
Abstract
Assessing evolution of cognitive structures across historical periods has remained challenging in the absence of direct access to humans from the past. Overcoming some of these challenges, we examined shifts in the implicit cognitive structures in the Epic of Gilgamesh, which is one of the earliest surviving pieces of literature, circulating in various versions over a period of approx. 2000 years in ancient Mesopotamia. Using a canonical English translation, we applied natural language processing (NLP) and human coding to extract low-dimensional representations of the implicit personality structure in three different historical epochs. We found systematic shifts over time with increasing complexity and increasing resemblance of contemporary personality models in later periods. We discuss how lexical analyses of ancient texts using trait co-occurrence analyses can provide novel insights on the evolution of human behaviour of relevance for contemporary social and behavioural science and the study of ancient societies.
Keywords
Stories open windows into the minds of the distant past, describing salient features of human behaviour that engage the imagination of listeners and revealing what was considered worth passing on. By analysing how key characters in stories are described, we can unpackage what was deemed relevant to convey about a person and in turn, gain rich insights into cognition of past societies. Today, analyses of life stories are the realm of personality science (McAdams et al., 2004), yet personality judgements have been of interest for people throughout history (Diggle & Theophrastus, 2007; Mayer et al., 2011). An important question is whether such person descriptions follow the same logic, that is, whether they show comparable dimensionality across time and place. Although a five-factor model of personality had been assumed to be an evolutionarily stable feature (Buss, 1991, 1997), recent evidence suggests that person descriptions may be shaped by the cultural and ecological conditions (Durkee et al., 2022; Fischer, 2017; Fischer & Karl, 2021). Hence, person descriptions are likely to evolve over historical periods and it may be possible to trace evolutionary patterns across human history.
Nevertheless, attempts to capture change in personality descriptions are complicated because peculiarities of specific stories, texts or formats might obscure potential insights into the structure and changes in underlying cognition. We present an analysis of the Epic of Gilgamesh, which is one of the earliest bodies of literary texts in human history that has survived nearly completely till today. Importantly, for our purposes, recorded versions of the story circulated and evolved over approximately 2000 years in Ancient Mesopotamia with the first documented scripts from around 2200 BC and the last scripts being dated to 100 BC. Having a central story with a common set of characters and key shared elements, it becomes possible to analyse temporal change and to trace developments of cognitive structures through the lens of person descriptions. Using automated text-mining tools and English translations of the key source material by a single translator, we start to gain insights into what was deemed worth recording in person descriptions. Our study therefore provides snapshots of the minds of the people at the beginning of the first human civilisations.
Our work builds on the long-standing psycho-lexical hypothesis first sketched by Francis Galton, which proposes that all important personality traits are represented in language as single terms (Goldberg, 1981). This idea has inspired factor-analytical studies of self- and other-ratings of words that resulted in the description of major dimensions of personality (Ashton et al., 2004; Cheung et al., 2008; Goldberg, 1990; Nel et al., 2012). There is general consensus that the Big Five model (including Extraversion, Agreeableness, Conscientiousness, Neuroticism and Openness) captures the major dimensions of personality at least in English and other Germanic languages (Saucier & Goldberg, 2001), although various extensions have been proposed, notably adding the honesty–humility factor in the HEXACO model (Ashton & Lee, 2007, 2020). At the same time, observed personality structure may not be independent of their socio-cultural context. Studies of Chinese (Cheung et al., 2008) and indigenous languages in South Africa (Nel et al., 2012) revealed additional factors that emphasised the social-relational aspects of personality in more group-oriented contexts, but there is also evidence pointing to fewer stable factors (De Raad et al., 2010, 2014; Saucier et al., 2014) as well as substantively different structures in some non-Western languages (Fischer, 2021; Gurven et al., 2013; Singh et al., 2013). Of the contemporary languages that have been studied in psycho-lexical research, Arabic is the closest to Akkadian, the language used for the most complete version of the epic that is available today (whereas Sumerian, the language of the earliest version of the epic, is a language isolate and thus does not have a documented modern cognate). Research on personality concepts in modern Arabic has found a structure similar to the Big Five model but with some additional elements of morality and unconventionality (Zeinoun et al., 2017, 2018).
One potential driver underlying the degree of complexity of person descriptions are socio-economic conditions leading to niche construction effects for personality (Laland et al., 2000; Odling-Smee et al., 2003): in more complex and larger societies, individuals need to differentiate relevant characteristics of a larger number of individuals as they fulfil important roles within a society; this requires finer distinctions aligned with more diverse social roles. These cognitive demands are accompanied by more clearly differentiated behavioural clusters across different niches and together these dynamics lead to more clearly differentiated cognitive representations of individual differences (Fischer, 2017; Lukaszewski et al., 2017; Smaldino et al., 2019).
Niche construction effects in the personality domain raise interesting questions about our evolutionary past. Can we identify salient dimensions in the minds of ancient people? Is it possible to trace cognitive differentiation of implicit personality models that individuals may have held over historical time periods? Descriptions of heroes in epic narratives may offer evidence from the distant past of cognitive changes during early civilisations. Descriptions of characters in cultural stories had to be based on a shared understanding of human behaviour, otherwise, these descriptions would not have been intelligible to their audiences. Based on this assumption, analyses of the occurrences and co-occurrences of descriptors of personality can reveal what the storytellers implicitly believed about which characteristics tend to go together and which do not in order to engage and capture the audience (Rosenberg & Jones, 1972). Since no writing is ever produced in isolation of context, the storytellers’ implicit concepts of personality reflect the broader historical and cultural context in which the author was situated (Hamilton, 2003; Porter, 2014).
Previous studies have demonstrated the possibility to extract personality information from ancient texts, using established personality models such as the Big Five (e.g. Passakos & de Raad, 2009). However, studying a text using pre-defined coding categories, behavioural scholars are unable to evaluate the historical developments of personality cognitions. Scholars in historical-philological disciplines examining these ancient texts, on the other hand, aim in the first place at providing accurate translations. They are further interested in the redaction history of single texts (e.g. George, 2003; Sallaberger, 2008; Tigay, 2002), and in the development of literary traditions in a given culture (Beckman et al., 2011; Foster, 2009) as well as the transfer of literary motives across cultures (West, 1999). What little there is of research into the social contexts of literature in Sumerian and Akkadian language has been often confined to rather technical aspects, such as the transmission of literary texts in the context of scribal education during the Old Babylonian period (Tinney, 1999), or to the political configurations to which these texts respond (Delnero, 2016; Konstantopoulos, 2017). However, there has been hardly any research attempting to provide insights into the possible cognitive models of those who produced the texts. To uncover cognitive structure, a bottom-up approach is needed in which co-associations of lexical units are examined and no equivalence of contemporary meaning is imposed, but the patterns can nonetheless be interpreted based on contemporary theories of the human mind and social conditions (Berry, 1989). We suggest that a focus on the character descriptions, especially the co-association of trait-relevant information within narratives, may provide novel insights into possible implicit theories about characters and, ultimately, individuals and social actors (Rosenberg & Jones, 1972). We believe this shift in analysis utilising text-analytical quantitative tools combined with a qualitative, historically informed analysis of the textual remains of Ancient Mesopotamia can offer rich new insights both for scholars of antiquity and for psychologists interested in personality and the evolution of human societies.
