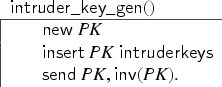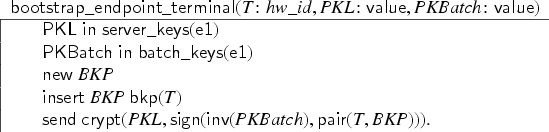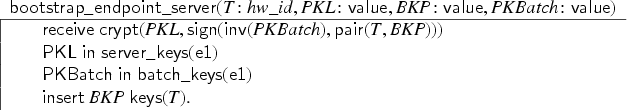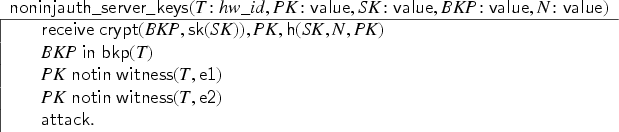In protocol verification, we observe a wide spectrum from fully automated methods to interactive theorem proving with proof assistants such as Isabelle/HOL. The latter provides overwhelmingly high assurance of the correctness, which automated methods often cannot: due to their complexity, bugs in such automated verification tools are likely, and thus the risk of erroneously verifying a flawed protocol is nonnegligible. There are a few works that try to combine the advantages from both ends of the spectrum: a high degree of automation and assurance. We present here a first step toward achieving this for a more challenging class of protocols, namely those that work with a mutable long-term state. To our knowledge, this is the first approach that achieves fully automated verification of stateful protocols in an LCF-style theorem prover. The approach also includes a simple user-friendly transaction-based protocol specification language embedded into Isabelle, and can also leverage a number of existing results, such as the soundness of a typed model.
There are at least three reasons why it is desirable to perform proofs of security in a proof assistant such as Isabelle/HOL or Rocq. First, it gives us an overwhelming assurance that the proof of security is actually a proof and not just the result of a bug in a complex verification tool. This is because the basic idea of an LCF-style theorem prover is to have an abstract datatype theorem so that new theorems can only be constructed through functions that correspond to accepted proof rules; thus implementing just this data type correctly prevents us from ever accepting a wrong proof as a theorem, no matter what complex machinery we build for automatically finding proofs. Second, a human may have an insight into how to easily prove a particular statement where a “stupid” verification algorithm may run into a complex check or even be infeasible. Third, the language of a proof assistant can formalize all accepted mathematics, so there is no narrow limit on what aspects of a system we can formalize. For instance, we have proved in Isabelle/HOL a compositionality result1 for our protocol model: given a set of protocols for which we have proved security and that meet a number of requirements, then also their composition is correct. Since also the said requirements are proved in Isabelle, we arrive at a full security proof of the entire system checked by Isabelle. A result like this is beyond the scope of any standard verification tool. Note also that as part of the composition, some of the component protocols may be proved secure by different methods or even automatically.
Paulson2 and Bella3 developed a protocol model in Isabelle and performed several security proofs in this model, for example, Paulson.4 That the proof of a single protocol (for which even some automated security proofs exist) is worth a publication, underlines how demanding it is to conduct proofs in a proof assistant. This raised the question of how one can automatically generate machine-checkable proofs. Goubault-Larrecq5 shows how one can verify Horn-clause based descriptions (e.g., in ProVerif6 internally) by finding a (finite) model for it that can easily be machine-checked. Scyther-proof7 produces Isabelle proofs for the backward search-based tool Scyther.8
A drawback of these approaches so far is that they only apply to Alice-and-Bob style protocols where there is no relation between several sessions. When we consider, however, any system that maintains a mutable long-term state, for example, a security token or a server that maintains a simple database, we hit the limits of several tools for infinite sessions such as Scyther. For instance, ProVerif is based on an abstract interpretation that basically abstracts away from states (and time). To overcome these limitations, several amendments to the abstraction were suggested, such as set-based abstraction,9 which our approach is based on, StatVerif10 and GSVerif,11 and many of these ideas are now incorporated into ProVerif.
Moreover, there is also a tool that went a completely different way: Tamarin12 (which also is not limited to protocols without long-term state) is actually inspired by Scyther-proof and has the flavor of a proof assistant environment itself, namely combining partial automation with interactive proofs, that is, supplying the right lemmas to show. Interestingly, there is no connection to Isabelle or other LCF-style theorem provers, while one may intuitively expect that this should be easily possible. The reason seems to be that Tamarin combines several specialized automated methods, especially for term algebraic reasoning, that would be quite difficult to “translate” into Isabelle/HOL—at least the authors of this paper do not see an easy way to make such a connection. In fact, if it were possible for a large class of stateful protocols, the combination of overwhelming assurance of proofs and a high degree of automation would be extremely desirable.
The goal of this work is to achieve exactly this combination for a well-defined fragment of stateful protocols. We are here using as a foundation the Isabelle/HOL formalization and protocol model by Hess et al.13 There are several reasons for this choice. First, the proof technique we present in this paper works only in a restricted typed model. Fortunately, that formalization ships with a typing result,14 namely an Isabelle theorem that says: if a protocol is secure in this typed model, then it is also secure in the full model without the typing restriction—as long as the protocol in question satisfies a number of basic requirements. Thus, we get fully automated Isabelle proofs for most protocols even without a typing restriction.
Second, as described already in Hess et al.,1 building on this protocol model has allowed us to seamlessly integrate the PSPSP tool with the compositional reasoning results: a user can specify multiple protocols in PSPSP and give annotations for their composition. The PSPSP tool can then automatically check the requirements for the composition, automatically verify each component individually, and obtain a proof of the composed system entirely verified by Isabelle/HOL from beginning to end.
Third, related to that, one may of course prove only some components of a composition automatically with PSPSP and prove other components manually when they do not fall into the scope of what PSPSP can support. Also, one may integrate manual reasoning with automated PSPSP analysis: when the runtime of automated analysis is high, a human prover may have an idea to prove some aspect more easily avoiding, for example, some lengthy enumerations.
The automated proof technique we employ in PSPSP is based on the set-based abstraction approach of Mödersheim and Bruni15 and Bruni et al.16 The basic idea is that we represent the long-term state of a protocol by a number of sets; the protocol rules specify how protocol participants shall insert elements into a set, remove them from a set, and check for membership or nonmembership. (The intruder may also be given access to some sets.) Based on this, we follow an abstract interpretation approach that identifies those elements that have the same membership status in all sets and compute a fixed point, more precisely a representation of all messages that the intruder can ever know after any trace of the protocol (including the set membership status of elements that occur in these messages). One may wonder if considering just intruder-known messages limits the approach to secrecy goals, but thanks to sets, a wide range of trace-based properties can be expressed by reduction to the secrecy of a special constant . (We cannot, however, handle privacy-type properties in this way.)
We thus check if the fixed point contains the constant, and if so, we can abort the attempt to prove the protocol correct. This may also happen for a secure protocol as the abstraction entails an overapproximation. However, vice versa, if is not in the fixed point, then the protocol is secure—if the fixed point is indeed a sound representation of the messages the intruder can ever know. The proof we perform in Isabelle now is thus basically to show that the fixed point is closed under every protocol rule: given any trace where the intruder knows only messages covered by the fixed point, then every extension by one protocol step reveals only messages also covered by the fixed point.
Contributions
Our main contribution is the formalization in Isabelle of the abstract interpretation approach for stateful protocols, as the PSPSP tool. In a nutshell, we have implemented in Isabelle the computation of the abstract fixed point—the proof idea, so to speak—and how Isabelle can convince herself that this fixed point covers everything that can happen in the concrete protocol. The Isabelle security proof that one obtains consists of two main parts: first, we have a number of protocol-independent theorems that we have proved in Isabelle once and for all, and second, for every protocol and fixed point, we have a number of checks that Isabelle can directly execute to establish the correctness of the given protocol. The entire protocol-independent formalization consists of more than 25,000 lines of Isabelle code (definitions, theorems, and proofs).
A second contribution is the development and integration into Isabelle of a simple protocol specification language for stateful protocols that is based on a notion of atomic transactions: in a transaction, an entity may receive a message, consult its long-term database, make changes to the database, and finally send out a reply. This language is more high-level than, for instance, multiset rewriting while directly defining a state-transition system. The language additionally allows the specification of analysis rules, which are rules that express how the intruder can extract knowledge from received messages built using cryptographic functions.
New contributions in this journal paper
The aforementioned contributions were also part of the conference version of the present paper.17 In the present journal version, we additionally have a number of new contributions and improvements. First, we have improved the verification method itself. We have devised a novel method for checking the fixed point coverage that significantly improves the runtime for two of our examples. We have also improved the check that the fixed point is analyzed, that is, covers also the knowledge that the intruder can gain by applying the analysis rules.
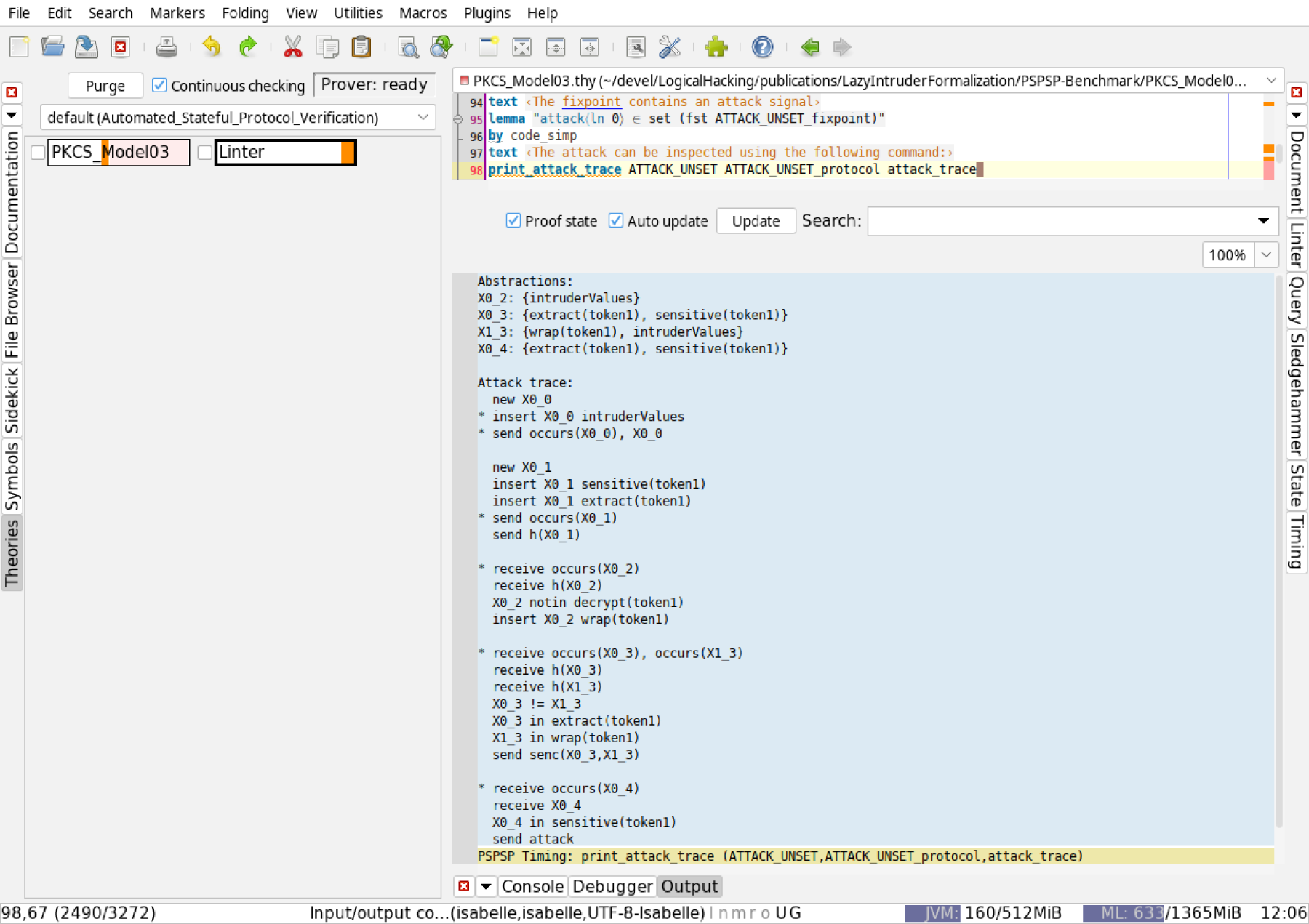
Second, we have improved the user experience of the tool, for example, by better error messages and support for understanding attacks. A trace of derivation steps for the constant can be of great help: either this is a true attack and one can strengthen the protocol to prevent the attack, or it is a false positive induced by the over-approximation, and this may give a hint how to refine the model of the protocol. Our tool can now calculate such traces and present them to the user.
Third, we have two improvements on the semantic level of PSPSP. One improvement on the semantic level of PSPSP is that we have a soundness proof for the transformation that the tool is doing. The abstract interpretation approach requires that all values be sent out in the network as part of some message. However, our syntax for transactions does not enforce this, because it is reasonable to have a transaction that inserts a value in a set/database without sending it out as part of some message. Our tool solves this by a transformation that for every newly generated value in a transaction sends out a special message and modifies each transaction to receive for every nonfresh value . The tool includes this transformation, so the modelers do not have to make this encoding themselves. Now we have proved the soundness of this transformation. Another improvement concerns the definition of the semantics of transactions. While it is defined via symbolic traces of unbounded length (which is particularly practical for relative soundness results such as typing and compositionality), we have also proved the equivalence with a more standard ground semantics.
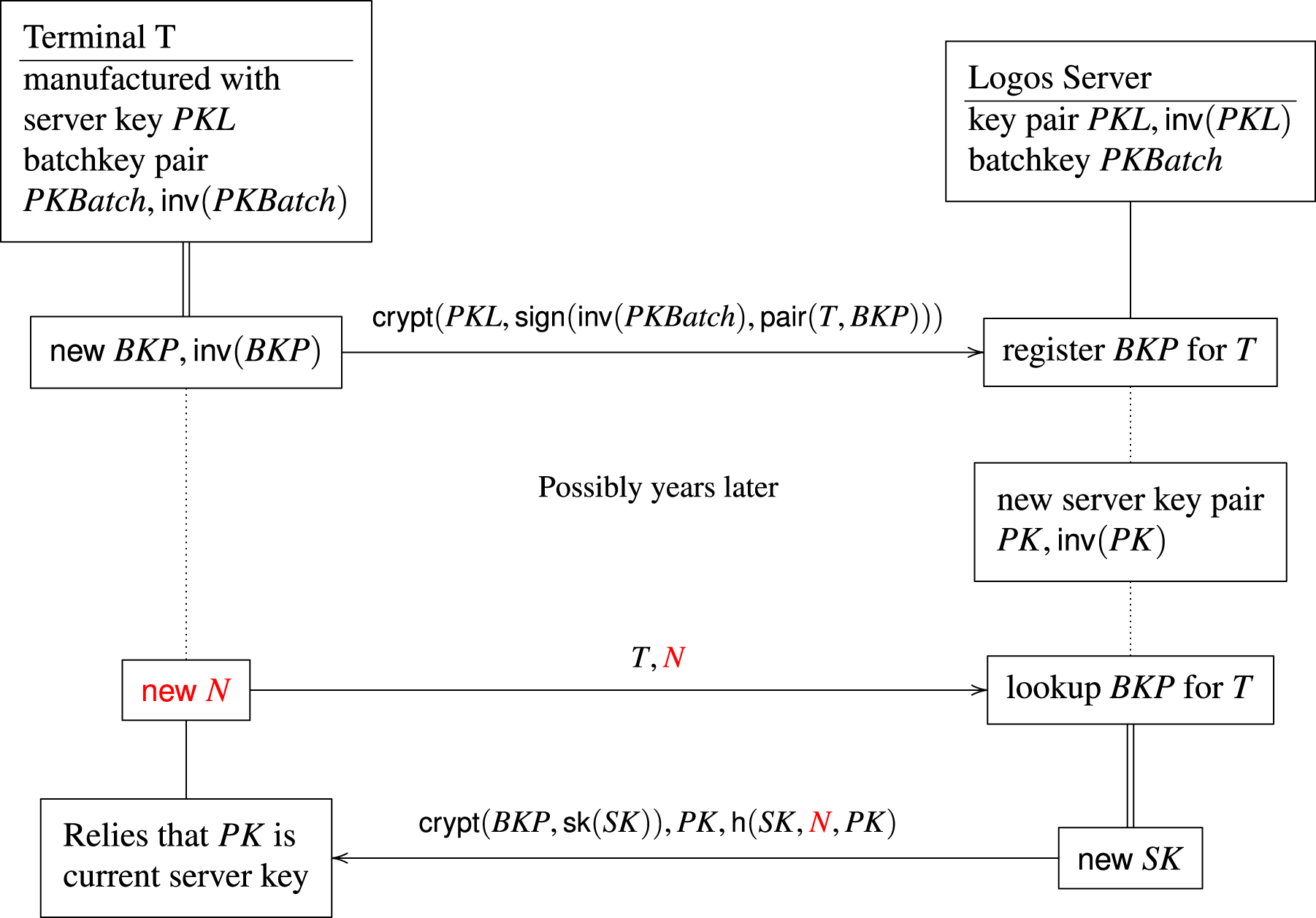
Fourth, we have a major new case study from working with the Danish company Logos. In this case study, we verify a protocol that the company is using for a travel card solution. The verification with PSPSP revealed a flaw in the protocol. After repairing the flaw, we were able to prove the security of the fixed protocol using PSPSP.
