
Abstract
Abstract
Thalassemia is a hereditary blood disorder characterized by abnormal hemoglobin production. Common diagnostic methods include complete blood count, high-performance liquid chromatography, and hemoglobin electrophoresis. While physicians make the final diagnosis, advancements in artificial intelligence, specifically machine learning (ML) and deep learning, offer significant potential as auxiliary tools and decision support systems to reduce diagnostic errors. This study investigates ML algorithms for classifying thalassemia and its subtypes, including alpha (α) thalassemia and beta (β) thalassemia (minor, intermedia, and major). A synthetic training dataset of 1534 samples was generated based on the statistical properties and correlation structures of real clinical data. The models were then evaluated using an external real-world dataset of 349 patients from the Hematology Department of Atatürk University Research Hospital. Support Vector Machines (SVM), Logistic Regression (LR), XGBoost, Artificial Neural Networks (ANN), and a hybrid stacking model named ThalP were implemented. The ThalP model integrates the probability outputs of SVM, LR, and XGBoost through a neural network meta-classifier. Experimental results demonstrate that the proposed ThalP model achieved strong performance on the real clinical dataset with an accuracy of 83.1% and a macro-F1 score of 0.80. These findings indicate that ML-based hybrid models can serve as effective decision-support tools for classifying thalassemia subtypes using routine hematological parameters.
Keywords
Introduction
Hereditary hemoglobin disorders are among the most commonly observed types of monogenic diseases. Thalassemia, also known as Mediterranean anemia, is an inherited disorder caused by the body's inability to produce sufficient hemoglobin. 1 Based on the deficiency or defect in the hemoglobin chain, it is classified as either alpha thalassemia (α-thalassemia) or beta thalassemia (ß-thalassemia). α-thalassemia occurs due to a disruption in the production of the alpha chain, which is encoded by four genes. The severity of the disease is directly proportional to the number of gene defects in this chain. ß-thalassemia, on the other hand, results from a deficiency or limited synthesis in the beta chain of hemoglobin. The beta chain is encoded by two genes, and the number of defects in these genes determines the severity of the disease. 2
Thalassemia is a genetic blood disorder that occurs due to insufficient production of hemoglobin in the body. Hemoglobin is a protein that helps red blood cells transport oxygen, and its deficiency leads to anemia. Anemia manifests itself through symptoms such as fatigue, weakness, and pale skin. According to the World Health Organization, thalassemia is a serious health problem that affects millions of people worldwide. 1
Thalassemia is classified into three types: minor, intermedia, and major. Thalassemia major is the most severe form, in which patients require regular blood transfusions and face life-threatening complications. Thalassemia intermedia, also known as mild to moderate anemia, refers to cases where patients occasionally need blood transfusions. In thalassemia minor, patients are asymptomatic and do not require transfusions. Individuals in this group can live healthy lives as carriers. 3
In countries where consanguineous marriages are common, the number of thalassemia patients is increasing. If a thalassemia carrier marries a non-carrier, there is a 50% chance that each child will be a carrier. However, if two carriers marry, each child has a 25% chance of being affected by the disease, a 50% chance of being a carrier, and a 25% chance of being completely healthy. An increase in the carrier rate within a society also increases the likelihood of two carriers randomly marrying each other. This, in turn, leads to a higher probability of having children affected by the disease 4 (Table 1).
Hereditary transmission rates of thalassemia disease.

Hereditary transmission rates of thalassemia disease.
Notes:
Early diagnosis of thalassemia carriers and monitoring these individuals is crucial in terms of preventing and controlling the spread of the disease.
Traditional diagnostic methods are generally based on laboratory tests such as serum iron levels, complete blood count, and high-performance liquid chromatography. However, the results of these tests may not always be sufficient for making a definitive diagnosis. 5 Additionally, the high cost of these tests and the time required to obtain results pose significant drawbacks. As a result, there is a growing need for faster and more cost-effective diagnostic methods. 6
This is where machine learning algorithms come into play. Machine learning involves the development and implementation of algorithms that learn from data and perform specific tasks. 7 These algorithms can analyze large datasets, identify patterns, and predict future events. Widely used in many fields for tasks such as management and analysis, machine learning algorithms also play an important role in healthcare. The use of machine learning in the health sector holds great potential for early diagnosis of diseases, determining treatment methods, and improving patient care.8,9
Using machine learning algorithms in disease diagnosis not only enables more accurate diagnoses but also contributes to optimizing treatment processes.7,10 These algorithms can analyze individual patient data and facilitate the development of personalized treatment plans. As a result, patients’ quality of life can be improved, and treatment processes can become more effective.8,11
The application of machine learning algorithms in the diagnosis of thalassemia can produce more accurate and faster results by relying on genetic and clinical data.10,12 For instance, genetic data plays a crucial role in identifying the hereditary nature of the disease. Moreover, blood tests and other clinical data can be used to determine the severity and prognosis of the disease. The combination and analysis of this data can increase the accuracy of machine learning algorithms and enable earlier diagnosis of the disease. 13
Despite the increasing number of machine learning studies on thalassemia detection, most existing works focus on binary classification tasks (e.g., carrier vs non-carrier). Studies addressing the multi-class classification of thalassemia subtypes remain limited. Therefore, this study proposes a hybrid machine learning architecture capable of distinguishing multiple thalassemia subtypes using routinely available hematological parameters.
Diagnosing thalassemia carriers and the disease itself is both time-consuming and costly. Performing the diagnosis in a shorter time and at a lower cost is of great importance for healthcare professionals and decision-makers. At this point, artificial intelligence and its subfields, machine learning and deep learning, come into play. Several studies have shown that machine learning and deep learning can help healthcare professionals make diagnostic decisions with less time and cost.
In 2023, Ferih and colleagues conducted a study using complete blood count parameters to predict thalassemia using machine learning models such as K-Nearest Neighbors (KNN), Naive Bayes, Decision Trees, and Multilayer Perceptron (MLP). The study concluded that MLP achieved the highest result with an accuracy rate of 92%. 14
In another study conducted by Rustam and colleagues to predict thalassemia carriers using complete blood count data, Adaptive Synthetic Sampling (ADASYN) and Synthetic Minority Over-sampling Technique (SMOTE) were used to obtain a balanced distribution of target classes in the dataset. On this balanced dataset, different machine learning models such as Support Vector Classifier (SVC), Logistic Regression (LR), Random Forest (RF), Decision Trees (DT), AdaBoost (ADA), Gradient Boosting Machine (GBM), and Extra Trees Classifier (ETC) were compared. As a result, the Two-Level Tree model achieved 92% accuracy on the original dataset. On the SMOTE-resampled data, RF and ETC models achieved 95%, while on the ADASYN-resampled data, RF and ETC achieved 94% accuracy. 15
Masala and colleagues developed a two-layer classifier based on the Radial Basis Function (RBF) to screen for thalassemia. In the first layer, the classifier distinguished between thalassemia patients and healthy individuals, while the second layer classified different types of thalassemia. In a study conducted on 304 samples, it was observed that the model obtained from the combination of SVM and KNN detected ß carriers with 100% accuracy in the first stage. In the second stage, it distinguished healthy individuals from alpha thalassemia carriers, identifying normal cases with 93% accuracy and carriers with 91% accuracy. As a result, it was observed that the proposed RBF model performed better than MLP.. 16
Devanath and colleagues applied various machine learning models—including KNN, Logistic Regression, SVM, Naive Bayes, Random Forest, AdaBoost, XGBoost, Decision Trees, MLP, and Gradient Boosting—to a dataset consisting of 594 samples (297 thalassemia-positive and 297 thalassemia-negative) to predict thalassemia. At the end of the study, the ADA model achieved 100% accuracy. 17
In another study, Ibrahim and colleagues used Naive Bayes, Decision Trees, Logistic Regression, and Neural Networks, along with a late fusion-based machine learning model, to identify beta thalassemia carriers. On a dataset obtained from the Punjab Thalassemia Prevention Program (PTPP), they reported accuracy scores of 94.01% for logistic regression, 93.15% for Naive Bayes, 97.93% for decision trees, 98.07% for neural networks, and 96% for the late fusion model. 18
Farzaliyev and colleagues aimed to diagnose anemia in children using a dataset of 600 samples collected from Iraq Haditha General Hospital and clinics. In addition to traditional machine learning models such as decision trees, SVM, random forest, logistic regression, and KNN, they also applied ensemble learning methods like bagging, boosting, and stacking. As a result, among the ML models, decision trees achieved the highest accuracy (98%), while among ensemble methods, boosting achieved the highest performance with an accuracy of 91%. 19
In 2021, Sadiq and colleagues used a dataset of 5066 samples obtained from the Pakistan Punjab Thalassemia Prevention Project Laboratory to detect beta thalassemia carriers based on red blood cell parameters. They compared the performance of SVM, RF, GBM, and a hybrid model named SGR-VC, which combined these three models. The study showed that the hybrid model achieved an accuracy rate of 93%, successfully distinguishing carriers from healthy individuals. 20
Although previous studies have demonstrated promising results using machine learning techniques, most of them focus on binary classification problems and utilize relatively small datasets. Furthermore, the integration of hybrid models and explainable artificial intelligence techniques remains limited. In this study, we address these gaps by proposing a hybrid stacking model and performing a detailed performance evaluation on both synthetic training data and real-world external test data.
Materials and methods
Materials
In this study, two datasets were used: a synthetic dataset for model training and a real clinical dataset for model evaluation.
A synthetic dataset consisting of 1534 samples was generated to train the machine learning models. The dataset was constructed using statistical characteristics derived from real clinical data obtained from the Hematology Department of Atatürk University Research Hospital. The synthetic dataset included hematological parameters obtained from complete blood count (CBC) tests together with iron and ferritin measurements, which are considered to have an indirect effect on thalassemia diagnosis. Specifically, class-wise mean and standard deviation values of hematological parameters were estimated from the real data. In addition, the empirical correlation matrix of the variables was incorporated into the generation process to preserve clinically meaningful relationships between features.
To ensure that the generated dataset closely matches the distribution of the real data, the similarity between the real and synthetic datasets was evaluated using Standardized Mean Difference (SMD) analysis. All variables showed SMD values below 0.30, indicating acceptable distributional similarity. All machine learning models evaluated in this study were trained on this synthetic dataset.
The parameters included in the dataset were WBC, RBC, PLT, HCT, HGB, HGB A, HGB A2, HGB F, MCV, MCH, Ferritin, Iron, as well as demographic variables such as age and gender. The dependent variable of the dataset was the diagnosis label, which was categorized into five classes: Alpha thalassemia, Beta thalassemia minor, Beta thalassemia intermedia, Beta thalassemia major, and Normal (healthy individuals) (Figure 1).
