
Abstract
The proliferation of misinformation in the digital age has emerged as a pervasive and pressing challenge, threatening the integrity of information dissemination across online platforms. In response to this growing concern, this survey paper offers a comprehensive analysis of the landscape of misinformation detection methodologies. Our survey delves into the intricacies of model architectures, feature engineering, and data sources, providing insights into the strengths and limitations of each approach. Despite significant advancements in misinformation detection, this survey identifies persistent challenges. The paper accentuates the need for adaptive models that can effectively tackle rapidly evolving events, such as the COVID-19 pandemic. Language adaptability remains another substantial frontier, particularly in the context of low-resource languages like Chinese. Furthermore, it draws attention to the dearth of balanced, multilingual datasets, emphasizing their significance for robust model training and assessment. By addressing emerging challenges and offering a comprehensive view, our paper enriches the understanding of deep learning techniques in misinformation detection.
Introduction
In an era dominated by information dissemination and rapid communication, the proliferation of fake news has emerged as a profound concern. The term “fake news” broadly encompasses fabricated or deceptive information presented as genuine news (Lazer et al., 2018). Within this broad category, it is important to differentiate between two specific types of false information: misinformation and disinformation. Misinformation refers to incorrect or misleading information spread without malicious intent, often shared by individuals who believe it to be true. In contrast, disinformation is deliberately deceptive information disseminated to mislead or manipulate the audience, typically for political, financial, or ideological purposes. The impact of these forms of false information on society is profound and multifaceted. For instance, during the 2016 U.S. presidential election, disinformation campaigns garnered significant attention for their potential influence on electoral processes and public opinion (Allcott & Gentzkow, 2017). Malicious actors, including foreign entities, used social media platforms to propagate false information, deepen societal divisions, and foster confusion. Similarly, recent events have underscored the critical need for effective detection mechanisms, particularly in fast-evolving situations such as the COVID-19 pandemic. In the early months of 2020, an alarming surge of both false and accurate information related to COVID-19 spread across social media and online platforms. The World Health Organization (WHO) reported the severe consequences of misinformation, noting that around 6000 people were hospitalized and at least 800 people lost their lives due to the influence of misleading information during the pandemic. 1 This devastating outcome emphasizes the urgent need for advanced detection methods that can effectively navigate the challenges posed by rapidly evolving events, where misinformation can have fatal consequences. Given the complexities and impacts of false information, this paper focuses specifically on misinformation detection methodologies. Our survey delves into the intricacies of model architectures, feature engineering, and data sources used to detect misinformation. By addressing these emerging challenges and providing a comprehensive analysis, we aim to enrich the understanding of deep learning techniques in misinformation detection.
Efforts to combat misinformation have evolved from traditional machine learning techniques to advanced deep learning methods. Early approaches focused on extracting explicit features from news content, such as linguistic and temporal attributes, but required extensive feature engineering and struggled to adapt to new misinformation tactics. To address the limitations of traditional methods, deep learning approaches have gained significant attention for misinformation detection. These methods leverage neural networks to automatically learn complex patterns from data, offering a more efficient and adaptable framework for detecting misinformation. News content-based methods delve into the textual and visual components of news stories, encompassing text features (Chen et al., 2019; Ma et al., 2016; Yu, Liu, et al., 2017), image features (Khattar et al., 2019; Qi et al., 2019; Wang et al., 2018), and multi-modal approaches (Wang et al., 2021; Zhang et al., 2019; Zhou et al., 2020). Alternatively, social context-based methods delve into the behaviors and engagements of users on social media platforms, drawing insights from user credibility, personal information, and social interactions (Dong et al., 2018; Khoo et al., 2020; Silva et al., 2021). However, analyzing users’ engagement behaviors and personal information raises privacy concerns. Moreover, the acquisition of propagation information at the early stages of news dissemination often remains a challenge.
Challenges in Misinformation Detection
Despite advances in misinformation detection, significant challenges remain, particularly as seen during emerging events like the COVID-19 pandemic. These challenges include limited labeled data, domain shifts, and difficulties in multilingual detection, which call for a thorough evaluation of current methodologies. Here are the primary challenges faced in misinformation detection amidst recent events and multilingual environments: • • •
By addressing these challenges, the field has the opportunity to stride ahead, devising more robust and adaptable deep learning techniques that effectively combat misinformation, particularly in the ever-evolving landscape of recent emerging events and multilingual contexts.
Novel Perspective and Contributions
The landscape of misinformation detection has been comprehensively examined through various review papers (Gong et al., 2023; Hu et al., 2022; Li & Lei, 2022; Shu et al., 2017; Zhou & Zafarani, 2018), primarily focusing on dissecting the methodologies based on feature categories and learning paradigms. However, in recognition of the evolving challenges posed by recent events and the complexities of multilingual detection, our paper takes a novel perspective that sets it apart from the existing literature. 1. Rather than solely focusing on analyzing methods through a feature perspective, our paper addresses the unique challenges arising from recent dynamic events, such as the COVID-19 pandemic, and their implications for misinformation detection. By delving into the impact of these events on data availability, news propagation, and language diversity, our work provides insights that extend beyond the traditional scope of feature-centric analyses. 2. Our paper uniquely emphasizes the limitations of multilingual misinformation detection. We delve into the complexities of adapting methods to diverse languages, acknowledging the disparities in linguistic structure, cultural nuances, and linguistic intricacies. Our paper contributes to a deeper understanding of the challenges and strategies in this area. 3. Recognizing the importance of empirical evaluation, our work provides a comprehensive overview of datasets available for tackling the aforementioned challenges. We not only highlight the datasets’ suitability for addressing specific issues but also shed light on their limitations and potential biases. This contribution serves as a practical guide for researchers looking to evaluate their methods under real-world scenarios.
In essence, this paper strives to bridge the gap between existing literature and the evolving landscape of misinformation detection. By embracing a comprehensive perspective that encompasses recent challenges, multilingual intricacies, dataset considerations, and future trajectories, our review paper contributes to a holistic understanding of deep learning techniques in misinformation detection.