The rest of this paper is organized as follows: Section 2 introduces preliminaries, Section 3 defines the protocol model, Section 4 explains the set-based abstraction approach, Section 5 introduces the protocol checks with optimizations introduced in Section 6, Section 7 presents and reports on the results of a number of experiments applying our approach to a selection of protocols, Section 8 gives a short demonstration of PSPSP from the user’s perspective (and discusses the application of the compositionality result1), Section 9 presents and reports on a case study where we apply PSPSP to a protocol by the Danish company Logos and finally Section 10 is the conclusion where we also discuss related work.
Preliminaries
Terms and substitutions
We model terms over a countable set of symbols (also called function symbols or operators) and a countable set of variables disjoint from . Each symbol in has an associated arity, and we denote by the symbols of of arity . A term built from and is then either a variable or a composed term of the form where each is a term built from and , and . The set of terms built from and is denoted by . Arbitrary terms usually range over , unless stated otherwise. By we denote the set of subterms of .
The set of constants is defined as the symbols with arity zero: . It contains the following disjoint subsets:
The countable set of concrete values (or just values).
The finite set of abstract values.
The finite set of enumeration constants.
The finite set of database constants. [The databases that they refer to are simply sets of messages, and we therefore often refer to them simply as “sets” in this paper.]
And a special constant .
Terms represent the messages sent during the run of a protocol, and the concrete values are atomic parts of these messages that are generated during the execution of the protocol, such as public keys, nonces, shared keys, and other data. The abstract values are then abstractions of the concrete values in the abstract interpretation approach that we are using. We elaborate on these in Section 4 and choose there a specific set for that suits the concrete abstract interpretation approach we are using.
The analyst, that is, the author of a protocol specification, may freely choose and as well as any number of function symbols with their arities (disjoint from the above subsets) which represent constructors and cryptographic functions used to build the messages.
Consider a protocol with two users and , where each user has its own keyring , and the server maintains databases of the currently valid keys and revoked keys for . For such a protocol we define and .
We regard all elements of as constants, despite the function notation, which is just to ease specification. This work is currently limited to finite enumerations and finite sets, as handling infinite domains would require substantial complications of the approach (e.g., a symbolic representation or a small system result).
Arbitrary constants are usually denoted by , , , and , whereas arbitrary variables are denoted by , , and . By , we denote a finite list of variables.
We furthermore partition into the public symbols (those symbols that are available to the intruder) and the private symbols (those that are not). We denote by and the set of public and private symbols, respectively. By and , we then denote the sets of public and private constants, respectively. The constant , the values , the abstract values , and the database constants are all private.
The set of variables of a term is denoted by , and we say that is ground iff . Both definitions are extended to sets of terms as expected.
A substitution is a mapping from variables to terms. The substitution domain (or just domain) of a substitution is defined as the set of those variables that are not mapped to themselves by : . The substitution range (or just range) of is the image of the domain of under : . For finite substitutions, we use the notation to denote the substitution with domain and range that sends each to . Substitutions are extended to composed terms homomorphically as expected. A substitution should be applied to a term only when . A substitution is injective iff implies for all . An interpretation is a substitution such that and is ground. A variable renaming is an injective substitution such that . An abstraction substitution is a substitution such that .
The intruder model
We employ the intruder model from Hess et al.,13 which is in the style of Dolev and Yao: the intruder controls the communication medium and can encrypt and decrypt with known keys, but the intruder cannot break cryptography. More formally, we define that the intruder can derive a message from a set of known messages (the intruder knowledge, or just knowledge), written , as the least relation closed under the following rules:
where is a function that maps a term to a pair of sets of terms and . We also define a restricted variant of as the least relation closed under the and rules only.
The rule simply expresses that all messages directly known to the intruder are derivable, the rule closes the derivable terms under the application of public function symbols such as encryption or public constants (when ). The rule represents decomposition operations: means that is a term that can be analyzed, provided that the intruder knows all the “keys” in the set , and he will then obtain the “results” in . This gives us a general way to deal with typical constructor/destructor theories without needing to work with algebraic equations and rewriting. We may also write and to denote the set of keys, respectively, results from analyzing , that is, .
To model asymmetric encryption and signatures, we first fix two public and one private function symbols. The term then denotes the message encrypted with a public key , and denotes signed with the private key of . To obtain a message encrypted with a public key , the intruder must produce . Formally, we define the analysis rule . For signatures, we define the rule modeling that the intruder can open any signature that he knows. We also model a transparent pairing function by fixing and defining the rule .
Note that we have in this example used a simple notation for describing for an arbitrary term : each rule defines for a constructor . Here are distinct variable symbols, and and are sets of terms such that and . Note that for each constructor , we have at most one analysis rule. For those constructors that have such a rule we define for each term the function as and for all constructors without an analysis rule we just have . (An example for the latter is a hash function: the intruder cannot obtain information from a hash value.)
The reason for this convention is that the formalization of Hess et al.13 requires that the function satisfies certain conditions, most notably that it is invariant under substitutions. [One may wonder why we do not allow for analysis rules of the form , where the are arbitrary terms instead of just variables. Because of the substitution invariance requirement from Hess et al.13 on , such analysis rules would not lead to more expressive functions.] Without going into detail, our notation of the rules allows for an automated proof that all these requirements are satisfied. Thus, this allows the user to specify an arbitrary constructor/destructor theory with these rules without having to prove anything manually.
Typed model
PSPSP works in a typed model. That means every variable has an intended type, and the intruder can send only well-typed messages. Many protocol verification methods2–4,19,20 rely on such a typed model since it simplifies the protocol verification problem. There exist many typing results14,21–25 that show that a restriction to a typed model is sound for large classes of protocols: for a protocol falling in such a class, it is without loss of attacks to restrict the intruder to well-typed messages. Hess and Mödersheim14 is such a result that is part of the Isabelle formalization we employ. Since this result has itself been proved in Isabelle, to obtain the Isabelle proof that a protocol is secure in the unrestricted model, it is sufficient to have a proof that the protocol is secure in the typed model (e.g., automatically using PSPSP) and that the protocol satisfies type-flaw resistance, that is, the requirements of the typing result. We have automated the Isabelle proof of type-flaw resistance for the protocol specification language we present. Note that PSPSP only assumes a typed model, and the typing result here is just one way to discharge this assumption; there may be other ways to prove it, or one may leave it as an assumption. As PSPSP is not conceptually tied to the typing result, we give here only a brief summary of the result of Hess and Mödersheim.14
The typed model is parameterized over a typing function and a finite set of atomic types satisfying the following:
for (where here acts like a set of “variables”).
for .
for .
A substitution is then said to be well-typed iff for all variables .
For instance, we may have a transaction with a step , where . Note that in general the recipient would be unable to check if the received message is really of this form (e.g., the intruder could send them any value); the typing result shows that (if the protocol satisfies type-flaw resistance), if there is an attack, then there is a well-typed attack, and it is thus sound to replace the above step by for a new variable of type (and replace all occurrences of with in the rule). This does not mean that the recipient would learn , but only that the term can only be of the form for some of type .
For such a typing result, one considers a set of submessage patterns () that contains the messages of the protocol description and is closed under well-typed instances, subterms, and key terms that can occur during analysis steps. For instance with the operators in Example 2, if , then also . The main requirement of type-flaw resistance is: if two terms have a unifier, then .
For example, if contains messages and for and , then have a unifier, but , so this violates type-flaw resistance. There is a cheap way to make basically any protocol type-flaw resistant: instead of pairs, consider formats, that is, public functions that represent a particular way of structuring clear-text messages (e.g., XML), one format for each type of message. In the example, it can be a binary format and a unary format , and using them for the different types of encrypted messages: and . Now and are no longer unifiable, since they use different formats, and it is just following prudent engineering principles that one should not encrypt raw data such as nonces, but add a few bits identifying what type of data it is.
As mentioned, we have now automated this check for type-flaw resistance; of course, is infinite, so we cannot directly compute it, but it is rather straightforward to compute the property symbolically. (One can avoid concrete constants and does not need to consider variants of terms that are equal modulo renaming of variables.)
The typing result for type-flaw resistant protocols is proved in Hess and Mödersheim14 by considering a symbolic search technique called the lazy intruder. The key idea is that the only way that the lazy intruder instantiates variables is by a substitution that is the most general unifier of two nonvariable terms. For a type-flaw resistant protocol, the considered terms are always within , and the unifier between two nonvariable terms of is thus necessarily well-typed (thus, applying the unifier to other terms in the search keeps them also in ). Because the technique is sound and complete, it will find an attack if there is one, and this attack is well-typed for a type-flaw-resistant protocol.
In fact, like Hess and Mödersheim,14 we consider here stateful protocols where a message can be inserted, deleted, and checked for containment/noncontainment in a set . The requirement here is the following: if we have in the protocol a set operation with message and set and another set operation with message and set and if the pairs and have a unifier, then they must be of the same type. For instance, we cannot put messages of different types into the same set.
In this paper, we use as atomic types only , and the elements of have type , the elements of have type , the elements of have type and has type .
As a consequence of the typing result, when we have a variable of a composed type , it is sound to replace it by the term where are fresh variables of type . Repeatedly applying this, it is thus not a restriction to have variables of only atomic types.
Transactions
The Isabelle protocol model of Hess et al.13 consists of a number of transactions (also called rules) specifying the behavior of the participants. A transaction consists of any combination of the following: input messages to receive, checks on the sets, modifications of the sets, and output messages to send. A transaction can only be executed atomically, that is, it can only fire when input messages are present, such that the checks are satisfied, and then they produce all changes and the output messages in one state transition. Instead of defining a ground state transition system,13 consider building symbolic traces as sequences of transactions with their variables renamed apart, and with any instantiation of the variables that satisfies the checks and the intruder model in the sense that the intruder can produce every input message from previous output messages. (Transactions can also describe additional abilities of the intruder, such as reading a set.) Security goals are formulated by transactions that check for a situation we consider as a successful attack, and then reveal the special constant to the intruder. Thus, a protocol is safe if no symbolic constraint with the intruder finally sending has a satisfying interpretation. Note that the length of symbolic traces is finite but unbounded (i.e., an unbounded session model), and that the number of enumeration constants and databases currently supported is arbitrary but fixed in the specification.
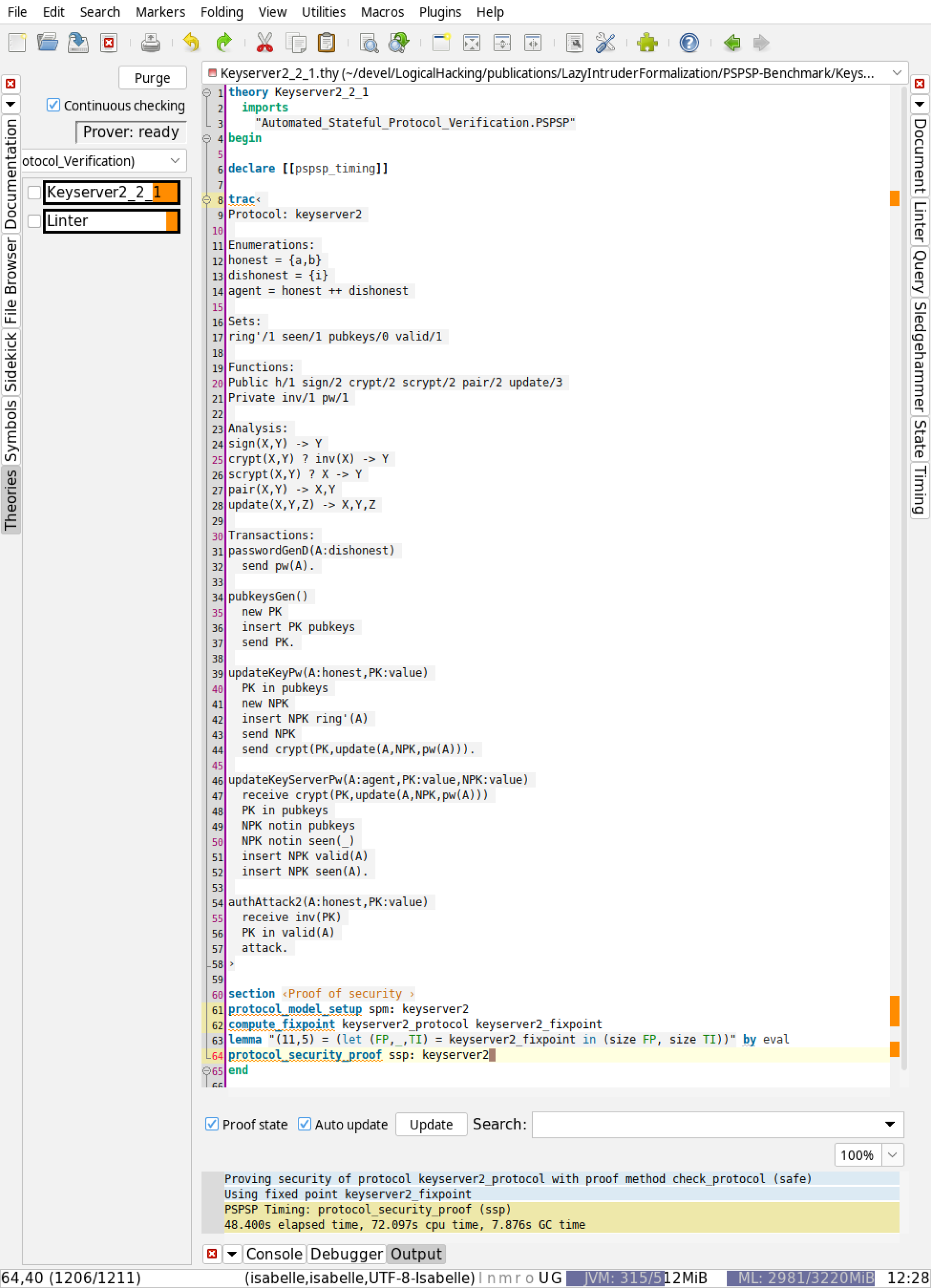
For the convenience of an automated verification tool, we have defined a small language called trac based on transactions with a bit of syntactic sugar, and this language is directly embedded into Isabelle. It is a simple text-based format directly accepted by our tool—see Section 8. To begin with, we introduce this language using a keyserver example adapted from Hess et al.13 that we also use as a running example for the remainder of this paper.
A keyserver protocol
Before we proceed with the formal definitions, we illustrate our protocol model through the keyserver example. The protocol specifies and uses the specification of from Example 1 and of from Example 2. We consider users and as honest users and as dishonest. In the specification, we will use sets , , and as types in the parameters of the transaction we specify. In the keyserver example, users can register public keys at a trusted keyserver, and these keys can later be revoked. Each user has an associated keyring with which it keeps track of its keys. (The elements of are actually public keys; we implicitly assume that the user knows the corresponding private key.)
First, we model a mechanism by which a user can register a new key at the keyserver out-of-band, for example, by physically visiting the keyserver. The user first constructs a fresh public key and inserts into its keyring . We model that the keyserver—in the same transaction—learns the key and adds it to its database of valid keys for user , that is, into a set . Finally, is published:
Note that there is no built-in notion of set ownership, or who exactly is performing an action: we just specify with such transactions what can happen. The intuition is that is a set of public keys controlled by (and has the corresponding private key of each) while is controlled by the server (who is not even given a name here). Putting it into a single transaction model that this is something happening in collaboration between a user and a server.
Next, we model a key update mechanism that allows for registering a new key while simultaneously revoking an old one. We model this as two transactions, one for the user and one for the server, since here we model a scenario where the user and server communicate via an asynchronous network controlled by the intruder. To initiate the key revocation process, the user first picks and removes a key from its keyring to later revoke, then freshly generates a new key and stores it in its keyring. (Again, the corresponding private key is known to , but this is not explicitly described.) As a final step, the user signs the new key with the private key of the old key and sends this signature to the server by transmitting it over the network:
The check represents here a nondeterministic choice of an element of . (Observe that a user can register any number of keys with the transaction.) We declare as a variable of type , because is not freshly generated here; all freshly generated elements, such as here, are automatically of type .
When the server receives the signed message, it checks that is indeed a valid key, that has not been registered earlier, and then revokes and registers . To keep track of revoked keys, the server maintains another database containing the revoked keys of :
As a last action, the old private key is revealed. This is, of course, not what one would do in a reasonable implementation, but it allows us to prove that the protocol is correct even if the intruder obtains all private keys to revoked public keys. (This could also be separated into a rule that just leaks private keys of revoked keys.)
Actions of the form for are syntactic sugar for the sequence of actions for each .
Finally, we define that there is an attack if the intruder learns a valid key of an honest user. This, again, can be modeled as a sequence of actions in which we check if the conditions for an attack hold, and, if so, transmit the constant that acts as a signal for goal violations. Recall that is a subset of that contains only the honest agents. Then we define:
The last action is just syntactic sugar for .
Protocol model
The keyserver protocol that we just defined consists of transactions (also called rules) that we now formally define. To keep the formal definitions simple, we omit the variable declarations and the syntactic sugar employed in our protocol specification language. Thus, only -typed variables remain in transactions since the enumeration variables are resolved as syntactic sugar.
A transaction is then of the form where the are strands built from the following grammar:
where , , , , and where denotes the empty strand. We remark that only values can be inserted in the sets, which is why we require . This is needed for the abstract interpretation approach we present in Section 4.
The function is extended to transactions by letting it collect all variables occurring in the strands of the transaction, and for a transaction we define (i.e., iff occurs in ).
Protocols are defined as finite sets of such transactions . Their semantics is defined in terms of a ground transition system in which each configuration is of the form , where is the intruder knowledge (the messages sent so far), is a set of pairs representing the current state of the databases (e.g., iff is an element of the database ) and keeps track of the constants that have been used already and thus cannot be considered fresh. For a configuration and a transaction, we can check if the transaction is executable from that configuration, and if so, then there is a transition to the new configuration that results from executing the transaction. When executing a transaction, variables occurring in actions will be instantiated with fresh values. To ensure that these values are indeed fresh, they must not be in already. This instantiation takes care of the actions, which are then no longer needed. The instantiation also requires a slightly more flexible syntax compared to the transaction syntax, to allow for actions such as , where . We introduce a syntax that accounts for this, called constraints or traces:
where and is the empty constraint. Note also that in contrast to transactions, constraints are seen from the intruder’s point of view, in the sense that the directions of transmitted messages are swapped (so s become s and vice-versa).
