
Abstract
In the process of product design, it is usually difficult for engineers to find and reuse others’ lesson-learned knowledge, which is usually not well collected by an enterprise. This study proposes a model of an inner-enterprise wiki system integrated with a semantic search framework to support the accumulation and reuse of lesson-learned knowledge in product design. The accumulated wiki web pages in inner-enterprise wiki system can be viewed as a large lesson-learned knowledge repository, which stores engineers’ wisdom of product design and is the basis of semantic search for knowledge reuse. The semantic-based knowledge search mechanism of inner-enterprise wiki system is presented, which can overcome limitations of traditional keyword-based search in existing wiki systems. To validate our approach, an inner-enterprise wiki system implementation is introduced and some experiments are done. Effectiveness of semantic search mechanism in inner-enterprise wiki system is verified from several viewpoints such as comparison of precision and recall between proposed method and a keyword-based one. The performance of utilizing inner-enterprise wiki system for knowledge reuse is evaluated and the results show that inner-enterprise wiki system can improve the performance of learning. The promising results confirm the feasibility of our approach in helping engineers to better reuse needed lesson-learned knowledge.
Introduction
In recent years, more and more enterprises begin to realize that knowledge is extremely important, 1 and management of knowledge resources is an essential way to enhance business efficiency and competitiveness. 2 Product design is a knowledge-intensive activity in manufacturing enterprises.3–5 Researches suggest that about 80% of product design activities are reusing historical experience and knowledge to solve current problems. 6 In the process of product design, engineers usually write lesson-learned documents for empirical knowledge sharing to others, and lots of empirical knowledge are in the forms of lesson-learned documents which are stored in the hard disk of local network of an enterprise (see Figure 1). Lesson-learned knowledge reuse can reduce the repetitive work, shorten the design cycle time, and improve the product innovation competence.7,8 In an enterprise, top-level management wants the lesson-learned knowledge, which is created by each engineer, to be shared and reused. It is also a shortcut for engineers to get inspiration and hints from existent lesson-learned knowledge. However, when an engineer wants to learn from others’ lesson-learned knowledge, he or she usually finds it is difficult to seek related lesson-learned knowledge resources for reuse, which are also usually not well collected by the organization.

(a) A file folder and (b) content of a lesson-learned document.
Although many knowledge managing models and systems have been designed and developed to strengthen knowledge sharing and reuse in product design for enterprises,9,10 they mainly manage knowledge resources, such as design patents, standards, formulae, and rules. However, this study differs from them on that the proposed model focuses on lesson-learned knowledge in product design, which needs to be collaboratively created and accumulated among engineers of different disciplines by several rounds of revisions and reviews to reach a high-quality level. For this issue, the wiki technique may provide us a feasible direction for the accumulation of lesson-learned knowledge in product design. After enterprises accomplish the accumulation process of lesson-learned knowledge, knowledge sharing and reuse is a key issue to be solved. This research proposes a novel model of an inner-enterprise wiki system (IWkS) integrated with a semantic search framework to support lesson-learned knowledge reuse in the process of product design.
The rest of this article is organized as follows. Some related work is briefly introduced in the next section. Section “The framework of an IWkS for lesson-learned knowledge reuse” presents the framework of IWkS for lesson-learned knowledge reuse. In section “A novel semantic search approach for lesson-learned knowledge,” a novel semantic-based search method is proposed for engineers to reuse lesson-learned knowledge resources in IWkS for product design. Section “IWkS scenario and experiments” shows a demo scenario of IWkS, and some experiments are done to evaluate performance influenced by changing the weight parameters, effectiveness of the semantic-based search method, and performance of utilizing IWkS for knowledge reuse among a product design team in a shipbuilding enterprise. Conclusions are then outlined in the last section.
Related works
For industrial product design, almost all departments must be involved to the successful completion of design efforts through inter-departmental teamwork, coordination, and communication with each other. When enterprises want to create and accumulate lesson-learned knowledge accurately, a collaborative mechanism among engineers is needed to accomplish several rounds of revisions and reviews. As an example of Web 2.0 online tools, wikis are often used collaboratively by multiple users and they have been successfully used as community websites, corporate intranets, knowledge management systems, and so on.11–13 In product design domain, Bertoni and Chirumalla 14 explore the application of wiki to support product development efforts in a global, virtual, and cross-functional setting. Chung 15 demonstrates a project development example of wiki-based enterprise-level product design, specifically on multiple-function printer mechanism. The project goal is to enhance competitiveness by taking advantages of knowledge sharing and speeding up information flow on the base of wiki website with team-member discussions.
In product design, a large amount of lesson-learned knowledge resources collected in an enterprise may be accumulated easily through certain mechanism of knowledge accumulation based on previous studies by standard wiki technology.16–19 However, when engineers want to reuse the accumulated knowledge in wikis, the existing wiki technologies and systems show limitations that only a simple keyword-based search mechanism is available. 20 The keyword-based search methods are looking whether keywords in a user query match the content of web pages, which suffer from the vague-meaning problem that is created by the following causes: 21 First, keyword-based search methods are not able to understand the meaning of a user query. For example, some wiki pages referred to the same semantic information may be omitted if the pages do not contain same keywords as the user query. Second, keyword-based search methods are not able to figure out the semantic relationships among concepts in a user query and lesson-learned knowledge resources. In general, the keyword-based search determines relationships of knowledge resources and query keywords mainly on the occurrence of the keywords in their textual descriptions of wiki web pages. It cannot ensure that returned results preserve semantic relationships among the keywords which users have intended to submit to the search box. Because of this, keyword-based search methods in existing wiki systems sometimes miss highly relevant results and return some irrelevant results for user queries. 22
To address this issue, some semantic-based search methods have been proposed as complements in both academics23–25 and industries (Hakia, SenseBot). 26 However, most researches deal with the problem of semantic search for various types of data in the whole semantic web, while this study focuses on textual web pages in a lightweight level IWkS, which mainly covers search scenarios of lesson-learned knowledge in an enterprise.
What is more, a lot of previous semantic algorithms are based on a large-scale semantic annotation work for knowledge resources, which is difficult and time-consuming. While this research supports a semantic-based search framework to overcome such limitations by enriching the search process with a semantic matching method that bases on a predefined product design ontology, which is designed in our research group’s previous studies.27–29 There is no need for any semantic annotation work on the lesson-learned knowledge resources. Ontology is a formal knowledge description of concepts and their relationships. The semantic relationships among concepts can complement the keyword-based search method. The semantic search makes hidden relationships between keywords of lesson-learned knowledge resources and user queries explicit by using diverse semantic relationships defined in the ontology.
This research proposes an IWkS integrated with a novel semantic search approach for lesson-learned knowledge reuse situated in product design. By the proposed semantic-based search method, engineers may get the corresponding wiki pages with a rank according to similarity through semantic matching between user queries and lesson-learned knowledge resources. Consequently, we expect that the precision and recall of the search would be improved. The usefulness and feasibility of IWkS for lesson-learned knowledge reuse could be confirmed.
The framework of an IWkS for lesson-learned knowledge reuse
Lesson-learned knowledge
In product design, lesson-learned knowledge represents the skill-related knowledge acquired from an engineer’s past experience in performing design tasks. In the process of product design, a lot of such knowledge exists, which makes it possible for an engineer to reuse others’ experience in accomplished various tasks. In many enterprises without knowledge management tools, the lesson-learned knowledge is in the forms of lesson-learned documents which are stored in the local network (as the example shown in Figure 1). Figure 1(a) shows a file folder that contains lesson-learned documents in the local network of a shipbuilding company, and the types of documents are Microsoft Word documents. Figure 1(b) shows content of a lesson-learned document on outfitting design which is written by the design department, and each document has main parts such as item title, problem description, and method description. By finding and reading related lesson-learned documents, engineers can learn from others’ methods when facing with similar problems and difficulties.
With a wiki system, the enterprise can have a better knowledge accumulation mechanism for engineers to create and share lesson-learned knowledge. As shown in Figure 2, each piece of lesson-learned knowledge inserted in wiki system will be revised and reviewed several rounds to make sure of its accuracy and integrity. The accumulated wiki web pages can be viewed as a large lesson-learned knowledge repository, which stores engineers’ wisdom of product design and is the basis of semantic search for knowledge reuse.
