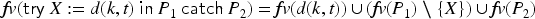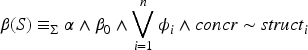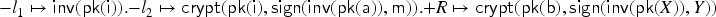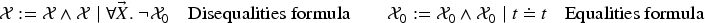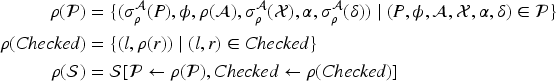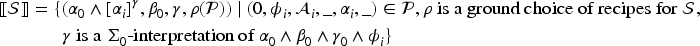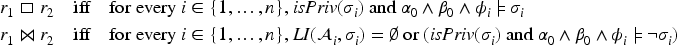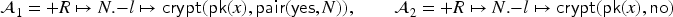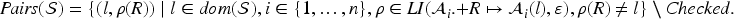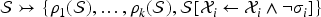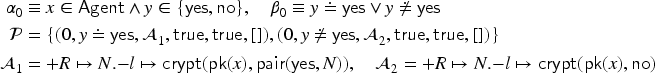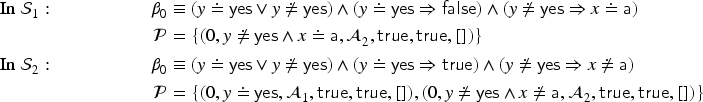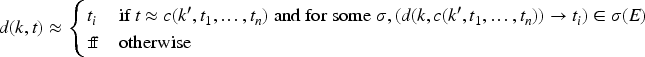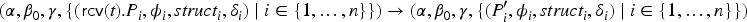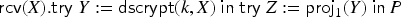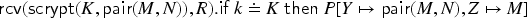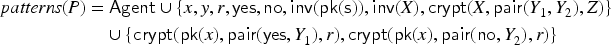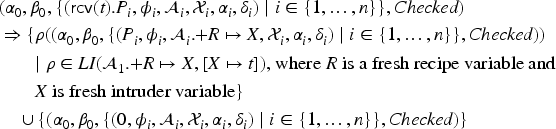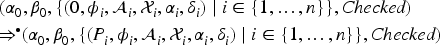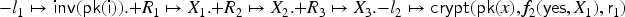We present a decision procedure for verifying whether a protocol respects privacy goals, given a bound on the number of transitions. We consider multi message-analysis problems, where the intruder does not know exactly the structure of the messages but rather knows several possible structures and that the real execution corresponds to one of them. This allows for modeling a large class of security protocols, with standard cryptographic operators, non-determinism, branching and statefulness. Our first contribution is the definition of a decision procedure for a fragment of alpha-beta privacy. Moreover, we have implemented a prototype tool as a proof-of-concept and a first step towards automation. Our second contribution is to show that, for a class of protocols satisfying certain syntactic conditions, it is sound to restrict the intruder model to a typed model, where the intruder only sends well-typed messages. Our typing result holds for an unbounded number of transitions.
The concept of -privacy was introduced as an alternative way to define privacy-type properties in security protocols.1,2 The most widespread models of privacy use an equivalence notion between two processes to describe the goal that the intruder cannot distinguish between two possible realities. In contrast, -privacy considers states that each represent one possible reality, and what the intruder knows about the reality in that state. This knowledge is not only in form of messages as in classic intruder models, but also in form of relations between messages, agents, and so on. Together with a notion of what the intruder is allowed to know in a given state, we define a privacy violation if the intruder in any reachable state knows more than allowed. Privacy is then a question of reachability—a safety property—which is often easier to reason about and to specify than classical equivalence notions. First, one does not have to boil the privacy goal down to a distinction between two situations, which is often unnatural for more complicated properties. Second, one specifies goals positively by what the intruder is allowed to know rather than what they are not allowed to know (and thus unable to distinguish). This essentially means that in the worst case one is erring on the safe side, that is, allowing less than the protocol actually reveals, and thus can be alerted by a counterexample. The expressive power of equivalence notions and of -privacy is actually hard to relate in general, due to the different nature of the approaches. However, on concrete examples it seems one can always give reasonable adaptations from one approach to the other.1,2
A decision procedure
-privacy shifts the problem from a notion of equivalence (that is a challenge for automation) to a simple reachability problem where however the privacy check for each reached state is more involved. So far, there is only one work3 that considers a solution to checking a given state in -privacy. However, that work is only applicable to specifications without conditional branching and it is based on an exploration of all concrete messages that the intruder can send, which are infinitely many unless one bounds the intruder.
Our first contribution in this article is a decision procedure for the full notion of transaction processes defined by Gondron et al.1 for constructor/destructor theories.4–8 This notion in fact entails that the intruder performs a symbolic execution of the transaction that in general yields several possibilities (due to conditional branching if the intruder does not know the truth value of the condition) and the intruder can then contrast this with all observations and experiments (constructing different messages and comparing them) to potentially rule out some possibilities. The core of our work is in a procedure to model this intruder analysis without bounding the number of steps that the intruder can make in this process. To that end, we use a popular constraint-based technique to represent the intruder symbolically, that is, without exploring infinite sets of possibilities, which we call here the lazy intruder. In fact, we use several layers of symbolic representation to make the approach feasible.
Our decision procedure tells us whether from a given state we can reach a state that violates privacy for a fixed bound on the number of transitions. Our procedure is limited to such a bound on transitions, corresponding to the restriction to a bounded number of sessions in many approaches.9 This is similar to the bounds needed in tools like APTE,10 AKiSs,11 SPEC12,13 and DeepSec.7 In fact, this article draws from the techniques used in these approaches, such as the symbolic representation of the intruder, a notion of an analyzed intruder knowledge, and methods for deciding the equivalence of frames. There are, however, several basic differences and generalizations. In particular, we use a symbolic handling of privacy variables (that in the equivalence-based approaches are simply one binary choice) and this is linked to logical formulas about relations between elements of the considered universe. In fact, in the prototype implementation of our decision procedure that we provide as a further contribution, we employ the SMT solver cvc514 to handle these logical evaluations. Moreover, we have multiple frames with constraints for the different possibilities resulting from conditional branching and we analyze if the intruder can rule out any possibilities in any instance.
In contrast, the tools ProVerif5 and Tamarin15 do handle unbounded sessions but require the restriction to so-called diff-equivalence,8,16 which drastically limits the use of branching in security protocols, though Cheval and Rakotonirina17 recently relax these restrictions a bit. It seems thus in general that one has to choose between expressive power and unbounded sessions, and our approach is decidedly on the side of expressive power.
A typing result
Type-flaw attacks occur when a security protocol uses several messages that have different meanings but have a similar shape so that an intruder can exploit it and send a message of one type where a message of another type is expected. For example, one message of the protocol is a signature on a nonce for challenge-response, say (where denotes the private key to the public key of agent ), and another message is a signature on an encrypted message like . It is actually easy to prevent type-flaw attacks by good protocol design: messages should not sign or encrypt raw data, but rather include a few bits of information that specify the meaning of the message. In the example, the signatures should contain at least some kind of tag that distinguishes the different types of signed statements. Such a countermeasure is not only almost for free, it is completely in line with prudent engineering principles.18,19
Formal verification of security protocols generally gets easier if we can rule out type-flaw attacks and analyze everything in a typed model where the intruder is restricted to sending well-typed messages. Then, many security problems become decidable (and, e.g., one can guarantee termination of tools like ProVerif20).
This motivates a relative soundness result of the form: “if a protocol that obeys certain type-flaw resistance requirements has an attack, then it has a well-typed attack.” It is then sound to verify such a protocol in the typed model. This is particularly relevant in practice, if many existing protocols without modification already satisfy type-flaw requirements.
Most of the existing typing results, for example, Almousa et al.,21 Arapinis and Duflot,22 Arapinis and Duflot,23 Cortier and Delaune,24 and Hess and Mödersheim,25,26 use a constraint-based method for analyzing security protocols that is based on a symbolic approach: this technique avoids exploring all the messages that the intruder could generate at a given point, but instead uses a variable with the constraint that this variable represents any message that the intruder can generate from their current knowledge. This variable is only instantiated when the choice matters for the attack. One can then show that in a type-flaw resistant protocol, these instantiations are always well-typed, and that all remaining variables (that do not matter for the attack in the end) can be instantiated with something well-typed as well. Thus, if an attack exists, there exists a well-typed one. Although this method yields a decision procedure only for a bounded number of sessions, since the argument applies to an attack of arbitrary length, the typing result is not bounded to a fixed number of sessions and can be used in approaches/tools that do not use the lazy intruder (like ProVerif).
A trend in protocol verification is the support for privacy-type properties such as unlinkability or vote-secrecy, that is, secrecy of a choice over a small domain of intruder-known values. This is challenging for verification tools and thus many tools require a restriction like diff-equivalence where, roughly speaking, conditions—and thus control flow—cannot depend on the private choice. It is thus very desirable to simplify the tools’ lives by a typing result, but that is harder to obtain for privacy as well. For instance, a typing result needs to exclude that the intruder can gain any insight about a condition (and thus possibly private choices) by sending an ill-typed message. This is in fact related again to the problem of control flow (that classical diff-equivalence sidesteps): the intruder may not know in general what exactly is happening in the protocol, while in standard protocol verification the intruder is only unclear about the concrete value of some cryptographically strong secrets.
Our second contribution in this article is a typing result for -privacy: “if there is an attack, then there is a well-typed one.” We define a set of requirements for protocols and algebraic theories we can support, and prove that under these requirements the procedure performs only well-typed instantiations of variables and well-typed intruder experiments. As in previous typing results, this is independent of the number of transitions considered. This result is, to our knowledge, not only more general than previous typing results for privacy, since the requirements are less restrictive and a larger class of protocols is considered, but it also has a more declarative proof.
Outline
In Section 2, we present the notion of -privacy in transition systems and define the problem that our procedure decides. In Section 3, we define how we symbolically represent messages sent by the intruder and how to solve constraints with the lazy intruder rules. In Section 4, we introduce the notion of symbolic states with their semantics. In Section 5, we explain how the intruder can perform experiments and make logical deductions relevant for privacy by comparing messages in their knowledge. In Section 6, we define the algebraic theories supported and how they are handled in the procedure. In Section 7, we discuss the prototype tool that we have developed and the case studies we have applied it to. In Section 8, we define the class of type-flaw resistant protocols that our typing result supports. In Section 9, we present the typing result for an unbounded number of transitions. In Section 10, we discuss related and future work. The Supplemental Appendix contains additional technical details and all the proofs of correctness.
This journal article is based on the conference paper,27 which presented the decision procedure. Our main new contributions are the support for stateful protocols and, most importantly, the typing result.
Preliminaries and problem definition
Mödersheim and Viganò2 introduce -privacy as a reachability problem in a state transition system, where each state contains two formulas and . Intuitively, represents what the intruder may know (e.g. the result of an election) and what the intruder has observed (e.g. the encrypted votes). Then, a state violates privacy iff some model of can be excluded by the intruder knowing , that is, the intruder in that state can rule out more than allowed. The transition system violates -privacy iff some reachable state does.
()-privacy for a state
Mödersheim and Viganò2 focus on how to define pairs for a fixed state, and describes a state-transition relation only briefly by an example. Let us also start with a fixed state. The formulas and are by Herbrand logic,28 a variant of first-order logic (FOL), with the difference that the universe is the quotient algebra of the Herbrand universe (the set of all terms that can be built with the function symbols) modulo a congruence relation . This congruence specifies algebraic properties of cryptographic operators. For concreteness, we use the congruence defined in Figure 1; the class of properties supported by our result is in Definition 6.1. The quotient algebra consists of the -equivalence classes of terms.
The congruence used in this article: and are asymmetric encryption and decryption, and are symmetric encryption and decryption, and are signing and verification/opening, is a transparent function and the are the projections, gives the private key corresponding to a public key, and gives the public key from a private key. Here , , , and the are variables standing for arbitrary messages. When the conditions are not met, the functions give , which is a constant indicating failure of decryption or parsing. If and are used as binary functions, we consider their deterministic variants where the random factor has been fixed and is omitted for simplicity.
Given an alphabet , a -interpretation interprets variable and relation symbols as usual in the Herbrand universe induced by and ; the interpretation of the function symbols is determined by the Herbrand universe. We have a model relation as expected. By construction, iff . We say that entails , and write , when every -interpretation that is a model of is also a model of . We write when and . We also use to define formulas.
We now fix the alphabet that contains all symbols we use, namely cryptographic functions, a countable set of constants representing agents, nonces and so on, and some relation symbols. We also have the set of variable symbols . Each protocol specification will fix a sub-alphabet of payload symbols; we call the technical symbols. All formulas use only symbols in and variables. In the rest of the article, we often omit the alphabet and just write to mean , and to mean .
The main idea of -privacy is that we distinguish between the actual privacy goal (e.g. an unlinkability goal talking only about agents) and the means to achieve it (e.g. the cryptographic messages exchanged).
Given two formulas over and over with , where denotes the free variables, we say that -privacy holds iff for every -interpretation there exists a -interpretation such that and agree on the variables in and on the relation symbols in .
We call the formula the payload, defining the privacy goal. For example, for unlinkability in an RFID-tag protocol, we may have a fixed set of tags and in a concrete state, the intruder has observed that two tags have run a session. Then in that state may be , meaning that the intruder is only allowed to know that both and are indeed tags, but not, for instance, whether . In our approach, the formulas that can occur fall into a fragment where we can always compute a finite representation of all models, in particular the variables like the in the example will always be from a fixed finite domain.
