
Abstract
This manuscript details the different attributes associated with the problem of common-method variance. First, upon defining validity, we review the two primary ways by which scholars attempt to control for common-method variance, and in doing so discuss their merits. Second, we provide two alternative explanations that may also account for the appearance of disparate correlations, neither of which have to do with common-method variance. Finally, we offer a set of parsimonious solutions for the problem of common-method variance, namely CFA without correlated residuals or modeled method factors. Overall, the purpose of this manuscript is to provide guidance for organizational communication scholars when dealing with this problem.
Introduction
Over the years, organizational communication scholars have made increased use of quantitative methods (e.g., Manata & Fu, in press; Miller et al., 2011). This increase in use has yielded a spate of different quantitative approaches, the most common of which is the survey design (see Stephens et al., 2017). Preference for this method likely rests on the lack of other practical alternatives for collecting data from real organizational members. Nevertheless, it is not uncommon for cross-sectional survey designs to be approached with a healthy dose of skepticism.
One reason for such skepticism stems from the purported confounding nature of shared- or common-method variance (e.g., Podsakoff et al., 2003). Concerns about common-method variance can be traced back to the work of Campbell and Fiske (1959), who suggested that using the same method or measure could either artificially inflate or attenuate effect sizes. Despite having been challenged by others (e.g., Conway & Lance, 2010; Spector, 2006), such concerns have remained pervasive in fields where the same method (e.g., survey) is used to investigate associations between different constructs (e.g., see Baumgartner & Weijters, 2021; Kaltsonoudi et al., 2022; Malhotra et al., 2006). Organizational communication constitutes one such arena (see also Stephens et al., 2017). Indeed, a perusal of the available literature will show that common-method variance is a problem mentioned frequently by organizational communication scholars (e.g., see Child & Shumate, 2007; Fu, 2022; Manata & Fu, in press; Rice et al., 2017; Tucker et al., 2013).
Such concerns are perhaps justified, for constructs that are employed commonly in organizational communication research are likely prone to the influence of method factors. For example, when examining the constructs of organizational performance and commitment (e.g., Manata, 2023), concerns about social desirability biases, halo effects, etc. are intuitive and even unremarkable (e.g., see Podsakoff et al., 2003). Importantly, if the aforementioned constructs were confounded by some unknown method factor, then any inferences made would also be confounded. In this manuscript, we discuss the merits of various strategies that attempt to deal with this problem. Because common-method variance has not been addressed adequately in the organizational communication arena, we believe that this essay will be of decided value to those that perform quantitative organizational communication research (e.g., Child & Shumate, 2007; Fu, 2022; Manata, 2023; Rice et al., 2017; Tucker et al., 2013).
Further, this manuscript will inform the review process as the common-method variance problem is raised frequently during peer review, often creating a vexing problem for authors (see Conway & Lance, 2010). As an example of how such concerns might arise, one reviewer for the International Communication Association queried recently, “your sample had organizational members from many different organizations, how did you address common method biases?” Comments such as these are frequent and suggest a profound misunderstanding of the problem. In this manuscript, we endeavor to correct such misperceptions.
We begin by defining method and validity and defining further the problem of common-method variance. We also examine the merits of different commonly-used remedies, consider alternative explanations that might account for differences in effect sizes, and end by offering a set of parsimonious solutions to this problem. In doing so, we offer a discussion of the common-method variance problem at two different levels of analysis—item- and trait-level –mimicking the way the problem is discussed in different literatures. Overall, the aim of this manuscript is to provide an overview of the common-method variance problem for organizational communication scholars who deal with this problem frequently.
What Constitutes a Method
To measure something consists of the process of assigning numbers to the values of a variable. One way to define a method is in terms of the point of view of the person(s) producing the measure (Cushman, personal communication, 1973). Investigators might attempt to control (i.e., induce) an independent variable, in which case the value of the variable is determined by the investigator. We refer to this method as the experienced mode. It applies only to experimentally-induced independent variables. Second, self-report can be employed to measure a variable. We refer to this method as the experiencer mode. Finally, observations by someone who is neither the investigator nor the subject of study can be employed as a measure. We refer to this method as the experiencing mode, and this mode is broad. It could include participant observation, non-participant observation, projective or other tests scored by raters, public or private documents, coders’ rating of media content, and perhaps others.
A second way to define a method (not necessarily exclusive of the first) involves the measures having different item characteristic curves (ICC) 1 . For example, attitude measures could all involve self-report but differ in that the indicators for one measure (X1) employ Likert or Osgood Semantic Differential response scales (and hence linear ICC), the indicators for another (X2) could employ Guttman indicators (and hence ogival ICC), and the indicators for a third (X3) could use Thurstone indicators (and hence non-monotonic ICC).
What Constitutes Validity
Validity refers to the extent to which a measuring instrument measures what it purports to measure, and nothing else. Those assessing the validity of a measuring instrument might examine face validity, content validity, or the various forms of construct validity (e.g., discriminant validity; Campbell & Fiske, 1959; see also Cronbach & Meehl, 1955).
When ICCs are linear, one procedure used to assess a measure’s validity is confirmatory factor analysis (CFA). CFA assesses validity by analyzing the pattern of correlations or covariances between measures. Specifically, two theorems apply: the internal consistency and parallelism theorems (see Hunter & Gerbing, 1982).