Summary of the Four Developmental Stages of the Gilgamesh (Approximate Years).

The Old Babylonian (OB) period saw the emergence of an integrated story line in the Akkadian language, with new fragments still being published (George, 2009, 2019, George & Al-Rawi, 2020). The new epic known under its incipit šūtur eli šarrī incorporated many elements already present in the Sumerian poems, most prominently the account of the journey to the Cedar Wood and the fight against its monstrous guardian Huwawa. Further revisions and edits took place during Middle Babylonian (MB), when the epic spread over the whole of the Ancient Middle East; pertinent tablets translated into different languages are found in places such as the Hittite capital Bogazköy in modern Turkey and Megiddo in present-day Israel (George, 2007). Finally, towards the end of the second millennium BC, the Standard Babylonian version (SB) of the epic saw the light of the day; a scribe called Sîn-leqe-unninnī was credited as its author. Of this latter recension of the epic (with the Akkadian title ša nagba īmur), about 3000 lines of cuneiform text are extant in a standardised version consisting of 12 tablets. The evolution in the epic was accompanied by significant changes in the social, political, economic and religious conditions which took place between the emergence of the first stories revolving around Gilgamesh in the late third millennium BC and the consolidation of large empires, most notably the Neo-Assyrian Empire and the Neo-Babylonian Empire in the first millennium BC, when the SB version is best attested (Van de Mieroop, 2007). During the Sumerian circulation of the epic, local government was mostly in the hands of aristocratic families, sometimes tied to the royal household by means of marriage. Yet, these rulers had to rely on alliances and support by the local population, which to a large extent limited autocratic powers. Conversely, the Neo-Assyrian Empire at its climax reigned over large swathes of the Ancient Near East, from the Levantine coast in the west to parts of modern Egypt in the south and various small kingdoms in present-day Turkey, such as Phrygia and Lydia in the north (Radner, 2015). These conquests were enabled by – and at the same time necessitated – a bureaucratic apparatus of hitherto unseen complexity and based on a stricter division of functions than in earlier periods. We are using the epic within this context to examine the structure and changes in personality descriptions across these discrete social-historical contexts in the early ages of large-scale human civilisation.
We use both adjectives and verbs as descriptors of personality to gain an insight into the implicit personality structure of these periods. By analysing both verbs and adjectives, we aim to circumvent the problem of the imperfect correspondence in word classes between languages, which is bound to come with any translation, especially in distant languages. For example, Akkadian has a grammatical category of the stative, a predicative construction of verbal adjectives (and sometimes nouns), which expresses the outcome of an action indicated by the verbal root, or a condition/state. Essentially, the stative constitutes a verbless clause and, depending on the word and the context, it may be translated with a (passive) verb, a noun or an adjective in English (e.g. ‘I am sick’ is rendered by a single form, marṣāku). Our analysis is thus aiming at a broader semantic representation and is less sensitive to artefacts of translation than a purely adjective-focused analysis, typical for most psycho-lexical research, would be. To examine the robustness of our approach, we will explore translation variability in Akkadian.
The Research Questions
The current study explores a number of questions about implicit personality structure based on character descriptions across different versions of the Epic of Gilgamesh. The circulation of the epic for more than two millennia and covering four discrete socio-historical periods provides a unique opportunity for studying both the possible stability and change in personality descriptions in the early stages of large-scale human civilisation. Our study is motivated by three overarching questions. First, how well do contemporary personality theories apply to person descriptors in such an ancient text? Second, can we use character descriptions in this epic to gain some understanding of the implicit personality structures that may have guided our ancestors? Third, how stable or malleable are personality descriptions over this period? To make sense of possible changes over this time period, we are inspired by the niche construction hypothesis and will qualitatively interpret emerging structures against currently available information from historical research.
Using a mixture of natural language processing (NLP) and human coding, we answer these questions through a combination of analyses. First, we map the adjectives and verbs used to describe characters in the epic to contemporary psychological trait dictionaries, specifically a list of adjectives in which the Big Five has been identified (Goldberg, 1982), and two lists of verbs (De Raad, 1999). This provides us with a first descriptive snapshot of how relevant contemporary trait dictionaries may be for character descriptions in ancient texts, which is relevant for our first research question. Examining changes in the matching to contemporary dictionaries, we start addressing our third research question. Second, we examine whether the same terms (independent of their classification into modern dictionaries) were used in different versions of the epic, which provides a different perspective to help us address the third research question. To the extent that word frequency may reveal information about culturally shared meaning structures, we can uncover insights into the relative stability versus evolution of culturally shared implicit personality models. Third, we apply multidimensional scaling (MDS) on the term co-occurrence matrices across characters in each epoch to capture the implicit personality structures embedded in the different versions of the epic. We interpret these structures qualitatively using available evidence from archaeology and historical records and compare the emerging structures with contemporary personality concepts. This analysis allows us to directly address the second research question. Finally, we compare the MDS models of common terms across the different versions of the epic to explore the temporal stability of the implicit personality structure, which provides yet another perspective for addressing our third research question. In combination, these different analyses provide complementary answers to our three motivating questions. As our employed methods are relatively novel in personality science research, our study aims to provide some guidance and evidence for the usefulness of these analytical tools for studying personality in ancient texts.
Methods
Data sources
We used the English translation published in George’s book for the Old, Middle and Standard Babylonian texts (George, 2003) as well as recently translated scripts (George, 2007, 2009, 2018, George & Al-Rawi, 2014, 2020). For the Sumerian poems, we used the English translation published by George (1999). The original Sumerian and Akkadian texts were written in cuneiform on clay tablets, which were deciphered and translated into English.
