
Abstract
This article presents a study on the clustering and selection of knowledge meshes in the knowledgeable manufacturing system that transforms all types of advanced manufacturing modes into corresponding knowledge meshes and selects the best combination of knowledge meshes to satisfy enterprise requirements. The appropriate knowledge mesh for enterprises not only includes the matching of knowledge mesh function but also that of performance perfection and structure. Thus, the similarity degree of knowledge meshes, whose properties are proved to relate to the operations of knowledge meshes, is constructed from the functional matching, the perfection degree and the layer number of lowest-layer knowledge point. The similarity values, taken as cluster data, are used to construct the fuzzy relational matrix to compress the high-dimensional feature space. The decomposition of the matrix is transformed into an optimization problem solved by the gradient method. The knowledge meshes with higher membership degree in each class are taken as reference knowledge meshes to identify user’s requirements exactly. The comparison of target knowledge mesh with reference knowledge meshes definitely narrows down the knowledge mesh selection to a certain type. Based on the above, the knowledge mesh clustering and selection method is exemplified. The results show that the proposed method works well in narrowing the search range and clarifying user requirements.
Keywords
Introduction
With the development of advanced manufacturing technologies, various advanced manufacturing modes have emerged. They are predicated on certain requirements of enterprises, so each one has its advantage. Because of the diversity of user requirements, these modes are basically independent with their own limitations. It is likely that some enterprises may adopt only one type of advanced manufacturing mode while others may employ a combination of several. In fact, an advanced manufacturing mode can be taken as a kind of advanced manufacturing knowledge. If all types of complementary advanced manufacturing modes are transformed into their corresponding advanced manufacturing knowledge in the advanced manufacturing system, the enterprise can be allowed to select the most appropriate combination of advanced manufacturing modes or the best mode for operation. Therefore, the concept of knowledgeable manufacturing system (KMS) was proposed in 2000 1 and has been paid more and more attention to since then.2–4
In KMS, all types of advanced manufacturing modes are transformed into corresponding knowledge meshes (KMs) and stored in the KM base of KMS. 5 New KMs are obtained by the operations of KM multiple set.6,7 Once a KM multiple set operation expression is obtained, a new KM can be inferred from the expression by the developed KM-based inference engine and transformed into its corresponding software of KMS automatically by the developed automatic program construction software. Then the enterprises can choose the most appropriate combination of the modes or the best when necessary. Related studies have been conducted on the concepts, systematic structure and primary characters of KMS. 1 A KM-based knowledge representation method for advanced manufacturing modes and a new approach to self-reconfiguration of KMS were proposed by Yan. 5 A topological structure and simplification of KM were discussed by Yang and Yan. 8 The automatic construction and optimization of the KM based on the user’s function requirements were studied by Yan and Xue.7,9 The fuzzy classification and searching for KM based on information granular were further explored by Yang and Yan. 10 But the selection method of single KM in the optimization of KM multiple set operation expression has not yet been explored. 7 And the fuzzy classification and searching method for KM was used for the high-level users who can describe their specific needs clearly. 10 However, there are many various KMs and reconfigured KMs in the KM base. These KMs have both advantages and disadvantages, and certain parts overlap each other. The similar KMs complicate the selecting of KM. Thus, selecting KM from KM base for all users is the problem to be solved in this article.
Various methods have been proposed for the reference model. Hwang et al. 11 proposed a neutral reference model that consists of a neutral skeleton model and an external reference model. It can effectively share and propagate engineering change information in a distributed collaborative design environment in which different computer-aided design systems are used by participating companies. Sharifi et al. 12 presented a conceptual agile manufacturing model based on a wide-ranging review of agile manufacture and manufacturing architectures and described a framework for analyzing and developing a company’ s agile characteristics. Kong et al. 13 introduced a pervasive representation model as a basis to realize computer automatic processing for modular product development because partitioning, development, fabrication and management of construction blocks of modular products still rely heavily on manual labors of sophisticate designers. Oztemel and Tekez 14 introduced a reference model called reference model for intelligent integrated manufacturing system to promote the adaptation of integrated manufacturing system. However, these reference models are not aimed at the reference model of KMS. In KM base, each KM is stored separately and any calling of KM’s elements is realized by KM multiple set operation. If some typical KMs could be taken as reference models, KMs can be better selected and optimized.
Clustering algorithms have been used extensively for pattern recognition,15–17 data mining,18–21 information compression 22 and fuzzy modeling.23–26 Traditional hard clustering puts each object into exactly one cluster, while fuzzy clustering allows for partial membership of objects to cluster. Therefore, fuzzy clustering is among the most widely employed due to its effectiveness, simplicity and computational efficiency. Since Zadeh27,28 proposed fuzzy sets using the idea of partial membership and described by fuzzy membership functions, many fuzzy clustering methods have been proposed and studied by researchers, among which are fuzzy c-means clustering, 29 fuzzy relational clustering, 30 fuzzy subspace clustering, 31 fuzzy kernel clustering with outliers, 32 entropy-based fuzzy clustering 33 and vector fuzzy c-means. 34 However, KM is a new knowledge representation for advanced manufacturing mode. Each KM contains lots of data and inherent information. Yang and Yan 10 proposed a dynamic clustering of KMs by adjusting the clustering number according to user requirements to simplify the next self-reconfiguration operations. However, the feature space under no user demands is high dimensional, under which the distribution of KMs goes sparse. Thus, considering the relevance and complexity of KMs, it is necessary to develop a new KM clustering method for optimal selection of KMs.
A new method for KM selection based on fuzzy relational clustering is proposed, whose clustering data are the similarity degrees between KMs. The reasonable similarity is an important factor of mining KMs’ relations. The perfection degree, matching degree and similarity of KM are defined in turn in terms of performance, function and structure. Their properties are discussed. The sample-class relation is constructed by decomposing fuzzy relational matrix. As KMs having higher membership in each class with the target KM give a good reference, they are compared to determine the most similar class. Users tend to select KMs in a certain class, which narrows the scope of their choice. The test example has verified the validity of the proposed method for KMs selection.
The rest of the article is organized as follows: section “Similarity measure of KMs” presents the similarity model of KM, which includes the introduction of KM, the definitions of KM matching degree, perfection degree and similarity degree as well as related properties and computation steps. In section “KM fuzzy clustering and selection,” the decomposition of fuzzy relational matrix by gradient method is discussed, and a new selection method for KM is proposed, and their implementation steps are listed. Section “Empirical analysis” provides an empirical study to verify the proposed methods. Final conclusions and remarks are given in section “Conclusion.”
