
Abstract
Anomalies in the work of data center users can be caused by both Structured Query Language (SQL) injection attacks and user attempts to make unauthorized access to data. The paper explores various machine learning models to detect such anomalies. The peculiarity of the problem being solved is its focus on the university data centers, whose databases have a non-normalized structure. In this case, the problem of reducing the feature space arises. The paper proposes an algorithm for generating a dataset based on typing the data table names. The experimental results obtained on supervised, unsupervised and semi-supervised machine learning models confirmed the high efficiency of the proposed approach. They showed that the support vector machine, random forest, Gaussian Naive Bayes, and neural network models are the most effective in detecting known SQL injections, and the local outlier factor semi-supervised learning model is the most effective in detecting unknown SQL injections and unauthorized access attempts.
Introduction
Nowadays the popularity of using data centers (DCs) in control systems has significantly increased (Alqahtani et al., 2020). DCs provide their users with the possibility of joint sustainable and timely use of information resources in the interests of solving various problems (Mujib & Sari, 2020; Welsh & Benkhelifa, 2021). For this reason, DCs are the primary targets for internal and external security violators to obtain information or disrupt centers (Klymash et al., 2019; Paiusescu et al., 2018).
Different methods of anomaly detection can be used in the creation of DC information security systems. As a rule, anomalies are detected in the network traffic with the help of various network security tools (e.g., intrusion detection systems, firewalls, antiviruses). However, traffic anomalies do not fully reflect abnormal (anomalous) DC user behavior. It manifests itself in the form of user requests to databases with incorrect, anomalous requests that allow to make malicious changes in the content of databases or to obtain unauthorized information from databases. Such queries are a special kind of computer attacks—Structured Query Language (SQL) injection (Marashdeh et al., 2021). In addition, anomalous queries may look normal and not contain SQL injection, but access to forbidden areas of the database. Protection against such accesses is usually assigned to the database access control system. However, for complex databases with a large number of data tables, creating an access control system that completely bans abnormal queries is a very difficult task.
The proposed approach, based on machine learning, is designed to help to fulfill this task. At the same time, it is proposed to use database logs as the initial data, on the basis of which the datasets used in machine learning methods are formed. These logs record the texts of queries the users accessed the databases. If the databases are based on the relational model, then queries are written in SQL. However, the proposed approach is not strictly tied to SQL and can be applied to any types of databases, such as NoSQL. The paper discusses the possibility of using machine learning methods to detect abnormal user behavior in DCs stored information and solved problems related to the university educational process. The choice of this type of DCs is explained by two reasons. First, the educational process databases contain a very large number of data tables. As a result, if you use table names to form a feature space, then the number of features will be very large. This makes the application of machine learning impossible or extremely difficult. Secondly, there are a large number of insider security threats in the university DC. Students should be considered as potential insiders. Therefore, the development of an additional security frontier for the university DC that allows detecting anomalous requests to DC databases is an urgent task. At the same time, it should be noted that a few known works are currently devoted to the topic of detecting or analyzing the possible malicious behavior of DC users.
The main contribution of the paper is as follows: (1) an original formal statement of the problem of detecting anomalous actions of DC users is proposed, oriented to the use of machine learning methods; (2) a new proposal to form a feature space, which determines the structure of training and testing datasets from the three categories of features—the keywords of the SQL language, signatures specific to SQL injection, and names of data tables; (3) an heuristic approach is proposed to reduce the dimension of the original feature space and an algorithm that implements it; (4) the implementation of the proposed approach was carried out using a variety of the most well-known machine learning models; (5) an experimental evaluation of the proposed approach was carried out, which confirmed its effectiveness and high efficiency.
The results of this study were reported at the 15th International Symposium on Intelligent Distributed Computing (IDC 2022) (Kotenko & Saenko, 2023). This article presents an extended description of the results obtained. In addition to Kotenko and Saenko (2023), we updated the results of the analysis of related works, and also examined in more detail approaches to feature space optimization and ensuring timely detection of anomalous user behavior. In the experiments, we used not only supervised machine learning methods, but also unsupervised and semi-supervised learning. In this case, the experiments were carried out using 10-fold cross-validation in order to increase the accuracy of the results and with optimization of parameters, which was especially necessary for the use of the principal component analysis (PCA) method.
The paper is structured as follows. Section 2 provides an overview of related works. Section 3 discusses the theoretical foundations of the proposed approach. Section 4 describes the details of the software implementation of the proposed approach and the generation of a dataset for its experimental evaluation. Experimental results and their discussion are considered in Section 5. Section 6 contains conclusions and directions for further research.
Related Work
Works related to the topic of detecting anomalies in the operation of DCs can be divided into two groups: (1) detecting anomalies in the operation of DCs and (2) detecting computer attacks such as SQL injection. Among the works of the first group, the works (Chen et al., 2020; Decker et al., 2020; Deka et al., 2019; Nanekaran et al., 2020; Salman et al., 2017; Shahid & Ali Shah, 2021) should be marked. Decker et al. (2020) notes that log entries in DC are stochastic and non-stationary in nature. Therefore, this work proposes an approach in which features are extracted from time windows and used to develop and update an evolving Gaussian Fuzzy Classifier on the fly. Shahid and Ali Shah (2021) proposes to use the word2vec algorithm to extract features from logs, and to use an LSTM neural network (NN) to detect anomalies. In Nanekaran et al. (2020), it is proposed to use unsupervised machine learning methods to determine the normal and abnormal behavior of DC cooling systems. The issues of preventing hostile influence on the detection of anomalies in DC are considered in Deka et al. (2019). This work proposes a linear regression-based optimization framework with the ability to poison data in the training phase. Chen et al. (2020) suggests to detect anomalies by judging the deviation of predicted data and true data in DC operating using various machine learning methods. Salman et al. (2017) uses linear regression and random forest (RF) to not only detect but also classify attacks in DC network traffic.
