
Abstract
How does media coverage of electoral campaigns distinguish parties and candidates in emerging democracies? To answer, we present a multi-step procedure that we apply in South Africa. First, we develop a theoretically informed classification of election coverage as either “narrow” or “broad” from within the entire corpus of news coverage during an electoral campaign. Second, to deploy our classification scheme, we use a supervised machine learning approach to classify news as “broad,” “narrow,” or “not election-related.” Finally, we combine our supervised classification with a topic modeling algorithm (BERTTopic) that is based on Bidirectional Encoder Representations from Transformers (BERT), in addition to other statistical and machine learning methods. The combination of our classification scheme, BERTTopic, and associated methods allows us to identify the main election-related themes among broad and narrow election-related coverage, and how different candidates and parties are associated with these themes. We provide an in-depth discussion of our method for interested users in the social sciences. We then apply our proposed techniques on text from nearly 100,000 news articles during South Africa’s 2014 campaign and test our empirical predictions about candidate and party coverage of corruption, the economy, health, public infrastructure, and security. The application of our method highlights a nuanced campaign environment in South Africa; candidates and parties frequently receive distinct and substantive coverage on key campaign themes.
Introduction
Scholarship on democratic politics portrays contrasting perspectives regarding whether media coverage of campaigns informs an understanding of a country’s election environment. One perspective argues that information revealed in campaign coverage serves a critical role educating and persuading voters (Price & Zaller, 1993; Zaller, 1992); if true, such coverage may shape their attitudes about and choices among candidates (Gerber et al., 2009; Popkin, 1994). A contrasting viewpoint suggests that campaigns do little more than reinforce political fundamentals (Lewis-Beck & Rice, 1992), indicating coverage would at best “remind” voters of the limited choices they face, implying little to no role for persuasion (Horowitz, 1985). The tension between these perspectives is particularly salient in emerging democracies, where on the one hand campaign coverage could possibly help to address voters’ informational deficiencies given the newness of democratic procedures, while on the other media often appear as simply epiphenomenal to underlying institutional realities of unconsolidated democracies.
Text-as-data techniques provide a new entry point into this debate by investigating the extent to which media coverage of campaigns meaningfully differentiates parties and candidates in substantive ways, allowing researchers to characterize more fully the information environment that voters confront. Previous studies have tackled related concerns and made advances in measuring the valence of political and economic news coverage and changes over time (Soroka, 2014), media bias (Watanabe, 2017), and personalized content of specific candidates (e.g., Hall & Lim, 2018; Vliegenthart et al., 2011) or speech (Müller, 2020). Despite qualitative analyses (e.g., McCombs & Shaw, 1972) and hand-coding of stories (Hayes & Lawless, 2018), developing automated ways to measure how the news media differentiates candidates and parties during election campaigns has remained a challenge. Automated applications have the potential to deepen our understanding of political campaigns, particularly in emerging democracies, and potentially in real time.
To address these lacunae, we first develop and present a procedure for identifying election-related news coverage from within the entire corpus of news coverage during an electoral campaign, irrespective of identifying a specific set of political actors. Second, we show how to compare candidate and party coverage from within that election-related corpus. To do so, we develop a theoretical distinction between “broad” and “narrow” election coverage and then employ new text-as-data techniques to classify the universe of election-related stories into either of these categories, which are distinguished from “not election-related” stories. Subsequently, we combine our predictions of election-related stories with BERTTopic, a topic modeling technique, which leverages word embeddings from Bidirectional Encoder Representations from Transformers (BERT), to estimate the extent to which candidates and parties are able to differentiate themselves from each other on election-related topics during an election cycle.
Applying this architecture to a news corpus from South, further informed by our knowledge of the case, our procedure helps ascertain what information is salient in election-related news coverage and what news coverage might actually relay to voters and what this implies about electoral competition. We identify common “election-related themes” that appear across different coverage and article aggregation schemes, and show how each party/candidate relates to them using contextual word embeddings. Our findings portray campaign coverage that not only signals political fundamentals, but in many cases provides a more nuanced set of coverage that makes important substantive distinctions between relevant political actors.
Election-Related News Coverage Classification Approach
Our approach derives from two theoretically grounded classifications of “election-related” coverage, which we define as “narrow” and “broad,” and distinguish from “not election-related” stories. At a minimum, an election is the process by which voters cast ballots to select aspirants for office; we denote “narrow” media coverage of an “election” as stories specifically mentioning electoral actors or processes (e.g., candidate/party names, voting procedures, and results declarations) which convey only basic information about them. Examples might include the announcement by the election commission of voter registration drives, published polls showing the horse-race, or the certification of final results.
Less obviously but fundamental to understanding the totality of election coverage, a “broad” definition constitutes any information about political actors, procedures, or institutions regardless of whether stories explicitly mention the election. This broad classification is based on the idea that general political content may gain electoral salience if covered during the campaign period because such coverage plausibly links distributional and policy outcomes with government performance or partisan platforms. Examples might include reporting on crime and policing, which does not directly portray election-related content because the police do not contest election, but may gain importance during the campaign if citizens attribute management of the police to elected officials.
Narrow and broad classifications together compose the totality of “election-related” labeling, which we differentiate from “not election-related” news (stories that do not mention politics at all, such as a wedding announcement). Narrow and broad classifications vary depending on whether media coverage of politics during the campaign includes only coverage focused on the election or also the totality of any political coverage. Therefore, what comprises election-related news quickly complicates any obvious portrayals of the election-related news coverage since coverage of politics does not always easily, clearly, or consistently delineate election-related material. Our argument is not that electoral media definitively contain either exclusively narrow or broad content; rather, simply changing the scope of inquiry around election coverage potentially leads to different substantive representations of the election-related news coverage. As a result, it is important to examine different conceptions of electoral coverage.
We apply this method to examine the coverage of political actors and events within narrow and broad categories to assess how variation in these labels reveals differences in coverage of electoral dynamics. Regardless of narrow or broad, if election-related news coverage provides meaningful information, campaign content should cluster around certain election-related themes and issues; that is, information “sets” should emerge following institutional and situational factors associated with political actors and government agencies. For example, parties associated with different economic platforms might enjoy more coverage on the state of the economy or economic policies; parties making issue-specific appeals (e.g., regarding health or security) should have their names associated with attendant policy promises and campaign issues; incumbent parties’ content might have more coverage around government performance themes like corruption, the economy, or service delivery; and opposition parties might be associated with messaging on government failures and alternative policy directions.
From this, we propose that for any corpus of news coverage during an election period, stories can be classified into one of three types: narrow, broad, or not election-related. Hand-coders can code a random sample of stories into one of these three categories. Because many newspaper corpora will be too large to code all stories by hand, we advance supervised machine learning to classify all stories not hand-coded, a technique which has been used to find “politically-related” news from within all news coverage (Budak et al., 2016). Since the performance of machine learning classifiers will likely vary by application, we recommend evaluating a range of classifiers and the inclusion of non-textual covariates. As we discuss in the Results section, Ridge Classifier has the best performance in our application. Moreover, we suggest exploring models with only textual covariates and ones with additional features, including days to the election, article language, publication, and publication owner. We propose using accuracy and F1-scores to choose the best model. In our application, we find the model with textual covariates performs best.
Using Topic Modeling to Capture Election-Related Themes
Regardless of whether the coverage being analyzed is broad or narrow, each election has a distinct set of politically relevant campaign themes or issues, 1 which will vary by context and time period (Budge & Farlie, 1983). Historically, most scholarship has pre-coded election-related themes. For example, several articles on media coverage of U.S. politics focus on an eight-themed model of campaigns (Hayes, 2010), based on Petrocik (1996). Druckman (2004) suggests 28 campaign-related issues. Hall and Lim (2018) suggest six themes of candidate-related news coverage.
More recently, scholars have begun to use topic modeling to determine politically relevant media themes. For instance, Budak et al. (2016) code 15 themes, which were manually created with the aid of an LDA algorithm. We build on this approach. Following Rodriguez et al. (2023), we take an agnostic approach regarding what themes might emerge by not beginning with a specific set of words or election-related themes. 2 Therefore, based on our categorization of election-related stories as broad or narrow, we can then apply unsupervised topic modeling to help reveal election-related topics.
Before discussing the technical specifics of our procedure, we briefly highlight the benefits of topic modeling to studying the themes of campaign coverage. Topic modeling involves the process of finding topics that best represent the information contained in a corpus that is divided into different documents. Each topic is represented as the set of weighted words most informative of its unique topic. The weight of each word is determined by its similarity with the topic.
A traditional method for topic modeling is the Latent Dirichlet Allocation (LDA) (Blei et al., 2003), which represents each document as a combination of topics and each topic as a distribution of words. Despite its popularity and utility, the LDA has two main drawbacks. First, it requires the topic space be discretized into N topics beforehand, but the mis-specification of the number of topics N can produce uninformative results and the real number of topics is rarely known (Syed & Spruit, 2017). The second limitation relates to the representation of documents, which is generally done using bag-of-words (BOW) and ignores semantics. In other words, similar words in the semantic space (e.g., professor and teacher) are treated as different terms despite similarities.
