
Abstract
Researchers examining the social relationship between humans and machine agents have been faced with a series of obstacles, mainly due to the lack of appropriate study tools. To address this need for measurement toolkits, this article examines the development and validation of the Machines As Social Entities (MASE) scale. MASE was created to measure people’s beliefs in machine agents as social entities. Together, the results from a series of studies, including exploratory factor analysis (EFA) and confirmatory factor analysis (CFA), demonstrate that the MASE is a reliable and valid measure. Potential uses of the scales are then discussed.
Keywords
Introduction
In 2022, a computer scientist claimed that his AI partner should be acknowledged as an individual and be eligible to be a patent holder (Brittain, 2002). In the same year, an AI-generated image won an art prize, which brought controversy about the legitimacy of AI artists (Roose, 2022). These cases indicate that there are perspectives of seeing intelligent machines not as tools but instead as other social entities. It has been an inevitable concern since Turing (1950) predicted that intelligent machines may possess indistinguishably human-like intelligence, which led to the emergence of the Turing test. By engaging in traditionally human actions and behaviors, machine agents gain social status and expectations that accompany their social position. From this perspective, the more intelligent machines substitute human roles in society, the more they become actors by taking over social functions that have previously been ascribed only to human agents. Autonomy is the main reason that machines have been able to replace human labor and become social actors since the emergence of artificial intelligence (AI) technology.
Sundar (2020) pointed out the importance of studying human experiences and perceptions of machine agency, particularly during human–AI interaction (HAII). As AI technology improves, machines function as independent social entities with different roles. This means that people’s relationships with machines should be defined as interaction, not usage. Interaction is more than simply giving input and receiving output—it is about building a relationship. As people create more interactive machines, such as personal AI assistants or social robots, people are more likely to build relationships with the machines. Moreover, the machines’ improved interactivity and humanness make human–machine relationships similar to interpersonal relationships. Therefore, several communication scholars have started to examine the machine’s role as an interlocutor, calling the field “human–machine communication” (HMC; e.g., Gunkel, 2012; Guzman, 2018). It is believed that the understanding of machines’ social roles in human–machine communications is a crucial issue in the field of HMC.
As social interactions between people and intelligent machines become more prevalent, it becomes more important to know how people perceive machines’ social positions. Intelligent machines are now perceived as teammates rather than tools (Seeber et al., 2020). It is expected that more studies about the perception of machines can help diffuse the tension of viewing machines as a part of society. However, there is still no scale to measure how people see social intelligence from machine agents. Therefore, the aim of this paper is to create a scale that can measure beliefs in machines as social actors. Not only have recent studies focused less on the role of machines as social actors, but there has also been a lack of tools with which to measure how people see machines as social actors. A new measurement tool is needed in order to assess the beliefs in machines as social actors, which can facilitate more studies about the social roles of machines. This paper reports on the development and validation of a scale that measures people's beliefs in machine agents as social actors like other humans. The scale is called the Machines As Social Entities scale or, in short, MASE.
This paper consists of laying out relevant concepts, developing survey items, providing proposed measures, and validating them. The concepts of actors and roles are key when designing the framework of this scale. Also, the theoretical framework for the scale will include the theory of mind because previous studies claim that it has a substantial influence on understanding others during interactions (Paal & Bereczkei, 2007; Preckel et al., 2018). The way that these three concepts—actor, roles, and the theory of mind—tie into the scale will be discussed. It is expected that the development of this scale will provide a measurement tool for social science researchers in the field of human–machine communication.
Actors and Roles
Banks and de Graaf (2020) asserted the importance of understanding the role of machine agents in terms of agency, interactivity, and influence when they are not based on traditional communicative functions. While “role” is a slippery term with multiple definitions, Biddle (1986) conceptualizes it as a characteristic behavior pattern based on the presumption that people have social positions and hold expectations for their own and others’ behaviors. Biddle's definition of the role is widely accepted, as his approach was the first attempt to encompass the basics of role theory (van der Horst, 2016). The function of “role” in the context of human–machine communication is important because people have expectations for both roles and machines, such as a belief that computers are more trustworthy and unbiased than people, called the machine heuristic (Hindin, 2007; Sundar & Kim, 2019). Machine heuristics are identified by the Modality–Agency–Interactivity–Navigability (MAIN) model, which argues that technology traits function as cues inducing cognitive heuristics that affect the level of trust (Molina & Sundar, 2022). Lee and her colleagues (2022) pointed out that the social role of a machine agent is one of the cues that has traditionally been associated with humans. Based on the literature, it is expected that people will trust an intelligent machine with a social role (e.g., an AI journalist) more when there are fewer discrepancies between machine heuristics (e.g., the AI is always neutral and logical) and presumptions about their role (e.g., journalists must be fair and unbiased).
The concept of actors, which refers to social entities that compose and interact with networks, is closely related to roles because people engage with others as social actors by conforming to role expectations (Latour, 1994; Lynch, 2007). Role theory defines actors as people with the capacity for logical functioning since having roles requires learning from experience and acknowledging attributed expectations (Biddle, 1986). In short, one should first be regarded as an actor in order to have his or her role in social relations. So, beliefs in machines being actors, which the MASE aims to measure, should be considered with the examination of machines’ role adequacy.
The importance of studying social relationships between machines and humans grows as machines become autonomous and independent (Fast & Schroeder, 2020). However, many studies simply assume machines act as social actors in communication settings without empirically testing whether people genuinely regard their machine counterparts as social actors. Studies using the Computers-Are-Social-Actors (CASA) paradigm would be great examples, as they mostly focus on how people react to machines’ social presence and social responses (see Lee et al., 2005; Lee et al., 2006; Lombard & Xu, 2021). However, even though the paradigm uses the term “social actors” in its name, its core argument is that people mindlessly behave socially toward machine interlocutors with human-like traits (Nass & Steuer, 1993). From the CASA perspective, a machine is seen as a mere recipient of people’s mindlessly done social behaviors without its social traits and influences as a social entity considered. So, CASA is not applicable when explaining social interactions with machine agents in mindful situations (Hong et al., 2020 a). Considering that treating machines as social entities like other people involves cognitive efforts, there should be a new line of studies deviating from the CASA perspective. The development of the MASE, which is based on the concept of roles and actors that involve mindful interaction, will provide a tool for this testing.
