
Abstract
This article deals with the two-stage assembly flow shop problem considering preventive maintenance activities and machine breakdowns. The objective is to minimize the makespan. This problem is proven to be NP-hard; thus, we proposed two meta-heuristic algorithms, namely, imperialist competitive algorithm and genetic algorithm, to obtain solutions of the problem. This article describes an approach incorporating simulation with imperialist competitive algorithm for the scheduling purpose having machine breakdowns and preventive maintenance activities. The results obtained are analyzed using Taguchi experimental design, and the parameters of proposed algorithms are calibrated by artificial neural network. The computational results demonstrate that imperialist competitive algorithm is statistically better than genetic algorithm in quality of solution and reaches to better solutions at the same computational time.
Keywords
Introduction
International competition and the ability to respond to the changing demand in the markets are some of the key attributes in designing effective production systems. Two-stage assembly flow shop is a combinational production system, where different parts are manufactured on parallel machine independently. This system can be used as a method to produce a variety of goods by assembling and combining different set of parts. From production point of view, the two-stage assembly flow shop problem consists of two stages, where m machines are at the first stage and only one machine at the second stage. There are n jobs, and each job is composed of m + 1 operations; m operations are performed by m machines in parallel at the first stage, and the last operation is done by the assembly machine in the second stage. The two-stage assembly flow shop has several applications in real-life problems such as computer manufacturing, 1 fire engine, 2 production and queries scheduling on distributed database systems, 3 as shown in Figure 1. The problem under study is common in an electronic industry like TV fabrication or air conditioner manufacturers.
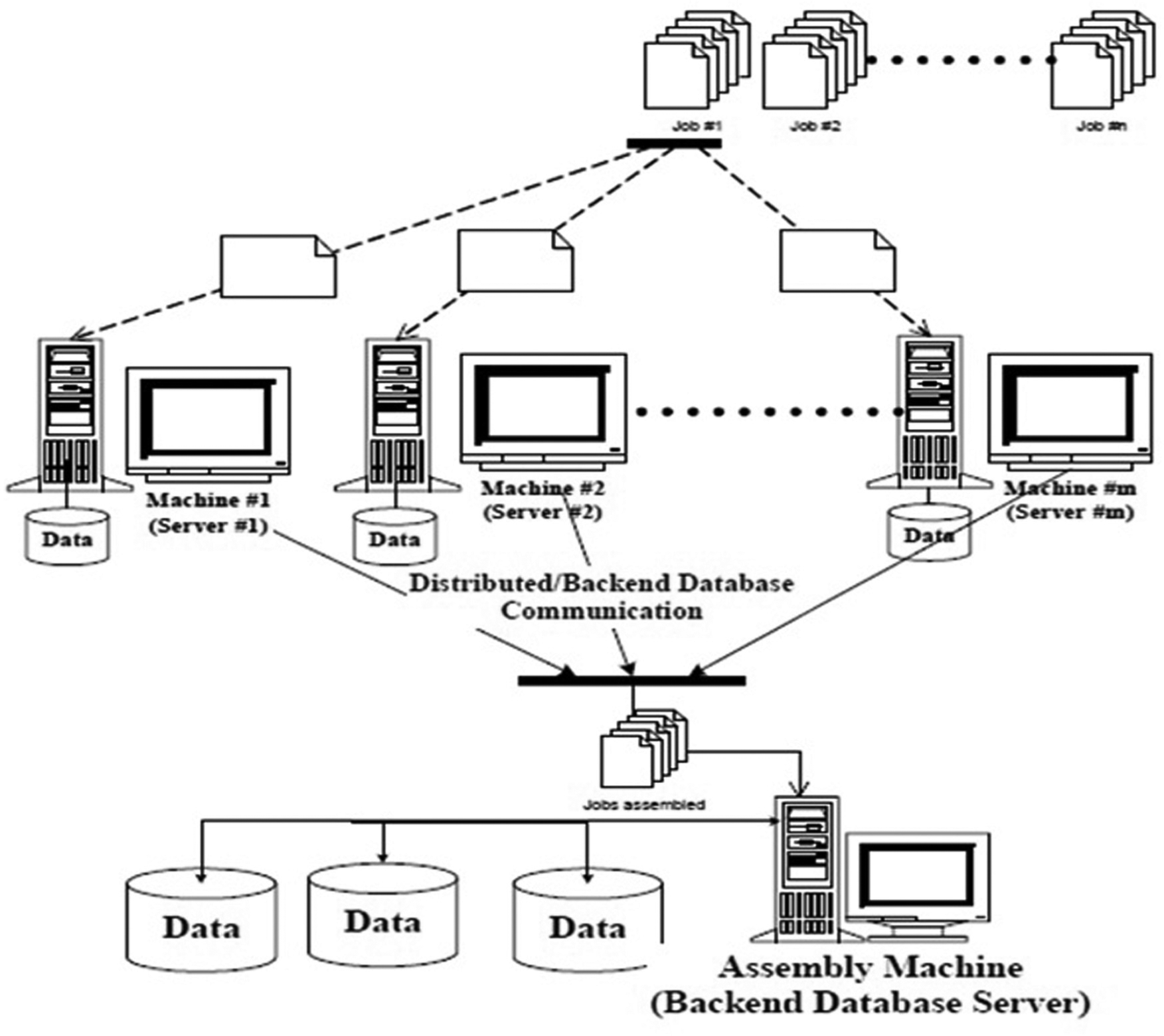
A two-stage assembly (distributed database) structure. 3
Manufacturing environments are dynamic in nature, and these environments are subject to various disruptions, referred to as real-time events, which can change system conditions and affect its performance. Real-time events have been classified into two categories:4–8
Resource related: machine breakdown, operator illness, unavailability or tool failures and delay in the arrival or shortage of material.
Job related: rush job, job cancelation, due date changes, early or late arrival of jobs, change in job priority and changes in job processing time.
In the face of the clear relationship between the maintenance planning and production scheduling in manufacturing systems, most production scheduling literature assumed that the machines are available during the planning horizon and employed separately. But this assumption is not reasonable since machines are not available for processing while machine breakdowns occur or preventive maintenance (PM) activities are done. PM activities carry out the operations on machines and tools before the breakdown takes place. Therefore, they prevent failures before breakdowns occur. In other words, system stays in good condition by PM activity.
This research is concentrated on machine breakdown and PM as the real-time event. For handling the structural and functional complexities of the problem, an approach incorporating simulation into imperialist competitive algorithm (ICA) is considered to solve the problem. Due to stochastic properties that exist in this problem, a scheduling method with predefined parameters cannot be suitable because it reduces the performance of the methods. Recently, artificial neural network (ANN) is employed as an efficient approach in engineering issues. ANNs can be used to predict suitable parameters for a scheduling method in real-time events by a pattern taken from a learning sample. To enhance the efficiency and effectiveness of proposed algorithms, their parameters are updated by the ANN.
The remainder of this study is organized as follows: section “Literature review” presents a literature review of two-stage assembly flow shop scheduling and scheduling with maintenance and breakdown constraints. Section “Problem description” describes the problem. The proposed ICA is given in section “The proposed algorithms.” ANN which tunes parameters of algorithms is described in section “ANN.” Section “Experimental design” presents the experimental design analyzing parameters of the problem. Finally, section “Conclusion and future works” presents the conclusions and directions for future work.
Literature review
The two-stage assembly flow shop problem with two machines was first introduced by Lee et al. 9 Potts et al. 1 proved that two-stage assembly flow shop problem is NP-hard, and a solution with two machines was proposed by a branch-and-bound algorithm and then three heuristics have been presented. Different criteria have been considered in this problem. For instance, Lee et al., 9 Potts et al., 1 Haouari and Daouas, 10 Sun et al. 11 and Allahverdi and Al-Anzi 3 considered the problem with makespan criterion. Tozkapan et al. 12 defined the problem with the total weighted flow time objectives. On one hand, Allahverdi and Al-Anzi 13 reported this problem with total completion time criterion, and, on the other hand, Al-Anzi and Allahverdi 14 addressed the problem with maximum lateness criterion. Shokrollahpour et al., 15 Torabzadeh and Zandieh, 16 and Allahverdi and Al-Anzi 18 defined this problem with bi-criteria of makespan and mean completion time. Al-Anzi and Allahverdi 14 considered this problem with total completion time and solved it by three meta-heuristics. The computational results reveal that hybrid tabu search (TS) was better than two other meta-heuristics. Allahverdi and Al-Anzi 13 presented the same problem. They applied three meta-heuristics, namely, simulated annealing (SA), self-adaptive differential evolutionary algorithm (SDE) and ant colony optimization (ACO), among which SA outperforms ACO and SDE. Allahverdi and Al-Anzi 18 considered the two-stage assembly flow shop scheduling problem with setup times for minimizing the total completion time; they presented hybrid tabu search (Ntabu), SDE and a new version of SDE (NSDE). Computational results demonstrate that NSDE was better than other algorithms. Hwang and Lin 19 addressed a two-stage assembly flow shop batch scheduling problem with a fixed job sequence. They considered four regular performance metrics with the goal of obtaining an optimal batching decision for the predetermined job sequence at stage 2. Mozdgir et al. 20 presented the two-stage assembly flow shop problem with the objective of minimizing the weighted sum of makespan and mean completion time; they considered sequence-dependent setup times at the first stage and multiple non-identical assembly machines in the second stage. They applied a variable neighborhood search (VNS) algorithm and developed a novel heuristic and compared its solutions with solutions obtained by general algebraic modeling system software (GAMS). Percentage errors and computational time in experiments showed that the hybrid VNS heuristic performs much better than GAMS. Seidgar et al. 21 considered the two-stage assembly flow shop problem and proposed a hybrid ANN and ICAs for solving the generated problems. They compared proposed algorithm with the cloud theory based simulated annealing (CSA) introduced by Torabzadeh and Zandieh and showed that their obtained solutions are better and more efficient. Xiong and Xing 22 focused on the distributed two-stage assembly flow shop scheduling problem for minimizing the weighted sum of makespan and mean completion time. They presented a mathematical model and solved the small-sized instances of the proposed problem. Because of the NP-hardness of the problem, they also proposed a VNS algorithm and a hybrid genetic algorithm (GA) combined with reduced variable neighborhood search (GA-RVNS) to solve the problem. Computational experiments have been conducted for comparing the performances of the model and proposed algorithms. For a set of small-sized instances, both the model and the proposed algorithms were effective. The proposed algorithms were further evaluated on a set of large-sized instances. The results statistically illustrated that both GA-RVNS and VNS obtain much better performances than the GA without RVNS-based local search step (GA-NOV). Hong-Sen Yan et al. 23 investigated two-stage assembly flow shop problem (TASFP) to minimize the weighted sum of makespan and earliness and tardiness. They used a hybrid neighborhood search electromagnetism-like mechanism (VNS-EM) for solving the problem. Simulation results illustrated that the proposed hybrid VNS-EM algorithm outperforms the EM and VNS algorithms in both average value and standard deviation.
Recently, extensive studies are done to solve production planning and PM scheduling problems. Lee,17,24 Blazewicz et al. 25 and Kubiak et al. 26 surveyed production scheduling with PM activities being presented based on the “machine availability.” In these studies, time interval of PM activities was predefined and fixed. Sherif and Smith 27 and Wang 28 surveyed the comprehensive study on PM models. Kaabi et al. 29 studied single-machine and flow shop problem. In their research periods, maintenance activities were fulfilled during pre-known interval. Gharbi and Kenne 30 considered the production and PM activities control problem for a manufacturing system with multi-machine. Ruiz et al. 31 considered different PM policies on machines regarding flow shop scheduling, while the aim was maximizing the availability or minimizing the level of reliability during the production horizon. Safari and Sadjadi 32 explained flow shop scheduling problem subject to condition-based maintenance and unpredicted breakdown to minimize expected makespan with non-resumable jobs. They proposed a hybrid algorithm based on GA and simulated annealing and used the Taguchi experimental design method to set the parameters.
Berrichi et al. 33 proposed a mathematical model for parallel machine problem to joint production and maintenance scheduling. In their work, minimization of the makespan and system unavailability were considered, and two meta-heuristics were applied to find approximation of the Pareto-optimal front of the problem. Moradi et al. 34 studied flexible job shop problem where PM and the reliability concept were considered. Mokhtari et al. 35 jointed production and maintenance scheduling with multiple PM services, and the reliability approach was employed to model the maintenance aspects. Majazi Dalfard and Mohammadi 36 developed a new mathematical model for a multi-objective flexible job shop scheduling problem with parallel machines. They considered maintenance constraints and maintenance cost for the problem and applied two meta-heuristic algorithms, a hybrid GA and a simulated annealing algorithm. Sarker et al. 37 considered the job scheduling problem (JSP) and explained the effect of machine maintenance, whether preventive or breakdown. They proposed a hybrid evolutionary algorithm (HEA) for solving the problem and compared it with the existing algorithms. Benmansour et al. 38 presented a single-machine problem with periodic PM with the goal of minimizing the weighted sum of maximum earliness and maximum tardiness costs.
By reviewing the literature, no work focusing on assembly flow shop problem with machine breakdown was found, and thus, we will review the literature on scheduling under maintenance and random breakdown constraints. Yamamoto and Nof 60 studied job shop scheduling problem with random machine breakdowns by considering event-driven rescheduling policy. Allahverdi 2 considered the problem of scheduling in a two-machine proportionate flow shop, where the objective function is to maximize the lateness and machine random breakdowns are allowed. Allaoui and Artiba 40 employed simulated annealing for scheduling a hybrid flow shop with maintenance; they noted that amount of breakdown can be affected by heuristics. Gholami et al. 8 explored the hybrid flow shop scheduling problems with sequence-dependent setup times and breakdown constraints for machines. A GA was used to find production sequence and simulation to obtain expected makespan. Zandieh and Gholami 41 presented an immune algorithm for scheduling a hybrid flow shop with sequence-dependent setup times and machines with random breakdowns. Jabbarizadeh et al. 42 considered the hybrid flow shop scheduling problems with sequence-dependent setup times and maintenance activities for machines. Ghezail et al. 43 proposed a qualitative graphical approach to deal with disruptions in the flow shop problem. Their graphical approach showed the consequences of random failures to the decision maker, so they can choose the best sequence. Lei 44 studied stochastic job shop scheduling problem with random breakdowns for minimizing the stochastic makespan. He proposed an efficient GA and considered exponential processing time and non-resumable jobs. Naderi et al. 45 investigated scheduling flexible flow shops subject to periodic PM on machines. The objective was to minimize makespan. Two meta-heuristics, including GA and artificial immune system, and some constructive heuristics were developed to tackle the problem. The performance of the algorithms was evaluated by comparing their solutions. The results of the computational experiments indicated that the artificial immune system outperforms the other methods. Al-Hinai and ElMekkawy 46 studied the flexible job shop problem (FJSP) with random machine breakdowns using a two-stage hybrid GA to find robust and stable solutions. They used a bi-objective approach, and three stability measures were suggested. Dong and Jang 47 considered production scheduling at a job shop problem under machine breakdowns. They developed two novel heuristic rescheduling procedures, AWI-J and AWI-O, for minimizing mean tardiness and compared their performances with those of the affected operations rescheduling (AOR) procedure. Li et al. 48 presented a novel discrete artificial bee colony (DABC) algorithm for solving the multi-objective flexible job shop scheduling problem with maintenance activities. Performance criteria considered are the maximum completion time so-called makespan, the total workload of machines and the workload of the critical machine. Unlike the original ABC algorithm, the proposed DABC algorithm presented a unique solution representation where a food source was represented by two discrete vectors and TS was applied to each food sourceto generate neighboring food sources for the employed bees, onlooker bees and scout bees. The proposed DABC algorithm is tested on a set of well-known benchmark instances from the existing literature. Through a detailed analysis of experimental results, the highly effective and efficient performance of the proposed DABC algorithm was shown against the best performing algorithms from the literature. Moghadam 49 presented a new multi-objective nonlinear mixed-integer optimization model to determine Pareto-optimal PM and replacement schedules for a repairable multi-workstation manufacturing system with increasing rate of occurrence of failure. The operational planning horizon was segmented into discrete and equally sized periods, and in each period, three possible maintenance actions (repair, replacement or do nothing) have been considered for each workstation. The optimal maintenance decisions for each workstation in each period were investigated such that the objectives and the requirements of the system can be achieved. The multi-objective model was solved using a hybrid Monte Carlo simulation and goal programming procedure to obtain set of non-dominated schedules. The effectiveness and feasibility of the proposed solution methodology were demonstrated in a manufacturing setting, and the computational performance of method in obtaining Pareto-optimal solutions was evaluated. Such a modeling approach and the proposed solution algorithm could be useful for maintenance planners and engineers tasked with the problem of developing optimal maintenance plans for complex productions systems.