Survey Methodology: Inclusion Criteria and Search Strategy
This survey follows a systematic approach based on principles similar to the PRISM guidelines, ensuring transparency in the review process. Studies were selected based on specific inclusion criteria, focusing on papers directly related to misinformation detection, fake news, rumor detection, and deep learning techniques for combating misinformation. We considered only works published between 2015 and the present to capture recent advancements and prioritized studies that addressed multilingual misinformation detection or challenges during emerging events, such as the COVID-19 pandemic. Our search strategy involved querying academic databases such as IEEE Xplore, Google Scholar, ACM Digital Library, PubMed, Scopus, Web of Science, and ScienceDirect, using keywords like “misinformation detection,” “deep learning for fake news,” “rumor detection,” “emerging event misinformation,” and “multilingual misinformation detection.” Papers were reviewed and categorized based on methodologies, model architectures, feature engineering techniques, and data sources. While we aimed to capture a broad range of relevant studies, limitations of this survey include the potential exclusion of the focus on English language papers, which may affect the generalizability of the findings in multilingual contexts. Nevertheless, we believe this survey provides a comprehensive overview of current methodologies, challenges, and trends in misinformation detection.
Multi-Lingual and Emerging Event Misinformation Detection Methods
Current misinformation detection methods primarily integrate news content with social context (Chen & Freire, 2020; Jin et al., 2016; Liu & Wu, 2018), but this approach can be limited when social context is absent. In these challenging scenarios, where misinformation publishers may lack significant user context or social network engagement, alternative methods are crucial. To address this, Natural Language Processing (NLP) techniques, including sentiment analysis, topic modeling, and text classification, are essential. These techniques utilize linguistic features and semantic analysis to identify patterns and anomalies that may indicate misinformation. Moreover, deep learning methods, such as Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs), have proven effective in capturing complex textual relationships, thereby enhancing the accuracy and robustness of misinformation detection in varied contexts. A notable advancement in this area is the approach proposed by Li et al. (2021), which employs Capsule Networks to focus solely on text-based classification, circumventing the need for extensive contextual information. This method aggregates local features from various parts of the news content to construct high-level features, achieving an impressive F1-score of 94.25% on the Chinese BiendataFake dataset. 2 However, its performance declined on the CHECKED dataset (Yang et al., 2021), with an F1-score of 84.52%. This decrease is attributed to the limited data in the CHECKED dataset, particularly related to misinformation about rapidly emerging events like COVID-19, in contrast to the more comprehensive Chinese BiendataFake dataset.
In social media news, noise and redundancy challenge deep learning models. To address this, Ma et al. (2023) proposed a method using a Dynamic Word Embedding layer to remove extraneous elements like emoticons and symbols. They also introduced a parallel dual-channel pooling layer, replacing the conventional CNN pooling. This model combines a Max-pooling layer for local information and an Attention-pooling layer with multi-head attention to capture global dependencies. Tested on the COVID-19 Biendata 2 and CHECKED datasets (Yang et al., 2021), the method achieved an F1-score of 98.16% on Biendata and 94.81% on CHECKED. These results highlight the ongoing challenge of learning long-distance dependencies in datasets with over 80 tokens, emphasizing the complexity of balancing local and global features for effective misinformation detection.
Patwa et al. (2021) undertook the task of COVID-19 misinformation detection in the form of binary classification, distinguishing between real and fake news. They conducted an evaluation of four foundational machine learning baselines: Regression (LR), Support Vector Machine (SVM), Decision Tree (DT), and Gradient Boosting Decision Tree (GDBT). Among these, the highest performance was attained using SVM, achieving an impressive F1-score of 93.32% on the test set of the COVID-19 fake news dataset specifically curated for this purpose. Alhakami et al. (2022) conducted an assessment of various machine learning and deep learning models, including DT, LR, KNN, SVM, CNN, and Long Short-Term Memory (LSTM) model, for the automated identification of COVID-19-related misinformation. Notably, the LR machine learning model and the LSTM model emerged as frontrunners, surpassing other approaches with impressive F1-scores of 92% and 81%, respectively, on the COVID-19 fake news dataset. Additionally, Wani et al. (2021) conducted an evaluation of various supervised text classification algorithms on the COVID-19 misinformation detection dataset. Their approach involved employing CNN, LSTM, and BERT models. They also investigated the influence of unsupervised learning through the utilization of pre-trained language models and distributed word representations derived from an unlabeled corpus of COVID-19-related tweets. Remarkably, the BERT model demonstrated superior performance compared to the others, achieving an impressive F1-score of 98.41% on the COVID-19 fake news dataset.
Goldani et al. (2021) tackled the challenge of misinformation detection by employing capsule neural networks, harnessing the power of multiple parallel capsule networks tailored for misinformation identification across statements of varying lengths. Impressively, their approach achieved an accuracy rate of 99.80% on the ISOT dataset (Ahmed et al., 2018) and 28.20% on the Liar dataset (Wang, 2017), which poses a greater challenge due to its multi-label nature and shorter news statements. Building on their earlier work, (Goldani et al., 2023) introduced X-CapsNet to address variability in news sentence lengths, employing two distinct structures for misinformation detection. The model integrates a CapsNet layer for all input text and a size-based classification layer: a Deep Convolutional Neural Network (DCNN) with pre-trained language models for longer text and an MLP layer using features like word count and unique words for shorter text. This approach achieved an F1-score of 97.29% on the COVID-19 fake news dataset, but showed a significant performance drop to 41.77% accuracy on the Liar dataset (Wang, 2017), consisting of shorter news statements with an average length of 17.9 tokens, highlighting the challenge of generating effective representations for shorter statements.
