
Abstract
Topic discovery and integration are vital for maintaining vocabularies that categorize textual corpora. Automated approaches are often computationally expensive and lack domain-specific conceptual nuance; manual approaches are costly in terms of time and potential bias. To address this dilemma, we introduce the segments-as-topic (SAT) methodology, a four-stage process that combines automation and human expertise to assess candidate topics for vocabulary inclusion. In the SAT generation stage, a topic is formulated and refined through collaboration with domain experts, and then a sentence-level semantic similarity model retrieves corpus segments semantically aligned with the topic. The SAT expansion stage uses this seed set to find additional semantically similar segments, which are iteratively accepted or rejected to build a final segment set. During the review stage, a panel of scholars evaluates the topic for inclusion. In the integration stage, all segments in the final segment set are automatically tagged with the new topic. We apply this methodology to the Comparative Constitutions Project vocabulary that tracks over 330 topics in national constitutions, and demonstrate the addition of three new topics to the vocabulary. The SAT approach balances computational efficiency with expert judgment, offering a systematic, user-friendly, and replicable framework for social scientists to expand domain-specific vocabularies.
Introduction
“The limits of my language mean the limits of my world,” the Austrian philosopher Ludwig Wittgenstein (1922) observed more than a century ago. This statement captures the relationship between language and perception—our language shapes our understanding of the world around us. 1 For social scientists, this relationship is critical when connecting evolving corpora with a conceptual vocabulary (closely related to taxonomy, schema, and ontology) that represents domain knowledge. Robust vocabularies must evolve to accommodate emerging topics from new corpus additions, paradigm shifts, or cross-disciplinary influences. To extend Wittgenstein’s dictum, the limits of our scholarly vocabularies mean the limits of our domain of study.
Political scientists have wrestled with vocabulary curation at least since Giovanni Sartori’s (1984) influential work on concepts. Sartori recognized that concepts are critical for representing knowledge and that coordination among scholars about vocabulary advances scientific discovery. Building on this foundation, subsequent contributions—such as Collier and co-authors’ (Collier & Levitsky, 1997; Collier & Mahon, 1993; Elkins, 2026) distinction between classical and more probabilistic approaches, and Gerring’s (2011) and Goertz’s (2020) works on concept structure and measurement—have further refined how political scientists think about conceptual validity and the relationship between concept and indicators. Our work here continues in this tradition.
The advance of computational methods provides significant leverage for the organization and use of concepts. One core challenge is to update conceptual vocabularies and apply them to related examples in text. We present a methodology to formulate, evaluate, and incorporate new topics into existing vocabularies. The assumed context is a domain in which a core set of texts represents domain knowledge. We focus on constitutional texts and a corpus of world constitutions as our exemplar domain. Our framework employs a semantic similarity model, which represents both the candidate topics and relevant text segments as vectors of numbers (Cruz et al., 2023; Gardner, 2023). Segments are discrete units of constitutional text, ranging from shorter clauses such as list items to one or more sentences, and serve as the unit of analysis (see the Data Sources and Text Processing section). We develop what we call the segments-as-topic (SAT) approach that uses corpus text segments to represent candidate topics and then identifies additional similar segments in the corpus to define the topic’s full conceptual scope. 2 Throughout this process, domain experts actively participate in topic refinement rather than being limited to post-hoc validation.
Our methodology comprises four stages: (1) SAT generation; (2) SAT expansion; (3) SAT review; and (4) SAT integration into the corpus. We demonstrate this process using vocabulary that authors of the Comparative Constitutions Project (CCP) developed to track topics within a corpus of national constitutions (Elkins & Ginsburg, 2025 [2005]). 3 The CCP’s indexed repository of constitutional texts, Constitute, includes 330 core topics and is widely used by scholars and constitutional drafters. As such, the integration of new topics is potentially consequential for future constitutional development.
This approach demonstrates the synergy between natural language processing and human expertise, producing topics that are both semantically coherent and resonant with domain experts. We seek to empower curators—scholars and practitioners alike—to identify and develop candidate topics that enrich their own vocabularies. The tools implementing this methodology are available via GitHub, including code, documentation, example datasets, and a video tutorial demonstrating the full workflow. The framework also supports multiple input formats 4 to enable applications beyond the constitutional domain.
The Problem
What we describe is a general and common concern for scholars studying ideas in any corpus. Our running example involves national constitutions, but similar challenges exist in other scholarly projects. For example, the Policy Agendas Project inventories policy ideas in national legislation (Jones et al., 2023) and the Manifesto Project codes election platforms of major political parties across countries with different vocabularies (Lehmann et al., 2022). Beyond political science, comparable challenges exist in analyzing news, social media, books, film scripts, music lyrics, or academic articles. For any such corpus, scholars often aim to develop explicit topic sets to track ideas in the genre—a type of study known as “conceptual ecology” (Cruz et al., 2023, p. 19). Our focus is how to systematically update such vocabularies in evolving genres. This includes both adding new topics and expanding the application of existing topics to more segments where that topic appears—two complementary use cases we demonstrate below.
Maintaining and updating vocabularies presents significant challenges. When corpus expansion reveals the need for vocabulary refinement, researchers often hesitate due to the daunting nature of the task. Evaluating potential vocabulary modifications requires examining the entire corpus to identify segments that would require recoding under a new schema—a prohibitively time-consuming process for large corpora.
Researchers often resort to shortcuts rather than comprehensive recoding. One common approach involves searching the corpus using keywords or embeddings to identify potential matches. However, this method operates in isolation from existing topic coding and fails to contextualize proposed modifications within the established vocabulary framework. More critically, the quality of results depends entirely on the search query, which inevitably produces both false positives and false negatives while creating a “moving target” when parameters are modified.
An alternative approach leverages topic modeling (TM) to discover latent topics absent from the current vocabulary. Traditional models like LDA (Blei et al., 2003) or STM (Roberts et al., 2013) typically rely on “bags of words,” while recent advances incorporate embeddings to better capture contextual nuances (Dieng et al., 2020; Grootendorst, 2022). KeyATM (Eshima et al., 2024) presents a promising deductive approach—a guided algorithm that retrieves specified topics through keywords while allowing discovery of new topics. Despite their appeal, automated TM approaches remain insufficiently robust for effective topic curation, requiring extensive human validation even for simple classification tasks (Ying et al., 2022).