For the semantics of constraints, we define a relation where is a constraint, is the intruder knowledge, is a set of pairs representing the current state of the databases, and is an interpretation:
We say that is a model of , written , iff . We may also apply substitutions to constraints , written , by extending the definition of substitution application appropriately. The function is also extended to constraints.
We define what an intruder learns when a constraint is executed: . We also define the database , which is the update of the database after the execution of the constraint from database under interpretation :
With this in place, we define a transition relation for protocols in which states are configurations and the initial state is the empty configuration . First, we define the dual of a constraint , written , as “swapping” the direction of the sent and received messages of : , , , and otherwise. The transition
is then applicable for a transaction if the following conditions are met:
for some ,
is an injective substitution mapping to fresh values (i.e., , , and ),
, and
.
A configuration is said to be ground reachable in iff where denotes the transitive reflexive closure of . For any configuration ground reachable in this transition system, and are ground because in each step the substitutions and replace variables with ground terms in the elements added to these sets.
We now define a different semantics for protocols, namely one defined in terms of a symbolic transition system in which a single constraint is built up during transitions, essentially representing a trace of what has happened. We use this system as a basis for our formalization of both typing and compositionality because, for these two aspects, it is convenient to reason about the mentioned single constraint. For typing, it is convenient to reason about the many solutions it may have, and for compositionality, it is convenient to split the constraint into parts that then constitute constraints of the individual protocols. We call the system symbolic because we allow the built constraint to contain variables—this is in contrast to the ground transition system, which picks and applies a new interpretation in each transition. The symbolic transition system is defined using a transition relation for protocols in which states are constraints and the initial state is the empty constraint . The transition
is applicable for a transaction if the following conditions are met:
for some ,
is an injective substitution mapping to fresh values (i.e., , , and the elements of do not occur in ), and
is a variable renaming sending the variables of not in to new variables that do not occur in or (that is, and ).
A constraint is said to be symbolically reachable in iff where denotes the transitive reflexive closure of . The protocol then has an attack iff there exists a symbolically reachable and satisfiable constraint where the intruder can produce the attack signal, that is, there exists a symbolically reachable in and an interpretation such that . If does not have an attack, then is secure.
We show that the notions of reachability in the two systems correspond to each other:
[This theorem is called protocol_model_equivalence in the Isabelle formalization and can be found in the Stateful_Protocol_Model.thy theory file.]
For the remainder of the paper, we will focus our attention on the symbolic transition system as justified by the above theorem, and thus by reachable we will mean symbolically reachable.
Well-formedness
We are going to employ the abstraction-based verification technique from Mödersheim and Bruni15 in the following to automatically generate security proofs. The technique has a few more requirements in order to work and which we bundle in a notion of well-formedness.
First, if a transaction uses a variable for sending a message or performing a set update, then that variable must either be fresh or have occurred positively in a received message or check. Intuitively, transactions cannot produce a value “out of the blue,” but the value either has to exist before the transaction (in some message or set) or be created by the transaction. Formally, let . Then, we require:
The second condition simply states that values that are freshly generated by a transaction must neither occur in the received messages nor in the checks of .
A second concern is whether protocols allow the intruder to actually produce fresh values. That is not ensured in the protocol model we have presented so far, but the intruder being able to produce fresh values is standard in many models of security protocols, and we want it to be the case for our work. Suppose, for example, that a specification contains no transaction that generates any fresh value, but, say, only an attack rule like this:
One might naturally expect that said protocol is not secure, but this is only the case if the intruder can actually produce fresh values.
We will therefore require that protocols include transactions that immediately produce and reveal fresh values to the intruder. We denote such transactions as initial-value-producing transactions. If the user does not include an initial-value-producing transaction, then our tool will automatically insert one. If the user does include one, then it is the design choice of the user to define exactly how it should look, as long as it lives up to the definition of being an initial-value-producing transaction. This is, in our opinion, more flexible than strictly enforcing a specific rule, since the user can adapt the rule to the context of a particular model. For instance, in the keyserver example, where values represent public keys, one may define the intruder rule that gives the corresponding private key to the intruder and inserts it into a dedicated set:
Thus, we require (and automatically check) that each protocol specification includes an initial-value-producing transaction:
A transaction is an initial-value-producing transaction for a protocol if it is of the form where for some , no other variable than occurs in and where is either or for a set such that no transaction in deletes from nor does any check on .
It is clear that an initial-value-producing transaction is applicable in every state and generates a fresh value.
A third concern is that the abstraction approach that we employ would not work if, for example, an agent freshly creates a value and stores it in a set, but never sends it out as part of a message. This is because the abstraction discards the explicit representation of sets and just keeps the abstracted messages. As an easy workaround, we define a special private unary function symbol and then do a transformation. The transformation augments every rule containing action with the action , and also augments every transaction where variable occurs but is not freshly generated with . To avoid bothering the user with this, our tool can make this transformation automatically using the following function:
Let be a transaction, let be its (possibly empty) set of fresh variables, and let be its (possibly empty) set of other free variables.
We define a function that ensures that messages are being received and sent:
where
Note that the messages are only added during verification. One may wonder if the transformation is sound—after all, there is now the additional requirement that the intruder needs to send messages in order to run the transactions. The transformation is sound, and the argument is essentially that if there was an attack in the original protocol, then the transformed protocol will have a similar attack that simply receives and sends the introduced messages as needed. However, proving the transformation sound involves a challenge that stems from an interaction between the modified protocol and the typing result from Hess and Mödersheim.14 A requirement of applying the typing result is namely that there are infinitely many public constants of type that the intruder can get access to through the Compose rule. [The reason is that one of the main arguments used in the typing result is essentially that for attacks on type-flaw resistant protocols that use ill-typed messages, the intruder might as well have picked well-typed messages. For this to be true for an unbounded number of messages containing terms that should have had an atomic type such as , the intruder thus needs to be able to pick enough of such constants, and this is what this requirement ensures.] This is in contrast to the presentation we gave in Section 2, where we defined the type to contain only private values (i.e. ). The public constants of type are problematic because the intruder does not have messages for those. Furthermore, one might fear that attacks that used public constants of type before the transformation are “blocked” after the transformation because they do not have corresponding messages. As part of the following soundness proof, we will therefore prove that whenever the intruder might have used one of these public constants of type , he can instead use private constants of type that he obtains by using an initial-value-producing transaction. This is both central to the soundness of the occurs transformation and for us to justify not including public constants of type in the model presented in Section 2. We prove the following lemma, which transforms a run of relying possibly on public constants into one that relies only on private ones:
Let be a protocol that includes an initial-value-producing transaction and which has a well-typed attack with model . Then there exists constraint and interpretation such that is a well-typed attack on with model and such that maps all ’s free variables to values from .
Proof Sketch
The proof is essentially by induction on how was reached by . Thus, we have to consider an being extended with a transaction to and then show that the corresponding can similarly be extended in a way that preserves the properties required by the lemma. The substitution picked some number of public constants. In the extension of , we will apply first an initial-value-producing transaction times to obtain values, and then use , but with a substitution that uses these values instead of the public constants. The formalized proof is tricky, as it requires us to keep track of which fresh values and variables have been used so far in the induction, and we also need to meticulously update our model to ensure that it is indeed a model of . Therefore, in the formal proof, the induction is done in a central step where the property proved is strengthened to account for these aspects.
Let be a protocol that includes an initial-value-producing transaction and which has a well-typed attack. Then the protocol also has a well-typed attack. [This theorem is called add_occurs_msgs_soundness in the Isabelle formalization and can be found in the Stateful_Protocol_Verification.thy theory file.]
Proof Sketch
The proof has essentially three steps: The first step relies on Lemma 1 by obtaining the attack and model described by that lemma’s conclusion. The second step inserts in the sending and receiving of appropriate messages, thus turning it into an attack on . The third step proves that is also a model of .
The final concern to be discussed in this section is a small technical difficulty that arises when a transaction has two variables that could be the same value, that is, that allows for a model with . This is difficult to handle in the verification since the transaction may require inserting into a set and deleting from that very set. To steer clear of this, the paper15 simply defines the semantics to be injective on variables. [We elaborate on this in Section 5.1 after Definition 8.] For user-friendliness, we do not want to follow this, and rather do the following: for any rule with variables and that are not part of a construct, we generate a variant of the rule where we unify and , checking whether this yields a consistent transaction, that is, a transaction that avoids logically inconsistent checks such as followed by , which will necessarily fail. If so, we add it to the protocol. Then we add the constraint to the original rule. We do that until all rules have for all pairs of variables that are not freshly generated. For instance, in the keyserver example, we have only one rule to look at: with variables and . Since unifying and gives an unsatisfiable rule, it is safe to add to it.
Set-based abstraction
We now come to the core of our approach: for a given protocol, how to automatically verify and generate a security proof that Isabelle can accept. As explained earlier, this is based on an abstract interpretation method called set-based abstraction.9,15,16 Essentially, the method computes a fixed point which overapproximates the intruder’s accumulated knowledge in any sequence of transactions. While it is relatively easy to formalize the computation of this fixed point in Isabelle, the main work consists of convincing Isabelle that every transaction is covered by the fixed point in the following sense. Given any trace that is represented by the fixed point and in which a transaction is executable, then the resulting trace is covered by the fixed point. Thereby, all traces are covered by the fixed point, and when the attack predicate is not contained in the fixed point, it is not reachable in any trace of the protocol. The core of PSPSP is this coverage check that automatically performs a security proof in Isabelle. The fixed point can thus be regarded as a proof idea that no trace can contain an attack. If there was any mistake in the fixed point computation (or if the abstraction approach were actually unsound), then in the worst case, Isabelle would fail to be convinced by the coverage check.
Recall that in the previous section we formalized a protocol model by reachable constraints (i.e., a sequence of transactions where variables have been named apart and the send/receive direction has been swapped in order to express it from the intruder’s point of view) with their satisfying interpretations . Note that is defined via a relation , where here denotes the intruder knowledge (all the messages received so far) and denotes the state of the sets (all values inserted into a set that were not deleted so far). Note also that the values that can no longer be considered fresh are the set . We can thus characterize the state of the entire system after a number of instantiated transactions by these three items , , and .
In our keyserver example, the following trace is possible (after taking a transition of with variables instantiated by followed by a transition of with variables instantiated by ):
Suppose we start in state , , and . After this trace, we have
In general, consists of pairs where is a value and is a set. The idea of our abstract interpretation is that we stop distinguishing values that are members of the same sets. Let thus be the powerset of and define an abstraction function from to that depends on the current state :
and we extend it to terms and sets of terms as expected. We thus write for the abstract value that corresponds to the subset of , for example, if then . Remember that is included in , so we can build abstract terms that include elements of as abstract constants. [In fact, in the Isabelle type system, cannot contain both and subsets of ; we thus technically define the elements of as a constructor applied to any subset of . This is reflected here by the shading to ease presentation.]
In the previous example, we have and . Thus .
The key idea is to compute the fixed point of all the abstract messages that the intruder can obtain in any model of any reachable constraint. Note that this fixed point is, in general, infinite, even if is finite (and thus so is ), because the intruder can compose arbitrarily complex messages and send them. This is why tools such as those in the literature9,15,16 do not directly compute the fixed point but represent it by a set of Horn clauses and check using resolution whether is derivable.
However, remember that we can restrict ourselves to the typed model and use the typing result of Hess and Mödersheim14 to infer the security proof without the typing restriction. All variables that occur in a constraint are of type (the parameter variables of the transactions are desugared) and thus, in a typed model, it holds that for every variable and well-typed interpretation . While is still countably infinite, the abstraction (in any state ) maps to the finite . Thus, the fixed point is always finite in a typed model.
There is a subtle point here: even though we limit the variables to well-typed terms, and thus also limit all messages that can ever be sent or received, the Dolev-Yao closure is still infinite, that is, for a (finite) set of messages there are still infinitely many such that . Only finitely many of these can be sent by the intruder in the typed model, but one may wonder if the entire derivation relation can be limited to “well-typed” terms without losing attacks. Indeed, we define well-typed terms as the set of terms that includes all well-typed instances of sent and received messages in transactions, and that is closed under subterms and . We have proved in Isabelle that for the intruder to derive any well-typed term, it is sound to also limit the intruder deduction to well-typed terms, so no ill-typed intermediate terms are needed during the derivation. (This is indeed very similar to some lemmas we have proved for parallel compositionality, namely for so-called homogeneous terms, the deduction does not need to consider any inhomogeneous terms.13) Thus, it is sound to limit the fixed point and the intruder deduction to well-typed terms, which makes the fixed point finite.
Defining fixed points
Let us now see in more detail how to formally define the fixed point. An important aspect of the abstraction approach is that the global state is mutable, that is, the set membership of concrete values can change in transitions, and so their abstraction changes.
The value in Example 3 is created in the first transaction and has, after the first transaction, the abstraction . Since the second transaction deletes from , it changes its abstract class to .
As such, transitions of the abstraction of values play a crucial role in the approach; we define the following notion:
(Term implication)
Aterm implication is a pair of abstract values and a term implication graph is a binary relation between abstract values, that is, . Instead of , we may also write .
The reason we use the word “implication” is as follows. Suppose an abstract set of messages contains several occurrences of the same abstract value , say . Due to the abstraction, we have lost the information of how many distinct constants are represented here, for example, two corresponding concrete set of messages could be and where both and have the same set memberships . If now value changes its set memberships to, say, , then the abstraction of becomes and the abstraction of becomes . Thus, in general, to include all possible terms that can be reached by a term implication , each occurrence of can independently change to . This means that all of the original terms with now changed to are also reached, and hence we call it an implication. This is captured by the following definitions:
(Term transformation)
Let be a term implication. The term transformation under is the least relation closed under the following rules:
Note that this relation is also reflexive since for holds because of the third rule. If then we say that is implied by under , or just is implied by for short.
(Term implication closure)
Let be a term implication graph and let be a term. The term implication closure of under is defined as the least set closed under the following rules:
This definition is extended to sets of terms as expected. If then we say that is implied by (under ).
Closing the fixed point under the term implication graph is actually quite large in many practical examples, and thus we just record the messages that are ever received by the intruder together with the term implication graph, but without performing this closure explicitly:
(Fixed point)
Aprotocol fixed point candidate, or fixed point for short, is a pair such that [here “candidate” is to emphasize that this is just a proof idea that has yet to be verified by Isabelle]
is a finite and ground set of terms over .
is a term implication graph: .
Limitations
There are some limitations of our approach that we now mention. First, PSPSP is limited to reachability properties. This is because privacy-type properties are quite hard to handle in infinite-state verification. To our knowledge, regarding automated tools for infinite sessions, only Tamarin12 and ProVerif6 handle this by restriction to diff-equivalence.26
We inherit the free algebra term model from Hess et al.13 (two terms are equal iff they are syntactically equal), and so we do not support algebraic properties such as needed for Diffie-Hellman. We inherit the limitations of AIF’s set-based abstraction approach:
We require each protocol to have a fixed and finite number of enumeration constants and sets. This typically means that also the number of agents is fixed—at least if the protocol has to specify a number of sets for each agent.
We require that the sets can only contain values. The reason is to allow these values to be abstracted by set membership. That would not work if we allowed composed terms in the sets.
We cannot refer directly to particular constants of type . This would not be very useful, as every value with the same set-membership status is identified with the same abstract value under the set-based abstraction.
We cannot check the equality of values, again, because two values may have the same abstraction.
As the following protocol shows, the abstraction may lose “connections” between values, and this can lead to spurious attacks. The example illustrates this using the transactions and which result in the intermediate fixed point and the term implication . Thus under term implication we get the terms , , , and . The latter term triggers , which emits an attack. However, on the concrete level. This attack is not possible because there any concrete chosen values for and in , are either both in or both not in . We remark that many protocols do not rely on such “connections” between values, as demonstrated by our benchmark suite.
Our approach allows for an unbounded number of sessions. The only difference here between our work and, for example, Tamarin12 and ProVerif6 is that we need, as mentioned, to fix the number of enumeration constants and sets, and thereby, in a typical specification, also fix the number of agents. However, there is no difference in the notion of unbounded sessions: We allow for an unbounded number of transitions, every set can contain an unbounded number of values, and the intruder can make an unbounded number of steps. There is potential for overcoming this limitation: Comon-Lundh and Cortier27,28 show that a restriction to finitely many agents can often be without a loss of attacks. Mödersheim and Bruni15 indirectly show that similar results are possible for set-based abstraction, since one can compute a symbolic fixed point leaving agents uninstantiated variables. This, however, requires several restrictions on the use of negation, suggesting close limits of such an approach for set-based abstraction. As this would have also required a substantially more complicated concept for the fixed point computation and checking, we opted for not using this approach in Isabelle/PSPSP.
A minor limitation is that the method of PSPSP requires a typed model. In order to also be safe against type-flaw attacks one needs to employ a typing result like14 and thus also needs to satisfy the requirements of that result, but this is not a serious limitation for the class of protocols we consider and it is automatically checked (see Section 2.3).
Finally, PSPSP has a number of smaller limitations that we list here for completeness:
We require that all variables must have an atomic type. This restriction could actually be overcome because, for a type-flaw resistant protocol, it is sound to replace a variable of composed type with a corresponding composed term of atomic type variables. However, we consider it out of scope to implement and formally verify this transformation and its soundness, and thus require that all variables must have atomic type.