This latter shortcoming can be addressed using word embeddings, such as word2vec Mikolov et al. (2013) and GloVe (Pennington et al., 2014). Word embeddings capture both the semantic and syntactic information underlying words. In this approach, each word is represented by a multi-dimensional vector, where each entry represents information about the word’s meaning. Word embeddings later expanded to include documents in the doc2vec model (Le & Mikolov, 2014). This methodology is capable of learning document and word vectors that are jointly embedded in the same space, which improves the quality of the learned vectors (Lau & Baldwin, 2016). Semantically similar words and documents appear close to each other in the embedding space. As a consequence, the most similar word vectors to a document are likely good representations of the document’s topic.
The doc2vec model can also be used in the context of topic modeling (Angelov, 2020). However, one limitation is that the embeddings are often pre-trained. In other words, they are derived without considering the relevant context. The word “virus” in “respiratory virus” and “computer virus” would be represented by the same vector encoding despite their different meanings. Training contextual representations on text corpus helps to overcome this hurdle and was first achieved by training a deep bidirectional language model, called ELMo (Embeddings from Language Models) (Peters et al., 2018) on a large corpus, where each word is assigned to an embedding that is a function of the entire input sentence and not just the specific word. ELMo is expanded by the Bidirectional Encoder Representations from Transformers (BERT) (Devlin et al., 2018), which pre-trains deep bidirectional representations from unlabeled text by jointly conditioning on both left and right contextual words in all of the neural nets’ layers. As a consequence, this BERT can be easily fine-tuned for a wide range of tasks and results obtained from BERT outperformed previous state-of-the-art models in several tasks (Liu et al., 2019; Sanh et al., 2019; Wang et al., 2019).
Proposed Topic-Modeling Approach
On the subset of the data that has been machine classified as election-related (either broad or narrow) from the corpus of all news coverage, we use BERTTopic (Grootendorst, 2022), a multi-step algorithm based on the BERT embedding model, to perform topic modeling. Due to impressive recent results of contextual NLP models, we employ as our embedding model Sentence-BERT (Reimers & Gurevych, 2019), a modification of the pre-trained BERT network to create sentence embeddings that can be compared using cosine similarity to find other sentences with a similar meaning. This method transforms sentences or documents in a numerical representation with a semantically meaningful relationship. Each word is tokenized and mapped according to its context.3, 4
BERTTopic is a processing pipeline algorithm, which aims to use BERT contextual embeddings together with other steps such as dimensionality reduction and similarity methods, to generate relevant topics from a large corpus. Using BERTTopic to measure how the media distinguishes parties and candidates in its coverage requires making choices related to BERTopic’s intermediate steps, as well as other applied research problems. We provide guidance for researchers on the following five issues related to using the BERTTopic algorithm: (1) dimensionality reduction, (2) cluster recognition, (3) converting clusters to topics, (4) topic selection, and (5) hyperparameter selection.
Using BERTTopic alone, however, is not sufficient for our needs. We therefore suggest additional methods to: (1) convert topics to themes; (2) measure topic similarity to election-related themes in news coverage; and (3) estimate uncertainty. We address these eight issues in turn.
BERTTopic Issue 1: Dimensionality Reduction
After converting all articles into document embeddings, the BERTTopic algorithm requires that documents be grouped based on their similarity. In other words, we want to derive topics (clusters) based on the documents’ content. However, due to the “curse of dimensionality,” this task is often non-trivial. The sparsity of document vectors makes it challenging to find dense clusters, resulting in high computational costs (Marimont & Shapiro, 1979).
One solution to overcome this limitation is to use an algorithm to reduce the dimension of embedded documents before clustering them (Angelov, 2020). In this reduced space, clusters can be found more effectively. Out of the dimensionality reduction algorithms, two of the most applicable are the Uniform Manifold Approximation and Projection for Dimension Reduction (UMAP) (McInnes et al., 2018) and T-distributed Stochastic Neighbor Embedding (t-SNE) (Van der Maaten & Hinton, 2008). According to Angelov (2020), t-SNE does not preserve global structure as well as UMAP; moreover, it does not scale well to large datasets. Thus, we use UMAP for reducing the dimensionality while preserving most of the global and local structure of the embeddings.
BERTTopic Issue 2: Cluster Recognition
With the new compressed semantic space, the task of finding similar clusters can be carried out by using a density-based algorithm such as DBSCAN (Ester et al., 1996) and their variants (Campello et al., 2013; McInnes & Healy, 2017). This class of methods’ main advantage is that it does not enforce a cluster to every datapoint. In other words, documents that have no clear underlying topic are treated as noise and do not interfere in clusters of similar documents. For this step of the BERTTopic algorithm, we find the dense areas of the reduced space using HDBSCAN (Campello et al., 2013), an extension of DBSCAN that also deals with variable density clusters and requires less parameter tuning.
BERTTopic Issue 3: Cluster to Topic Conversion
Once clusters have been identified, the researcher needs to transform them into topics. Achieving topics requires finding the most representative words within each cluster. The idea of finding the most relevant words in each document is the foundation of the term frequency–inverse document frequency (TF-IDF) method (Jones, 1972). The purpose of TF-IDF is to increase the value of a feature based on the frequency it appears in a document and based on the inverse document frequency of the same word across all documents. In other words, TF-IDF compares the importance of words between documents.
Since our goal is to determine the most important words for each topic, we employ a modified version of the TF-IDF equation to deal with clusters by grouping all documents within a topic. In this case, the description of a topic is defined by the more relevant words within that cluster. The score of a given word x in the topic c is defined as

BERTTopic Issue 4: Topic Selection
The output of the c-TF-IDF is a set of relevant words describing a collection of documents, in this case, a topic. Nevertheless, this collection of words is not guaranteed to describe a coherent topic. In some cases, variations of the same word or idea can end up in the topic representation. For example, imagine the top terms for a topic are: “good government,” “great government,” “excellent government,” “innovation,” “research.” The first three terms are similar and define the same characteristic. Therefore, we would like to improve the diversity and coherence of words, avoiding the overlap between the words themselves.
We achieve this aim within BERTTopic by using Maximal Marginal Relevance (MMR) (Carbonell & Goldstein, 1998), a diversity-based ranking technique that aims to maximize the relevance and novelty of the retrieved items. In our application, the MMR can be used to improve the relevance of keywords that define a topic (Bennani-Smires et al., 2018). This metric is defined as
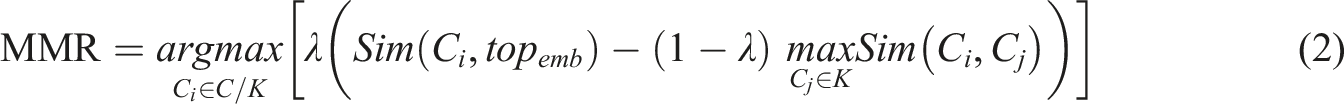
In the topic modeling context, higher MMR values represent terms that are both relevant to the topic and contains minimal similarity to the other top-ranked words. We employed λ = 0.1 as greater values than this resulted in creating topics with keywords that were irrelevant to that topic.
BERTTopic Issue 5: Hyperparameter Selection
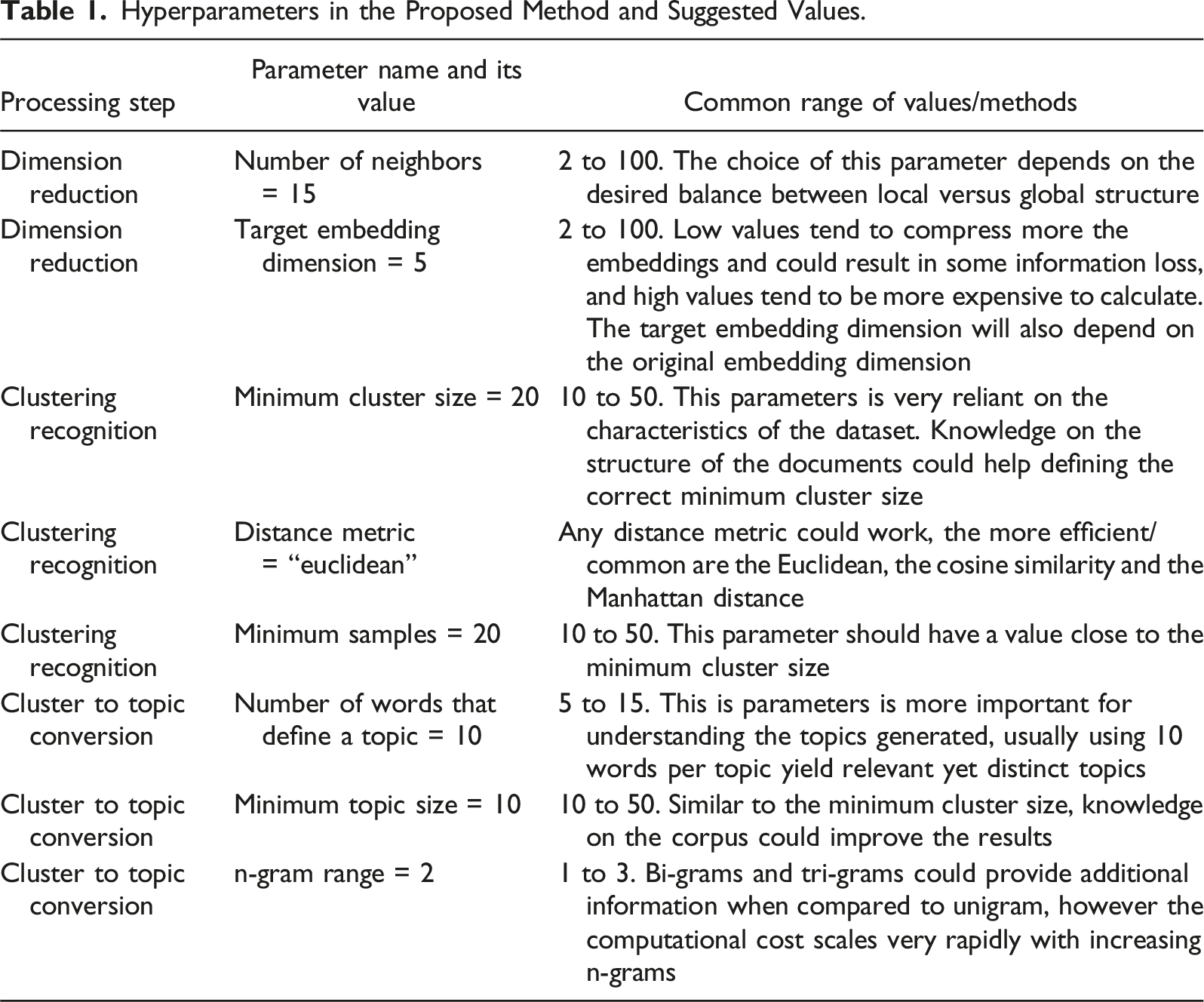
The processing steps in BERTTopic have several parameters that must be set. For the dimension reduction, the main parameters are (1) the number of neighbors, which controls the balance between preserving global structure vs. local structure in the low dimensional embedding, (2) the target dimension of the reduced embedding space and the method for calculating the distance between embeddings. Similarly, we also need to set parameters for the clustering step. The three main parameters include the (1) minimum cluster size (minimum number of points to consider a cluster), (2) the minimum number of samples in a neighborhood for a point to be considered a core point, and (3) the metric to be used to calculate the distance between points. Finally, we also need to define some topic model hyperparameters, such as (1) the number of words that are used to define a topic, (2) the minimum number of documents in a topic, and (3) the n-gram range.