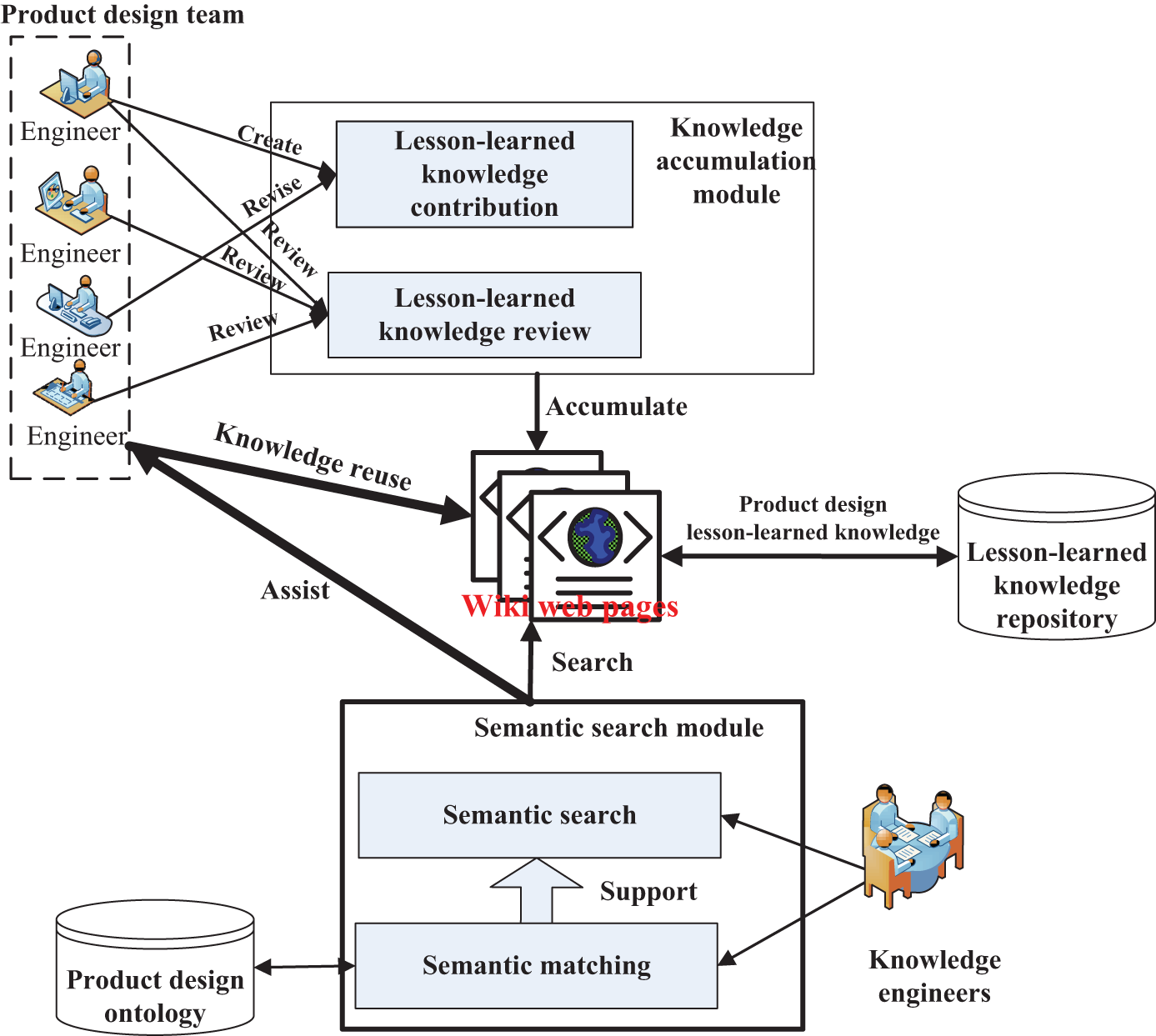
Architecture of an inner-enterprise wiki system.
The framework of IWkS for lesson-learned knowledge reuse
The architecture of IWkS is proposed as shown in (Figure 2). Besides accumulated lesson-learned knowledge through engineers’ collaborative contribution and review, the system should have the abilities to help engineers find and reuse the lesson-learned knowledge with a novel semantic-based search method.
In IWkS, semantic search module is the core module to execute the knowledge reuse process that concerns searching corresponding lesson-learned items from the accumulated wiki web pages and displays search results to the engineers. The module will employ a semantic matching method to determining the correlative degree between users’ queries and lesson-learned knowledge resources. As to this part, the following section “A novel semantic search approach for lesson-learned knowledge” will give detailed introduction.
A novel semantic search approach for lesson-learned knowledge
The semantic-based knowledge search process in IWkS
A novel semantic search framework integrating in IWkS is proposed in this section. Figure 3 shows the overall semantic search process for knowledge reuse. Before searching lesson-learned knowledge resources that are in the format of web pages in IWkS, a set of domain ontology should be constructed to describing the concepts and their semantic relationships in the web pages. For this work, our research group has already constructed a set of product design ontology. 30 Given a user query containing a set of keywords, the semantic search engine finds the relevant knowledge resources through a semantic matching method and returns a ranked list of the URIs of the knowledge resources in the order of their matching results. Finally, the wiki web page retriever retrieves the web pages corresponding to the returned URIs.
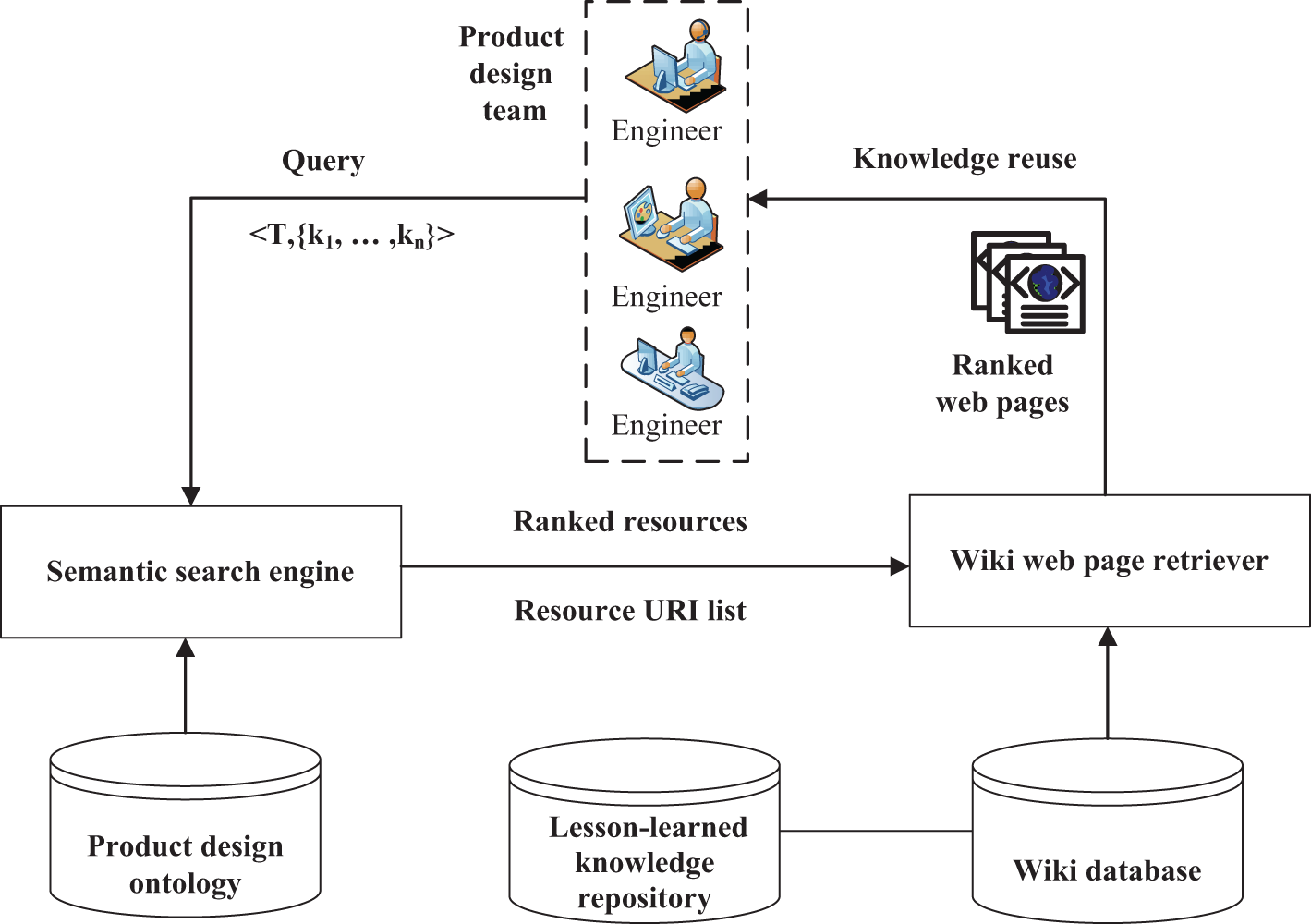
The semantic-based knowledge search process in IWkS.
Since we consider semantic relationships between lesson-learned knowledge resources and query keywords in the search process, the rank of search results should reflect how well each semantic similarity discriminates a result from other results in the set. Thus, we propose a novel semantic matching approach for the semantic similarity calculation, such that it assigns a higher weight to semantic similarity with less ambiguity in identifying the target resources. Finally, engineers may get the corresponding wiki pages with a rank according to similarity through semantic matching between user queries and lesson-learned knowledge resources.