The internal consistency theorem is defined as:
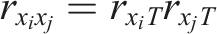
When indicators of other factors, say U, are added to the measurement model, the parallelism theorem yields predictions of the correlations or covariances between items from different factors. Specifically,
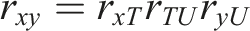
Measurement Model With Perfect Fit.
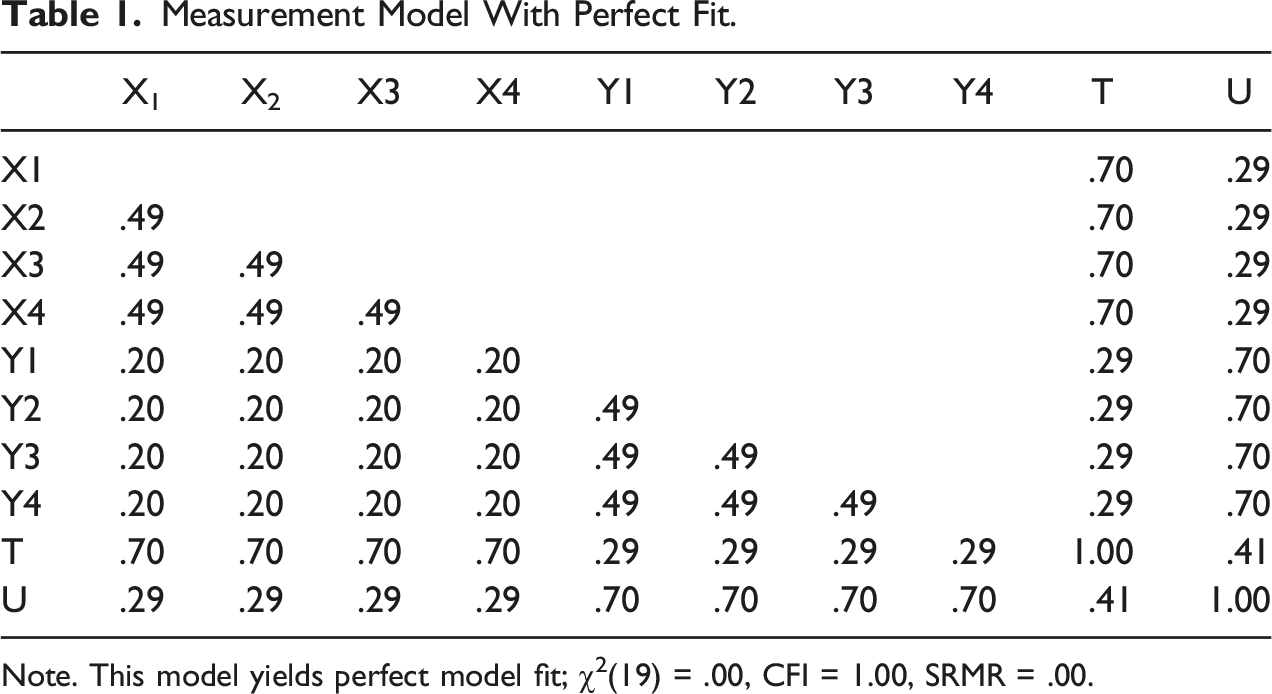
Note. This model yields perfect model fit; χ2(19) = .00, CFI = 1.00, SRMR = .00.
Measurement Model With Unsatisfactory Fit.
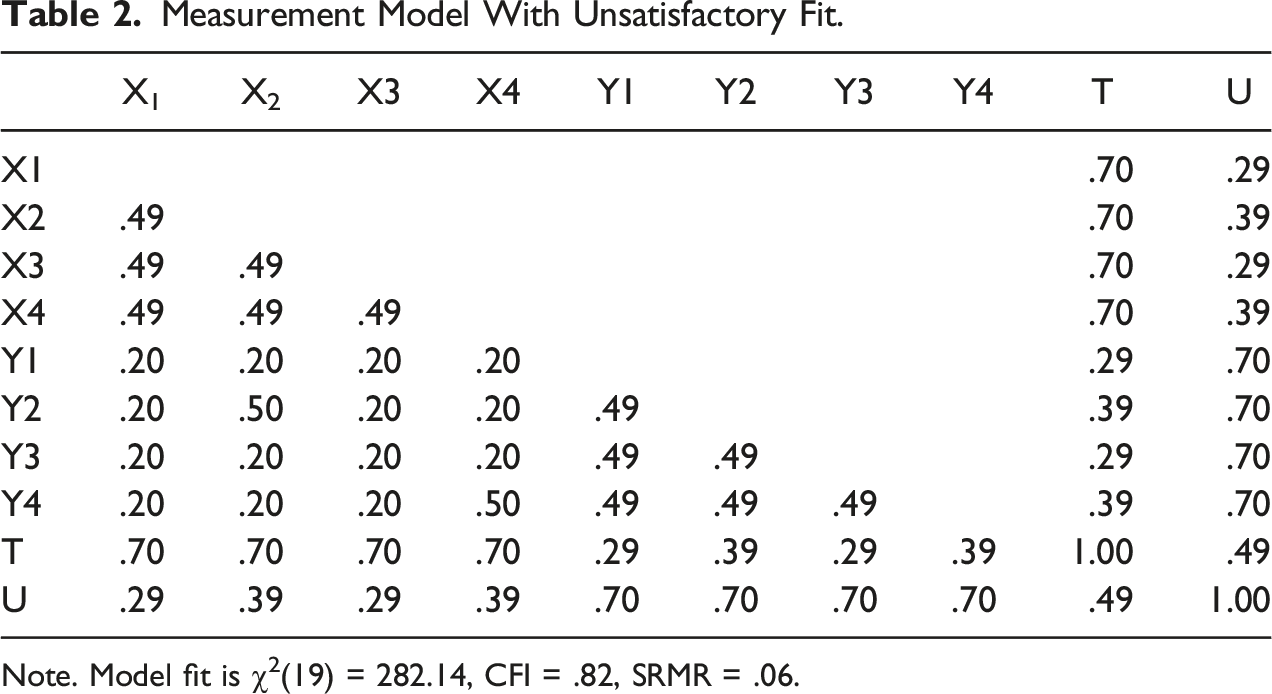
Note. Model fit is χ2(19) = 282.14, CFI = .82, SRMR = .06.