Sampling statement
All currently documented and publicly available texts were included. Each text found on an individual tablet was coded in the relevant temporal category using the standard archaeological conventions. Following current standards for the translation and interpretation of the epic, we included material across different tablets in cases where the texts were missing due to damages or were present but not deciphered (George, 1999).
Summary of the Number of Total Words, Adjectives and Verbs Across Four Periods.

Note. Total counts may include repetitions of the same word; unique counts include counts of distinct adjectives or verbs.
Data processing
Example of the Text in the Coded Spreadsheet, Showing the Tokenisation, Lemmatisation, Part-of-Speech Tagging Using spaCy, and Human Coding of Adjective and Verb Attributions.

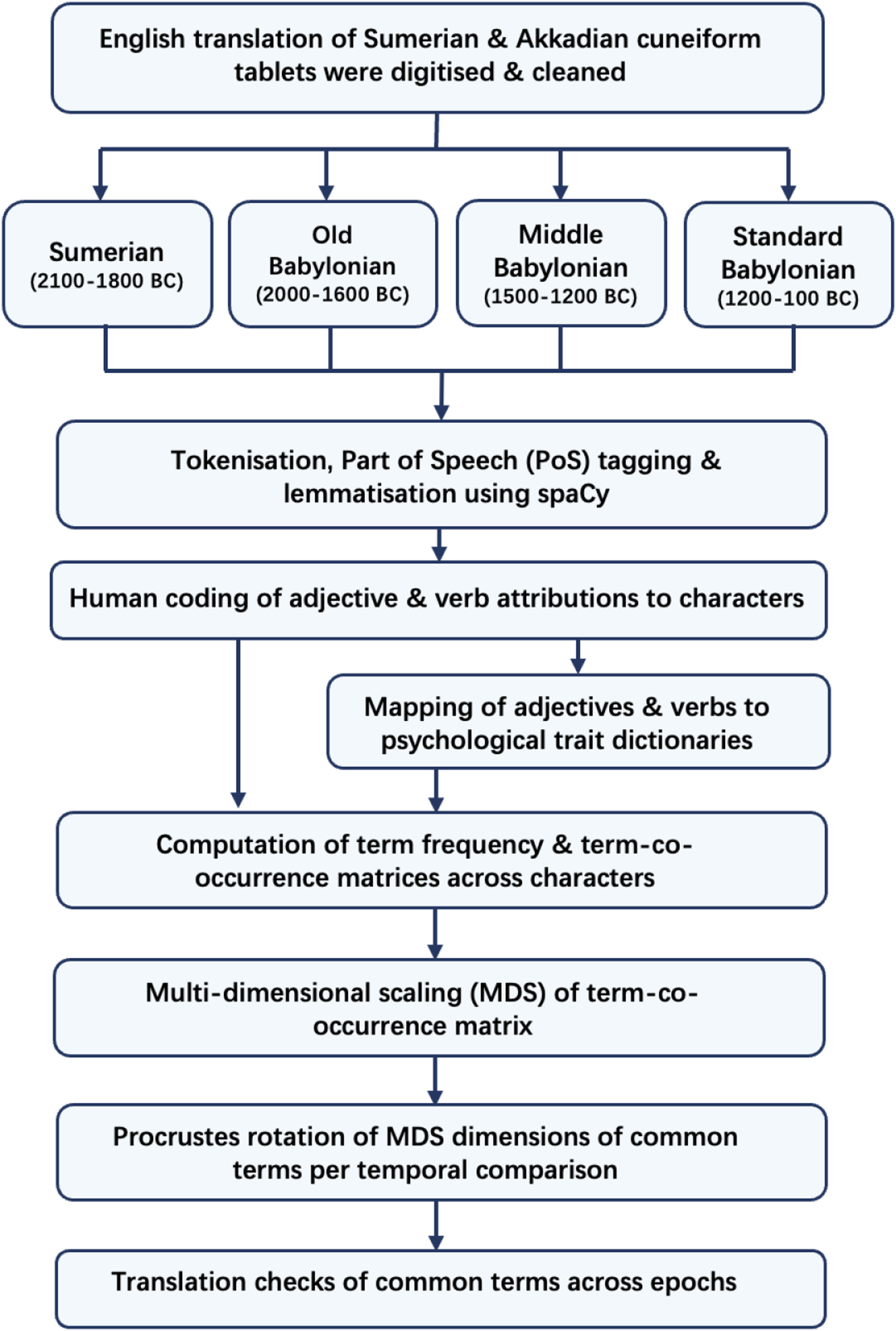
Flow chart detailing the data acquisition, transformation, pre-processing and statistical analysis.
With the texts broken down into single word units, the first author reviewed all the words that were automatically annotated as adjectives and verbs, and referenced the entities that these adjectives and verbs referred to based on human reading of the text (see Table 3 for an example). We used a manual coding process due to the fragmented nature of the tablets and the poem structure of these ancient texts, which made accurate and reliable automatic attribution of words to characters difficult. The automatically extracted entities included all the named entities, such as Gilgamesh, Enkidu, Humbaba, as well as any other single characters or groups of entities that are not named explicitly, such as man, men, a person, mankind and gods. A list of the adjectives that are used to describe these named entities is presented in Supplementary Table 1. The acting entity and the receiving entity of each action as captured by the verb were coded in the format of actor:verb:receiver. For example, ‘Gilgamesh hugged him [Enkidu] tight’ was coded as Gilgamesh:hug:Enkidu. Intransitive verbs such as in ‘Gilgamesh began to weep’ were coded as Gilgamesh:weep:x. Auxiliary verbs were excluded from further analysis.
When a single verb did not capture the specific action, verbal phrases were coded. For example, the verb take by itself is ambiguous in meaning in English and can refer to different actions when followed by different nouns. As a result, verbal phrases such as take notice, take pity, take prisoner were coded. Similarly, when two verbs were used together to specify one type of action, such as ‘go weep’, ‘make grow’, they were coded together as a verbal phrase. We calculated the total number of words, adjectives, verbs and verb phrases (after excluding auxiliary verbs) in each period’s version of the texts (see Table 2).
Data availability, reproducible script and open material statement
The co-occurrence matrices at the character level and code are available on the OSF: https://osf.io/fzbgv/.