Similarity measure of KMs
KM
An advanced manufacturing system is the concrete realization of a manufacturing mode, and it consists of a number of relatively independent modules linked to each other. Any sub-module of a module or even sub-sub-modules can also be viewed as this. Setting the module as a knowledge point, the advanced manufacturing mode is supposed to consist of the points and the relationships between them. Then a network structure can be formed, whereby an advanced manufacturing mode can be transformed into a KM. 5 The KM definition is as follows:
Definition 1
The KM can be defined as a six-tuple
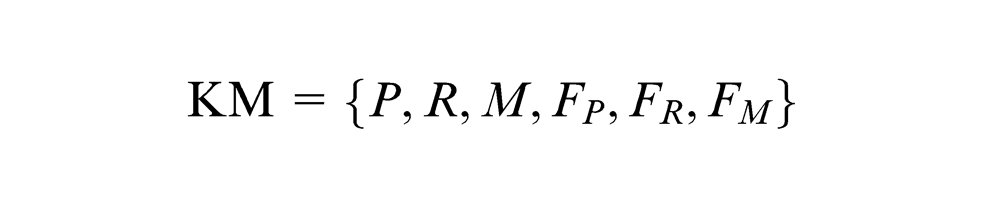
where
As shown in Definition 1, a KM is a large set including knowledge points, message relationships, message flows and functions of knowledge points. Any KM corresponds to a set of functional topological space generated by knowledge points under the different functional environments. 8 The reconfigured KMs are continually constructed by the topological bases of functional topological space. These topological bases are in fact the lowest-layer knowledge points of KM, that is, the smallest function modules in actual system. Once a new KM determines the lowest-layer knowledge points, the other elements of KM and corresponding operations will be called to reconfigure the KM. If the root knowledge point is taken as the first-layer knowledge point, its son knowledge point connecting the root knowledge point through a complexity relationship can be regarded as the second-layer knowledge point, and the son knowledge point of son knowledge point as the third-layer knowledge point, which connects the root knowledge point through two complexity relationships. To compare two KMs, the lowest-layer knowledge point of KM and its layer number are defined as follows.
Definition 2
The lowest-layer knowledge point of KM is the knowledge point that has no son knowledge point in KM and connects the root knowledge point through at least
Because the lowest-layer knowledge point of KM plays an important role in the construction of KMs, the similarity model is based on its characteristics.
Similarity model
To cluster and select KMs, it is necessary to discuss the similarity of KM. Yan and Xue 7 regard the fuzzy function–satisfaction degree as similarity, while Ding et al. 35 take the number of the same functions as such. However, a KM is an abstract model of a manufacturing mode in KMS. The KM similarity is not only the match of lowest-layer knowledge points’ function but also that of its satisfaction degree. And the structure of KM also influences its similarity. The matching degree of KMs’ function is defined as follows.
Definition 3
Suppose the lowest-layer knowledge point sets of KMs
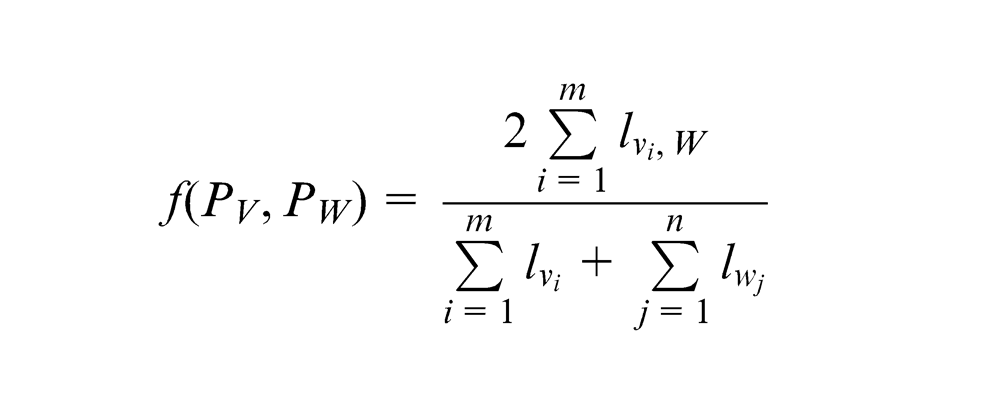
It is obvious that
Property 1
If the functions of KM
Suppose
Suppose
Proof
Suppose the lowest-layer knowledge points of KMs
1. The total functional number of KMs
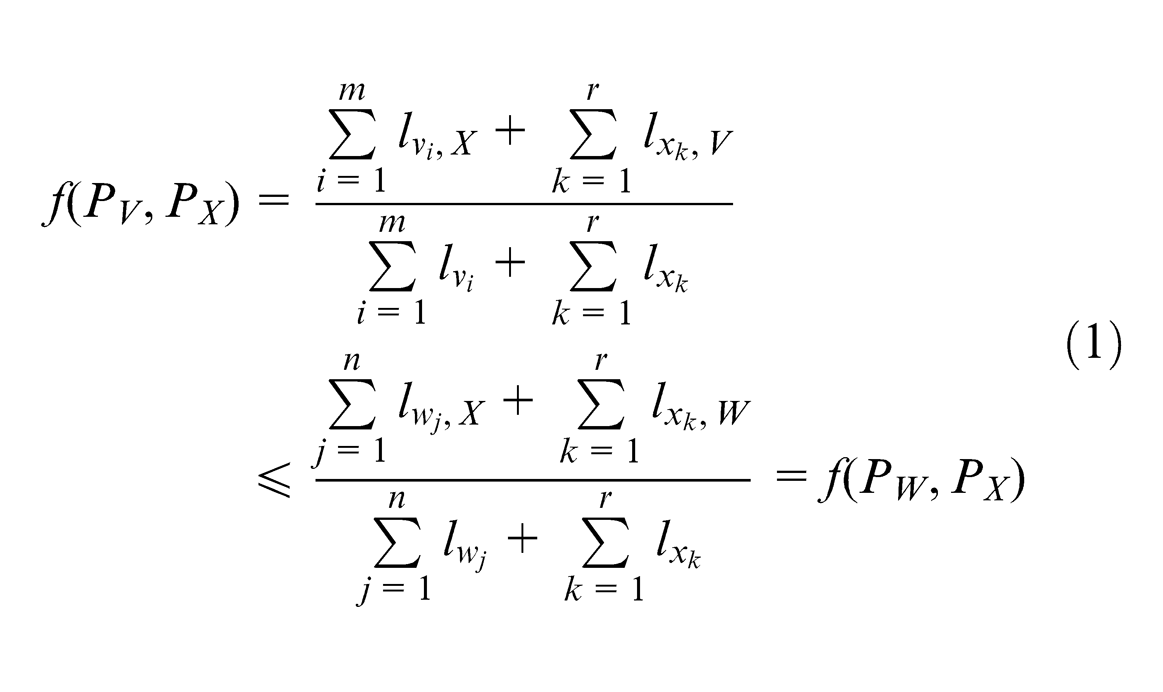
2.
