
Abstract
Computer vision–based inspection has been widely applied in automated quality inspection of lots of products. Extant research pays more attention to non-deformable parts, but little to deformable parts, such as hoses, which are popularly used in mechanical and electronic products to transport liquid because of advantages of deformability. Hence, a problem of automated inspection of hose assembly was defined and divided into four subproblems of online inspection, offline data analysis, improvement of inspection, and online quality control. Focusing on the first subproblem, a computer vision–based system was developed to deal with online inspection. Concerning the crucial unit of the system, objection recognition, features of hoses, and related fasteners were analyzed to present four propositions on shape and color constraints, and then a series of systematic techniques both in the spatial and spectral domains were put forward and discussed to perform image processing, object extraction, and feature recognition. Experiments show that average accuracies of object recognition and inspection are over 92% and even up to 100%, respectively, within an average running time of less than 30 s, which meets requirements of online inspection both on accuracy and efficiency. Since the system structure and corresponding methods are task-irrelevant, it can be generalized to figure out other inspection applications involving rotational parts.
Introduction
As an effective method of quality assurance, inspection performs an indispensable role. With the goal of reducing labor costs and ensuring consistent product quality, computer vision (CV)-based inspection is widely used and becoming more and more popular in automated quality inspection of mechanical and electronic products.
Almost all CV-based systems consist of image acquisition, processing, feature extraction, and defect identification. Mostly, image acquisition is regarded as a relatively independent unit employing techniques from the field of optics, so the latter ones are paid more attention to while designing a system and related algorithms. As a main application, a CV-based inspection system was used to identify surface defects such as scratches, cracks, and bubbles and measure cutting tool wear as well as welding quality, with machine learning enhancing its automation ability, which shows really good performance. 1 An objective fuzzy approach for CV-based inspection was applied in a Canadian automotive parts manufacture to identify the presence or absence of metal fastening clips on a structural member supporting a truck dash panel and shows strong robustness. 2 Solar wafers were effectively identified to their corresponding ingot with methods of wavelet decomposition and packets in the spectral domain as well as histogram matching of gradient angles in the spatial domain. 3 During large-volume fabrication and taping of light-emitting diode (LED), surface-mounted devices (SMDs), a CV-based inspection system was used to identify defects such as missing components, incorrect orientations, inverse polarity, mouse bites, missing gold wires, and surface stains with up to 95% accuracy. 4 Also, a CV-based approach could be used to measure electrode tip displacement during welding. 5 Even stents, which are wire–metal–mesh tube used for cardiovascular remedy and have hundreds of critical features with tight tolerances, can be well inspected by a CV-based system. 6 Besides, a scheme for an adaptable automated visual inspection system was designed to improve the adaptability to perform different inspection tasks without excessive retuning or retraining efforts. 7
Extant research mainly cares about non-deformable parts that have a fixed assembly shape, but little pays attention to deformable parts that could exist in different shapes, such as hoses, which are elastic and can be bended to arcs with a wide range of radians, hence usually applied to connect two irregularly arranged parts to transport liquid in mechanical and electronic products. Traditional CV-based extraction and identification methods for non-deformable parts are not applicable for hoses. Fortunately, shapes of blood vessels are very similar to hoses, then methods or ideas to cope with vessels may be employed to hoses.
In term of the shape, blood vessels could be treated as two perceptually parallel curves and recognized by means of parallelism detection, which was then formulated as a problem of line detection within an affine-invariant local similarity matrix. 8 However, it is complicated to model and not appropriate under some circumstances, such as there is not enough information about forces on objects. Retinal vessel recognition is a hot topic recently, whose segmentation algorithms were divided into seven categories: (1) pattern recognition techniques, (2) matched filtering, (3) vessel tracking/tracing, (4) mathematical morphology, (5) multiscale approaches, (6) model-based approaches, and (7) parallel/hardware-based approaches. 9 Two kinds of matched filtering methods based on the evaluation of phase symmetry information using complex logarithmic Gabor wavelets with no need of either eye-specific knowledge or supervised classification methods were evaluated and achieved an average accuracy of over 94%. 10 A direction-based, vascular-pattern extraction method was used to design a hand biometric authentication method together with hand geometry information, and the equal error rate was only 0.06%. 11
From the foregoing, image segmentation and object recognition are key techniques for vessel identification. Especially dealing with objects of interest affected by a group of transformations, geometric invariants-based object recognition play a crucial role. 12 The region-growing algorithm, which can identify regions by selecting seed points, is commonly used for image segmentation. A neural network–based adaptive region-growing algorithm, which transforms input images into a gray-level space and then adaptively segments the images by merging regions based on artificial neural networks, was developed and produced superior results than existing methods. 13 To design a fully autonomous CV-based system, an approach relying on salient object detection was proposed to extract salient objects, which can be efficiently used for training, so as to enable the system to learn autonomously individual objects present in real environment. 14 Another salient object detection method introduced a region-based solution, which extracts superpixels based on an adaptive mean shift algorithm to find perceptually and semantically meaningful salient regions as the basic elements for saliency detection, and then applied the achieved saliency map to better encode the image features for object recognition, which does not only improve saliency detection with large salient region and noise tolerance in messy background, but also generate saliency maps with a well-defined object shape. 15 Crowding, generally defined as the negative influence of nearby contours on visual discrimination, is a bottleneck of object recognition, and corresponding theories are categorized as optical, neuronal, computational, and attentional proposals. 16
Existing techniques provide a clue and basic ideas to develop an effective recognition method for hoses, but they cannot be applied directly, because several issues on special features of hoses must be noticed. First, unlike blood vessels, there are no well-known structures between hoses served as a reference. Second, there are no radial forces imposed on hoses in general. Third, relative positions between hoses may be quite different among different assemblies even for a same product. Finally, there are lots of possible bended shapes of a same hose due to different forces acting on both ends.
The facts above motivated us to define the problem of automated inspection of hoses assembly (AIoHA) and put forward a CV-based application, that is, the automated inspection system for hose assembly (AISHA) on the basis of a primitive prototype presented in Wen et al., 17 which validated the possibility of performing CV-based inspection on hose assembly, but was rough and imperfect on the structure, process, and corresponding methods.
The rest of this article is organized as follows. Section “System design” defines the AIoHA problem and sketches out an overall schema of AISHA. Typical features of objects of interest are analyzed, and four propositions about feature constraints are brought forth in section “Feature analysis of hoses and fasteners.” Key techniques of object recognition are developed and discussed in detail in section “Key techniques of object recognition.” Section “Application” validates the effectiveness and robustness of AISHA with several groups of experiments. Finally, conclusions appear in section “Conclusion.”
System design
The AIoHA problem is explicitly defined to declare a specific objective of the system first, and then, an overall schema is put forward including the framework, layout, and working process of AISHA.
Problem definition
Hoses, which are mainly used to transport liquid such as water and oil, are installed by fasteners at both ends in mechanical and electronic products. Hence, objects of interest in quality inspection of hose assembly refer to both hoses and related fasteners. There may be three types of typical defects: missing objects, wrong connections, and abnormal parameters. The defect of missing objects stands for that some hoses or fasteners are not installed; the defect of wrong connections means that some pairs of hoses and fasteners are not matched correctly; as well the defect of abnormal parameters denotes that diameters of some hoses or obliquities of some fasteners are not in accordance with the designed. Consequently, the AIoHA problem is defined to find out whether or not there are the above three types of defects in an instance of hose assembly and give feedbacks including necessary information with CV-based methods in order to ensure and improve quality.
The AIoHA problem can be further divided into four subproblems: online inspection, offline data analysis, improvement of inspection, and online quality control, as shown in Figure 1. The subproblem of online inspection is a real-time processing unit acting as a part of an assembly line and inspects whether or not there are defects; the subproblem of offline data analysis is a statistical analyzing process using online collected data to find out inherent rules about defects so as to promote accuracy and efficiency of inspection, even more make it possible to perform quality control; the subproblem of improvement of inspection is a self-reinforcement mechanism using results of data analysis to revise parameters of online inspection to obtain better performance; and the subproblem of online quality control is a further quality insurance approach using results of data analysis to work out some norms in order to guide assembly processes by optimal means.
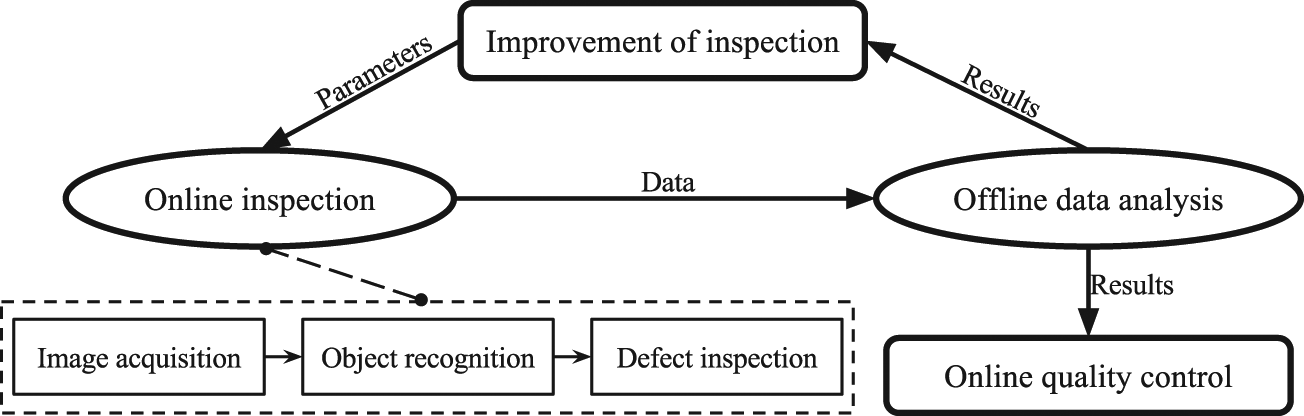
Modulars of AISHA.