Poor model fit can occur for myriad reasons including content invalidity, non-linear ICCs, and sampling error (see Hunter, 1980), but one critical reason is the presence of unwanted specific factors common to different measures (Gerbing & Anderson, 1988). Stated differently, large residuals can occur because specific factors are shared between measures. Specific factors are factors that are systematic and unique to the measure in question (e.g., item wording) but that are also unrelated to the theoretical construct of interest (Schmidt & Hunter, 1999). For example, in addition to the construct in question, a strong need for social approval (i.e., social desirability) may also drive item responses. In this case, social desirability would constitute the specific factor.
Importantly, Podsakoff et al. (2003) specify that shared- or common-method factors constitute specific factors (p. 879). That is, when Podsakoff and colleagues refer to method factors, they equate such factors to specific factors. Podsakoff et al. also distinguish between substantive and methodological method factors. For example, in addition to the construct of interest, these authors argue that subjects’ mood may drive item responses (e.g., rating items negatively when in a bad mood), as could straight-lining responses when scale anchors are all the same (i.e., acquiescence). Nevertheless, in either case, dealing with the problem of common-method variance is equivalent to dealing with the problem of specific factor error as common-method variance constitutes a form of specific factor error.
The Problem of Specific Factor Error
As noted previously, common-method variance is problematic because it may either inflate or attenuate observed correlations in an artificial manner (Conway & Lance, 2010; Podsakoff et al., 2003). To understand how this may occur, it useful to know how specific factor variance may manifest in a measurement model. This requires a basic understanding of factor analysis.
When data are collected cross-sectionally, specific factor error is relegated to the model’s residual term (i.e., unreliability). Specifically, in a first-order measurement model, values assigned to an observed variable are driven by some unobserved latent variable and a residual (i.e., error variance). Generally,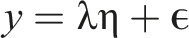
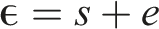
To the extent that unmeasured method factors are shared or common between variables, model residuals will correlate, and model fit will be attenuated significantly because the measurement model is incomplete. Indeed, if method factors are present, then a strict unidimensional model will provide a poor representation of the data because it is not accounting for all the relevant factors responsible for item responses.
If this type of invalidity is allowed to remain in a measurement model, then the correlations produced between different factors may be either attenuated or inflated artificially. As an example, consider the data presented in Table 2, which is equivalent to Table 1, save that the x2-y2 and x4-y4 correlations are now r = .50. In addition to providing a poor fit to the data, this model also yields a corrected correlation between T and U of r’ = .49 (uncorrected r = .39), which is now larger than it was when the model provided a perfect fit to the data (i.e., r’ = .41; uncorrected r = .33). Alternatively, changing the x2-y2 and x4-y4 correlations to r = −.10 would yield a corrected correlation between T and U of r’ = .33 (uncorrected r = .26), which is now noticeably smaller than r’ = .41. Indeed, to the extent that such invalidity is allowed to remain in a measurement model, effect size information will be inaccurate. Effect size information will also be substantively meaningless because the variable composites would represent more than one construct, i.e., correlations between constructs that are composites of two or more variables cannot accurately test the hypotheses they are designed to test.
One way to fix this problem is to remove the items that are plagued by such forms of invalidity. For example, the removal of x2 and y4 from the measurement model would yield a model that provides a perfect fit to the data. Moreover, the corrected correlation would once again be r’ = .41. Alternatively, removing y2 and x4 from the model would have the same effect. In either case, the result would be a measurement model in which method factors were no longer shared between measures (i.e., common-method factors would be removed). Instead, the specific factors that were once shared would be relegated to the retained items’ residual terms and treated as error variance (Gerbing & Anderson, 1988), and would thus have little to no impact on the resultant factor composite scores. Because such specific factors would be item specific (i.e., not shared with other items), and because they would be sampled independently and thus uncorrelated, they would be effectively controlled when averaged (i.e., they would cancel each other out; see Schmidt & Hunter, 1999).