This study is not the first attempt to create a scale that measures people’s reactions to machines’ social roles. Johnson et al. (2008) examine beliefs about computers’ social roles and capabilities and call their analysis “the computing technology continuum of perspective (CP).” The authors claim that CP has four dimensions: intelligence, socialness, control of human–computer interaction, and control of rights and privacy. They also asked for public opinions on these dimensions when devising survey items. Furthermore, they provided a 13-item scale that can measure CP. While the theoretical perspective CP provides is coherent, the measurement in the paper lacks generalizability since it focuses narrowly on particular functions of computers (e.g., computers are capable of effectively teaching people; computers are capable of telling doctors how to treat medical problems). Because the current machine agents are becoming more versatile, a measurement should generally be applicable to encompass such trends. While this CP measurement could not resolve the need for a new measurement regarding the evaluation of machines as social actors, it contributed by suggesting four dimensions that should be considered for scale construction. MASE did not follow those four dimensions exactly because the logic behind the conceptual categorization described in the paper was not theoretically reasoned and sound. Still, people’s thoughts on the four dimensions were asked when developing survey items in order to reflect public opinions about the machines’ social roles.
Theory of Mind
Theory of mind (ToM) refers to the ability to attribute mental states (e.g., beliefs, emotions, intents, and perspectives) and acknowledge that others’ mental states are not always equivalent to ours (Premack & Woodruff, 1978; Happé, 1993). ToM also makes it possible for people to infer the mental state of others from their behaviors, which makes it a crucial part of social interactions (Hellendoorn, 2014). People with autism, schizophrenia, and substance addictions are often found to have deficits of ToM (Corcoran et al., 1995; Frith & Happé, 1994; Sanvicente-Vieira et al., 2017; Uekermann & Daum, 2008). ToM is highlighted as a crucial component of artificial social intelligence because recognizing and attributing other people’s mental states is a core process in social cognition (Williams et al., 2022). Also, ToM is closely related to the construction of roles because it enables people to distinguish the self from the other (Bratu, 2014). This can carry into interactions with non-human actors. Laurent-Simpson (2017) used animals in a test of interaction context and human perception as sources of role identity and found that a ToM for animals can influence the formation of non-human actors’ roles. As non-human actors, the use of animals suggests that there can be roles and ToM in interactions with other entities, including machines.
A previous study found that people attempt to understand the mental model of AI systems when interacting with AI agents (Gero et al., 2020). Still, it should be noted that the application of ToM in the human–machine communication context may be dissimilar to the interpersonal communication context. This is because ToM, during an interaction with machines, perceives a machine interlocutor as an agent with a human-like cognitive process. For instance, a study found that people felt stronger sympathy toward a mistreated machine when it possessed more human traits (Carlson et al., 2019). Even if people think that a machine’s beliefs, emotions, intents, and perspectives are different from their own, they can still believe that machines have mental states like humans. ToM in interpersonal communication studies has examined how people deal with the different mental states of others, such as the influence of mind-reading abilities on relationship development (Dunn & Brophy, 2005; Wang et al., 2015). However, ToM in human–machine communication should rather focus on whether people see machines as human-like beings during interactions. People’s ToM for the machine will increase if they perceive its human traits.
ToM studies have found that the anthropomorphic aspects of machines induce social behaviors (Hegel et al., 2008; Kwon et al., 2016). However, these studies were based on participants’ reactions without measuring their genuine thoughts on regarding their machine counterparts as human-like actors. Because ToM is a cognitive ability, behavioral outcomes alone cannot be evidence of how people perceive machines. The MASE can fill the gap between the behavioral outputs and cognitive processes in regard to ToM in human–machine communication.
As mentioned earlier, there is a contextual difference between the interpersonal and the human–machine types of communication in terms of the application of ToM. The MASE is based on the latter by measuring the level of mind perception from machines. Gray and her colleagues (2007) claim that there are two mind perception dimensions: experience and agency. The experience dimension refers to eleven capacities—pleasure, pain, desire, hunger, fear, personality, pride, consciousness, embarrassment, rage, and joy. The scale construction included the experience dimension because it was about how people see the ontological similarity between humans and machines. People are more likely to regard a machine agent as a person if it possesses those 11 capacities. On the other hand, agency refers to seven capacities—emotion recognition, thought, planning, memory, communication, self-control, and morality. Both dimensions were considered when developing the items. The agency dimension was also used because it was about the basic qualifications of being a social entity. If a machine agent fulfills the two dimensions, people will see it as a communicative human-like being. The creation of survey items included querying people’s opinions on these two dimensions of mind perception.
Methods
This paper consists of three survey studies. First, an open-ended survey with seven items was conducted for item development. Based on data gathered from the first study, candidates for the MASE questionnaire items were created using a qualitative thematic analysis. The second survey was done to create a scale with high reliability. An exploratory factor analysis was used to select items. Finally, a survey with the finalized MASE and other existing scales was conducted to test the model fit and validity.
Item Development
Multiple factors, such as perceiving the minds of machines and their social position as actors, were considered when devising the scale. Items for the scales were developed by extending ToM and the concepts of roles and actors in the context of human–machine communication and drawing on existing questions from previous scales. When devising question items, wordings from the Prejudice toward Immigrants Scale (Stephan et al., 1999) and Negative Attitude toward Robots Scale (NARS) (Nomura et al., 2006) were referenced because the questions asked were relevant to what the MASE aimed to measure. The scale of prejudice toward immigrants measures how people react when a new type of actor is introduced in society—originally immigrants but machines in this case. This scale mainly focuses on people’s concerns about whether newcomers can follow and adjust to the preestablished roles and systems of society. It is believed that people’s worries about the intrusion of machines as a new type of social actor resemble the concern about immigrants. On the other hand, NARS measures people's attitudes toward machines. Even though the MASE asks questions in a more specific context than NARS, the questions posed by the MASE resemble those of NARS since both of them measure how people think of interactive machines.