Semantic search engine
In order to complement traditional keyword-based search, the semantic search considers semantic relationships between a user query and knowledge resources in IWkS.
A user query Q and a lesson-learned knowledge item in IWkS are described by
Topic extraction and weight calculation from a lesson-learned knowledge item
For knowledge resources in IWkS, each web page is a lesson-learned knowledge item, and we have to extract topic concepts to represent each web page. In order to do this, two stages of web page pre-processing and topic extraction are introduced as follows.
Web page pre-processing. This stage is responsible for determining morphological features of lesson-learned items, which is necessary before topic extraction. This study employs the CKIP technology 31 to perform sentence segmentation and text tagging for the web pages. Several keywords are then located automatically in the content of each web page and tagged with appropriate morphological feature tags. Before topic extraction, stop words such as “hence” and “the” are deleted. Next, a stemming process, which cuts the original word down to the root, is conducted with those sentences that do not have stop words. For instance, after the stemming process, the words “design,”“designing,” and “designs” become the same word, which is design, because all the words have the same meaning. Porter’s 32 algorithm is used to stem words in the IWkS. Once these pre-processes are finished, important topics will be selected and superfluous keywords will be filtered out, and then, key topic candidates can be identified and sent to the next stage.
Topic extraction. Engineers can add or modify an initial topic vocabulary, 33 producing a list of important topics that are then defined as the topic vocabulary or thesaurus of lesson-learned knowledge repository. One of the training datasets is used to construct a topic extraction model, which is then employed to extract topics accurately from test web pages.
In this phase, topics are extracted from a set of web pages in IWkS. Each topic will receive a weight after a term weighting process, which is based on the Term Frequency/Inverse Document Frequency (TF/IDF) method. 34 The weighting method is shown in formula (1) as follows

Wmt is the weight of topic t in a web page m, tfmt is the topic frequency of topic t in a web page m, N is the total number of web pages, nt is the number of web page that contains topic t, and k is the number of topics.
After the weighting process, each topic has its own weight in a web page. Once topics are ordered by weights, topics are selected from top-ranked topic list according to the limit that the user set.
Semantic matching between a user query and lesson-learned knowledge resources
As mentioned in previous sections, in the semantic search, semantic similarity exists between a user query and a lesson-learned knowledge item in IWkS, and “correlative value”Cor_v is used to denote value of semantic similarity. Since a lesson-learned knowledge item mainly contains three parts, which are item title, problem description, and method description, different part may have different weights. The correlative value Cor_v could be calculated as formula (2)
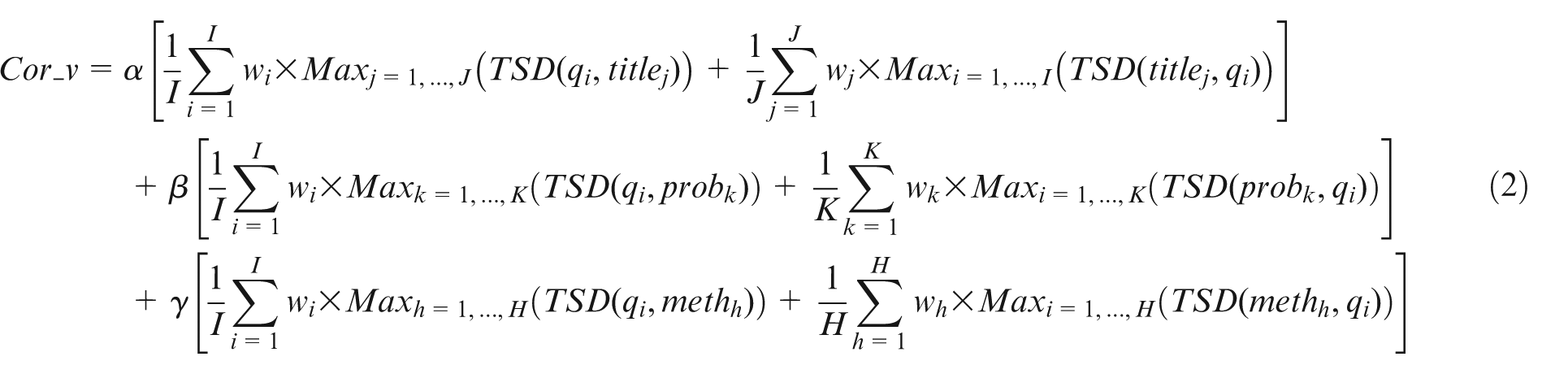
where α + β + γ = 1; qi denotes the ith concept in a user query, wi denotes weight coefficient of the ith concept in a user query, I denotes number of concepts in a user query; titlej, probk , and methh denote the jth concept, the kth concept, and the hth concept extracted from item title, problem description, and method description of a lesson-learned item, respectively; J, K, and H denote the number of concepts extracted from item title, problem description, and method description of a lesson-learned item, respectively; wj, wk , and wh denote weight coefficients of concepts extracted from titlej, probk , and methh , respectively; α, β, and γ denote weight coefficients of titlej, probk , and methh in a lesson-learned item; and TSD denotes topic semantic distance between two concepts.
Once the user query and lesson-learned knowledge resources are decided, the next issue is to determine the TSD among concepts, TSD (ti, tj ), which is introduced in Definition 3 that bases on Definitions 1 and 2.
Definition 1 (semantic relation coefficient)
Semantic relation coefficients (SRCs) denote semantic relations between topics, which are defined in the product design domain ontology.27–29 The value of SRC is between 0 and 1. Several semantic relations between topics on pipeline system of outfitting design and the SRCs are shown in Table 1. The set of SRCs can be changed by product design experts and knowledge engineers. In Table 1, SRC of is-a−1 is lower than is-a because attributes of parent nodes are inherited by child nodes, for example, “heater pipe” inherits all attributes of “pipe.” When an engineer searches for topics of parent nodes pipe, items about heater pipe may also be shown.
Semantic relation coefficient.
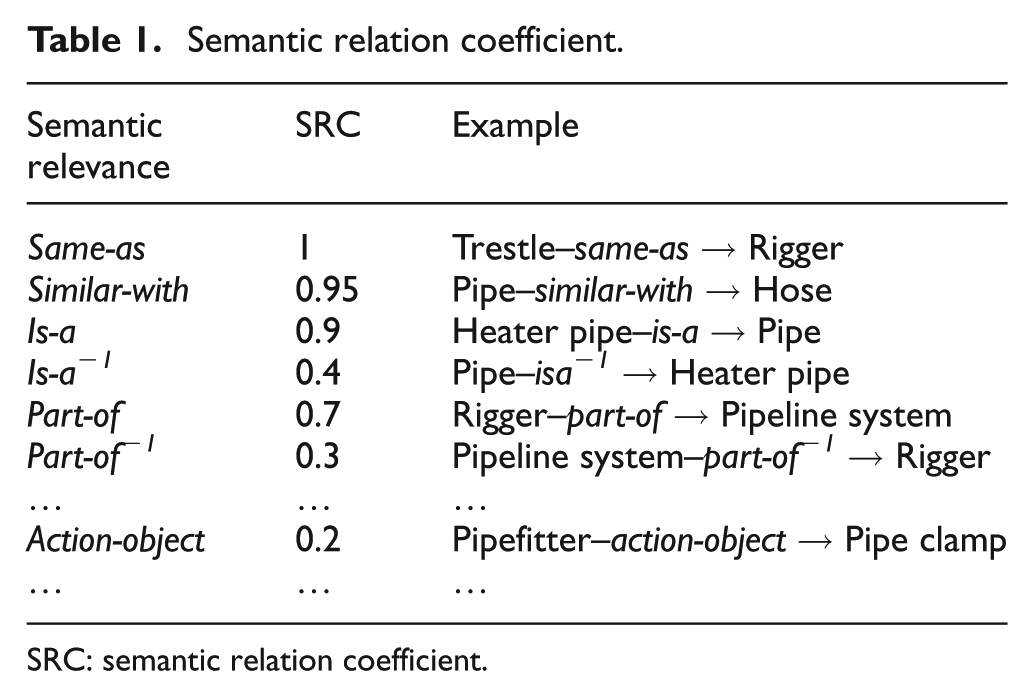
SRC: semantic relation coefficient.
Part of ontology about “pipeline system of outfitting design” is illustrated in Figure 4. In this figure, arrows from the source topic to the destination topic represent semantic relevancies, such as same-as, similar-with, is-a, is-a−1, part-of, part-of− 1, and action-object, which are listed in Table 1.