Problem description
A set of n multiple-operation jobs is simultaneously available at time 0, and preemption is not allowed. Each job requires m + 1 operations, and m operations are done at the first stage by m parallel machines and the last operation performed at the assembly stage. The operation of each job in assembly stage starts only after all the operations of job in the first stage. Each job is completed after finishing all of its operations in both stages. In this research, the sequence of jobs on all of the machines in both stages is the same.
In this problem, some assumptions are presumed, which are listed below:
All jobs are available for processing at time zero.
A job is composed of m + 1operations.
There are no preference constraints among the jobs.
Jobs are always processed without error.
Processing times of jobs are known.
Setup times among operations of jobs are negligible or included in the processing times (sequence-independent setup times).
Each job is processed on one machine at a time.
Infinite buffers exist between two stages; in other words, machines cannot be blocked.
Preemption is not allowed for jobs.
Machines can only process one job at the same time.
Machines are not available at all times due to breakdowns and PM. The breakdown occurs during time when machines are processing the operations.
The processing of job continues after the repairing of machine without change in time resumption.
Mean time between failures (MTBF) that show number of breakdowns follows the exponential distribution.
Mean time to repair (MTTR) follows the exponential distribution.
All machines have the same MTBF and MTTR values.
Traveling time between two stages is negligible.
When production planning joints to maintenance, we can consider different policies presented by researchers such as Cassady and Kutanoglu, 50 Sherif and Smith 27 and Ruiz et al. 31 Three possible PM policies are explained as follows:
Policy 1. In this policy, PM activities are periodically carried out at fixed predefined time intervals. This policy is widely applied in industry. 31
Policy 2. The objective of this policy is to maximize the availability of system by creating a balance between the effects of a failure and PM. In this policy, we assume that the time to failure follows a Weibull probability distribution
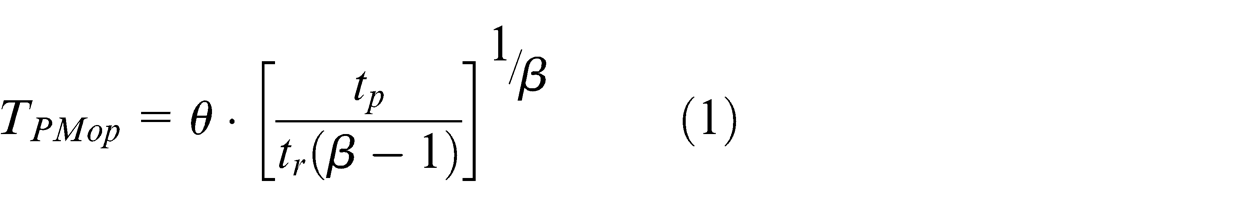
Policy 3. This policy makes a PM after a time
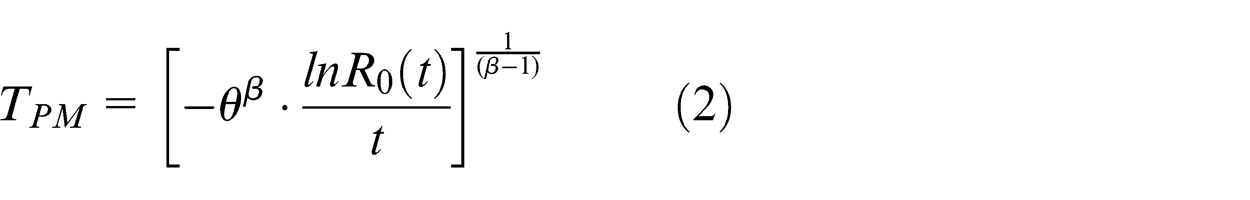
This article manipulates a strategy to insert PM activities, and this strategy was called rational strategy by Berrichi et al. 33 In this strategy, it is possible to delay or to advance a maintenance activity. To our knowledge, there is no study related to the integrated approach in the two-stage assembly flow shop scheduling problem with PM activities and machine breakdowns as unavailability constraints. In this paper, Policy 1 is used and adapted with rational strategy that introduced by Berrichi et al. 33
Let
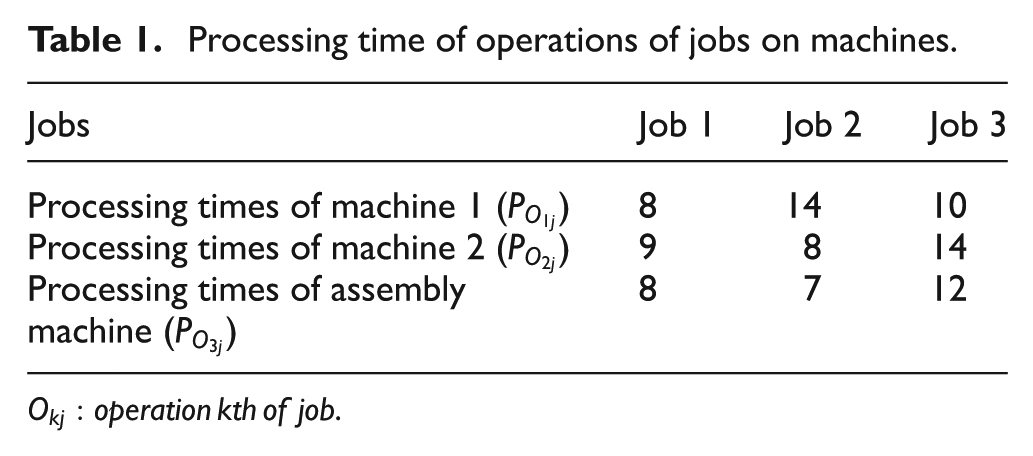
Consider a system works based on policy 2 and rational strategy. This system consists of two stages, where two machines are in the first stage and only one machine is in the second stage. Suppose that there are three jobs which must be processed on three machines, and PM activities are carried out every 12 time units with 2 time units for duration of PM activities. Also, the processing times are shown in Table 1. The Gantt chart of two-stage assembly flow shop scheduling is shown in Figure 2, and Gantt chart for the integrated production and maintenance scheduling is shown in Figure 3.
Processing time of operations of jobs on machines.
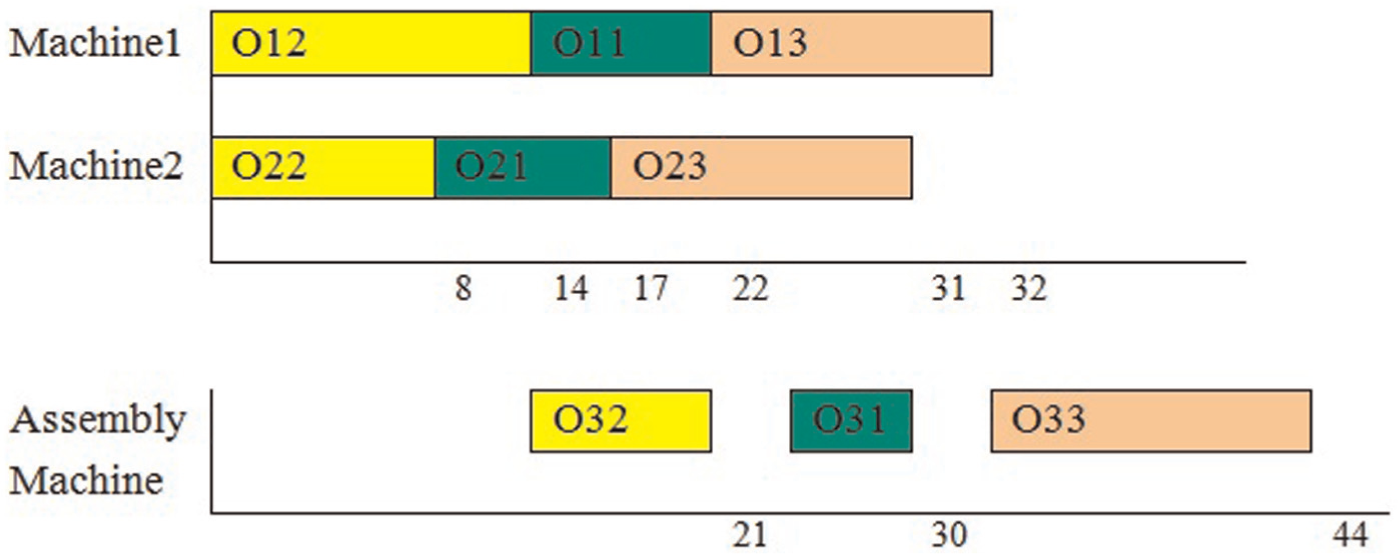
Gantt chart of assembly flow shop without maintenance activities.
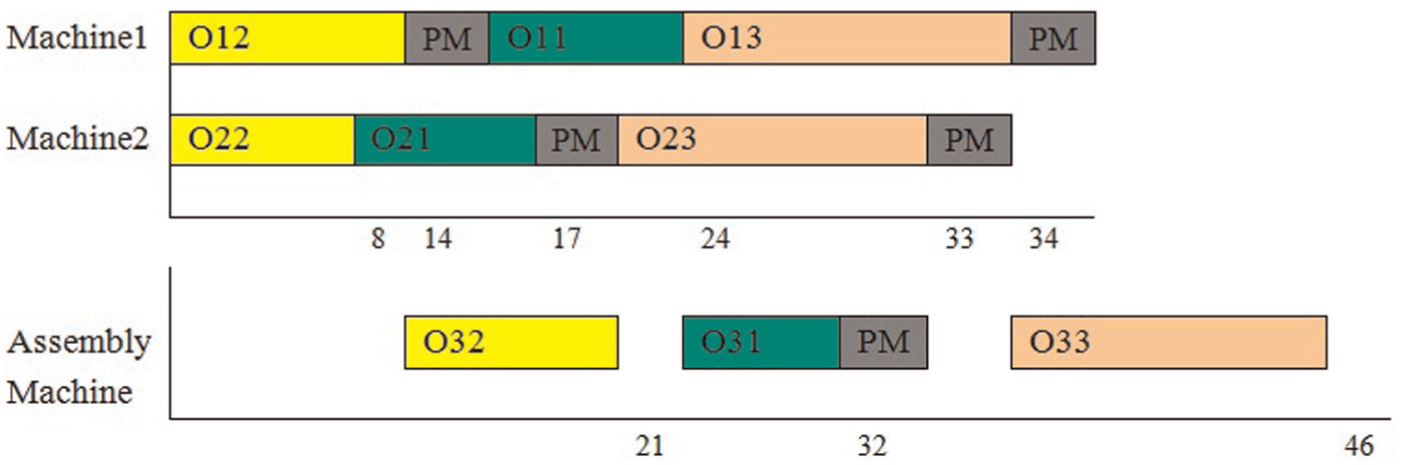
Gantt chart of the integrated production and maintenance activities.
Consider the instance illustrated in Table 1 and Figure 2. Figure 3 indicates Gantt chart of the integrated production and maintenance scheduling. As shown in Figure 3, PM activities are done at times 14 and 34 on machine 1, at times 17 and 33 on machine 2 and at time 32 on assembly machine.
The proposed algorithms
Due to breakdowns, time is not specific and occurs randomly on machines, and we used a simulator for simulating these statuses. The simulator allows us to disrupt operation of jobs when breakdown occurred on machines. We indicate how to handle the two-stage assembly flow shop scheduling with machine breakdowns to optimize the objective based on expected makespan using simulation incorporated into ICA.
For incorporating simulation into proposed meta-heuristics, it is necessary to note the following:
The time when breakdowns occur on machine m at the first or second stage must be calculated.
After each breakdown, repairing time must be calculated.
The time that is left for the last breakdown on the machine must be saved.
Repairing time is added to the completion time of operation of jobs at each stage.
Rational strategy is applied to consider the PM policy.
The objective value for algorithms is calculated (the expected makespan).
Future event list (FEL) indicates the failure time of a machine after it starts processing. It indicates the interval between every two events of breakdown for each machine; FEL follows exponential distribution.
After the machine repairs, the life time (life) will set to 0 because the exponential distribution has memoryless property.
Simulator algorithm
The basic notion of the simulator algorithm is derived from SPTCH and Johnson’s rule-based heuristic developed by Kurz and Askin. 51 The simulator algorithm used in the proposed algorithms has the following steps:
1. Initialize FEL by random number that follows exponential distribution in which the mean value is MTBF for all of the machines in the two stages
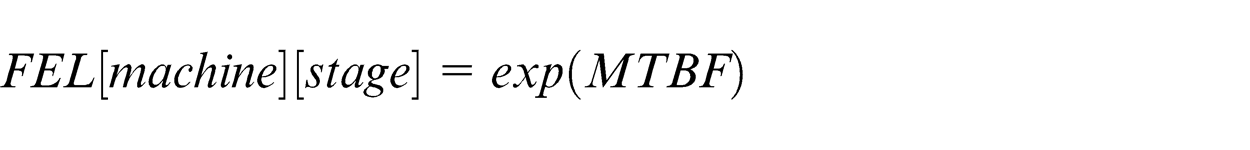
2. In the first stage 2.1. Decode the country 2.2. For i = 1:n 2.3. For k = 1:m 2.4. Run breakdown algorithm End for (k) End for (i)
3. In the second stage 3.1. Update the ready times in second stage to completion at the first stage 3.2. For k = 1:m 3.3. Run breakdown algorithm End for (k).