Despite the good results obtained in these anomaly detection works, it should be noted that these works did not consider anomalies in SQL queries and SQL injection detection. The works of the second group are devoted to this, for example (Gowtham & Pramod, 2022; Hlaing & Khaing, 2020; Prarthana & Gangadhar, 2017; Xiao et al., 2017; Xie et al., 2019). Hlaing and Khaing (2020) emphasizes that SQL injections became possible due to lack of validation of input queries. This paper presents an approach which detects a query token with reserved words-based lexicon to detect SQL injections. Gowtham and Pramod (2022) proposes a robust semantic query ensemble learning model for SQL injection prediction. The proposed learning model used a set of nine basic classifiers designed to provide maximum prediction based on the voting ensemble. In Prarthana and Gangadhar (2017), it is proposed to use multivariate statistical tests to detect anomalies in the behavior of DC users. In Xie et al. (2019), a method for detecting SQL injections in web applications based on the Elastic-Pooling convolutional NN is presented. Xiao et al. (2017) proposes an approach to detecting SQL injections based on the analysis of the response and state of a web application during various attacks.
It should be noted that most of the recent SQL injection detection work focuses on the use of machine learning. So, Hasan et al. (2019) considers a machine learning-based approach to prevent SQL attacks, in which over 20 different classifiers are tested and the top five are selected. The potential of using machine learning techniques to detect SQL injections at the application level is explored in Tripathy et al. (2020). In this work, classifiers trained with malicious and secure SQL queries are investigated. Adebiyi et al. (2021) believes that machine learning is the most effective approach to detect and identify SQL injections. In this work, using the Decision Tree (DT) classifier, the accuracy of detecting SQL attacks was more than 0.98. In Balaji B et al. (2021), the possibilities of using deep learning on the multilayer perceptron model were studied. The same accuracy of attack detection was obtained. In Hosam et al. (2021), a study was made of the possibility of using six binary classifiers to detect SQL injections. A feature space was proposed, consisting of 13 most important features. Logistic regression (LR) was indicated as the best classifier. In the study (Roy et al., 2022), the best classifier was the naive Bayes method. Misquitta and Asha (2023) comes to the conclusion that supervised machine learning methods are quite effective, and it is proposed to use convolutional NNs to identify SQL attacks in real time.
We used the ideas proposed in related works on machine learning to detect SQL attacks in our work when selecting and evaluating classifiers.
Theoretical Background
Task Statement
Let us first consider the task statement for detecting anomalous actions of DC users, focused on the use of machine learning methods.
By a university DC we mean a DC with several databases, which are used in the interests of organizing and conducting the educational process. We will assume that the behavior of DC users consists in accessing the databases available in the DC using queries written in some language (e.g., SQL). Databases can be stored on nodes of a distributed file system (e.g., HDFS). Then parallel anomaly detection will be possible. In the paper, however, we do not focus on this. Database queries are recorded in the database management system (DBMS) logs (e.g., PostgreSQL, MySQL and others). The log consists of separate records. Each record reflects the fact of some user accessing the database and contains the following fields: date, time, user identifier and SQL query text. Therefore, the task of detecting abnormal behavior of university DC users comes down to detecting anomalous SQL queries to DC databases, which leads to searching for anomalous records in the logs.
If we imagine the DBMS log as a dataset consisting of records, then a possible technique for analyzing such a dataset for anomaly detection involves the following possible steps: (1) the formation of a set of features that characterize SQL queries; (2) transformation of the log dataset into a dataset, the records of which contain the values of the generated features; (3) formation of a training sample on which the machine learning process will be carried out; (4) the use of trained tools to directly identify anomalous requests.
The initial data of the task are:
a set of DC users each log is represented as a set of records each log record is represented as a tuple each SQL statement can be represented as well-known machine learning models (binary classifiers), which are most often used to detect anomalies in the analysis of various types of data (Branitskiy & Kotenko, 2016; Kotenko & Saenko, 2019); requirements for detecting attacks such as SQL injection: Probability of correct attack detection:
To calculate these probabilities, it is proposed to use the following formulas:
As a result of solving the task, it is required to develop a feature space model containing features used in machine learning, conduct an experimental evaluation of machine learning methods used to detect anomalous user behavior, and develop a methodology for ensuring the timeliness of detecting anomalous user behavior.
The experimental evaluation of machine learning methods is described in detail in Section 5. Below are the results of the development of a feature space model and a methodology for ensuring the timely detection of anomalous user behavior
The feature space model is the result of one of the initial operations in machine learning technology, which is called feature selection. The essence of this model is a set of features that characterize some object or process and are used to analyze data about this object or process (Brownlee, 2020).
In well-known works on detecting anomalies in log files, discussed in Section 2 (for example, in Gowtham & Pramod, 2022; Shahid & Ali Shah, 2021), it is proposed to use the word2vec method to extract features. This method applies to any text data. However, it does not take data structure into account. Therefore, its application to SQL queries that have a strict structure was recognized by us as insufficiently effective, since this method produced a very large number of features at the output, and most of them were not informative. In addition, the accuracy of anomaly detection in SQL queries when using the word2vec method was lower than required.
Therefore, the proposed feature space model was formed heuristically as follows. It included features of three categories. The features of the first category determine the number of occurrences of a keyword in the SQL query. A total of 30 keywords were selected, such as SELECT, INSERT, CREATE, etc. The features of this category are designed to determine the complexity level of the SQL query and its type.