Importantly, our use of the term “topic” differs from its meaning in topic modeling. In that context, topics are latent distributions over words discovered inductively from corpus statistics, and researchers interpret their meaning in a post-hoc fashion. In our framework, topics are expert-defined conceptual categories within a structured vocabulary, thus having a more deductive character. Each topic has a label, description, and position within a hierarchical ontology (see Supplemental Figures in Appendix A). Currently, topics may nest within a dozen parent categories, and segments may be tagged with multiple topics. Using a topic set designed to capture the conceptual field allows us to identify the topics found in a corpus but also those that are not present in the corpus. The SAT method provides a systematic process for expanding such vocabularies while maintaining their conceptual coherence.
Given the limitations of automated approaches, topic curation in practice typically follows an eclectic but informal procedure combining manual revision, automated search and recoding, and expert judgment. We contend that the difficulty of this process inhibits experimentation with new or revised topics, resulting in undue inertia in vocabulary development. We propose a method that streamlines this process, facilitating and accelerating vocabulary enrichment.
Methodological Framework
We develop an approach to topic curation that uses semantic similarity tools to gather a set of text segments in the corpus that represents the topic we want to add to our vocabulary. We then leverage these segments to find additional similar segments in the corpus, ultimately identifying the full set of segments to which the topic applies and allowing us to seamlessly integrate the new topic into our vocabulary and corpus. A summary of the framework is in Figure 1. We detail the steps in the following sections. Diagram of the SAT approach to topic integration (examples in italics)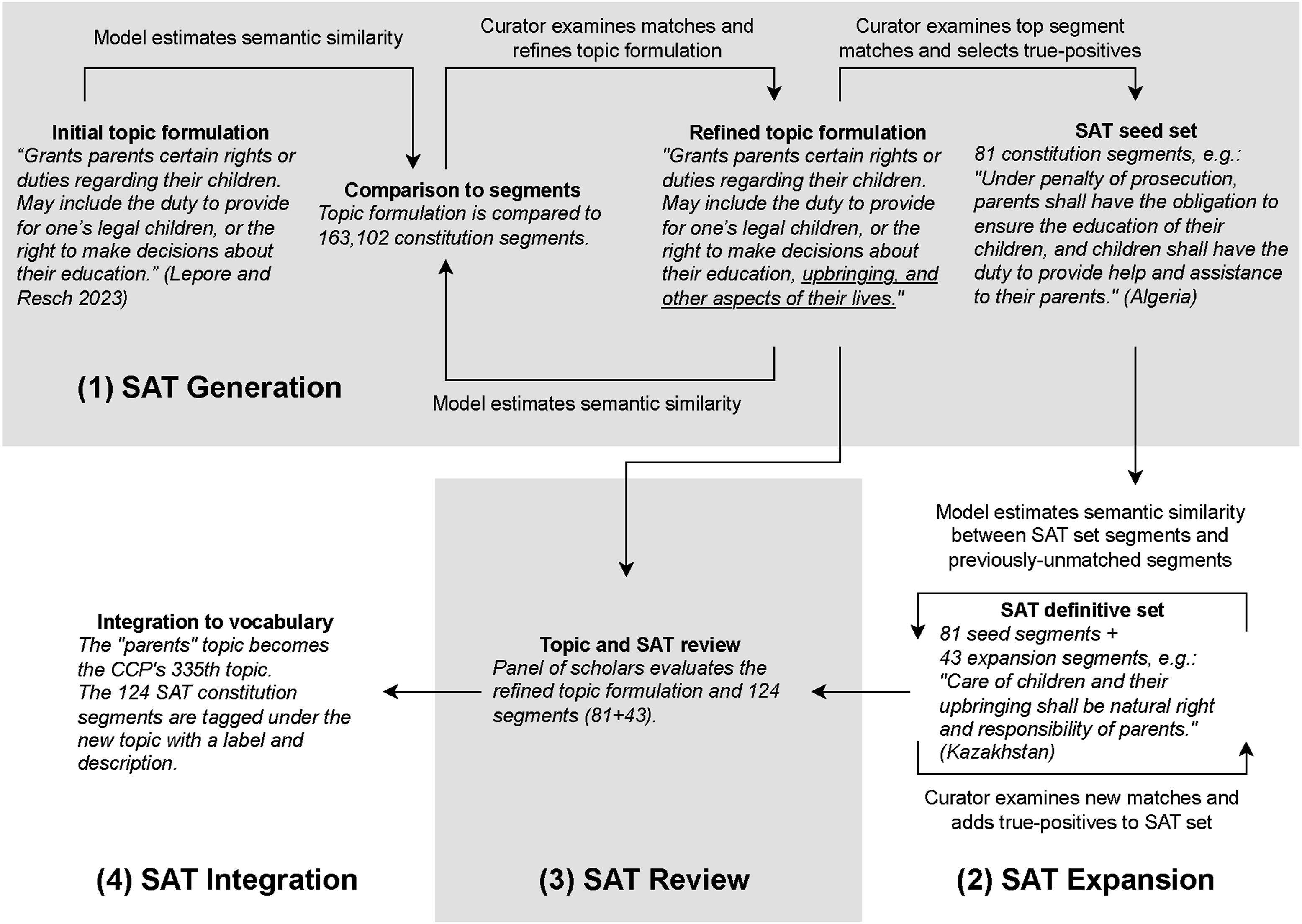
Measuring Semantic Similarity
Semantic similarity measures the degree to which two or more text segments convey similar meaning. This approach has been applied to a range of tasks including text search (Farouk, 2018) and machine translation (M. Yang et al., 2019). Among the methods used to calculate sentence-level similarity, those that represent both the meaning and order of words—known as sentence-sequence representations—show significant promise (Bestvater & Monroe, 2023; Cruz et al., 2023; Gardner, 2023). While “bag of words” methods assessing word frequency and other word-level representations can be aggregated to the sentence level (Rodriguez & Spirling, 2022), sentence-sequence representations natively account for both the meaning of individual words and their sequential relationships within a sentence (Aggarwal, 2022). This approach captures the context of the natural language in which words appear, allowing the model to recognize subtle differences in meaning that arise from word order or phrasing. These representations are particularly effective in comparing sentences that convey similar ideas but use different vocabulary or structure.
Here, we employ version 4 of Google’s Universal Sentence Encoder (USE v4) to generate high-dimensional numerical representations of segments, referred to as encoding vectors or embeddings (Cer et al., 2018). Text segments are represented as discrete points in a 512-dimension semantic space, and the distance between two points is used to measure the divergence in the meaning of the corresponding texts.