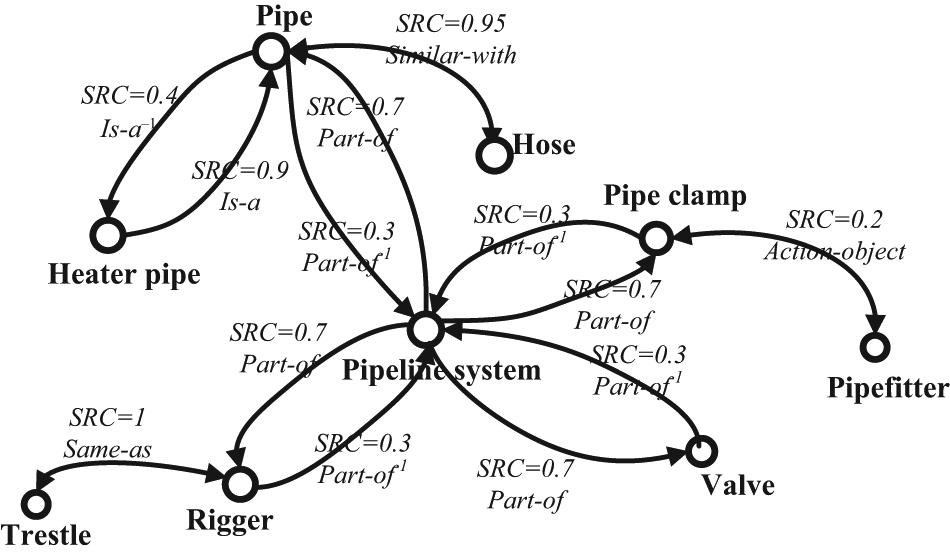
Part of ontology about “pipeline system of outfitting design.”
Definition 2 (topic semantic path)
Suppose
Definition 3 (TSD)
Suppose ti and tj are two topics, “Topic semantic distance” is defined as the maximized semantic distance’s value of all the semantic paths from ti to tj , which is shown in formula (3)
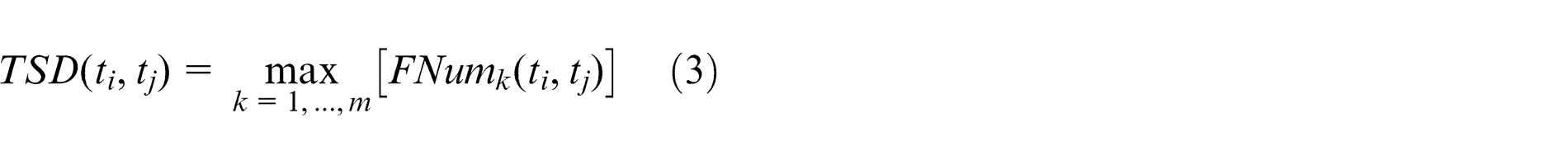
Here, m denotes the number of paths between ti
and tj
. If there is no path between two topics, their TSD is 0. For example, there are two topics “Pipefitter” and “Rigger” in Figure 4,
IWkS scenario and experiments
IWkS scenario
According to the framework and approach in the above sections, an operational IWkS is designed. Then, the IWkS is applied for lesson-learned knowledge accumulation and reuse in outfitting design in a famous shipbuilding company in China.
Participants for knowledge accumulation are engineers in the field of outfitting design, who are from a design institute of the company. The engineers are asked to use IWkS to share their lesson-learned knowledge. They are encouraged to give contributions and reviews for lesson-learned items. They participate in the experiments throughout 3 months to complete the knowledge accumulation. In the company, although most of the engineers are Chinese, the design platforms are English software systems, such as TRIBON, so lesson-learned items are usually written in English and this whole prototype system is developed in English language. Figure 5(a) shows a piece of lesson-learned item that is written by an engineer of the product design institute of the company. Each item’s content is displayed in a web page of IWkS. Figure 5(b) shows an engineer’ user space, which includes a list of lesson-learned items contributed by him or her.
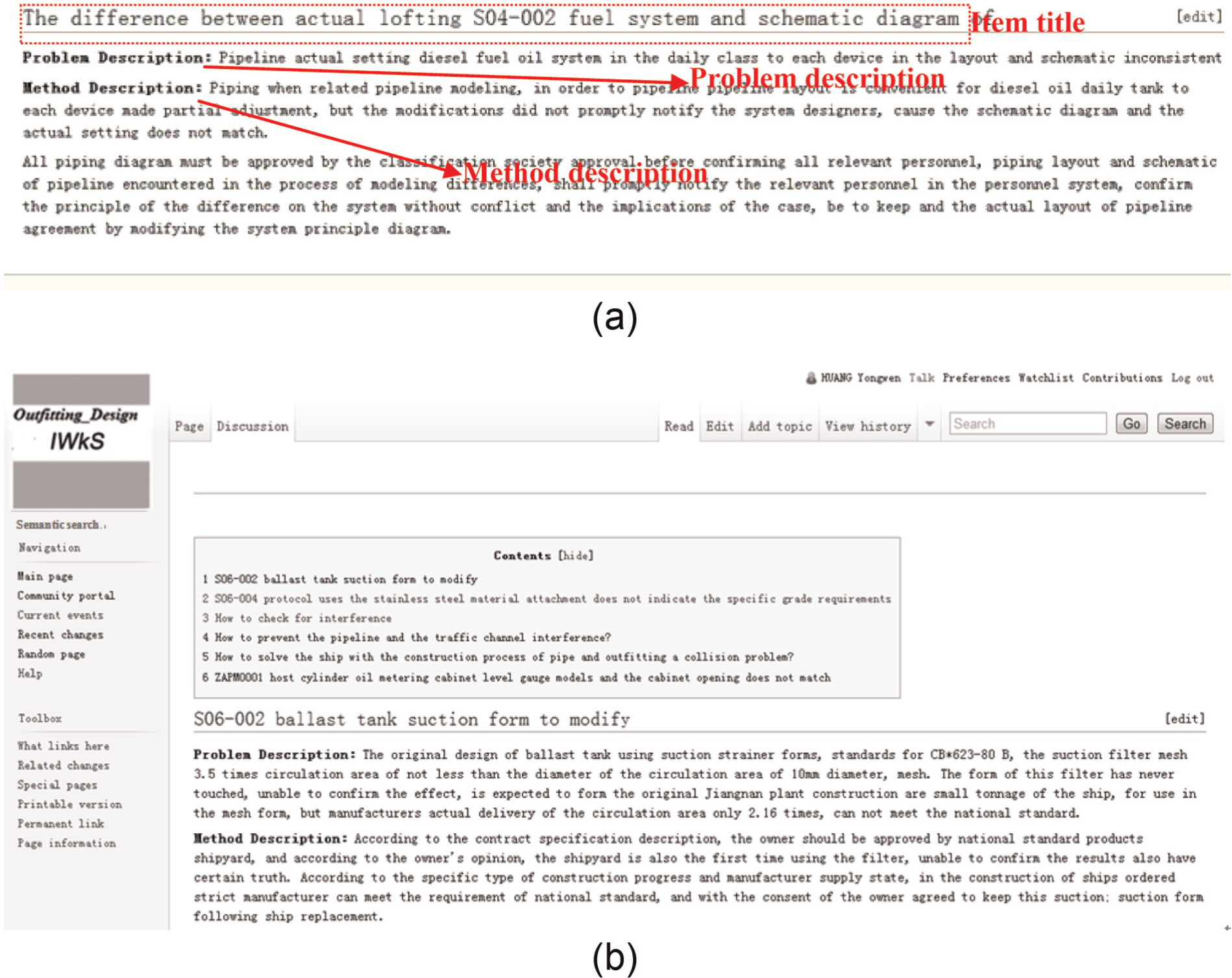
Accumulated wiki web pages in IWkS: (a) a piece of lesson-learned item and (b) the contributions of an engineer.
When an engineer wants to learn from others’ lesson-learned knowledge with the semantic search method, as shown in Figure 6, he or she may first click the “semantic search” tab, input the keywords into the search textboxes, input the weight of each keyword and value of TSD, and then click the “semantic search” button. IWkS then conducts an analysis on the lesson-learned items by the proposed method. All the relevant items will be displayed afterward, showing the results according to the engineer’s query. When performing an outfitting design work, under the help of IWkS, an engineer can directly access the detailed web page of a lesson-learned item through the hyperlink.