Breakdown algorithm
The steps of breakdown algorithm applied in simulator algorithm are as follows:
1. Add the processing time of operation of job on that machine at that stage to the life variable
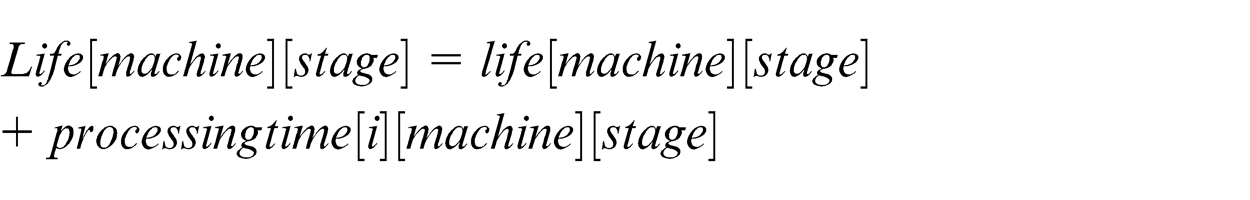
2. If (life[machine][stage]>FEL[machine][stage]), do step 3 otherwise do step 4
End if
3. In this time breakdown occurred in machine, and we must do the following steps
3.1. Generate a random number called repair time; repair time follows exponential distribution, where mean value is MTTR
3.2. Repair time is added to the operation of job’s completion time on that machine at that stage
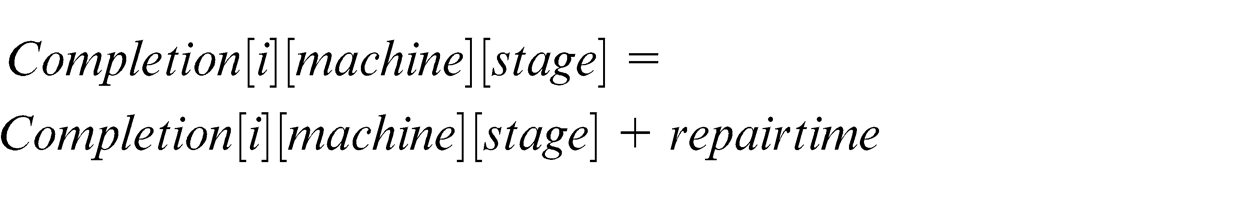
3.3. Apply the rational strategy to insert PM activity
If (
Else, the PM activity is postponed to the date
End if
3.4. Update the time of next breakdowns for machines
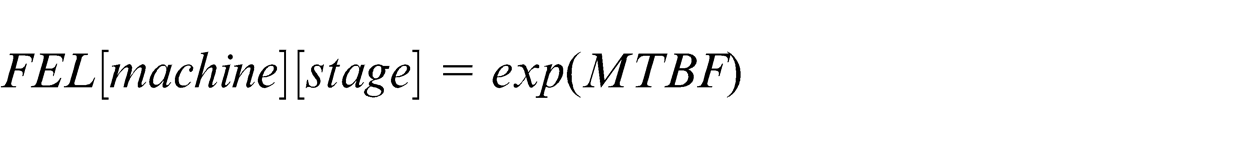
3.5. Assign zero to the life variable for machine

4. Run the simulator algorithm.
Proposed ICA
The ICA is an evolutionary algorithm presented by Atashpaz-Gargari et al.52,53 ICA is based on the concept of imperialist competition in the real world. ICA is a population-based algorithm; in other words, it starts its work by an initial population of solution which is named countries. Countries are solutions in the solution space, and they can be divided into two sections: imperialism and imperialistic. Each imperialism based on its power controlled and moved a number of imperialistic in its direction. The assimilation and competition policy are the basic core of this algorithm. Each solution in this algorithm is shown as a country. The country in ICA is similar to chromosome in GA. The countries have several attributes including culture, language, religion, economic policy and so on and are shown by vector F

in which
Countries based on its cost may be classified into imperialist and may create their own empire or classified into imperialistic and join an empire. In these competitions that occur in the real word, the weak empires lose their countries and powers. The imperialistic competition will increase in the power of great empires and decrease in the power of weaker ones. Finally, they are destroyed and the powerful ones expand to colonies which are grabbed from the weak empires. In each iteration of ICA, imperialistic moves in the direction to their imperialist, and if an imperialistic was better than its imperialist, then imperialistic is swapped with the imperialist. These processes iterate to meet the stop criteria.
In this problem, a country is a 1 × n array. The array of country represents a sequence of jobs. Initial population is produced as follows: one initial sequence is obtained by ordering all of the jobs into increasing order of
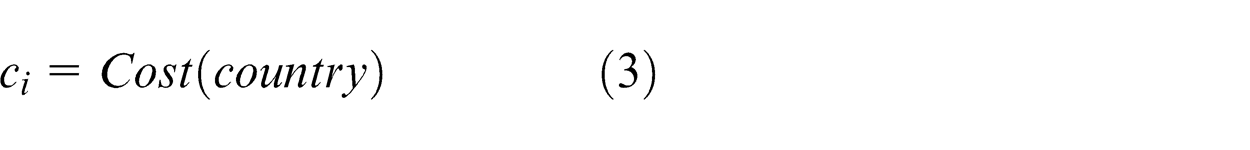

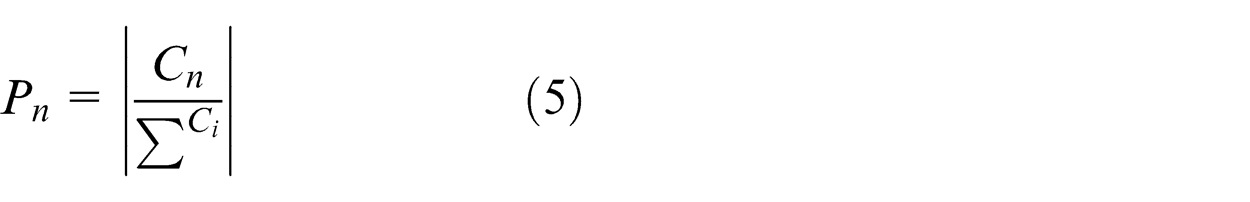
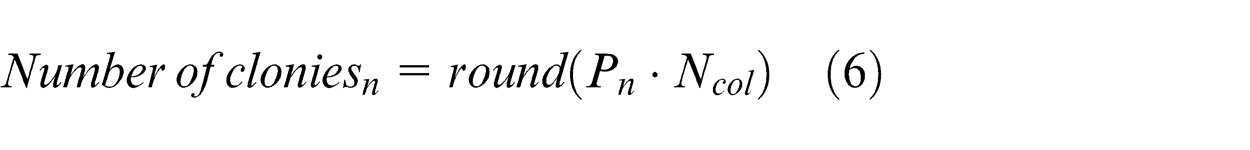
where

Generation of initial empires. 15
After specifying imperialists and their colonies, ICA devices assimilation policy and revolution operators to search for better countries. Assimilation policy is performed on all colonies to form new ones. In this policy, each imperialist absorbs colonies by making changes in their attributes such as social, cultural, regional and so on. Next, the cost of new colonies that are absorbed to the current imperialist must be recalculated (Figure 5).
Movement of colonies toward their relevant imperialist. 52
The steps of assimilation operator are explained as follows:
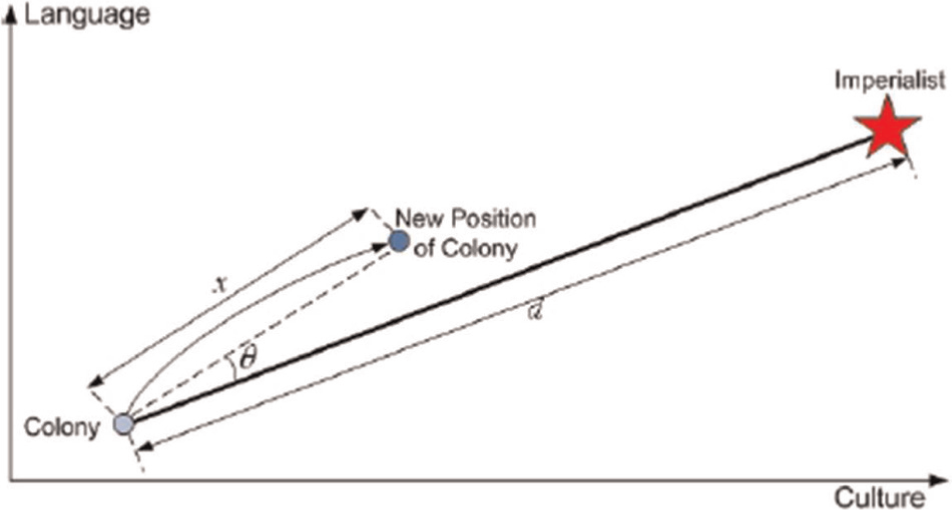
Select one cell randomly in imperialist array (cell 4, number 6).
Find that number in the colony’s array and shift that until it comes to the same position as in imperialist array (cell 2, number 6).
Put the right-hand side number in the imperialist’s array (it is 5 in this representation) at the right-hand side of the shifted cell in the colony’s array (swap numbers 5 and 4). This operator is shown in Figures 6–8.
Assimilation operator.
Exchanging the positions of a colony and the imperialist. 15
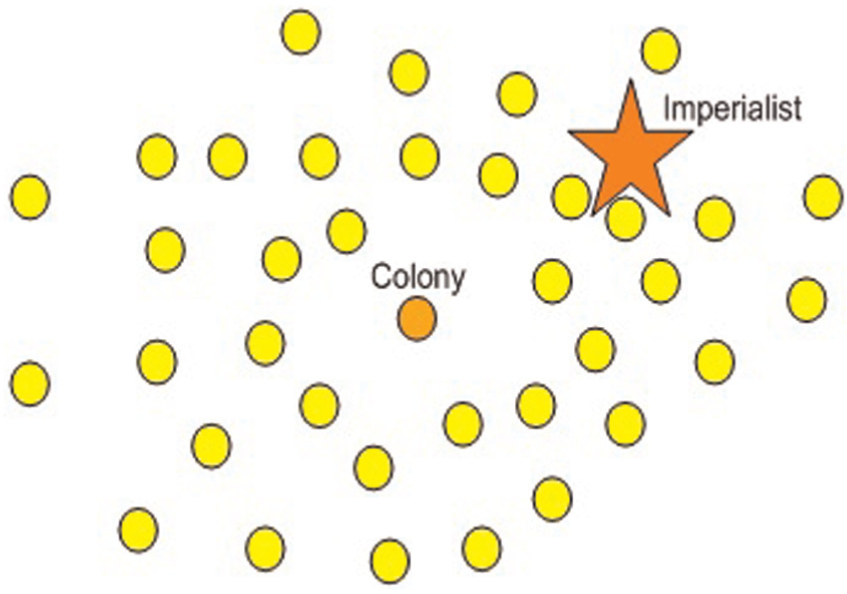
The entire empire after position exchange. 15
The second operator is revolution that creates diversification in countries. This operator randomly selects two attributes in a country and exchanges their values (Figure 9).
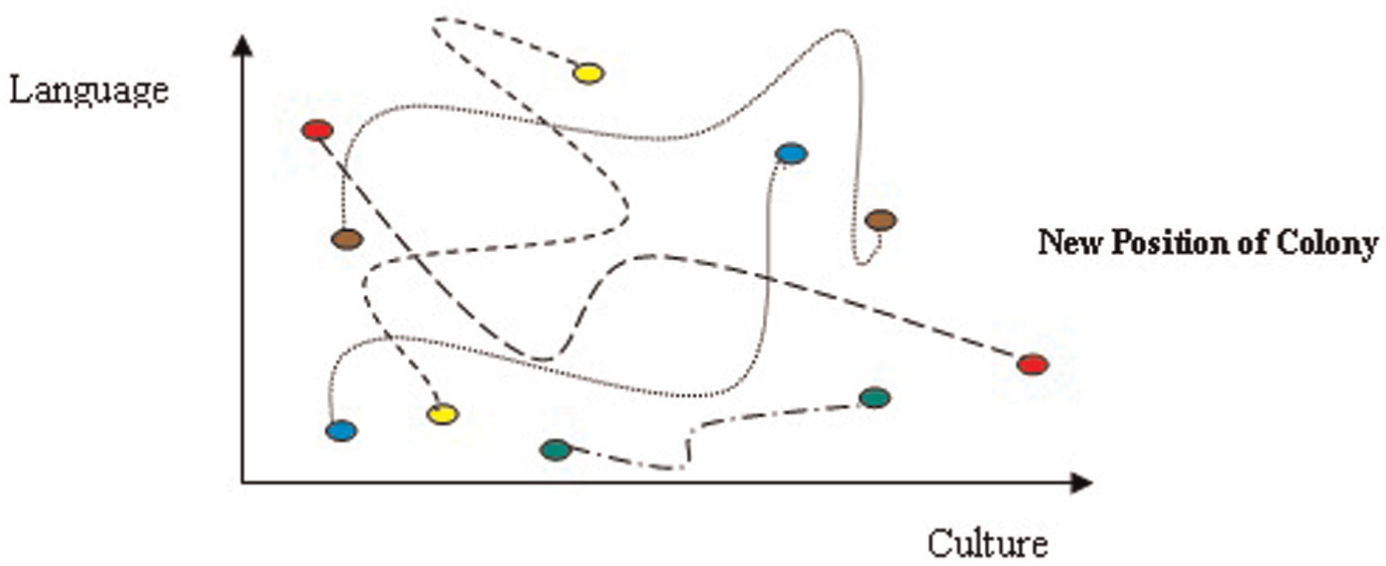
Revolution: a sudden change in socio-political characteristics of a country. 53
After assimilation and revolution operators, the power of each emperor is calculated by equations (7)–(9)
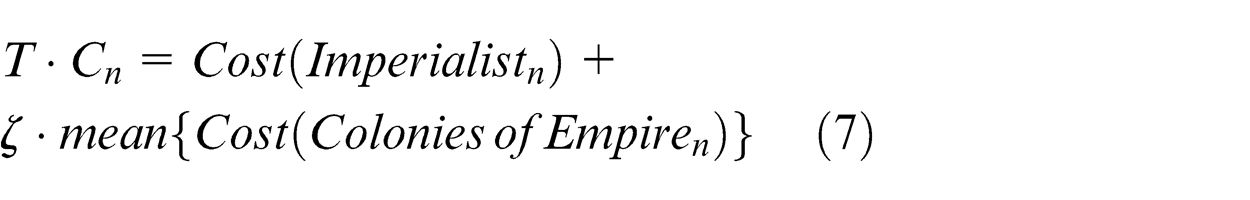
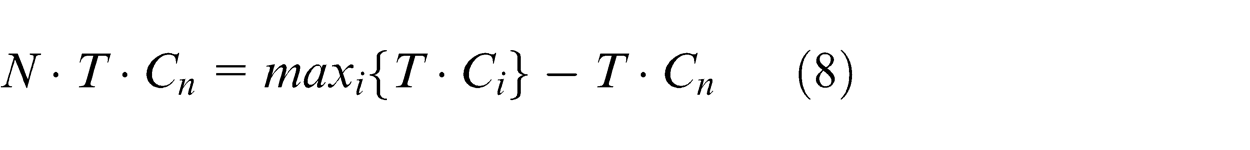

where

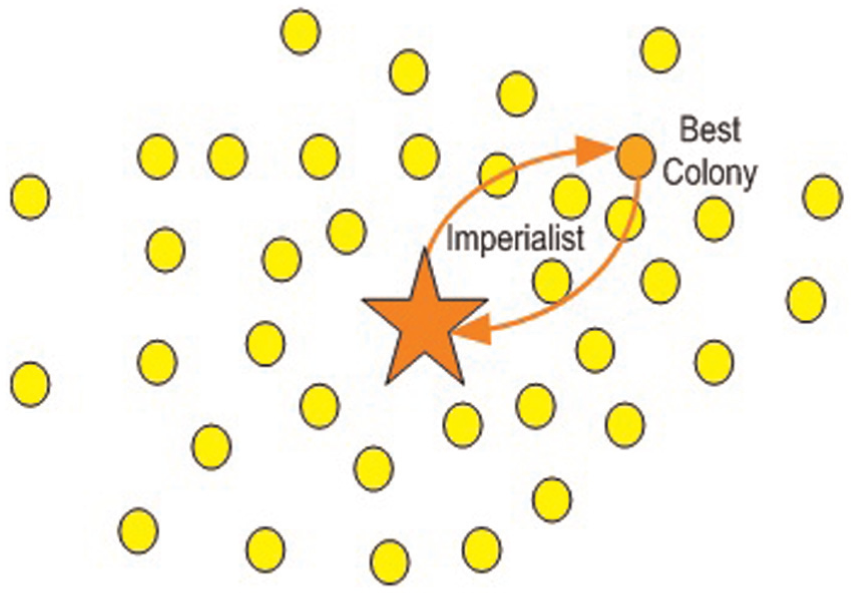