Such materials may seem tangential, but we believe they are critical to understanding the common-method variance problem (i.e., where specific factors manifest, and how they may be controlled). We also believe they are critical to making a case for valid measurement, which we believe constitutes a basic prerequisite for making valid inferences. For example, if an organizational communication scholar were to investigate the effect of normative communication on performance (e.g., Manata, 2019), then valid inferences would require, at minimum, the use of valid measures. Thus, we believe establishing unidimensional measures is critical to making valid inferences. As suggested previously, this involves ensuring that available measures remain unconfounded by shared specific-factor error.
Below, a few additional procedures are discussed that have been proposed as remedies for the common-method variance problem. Importantly, such procedures are frequently employed in organizational communication (e.g., Fu, 2022; Tucker et al., 2013). Thus, we believe the following discussion is important for organizational communication scholars.
Common Statistical Remedies for Common-Method Variance
In the previous section, we suggested that dropping items from a measurement model constituted one solution to the problem of common-method variance. In this section, we consider the merits of two alternate statistical solutions used commonly as remedies: the correlated uniqueness model and modeling the common-method factor explicitly. We also discuss the merits of Harman’s single-factor test, which constitutes a popular diagnostic technique in communication science (e.g., Rice et al., 2017; Tucker et al., 2013). Each of these procedures are discussed subsequently (for a review of other proposed solutions, see Podsakoff et al., 2003).
The correlated uniqueness model involves stipulating a measurement model and then allowing error terms to correlate. As mentioned previously, common method factors, when unmeasured, are expected to manifest as specific factor errors. Moreover, because such factors are shared or common between different measures (e.g., survey items), model errors are expected to correlate; if this is left unaccounted for, it will attenuate model fit.
One proposed solution to this problem is to allow model errors to correlate. This procedure is expected to yield improved model fit because it accounts for any additional, unwanted factors that are shared between measures (Anderson & Gerbing, 1988). As an example, consider the model found in Figure 1, which uses the data found in Table 2. As mentioned previously, when a strict definition of undimensionality is used (i.e., when items load only on one factor, and residuals remain uncorrelated), this model yields a poor fit to the data: χ2 (19) = 282.14, CFI = .82, SRMR = .06. However, allowing the x2-y2 and x4-y4 residuals to covary yields a model that provides a perfect fit to the data: χ2 (17) = .00, CFI = 1.00, SRMR = .00. This procedure improves model fit because it accounts for the unwanted covariation left unexplained by the two-factor measurement solution. Stated differently, this procedure allows invalidity to remain in the model. Correlated uniqueness model.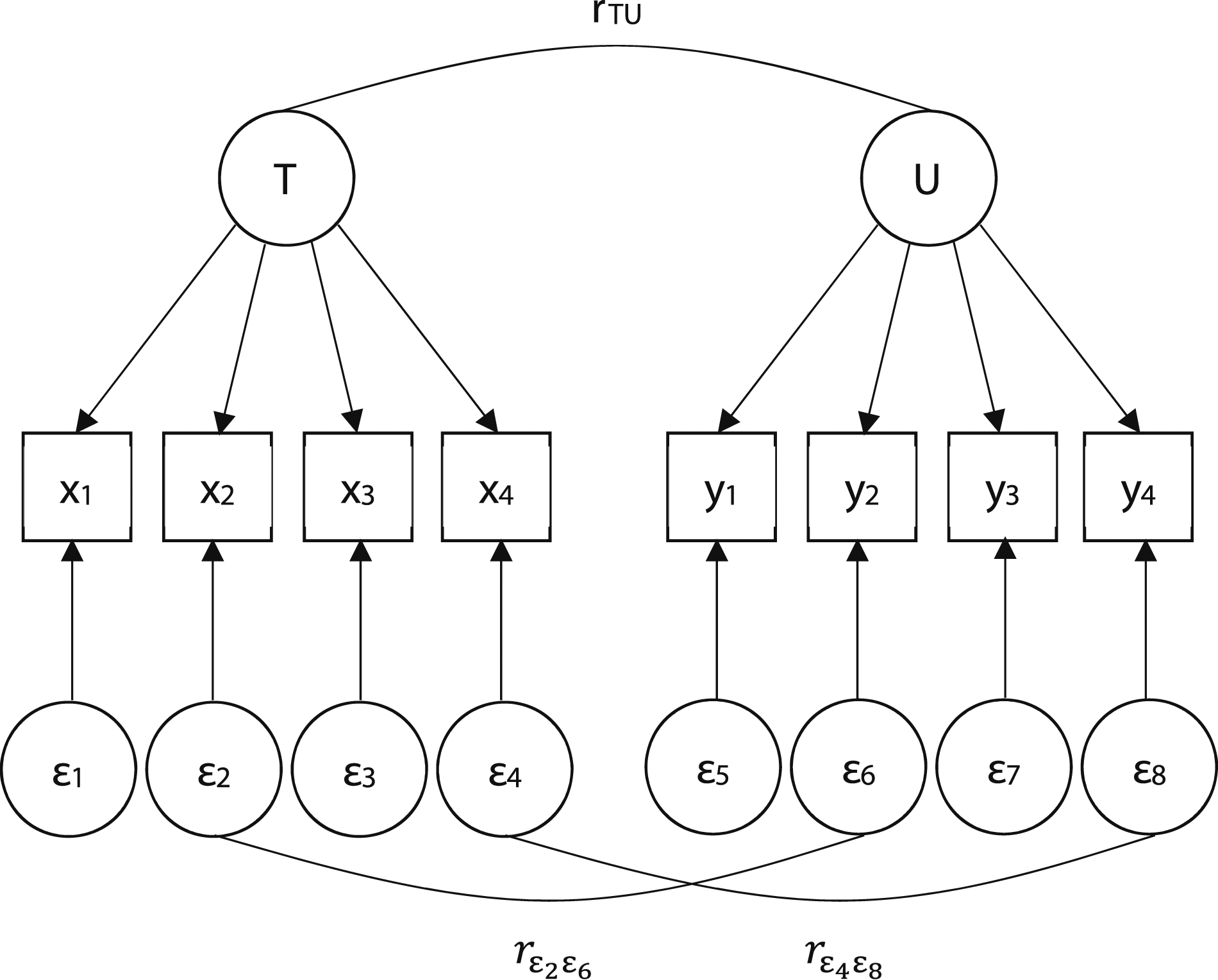
A second common way to control for common-method factors is to model the common-method factors explicitly. In this procedure, items are made to load on their respective latent factor, and also made to load on some unknown common-method factor (i.e., items are multidimensional).