Hyperparameters in the Proposed Method and Suggested Values.
Interpretation Issue 1: Converting Topics to Themes
The number of topics in our approach is defined according to how different documents cluster in the embedding space. The limitation of using a predefined number of topics before clustering is that the resulting topics could be noisy, as topics that are unrelated could be merged together if the number of topics is set too small, or there could be topics that do not have the same “theme” if the number of topics is set too large. We chose 50 topics in our application.
We recommend a two-step process to move from topics in the topic model to the primary election-related themes. First, use a dimensionality reduction algorithm to cluster similar topics in a two-dimensional space. In our application, we employed UMAP for a second time due to its advantages.
Once the topics are represented as points in the space, the researcher can use their contextual knowledge to define the main themes. For instance, if several topics are closely related to a specific subject, it may suggest a potential election theme. We identified such themes based on our knowledge of the context. However, an alternative approach involves using clustering metrics to define these topics, which could be explored in future research. It is worth noting that not all clusters may pertain to elections, underscoring the significance of contextual knowledge, even when clusters are determined using a metric threshold.
Interpretation Issue 2: Similarity Between Topics and Election-Related Parties and Candidates
Once the themes of election-related news coverage have been defined, the researcher can use them for a variety of purposes. Our goal is to measure the differences between parties’ and candidates’ associations with these themes among the broad and narrow election-related coverage. If there are differences in associations, then there is reason to believe that the media more strongly associates a particular party with a particular theme. If there are no differences, then we do not have strong reason to believe that any party is distinguishing itself on a particular election-related theme.
To estimate the association of each party with a theme (among the narrow subset, the broad subset and all-election-related coverage), we follow Rodman (2020) and employ cosine similarity between a target term and a topic, defined as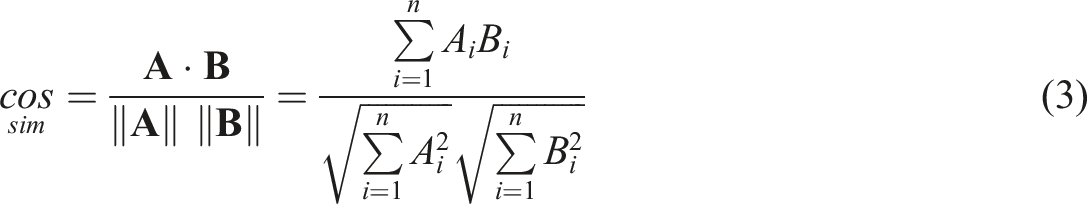
We first detect all of the mentions of our target terms (political parties and candidates) in our corpus of text. There are different ways to estimate the similarity between two features of a corpus. For example, if we want to estimate how “Jacob Zuma” is related to the theme of “corruption,” we could calculate the similarity between “corruption” and “Jacob Zuma.” While this approach is intuitive, it does not leverage all contextual embedding capability. Instead, we use a different approach.
For each target term, we propose selecting a six-word symmetric context window to calculate its context embedding. In other words, we selected twelve words that surround each detected term in the corpus to estimate the context in which they are presented. Then, for each election theme, we generate its embedding by using the topic embedding most related to that theme. Finally, we calculate the similarity between the target term contextual embedding and each election-related theme.
The result of this technique is that the embeddings of each target word are generated according to the context in which they occur on the corpus. For instance, if the name of a candidate often appears in the articles close to words like dishonesty, scandal, and misconduct in narrow subset, this target embedding would be closer (more similar) to the embeddings of the corruption theme.
Interpretation Issue 3: Uncertainty Estimation
Once we have estimated the cosine similarity for different parties and candidates, it is possible to estimate the differences. However, these differences measure neither uncertainty nor how likely it is the differences between candidates/parties and topics may have occurred by chance.
To account for uncertainty, we employ a similar approach to Rodriguez et al. (2023). Specifically, we take 100 different realizations using 10% of the available data for each target term separately for our two subsets and for all election-related coverage. Then we calculate the similarity between these terms and the main-election themes. As a result, we have 100 measurements of similarity for each party/candidate and theme combination.
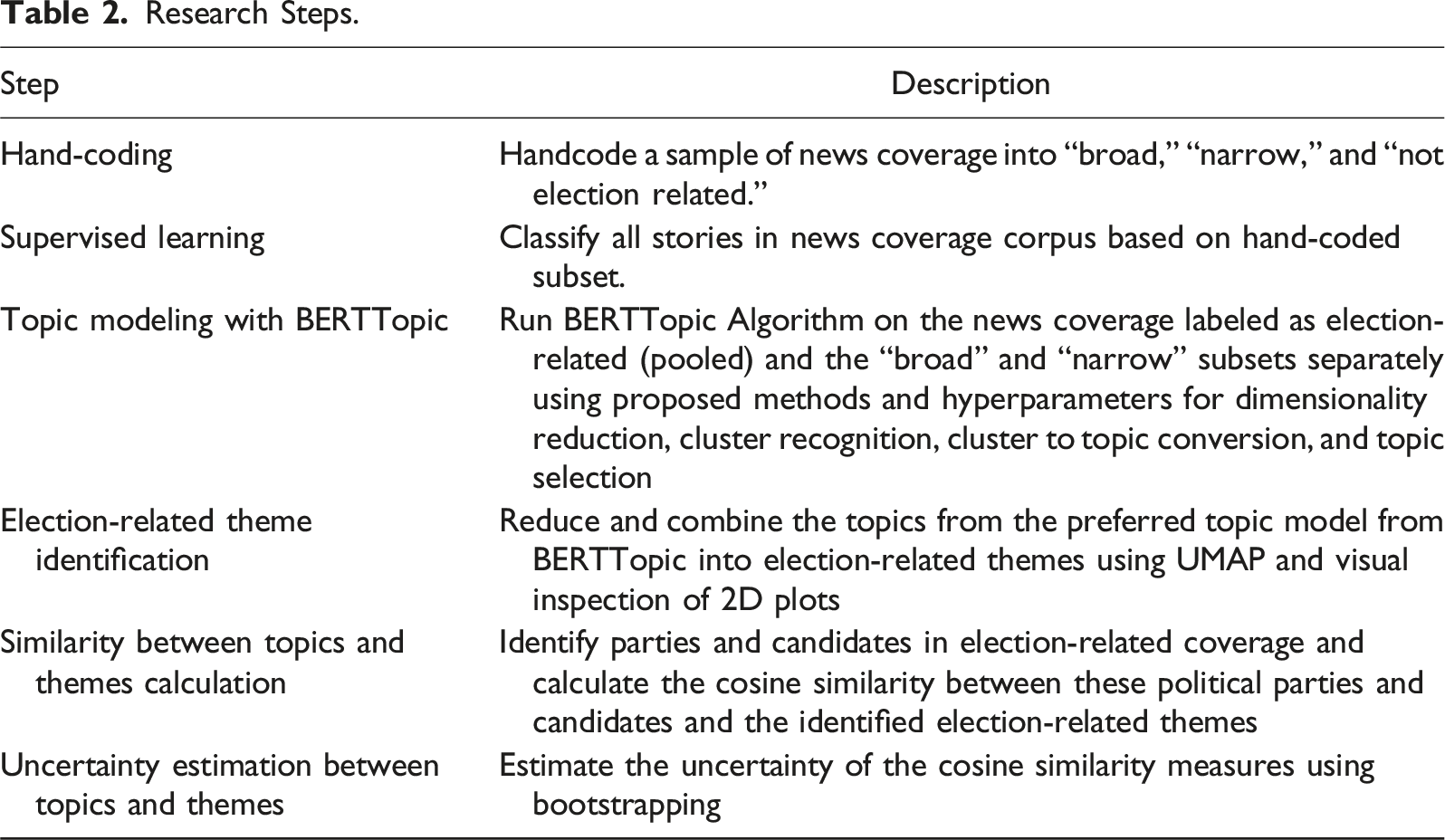
Research Steps.