Boateng and colleagues (2018) recommend using both inductive methods, such as developing items from people’s responses, and deductive methods, such as referencing literature reviews and assessing existing scales, when generating items. Therefore, a free-written form of a survey with seven items asking about the machine’s social roles and its mind perceptions was used as an item development. The seven open-ended questions were created based on the dimensions of ToM and the dimensions of CP mentioned above (see Appendix A). Johnson and colleagues (2008) suggest not recruiting participants from similar environments when developing a scale for its generalizability, so this study distributed the survey to people from diverse backgrounds in terms of their expertise and culture. Qualitative thematic analysis was used when extracting materials for candidate questions, which is a widely used qualitative analytic method to search for themes and patterns (Braun & Clarke, 2006). So, the words and sentences that were frequently shown in their responses were selected and reviewed. After removing irrelevant terms, the remaining ones were used when devising questions. From the responses collected from the 65 respondents (colleagues and those recruited from social media who were mostly undergraduate and graduate students) who voluntarily participated, 53 items (13 items relevant to seeing machines as society members, 22 items relevant to the concept of roles and actors, and 18 items relevant to the ToM) were extracted. It should be noted that these three dimensions are not mutually exclusive, as they have a social element. When devising questions about people’s beliefs in machines treated as society members, the aforementioned NARS and the prejudice toward immigrants scale were referenced.
Even though two dimensions (social roles and ToM) were considered when asking questions, the responses were clustered into three groups based on the theorized underlying dimensions of including machines as society members. This was because some responses expressed thoughts about treating machines as other people in society, which was not relevant to the concept of roles or ToM. Then, the content validity of these 53 items was discussed with five senior-level professors in the communication and engineering department who study with expertise in human–AI interaction. Then, piloting with five other researchers followed to polish elements of the survey design, such as wording, order, and measurements. After revisions through these processes, 53 items were chosen as candidates for the MASE questionnaire items (see appendix B). For the validation of this scale, both an exploratory and a confirmatory factor analysis were followed.
Scale Validation
For the scale validation, two studies were conducted: one for exploratory factor analysis (EFA) and the other for confirmatory factor analysis (CFA) and validity tests. The first study consisted of a survey with 53 candidate questions and eight rounds of EFAs for eliminating problematic items while keeping high reliability. The second study was done using another survey to confirm the revised scale's model fit and validities, both convergent and discriminant. Two separate surveys were conducted because responses may differ based on the constitution of questions.
A pretest with an exploratory factor analysis was conducted to verify internal consistency and factorial validity, identifying appropriate items and eliminating problematic ones from the above 53 questions, which made the scale stronger and more manageable. All measures (e.g., Machines can become sociable beings) took the form of seven-point Likert-type scales ranging from strongly disagree (1) to strongly agree (7).
Survey 1 sample statistics.
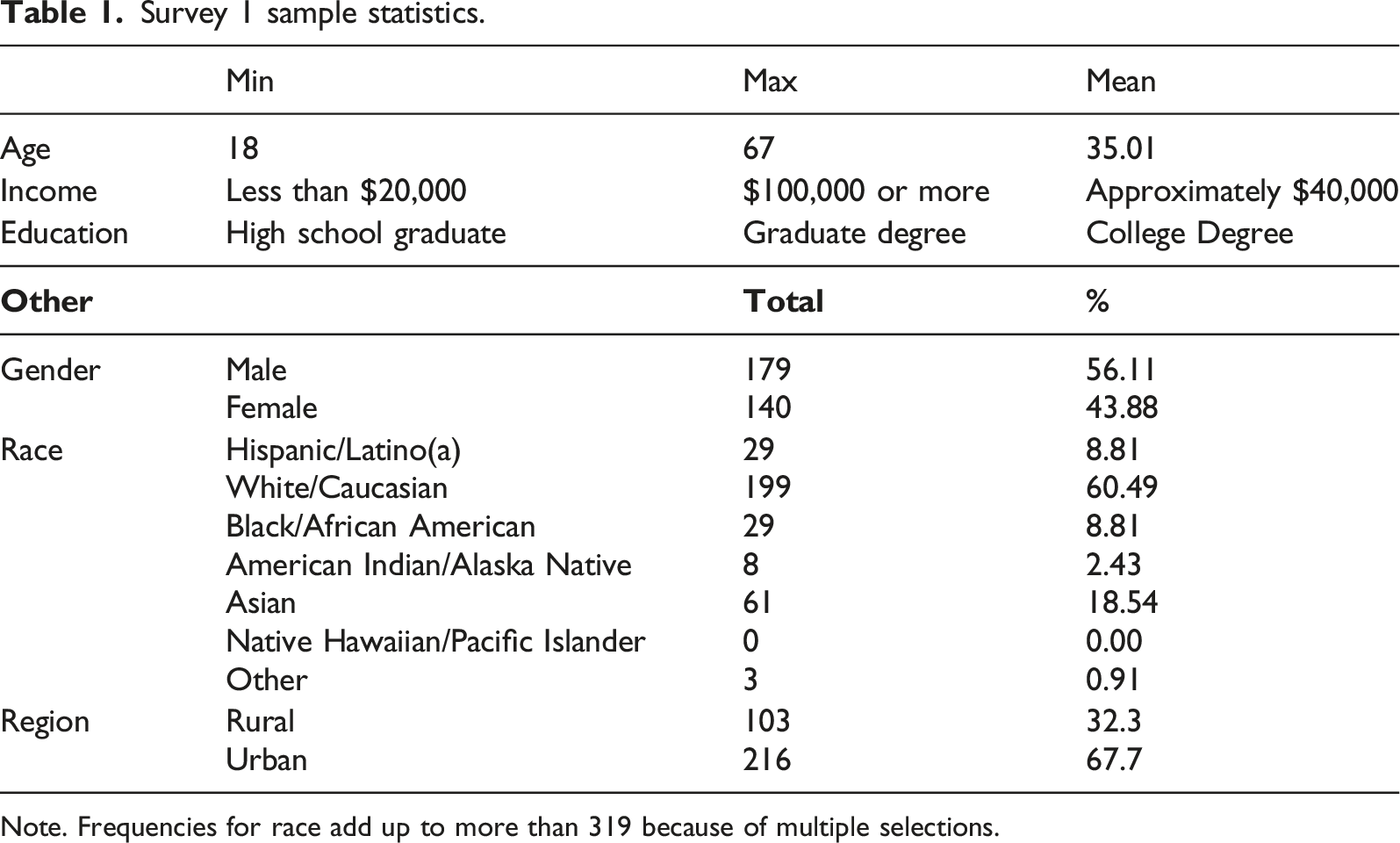
Note. Frequencies for race add up to more than 319 because of multiple selections.