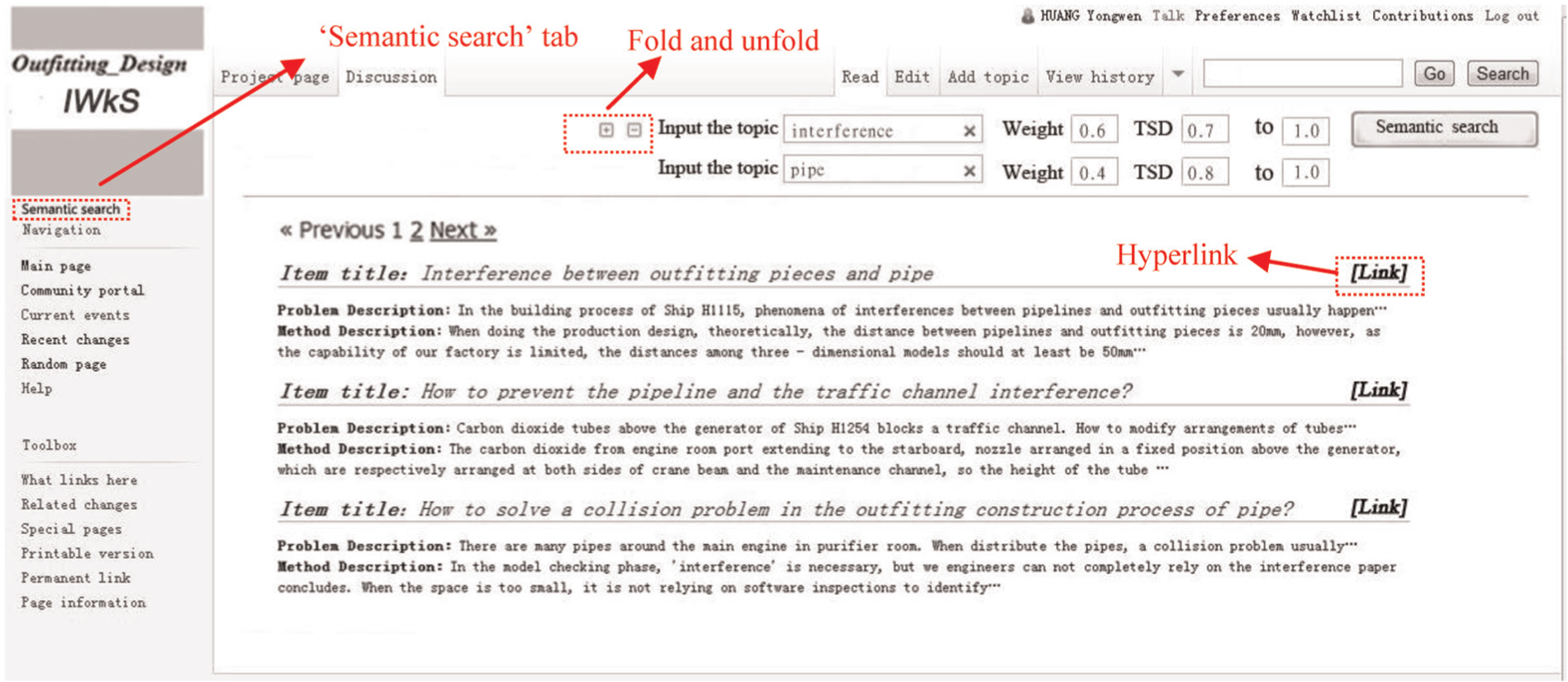
Semantic search for lesson-learned knowledge reuse in outfitting design.
Figure 6 illustrates an interface of semantic search for lesson-learned knowledge reuse in outfitting design. The input textboxes for keywords, weights, and TSD values are shown in the interface. For example, if an engineer inputs the two keywords “interference” and “pipe,” set the weights of them as 0.6 and 0.4, respectively and set the values of TSD of the topic “interference” and “pipe” between 0.7 and 1 and between 0.8 and 1, respectively. Then, search results that satisfy the conditions will display. If the engineer wants to increase or decrease the number of keywords in the query, “fold and unfold” icon will help.
Performance influenced by changing the weight parameters for item title, problem description, and method description (α, β, and γ)
Experiment design
This subsection will illustrate the results and sensitivity analysis of the weights for item title, problem description, and method description of a lesson-learned item. As mentioned in previous section “Semantic matching between a user query and lesson-learned knowledge resources,” the weights for “item title,”“problem description,” and “method description” (denoted by α, β, and γ in formula (2)) are three important parameters to calculate “correlative value”Cor_v between a user query and a lesson-learned knowledge item in IWkS. Through analyzing the characteristics of lesson-learned resources in outfitting design of the company, the assignments of α, β, and γ values are a priori decided by domain experts and knowledge engineers as follows for comparison, respectively:
Weights 1: α = 0.5, β = 0.3, γ = 0.2
Weights 2: α = 0.3, β = 0.5, γ = 0.2
Weights 3: α = 0.2, β = 0.3, γ = 0.5
Weights 4: α = 0.2, β = 0.5, γ = 0.3
Weights 5: α = 0.3, β = 0.2, γ = 0.5
Weights 6: α = 0.5, β = 0.2, γ = 0.3
Afterward, 10 queries that contain various topics are randomly determined by 10 different engineers. After each run of the query with the six different combinations of weights for α, β, and γ, the lesson-learned items displayed are evaluated by precision and recall measures according to the experts’ judgments. Precision is the number of relevant items displayed by a query divided by the total number of items displayed by that query. Recall is the number of relevant items displayed by a query divided by the total number of existing relevant items in IWkS.
Results and sensitivity analysis of the weights for item title, problem description, and method description (α, β, and γ)
From the experimental results, the precisions of the 10 queries with different combinations of weights for α, β, and γ are the same as 100%. The recalls of the 10 queries with different combinations of weights for α, β, and γ are shown in Figure 7. From the recalls shown in Figure 7, we could see that some curves are detached to others, which means the changes in the assignment of weights α, β, and γ have some impacts on final results. Based on the results shown in Figure 7, we could find that the curve of “weights 2” and “weights 4” are better than other four, and they are close with each other. The β value of “weights 2” and “weights 4” are 0.5, which is larger than other two. It means the “problem description” may be the most important in a lesson-learned item. The curve of “weights 4” is a little better than “weights 2” in experiments. The γ value is larger than α value in “weights 4,” which denotes “method description” may be a bit more important than “item title.”
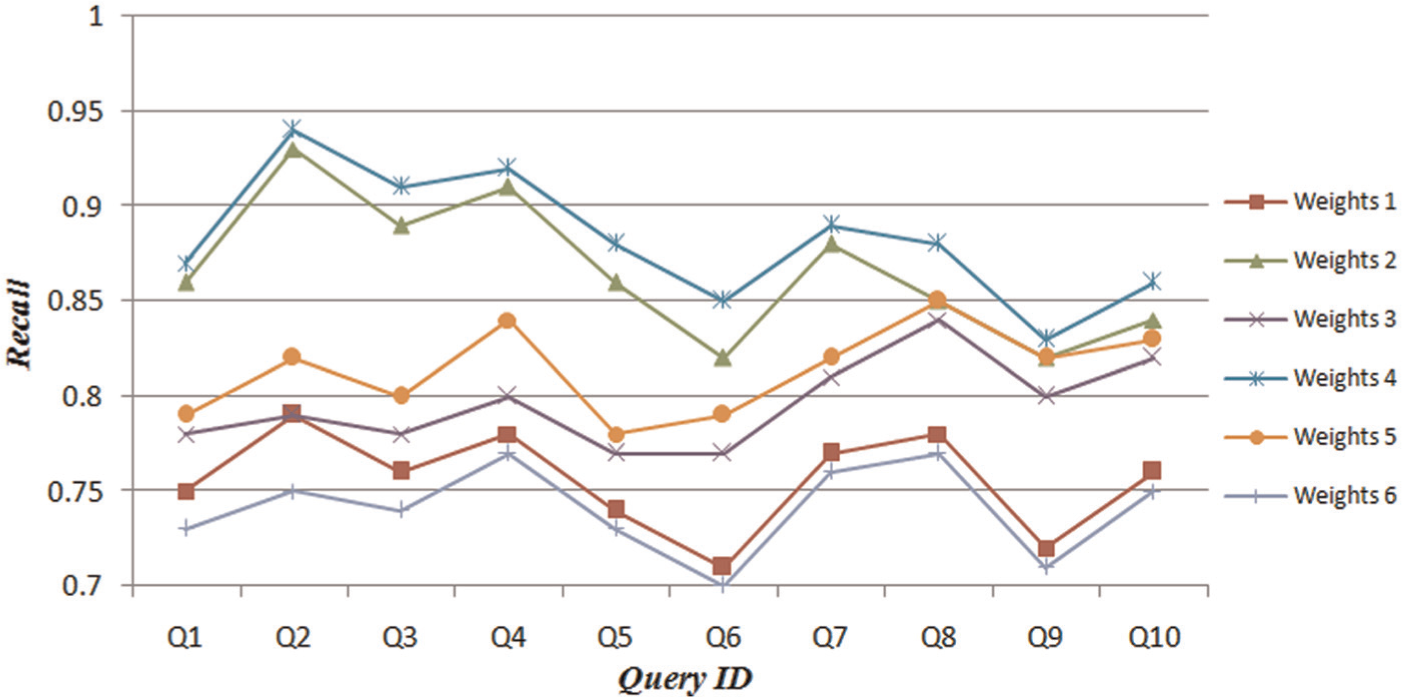
The results of recall with different weights for α, β, and γ.
So, the experimental result reflects that the β value should be set higher, and γ value and α value should be lower in order. The reason may lie in: more relevant topics and semantic information are involved in “problem description” than “method description” and item title.