Li et al. (2022) introduced HetTransformer, a transformer-based model for misinformation detection in social networks. Using the encoder-decoder architecture, it captures both local semantic information from news articles and social media posts and global structural patterns of news propagation. This method achieved an 81.4% F1-score on the PHEME dataset (Zubiaga et al., 2016). Similarly, Biradar et al. (2023) proposed a fusion-based approach combining context-based embeddings like BERT, XLNet, and ELMo with classifiers such as LR, BERT, and ULMFit. Their ensemble model reached 98% accuracy on the COVID-19 Fake News dataset and 61% on the Liar dataset.
In Gautam et al. (2021), the researchers employed a pre-trained transformer model known as XLNet, which was integrated with Latent Dirichlet Allocation (LDA). This fusion involved combining contextualized representations from XLNet with topical distributions generated by LDA. Remarkably, their model achieved an impressive F1 score of 96.7% on the COVID-19 fake news dataset. An approach combining contextual representations like BERT with knowledge graph-based features (Koloski et al., 2022) achieved an F1-score of 95.69% on the same dataset. Koloski et al. (2021) employed handcrafted features, such as word length statistics and character counts, to capture the distribution of characters and words in tweets. BERT-based representations were used to identify contextual differences between fake and real COVID-19 news, with distilBERT tokenizer achieving the best performance, reaching an F1-score of 97.05% on the COVID-19 fake news dataset (Patwa et al., 2021).
Shifath et al. (2021) developed an ensemble classifier consisting of eight transformer models (BERT, GPT-2, XLNet, RoBERTa, DistillRoBERTa, ALBERT, BART, and DeBERTa), each supplemented by an additional multi-layer perceptron. The ensemble model’s performance was evaluated on the COVID-19 fake news dataset, yielding a remarkable F1-score of 98.4%. Similarly, Samadi et al. (2021) employed three distinct neural classifiers utilizing text representation models such as BERT, RoBERTa, Funnel Transformer, and GPT2. They incorporated Single Layer Perceptron (SLP), MLP, and CNN architectures, connecting them to various contextualized text representation models. Additionally, they introduced a Gaussian noise layer to the fusion of contextualized text representation models with the CNN classifier. This integration aimed to counter overfitting during the learning process, leading to enhanced performance in comprehending COVID-19 and other datasets. Impressively, the outcomes of these techniques exhibited a 1% enhancement compared to the method proposed by Shifath et al. (2021) on the COVID-19 fake news dataset. For optimizing the COVID-19 misinformation detection efficacy, Alghamdi et al. (2023) delved into the potential of several transformer-based models. Their investigation involved the integration of neural networks such as CNN, BiLSTM, and BiGRU on top of the BERT and COVID-Twitter BERT (CT-BERT) models. Through comprehensive experiments, it was revealed that the addition of BiGRU on the CT-BERT framework outperformed other model combinations, achieving an impressive F1-score of 98.54% on the English COVID-19 fake news dataset. This notable success was attributed to the advantageous pre-training of CT-BERT on a substantial corpus of Twitter posts centered around COVID-19 discussions. Gundapu and Mamidi (2021) proposed a COVID-19 rumor detection model using an ensemble of BERT, ALBERT, and XLNET transformers, with pre-processing to remove noise. By averaging softmax probabilities from each model, they achieved an F1-score of 98.55% on the COVID-19 fake news dataset, consisting of English news articles related to COVID-19.
In the realm of traditional rumor detection techniques, the primary focus has been on identifying well-established events with an adequate number of training instances. However, the challenge that arises is the effective detection of rumors pertaining to events that unfold suddenly, where only a limited number of instances are accessible during the initial stages of these events. To confront this challenge, researchers have turned their attention to detecting COVID-19-related rumors on Sina Weibo, a Chinese microblogging platform, where only a minimal number of labeled instances are available. In response, Lu et al. (2021) proposed a method known as COMFUSE, which harnesses the power of few-shot learning and multi-modality fusion. The foundation of COMFUSE lies in a pre-trained BERT model, skilled at generating word embeddings for microblogs containing both posts and comments. The feature extraction process involves utilizing Bi-directional Gated Recurrent Units (Bi-GRUs). The innovation lies in the fusion of posts and comments within an instance, which is then fed into the few-shot learning model, where the instances of both rumors and non-rumors collectively form a support set for the few-shot learning process. For the Weibo 3 dataset, which encompasses 11 COVID-19-irrelevant events along with 3 relevant events, an accuracy of 78.61% was achieved. Additionally, on the PHEME dataset, which comprises the latest events in the form of English tweets from Twitter (including merely 5 events), an accuracy of 66.77% was attained. These findings suggest that the number of events and instances play a pivotal role in the effectiveness of learning mechanisms, enabling the model to adapt to new and swiftly emerging events. In essence, the COMFUSE approach sheds light on a pathway to address the limitations posed by limited data availability during the early stages of rapidly unfolding events, showcasing the potential of few-shot learning and multi-modality fusion in rumor detection. Kaliyar et al. (2021) introduced a hybrid model that employs multiple branches of CNN with LSTM layers featuring diverse kernel sizes and filters. To enhance the model’s depth, three dense layers were incorporated to automatically extract more robust features. The researchers curated a dataset (FN-COV) comprising 69,976 English news articles acquired during the COVID-19 pandemic, of which 44.84% were classified as fake news articles. The model’s performance was assessed using another real-time fake news dataset, namely PHEME. Notably, the proposed approach achieved an accuracy of 91.88% on the PHEME dataset, surpassing the performance of existing models, and achieved an impressive accuracy of 98.62% on the FN-COV dataset Kaliyar et al. (2021).