From vector D in equation (6), the emperor with highest value will be selected, and the weakest colony of the weakest emperor will be assigned to it
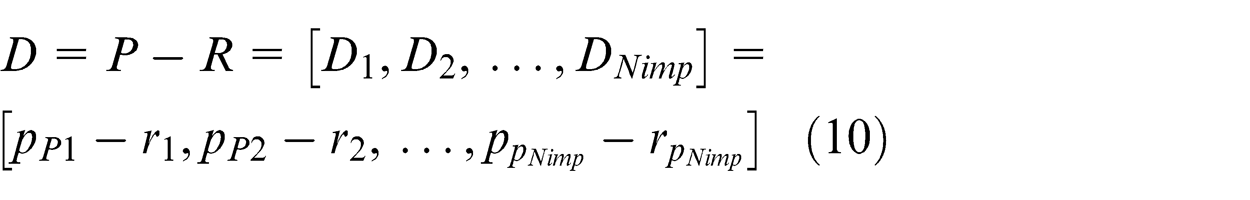
The stopping criterion of the algorithm is the remaining of one emperor (Figure 10).15,52,53
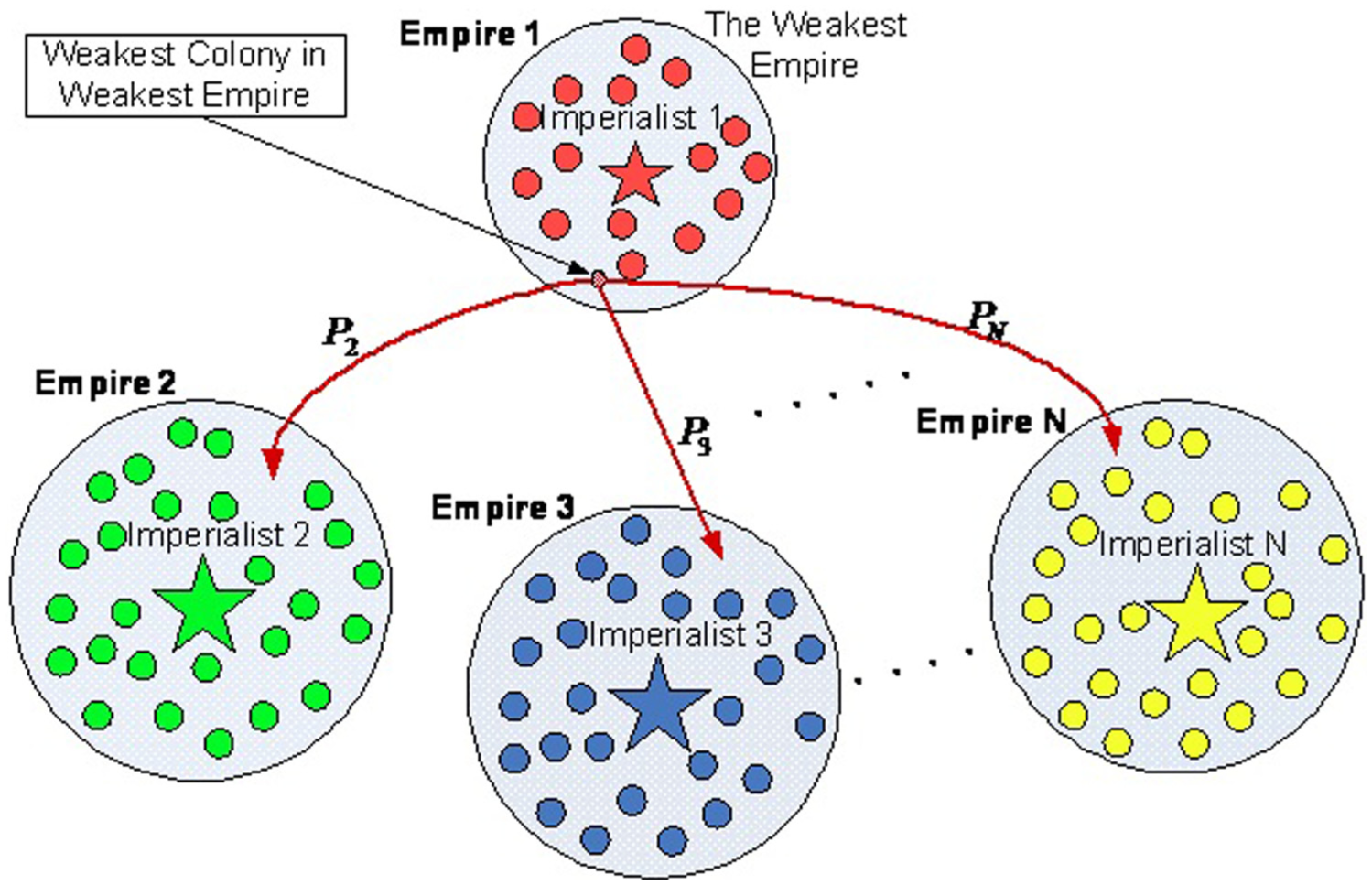
Imperialistic competition. 15
GA
GA is an evolutionary method which can be used to solve optimization problems. This method is based upon Darwin’s theory about evolution, and it was first used by John Holland. During the last decades, GA has become one of the most well-known meta-heuristics and is widely used in many combinatorial optimization problems including machine scheduling. GA starts with a population which consists of population size (PS) of individuals, and it is suitable for encoding or representation of the solution to a problem. Each individual has a fitness value that measures the quality of the solution which is associated with the chromosome. A simple GA has most generation’s numbers in order to evolve the current population to the new one for each iteration. There are basic operations which are included: Selection, Crossover, Mutation and Elitisms.
By selection, parents are selected from the population. In a crossover operation, the parents are combined by crossover operator to produce one or more offspring based on crossover probability (Pc); the mutation operator alters offspring according to the mutation rules to offset convergence effect and guarantees the population diversity based on mutation probability (Pm); and sometimes in a GA, a number of fitter individuals are copied directly from current to the new population which is called elitisms. A quite large number of articles investigated GAs; some studies describe GA approach and its applications in detail.54–56 One of the most important advantages of GA is considering a large number of sets of solutions in parallel. 57 We briefly describe crossover and mutation operator for the proposed problem.
Crossover operator
Crossover has the main rule in the processing of GA. It started its work with chromosomes that are selected by selection mechanism as parents and combined them to produce offspring. Crossover operator makes an optimistic attempt to swap parent sections and produce offspring that inherit promising features from their parents. The steps of the crossover operator are as follows:
The position-based crossover (PBX) selects a subset of positions in the first parent and copies the jobs at these positions into the offspring. The remaining positions are filled with the missing jobs appearing in the same relative order as in the second parent. This crossover is illustrated in Figure 11.
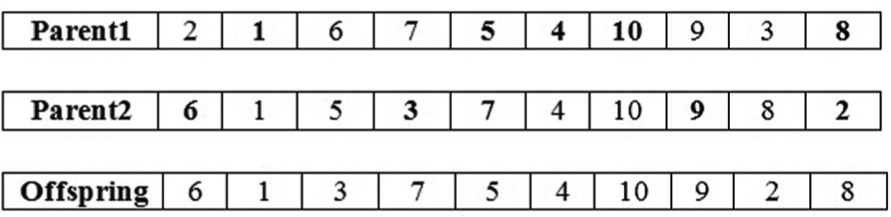
PBX crossover.
Mutation operator
The mutation operator revolves the structure of some chromosomes in the generation in order to guaranty diversification of solutions. It also helps to prevent from falling into local optimum trap; in other words, mutation can be considered as a background operator in GA, and the use of a mutation is also controlled by a probability parameter, which is called the mutation rate. The simple mutation operator that is used here randomly selects two positions in a chromosome and exchanges their genes with each other. This procedure is shown in Figure 12.
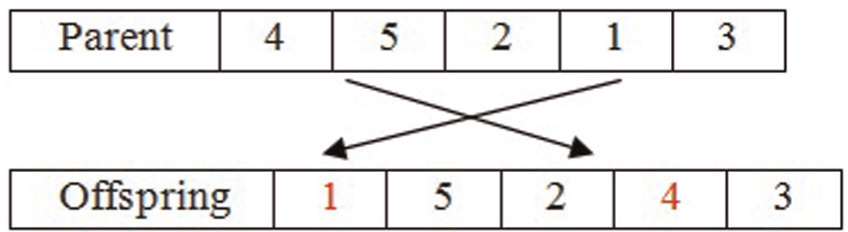
Mutation operator.
ANN
Neural networks are composed of simple elements operating in parallel. These elements are inspired by biological nervous systems. We can train a neural network to work by adjusting the weights between elements. Commonly neural networks are adjusted or trained so that an input leads to a target output. 39 Such a situation is shown in Figure 13.
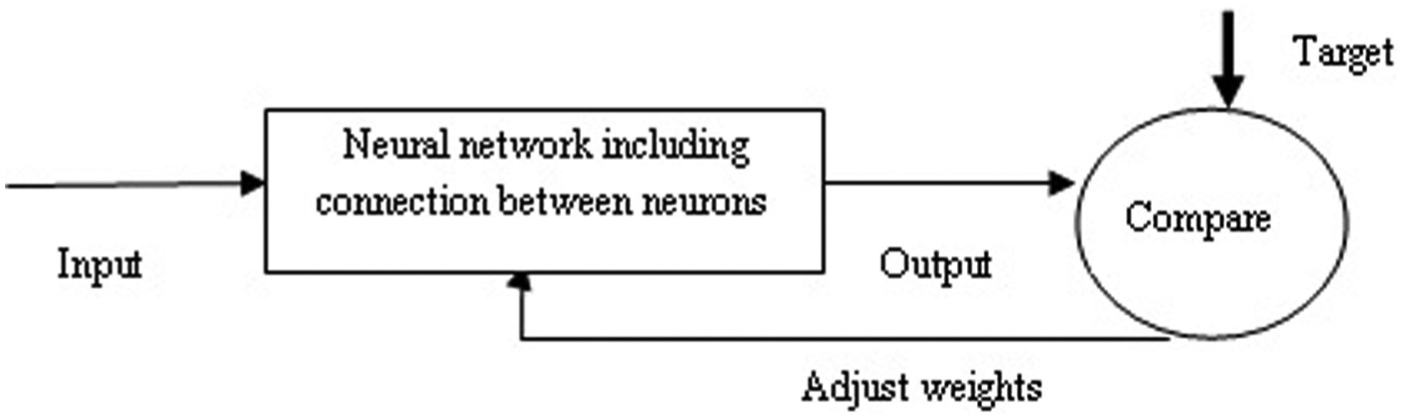
Structure of ANN.
In this research, ANN is applied to calibrate parameters of the proposed algorithm. The effective attributes for a learning sample on an optimization process (inputs) can be number of jobs (n), number of machines (m), mean operation processing time (MOPT) and operation processing time variance (OPTV), MTTR, the time between two consecutive PM activities on machine (TPM) and breakdown level of the shop floor (Ag). Therefore, ANN consists of seven neurons
We assume that the weight matrix between input and hidden layers is W and weight matrix between hidden and output layers is V. the parameters of the algorithms are determined using weights obtained from ANN. The samples and related desired algorithm parameters are obtained by experimental study. Back propagation network is indicated in Figure 14.
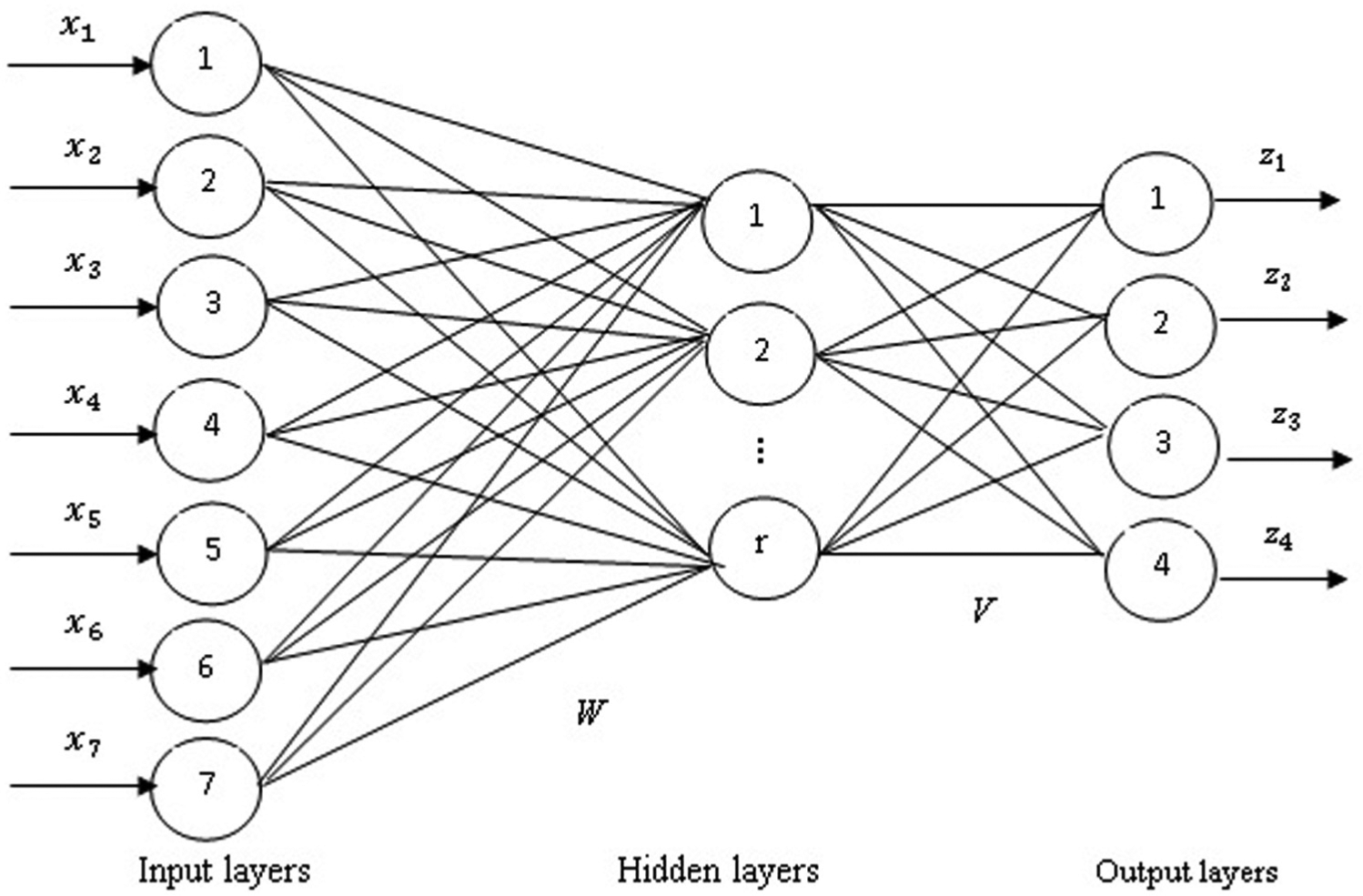
The structure of three layers of back propagation network for the proposed algorithm.