In addition, as the combination “weights 4” is the best one in the six combinations, in later experiments, α, β, and γ are assigned with 0.2, 0.5, and 0.3, respectively, as the preferable parameters.
Experiment 2: analysis of effectiveness of the semantic search mechanism
Experiment design
The proposed IWkS system comprises a novel search mechanism based on semantic relations. The effectiveness of the semantic search mechanism is compared with that of keyword search mechanism in existing wiki systems by precision and recall measures. Precision is the fraction of retrieved lesson-learned items that are relevant to the query. Recall is the fraction of the lesson-learned items that are relevant to the queries that are successfully retrieved.
To evaluate the effectiveness, we search for lesson-learned knowledge resources with five queries by keywords “Fitting”; “Bulk Carrier”; “Electric, Fitting”; “HVAC, Spool, Pallet”; and “Pipe, Hole, Design, Inconsistency.” The weight of each keyword in a query and TSD of the keyword are set, as shown in the first column of Table 2. We choose these keywords because they are main topics in the field of outfitting design. Their relations with other concepts in the included lesson-learned content of IWkS are considered in the semantic search, while the keyword search could not understand the relations.
Precision and recall associated with the searching mechanisms.
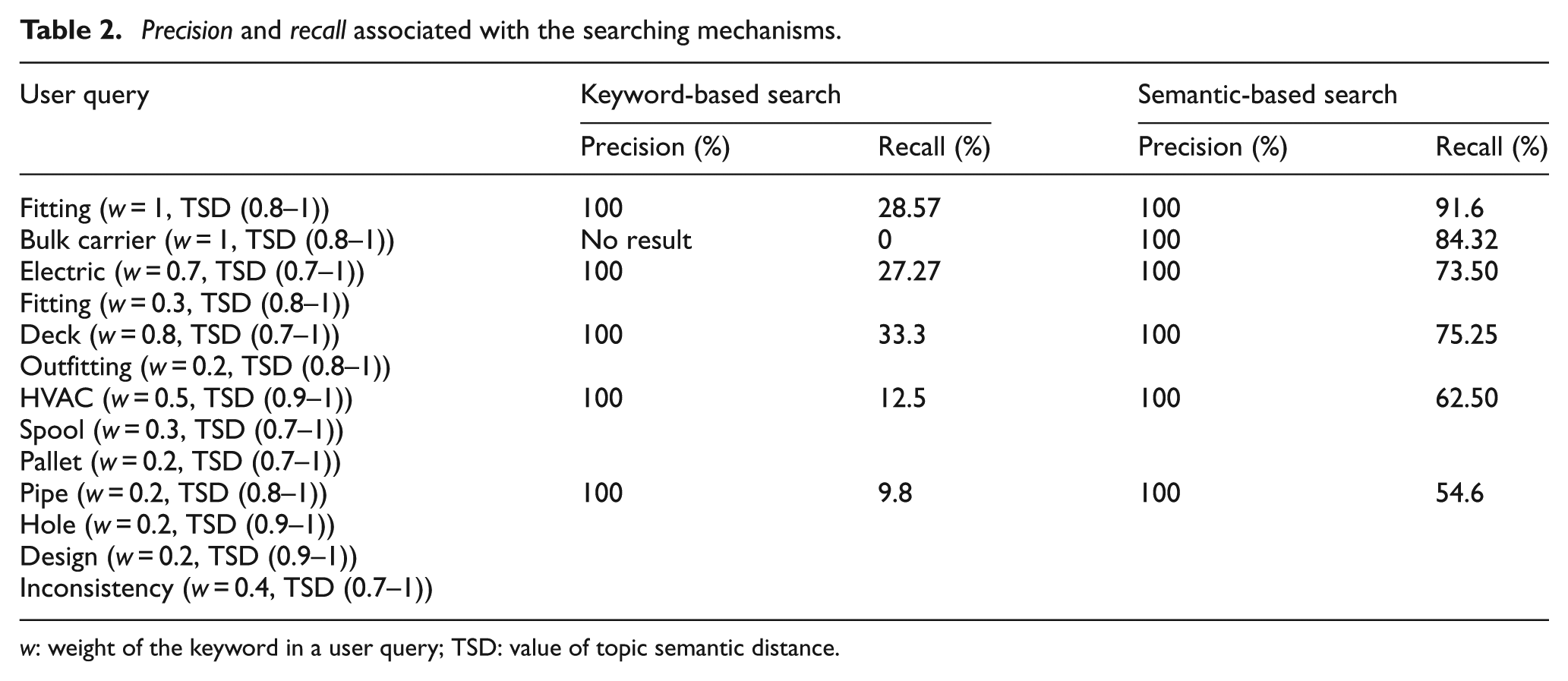
w: weight of the keyword in a user query; TSD: value of topic semantic distance.
Experiment results
The results of precisions and recalls with the two search mechanisms are evaluated by domain experts of outfitting design, which are listed in Table 2.
From the results, we find that some keywords of user queries may have problems involving synonyms. For instance, the concepts “Bulk Carrier” and “BG” actually have the same meaning. When engineers write the lesson-learned items, they usually like to use the abbreviations. However, when a novice engineer uses “Bulk Carrier” as the keywords to search for knowledge resources by a keyword search, the results are none. Comparatively, the semantic relation between “Bulk Carrier” and “BG” is predefined as having a “same-as” relationship in the ontology. When an engineer either uses “Bulk Carrier” or “BG” as a query by the semantic-based search, the results are the same, because the proposed mechanism is able to understand the meanings and relationships of the concepts, according to a set of product design ontology.
Moreover, from the results we can see, when an engineer inputs more keywords, both keyword-based search and semantic-based search have the lower “recall”; however, the recall of semantic-based search is always much higher than keyword-based search. The results indicate that the semantic-based search is able to improve precision and particularly recall, and therefore, it is more effective than keyword-based search.
Effectiveness of the proposed semantic-based search mechanism supported by semantic relations in IWkS is verified to be more useful than a keyword search in existing wiki systems.
Experiment 3: evaluate the performance of utilizing IWkS for knowledge reuse
Experimental design
In this research, we have to validate the performance of utilizing IWkS for lesson-learned knowledge reuse. Our hypotheses are as follows:
H: IWkS-based lesson-learned knowledge reuse is more effective than keyword search–based one on learning performance.
Ha: IWkS-based lesson-learned knowledge reuse is more effective than keyword search–based one on learning score.
Hb: IWkS-based lesson-learned knowledge reuse is more effective than keyword search–based one on learning satisfaction.
An experimental design for laboratory testing is used to test the hypotheses, and participants, measurements, lesson-learned resources, and procedure are given as follows.
Participants
Participants of the experiment are assistant engineers in the field of outfitting design. We have invited 84 assistant engineers whose professional degree and project experience are similar. They are randomly divided into two groups, which are the experimental group (IWkS-based) and the control group (keyword search–based). Each group consists of 48 members.
Measurements
Learning performance in hypothesis H can be measured by learning score in Ha and learning satisfaction in Hb. A test sheet, including several questions about major methods and principles of outfitting design, is used to measure learning score. In order to make sure of the validity of the test sheet, it is set across all lesson-learned resources and then reviewed and checked by principal designers of outfitting design. A question in the sheet is asked like this: which one does not belong to the category of regional outfitting? (A) Unit outfitting, (B) Block outfitting, (C) Plate outfitting, and (D) Machinery fitting.
A post-test questionnaire is used to measure learning satisfaction. For this, Likert’s 7-point scale is utilized. 35
Lesson-learned resources
The lesson-learned resources used for the experimental and control groups are same, which are selected from accumulated wiki web pages of lesson-learned knowledge created by the design department of a famous shipbuilding company in China. A same set of lesson-learned knowledge items is learned by all of them to make the experiment more reliable.
Procedure
The procedure of the experiment is described in Table 3. First, participants in the experimental and control groups are required to independently read IWkS-based and keyword search–based user guide, respectively, which costs them 10 min. Second, participants spend about 50 min to learn lesson-learned resources. The experimental group learns with the assistant of IWkS with a semantic search mechanism, and the control group learns by browsing lesson-learned web pages in IWkS utilizing the keyword-based search mechanism. Finally, participants are asked to finish a test sheet and a post-test questionnaire within 30 min.
Experimental procedure.
IWkS: inner-enterprise wiki system.