Description of dictionary and statistical analyses
Adjective dictionaries
Following the human coding of adjectives and verbs, our first step of analysis was to map all the adjectives from the Gilgamesh to existing modern psychological trait dictionaries (see Figure 1). We used Goldberg’s (1982) set of 1710 English trait adjectives. This set of words traces its origins to the first comprehensive list of 17,953 person-descriptive words (Allport & Odbert, 1936), narrowed down and supplemented by Norman (Norman, 1967) and further refined by Goldberg (1982). The list of 1710 words has been used in psycho-lexical research leading to the identification of the Big Five and the HEXACO models in English data (Ashton et al., 2004; Goldberg, 1990; see also Saucier & Iurino, 2020, for a recent re-analysis of this set of words). Previous work on text analysis of fiction literature (Fischer et al., 2020) compared the implicit personality structures emerging from the 1710 words to results using Allport and Odbert’s complete list and Saucier’s (1997) shorter yet conceptually broader list of 500 person-descriptive words. The results were comparable across the three lists, but the clearest interpretation was obtained using the 1710 list. This list was thus chosen for the present study. Because we were interested to relate our findings to the arguably most widely used current model of personality, the Big Five, we selected from the 1710 words only those terms that clearly and unambiguously loaded on a single trait factor in the original analysis by Ashton et al. (2004), with an absolute factor loading above .30 and no cross-loadings above a difference threshold of .20 (k = 207). Second, we used Goldberg’s 100 trait markers for the Big Five factor structure (Goldberg, 1992). This list is commonly used as marker terms in lexical studies (e.g. Thalmayer et al., 2021). These two sets were used in the combined dictionary list analyses reported below.
Finally, we also manually coded adjectives from the Sumerian, Old Babylonian and Standard Babylonian version of the epic according to a synonym cluster approach (Wood et al., 2020). Three coders separately coded each adjective into one of 100 personality synonym clusters developed by Goldberg (1990). An adjective was assigned to a trait if two of the three coders agreed with each other about the clustering (e.g. angry, not a part of the 1710 list, was consistently coded as belonging to Agreeableness by all three coders); 1 the adjectives are presented in the supplement (Table S1). This procedure allowed us to use all adjectives that are present in the epic and derive a consensus synonym-clustering classification in terms of the Big Five. At least two coders agreed on 95.2% of the coding. All three coders completely agreed on 46.4% of the coding. Fleiss’ kappa was .48, which indicates moderate interrater agreement (Landis & Koch, 1977).
Verbs dictionaries
First, we included an interpersonal verbs dictionary developed by De Raad (1999), which was derived from principal component analysis of self- and peer-ratings of 303 interpersonal trait verbs. A two-factor circular structure showed Dominance and Nurturance factors, which were further divided into four segments: positive Dominance (e.g. order, attack), negative Dominance (e.g. agree, permit), positive Nurturance (e.g. help, support) and negative Nurturance (e.g. betray, ignore). We used a list of 164 verbs that had projections of .30 or higher on the circular structure in the study by De Raad (1999).
Second, we used a list of 160 interpersonal behaviour verbs (De Raad, 1999) which showed an eight-factor structure in a factor analysis based on similarity ratings. These factors were interpreted as: Love (e.g. kiss, caress), Hate (e.g. overpower, insult), Instructional Behaviours (e.g. demonstrate, explain), Repairing Behaviours (e.g. give, provide), Seeking Contact (e.g. approach, listen), Avoiding Contact (e.g. flee from, avoid), Emotional Demonstrative (e.g. lament, cry) and Behavioural Demonstrative behaviours (e.g. justify, reveal). We again matched any character-assigned verbs to these two dictionaries and counted the relative frequency across epochs.
Bottom-up dimensional analysis of person descriptors in each epoch
We treated each named character within the text as an individual and computed a Spearman rank-order correlation based on the term co-occurrences per named character (Fischer et al., 2020). These correlations were transformed into dissimilarities using Euclidean distances and we ran an ordinal MDS with the R package smacof (Mair et al., 2021).
Stability of the individual solutions was estimated using bootstraps with 250 replication samples. A new dissimilarity matrix was generated from each bootstrap sample with replacement; this dissimilarity matrix was submitted to an ordinal MDS as described above and the similarity with the original matrix was calculated after Procrustes rotation (Jacoby & Armstrong, 2014). Here we focus on the replicability of the solution, using a stability measure that compares the variability of each replication with the centroid configuration divided by the total variance across replications (Mair et al., 2022). Larger values imply better replicability. We also report the mean stress value across all bootstrap samples as well as the 95% confidence interval. Lower stress values with smaller confidence intervals suggest better representation of the data in the two-dimensional space.
For the structural comparison across epochs, individual MDS solutions of temporally matched descriptors were Procrustes-rotated to maximal similarity. We always used the older text as the target matrix. Similarity was judged using Tucker’s Φ with values above .85 indicating similarity in structure (Fischer & Karl, 2019). Because there are questions about the applicability of overall congruence coefficients and coefficients of alienation a) when using a relatively large number of categories to represent in a multidimensional space and b) when there is the possibility of noise (both of which could be expected in our data), we focus in our interpretation on the similarity of each dimension separately (Borg & Groenen, 2005; Borg & Mair, 2022). We examined the similarity of the dimensions using correlations of the Procrustes-rotated dimensions.
Considering the choices available for NLP analyses, we chose this MDS analysis for two main reasons. First, it is a relatively assumption-free approach that examines the co-occurrence of terms in relation to specific fictional characters. In this sense, it is the equivalent of using data-reduction techniques on survey-based data with participants (e.g. we treat fictional characters as if they were participants in a survey). Using ordinal MDS with Procrustes rotation requires fewer assumptions about the data quality than typically employed data-reduction techniques such as exploratory factor analysis or principal component analysis (Fischer & Fontaine, 2011). It may be possible to use some variant of a latent semantic analysis (LSA) (Landauer & Dumais, 1997) which analyses the distribution of words within sets of documents to quantify the similarity of documents and/or to index documents more efficiently to optimise information retrieval. These techniques do considerably more than what we are interested in, while the applicability to the type of text that we are using has not been carefully evaluated. We used human coding to assign words as information tokens to fictional characters, therefore, preserving human-perceived meaning and not relying on statistical relationships in sparse text (Bender & Koller, 2020).
For all statistical analyses, we used two-sided tests. Our analyses focus on the magnitude of the correlation; we did not adjust significance values for multiple testing. Our research was purely exploratory and we clearly describe it as such.
Effects statement
We report basic descriptive statistics, effect sizes where applicable, exact p-values and 95% confidence (credible) intervals.