The second category of features was the number of occurrences of certain signatures specific to SQL injection. The following signatures were selected for this purpose: “Execute,” “or,” “txtUserId,” “getRequestString,” “1=1,” “- -,” “CHAR,” “#” and “;”. The presence of such signatures in SQL statements indicates the presence of known SQL injections in queries. Thus, the features of the second category reflect queries with SQL injections.
The third category was formed by the number of occurrences of data table names. Using this group of features, as expected, it is possible to detect anomalous SQL queries in which users attempt unauthorized access. Thus, the features of the third category reflect the preferences of users in accessing the structure of the database.
The DC University database used to experimentally evaluate the proposed approach contained over 4,000 data tables. This is due to the non-normalized nature of its structure. Approximately 2,000 tables contained faculty data, one table per faculty member. Each course, discipline, and study group also had its own data table.
Due to such a large number of tables, we made the following two decisions. First, we decided not to use field names and values when forming the feature space. Second, we decided to reduce the number of table names in the feature space by replacing them with a generic type name. So, all table names for teachers were replaced with the type name “Teacher_Table,” table names for study groups were replaced with “Group_Table,” etc. Thus, it was possible to reduce the number of table names taken into account to 141.
The feature space formed in this way was called the initial space. Its composition is presented in Table 1. It shows that the total number of features has become 181. Of these, 30 features belong to the first category, 10—to the second category and 141—to the third category.
The Composition of the Initial Feature Space.
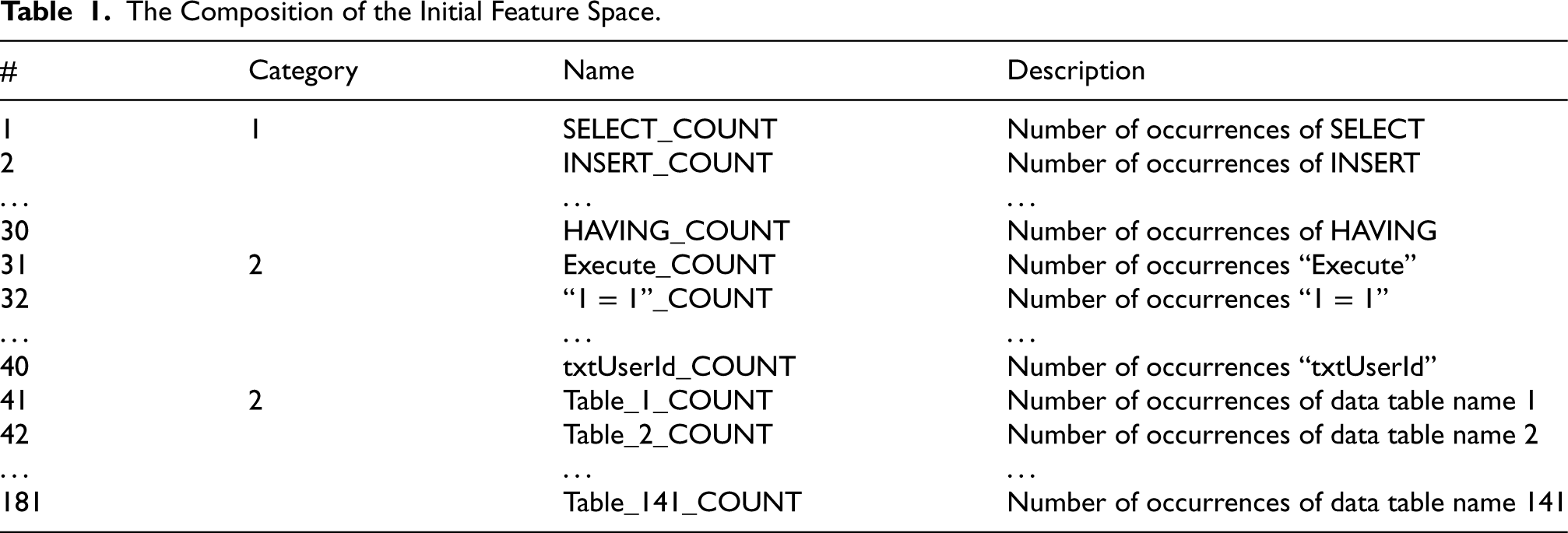
The Composition of the Initial Feature Space.
As noted above, an excessively large number of features can have a negative impact on the accuracy of anomaly detection. Therefore, in this work, we solved the problem of maximizing the reduction of the initial set of features, in which the resulting accuracy of anomaly detection does not decrease and/or, if possible, can even increase.
Optimization of the initial set of features was carried out on the basis of an assessment of their information content. For this purpose, the following well-known metrics were used (Brownlee, 2020):
Information Gain (Info.Gain), Information Gain Ratio (Gain Ratio), ANalysis Of VAriance (ANOVA).
The Info.Gain metric defines “information gain”. It shows the decrease in entropy caused by dividing the original set of features and looking for the optimal feature that gives the highest value using the following formula:

The Gain Ratio metric is the ratio between the value of the Info.Gain metric calculated according to (1) and the value of the Split Information metric defined as follows:

ANOVA is a set of statistical models and associated estimation procedures used to analyze differences between means. In its simplest form, ANOVA provides a statistical test for the equality of two or more population means. The ANOVA metric was calculated using built-in software.
To minimize the number of features that make up the optimal feature space, we use the Guttman-Kaiser criterion (Arnaut, 2014). This criterion states that the features included in the optimal feature space must have information content that exceeds the average information content for the entire set of initial features.
Then for the feature 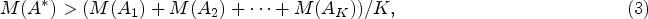
To ensure timely detection of anomalous user behavior, it is necessary to determine what limit the size of the log file should have in order to meet the requirements for the timeliness of processing queries to databases. To do this, it is necessary to solve the optimization task in the following formulation.