The steps of the back propagation algorithm are as follows:58,59
Step 1. Choose the learning coefficient (0 < η < 1).
Step 2. Choose initial V and W randomly.
Step 3. The learning samples that are obtained by experimental study are entered, and input and output net values of every neuron layer are calculated by layer set E = 0:
For hidden layers
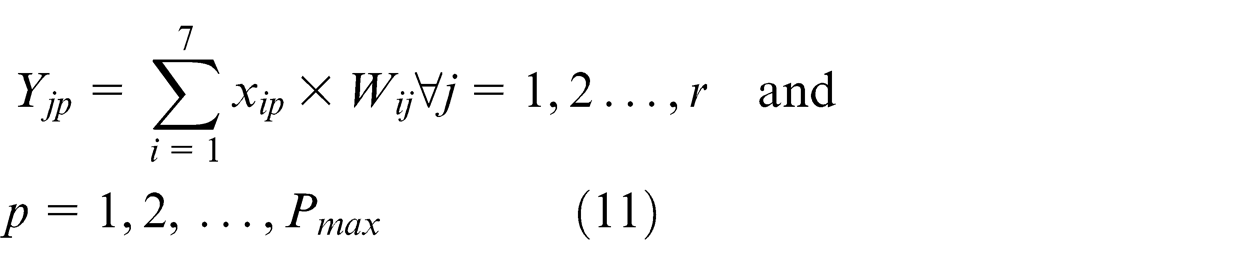
Sigmoid function is used as transfer function for all hidden layers’ neuron
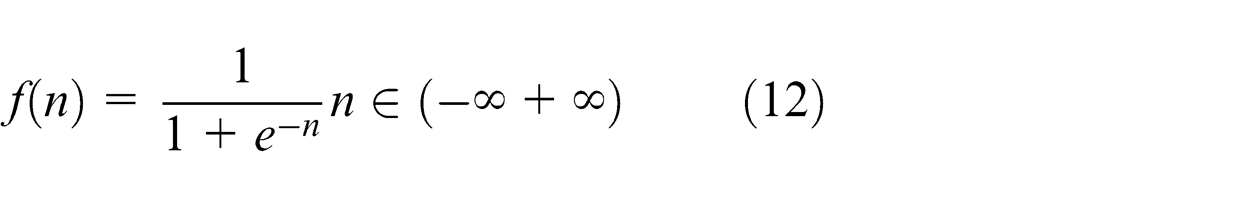
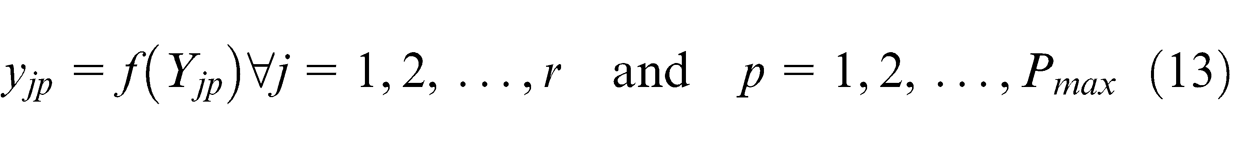
For output layers
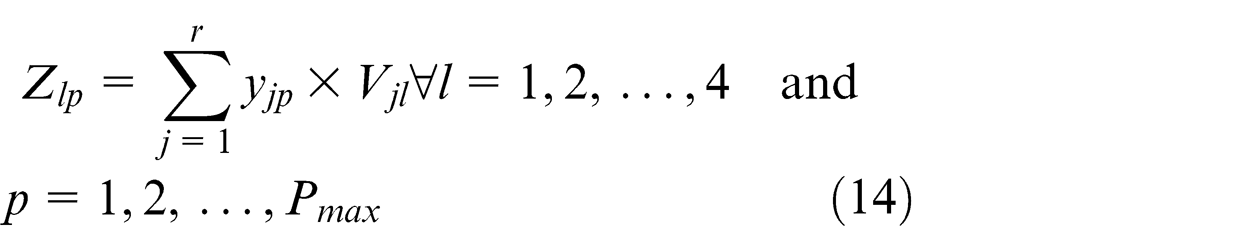
Linear function is used as transfer function for all output layers’ neuron
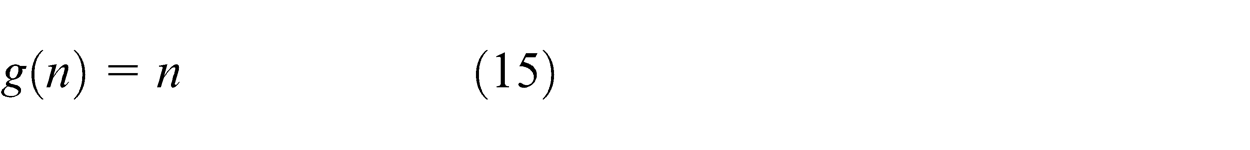
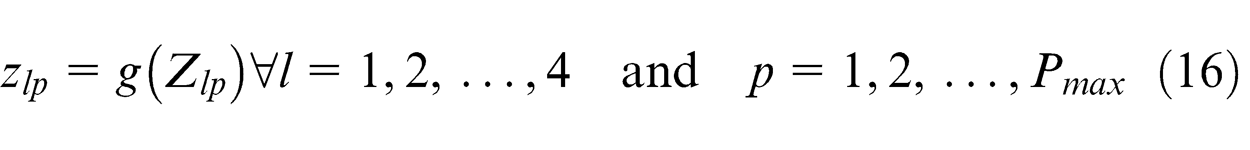
Step 4. Calculate the error (E)
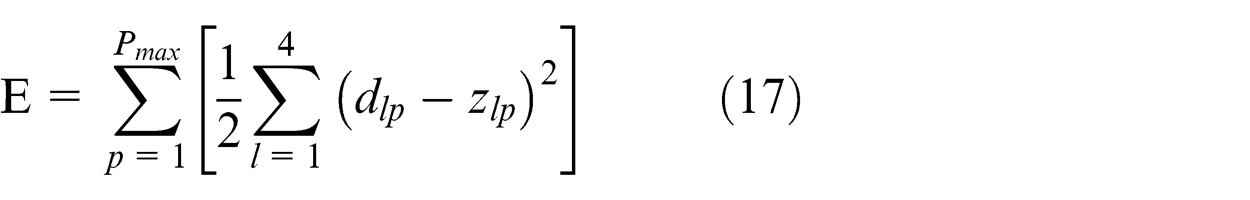
where nm is the number of parameters of the proposed algorithm that should be tuned,
Step 5. Calculate error signal of every neuron layer by layer
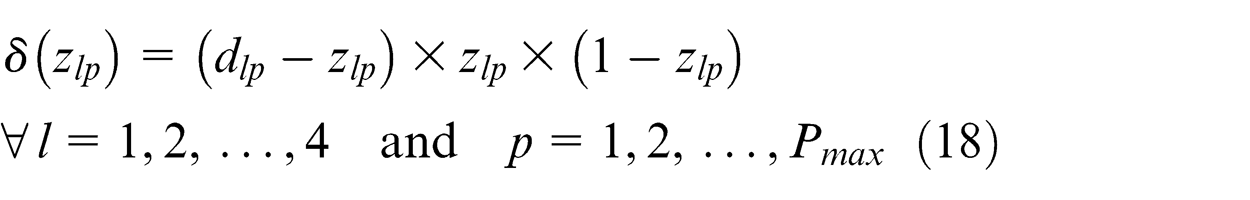
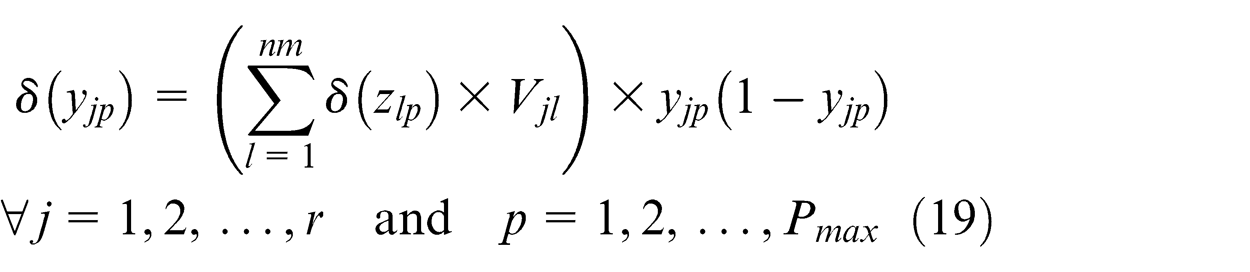
Step 6. Update V and W matrixes
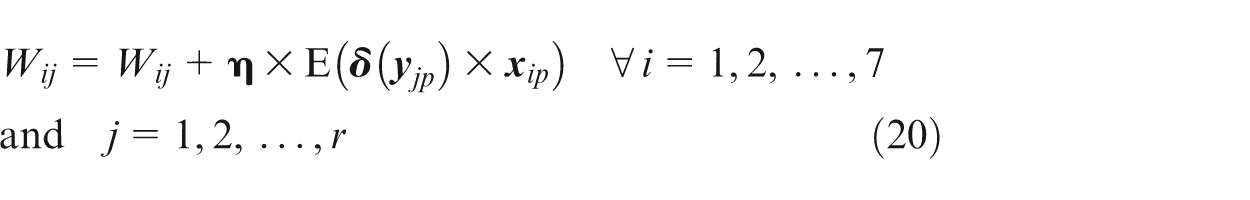
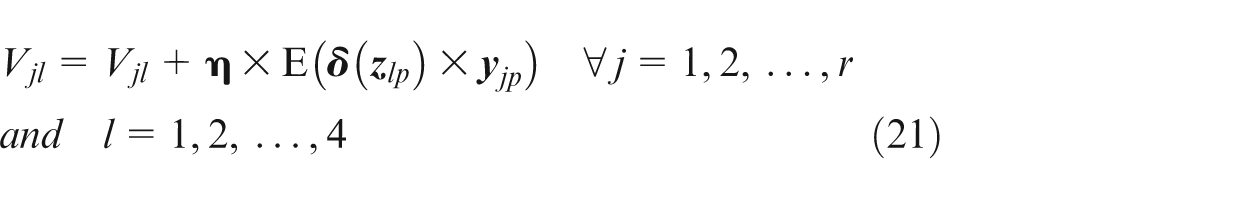
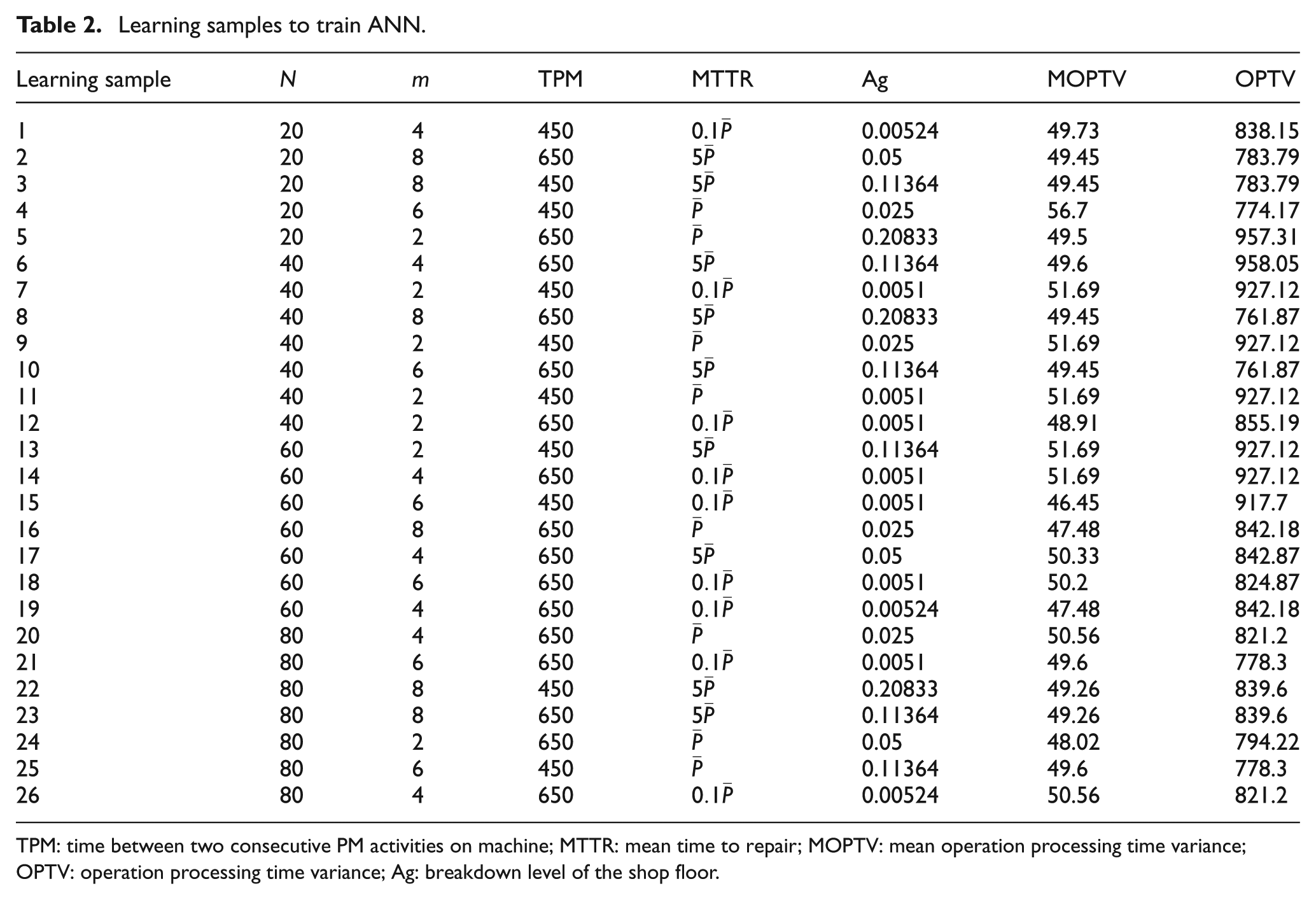
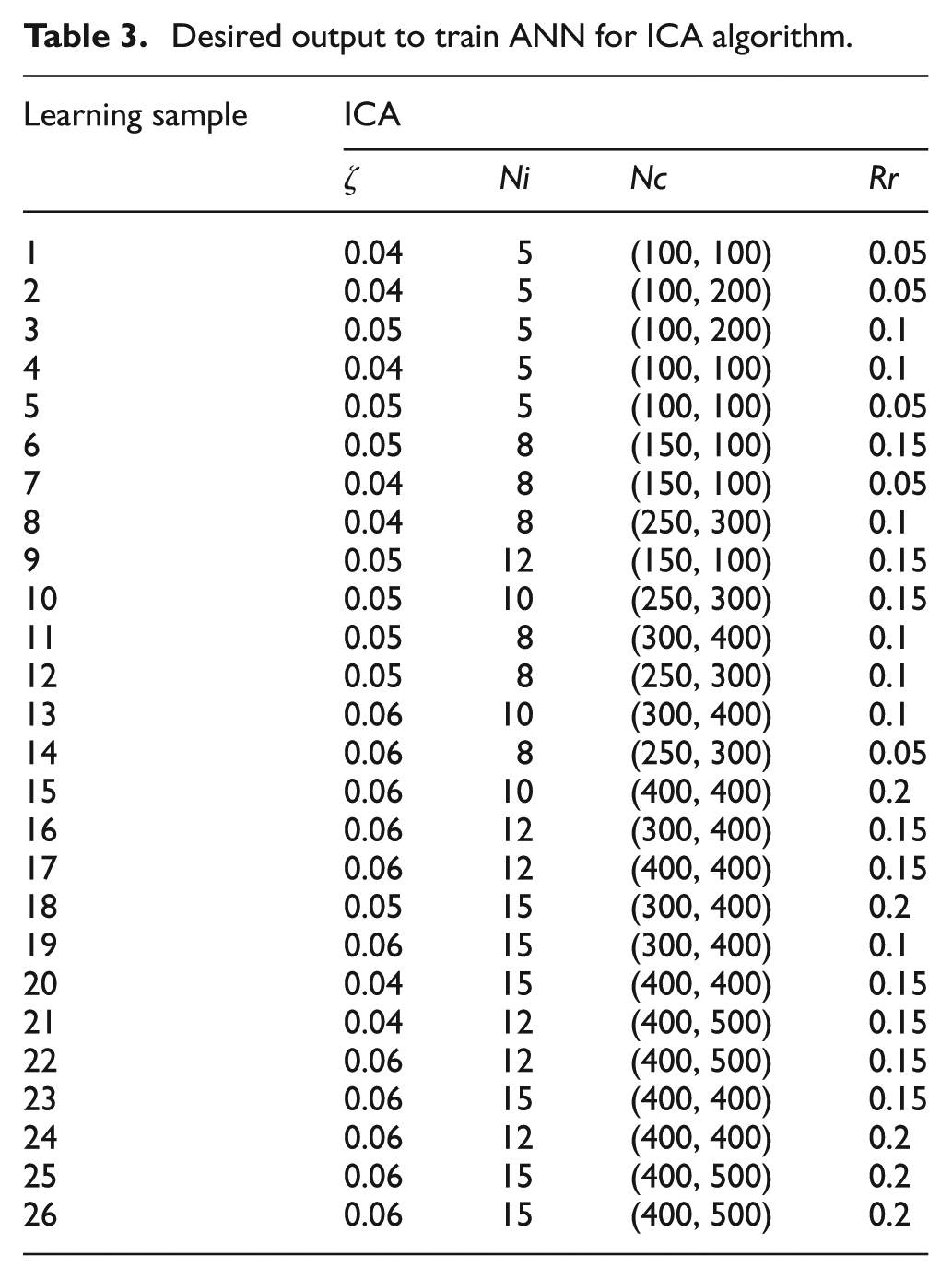
Learning samples and related desired ICA parameters are obtained by experimental study. These learning samples are presented in Tables 2 and 3. For these calculations, the learning coefficient is assumed to be 0.95, number of layers in hidden layer is chosen as 11 and number of iteration is selected as 100,000, which is the stopping criterion. The effect of the number of neurons in hidden layer on E is computed 10 times, and mean values in ICA algorithm are shown in Figure 15. ICA parameters are determined by weights being obtained by ANN with the optimum number of neurons in the hidden layers.