Our definition of the rule using means that one cannot let secret keys be values and then define the corresponding public key as . This is because does not allow definitions on the form . We consider this a small restriction because, as the examples show, one can instead let the public keys be values, and then have a function mapping them to private keys.
We are using pattern matching in the receipt of messaging. The user of our tool thus needs to understand that to implement a specified protocol, they need their implementation to reject messages received that are not in the expected format. This is in contrast to ProVerif’s -calculus,6 where the steps checking the format are stated more explicitly in the specifications. We do not consider this a significant limitation because this kind of pattern matching is quite standard in the modeling of security protocols, for example, AVISPA, and Meier et al.12
Example of a fixed point computation
Consider again the keyserver protocol defined in Section 3.1; for simplicity, we do this example for just one user who is also honest: . We show how the fixed point (or rather the candidate that we then check with Isabelle) is computed; to make it more readable, let us give the fixed point right away and then see how each element is derived: where
The term implication graph can be represented graphically as follows with each edge corresponding to an element of :
Note that we can actually reduce the representation of the fixed point a little, as we do not need to include facts that can be obtained via term implication from others; with this optimization, we obtain:
To compute , we first consider the transaction where a fresh key is inserted into both and and sent out. The abstraction of this key is thus the value . This value is in the intruder’s knowledge in but redundant due to other messages we derive later. [In fact, the well-formedness conditions of the previous section require us to also include facts, but for illustration, we have simply omitted them (as the intruder knows every public key that occurs).] Note that this rule cannot produce anything else, so we do not consider it for the remainder.
Next, let us look at the transaction . For , we need to choose an abstract value for that satisfies the check . At this point in the fixed point computation, we have only . Since the transaction removes the key from , we get the term implication . A fresh value is also generated and inserted into , and a signed message is sent out which gives us: . Also, this one is a message that later becomes redundant with further messages. By analysis, the intruder also obtains .
The new value allows for another application of the rule, namely with this key in the role of . This now gives the term implication and the message . After this, there are no further ways to apply this transaction rule, because we will not get to any other abstract value that contains .
Applying the transaction to the first signature we have obtained (i.e., with and ), we get the term implications and , and the intruder learns . Applying the transaction with the second signature (i.e., with and as before) is not possible because and thus the transaction’s check of will not be satisfied. However, because of the intruder’s knowledge of the first signature and the previously stated term implication , the intruder also knows the signature . If we apply the transaction with this signature (i.e., with and ) then we get the new term implication , the term implication , which we already knew, and the intruder learns , but that was already in the intruder knowledge.
Any other signature that the intruder knows as a consequence of the two signatures sent by the agent and the term implications will not satisfy the checks of the transaction. Note though, that we must also check if the intruder can generate a signature that works with : however, the only private keys he knows are those represented by , and they are not accepted for this transaction. (In a model with dishonest agents, the intruder can, of course, produce signatures with keys registered to a dishonest agent’s name, but here we have just one honest user .)
No other transaction can produce anything we do not have in already—in particular, we cannot apply the attack transaction, and this concludes the fixed point computation. Thus—according to our abstract interpretation analysis—the protocol is indeed secure. Next, we try to convince Isabelle.
Computing fixed points and checking fixed point coverage
In this work, we automatically calculate fixed points with the abstract interpretation approach as a “proof idea” for conducting the security proof on the concrete protocol. A major contribution of our work is the ability to turn this fixed point into a formal security proof in Isabelle. Essentially, we prove that the fixed point indeed “covers” everything that can happen. We break this down into an induction proof: given any trace that is covered by the fixed point, if we extend it by any applicable transition, then the resulting trace is also covered by the fixed point. This induction step we break down into a number of checks that are directly executable within Isabelle using the built-in term rewriting proof method code-simp. The induction is done in the proof of a protocol-independent Isabelle theorem (Theorem 3) that shows that any protocol that passes said checks is indeed secure. Note that these checks are not only fully automated, but they also terminate in all but a few degenerate cases. [It is technically possible to specify protocols for which the checks do not terminate. For instance, an analysis rule of the form , for some , and , would lead to termination issues when automatically proving the conditions for the typing result which we rely on, because we here need to compute a set that contains the terms occurring in the protocol specification and is closed under keys needed for analysis, and such a set would in this case be infinite. However, this is an artificial example that normally does not occur since it is usually the case that keys cannot themselves be analyzed.]
Automatically checking for fixed point coverage
Let us look at how we can automatically check if a fixed point covers a protocol. We first explain how this works in general and thereafter give an example, in Example 6, of how it works using the keyserver example.
A transaction of the protocol after resolving all the syntactic sugar has only variables of type . Thus, in a typed model and under the abstraction, we can instantiate the variables only with abstract values, that is, elements from . We first define what it means that a transaction is applicable under such a substitution of the variables with respect to the fixed point computed by the abstract interpretation:
(Fixed point coverage: preconditions)
Let be a transaction and let be a fixed point. Let further be an abstraction substitution mapping the variables of to abstract values of . We say that satisfies the preconditions (for and ), written , iff the following conditions are met:
for all occurring in and for all .
for all occurring in .
for all occurring in .
for all .
Here, F1 checks that the intruder can produce all input messages for the transaction under the given . Note that the intruder has control over the entire network, so he can use any message honest agents have sent and also construct other messages from that knowledge (hence the ). Moreover, we consider here the closure of the intruder knowledge under the term implication rules, since that represents all variants of the messages that are available to the intruder; we will later show as an optimization that we can check whether holds without first explicitly computing . The two next checks, F2 and F3, verify that are that all set membership conditions are satisfied, and F4 checks that all fresh variables represent values that are not members of any set.
Now, for every under which the transaction can be applied (according to ), we compute what can “produce” and check that it is already covered by . The transaction can produce outgoing messages and changes in set memberships. The latter is captured by an updated abstraction substitution that is identical with except for those values that changed their set memberships during the transaction:
(Abstraction substitution update)
Let be a transaction and an abstraction substitution. We define the update of w.r.t. , written , as follows:
Note that according to this definition, if a transaction contains insert and delete operations of the same value for the same set, then “the last one counts.” But there is a more subtle point: suppose the transaction includes the operations and . The above definition would not necessarily formalize the updates of the set memberships if the transaction were applicable (in the concrete) under an interpretation with . Thanks to the preparations described in Section 3.3, we have in every transaction the constraint that all value variables have pairwise disjoint concrete values.
This leads to the following two postconditions:
(Fixed point coverage: post-conditions)
Let be a transaction and let be a fixed point. Let be an abstraction substitution and the update of w.r.t. . We say that satisfies the postconditions (for and ), written , iff the following conditions are met:
for all .
for all occurring in and for all .
Here G1 expresses that every update of a value must correspond to a path in the term implication graph (it does not need to be a single edge). G2 means that the intruder learns every outgoing message and thus it must be covered by the fixed point when closed under term implication.
We can now put it all together: the preconditions restrict the coverage check to those abstraction substitutions that are actually possible in the fixed point. The postconditions check that the fixed point covers everything that the transaction produces under those same substitutions. Fixed point coverage is thus defined as follows:
(Fixed point coverage)
Let be a transaction and let be a fixed point. We say that covers iff for all abstraction substitutions with domain , if then . For a protocol we say that covers iff covers all transactions of .
With this defined, we can prove the following theorem:
Let be a protocol and let be a fixed point. If , and if is covered by , then is secure. [This theorem is called protocol_secure in the Isabelle code and can be found in the Stateful_Protocol_Verification.thy theory file.]
Proof Sketch
We gave the intuition of this proof in the introductory text of this section. We supplement that here with some further intuition. First, we define a notion of abstract intruder knowledge, namely . The proof then relies on two insights about this abstract intruder knowledge.
The first insight is that if a term is in the intruder’s knowledge, then its abstraction is also in the abstract intruder knowledge. Formally if then .
The second insight is to prove that for any reachable constraint , with satisfying interpretation , it is the case that any message (e.g., the constant) in the abstract intruder knowledge is also derivable from the fixed point. Formally if then . The proof of this second insight is by an induction on how was reached by . The central part is the induction step where a reachable constraint is extended with the dual of a transaction . Here we see that the abstract intruder knowledge achieved by running the dual of is a result of messages sent in . The definition of coverage ensures that these sent messages are also derivable from the fixed point’s term implication closure.
Consider the key update transaction from Section 3.1. We now show that the fixed point defined in Example 4.3 covers this transaction, that is, satisfies Definition 10.
The only variables occurring in are and , so we can begin by finding the abstraction substitutions with domain that satisfy the preconditions given in Definition 7. We denote by the set of these substitutions. Afterwards, we show that all satisfy the postconditions given in Definition 9.
The variables and are not declared as fresh in so condition F4 is vacuously satisfied. From F2 and F3 we know that and , for all . From F1 we know that . The intruder cannot compose the signature himself since he cannot derive a private key of the form where and . Hence, the only signatures available to him—that also satisfy the constraints for that we have deduced so far—are for each . The only surviving substitutions are
That is, .
Next, we compute the updated substitutions w.r.t. the transaction :
Now we can verify that conditions G1 and G2 hold for and : We have that is covered by , for all and all . We also have that the outgoing message is in under each . Thus is covered by .
We can, in a similar fashion, verify that the remaining transactions of the keyserver protocol are covered by the fixed point. Thus, the keyserver protocol is covered by .
Automatic fixed point computation
An interesting consequence of the coverage check is that we can also use it to compute a fixed point for protocols . In a nutshell, we can update a given fixed point candidate for as follows: For each transaction of , we first compute the abstraction substitutions that satisfy the preconditions F1 to F4. Secondly, we use the postconditions G1 and G2 to compute the result of taking under each and add those terms and term implications to . Starting from an empty initial iterand , we can then iteratively compute a fixed point for . Definition 11 gives a simple method to compute protocol fixed points based on this idea.
Let be a protocol and let be the function defined as follows:
where
Then we can compute a fixed point for by computing a fixed point of . This can be done, for example, by computing the least such that because then is indeed a fixed point.
We provide, as part of our Isabelle formalization, a function to compute such a fixed point (with some optimizations to avoid computing terms and term implications that are subsumed by the remaining fixed point), using the built-in code generation functionality of Isabelle.
Improving the coverage check
We describe a number of improvements that are essential to an efficient check. Since we have proven the checks correct in Isabelle, there is no risk of affecting the correctness of the entire approach.
There are two major issues that make the coverage check from the previous section quite inefficient when implemented directly. One concerns the fact that to see if a protocol is covered, we need to consider for every received term any message that is in the fixed point closed under term implications and intruder deduction. Even though the typed model allows us to keep even the intruder deduction closure finite, explicitly computing the closure is not feasible even on rather modest examples. The second issue is about the abstraction substitutions of the check: recall that in the check we defined above, for a given transaction we consider every substitution of the variables with abstract values, which is of course exponential both in the number of variables and the number of sets.
Let us first deal with this second issue. We can indeed compute exactly those substitutions that satisfy conditions F2 to F4: every positive set-membership check of the transaction requires that , and similarly for the negative case. Moreover, can be only an abstract value that actually occurs as a member of the fixed point or as a subterm in the fixed point. Starting from these constraints often substantially cuts down the number of substitutions that we need to consider in the check, especially when we have more agents than in the example. This is because typically (at least in a good protocol) most values will not be members of many sets that belong to different agents (but rather just a few that deal with that particular value).
The first issue, that is, avoiding computing the term implication closure when performing intruder deductions, is more difficult. The majority of this section is therefore dedicated to improving on conditions F1 and G2 so that we can avoid computing the entire closure —only in a few corner cases do we need to compute the closure for a few terms of . A key to that is to saturate the intruder’s knowledge with terms that can be obtained by analysis and then work with composition only, that is, .
Intruder deduction modulo term implications
Recall that is the intruder deduction without analysis, that is, only the and rules. We first consider how we can handle in this restricted deduction relation the term implication graph efficiently, that is, how to decide (for given , , and ) without computing . In a second step, we then show how to also handle analysis, that is, the full relation.
In fact, it boils down to checking the side condition of , that is, in our case, whether , without having to compute first. (The composition rule is then easier because it does not “directly look” at the knowledge.) For this, it is sufficient if we can check whether for any , without having to compute .
Consider again Definition 5. We can use this to derive a recursive check function for the question : it can only hold if either
and are the same variable,
or , are abstract values with a path from to in ,
or and , where recursively holds for all .
With this we can define a recursive relation that checks for given , , and whether without computing :
This relation indeed fulfills its purpose:
.
Next, we show how to reduce the intruder deduction problem to the restricted variant .
Analyzed intruder knowledge
It has been observed that many intruder deduction problems can be regarded as local theories, that is, so that all intermediate terms in the deduction are subterms of the given intruder knowledge or the goal term to construct. This is because the intruder may, of course, compose a message and then decompose it again, but in most theories, that would only yield one of the terms that we started with. Observe that we only support theories where the result of an analysis step is direct subterms of the term being analyzed. This means that all deduction proofs that contain such a pair of encryption–decryption steps can be normalized to a simpler proof, eliminating the unnecessary detour. Thus, all decomposition steps are applied to messages composed by an honest agent, and thus all intermediate steps in an intruder deduction are subterms of what the intruder wants to construct or knows in advance. [We only mention here that this is indeed close to the concept of a local theory: it is sufficient to consider in a deduction only intermediate terms that are subterms of or . However, there are some exceptions to the locality property: in decomposition, the necessary key may not be a subterm of or . For instance, to decrypt , one needs , which may neither be part of nor . (In that case, since is private, the deduction step is only possible if already occurs in .)]
The proof normalization argument we just sketched would be very difficult to integrate into Isabelle directly, since we would have to meta-reason in Isabelle about the definition of the intruder deduction rules. In fact, we have a similar way when reasoning about homogeneous message deduction in compositional proofs (i.e., that the intruder never needs to mix messages from the protocols being composed). Our Isabelle proofs work by induction over the size of terms (not over the structure of the deduction) that everything deducible is also deducible with a more restricted notion, in this case, that it is sufficient to only compose terms if the intruder’s knowledge is already analyzed. We note that such arguments do not hold in general when algebraic properties are considered (such as commutativity of exponents in Diffie-Hellman). For that case, our theory would need nontrivial adaptations.
The idea is thus that is actually already sufficient, if we have an analyzed intruder knowledge: we define that a knowledge is analyzed iff implies for all . More in detail, we can consider a knowledge that is saturated by adding all subterms of that can be obtained by analysis. Then is analyzed, that is, we do not need any further analysis steps in the intruder deduction. This is intuitively the case because the intruder cannot learn anything from analyzing messages he has composed himself.
We define formally what it means for a term to be analyzed using the keys () and results () from the analysis as defined in Section 2.2:
(Analyzed term)
Let be a set of terms and let be a term. We then say that is analyzed in iff (where for sets of terms and is a shorthand for ).
The following lemma then provides us with a decision procedure for determining if a knowledge is analyzed:
is analyzed iff all are analyzed in .
We consider again an intruder’s knowledge given as the term implication closure of a set of messages, that is, instead of . Efficiently checking whether an intruder’s knowledge term implication closure is analyzed, without actually computing it, is challenging. The following lemma shows that if we can derive the results of analyzing a term in the knowledge , then we can also derive the results of analyzing any implied term :
Let . If then for all , .
Therefore, if all can be derived and is analyzed in then we can conclude that all implied terms are analyzed in . If, however, some of the keys for are not derivable, then we are forced to check the implied terms as well as the following example shows:
Let , , and . Define the analysis rules and . Then . The term is analyzed in because the key cannot be derived: . However, and is not analyzed in : but the key is derivable from in , whereas the result is not. Thus is not an analyzed knowledge.
So in most cases we can efficiently check if is analyzed, and in some cases we need to also compute the term implication closure of problematic terms (but not necessarily compute all of ). The former corresponds to the three “if” cases of the following definition, and the latter corresponds to the final “else”-branch:
is analyzed iff for all , the following holds:
Lemma 5 provides us with the means to extend a knowledge to one whose term implication closure is analyzed: Suppose for a term the three if conditions of the lemma fail, that is, when we have to check for every that is analyzed in . If can be decrypted and the keys are available, but the result of the decryption cannot be composed in , then (and only then) we add this result to . For instance, in Example 7, we need to extend with , resulting in the analyzed knowledge .
The two “else–if”-branches are an improvement we have made for this journal version of the paper. The idea is the following:
If are not derivable from the term-implication closed knowledge , and if there is no abstract value occurring in , then for all implied terms of , and so is analyzed in .
If none of the implied keys of are derivable then is also analyzed in .
These two special cases are useful to speed up the analyzed-fixed point check when the fixed point contains terms that have lots of abstract values in them and that cannot be analyzed by the intruder (the last else branch would in such cases take a lot of time to compute since the size of grows exponentially with the number of occurrences of abstract values in )—also, it is often the case that has fewer abstract values in it than , and so the size of is likely to be much smaller than , hence the second “else–if” condition is usually much faster to check than the last else-branch.
As an example, when modeling private channels one may use terms of the form , denoting that is sent on a private channel from agent to agent , where the term is derivable if the secret is known, and where there would be an attack on the protocol if the intruder knew for honest and . In a secure protocol, the term , for honest and , would not be derivable by the intruder, and so it is sufficient to check that and instead of checking that all elements of are analyzed in , which may take a significant amount of time since may contain a lot of abstract values.
The improvements described from Section 6 up to here are the Default version of our coverage check. We will now explain an alternative check that improves the run time for some protocols. Note that in our implementation, we can make use of Isabelle’s parallelization framework, executing the default version and the alternative version in parallel, returning the result of whichever check terminates first. By that, we can ensure that the user always benefits from the runtime of the fastest check.
Restricting the number of abstraction substitutions further
We return to the second issue described at the beginning of this section: restricting how many abstraction substitutions need to be considered in order to conclude that a transaction is covered. The solution presented so far restricted the set of abstraction substitutions considered to those that satisfy conditions F2 to F4 of Definition 7. We now show how to take into consideration also condition F1 to further restrict that set. This will not be exactly the set of substitutions that satisfy F1 to F4, but rather an overapproximation that can be computed in an efficient way.