Current AISHA focuses on the subproblem of online inspection, which is the basis of the other three. Subproblems of offline data analysis, improvement of inspection, and online quality control will be studied in future research serving as upgraded parts of the system. To perform CV-based inspection, images are first needed; then, objects of interest should be correctly recognized, and necessary corresponding characteristic parameters ought to be computed accurately; moreover, relationships between objects of interest and characteristic parameters are analyzed and compared to check specific types of defects. Hereby, online inspection consists of three main phases: image acquisition, object recognition, and defect inspection.
The mission of image acquisition is to capture images satisfying “requirements of inspection”; the mission of object recognition is to extract and recognize objects of interest from captured images and also compute necessary characteristic parameters; and the mission of defect inspection is to judge whether or not an instance of hose assembly expressed by current images are correct and give feedbacks in use of results of object recognition. The above “requirements of inspection” stands for unambiguous images with bright color, little noise, dominated by objects of interest, and including related other objects. The following four prerequisites are required to cripple interference of noises in complex industrial environments as much as possible so as to meet “requirements of inspection.” Meantime, it also embodies the idea to throw things that hardwares are good at to hardwares.
Prerequisites of AISHA
Keep stable lighting with shadowless illumination;
Keep relative positions between cameras and the assembly workbench fixed;
Keep axes of cameras perpendicular to a plane of objects of interest;
Keep hoses assembled at the last.
Condition (1) impairs specular and shaded effect to ensure the conformity of colors in images to the real; condition (2) makes sure relative coordinates are consistent, which is the basis of image comparing, template matching, multicamera data fusion, and transformation between image and global coordinates; condition (3) maintains similarities between real objects and related projection in images, which helps to simplify object recognition; and condition (4) makes it convenient to extract hoses.
In case of confusion, specialized concepts referred to frequently in this article are defined as follows, including standard image (STD-image), to-be-inspected image (TBI-image), related-component image, composite-component image, hose image, sub-image, dominant object, and dominant sub-image.
Definition 2.1
For a specific kind of assembly, an image representing an instance of hose assembly that has been inspected to be correct is called a STD-image, whereas an image representing an instance of hose assembly that needs to be inspected is called a TBI-image.
Definition 2.2
For a specific kind of assembly, an image representing a status that all components except hoses are installed is called a related-component image (R-image); an image representing a status that all components are installed is called a composite-component image (C-image); and an image representing a status that all related components are removed leaving only hoses is called a hose image (H-image).
Definition 2.3
An image extracted from an R-image or H-image with a rectangle parallel to image coordinates is called a sub-image of the original image. In a sub-image, an object with apparently much bigger area and longer contour than others is called the dominant object of the sub-image, and the sub-image is called the dominant sub-image of the object.
Overall schema
The framework of AISHA is composed of software and hardware systems, as shown in Figure 2. The software system serving the whole process of online inspection is designed as a four-layer structure including data, function, logic, and interface layers, with each layer containing several modules that connect to each other organically. The data layer deals with data access and maintenance; the function layer is responsible for executing basic functions; the logic layer is used to realize working processes; and the interface layer is in charge of human–computer interaction.
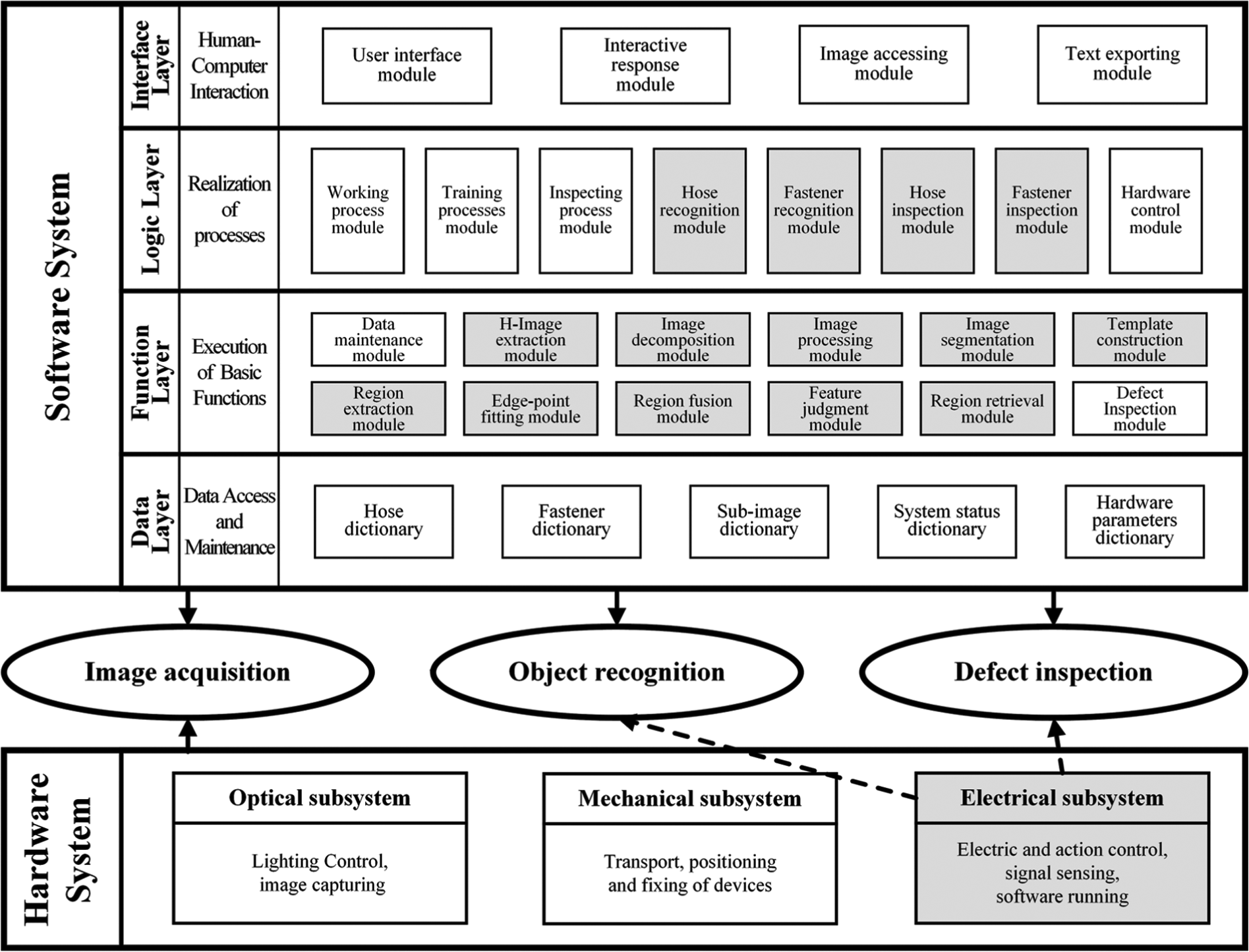
Framework of AISHA.
Correspondingly, the hardware system consists of optical, mechanical, and electrical subsystems, which mainly serves image acquisition with only the electrical subsystem also serving object recognition and defect inspection. The optical subsystem is in charge of lighting control and image capturing; the mechanical subsystem is responsible for transport, positioning, and fixing of devices; and the electrical subsystem copes with electric and action control, signal sensing, and software running.
Figure 3 gives a sketch map of the hardware system. A worker, who is in charge of hose assembly and inspection, operates AISHA running on a computer to send controlling signals to cameras at some proper time. Cameras surrounding the workbench, whose positions and angles are adjusted by movement devices in advance, receive signals to capture R-images and C-images, and transfer them back to the computer.