Results
Person descriptor matching to modern dictionaries
We mapped all the adjectives and verbs that were matched to characters in the epic onto contemporary psychological dictionaries (Ashton et al., 2004; De Raad, 1999; Goldberg, 1992). To test whether the dictionary matches increased over time, suggesting increasing similarity with modern psychological models of personality, we ran a general linear model to test temporal effects. We adjusted the dictionary matches by the overall frequency of adjectives and verbs, respectively, and included word class as a random effect. We found a significant effect of time period on overall term frequency: b = 0.004, SE = 0.000, t = 11.02 and p < .005 (see Figure 2 for graphical representation of the trends over time). The number of adjectives and verbs, relative to all adjectives and verbs in the epic, that could be clearly mapped to a contemporary personality factor increased over time. The total explained variance via the fixed time effect was .63% (Rights & Sterba, 2019). Period effects on dictionary mapping. The results show an increase in mapping of words to contemporary psychological dictionaries. Scores are adjusted for the relative frequency of word class in the texts of each epoch and analyses reported in the text are adjusted for type of word class. Sumerian is coded as 0, Old Babylonian as 1 and Standard Babylonian as 2.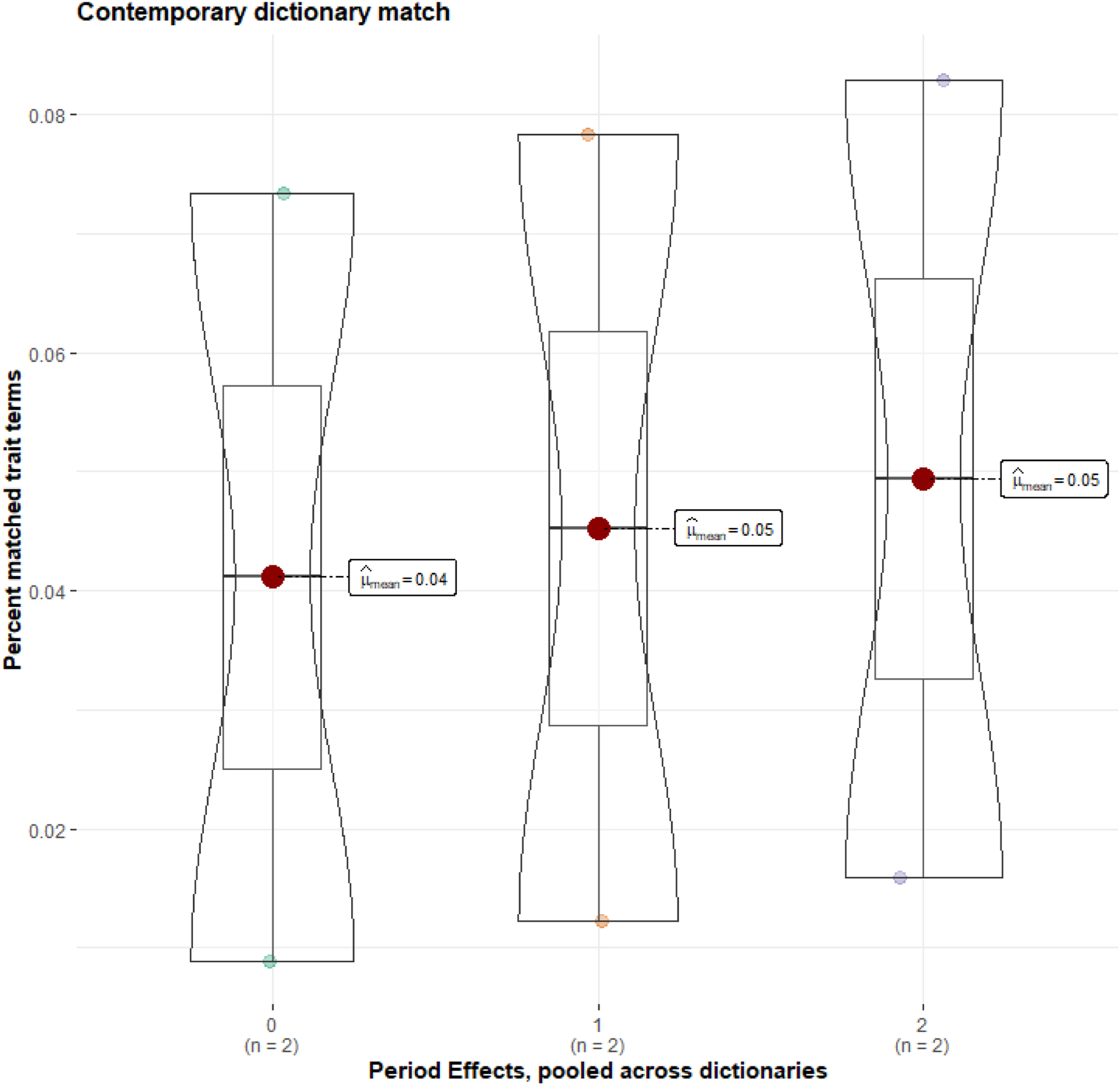
We next analysed whether descriptions captured a broader range of personality factors over time, that is, whether the number of factors out of the Big Five (identified by adjectives) as well as the number of contemporary verb-based personality dimensions increased over time when describing characters in the epic. Considering the distribution of our count data, we ran a zero-inflated Poisson regression, with number of factors as the outcome, time period as the predictor and dictionary as a random effect. When focussing on all characters mentioned at least once in any version of the epic, we found no significant effect: b = .216, SE = .192, z = 1.13 and p = .25. However, different characters appeared over the different epochs. When focussing on the 10 most frequently mentioned characters across the versions to see whether the descriptions of the more common characters became more complex, we found a significant effect: b = .466, SE = .236, z = 1.98, p = 0.048 (see Figure 3). This suggests that the same characters over time were described in more complex ways – that is, more of the modern Big Five and verb dimensions were employed by the scribes of the epic in later versions of the epic compared to earlier versions. Considering the different dictionaries and factor structures leading to a maximal possible number of 20 factors across all lists in our analysis, in the earlier versions, approximately two out of 20 possible factors were used to describe the key characters; in the last version of the epic, 4 out of the 20 possible factors were present. To extract explained variance estimates, we respecified the model as a multilevel model. The time effect was significant: b = 1.125, SE = 0.305, t = 3.69, p = .008 and the fixed slope time effect explained 20.5% of the variance. Over time, the more central characters were thus described in terms that captured a broader set of personality factors. This suggests that a greater number of terms can be matched to modern dictionaries in later periods of the epic and that descriptions of central characters in the epic capture a broader set of personality factors over time. Period effects on psychological trait factor presence among the 10 most frequently mentioned characters. The results show an increase in the number of trait factors according to contemporary psychological models. Analyses reported in text are adjusted for dictionary. Sumerian is coded as 0, Old Babylonian as 1 and Standard Babylonian as 2.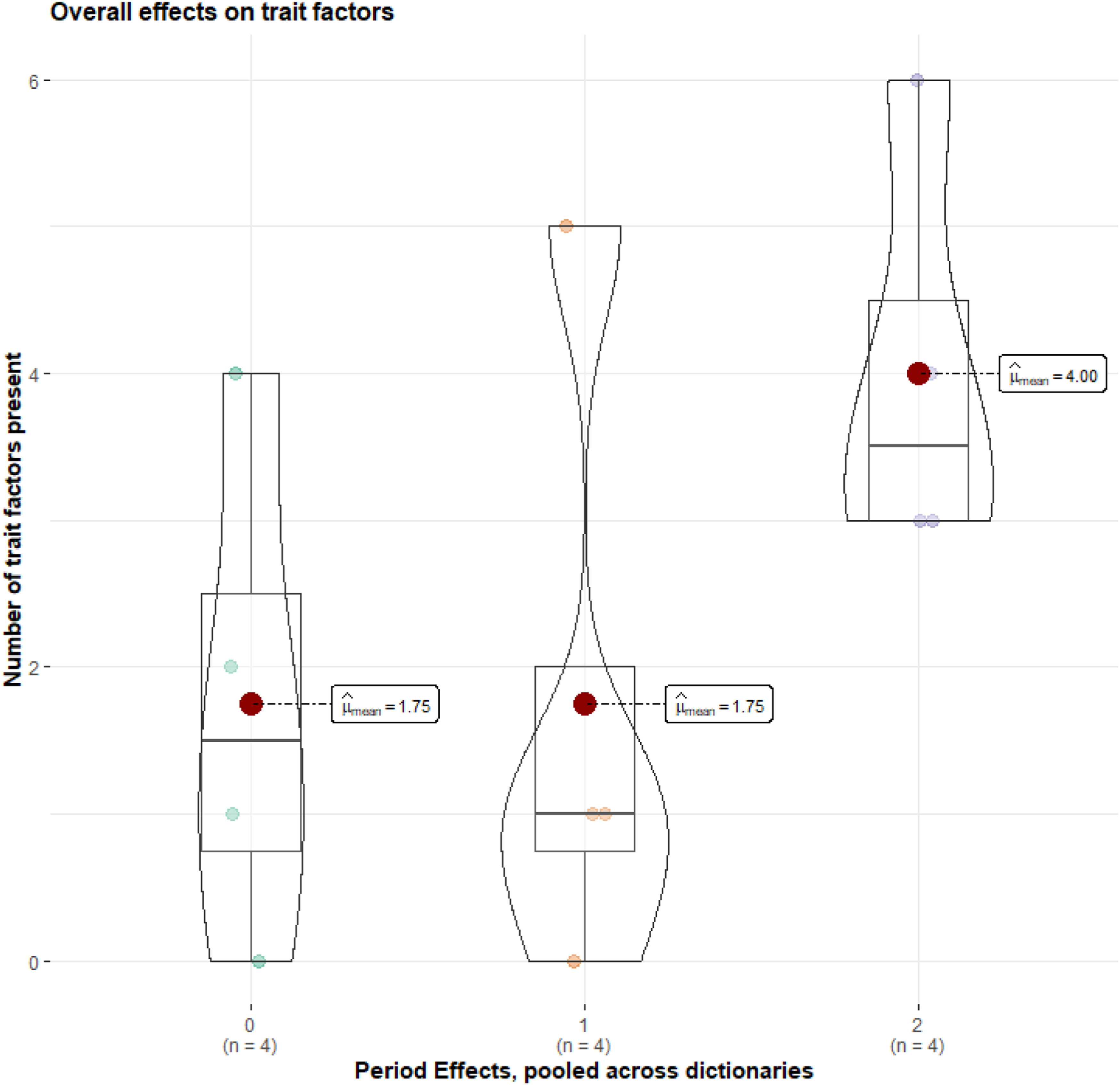