The semantic similarity score
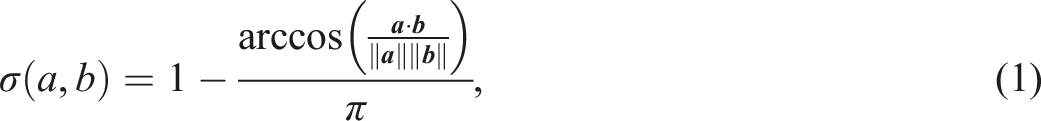
The inverse of this distance produces a semantic similarity score ranging from 0.0 to 1.0. A score of 1.0 indicates that two segments are identical in meaning and comprise the same words in the same order. As the meanings of the segments diverge, the similarity score decreases; a score of 0.0 indicates completely distinct meanings.
USE models facilitate efficient and accurate computation of encoding vectors, enabling large-scale semantic similarity tasks across multilingual datasets with minimal text preprocessing (Cruz et al., 2023; Gardner, 2023). Our selection of the version 4 USE model was based on its optimal balance between robust performance on standard benchmarks and computational efficiency. In our own tests, we found that USE version 4 was 70 times faster than USE version 5 when generating encoding vectors, and 30 times faster than sBERT models. USE v4 generates embeddings at a rate of approximately 0.25 to 0.47 seconds per thousand segments on consumer hardware (depending on the machine), embedding the full corpus of 163,102 segments in under 80 seconds. 5 In benchmark tests against standard semantic similarity datasets (STS, SemEval, SICK), USE v4 achieved Pearson’s correlations of 0.72–0.81 with human similarity ratings, comparable to other sentence-level embedding models while being substantially faster. While systematic comparison across sentence-level embedding models is beyond the scope of this paper, these comparisons suggest our chosen model is competitive with, and in our view more advantageous than, the alternatives. However, our framework is model-agnostic, meaning superior models can be substituted as they emerge. Most importantly, the current implementation demonstrably outperforms manual coding (see the Validation section), suggesting USE v4 provides a strong foundation for the SAT approach.
Data Sources and Text Processing
Our document corpus comprises the text of 192 constitutions in force as of January 2025. CCP has organized these constitutional texts according to their structure (sections, subsections, etc.). We adopt the CCP’s segmentation approach, ignoring titles and headers, and keeping only those segments containing the substantive content of the constitution sections. The resulting segments serve as our unit of analysis, following the approach we developed in Cruz et al. (2023). In this context, a segment may comprise a single sentence, more than one sentence, or shorter clauses such as bullet points in a list. When individual segments lack sufficient context for topic identification, the curator can use hyperlinks to the Constitute website that are provided in the review interface, where they can view segments within their full constitutional context. Altogether, the 192 national constitutions provide a total of 163,102 text segments, with an average length of approximately 170 characters. 6
We then process constitution segments for inclusion in our semantic similarity model. This produces a set of indexed identifiers for constitution segments,
Constitution segment text is stored in a dictionary where each key is a segment identifier. The segment identifier also identifies the segment’s constitution and provides access to constitutional metadata.
These constitution segments form the core text against which we test potential new topics for inclusion in the CCP vocabulary. Following these initial preprocessing steps, we begin our segments-as-topic (SAT) approach, using constitution segments to represent and identify a potential new (candidate) topic in our constitutional corpus. Below we detail the four stages of this methodology: SAT generation, SAT expansion, SAT review, and SAT integration into the corpus.
SAT Generation
SAT generation is an iterative process in which topic formulations—short phrases that capture the meaning of a candidate topic—are tested against the corpus of constitution segments. The output of this process is a small set of constitution segments (the SAT seed set) that best capture the meaning of the candidate topic.
SAT generation involves two steps: (1) measuring the semantic similarity of a topic formulation to text segments in the corpus and identifying segments that are at or above a similarity threshold; and (2) selecting a small set of segments that best match the meaning of the topic—the SAT seed set.
Measuring Semantic Similarity to Constitution Segments
The candidate topic’s formulation is used to find semantically similar text segments in the constitutions comprising our corpus. This step involves computing similarity scores between the candidate topic and every text segment in the corpus to identify relevant matches.
A vector
The curator selects a threshold

The search threshold determines the degree of similarity and thus also the number of returned search results. The curator can experiment with different search thresholds until they find a threshold that returns a manageable number of search results, that is, enough results to create a SAT seed set, but not so many that the task of finding the seed set becomes overwhelming. From our experience with constitutions, we found that using a search threshold between 0.62 and 0.68 is a useful starting point. Employing a relatively high threshold can keep the number of matched segments manageable at this stage, as the seed set need not be exhaustive.
Clustering Search Results
The search results in
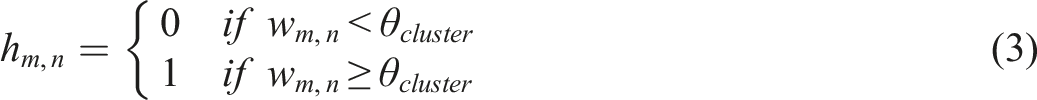
The matrix
The curator can experiment with the cluster threshold. A low threshold will cluster the results into a few large clusters; a high threshold will cluster the results into many smaller clusters. The curator must select a threshold that best facilitates the process of selecting segments for the seed set. From our work with constitutions, we found that workable cluster thresholds typically land between 0.7 and 0.78.
Clustering groups of semantically similar text segments makes it easier for the curator to identify patterns and determine whether a particular topic formulation finds segments that best capture the essence of the candidate topic. The curator can reformulate the topic text and repeat the process. Different formulations can be tested until the curator can select appropriate segments for the SAT seed set.
SAT Expansion
SAT expansion is also an iterative process. As the name implies, the process expands the SAT set of a candidate topic created in the SAT generation stage. The SAT expansion process, described below, uses the seed set to search the corpus for additional segments that match the meaning of the candidate topic. This represents a change from the SAT generation stage, which used the topic formulation to search the corpus.
Finding New Constitution Segments
A semantic similarity matrix

The segments in
Clustering Search Results
Using the method described above for SAT generation, search results are clustered and both clusters and individual segments are presented to the curator for evaluation. Again, one should use a threshold slightly higher than at the preceding stage. We use a clustering threshold of 0.74 below. The curator selects segments that align with the meaning of the topic, which are added to the SAT set. Unselected segments are added to the rejected set. This process is repeated to expand the SAT set, while ignoring the segments in the expanding SAT set and the expanding rejected set, until no additional matching segments can be found.
Confirming Completeness With N-gram Search
Finally, we use an n-gram search in the review tool to complement the semantic similarity approach. The n-gram search provides a straightforward mechanism to locate specific terms or phrases within the search results returned by the semantic similarity model. This allows the curator to efficiently identify segments containing key phrases appearing in accepted segments to ensure similar segments have not been missed. At this point, the curator has the completed SAT set.