Survey 2 sample statistics.
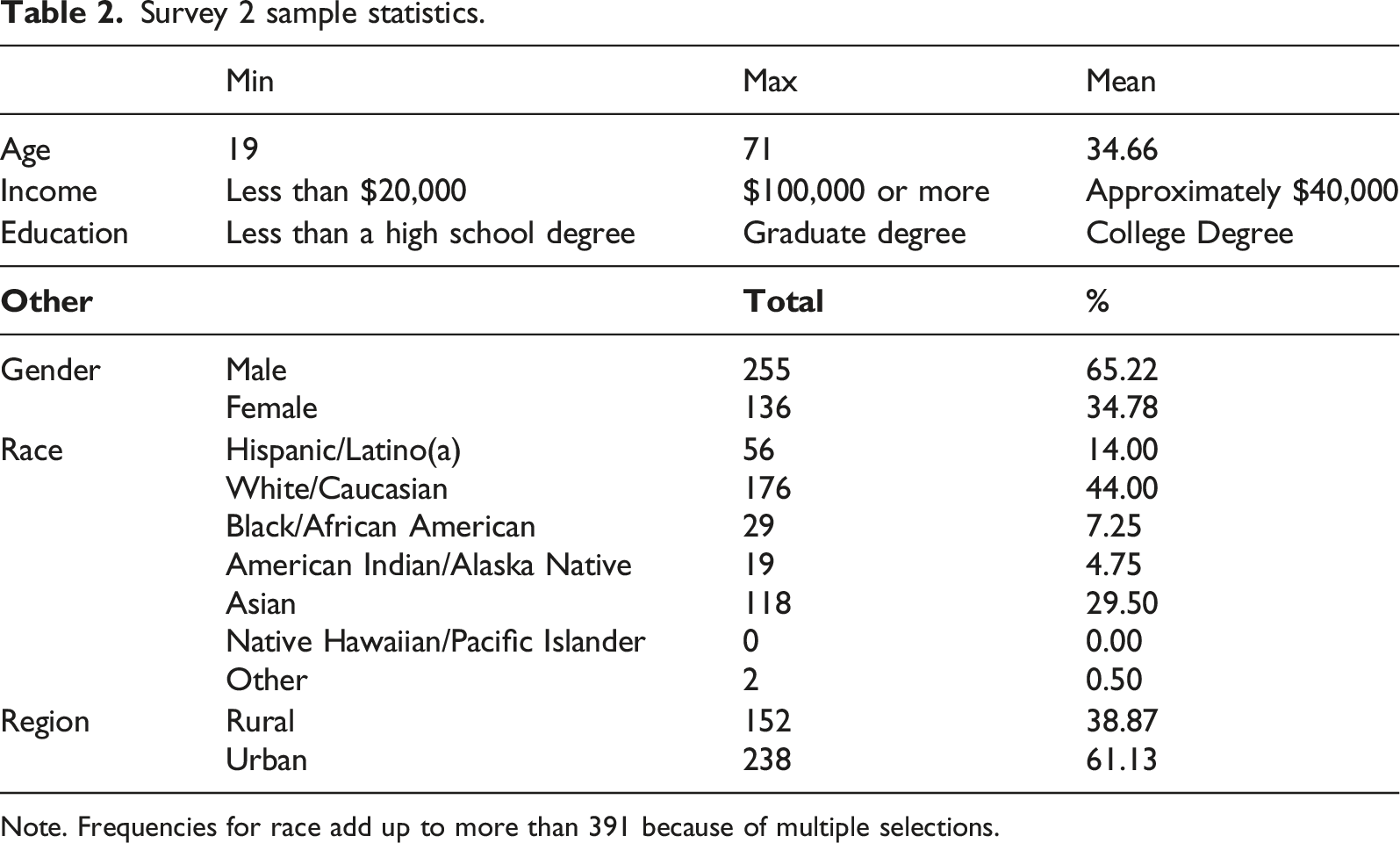
Note. Frequencies for race add up to more than 391 because of multiple selections.
Results
Exploratory Factor Analysis
An initial round of EFA of 53 items using principal axis factoring with orthogonal (varimax) rotation yielded seven factors with eigenvalues > 1 (see Appendix B). The orthogonal rotation was done to minimize the complexity of factors by maximizing the variance of loadings on each factor, which made the contrast between variables more distinguishable. An initial EFA yielded seven factors, with all of the variables loading strongly in clusters with one of three theoretical dimensions: machines’ social role performance, machines’ mind perception, and machines as society members. The outcomes provided evidence that the items loaded within the three dimensions were distinct from each other. However, there were multiple cross-loadings and items with low values of commonalities. Another round of factor analysis was run with three fixed factors for the extraction after removing items with multiple factor loadings or communality values lower than .50. It was repeated, seven rounds overall, until every item had a communality value higher than .50. A Kaiser–Meyer–Olkin value (KMO) above .80 indicates high sampling adequacy, and a significant outcome from Bartlett’s test of sphericity indicates sufficient inter-item correlations for analysis. The sixth factor analysis produced three dimensions (KMO = .96), accounting for 67.23% of the total variance with no cross-loading, with significant Bartlett's test of sphericity, χ2(231) = 5328.37, p < .001. Twenty-two items were extracted and grouped into three subscales (first factor: eight items; second factor: seven items; and third factor: seven items) based on the factor loadings. As the factor analyses and item extractions were repeated, the three subscales were not identical to the three theoretical dimensions mentioned above. The subscale items about roles and actors became more oriented to examining the capacity of machines as social actors. Questions about ToM that survived were more relevant to examining machines’ emotional experiences as social entities. Finally, the items about machines as society members that were left mostly asked about machines’ legitimacy as social actors. So, the subscales were newly named based on their items: (a) social capacity (SC), (b) emotional experience (EE), and (c) social legitimacy (SL). While not equivalent, SC is relevant to machines as actors, EE is mostly based on the ToM, and SL is related to the social role of machines. Overall, the MASE (α = .96) and its subscales, SC (α = .90), EE (α = .96), and SL (α = .90), displayed high reliability.