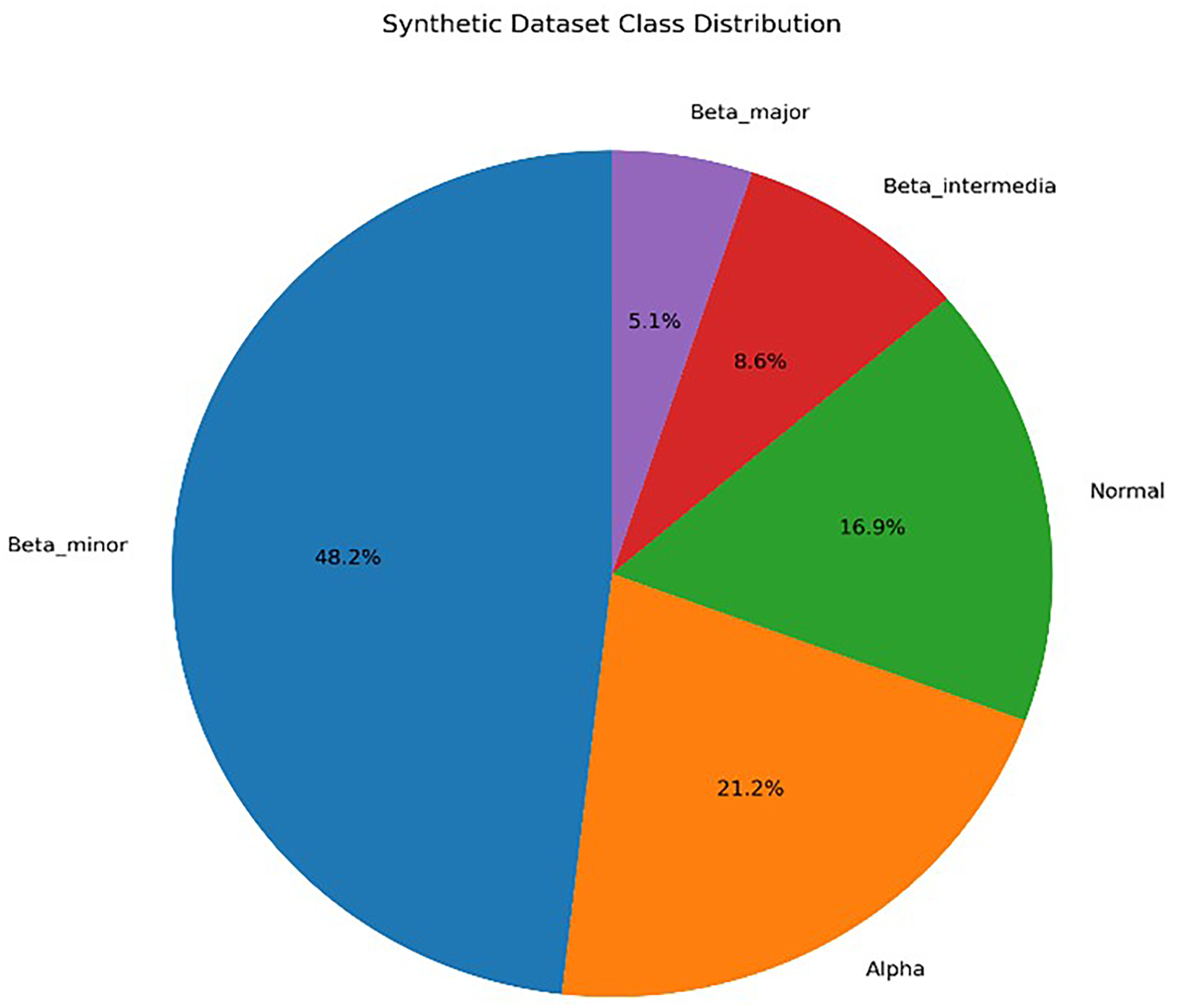
Distribution of the training dataset by class.
The test dataset used for model evaluation consists of 349 patients who applied to the Hematology Department of Atatürk University Research Hospital for thalassemia diagnosis. The dataset includes demographic and laboratory data collected during routine clinical evaluation (Figure 2).
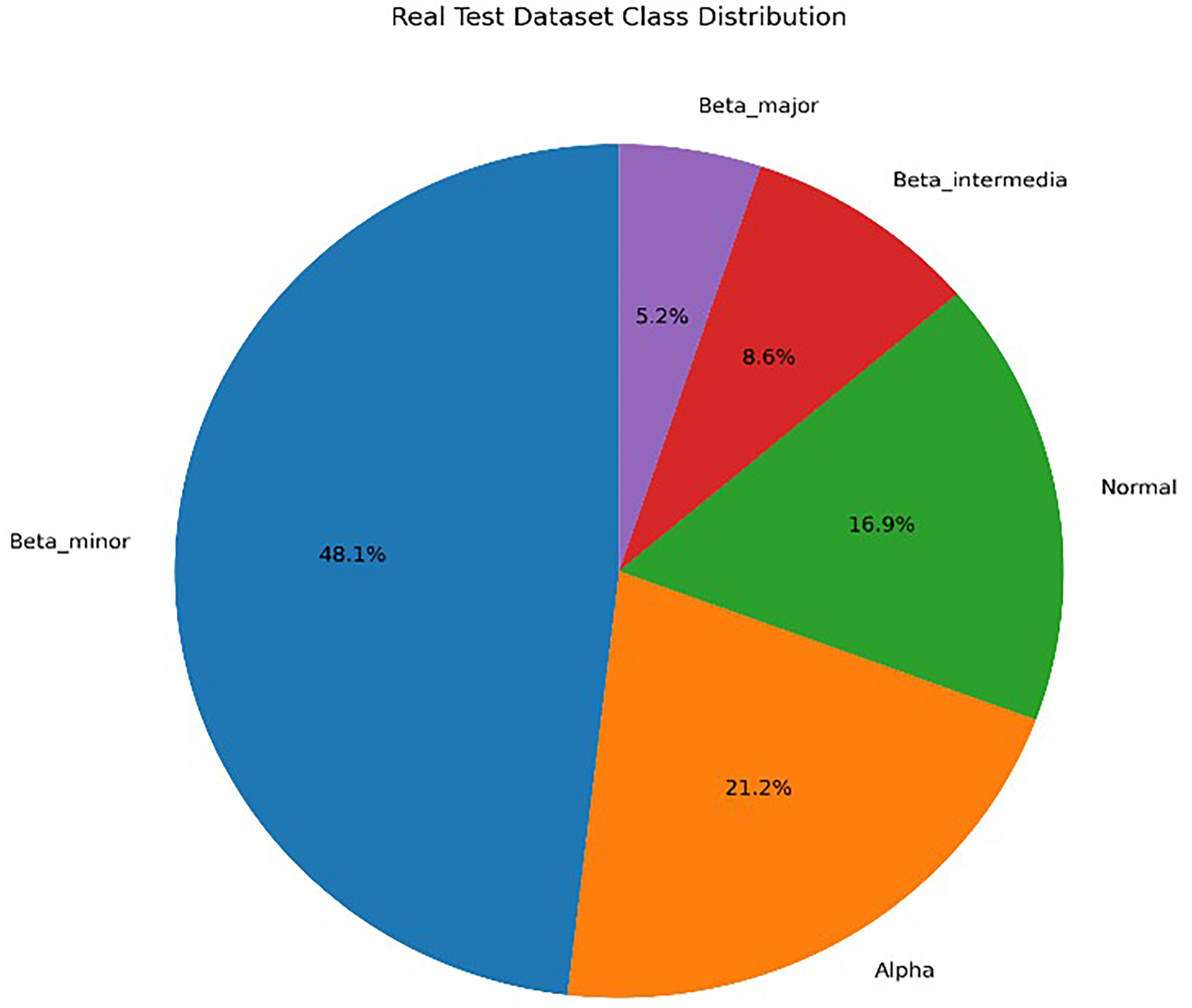
Distribution of the test dataset by class.
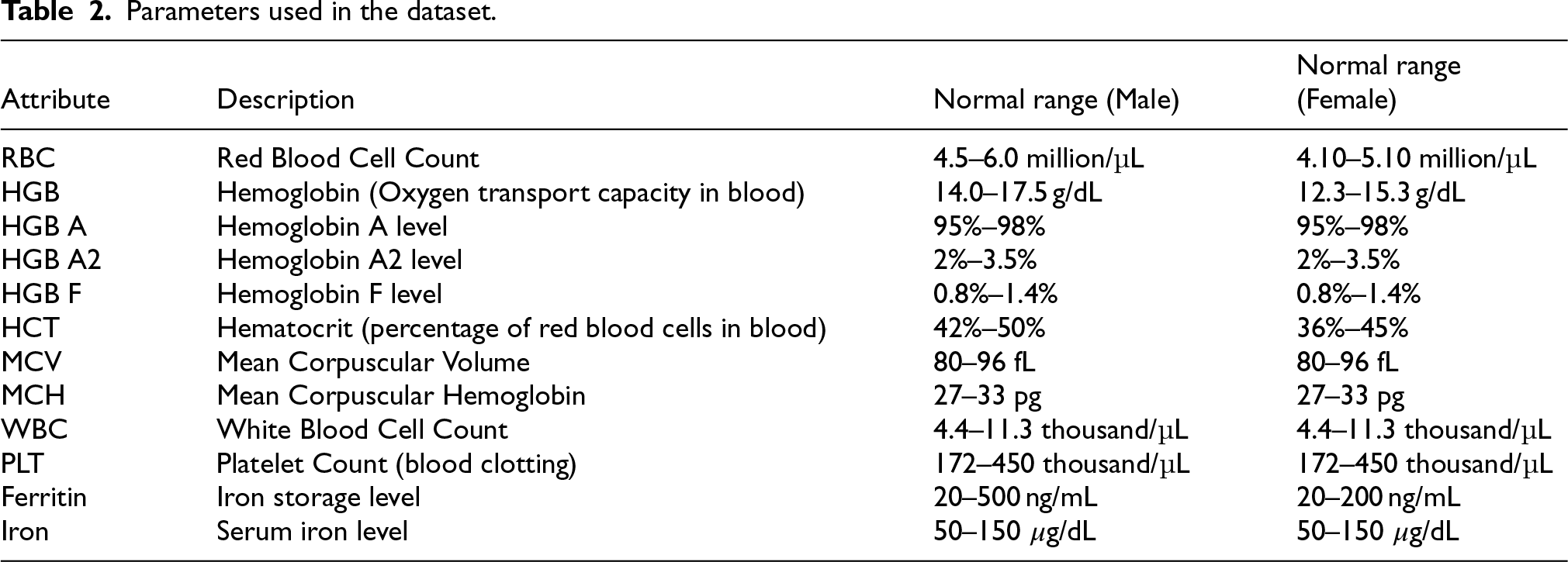
The characteristics of the complete blood count and iron and ferritin parameters used in the data set are shown in the Table 2, taking into account gender status. 21
Parameters used in the dataset.
The methodology of this study consists of four distinct stages, which are described below:
The synthetic dataset was created using the statistical properties of the real dataset. Specifically, the class-wise mean and standard deviation values of hematological parameters were calculated from the real clinical dataset. In addition, the empirical correlation matrix of the variables was incorporated into the data generation process to preserve clinically meaningful relationships between hematological parameters.
Synthetic samples were then generated using a multivariate normal distribution, allowing the preservation of both individual feature distributions and inter-feature dependencies. This approach ensures that clinically meaningful relationships among parameters such as hemoglobin, hematocrit, and mean corpuscular volume are maintained in the synthetic dataset.
To validate the similarity between the real dataset and the generated synthetic dataset, Standardized Mean Difference (SMD) analysis was performed. All features showed SMD values below 0.30, indicating acceptable similarity between the real and synthetic distributions.
To visually assess the similarity between the real and synthetic datasets, the distributions of key hematological parameters were compared using histogram overlays. The distributions of the synthetic data closely follow those of the real dataset, indicating that the statistical properties of the original dataset were successfully preserved during the synthetic data generation process (Figure 3 and 4).
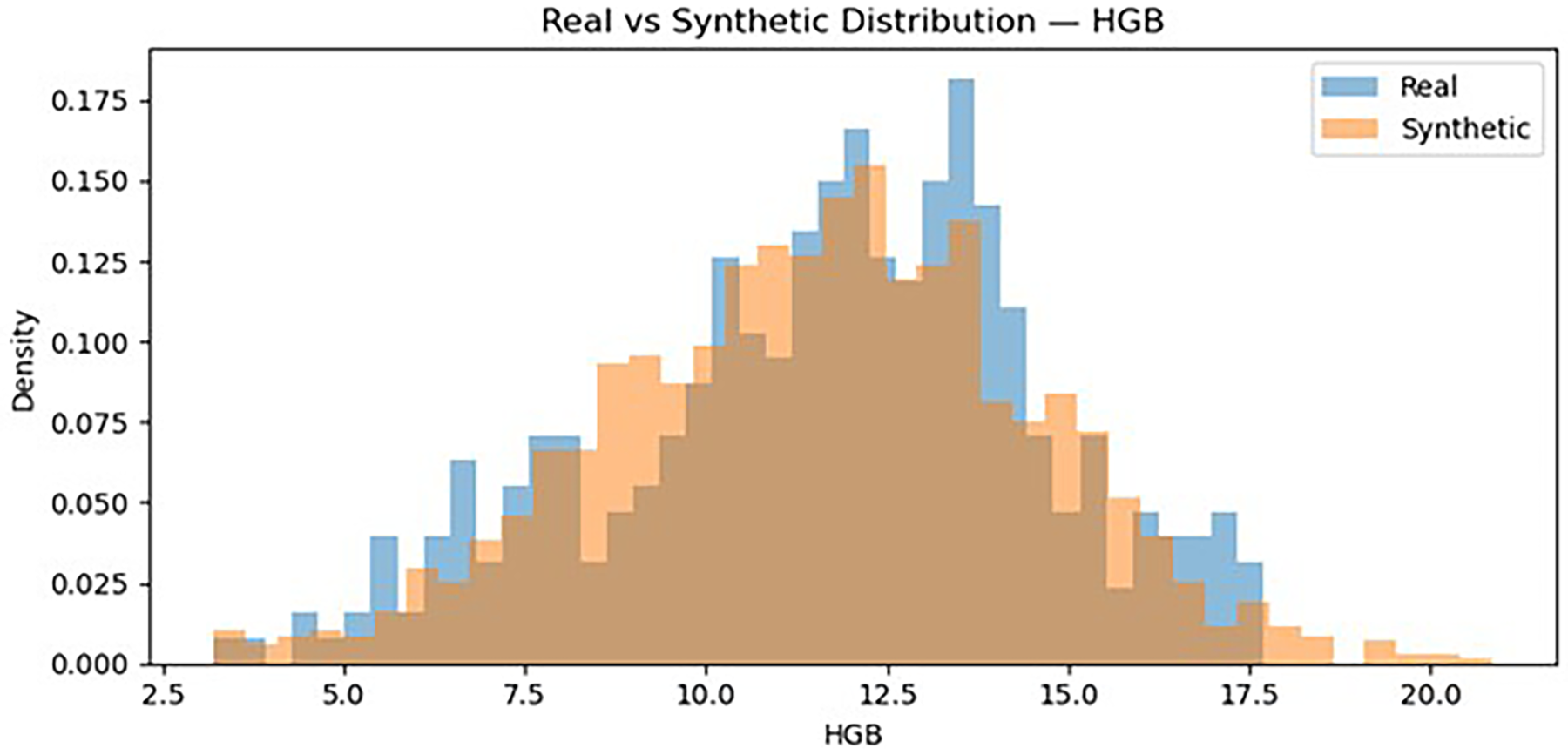
Distribution HGB (real vs synthetic).