This procedure offers several key advantages. Firstly, it supports systematic refinement and validation of the candidate topic, improving the robustness and reliability of the expanded vocabulary. Secondly, it allows for the tracking of rejected segments, ensuring that only those truly reflecting the core of the topic are included. Lastly, because curator decisions and segment selections are documented, the process is transparent and reproducible.
SAT Review
A completed SAT set represents the final set of constitution segments that represent the candidate topic. A completed SAT set is evaluated by a panel of scholars who assess its relevance and accuracy in relation to the corpus. Although the topic should have undergone a thorough review before this stage, further revisions may still be necessary to ensure its substantive value. In our implementation, 5-7 team members review not only the topic’s conceptual coherence but also the individual segments comprising the SAT. Panel members may veto specific segments, reconsider the topic’s placement within the vocabulary structure, or reject the topic entirely. We recommend a relatively conservative approach to acceptance, erring toward minimizing conceptual overlap with existing topics and preserving clear boundaries for future candidate topics. Throughout the process, no results are accepted at face value; rigorous scrutiny is maintained at every step, and all changes are automatically documented to ensure transparency.
SAT Integration
Once the final revisions are complete, the new topic is given a label and description before being formally integrated into the vocabulary. Every constitution segment belonging to the completed SAT set is automatically tagged with the new topic.
Application
New CCP Topics Created Using the Process Described in This Paper

SAT Generation
The SAT generation process involves iterative refinement, ensuring alignment of the topic formulations with the intended conceptual scope of the candidate topics. In general, it is best to start with a topic formulation that sits relatively high on the so-called “ladder of abstraction” (Sartori, 1970). One then identifies, through the review of initial search results, “multiple, specific instances that constitute the concept’s common core” (Collier et al., 2006) before settling on a formulation used to construct the seed set. The formulation need not be perfect, as the expansion stage leverages the seed set—rather than the formulation—to identify additional semantically similar segments.
SAT Generation for Three New CCP Topics

Each candidate topic had unique advantages or challenges during this stage. For the parents topic, the relatively narrow linguistic range of the topic made SAT generation straightforward. The limited synonyms or alternative formulations available for parental rights and responsibilities (e.g., terms such as mother and father) resulted in a manageable and sharply defined set of possible matches to our new topic (203 constitution segments). This linguistic specificity facilitated straightforward identification of relevant segments, resulting in an accepted seed set containing 81 segments.
To better understand the paradigmatic segments comprising the seed set, consider a few examples. The seed set for the parents topic included segments such as: “Parents have the right and the duty to raise and care for their children” (Estonia_2015/101); “It is the right and duty of parents to nourish, educate, and protect their children. Children have the duty to respect and aid their parents” (Peru_2021/94); and “Parents shall have the right and obligation to take care of the rearing, education, health, and comprehensive and harmonious development of their children” (Armenia_2015/199). These examples illustrate variation in how constitutions express parental rights and duties—from concise statements to provisions encompassing reciprocal obligations and broader developmental concerns. The Peru example provides an interesting case of a multi-topic segment, also invoking the rights and duties of children—another potential candidate topic.
In contrast, the recall topic presented challenges due to both its conceptual specificity and the substantial volume of initial search results (4,064 segments). The term “recall” frequently appeared in diverse contexts involving multiple agents and procedures beyond the voter-initiated recall of elected officials, such as legislative- or executive-driven mechanisms. Given that our formulation explicitly targeted voter recall of elected officials, we encountered numerous false positives. Initial searches at higher thresholds also missed segments we expected to find based on domain knowledge of recall mechanisms. To comprehensively address this issue, we selected a relatively lower similarity threshold to ensure extensive retrieval of potential matches, yielding 4,064 segments for review and ultimately 51 accepted segments. Although the lower similarity threshold required an extensive manual review to exclude irrelevant segments, it ultimately ensured more comprehensive coverage of the topic.
The replace topic involved conceptual overlaps, particularly with the existing CCP topic on constitutional amendment provisions. The semantic distinctions between “amendment” and “replacement” are often subtle and highly context-dependent, complicating the identification of relevant constitution segments. To mitigate this ambiguity, we iteratively refined our topic formulation, emphasizing explicit references to complete constitutional replacement or the enactment of entirely new constitutions. This refinement successfully clarified the conceptual boundary, resulting in a precise SAT seed set of 19 segments.
Each topic was curated by a single team member through the generation and expansion stages, and then brought to the full panel for review. This workflow empowers individual experts to identify candidate topics through their own reading of the corpus while ensuring collective validation. Of course, not all candidates succeed, nor should they. For example, we attempted to create a topic for religious support (state support, recognition, and establishment of religion) but found excessive overlap with existing CCP topics (establishment of an official religion, freedom of religion), producing an unruly set of results. Our expert panel ultimately rejected this candidate, illustrating how the review stage filters topics that lack sufficient conceptual distinctiveness. We have included the SAT for this rejected topic in the repository of our results. We advise researchers adopting our approach to follow a similar workflow whereby curators develop candidates, and then a panel convenes for review, thus balancing individual initiative with collective decision-making.
It is important to emphasize that SAT generation does not require identification of an exhaustive set of similar segments when selecting segments for the seed set. Relevant segments inadvertently overlooked at this stage are typically identified during the subsequent SAT expansion phase. This is because SAT expansion uses the seed set segments to search the corpus, and these initial seed set segments should exhibit higher semantic similarity to relevant segments than the original topic formulation used in SAT generation, ensuring that missed segments will likely emerge later. This iterative approach fosters continuous refinement, contributing to comprehensive and robust topic coverage.