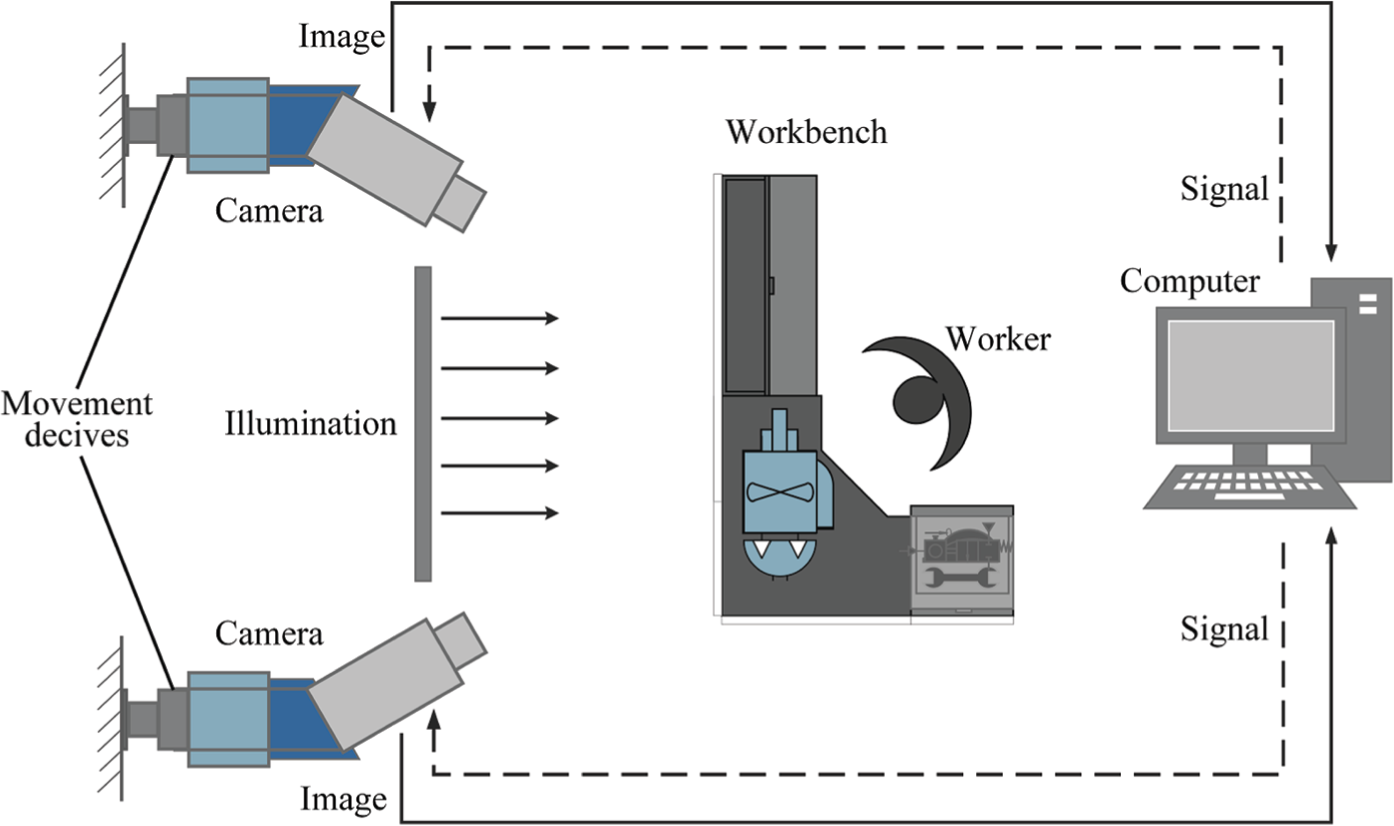
Sketch map of the hardware system.
Lots of types and models of mechanical and electronic products refer to hose assembly; hence, AISHA is designed to be a self-learning and self-reinforcement system so as to reduce human involvement and predetermination of parameters. As to each type or model of products, several times of human-aided training have to be performed first selecting the averages to construct a reference set of characteristic parameters, and then automated inspection can be run. Thereby, the whole working process of AISHA includes both training and inspecting processes, whose operations correspond to modules of the software system, as illustrated in Figure 4.
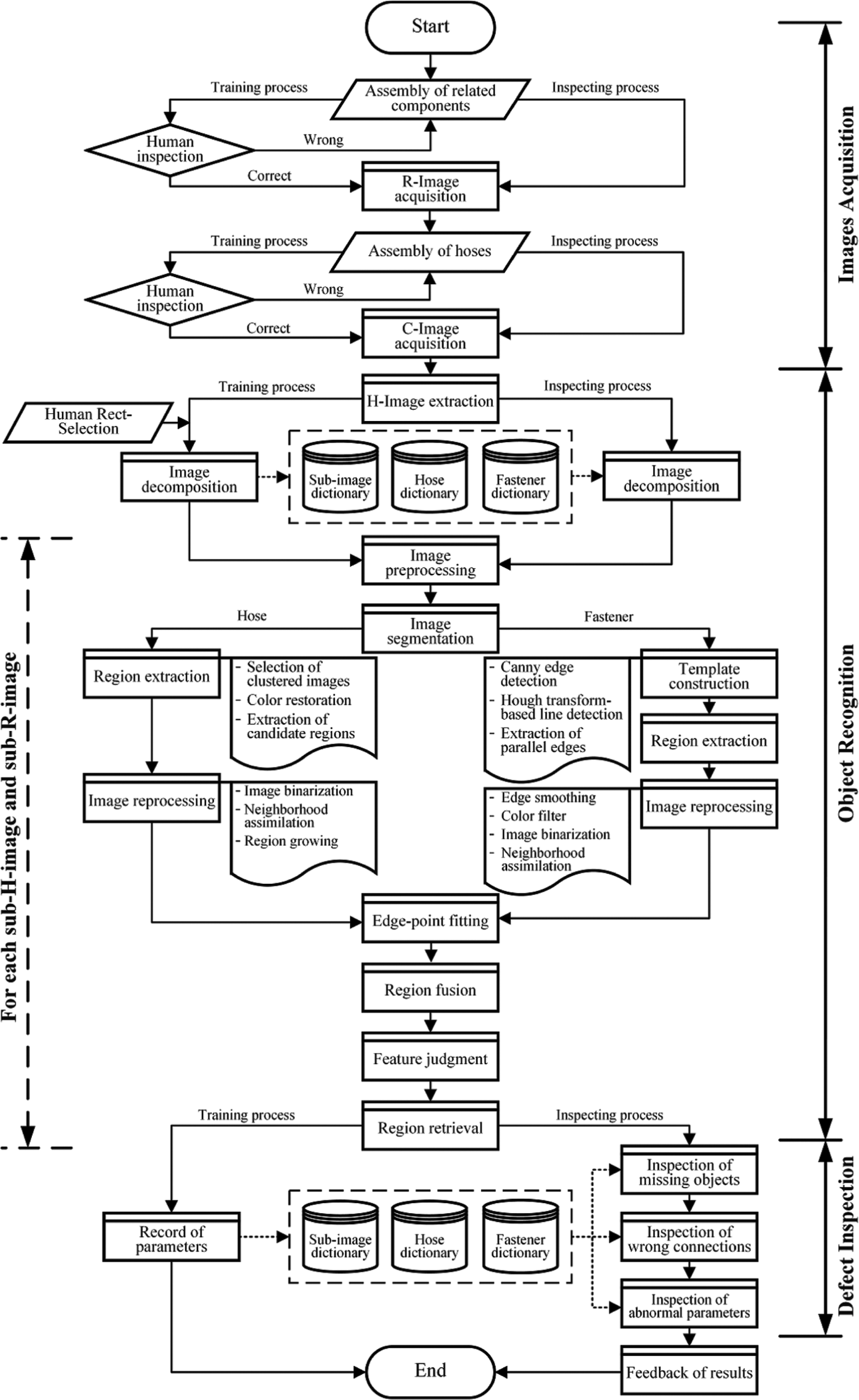
The whole working process of AISHA.
There are two kinds of major differences between training and inspecting processes. One is human involvement in the training process, including human inspection before R-image and C-image acquisition, respectively, as well as human rect-selection before image decomposition. The other is about characteristic parameters. During the training process, after operations of image decomposition and region retrieval, parameters are recorded to related dictionaries of a database. Whereas during the inspecting process, parameters are fetched from related dictionaries to be used as vertexes of sub-images or references of inspection. Certainly, captured images are STD-images and TBI-images in the training and inspecting processes, respectively.
As to three phases of the whole working process, image acquisition, which is a hot topic and paid much attention to,18–20 can be realized by kinds of classical or innovative approaches, and so was not taken as an emphasis in this article.
With regard to object recognition, an intuitive impression is first given by classifying operations in terms of operational purposes and ranges as shown in Table 1. In relation to operational purposes, operations can be classified into three groups of image processing (IP), object extraction (OE), and feature recognition (FR). Whereas operational ranges include whole images (WIs) and sub-images (extracted from a WI), where sub-images are further divided into regions (RN) and edges (ED). Signs of “⋆” and “•” denote the operations of hose and fastener recognition in the row belong to the corresponding group of the column, respectively. Object recognition plays a key role in the whole working process and will be focused on in the following two sections.
Analysis of object recognition-related operations according to operational purposes and ranges.

“⋆” and “•” denote the operations of hose and fastener recognition in the row belong to the corresponding group of the column, respectively.
IP: image processing; OE: object extraction; FR: feature recognition; WI: whole images; RN: regions; ED: edges.
Defect inspection extremely depends on results of object recognition. Once object recognition is achieved, three types of defects can be inspected by uncomplicated means. Table 2 gives some critical information regarding inspection of different kinds of defects. It is found that kinds of inspected indexes are all derived from recognition results, checked, or compared with corresponding data in dictionaries; also, no matter what kind of defects, defective, related, and/or current connected objects are involved; sub-image, hose, and fastener dictionaries are required to be a data source; a feedback of defects containing types of defects and involved objects together with corresponding positions will be reported if failing the inspection, and a feedback of no defects will be posted if passing.
Defect inspection-related information.