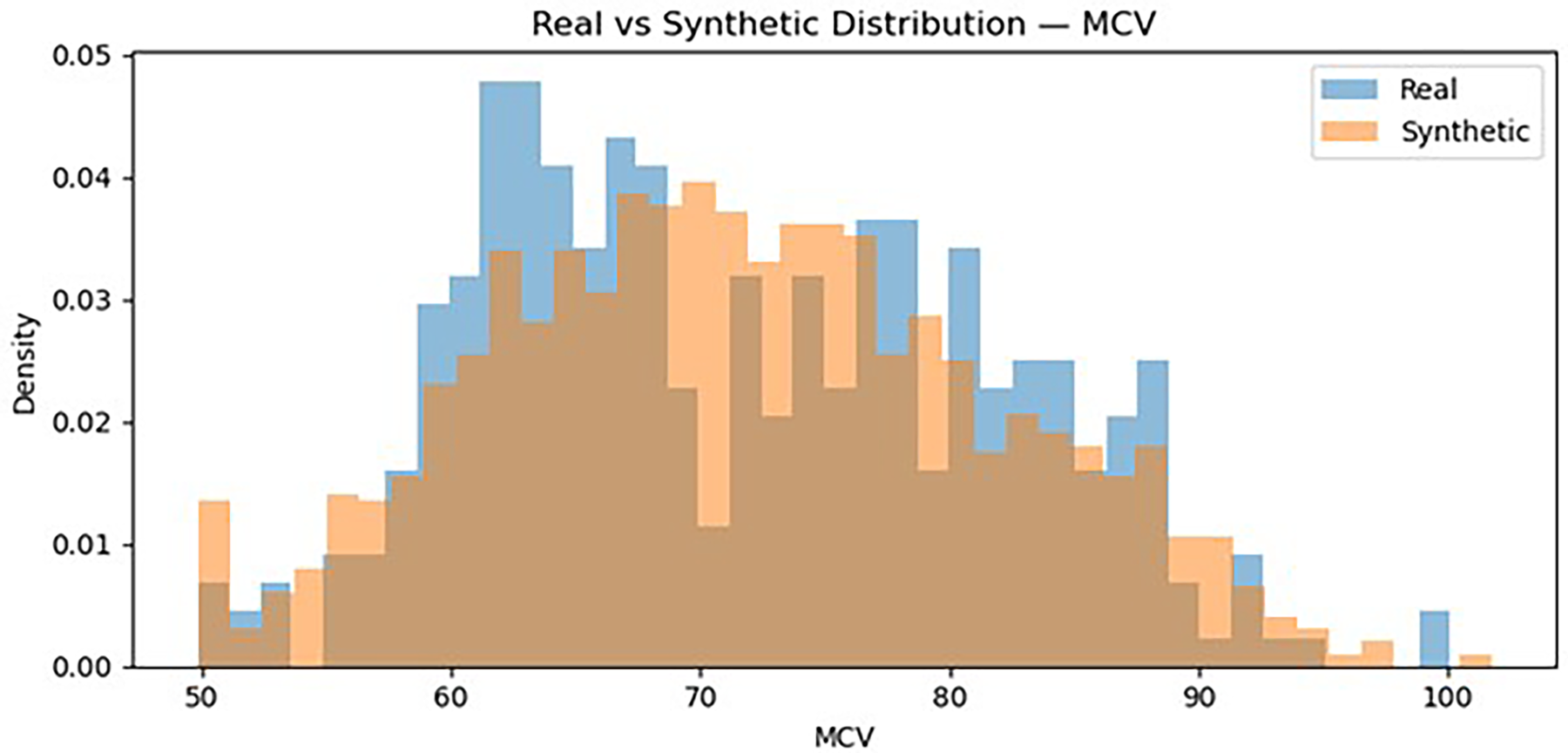
Distribution MCV (real vs synthetic).
The model was trained using a synthetic dataset and evaluated on a real clinical dataset to assess its practical performance in a clinical context.
Correlation analysis provides insight into the interactions between hematological parameters and helps identify potential multicollinearity among variables (Figure 5).
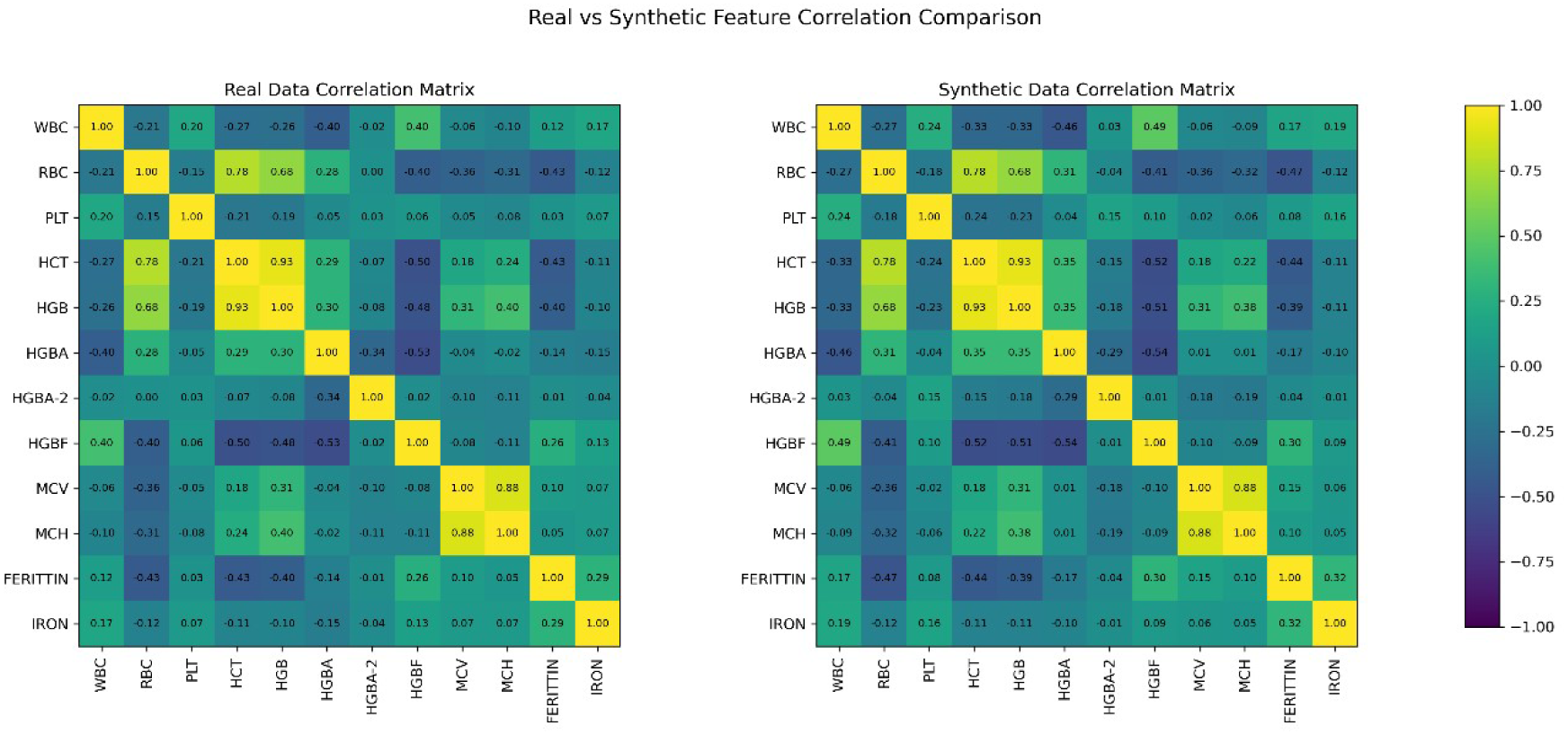
Real and synthetic data correlation matrix.
Finally, the performance of the algorithm was evaluated using the test dataset and a range of performance metrics (Figure 6).
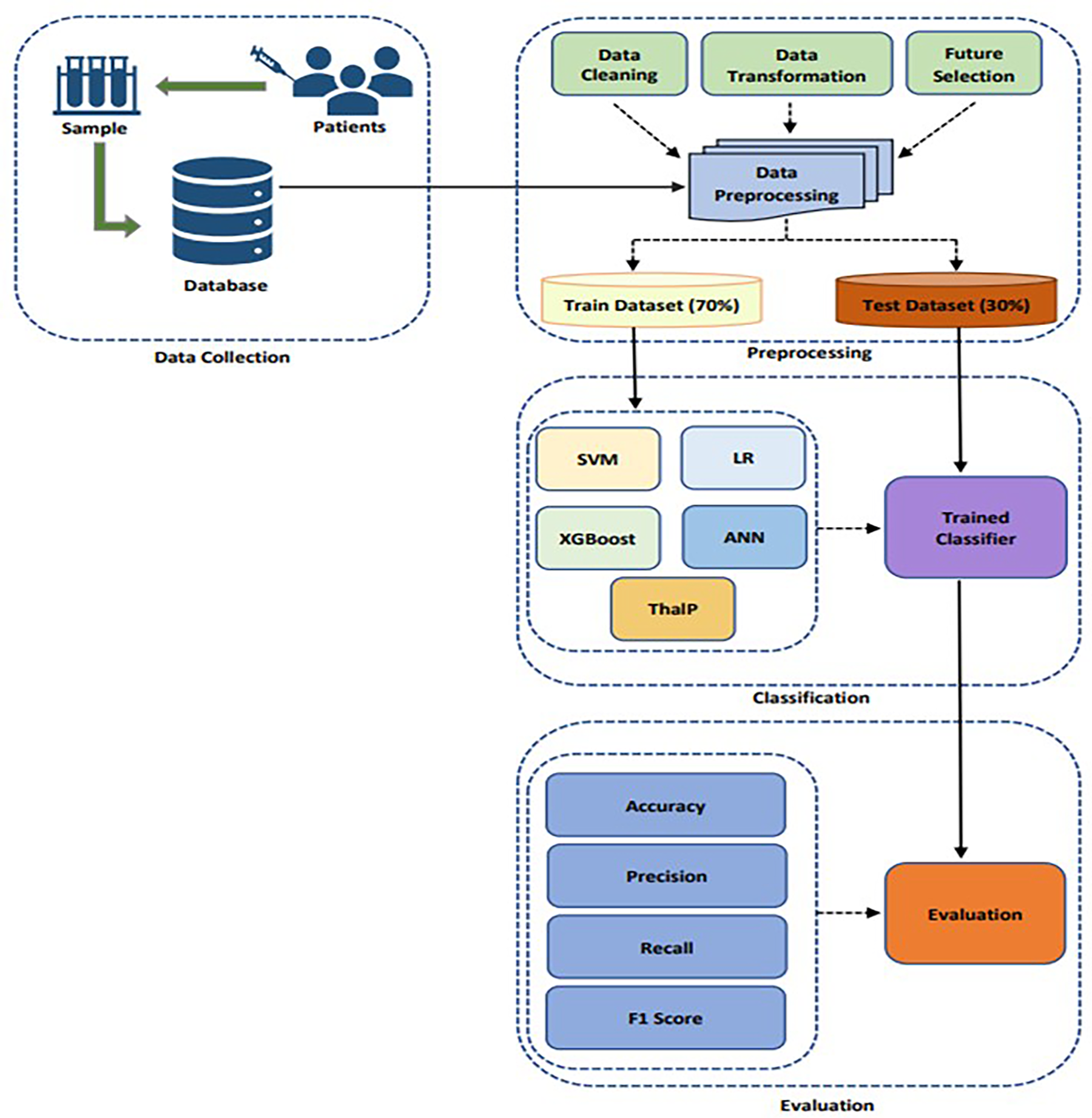
Methodology steps applied for classification.