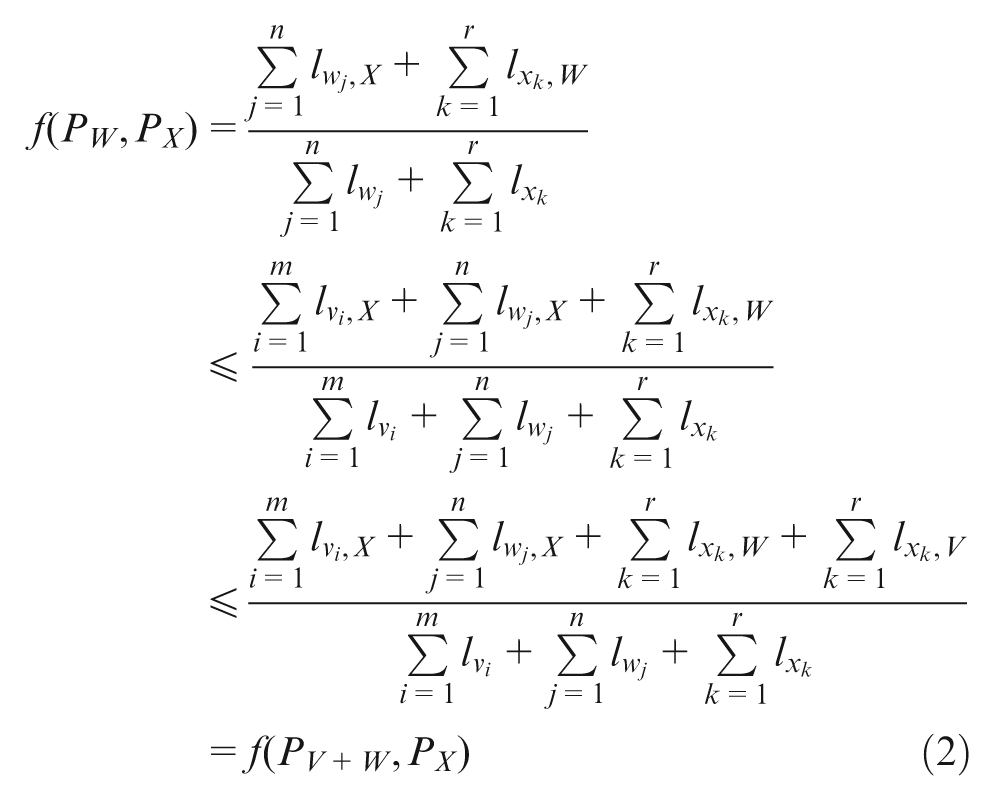
3. Suppose
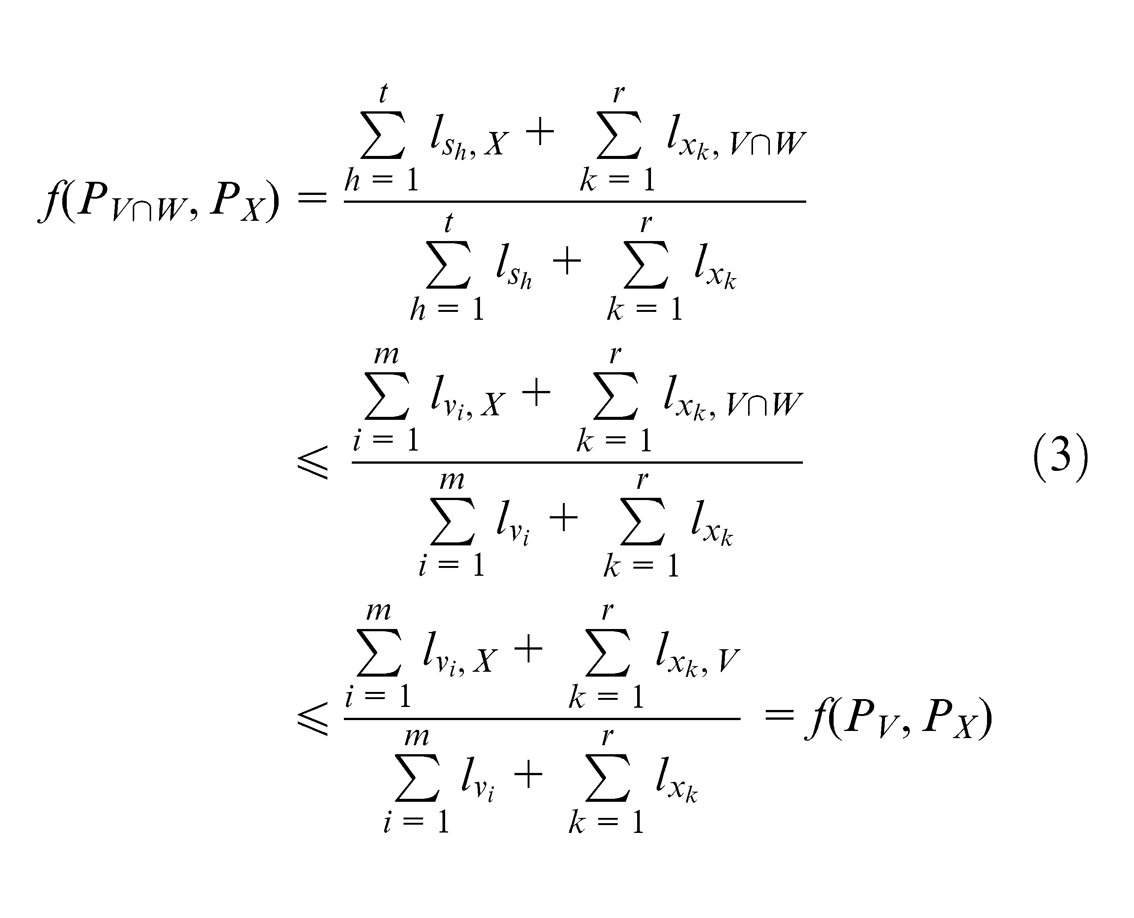
Similarly,
Property 1 shows that matching degree of union is not necessarily higher than that of subset, as presented in Property 1 (1). However, the former may be higher than the latter under the conditions of Property 1 (2). Similarly, the matching degree of intersection is not necessarily lower than that of the original set. But the former may be lower than the latter under the preconditions of Property 1 (3).
The above shows that Definition 1 reflects the functional similarity between KMs. However, for user, the KM that has user functional requirements is necessary but not enough. How much a KM implements functions, that is, the satisfaction degree of user for these functions, is the same important. Some users hope to improve functions to meet the further development, while others only need the basic functions to save the cost. In addition, as we know, the representation of knowledge point is the same while the corresponding contents in practical system may vary a little. For example, for knowledge points “c” in Figures 3 and 4, which have the functions of production management, their son knowledge points have not be the same in KMs
Definition 4
Suppose the lowest-layer knowledge point’s set of KM
According to Definition 2, there is one-to-one correspondence between each KM and its fuzzy set
Definitions 1 and 2 reflect the similarity from the two aspects of functional quality and quantity. Even if the matching degree and perfection degree of two KM are completely the same, their corresponding structures of KM may differ. The layer number of knowledge point can reflect the KM’s structure, which is then introduced into the definition of KM’s similarity. Taking function, performance and structure into account, Definition 5 is set up as follows.