South Africa 2014
We apply our method to a novel corpus of electoral news coverage around the 2014 South African election. While our approach described above is generalizable, any analysis requires appropriate contextualization. South Africa’s media and institutional environments generate national campaigns; therefore, studying election-related news reveals important dynamics about the campaign as a whole.
South Africa’s print media provided significant reporting on the horse-race, political rallies, corruption scandals, strikes, and the state of public services. The government does not own or limit the publication of stories by the main print media houses, 6 which are widely perceived by South Africans as unbiased (Schreiner & Mattes, 2011). In 2014, the country enjoyed a 95% literacy rate (93% among women) and a history of accessible, widely consumed national and local newspapers. 7
The media environment in South Africa could have simply reiterated well-worn and static statements regarding the fundamentals, including partisan politics. Since the end of apartheid and transitional elections in 1994, the African National Congress (ANC) has maintained dominance and won a majority of legislative seats in every election. The leader of the majority party forms the government (for whom the title “president” is functionally equivalent to prime minister), and politicians therefore lean on party mobilization, and coverage of party activities, to organize support (Lodge, 2004), including through media.
The ANC’s campaign dynamics revolve around turning out their base through appeals to predominantly black voters (Ferree, 2011; Southall, 2014), about 80% of the electorate. In 2014, the ANC ran its controversial incumbent president Jacob Zuma. While few observers thought the ANC would lose its parliamentary majority, any seat loss would be viewed as a referendum on government performance. Nelson Mandela’s death a few months prior encouraged party leaders to frame many appeals as “reminding” black voters of the ANC’s role in fighting apartheid. Party stalwarts argued that stressing this legacy was vital because they feared “born free” voters—adults (18+) born post-apartheid—would take the ANC for granted and not turn out in 2014, or swing to the opposition. For their part, opposition parties have had difficulty winning seats beyond pockets of regional or demographic support. The main 2014 challenger was the Democratic Alliance (DA), whose base primarily consists of white and “coloured” (mixed race) voters and was led by Helen Zille, the (white) former Cape Town mayor. Another important competitor was Julius Malema, former ANC youth leader turned founder of the Economic Freedom Fighters (EFF), a new party contesting for the first time, whose base primarily consists of young, urban, and left-wing black voters.
Electoral advantages enjoyed by the ANC do not mean campaigns lack policy substance, and the 2014 coverage provided a rich environment of themes. Opposition parties use the ANC’s institutional advantages against it, hoping to increase the rate of black defection by mentioning ANC failures. Both Zille and Malema put Zuma’s scandals at the front of their campaigns to leverage the fact that voters increasingly perceived him as corrupt given a long history of credible misdeeds; his use of state funds to build an opulent rural home (Nkandla) was a frequent point of attack in 2014. The DA launched a ten-point platform; the first two items focused on rooting out government corruption followed by a promise to create six million new jobs.
The parties attempted different messaging on the economy. The ANC campaigned on past performance on economic growth and further promises to address poverty alleviation. The DA employed explicit messages geared toward a rising black middle class and urban population that promised policy improvements regarding income, growth, and employment opportunities. Because the DA’s messaging was less geared toward marginalized South Africans, that provided a space for the EFF to more explicitly gain lower-class and youth black support with appeals regarding redistribution, expanding workers’ rights, and fighting inequality. Malema may have differentiated himself by calling for uncompensated expropriation of wealthy South Africans’ land and nationalization of mines and banks (Mbete, 2015).
The quality of public services is persistently a salient campaign theme, and widespread anti-government protests—often led by ANC supporters—occur in response to the government’s poor record of service delivery (Alexander, 2010). Healthcare is one such issue, given the country’s massive racial and regional inequities in health access, coupled with the repercussions of AIDS and other public health crises. At the time of the 2014 election, Zille had been a prominent opposition politician with a history of criticism of health services, suggesting she may have differentiated herself on that issue. Further and throughout the election cycle, issues of the power grid were constantly in the news headlines, as were the poor quality of roads, suggesting that opposition parties could have benefited from coverage on the theme of public infrastructure. Given the violence of the apartheid regime, security has been a perennial issue for all South Africans regardless of race. Although the crime rate had initially declined after apartheid, it began to rise after 2011. Both opposition candidates and parties railed against the ANC and Zuma for failing to address crime adequately.
The 2014 results revealed the tension between institutional stability and opposition gains: the ANC won 62% of the vote (249 seats), but lost 15 seats (4% of voteshare) from 2009; the DA outperformed expectations, gaining 22% (89 seats, a pick-up of 18), and the EFF achieved 6% (25 seats). 8
Predictions
South Africa’s institutional and campaign dynamics are likely to be observed in the media coverage in several ways. Specifically, given our tracking of the campaign, we outline some predictions of how stories related to corruption, the economy, and government services might have been associated with parties and presidential aspirants. Additionally, our method will also likely pick up differentiation in the media that might not have been predicted by researchers ahead of time. We note that our retrospective approach provides a good opportunity to benchmark our method and contextualize findings: the election and its outcome are known, which allows for validation of the method drawing on expertise in the field.
Corruption
Because these predictions are plausibly the most intuitive, finding corruption-related results should provide a face validity test of our method.
Economy
Our reasoning with respect to the economy is that although the policy platforms of the ANC, DA, and EFF stressed different priorities, it would be harder to differentiate themselves in coverage because these priorities all generally fall under a large umbrella of the economy-related theme.
Public Services: Health, Infrastructure, and Security
In light of her longer history as a governing member of the DA (as Cape Town mayor), Zille had a track record working on infrastructure and health issues and made them a focus of her campaign; in contrast, the EFF focused on economic and youth issues disproportionately. Both the DA and EFF criticized the ANC regarding services and infrastructure.
The rising crime rate was a vulnerability for Zuma and the ANC as incumbents; the opposition candidates and parties ran on this as a failure of government performance, although they did not appear distinct from each other in this regard.
Application
Our newspaper corpus consists of 97,428 articles from 167 South African newspapers for the period from 53 days before the 2014 election (March 15, 2014) to 23 days after (May 30, 2014). We constructed the corpus by scraping the websites of South African daily or weekly print newspapers—both national and local—that publish online, along with other online-only sources (e.g., News24). We systematically reviewed every print newspaper mentioned by the South African Audience Research Foundation (SAARF) and Wikipedia in South Africa and downloaded all available stories without regard to article content. Among the 37 print publications with the highest circulation in 2014, we scraped stories from 23. 9 Because the corpus is multilingual, we first used Microsoft Azure’s Translator Text API to translate all isiZulu and Afrikaans stories into English.
To classify articles’ election-relatedness, with 80% agreement, two coders labeled a random subset of 1000 articles (approximately 1%) into three categories: election-related-“narrow” (11%), election-related-“broad” (14%), and “not election-related” (74%) (see Appendix B.1 on coding). 10 Political actors or institutions specifically related to or mentioning the election or election day were coded as narrow (e.g., Jacob Zuma, Democratic Alliance, voter registration). The mention of any political actor or institution was coded as broad regardless of whether the story was specifically related to the election (e.g., health ministry, police, prosecutors). Broad therefore subsumes the same coverage as narrow but also includes reference to government agencies not necessarily directly related to the election. Appendix B.1 provides examples of typical stories of broad and narrow categories. 11
Before engaging in either classification or topic modeling, we preprocessed our data in a pipeline composed of two stages. In the first stage, numbers and dates were tagged, and we performed named entity recognition—that is, we combined all recognized named entities into single tokens (e.g.,“Jacob Zuma” was treated as a single token). We also de-duplicated important South African individuals, organizations, and places using pattern matching and converted them to a canonical form (e.g., “ANC” and “African National Congress” are standardized to “African National Congress”). In the second stage, typical bag-of-word preprocessing techniques were employed, stop-words were removed, and the text was lemmatized.