In this study, Support Vector Machines (SVM), Logistic Regression (LR), XGBoost, Artificial Neural Networks (ANN), and a hybrid model named ThalP were used to predict thalassemia. Model hyperparameters were selected based on empirical evaluation and standard configurations commonly used in similar biomedical classification tasks. The goal was to achieve a balance between model performance and generalization while avoiding unnecessary model complexity.
Below is a brief explanation of each model:
To prevent information leakage between models, a five-fold out-of-fold (OOF) stacking strategy was applied. In this approach, base models were trained on four folds and generated probability predictions for the remaining fold. These out-of-fold predictions were then used as input features for training the meta-classifier.
The meta-classifier of ThalP is a neural network consisting of three hidden layers with 128, 64, and 32 neurons. The combined probability outputs of the base models serve as the input features of the neural network. The final classification is performed using a softmax activation function in the output layer.
Performance metrics
In this study, several standard performance metrics were used to evaluate the success of the machine learning models. These metrics include:
Confusion matrix
A confusion matrix is a table that allows the visualization of the performance of a classification model. It shows the number of correct and incorrect predictions made by the model and is composed of the following elements (Figure 7):
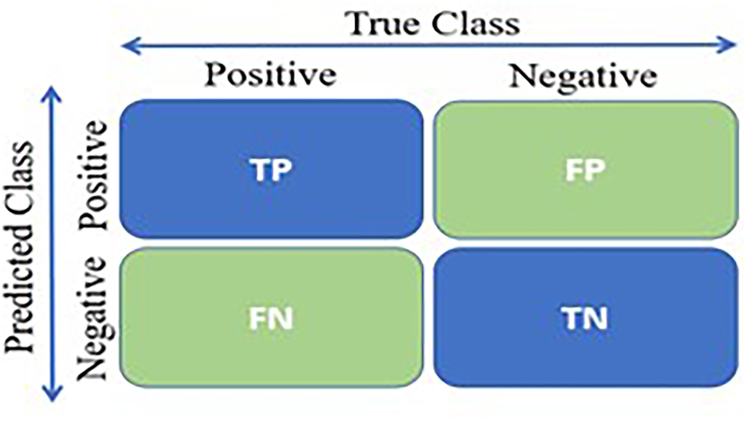
Confusion matrix.
Our hybrid model, ThalP, was trained on a dataset consisting of 1534 samples, based on the value ranges of normal individuals and those with thalassemia (alpha, beta minor, beta-intermedia, beta major). It was then tested on a dataset consisting of 349 samples who presented to Atatürk University Research Hospital with a thalassemia diagnosis. The performance scores of the test results are shown in the Table 3 (Table 3).
Classification results of models on the test (real) dataset
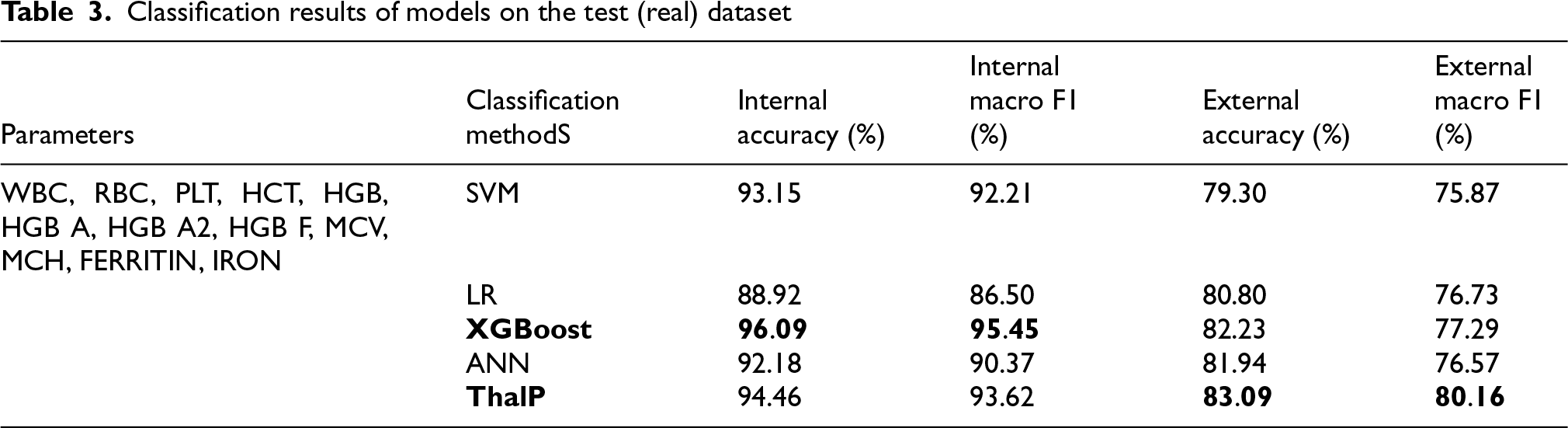
Classification results of models on the test (real) dataset
Figures 8, 9, 10, 11 and 12 present the multiclass confusion matrices of the SVM, LR, XGBoost, ANN, and ThalP algorithms employed in the study (Figure 8, 9, 10, 11 and 12).
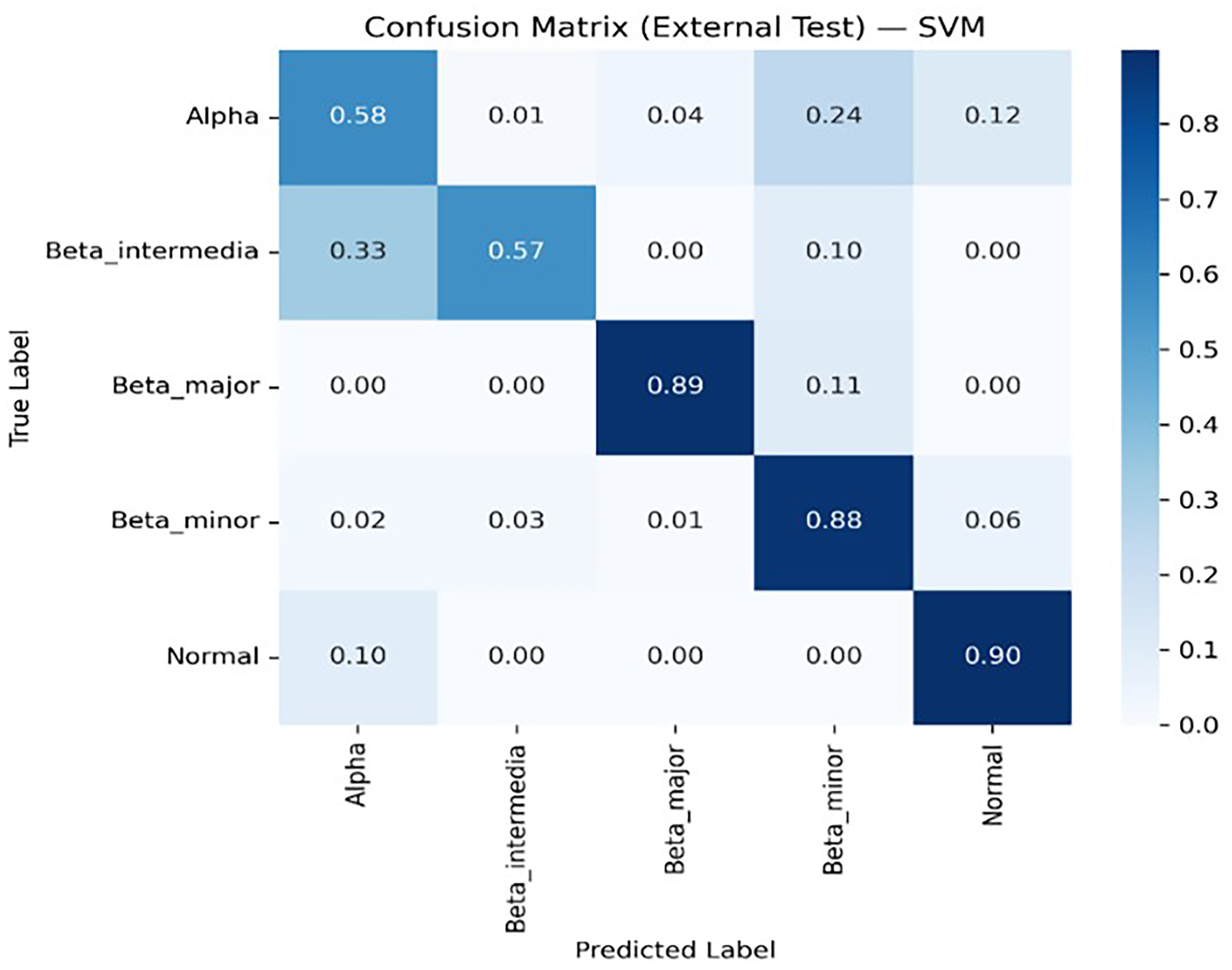
SVM multiclass confusion matrix.
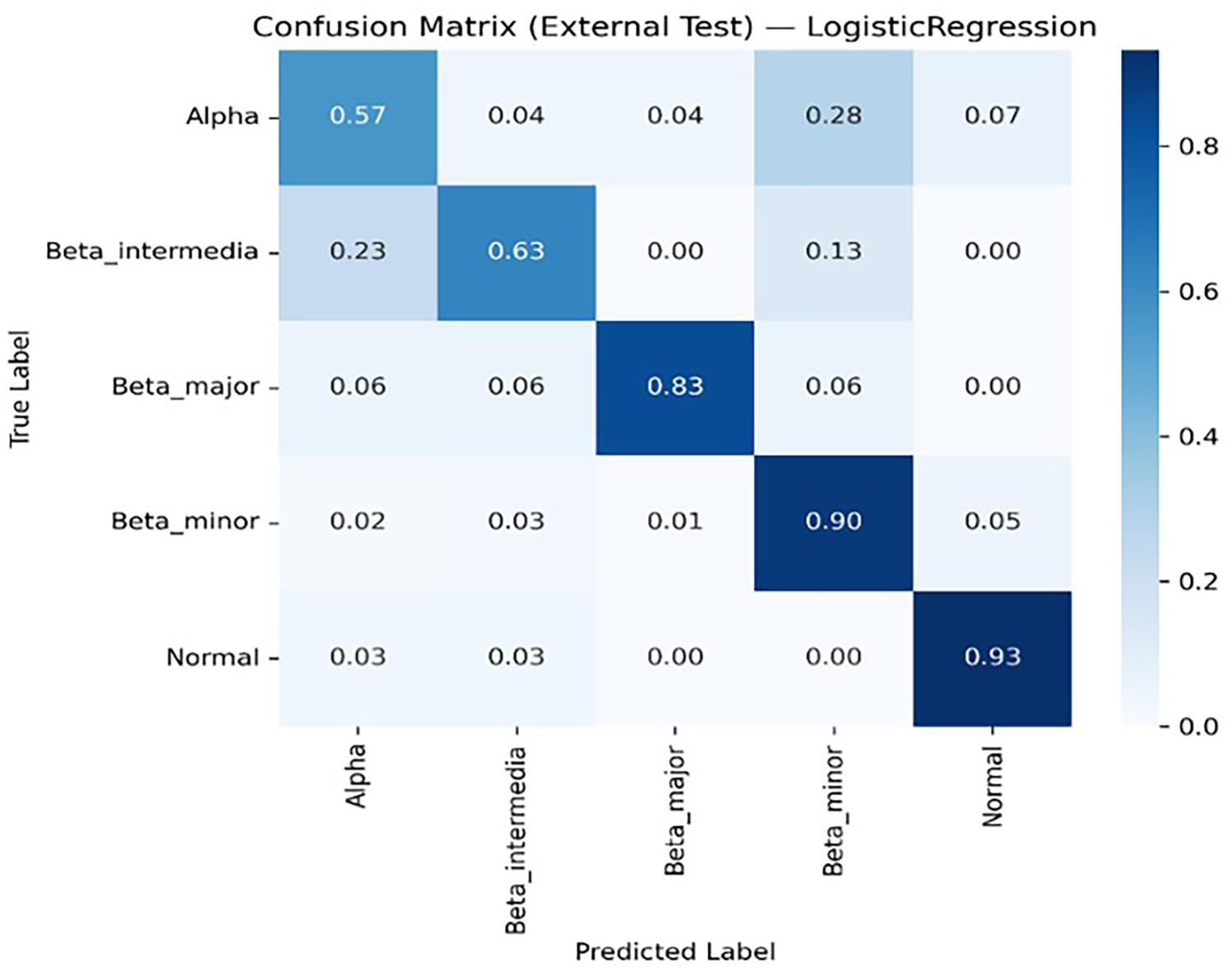
LR multiclass confusion matrix.