For the formula , we employ the concept of frames: a frame has the form , where the are distinguished variables called labels and the are messages (that do not contain labels). This represents that the intruder has observed (or initially knows) messages and we give each message a unique label. We call the set the domain of . A frame can be used as a substitution, mapping labels to messages.
To describe intruder deductions, we define a subset of the function symbols to be public: they represent operations the intruder can perform on known messages. For instance, all symbols used in Figure 1 are public except for , since getting the private key is not an operation that everyone can do themselves.a A recipe (in the context of a frame ) is any term that consists of only labels (in the domain of ) and public function symbols, so it represents a computation that the intruder can perform on . We write for the message generated by the recipe with the frame .
Two frames and with the same domain are statically equivalent, written , iff for every pair of recipes, we have . This means that the intruder cannot distinguish and , since any experiment they can make (i.e. comparing the outcome of two computations ) either gives in both frames the same result or in both frames not.
Static equivalence can be encoded in Herbrand logic2 and so for instance we can have as part of formulas like , where is a frame with variables and for some model is the concrete frame of intruder observations. As an example, let , and . Observe that has four models, but in the two models where we have , because for these models and give the same message in but different messages in . Since in this example is part of , allows the intruder to rule out two models of , thus -privacy does not hold.
()-privacy for a transition system
So far we have been talking about only a single pair, that is, a single state of a larger transition system. Gondron et al.1 define a language for specifying transition systems where the reachable states and their pairs are defined by executing atomic transactions. We present their formalization with some minor adaptations to ease our further development.
We distinguish two sorts of variables: the privacy variables, which are denoted with lower-case letters like and are all introduced in the form for a finite domain of public constants from , and the intruder variables, which are denoted with upper-case letters like for messages received and cell reads in a transaction.
We also distinguish destructor and constructor function symbols. In Figure 1, we have that , , , , , and are destructors whereas the rest are constructors. Moreover, we call and transparent functions, because one can get all their arguments without any key (but recall that is not a public function).
(Protocol specification)
A protocol specification consists of
a number of transaction processes, where the are left processes according to the syntax below, describing the atomic transactions that participants in the protocol can execute;
a number of memory cells, for example, , together with a ground context for each memory cell defining the initial value of the memory, so that initially ;
a -formula that fixes the interpretation of the relation symbols.
We define left, center, and right processes as follows:
where is either or , is a quantifier-free Herbrand formula, and is a destructor. Destructors are not allowed to occur elsewhere in terms. For simplicity, we have denoted destructors as binary functions, but we may similarly use unary destructors (like and in the example).
We require that a transaction is a closed left process, that is, —we define the free variables of a process as expected, where the non-deterministic choices, receives, cell reads and fresh constants are binding. Moreover, for destructor applications:
Finally, a bound variable cannot be instantiated a second time.
(Running example)
Let us consider the following transaction where a server non-deterministically chooses an agent and a yes/no-decision , receives a message, tries to decrypt it with their own private key and then sends the decision encrypted with the public key of :
Here the means that the choice of and is privacy relevant and the intruder may (at least for now) only learn that and . The outgoing message has a different form depending on : in the positive case the server also includes the content of the encrypted message they received (and if the message is not of the right format, then the transaction simply terminates); in either case the encryption is randomized with a fresh . We may omit if we want to model non-randomized encryption. is a public function (modeling a fixed public-key infrastructure known to everybody).
Much of these processes follows standard process calculus constructs. The special constructs of -privacy are the non-deterministic choice and release. Choice comes in two flavors: if the choice is privacy relevant (as in the example), and if not. The release is used to declare that a certain fact may now be known to the intruder; we discuss this construct and what formulas can be released a bit later.
Observe that privacy variables are introduced only by non-deterministic choices . If the is , the transaction augments by , thus specifying that the intruder may not know more about unless we also explicitly release some information about . If the is , the transaction augments by . In this case, it is not in itself a violation of privacy if the intruder learns more about , but it may lead to a privacy violation if this allows for finding out more about the variables in . This is useful if one wants to keep the privacy specification independent of some rather technical secret. In our model, the intruder knows which transaction is executed, but in general does not know which branch is taken. Using, for example, , one can reduce the visibility of processes and by putting them in a single transaction. In some execution the intruder may find out, for example, , and it is not a privacy violation in itself.
Semantics. The semantics follows Gondron et al.,1 with small adaptations. It is defined as a state transition system where each transition corresponds to the execution of one transaction. Thus, transactions are atomic: they cannot run concurrently with another transaction. In particular, when reading from and writing to memory cells, no race conditions can occur and we thus do not need locking mechanisms. A transaction thus consists in receiving input, checking this input (possibly reading from memory), then making a decision (possibly updating the memory), and finally sending an output and releasing information.
The atomicity of transactions has an advantage: we can easily formalize how the intruder can reason about what is happening. In particular, we assume that the intruder at each point knows which transaction is executed and what process a transaction contains. What the intruder does not know in general are the concrete values of the variables and the truth values of conditions, and thus in which branch of an -- or - we are. However, the intruder can always contrast this knowledge with the observations about incoming and outgoing messages: if an observed sent message does not fit with one branch of the transaction, then the intruder knows that branch was not taken, and thus they also learn something about the truth value of the corresponding conditions. In other cases, the intruder may know what is in a received message and thus know the truth value of some condition. The intruder thus performs a symbolic execution of the transaction, leaving open what they do not know, keeping a list of possibilities, and in fact the semantics of transactions formally models this symbolic execution by the intruder.
Let a possibility be a tuple , where is the transaction being executed, is the conditions under which this possibility was reached, is a frame that we call the structural knowledge about the messages in this possibility and is a sequence of memory updates. A state is a tuple , where , , and are -formulas, and is a non-empty finite set of possibilities , where one of the possibilities is marked by underlining as the possibility that is actually the case in the real execution (but the intruder does not know which one, in general). In this article, we consider only well-formed states, where a state is well-formed iff all have the same domain, describes a unique model of and the both are mutually exclusive, that is, , for , and cover all models, that is, . We define the concrete frame as the instantiation of the from the possibility underlined by .
(Multi-message-analysis problem)
Given a well-formed state , let where is the marked possibility in . Define
We say that satisfies privacy iff -privacy holds.
The semantics models that the intruder can symbolically execute transactions, but at branchings they do not know in general whether the condition is true; the possibilities reflect the different possible truth values of the conditions and what would have happened in that case. The underlined possibility is the one that really happened. Contrasting and each , the intruder may be able to exclude some possibility (because and are distinguishable) and thus learn about the truth value of conditions . Vice-versa, what the intruder knows about variables may allow them to exclude some possibilities.
To model the symbolic execution of a transaction , we start in a state where all possibilities contain that process . The semantics defines an evaluation relation on states that works off the processes in each possibility until in all possibilities, the process is . We call such a state finished. The branching of represents the non-deterministic choices of the process as well as choices of messages by the intruder.
To give a gentle introduction to -privacy in transition systems, we present the symbolic execution at hand of the running example from Example 2.1. The complete definition of the rules is in Table 1. Notation: is the largest subsequence of that only contains memory updates on and is the disjoint union of sets.
As a starting point for the symbolic execution, we use the singleton set of possibilities , where is the process from the running example. Let , , and be ; denotes the empty frame and empty memory. We list in Table 2 the successive states that are reached when executing and we explain below the transitions.
Non-deterministic choice. The first steps in the running example are two non-deterministic choices of privacy variables. In general, there are several successor states, one for each possible choice of the variables. Let us follow the case where and ; this is added to , and we add to that and . We reach states then . Note that and are not replaced in the remaining process—this is a symbolic execution by the intruder. Also note that the general rule assumes that all possibilities start with the same ; this is ensured since this choice can only occur in the left part of the transaction, before any branching on conditions and tries can occur.
Semantics of the execution for states.
Choice
for every
where and if , and and if
Receive
for every recipe over the domain of the
Cell read
where , the initial value of is given by ground context
and
Cell write
Conditional
Release
where if , and otherwise
Eliminate
if
Send
if and every process in is , where is a fresh label
Terminate
if , is non-empty and every process in starts with
States of the running example.
State
Receive. The next step is now . Again the construction ensures that every process in the possibilities starts with a receive step (with the same variable). Here, the intruder can choose an arbitrary recipe (over the domain of the ) for the message that should be received as . In fact, in general, we have here infinitely many possible and thus infinitely many successors. (Our decision procedure uses a constraint-based approach to handle this in a finite way.) Note that the message that is being received depends on the possibility: it is in the th possibility, that is, whatever the recipe yields in the respective intruder knowledge . As the intruder knowledge at this point is empty in the example, can only be a recipe built from public constants and functions. Let us consider , which then replaces in the process. This leads to state .
Cell read and write. The running example does not use memory cells, and we describe briefly the rules here. When reading from the memory, we add conditional statements to substitute in the process the appropriate value from the memory (that depends on the argument term). When writing to the memory, the update is simply prepended to the sequence of memory updates .
Conditional statement. The process is now . For the sake of this semantics, we can just consider as a syntactic sugar for (for the decision procedure it is important that destructors only occur in this - form, however). We have to evaluate the condition , which we can simplify to , that is, the intruder knows that the received message will decrypt correctly. We thus have in state two possibilities of which the second is underlined and where has been substituted with the content of the encryption, that is, the constant . The Eliminate rule allows removing possibilities with the condition , so we reach state . The underlined possibility is what really happened (which is here obvious). We apply a second time the Conditional rule, again splitting into two possibilities and leading to state . The first possibility is what really happens (as stated by ) and is thus underlined, and here the intruder does not know which one is the case.
Fresh constants. The operator can be implemented by replacing the placeholder with a fresh non-public constant, say . We can in fact do this as a preparation before executing the transaction.
Send. When all the rules for the other constructs have been applied as far as possible, each of the remaining processes must be either a send or . If the intruder observes that a message is sent, this rules out all possibilities where the remaining process is (the counterpart is the transition for Terminate). For all others, each is augmented by the message sent in the respective possibility. Moreover, is updated with the disjunction of the that are consistent with the intruder observations. In our example, we reach state , where . We have reached a finished state, and the intruder has thus completed the symbolic execution of this transaction.
Let us point out a few more interesting features of our running example. At the finished state, without further knowledge, the intruder is unable to tell which of the two possibilities is the case. This would be different if the encryption were not randomized: suppose we drop the third argument of . Then the intruder could now construct for each value and compare the result with the observed message. Since this does not succeed in any case, the intruder learns that the second possibility is excluded, thus , violating -privacy. Even worse, if we look at the state where the non-deterministic choice was , the intruder would find out because exactly one of the guesses succeeds.
Reverting to randomized encryption, suppose that there had been an earlier transaction where the intruder observed for some privacy variable . If the intruder uses this as input for the next transaction, then the decryption works iff . Thus, we have a third possibility at the final sending step, namely . Then from the fact that a message was sent, the intruder can rule out this third possibility and thus deduce that , again violating -privacy.
Release. This construct is used to declare information that the intruder is now allowed to learn, for instance in some cases we may let the intruder learn the true value of a privacy variable. In our running example, we did not use the release. However, in case the server is replying to the intruder, then the intruder can decrypt the message and observe what was the decision. Thus they would learn both the value of (i.e. the agent was the intruder) and (i.e. they know the server’s decision), which would violate -privacy. We could thus add a release if is the intruder to allow this deduction.
We consider it a specification error if when applying the Release rule, the formula released contains symbols which are in and variables not in . Thus, the specification can use symbols from the technical level in a release as long as the evaluated terms use only symbols in and (i.e. the payload level) when executing the protocol. This means that releasing technical information in the payload is not allowed. Additionally for our decision procedure below, the same requirement applies to a relational formula in the symbolic execution of conditional statements. This kind of specification error can be detected during the symbolic execution and means that insufficient checks are made over the terms before the release or conditional statement.
Privacy as reachability
We have defined in Table 1 the relation that works off the steps of a transaction, modeling an intruder’s symbolic execution of a transaction . We now define a transition relation on finished states (i.e. the process in every possibility is ) such that iff there is a transaction such that , where denotes replacing the -process in every possibility of with process . Then one transition with relation means executing exactly one transaction. Let the initial state be .
(The reachability problem)
Let . A protocol specification satisfies privacy until bound iff -privacy holds for every and such that .
A protocol specification satisfies privacy iff for every , it satisfies privacy until bound .
The first contribution of the present article is a procedure to solve the reachability problem given a bound , that is, whether a violation is reachable in at most transitions, under the restriction of the algebraic properties to constructor/destructor theories of Definition 6.1.
FLICs: Framed lazy intruder constraints
The semantics of the transition system says that, in a state where the processes are receiving a message, the intruder can choose any recipe built on the domain of (respectively, the : they all have the same domain). The problem is that there are in general infinitely many recipes the intruder can choose from. A classic technique for deciding such infinite spaces of intruder possibilities is a constraint-based approach that we call the lazy intruder9,29,30: it is lazy in that it avoids, as long as possible, instantiating the variables of receive steps like . The concrete intruder choice at this point does not matter; only when we check a condition that depends on , we consider possible instantiations of as far as needed to determine the outcome of the condition. Note that this is another symbolic layer of our approach: a symbolic state with variable represents all concrete states where is replaced with a message that the intruder can construct. In fact what the intruder can construct depends on the messages the intruder knew at the time when the message represented by was sent. Due to the symbolic execution, in a state there are in general several , and thus we need to represent not only the messages sent by the intruder with variables but also the recipes that they have chosen, because a given recipe can produce different messages in each .