SAT Expansion
SAT Expansion for Parents Topic (Rights and Duties of Parents)
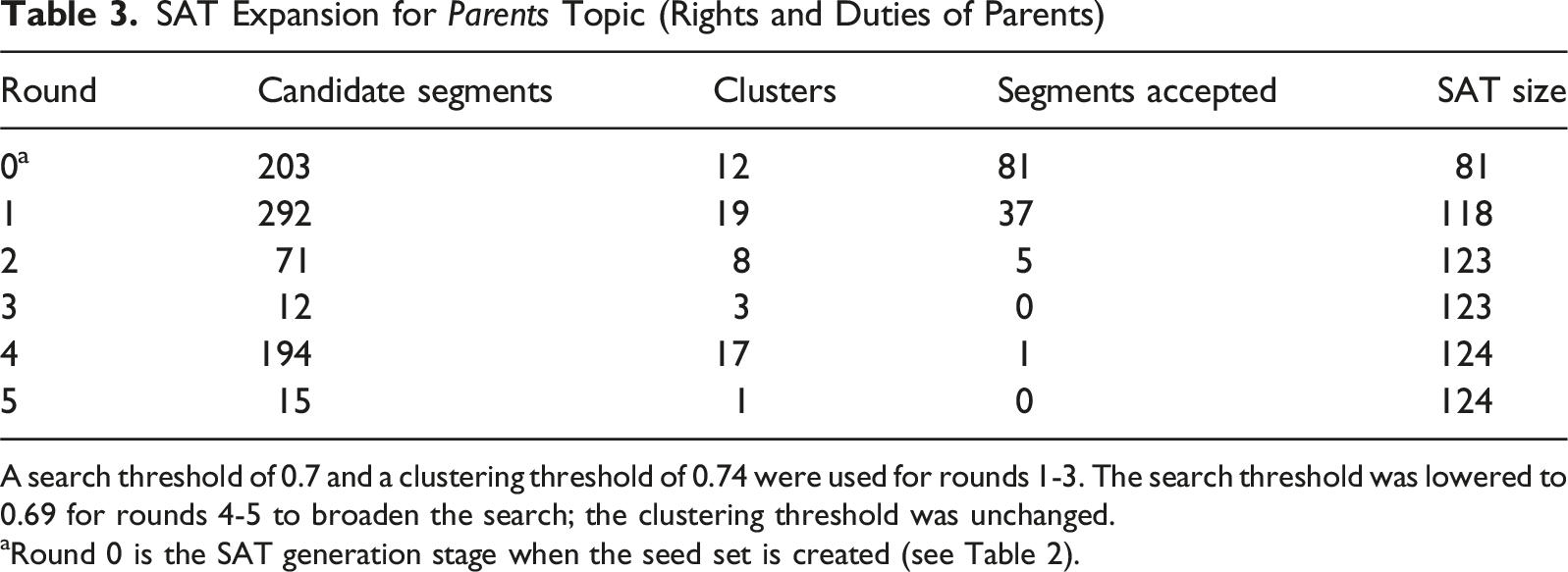
A search threshold of 0.7 and a clustering threshold of 0.74 were used for rounds 1-3. The search threshold was lowered to 0.69 for rounds 4-5 to broaden the search; the clustering threshold was unchanged.
aRound 0 is the SAT generation stage when the seed set is created (see Table 2).
SAT Expansion for Recall Topic (Voter Recall of Elected Officials)
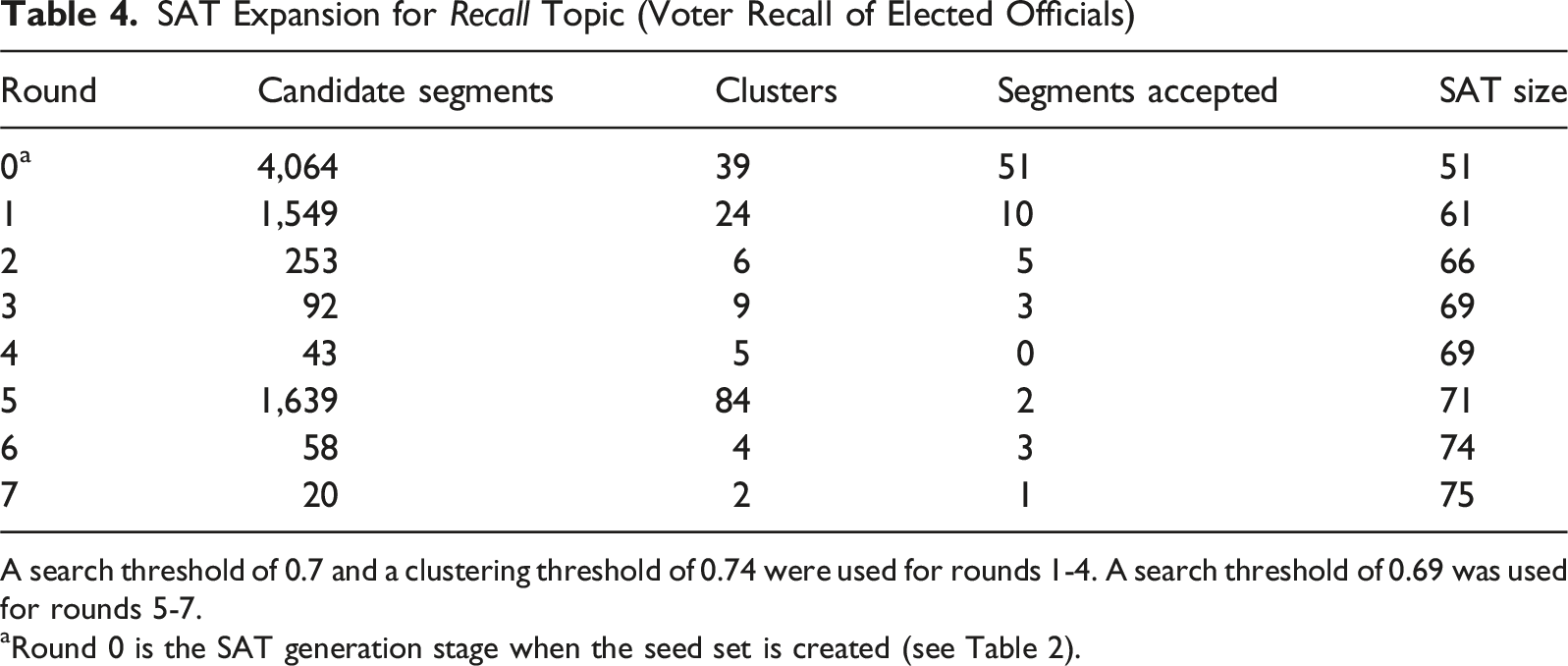
A search threshold of 0.7 and a clustering threshold of 0.74 were used for rounds 1-4. A search threshold of 0.69 was used for rounds 5-7.
aRound 0 is the SAT generation stage when the seed set is created (see Table 2).