For the supervised learning component, we used both stages of preprocessing before running classification models. We compared the performance of logistic regression, random forest, xgboost, and Ridge classifiers, and implemented these models with only textual covariates and with additional features that include days to the election, article language, publication, and publication owner, using a 10-fold cross-validation stratified by outcome category. The Ridge classifier using the textual information and extra features achieved the best performance with an accuracy of 87% and F1-score of 0.74. 12
Since we labeled only a subset of articles, we predict the labels for the remaining unlabeled articles using Python’s scikit-learn package (Pedregosa et al., 2011). In subsequent analyses, we used the label if it was hand-coded and the predicted label otherwise. 13
For the topic modeling component, we used only the first stage of the preprocessing pipeline. It is important to note that traditional topic models often benefit from corpus preprocessing techniques such as lemmatization, named-entity and part-of-speech tagging, and dependency parsing (Denny & Spirling, 2018). Because BERT is based on contextual embeddings, the words surrounding each word are helpful to create the topic embedding. As a result, preprocessing techniques can hinder the quality of the topics. Therefore, we use minimal preprocessing.
Next, we applied the procedure modified from BERTTopic introduced above. Specifically, we ran the BERTTopic algorithm on six versions of the data based on document definition (2) and subset (3). For document definition, we use article as a document or five-sentence (paragraph) as a document, and we also use three subsets: the broad only subset the narrow only subset and the broad and narrow subsets combined.
Across all of the topics in the six models, by visually inspecting the two-dimensional plots and applying our contextual knowledge, we identified eight common election-related themes (discussed below) by looking at all of the resulting six models’ topics. These themes appeared in at least four of the six models trained. The model trained on pooled broad and narrow coverage using five sentences as a document contained all of the election-related topics we identified. 14 Therefore, we chose this model to perform all of the subsequent analysis; however, we acknowledge these themes will vary across contexts, elections, and the number of models (e.g., sentence vs. document aggregation) researchers wish to evaluate.
We then labeled the relevant topics in our chosen model from BERTopic with one of the eight themes we identified, presenting five of those here: (1) corruption, (2) economy, (3) health, (4) public infrastructure, and (5) security; with the three remaining themes in Appendix D: (6) education, (7) housing, and (8) voting. We note that not all topics that BERTTopic detects will have an election-related theme, and these topics will not be analyzed. All election-related themes and the corresponding topics are found in Appendix Table F.6. We then calculated the cosine similarity between the three main parties (ANC, DA, EFF) and candidates (Zuma, Zille, Malema), and the eight election-related themes on the pooled data and on narrow and broad subsets separately. Finally, we estimate uncertainty with the technique described above for all estimates of cosine similarity.
Results
Before showing our core results, we first use our data to describe how election coverage varies as election day approaches, with the overall proportion of election-related articles in broad and narrow categories over time. While voting occurred on May 7, 2014, the concept of the “2014 South African election” could be interpreted as referring to a more extensive time period. Including both the broad and narrow categories accounted for on average 0.44 of articles, with a range between 0.31 and 0.67, and the maximum fraction occurring on election day itself. The bottom panel of Figure 1 displays this change in coverage, which is primarily due to the change in narrow (but not additional broad). Including narrow categories accounted for on average 0.54 of all election-related articles, with a range between 0.41 and 0.77, and the maximum narrow fraction occurring on election day. Figure 2 examines the prevalence of the mentions of the largest political parties and their leaders (Zuma/ANC, Zille/DA, Malema/EFF). Unsurprisingly, Zuma and the ANC receive the most coverage. These results show that politically relevant coverage is approximately constant, but candidate and party-focused content increased significantly two weeks before the election. Highly engaged voters would have received information in the months before the election, but closer to election day any potential voter consuming news was reasonably exposed to candidate/party coverage. Proportion of articles in the Narrow, Broad, and Non-election categories by day. Proportion of articles containing at least one mention of the three largest parties and their candidates (“African National Congress” and Jacob Zuma,“Democratic Alliance” and Helen Zille, and “Economic Freedom Fighters” and Julius Malema). Dots are daily values, and lines are seven-day centered moving averages of the proportion of articles containing at least one mention of the terms. The horizontal line is the average daily proportion of the term. The x-axis is 42 days (6 weeks) before the election through 14 days (2 weeks) after. The vertical line is election day.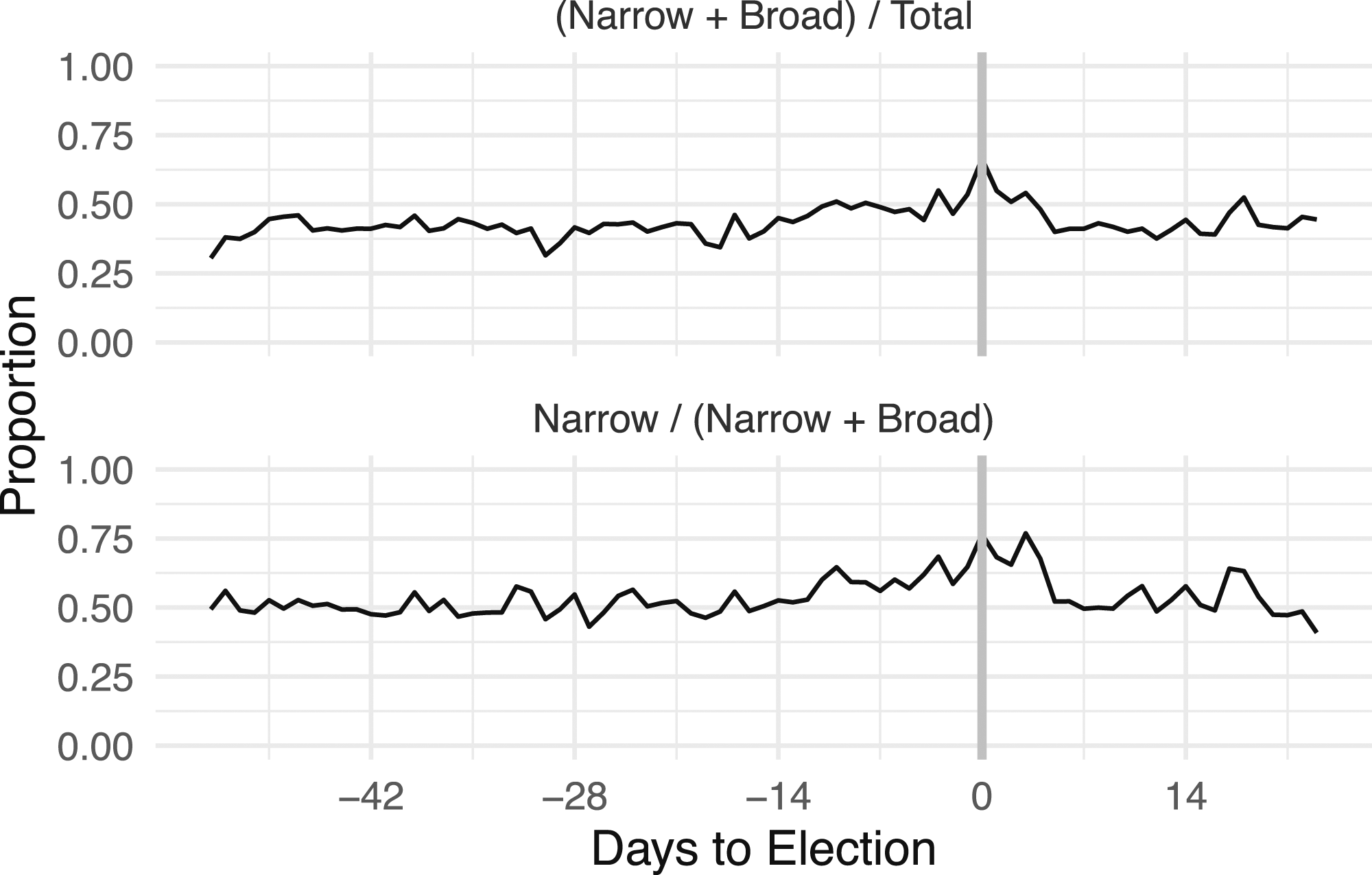
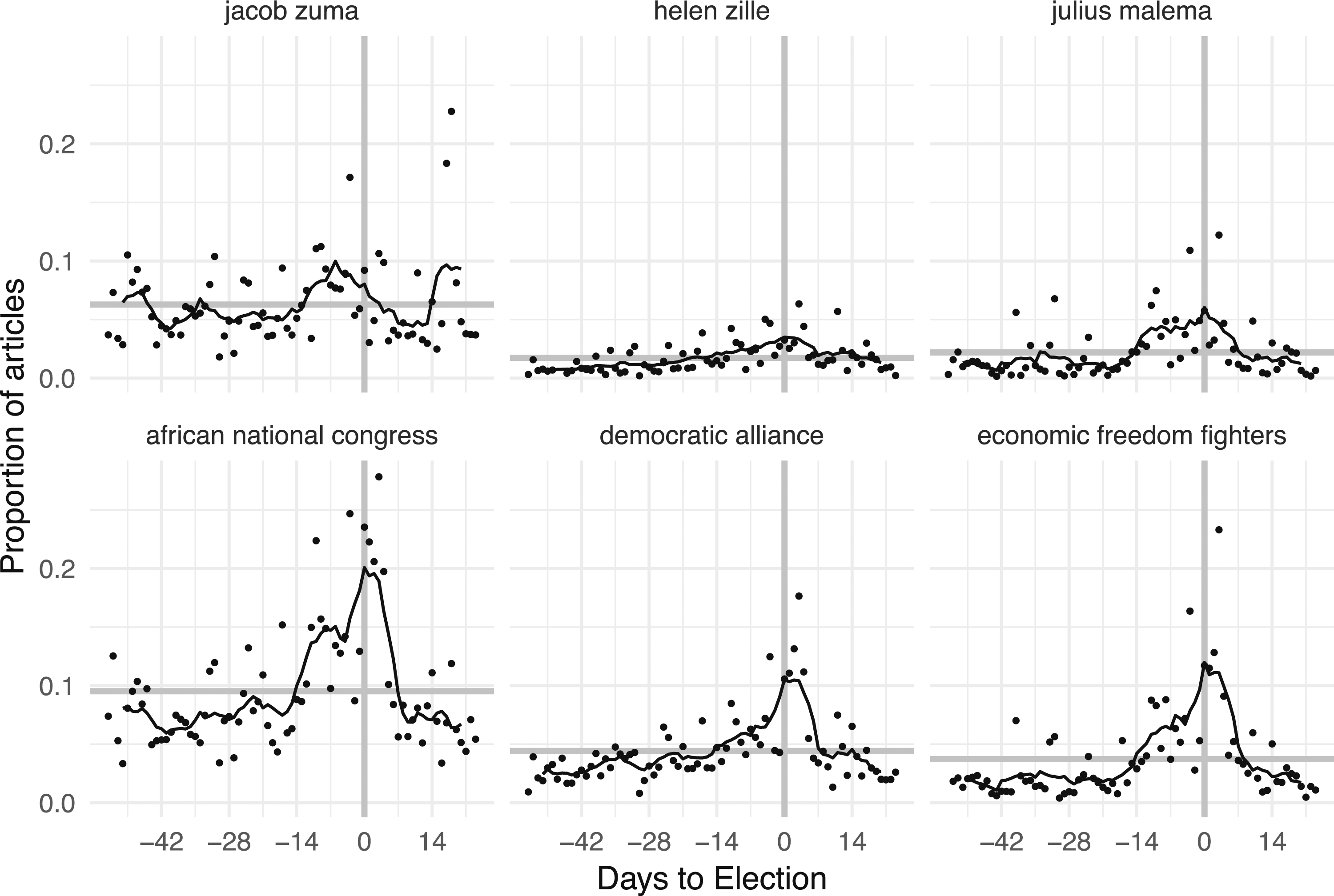
We now turn to the main application of our technique by examining the relationship between parties and candidates and the main-election topics. We do so under pooled coverage, and then separate broad and narrow—specifically to examine patterns or cosine similarity both between candidates and parties within topics and across topics. Because eight topics are too many to discuss in detail, here we highlight five for which we have predictions (corruption, economy, health, public infrastructure, and security) and include the figures for the other three (education, housing, and voting) in the Online Appendix (which have similar patterns to the topics presented). Overall, the cosine similarities range from 0.05 to 0.65.