In the experiment, Kuder–Richardson Formula 20 (KR-20) 36 and Cronbach’s α are used to test the internal consistency of the test sheet and the post-test questionnaire, respectively. SPSS tools are used for one-way analysis of variance (ANOVA) and regression analysis. The procedure and statistical method of this experiment are referred to previous researches and checked by experts to make sure they satisfy the validity. 37
Evaluation results and data analysis
Reliability of test sheet
Since scores of questions in the test sheet are very important for the performance analysis, the reliability of questions is validated by the measure of KR-20. There are 18 questions in the original test sheet. Through KR-20 methods, the results of item difficulty and discrimination for each question are calculated, which are shown in Table 4. According to the suggestion of Xue, 38 the value of item difficulty should be larger than 0.2 and smaller than 0.8, and the value of item discrimination should be larger than 0.3. From Table 4, it is easy to see that questions S-4, S-13, F-1, and F-2, which are in the original test sheet, do not meet requirements of item difficulty and discrimination. After the four questions are deleted, the KR-20 for the revised test sheet is 0.78, larger than the standard threshold of 0.70 suggested by Nunnally. 39 The revised test sheet is used in the experiment.
Item difficulty and discrimination for the questions.
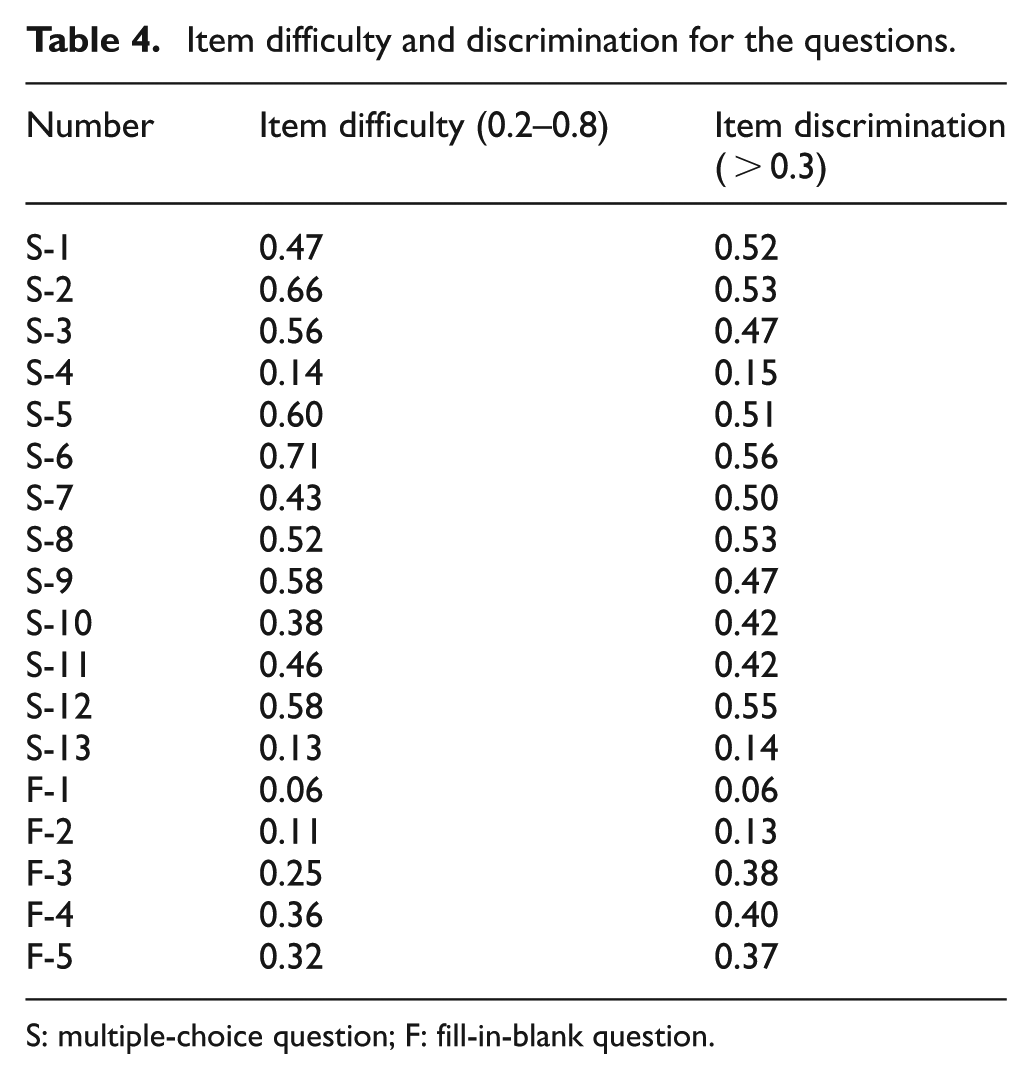
S: multiple-choice question; F: fill-in-blank question.
Reliability of post-test questionnaire
Coefficient of Cronbach’s α of the post-test questionnaire to measure learning satisfaction is 0.91, which exceeds the water mark of 0.70, so the questionnaire is reliable.
Hypothesis testing of learning performance
Hypothesis H suggests that IWkS-based lesson-learned knowledge learning is more effective than keyword search–based one on learning performance, which can be measured by learning score (Ha) and learning satisfaction (Hb). A one-way ANOVA to test Ha and Hb is used, by which the results for Ha and Hb are shown in Tables 5–8, respectively.
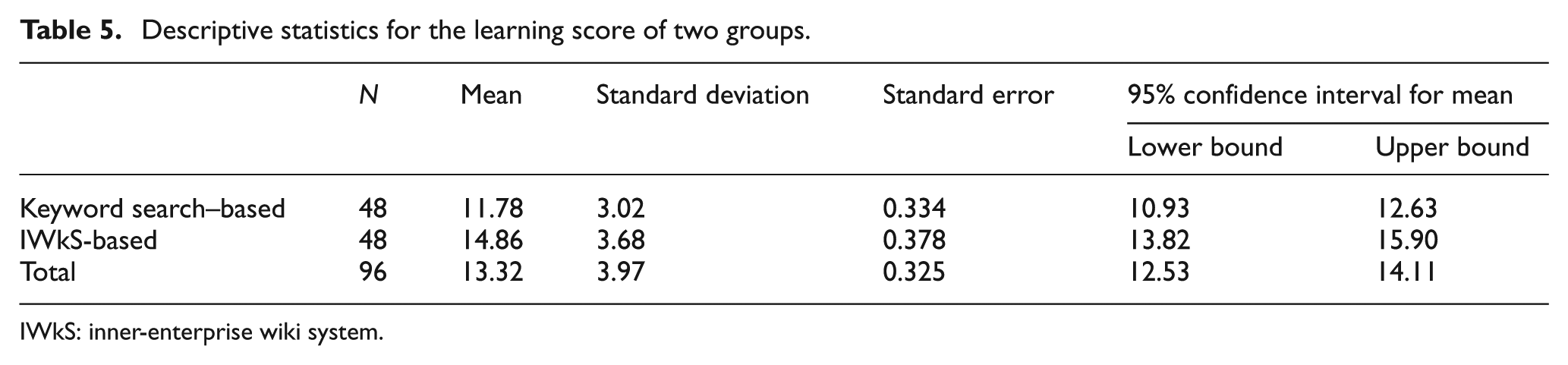
Descriptive statistics for the learning score of two groups.
IWkS: inner-enterprise wiki system.
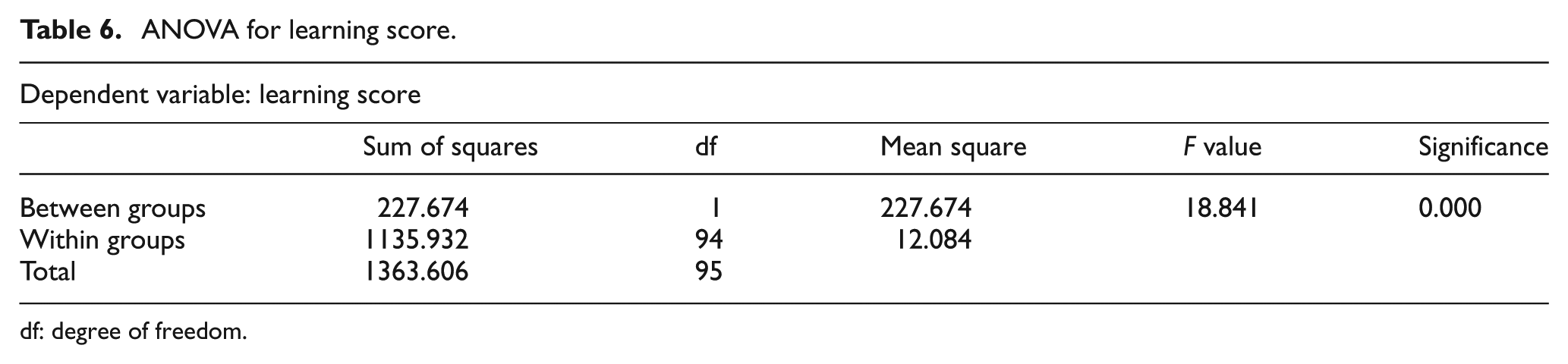
ANOVA for learning score.
df: degree of freedom.