Definition 5
The similarity degree of KMs
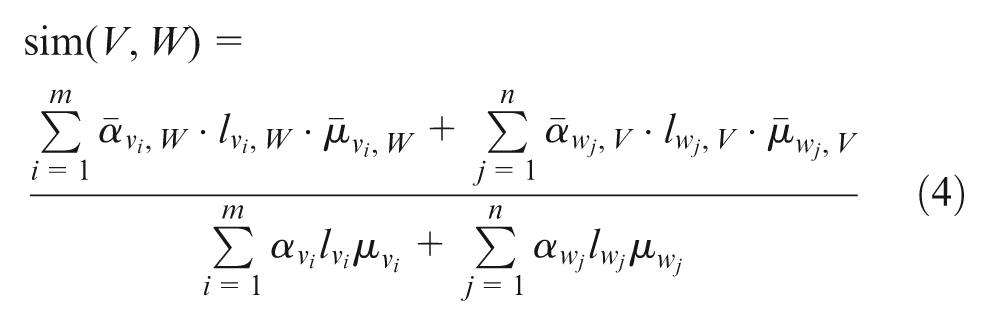
The lowest-layer knowledge point sets of
If the knowledge point having the same function as knowledge point
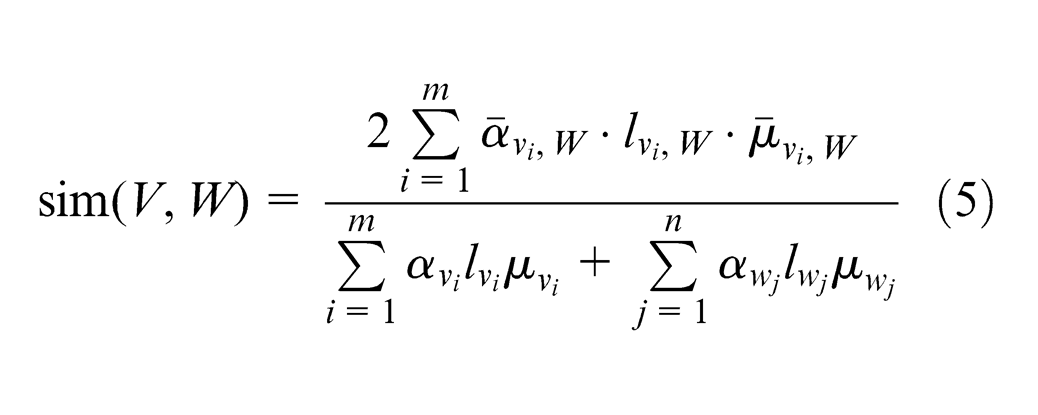
It is obvious that
Property 2
When the lowest-layer knowledge point’s functional number of KMs
KM
KMs
The functions of KM
Proof
Suppose the lowest-layer knowledge point sets of KMs
1. When the lowest-layer knowledge point’s functional number of KMs (a) If (b)
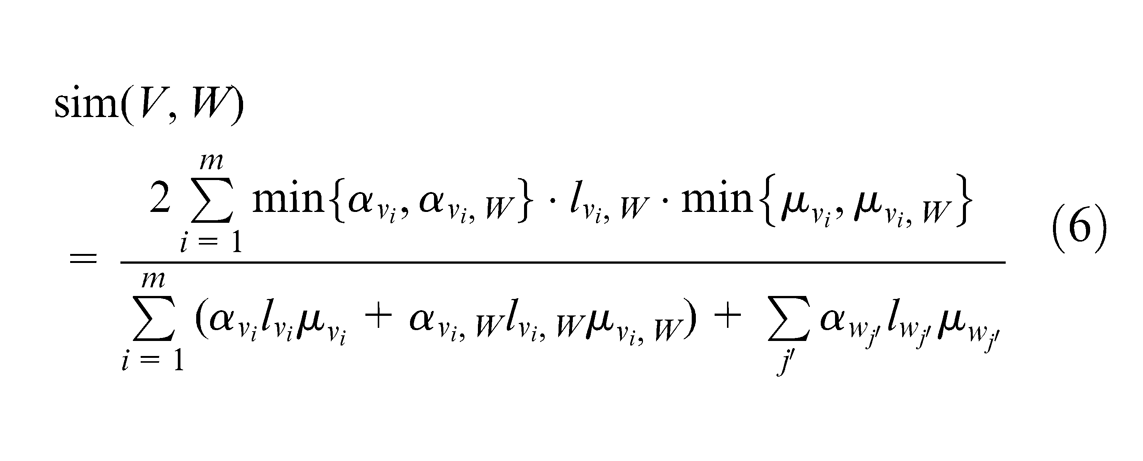
When
Case 1. If
Case 2. If
It has been proved that the smaller the
(c) Similarly,
2. KM
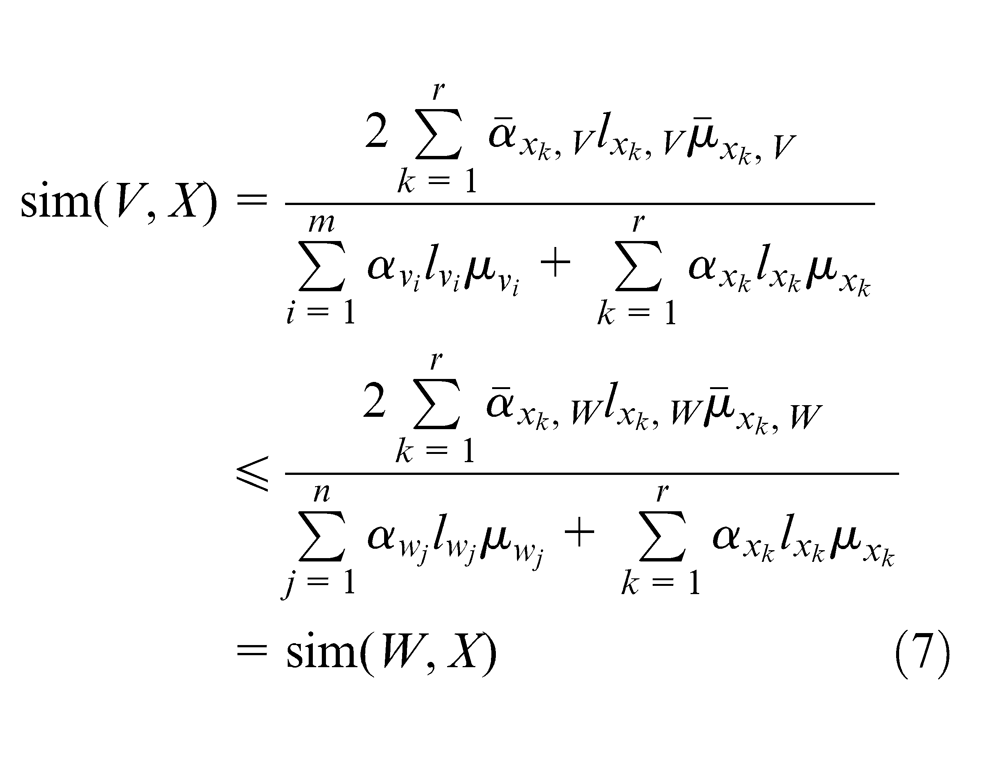
3. Since KMs

4. The functions of KM

Similarly,
Property 2 indicates that similarity of KMs relates to the functional number, the matching degree of perfection degree and layer number of knowledge points having identical functions. The greater the number of knowledge points having identical functions, the more similar the KMs, and the smaller the dissimilarity of the perfection degree and layer number of corresponding knowledge point, the more similar the KMs. Property 2 also suggests that the similarity degree of union is not necessarily higher than that of subset, but the former may be higher than the latter under the preconditions of Property 2 (3). In a real system, although the combined KMs may complement each other, they are not necessarily the best choice for user, the reason being that some KM combinations may lower the similarity degree. Similarly, the similarity degree of intersection is not necessarily lower than that of the original set. But the former may be lower than the latter under the preconditions of Property 2 (4). Therefore, when KMS has secured the desired KMs through KM operations, the impacts caused by the operations should be considered in the similarity.