Let’s designate the length of the period of time during which the system works, through
Let’s introduce the variable
Let us assume that the dataset processing time 
The total processing time of all data sets for the period 
On the other hand, let’s assume that the duration of processing one request is imposed by the requirement that it does not exceed some given value of
Then the formal statement of the optimization task with decision variable x has the following form:




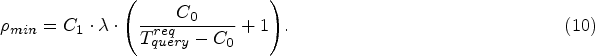
To implement the approach, the Python v.3.8.8 was used with the following libraries: sklearn, numpy, pandas, matplotlib, Scipy, Re, Pylab, Math. The computing environment was organized on a Jupyter notebook.
Both supervised machine learning methods using binary classifiers, as well as unsupervised and semi-supervised methods were studied. Supervised learning methods were used to detect SQL attacks with known signatures. The unsupervised and semi-supervised methods were used to detect unknown SQL attacks and unauthorized access attempts to data tables.
The university DC used DBMS PostgreSQL v.13.4 running under Ubuntu v.13.4 to create the database.
To form a dataset used to train binary classifiers, a fragment of the log of the university DC database was selected, showing the work of users with the database for 15 minutes. In total, this fragment initially contained 82,192 statements. Figure 1 presents the instructions included in this log.
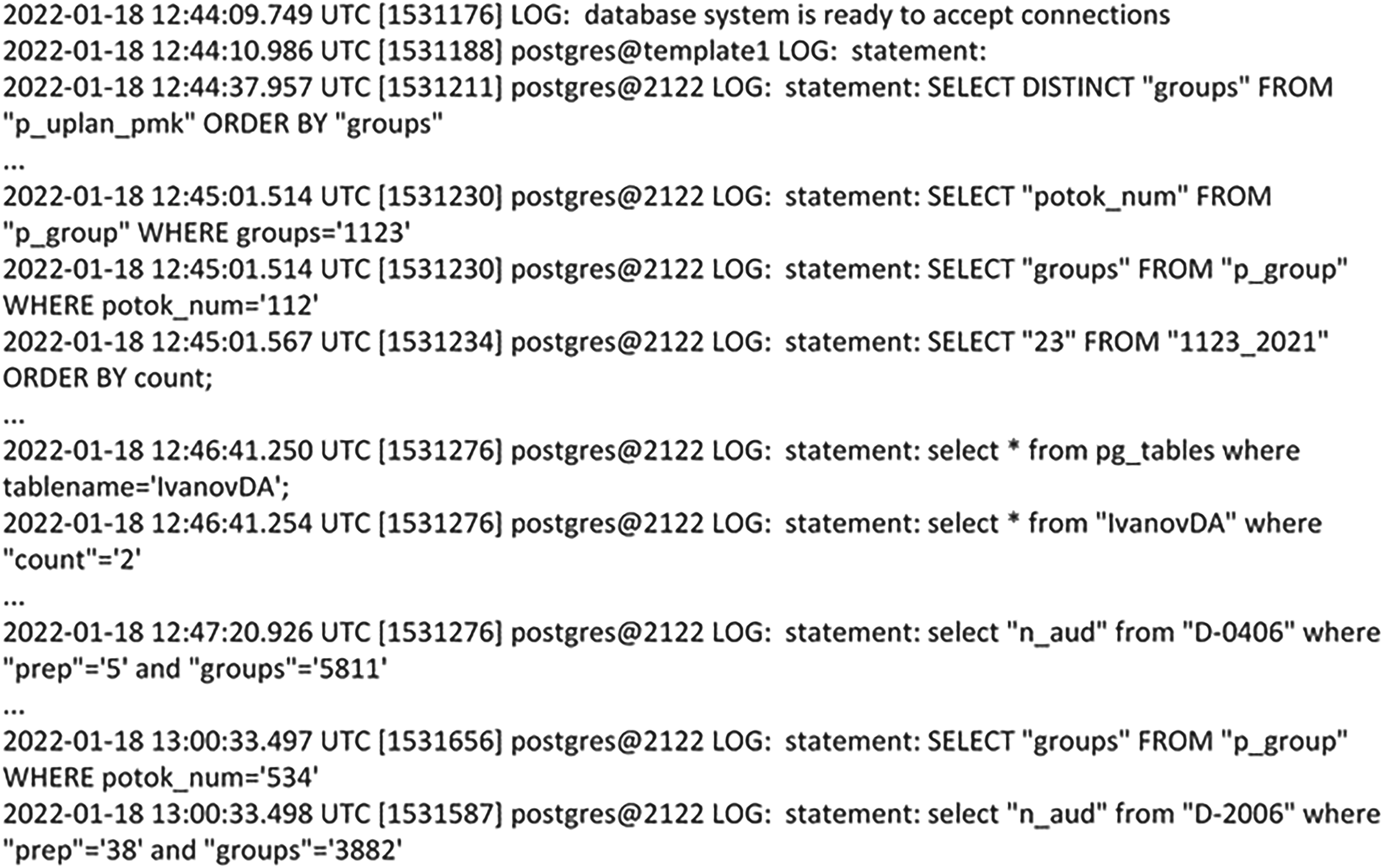
Log’s fragment of the university data center (DC).