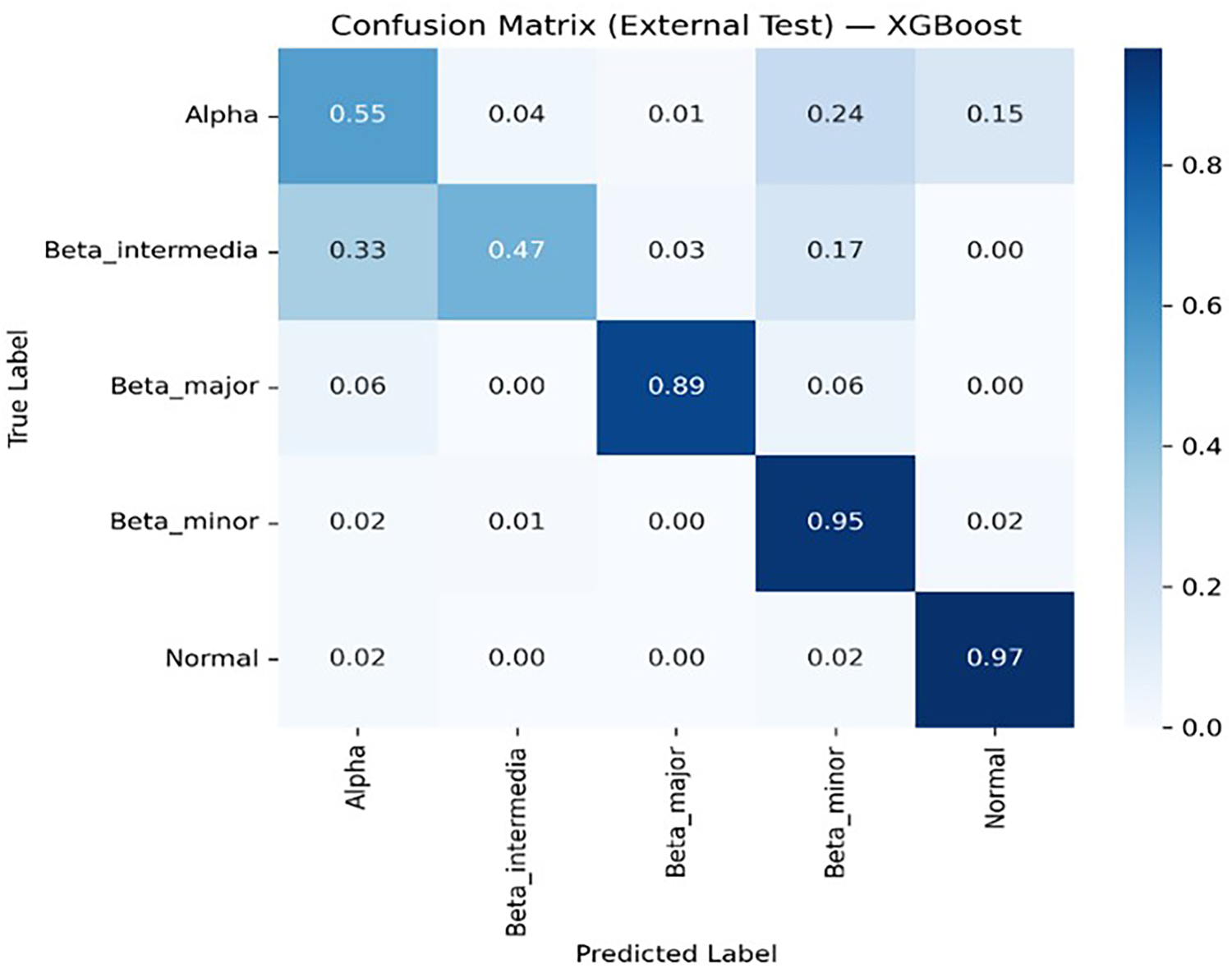
XGBoost multiclass confusion matrix.
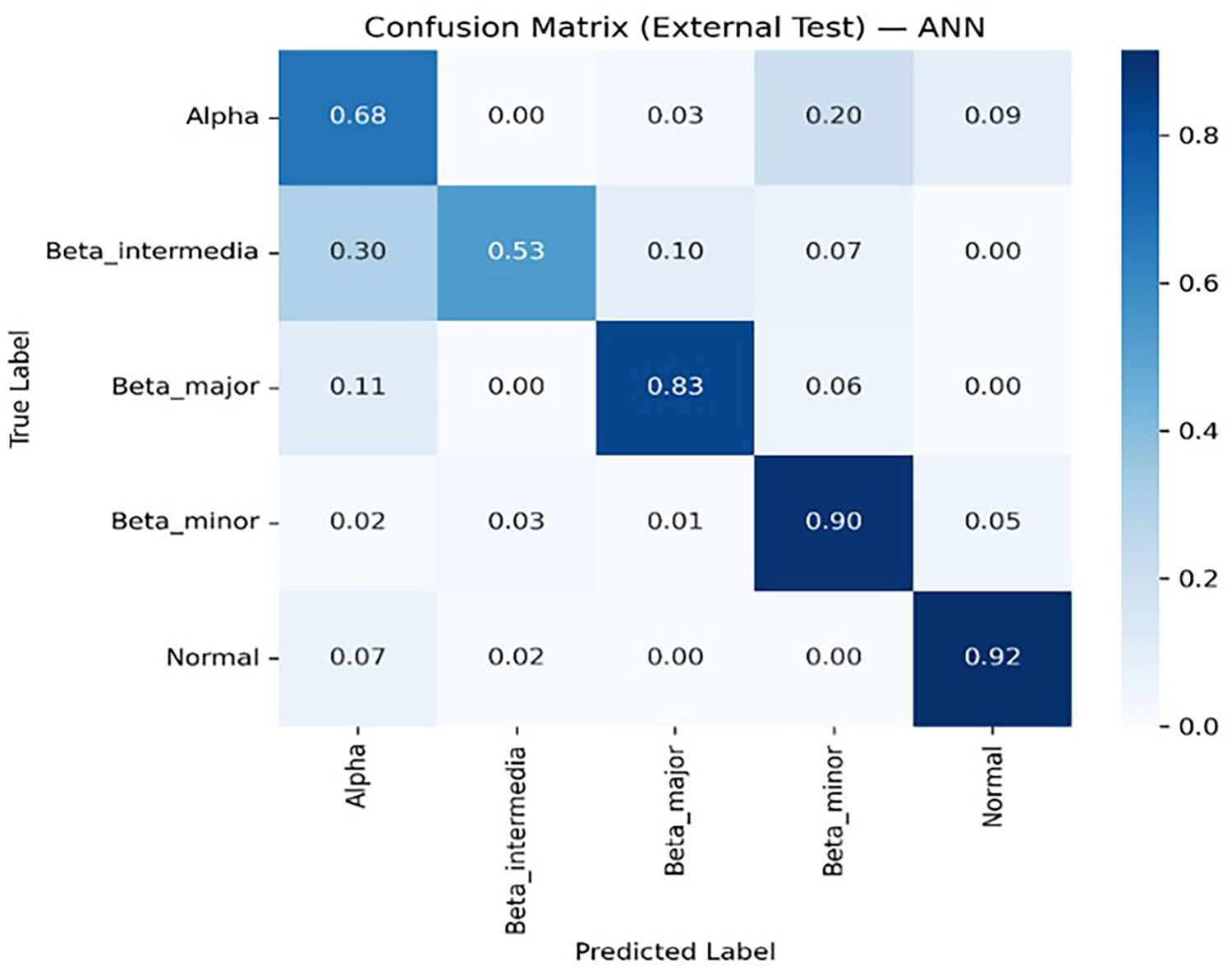
ANN multiclass confusion matrix.
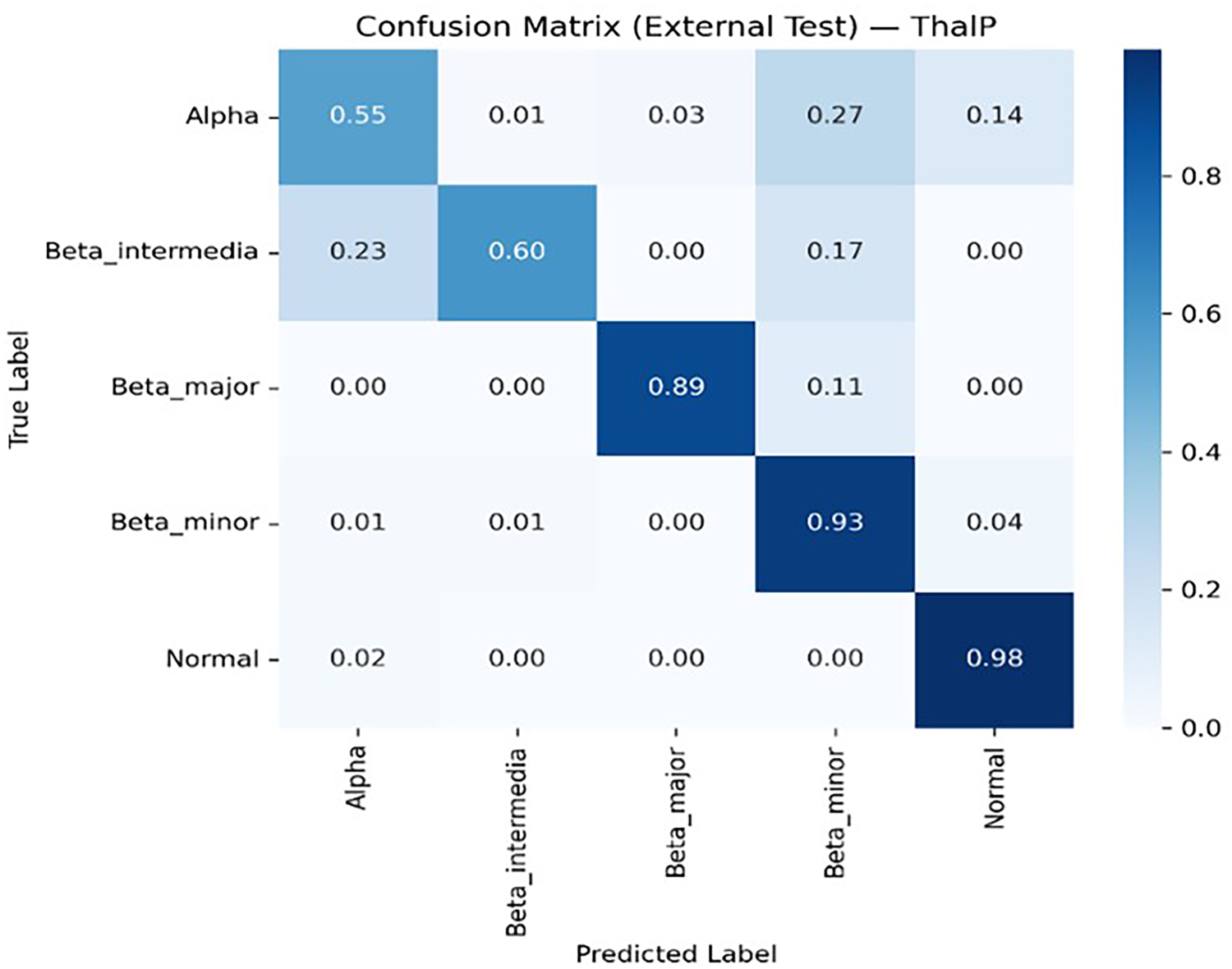
ThalP multiclass confusion matrix.