Computation of KM similarity degree
Steps to compute similarity degree are as follows:
Step 1. Suppose the lowest-layer knowledge point sets of KMs
Step 2. Keep searching for father knowledge points of a lowest-layer knowledge point till the root knowledge point is found. Obtain the layer numbers
Step 3. Compare the knowledge points in different KMs. Loop each function of knowledge point
Step 4. Following Steps 1–3 and Definition 5, obtain the similarity degree
KM fuzzy clustering and selection
Decomposition of fuzzy relational matrix
Suppose that there are KMs
For this, suppose fuzzy relational matrix
The operator is s-t convolution of fuzzy set. Let
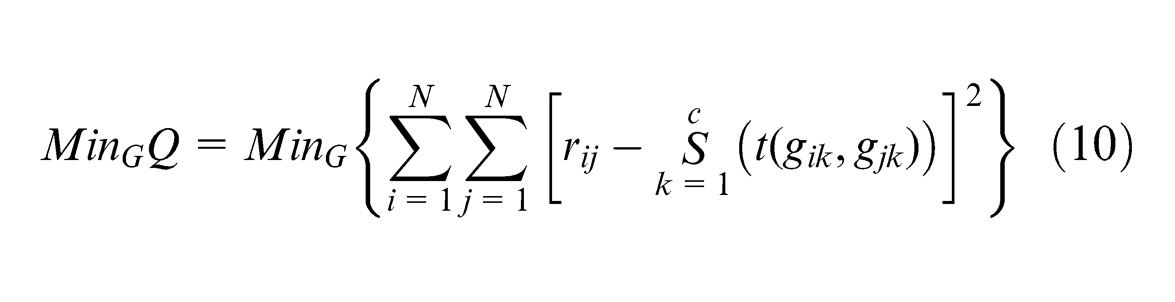
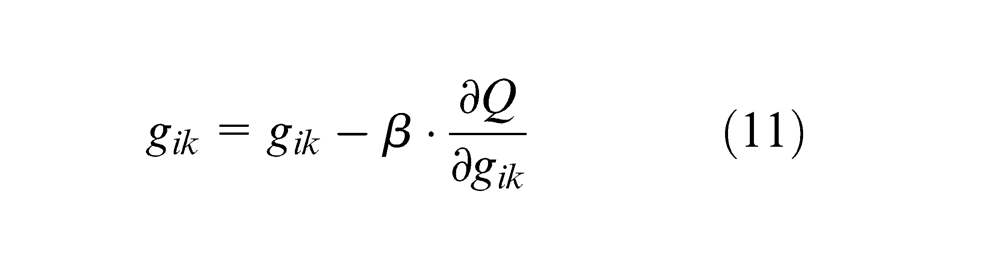
where
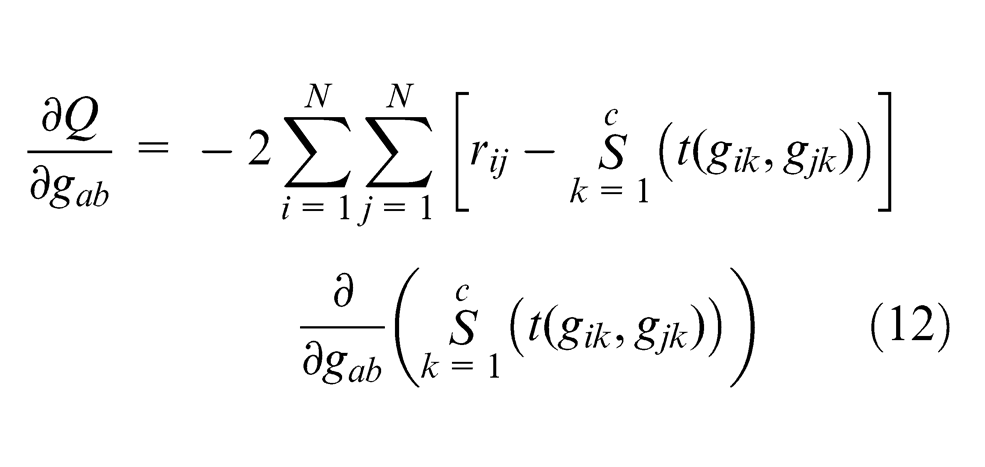
where the derivative is divided into four cases:
When
If
If
If
Selection of KMs
Each KM in the KM base is affiliated with a class by the above method and maximum membership principle. The KMs having the highest membership are taken as reference KMs for user, especially for the low-quality user who may fail to identify his specific needs clearly. For high-level users, these reference KMs are not necessarily of the best choice, but can narrow the range of choice.