To keep track of this, we define an extension of frames called framed lazy intruder constraints (FLICs): the entries of a standard frame represent messages that the intruder received and we write them now with a minus sign: . We extend this by also writing entries for messages the intruder sends with a plus sign: , where is a recipe variable (disjoint from privacy and intruder variables). When solving the constraints, may be instantiated with a more concrete recipe, but only using labels that occurred in the FLIC before this receive step; the order of the entries is thus significant. The messages can contain variables representing intruder choices that we have not yet made concrete. We require that the intruder variables first occur in positive entries as they represent intruder choices made when sending a message.
Since we deal with several possibilities in parallel, we will have several FLICs in parallel, replacing the in the ground model. Each FLIC has the same sequence of incoming labels and outgoing recipes. The intruder does not know in general which possibility is the case, but knows how they constructed messages from their knowledge, that is, the same recipe may result in a different message in each possibility.
A FLIC is a constraint, namely that the intruder can indeed produce messages of the form needed to reach a particular state of the execution. We show that we can solve such FLICs, that is, find a finite representation of all solutions (as said before, there are in general infinitely many possible concrete choices) using the lazy intruder technique, similarly to other works doing constraint-based solving with frames such as Cheval et al.7,31 In the rest of this section, we focus on defining and solving constraints by considering just one FLIC and not the rest of the possibilities, and we will explain in Section 4 how the lazy intruder is used for the transition system with several possibilities.
Defining constraints
(FLIC)
A framed lazy intruder constraint (FLIC) is a sequence of mappings of the form or , where each label and recipe variable occurs at most once, each term is built from function symbols, privacy variables, and intruder variables. The first occurrence of each intruder variable must be in a message sent.
We write if occurs in , and similarly . The domain is the set of labels of and are the privacy and intruder variables that occur in ; similarly, we write for the recipe variables.
The message produced by in is: if , if and .
For recipes that use labels or recipe variables not defined in the FLIC, the result is undefined. We also define an ordering between recipes and labels: iff every label in occurs before in .
Consider the transaction from Example 2.1, step . Using FLICs, we add to the FLIC (where both and are fresh variables). We are lazy in the sense that we do not explore at this point what and might be, because any value would do. Now the server checks whether can be decrypted with the private key . This is the case iff has the form (we will show in Section 4 how exactly the - construct works in the presence of the lazy intruder). In the positive case, is instantiated with for two fresh intruder variables and , thus requiring that indeed yields a message of this form. The constraint solving in Section 3.2 computes a finite representation of all solutions for . The negative case is considered separately, where we remember the negated equality .
(Semantics of FLICs)
Let be a FLIC such that , that is, the messages in are ground, so has only recipe variables. is constructible iff there exists a ground substitution of recipe variables such that for every recipe variable , where (this implies that only labels from can occur in ). We then say that constructs.
Let be an arbitrary FLIC and be an interpretation of all privacy and intruder variables. We say that is a model of , written , iff is constructible. is satisfiable iff it has a model.
A FLIC is thus satisfiable if there exist a suitable interpretation for the variables in messages and a suitable intruder choice for the variables in recipes such that all the constraints are satisfied.
Suppose that Alice sent a signed message to the intruder and the constraint is to send some signed message to Bob. This is recorded in the following FLIC :
Here is a model, because is constructible using the recipe . For every ground recipe over also is a model, using ; note there are infinitely many such .
Solving constraints
We now present how to solve constraints when the intruder does not have access to destructors, that is, as if all destructors were private functions and thus cannot occur in recipes. Hence the only place where destructors can occur are in transactions using -. This allows us to work in the free algebra for now and with only destructor-free terms. To achieve the correctness of our procedure for the full intruder model with access to destructors, we show in Section 6 how all intruder applications of destructors can be handled by special analysis steps. This allows us to keep the core of the method free of destructors and algebraic reasoning.
(Simple FLIC)
A FLIC is called simple iff every message sent is an intruder variable, and each intruder variable is sent only once, that is, every message sent is of the form and the are pairwise distinct.
Simple FLICs are always satisfiable, since there are no more constraints on the messages, and the intruder can choose any recipes they want. In order to solve constraints in a non-simple FLIC, we instantiate privacy, intruder and recipe variables until we reach a simple FLIC. Computing a finite representation of all solutions is then done by keeping track of the substitutions applied to instantiate the variables.
Let be a substitution that does not contain recipe variables. We define and .
However, we cannot directly define the instantiation of recipe variables for an arbitrary FLIC, because we always need to make sure we instantiate both the recipe and the intruder variables according to the constraints. We thus define how to apply a substitution of recipe variables for simple FLICs.
(Choice of recipes)
A choice of recipes for a simple FLIC is a substitution mapping recipe variables to recipes, where .
Let be a choice of recipes for that maps only one recipe variable, where . Let be the fresh variables in , that is, , taken in a fixed order (e.g. the order in which they first occur in ). Let be fresh intruder variables. The application of to the FLIC is defined as where and .
For the general case, let be a choice of recipes for . We define recursively where one recipe variable is substituted at a time, and we follow the order in which the recipe variables occur in : if , where occurs in before any , then . Every application corresponds to a substitution (as defined above), and we denote with the idempotent substitution aggregating all these substitutions from applying to .
Note that if is a choice of recipes for a simple FLIC , then is simple, because the fresh recipe variables added in map to fresh intruder variables.
We denote with the result, called most general unifier (mgu), of unifying the and , which is either some substitution or whenever no unifier exists. Slightly abusing notation, we consider a substitution as the formula and as . We modify the standard mgu algorithm so that when we have to unify an intruder variable with a privacy variable , it will always result in (i.e. privacy variables are never substituted with intruder variables).
Moreover, we add a postprocessing step to : if the resulting contains where is a privacy variable chosen from a domain that does not contain , then the result is .
In order to solve the constraints, we define a reduction relation on FLICs: is Noetherian and a FLIC that cannot be further reduced is either simple or unsatisfiable. Moreover, is not confluent, but rather is meant to explore different ways for the intruder to satisfy constraints, and thus we will consider the set of all simple FLICs that are reachable from a given one: the simple FLICs together will be equivalent to the given FLIC. Since is not only Noetherian, but also finitely branching, the set of reachable simple FLICs is always finite by König’s lemma.
(Lazy intruder rules)
The relation is a relation on triples of a choice of recipes , a FLIC and a substitution , where and keep track of all variable substitutions performed in the reduction steps so far and are such that and . The rules are defined in Table 3.
Lazy intruder rules.
Unification
if is simple,
where and
and
Composition
if is simple,
and
where the are fresh recipe variables and
Guessing
if is simple,
where and
and
Repetition
if is simple
and
where
Unification. When the intruder has to send a message, they can use any message previously received and that unifies, choosing a label for the recipe variable. There is one less message to send, but the unifier might make other constraints non-simple. This rule is not applicable for variables: the intruder is lazy.
Composition. When the intruder has to send a composed message , they can generate it themselves if is public and they can generate the . The intruder thus chooses to compose the message themselves, so the recipe is the application of to other recipes.
Guessing. When the intruder has to send a privacy variable , they can guess the actual value of , say . In fact, this is a guessing attack as we let the privacy variables range over small domains of public constants. This rule represents the case that the intruder guesses correctly, and the variable is replaced by the guessed value . Note that using the Guessing rule does not yet mean that the intruder knows that is the correct guess: in the rest of the procedure, whenever there is such a guess we model both the right and wrong guesses, and the intruder may not be able to tell what is the case.
Repetition. If the intruder has to send an intruder variable that they have already sent earlier, they use the same recipe. Since there may be several ways to generate the same message, one may wonder if this is actually complete: could there be an attack where constructing the same message in two different ways would tell the intruder anything more? In fact, for what concerns the behavior of the honest agents, it cannot make a difference, and comparing different ways to construct the same message is covered in the intruder experiments in Section 5.
We now define the lazy intruder results as the set of choices of recipes that solve the constraints.
(Lazy intruder results)
Let be a FLIC and be a substitution. Let be the identity substitution. We define .
Following Example 3.1, let us assume that the intruder has already observed a message encrypted for the server from another agent , and is now symbolically executing the transaction. With the constraint induced by the decryption from the server, the FLIC is now . Since is public, the lazy intruder returns two choices of recipes: , meaning the intruder replays the message from the knowledge (since it unifies), and , meaning the intruder composes the message themselves where and stand for arbitrary recipes.
(Representation of choice of recipes)
Let be a FLIC, , be a ground choice of recipes and be a choice of recipes. We say that represents w.r.t. and iff there exists such that is an instance of and for every , and:
If , then and either or .
If is a composed recipe and , then .
This notion of representation gives the lazy intruder some “liberty,” namely to be lazy in not instantiating recipe variables that do not matter, and to replace subrecipes with equivalent ones (that may be smaller according to our ordering between recipes and labels). In the completeness proof we show that, despite all these liberties, every solution of the constraint is represented by some choice of recipes that the lazy intruder finds. The lazy intruder rules are sound, complete and terminating.
(Lazy intruder correctness)
Let be a FLIC, be a substitution, such that and let be a ground choice of recipes. Then constructs iff there exists such that represents w.r.t. and . Moreover, is finite.
The symbolic states
Our approach explores a transition system on symbolic states, where each symbolic state represents an infinite set of ground states. In the rest of the article, we denote symbolic states by , , and so on, and ground states by , , and so on.
Our notion of ground states in Section 2 is an adaptation of the states defined by Gondron et al.1 A ground state may actually contain privacy variables, representing the possible uncertainty of the intruder in this state, but each variable has one concrete value that represents the truth in that state, which is expressed by a formula that the intruder does not have access to (and the frame is an instance of one of the under ). This is the reason why we call it a ground state, even though it contains variables. A symbolic state includes actually two symbolic layers. For the first symbolic layer, we define a symbolic state to merge all those ground states that differ only in the concrete and thus the concrete frame , that is, where the intruder has the same uncertainty. Therefore, a symbolic state does not contain and , and has no underlined possibility. Thus, we need to keep track of the released formula for each possibility separately. A second symbolic layer is to use intruder variables and FLICs to avoid enumerating the infinite choices that the intruder has when sending messages, thus the frames are generalized to FLICs in symbolic states. We will introduce in Section 5 the intruder experiments, and a symbolic state contains a record of all experiments the intruder has already performed.
(Symbolic state)
A symbolic state is a tuple such that:
is a -formula, the common payload;
is a -formula, the intruder reasoning about possibilities and privacy variables;
is a set of possibilities, which are each of the form , where is a process, is a -formula, is a FLIC, is a disequalities formula (in the grammar below), is a -formula called partial payload, and is a sequence of memory updates of the form for messages and ;
is a set of pairs , where is a label and is a recipe.
where disequalities formulas are of the following form:
A symbolic state is finished iff all the processes in are .
We may write to denote the symbolic state identical to except that is replaced with .
We have augmented the FLICs here with disequalities , that is, negated equality constraints, which allows us to restrict the choices of the intruder in a symbolic state. This is needed when we want to make a split between the case that the intruder makes a particular choice and the case that they choose anything else. This is formalized in the following definition of applying a recipe substitution which is only possible when all the respective are consistent with it:
(Choice of recipes for a symbolic state)
Let be a symbolic state and be a recipe substitution. We say that is a choice of recipes for iff is a choice of recipes for all FLICs in and for every FLIC and associated disequalities in , the formula is satisfiable, that is, the disequalities are satisfiable under the substitution induced by in (Definition 3.5). Moreover, we define
When writing in the following, we implicitly assume that all disequalities in are satisfiable under , and that is discarded otherwise. To decide whether disequality is satisfiable it suffices to replace the free variables with distinct fresh constants and check that the corresponding unification problems have no solution. Moreover, we will always use the lazy intruder in the context of a symbolic state, so we further assume that only returns choices of recipes for the current symbolic state, that is, excluding any that would contradict a disequality.
From a symbolic state we can define all the choices of recipes (instantiations of the recipe and intruder variables) for the messages sent by the intruder and all the concrete executions (instantiations of privacy variables) that the intruder considers possible. A symbolic state represents a set of ground states, where each ground state corresponds to one multi message-analysis problem. For every ground state, the common payload is augmented with the partial payload released in the corresponding possibility. Moreover, every model of the privacy variables needs to be augmented with the fixed interpretation of the relation symbols (recall that this -formula is part of the protocol specification).
Meta-notation. In the specification of transactions, we allow in the release steps the use of the meta-notation for a message . Recall that in every ground state, the real values of privacy variables is defined by a ground interpretation . Thus, for instance, releasing means allowing the intruder to learn the true value of . In the symbolic execution for ground states, the meta-notation can be resolved by using as a substitution before adding the formula to .
In Example 2.1, in case the agent is actually the intruder , that is, , then the intruder can decrypt the message and observe what was the decision. Thus they would learn both that as well as the value of (i.e. they know the server’s decision). This leads to a privacy violation, unless we declassify and by releasing, if is the intruder, the formula . Releasing this information is still not enough because in case the intruder can also deduce that; so we additionally need to release in that case to remove the privacy violation.
In a symbolic state, however, there is no since the symbolic state represents all possible at once. Hence, in order to define the semantics, we need to resolve the meta-notation that we allow in the . Given and the truth , let be the instantiation of the meta-notation in , that is, replacing every occurrence of a term in (for a variable ) with the actual value of in the given . For instance, if , then .
(Semantics of symbolic states)
Let be a finished symbolic state. The ground states represented by are given by
where returns possibilities of the form , that is, the additional components of symbolic possibilities are dropped because they are irrelevant for ground states (note that the have already been used as part of the payload ); moreover, the possibility for which is underlined.