The topic of corruption, per Corruption theme.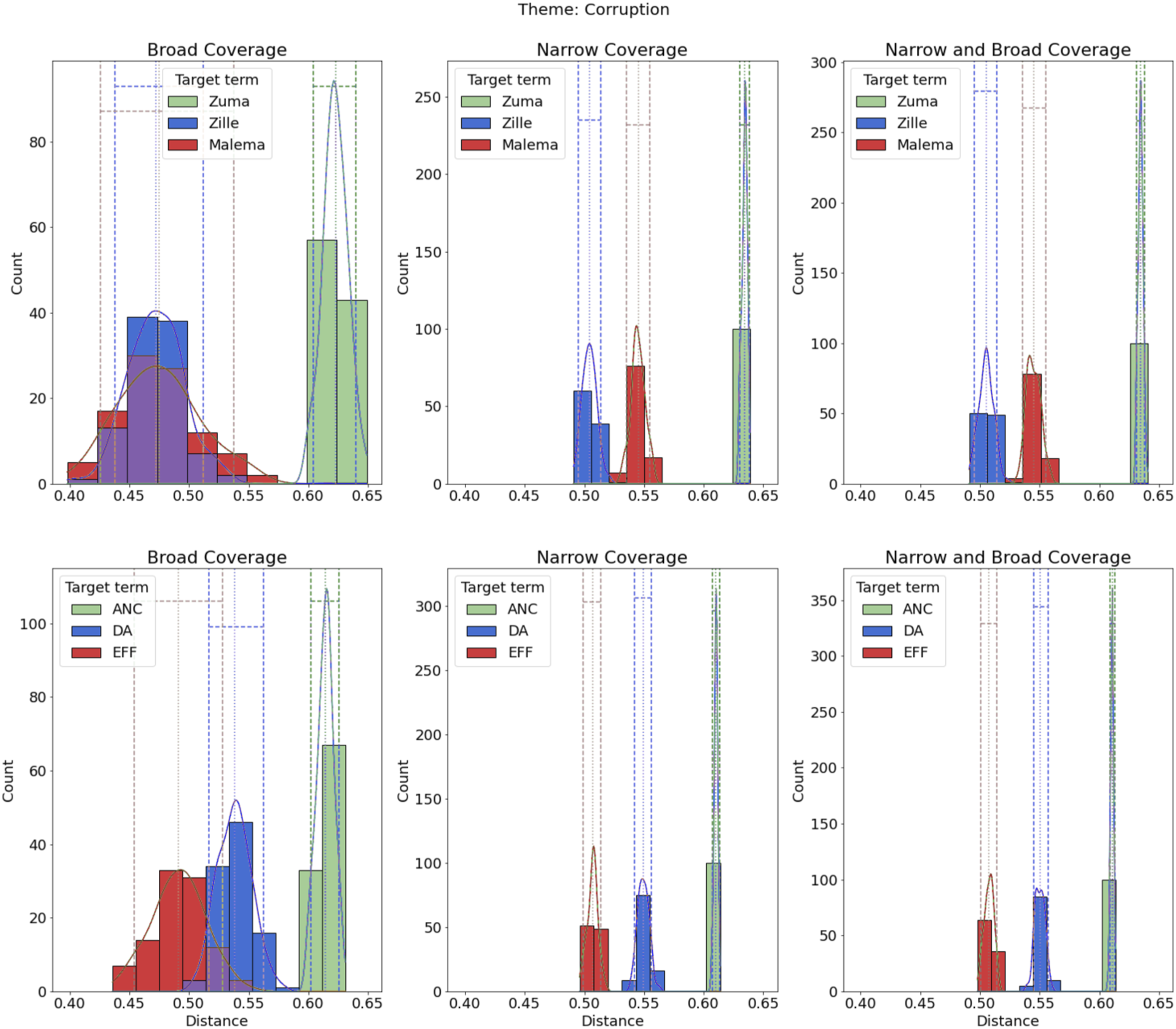
Our prediction Economy theme.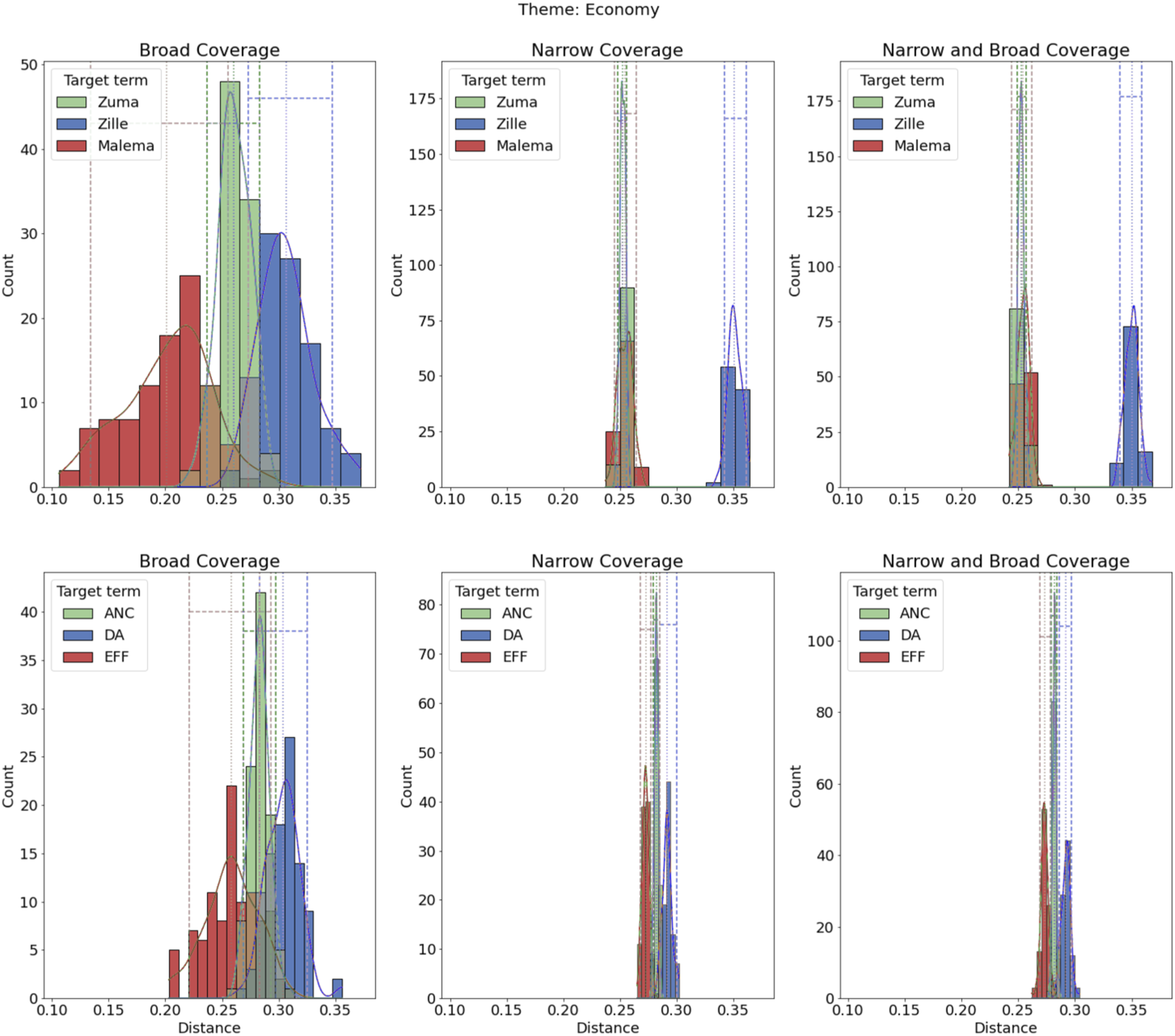
As seen in Figure 5 regarding health, contrary to Health theme.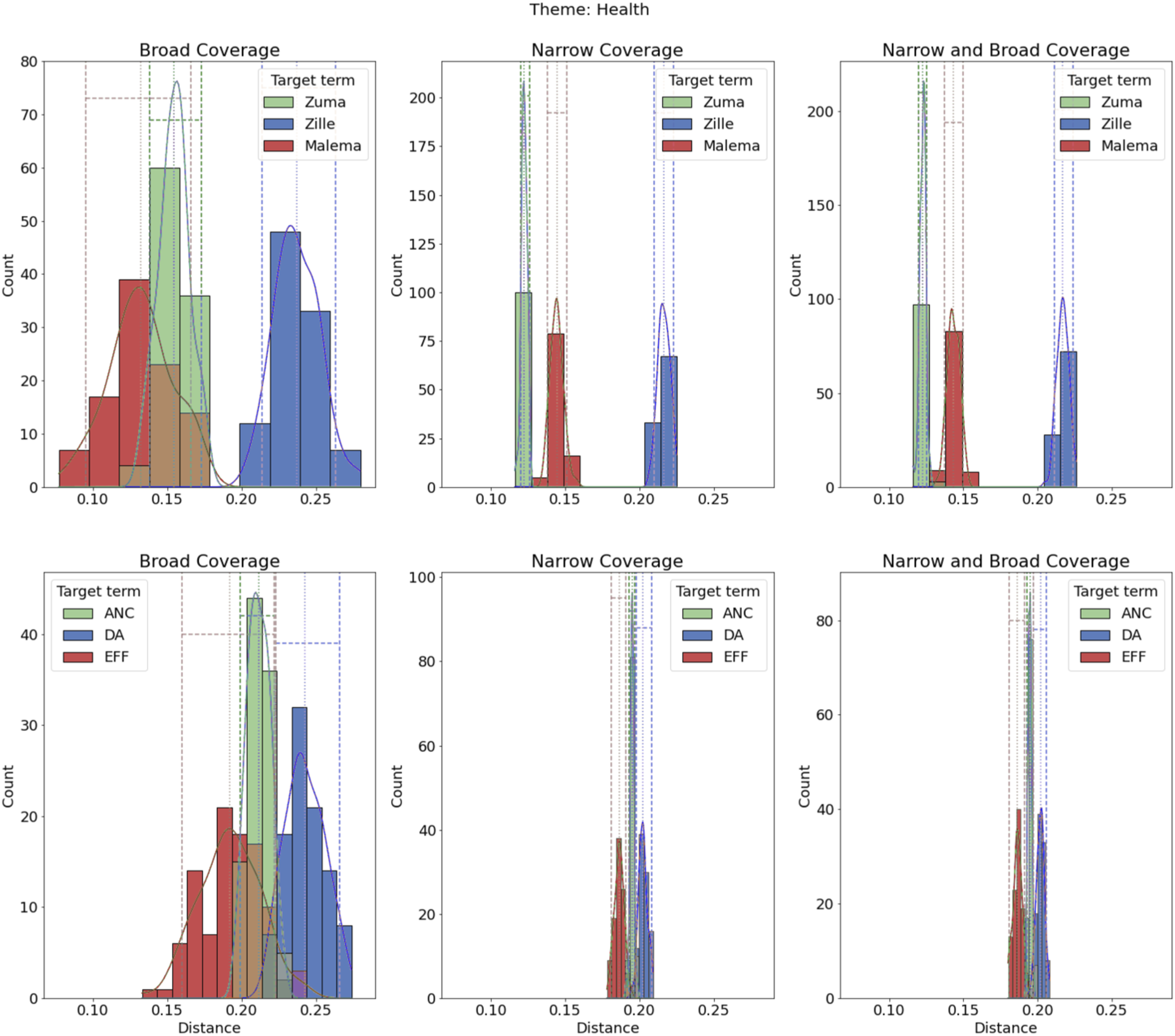
On the theme of infrastructure, we find support for Public infrastructure theme.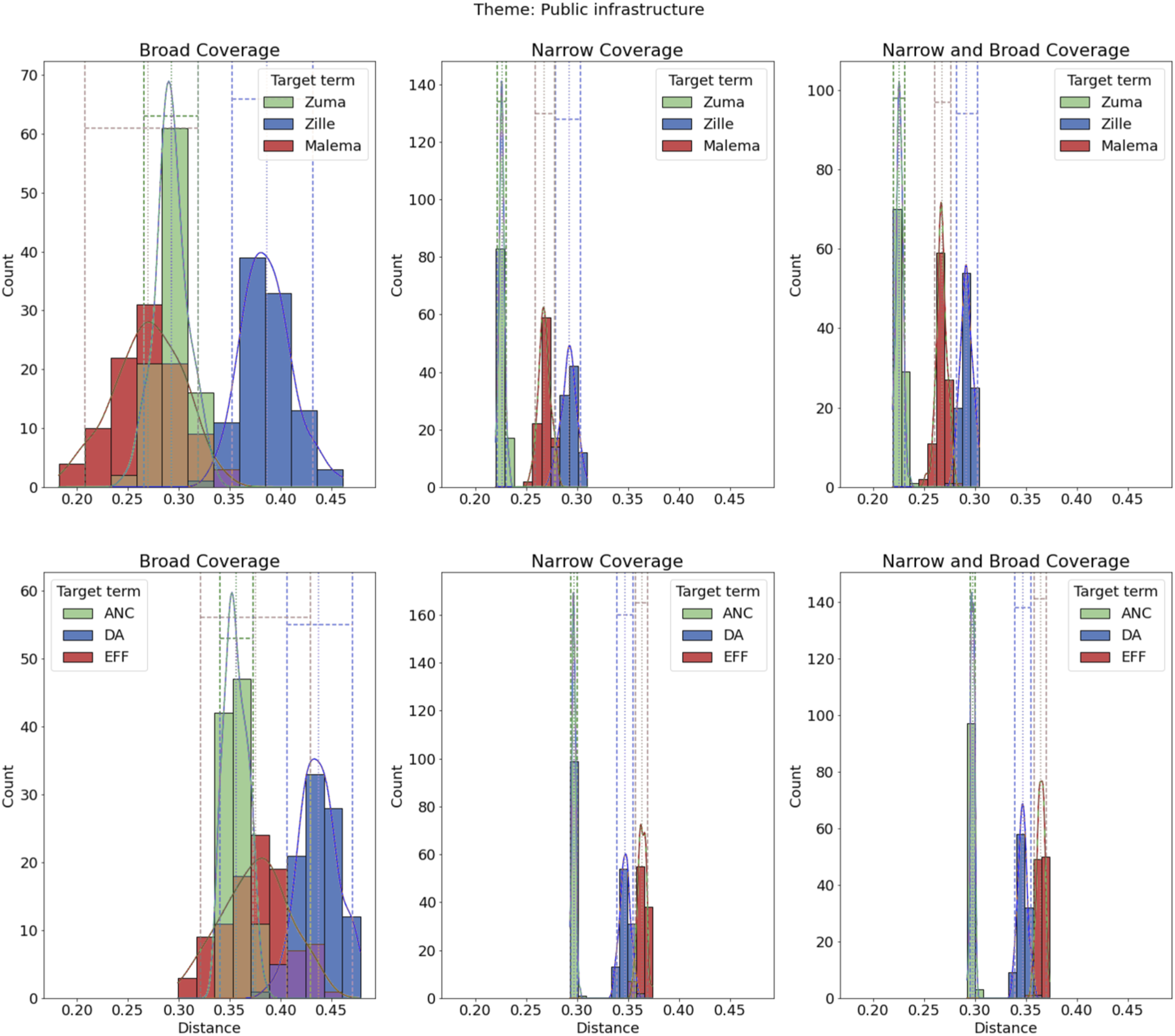
On security, we find some support for Security theme.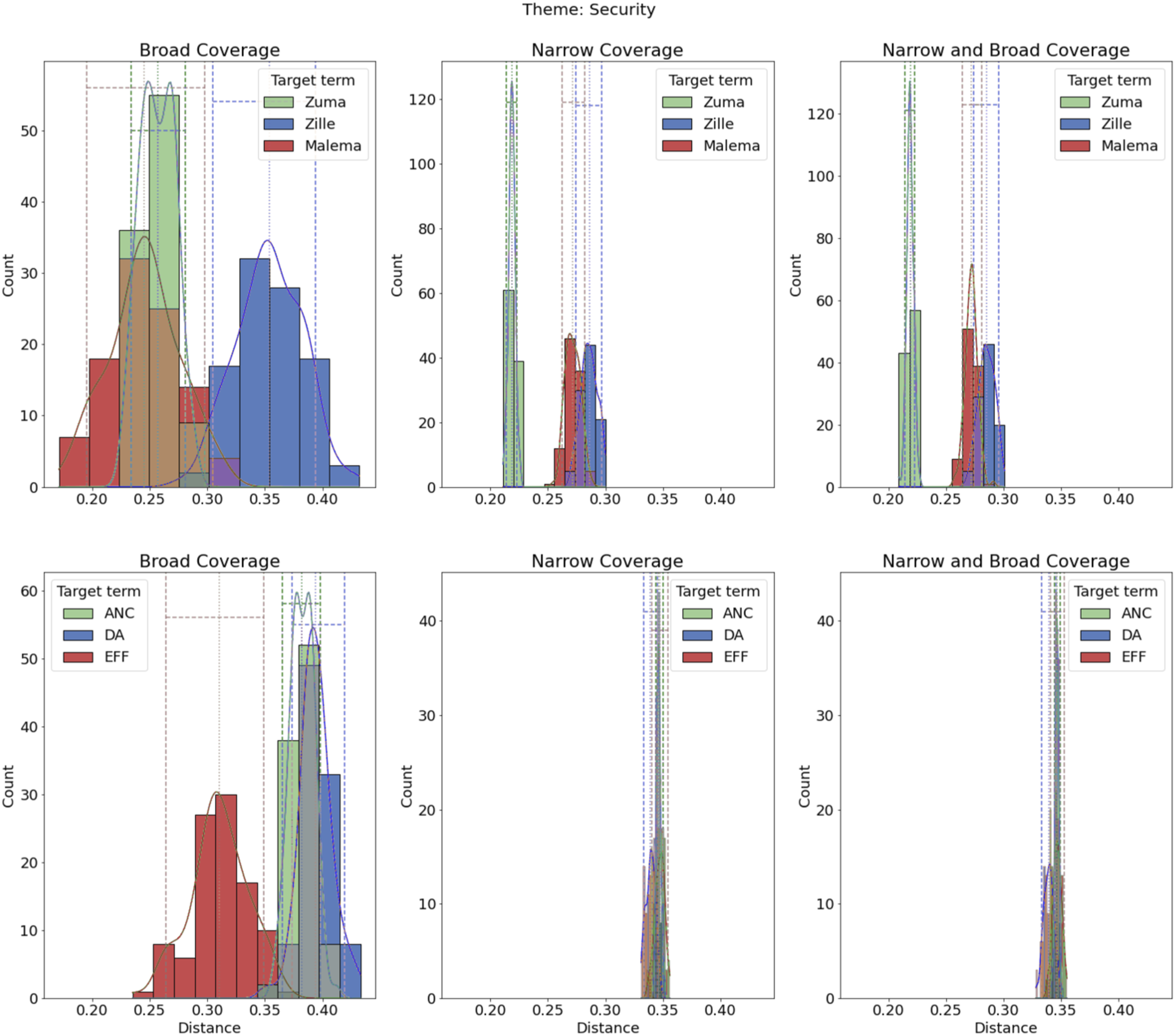
Returning to our discussion of the implications of measuring coverage as broad or narrow, the differences between candidates and parties on all election-related coverage and just narrow are almost identical, suggesting that differences between parties and candidates in their coverage are generated primarily in coverage that is directly related to the election. Within the broad category, there is much less clarity in the estimations compared to the narrow, and parties and candidates are often substantively and statistically indistinguishable. In some cases, however, while the differences are not statistically significant, there appear to be substantive differences that further research could disentangle. Nevertheless, one implication is that news readers who specifically read election-related (i.e., narrow) news articles would get more distinct impressions of the parties and candidates.
The difference between broad and narrow in how candidates and parties are associated with themes highlights the importance of coding election-related stories in multiple theoretically informed ways. Admittedly, what we found in South Africa may not appear in different campaign environments, and our findings may reflect the relatively short duration of the campaign; an avenue for further research would be to investigate how coverage varies by electoral environments. And although we expected individuals and candidates to distinguish themselves from the other parties on specific issues (e.g., Zuma regarding ongoing corruption scandals, Zille on health), we sometimes found similar estimates, particularly among opposition parties, which were often indistinguishable from one another in their coverage.
In sum, a textured picture of South Africa’s election-related news coverage and its association with parties and candidates emerges from these results. Our data show that candidates and parties can and do distinguish themselves in meaningful ways and on substantive issues, suggesting that the South African campaign news coverage is dynamic and responsive to the actors and issues.
Conclusion