Analyzing Figure 1 we observe that the recording of this fragment was made on March 18, 2022. It started at 12:44:09 and ended at 13:00:33. Several users worked with the data-base and their IDs were 1174, 1187, 1211, 1230, 1234, 1276, 1565, and 1587. The queries accessed various data tables. So, the query with time 12:44:37 turned to the system table “p_uplan_pmk” (it contained planning information on the educational process). The name of this table appears in the statement after the word FROM. Other queries addressed the following tables: “p_group”, “1123–2021”, “pg_tables”, “IvanovDA”, “D-0406”, “D-2006”. The “p_group” and “pg_tables” tables were system ones. They were created by the system when the database itself was created. Other tables are non-system created by users using the CREATE command while working with the database. The table “IvanovDA” contains data about the teacher D.A. Ivanov. Table “1123–2021” contains data on study group
Since the database contained a very large number of tables with data on teachers, study groups and academic disciplines, it was decided to type such tables, that is, replace them with names of types. For example, the names of all data tables containing teacher data are replaced with the name “Teacher_Table”. This leads to the fact that in the feature space of the dataset, instead of 2000 names of data tables characterizing teachers, there will be the name of only one table. Similarly, the number of data table names that characterize study groups and academic disciplines is reduced.
This procedure has become one of the initial steps of the developed dataset formation algorithm. In total, this algorithm contains the following 5 steps.
Extracting all table names from the log fragment and forming a set of table names used in the fragment. In total, 310 table names were extracted. Generation of a set of new, typical table names. For the names of tables with data about teachers, the name “Teacher_Table” was used, for the names of tables with data about groups “Group_Table”, etc. In total, this set included 141 names, including the names of system tables. Replacing the original table names in the log fragment with generic names. At the same time, the number of statements in the fragment was still 82192. Formation of the initial dataset in CSV format. For each instruction, a CSV record was created from the fragment. The fields of this record were the features that were included in the feature space model and shown in Table 1. In addition, the Result field was included in the initial version of the dataset, which value played the role of a label for a normal or abnormal record. It was assumed that if Result = 0, then the record is normal, and if Result = 1 abnormal. Removing duplicate records from the dataset and introducing anormal records into it. Since the date and time of the query were excluded from the feature space at this stage of the study (this was done deliberately to test the effectiveness of machine learning on SQL query structures), a large number of duplicate records appeared in the dataset. At this stage such records were deleted. After their removal, only 1,026 records remained in the dataset. In addition, a few randomly selected records were changed to match various possible anomalies (SQL injection and access violation attempts). A total of 50 such records were modified and marked as anomalous in the Result field. SELECT * FROM users WHERE username = ‘administrator’–’ AND password = ”; SELECT name, description FROM products WHERE category = ‘Gifts’ UNION SELECT username, password FROM users; SELECT UserId, Name, Password FROM Users WHERE UserId = 105 or 1 = 1; uName = getRequestString(“username”); SELECT * FROM Users WHERE Name = “” or ““=”” AND Pass = “” or ““=””; SELECT * FROM Users WHERE UserId = 105 UNION DROP TABLE Suppliers; UPDATE users SET password = ‘newpwd’ WHERE userName = ‘admin’ – ’ AND password = ‘oldpwd’; SELECT accounts FROM users WHERE login = “legalUser”; exec(char(0x73687574646f776e)) - - AND pass = “” AND pin =.
Examples of such anomalous requests are:
The dataset formed using the algorithm described in this section was further subjected to more detailed evaluation and analysis above using the selected machine learning models.
Application of Supervised Machine Learning Methods
Supervised machine learning methods were used to detect known SQL injections. The following most popular models of supervised machine learning were studied (Branitskiy & Kotenko, 2016; Kotenko & Saenko, 2019):
Support Vector Machine (SVM) with linear kernel, DT, LR RF, Gaussian Naive Bayes (GNB), k-Nearest Neighbors (KNN), Multilayer Neural Network (NN).
Before training the models, the feature space was optimized as discussed in subsection 3.3. For this purpose, we used the capabilities that the open source machine learning framework Orange 3.34 (https://orangedatamining.com).
Figure 2 shows a fragment of the resulting table that Orange generates to analyze the information content of features for the selected metrics Info.Gain, Gain Ratio and ANOVA. The rows in the table are not sorted. It can be seen from the figure that different features have different qualities for including them in the final data set with respect to different information content metrics.