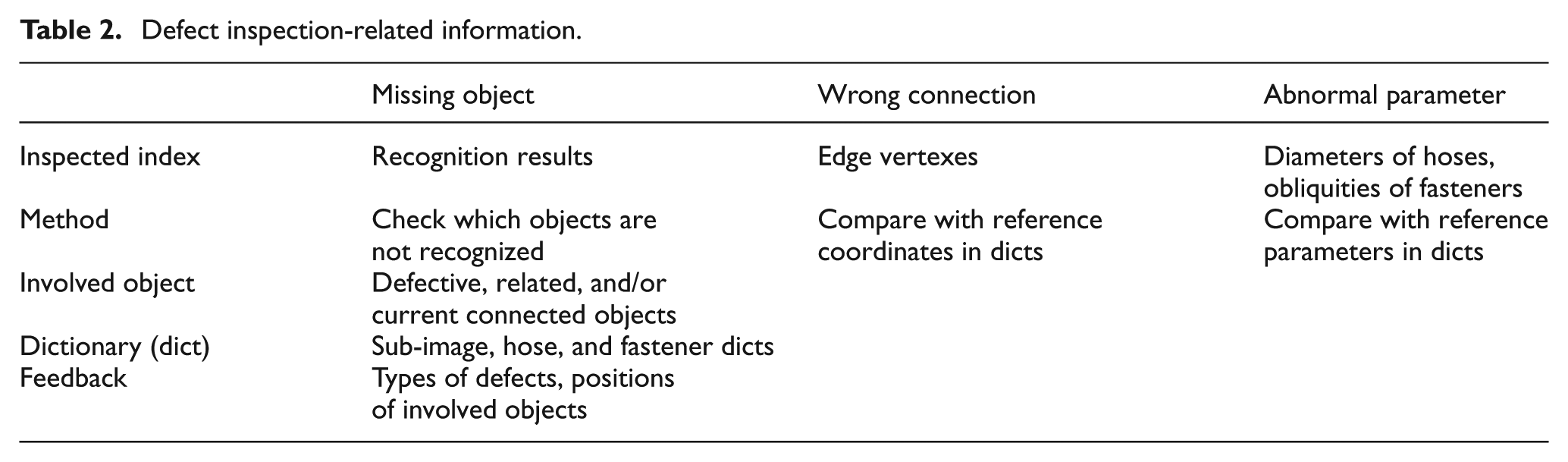
Specifically, in regard to identify missing object, recognition results are checked to see whether or not all hoses and fasteners are recognized; with reference to wrong connection, edge vertexes of each recognized objects are compared with corresponding records in sub-image, hose, and fastener dictionaries to check whether they are matched; as to abnormal parameter, diameters of hoses and obliquities of fasteners are compared with corresponding records in sub-image, hose, and fastener dictionaries to check whether they are matched.
Feature analysis of hoses and fasteners
Object recognition is the core module of AISHA and still a challenge for CV-based applications. As a preliminary work, features of hoses and fasteners are first explored. Figure 5 gives an example C-image of hose assembly, where rubber hoses and metal fasteners are objects of interest. Information that can be effectively acquired from the image includes shape, color, and position. Hereby, features of shape and color are studied as follows, because they are inherent features of objects that have some invariant rules and act as principal characteristics of object recognition.

An example C-image of hose assembly.
Analysis of shape features
Shape features of two-dimensional (2D) objects are mainly about relationships between edges. Hoses and fasteners are both rotational parts, with axial edges indicating major characteristics. Therefore, edges referred to in the following denote axial ones without special instructions.
Hoses bend when assembled due to transferred forces from fasteners at both ends, but diameters of all cross sections still keep the same because there are no radial forces. Free-state hoses can be directly abstracted as cylinders, then bended hoses can be regarded as a series of end-to-end micro-cylinders from the view of finite element analysis. That is, assembled hoses can be perceptually abstracted as variants of cylinders with curve axes, whose edges of 2D projections are two perceptually parallel curves, as illustrated in Figure 6.
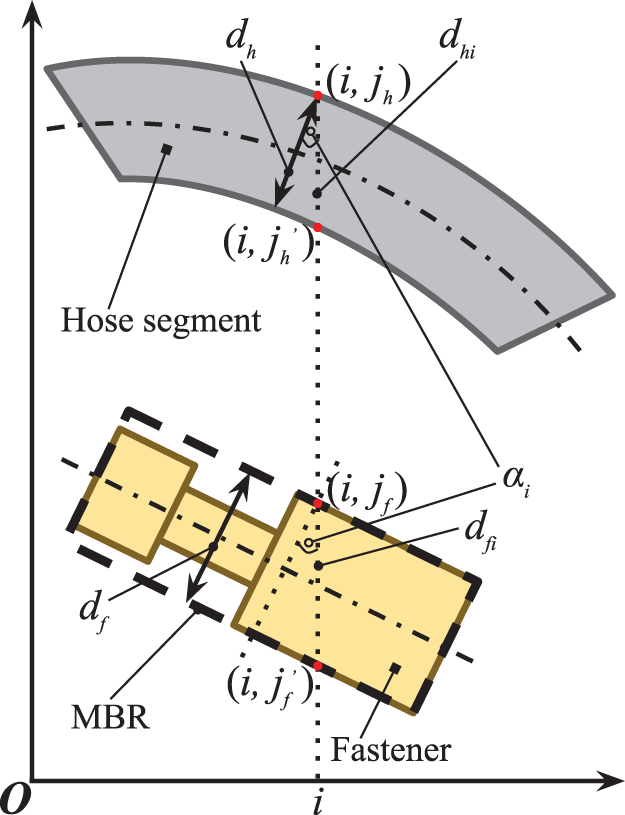
Shape constraint of edge-points.
Similarly, fasteners do not transform when assembled and can be abstracted as a series of end-to-end cylinders, whose edges of 2D projections are two piecewise parallel broken lines, also illustrated in Figure 6. To further analyze, edge-distance of points, hoses, and fasteners, as well as coordinate-distance, are defined as follows.
Definition 3.1
The minimum distance between a point on one edge and all points on the other edge is called the edge-distance at this point. The minimum of edge-distances at all edge-points of a hose is called the edge-distance of the hose, denoted by dh . The maximum of edge-distances at all edge-points of a fastener is called the edge-distance of the fastener, denoted by df .
Definition 3.2
An absolute difference value between different coordinates of two points with a same horizontal or vertical coordinate is called the coordinate-distance between these two points.
Denote dhi
and dfi
as coordinate-distances between points (i, jh
) and (i,
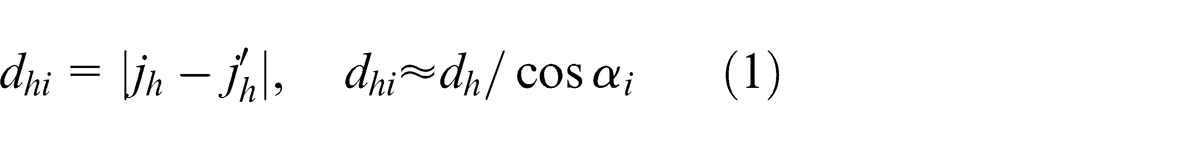
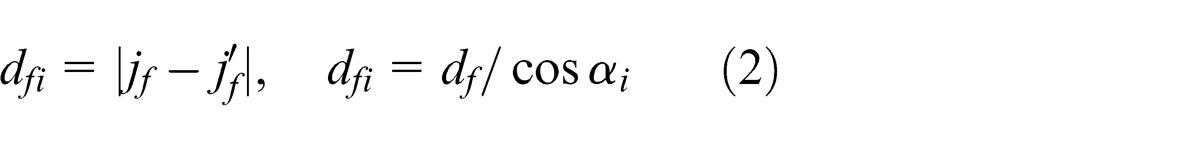
It is always feasible to exchange horizontal and vertical axes to make sure αi
∈ [0, π/4], so
Proposition 3.1. (Shape constraints of hoses)
In image coordinates, both edges of a hose are two perceptually parallel curves, and the minimum coordinate-distance between a point on one edge and its all corresponding points with a same horizontal or vertical coordinate on the other edge is on [dh
, δhdh
], where δh
is called the coordinate-distance coefficient of a hose, and
Proposition 3.2. (Shape constraints of fasteners)
In image coordinates, both edges of a fastener are two piecewise parallel broken lines, and the distance between both edges of its MBR is on [df
, δfdf
], where δf
is called the edge-distance coefficient of an MBR, and
Analysis of color features
Unlike shape features, color features depend on specific kinds of objects. Fortunately, rubber hoses and metal fasteners are widely applied under most circumstances. Hence, they are taken as example to analyze color features.
Colors of rubber hoses distribute around a body diagonal between (0, 0, 0) and (255, 255, 255) of the red, green, and blue (RGB) color cube, where values of R, G, and B change continuously, also differences between values of R, G, and B of a same color are not remarkable. With help of chromatographic analysis, color constraints of hoses are presented as follows.
Proposition 3.3. (Color constraints of hoses)
In RGB color space, colors of hoses obey
R, G, B ∈ [0, 150];
|R − G|, |G − B|, |B − R| ∈ [0, 30].
Different from rubber hoses, metal fasteners are very sensitive to illumination, so that colors spread widely in the range from light yellow to dark orange. It is difficult to find out an interval for values of R, G, and B, but there are comparative relationships between them, such as for a same color, R is always the biggest one, B is always the smallest, and the difference between R and G is always the smallest. Therefore, color constraints of fasteners are put forth as follows.
Proposition 3.4. (Color constraints of fasteners)
In RGB color space, colors of fasteners obey
R > G > B;
|R − G| < |G − B|, |R − G| < |R − B|.
Recognizable objects
Even though features of hoses and fasteners are explored, also the whole working process together with a system of approaches are designed by introducing kinds of classical or innovative methods, not all objects of interest can be recognized under any circumstances. According to the definition of the AIoHA problem and the above feature analysis, objects of interest that can be recognized are defined as “recognizable objects” as follows. Without special instructions, objects of interest referred to in the rest are all recognizable objects.
Definition 3.3
Objects of interest should meet the following constraints:
Have dominant sub-images with all critical shape-transformed regions visible;
Can be abstracted as end-to-end cylinders;
Have different color features from other objects and are called recognizable objects.
Key techniques of object recognition
In use of shape and color constraints of hoses and fasteners presented above, key techniques and corresponding algorithms of object recognition are developed and discussed in terms of three types of operational purposes.