Suppose that the target KM
As maximizing user’s needs is the requirement of selection, calculating similarity according to user’s needs is different from comparing KMs in the KM base. Modify equation (4) into equation (13), where
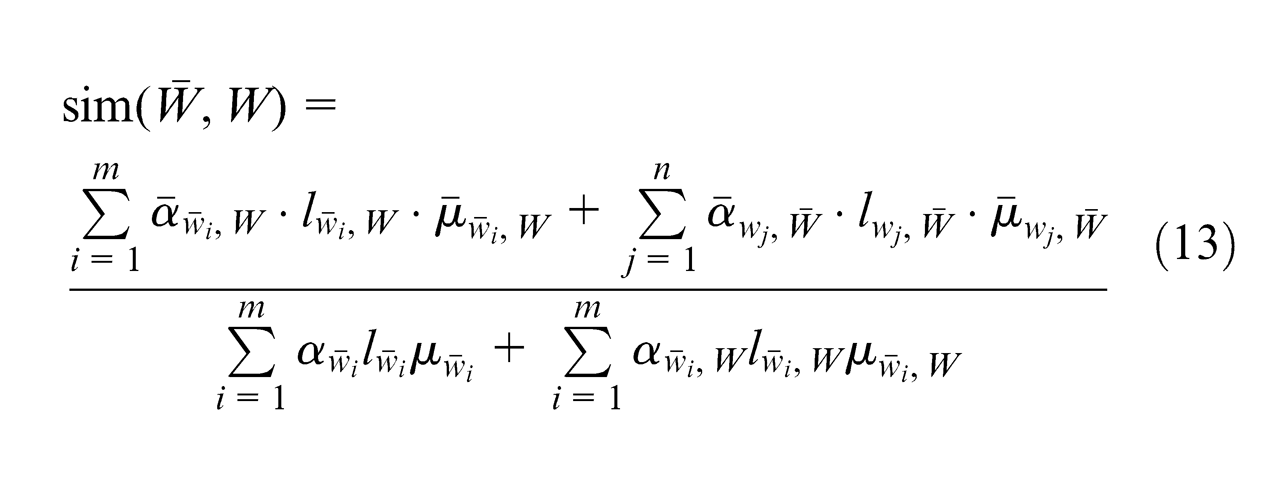
Fuzzy clustering realization and KM selection
The process goes as follows:
Step 1. Suppose three are
Step 2. Decompose
Step 3. Calculate
Step 4. The KM having the highest membership in each class is taken as reference KM.
Step 5. The user’s function requirements are layered by modules and sub-modules to map the target KM
Empirical analysis
Suppose that there are 15 KMs
Calculation of similarity degree
As similarity degree calculation needs complete data of each KM, here only that of KMs
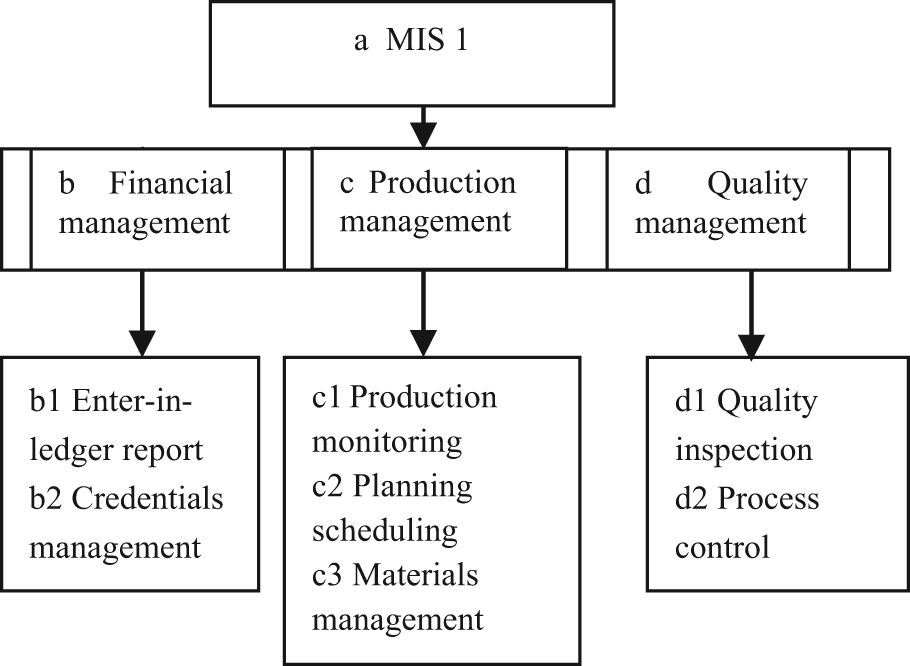
Management information system 1.
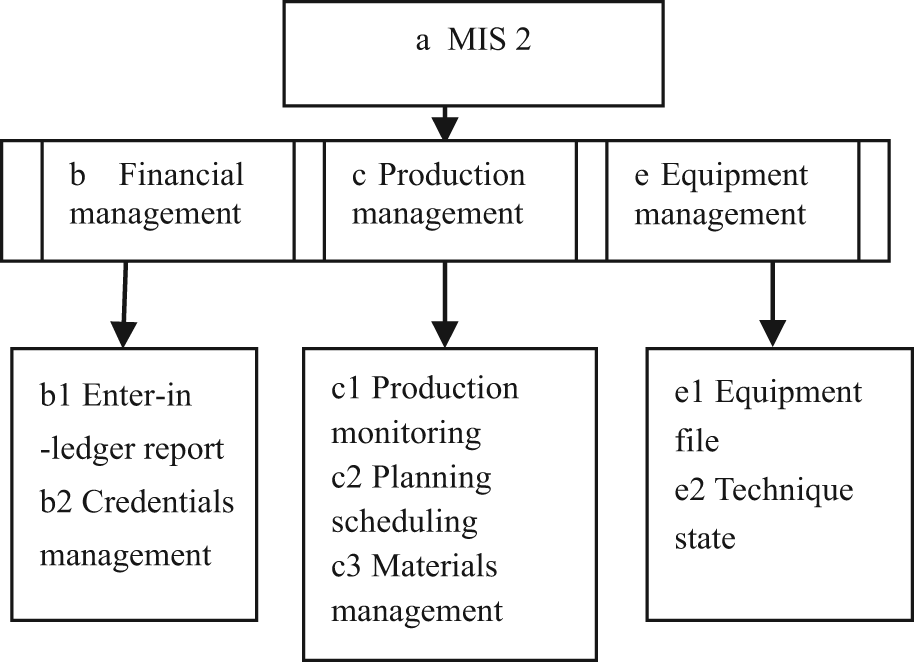
Management information system 2.