Detecting misinformation across multiple domains presents a unique set of challenges due to variations in data characteristics—such as vocabulary, style, and dissemination patterns—that differ across topics. This variability, known as domain shift, can significantly impact detection performance, especially when models trained on one domain struggle to generalize effectively to others. Multi-domain Fake News Detection (MDFEND) model (Nan et al., 2021) was designed to handle domain-specific nuances by using a domain gate mechanism that aggregates information from multiple representations tailored to each domain. This approach achieved a 91.37% accuracy with a full-scale Weibo21 dataset (Nan et al., 2021). Prompt Learning for Low-Resource Multi-Domain Fake News Detection (PLDFEND) (Peng et al., 2023) model, conversely, is designed for low-resource scenarios, employing prompt learning techniques that leverage domain information to improve prompt templates and optimize verbalizers. In few-shot conditions, PLDFEND reached a 71.85% F1-score, demonstrating its adaptability with limited data. When applied to the full-scale dataset, it achieved a slightly higher F1-score of 92.45%, surpassing MDFEND. Building on these approaches, a recent model introduces a contextualized, cross-domain, prompt-based zero-shot method using a Generative Pre-trained Transformer (GPT) framework (Alghamdi et al., 2024a). Unlike conventional models that require extensive labeled data for fine-tuning, this approach refines prompt integration and classification logic within the model, effectively capturing domain-specific nuances with minimal data. Extensive testing demonstrates its strong generalizability across domains, showing significant promise in zero-shot learning for text classification. Together, these models advance multi-domain misinformation detection by addressing both domain shift and data scarcity, providing robust solutions for cross-domain misinformation detection on diverse platforms.
Yue et al. (2023) introduced MetaAdapt, a meta-learning approach to tackle the challenge of domain adaptation in few-shot misinformation detection, particularly in emerging topics like COVID-19 on social media. MetaAdapt leverages limited target domain examples to guide knowledge transfer from the source domain, enhancing model performance in the target domain. The method demonstrated its capabilities by achieving an impressive source domain performance of 71.2% on the Liar dataset and 89.8% on the PHEME dataset. Notably, in the target domain, it delivered outstanding performance with accuracy rates of 94.8% on the CoAID dataset (Cui & Lee, 2020) and 82.8% on the COVID-19 Fake News dataset. These results outperformed state-of-the-art baselines and large language models (LLMs), all while utilizing significantly fewer parameters, making it a promising solution for real-world misinformation detection challenges. However, due to the scarcity of early-stage misinformation data, the study confines the selection of the target domain to COVID-19. This limitation may potentially impact the generalizability of the proposed method to other domains. In a study conducted by Dua et al. (2023) the performance of various machine learning and deep learning models, including LR, LSTM, and BERT, was compared on two widely used datasets: Liar and COVID-19 Fake News datasets. Among these models, BERT demonstrated superior performance, achieving an accuracy of 94.10% on the COVID-19 Fake News dataset and 51.54% on the Liar dataset. The study also assessed the models’ effectiveness in a cross-dataset evaluation scenario. When the model was trained on the FactCheck2 dataset, consisting of 600 real news and 120 fake news articles, it achieved an F1-score of 42.76% on the COVID-19 dataset and 49.53% on the Liar dataset. However, models trained on COVID-19 and Liar datasets exhibited a decline in performance during cross-dataset evaluation, with scores of only 38.22% and 27.98% on the FactCheck2 dataset, respectively. These results highlight the limitations of domain-specific publicly available datasets like COVID-19 and Liar when applied to generalized datasets like FactCheck2, which encompass various domains within society. Zhou et al. (2024) introduced Clip-GCN, a multimodal detection model designed to address the challenges of detecting emergent fake news with limited labeled data. The proposed model leverages the Clip pre-training model for joint semantic feature extraction from both image and text data, with text serving as the supervisory signal to enhance semantic interaction between modalities. Additionally, the model incorporates adversarial neural networks and graph convolutional networks (GCN) to extract inter-domain invariant features and utilize intra-domain knowledge, respectively. Through extensive experiments on Chinese and English datasets from Weibo and Twitter, Clip-GCN demonstrates superior performance in detecting fake news, achieving an average accuracy of 87.79%. The paper’s key contribution lies in providing a robust solution for emergent news detection in scenarios with limited labeled data, significantly improving model performance in multimodal contexts.
Chen and Lai (2022) addressed the often-overlooked aspect of model detection time in misinformation detection. Their method integrates fuzzy logic with deep learning to handle COVID-19 misinformation efficiently. Their approach reduces training time by discarding words with a frequency over 5000 and using fuzzy clustering to eliminate redundant features with an impact threshold below 0.6. Evaluations on the CHECKED (Chinese) dataset (Yang et al., 2021) achieved an F1-score of 88.25% in 771 seconds, dropping to 76.35% with feature reduction. On the FakeCovid (English) dataset (Shahi & Nandini, 2020), the F1-score was 99.40% in 2295 seconds, decreasing slightly to 98.81% with a reduced detection time of 1996 seconds. The method was effective for English but less so for Chinese due to data imbalance.
Considering the predominant usage of English in news articles, Du et al. (2021) embarked on a unique attempt to detect COVID-19 disinformation within a low-resource language, like Chinese, by leveraging high-resource English news articles. Their approach, termed CrossFake, formulated a deep learning-based framework. This involved training a neural network classifier on BERT-generated English news data embeddings. To assess the truthfulness of Chinese news articles, they were translated into English using the Google Translator API, with the final predictions being made based on the translated content. In this cross-lingual context, the method yielded a noteworthy F1-score of 73.51% on the Cross-lingual Fake News dataset (Du et al., 2021), designed to evaluate this specific technique. Nonetheless, it’s worth noting that the quality of machine translation can pose challenges for cross-lingual tasks, particularly in emerging events. The potential for mistranslations introduces the risk of misleading the fake news classifier.