IP
Four operations including H-image extraction, image decomposition, image preprocessing, and image reprocessing belong to IP. The former two act on a WI, whereas the latter two operate on regions of a sub-image.
H-image extraction aims at reducing influence from other objects on hose recognition. A classical elimination–subtraction method, which compares an R-image with its corresponding C-image pixel by pixel and directly assign pixels whose color difference between two images is smaller than a predefined threshold (generally 50) to while, is applied to obtain an H-image. Take Figure 5 as a C-image; thus, the resulting H-image is shown in Figure 7.

The corresponding H-image of Figure 5.
Image decomposition divides a whole H-image or R-image into a series of dominant sub-images of objects of interest, each of which contains an unique dominant object completely with minimum other parts, so as to suppress mutual interference between objects. Considering requirements of automation and feasibility, it is designed to be very different to decompose images between training and inspecting processes. Training processes are run offline, so human aid is involved to draw rectangles parallel to image coordinates to select objects of interest one by one so that every rectangle contains an unique dominant object. Thus, regions in rectangles are expected sub-images. Information about rectangles, such as coordinates of left-top and right-bottom points, is recorded to a sub-image dictionary and then used during an inspecting process to decompose images automatically.
Almost all images captured in industrial environments are subject to various noises resulting from uneven illumination, dirt, complex background, and so on; therefore, image preprocessing is required to reduce noises and enhance regions of interest (ROIs). In the spatial domain, linear or nonlinear smoothing and sharpening filtering are usually used for noise reduction and enhancement of ROIs, respectively; whereas in the spectral domain, low-pass and high-pass filtering are usually used for noise reduction and enhancement of ROIs, respectively. Hereby, Gaussian filtering (spatial domain) and Butterworth high-pass filtering (spectral domain) are applied with built-in functions of the Intel Open Computer Vision Library (OpenCV) to reduce Gaussian noise and enhance ROIs, respectively.
All of the above three operations are before OE, only image reprocessing is mixed with OE, just after region extraction in order to discriminate regions of an object from its background even explicitly. Due to the difference of region extraction between hoses and fasteners, their image reprocessing methods are also developed, respectively.
With regard to hoses, image reprocessing consists of three steps: image binarization, neighborhood assimilation, and region growing. Image binarization converts an image into a binary one, with the black denoting candidate object-regions and the white denoting a background, by comparing pixel by pixel with a threshold predefined according to color constraints of hoses.
Neighborhood assimilation is based on the idea that a central pixel should have a same color with the majority of its neighborhood. Denote
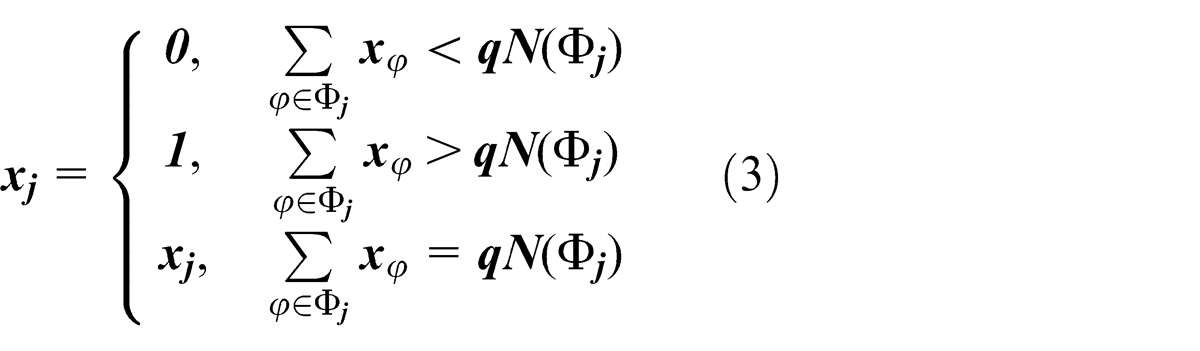
Region growing initially selects a seed point randomly from a candidate object-region with the largest contour and then performs seeded region growing, which compares colors between the seed and four pixel neighbors, labels a pixel with the same color as “congener,” treats congeners as new seeds and iterates the process. After region growing, all congeners form a new unique connected candidate object-region.
Candidate regions of fasteners are obtained from matching results of image segmentation with a template (refer to section “OE” for details), whose image reprocessing adds two operations of edge smoothing and color filter, but omits region growing compared with hoses. A neighbor average filtering method was designed to smooth all edges, which uses an average of pixel neighbors with similar colors to update the color of a central pixel. Denote Ω j as a “congener neighborhood” of j, if the color difference between φ ∈ Φ j and j is smaller than a predefined threshold related to color constraints of fasteners, then φ ∈ Ω j , and the updated equation of the color of j is

where N(Ω j ) is the number of pixels in Ω j .
Accomplished edge smoothing, color filter is called to scan color of pixels within candidate object-regions in accordance with color constraints of fasteners to reject unqualified pixels. Then, image binarization and neighborhood assimilation act similarly to that of hoses to produce a new unique connected candidate object-region.
OE
OE contains five operations: image segmentation, region extraction, template construction, edge-point fitting, and region fusion, where the former two are regional operations, the middle two operate on edges, whereas the last one acts both on edges and regions.
Image segmentation, whose operands are sub-H-images and sub-R-images, is a key step determining the accuracy of object recognition. A hybrid fuzzy method of spatial credibilistic clustering and particle swarm optimization21,22 is employed to distinguish and segment different regions of an image with the assistance of color and position information. H-images extracted from C-images have simpler backgrounds than R-images, so segmentation for hoses and fasteners employs the same method, but assigns different initial parameters, such as number of clusters. Less clusters are initially assigned for hoses than fasteners so as to develop different methods to extract candidate hose-regions and fastener-regions, respectively.
Region extraction for hoses consists of selection of clusters, color retrieval, and extraction. First, clusters in accordance with color constraints of hoses are selected and merged to one candidate cluster; second, pixels in the candidate cluster are retrieved to original colors in the corresponding H-image; finally, the color-retrieved candidate cluster is checked pixel by pixel to reject pixels whose color are no longer subject to color constraints of hoses, leaving pixels forming a candidate hose-region.
As to fasteners, which are usually over-segmented to a series of unconnected clusters because of complex backgrounds and specular reflection, a template is constructed first to assist region extraction with two classical methods, Canny edge detection (CED) and Hough transform (HT), embodied in OpenCV. CED uses a multistage algorithm to detect a wide range of edges, resulting in a binary image containing white edge-points and a black background. HT finds imperfect instances of objects within a certain class of shapes by a voting procedure, which is used to detect lines from a result image of CED in our application and outputs a series of straight lines. Then, a template, which could be also regarded as the MER with the same obliquity of an expected fastener, is formed by connecting both ends of two straight lines, respectively, both of which satisfy shape constraints of fasteners and
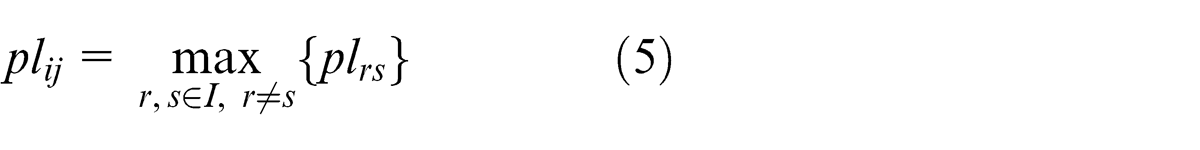
with
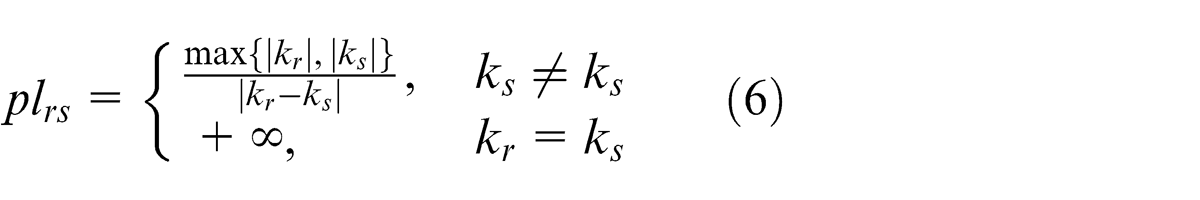
where plij is a degree of parallelism between straight lines Li and Lj , i≠j and i, j ∈ I = 1, 2, ..., and kr and ks are slopes of straight lines Lr and Ls , respectively.
Consequently, fastener-regions can be extracted by matching segmentation results with a template, which computes a proportion of public pixels both in the template and each segmented cluster to a total number of pixels in each cluster, adding clusters whose proportions are larger than a predefined threshold into a candidate fastener-region. Denote Ri , i = 1, 2, ..., c as c segmented clusters, Ni as the number of pixels in Ri , ni as the number of public pixels between Ri and a template, F as a candidate fastener-region, then

where rT ∈ [0,1] is a predefined threshold reflecting the strictness of template matching. The larger the rT is, the stronger it is to eliminate noise pixels. Of course, rT should not be assigned too large to accept expected pixels, generally rT = 0.8.
According to shape constraints of hoses and fasteners, edges of hoses and fasteners are perceptually parallel curves and piecewise parallel broken lines, respectively. Therefore, a similar process for edge-point fitting is developed with the following median error method.
Median error method
Extract edge-points from an image reprocessing result using CED.
Divide edge-points into two groups:
For hoses: scan edge-points in horizontal and vertical directions, classify edge-points with a same horizontal (vertical) coordinate into two groups according to different coordinates, and then select the one having more number of edge-points from the above two cases.