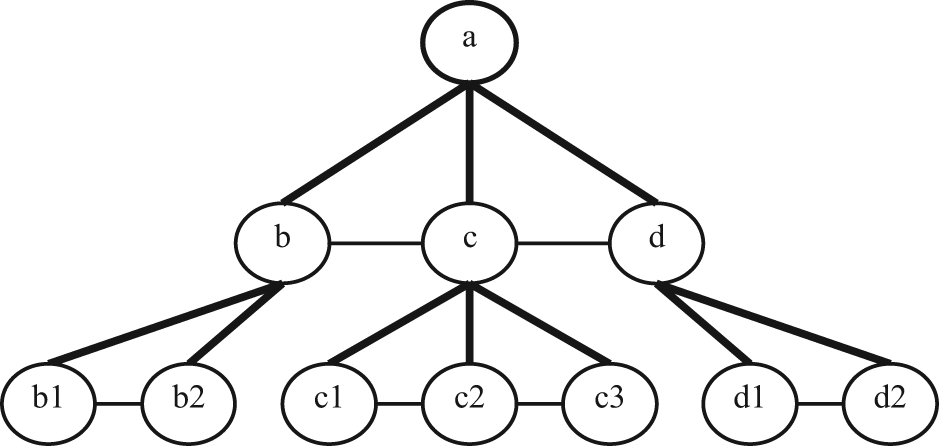
KM
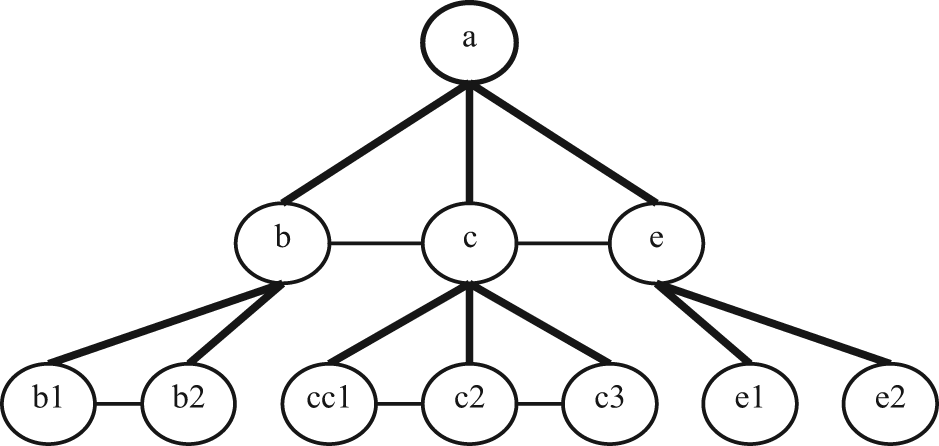
KM
The lowest-layer knowledge point sets of
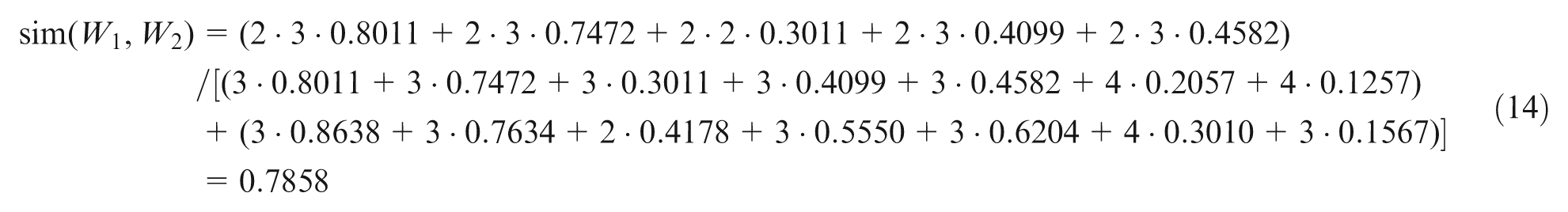
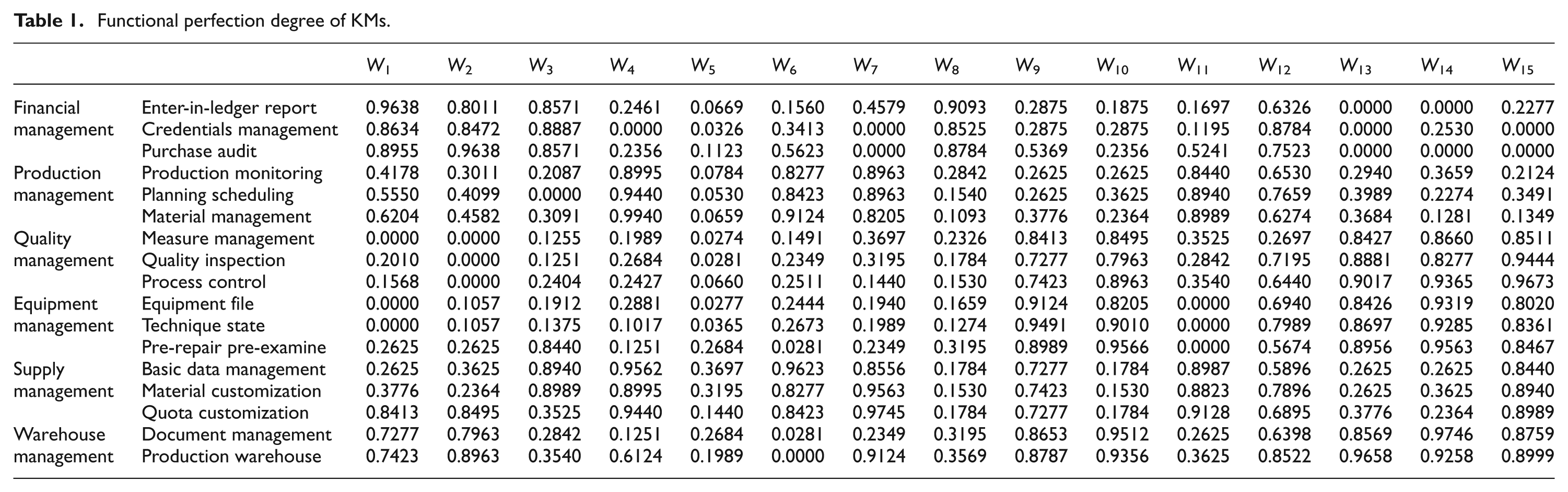
The functional perfection degrees of 15 KMs are listed in Table 1. And all KMs are normalized into the KMs having the same lowest-layer knowledge points by regarding the missing lowest-layer knowledge points as knowledge points of - perfection degree. Data are optional upon certain rules. The financial management of
Functional perfection degree of KMs.