Learning samples to train ANN.
TPM: time between two consecutive PM activities on machine; MTTR: mean time to repair; MOPTV: mean operation processing time variance; OPTV: operation processing time variance; Ag: breakdown level of the shop floor.
Desired output to train ANN for ICA algorithm.
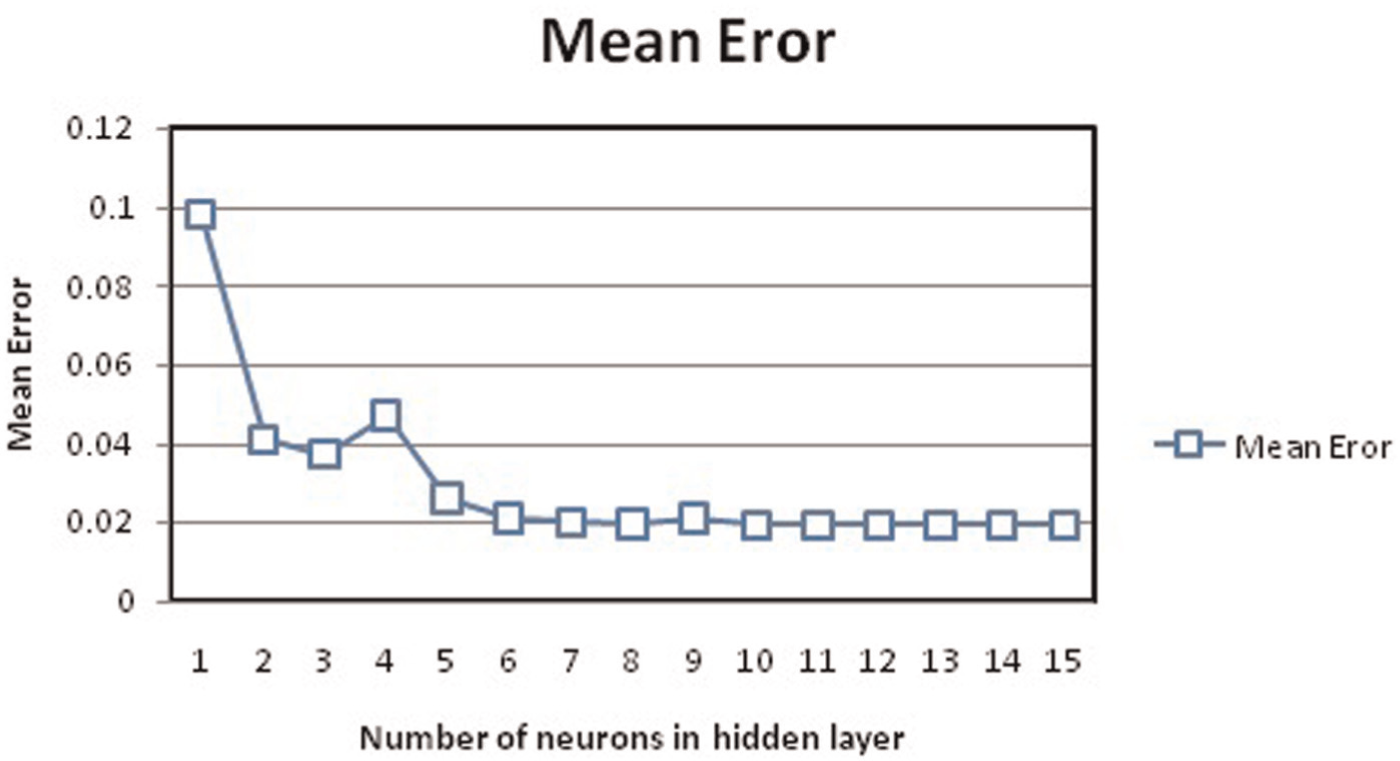
Effect of number of neurons in the hidden layer on mean error.
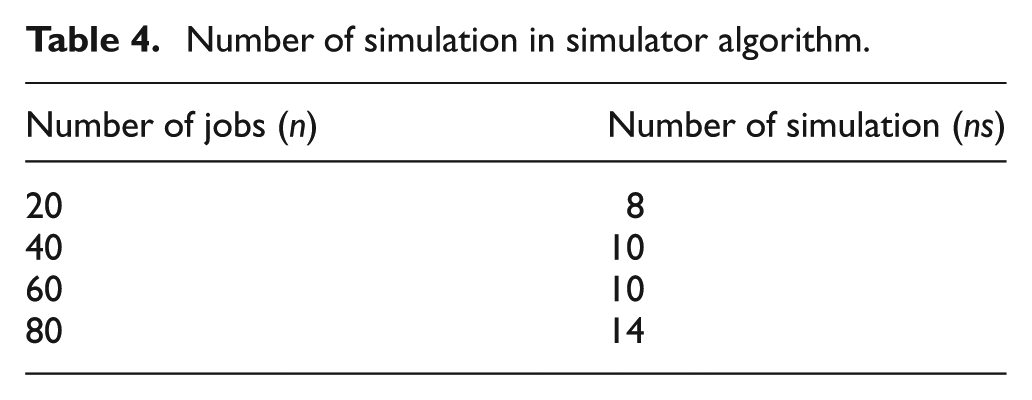
In this research, the number of simulations was selected by sensitivity analysis; in other words, the best value of this parameter is obtained by changing its value while keeping other parameters as constant after some experimentations, and after no major changes in the performance have been noted, the parameter was set as given in Table 4.
Number of simulation in simulator algorithm.
Experimental design
Data required for this problem are classified into two groups: (1) data related to the production part and (2) data related to the maintenance and machine breakdown parts. The first group consisted of the number of jobs (n), number of machines (m) and processing time of jobs (P). Processing times are randomly generated from a uniform distribution (1,100). The second group consisted of duration of PM activities (DPM) and the interval between two consecutive PM activities (TPM) that we defined TPM by the number of jobs (n). If n ⩽ 40, then TPM = 450; otherwise, TPM = 650. The values for MTTR are chosen as
Problems factor levels.
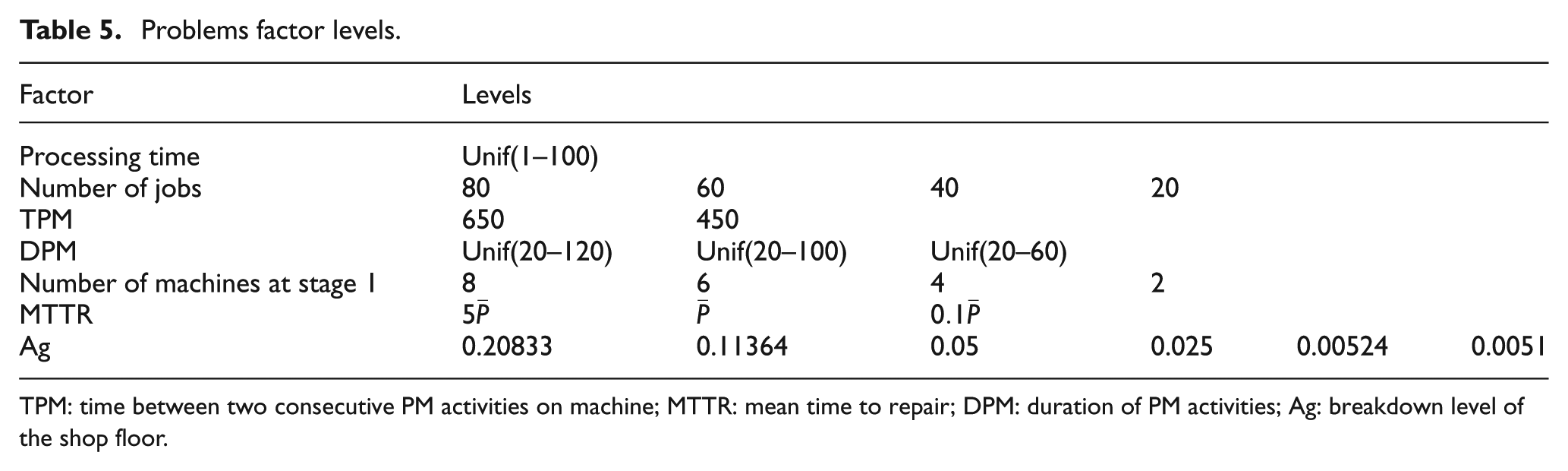
TPM: time between two consecutive PM activities on machine; MTTR: mean time to repair; DPM: duration of PM activities; Ag: breakdown level of the shop floor.
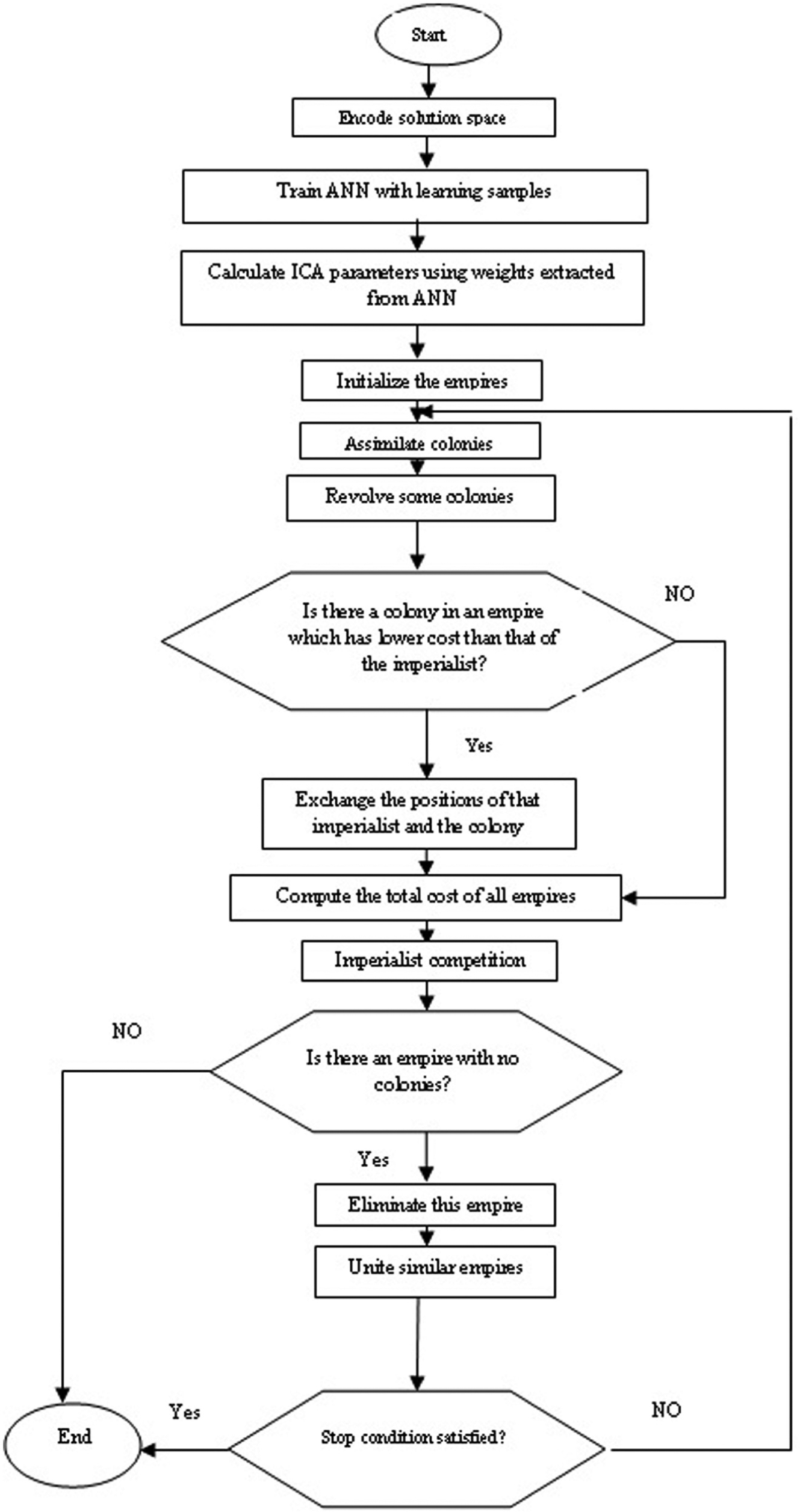
Flowchart of the proposed ICA.
In this study, the Taguchi experimental design is applied to analyze the effect of parameters of the problem. The “parameter design” developed by Dr Taguchi in early 1960s can be applied to process design. Taguchi classifies factors into controllable and noise factors; this method searches to minimize the effect of noise factors and determine optimal level of important controllable factors based on the concept of robustness.