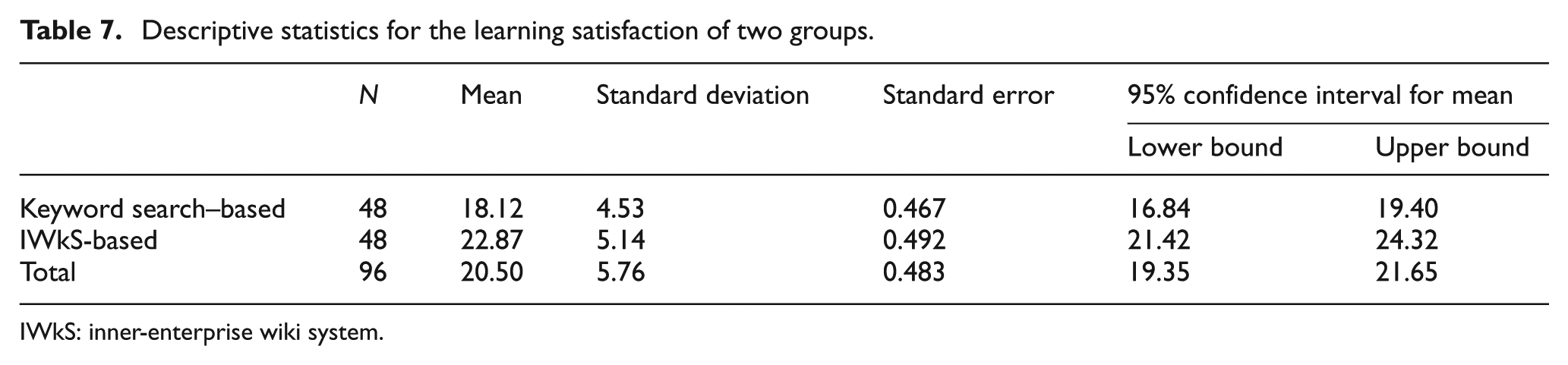
Descriptive statistics for the learning satisfaction of two groups.
IWkS: inner-enterprise wiki system.
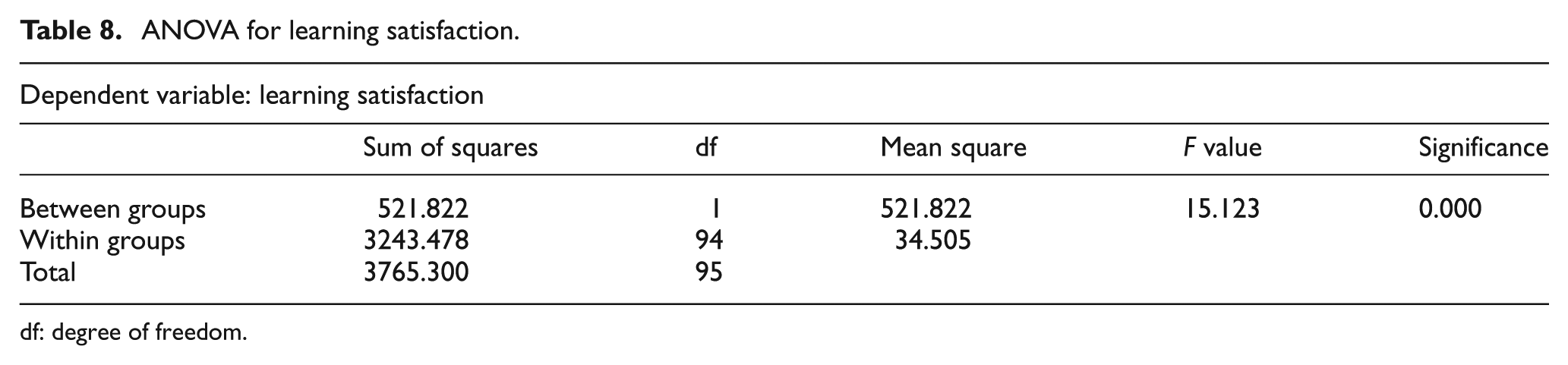
ANOVA for learning satisfaction.
df: degree of freedom.
In Table 5, the average scores of IWkS-based lesson-learned items learning (experimental group) and keyword search–based one (control group) are 14.86 and 11.78. Table 6 shows that the differences are significant (F(1, 94) = 18.841, p < 0.001). Thus, findings support hypothesis Ha. The IWkS-based lesson-learned items learning could help participants attain higher scores than the keyword search–based one.
In Table 7, the average learning satisfaction of IWkS-based lesson-learned items learning and keyword search–based one are 22.87 and 18.12. In Table 8, the results suggest that the differences are significant (F(1, 94) = 15.123, p < 0.001). Hypothesis Hb is statistically supported. The IWkS-based lesson-learned items learning could help participants get higher satisfaction than keyword search–based one.
Findings from Tables 5–8 suggest that the learning performance of IWkS-based lesson-learned items learning is more effective than keyword search–based one.
Discussion
In this research, we construct IWkS, utilize it for lesson-learned knowledge reuse, analyze effectiveness of its semantic search mechanism, and test its utilizing performance.
Effectiveness of semantic-based search mechanism in IWkS is verified from several viewpoints such as comparison of precision and recall between proposed method and a keyword-based one. There are some studies that emphasize developing semantic-based search system, such as Hakia and SenseBot. However, these systems would not be adequate as the baseline system for comparing with proposed system because IWkS focuses on the lesson-learned knowledge at the enterprise level. Moreover, these studies, however, have not tested the learning performance of materials for knowledge reuse with those developed system.24,26
The performance of utilizing IWkS for knowledge reuse is evaluated. The results suggest that participants with IWkS integrated by a semantic search mechanism make better learning achievements than those with traditional keyword search mechanism in existing wiki systems. However, there are also some limitations. For example, Table 5 shows that the control group has a lower standard deviation than the experimental group, which indicates that the scores of the experimental group are a little more dispersed than those of the control group. This implies that a few participants may not make clear usage of the semantic search mechanism very well. User-friendly interface to realize the semantic search function should be designed.
In general, the IWkS makes accumulation and reuse of lesson-learned knowledge resources better among engineers in the shipbuilding enterprise, which could improve working efficiency and effectiveness of engineers for outfitting design. There are many advantages of utilizing IWkS:
By using IWkS, engineers could browse much more relevant and useful lesson-learned knowledge according to topics of their design tasks, which could accelerate the speed of problem-solving for engineers obviously.
IWkS provides a platform that makes it convenient for engineers to share their lesson-learned knowledge and reuse others’ knowledge. Engineers could contribute new empirical knowledge to the knowledge accumulation module. Other engineers’ browsing frequency and evaluation results of the lesson-learned knowledge can give a quantitative standard of an engineer’s “knowledge contribution,” which can be considered as an important aspect of engineers’ performance management.
However, there are preconditions for utilizing IWkS for knowledge reuse in an enterprise, which are listed as follows:
Several knowledge engineers are needed for maintenance support to handle with product design ontology management, lesson-learned knowledge resources enrichment, SRC maintenance, and so on, which make it possible for the semantic search.
It is necessary for top managers of an enterprise to fully support the implementation and utilization of IWkS. With the encouragement from officers of department of product design, engineers are willing to participate in lesson-learned knowledge accumulation and reuse process.
Conclusion
Through exploiting the functionalities in search mechanisms of existing wiki systems, this study presents a novel approach method to build an IWkS integrated with semantic search for lesson-learned knowledge reuse situated in product design, which covers knowledge search scenarios for engineers in an enterprise. The results of experiments show that our method of semantic-based search mechanism is effective, and the utilization of IWkS in lesson-learned items learning and reuse has positive effects on performance.
However, some research limitations for the proposed approach should be mentioned:
This study only focuses on inner-enterprise accumulation and reuse of lesson-learned knowledge, which is a little narrow in the scope of the whole industry. What is more, we address the issues of reusing lesson-learned knowledge only in the domain of product design, which makes the proposed approaches seem to be not so general. The research scope should be expanded to a more extensive range.
The definition of TSD may be a little simple. How to make the IWkS involves much more semantic reasoning capacities. It needs us to study the deep semantic relations among the topics in product design domain. Without richer semantic information to reflect professional concepts among lesson-learned items, the IWkS could not be more affective.
In future, our research group will try to make lesson-learned knowledge accumulation and reuse by the current IWkS to a much wider range, such as cooperation with other enterprises, and extend to other knowledge domains, such as production scheduling. At the same time, we will do some exploratory studies on semantic relations and get richer semantic information among professional concepts in product design domain. Then, more abundant semantic information could be utilized for semantic search, so as to make knowledge reuse much more accurate and effective.
Footnotes
Acknowledgements
The authors would like to thank all the participants for their efforts in our experiments and also thank the editors and reviewers for their useful comments.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research was supported by National Nature Science Foundation of China (Nos 70971085, 71271133), Shanghai Science and Technology commission (No. 13111104500), Shanghai Municipal Education Commission (13ZZ012), and the Doctoral Program of Higher Education of China (No. 20100073110035).