F1 essentially says that for each received term of a considered transaction, its abstraction must be derivable from the fixed point using the relation. However, we will, based on the previous two sections, restrict ourselves to the relation.
We, therefore, in this section, define functions that together calculate an overapproximation of the set of these . These functions can be seen as implementing the relation. We will now, in this first part of this section, consider two functions based on the Axiom rule of , and in the second part of this section, we will then consider a function combining the Axiom rule and the Compose rule. We therefore will now introduce two functions and that are based on the Axiom rule. They work by matching terms in -steps, possibly containing variables, with ground terms in the fixed point, possibly containing abstract values. The idea is that by inspecting a term from the -steps and comparing it to the terms available in the fixed point we will be able to see what the variables in could be instantiated to if is to be a term from the fixed point. This is illustrated by the following example:
Consider the term from a -step in a transaction of a protocol and the term from a given fixed point. Observe that and have a similar structure, but the first and second arguments of are different, so there is no match between and . However, modulo term implication, there could be a match if the two abstract values in can flow together.
Consider the following term implication graph:
The closure of is the set and the term implication closure of is . We can see that both considered abstract values share that they actually represent and . Thus, can be made equal to modulo term implication by choosing either to replace all occurrences of with or by choosing to replace all occurrences of with . Therefore there are two abstraction substitutions such that , namely and .
What we have done in this example is to use three steps to find out if there is a such that can be found in . More generally, step 1 is to see if there is a term that matches , where different occurrences of the same variable may need to be matched with different abstract values (as for in the above example). Step 2 is to collect for each variable the set of every abstract value that works for every occurrence of simultaneously modulo term implication, that is, for every abstract value computed in step 1, . Step 3 is to calculate every possible abstraction substitution from step 2.
Let us first consider that captures the idea of step 1. It takes two terms and , where is a term from a rule (that may have variables) and is a term from the fixed point (that may not have variables). The function checks if and can be made equal by replacing occurrences of variables in with abstract values. If this is possible, it returns a singleton set containing function mapping each variable to a set of abstract values, where each member of is a possible replacement for . If it is not possible, it returns the empty set. When trying to match a variable with an abstract value , returns a singleton set and maps to . For a composed term, we recursively compute the set of matches for each subterm and then pointwise merge the results, so that for each variable we get all abstract values it needs to have in some occurrence of in in order to allow for the match with . Note that in the following definition, and map from variables to sets of abstract values.
The function is defined as follows:
We return to Example 8 and see that indeed will calculate what the occurrences of should be replaced by. Here we have that . We notice that the set to which is mapped to consists exactly of the two abstract values that we expected to get from Example 8.
Having defined a function that implements step 1, we now turn to implementing a function that combines this with step 2. The function checks if and can be made equal modulo term implication by replacing variables in with abstract values. If this is possible, it returns a singleton set containing a function mapping each variable to a set of abstract values, where each member of is a possible replacement for . If it is not possible, it returns the empty set.
The function does this as follows: If gave the solution , is a variable, and , that is, is one of the abstract values needs to match in some occurrence, then we compute all that can be reached from with term implication. Next, is the intersection of these sets (for any ). Thus, holds iff for every . This ensures that the term of the given fixed point can be rewritten by term implications so that it matches in every occurrence of . For instance, in Example 8, the variable could either be or , to allow a match between and modulo term implication. Match also checks that all free variables in can actually represent some abstract value, because if not, then it is not at all possible to make equal to modulo term implication. Finally, every variable that does not occur in we map to , the set of all abstract values that can occur.
Let be a fixed point. Let be the abstract values that occur in , that is, . The function is defined as follows:
We additionally lift to sets of terms using the following definition:
We can finally conclude with step 3: either is empty (if there is no match) or a single map that tells for every variable the possible values under which we can match the terms. Now every abstraction substitution that maps each variable to an element of is a solution:
If and , there are no abstract values occurring in , and is an abstraction substitution, then for some such that for all variables , if then , and if then .
Assume that the term implication graph is as in Example 8. Consider then the following calculation by the function:
Here the terms and are indeed equal to the term modulo term implication. As explained in Example 8, this will lead to two abstraction substitutions that map the term into the term modulo term implication, namely and .
This concludes our explanation of the two functions that are based on the Axiom rule of the relation: For a term from a -step and a fixed point the function allows us to calculate the abstraction substitutions such that , or in other words, the abstraction substitutions such that can be derived from using the Axiom rule.
As promised, we will now introduce a function that combines the Axiom and Compose rules. This function works by matching terms in -steps, possibly containing variables, with ground terms derivable from the fixed point. The idea is that by inspecting the terms from the -steps and comparing them to the terms derivable from the fixed point we will be able to see what the variables in could be instantiated to if all terms are to be terms derivable from the fixed point. This is illustrated by the following example:
Consider a transaction receiving the set of terms where is a public constant, and are private functions, and is a public function.
Assume that we have the following fixed point:
Assume also, for the sake of simplicity, that there are no analysis rules. Then this fixed point is clearly analyzed because all messages that the intruder can derive from using can also be derived using . We will now investigate whether each of the received terms matches a term derivable from the fixed point, and additionally determine for the variables and the set of possible abstract values. The first step is to compute for every term in the received messages and every term in the fixed point. Additionally, if for a public such as , then we recursively check each (for every in the fixed point) since the intruder can then apply to the respective instances of to generate an instance of that matches. We summarize this in Table 1.
Matching received terms with terms derivable from the fixed point.
Consider the row for . The term is immediately derivable using the Comp rule and this is the case with any replacement of or in the term because these variables do not occur in . Consider the row for . For this to be a derivable abstract value, it needs to be some abstract value in , that is, either or . Consider the row for . Since is private, we cannot derive it by composition, and so the only option is to use the two matching terms in the fixed point. Consider the row for . No term in matches it, but two matching terms can be constructed from the fixed point using the Comp rule.
Let us now construct the abstraction substitutions that map the variables in such a way that all the received terms are terms derivable from the fixed point. For , we thus need to pick the abstract values that appear in all cells in the “Replace with” column. In this case, there is only one such abstract value, namely . For , we can pick or . This leads to two possible abstraction substitutions: and .
Consider a transaction receiving the set of terms , where is a private function. Consider the fixed point and . Assume also, for the sake of simplicity, that there are no analysis rules. We apply the approach from Example 11. Thus, both and can be or , and thus we get four possible abstraction substitutions, namely , , and . Notice that we see here that an overapproximation is happening because actually only the first two abstraction substitutions will generate terms represented by the fixed point. We will tolerate this overapproximation.
The function implements the idea from Examples 11 and 12. The function computes the set of abstract values that the variable can take so that the intruder can produce all terms in the set . This set is empty in case the intruder cannot produce all the terms in (for any choice of ). We will use this for a transaction that has the terms as receive steps and is any free variable in .
Let be a set of messages, be a variable, and be an analyzed fixed point. We define recursively as follows:
The definition of expresses how the requirement that the intruder has to produce the messages in constrains the choice of abstract values of . The first equation says that if is the message the intruder has to produce, we can choose for only abstract values that are in the fixed point or reachable via term implication. The second equation is the case where the intruder has to produce any other variable . In this case, this gives no constraint on , and we have thus . The third equation says that the intruder cannot produce a private constant that is not in the fixed point. The fourth equation says that the intruder can always produce all public constants and all constants in the fixed point, again not constraining the choice of . The fifth equation says that if the intruder has to produce a term that is composed of a private function then we use the function to determine all the mappings that map variables to set of abstract values under which said term is in the fixed point modulo term implication. We then return the union of all abstract values that any of these mappings allow for . The sixth equation is similar, but here is public, so we additionally consider the case that the intruder can produce the subterms (and apply to them), so we have the union of the values that give a direct match in the fixed point with the values under which the subterms can be produced. The final equation lifts to sets of terms: to produce all the terms, the intruder must produce every single one of them.
In our implementation, we have one small optimization not presented above to avoid cluttering the presentation here. Consider again the sixth equation. If one of the is a private constant not in , then we can “short circuit” the calculation of because we then know that it will be equal to .
In Example 11, we saw how calculating the possible replacements for each variable related to the abstraction substitutions that instantiate the received terms to derivable terms. We express this idea in the following lemma that captures the idea of :
Let be a transaction with at least one -step, be a fixed point where is analyzed, , be an abstraction substitution with domain , and let be the terms occurring in the -steps of . If then .
This lemma essentially says that if there is an abstraction substitution that will instantiate a set of received terms to terms that the intruder can actually derive, then the application of that abstraction substitution to any variable will indeed be one of the abstract values that calculates.
The following examples illustrate the idea:
We here return to Example 11 and now apply the and functions:
We see that this corresponds to the choices for and that we saw in Example 11. As in that example, this leads to two possible abstraction substitutions, namely and .
We here return to Example 12 and now apply the and functions:
We see that this corresponds to the choices for and that we saw in Example 12. As in that example, this leads to four possible abstraction substitutions, namely , , , and . We see again here that an overapproximation is happening because actually only the first two abstraction substitutions will generate terms represented by the fixed point.
We combine the techniques described from Section 6 up to here into an implementation of the coverage check that we denote the Receive coverage check.
This section demonstrates how the Isabelle formalization allows for describing different strategies in order to prove to Isabelle that the computed fixed point covers the transactions. Indeed, as part of such arguments, we show in Isabelle that the strategy is sound, such as in Lemma 7. Proving such theorems means that we do not need to be suspicious of implementation bugs even if a strategy gives significant improvements on some examples. The strategies can often negotiate an efficient solution between different extremes. For instance, not considering the messages the intruder needs to produce (F1) leads to an unnecessarily large set of abstractions to consider, while computing the precise set of abstractions that satisfy (F1) would often waste a lot of time on an optimization that is just not worth it (or it may even be undecidable). While we here used our intuition and experience with examples, in general, an extensive study of different variants on a larger benchmark suite could allow for further improvements.
Experimental results
In this section, we discuss empirical results. We start by introducing our main benchmark suite for individual protocols and discussing the performance of our tool, PSPSP, on this benchmark suite. Finally, we discuss an example of a composed protocol.
Our benchmark suite
We evaluated our tool, PSPSP, using the following protocols (see Table 2): The first group of protocols is based on a keyserver. The example KS__ is our keyserver running example for honest agents and dishonest agents. [We verify here a generalized version of the keyserver example (as compared to the running example): we include dishonest agents who can participate in the protocol. This also requires that agents maintain a set of deleted keys, because otherwise the abstraction leads to false attacks.] The example KS_Comp__ with honest agents and dishonest agents is inspired by Hess et al.13 where another keyserver protocol—named KS2__ here—runs in parallel on the same network and where databases are shared between the protocols.
Runtime measurements (time format: hh:mm:ss) experiments that took longer than 12 hours are marked with “-- : -- : --.”
Verification
Initialization
Fixed point
Safe check
NBE check
Eval check
Protocol
Transl.
Setup
Comp.
|FP|
|TI|
Default
Receive
Default
Receive
Default
Receive
Heuristic
KS__
00:00:03
00:00:27
00:00:03
13
28
00:00:28
00:01:07
00:00:19
00:00:15
00:00:14
00:00:12
00:00:46
KS__
00:00:04
00:00:26
00:00:03
17
41
00:00:40
00:03:02
00:00:21
00:00:18
00:00:16
00:00:12
00:01:01
KS__
00:00:04
00:00:26
00:00:03
21
54
00:01:29
00:07:58
00:00:20
00:00:26
00:00:14
00:00:13
00:01:52
KS2__
00:00:04
00:00:27
00:00:03
11
5
00:00:30
00:00:29
00:00:17
00:00:15
00:00:13
00:00:13
00:00:46
KS2__
00:00:04
00:00:28
00:00:04
14
7
00:00:43
00:00:40
00:00:19
00:00:16
00:00:16
00:00:13
00:01:00
KS2__
00:00:04
00:00:28
00:00:03
17
9
00:00:55
00:01:05
00:00:20
00:00:18
00:00:15
00:00:15
00:01:14
KS_Comp__
00:00:05
00:00:27
00:00:04
22
108
00:07:35
00:47:07
00:00:50
00:01:52
00:00:16
00:00:14
00:07:49
KS_Comp__
00:00:05
00:00:27
00:00:06
29
156
00:33:57
03:16:32
00:02:13
00:06:13
00:00:19
00:00:14
00:33:21
KS_Comp__
00:00:05
00:00:25
00:00:10
36
204
01:44:22
10:18:07
00:06:08
00:16:19
00:00:26
00:00:16
01:45:54
NSLclassic
00:00:03
00:00:26
00:00:03
35
6
00:03:15
00:03:06
00:00:20
00:00:18
00:00:32
00:00:14
00:03:28
NSPKclassic
00:00:04
00:00:28
00:00:03
16
6
attack
attack
attack
attack
attack
attack
attack
PKCS#11_3
00:00:06
00:00:36
00:00:08
8
4
attack
attack
attack
attack
attack
attack
attack
PKCS#11_7
00:00:06
00:00:37
00:00:26
13
30
attack
attack
attack
attack
attack
attack
attack
PKCS#11_9
00:00:05
00:00:37
00:00:12
40
20
attack
attack
attack
attack
attack
attack
attack
TLS12_auth_simp
00:00:08
00:00:34
00:00:07
40
20
-- : -- : --
04:23:08
01:31:14
00:03:05
00:00:38
00:00:30
04:30:37
Logos
00:00:07
00:00:37
00:00:14
48
31
-- : -- : --
11:01:55
01:38:56
00:36:29
00:01:23
00:01:07
11:13:23
TLS12_SSO
00:00:13
00:00:26
00:15:25
359
35
-- : -- : --
-- : -- : --
02:58:21
04:49:35
00:00:37
00:00:23
-- : -- : --
The next groups are NSLclassic and NSPKclassic, which are based on the NSL and Needham–Schroeder protocol specifications shipped with AIF-.15
Then, we have several scenarios of the “PKCS#11” model that is distributed with AIF-.15 Scenarios 3 and 7 (PKCS#11_3 and PKCS#11_7) are examples of another flavor of stateful protocols, namely security tokens that can store keys and perform encryption and decryption, and with which the intruder can interact through an application programming interface (API). Generally, modeling such tokens and their APIs works quite well with the set-based abstraction. There is a third scenario (PKCS#11_9) that is marked as correct in the AIF- distribution, but that is actually due to a mistake that our attempt to verify it in Isabelle has revealed. We discuss this example in more detail in the Appendix. This illustrates our main point that there can be surprises when one tries to verify in Isabelle the results of automated tools.
With TLS12_auth_simp, we have looked at one protocol that has been inspired by a practical protocol, that is, transport layer security (TLS) 1.2. For our experiments, we simplified the protocol by modeling only one variant of the flow and also simplifying the hashing.
Finally, we modeled a protocol developed by the Danish company Logos and a single sign-on protocol (TLS12_SSO) that composes the TLS key exchange with a custom SSO protocol. We will discuss TLS12_SSO in Section 7.3 and the industrial case study (Logos) in Section 9.
Evaluation of our benchmark suite
Table 2 shows the fixed point sizes of various example protocols together with measurements of the elapsed real time it takes to generate and verify the Isabelle specifications. All experiments have been conducted on a shared Linux server with an Intel Xeon E5-2640 CPU and 96 GB main memory using PSPSP based on Isabelle 2024. PSPSP provides an option to measure the elapsed time (wall-clock) required for executing individual “top-level” commands (e.g., protocol_security_proof, see Section 8). We only report the times that are specific to the individual protocols using a “pre-compiled” session that contains our generic protocol translator as well as the protocol-independent formalizations and proofs. First, we report the time for translating the protocol specifications into Isabelle/HOL (translation), the time for showing that the given protocol is an instance of the formal protocol model (setup), and the time for computing the fixed point and its size. [This includes the time for parsing the trac specification and, more importantly, the generation of the conservative HOL definitions.] In the next six columns, we report the run-time of four different strategies for the security proof that we will explain in the following. The last column reports the run-time of a heuristic that aims to select the fasted strategy automatically. We will explain the details of this heuristic later.
In the safe configuration, all proof steps are checked by Isabelle’s LCF-style kernel; internally, this makes use of the simplifier configuration called code-simp of Isabelle’s simplifier. NBE employs normalization by evaluation, a technique that uses a partially symbolic evaluation approach that, to a limited extent, relies on Isabelle’s code generator. Finally, eval is an approach that directly employs the code generator and internally uses the proof method eval. In general, the configurations NBE and eval require the user to trust the code generator. From a correctness perspective, the main difference is that the configuration of the code generator used by NBE is very small and cannot be changed by Isabelle users. Hence, this configuration can be easily audited manually and, moreover, is thoroughly tested. In contrast, eval uses a user-configurable configuration of the code generator and, hence, is hard to audit, and any theory our work depends on could, potentially, have modified this configuration. While Isabelle’s code generator is thoroughly tested, it is not formally verified. While, at the end, it is up to the user to decide which approach to use, we consider NBE to be a trustworthy configuration. [Interested users should consult29 to understand the software stack that needs to be trusted for each configuration.] Furthermore, a pragmatic approach is to use eval during the development (specification) of the protocol and only after no attacks are found, switching to NBE or safe for a higher level of trust.
For the first three strategies, we report the time of our default version of the coverage check (Default), which implements the improvements described in Section 6 up to and including Section 6.2. We also report the time of our alternative version of the coverage check (Receive), which also implements these improvements in addition to the further restriction of the number of abstraction substitutions described in Section 6.3. There is a fourth strategy, called Heuristic, that automatically selects the faster coverage check in the configuration Safe. We will explain its details at the end of this section.