6
As an example, see Figure 2, which also models the data found in Table 2, save that two, unknown method factors are now included to account for the additional, unwanted covariation between x2-y2 and x4-y4. Similar to the correlated uniqueness model, this model yields a perfect fit to the data: χ2 (12) = .00, CFI = 1.00, SRMR = .00
7
. According to Podsakoff et al. (2003), such procedures are useful because they account simultaneously for trait, method, and random error variance. Modeled method factors.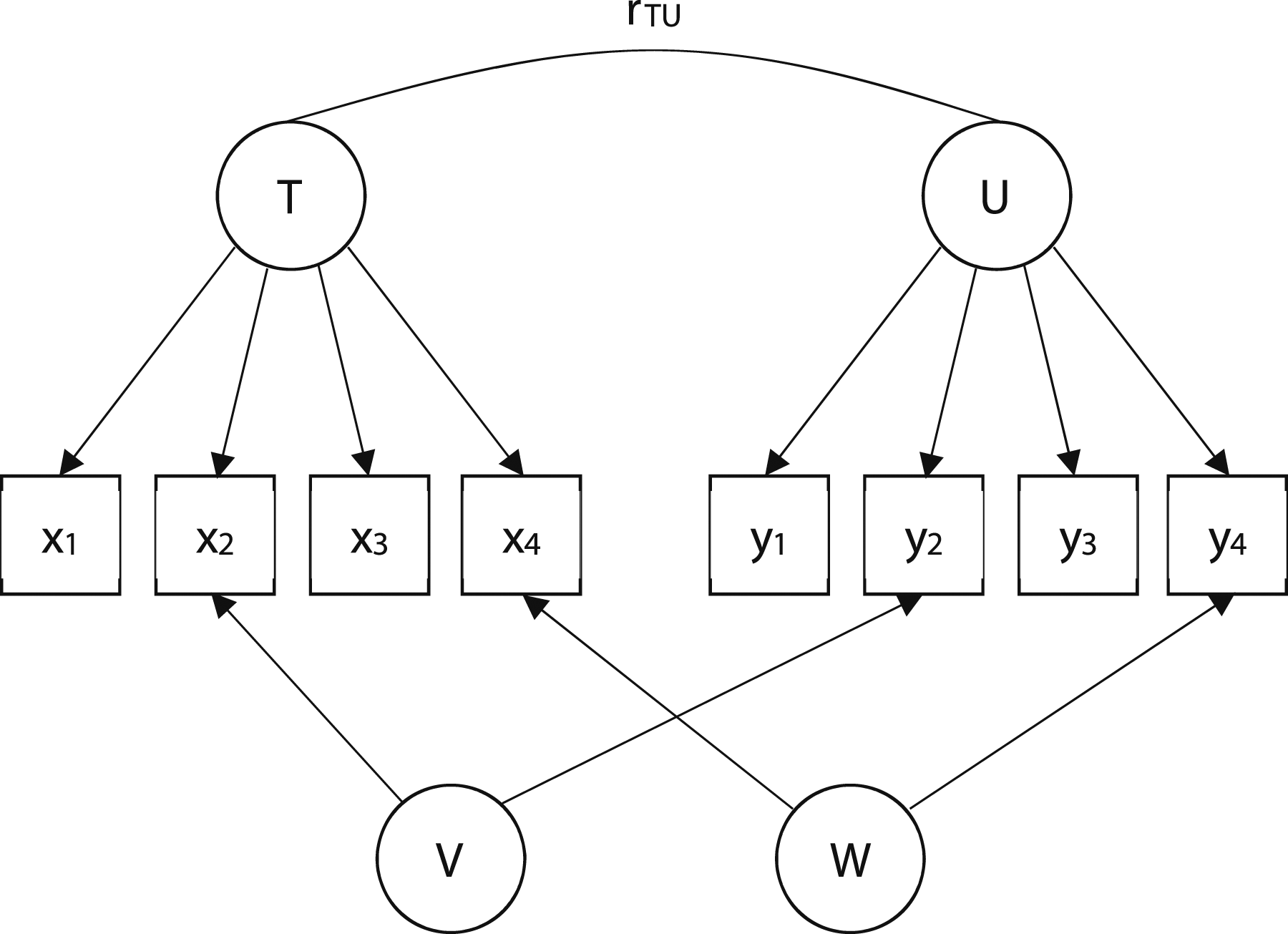
Nevertheless, there are good reasons to avoid the use of such procedures as both yield measurement models that are uninterpretable theoretically (Gerbing & Anderson, 1984). Correlating error terms constitutes an admission of additional, unknown factors driving item responses that are extraneous to the model. Similarly, modeling a confounding method factor makes it explicit that measures are in fact confounded by some unknown factor. In either case, one cannot claim that items are measuring one construct and one construct only. Importantly, when analyses (e.g., regression) are performed with confounded item composites, the interpretations of results are meaningless.