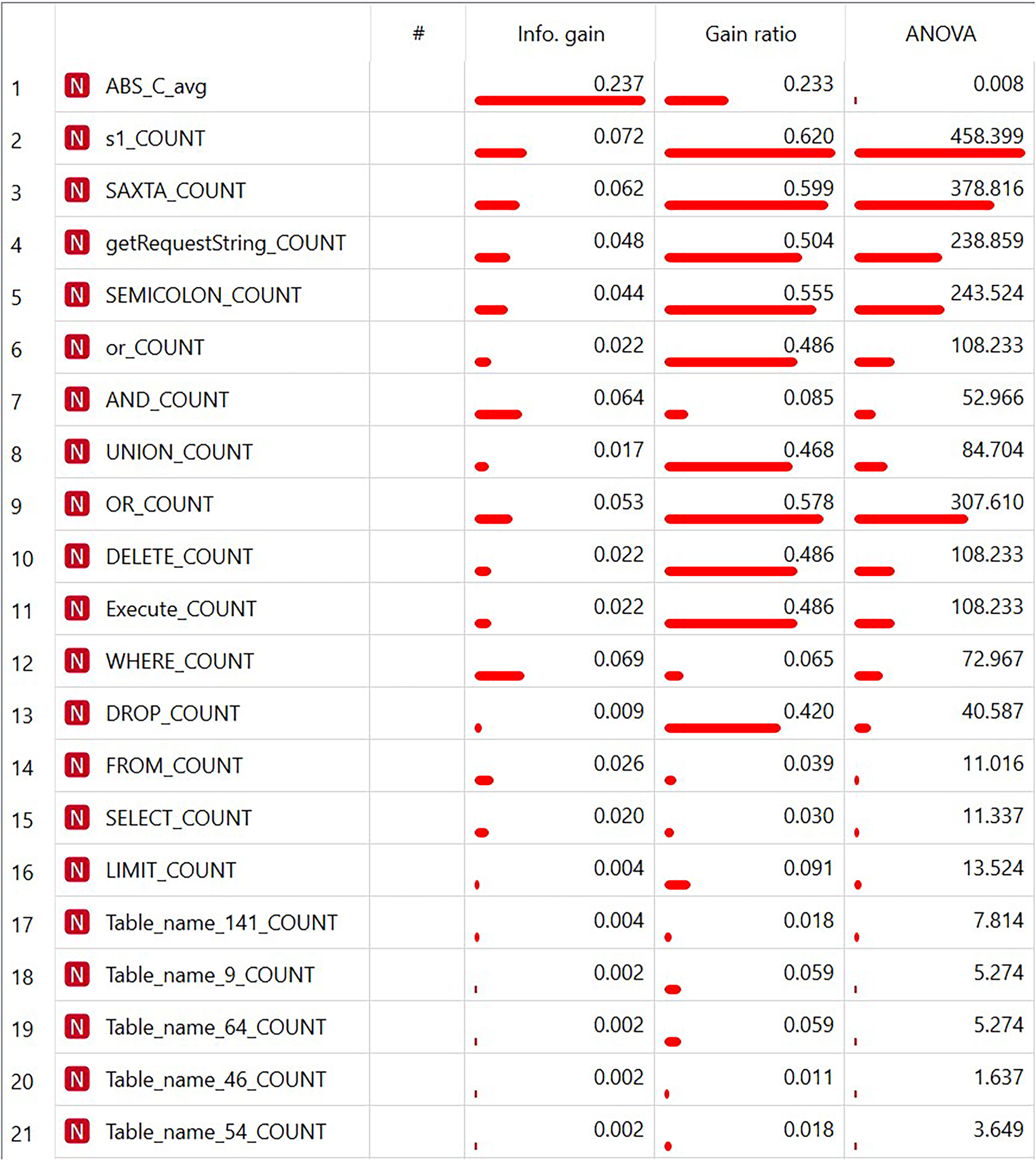
Tabular presentation of feature information content metrics.
The results of anomaly detection efficiency evaluation (F-score) for the complete and optimized feature sets according to control testing data for various machine learning models are presented in Table 2. 10-fold cross-validation was used to obtain these results.
The Composition of the Initial Feature Space.
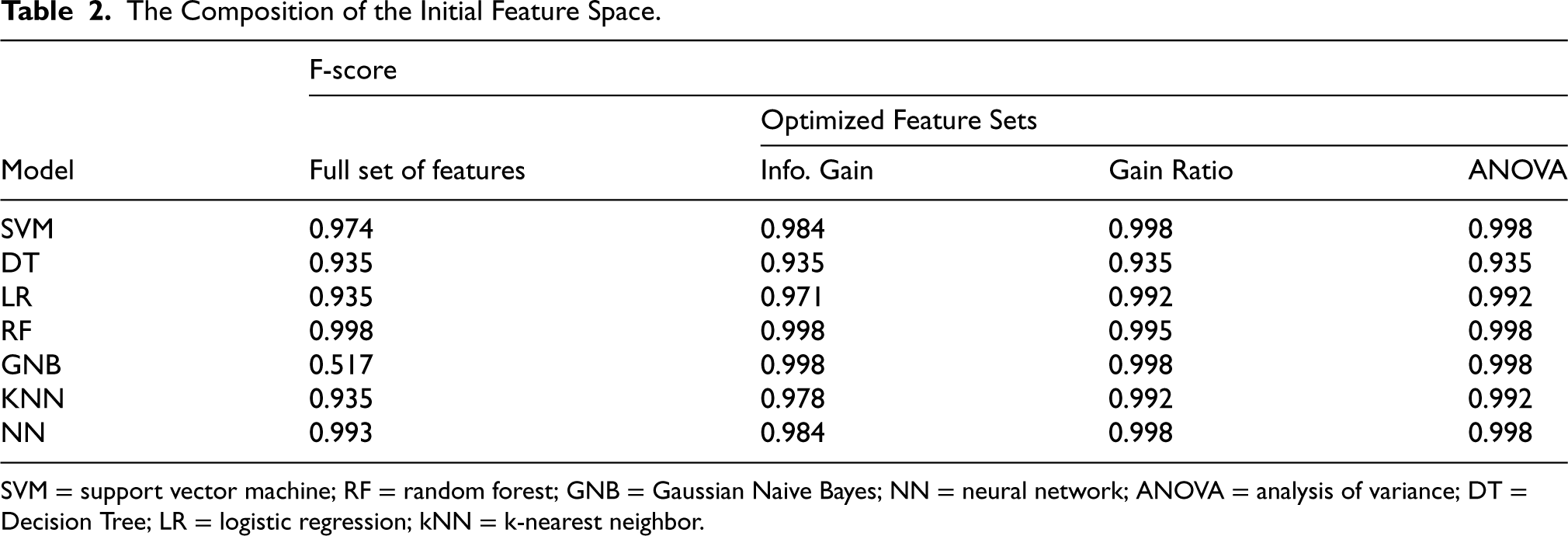
SVM = support vector machine; RF = random forest; GNB = Gaussian Naive Bayes; NN = neural network; ANOVA = analysis of variance; DT = Decision Tree; LR = logistic regression; kNN = k-nearest neighbor.