For fasteners, classify edge-points into two groups with the central axis of a template rectangle and divide each group into three segments according to diameters;
Compute edge-distances at all edge-points and a related median, then remove points where differences between edge-distances and the median are larger than a predefined threshold (generally 25%).
Fit edge-points of hoses and fasteners with cubic splines and piecewise straight lines, respectively.
Compute a quadratic sum of residuals (QSR) for each group of edge-points and compare with a predefined threshold, if a QSR of any group is larger than the threshold, then report the extracted region is not an object-region and exit.
The QSR in the above process is
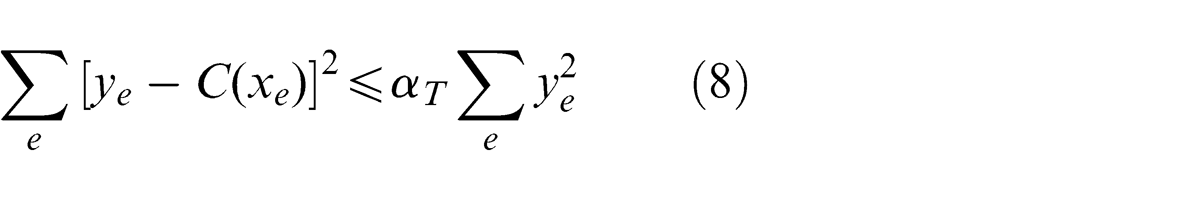
where (xe , ye ) is an edge-point, y = C(x) is a fitting curve, and αT is the coefficient of a QSR threshold, generally αT = 1%.
The method to group edge-points of fasteners is designed as follows. Denote E 1: y = C 1(x) = kx + b 1 and E 2: y = C 2(x) = kx + b 2 as equations of axial edges of a template, then the equation of central axis of the template is y = kx + (b 1 + b 2)/2, and an edge-point
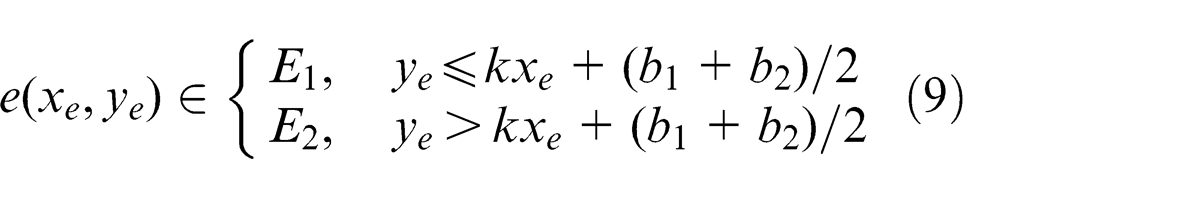
For e(e > 1) on each edge, if
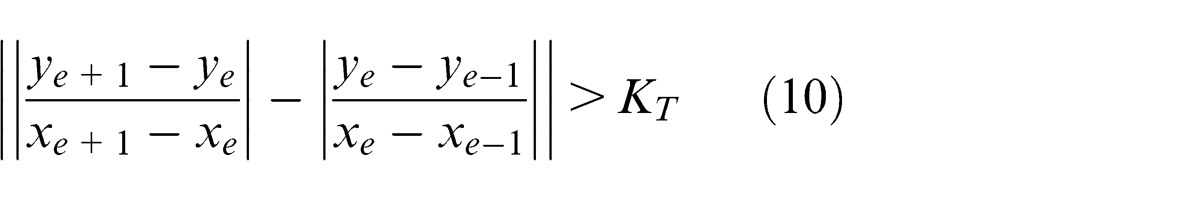
then, group edge-points at e, where KT
is a slope-varying threshold,
After edge-point fitting, region fusion is applied to refine an object-region by extending fitting curves to form a stripe region and judging whether regions removed during region extraction and image reprocessing can be merged in with the following method.
Region fusion method
Extend a candidate object-region with a fitting curve to edges of current image to construct a stripe generalized candidate object-region (GCOR);
Compute superposition rates between the GCOR and regions removed during region extraction and image reprocessing;
Merge regions with larger superposition rates than a predefined threshold (generally 90%) along with intermediate regions to form a new region and fit edge-points, if fitting curves satisfy shape constraints, then select the new region as a candidate object-region; otherwise, extract a candidate object-region from the merged region.
FR
Feature judgment and region retrieval belong to FR, operating on edges and regions, respectively. Feature judgment judges whether an extracted object-region is an expected one in use of shape constraints as follows.
Feature judgment method
Extract two groups of edge-points of a candidate object-region after region fusion, and check numbers, respectively, if the number of each group of edge-points is less than a predefined threshold related to the image resolution (generally 0.6max{n 1, n 2} with an image resolution of n 1 × n 2), report the extracted object-region is not an expected one and exit;
Compute the coefficient of standard deviation of edge-distances at all points, if it is smaller than a predefined threshold (generally 25%), then the extracted candidate object-region is an expected one.
Region retrieval is to redraw a recognized object-region according to edge-point fitting results in order to compute characteristic parameters and inspect defects. Denote A(xa , ya ), B(xb , yb ), C(xc , yc ), and D(xd , yd ) as end-points of two edges of an object, and
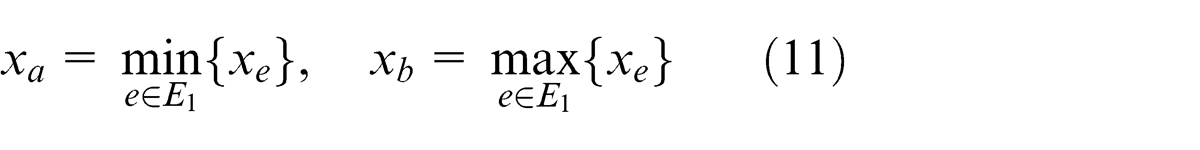
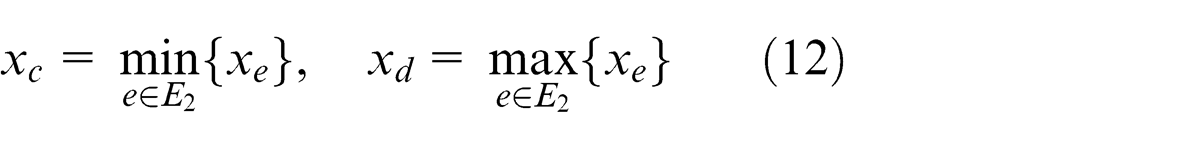
then equations of lines AC and BD are
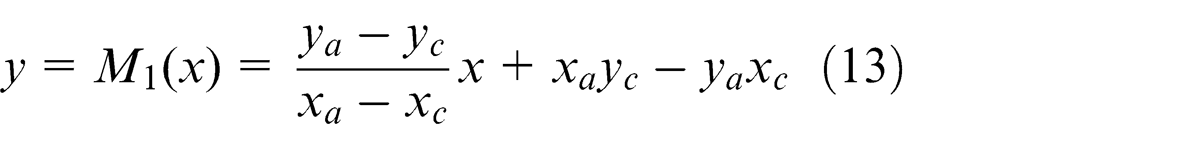
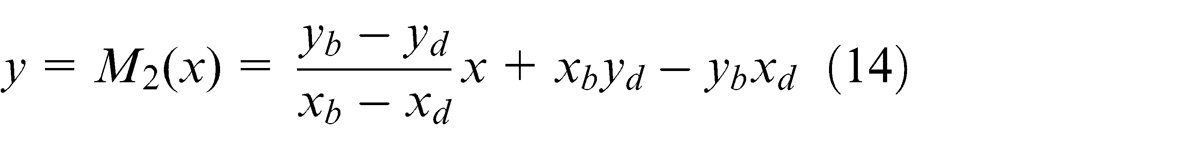
respectively. If a pixel (xi , yi ) meets
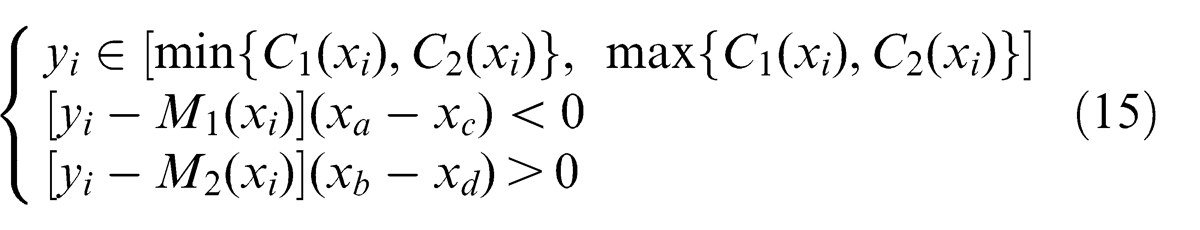
then it is an object point and colored black; otherwise, it is a background point and colored white. Likewise, all pixels in a sub-image are scanned and colored to retrieve an object-region.
Note that characteristic parameters of hoses and fasteners are diameters measured by the edge-distance of the hose and obliquities denoted by the slope of axial edges of its template, respectively.
Application
AISHA was developed based on the overall schema illustrated in Figures 2–4. The hardware system was realized through cooperation with an engine manufacture, including core devices of two industrial digital cameras (Ricoh 500G: 8 million pixels, 1/1.8″ charge-coupled device (CCD), 28 mm wide-angle), and a workstation (Intel Xeon E5-1620 Duo Processor 3.60 GHz, 16 GB memory). The software platform is developed on the platform of Windows 7 Professional with Microsoft Visual Studio C++ 2013 and OpenCV.