SAT Expansion for Replace Topic (Constitutional Replacement)
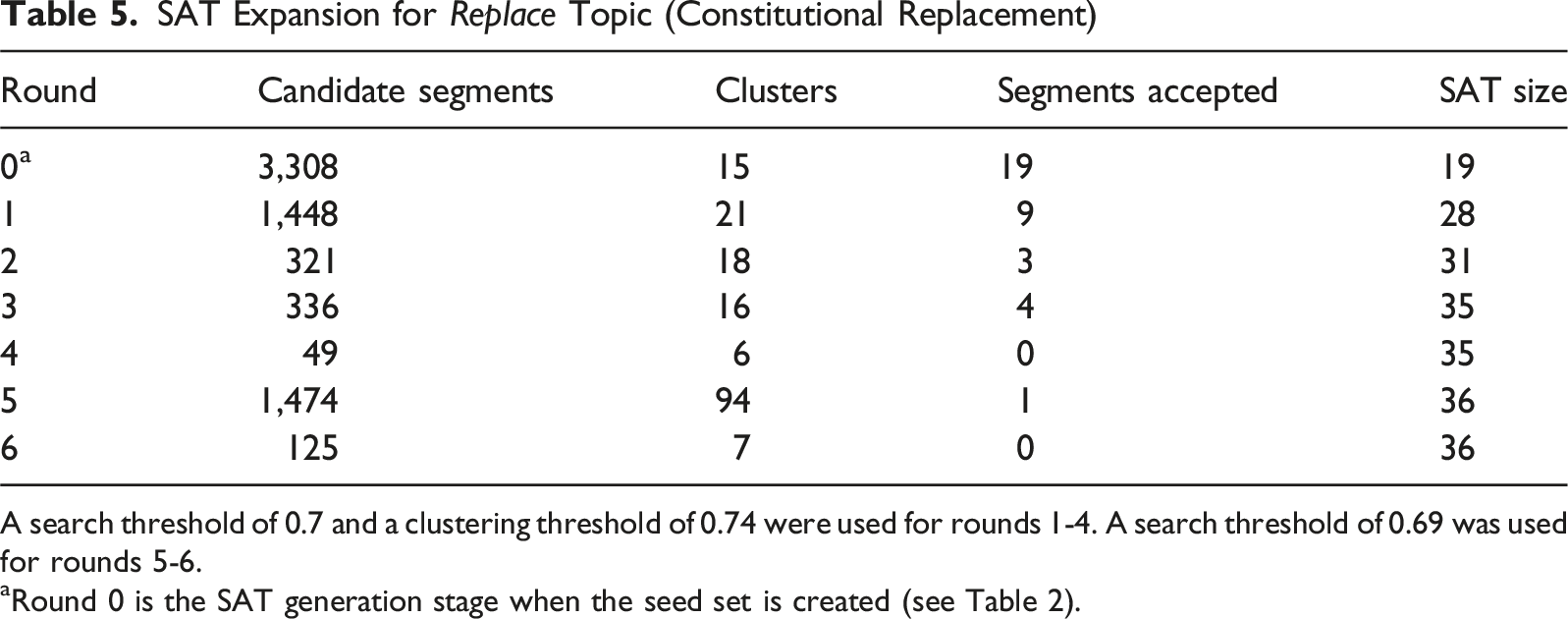
A search threshold of 0.7 and a clustering threshold of 0.74 were used for rounds 1-4. A search threshold of 0.69 was used for rounds 5-6.
aRound 0 is the SAT generation stage when the seed set is created (see Table 2).
For the parents topic, the first SAT expansion round added 37 segments, increasing the total SAT size to 118 segments. Subsequent rounds yielded diminishing returns, ultimately stabilizing at 124 segments after five rounds of SAT expansion. The similarity threshold was lowered slightly after the third round to broaden the search scope, but this produced minimal further gains, indicating sufficient prior inclusion of relevant segments. Relevant segments reveal how constitutions typically frame parental rights alongside corresponding duties, particularly regarding children’s education and welfare. These provisions often reflect broader societal tensions between family autonomy and state protection interests, illustrating constitutional attempts to balance these competing values across different legal systems.
The conceptual specificity of the recall topic required particular attention in this stage as well. After an initially large number of 1,549 matches to review, the rejections made in that round honed the topic focus and produced smaller segment sets for review in subsequent rounds, ultimately reaching a final SAT size of 75 segments. Notably, the threshold adjustment at the fifth round enabled the identification of additional relevant segments missed earlier, demonstrating the value of iterative threshold calibration. Many rejected segments referenced recall mechanisms initiated by legislatures or courts, underscoring the importance of human review of these matches to ensure constitution segments matched our topical focus on citizen-initiated recall. Accepted segments tended to come from a smaller group of constitutions—particularly those in Africa, Latin America, and East Asia—where provisions for popular recall are more common.
The replace topic experienced steady but limited growth during expansion rounds. Beginning with 19 segments in the seed set, it expanded to a final SAT size of 36 segments. The threshold adjustment midway through the expansion rounds allowed for the capture of one additional segment, though a further iteration yielded no new additions, confirming that comprehensive coverage had been achieved. One of the main challenges for this topic during expansion was distinguishing provisions about full constitutional replacement from those concerning major amendments or reform procedures. Accepted segments typically included clear references to constituent assemblies or the enactment of a new constitution, while more ambiguous cases were conservatively excluded. Notably, references to constitutional replacement were prevalent among Latin American constitutions.
Clustering played a crucial role throughout the SAT expansion process by organizing search results into coherent groups of semantically related segments. This approach facilitated the identification of potential sub-topics and regional patterns within segments, enabling recognition of specific regional language patterns (which can be used to hone topic formulations) or localized constitutional practices (which can inform our future analysis). For instance, clustering revealed that several constitutions from Latin America (e.g., Costa Rica, El Salvador, Panama, and Uruguay) explicitly stipulate that parents have identical obligations to children born out of wedlock as to those born within marriage, highlighting a clear regional pattern. Likewise, our clustering analysis identified a distinct cluster containing four segments from Sub-Saharan constitutions (Central African Republic, Gabon, Niger, and Senegal) that uniquely reference parents’ entitlement to support from “public collectivities” in addition to the state.
Additionally, the n-gram search functionality in the review tool was an important complement to the semantic similarity approach. It provided a way to locate specific terms or phrases, enhancing precision when approving or rejecting candidate segments. This feature proved especially beneficial in identifying segments containing critical keywords. We selected n-grams by noting terms that appeared frequently among relevant segments during review. For the parents topic, we searched: parent, parents, mother, father, spouse, spouses. For recall: recall, revoke, revocation, petition. For replace: replace, replacement, revision, constituent assembly, constitutional convention. While the n-gram search primarily improved efficiency when sifting through large pools of search results, it also served as a final verification step to ensure no relevant segments were overlooked by the semantic similarity approach.
Overall, the SAT expansion results for these three topics demonstrate the effectiveness of our iterative methodology in systematically capturing a comprehensive set of relevant segments for each topic. By combining sentence-level semantic similarity, clustering, and n-gram search, the process enables not only the broad identification of conceptually aligned provisions but also the inductive discovery of sub-topics and regional patterns. Together, these features contribute to a transparent, reproducible, and scalable approach to vocabulary expansion, grounded in both linguistic precision and domain expertise.
