieval algorithm. We apply the PCA algorithm to extract eigenvectors as representative views in abstract space. Then, we rebuild the query using these eigenvectors and apply the reconstruction error to represent the similarity between the query and a stereo model. Experimental comparisons conducted using the ETH dataset have demonstrated the effectiveness and efficiency of the proposed framework.
This proposed method still relies on 2D images; however, for practical applications, users need not capture many query views for accurate object retrieval. Thus, it is important to determine how to extract a ‘perfect’ feature to represent a given stereo model. Thus, the matching algorithm between a query and a stereo model should be investigated in more detail. We will focus on designing a method to accurately represent a stereo model and provide an effective match query with a stereo object in future research.
Footnotes
Declaration of conflicting interests
The authors declare that no conflicts of interest exist.
Funding
This work was supported by the National Natural Science Foundation, P.R. China, under Grant Nos 61162003 and 61363071.