Taguchi classifies objective functions into three categories:
The smaller is the better;
The larger is the better;
The nominal is the best.
Taguchi introduces signal-to-noise (S/N) ratio and relative percentage deviation (RPD). The S/N ratio denotes the amount of variation in the response variable that must be maximized. The formula is
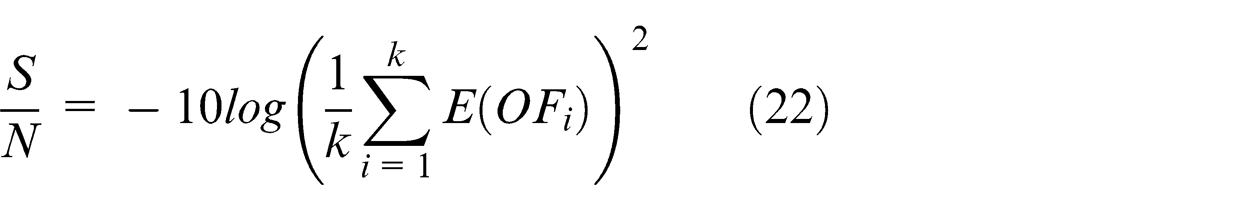
In the following, Taguchi scheme is explained and then the Taguchi experimental design and the analysis of variance (ANOVA) results are analyzed.
In the Taguchi method, for selecting the appropriate orthogonal array it is necessary to obtain the number of degrees of freedom. The appropriate scheme should have degrees of freedom 17 (1 + 3 + 1 + 2 + 3 + 2 + 5). Therefore, the appropriate design must have at least 17 rows. An appropriate array that satisfies this condition is
The orthogonal array
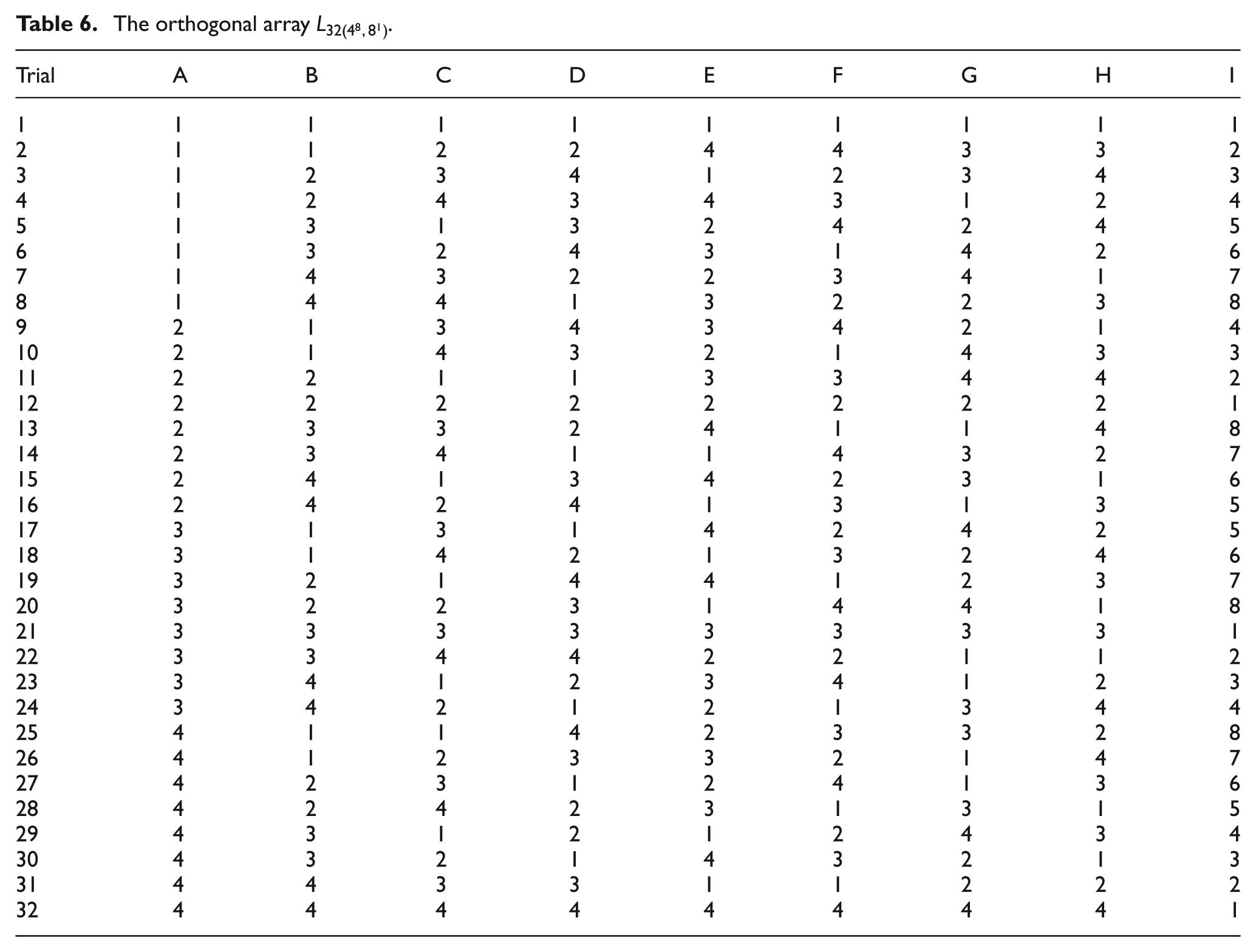
S/N and RPD ratios for values of objective function.
TPM: time between two consecutive PM activities on machine; MTTR: mean time to repair; DPM: duration of PM activities; Ag: breakdown level of the shop floor; S/N: signal-to-noise; ICA: imperialist competitive algorithm; RPD: relative percentage deviation.
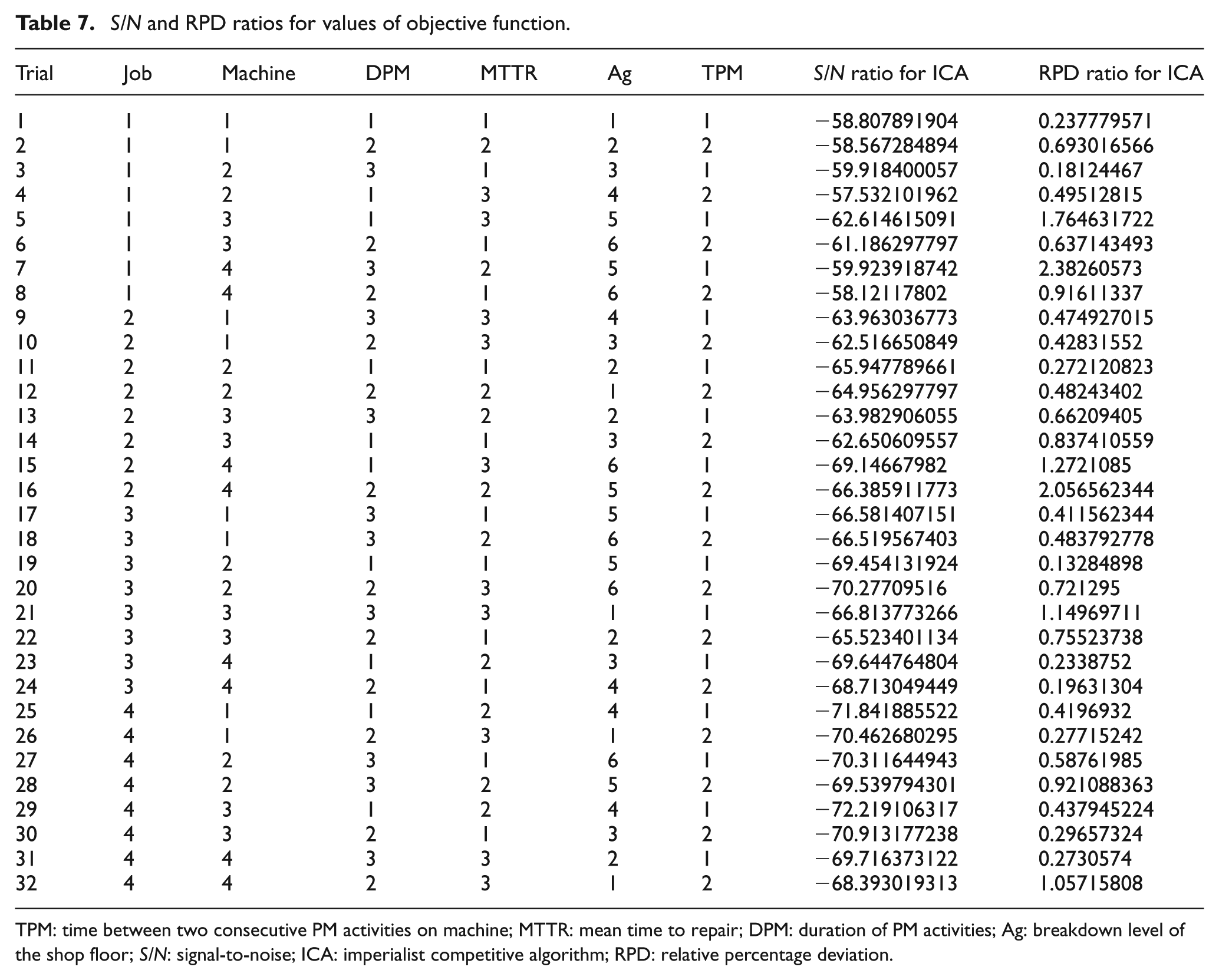
As indicated in Figure 17, better robustness of the algorithms is achieved when we have problem with the following characteristics: job 2, machine 2,
The average signal-to-noise (S/N) ratio plot at each level for ICA algorithm.
ANOVA for S/N ratio in ICA algorithm.
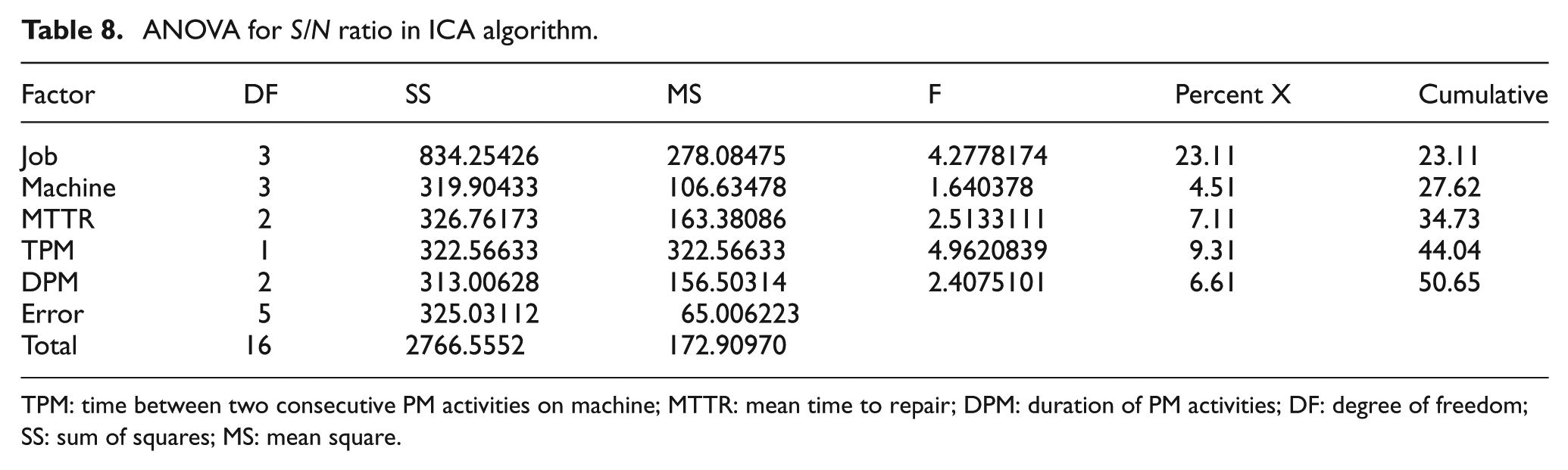
TPM: time between two consecutive PM activities on machine; MTTR: mean time to repair; DPM: duration of PM activities; DF: degree of freedom; SS: sum of squares; MS: mean square.
The goal of ANOVA is to inspect the relevant implication of individual parameters based on the objective value. In other words, by means of ANOVA, the parameters that are more effective in problem will be identified. Results that are obtained from ANOVA indicate that the job and TPM factor have a significant impact on the robustness of the algorithm. RPD is used to understand adjustment factors and is calculated from the formula
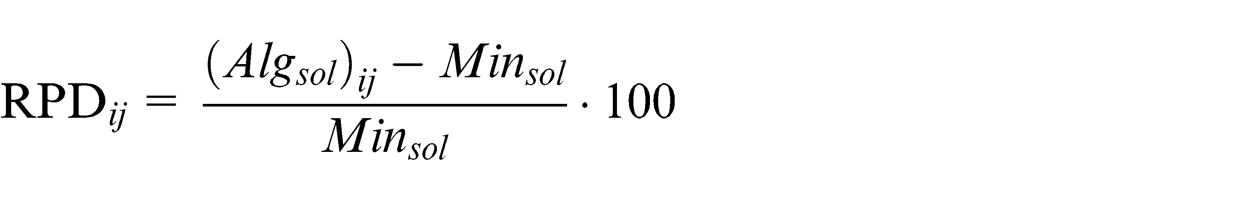
where
Figure 18 shows the mean RPD in each level of factors; ANOVA for RPD is given in Table 9, and they show that machine, MTTR and Ag are considered as adjusting factors. The other factors that have no significant impact on the S/N or RPD ratio are economic factors, and the levels that reduce the CPU time can be selected.
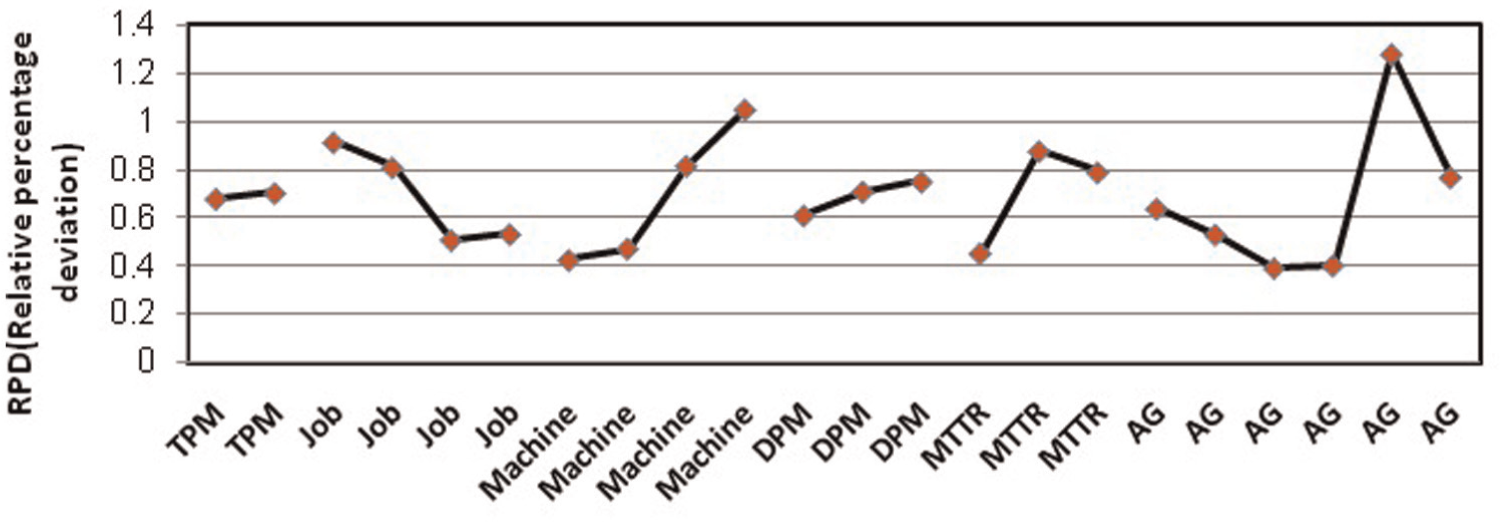
The average relative percentage deviation (RPD) ratio plot at each level for ICA algorithm.