Software platform
A user interface of AISHA is shown in Figure 8. The left view is a STD-C-image, where recognized objects are encircled with red and blue contours. And the right view contains a set of TBI-C-images, where three errors of missing objects (i.e. two fasteners and one hose) are inspected in current image, with corresponding regions marked with red rectangles.
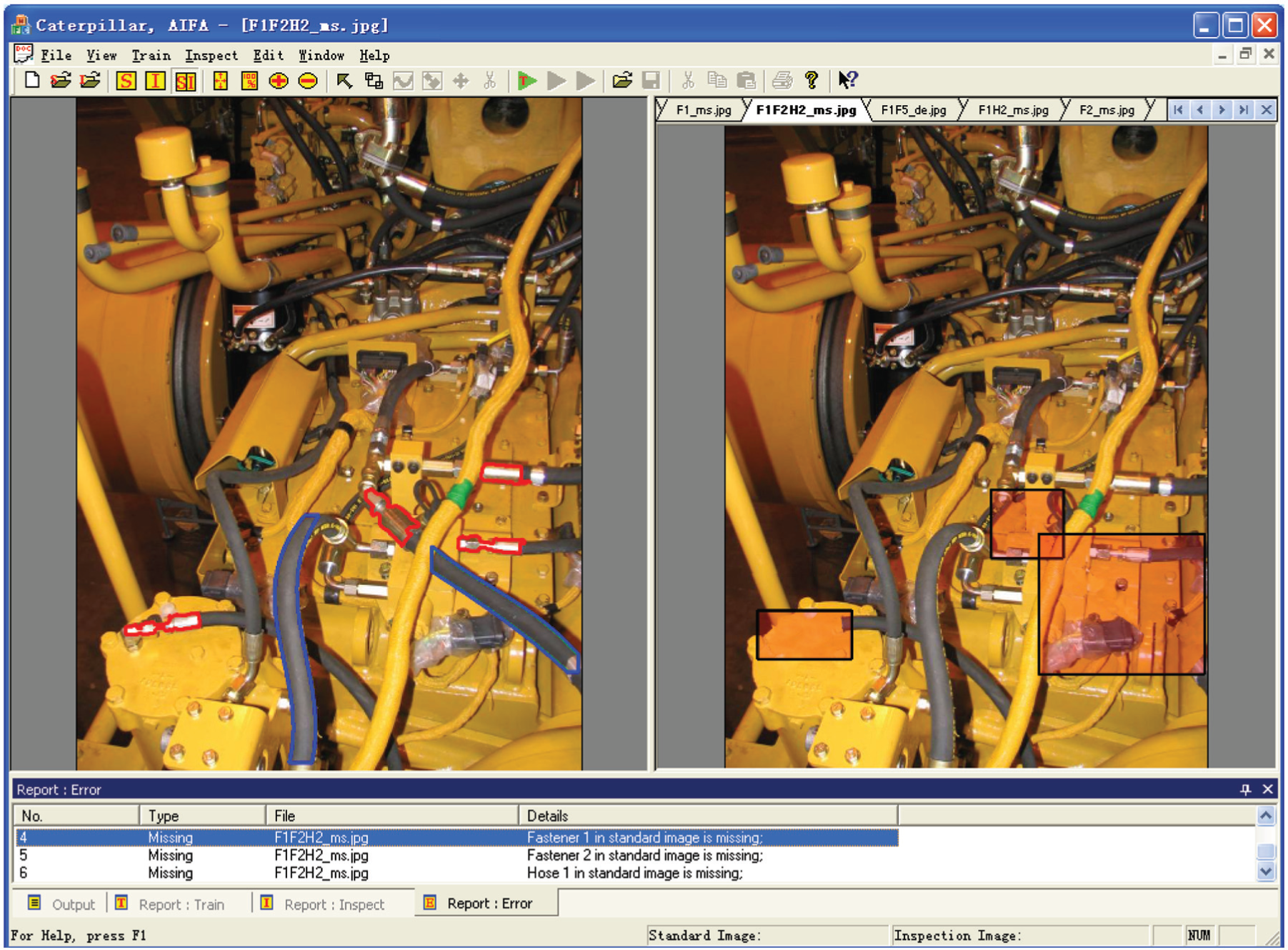
User interface of AISHA platform.
The dock-page bar at the bottom contains four tabs: “Output,”“Report: Train,”“Report: Inspect,” and “Report: Error.” The first one shows some context-sensitive prompts of help and notice, whereas the latter three show detailed information such as a list of inspected objects with corresponding parameters about training and inspecting processes, as well as an error list with error-types and involved objects, respectively.
Experiments and discussion
A total of 10 hoses and 2 fasteners are taken as examples from Figure 5 to validate the performance. Numbers of clusters during image segmentation are assigned to 5 and 20 for hoses and fasteners, respectively, whereas other parameters are assigned as recommended ones in section “Key techniques of object recognition.” Recognition results of hoses and fasteners together with corresponding intuitive drawings depicted with pixel-by-pixel human identification of object-points are shown in Figures 9 and 10.

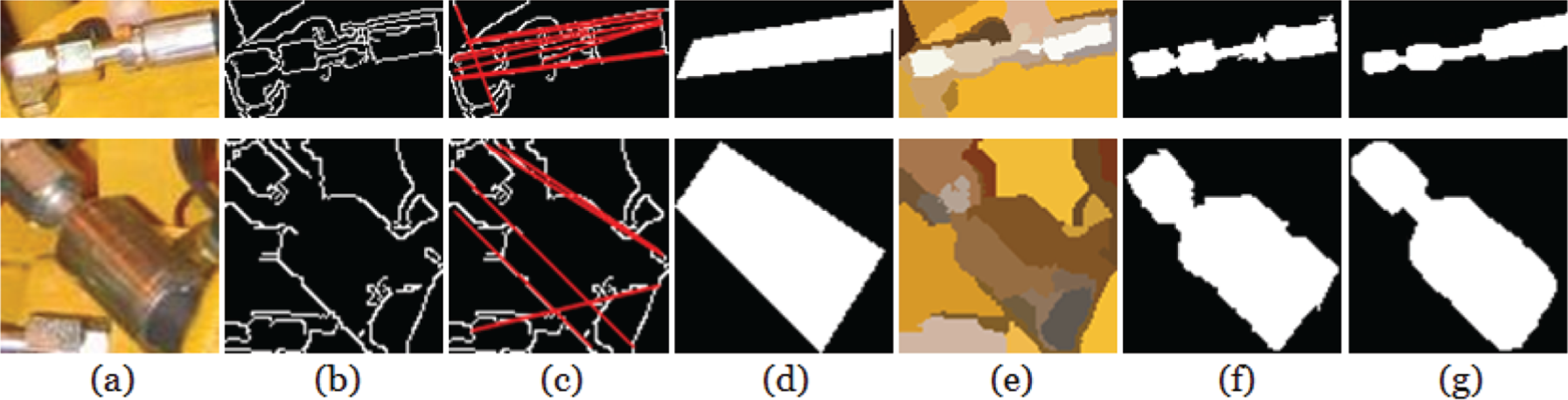
Step-by-step recognition results of example hoses. Columns (a)–(g) are related results of image preprocessing, image segmentation, region extraction, image reprocessing, edge-point fitting, region retrieval, and intuitive drawing, respectively.
Step-by-step recognition results of example fasteners. Columns (a)–(g) are related results of image preprocessing, Canny edge detection, Hough transform, template construction, image segmentation, region retrieval, and intuitive drawing, respectively.
In Figure 9, columns (a)–(g) are related results of image preprocessing, image segmentation, region extraction, image reprocessing, edge-point fitting, region retrieval, and intuitive drawing, respectively. By comparing columns (a) and (b), it shows that major backgrounds are separated from hoses through image segmentation. By comparing columns (b) and (c), it is found that lots of noises are removed due to imposing color constraints of hoses during region extraction, leaving mainly regions of other overlapped hoses. By comparing columns (c) and (d), image reprocessing highlights dominant hoses of sub-images and remove unconnected candidate object-regions, especially evident in images of Rows 4 and 5, which expresses the importance of neighborhood assimilation and region growing with position information. By comparing columns (d) and (e), it depicts that edge-point fitting eliminates overlapped hoses, especially evident in images of Row 3, in use of shape constraints of hoses. By comparing columns (f) and (g), retrieved hoses are highly consistent with human-identified ones, which explicitly validates the effectiveness of AISHA and corresponding methods.
In Figure 10, columns (a)–(g) are related results of image preprocessing, CED, HT, template construction, image segmentation, region retrieval, and intuitive drawing, respectively. By comparing columns (c) and (d), it is found that template construction selects parallel straight lines by means of shape constraints of fasteners. By comparing columns (d) and (e) with (a), it obviously shows the under-segmentation of template construction and the over-segmentation of image segmentation. A template contains regions that do not belong to a fastener, but segmentation divides regions of a fastener into several different clusters, which calls for region fusion. By comparing columns (d)–(f), it shows that color constraints of fasteners together with position information helps to refine fastener-regions. By comparing columns (f)–(g), retrieved fasteners are highly consistent with human-identified ones, which also explicitly validates the effectiveness of AISHA and corresponding methods.