An analysis of the obtained experimental results shows that the studied machine learning models demonstrate different accuracy in detecting anomalous queries. Thus, the DT and LR models turned out to be insufficiently effective. Perhaps this is due to the insufficiently large size of the training sample. In turn, the SVM, RF, GBN, KNN and NN models showed a fairly high efficiency. The GNB model showed the highest efficiency, which did not make a single error in anomaly detection on the optimal set of features.
Unsupervised and semi-supervised machine learning methods were used to detect unknown SQL attacks, as well as unauthorized access attempts to data tables.
The following models were chosen for the study:
the method of k-means together with the method of PCA, Isolated Forest (IF), Local Outlier Factor (LOF); One-Class SVM (OCSVM).
The study of the k-Means method on a dataset with an optimal feature space showed that its highest accuracy is achieved when the number of clusters is 5. However, the accuracy achieved was 0.82, which does not correspond to requirements.
To study the remaining models of unsupervised machine learning, the size of the original data set was increased by 50 times and brought up to 507,232 records. The optimal feature space was expanded by all features of the third category. The number of anomalous records was 20. However, as the experiments showed, in this case all three models gave a large number of FP and FN cases.
For this reason, the IF, LOF, and OCCVM models were studied in the semi-supervised learning mode, when the model is trained on a dataset containing only normal records. The results obtained on such a dataset with an extended composition of features are presented in Figure 3.
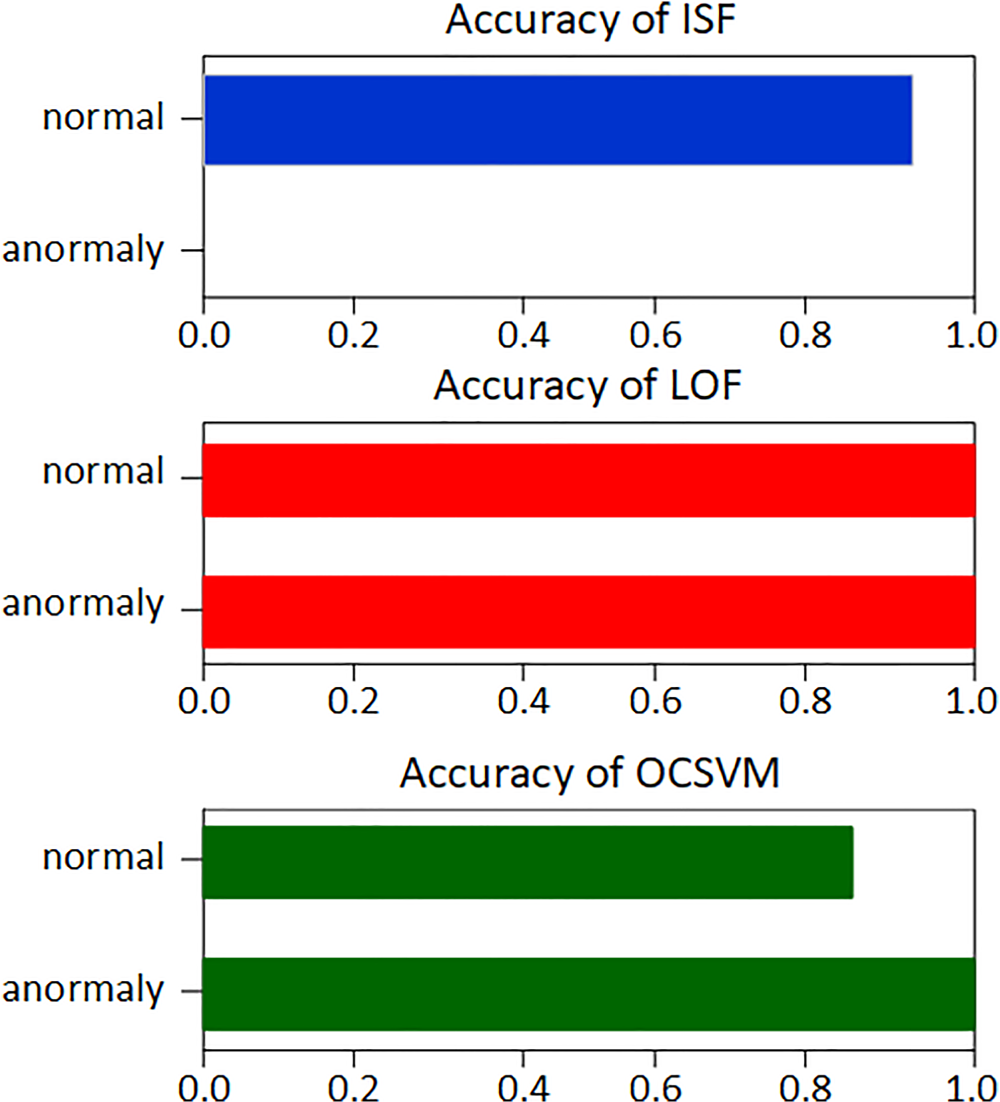
Results of semi-supervised machine learning.
The accuracy of detecting normal records for the LOF model was 0.9989, and for abnormal records, 1.0. The ISF model, despite the high accuracy of detecting normal records, could not detect any anomalous records. The OCSVM model showed an accuracy of 1.0 for detecting anomalous records, but for normal records, the accuracy was only 0.8567.
Based on the experiments, the final Table 3 was formed, which, based on a comparative assessment, presents performances of using machine learning models to detect various anomalies. The best performing machine learning models are marked with “Ok”.
Comparative Evaluation of Machine Learning Models.