For all our examples, verification times, using the eval check (i.e., making full use of Isabelle’s code generator), are at most 1 1/2 minutes. [We do not report runtimes for protocols with an attack. After the fixed point computation, checking for an attack takes less than a second, as we only need to check for the presence of the constant. We will discuss the presentation of attack traces for such protocols in Section 8.] This makes this configuration ideal for interactive development, for example, while refining a protocol specification. In contrast, the verification using only Isabelle’s simplifier can take more than 12 hours (we record runtimes of more than 12 hours as ) for our example protocols. Thus, in most cases, this configuration will be used in “batch-mode” after the protocol has been checked using the configuration employing the code generator. For most protocols, NBE provides a good middle ground, bringing the verification times down to under a minute for most examples, and below 40 minutes for all examples using the fastest variant of the coverage check.
Furthermore, the Receive coverage check introduced in Section 6.3 significantly reduces the safe verification time for TLS12_auth_simp and Logos in safe mode from over 12 hours to around 4 1/2 (TLS12_auth_simp) and around 11 hours (Logos). For NBE, it reduces the runtime for both protocols from around 1 1/2 hours to 3 minutes (TLS12_auth_simp), respectively, and around 40 minutes (Logos). For the configuration fully relying on code generation (eval), the improvements are minor.
Comparing the runtime of the two coverage checks for all examples shows that the relative runtime behavior of the two coverage checks seems not to depend on the simplification strategy (i.e., eval, NBE, and safe). This motivated us to implement a heuristic that, first, runs the security proof for NBE for both coverage checks in parallel, measures their runtime, and then runs the Safe strategy using the coverage check that, for the given protocol, was faster for NBE. We have chosen NBE as the basis, as the runtimes for eval for both coverage checks are often very similar and, hence, cannot provide a solid base measurement. In theory, this heuristic should show a runtime behavior that roughly is the maximum of the runtime of the two coverage checks for NBE, plus the runtime for the faster coverage check in a safe configuration. Our measurements (last column in Table 2) do confirm this behavior for our example protocols. This makes our heuristic a reliable way for automatically selecting the faster coverage check.
Finally, as mentioned at the beginning of this section, we report the elapsed time in Table 2 and not the total CPU time. On average, the security proof using the default coverage check can run certain parts in parallel, resulting (in our benchmark suite) on an average speedup of 2.5. The Receive coverage check cannot be parallelized that well (having an average speedup of 1.3).
An example of protocol composition
Table 3 shows the runtimes for an example of a protocol composition, implementing a TLS-based single sign-on (TLS12_SSO). Note that the format of the table differs from Table 2: we report the runtimes for the three different verification checks (safe, NBE, and eval) on three separate lines. For each of these checks, we report the running time for the initialization and the fixed point computation (as well as its size) for each subprotocol (i.e., TLS and SSO). These aspects are the same for all three verification checks, as their implementation does not make use of the optimizations provided by the code generator. Next, we report the runtimes (as in Table 2 for both coverage checks) for the individual verification of the two subprotocols. The final column reports the runtime for the proof that the composition of the two sub-protocols is secure. Here, “-- : -- : --” denotes that the check takes more than 12 hours. Notably, the security verification of the individual protocols takes significantly longer than the proof that the composition of the two protocols is secure. For instance, the security proof for SSO takes several hours using the NBE check (the safe check takes more than 12 hours), while the proof that the composition of the two protocols (TLS and SSO) is secure only takes a few seconds.
Runtime measurements (time format: hh:mm:ss) for the composed protocol TLS12_SSO.
Verification
Initialization
Fixed point (TLS)
Fixed point (SSO)
TLS
SSO
Check
Trans.
Setup
Comp.
|FP|
|TI|
Comp.
|FP|
|TI|
Default
Receive
Default
Receive
Composition
Safe check
00:00:13
00:00:30
00:00:05
25
16
00:07:57
202
38
00:04:57
00:10:24
-- : -- : --
-- : -- : --
-- : -- : --
NBE check
00:00:13
00:00:30
00:00:05
25
16
00:07:57
202
38
00:00:41
00:00:46
02:18:27
01:59:03
00:00:12
Eval check
00:00:13
00:00:30
00:00:05
25
16
00:07:57
202
38
00:00:20
00:00:15
00:00:18
00:00:10
00:00:04
TLS: transport layer security; SSO: Single-Sign-On.
More importantly, the total runtime of the fastest NBE configuration is roughly two hours, compared to 3 h 15 min 25 s for directly verifying the monolithic TLS12_SSO protocol model using the default coverage check (cf. Table 2). The compositional verification takes only 2 h 8 min 41 s in total using the default coverage check for the TLS component and the receive coverage check for the SSO component (see Table 3). [Using the receive coverage check for both components increases the total runtime only by 5 s.]
Finally, note that the TLS protocol used in this composition case study focuses only on the core of TLS: the key exchange. In contrast, TLS12_auth_simp in Table 2 also includes the password authentication and the transmission of some dummy data. This explains the difference in runtimes (and fixed point sizes) between these two versions of TLS.
Isabelle/PSPSP
We implemented our approach on top of the Isabelle framework,30 resulting in a tool called Isabelle/PSPSP,18 which is now part of the AFP [As part of the AFP, PSPSP will be maintained and, for instance, ported to the latest official release of Isabelle.] This includes a formalization of the protocol model in Isabelle/HOL, a data type package that provides a domain-specific language (called trac) for specifying security protocols, and fully automated proof support.
The architecture of Isabelle/PSPSP
For our implementation of Isabelle/PSPSP, we make use of the fact that Isabelle is not only an interactive theorem prover; it also provides an extensible framework for developing formal methods tools.31
Figure 1 shows an overview of the Isabelle architecture, highlighting in green the additions provided by Isabelle/PSPSP. In particular:
Protocol formalization: PSPSP is built on, and re-uses, our stateful protocol formalization (and its typing results) formalized in Isabelle/HOL. This part is available as a stand-alone AFP entry,32 consisting of lines of code. The formalization presented in this paper, formalizing the presented method for the automated verification of security protocols, adds another lines of code.18 Note that these formalizations (proofs and definitions) are reusable, that is, independent of any concrete security protocol.
Automated proof support (PSPSP methods): We developed several proof methods using both Isabelle’s high-level proof development language Eisbach33 and the Isabelle/ML interface. Isabelle/ML is Isabelle’s programming API that allows one to extend Isabelle using the SML34 programming language. We use this, in particular, for computing fixed point that builds the backbone of our automation.
Support for trac: To improve the user-friendliness of PSPSP, we defined a trace-based specification language for security protocols, called trac. By supporting trac as input language, we allow users to use PSPSP without the need to understand all the details of our protocol formalization. Actually, users of PSPSP mostly need to understand trac, and our new Isabelle commands for verifying security protocols. Supporting trac requires a parser for trac (implemented in Isabelle/ML) and implementing an encoder (or datatype package) that translates trac into the corresponding HOL definitions. Furthermore, the trac datatype package also proves automatically a number of basic properties that are used within the actual security proof.
It is noteworthy that all our additions have been implemented in a logically safe way, that is, a bug in our implementation cannot result in an insecure protocol being successfully verified: any bug could only result in PSPSP not being able to verify a secure protocol.
The system architecture of Isabelle and Isabelle/PSPSP.
Isabelle/PSPSP—A guided tour
Figure 2 shows the Isabelle IDE (called Isabelle/jEdit). The upper part of the window is the input area that works similarly to a programming IDE, that is, supporting auto completion, syntax highlighting, and automated proof generation and interactive proof development. The lower part shows the current output (response) with respect to the cursor position. In more detail, Figure 2 shows the specification and the fully automated verification of a toy keyserver protocol:
The protocol is specified using the domain-specific language trac that, for example, could also be used by a security protocol model checker (lines 8–58). Our implementation automatically translates this specification into a family of formal HOL definitions. Moreover, basic properties of these definitions are also already proven automatically (i.e., without any user interaction): for this simple example, already over 350 theorems are automatically generated.
Next (line 61), our implementation automatically shows that the protocol satisfies the requirement of our model (technically, this is done by instantiating several Isabelle locales, resulting in another 1750 theorems “for free”).
In line 62, we compute the fixed point. We can use Isabelle’s value command (line 74) to inspect its size.
After these steps, all definitions and auxiliary lemmas for the security proof are available. We can now perform a fully automated proof (line 64). The top-level command protocol_security_proof proves automatically a theorem showing the security of the defined protocol. This successful proof took s (see lower part of the Isabelle/jEdit window).
Using Isabelle/PSPSP for verifying a keyserver protocol (KS2__).
Moreover, for the security proofs, we have also manual variants (e.g., manual_protocol_setup, manual_protocol_security_proof, or manual_protocol_composition_proof) of the automated proof commands that only create a proof obligation (i.e., establish the proof state) allowing the user to do an interactive proof utilizing the full power of Isabelle, instead of using the automated proof methods provided by us. [The commands still allow the user to copy the automated proof script, using “point-and-click” in the same way as the default sledgehammer tool, into the theory file.] This is potentially useful for introducing protocol-specific optimizations or for inspecting what the automated proof methods do.
In case of an insecure protocol, that is, the fixed point containing the constant, Isabelle/PSPSP can support the protocol developer with an attack trace: optionally, while computing the fixed point, the computed traces are bound to a logical constant, which can then be printed in a user-friendly way. Figure 3 shows an example for the protocol PKCS#11_3: the proof that the constant is contained in the fixed point (line 95) usually takes only a few seconds. The Isar top-level command print_attack_trace (line 98) then prints an attack trace (lower part of the window in Figure 3) showing the steps executed until an attack event is created.
An example attack trace (for the protocol PKCS#11_3).
Compositionality
PSPSP is part of a larger Isabelle infrastructure for security protocols that also allows for compositionality,1 that is, for a result of the form: if two or more protocols are secure in isolation and satisfy certain requirements, then also their composition is secure, that is, when they run in parallel sharing the same network and even some sets. Especially the support for shared sets allows us to consider also complex interactions between two protocols, for instance, where one protocol negotiates keys and another protocol uses them.
The compositionality framework uses the same specification language (trac) as PSPSP. One can thus specify a set of component protocols, use PSPSP to prove the security of each of them in isolation, and use the compositionality framework to check that they fulfill the requirements for compositionality and then obtain an Isabelle proof that the composed system is secure.
As an example, we have modeled in Hess et al.,1 a composition of TLS 1.2 and security assertion markup language (SAML) Single-Sign-On (SSO): TLS establishes a secure channel between a client and a server where the client is not yet authenticated. SSO then uses such a channel between a client and the identity provider to first authenticate the client to the identity provider (e.g., using a password); the identity provider then provides a credential for the client that the client can use to authenticate another TLS channel with a relying party. More in detail, the TLS protocol stores any exchanged keys that a client has negotiated with server in a set on the client side, and in the set on the server side. The latter set of keys is only parameterized over the agent name , since is not authenticated. Each of these sets reflects the local point of view of each agent, and it is part of the verification that, for instance, the intruder does not find out a key between two honest agents and . Finally, the SSO protocol can just retrieve and use these keys, both to authenticate the connection between client and server, as well as between client and identity provider (where the password is transmitted). The composed protocol is specified in the trac specification language (see Figure 4, until line 299). We compute the common between both protocols (lines 305–309, see Hess et al.1 for more details) and fixed points (lines 312 and 313) for both protocols “in isolation.” These are used to prove the security of each of the two subprotocols (lines 315–318). Then we prove the security of the composition: we compute the shared secrets (line 321) and then use an automated proof method for the protocol composition proof (lines 323–237). Finally, we show the security of the composition (lines 329—340) with a simple proof “by auto.”
Using Isabelle/PSPSP for verifying the composition of TLS 1.2 and SAML. TLS: transport layer security; SAML: security assertion markup language.
Note that the run time (recall Tables 2 and 3) for the TLS component of the composition is much smaller than the runtime of TLS12_auth_simp, because it is purely the key-exchange while all authentication and data-transmission is “outsourced” to the SSO protocol. Thus, in general, verification can be improved by using compositional reasoning, if one can split a complex system into smaller components.
The compositionality framework supports strictly more protocols than PSPSP; most importantly, it allows for composed messages in sets. In these cases, one cannot use PSPSP to verify the respective components, but of course, one can also consider compositions where a subset of the components is proved by PSPSP and the others are verified manually.
Case study: Logos
We had the opportunity to use PSPSP to formally verify a protocol by the Danish company Logos. This protocol stems from the area of reader terminals for a travel card solution, namely, to establish a secure connection between a terminal and the Logos server. The particular challenge here is that this should work after a terminal has been in storage for years and all public keys of the servers have been updated in the meantime; we do want to model the possibility that an intruder obtains old private keys—after all that is the reason for updating them regularly. Such a protocol, even though its messages are fairly simple, can be a challenge for verification tools as it requires mutable long-term states at its core. With some simplifications, we have built a model in PSPSP and found a security flaw. We then verified the protocol with PSPSP under a minor modification. Logos has applied this modification and has thus an Isabelle-verified product, one might say, although this should of course be taken with a grain of salt, given that we only verified a simplified model of the protocol (and in a black-box model of cryptography). The protocol is summarized in Figure 5, and we discuss it together with the PSPSP model of every step in the following.
The Logos system in Alice-and-Bob notation.
Epochs
The abstract interpretation approach of PSPSP was originally inspired by ProVerif; both approaches essentially discard the notion of time to arrive at an overapproximation of everything that the intruder can ever know without the normal state explosion and restriction to bounded sessions. That, however, makes it challenging to model any aspect of time, such as injective agreement. However, the only aspect of time that we really need in the model of the Logos protocols is a distinction between past and present events, for example, distinguish nonces that were generated a long time ago from nonces that are fresh. More precisely, we divide the timeline into two epochs. We do not care about the order of events in each epoch: as a notion of time, the model only distinguishes between events that happened in and those that happened in . In this model, all events of happen before all events of .
Key generation and revocation
First, we define that the intruder can generate public–private key pairs. Note that when no epochs are mentioned, the rule can uniformly be applied in all epochs:
The Logos server has a public–private key pair that is updated regularly. [In fact, there are several kinds of keys for different purposes; for simplicity, we consider only one kind of key.] We model this in PSPSP by the following two rules that can be applied in either epoch :
Disregarding the epochs briefly, this simply means that the server can at every time point generate a new public–private key pair (publishing the public key) and at any time revoke one. (Like in the keyserver examples before, the knowledge of the corresponding private key is implicit for honest agents like the Logos server.) In this model, the server may thus have any number of public keys at the same time; this is just an overapproximation. The fact that the set is parameterized over the epoch means that no key generated in the first epoch is available in the second and vice versa. Thus, the “cut” between the two epochs coincides with a key update, reflecting our intention that represents events that happened longer in the past while represents recent events.
When a batch of terminals is manufactured, each gets a unique hardware-id in . Since some sets will be parameterized over this hardware id, we need to give a finite enumeration, and we limit ourselves to two hardware-ids . During manufacturing, all terminals of a batch have the same public–private key pair, called the batch key, which is registered also with the Logos server, so the terminals can authenticate themselves as legitimate terminals to the Logos server later. We assume here that batch generation happens only in epoch , because with we want to model only what happens long after manufacture. Before terminals can be manufactured, we first need to create a public/private key pair, and like for the Logos server, we allow for arbitrary such events and revocation at any point as an overapproximation of several manufacturing batches that can happen in :
Again, the corresponding private key is implicit, since only the manufactured terminals would have it and are assumed to be honest. When manufactured, the terminals also have the current public key of the Logos server. This is the starting state for the Logos protocol of Figure 5.
The bootstrap protocol
Each terminal is required to run a bootstrap protocol with the server in order to establish an individual key . This must happen within 30 days after manufacture. We assume here that this is still within epoch . (Failure to run it is modeled here by the fact that the batch and/or server key can be revoked, and thus the terminal cannot do any transactions.) In the bootstrap protocol, the terminal creates a fresh key pair, consisting of the bootstrap public key , and the corresponding private key . For now, even the public key is kept secret between the terminal and server. This later allows the server to send messages to the terminal that can only come from the server. This is an unusual way to employ a public key; a more conventional solution would probably be a shared symmetric key instead. However, this is how the protocol works, and we have not found a principal security problem with it (other than the attack reported below that is independent of this).
This rule corresponds to sending the first message in Figure 5. Here we have modeled that the terminal knows the batch key pair and the public key of the Logos server simply by looking them up in the respective sets. We have drastically simplified the bilaterally authenticated TLS session between terminal and server, by encryption of the message with the public key of the server and signing by the private key of the entire batch of terminals . The terminal remembers its bootstrap key (and implicitly the private key) in the set . The server receives the public key in the following transaction and stores it in :
This corresponds to the reception of the first message in Figure 5. The server expects a message that is encrypted with its current public key (and thus discards the message if decryption with the current private key failed), and then checks that the content is a signature that verifies with (one of) the current batch public keys (and discard the message if signature verification fails). The signed message is expected to be a pair where the first is interpreted as a hardware-id and the second as the bootstrap public key which the server stores in the , so that later a secure connection with can be established using . Note again that this bootstrap protocol can only be executed in epoch as demanded by the parameters of the server and batch key sets, but it can happen for arbitrarily many batches and updates of the server keys in .
The truststore protocol
The second part of the Logos protocol, in Figure 5 separated by the dotted lines, is the truststore protocol. This protocol may be executed by a terminal after it was many years in storage. This is possible in both epochs. To initiate, the terminal sends its unique hardware ID and a fresh nonce :
For simplicity, we omit that this is also done via TLS: since in general neither the terminal nor the Logos server can verify the certificate of the other, this is not much better than plaintext, and so we do not bother with modeling TLS here. Also, the nonce is inserted into an epoch-specific set, in order to express the property that the terminal would not accept an answer in epoch with a nonce it has generated in epoch .