To simplify the calculation process of fuzzy relational matrix, suppose that the layer numbers of lowest-layer knowledge point are the same and all matching degrees are 1. And
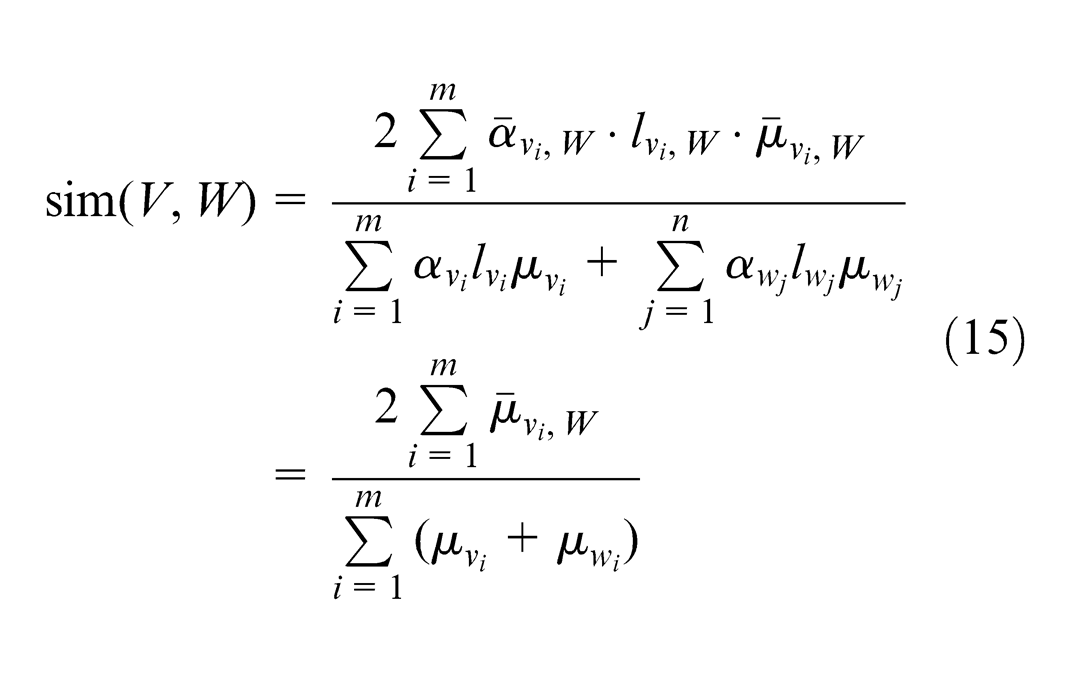
Obtain the fuzzy relational matrix of 15 KMs by equation (15) as shown in Table 2. The lower part of fuzzy relational matrix is given because of symmetry.
Fuzzy relational matrix of KMs.
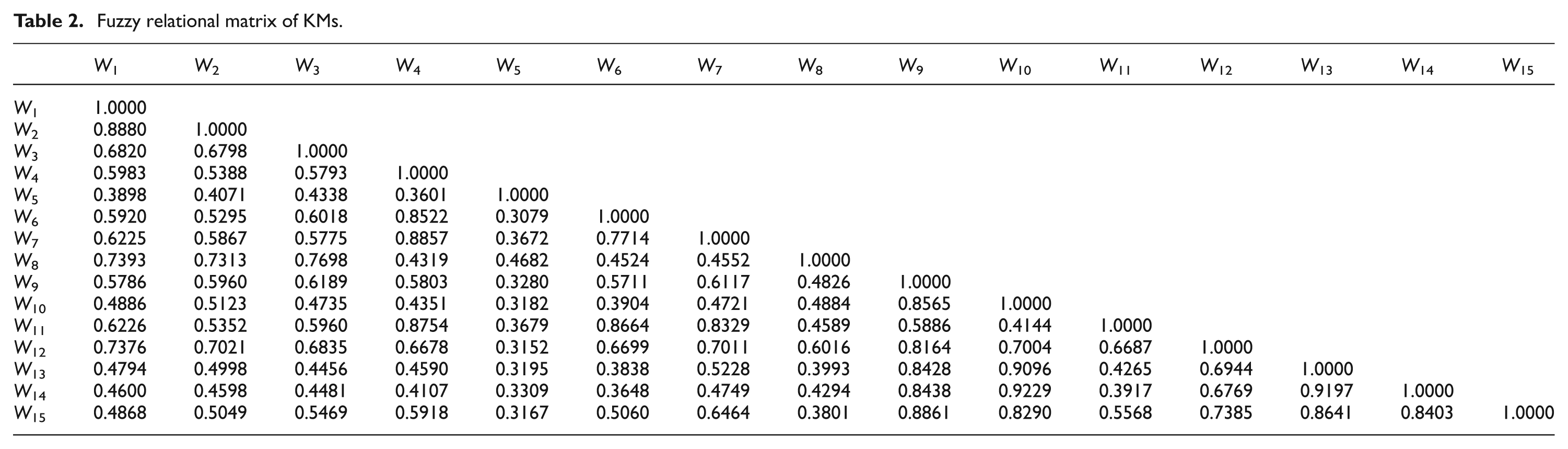
Clustering and selection of KMs
The fuzzy relational matrix is decomposed using MATLAB 7.5. The initial value of
Membership of KMs’ class.

On the other hand, KMs in the KM base are automatically classified in Table 3 without any user participation. The KMs having higher membership in class, such as
Conclusion
KMS realizes the optimal implementation of advanced manufacturing modes by KM. Meanwhile, more and more KMs are stored in the KM base, intensifying the difficulty of selection by user, especially low-level user. To solve this problem, the clustering and selection methods of KMs based on decomposition of fuzzy relational data are proposed.
In terms of the KM representation, there exist certain inevitable overlapping parts among KMs. So in this article, the reference KMs gained by clustering are selected to clarify the relationships of KMs, thus narrowing the scope of user’s choice. For typical reference KMs, the similarity model between KMs plays an essential role. Starting from the representation of KM, the matching degree is a quantitative comparison of KM, while the perfection degree is a performance comparison. The layer number is an influence factor of KM’s structure. Based on the above, the similarity function is constructed. As proven by a number of tests, similarity degree varies with the changes in self-reconfiguration operations and can well reflect the KM’s characteristics.
The similarity values between KMs as clustering data convert the original clustering space into that constituted by similarity and overcome the sparse distribution of high-dimensional sample sets. The decomposition of fuzzy relational matrix yields a KM–class relationship enabling user to select KMs in the class rather than to choose from all KMs. The KMs having higher membership are taken as reference KMs for low-level users. Meanwhile, they narrow the scope of selection for high-level users. It is a new idea that KMs are selected by mining the relationships among them. The reference KMs do help user identify his demands for proper choice.
Although the simulation has verified the effectiveness of the proposed method, further exploration into the acquisition of perfection and matching degrees is a must, and that makes the focus of our future study. In addition, for other possible fuzzy clustering methods, classification number and validity of clustering are worthy to be studied as well.
Footnotes
Acknowledgements
The authors thank the two anonymous referees and Professor Li Lu for their valuable comments and suggestions.
Declaration of conflicting interests
The authors declare that there is no conflict of interest.
Funding
This research was supported by a key program of National Natural Science Foundation of China under Grant No. 60934008 and Postdoctoral Foundation of Jiangsu Province under Grant No. 1107010145.