We say that a symbolic state satisfies privacy iff every ground state satisfies privacy.
When computing the mgu between messages or solving constraints with the lazy intruder rules, we may deal with substitutions that contain both privacy and intruder variables. However, it is important to remember that the instantiation of privacy variables does not depend on the intruder, it is actually the goal of the intruder to learn about the privacy variables. On the other hand, intruder variables are instantiated according to the recipes chosen by the intruder. Thus, we distinguish substitutions that only substitute privacy variables (we will compute substitutions as mgus so we also have to consider when no mgu exists).
(Privacy substitution)
Given a substitution , the predicate is defined as: iff . We also define as the privacy part of , that is, if , and otherwise. Moreover, define and .
Table 4 defines the transitions on symbolic states to evaluate processes (with the lazy intruder) as a relation between one symbolic state and a set of symbolic states. We extend the definition to relate sets of symbolic states: iff , and . We summarize here this semantics and we discuss in Supplemental Appendix A the correctness of the correspondence to Table 1.
Semantics of the execution for symbolic states.
Choice
where and if , and and if
Receive
where is a fresh recipe variable
Cell read
where , the initial value of is given by ground context
and
Cell write
Let , consider a fresh instance
of the rewrite rule for , let , and .
The rules for - are:
Destructor (1.1)
Destructor (1.2)
if , where
Destructor (2)
if
Conditional
For , the transitions are like Destructor but with
Release
Eliminate
if
Send
if every process in is , where is a fresh label
The non-deterministic choice is quite simple: instead of splitting into one successor state for each value in the domain, all these are handled in one symbolic state where we only add the domain constraint to or , respectively. For a receiving step , recall that the ground model has here an infinite branching over all the recipes that the intruder could use. This is the very reason for introducing the FLICs in the symbolic model: we simply choose a fresh recipe variable and augment every FLIC with , saying that the intruder can choose any recipe (over the labels of the FLIC so far) to form the input message .
Due to the two symbolic representations of privacy choices and intruder choices, treating - is quite complicated. Consider a symbolic state where one possibility has process . The class of algebraic theories we support (we give the precise definition in Definition 6.1) ensures that there is a unique rewrite rule for destructor . Let be a fresh instance of this rule (all variables renamed to fresh intruder variables). The destructor succeeds iff the formula is satisfied. Let ; note that this mgu may not exist (). Note also that may instantiate both privacy variables (that the intruder cannot control) and all the other variables (that the intruder can, at least indirectly, control by the choice of recipes for messages received). We now have several symbolic states for the different cases.
Destructor (1.1) is the case that there is a solution () and the intruder makes a choice of recipes that may satisfy . Note that can only determine intruder variables: it induces a substitution in the given possibility (Definition 3.5). It is now guaranteed that yields a term of the form , because we had required this in and cannot be a privacy variable. Thus we can now extract the exact term in case the destructor works. Whether it works depends however on the privacy variables. For instance if the destructor is asymmetric description with key and the intruder chooses a message encrypted with , this succeeds iff . We thus need to compute a unifier for , that is, the condition under the current choice of recipes, and is now the substitution of privacy variables under which the destructor succeeds. We thus split the possibility in two: one where we continue with , where is bound to the result of the destructor and condition , and one with and condition .
Destructor (1.2) is the case that there is a solution () and it depends on intruder choices ( is not simple), but the intruder chooses any recipe that does not satisfy . For this we simply add the disequality to , where are the intruder variables not bound by . (If is simple, then there is only one trivial choice of recipes, the identity substitution, so there is no symbolic state for excluding this choice.) Destructor (2) finally is the case that there is no unifier , so we necessarily end up in .
The -- conditional is handled in a very similar way when the condition is an equality , obtaining a most general unifier under which the condition is true. When the condition is a relation applied to some terms, we simply split on whether the relation holds. For a condition with negation, we swap the branches: is rewritten into . For conjunction, we nest the branches: is rewritten into .
For releasing information, recall that we have an in each possibility that we can augment with the formula released. For sending or terminating, compared to Table 1 we merge the two rules so one symbolic state yields in general two symbolic states, one where we only keep the possibilities that send a message and one where we only keep those already terminated.
During the symbolic execution, if a symbolic state has an empty set of possibilities, then this state is discarded since it does not represent any ground state (e.g. in the Send rule, if then the second state yielded by the rule is discarded). Moreover, if several rules are applicable at the same time, then it does not matter which one is applied first so the procedure fixes an arbitrary order for applying the rules.
The symbolic executions transform a symbolic state into a set of finished symbolic states. When all symbolic executions have terminated, we shall check whether the reached symbolic states satisfy privacy.
The intruder experiments
So far, we have a symbolic transition relation that, for a given symbolic state and protocol transaction, gives a finite number of symbolic states that can be reached by executing the transaction. This notion includes the intruder’s reasoning about what is potentially happening, namely whether conditions and try-statements are satisfied, depending on the intruder choices and the privacy variables. The FLICs in these states are simple, that is, the constraints are solved and thus every remaining intruder variable represents an arbitrary message from the intruder’s knowledge—the truth value of any conditions executed previously did not depend on the concrete choice of message.
Now we come to the next step: the intruder can make experiments by choosing two recipes and checking for each FLIC, if the two recipes give the same message in that FLIC. If that outcome is not the same in every FLIC, the intruder can thus distinguish some FLICs. This may allow the intruder to rule out some possibilities or some models of the privacy variables, and this may lead to a violation of -privacy. Since terms can contain privacy and intruder variables, the outcome of the experiment may depend on the value of such variables.
The intruder variables are due to our symbolic approach: the intruder has chosen a concrete recipe earlier, and a symbolic state only represents several such concrete states (in general infinitely many). When we now evaluate the intruder experiments and the outcome depends on an intruder variable, then we will split the symbolic state into several states: states where the intruder made a particular choice of messages (that makes a comparison true in some FLIC), and one state where the intruder made any other choice. Together these symbolic states represent the same concrete states.
We show in Theorem 5.1 that there is a finite such split into symbolic states that are normal, that is, where no further experiment distinguishes the FLICs. The intruder’s conclusions during these experiments are formalized in , and we finally show in Theorem 5.2 that a normal symbolic state satisfies -privacy if its does not exclude any models of .
We first define the equivalence relation between recipes. It formalizes that this pair of recipes does not distinguish any FLICs, that is, it will either give the same message () in all FLICs, or different messages () in all FLICs:
Let be a symbolic state, where the possibilities have conditions and FLICs . Let and be two recipes and for . We define iff or , where
This definition first considers the most general unifier between the terms that the recipes produce in FLIC . For the experiment to produce the same message in every FLIC under every instantiation (), the can only have privacy variables and must be entailed by , , and the condition from the respective possibility (if there were some intruder variables in then the outcome of the experiment would depend on past intruder choices and thus allow for a distinction). For the experiment to produce different messages in every FLICs under any instantiation (), we have two cases: each either depends on intruder variables but is unsatisfiable (so the experiment will always be negative, no matter what the intruder does), or substitutes no intruder variables and implies .
Based on Example 2.1, suppose that we reached a symbolic state containing two possibilities with , and
Here we again assume non-randomized encryption for the sake of the example. Then we have , because in there is no unifier and in the unifier is excluded by .
We now make use of the set to keep track of the experiments that the intruder has already performed. It is an (initially empty) set of pairs of recipes. As part of well-formedness of states we require that holds for all :
(Well-formed symbolic state)
Let be a symbolic state, with the possibilities . We say that is well-formed iff
the are such that for , and ;
the are simple FLICs with the same labels and same recipe variables, occurring in the same order;
the disequalities are satisfiable;
the are such that and ; and
for every , we have .
Recipe variables can only occur in the FLICs . Since , we may write for the domain of the symbolic state.
In the rest of the article, we only consider well-formed symbolic states (and well-formedness is preserved by the procedure).
Remember that so far, we considered an intruder who has no access to destructors (the next section will introduce destructors). Since we have no algebraic properties between constructors, everything behaves like in a free algebra, that is, implies and . Thus we do not consider experiments where both recipes are composed, that is, it is sufficient to only consider experiments where is a label (and may be any recipe). In other words, we only need to check for every FLIC and for every label whether there is any recipe (other than ) to generate the same term . We can compute the set of all such pairs using the lazy intruder and thus a finite worklist of all experiments to perform:
(Pairs and normal symbolic state)
Let be a symbolic state with FLICs in . The set of pairs of recipes to compare in is
We say that is normal iff is finished and .
We define a reduction relation that, given a symbolic state and a pair , yields a set of symbolic states after the experiment of comparing and . We call these experiments compose-checks. We will show that when it follows that , thus this reduction does not change the represented ground states. Moreover, as long as there is an experiment , is a reducible expression for . Thus, a normal state is eventually reached (and thanks to the semantic equivalence, it is not relevant in which order the steps were taken). In such a normal state, no experiment can distinguish the FLICs.
(Compose-checks)
Let be a symbolic state , with possibilities , and for . Then the set of symbolic states after the compose-check w.r.t. is as follows.
Privacy split If for every , or : , where
Recipe split If there exists such that not and ():
Similarly to the symbolic execution, we extend the definition to relate sets of finished symbolic states: iff , and .
Note that given a pair , either Privacy split is applicable, or some Recipe split is. In the case of Privacy split, the outcome of the experiment is independent of the intruder choices (the unifiers between messages produced by and are only using privacy variables or is unsatisfiable). We split into two symbolic states. The first, , represents all those concrete states where and give the same result in the concrete intruder frame, and excluding all interpretations where they give different results. On the symbolic level this means that for possibility , if substitutes only privacy variables, the intruder learns , because under all other instances, this FLIC would give unequal terms. Otherwise (since the rule is only applicable when or is unsatisfiable), the possibility gives unequal terms no matter what the intruder sent earlier, and the intruder can thus rule this possibility out ().
The second, , represents the rest, that is, where and give different results in the concrete frame. This means for the th possibility, either the unifier depends only on privacy variables and the intruder learns that can only be true if (because under the comparison should have been positive); or is unsatisfiable and the intruder learns nothing.
In the case of Recipe split, for at least one FLIC, the unifier depends on intruder variables, making that FLIC not simple. For each lazy intruder result, there is one symbolic state in which the intruder takes a choice of recipes and the whole symbolic state is updated accordingly. Additionally, there is one symbolic state in which the intruder chooses something else for the recipes and one unifier is excluded.
Let us consider again Example 2.1, where for now we assume that encryption is not randomized. Let be the symbolic state such that:
is not normal since, for example, . We can perform a compose-check, in this case by applying the Privacy split rule. In , we have to unify and , which is not possible. In we have to unify and , which gives the mgu . Then we get two symbolic states and , which have the same as but we update and . Moreover, in both and we have .
Using the compose-checks, we can transform a symbolic state into a set of normal symbolic states, since by definition a symbolic state is normal when there are no more pairs to compare. Moreover, the compose-checks preserve the semantics of symbolic states by partitioning the ground states represented.
(Compose-check correctness)
Let be a finished symbolic state, and be the symbolic states such that w.r.t. . Then . Moreover, there does not exist any infinite sequence where for every , there exists such that and .
In a normal symbolic state, there are no more pairs of recipes that could distinguish the possibilities (they have all been checked). Thus, given a ground choice of recipes, all the concrete instantiations of frames are statically equivalent. This means that in a normal symbolic state, the FLICs do not contain any more insights for the intruder, and all remaining violations of -privacy can only result from any other information that the intruder has gathered. We thus define that a symbolic state is consistent iff cannot lead to violations either.
(Consistent symbolic state)
We say that a finished symbolic state is consistent iff -privacy holds for every .
Even though is infinite, we need to consider only finitely many pairs. This is because the corresponding and in do not contain intruder variables and we only need to resolve the meta-notation if present. For truth , we also have only to consider finitely many instances of the privacy variables (as they range over finite domains). We ensure that only contains symbols in , and for each and , the -models are computable as we show in Supplemental Appendix C. While that algorithm is based on an enumeration of models as a simple means to prove we are in a decidable fragment, our prototype tool uses the SMT solver cvc514 to check consistency more efficiently.
In the symbolic state from Example 5.2, we have and . Since -privacy holds, is consistent.
In the symbolic state that results from comparing recipes and , we have the same but now . Here -privacy does not hold anymore because rules out a model of , namely . Thus is not consistent.
To verify whether a symbolic state satisfies privacy, we perform all compose-checks to get a set of normal symbolic states, and then in each of these normal states it suffices to verify consistency.
Let be a normal symbolic state. Then satisfies privacy iff is consistent.
Lifting to algebraic properties
So far, our procedure consists in (i) executing a transaction with the rules of Table 4, (ii) normalizing symbolic states with intruder experiments, and (iii) checking consistency in the reached normal symbolic states. The above gives us a decision procedure for -privacy (under a bound on the number of transitions) as long as the intruder has no access to destructors. Note that transactions can apply destructors already. This allows for a very convenient and economical way to extend the intruder model with destructors as well without painfully extending all the above machinery to destructors: we define a set of special transactions called destructor oracles, one for each destructor. They receive a term and decryption key candidate, and send back the result of applying the destructor unless it fails. Note that calling these oracles does not count towards the bound on the number of transitions, but rather we apply them to a reached symbolic state until destructors yield no further results.