The server now receives the request, looks up the of the claimed , and constructs a so-called truststore message, that is, a message with the current public key of the Logos server that the terminal can verify. To this end, the server generates a new shared key , which is inserted into a set of current shared keys , encrypts it with the of the terminal, and then authenticates the trust-store by MACing it (and the nonce ) with the :
Here, the unary function is just a format to distinguish this message from other kinds of encrypted messages. This is the version for the case that the transaction is executed in . Here we actually require that . This does not correspond to a check that the server does, but our model that everything in epoch happens before , and this constraint reflects that cannot come from the future.
When this transaction is happening, however, in , we cannot exclude that the nonce was generated in (e.g., the intruder replaying an old request). Thus, we have a variant of the previous rule for :
We have also in both rules the insertion of into the set . This is just for formulating the authentication goal below.
To conclude the truststore protocol, the terminal receives the truststore message from the server:
Actually, we do not model here further the store of the terminal, but we have authentication goals as discussed below.
Goals
We formulate several goals by specifying again what would be an attack. First, for secrecy goals: the (both public and private key) are secrets, and so is the and the private key of the terminal batch:
For the receiving of the truststore, we have that it is an attack (noninjective agreement) if the terminal accepts a truststore that was not sent like this from the Logos server (in any epoch):
The injective aspect now needs the formulation with epochs: it is an attack if the terminal accepts a message in epoch that the server did not send in epoch :
Together with the , we have a goal close to injective agreement. Standard injective agreement35 in this case means that, on top of the noninjective agreement, it is an attack if the terminal accepts more often than it was sent by the server. In PSPSP, we would express this by using another set and when the terminal accepts a that is already in the set , then it is an attack; otherwise, it is added to the set . Thus, this means it is an attack if the same is accepted more than once. This way of defining the goal is not suitable in this case, because during the validity of a single it is allowed to run the truststore protocol several times, and then it is correct that the terminal in each run receives the same value . It is in fact a limitation of our abstraction approach that we cannot really define the existence of an injective function between events.
The formulation with epochs solves this: it is an attack if the terminal accepts a value in epoch that was not sent by the server in epoch .
The attack
Observe that in the protocol in Figure 5, we have highlighted the nonce in red. This is in fact the fixed version; the original version did not have this nonce. The goal (without the constraint ) is the one we found violated in the original protocol. The attack on the version without nonce is the following replay attack: a terminal gets manufactured, runs bootstrap, and sometime later it runs the truststore protocol with the intruder in the middle, who records the truststore message from the server. The terminal for some reason goes into storage and then later in epoch it runs the truststore protocol again, where the intruder just acts as the Logos server and replies with the old truststore messages from , so the terminal is made to accept the old Logos keys that are long revoked and possibly compromised by the intruder.
We note that this attack is not easy for the intruder to mount, but also not unrealistic, and invalidates exactly what the protocol should achieve, the reliable update of keys. The fix with the nonce is not very expensive, and in this version, all goals of the protocol are satisfied, including the subsequent server certification of new keys generated by the terminal, which we do not show here.
The PSPSP tool can verify this specification in about a minute with the eval strategy—see Table 2.
Conclusion and related work
The research into automated verification of security protocols resulted in a large number of tools (e.g., Blanchet,6 Boichut et al.,36 Chevalier and Vigneron,37 Basin et al.,38 and Cremers8). The implementation of these tools usually focuses on efficiency, often resulting in very involved verification algorithms. The question of the correctness of the implementation is not easy to answer and this is in fact one motivation for research in using LCF-style theorem provers for verifying protocols (e.g., Paulson,2 Bella,3 Hess and Mödersheim23 Butin,39 Bella et al.,40 and Bella et al.19). While these works provide a high level of assurance into the correctness of the verification result, they are usually interactive,that is, the verification requires a lot of expertise and time.
This tradeoff between the trustworthiness of verification tools and the degree of automation inspired research of combining both approaches.5,7,20 Goubault-Larrecq5 considers a setting where the protocol and goal are given as a set of Horn clauses; the tool output is a set of Horn clauses that are in some sense saturated and such that the protocol has an attack iff a contradiction is derivable. His tool is able to generate proof scripts that can be checked by Rocq41 from . Meier7 developed Scyther-proof,42 an extension to the backward-search used by Scyther,8 which is able to generate proof scripts that can be checked by Isabelle/HOL.43 Brucker and Mödersheim20 integrate an external automated tool, OFMC,39 into Isabelle/HOL. OFMC generates a witness for the correctness of the protocol that is used within an automated proof tactic of Isabelle.
Our work generalizes on these existing approaches for automatically obtaining proofs in an LCF-style theorem prover, first and foremost by the support for stateful protocols and thus a significantly larger range of protocols—moving away from simple isolated sessions to distributed systems with databases, or devices that have a long-term storage.
We achieve this by employing the abstraction-based verification technique of AIF,9 but with an important modification. The method of AIF produces a set of Horn clauses that is then analyzed with ProVerif6 (or SPASS44), and the same holds true also for several similar methods for stateful protocol verification, namely StatVerif,10 Set-,16 AIF-,15 and GSVerif.11 Note that a set of definite Horn clauses (i.e., Horn clauses with exactly one positive literal) in first-order predicate logic always has a trivial model, because one can simply interpret all predicates as true for all arguments. Thus, if we have modeled an attack by the truth of some predicate , then there is trivially a model of the Horn clauses where is true. Instead, one wants to check that does not hold true in one particular model, namely the least model corresponding to the free algebra interpretation of terms and being true for the least number of ground predicates. This least model is uniquely defined in the case of Horn clauses. This is achieved in ProVerif (and SPASS) by checking whether the Horn clauses imply: If they do, then the attack predicate is true also in the free model. If they do not, that is, if the Horn clauses are consistent with the negation of the attack predicate, then the attack predicate is not true in all models, and in particular not in the least model. Thus, in a positive verification, the result from ProVerif is a consistent saturated set of Horn clauses. As first remarked by Goubault-Larrecq,5 this is not a very promising basis for a proof, as one does not get a derivation of a formula (the way SPASS for instance is often used in combination with Isabelle) but rather a failure to conclude a proof goal. The only thing one can do to verify the result is to compute it again and compare the results. Therefore, Goubault-Larrecq5 uses a different idea: showing that the Horn clauses and the negation of the attack predicate are consistent by trying to find some finite model and, if found, then using this finite model to generate a proof in Rocq that the Horn clauses are consistent with the negation of the attack predicate.
The limitation of Goubault-Larrecq5 is that it checks the protocol proofs only on the Horn clause level, that is, after a nontrivial abstraction has been applied. In order to obtain Isabelle proofs for the original unabstracted stateful protocols, we use therefore another approach: rather than Horn clauses, we directly generate a fixed point of abstract facts that occur in any reachable state. This would in fact normally not terminate on most protocols due to the intruder deduction; however, we employ here the typing result we have formalized in Isabelle14 to ensure that the fixed point is always finite, and our method is in fact guaranteed to terminate. This fixed point, if it does not contain the attack predicate, is the core of a correctness proof for the given protocol, namely as an invariant that the fixed point covers everything that can happen, and we essentially have to check that this invariant indeed is preserved by every transition rule of the protocol.
An interesting difference to previous approaches is that we do not rely on an external tool for the generation of the proof witness, but it is implemented within Isabelle itself. The reason is more of a practical than a principle matter: Computing the fixed point in Isabelle is actually not difficult and—thanks to Isabelle’s code generation—without much of a performance penalty; however, the fact that we do not rely on an external tool for the generation of the proof witness reduces the chances of synchronization and update problems (e.g., with new Isabelle versions). In fact, this work is part of the AFP (see https://www.isa-afp.org), a collection of Isabelle proofs that are kept up to date with each new version of Isabelle. This means that for each protocol that works in today’s version, it is highly likely that the proof works in future versions, because the proofs of all theorems of our (protocol-independent) Isabelle theory will be updated, and the fixed point and the checks about it do not have to change. Thus, we will also automatically benefit from all advances of Isabelle.
Another difference from previous approaches is that we do not directly generate proof scripts that Isabelle has to then check. Rather, we have a fixed set of (protocol-independent) theorems that imply that any protocol is secure if we have computed a fixed point representation that gives an upper bound of what (supposedly) can happen, and this representation passes a number of checks. These checks can either be done by generated code or entirely within Isabelle’s simplifier. Especially with the generated code, we have a substantial performance advantage, while using Isabelle’s simplifier gives the highest level of assurance since we only rely on the correctness of the Isabelle kernel. Many small practical advantages arise from the integration: We do not have an overhead of parsing proof scripts (which can be substantial for a larger fixed point). By using the internal API of Isabelle, we avoid the need for the Isabelle front-end parser to parse and type-check the fixed point (as we can directly generate a typed fixed point on the level of the abstract syntax tree). Parsing and type-checking (on the concrete syntax level) of large generated theories (as, e.g., those containing the generated fixed point) is, in fact, slow in Isabelle.20
Another point is that there exists a number of protocol verification methods and results that use slightly different models. Here we actually seamlessly integrate a verification method into a rich Isabelle theory of protocols without any semantic gaps: We provide here a method that is integrated into a large framework of Isabelle theories for protocols (approximately 25,000 lines of code), in particular a typing and compositionality result. This allows, for instance, to prove manually (in the typed model) the correctness of a protocol, use our automated method to prove the correctness of a different protocol, and then compose the proof to obtain the correctness of the composition in an untyped model. This seamless integration of results without semantic gaps between tools we considered as an important benefit of this approach. Even though many protocol models are not substantially different from each other, bridging over the small differences can be very hard to do, especially in a theorem prover that prevents one from glossing over details. Our deep integration into the existing formalization of security protocols in Isabelle ensures that the same protocol model (same semantics) is used—which would otherwise require additional work (e.g., to ensure that the semantics of the protocol specified in a tool such as Scyther-proof is faithfully represented in the generated Isabelle theory).
It is, in general, desirable to have proofs that are not only machine-checked but also human-readable. A reason is that, for instance, mistakes in the specification itself (e.g., a mistake in a sent message so that it cannot be received by anybody) may lead to trivial security proofs that a human may notice when trying to understand the proof. Here, Scyther-proof has the benefit that it produces very readable Isar-style proofs; in our case, there is, however, something that is also accessible: the fixed point that was computed is actually a high-level proof idea that is often quite readable as well (see, for instance, our running example). Moreover, the entire set of protocol-independent theorems is hand-written Isar-style proofs. [To avoid trivial security proofs, one may check if all transactions can be executed. While this is a useful technique, it is, unfortunately, in general not sufficient to avoid trivial security proofs. Consider, for example, a protocol with two variants of a transaction where a participant sends out an encrypted message. In one variant, it is sent by the attacker who also adds the plain text to his knowledge, and in another variant, it is sent by an honest agent only in the encrypted form. Now, say that only the attacker’s version is wrongly specified. In this case, all rules of the protocol may be executable except for the final attack rule, but the protocol is nonetheless trivially secure because the attacker is sending out a wrong message. Thus, checking for the executability of rules is not sufficient in general to discover trivial security proofs; however, inspecting the Scyther proofs or the fixed point may save the day.]
Furthermore, our work shares a lot of conceptual similarities with Tamarin,12 which can also be regarded as a kind of theorem prover. In fact, it was inspired by the mentioned work of Meier43 that generates Isabelle proofs from the Scyther tool, but Tamarin is not based on Isabelle and has instead a specialized proving environment based on a sound and complete constraint solver. This in principle shares two very nice features of Isabelle: that there are less limitations in what can be modeled, and that a user can supply proof ideas, but it also shares the disadvantage of Isabelle: that most of the interesting proofs are not automatic. There is work on improving this situation, that is, finding more proofs automatically for Tamarin.45 In contrast, PSPSP is, with respect to attacks on the abstract level, a complete decision procedure, assuming that users provide reasonable analysis rules that do not lead to nontermination. One concession in order to achieve this is indeed the abstraction. It ensures that protocols proved secure on the abstract level are also secure on the concrete level, but it may deem some protocols to be not secure on the abstract level due to a spurious attack. While we consider having this kind of decision procedure a selling point of PSPSP, it is worth remarking that, in practice, PSPSP may time out. Another main difference is that PSPSP is entirely formalized in Isabelle, and, as explained, does not rely on the correctness of any external tools. Also, the core of Isabelle is so well studied and used in so many projects that it can be considered more trustworthy than the specialized prover of Tamarin. On the other hand, Tamarin can support algebraic properties that we cannot at this point.
Finally, another approach that, such as Tamarin, is very much related to performing actual proofs of security protocols automatically and semiautomatically is CPSA.46,47 Also here it might be possible to make a connection to a theorem prover, such as, Isabelle; however, the approach is even further away from our approach than Tamarin, because CPSA does not necessarily assume a closed world of transactions. Rather, it performs an enrich-by-need analysis, obtaining all ways to complete a particular scenario and thereby yielding the strongest security goals a given system would satisfy (even in the presence of other transactions). We believe it is even more challenging to integrate this kind of reasoning into a theorem prover such as Isabelle, but achievable. We like to investigate this as future work, as it could give interesting ways for an analyst to interact with the proving process and inject proof ideas.
Footnotes
Acknowledgments
For the purpose of open access, the author has applied a Creative Commons Attribution (CC BY) licence to any Author Accepted Manuscript version arising from this submission.
ORCID iD
Achim D Brucker
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partially supported by the Horizon Europe project Trustworthy And Resilient Decentralised Intelligence For Edge Systems (TaRDIS) and the Industriens Fond project Security by Design in Digital Denmark (Sb3D).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Appendix A. A problem with the AIF- ω specification 09-lost_key_att_countered.aifom
When we tried to model this specification from the AIF- distribution, which is classified as secure by the AIF- tool, we failed to prove it secure with our approach in Isabelle, and in fact, our fixed point generation was generating the constant. Going back to the AIF- verification, we noticed that there was a problem with the public functions, in this case, symmetric encryption and hashing. They were declared as public in the AIF- specification, but the intruder seemed unable to make use of them and get to the attack we had obtained.
In fact, the problem was that AIF- does not generate intruder rules for the function symbols that are declared as public, so unless the user explicitly states rules like “if the intruder knows then he also knows ),” the function symbol is like a private one that the intruder cannot apply himself. When we add appropriate rules for all public function symbols to the specification, also AIF- finds the attack.
One could argue that this is a problem of the specification (the modeler was in fact aware of this behavior); however, it can be considered a bug of AIF-, since the keyword “public” for a function symbol at least suggests that the composition rule would be automatically included. In this sense, our Isabelle verification has revealed a mistake, in particular, one that has led to an erroneous “verification” of a flawed protocol by an automated tool. In fact, the attack is not a false positive (i.e., the original specification also has an attack).
References
1.
HessAMödersheimSBruckerA. Stateful protocol composition in Isabelle/HOL. ACM Trans Privacy Sec2023; 26: 1–36.
2.
PaulsonLC. The inductive approach to verifying cryptographic protocols. J Comput Sec1998; 6: 85–128.
3.
BellaG. Formal correctness of security protocols. Information security and cryptography. Berlin, Heidelberg: Springer, 2007.
4.
PaulsonLC. Inductive analysis of the internet protocol TLS. ACM Trans Inform Syst Sec1999; 2: 332–351.
5.
Goubault-LarrecqJ. Towards producing formally checkable security proofs, automatically. In: 2008 21st IEEE computer security foundations symposium, Pittsburgh, PA, USA, 2008, pp. 224–238.
6.
BlanchetB. An efficient cryptographic protocol verifier based on Prolog rules. In: Computer Proceedings. 14th IEEE Computer security foundations workshop, 2001, Cape Breton, NS, Canada, 2001, pp.82–96.
7.
MeierSCremersCBasinDA. Efficient construction of machine-checked symbolic protocol security proofs. J Comput Sec2013; 21: 41–87.
8.
CremersC. Scyther: Semantics and verification of security protocols. PhD Thesis, Eindhoven University of Technology, 2006.
9.
MödersheimSA. Abstraction by set-membership: verifying security protocols and web services with databases. In: Proceedings of the 17th ACM conference on computer and communications security (CCS'10), 2010, pp. 351–360. New York, NY: Association for Computing Machinery.
10.
ArapinisMPhillipsJRitterE, et al.Statverif: Verification of stateful processes. J Comput Sec2014; 22: 743–821.
11.
ChevalVCortierVTuruaniM. A little more conversation, a little less action, a lot more satisfaction: Global states in ProVerif. In: 2018 IEEE 31st Computer security foundations symposium (CSF), Oxford, UK, 2018, pp.344–358.
12.
MeierSSchmidtBCremersC, et al.The TAMARIN prover for the symbolic analysis of security protocols. In: Computer aided verification, 2013, pp.696–701.
HessAMödersheimS. A typing result for stateful protocols. In: 2018 IEEE 31st computer security foundations symposium (CSF), Oxford, UK, 2018, pp.374–388.
15.
MödersheimSBruniA. AIF-: set-based protocol abstraction with countable families. In: Piessens F and Viganò L (eds) Principles of security and trust. POST 2016. Lecture Notes in Computer Science, vol 9635. Berlin, Heidelberg: Springer, 2016.
16.
BruniAMödersheimSNielsonF, et al.Set-: set membership p-calculus. In: Proceedings of the 2015 IEEE 28th computer security foundations symposium (CSF'15), USA, 2015, pp.185–198. IEEE Computer Society.
17.
HessAVMödersheimSBruckerAD, et al.Performing security proofs of stateful protocols. In: 2021 IEEE 34th computer security foundations symposium (CSF), Dubrovnik, Croatia, 2021, pp. 1–16.
BellaGMassacciFPaulsonLC. Verifying the SET purchase protocols. J Auto Reason2006; 36: 5–37.
20.
BruckerADMödersheimS. Integrating automated and interactive protocol verification. In: Formal aspects in security and trust, 2009, pp.248–262.