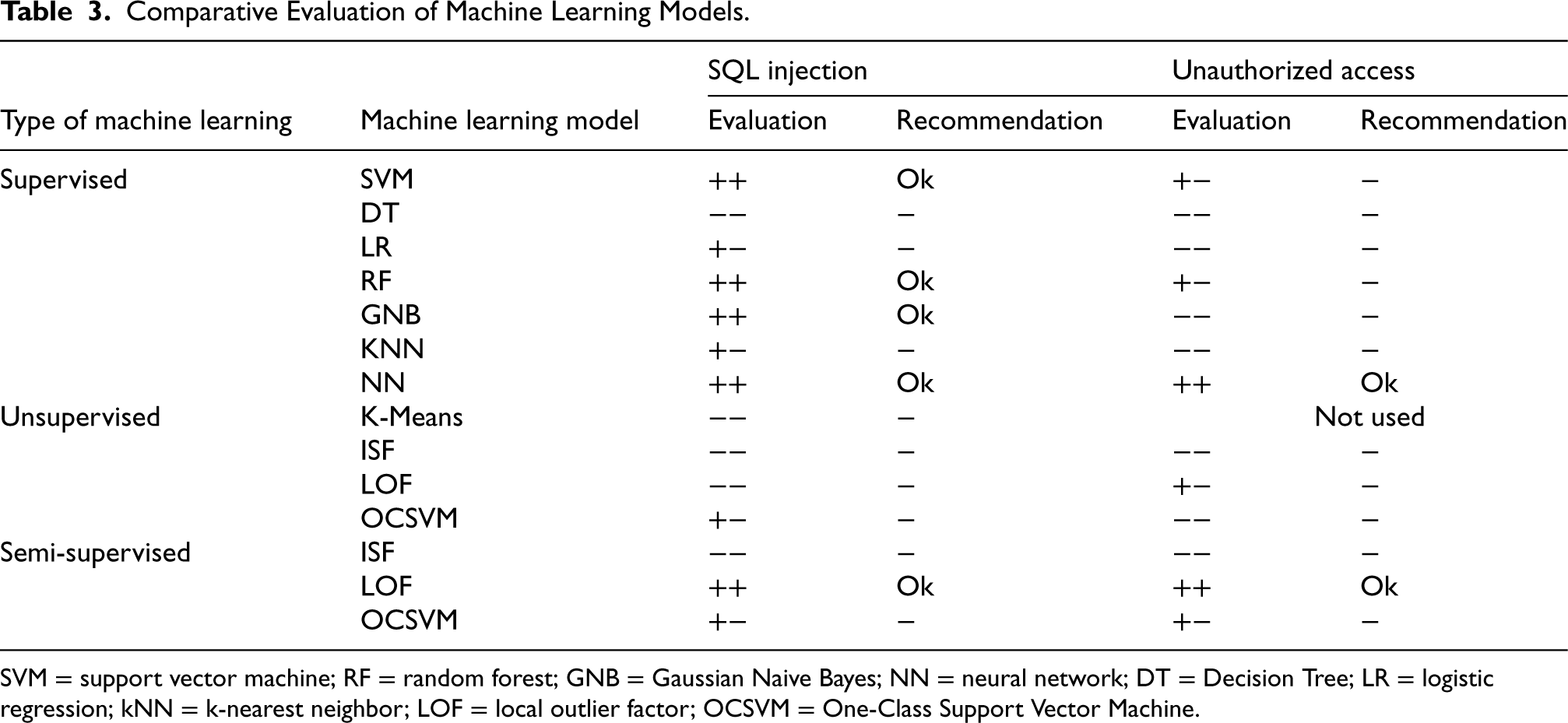
Comparative Evaluation of Machine Learning Models.
SVM = support vector machine; RF = random forest; GNB = Gaussian Naive Bayes; NN = neural network; DT = Decision Tree; LR = logistic regression; kNN = k-nearest neighbor; LOF = local outlier factor; OCSVM = One-Class Support Vector Machine.
Direct verification of current queries using the selected learning models is performed by submitting the current SQL query to the corresponding already trained model. This corresponds to the model being used in test mode. The current request is tested in real time, taking into account expressions (9) and (10). If the model detects an anomaly, the DC security administrator is notified of a possible SQL injection or the unauthorized access attempt.
In order to ensure timely detection of abnormal user behavior, we assumed that the parameters included in (9) and (10) take the following values:
The paper presents the task statement, algorithms, issues of implementation and the results of an experimental evaluation of a new approach to detecting anomalous queries to SQL databases, based on a heuristic algorithm for reducing the dimension of a feature space and using binary classification methods. The initial data of the task are logs, database users, selected binary classifiers, and requirements for the accuracy of detecting anomalous SQL queries. The result of the approach implementation is a feature space model, presented as a set of normal and abnormal data records containing the values of the generated features, and a technique for searching for abnormal queries.
An experimental evaluation of the proposed approach was carried out on real data sets generated during the work of university DC users with the database of the educational process. Supervised machine learning methods and an optimal set of features were used to detect anomalies caused by known SQL injections. Unsupervised and semi-supervised machine learning methods together with an extended set of features were used to detect unknown SQL injections and unauthorized access attempts to data tables. The evaluation results confirmed the effectiveness of the proposed approach and made it possible to choose the most preferable machine learning models. For detecting known SQL injections, these models include SVM, RF, GNB, and NN. For detecting unknown SQL injections and unauthorized access attempts, the LOF semi-supervised machine learning model is best. To ensure the timely detection of anomalous user behavior, an optimization problem was set and solved, which allows finding the maximum size of fragments into which the logbook should be divided.
Further research is aimed at improving the accuracy of detecting anomalous SQL queries by improving the parameters of classifiers and combining them.
Footnotes
Funding
The authors received the following financial support for the research, authorship and/or publication of this article: The reported study was partially funded by the budget project FFZF-2025-0016.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.