While numerous misinformation detection models primarily focus on a single language, typically English, Tian et al. (2021) introduced an innovative zero-shot cross-lingual transfer learning framework. This framework facilitates the adaptation of a rumor detection model trained in one source language to another target language, all without necessitating annotated data for the new language. The approach involves fine-tuning the multilingual BERT model on two English fake news datasets, namely, Twitter15/16 (Ma et al., 2017) and the PHEME dataset (Zubiaga et al., 2016), enabling its application to classify rumors in the Chinese dataset Weibo 3 . The model trained on the Twitter15/16 dataset attained an impressive 96.2% on the source data and 80.2% on the Weibo target data. Similarly, the model trained on the PHEME dataset achieved 85.3% on source data and 77.2% on the target Weibo dataset. This underscores the intricate challenges inherent in cross-lingual misinformation detection. In a recent study, Varshini et al. (2023) introduced an innovative GAN-based model aimed at acquiring discriminative features for the classification of COVID-19-related tweets as either genuine or fake news. The primary objective of their model was to adapt to data that falls outside the distribution observed during training within the context of the COVID-19 domain. This adaptation aimed to enhance the model’s ability to generalize effectively, even when confronted with variations between test and training data. Therefore, the method generates diverse adversarial representations of real data that align closely with the training data distribution. The model’s performance evaluation utilized the COVID-19 Fake News dataset, containing COVID-19-related tweets in English. Impressively, when tested on data within the same distribution as the training data, the proposed model achieved a F1-score of 98.97%. However, its performance took a noticeable dip when evaluated on out-of-distribution data, achieving an F1-score of 53.80%. Despite this reduction, the model’s performance surpassed that of other state-of-the-art methods. Notably, this performance drop can be attributed to the presence of Arabic tweets alongside English tweets within the COVID-19 Infodemic Dataset (Alam et al., 2021), challenging the model’s performance on out-of-distribution data. Interestingly, the model achieved 81.98% on the COVID-19 Twitter dataset (Paka et al., 2021) and 99.15% by considering solely the English language tweets within the FakeCovid (Shahi & Nandini, 2020) multilingual dataset. This achievement underlines the model’s capacity to excel when focusing on generalized representations within the confines of English language data. Nonetheless, despite the model’s efforts to capture broader representations, the complexities inherent in multilingual misinformation detection persist as a significant challenge.
De et al. (2021) introduces a robust neural model based on multilingual BERT, designed for low-resource languages, including Hindi, Swahili, Indonesian, and Vietnamese. By translating existing English datasets using Google Machine Translation, the need for neural machine translation is eliminated, allowing direct input from diverse languages. The model achieves high accuracy in both domain-specific and domain-agnostic settings, outperforming current state-of-the-art models. Cross-domain and zero-shot experiments demonstrate its effective language-agnostic and language-independent feature transfer capabilities. Building on these advancements, Mohawesh et al. (2023) proposes a multilingual deep learning framework for misinformation detection using a capsule neural network. The framework integrates BiLSTM to extract contextual features and a Capsule Network to capture hierarchical relationships, incorporating semantic variables such as sentiment and entities. Tested on the TALLIP fake news dataset developed by De et al. (2021), this model outperformed state-of-the-art methods, showing significant improvements across multiple languages. Continuing the exploration of multilingual misinformation detection methods, Ahuja and Kumar (2023) introduces Mul-FaD, an attention-based model designed to detect misinformation across multiple languages. The model leverages a dataset of approximately 40,000 articles in English, German, and French, created by combining existing English datasets with translations verified for accuracy. Using fast-text embeddings and an altered hierarchical attention network, Mul-FaD processes text representations at both word and sentence levels to improve detection accuracy. The model achieves a 93.73% accuracy and a 92.90% F1 score, outperforming other baseline models. Alghamdi et al. (2024b) presents a novel hybrid summarization approach addressing limitations of pre-trained language models like mBERT in handling long texts and noisy data. By combining extractive and abstractive summarization, the method condenses news articles while preserving crucial information, enhancing the efficiency and accuracy of the classification process. The pre-processed data is then classified using mBERT, demonstrating superior performance compared to state-of-the-art methods on the TALLIP dataset. This approach proves effective across diverse languages, particularly those with complex morphology or loanwords, without the need for translation to a common language. The study emphasizes the importance of preserving content richness for scalable multilingual misinformation detection. It sets new performance benchmarks and suggests future improvements with lighter transformer models and large language models like LLaMA and ChatGPT, demonstrating the framework’s adaptability in multilingual and emerging event scenarios. Raja et al. (2023) tackled misinformation in low-resource Dravidian languages using a novel transfer learning approach. By combining the Dravidian_Fake dataset with the English ISOT dataset, they fine-tuned mBERT and XLM-R models using adaptive learning, achieving 93.31% average accuracy. XLM-R outperformed mBERT, demonstrating effective cross-lingual transfer. This approach shows promise for other Indian languages and emphasizes the need for adaptable methods in a multilingual context.
Existing misinformation detection methods struggle with emerging events like the COVID-19 pandemic due to their reliance on historical data, which does not adapt well to rapidly changing news scenarios. Additionally, methods that excel in high-resource languages, such as English, often perform poorly in low-resource languages like Chinese. These issues highlight the need for improved strategies that address the challenges of both evolving events and multilingual misinformation.