In the interest of providing a layman example, suppose that one wanted to ascertain the effect of pure sugar on health, e.g., diabetes. Now, suppose that one’s measure of pure sugar became confounded because some salt fell into the mix. In this case, with a measure of neither sugar nor salt, but a measure of sugar/salt, could one use such a measure to make valid inferences about the effect of pure sugar on diabetes? Without a measure of pure sugar, we do not believe that such an inference would be possible. This example could be extended to consider constructs more applicable to organizational scholarship. For example, presuming a scholar measured the latent factor trust (e.g., Tucker et al., 2013), one could not say that a pure measure of trust was procured if errors were correlated, or if unwanted method factors were modeled and allowed to remain in the analysis.
There are also good empirical reasons for avoiding such methods. For example, Gerbing and Anderson (1984) showed that correlating model residuals could mask the correct measurement solution. In such cases, relationships between incorrect latent factors would be estimated, and incorrect inferences would be made. Ultimately, allowing errors to be correlated in sufficient magnitude will allow false models to fit the data. Moreover, as the number of correlated errors increases, the interpretability of the model decreases significantly. Relatedly, modeling method factors has been shown to yield inaccurate effect size information. Specifically, in their large-scale simulation, Richardson et al. (2009) found that such procedures were likely to produce inaccurate corrected correlations. Consequently, these authors recommend against the general use of this method, and others have made similar points (e.g., see Conway & Lance, 2010; Lance et al., 2010; Spector, 2006). Because the use of either method increases the probability of making the incorrect inference, we believe they should be avoided.
These two procedures are noteworthy because they attempt to control for the problem of common-method variance in a statistical manner. An additional, popular diagnostic technique deserves mention, i.e., Harman’s single-factor test (see Podsakoff et al., 2003). Harman’s single-factor test is used commonly in communication science to detect, but not necessarily remedy, the problem of common-method variance. This technique attempts to detect the presence of a shared method factor by assessing the fit of a model in which all available indicators are made to load on one factor. For example, for the data found in Table 1, this technique would test the fit of a model in which all 8 indicators were made to load on one factor. If this model provided a poor fit to the data, then there would be evidence against the hypothesis that some shared method factor was explaining the available item-by-item correlations. Although such a procedure is unproblematic, we believe it is redundant with producing evidence for a valid unidimensional model. For example, as shown previously, the data found in Table 1 yields a perfect-fitting two-factor solution, i.e., χ2 (19) = .00, CFI = 1.00, SRMR = .00. Unremarkably, forcing all 8 items to load on one factor yields a poor-fitting solution, i.e., χ2 (20) = 391.67, CFI = .68, SRMR = .13. This is occurring because it was already shown that there are two first-order unidimensional clusters in the data, so a one-factor measurement solution will yield attenuated model fit. If a model shows that numerous first-order factors are unidimensional and valid, then forcing all indicators to load on one factor will produce a poorer-fitting model. Stated differently, if a valid model is produced without having to correlate error terms or model unwanted method factors, then the Harman’s single-factor test is not required.
Multi-Trait Multi-Method Matrices
The previous section provided a treatment of common-method variance at the item-level of analysis. One additional way scholars attempt to make inferences about common-method variance involves inspecting correlations found in a multi-trait multi-method (MTMM) matrix, i.e., a correlation matrix composed of different traits measured using the same and different methods.
Example of MTMM.