An examination of the table reveals that our hybrid model, ThalP, achieved the highest accuracy score of 83.09% on the test dataset. XGBoost followed immediately with an accuracy score of 82.23%.
To evaluate the reliability of predicted probabilities, model calibration was assessed using Multiclass Brier Score and Expected Calibration Error (ECE). Calibration analysis provides information about how well predicted probabilities reflect actual outcomes (Figure 13 and Figure 14).
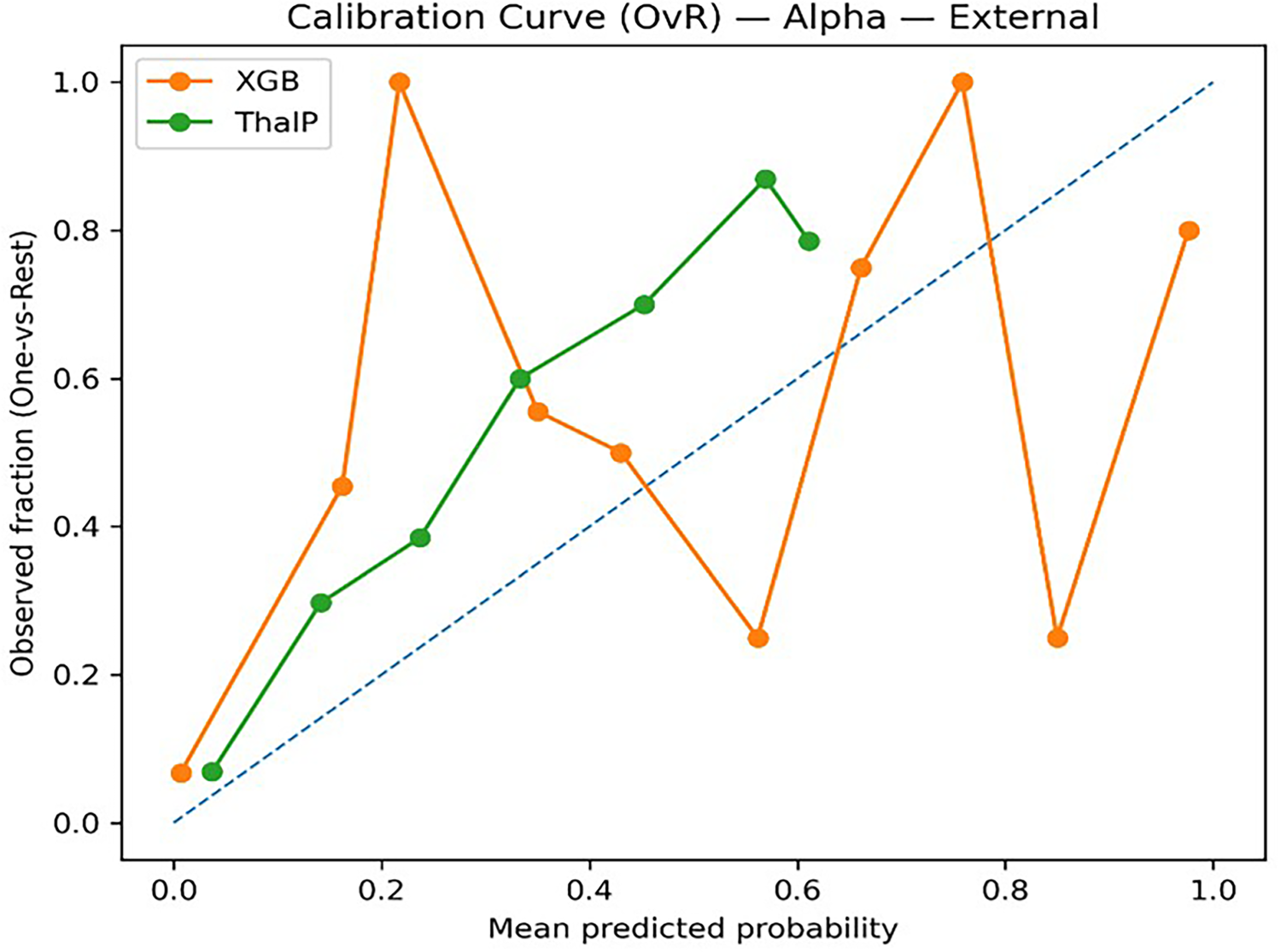
Calibration matrix alpha (XGB vs ThalP).
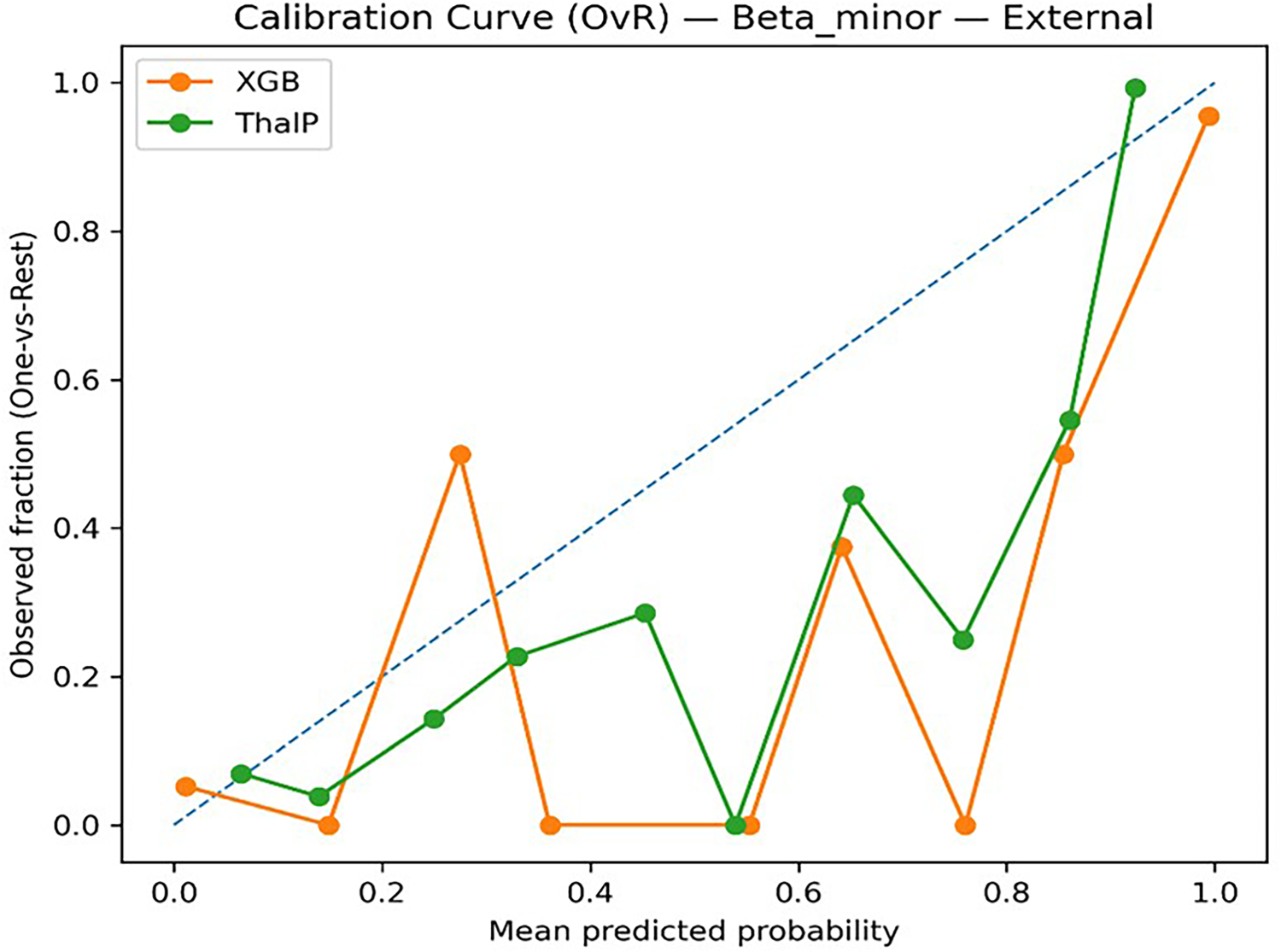
Calibration matrix Beta Minor (XGB vs ThalP).
To better understand the contribution of individual variables to model predictions, SHAP (SHapley Additive Explanations) analysis was performed. SHAP values provide a quantitative interpretation of the influence of each feature on the model output.
The SHAP analysis conducted on the XGBoost model revealed that HbA2, HbF, MCH, and MCV were among the most influential variables for the classification of thalassemia subtypes. These parameters consistently showed high SHAP importance values, indicating their strong contribution to model predictions (Figure 15, Figure 16).
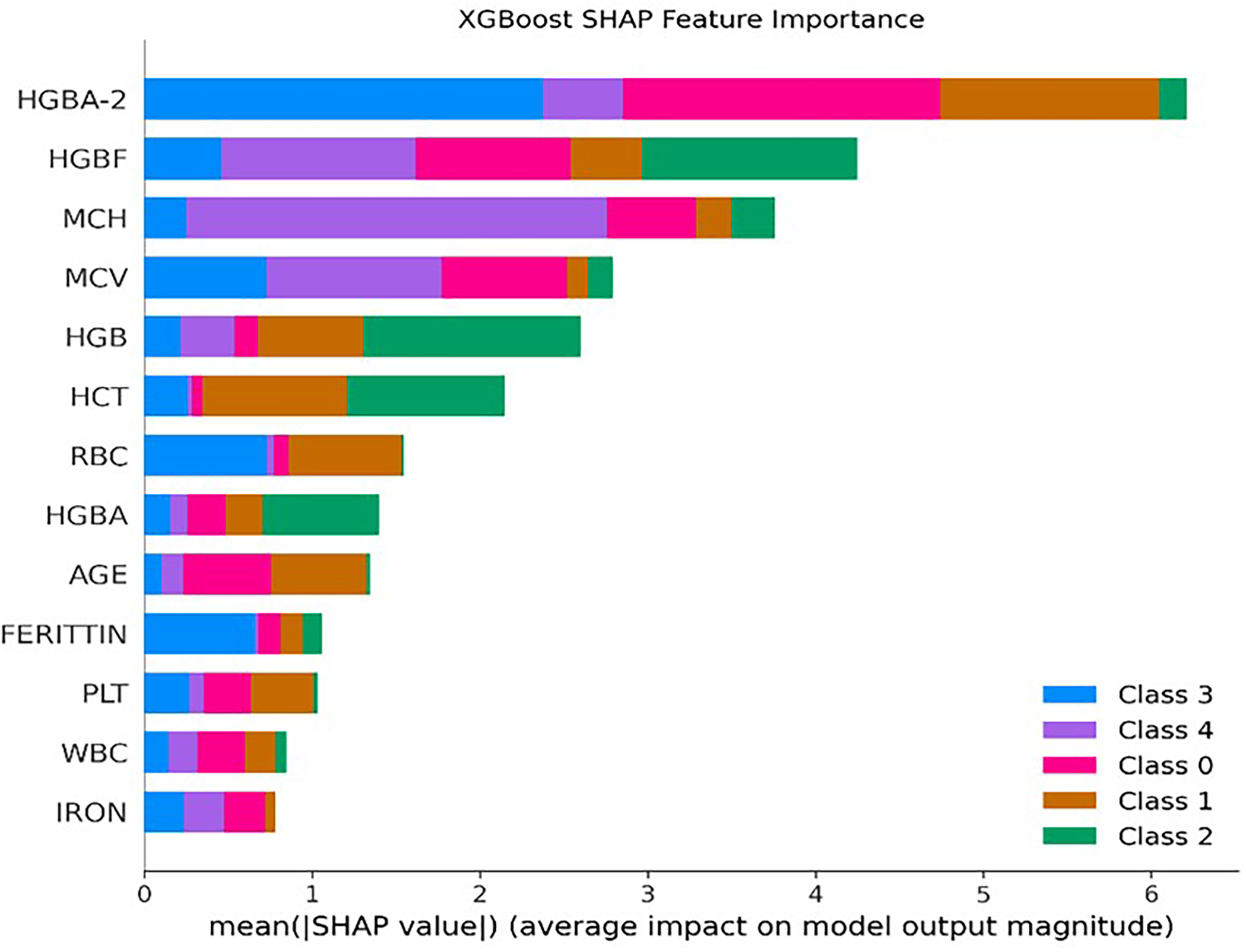
SHAP feature importance (XGB).