SAT Review
The final SAT sets were presented to a panel of experts at the Comparative Constitutions Project for review and approval. The CCP research team currently consists of two directors, a research director, a research associate, and five senior research analysts. Upon review by our full research team, the parents, recall, and replace topics were accepted for inclusion into the CCP vocabulary.
SAT Integration
To conclude the process, the CCP corpus of national constitutions was automatically tagged with the new parents, recall, and replace topics. In other words, the topics were applied to the accepted SAT segments for each topic in the XML files that comprise our corpus of 192 in-force national constitutions. For example, the parents topic can now be viewed on the Constitute website. Using the SAT segments to tag the corresponding constitution sections thus avoids potential human errors of manual tagging such as failing to tag an accepted SAT segment, or erroneously tagging a segment that does not form part of the SAT. Additional new topics are in the process of being added to the CCP vocabulary with this method.
Validation
A crucial question is whether our methodology can identify relevant segments that human coders overlooked. Manual coding of large corpora is inherently susceptible to false negatives—relevant segments that coders miss due to fatigue, cognitive load, or the sheer scale of the corpus (in our case, 163,102 constitutional segments). To assess whether SAT addresses this limitation, we applied the expansion process to three existing CCP topics that had been manually coded by our research team.
SAT Expansion for Three Existing CCP Topics

The original manual coding followed established CCP protocols (see Elkins et al., 2014). Two independent coders, usually political science graduate students and law students, tag constitutions using a guided survey instrument tracking over 600 attributes, with disagreements reconciled by a third coder and interpretive questions adjudicated by principal investigators. Topics are drawn from a subset of these attributes. Notwithstanding this rigorous process, the sheer scale of the corpus (163,102 segments) makes comprehensive manual coverage challenging. At the outset, “it took, roughly, 10 domain experts 9 months to clean and generate 180 [tagged constitutions]” (Elkins et al., 2014, p. 12). The SAT method was designed to help address these limitations, as the cognitive load of keeping an eye out for new topics when already tracking 600 attributes would be impracticable.
For these three topics, we treated the manually tagged segments as the original SAT set. The segments added through SAT expansion represent true positives—constitutionally relevant provisions that were inadvertently overlooked during the original manual coding process. This pattern held across all three topics despite their varying scope and categorical placement in the ontology: academic freedom increased by 29% (17 new segments), central bank by 21% (19 new segments), and natural resource ownership by 23% (27 new segments).
The consistency of improvement, ranging from 21% to 29% increases, suggests the SAT methodology addresses a systematic limitation of manual coding rather than topic-specific gaps. This approach mitigates the inherent constraints of manual coding through exhaustive semantic search paired with iterative human validation, providing comprehensive corpus recall with expert precision in acceptance decisions.
The error profile of the SAT approach differs fundamentally from manual coding. Where human coding errs through omission (false negatives), SAT expansion errs through over-generation during the candidate phase (false positives). However, these false positives are filtered through iterative human review, with all decisions documented in the resource files generated at the end of SAT review. The rejected segment sets for each topic demonstrate this filtering process, revealing how expert judgment maintains topic precision while benefiting from computational efficiency.
These results suggest SAT does not replace human expertise but rather augments it, combining computational thoroughness with expert judgment to achieve coverage unattainable through manual coding alone.
Discussion
The strength of our methodology lies in representing topics through sets of corpus segments—segments-as-topic (SAT)—rather than a single phrase that attempts to capture the meaning of a topic. Using corpus segments as topics provides better semantic similarity matching by capturing natural language patterns, contextual cues, and linguistic variations as they appear in the corpus. These segments implicitly represent different expressions of the same concept, which a single phrase cannot do.
Our methodology involves multiple stages, leveraging both automated tools and human expertise to refine and validate our findings. Validation ultimately depends on human decisions, making false positives and false negatives less of a concern than in fully automated systems. Automated classification or tagging may incorrectly identify sections as matching a particular topic (false positives), or fail to identify segments that belong to the topic of interest (false negatives). In contrast, manually tagging sections relies entirely on human judgment, making it more susceptible to false negatives due to the difficulty of reading and accurately applying topics to every line of the world’s constitutions.
The SAT method necessarily encourages the use of low search thresholds at the topic generation stage in order to harvest accepted and rejected results. Curators then reject segments that do not align with the conceptual intent of the topic (false positives) and accept segments initially overlooked (false negatives). These results provide insight into performance, specifically whether a curator’s formulated topic text is generating results with a satisfactory proportion of matching segments. Since a panel of scholars evaluates the final set, human validation is built into our process. If these domain experts conclude that some additional segment should be added to, or removed from, the final set defining a topic, the risk of false positives and false negatives is further mitigated.
We advocate combining automation with human expertise in vocabulary curation. Finding the proper balance, though, has been a learning process. Automated topic application without robust human review is unacceptable, for the reasons noted above. By contrast, our early efforts at comprehensive manual review were inefficient. Researchers had to sift through countless spreadsheets of machine-generated topic matches—only to start over whenever the topic formulations changed or the similarity threshold was adjusted. Through trial and error, we identified key steps that could be automated to strategically aid human review: initial topic matching, tracking accepted and rejected segments across iterations, clustering results, and documenting coding decisions. These components are now embedded in the SAT method and tool—now publicly available—which we see as an improved approach to integrating automation with human expertise in the expansion of conceptual vocabularies.
The selection of search and cluster thresholds in our methodology rests on empirical rather than theoretical foundations. Although text segment embeddings capture statistical patterns in language, they do not correspond to formal semantic representations and, thus, semantic similarity does not have a formal definition. Consequently, threshold selection becomes an inductive process determined by practical efficacy rather than theoretical imperatives. This flexibility allows curators to adjust thresholds during both SAT generation and expansion stages based on corpus-specific characteristics.
This empirical approach raises important questions about semantic similarity scores. Low-similarity pairings may not represent absence of semantic relationship but rather more subtle connections. Our analysis reveals that complex multi-concept segments containing relevant sub-clauses often fall below arbitrary thresholds despite their topical relevance. While percentile-based alternatives present their own challenges (particularly in determining appropriate cutoffs), examining similarity score distributions can justify topic-specific thresholds tailored to each topic’s unique distribution properties.