The supported algebraic theories
We give in Figure 1 a concrete example theory, but our result can be quite easily used for similar theories. For instance, many modelers prefer for asymmetric cryptography that private keys are defined as atomic constants and the corresponding public key is obtained by a public function . We like, in contrast, to start with public keys and have a private function to obtain the respective public key. This allows us to define a public function from agent names to public keys, which can be convenient in reasoning about privacy when the public-key infrastructure is fixed. Similarly, one may want to define further functions, in particular transparent functions like , that is, functions that describe message serialization and where the intruder can extract every subterm. Finally, in some cases it is convenient to model some private extractor functions when we are dealing with messages where the recipient has to perform a small guessing attack. For instance, in a protocol like Basic Hash32 (modeled in Supplemental Appendix D) the reader actually needs to try out every shared key with a tag to find out which tag it is. Rather than describing transitions that iterate over all tags and try to decrypt, it is convenient to model a private function that “magically” extracts the name of the tag, if the message is of the correct form, and returns false otherwise. This extraction must be a private function since the intruder should not be able to observe this unless they know the respective shared keys; if they do, then the experiments in our method automatically allow the intruder to perform the guessing attack. We thus distinguish three kinds of algebraic properties of destructors that can be used arbitrarily in our approach:
(Algebraic theory)
A destructor rule is a rewrite rule of one of the following forms:
Decryption: where is a destructor, is a constructor, , the are variables and .
Projection: where , is a public destructor called a projector, is a constructor of arity , the are variables. There must be such a rule for every and is then called transparent.
Private extraction: where is a private destructor called a private extractor, is a constructor and is a subterm of one of the .
Let be a set of such rules, where we require that every destructor occurs in exactly one rule of and forms a convergent term-rewriting system. Moreover, each constructor cannot occur both in decryption and projection rules. Define to be the least congruence relation on ground terms such that
and for unary destructors the definition is the same but are omitted. Moreover, we require for every decryption rule that or or for some public function .
The requirement or or for some public means that, given the decryption key one can derive the encryption key , or the other way around. In particular, in most asymmetric encryption schemes, the public key can be derived from the private key; for signatures the private key takes the role of the “encryption key.” This requirement forces us to define in our example theory the rule . Suppose that we omitted this rule, denying the intruder the ability to derive the public key to a given private key. Suppose further that the intruder has received two messages and and is wondering whether maybe . Then they could make the experiment whether and this would be the case iff . For our method, we want however to ensure that the intruder never needs to decrypt messages that they encrypted themselves. In the example, with the public-key extraction rule, the intruder can derive and now directly compare this with . The requirement allows us to show that the intruder cannot learn anything new from decrypting terms that they have encrypted themselves.
Observe that every ground term is equivalent to a unique destructor-free ground term and that can be computed by applying a rewrite rule, when possible, to an inner-most destructorb in and replacing by if no rewrite rule is applicable, and repeating this until all destructors are eliminated.
Destructor oracles
Since transactions can already apply destructors, we can model oracles that provide decryption services for the intruder, namely the intruder has to send a term to decrypt and the proposed decryption key and the oracle gives back the result of applying the destructor.
(Destructor oracle)
Given the decryption rule , its destructor oracle is the transaction: .
Given the projection rule , we define a single oracle:
.
For transparent functions, there is no need for a key and for each , the th subterm can be retrieved with destructor , so we define one oracle returning all subterms. There are no oracles for private extractors since these functions are not available to the intruder.
Obviously, such transactions are redundant if the intruder has access to the destructors and also it is sound to add such transactions. Also redundant is the output , because is already an input, but this ensures that different ways of composing the key will be considered by our compose-checks.
The reader may wonder why we do not do the same also for constructors, for example, using transactions of the form , so we could use an intruder who neither encrypts nor decrypts and just uses oracles for both jobs. The reason is that constructors give rise to an infinite set of terms that can be generated and it is difficult to limit that—this is why we use the lazy intruder technique as a way to represent the infinitely many choices in a finite and yet complete way. For destructors on the other hand, we do not have the same problem since it is limited what we can achieve here. In particular, there is no need for the intruder to destruct terms that they have constructed themselves, thus allowing us to limit the use of destructors, respectively, the destructor oracles, in a simple way.
Analysis strategy
In general the destructor oracles are applicable without boundary. We use a strategy to apply them that does not lead into non-termination, but covers all applications that are necessary for any attack. Note also that the application of oracles does not count towards the bound on the number of transitions.
(Term marking)
All received terms and subterms in a FLIC shall be marked with one of three possible markings: for terms that might be decrypted but have not been so far; for terms that cannot be decrypted at the given intruder knowledge for any instance of the variables; and for terms that either have already been decrypted or have been composed by the intruder themselves (so the intruder knows already the subterms that may result from a decryption).
The default initial marking is . The exceptions are privacy and intruder variables, as well as functions that do not have a public destructor; all such terms (and subterms if they have) are marked with . Markings are only changed according to Definition 6.4. In particular, when a variable gets instantiated, the resulting term keeps its marking.
Our strategy applies the destructor oracles to a given symbolic state to obtain a finite set of analyzed symbolic states that are together equivalent to except that the FLICs are augmented with the results of decryptions (or projections), which we call shorthands.
(Analysis strategy)
Let be a normal symbolic state (recall that in all FLICs are simple, and thus intruder variables represent messages the intruder composed; and is normal, that is, all compose-checks have been made).
The following strategy is applied as long as there exists a label that maps to a -marked term. Let be the first label (in the order of the domain) that maps to a term which is -marked in some FLIC; note that by construction, it can only be a constructor term. If is an encryption, that is, occurs in a decryption rule (the intruder can decrypt iff they can produce the appropriate key), then we apply the oracle for that rewrite rule under the specialization that the recipe for (the oracle input for the constructor term) must be the label . If is a transparent function, then we use the appropriate oracle that applies all its projectors and returns all subterms.
Executing the oracle transaction and performing experiments leads to a finite number of successor states (there is at least one, so ) that are again normal and have simple FLICs. In each , the decryption has either worked in every FLIC, or failed in every FLIC. We now update the marks in the as follows.
If in decryption has failed, assuming that is the constructor for which we had executed the corresponding oracle, then in every FLIC where that is marked , we change to mark because it is (with the current knowledge) not decipherable. If it was already marked , we do not change the label (note that in some FLIC, may map to a term with a different constructor ; if that term is marked , it maintains this marking, so that one of the next analysis steps will be to check if the respective destructor for can be applied).
If in decryption has worked, then we update and introduce markings in each FLIC as follows. In case of a decryption rule, and thus in a given FLIC, maps to some term , the result of the analysis is bound to a new label (for some ); the decryption key is bound to new label . If is the mark of in , then the new occurrence of at shall also be marked with . In turn, are now all marked , because they are fully analyzed. Similarly, the key term and all its subterms receive the mark, because they have been produced by the intruder already (and are thus taken from another label that is already analyzed, or composed by the intruder and thus not interesting for decryption). All terms that were marked are changed with marking , because the newly analyzed term may allow for some decryption that was impossible before. In case of projection rules, the marking is similar for the new subterms.
We repeat this process of attempting to decrypt the first -marked term until there are no more -marks. A symbolic state is analyzed iff it does not contain any -marked terms.
We call a label in a symbolic state a shorthand iff there exists a recipe over labels before such that for every FLIC in .
The analysis strategy augments FLICs only by shorthands and thus does not change what is derivable for an intruder who can decompose.
(Analysis correctness)
For a symbolic state , the analysis strategy produces in finitely many steps a set of symbolic states that are analyzed. Further, for every ground state there exists , for some , such that and are equivalent except that the frames in may contain further shorthands; and vice versa, for every there exists such that is equivalent to except for shorthands.
In the symbolic state reached after executing the transaction from Example 2.1, there is one FLIC that contains a received message (marked ) as well as . Then the strategy will execute the asymmetric decryption oracle for label . This gives two states: where for this possibility we unify and the intruder has a new label , and where we have and the intruder cannot decrypt (given the intruder knows no other private keys ). The encrypted message at label is now marked in and in .
Let be the initial symbolic state. Given a transaction and a finished symbolic state , let denote the symbolic state identical to but where the -process in every possibility of is replaced with process . Our decision procedure defines how to symbolically execute processes, perform intruder experiments and apply the analysis strategy such that, given a finished symbolic state and a bound on the number of transitions, we compute a finite set of normal, analyzed symbolic states that can be reached after executing at most transactions (not counting the destructor oracles). In normal analyzed states, the intruder does not need any destructors anymore, because we can show that for every recipe, there exists a destructor-free one (possibly using the shorthands added during analysis), and then there are also no relevant experiments that could be made with recipes using destructors. It then suffices to verify consistency in the reached normal analyzed symbolic states to decide whether -privacy holds.
We can now conclude the correctness of our decision procedure. All the proofs are shown in Supplemental Appendix B. Note that we need a bound on the number of transitions, and this bound is restricting the number of transactions that are executed. All “internal” transitions taken by our compose-checks and analysis steps do not count towards that bound.
(Procedure correctness)
Given a protocol specification for -privacy, a bound on the number of transitions and an algebraic theory allowed by Definition 6.1, our decision procedure is sound, complete and terminating.
Tool support and case studies
We have developed a prototype tool called noname33 implementing our decision procedure. The tool is a proof-of-concept showing that automation for -privacy is achievable and practical. The user must provide as input the protocol specification, consisting of the transactions that can be executed, and a bound on the number of transactions to execute. For the cryptographic operators, we make available by default primitives for asymmetric encryption/decryption, symmetric encryption/decryption, signatures and pairing (Figure 1). The user can define custom operators with the restriction to constructor/destructor theories given in Definition 6.1. We have also implemented an interactive running mode (the default is automatic, i.e., exploring all reachable states) in which the user is prompted whenever there are multiple successor states, so that one can manually explore the symbolic transition system.
In case there is a privacy violation, the tool provides an attack trace that includes the sequence of atomic transactions executed and steps taken by the intruder (i.e. the recipes they have chosen) to reach an attack state, as well as a countermodel proving that the privacy goals in that state do not hold, that is, a witness that the intruder has learned more in that state than what is allowed by the payload.
As case studies, we have focused on unlinkability goals in the following protocols: our running example, Basic Hash,34 OSK35 (which is particularly challenging as it is a stateful protocol), and several variants of BAC36 and Private Authentication37 (the -privacy specifications of these last two protocols are given by Fernet and Mödersheim38). For each protocol, we describe briefly our results on whether it satisfies -privacy. The models, together with more details, are in Supplemental Appendix D.
Running example. As explained in Example 4.1, if the server is replying to a compromised agent, then there is a privacy violation because the intruder is able to learn the identity of that agent, and the tool finds this attack. When permitting that the intruder learns the compromised agent’s identity, the tool discovers another problem: if the agent is not compromised, then the intruder is also able to learn this fact. When releasing also that information, no more violations are found. This illustrates how the tool can help to discover all private information that is leaked, and thus either fix the protocol or permit that leak, and then finally verify that no additional information is leaked (given the bound on the number of transitions).
Basic Hash.34 In this RFID protocol, a tag sends to a reader a pair of messages containing a nonce and a MAC, using a secret key shared between tag and reader. Then the reader tries to recompute the MAC with every secret key they know to identify the tag (this behavior of the reader is modeled with a private extractor that retrieves the tag name from the MAC). We have verified that the Basic Hash protocol satisfies unlinkability, but fails to provide forward privacy.32
OSK.35 This is also an RFID protocol with tags and readers. We have modeled two variants where, respectively, no desynchronization and one desynchronization step is tolerated. For both versions the tool finds the known linkability flaws.39
BAC.36 This standard RFID protocol is used to read data from passports. A tag and a reader perform a challenge-response, where the tag sends a nonce and an encrypted message containing that nonce, and the reader receives both and verifies that the nonces match. The tool finds the known problems in some implementations.40–42
Private Authentication.37 This protocol models agents that encrypt messages using a public-key infrastructure. The initiator sends a message containing their name and a nonce, and the responder either sends back a message with a fresh nonce or sends a decoy message. We consider several variants: AF0 denotes the situation where agents always want to talk to other agents, while AF denotes the situation where agents might not want to talk to some other agents. For AF0, there is one model with a privacy violation due to insufficient release in and another model fixing this issue; AF builds on top of the fixed AF0 and adds a binary relation to model whether agents want to talk.
Discussion of the results. Finding a privacy violation is usually fast, because the tool stops as soon as it finds one without exploring the rest of the transition system. Most protocols take a few seconds to analyze, but when incrementing the bound on the number of transitions we can notice a steep increase in the verification time. Table 5 in Supplemental Appendix D summarizes these results. Indeed, in our model, transactions can always be executed so there is in general a large number of possible interleavings. The tool seems thus to be limited by the substantial size of the search space, like earlier tools for deciding equivalence (APTE10). In our decision procedure, we are not deciding static equivalence between frames, but the experiments made by the intruder to try and distinguish the different possibilities seem to have a comparable complexity. For unlinkability goals, in particular, our tool and others (for bounded sessions) essentially provide similar privacy guarantees. We share the challenges and techniques such as symbolic representation of constraints for the unbounded intruder. Thus, we believe that optimizations implemented in tools such as DeepSec,43 for example, forms of symmetries and partial order reductions, could be adapted to our procedure.
Typed model
We now define a simple type system for messages and the protocol specification includes the type of every constant and variable, for example, or . This is first a mere annotation: we specify the intended type. The intruder is of course able to send messages of any type and an honest agent in general cannot check if a received message is of the intended type. We then develop a notion of type-flaw resistant protocols and show in the following section a typing result for them: if there is an attack, then there is a well-typed attack. Thus, given a type-flaw resistant protocol, it is sound to restrict the intruder model to well-typed messages.