Datasets for Multilingual and Emerging Event Misinformation Detection
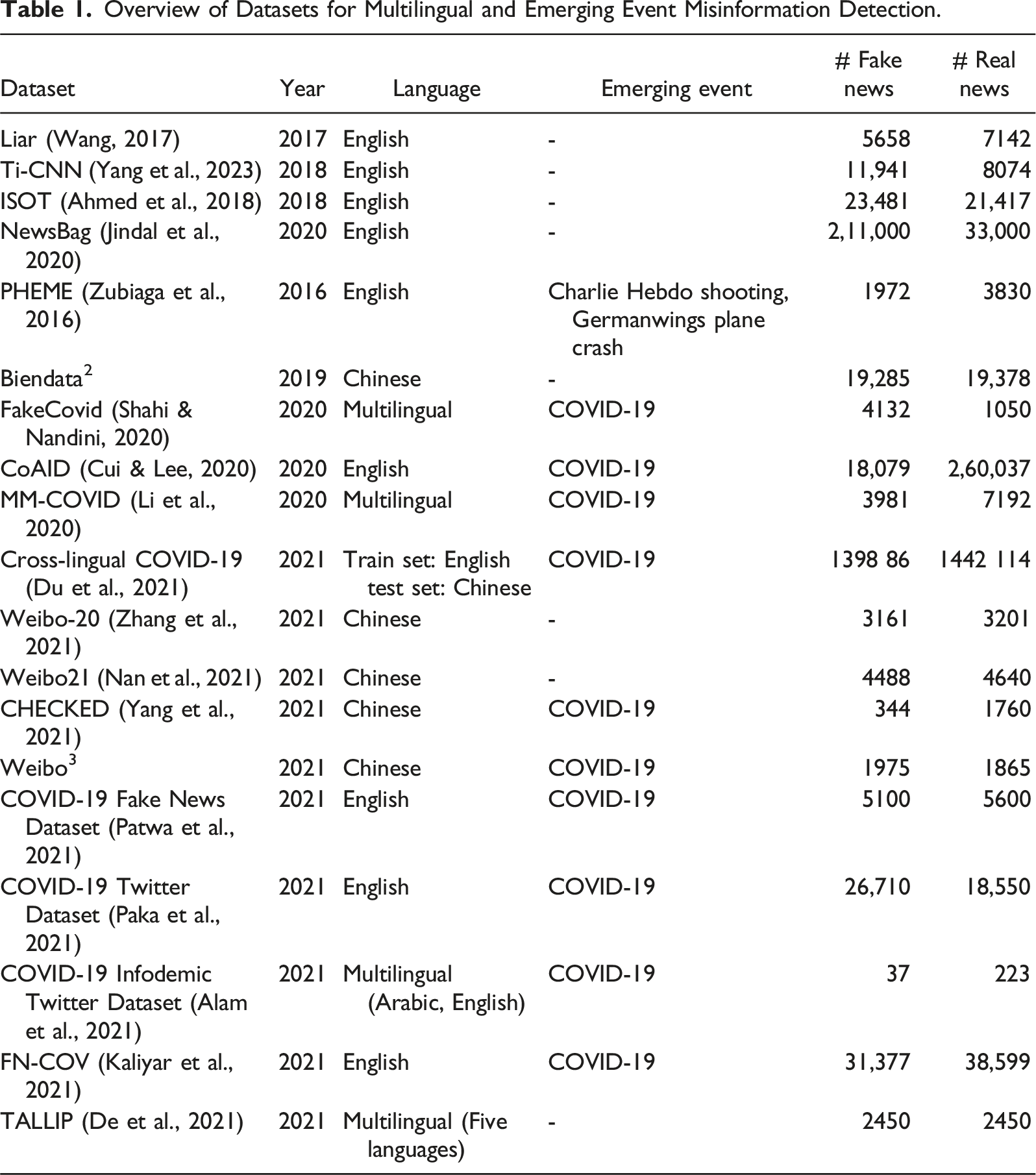
Overview of Datasets for Multilingual and Emerging Event Misinformation Detection.
Datasets Tailored for Historical Misinformation Detection
Liar (Wang, 2017): The Liar dataset, originating in 2017, is a valuable resource for misinformation detection research. Predominantly composed of English language news articles, it doesn’t have a specific emerging event associated with it. This dataset consists of 5658 labeled fake news articles and 7142 real news articles. It provides a diverse set of data for researchers to train and evaluate misinformation detection models, making it a fundamental asset in the field.
Ti-CNN (Yang et al., 2023): Created in 2018, the Ti-CNN dataset is another significant contribution to misinformation detection research. It primarily comprises English language news articles and doesn’t focus on a specific emerging event. The dataset contains a substantial collection of 11,941 fake news articles and 8074 real news articles. Researchers can leverage this dataset to explore various aspects of misinformation detection, benefiting from its extensive data volume.
ISOT (Ahmed et al., 2018): In 2018, the ISOT dataset was introduced as a valuable resource for understanding misinformation detection. Like the previous datasets, it primarily consists of English language news articles and does not center around a specific emerging event. The ISOT dataset encompasses a vast collection of 23,481 fake news articles and 21,417 real news articles, offering researchers ample data for training and evaluating misinformation detection models.
NewsBag (Jindal et al., 2020): NewsBag, established in 2020, is a substantial dataset designed for misinformation detection research, primarily comprising English language news articles. This dataset is particularly notable for its scale, featuring 211,000 fake news articles and 33,000 real news articles.
Biendata 2 Weibo-20 (Zhang et al., 2021) and Weibo21 (Nan et al., 2021): These dataset primarily consists of Chinese language news articles and does not specifically focus on a particular emerging event. However, its content is in Chinese, making it a valuable resource for researchers interested in studying misinformation detection in a multilingual context, particularly for the Chinese language. Researchers can use it in combination with other datasets to explore multilingual aspects of misinformation detection. Weibo21, in particular, is a benchmark dataset curated specifically for multi-domain fake news detection and includes 4488 fake news articles and 4640 real news articles across nine distinct domains. This diverse, domain-annotated dataset highlights the need to address challenges arising when applying detection methods across multiple domains.
Datasets Tailored for Misinformation Detection during Emerging Events
PHEME (Zubiaga et al., 2016): The PHEME dataset, established in 2016, focuses on real-time information propagation during emerging events like the Charlie Hebdo shooting and the Germanwings plane crash. It includes 1972 labeled fake news articles and 3830 real news articles primarily in English. This dataset provides valuable insights into misinformation spread during critical events, facilitating the study of misinformation dynamics in crisis situations.
COVID-19 related datasets in English: COVID-19 heAlthcare mIsinformation Dataset (CoAID) (Cui & Lee, 2020), COVID-19 Fake News (Patwa et al., 2021), COVID-19 Twitter (Paka et al., 2021), and FN-COV (Kaliyar et al., 2021) datasets primarily consists of English language news articles related to COVID-19. Researchers can explore multilingual aspects by combining it with other COVID-19-related datasets.
COVID-19 related datasets in Chinese: Developed in 2021, CHECKED (Yang et al., 2021) is a Chinese language dataset focused on misinformation detection during the COVID-19 pandemic. It offers researchers a unique opportunity to study misinformation dynamics within the Chinese-speaking online landscape during public health crises.