Correlations between survey items.
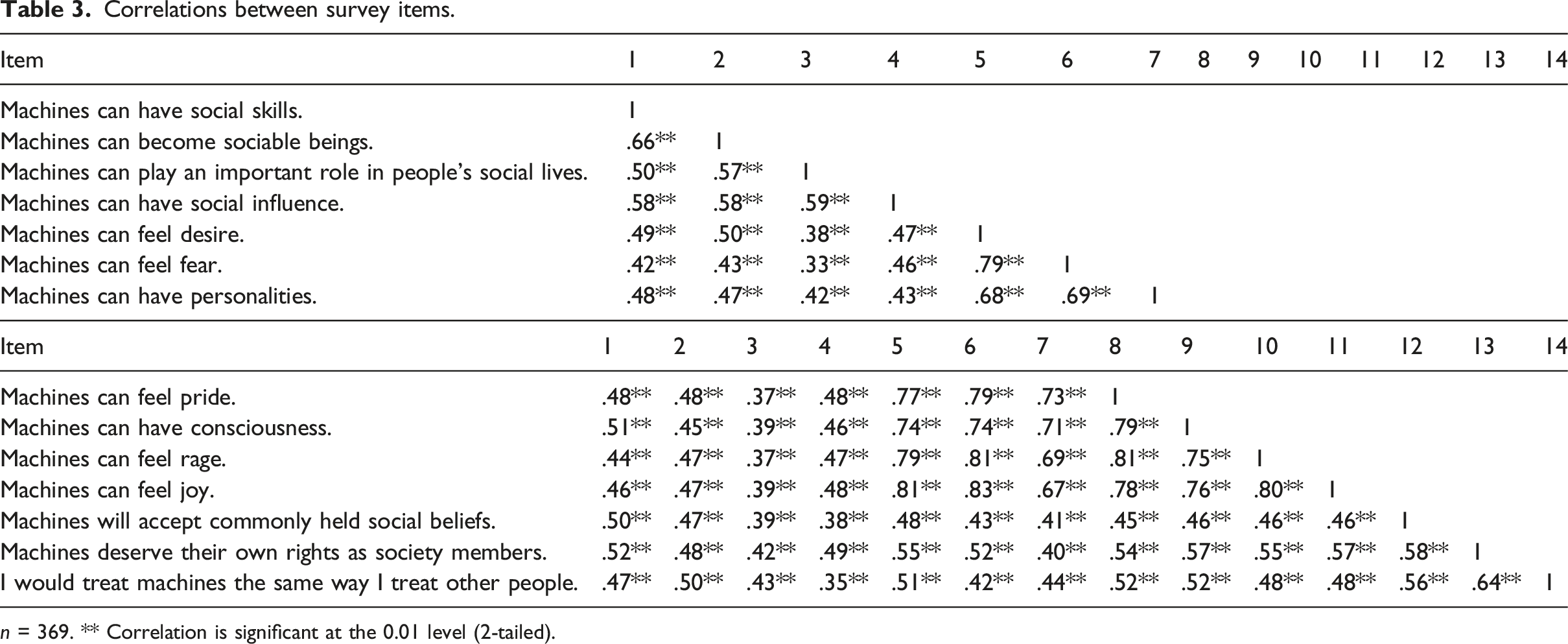
n = 369. ** Correlation is significant at the 0.01 level (2-tailed).
The questionnaire items in the MASE with factor loadings.
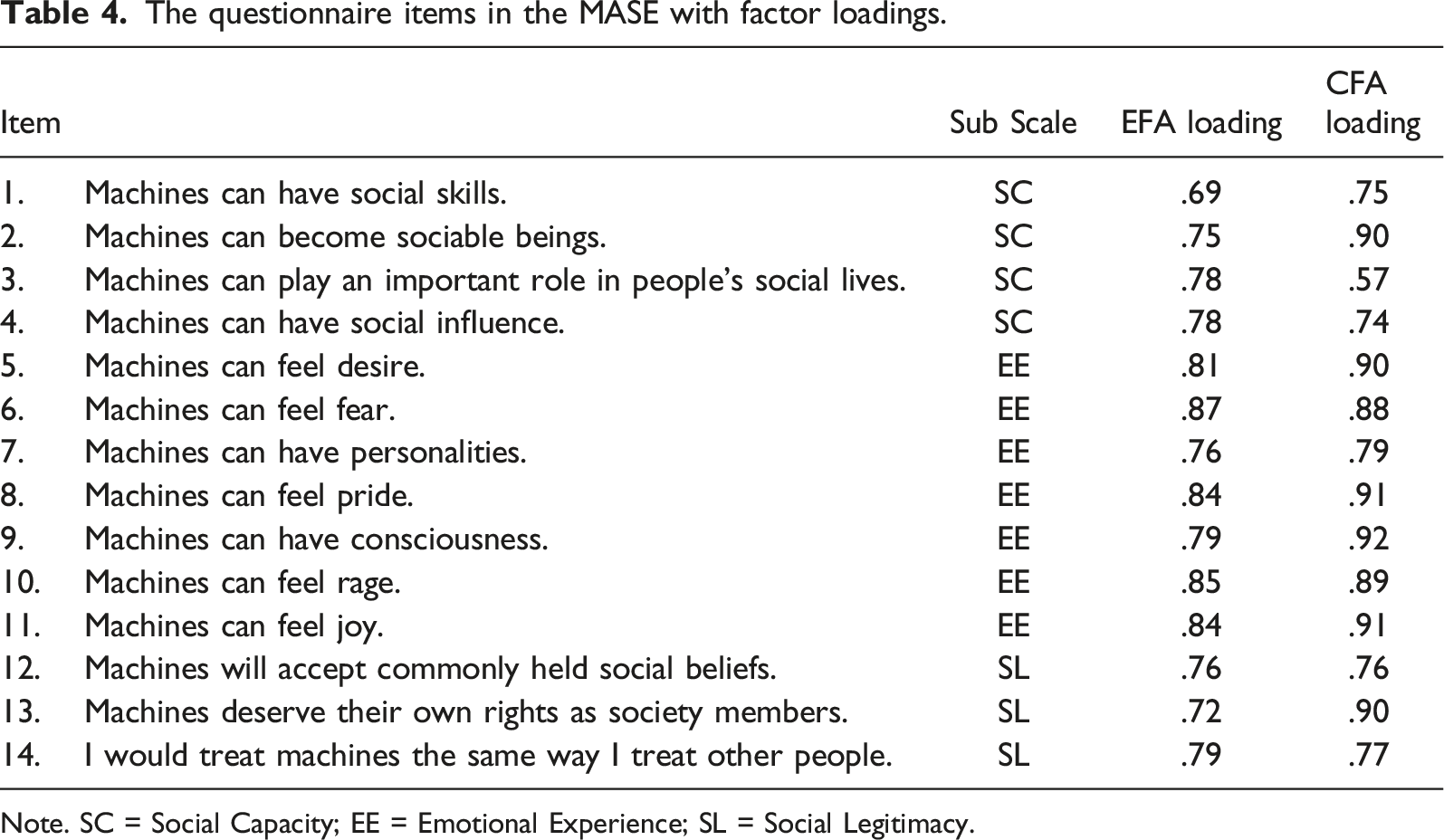
Note. SC = Social Capacity; EE = Emotional Experience; SL = Social Legitimacy.
Confirmatory Factor Analysis
A confirmatory factor analysis was conducted to test the goodness of fit of the final 14-item MASE scale using the AMOS software package. CFA was used to examine the final factor structure of the MASE because it is a theory-driven analysis, not data-driven like EFA, which enables researchers to test the underlying constructs of an a priori model. The data can then be analyzed to see the loading of the proposed factors and the model fit (Brown & Moore, 2012; Williams, 2006). Again, the overall MASE scale (α = .97) and its subscales, SC (α = .92), EE (α = .96), and SL (α = .92) showed high reliability.
There are two ways to see a model's goodness of fit: the chi-square test and the model fit index. However, this study used multiple indices instead of the chi-square statistic (χ2(74) = 253.52, p < .001), which easily rejects null hypotheses when the sample size is large due to its being size-sensitive. Both the relative fit indices—the normed fit index (NFI) and the comparative fit index (CFI)—and the absolute fit indices—the goodness of fit index (GFI), the Tucker-Lewis index (TLI; also known as the non-normed fit index), the standardized root mean square residual (SRMR), and the root mean square error of approximation (RMSEA)—were used. NFI, CFI, GFI, and TLI range from 0 to 1, with larger values indicating a better fit. Conversely, SRMR and RMSEA