Unique Counts of Terms Classified Into the Big Five, According to Synonym Cluster Coding (Raw and Adjusted for Unique Count of Adjectives, Table 2).

Note. Terms that were not classifiable into the Big Five or where no consensus was reached are excluded.
Temporal shifts in overall use of personality-descriptive terms
To examine the stability and differences across periods in word usage, we examined the shared frequency distributions of verbs and adjectives used across time epochs. This provides some estimation of stability of word usage over time, indicating whether more frequent terms in the older version continue to be more frequent in the subsequent period. To the extent that terms are more central, these terms should carry more consensually shared meaning and be used for similar purposes. Overall, we found a qualitatively greater similarity in word frequency across temporally closer periods: r = .72, 95% CI [.37; .89], p = .01 for the match between Sumerian and Old Babylonian texts that partially overlap in time, but differed in language, versus r = .40, 95% CI [.05; .66], p = .01, for the Old Babylonian and Standard Babylonian texts with a shared language; and r = .49 (95% CI [.17; .72], p = .01 for Sumerian with Standard Babylonian texts. When comparing these correlations with the time differences (using the earliest epoch dates from Table 1 as reference points), increasing temporal distance was negatively associated with word overlap: r = −.92, p = .25 (CI’s cannot be computed with three observations). This means that word choices were qualitatively more similar in the temporally closer periods.
Co-occurrence analyses to reveal implicit cognitive structures
Stress and Replicability Statistics of the Multidimensional Scaling Results Per Period.

The supplement (Table S2) shows keywords associated with the polar ends of the epoch-specific solutions. We identified the following core themes of person descriptions within the texts. In the Sumerian text, the first dimension separated emotions and sentiment from action (e.g. heartstricken, fine, sick, dead vs reach across, escape, go near, take pleasure); the second dimension concerned social and moral norms as well as exchange of information within a dominance hierarchy (e.g. bare lap, answer, respect, submit, help, captive vs receive reply, make answer, pay attention, come to, submit, wild, precious). Connotations of ‘wild’ in particular indicated both high status and wealth, but also danger (Sallaberger, 2008). Dimension 1 in the Old Babylonian texts appeared to focus on vigour and age-related activities and states (e.g. comely, young, happy, achieve, grown, hail, support, mighty, wise), which were salient sacred- and social-status markers in ancient Mesopotamia. Dimension 2 differentiated external expression (acting out) of (often negative) emotional states that have an impact on others from internally focused (negative) emotional states (e.g. enable, ferocious, make rage against, repel vs afraid, vexed, weary, pale). This externalising-versus-internalising distinction is a salient dimension in contemporary clinical studies (Clark, 2005; Lo et al., 2017).