Our paper presents a multi-step process for examining how news coverage distinguishes candidates and parties in an emerging democracy. We apply our method to investigate campaign media coverage based on an extensive corpus of news stories from South Africa in 2014.
Methodologically, we contribute a new technique that combines supervised and unsupervised machine learning to predict different types of election-related news coverage and estimates which political actors are most associated with the main topics within that news coverage. While our approach does not minimize the importance of identifying robust causal relationships regarding campaigns and voting behavior, we believe machine learning methods that identify and describe empirical regularities in large datasets constitute an important complement, contributing crucial forms of evidence to understanding the information environment during an election period (Monroe et al., 2015).
Our method validates most, but not all, of our empirical predictions. Both the ANC and its presidential candidate Jacob Zuma were much more associated with corruption than opposition parties; while opposition leaders were associated with some of their pet campaign themes, such as the DA’s Helen Zille on healthcare. Our method is also designed to explore whether coverage might have differed by party or candidate that a researcher may not predict ex ante; for example, we did not have a clear sense of how the presidential candidates might diverge on topics related to the economy, but this theme was most associated with the leading opposition candidate, Zille.
We also find our theoretical distinction between narrow and broad coverage yields different results. Intuitively, when examining exclusively broad coverage, candidates and parties distinguish themselves in the news coverage much less than when we examine all coverage or narrow coverage exclusively; but these findings suggest that how an analyst perceives election-related coverage matters significantly. Because narrow and broad news varies in quantity and content in many contexts, we believe our results have implications for the study of news and elections across a range of democracies, including characterizations of how media covers campaigns. Moreover, our findings in South Africa imply that voters may receive less differentiated coverage of parties when the coverage is broad, whereas more apparent and substantive distinctions may emerge when narrow.