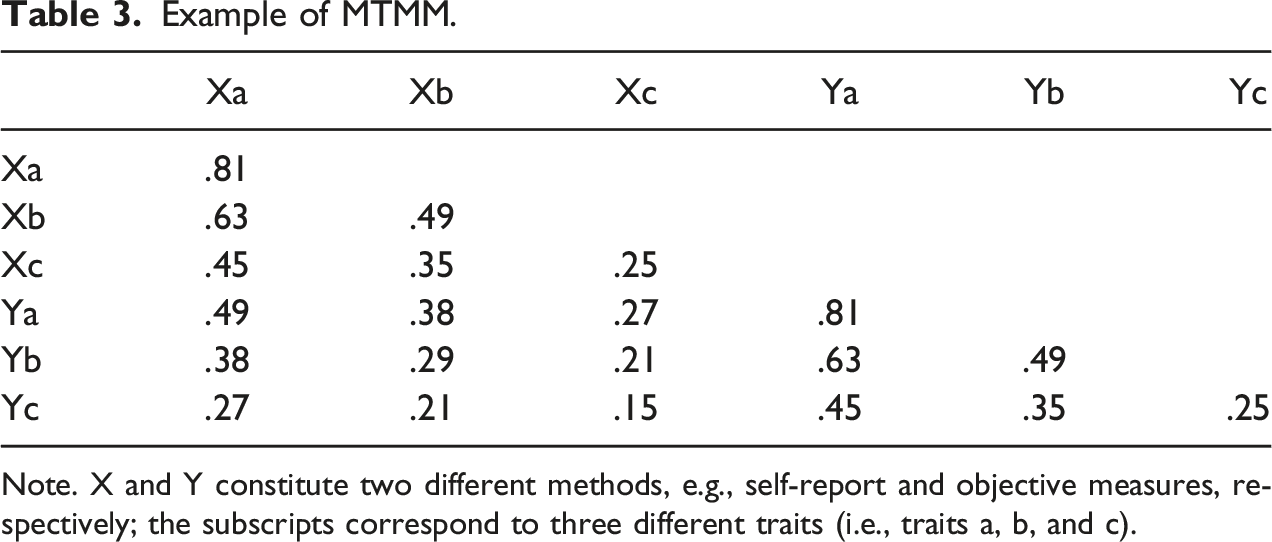
Note. X and Y constitute two different methods, e.g., self-report and objective measures, respectively; the subscripts correspond to three different traits (i.e., traits a, b, and c).
As argued by Campbell and Fiske, the problem of common-method variance can be diagnosed by inspecting and comparing the correlations found in the monomethod and heteromethod blocks. Specifically, if a correlation between different traits is stronger when measured with the same method than when measured with alternate methods, then it would be argued that the monomethod correlation was inflated due to shared-method variance.
As an example, consider again the values found in Table 3. In this table, traits a and b are correlated r = .63 when both are measured using method X (i.e., monomethod). However, the a-b correlation reduces to r = .38 when trait a is measured with method X but trait b is measured with method Y (i.e., heteromethod). Because the a-b correlation is larger in the monomethod block when compared to the heteromethod block, it would be argued that this correlation was inflated artificially by common-method variance and thus invalid.
Although this type of analysis may seem intuitive to some, there are other, more parsimonious reasons for why these correlations may differ. These explanations are provided below.
Alternate Explanations
Consider a scenario in which there are three variables, two of which were measured using self-report (experiencer mode) and the other of which was not measured using self-report (experiencing mode). Of the two self-report measures, one provides a measure of self-reported job performance, whereas the other provides a measure of self-reported job satisfaction. In addition, the objective measure yields an objective measure of job performance (e.g., sales figures). Now, consider that the correlation between the two self-report measures is r = .69, whereas the correlation between job satisfaction and objective performance is r = .49. Many would claim that this is evidence of common-method variance because the correlation produced between the two self-report measures was stronger than when the objective measure of performance was used in the analysis. Although such interpretations are common, there are at least two other viable explanations that might account for the noted difference in effect size. We term these alternative explanations differential reliability and differential validity.
One reason correlations might be discrepant when comparing mono- to heteromethods is because of differential reliability between the measures. By reliability we mean the extent to which a measuring instrument measures whatever it measures consistently. The reliability of a measuring instrument might be assessed by the test-retest method, the equivalence method, or both (Cronbach, 1951).
In general, if constructs are measured validly, unreliability attenuates correlations between constructs (Boster, 2012). One way to increase a measure’s reliability is to increase the number of parallel items or measures used in a test. For example, if a 2-item scale has a reliability of α = .60, then adding 2 parallel items to the measure will increase the instrument’s reliability to α = .75. Adding more parallel items to this measure would increase reliability further (Brown, 1910; Spearman, 1910) 8 .
We note that most objective measures of alternate constructs are 1-item measures. Moreover, although the composite reliability of a 1-item measure cannot be estimated, Schmidt and Hunter (2015) suggest that such reliabilities are likely very low (i.e., α ∼ .25) 9 . To the extent that alternate measures of the same construct evidence differential reliability, inferences made regarding the existence of common-method variance are confounded with unreliability. That is, using a MTMM matrix to make accurate inferences about common-method variance requires the condition that the available measures evidence equivalent reliability (Campbell & Fiske, 1959).
As an example, consider the scenario described previously, where the correlation between the two self-report measures of job satisfaction and performance was r = .69 and the correlation between job satisfaction and objective performance was r = .49. Now consider that the reliability of the job satisfaction measure is α = .89, that the reliability of the self-report performance measure is α = .71, and that the reliability of the objective performance measure is α = .45. 10 Notably, using the correction for attenuation (see Boster, 2012) shows that these correlations are not as discrepant as the uncorrected correlations would suggest. Specifically, the corrected correlation between the two self-report measures is r’ = .79, whereas the corrected correlation between the self-report job satisfaction measure and objective performance measure is r’ = .77. Put differently, correcting these correlations for unreliability shows that they are essentially equivalent and that any differences were due to unreliability.
As a second, alternative explanation, consider that effect sizes produced using heteromethods may be discrepant because they measure different traits. That is, making inferences about common-method variance requires the condition that different methods yield alternate measures of the same construct. For instance, in our previous example, it was assumed that the self-report measure of performance was an alternate indicator of the objective performance measure. However, if this condition is not met, then comparing one measure to the other for the purposes of making inferences about common-method variance constitutes a meaningless exercise.