To that end, we show that our procedure of the previous sections will never perform an ill-typed substitution, when it is applied to a type-flaw resistant protocol. This is in fact proved for an arbitrary reachable state, that is, our typing result holds without any bound on the number of transitions. We will make two adaptations to the procedure: we reduce the to pattern matching and conditions and we formulate analysis as built-in transitions instead of special transactions (destructor oracles); we also show that these transformations are correct.
Type system
Types are defined similarly to terms. Instead of a set of variables, we use a set of atomic types, for example, . The composed types are defined using the functions in , with the restriction to constructors of non-zero arity, that is, we forbid destructors and constants in composed types. The type system assigns an atomic or composed type to every message with the following requirements:
(Typing function)
A typing function is such that:
is atomic for every function of arity .
for every constructor of arity .
is a type (atomic or composed) for every variable .
Our type system does not include terms containing destructors, because they represent terms that need to be evaluated and we rather want to give a type to the result. In a protocol specification, destructors can only occur as part of a destructor application of the form where either the result is and the transaction stops (for the typing result, we will require that all branches are empty), or is bound to the respective subterm of , and thus shall have the respective (destructor-free) type.
The fact that instantiations of variables are well-typed is defined with the notion of a substitution being well-typed.
(Well-typed substitution)
A substitution is well-typed iff for every , we have .
We need to ensure that the intruder is always able to make a well-typed choice, therefore, they must be able to compose arbitrarily many messages of each type, even before receiving any message from honest agents. Hence, we require that, for each atomic type, there is an infinite set of public constants of that type, that is, the intruder initially knows an unbounded number of constants of each atomic type. Suppose all function symbols were public, then the intruder would also immediately have access to an unbounded number of terms of every composed type. In fact, Hess and Mödersheim26 observe that, even if all functions are public, one can still model a private function of arity by a public function of arity , where the additional argument is filled with a distinct secret constant. Thus, private functions like are just syntactic sugar. We adopt this suggestion and, for the rest of the article, continue to use public and private functions, with the subset to identify the public functions.
We first define the precise class of algebraic theories that our typing result supports. We consider linear terms, that is, terms in which every variable occurs at most once. Compared to Definition 6.1, we include the requirement of linearity for the constructor terms in the rewrite rules and we exclude constants in encryption/decryption keys (they may still use private functions). This will be used when proving the typing result for state transitions (in particular in proofs relying on Definition 9.2).
(Algebraic theory for typing result)
Let be a set of rewrite rules satisfying Definition 6.1. For every decryption rule , respectively, for projection and private extraction, we require that the constructor term , respectively, , is linear, and that neither nor contains a constant.
In a protocol specification, we write type annotations with a colon, that is, specifies that . We further define what it means for a protocol specification to type check. This does not yet include all the requirements for type-flaw resistance but simply ensures that the type annotations are consistent throughout the specification.
(Type checking)
For every constant , one has to specify , that is, the type of that constant. For every memory cell , one has to specify which is the type of the argument for cell reads. The type annotations of constants and memory cells are global to the specification, while type checking a transaction uses local type annotations for the variables bound in that transaction. Every transaction must satisfy the following:
For every choice , we have that is a set of public constants of the same atomic type , and we then set .
For every message received , we have that is a type and we then set .
For every destructor application , where the rule for is , there exist types for the free variables of the left-hand side such that . We then set .
For every cell read , we have and we then set , where is the ground context for the initial value of . For every cell write , we have and .
For every equality in a formula, we have .
For every step , the are atomic types and we then set .
In the rest of this section and in Section 9, we will only consider protocol specifications such that the type checking requirements above are satisfied.
In Definition 2.2, there can be a process for handling failure, for example, sending an error message, while for the typing result we only support transactions that silently stop in case of destructor failure. For notation, we now omit writing , and trailing ’s in processes. Moreover, in Definition 2.2 is part of the center process, while we now require it before branching, so that any destructor failure means that the entire transaction goes directly to . We also introduce additional requirements on protocols, which we use to ensure that the intruder knows the types of the messages in their knowledge and to control the shapes of messages that can occur during the protocol execution.
(Requirements)
For some control flow requirements on transactions, consider the tree that is induced by the conditionals of the transactions (i.e. every if-then-else is a node with the respective subprocesses as children). We say two execution paths are statically distinguishable for the intruder, iff a different number of messages are sent along the paths.c Every transaction must satisfy the following:
Every destructor application occurs before any cell read or conditional statement, and every branch is empty, that is, it only contains the nil process.
For any two execution paths that are not statically distinguishable (and thus have the same number of sent messages), and under any instantiation of the intruder variables (including ill-typed instantiations), the th message sent in either path has the same type.
In every cell write , the term does not contain intruder variables.
When a decryption destructor is applied to a variable, this variable does not occur in other destructor applications.
If several projectors or private extractors are applied to the same variable, then the rewrite rules for these destructors are defined over the same constructor term.
For every message sent and every subterm of , if is composed with a constructor occurring in a decryption rule , we have that is an instance of .
Requirement (1) is essential to ensure that the failure of a destructor does not reveal information about the type of the inputs.
An example for a protocol that does not satisfy Requirement (2) immediately, that is, that messages on two paths either are statically distinguishable or have the same type, is the model of Private Authentication given by Fernet and Mödersheim38: here an agent receives a message and performs a check on it. If the check succeeds, then sends an encrypted reply as an answer. Otherwise, sends a random nonce as a decoy to hide whether the check succeeded. Thus there are two paths where the messages sent have different types, and indeed the point is to hide from the intruder which message was really sent. In the original model by Abadi and Fournet,37 however, instead of a random nonce as decoy sends an encrypted message with a fresh key and random contents of the same type as the positive case. In that formulation, the protocol satisfies our requirement. The only example we can think of that would resist a similar transformation are onion-routing protocols where the intruder should not be able to tell the number of encryption layers of a given message. For protocols that do not rely on hiding the taken branch from the intruder, one can of course easily make the messages of the branches statically distinguishable and thus can also use messages of different types.
Requirement (3) is a significant restriction on cell writes, because it essentially means that we cannot update the memory with an arbitrary message sent by the intruder. Indeed, if the intruder was able to send some message to a transaction that writes this message in memory without doing any checks on it, then we could not maintain the invariant that the intruder always knows the types of the messages they observe.
Requirements (4) and (5) are not directly about the intruder knowing the types of the messages. We consider these requirements on the use of destructors as a reasonable restriction that ensures compatible destructor applications: whenever a variable is decomposed, we can instantiate the variable with a unique corresponding constructor term, because for this decryption there is a unique rewrite rule or for these projections/private extractions all rewrite rules are defined over the same term.
Requirement (6) on the use of constructor terms in messages sent will be useful when proving the well-typedness of analysis: if a subterm in a message sent is composed with a constructor that can be decomposed, it should be an instance of the constructor term in the corresponding rewrite rule. For instance, if we model signatures with the rewrite rule , then signatures sent by honest agents must have a key starting with and cannot use a variable in this place, for example, we do not allow sending , because is not an instance of .
Using Definition 8.5, we can maintain the invariant than in a reachable state, a given label maps to the same type in every possibility, that is, the intruder always knows the types of the messages they have observed. Thus whatever recipe they use when sending a message, it corresponds to the same type in every possibility.
Let be a reachable state in a protocol satisfying Definition 8.5, be the frames in and be a recipe over the domain of the . Then .
Message patterns
To show the typing result, it is convenient to replace the mechanism for handling destructors with pattern matching. In fact, the -privacy semantics does not have a notion of pattern matching, because in a general untyped model, it is unclear how to define such a construct in a suitable way. However, for a specification that satisfies Definition 8.5, the intruder knows the type of every message, and thus also knows whether a given message will agree with a given pattern. Hence, we make a conservative extension of the receive construct with pattern matching (under the restrictions of Definition 8.5).
Instead of for an intruder variable , we now allow also , where is a linear pattern term: it contains fresh intruder variables, where each intruder variable can only occur once, and no constants. The meaning is that the agent only accepts an incoming ground message , if is an instance of and then binds the variables of with the respective subterms of (this ignores how an agent would be able to check that is an instance of ). This is a conservative extension of the semantics on ground states (Table 1).
We extend the Receive rule of Table 1 with the following:
for every recipe over the domain of the , where for every , , and if , and otherwise.
Note that for protocols satisfying Definition 8.5, either the unifier exists in every possibility or every possibility goes to . Now we can replace with pattern matching and a condition, because the intruder already knows the type of every message in their knowledge and thus knows whether the messages they send will have the correct structures for every destructor application to succeed (of course, a message with the correct structure can still fail, e.g., if it does not have the right key). Consider, for instance,
If the intruder sends for any term that is not of the form (for some , , , and ), then the destructors are going to fail. Thus we can split the ’s into a structural check that we can describe with a linear pattern like and a condition on the pattern variables. This transformation allows us to get rid of destructors in processes entirely. The transformed example is
(Removing destructors)
Let be a transaction, from a protocol satisfying Definition 8.5, that contains a destructor application for decryption, that is, for some process context that does not contain any destructor applications. Let be the corresponding rewrite rule with all variables freshly renamed. Let . Then we replace the transaction with .
In case of projectors or private extractors, may appear in destructor applications: we have , , and rewrite rules of the form . Then we remove all destructor applications for since there are no keys, and we apply the substitution to the transaction.
This transformation is repeated until the transaction does not contain any destructor application anymore. The result is denoted .
We adapt Example 2.1, where now the agent sends a message containing two nonces to the server and the server includes one of these nonces in their reply. We assume that we have three atomic types , and . Every constant in the set and the constant are of type , and the constants are of type . We now apply the transformation to remove the destructors occurring in the following transaction :
The first step is to remove with the substitution , and the second step is to remove both projections with the substitution . We now have :
A protocol satisfying Definition 8.5 and its transformation to use pattern matching according to Definition 8.7 yield the same set of reachable ground states (up to logical equivalence of the contained formulas and ).
We now define how to compute the message patterns from a protocol specification using the version of transactions.
(Protocol message patterns)
For a protocol transaction , we define as the set of terms occurring in . For a memory cell , we define the message pattern as the message , where is the ground context for the initial value of and is a variable of type , that is, the argument type for the cell. For a protocol , we define as the union of the for every transaction and of the for every in the specification (up to -renaming of variables so they are distinct in each transaction/cell).
Continuing Example 8.1, for the messages patterns of transaction , we consider the terms occurring in and this gives the following:
where the type of is , is , is and are .
Type-flaw resistance
The core part in the proof of our typing result is that variables can always be instantiated with messages of the same type. We first define the set of sub-message patterns, which includes all subterms, well-typed instantiations and key terms. To prove our result we will use the fact that every message in the symbolic execution of the protocol is in this set of sub-message patterns.
(Sub-message patterns)
The set of sub-message patterns, , of a set of terms is the least set closed under the following rules:
If , then .
If and is a subterm of , then .
If and is a well-typed substitution, then .
If , and are terms such that for some destructor we have as an instance of the rewrite rule for , then .
With rule (4), we ensure that relevant decryption keys are in , because they may occur in the symbolic constraints when performing analysis steps.
We have now everything in place to formally define type-flaw resistance, which ensures that composed messages of different types cannot be unified.
(Type-flaw resistance)
A set of terms is type-flaw resistant iff for all we have that if and are unifiable.
A protocol is type-flaw resistant iff it satisfies Definition 8.5 and the set is type-flaw resistant.
The protocol from Example 8.2 is not type-flaw resistant, because in the message patterns we have the input pattern and an output pattern , which can be unified even though they have different types: the mgu is not well-typed since .
One can make the protocol type-flaw resistant by using formats, for instance, by replacing the function with in the input and with in the outputs, where the are transparent functions (this requires also replacing the projectors in the process).
Typing result
Well-typedness of the constraint solving
We now turn back to the lazy intruder rules (Table 3) and show that, for a type-flaw resistant protocol, none of the rules perform ill-typed instantiations of intruder variables. In particular, recall that for the Unification rule, we have to unify two terms and which are not variables. If the protocol is type-flaw resistant and and are unifiable, then they must have the same type and their most-general unifier thus by well-typed.
Using type-flaw resistance, we can show that every lazy intruder rule preserves the well-typedness of the substitution of variables performed in previous lazy intruder reduction steps. Let be the set of terms occurring in a FLIC . We extend the notion of well-typed substitutions to well-typed choices of recipes.
(Well-typed choice of recipes)
Let be a simple FLIC and be a choice of recipes for . We say that is well-typed w.r.t. iff for every , we have .
We can now conclude that the lazy intruder results are doing only well-typed instantiations.
(Lazy intruder well-typedness)
Let be a type-flaw resistant protocol, be a simple FLIC such that and let be a well-typed substitution. Then every is well-typed w.r.t. .
Well-typedness for state transitions
We have defined in Table 4 the relation that models the execution of processes for symbolic states. Since we have made an extension for pattern matching for ground states, we now define how to handle this construct for symbolic states, extending the relation and proving correctness for this case. To that end, we use the lazy intruder to consider all choices of recipes producing a linear pattern: the intruder can either use a label that produces a message of the same type, or compose the pattern themselves. We ensure that if a label is a solution in one FLIC, then it is a solution in every FLIC. This is why the linearity requirement in rewrite rules is crucial, since the type information cannot distinguish variables of the same type. For instance, if a message was expected, it might be that in one FLIC a label maps to for some message of type , and in another FLIC the label maps to , where but is still of type . We instead consider only linear patterns, so in the example we might have (the transaction could still check whether after the receive). Similarly, we forbid constants in patterns because otherwise we cannot, using only the type information, know which value matches a pattern.