The Standard Babylonian Dimension 1 captured descriptions related to the coordination of actions among equals as well as fitting into a social hierarchy and exerting power over others (e.g. comely, little, senior, wild, walk at side, great, welcome, brave, rule, prostrate, glorious). This dimension shows some resemblance to the mastery dimension of virtues (Dahlsgaard et al., 2005; Partsch et al., 2022). Dimension 2 featured descriptions that capture salient moral boundaries in that period, especially concern with the transition from uncivilised to human life (Sallaberger, 2008; Tigay, 2002) (e.g. take in scent, cloth, give bread, give beer, anoint, capture, spread clothing, delight), but also combat-themes (e.g. join combat, capture, join forces, bind arms, defeat) at one end from the display of power (e.g. free, angry, strong, able, precious, change, furious) at the opposite end. These patterns are consistent with the historical conditions, where the emergence of urban centres as the seeds of civilisations was accompanied by military conflict with nomadic neighbours (Scott, 2017).
Exploring word frequency effects on co-occurrence structures
To examine whether word frequency within the text is related to these dimensional properties, we computed the correlations between the position of the individual terms in the two-dimensional solution and the frequency of word occurrences within the text in each epoch. Across the three epochs, positioning along the first dimension was associated with more frequent character descriptions in the epic (Sumerian: r = −.21, 95% CI [−.33, −.08], p < .01; OB: r = −. 18, 95% CI [−.37, .01], p = .06; r = −.17, 95% CI [–.27, −.07], p < .01). Only in the SB version of the epic did we observe an association between structural features of the second dimension and word frequency (r = .21, 95% CI [.11, .31], p < .01), suggesting that issues of morality and power became more frequent during that period. Overall, this analysis suggests that word frequency had a small but significant effect on the positioning of person-descriptive words along the first dimension in each epoch.
Temporal stability of co-occurrence structures
So far, we primarily focused on structural analyses by epoch. The most intriguing information for evaluating cultural evolution in personality cognitions, however, is the extent of stability underlying the descriptions of characters within the epic across time. To directly examine temporal stability of the person descriptor structure over temporal epochs, we computed Procrustes rotations on the common adjectives and verbs for each pairwise temporal comparison and computed both overall congruence of the structures and the correlations of the main dimensions after rotation to maximal similarity. To preserve temporal progression, we always used the temporally older matrix as the target matrix and rotated the temporally more recent structure to be maximally similar to this historical target matrix.
The structural similarity of the Sumerian and Old Babylonian texts was .819, and the alienation coefficient .574 (common elements: 17). The similarity (or congruence) for Dimension 1 was r = .68, 95% CI [.30, .87], p < .01. For Dimension 2, the congruence was r = .09 (95% CI [−.41, .54], p = .74. Comparing Old Babylonian to Standard Babylonian scripts, the overall congruence coefficient was .788 (alienation coefficient = .616, 31 common elements). The similarity for Dimension 1 was relatively weak: r = .12, 95% CI [–.24, .46], p = .51, and somewhat higher for Dimension 2: r = .54, 95% CI [.23, .75], p < .01. Finally, comparing the most temporally distant matrices for Sumerian and Standard Babylonian, the overall congruence was .797 (alienation coefficient = .604, common elements = 31). Despite the overall similarity at the structural level, the correlation for Dimension 1 was r = .18, 95% CI [–.19, .50], p = .34, and for Dimension 2, r = .30, 95% CI [–.06, .59], p = .10 suggesting low structural similarity over the two millennia separating the two most distant versions.
We compared the cross-temporal correlations for each dimension with the temporal differences (the differences between earliest estimates for each epoch). For Dimension 1, we observed a qualitatively strong negative association (r = −.98, p = .14; CIs cannot be computed with three observations for this and the following analyses), whereas for Dimension 2, we found a positive association (r = .78, p = .43). We also examined the overall congruence (but see Borg & Mair, 2022 for some caution against using overall congruence coefficients) with the time difference and found a negative association: r = −.92, p = .26 (the association was proportionally inverse with the alienation coefficient: r = .92, p = .25). We note that these associations showed quite strong effect sizes (mostly r > .90) but due to the small number of observations, the effects were not statistically significant. As with the overall pattern of the word frequency analyses reported at the beginning, the similarity of the dimensions suggests that the temporally closer periods (especially for Dimension 1 in the Sumerian and Old Babylonian versions, and Dimension 2 for the Old Babylonian with the Standard Babylonian version, but also the overall congruence) show higher similarity in implicit cognitive structures compared to the temporally more distant versions of the epic. However, these qualitative interpretations need to be considered in light of the observation that none of the congruence coefficients were reaching commonly accepted thresholds of .80 or higher and that all our analyses are based on only three observations, which significantly limit our ability to draw quantitative conclusions.
Robustness check regarding translation stability
To evaluate the extent to which our analysis using the English translation can be considered as a fair representation of the original Akkadian text, we reviewed a list of key person descriptors in the English text and their corresponding Akkadian roots. Person descriptors were considered key for this purpose if the English term occurred at least two times in both the Old and Standard Babylonian versions of the epic. The list of the terms is the following: comely, ferocious, glad, happy, mighty, sick, strange, wild, young. We found that 87.2% of the key English descriptors correspond to the same roots in the original Akkadian text. Therefore, the English translations for the Akkadian text at least seem to be consistent with the original Akkadian words.
Discussion
Using the Gilgamesh epic as a case study, we traced person descriptors to modern psychological dictionaries and observed evolutionary change suggesting a gradual approximation towards modern psychological personality structure by the end of the original Akkadian circulation of the epic. This epic is unique source material because it is one of the oldest known (and reasonably complete) epics, which moreover is extant in different versions, spread over nearly two millennia.
The first insight is that individual character-descriptive words can be related to contemporary personality dimensions, suggesting at least a basic level of diachronic psychic unity of humanity. From a human evolutionary perspective, the relative consistency and importance of Extraversion and Agreeableness in both modern person descriptions (Wood et al., 2020) as well as the epic of Gilgamesh is noteworthy. This finding suggests a universal concern for describing the social features of literary characters, which maps onto a universal human need to communicate social information to and about others. This observation obviously reinforces and explains the appeal of the epic over millennia, but it is not a trivial observation given recent claims about niche construction effects for personality characteristics. Our findings provide a more nuanced perspective on such niche construction theories and suggest that narrators and preserved scripts captured descriptions that may relate to biologically shaped predispositions which are nevertheless expressed variably across time and space.