One way to test the extent to which two different composite measures are alternate indicators of the same construct is to perform a second-order factor analysis 11 . The validity of second-order factors can be analyzed using the internal consistency and parallelism theorems, albeit at a higher-level of abstraction (i.e., at the trait-level of analysis; see Hunter & Gerbing, 1982).
As a demonstration of this procedure, a second-order CFA was performed on the first matrix of real data presented by Campbell and Fiske (1959, p. 86). In this matrix, there are four traits (courtesy, honesty, poise, school drive) measured using two different methods (peer ratings and association tests). As such, four different second-order factors are possible (e.g., two measures of courtesy, two measures of honesty, and so on). Notably, an application of the internal consistency and parallelism theorems to these data yields a model that provides a poor fit to the data, χ2 (14) = 120.66, CFI = .89, SRMR = .11. Stated differently, although it was assumed by Campbell and Fiske (1959) that these data contained different measures of the same construct (e.g., two different measures of courtesy), this analysis shows that this assumption was false.
If this same analysis is applied to those matrices in Campbell and Fiske that include unique, analyzable information, then 7/9 (∼78%) of the matrices fail this validity requirement. Although these authors assumed that their analyzed matrices included alternate measures of the same constructs, the evidence was consistent with this hypothesis only ∼22% of the time.
In sum, when numerous methods are used to measure the same trait, there are numerous explanations for why different correlations may be produced between methods. Additionally, if either of the two alternative explanations are viable, investigators may be making incorrect inferences regarding the problem of common-method variance. For example, it may be concluded that results are confounded by an unknown method factor when the problem is instead differential reliability. Similarly, it may be concluded that the same construct behaves differently when using different methods when the problem is instead that different constructs were measured. Ultimately, when different traits are measured with different measures, we believe it is worth granting both alternative explanations additional consideration. In our experience, these alternative explanations, despite seeming self-evident, are usually ignored.
Proposed Solutions
So far, we have described the myriad ways by which scholars account for and make inferences about shared-method factors. Here, we propose a simple solution for the problem of common-method variance.
As suggested previously, one viable solution is CFA where invalid items are dropped from the analysis (e.g., removing either x2 and y4 or y2 and x4 from the models in either Figure 1 or Figure 2). We reiterate that items that conform to the internal consistency and parallelism theorems are being driven by some unobserved factor and nothing else, i.e., there are no other shared factors between items or measures. Moreover, and importantly, any remaining specific factors not common to different measures or items are controlled for by averaging the remaining items in each factor cluster. That is, because the remaining specific factors are item specific (i.e., not shared with other items), and because they are sampled independently and thus uncorrelated, they tend to cancel each other out when averaged (Schmidt & Hunter, 1999) 12 . If a measurement model provides an adequate fit to the data without having to correlate error terms or model unknown latent method factors, then common-method factors are likely to be of little consequence in the analysis. Indeed, dropping items that are invalid renders a model in which items are driven by one factor only, thus eliminating the shared-method variance problem. Implementing this solution precludes the estimation of additional models that are confounded theoretically (e.g., a model in which item responses are driven by two different latent factors), and it also means that performing Harman’s single-factor test, a common diagnostic procedure, is no longer required.
This solution deals with the problem of common-method variance at the item-level of analysis, which differs from Campbell and Fiske’s (1959) treatment of common-method variance at the trait-level of analysis. Ultimately, this is a question of whether common-method factors impact item responses directly, or whether they manifest as higher-order latent factors that impact items indirectly (i.e., through the first-order factors; see Podsakoff et al., 2003). In the event of the latter occurring, CFA may also be used to rule out the possibility that some shared-method factor is present in the data. That is, the presence of a higher-order common-method factor may be inferred by assessing whether all of one’s constructs measured with one measure load on one second-order factor. If such a model were to provide an adequate representation of the data despite the apparent unrelatedness of the traits in question, then a common-method factor (e.g., acquiescence) may provide a reasonable explanation for such a phenomenon. However, in our experience, if first-order factors are unidimensional and valid, then such occurrences are decidedly improbable. Instead, it is much more likely that first-order constructs cluster for theoretical reasons, i.e., it is much more likely that second-order factors of substantive meaning are evident in the data (e.g., Cruz & Manata, 2020; Gerbing & Anderson, 1984; Hunter & Gerbing, 1982; Manata et al., 2018; Manata & Grubb, 2022; Manata & Spottswood, 2022). When this occurs, first-order factors are more likely to cluster by content, as opposed to forming one general second-order factor composed of all the available measures in the study.
Conclusion
This manuscript has detailed the different attributes surrounding the problem of common-method variance. This manuscript has also reviewed the primary ways scholars have attempted to control for common method variance; in doing so, a set of parsimonious solutions were offered (e.g., CFA without correlated model residuals). Finally, two alternative explanations were offered for instances that may be construed falsely as the confounding influence of a shared method factor when examining a MTMM matrix. This essay, then, informs organizational communication scholars about the different attributes associated with common-method variance, and hopefully assists in both the conduct of scientific research and in responses to reviewer criticism.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.