(Receiving message patterns)
We extend the semantics of receive steps to support linear patterns, with the following transition if :
In case , the transition is the same as Receive in Table 4.
Continuing Examples 8.1 and 8.3, the transaction starts by receiving the linear pattern . The intruder may compose that message themselves with the recipe . Another solution, assuming they have observed earlier a message sent by an honest agent, is to use the label to instantiate the pattern (if there are multiple possibilities, this label could map in other FLICs to other messages of the same type, e.g., where the nonces are different, and the substitutions are done accordingly in each process).
This conservative extension means that even when receiving patterns, we keep FLICs simple.
Given a type-flaw resistant specification, then the set of reachable states in the symbolic semantics represents exactly the reachable states of the ground semantics.
The lazy intruder is used in two ways for the experiments: (i) to compute recipes that can be compared to labels, and (ii) to solve constraints whenever the outcome of an experiment depends on messages sent earlier. Since we have already shown that the lazy intruder results are well-typed, we have the guarantee that in a experiment with a pair , the label and the recipe produce messages of the same type and all transitions to determine the outcome of an experiment are only doing well-typed instantiations. Thus, there is nothing more to show for intruder experiments.
It remains to show that analysis also never introduces ill-typed instantiations. In a normal symbolic state, the intruder can perform analysis by decrypting messages in their knowledge, if they know the appropriate key. The analysis is always done in normal states, that is, after the experiments. In Definition 6.4, the analysis is performed through destructor oracles, which are defined as transactions available to the intruder. These destructor oracles do not work directly with the typing result: since they are defined as transactions, the computation of the sub-message patterns set would need to include the patterns from the destructor oracles. This prevents us from achieving type-flaw resistance even for reasonable protocols and when formats are used. For instance, consider a protocol that uses several times but with contents of different types, for example, and . To compute the message patterns, we have to consider the transformed destructor oracle that uses pattern matching instead of ; for , this would yield the transaction . We have the pattern , because the decryption does not care about the actual content of the message but just about whether the key is correct. If we assume that there are multiple instances of this transaction where only the type annotations change (to cover all possible types), we would have and in , with, for instance, , , , and . These two message patterns are unifiable but have different types, so type-flaw resistance is not achieved.
However, the procedure does not unconditionally apply destructor oracles but always restricts the step to using a label as recipe for message , where maps to a message composed with the top-level constructor corresponding to the oracle. Therefore, we can be more precise and specialize the processes coming out of the destructor oracles: instead of a general pattern like , we only consider instances of that pattern with messages that the intruder has observed, for example, .
We define analysis steps as part of the transition system instead of special transactions. We will show that, for a type-flaw resistant protocol, this alternative way of performing analysis is equivalent to using destructor oracles. The benefit of this formulation of analysis is that we ensure all messages are instances of the protocol message patterns, and thus we can obtain the typing result.
(Analysis transition)
Let be a reachable symbolic state in a type-flaw resistant protocol. The transition for analysis is:
if is normal and there exist a label and a public destructor such that may be analyzed with , that is, for every , where (for some ) is an instance of the rewrite rule for and for every , let . In case is transparent, we define .
Note that the processes that we put in each possibility are exactly the instances of the corresponding destructor oracle, after transformation to pattern matching and substitution of the message to analyze with the respective message that the label maps to in each FLIC.
Continuing Examples 8.1 and 8.3, suppose the intruder is an agent with their own private key, they have sent the message to the server and received a reply. The intruder knowledge is represented with two possibilities, where one contains the following FLIC:
The other possibility contains a similar FLIC with in the reply. Applying the transition for analysis means that we execute (respectively, ). Assuming the intruder does not know any other private key, the lazy intruder would return the label for instantiating the message , which means .
This yields two symbolic states, one in which decryption succeeded and one in which it failed. If it succeeded, the intruder would learn and receive the decrypted pair; projecting the pair, the intruder would learn whether . If it failed, they would learn but nothing about .
We now consider two transition relations. is a relation on finished symbolic states induced by the transitions of Table 4 for executing a transaction with the evaluation of the process and by the normalization through experiments, where the transactions include the destructor oracles. More formally, iff there is a transaction (including destructor oracles) such that and . In contrast, we define now a relation that replaces the destructor oracles with the analysis transitions: iff either (there is a transaction (excluding destructor oracles) such that and ) or (, and ).d
We have made two changes to the procedure of Section 6: first, we have replaced explicit destructor applications with pattern matching (Definitions 8.7 and 9.2) and second, we have replaced destructor oracles with analysis transitions (Definition 9.3). In Lemmas 8.2 and 9.1, we have already shown that, for type-flaw resistant protocols, using pattern matching instead of explicit destructor applications is correct. Thus, for every transaction in the protocol specification, we now consider that the transaction is executed instead of . That way, we ensure that the messages in the symbolic constraints are always in the set of sub-message patterns of the protocol. For type-flaw resistant protocols, we can show that the analysis transitions are equivalent to destructor oracles, and thus the two transition relations are actually the same: . Moreover, for type-flaw resistant protocols, all instantiations performed by the relation are well-typed. Hence, we conclude and obtain our main typing result, which holds for an unbounded number of transitions.
(Typing result)
Given a type-flaw resistant protocol, it is correct to restrict the intruder model to well-typed recipes/messages for verifying privacy.
Case studies for type-flaw resistance
We consider again the protocols already studied in Section 7, namely, our running example, Basic Hash, OSK, BAC, and Private Authentication.
Running example. We explained how to make the protocol type-flaw resistant using formats in Example 8.3.
Basic Hash.34 Basic Hash is type-flaw resistant, where for the type annotations, we consider that we have the following atomic types: , used for the names of the tags and the privacy variable representing some tag name; , used for the fresh number created by the tag; and , used for the reply from the reader when identification succeeds.
OSK.35 This protocol is out of the scope of our typing result. In OSK, similarly to Basic Hash, a reader tries to identify a tag. However, in OSK, both the tag and the reader use memory cells as ratchets (initialized with a shared secret), instead of a MAC. The processes contain steps like representing a turn of the ratchet with the application of a hash function, and thus the updates change the type of the content stored in memory, which is not allowed by Definition 8.4.
BAC.36 In the model from Fernet and Mödersheim,38 there is a non-empty branch and thus it violates our typing requirements. However, the interesting aspect of the in this case—namely that it can reveal whether it is the right agent—is independent of whether it is an encryption in the first place (which the intruder knows). Thus with the pattern matching notation introduced in Section 8, we can equivalently formulate this as a pattern match and an condition with a non-empty branch and achieve the requirements of type-flaw resistance.e
Private Authentication.37 The models of Fernet and Mödersheim38 violate our typing requirements in three regards. First, the decoy message is a fresh nonce, while a normal reply is an encrypted message. It is intended that the intruder in general cannot tell which one is the case, violating our requirement that in this case the messages must have the same type. However, the original model from Abadi and Fournet37 actually ensures that the decoy message is of the same type as the regular message: it is an encryption of a fresh nonce with a fresh key. Following this, the requirement is actually met, as the intruder now in each case knows the type of each message (just not whether its content and key are decoys or regular). Second, there are non-empty branches which however can now be solved using our pattern matching notation as in the case of BAC. Third, the message from the initiator and the reply from the responder are unifiable but do not have the same type. This is a type-flaw similar to Example 8.3, and we can use formats to solve this third issue and thus achieve type-flaw resistance.
For BAC and Private Authentication, we have been able to solve the issue of non-empty branches by using pattern matching. Thus, one may wonder if we could not do that in general and drop some restrictions on our typing result. In fact here is an example that we would not be able to transform to pattern matching: , where the message in the is a signed (error) message on the input . Even if the intruder knows a priori that a particular message is not decipherable, obtaining the signature on it may be relevant in an attack that cannot be done in a well-typed way.
Related and future work
Decision procedure
It is a striking parallel between -privacy and equivalence-based privacy models that the vast amount of possibilities leads to very high complexity for procedures, as mentioned in, for example, Delaune and Hirschi.16 In equivalence-based approaches, the underlying problem is the static equivalence of (concrete) frames, representing two possible intruder knowledges. In -privacy, we have instead the multi message-analysis problem: there is just one concrete frame , the observed messages, and one or more that result from a symbolic execution of the transactions by the intruder, where the privacy variables are not instantiated. Each possibility has a corresponding condition , exactly one of which is actually true, and the intruder knows that is an instance of the corresponding , that is, under the true instance of the privacy variables, for the true . Thus, evaluating the static equivalence can exclude several instantiations of privacy variables (even if there is just one ) or rule out an entire possibility . The methods for solving these two problems bear many similarities, in particular one essentially in both cases looks for a pair of recipes that distinguishes the frames, that is, the experiments that the intruder can do on their knowledge.
Like many other tools for a bounded number of sessions such as APTE10 and DeepSec,7 we also use the symbolic representation of the lazy intruder, using variables for messages sent by the intruder that are instantiated only in a demand-driven way when solving intruder constraints, turning frames into FLICs. This makes the frame distinction problems a magnitude harder (e.g. Baudet44). In recipes we have to also take into account variables that represent what the intruder has sent earlier and the actual choice may allow for different experiments now. We tackle this problem by first considering a model where the intruder cannot use destructors. It suffices then to check only if any message in any can be composed in a different way, which in turn can be solved with intruder constraint solving. This is the idea behind the notion of a normal state, that is, where all said experiments have been done, and we can thus check if the results of the experiments exclude any model of .
What makes the handling of destructors relatively easy is our requirement that all destructors yield a subterm or , which the intruder and honest agents can observe. Thus we have no problem with “garbage terms” like decryption of a nonce. This allows us to show that it is sufficient that the intruder has applied destructors as far as possible to their knowledge using the oracles—the notion of an analyzed state: for any recipe that contains destructors, there is an equivalent recipe that uses the result of an oracle.
Concerning the complexity of decision procedures, Cheval et al.7 show that trace equivalence and labeled bisimilarity are both co-NEXP-complete for a bounded number of sessions of processes that can be specified in DeepSec. As it is shown in Theorem 2 of Gondron et al.1, trace equivalence can be reduced to -privacy under a few restrictions. This indicates that also bounded-session -privacy may be co-NEXP-hard (since Cheval et al.7 like us limit algebraic reasoning to constructor/destructor theories) and also may be in co-NEXP (since the additional tasks in -privacy—reasoning about formulas and memory cells—are probably not exceeding co-NEXP). However, the details of such an argument are rather complicated so that we are at this point unable to prove a precise complexity class.
Recent work by Rajaona et al.,45 in a spirit similar to our work, departs from equivalence-based approaches for privacy and instead uses epistemic model checking. It is implemented in the Phoebe tool46 for a bounded number of sessions in a typed model. Rajaona et al.45express the privacy properties as formulas in epistemic modal logic and a protocol specification generates a Kripke structure of “possible worlds.” While this has some similarities to our approach, the successor relation in this Kripke structure does not correspond to reachability but rather to (a kind of) indistinguishability from the intruder’s perspective. In contrast, -privacy does model a state space as a reachability relation and then every state itself contains a representation of all the possibilities that the intruder cannot exclude at this point. This allows us to keep a standard operational model of processes and the intruder (spanning the reachable states) and then put the reasoning about possibilities on top. As far as we can see, Rajaona et al.45 do not support composed keys and cannot reason with ill-typed messages; an interesting question would thus be if our typing result can be adapted to their approach.
One may wonder if a procedure for an unbounded number of transitions is possible. If we look at the equivalence-based approaches, it seems the best option for this is the notion of diff-equivalence8,16 as used in ProVerif5 and Tamarin.15 Roughly speaking, diff-equivalence sidesteps the problem of the intruder’s uncertainty in branching by requiring that the conditions are either true in both executions or both false. A similar restriction could be obtained in -privacy if we require that the intruder can always observe whether a condition was true or false, and we thus have just one in each state. We are investigating whether this can allow for an unbounded-step procedure similar to ProVerif for -privacy. Again here is a striking similarity with equivalence-based approaches: it appears that one may either need a tight bound on the number of transitions or substantial restrictions on the processes one can model. There is, however, a static analysis approach47,48 in form of a type checking procedure that guarantees trace equivalence for processes that do type in their system. This type system is not related in any way to the typed model and typing results in this article.
The major difference with other tools is in the way properties are specified and verified. Our tool looks at the reachable states from an -privacy specification of a protocol, and the privacy goals are constructed by the tool when exploring the transition system. Instead of verifying whether a number of properties hold, we thus verify whether the intruder is ever able to learn more than the information allowed (payload ). One advantage is that, in case of successful verification, we ensure that the intruder cannot learn anything more (about the privacy variables) than what the protocol is intentionally releasing. For some protocols such as Private Authentication, we believe that a characterization of the privacy goals with -privacy can give a better understanding of what guarantees the protocol actually provides, as we do not see an obvious way of expressing all the privacy goals with equivalences between processes.
Typing result
There are in our view two main benefits of typing results: robust engineering and decidability. First, robust engineering: we spend a few extra bits (if not already present) to explicitly say what messages mean and thereby “solve” type-flaw attacks. In fact, the intruder can still take an encrypted message and send it in a place where a nonce is expected (thus still sending an “ill-typed” message), but due to the clear annotation of the meaning, every honest agent will always treat this bitstring as a nonce and never try to decrypt it. Hence, if there is an attack, the same attack would work if the intruder had indeed sent a random nonce, and it is thus sound to consider an intruder model with only well-typed messages.