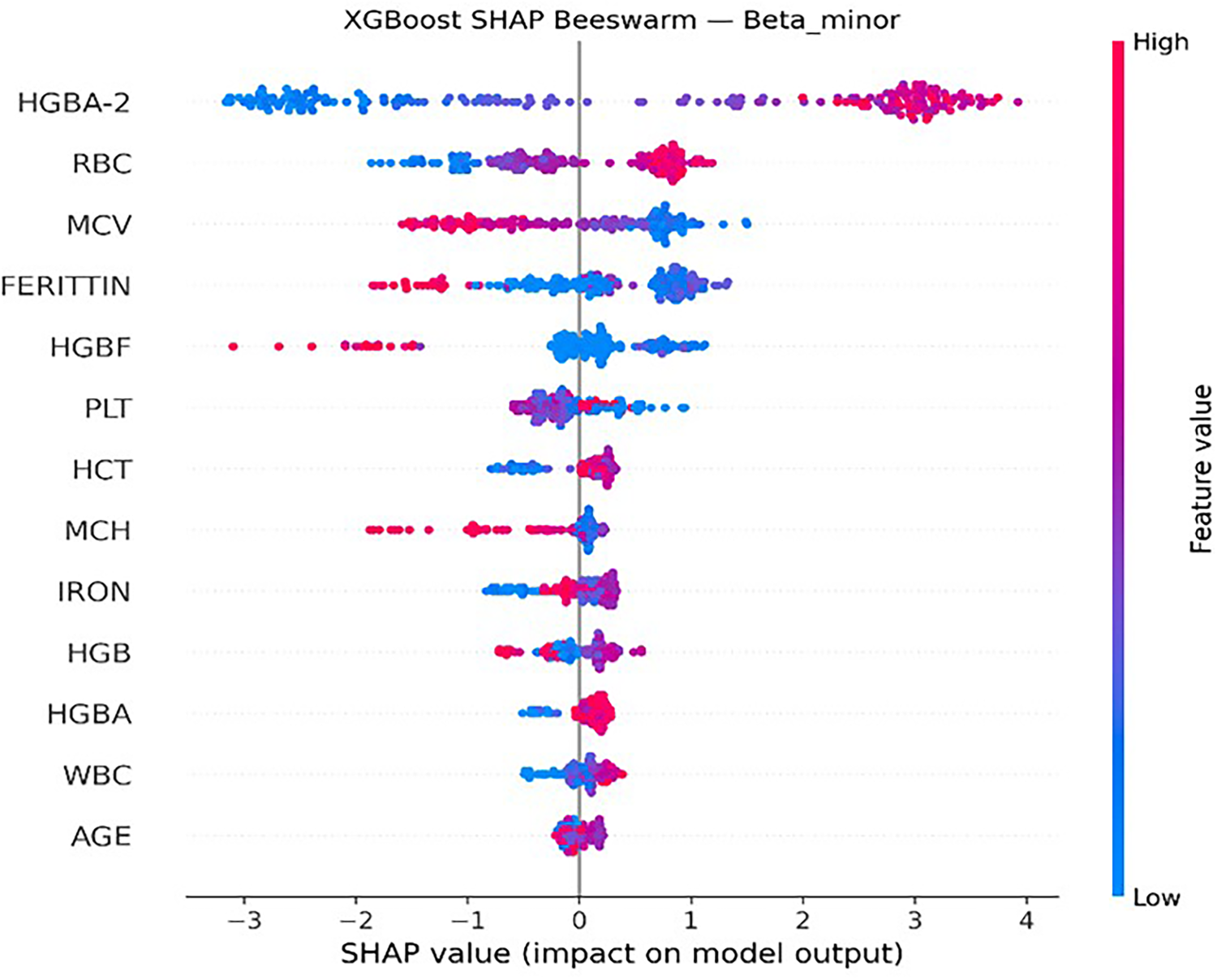
SHAP beeswarm Beta Minor (XGB).
In addition, SHAP analysis was applied to the proposed hybrid model (ThalP) to evaluate the importance of probability outputs generated by the base models. The results showed that probability outputs derived from the XGBoost model played a dominant role in the final classification decisions for several diagnostic classes (Figure 17 and Figure 18).
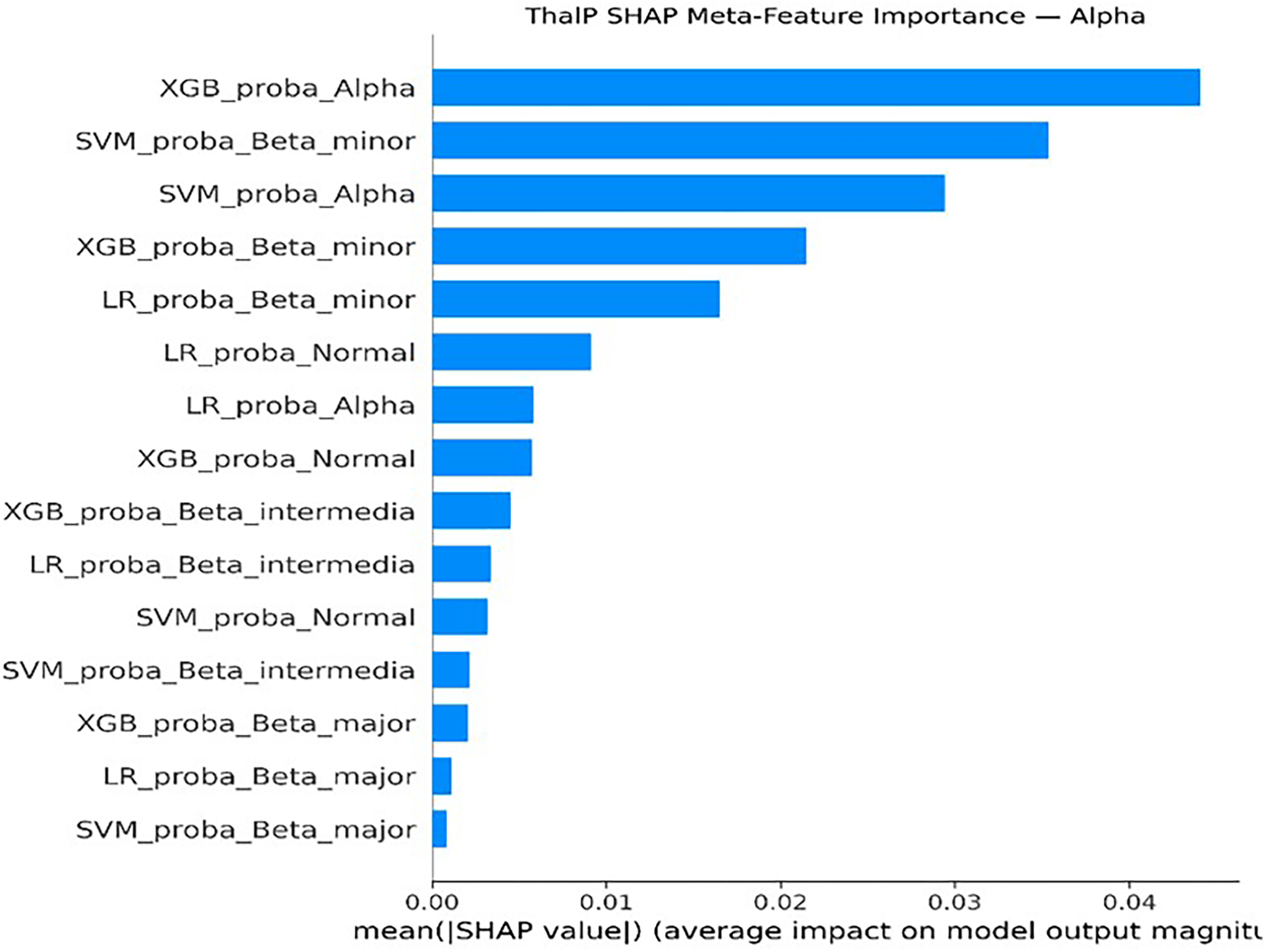
ThalP SHAP meta-feature importance (alpha class).
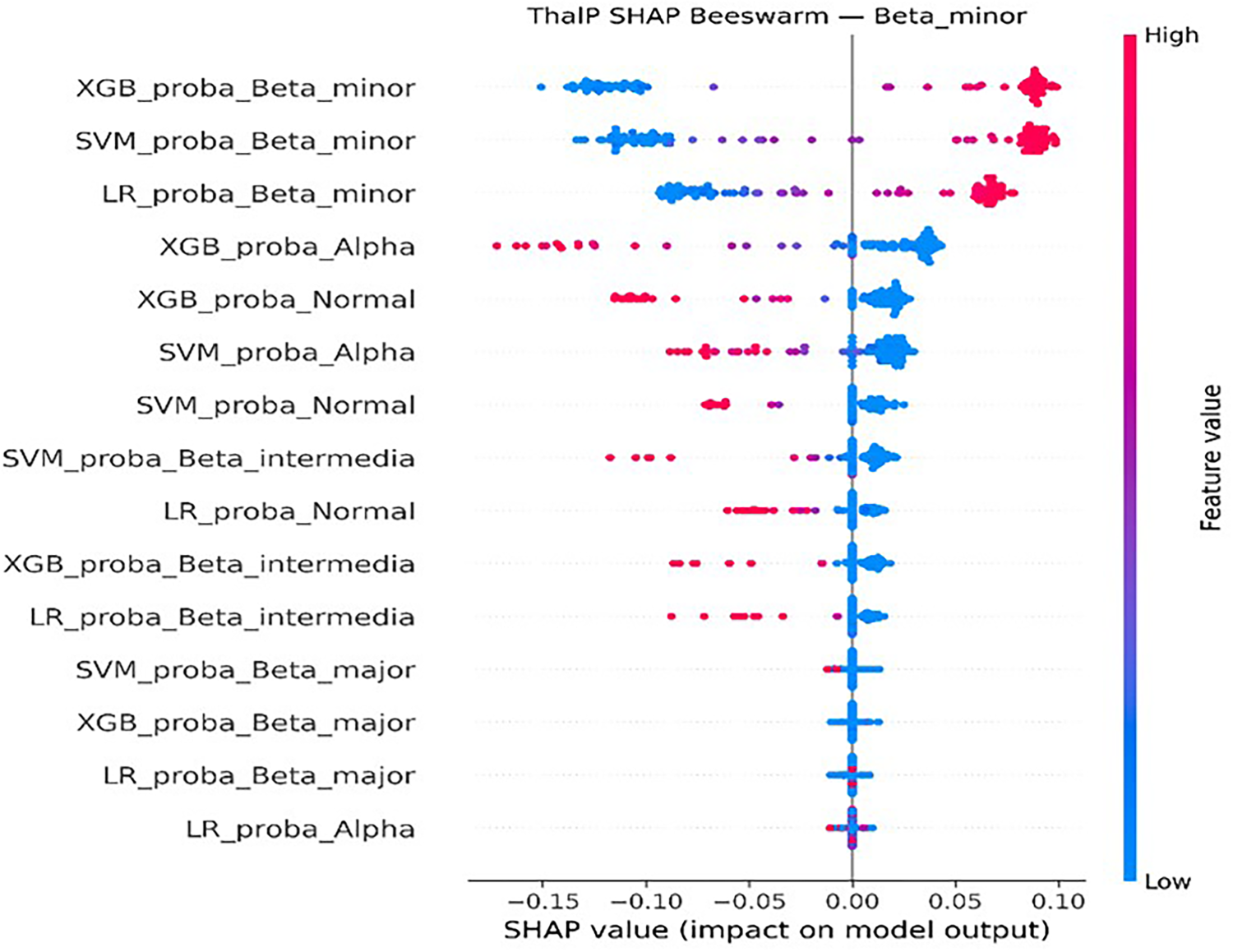
ThalP SHAP beeswarm (Beta Minor class).
Receiver Operating Characteristic (ROC) analysis was performed using a one-vs-rest strategy for the five-class classification problem. The ThalP model achieved strong discriminative performance across all classes, with a high macro-average AUC value, indicating reliable separation between thalassemia subtypes (Figure 19).