As in all machine learning applications, our results are subject to researcher decisions. Further work could validate many of our choices regarding the processing steps and hyperparameters we set, and also apply our method to different contexts and expand the coverage of media to include transcripts of television coverage and paywalled stories. Broader electoral and media markets would present more complex electoral settings for future applications. Given constraints on time and resources, particularly in emerging democracies, automated applications such as ours offer new opportunities for research of campaigns. This method allows for us to quickly extract political coverage from all coverage and to distinguish broad coverage from narrow. We see wide-ranging implications for this application to the further study of news and elections in a variety of settings.
Supplemental Material
Supplemental Material - Covering the Campaign: Computational Tools for Measuring Differences in Candidate and Party News Coverage With Application to an Emerging Democracy
Supplemental Material for Covering the Campaign: Computational Tools for Measuring Differences in Candidate and Party News Coverage With Application to an Emerging Democracy by Aaron Erlich, Danielle F. Jung, and James D. Long in Social Science Computer Review.
Footnotes
Acknowledgements
We acknowledge generous funding from the U.S. Agency for International Development (USAID) Development Innovation Ventures (AID-OAA-A-14-00,004); the Harvard Academy for International and Area Studies [Long]; the Center for Statistics and the Social Sciences (CSSS), University of Washington [Long]; and McGill University [Erlich]. We thank Jeff Arnold, John Beieiler, Adi Eyal and Code4SA, Wes Day, Jonathan Homola, Maura O’Neill, Phil Schrodt, Walter Mebane, Randy Stone, and seminar participants at the University of Washington’s Political Economy Forum, the Centre for the Study of Democratic Citizenship’s (CSDC) Speaker Series, and DevLab USAID for comments. Stefano Dantas, Ryan Sampana, Stephen Winkler, and Wesley Zudeima provided excellent research assistance. All mistakes remain with the authors and any opinions, findings, and conclusions or recommendations expressed in this paper are those of the authors and do not necessarily reflect the views of USAID. We provide the code used to generate the main results at ![]() . For the underlying data used to create the results, please contact the authors.
. For the underlying data used to create the results, please contact the authors.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Harvard Academy for International and Area Studies, Harvard University, United States Agency for International Development (AID-OAA-A-14-00004), Center for Statistics and Social Sciences - University of Washington, and McGill University.
Supplemental Material
Supplemental material for this article is available online.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.