For clustering thresholds, we employ sensitivity analysis to evaluate the empirical stability of resulting structures. This data-driven approach reveals how clustering patterns respond to threshold adjustments, allowing us to characterize their robustness. Our analysis of cluster number plotted against threshold values reveals clear optimization points—thresholds that avoid both the over-clustering that occurs at low values and the fragmentation that occurs at high values. Additional metrics like cluster size distribution and singleton set size further inform threshold optimization. These investigations are guiding the development of an adaptive method for determining optimal cluster thresholds automatically.
To enhance comprehensiveness, we integrate n-gram search capabilities with our semantic similarity approach. This hybrid methodology addresses a key limitation: segments where the overall semantic similarity falls below threshold despite containing specific relevant phrases. This integration proves particularly valuable for long, multi-concept segments where the relevant topic represents only a portion of the overall semantic content. By combining vector-based semantic similarity with targeted lexical searches, our methodology creates a more robust identification process capturing segments that otherwise might be missed by either approach in isolation. In other words, the SAT method may prove complementary to other techniques.
One final consideration is whether seed set selection introduces systematic bias—that is, whether the semantics of the seed set are sufficiently constrained that relevant segments are excluded throughout the SAT process. Without a gold standard, this cannot be definitively ruled out. It is possible that the SAT method still misses segments due to some combination of seed set selection, model performance, and human decisions. However, as our validation demonstrates, the method misses fewer segments than manual coding alone, suggesting it provides a meaningful improvement over existing approaches.
Conclusion
The approach described here demonstrates how to expand a vocabulary by combining automated text classification and expert-driven topic curation. We have developed the segments-as-topic (SAT) methodology in which a topic is defined by a set of segments from a corpus. Using the SAT methodology, we were able to identify and integrate new topics into the Comparative Constitutions Project (CCP) vocabulary. Importantly, all our team members have access to the software that implements the SAT methodology, giving us equal opportunity to propose new topics for collaborative expert review. By harnessing the individual initiatives of our domain experts, we ensure that our vocabulary remains up-to-date and reflects contemporary constitutional discourse.
The methodology also has considerable potential for tasks and domains beyond CCP. Notably, vocabulary expansion is but one application. The SAT methodology could be used as a robust form of semi-supervised classification more generally—starting with seed sets, expanding iteratively, and applying labels. One can imagine using the approach to start completely from scratch, annotating a novel dataset that has no existing vocabulary. Moreover, it could be used to extract all segments comprising a particular topic, thus paving the way for downstream analysis. For example, lawyers and legal researchers often sift through vast amounts of case law to find relevant precedents and legal principles. The SAT methodology could be used to automate the classification and integration of new case law into existing legal taxonomies, making it easier to identify pertinent sections of case law when conducting research.
There is also an open question as to how well the SAT methodology performs when applied to more informal, less legalistic texts. For instance, our framework could be used to analyze plenary transcripts from a constitutional convention (one of the datasets included in our repository), or social media posts, where the natural language under scrutiny is messier and more diverse. This reality may require downshifting the search thresholds used in the SAT methodology, potentially increasing the burden on the expert in the loop. We should note, however, that this approach likely would still be less cumbersome than existing, often manual, alternatives (see Chernykh & Elkins, 2022). Systematic comparison across text registers would help establish domain-specific threshold guidance, and we encourage scholars to do so.
Such comparisons may also reveal where large language models (LLMs) can complement the SAT methodology. For instance, LLMs could pre-filter low-threshold segments found at the expansion stage, flagging likely true positives and reducing the volume requiring human review. This would be particularly valuable for the informal texts mentioned above. LLMs, however, use an evolving set of often-unspecified methods, whereas we have sought to prioritize methodological transparency and open-source tools. We have already begun to experiment with LLMs at CCP in ways that integrate them with the SAT method and other components of our methodological toolkit.
It is worth emphasizing that not only is the SAT framework model-agnostic (see the Measuring Semantic Similarity section) but also, in principle, language-agnostic. Version 4 of Google’s Universal Sentence Encoder can be substituted with the multilingual version 3, which can embed text from up to 16 major languages (Yang et al., 2020). This model has been deployed to analyze Spanish text effectively (see Cruz et al., 2023), though performance across other languages warrants further investigation. USE v3 is included in our GitHub repository for easy access.
Within CCP, the methodology will be used to expand the range of topics CCP tracks in national constitutions to incorporate new topics being added to constitutions in recent years. It could also be utilized to create specialized sub-vocabularies of topics. For example, a sub-vocabulary related to constitution reform and drafting would enable researchers to track the evolution of themes across public consultation responses, the deliberations of drafting bodies, and versions of constitutional texts.
The methodology not only serves our forward-looking objectives discussed above but also encompasses retrospective goals. Most importantly, our next step is to expand the application of existing topics in the CCP vocabulary that were formulated before we adopted semantic similarity technology. In the past, these topics were manually tagged by the CCP team, meaning that we searched through our corpus of 192 constitutions, as well as a number of historical and draft constitutional texts, for specific provisions that matched the corresponding topics. Using the SAT approach, we can now identify additional constitutional provisions that may have been overlooked in our manual tagging process. In other words, our methodology enables us to reduce the margin of human error and ensure a more comprehensive exploration of our corpus, maximizing the coverage and depth of our topic integration efforts. In essence, we are not just expanding our vocabulary; we are expanding our understanding of the foundational ideals people value most around the world.
Supplemental Material
Supplemental Material - Expanding Your Vocabulary: A Framework for Topic Integration in Texts
Supplemental Material for Expanding Your Vocabulary: A Framework for Topic Integration in Texts by Roy Gardner, Matthew Martin, Ashley Moran, Zachary Elkins, Andrés Cruz, Guillermo Pérez in Social Science Computer Review
Supplemental Material
Supplemental Material - Expanding Your Vocabulary: A Framework for Topic Integration in Texts
Supplemental Material for Expanding Your Vocabulary: A Framework for Topic Integration in Texts by Roy Gardner, Matthew Martin, Ashley Moran, Zachary Elkins, Andrés Cruz, Guillermo Pérez in Social Science Computer Review
Footnotes
Acknowledgements
We would like to thank Jessie Baugher, Lucas Elkins, Kendall Lowe, Maya Mackey, Jamie Mahowald, Catalina Mulhollan, Elias Roldan, and Yaser Tahboub for their research assistance at the inception of this project.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The Concept Integration in Comparative Law program is supported by National Science Foundation Award No. 2315189. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the view of the National Science Foundation (NSF). The research team deeply appreciate NSF's Accountable Institutions and Behavior program and Human Networks and Data Science program for this support.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Disclaimer
Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation (NSF). The research team deeply appreciates NSF’s Accountable Institutions and Behavior program and Human Networks and Data Science program for this support.
Supplemental Material
Supplemental material for this article is available online.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.