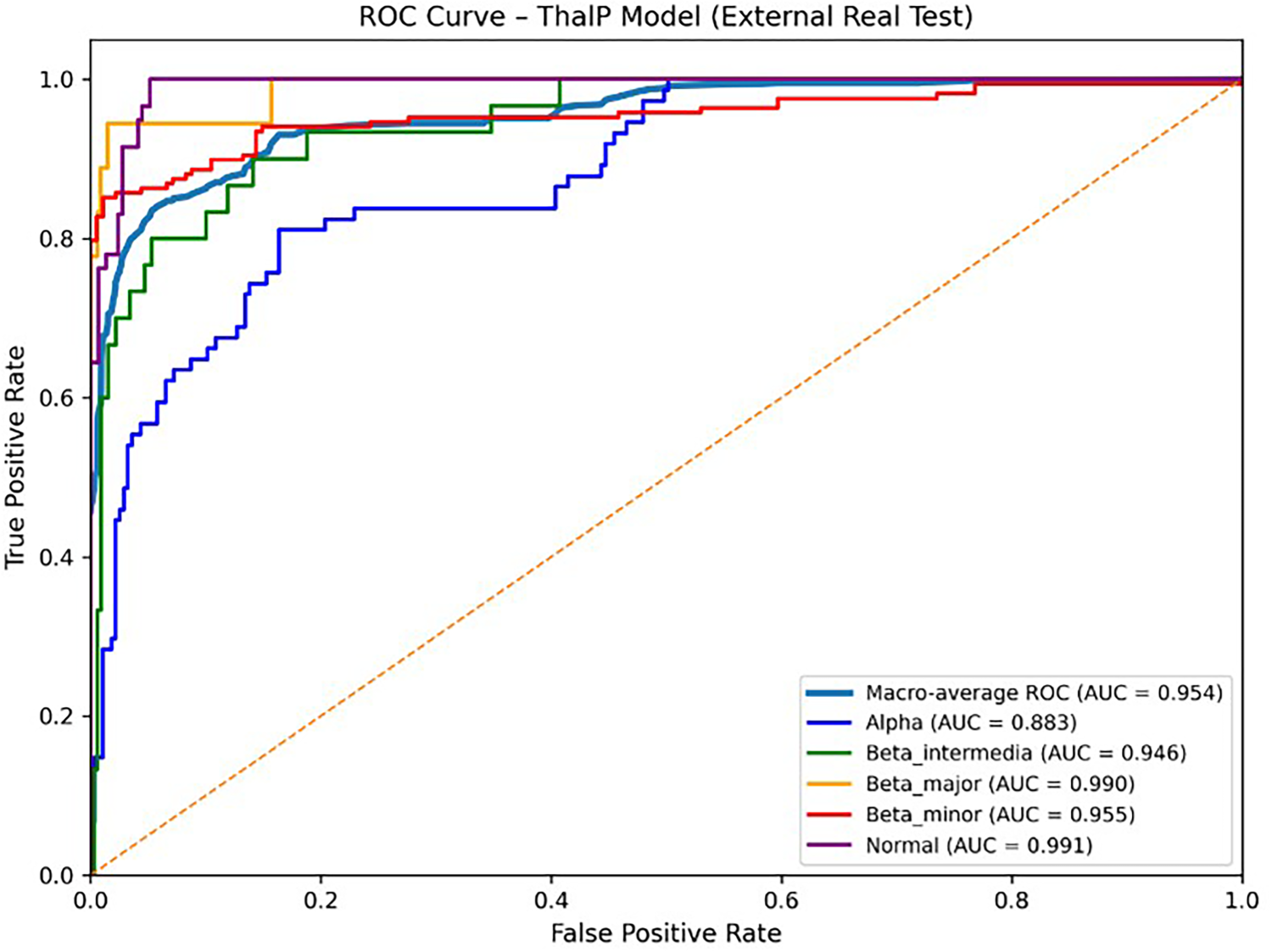
ThalP ROC-AUC curves.
A review of the literature reveals that Sadiq et al. (2021) applied SVM, Gradient Boosting Machine (GBM), Random Forest (RF), and a hybrid ensemble model named SGR-VC to predict beta thalassemia carrier status using red blood cell indices obtained from complete blood count tests. In their study, the proposed SGR-VC ensemble model achieved an accuracy of 93% in a binary classification task, distinguishing between thalassemia carriers and non-carriers.
In contrast to binary classification approaches, the present study focuses on multi-class classification of thalassemia subtypes. In addition to complete blood count parameters, biochemical markers such as ferritin and iron levels were also included as predictive features due to their potential indirect contribution to disease diagnosis. Using these features, the proposed hybrid model ThalP achieved an accuracy of 83.1% and a macro-F1 score of 0.80 on the external real-world dataset.
Although the reported accuracy is lower than the binary classification results reported in some previous studies, it should be emphasized that the proposed model addresses a significantly more complex problem by distinguishing between five diagnostic classes, including normal individuals, alpha thalassemia, beta thalassemia minor, beta thalassemia intermedia, and beta thalassemia major. Therefore, the results demonstrate that the proposed hybrid architecture provides a promising framework for multi-class thalassemia subtype classification using routinely available hematological and biochemical parameters.
In another study, Liu applied Principal Component Analysis (PCA) to reduce the dimensionality of hematological data for thalassemia diagnosis. Logistic Regression and Partial Least Squares (PLS) regression models were then applied to the reduced dataset. Their results showed that the PLS model outperformed the PCA-LR model, achieving a prediction accuracy of 92.5% on a dataset consisting of 110 samples.
However, similar to many studies in the literature, their approach focused on binary classification, distinguishing only between thalassemia patients and healthy individuals. The study did not investigate the classification of different thalassemia subtypes.
In contrast, the present study addresses a multi-class classification problem by distinguishing between five diagnostic categories: normal individuals, alpha thalassemia, beta thalassemia minor, beta thalassemia intermedia, and beta thalassemia major. Furthermore, our model was trained on a larger dataset consisting of 1534 synthetic training samples and evaluated using an external real-world dataset of 349 patients, providing a more comprehensive evaluation framework for thalassemia subtype classification. 26
In another study, Wang et al. evaluated the performance of a hybrid model called M-Thal-Classifier, which is based on the XGBoost algorithm, together with several traditional machine learning methods including Random Forest, Support Vector Classifier, Naive Bayes, Logistic Regression, and K-Nearest Neighbors. Their study was conducted on a dataset consisting of 1819 samples collected from the clinical laboratory of Ningde Municipal Hospital of Ningde Normal University. The dataset was divided into four diagnostic groups (Normocytic TT, Microcytic TT, IDA, and Normal), and class imbalance was addressed using the SMOTENC oversampling technique. The results showed that the M-Thal model achieved an accuracy of 97.06%.
Although the study shares similarities with the present research in terms of multi-class classification, there are several methodological differences. The current study focuses on the classification of five clinically relevant thalassemia subtypes, including alpha thalassemia, beta thalassemia minor, beta thalassemia intermedia, beta thalassemia major, and normal individuals. In addition, the proposed ThalP hybrid model was evaluated using an external real-world dataset, which provides a more realistic assessment of model performance. The experimental results demonstrate that ThalP achieves strong predictive performance for multi-class thalassemia subtype classification using routinely available hematological and biochemical parameters. 27
Overall, the literature review indicates that most machine learning studies on thalassemia focus primarily on binary classification tasks, such as distinguishing between thalassemia carriers and healthy individuals. In many of these studies, basic machine learning algorithms are applied to relatively limited datasets, and the classification of different thalassemia subtypes is rarely addressed.
In contrast, the present study investigates a multi-class classification framework capable of distinguishing between five clinically relevant diagnostic categories: normal individuals, alpha thalassemia, beta thalassemia minor, beta thalassemia intermedia, and beta thalassemia major. By integrating multiple machine learning models through the proposed ThalP hybrid architecture, the study demonstrates that multi-class thalassemia subtype classification can be effectively achieved using routinely available hematological and biochemical parameters. The results obtained from the external test dataset further highlight the potential of hybrid machine learning approaches as clinical decision-support tools in thalassemia diagnosis.
The explainability analysis performed using SHAP provided important insights into the clinical relevance of the predictive variables used in the models. The SHAP results indicated that HbA2, HbF, MCH, and MCV were the most influential hematological parameters in distinguishing different thalassemia subtypes.
These findings are consistent with established clinical knowledge regarding thalassemia diagnosis. Elevated HbA2 levels are widely recognized as a key indicator for beta-thalassemia carriers, while variations in HbF levels are commonly associated with more severe forms of the disease. Similarly, red blood cell indices such as MCV and MCH are frequently used in clinical practice to identify microcytic anemia patterns associated with thalassemia.
Therefore, the SHAP analysis not only improves the transparency of the machine learning models but also confirms that the proposed approach relies on clinically meaningful variables when making predictions. This interpretability strengthens the potential applicability of the proposed model as a decision-support tool in real-world clinical settings.
The ROC comparison further supports the effectiveness of the proposed ThalP model. In addition to achieving the highest external accuracy and macro-F1 score, ThalP also demonstrated the strongest overall discrimination capability in terms of macro-average ROC-AUC. This suggests that integrating multiple base learners through a hybrid stacking framework improves the separation of thalassemia subtypes in clinically heterogeneous data.
Although statistical significance tests such as confidence interval estimation were not included in this study, future work will focus on incorporating more comprehensive statistical validation methods to further assess model reliability.
Limitations
The present study has several limitations that should be acknowledged. First, the training phase relied on a synthetic dataset generated to address the limited availability of labeled clinical data, which may not fully capture the complexity and variability of real-world patient populations. Although the synthetic data were generated based on statistical distributions derived from real laboratory measurements, this approach may still introduce potential biases that could affect model generalizability. Second, the study utilized hematological parameters obtained from a single dataset, and therefore the performance of the proposed model should be further validated using larger, independent, and multi-center clinical datasets. Finally, while multiple machine learning algorithms were evaluated, the clinical applicability of the model requires prospective validation in real clinical settings before routine diagnostic use.
Another limitation of this study is the absence of formal statistical significance analysis. Future studies should incorporate confidence interval estimation and hypothesis testing to provide a more comprehensive evaluation of model performance.
Conclusion
In this study, several machine learning algorithms were evaluated for the classification of thalassemia using complete blood count parameters together with biochemical indicators such as ferritin and iron levels. Among the evaluated models, the proposed hybrid architecture ThalP demonstrated the best overall performance on the external test dataset, achieving an accuracy of 83.1% and a macro-F1 score of approximately 0.80.
The evaluation results on the real clinical dataset indicate that the model maintains strong performance when applied to real-world data.
The results indicate that integrating multiple machine learning models through a hybrid stacking framework can improve predictive performance compared with individual baseline models. In addition, the inclusion of routinely available hematological and biochemical parameters allows the model to capture clinically relevant patterns associated with different thalassemia subtypes.
Therefore, the proposed ThalP model has the potential to serve as a clinical decision-support tool that may assist physicians in the preliminary screening and classification of thalassemia subtypes. Such systems may help support clinical decision-making processes by providing additional insights derived from routinely collected laboratory data.
However, our model has been tested on a limited patient group consisting of 349 samples; therefore, it is recommended that the model performance be tested in the future on different populations and on datasets containing more samples.
Future studies will enhance the generalizability of the model by supporting ThalP with diverse genetic, biological, and biochemical data, as well as testing it on a larger, more diverse dataset, encompassing a wider patient population. Furthermore, using deep learning-based approaches, convolutional neural networks (CNN) and transfer learning methods may further improve model performance.
Furthermore, the development of a mobile and web-based decision support system is recommended for healthcare professionals to instantly analyze patient data, shorten diagnosis times, and increase the model's applicability in settings such as hospitals and clinics.
Such studies will increase the effectiveness of AI-based diagnostic systems in healthcare, contributing to both early diagnosis and treatment processes for decision-makers.
Footnotes
Abbreviations
Ethics approval and consent to participate
Ethical approval for this study was obtained from the Atatürk University Non-Interventional Clinical Research Ethics Committee with the decision number B.30.2.ATA.0.01.00/313 dated 02/05/2025.
Author contributions
Hakan Tekin: research concept and study design, literature review, data collection, reviewing/editing a draft of the manuscript, writing of the manuscript; Ece G. Abbasogullari: research concept and study design, data collection; Faruk B. Gunay research concept and study design, literature review, reviewing/editing a draft of the manuscript. All the authors have revised and approved the final manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
The data that support the findings of this study are available from the corresponding author, [RTD], upon reasonable request.
Clinical trial number
Not applicable.