Model-checking approaches such as SATMC, OFMC, and CL-Atse of the AVISPA Tool and AVANTSSAR Platform29,49–53 are concerned with bounded number of steps of the honest agents. However, for verifying protocol security without such bounds, one of the most popular tools is ProVerif,5 based on abstract interpretation, basically abstracting the fresh messages into a coarser set of abstract values, while maintaining unbounded steps of both honest agents and intruder. This is in general still undecidable, but with a typed model, it becomes decidable as shown by Blanchet and Podelski20: essentially, we will have finitely many equivalence classes and thereby a finite set of well-typed messages that can occur in the saturation of Horn clauses that represent “what can happen.” A similar tool based on abstract interpretation is PSPSP,54 which relies on a typed model and computes a finite fixedpoint for stateful protocols. While the abstraction is in general an over-approximation, PSPSP implements a decision procedure for the resulting abstraction under a typed model.
There are currently no tools and methods for -privacy that perform verification for an unbounded number of sessions; therefore we currently cannot demonstrate how a typed model can help here and possibly allow for a decision procedure here, as well, but this seems very likely.
Almost all existing typing results, for instance, Almousa et al.,21 Arapinis and Duflot,22,23 Cortier and Delaune,24 and Hess and Mödersheim25,26 are concerned with standard trace properties such as secrecy and authentication. These results do not support privacy-type properties. A major challenge, and in fact the focus of our second contribution, is to give a typing result for privacy-type properties, where the most common approaches work with models based on trace-equivalence. Chrétien et al.55,56 are, to our knowledge, the only major results for this question, and thus also the related work closest to ours. Since our approach is based on -privacy, it plays a quite different game but results in Section V of Gondron et al.1 suggest that the two notions have similar expressive power.
Chrétien et al.55 establish a typing result for trace equivalence in a process algebra, for an unbounded number of sessions. They introduce the notion of type-compliance, which requires that two unifiable encrypted subterms of the protocol are of the same type. The typing result is restricted to determinate processes and symmetric encryption. Significant extensions to this work are proposed by Chrétien et al.,56 most notably providing a typing result for trace properties as an intermediate step, and enriching the supported class of cryptographic primitives. There are several decision procedures and decidability results57–60 for privacy-type properties that rely on a typed model and use the existing typing results55,56 to justify this. In contrast, our decision procedure does not require a typed model (the intruder can send messages of any type): it is actually the basis to show our typing result, namely for a type-flaw resistant protocol our lazy intruder approach will not run into any ill-typed substitution of privacy variables, and the remaining variables in a simple constraint can always be filled with well-typed values—thus establishing that there exists a well-typed attack whenever there exists an attack.
Our work is more general than Chrétien et al.56 in the following three regards. First, they require that protocols are deterministic and they do not support if-then-else branching. In contrast, we allow non-deterministic choice of privacy variables by honest agents and if-then-else with conditions that can refer to all messages in scope (including privacy variables). This generalization is significant because it allows for protocols where the privacy also depends on the control flow, for example, where the intruder does not know whether a recipient accepted a message (and sent a legitimate answer) or not (and sent a decoy answer). Note also that a common restriction for verification tools is the notion of diff-equivalence which (at least in its original form) forbids dependence on conditions.
A second generalization is the handling of constructors and destructors. Chrétien et al.56 do not model destructors in the processes (only in the intruder model) and rather obtains decryption by pattern matching. We instead support the explicit application of destructors by honest agents that -privacy uses in try-catch statements, where we only require the catch branch to be the nil process, that is, honest agents just abort when decryption fails. We in fact turn this into a pattern-matching problem, but it is part of the method (and its soundness proof) rather than being part of the model. Note that we assume that failure of a destructor is detectable; this is significant as an intruder may learn something from this failure. It seems reasonable to assume for the constructor-destructor theories supported here as most standard cryptographic implementations of primitives like AES and RSA indeed reveal if decryption failed. An interesting question is how to handle more algebraic properties like those of exponentiation with inverses that does not allow to detect failure to “decrypt” in general. However, such algebraic properties are not supported by any of the mentioned typing results.
A final generalization is that our approach supports protocol with long-term state (the memory cells). An interesting aspect of this is that there are several results concerning decidability based on typing and bounding the number of fresh nonces, for example, Chrétien et al.55; one may wonder if this is also applicable in our case. However, there is an obstacle since our argument requires an infinite supply of constants of all types for the intruder to solve the disequalities that arise, among other things, from handling the long-term state. We thus leave this question to future work.
Another closely related problem is that of compositionality, which is also regarded as a relative soundness result: given that several protocols are secure in isolation, can we show that also their composition is secure? It works indeed also by similar methods, namely transforming an attack against the composed system to an attack against one component. Since here one of the key problems is when the attacker can use messages from one component in another component, and a solution can be similarly some form of tagging, one could call compositionality a form of “typing” for a family of protocols. In fact, typing can thus be a stepping stone for a compositionality result24,26,61 and we plan to investigate if this is possible for -privacy.
Funding
The authors thank King′s College London and JISC for the financial support for the publication of this article.
Supplemental Material
sj-pdf-1-jcu-10.1177_0926227X251378716 - Supplemental material for A decision procedure and typing result for alpha-beta privacy
Supplemental material, sj-pdf-1-jcu-10.1177_0926227X251378716 for A decision procedure and typing result for alpha-beta privacy by Laouen Fernet, Sebastian Mödersheim and Luca Viganò in Journal of Computer Security
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
ORCID iDs
Laouen Fernet
Sebastian Mödersheim
Luca Viganò
Notes
References
1.
GondronSMödersheimSViganòL. Privacy as reachability. In: CSF 2022, 2022, pp.130–146. IEEE.
2.
MödersheimSViganòL. Alpha-beta privacy. ACM Trans Priv Secur2019; 22: 1–35.
3.
FernetLMödersheimS. Deciding a fragment of (alpha, beta)-privacy. In: STM 2021, LNCS, Vol. 13075, 2021, pp.122–142. Springer.
4.
Aparicio-SánchezDEscobarSGutiérrezR, et al.An optimizing protocol transformation for constructor finite variant theories in Maude-NPA. In: ESORICS 2020, LNCS, Vol. 12309, 2020, pp.230–250. Springer.
5.
BlanchetB. An efficient cryptographic protocol verifier based on Prolog rules. In: CSFW 2001, 2001, pp.82–96. IEEE.
6.
BlanchetBAbadiMFournetC. Automated verification of selected equivalences for security protocols. J Log Algebr Program2008; 75: 3–51.
7.
ChevalVKremerSRakotonirinaI. DEEPSEC: deciding equivalence properties in security protocols theory and practice. In: SP 2018, 2018, pp.529–546. IEEE.
8.
ChevalVKremerSRakotonirinaI. The Hitchhiker’s guide to decidability and complexity of equivalence properties in security protocols. In: Logic, Language, and Security, LNCS, Vol. 12300, 2020, pp.127–145. Springer.
9.
RusinowitchMTuruaniM. Protocol insecurity with a finite number of sessions and composed keys is NP-complete. Theor Comput Sci2003; 299: 451–475.
10.
ChevalV. APTE: an algorithm for proving trace equivalence. In: TACAS 2014, LNCS, Vol. 8413, 2014, pp.587–592. Springer.
11.
ChadhaRChevalVCiobâcăŞ, et al.Automated verification of equivalence properties of cryptographic protocols. ACM Trans Comput Logic2016; 17: 1–32.
12.
TiuADawsonJ. Automating open bisimulation checking for the spi calculus. In: CSF 2010, 2010, pp.307–321. IEEE.
13.
TiuANguyenNHorneR. SPEC: an equivalence checker for security protocols. In: APLAS 2016, LNCS, Vol. 10017, 2016, pp.87–95. Springer.
14.
BarbosaHBarrettCWBrainM, et al.cvc5: a versatile and industrial-strength SMT solver. In: TACAS 2022, LNCS, Vol. 13243, 2022, pp.415–442. Springer.
15.
MeierSSchmidtBCremersC, et al.The TAMARIN prover for the symbolic analysis of security protocols. In: CAV 2013, LNCS, Vol. 8044, 2013, pp.696–701. Springer.
16.
DelauneSHirschiL. A survey of symbolic methods for establishing equivalence-based properties in cryptographic protocols. J Log Algebraic Methods Program2017; 87: 127–144.
AlmousaOMödersheimSModestiP, et al.Typing and compositionality for security protocols: a generalization to the geometric fragment. In: ESORICS 2015, LNCS, Vol. 9327, 2015, pp.209–229. Springer.
22.
ArapinisMDuflotM. Bounding messages for free in security protocols. In: FSTTCS 2007, LNCS, Vol. 4855, 2007, pp.376–387. Springer.
23.
ArapinisMDuflotM. Bounding messages for free in security protocols – extension to various security properties. Inf Comput2014; 239: 182–215.
ChevalVComon-LundhHDelauneS. A procedure for deciding symbolic equivalence between sets of constraint systems. Inf Comput2017; 255: 94–125.
32.
BrusóMChatzikokolakisKden HartogJ. Formal verification of privacy for RFID systems. In: CSF 2010, 2010, pp.75–88. IEEE.
33.
FernetLMödersheimS. noname: formal verification of (alpha, beta)-privacy in security protocols, 2024. DOI: 10.5281/zenodo.14198336.
34.
WeisSASarmaSERivestRL, et al.Security and privacy aspects of low-cost radio frequency identification systems. In: Security in Pervasive Computing, LNCS, Vol. 2802, 2004, pp.201–212. Springer.
35.
OhkuboMSuzukiKKinoshitaS. Cryptographic approach to “privacy-friendly” tags. In: RFID Privacy Workshop 2003, 2003.
FernetLMödersheimS. Private authentication with alpha-beta-privacy. In: OID 2023, 2023, LNI. GI.
39.
BaeldeDDelauneSMoreauS. A method for proving unlinkability of stateful protocols. In: CSF 2020, 2020, pp.169–183. IEEE.
40.
ArapinisMChothiaTRitterE, et al.Analysing unlinkability and anonymity using the applied pi calculus. In: CSF 2010, 2010, pp.107–121. IEEE.
41.
ChothiaTSmirnovV. A traceability attack against e-passports. In: FC 2010, LNCS, Vol. 6052, 2010, pp.20–34. Springer.
42.
FilimonovIHorneRMauwS, et al.Breaking unlinkability of the ICAO 9303 standard for e-passports using bisimilarity. In: ESORICS 2019, LNCS, Vol. 11735, 2019, pp.577–594. Springer.
43.
ChevalVKremerSRakotonirinaI. Exploiting symmetries when proving equivalence properties for security protocols. In: CCS 2019, 2019, pp.905–922. ACM.
44.
BaudetM. Deciding security of protocols against off-line guessing attacks. In: CCS 2005, 2005, pp.16–25. ACM.
45.
RajaonaFBoureanuIRamanujamR, et al.Epistemic model checking for privacy. In: CSF 2024, 2024, pp.1–16. IEEE.
46.
RajaonaFBoureanuIRamanujamR, et al.Phoebe: epistemic model checker for privacy properties in security protocols. 2024. https://github.com/UoS-SCCS/phoebe/.
47.
CortierVGrimmNLallemandJ, et al.A type system for privacy properties. In: CCS 2017, 2017, pp.409–423. ACM.
48.
CortierVGrimmNLallemandJ, et al.Equivalence properties by typing in cryptographic branching protocols. In: POST 2018, LNCS, Vol. 10804, 2018, pp.160–187. Springer.
49.
ArmandoACarboneRCompagnaL. SATMC: a sat-based model checker for security-critical systems. In: TACAS 2014, LNCS, Vol. 8413, 2014, pp.31–45. Springer.
50.
ArmandoABasinDBoichutY, et al.The AVISPA tool for the automated validation of internet security protocols and applications. In: CAV 2005, LNCS, Vol. 3576, 2005, pp.281–285. Springer.
51.
ArmandoAArsacWAvanesovT, et al.The AVANTSSAR platform for the automated validation of trust and security of service-oriented architectures. In: TACAS 2012, LNCS, Vol. 7214, 2012, pp.267–282. Springer.
52.
MödersheimSViganòL. The open-source fixed-point model checker for symbolic analysis of security protocols. In: FOSAD 2007/2008/2009 Tutorial Lectures, LNCS, Vol. 5705, 2009, pp.166–194. Springer.
HessAMödersheimSBruckerA, et al.Performing security proofs of stateful protocols. In: CSF 2021, 2021, pp.1–16. IEEE.
55.
ChrétienRCortierVDelauneS. Typing messages for free in security protocols: the case of equivalence properties. In: CONCUR 2014, Vol. 8704, 2014, pp.372–386. Springer.
56.
ChrétienRCortierVDallonA, et al.Typing messages for free in security protocols. ACM Trans Comput Logic2019; 21: 1–52.
57.
ChretienRCortierVDelauneS. Decidability of trace equivalence for protocols with nonces. In: CSF 2015, 2015, pp.170–184. IEEE.
58.
CortierVDallonADelauneS. SAT-Equiv: an efficient tool for equivalence properties. In: CSF 2017, 2017, pp.481–494. IEEE.
59.
CortierVDallonADelauneS. Efficiently deciding equivalence for standard primitives and phases. In: ESORICS 2018, LNCS, Vol. 11098, 2018, pp.491–511. Springer.
60.
CortierVDelauneSSundararajanV. A decidable class of security protocols for both reachability and equivalence properties. J Autom Reason2021; 65: 479–520.
61.
HessAMödersheimSBruckerA. Stateful protocol composition in Isabelle/HOL. ACM Trans Priv Secur2023; 26: 1–36.