21.
ChrétienRCortierVDallonA, et al.Typing messages for free in security protocols. ACM Trans Comput Logic2020; 21: 1:1–1:52.
22.
AlmousaOMödersheimSModestiP, et al.Typing and compositionality for security protocols: A generalization to the geometric fragment. In: Pernul G, Y A Ryan P, Weippl E (eds) Computer security – ESORICS 2015. Lecture Notes in Computer Science, vol 9327. Cham: Springer.
23.
HessAVMödersheimS. Formalizing and proving a typing result for security protocols in Isabelle/HOL. In: IEEE 30th computer security foundations symposium (CSF), Santa Barbara, CA, USA, 2017, pp.451–463.
24.
HeatherJLoweGSchneiderS. How to prevent type flaw attacks on security protocols. J Comput Sec2003; 11: 217–244.
25.
ArapinisMDuflotM. Bounding messages for free in security protocols - extension to various security properties. Inform Comput2014; 239: 182–215.
26.
DelauneSHirschiL. A survey of symbolic methods for establishing equivalence-based properties in cryptographic protocols. J Log Algebraic Methods Programm2017; 87: 127–144.
27.
Comon-LundhHCortierV. Security properties: Two agents are sufficient. In: Programming languages and systems, 12th European symposium on programming, ESOP 2003 held as part of the joint European conferences on theory and practice of software, ETAPS 2003 (ed. P Degano), Warsaw, Poland, April 7–11, 2003, proceedings, lecture notes in computer science, vol. 2618, 2003, pp.99–113. Berlin: Springer.
28.
Comon-LundhHCortierV. Security properties: two agents are sufficient. Sci Comput Program2004; 50: 51–71.
PaulsonLCNipkowTWenzelM. From LCF to Isabelle/HOL. Formal Aspects Comput2019; 31: 675–698.
31.
WenzelMWolffB. Building formal method tools in the Isabelle/Isar framework. In: Schneider K and Brandt J (eds) TPHOLs 2007. Lecture notes in computer science, vol. 4732, Berlin: Springer, 2007, pp.352–367.
MatichukDMurrayTWenzelM. Eisbach: A proof method language for Isabelle. J Auto Reason2016; 56: 261–282.
34.
PaulsonLC. ML for the working programmer. 2nd ed. Cambridge, MA: USA: Cambridge University Press, 1996.
35.
LoweG. A hierarchy of authentication specifications. In: Proceedings 10th computer security foundations workshop, Rockport, MA, USA, 1997, pp.31–44.
36.
BoichutYHéamPCKouchnarenkoO, et al.Improvements on the Genet and Klay technique to automatically verify security protocols. In: Proceedings of the 3rd international workshop on automated verification of infinite states systems (AVIS'04), 2004, pp.1–11.
37.
ChevalierYVigneronL. Automated unbounded verification of security protocols. In: Brinksma E and Larsen KG (eds) Computer aided verification. CAV 2002. Lecture Notes in Computer Science, vol 2404. Berlin, Heidelberg: Springer, 2002.
38.
BasinDAMödersheimSViganòL. OFMC: A symbolic model checker for security protocols. Int J Inform Sec2005; 4: 181–208.
39.
ButinDF. Inductive analysis of security protocols in Isabelle/HOL with applications to electronic voting. PhD Thesis, Dublin City University, 2012.
40.
BellaGButinDGrayD. Holistic analysis of mix protocols. In: 2011 7th international conference on information assurance and security (IAS), Melacca, Malaysia, 2011, pp.338–343.
41.
BertotYCastéranP. interactive theorem proving and program development. Coq’Art: The calculus of inductive constructions. Texts in theoretical computer science. An EATCS series, Berlin, Heidelberg: Springer-Verlag, 2004.
42.
MeierSCremersCBasinD. Strong invariants for the efficient construction of machine-checked protocol security proofs. In: 2010 23rd IEEE computer security foundations symposium, Edinburgh, UK, 2010, pp.231–245.
43.
NipkowTPaulsonLCWenzelM. Isabelle/HOL – A proof assistant for higher-order logic. Lecture notes in computer science. Berlin, Heidelberg: Springer-Verlag, 2002.
44.
WeidenbachCDimovaDFietzkeA, et al.SPASS version 3.5. In: Conference on automated deduction, 2009, pp.140–145.
45.
CortierVDelauneSDreierJ, et al.Automatic generation of sources lemmas in TAMARIN: towards automatic proofs of security protocols. J Comput Sec2022; 30: 573–598.
46.
DoghmiSFGuttmanJDThayerFJ. Searching for shapes in cryptographic protocols. In: Grumberg O and Huth M. (eds) Tools and algorithms for the construction and analysis of systems. TACAS 2007, Lecture Notes in Computer Science, vol 4424. Berlin, Heidelberg: Springer.
47.
RowePDGuttmanJDLiskovMD. Measuring protocol strength with security goals. Int J Inform Sec2016; 15: 575–596.

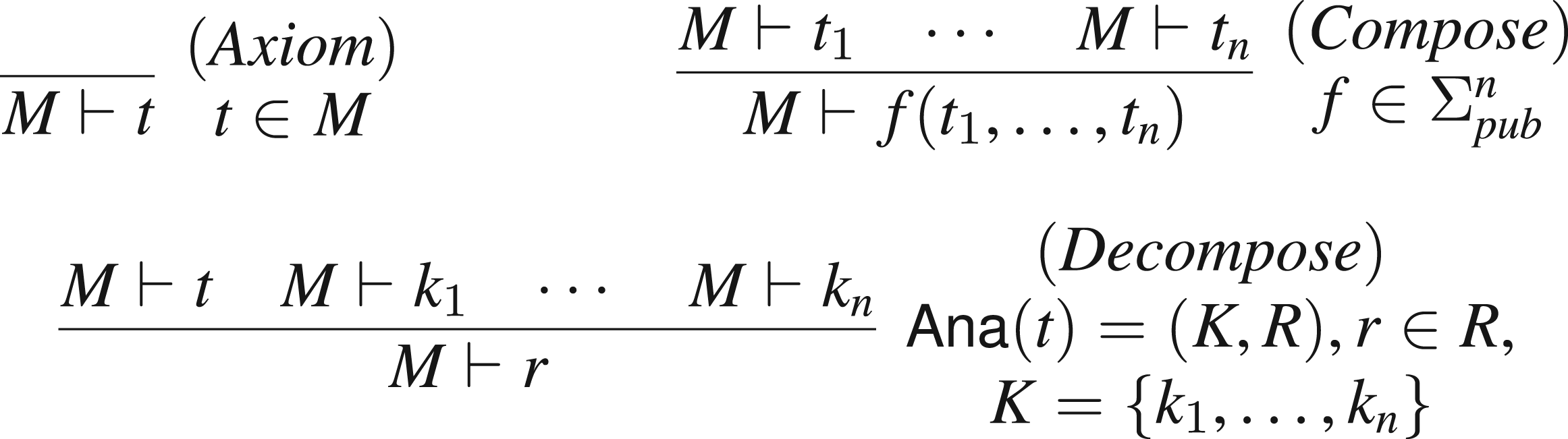



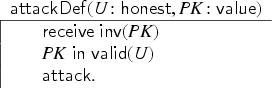

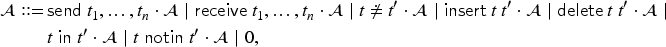
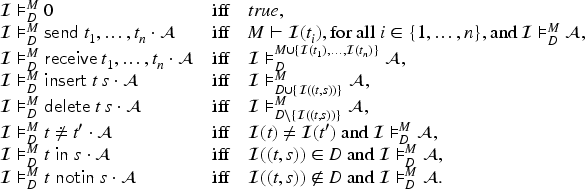
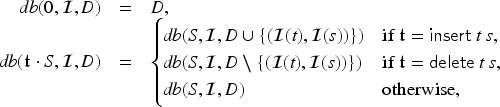
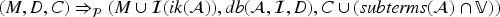
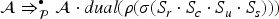
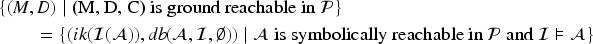

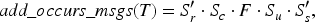


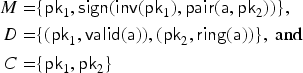
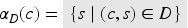
 for the abstract value that corresponds to the subset
for the abstract value that corresponds to the subset 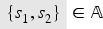 . Remember that
. Remember that 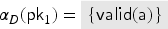 and
and 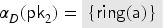 . Thus
. Thus 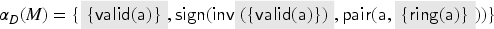 .
. . Since the second transaction deletes
. Since the second transaction deletes  .
.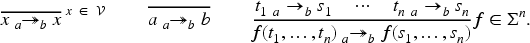
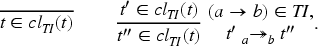
 and the term implication
and the term implication  . Thus under term implication we get the terms
. Thus under term implication we get the terms  ,
,  ,
,  , and
, and  . The latter term triggers
. The latter term triggers 

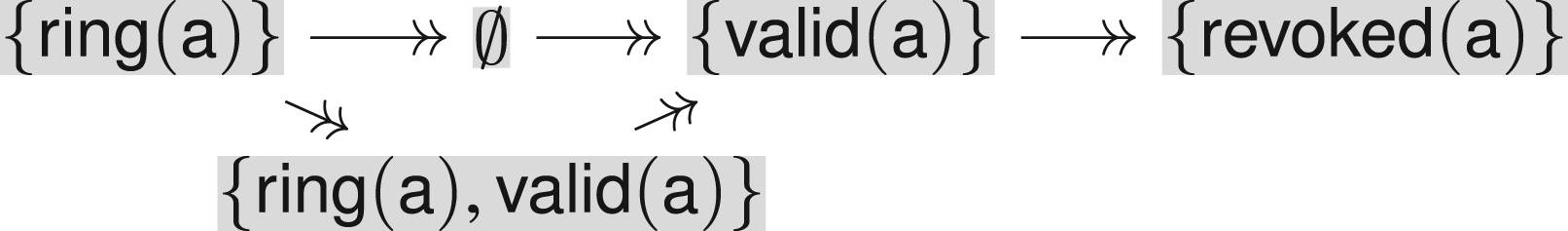
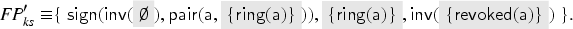
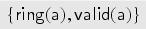 . This value is in the intruder’s knowledge in
. This value is in the intruder’s knowledge in 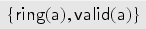 . Since the transaction removes the key
. Since the transaction removes the key 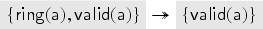 . A fresh value
. A fresh value 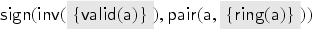 . Also, this one is a message that later becomes redundant with further messages. By analysis, the intruder also obtains
. Also, this one is a message that later becomes redundant with further messages. By analysis, the intruder also obtains 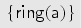 .
.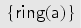 allows for another application of the
allows for another application of the 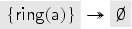 and the message
and the message 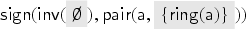 . After this, there are no further ways to apply this transaction rule, because we will not get to any other abstract value that contains
. After this, there are no further ways to apply this transaction rule, because we will not get to any other abstract value that contains 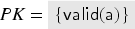 and
and 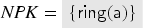 ), we get the term implications
), we get the term implications 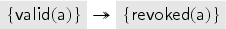 and
and  , and the intruder learns
, and the intruder learns  . Applying the
. Applying the 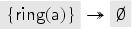 , the intruder also knows the signature
, the intruder also knows the signature  . If we apply the
. If we apply the  and
and 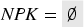 ) then we get the new term implication
) then we get the new term implication 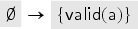 , the term implication
, the term implication 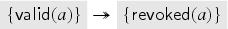 , which we already knew, and the intruder learns
, which we already knew, and the intruder learns  , but that was already in the intruder knowledge.
, but that was already in the intruder knowledge. , and they are not accepted for this transaction. (In a model with dishonest agents, the intruder can, of course, produce signatures with keys registered to a dishonest agent’s name, but here we have just one honest user
, and they are not accepted for this transaction. (In a model with dishonest agents, the intruder can, of course, produce signatures with keys registered to a dishonest agent’s name, but here we have just one honest user 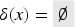 for all
for all 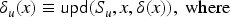

 for each
for each  . The only surviving substitutions are
. The only surviving substitutions are
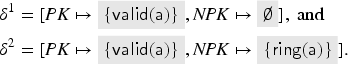
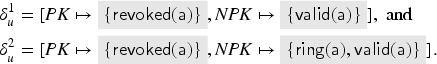
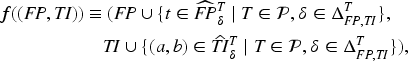
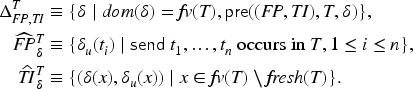
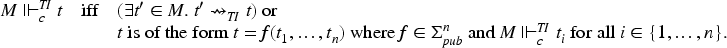
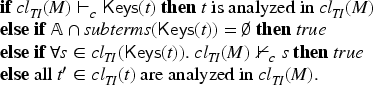
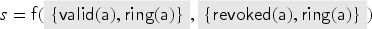 from a given fixed point. Observe that
from a given fixed point. Observe that  The closure of
The closure of  is the set
is the set  and the term implication closure of
and the term implication closure of  is
is 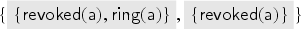 . We can see that both considered abstract values share that they actually represent
. We can see that both considered abstract values share that they actually represent  and
and  . Thus,
. Thus,  or by choosing to replace all occurrences of
or by choosing to replace all occurrences of  . Therefore there are two abstraction substitutions
. Therefore there are two abstraction substitutions  and
and  .
.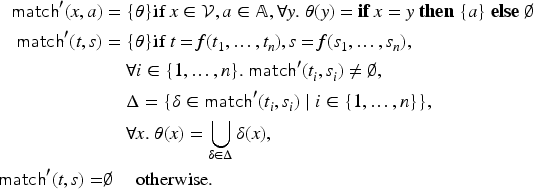
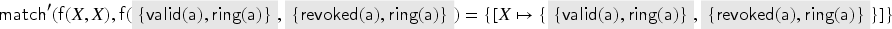 . We notice that the set to which
. We notice that the set to which  or
or  , to allow a match between
, to allow a match between 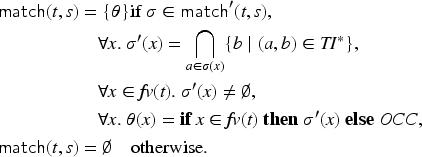
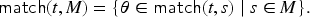
 Here the terms
Here the terms  and
and  are indeed equal to the term
are indeed equal to the term 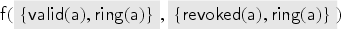 modulo term implication. As explained in Example 8, this will lead to two abstraction substitutions that map the term
modulo term implication. As explained in Example 8, this will lead to two abstraction substitutions that map the term 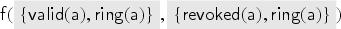 modulo term implication, namely
modulo term implication, namely  and
and  .
.

 or
or  . Consider the row for
. Consider the row for  . For
. For  or
or  . This leads to two possible abstraction substitutions:
. This leads to two possible abstraction substitutions: 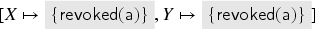 and
and 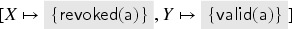 .
.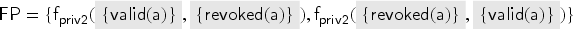 and
and  or
or  , and thus we get four possible abstraction substitutions, namely
, and thus we get four possible abstraction substitutions, namely 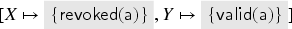 ,
, 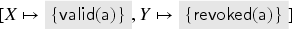 ,
, 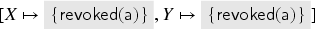 and
and 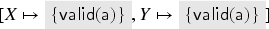 . Notice that we see here that an overapproximation is happening because actually only the first two abstraction substitutions will generate terms represented by the fixed point. We will tolerate this overapproximation.
. Notice that we see here that an overapproximation is happening because actually only the first two abstraction substitutions will generate terms represented by the fixed point. We will tolerate this overapproximation.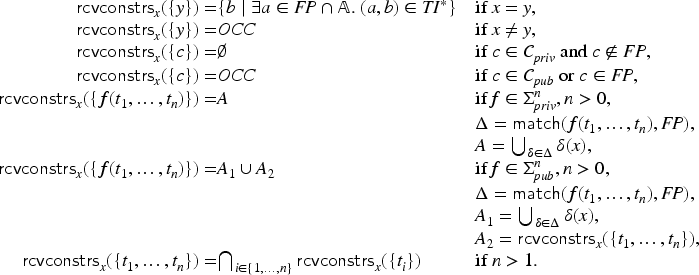
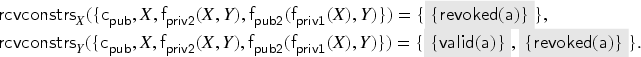 We see that this corresponds to the choices for
We see that this corresponds to the choices for 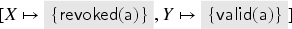 and
and 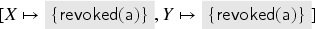 .
.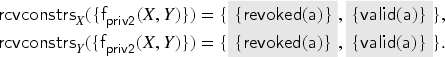 We see that this corresponds to the choices for
We see that this corresponds to the choices for 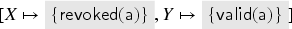 ,
,  ,
, 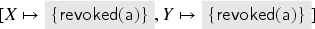 , and
, and 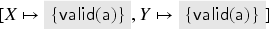 . We see again here that an overapproximation is happening because actually only the first two abstraction substitutions will generate terms represented by the fixed point.
. We see again here that an overapproximation is happening because actually only the first two abstraction substitutions will generate terms represented by the fixed point.