range from 0 to 1, with smaller values indicating a better fit and .08 or less recommended (Hu & Bentler, 1999; MacCallum et al., 1996). The results (NFI = .95, CFI = .97, GFI = .92, TLI = .96, SRMR = .04, RMSEA = .08) showed that the models were reasonable fits for the data. CFA confirmed the single-factor structure of the MASE, indicating a good model fit. The CFA model with factor loadings is shown in Figure 1. Factor loadings from both exploratory and confirmatory factor analyses are shown in Table 4. CFA model with standardized estimates.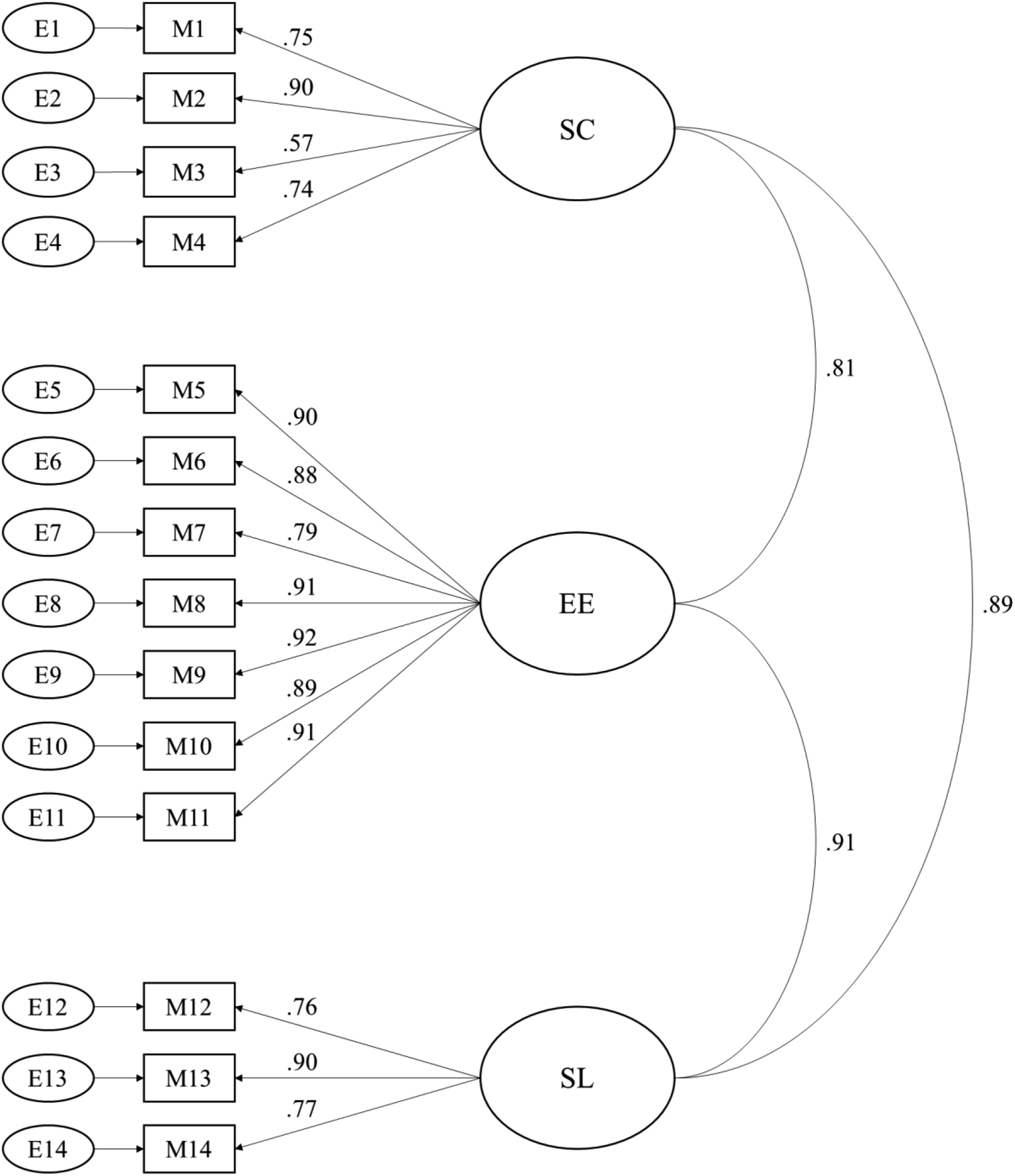
Construct Validity
A convergent validity test tests a construct's validity by examining how similar the constructed scale is to other measurements or scales with theoretically related concepts (Boateng et al., 2018). In other words, a positive correlation is expected when the concepts of the MASE and the preexisting measurements are similar. A method used in a previous scale construction was employed (Billard, 2018). CPS (α = .80) was used for this test because it also measures people’s attitudes toward computers’ social roles. So it is assumed to have a positive relationship with the MASE. On the other hand, NARS (α = .83) was used as a test of discriminant validity, which ensures a new measure is empirically unique and distinctive (Henseler et al., 2015). While extremely low correlations with other measures can invalidate the convergent validity of the newly developed scale, extremely high correlations can invalidate its discriminant validity (Boateng et al., 2018).
Intercorrelations among scales.
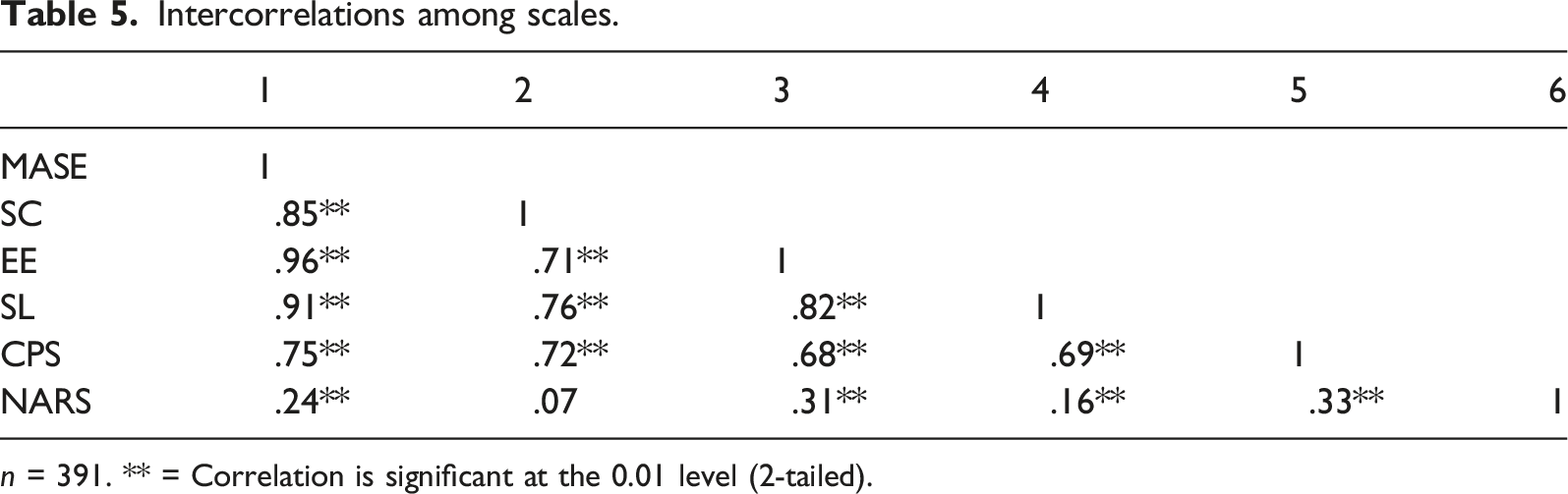
n = 391. ** = Correlation is significant at the 0.01 level (2-tailed).
Discussion
Not having proper measurements or importing scales from other fields can stymie conducting proper research. A suitable measurement was needed to facilitate more studies about the role of intelligent machines in society. This paper generated and developed a new scale for measuring people’s beliefs in machines as social actors. Also, the reliability and validity of this scale were established across multiple tests with large samples. The MASE is expected to contribute to the study of human–machine communication as a measurement that helps better explain the relationship between humans and machines. This is because people’s intentions to interact with intelligent machines can be determined by people’s preexisting knowledge and attitudes toward forming relationships with machines.
The first study generated 53 perspective scale items using a qualitative thematic analysis of 65 participants’ responses from an open-ended exploratory survey as an item development. This survey sought participants’ thoughts on intelligent machines as social actors according to four dimensions regarding the understanding of computers’ social role that Johnson and colleagues (2008) proposed and two dimensions in terms of the mind perception that Gray and her colleagues (2007) proposed. Through the process, public opinions about the topic were reflected in the survey items. One limitation of this part of the process is that the demographic information of the participants was not collected. Before running the EFA, the prototype of the scale was refined based on comments from three senior-level professors in the communication and engineering departments with expertise in human–AI interaction to ensure its content validity.