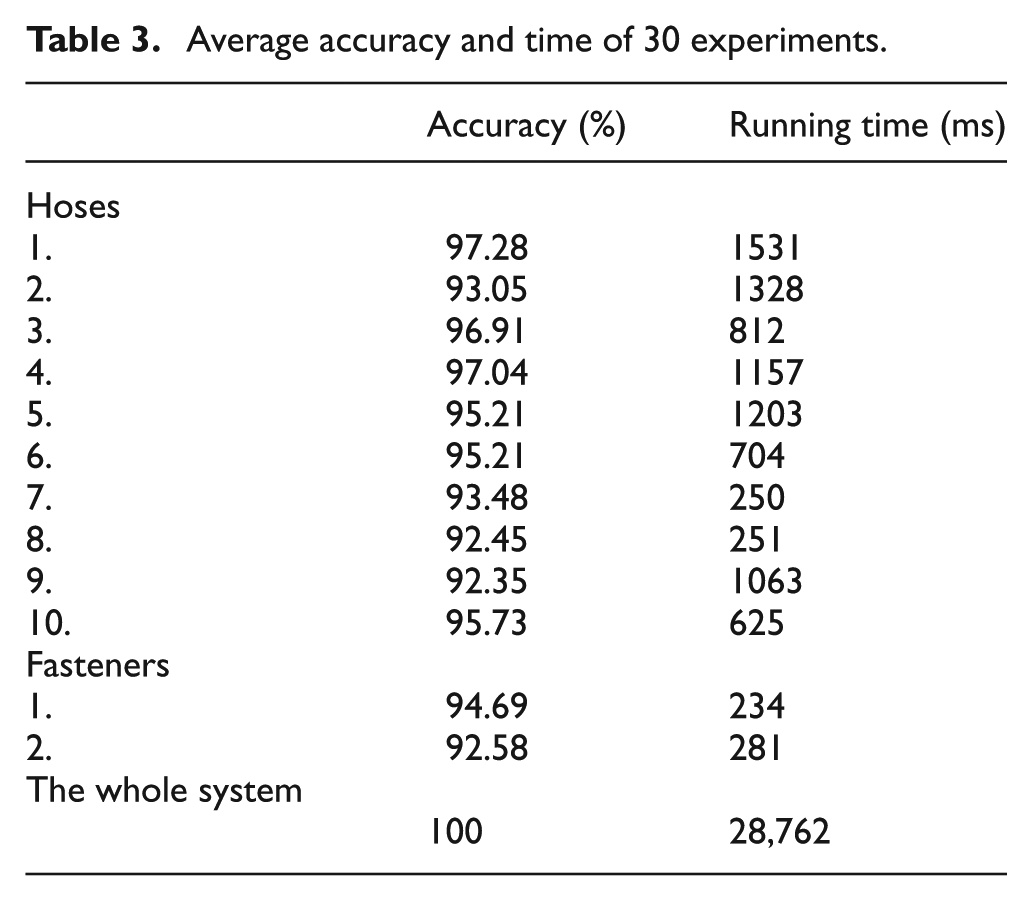
A total of 30 experiments were run on selected hoses and fasteners to quantitatively test the system performance, with main evaluation indexes and parameters shown in Tables 3 and 4. Accuracies are important evaluation indexes, which are defined for object recognition and system as follows.
Average accuracy and time of 30 experiments.
Averages of hose-parameters of 30 experiments.
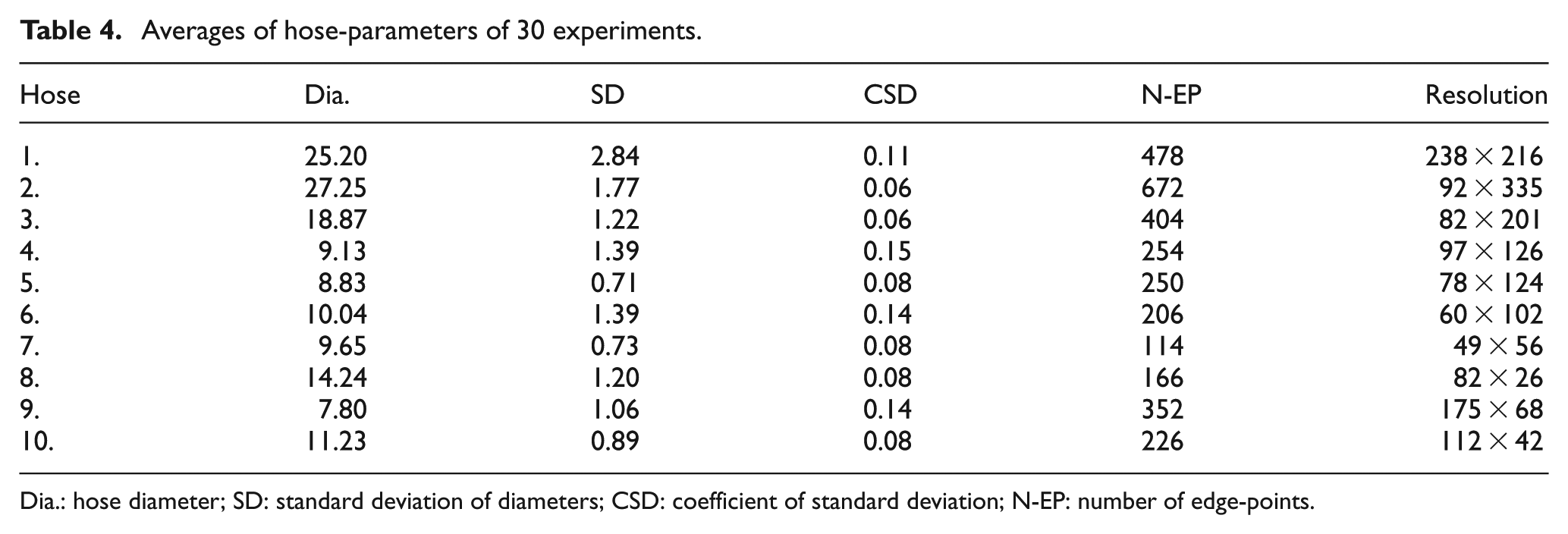
Dia.: hose diameter; SD: standard deviation of diameters; CSD: coefficient of standard deviation; N-EP: number of edge-points.
Definition 5.1
The proportion of public pixels between a retrieved object-region and corresponding human-identified one to a total number of pixels in the human-identified one is called the accuracy of object recognition on current image; and the proportion of times correctly recognizing objects and inspecting defects to a total number of experiments is called the accuracy of the system.
It follows Table 3 that average accuracies of all selected hoses and fasteners are over 92%, and an average accuracy and running time of AISHA are up to 100% and less than 30 s, respectively, which can fully meet requirements on accuracy and efficiency of online automated inspection.
Main parameters of hose recognition involved in Table 4 are diameter (Dia.), standard deviation of diameters (SD), coefficient of standard deviation of diameters (CSD), number of edge-points (N-EP), and image resolution. It is found that CSDs are all really small, meaning that diameters computed in 30 experiments vary quite little, that is, parameters computed within the system are accurate and robust.
Conclusions
CV-based inspection is becoming more and more popular during the production of mechanical and electronic products, quite a few of which apply hoses to transport liquid because they are deformable and easy to connect irregularly arranged ends. However, current research mostly focus on products with non-deformable parts having a fixed assembly form, little cares about deformable parts like hoses. Therefore, a problem of automated quality inspection of assembly with hoses, AIoHA, was first defined explicitly with two kinds of objects of interest, hoses and fasteners, as well as three types of defects—missing objects, wrong connections, and abnormal parameters—and divided into four subproblems: online inspection, offline data analysis, improvement of inspection, and online quality control.
The first subproblem was focused on in this article and composed of three phases including image acquisition, object recognition, and defect inspection. An overall schema, including a system framework, a sketch map of main hardwares, and a working process, was put forward based on four prerequisites to develop a CV-based system, AISHA, so as to deal with online inspection of the AIoHA problem.
Object recognition is the core of AISHA. Related shape and color features of hoses and fasteners were analyzed first, resulting in four propositions on shape and color constraints of hoses and fasteners, respectively, based on which, recognizable objects were also defined. Then key techniques of object recognition were presented and discussed in detail, in terms of three different types of operational purpose: IP, OE, and FR. A series of integrated approaches, such as image reprocessing method, region extraction method, median error method, region fusion method, and feature judgment method, were developed for both hoses and fasteners to achieve the whole process of object recognition.
Experiments show that recognized objects are quite consistent with human perceptual ones, the average accuracy of object recognition is over 92% and even up to 100% for the whole system. Also, the average running time of the whole system is less than 30 s, with accurately and robustly computed characteristic parameters. It is validated that AISHA can meet requirements of online inspection both on levels of accuracy and efficiency.
Since the system structure and corresponding methods are task-irrelevant, AISHA can be generalized to apply in other inspection applications concerning rotational parts. However, two issues must be paid attention to. First, techniques to deal with hoses and fasteners at some steps of the whole working process are different. Hoses and fasteners can be regarded as representatives of deformable and non-deformable parts, respectively. One should pick up proper methods according to the deformability of related parts. Second, basic rules of shape and color constraints of rotational objects, as well as kinds of techniques within the whole working process, remain unchanged, but related parameters probably need to be reassigned.
Current system imposes three conditions on objects to be inspected by defining recognizable objects, which should be reduced till eliminated through further research. Furthermore, only the first of four subproblems of the AIoHA problem is figured out in this article, the other three still need to be studied to make full use of the potential of CV-based inspection and improve AISHA, which is also an emphasis of further research.
Footnotes
Declaration of conflicting interests
The authors declare that there is no conflict of interest.
Funding
This work was supported in part by the Fundamental Research Funds for the Central Universities (no. CDJZR11 11 00 01) and partly sponsored by Caterpillar Inc., USA.