The Weibo 3 dataset, also in the Chinese language, revolves around the COVID-19 pandemic and serves as a valuable resource for understanding how misinformation propagate on the Weibo social media platform within the context of this public health crisis.
Datasets Tailored for Multilingual Misinformation Detection
FakeCovid (Shahi & Nandini, 2020): Introduced in 2020, the FakeCovid dataset emphasizes the COVID-19 pandemic with a multilingual approach. It comprises around 5000 news articles from 105 countries published between January 4, 2020, and May 15, 2020, in 40 languages. English articles make up 40.8% of the dataset. It includes 4132 labeled fake news articles and 1050 real news articles, offering a valuable resource for in-depth analysis.
Multilingual and Multidimensional COVID-19 (MM-COVID) (Li et al., 2020): Established in 2020, the MM-COVID dataset supports research amid the global COVID-19 pandemic. Notable for its multilingual composition, it contains 3981 instances of fake news and 7192 reliable pieces across six languages: English, Hindi, French, Portuguese, Italian, and Spanish.
Cross-Lingual COVID-19 (Du et al., 2021): Introduced in 2021, the Cross-Lingual COVID-19 dataset aids research amid the global pandemic, facilitating cross-lingual investigations. It includes high-resource (English) and low-resource (Chinese) languages, utilizing English for robust training data to predict credibility in Chinese. This unique approach enhances understanding of cross-lingual dynamics in COVID-19 misinformation detection.
TALLIP Fake News Dataset (De et al., 2021): Developed in 2021, the TALLIP dataset supports cross-lingual fake news detection by providing news items across multiple languages, including low-resource Asian languages like Hindi, Swahili, Indonesian, and Vietnamese. The dataset, derived from English news sources, includes 980 news items per language, combining legitimate and fake news generated through crowdsourcing.
COVID-19 Infodemic Twitter Dataset (Alam et al., 2021): Launched in 2021, the COVID-19 Infodemic Twitter Dataset aids global pandemic research with content in Arabic and English. Despite its thematic relevance, its limited volume poses challenges for training deep learning-based misinformation detectors, suggesting supplementation with larger datasets for robust model development and evaluation.
While numerous datasets exist for misinformation detection, many lack focus on multilingual contexts and emerging events like COVID-19. Historical datasets such as Ti-CNN, ISOT, and NewsBag provide extensive English-language samples but fall short for emerging events. For example, NewsBag includes 211,000 real and 33,000 fake news samples, while the CHECKED dataset for COVID-19 has only 1760 real and 344 fake news items. The PHEME dataset addresses real-time information propagation during critical incidents but is limited in scope. Multilingual datasets like FakeCovid, MM-COVID, Cross-Lingual COVID-19, and TALLIP offer resources across languages but often have limited volumes, posing challenges for deep learning models. Data augmentation or fusion strategies may be needed to address these gaps. Additionally, a few datasets for low-resource languages, including Bangla, Hindi, Urdu, Russian, Malay, and Arabic, are available, though they typically contain limited samples of real and fake news. Further details on these datasets can be found in the supplemental material.
Performance of State-of-The-Art Methods on Multilingual and Emerging Event Misinformation Detection
Performance of State-of-The-art Misinformation Detection Methods on Various Datasets (Results Taken From Original Papers).
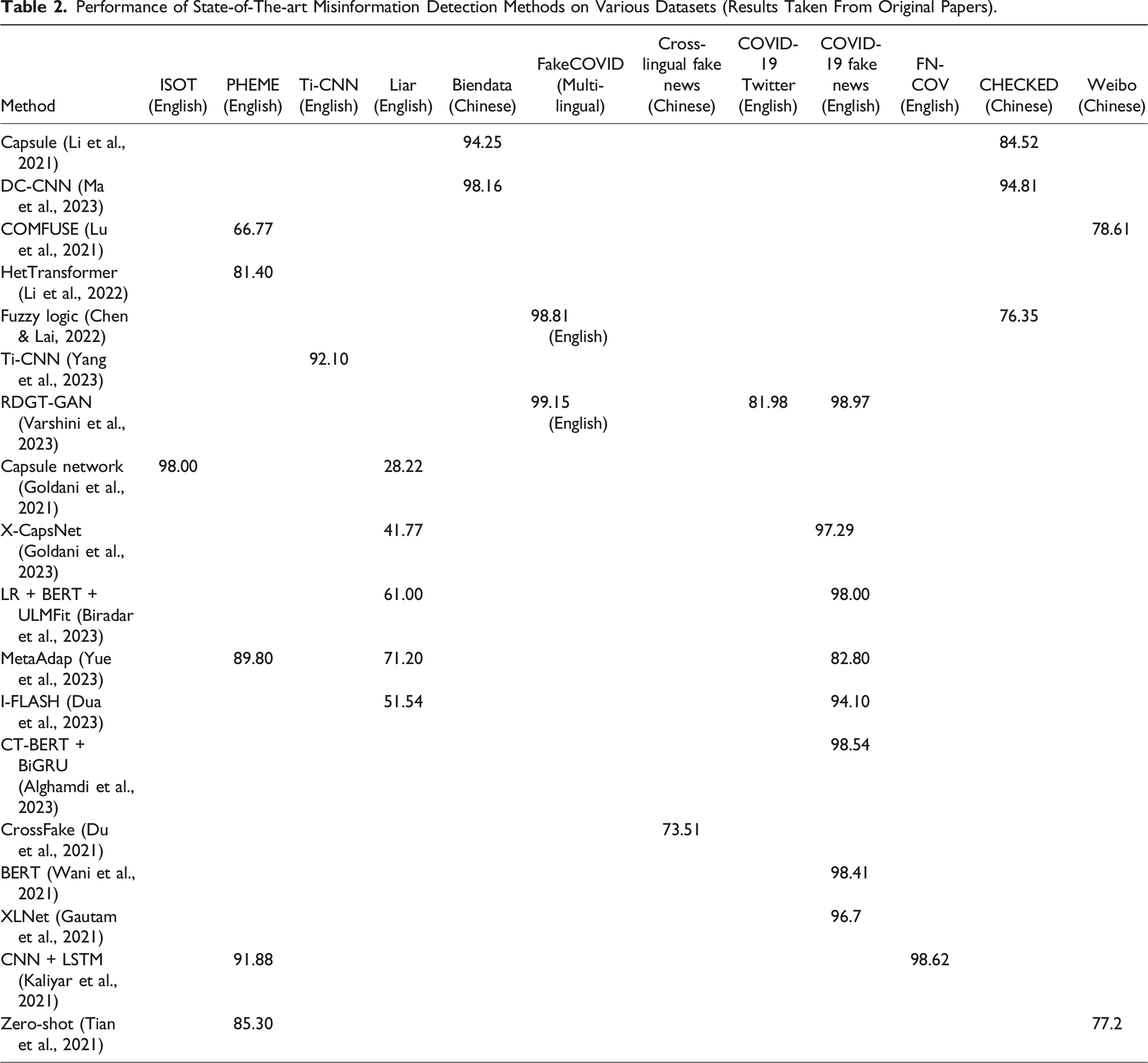
Performance variation: Table 2 illustrates that various methods achieve different levels of F1-score in misinformation detection across different datasets spanning a wide range, from 28.22% to 99.15%. For instance, the RDGT-GAN model (Varshini et al., 2023) showcased an impressive performance of 99.15% on the English-based fake news dataset encompassing COVID-19 emerging event. This indicates that while some methods are highly accurate, there is still room for improvement in achieving perfect or near-perfect detection.