ANOVA for RPD ratio in ICA algorithm.
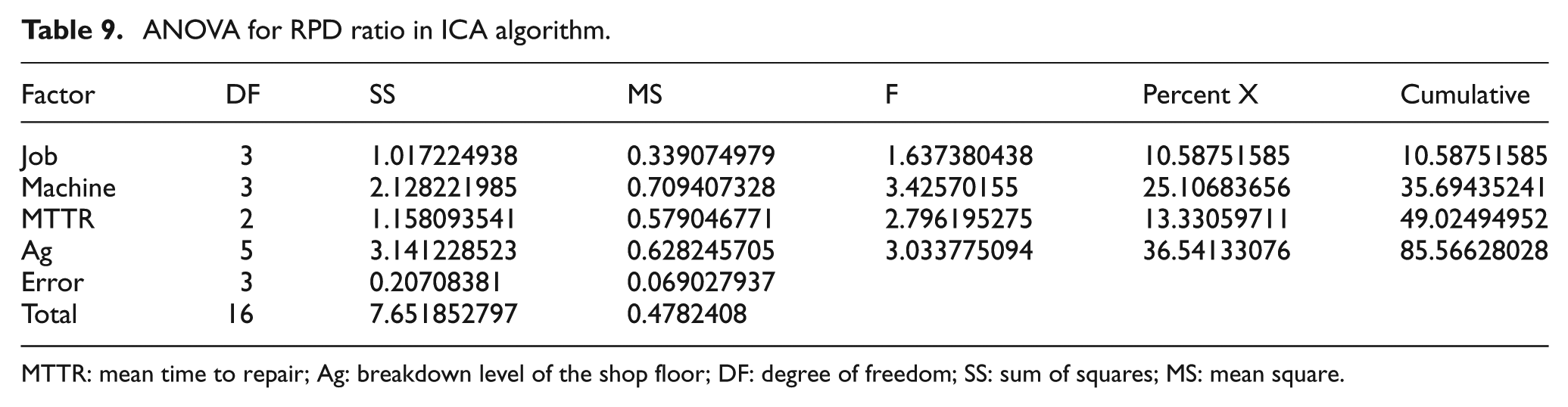
MTTR: mean time to repair; Ag: breakdown level of the shop floor; DF: degree of freedom; SS: sum of squares; MS: mean square.
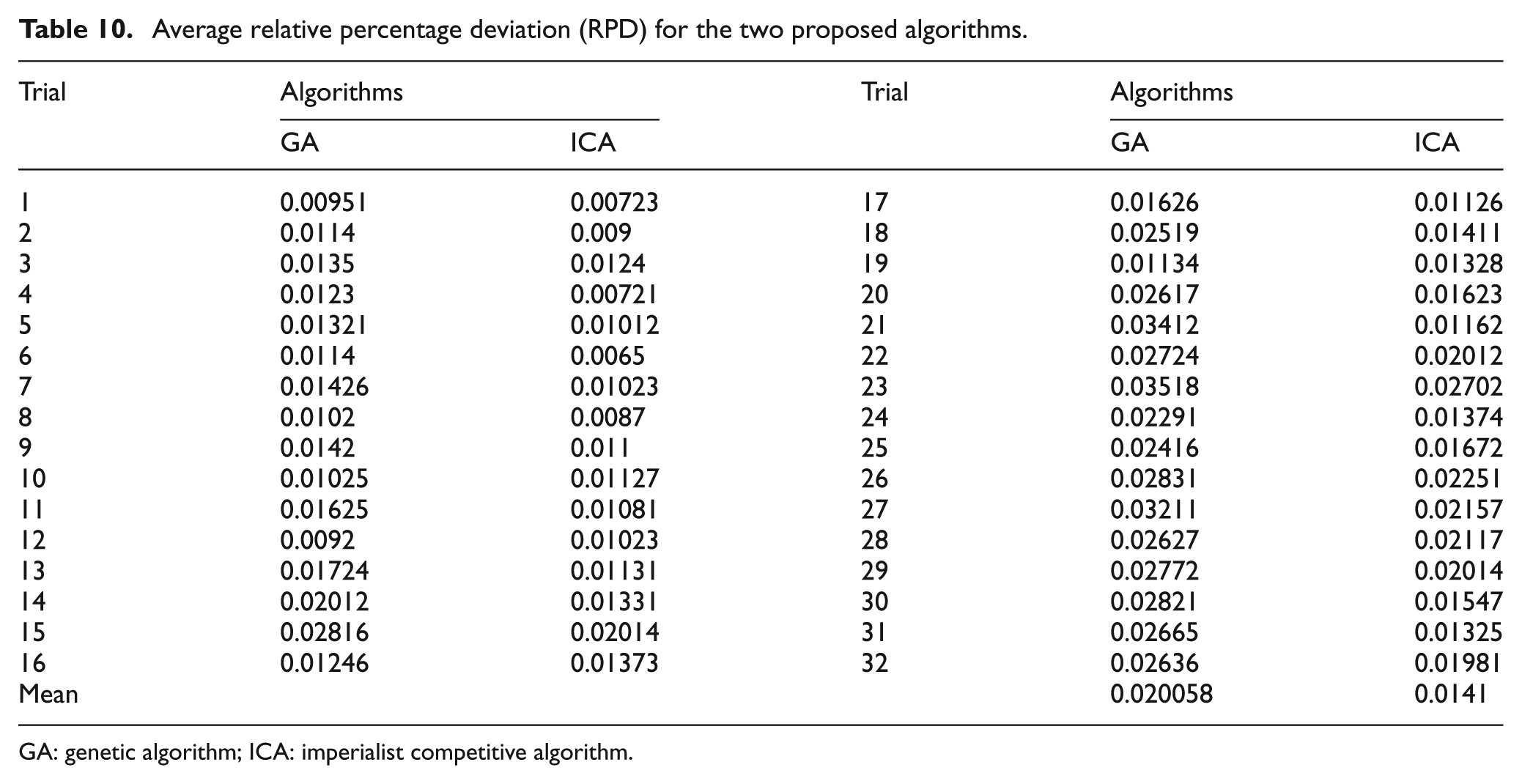
To compare proposed ICA, 32 combinations are considered that these are based on different values of number of job, number of machines at the first stage, DPM, TPM, MTTR and Ag. We used the Taguchi design to obtain them, and the computational results are transformed into RPD measure, which are illustrated in Table 10 for the two proposed algorithms.
Average relative percentage deviation (RPD) for the two proposed algorithms.
GA: genetic algorithm; ICA: imperialist competitive algorithm.
Based on computational results that are demonstrated in Table 10, ICA performs better than GA; we used least significant difference (LSD) method for calculating significant difference. LSD is illustrated in Figure 19, and it shows that there is no significant difference between ICA and GA; in other words, ICA has better performance than GA.
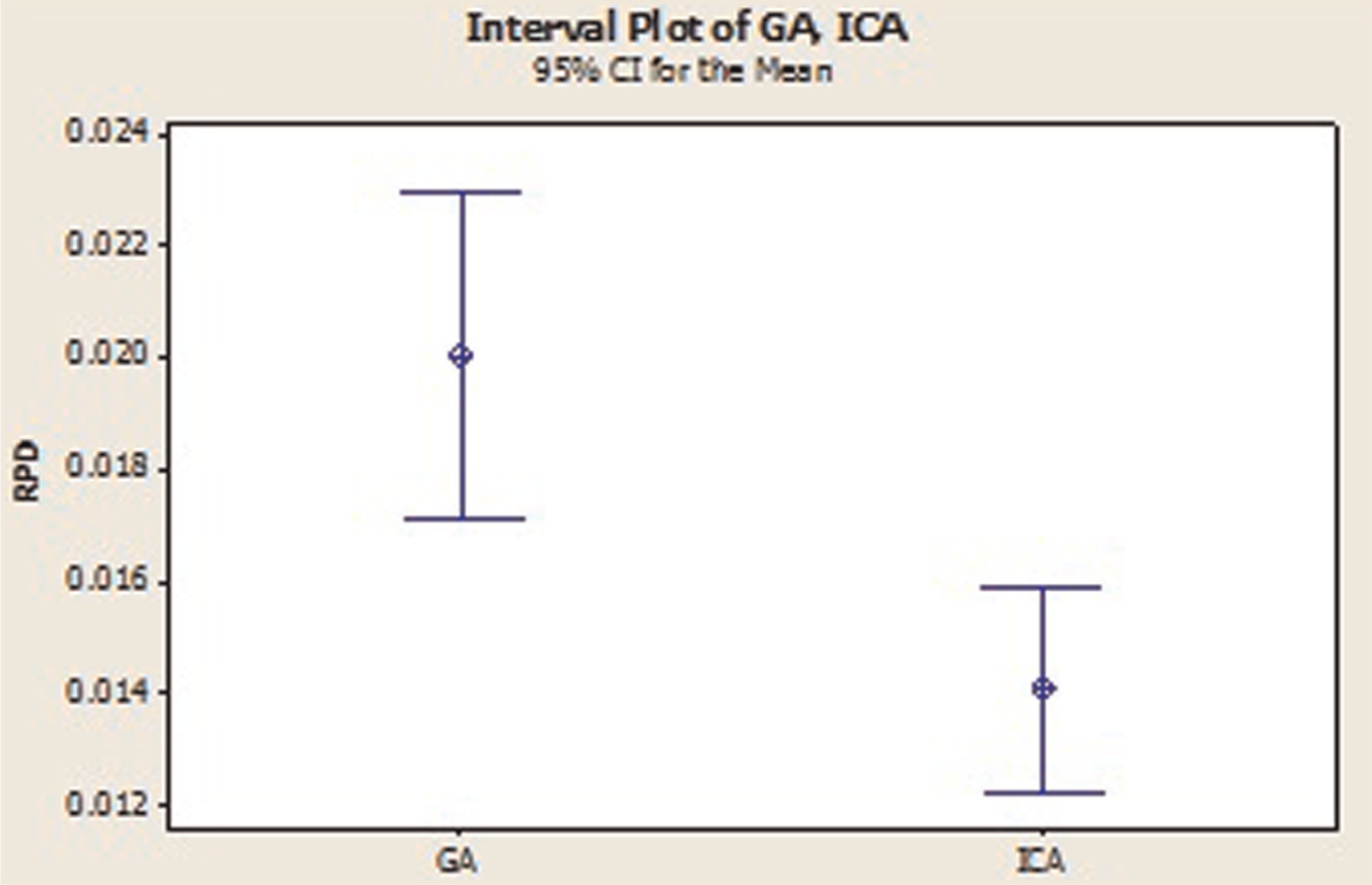
Means plot and LSD intervals (at the 95% confidence level) for the two proposed algorithms.
Moreover, the t-test is used as a method for statistical testing, and hypothesis testing is as follows


The null hypothesis was rejected for all combinations of parameter at a 95% significance level. Thus, average RPD of ICA is statistically smaller than GA; in other words, ICA performs better than GA in most of the problems. Figures 20 and 21 show the RPD values for GA and ICA in different values of number of jobs and machines.
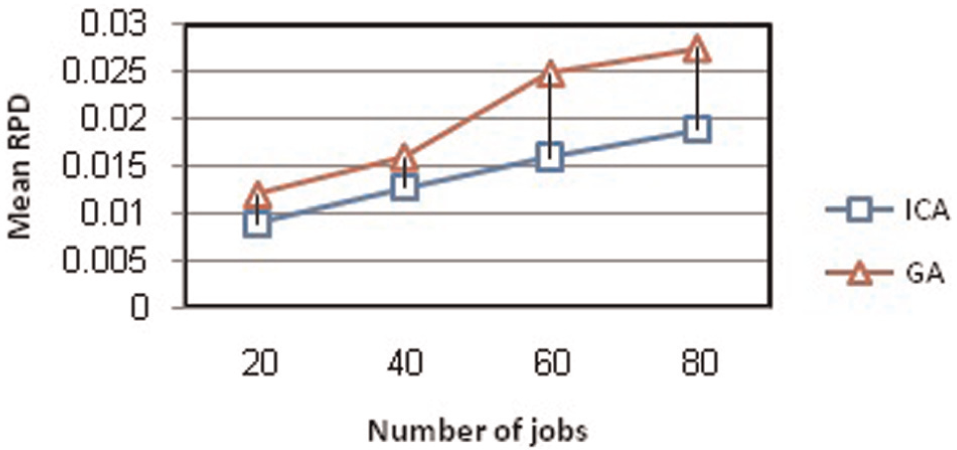
Average percent error for different values of number of jobs.
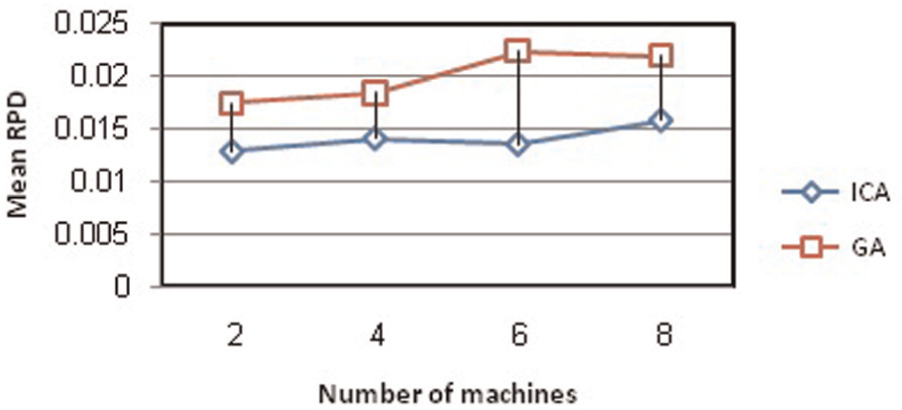
Average percent error for different values of number of machines at the first stage.
Conclusion and future works
In this article, we considered the two-stage assembly flow shop scheduling problem with PM activities and random machine breakdowns. ICA and GA were proposed for finding schedules that minimize the expected makespan. For better performance of the proposed algorithms, parameters of them were tuned by the ANN, and then problem parameters were analyzed by the Taguchi experimental design to reach their effects on response. At the end, the conducted t-test showed that the average error of ICA is statistically smaller than GA; in other words, ICA performs better than GA in most of the problems. As future studies on this problem, it is possible to consider other objectives. As future studies, it is possible to find robust or stable schedules in the uncertainty condition. Another interesting direction for future research is to suggest the use of Weibull distribution that is used in many of the shops. A future research is to develop a multi-objective approach for this problem to create a balance between makespan and system reliability.
Footnotes
Declaration of conflicting interests
The authors declare that there is no conflict of interest.
Funding
This research received no specific grant from any funding agency in the public, commercial or not-for-profit sectors.