In the second study for the EFA, 319 participants recruited from an online platform, MTurk, participated in the prototype version of the MASE. The responses from the respondents were analyzed using exploratory factor analysis, which reduced the size of the scale to 22 items that can be categorized into three dimensions, (a) capacity as social entities, (b) emotional experience as social entities, and (c) legitimacy as social entities. This newly developed MASE scale and its subscales were highly reliable.
In the final study, another round of surveys with the refined MASE and a series of preexisting scales for validity testing was administered to 391 participants recruited from MTurk. Through confirmatory factor analysis, it was confirmed that SC, EE, and SL are three different but related dimensions under the attitude toward machines as social actors. Also, the convergent and discriminant validities of the MASE were established through comparisons with other scales. The reliability of the survey and its subscales continued to be shown as high during this analysis. Additionally, the study found that some demographic factors, such as age, type of residence, and level of education, affect beliefs in intelligent machines as social actors.
The findings of reliability and validity from these studies confirm that the MASE is a useful measurement for studies about how people see machines performing as social entities. As mentioned earlier, this study is not the first attempt to measure how people think about their relationship with intelligent machines as social beings. This study improves upon the previous scale by (1) using both inductive and deductive methods to reflect the opinions of both the general public and experts; (2) encompassing different types of machines, not restricted to computers, with more generalizable approaches to machines’ performance; (3) using a broader subject base for wider generalizability; and (4) reflecting attitudes toward recent technologies, such as artificial intelligence and humanoids, that were less discoursed at the time CPS was developed.
While this study was rigorously conducted, there are a few limitations to note. First, there are always concerns about the quality of data from MTurk (Peer et al., 2017). Researchers overcame this issue by taking precautions during both surveys and adding attention-checking questions to sort out high-quality responses from low-quality ones. Still, there is a possibility of getting different results from studies using different samplings. Also, when devising items, this study relied on qualitative thematic analysis only, even though the study collected hints from preexisting scales in terms of styles and nuances. Using both the items from qualitative measures and preexisting measures would have shown different questions and results. Additionally, participants’ expertise in intelligent machines and competence in AI knowledge were not measured in the surveys. Based on the sampling methods used in the studies, it is assumed that the participants are not biased about intelligent machines in one way or the other in general. Still, having the evidence would have supported the findings of the studies. Finally, a term like “machines,” which was used in the study, could be too broad because there are many technologies that could fall under the term. Some people might think of advanced technology, such as artificial intelligence, during the survey, while others might think of traditional machines, like automobiles. This was intended based on the claim of the actor-network theory that every non-human entity, including old machines with no autonomy, can be a social actor (Latour, 2005). Still, this scale focuses more on machines that can socially interact. Therefore, adopting this scale in the context of machines with no social capacity may produce different outcomes.
The MASE is not the first scale that measures how people see machine agents. There are the robotic social attributes scale (RoSAS) and the Godspeed scale that measure the social perception of machines (Bartneck et al., 2009; Carpinella et al., 2017). However, these scales focus on people’s reactions toward different attributes of machines. The MASE should be distinguished from these measurements because it examines how people see social positions that machine agents hold. In other words, the MASE is oriented more toward the social relationship between machines and humans than previous scales. While the RoSAS and the Goodspeed scale share similar variables with the MASE, the latter’s scope is limited to the evaluation of robots. Also, attitudes toward machines, which most preexisting scales like NARS measure, do not always lead to machines being treated as members of our society. Therefore, a new scale that specifically measures how people see machines as social actors is needed, which can be resolved by the MASE. Because the MASE measures people’s beliefs in machines as social entities, research on various patterns found in social interactions between machines and humans, both cognitive and behavioral, can use this measurement to inquire about the causal relationship between people’s attitudes and actions toward machines. The MASE is expected to be used in both the broad application of social interaction with machines in general and more specific settings of human–machine communication, such as interaction with artificial intelligence agents, social robots, and chatbots. The scale can be used widely by putting a specific product or service (i.e., Siri, AI doctors, self-driving cars) in the items instead of the term “machines.” Recent studies claimed that successful interactions with machines were often determined by preexisting understanding and beliefs people had about machines (Gillath et al., 2020; Hong et al. b, 2020; Shank et al., 2019).
Whether intelligent machines can become genuine members of society is a topic that becomes more important as machines perform human-like social functioning. Within a few decades, intelligent machines have become more interactive than before and have replaced human labor, even in white-collar fields that require cognitive efforts, such as journalism, eldercare, and human resources. Moreover, machines are now challenging creativity; the realm believed to be uniquely human. We may need policies and laws that allow machines to become social actors as more people treat them as such.
This research has expanded the framework of human–machine communication to account for the attitude toward machines as social actors, not merely as things. People may confuse deeming intelligent machines as social entities with treating them as human beings. While those two concepts are not mutually exclusive, they should still be distinguished. There should be more studies about the role of machines in society and how people see them. This study also provides social science researchers with a measurement tool that can be utilized for surveys or experiments to support those future studies. For instance, there was a case where an AI hiring tool made sexist decisions and gave higher ratings to male candidates than female candidates with similar performance (Dastin, 2018). The company said the decisions were purely made by AI, and it happened because the training dataset they used was, by the nature of the industry, male-dominant. In other words, because their AI merely reflected what was happening in the real world, they claimed that the incident was due to the real-world bias, not the algorithmic bias. This approach not only violates AI transparency and explainability but also makes responsibility attribution difficult. It is because there was a sexist action, but there was no single actor who was clearly responsible for the behavior. So, if people think AI has its own social agency, they are more likely to blame it, not its producer. Because intelligent machines’ accountability and trust are closely connected to what extent they are perceived as social beings, the scale is useful for understanding cognitive processes in social settings with machine agents with roles.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.