Dataset Dependency: In the context of events like the COVID-19 pandemic, several techniques face challenges. For example, the method based on capsule network (Li et al., 2021) achieved an impressive 94.25% F1-score on the Biendata dataset, highlighting its proficiency in handling historical data. However, when applied to the CHECKED dataset, it encountered limitations, achieving an F1-score of 84.52%. Similarly, the DC-CNN approach (Ma et al., 2023) demonstrated adaptability by attaining a high F1-score of 98.16% on the Biendata dataset. Yet, it faced a reduction in performance on the CHECKED dataset, achieving an F1-score of 94.81%. These findings suggest the need for adaptable methodologies capable of handling diverse event contexts.
Model Flexibility: The X-CapsNet (Goldani et al., 2023) model demonstrates the ability to handle emerging events by achieving an F1-score of 97.29% on the COVID-19 fake news dataset, which features lengthy news statements. However, its performance drops to 41.77% on the Liar dataset, consisting of shorter news statements. This highlights the challenge of adapting models to varying text lengths.
Data Scarcity: The COMFUSE model (Lu et al., 2021), designed for emerging event detection, obtained an F1-score of 78.61% on Chinese Weibo dataset and 66.77% on the PHEME dataset. This performance disparity highlights the challenge of limited data associated with rapidly evolving events. Similar data scarcity is evident in the case of the CrossFake model (Du et al., 2021), which attained an F1-score of 73.51% when tested on the Cross-lingual Fake News dataset. This underlines the difficulty of obtaining adequate training data for accurate cross-lingual misinformation detection.
Multilingual Adaptability: Methods like Fuzzy Logic (Chen & Lai, 2022) and MetaAdapt (Yue et al., 2023) exhibit potential for multilingual misinformation detection, as they achieve competitive results on datasets in both English and Chinese. However, multilingual misinformation detection remains an ongoing challenge. Moreover, the Zero-shot method (Tian et al., 2021) struggled with cross-lingual transfer, with an F1-score of 77.2% on the Weibo dataset, highlighting the language-specific intricacies that hinder multilingual detection.
Table 2 highlights the effectiveness and limitations of various misinformation methods across datasets, languages, and domains. While some methods are broadly effective, others may excel in specific contexts or struggle with emerging events and non-English languages. Researchers should consider these factors when selecting a method for specific misinformation detection tasks.
Research Gaps and Future Directions
Based on the above review and analysis, we discuss the gaps and emerging trends for further exploration in misinformation detection research, specifically for emerging events and multilingual context. 1. 2. 3. 4. 5.
As we navigate the challenges posed by rapidly emerging events, the adaptability of misinformation detection models takes center stage. Developing models capable of efficiently evolving with dynamic contexts while ensuring accurate detection during crises remains a pressing need. In the pursuit of more effective misinformation detection, these research gaps and future directions pave the way for innovative solutions, ultimately contributing to a more informed and resilient society in the face of misinformation
Conclusion
This review paper has meticulously examined the current landscape of misinformation detection research, shedding light on both its advancements and persistent challenges. Through the lens of our analysis, it becomes evident that while substantial progress has been made, several challenges continue to persist. The multifaceted nature of misinformation, driven by the rapid evolution of language and context, demands dynamic and adaptable models. The need to effectively detect misinformation across languages, particularly in low-resource settings, remains a pressing concern. Furthermore, addressing the issues of short text and real-time performance optimization is crucial for deploying these systems in practical, real-world scenarios. Amidst these challenges, we have also highlighted the importance of comprehensive, balanced datasets for training and evaluating detection models.
As we venture forward in the quest to combat the proliferation of misinformation, it is equally important to consider the challenges posed by disinformation. Future research could benefit from exploring techniques to address disinformation, complementing the strategies discussed here for misinformation. Advancing methods to tackle disinformation will complement existing efforts in misinformation detection, ultimately strengthening our defenses against the spread of false information and safeguarding the integrity of information in the digital age.
Supplemental Material
Supplemental Material - Survey on Deep Learning for Misinformation Detection: Adapting to Recent Events, Multilingual Challenges, and Future Visions
Supplemental Material for Survey on Deep Learning for Misinformation Detection: Adapting to Recent Events, Multilingual Challenges, and Future Visions by Ansam Khraisat, Manisha Manisha, Lennon Chang, and Jemal Abawajy in Social Science Computer Review
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.