Focussing on the personality dimensions that we extracted using MDS, probably the key finding is that the emergent dimensions and clusters could not easily be classified according to modern personality taxonomies. Instead, the main themes of these dimensions seem to be compatible with some of the major themes that have been discussed in the classical literature, such as issues of social status and hierarchy relations, in particular dominance themes related to social hierarchy, war and conquest as well as markers of youth-related hedonistic indulgence and vigour that reflect warrior or god-like qualities (George, 2003; Sallaberger, 2008; Tigay, 2002). Another theme that is meaningful within the historical context is the discussion of markers and actions that imply a transition from barbarian status to human civilised life. These have been central themes in historical texts on Sumerian and Akkadian culture (Selz, 2016) and our findings suggest that these can also be traced in the implicit personality concepts when describing characters in this epic.
Bringing these patterns back to the frequency distributions, it is important to consider our patterns in light of the relatively small number of words that can be clearly matched to contemporary dictionaries. We used a rather strict criterion (primary loading >.30 and no cross-loadings >.20) for deciding whether a word was clearly applicable to one of the Big Five in a classical analysis of this set of words (Ashton et al., 2004) (but see also Saucier & Iurino (2020) for a recent re-analysis of the same dataset). Using both such a strict criterion and a more lenient category classification, we did not encounter many words within the epic that would unambiguously be related to contemporary definitions. Although it may appear disappointing at a first sight, such a finding is in fact consistent with Galton’s original speculations when first proposing the lexical hypothesis: it is possible to measure the core features of what we now call personality dimensions but the individual features are ‘so intermixed that they are never singly in action’ (Galton, 1949, p. 181). What our results nevertheless suggest is that over the two millennia of circulation of this epic, the number of words and the number of personality factors that can be unambiguously matched to contemporary models increased with greater societal complexity.
We interpret these patterns in line with a more nuanced niche construction process. As mentioned above, we observed that translations of the more recent stories contained a relatively higher proportion of terms that could be mapped onto modern trait dictionaries. We must presume that the translator was unaware of these trait dictionaries, and we hypothesise that this increased mapping suggests that the language within Gilgamesh gradually started to resemble more contemporary concepts that can be mapped onto relevant personality dictionaries. Furthermore, in terms of the temporal shifts more broadly, independent of modern dictionaries, both the word frequency analyses and the structural stability analyses of character-mapped word co-occurrences suggested that temporally closer periods tended to be more similar. This effect was clearest for the relationship between the Sumerian version and the Old Babylonian version, which showed the qualitatively highest correlation of words in common use and greatest overlap for Dimension 1 of the MDS. The Old Babylonian and Standard Babylonian versions showed some convergence in the word frequency and also some similarity along Dimension 2 of the MDS. In contrast, the historically most distant Sumerian and Standard Babylonian versions showed moderate overlap in word frequency and weak overlap along the two dimensions of the MDS (max r = .30). Together with the overall dictionary matching results and overall congruence effects, these qualitative observations suggest a gradual psychological progression over the periods towards greater resemblance of modern personality concepts.
This temporal development coincides with a larger trend in ancient literature in the waning centuries of the second millennium BC (during the circulation of the SB version), when a ‘greater profundity of reasoning (…) was not without its counterpart in a sobering of the Old Babylonian joie de vivre’ (Lambert, 1996; p. 17). The second half of the second millennium BC also saw the intensification and regularisation of written exchange with wider regions beyond Mesopotamia, and the content of such exchanges pertained to not only the sphere of international diplomacy, but also ideas and literary topoi (themes). Military defeat and foreign rule that took place in Babylonia itself were characterised by a tension between cultural assimilation on part of the conquerors and significant changes in the social framework of the societies. The increasing distinction of internalising versus externalising psychological characteristics in the structural analyses also coincides with previously identified trends of greater individualisation (e.g. recognition of individuals as authors of texts, presence of ownership records and personal deeds mentioned instead of role descriptions; Selz, 2016). While a more in-depth social-historicist contextualisation of Babylonian literature is long overdue, we suggest reading the present results as tantalising evidence that the growing complexity of the authors’ social and political environment may be associated with personality concepts that gradually start to resemble those found in modern-day societies; in other words, that social structure leads to a shaping of cognition in the form of implicit personality models.
Alternative interpretations of the historical significance of the data – for example, by focussing on developments in the language – would be less convincing. It is true that the SB version was significantly expanded, modernised and edited to reflect the changed cultural, religious and literary preferences; yet, it was still close to the OB one as regards its main plot (and some authors such as Tigay, 2002, actually consider the Old Babylonian version more innovative and revolutionary in its changed scope and focus, compared to the ritualistic changes made in the Standard Babylonian version). Overall, the poem’s structure is rather stable over time, as evidenced by a simple count of the ratio of the word groups: adjectives make up about 4% in all three variants (Sumerian, OB and SB) analysed here, while verbs make up about 14–15% in both Sumerian and OB version and 11% in SB. Moreover, as observed by George (2003), alterations included both expansions, but mainly only by means of repetition (e.g. a passage of 22 lines occurs five times in the SB version; see George 2003, p. 46), and cuts and syncopations of the text. In an overwhelming majority of cases of altered words, these were replaced by roughly synonymous terms, while other changes may have been introduced by concerns regarding poetic metre.
How do our findings match onto previous interpretations of the epic by Assyriologists? A number of scholars have discussed the evolution of the story (George, 1999; Sallaberger, 2008; Tigay, 2002), pointing out a shift in both content and style. Hence, the Sumerian stories are regarded as tales of a heroic warrior king, intended to provide entertainment at the royal court. In the Old Babylonian period, the casting of isolated stories into a coherent single narrative was accompanied by a shift in focus, though scholars differ in their interpretation. For Sallaberger (2008), the OB version centres on Gilgamesh as a human being, resulting in a moral tale about friendship and life in the knowledge of death’s inevitability, while the SB work is grounded in ‘wisdom literature’ which was salient at the time of the Assyrian empire, adding not only a didactic facet but also a concern with one’s afterlife. For George, on the other hand, the OB poem ‘was a hymn to heroism and kingly might’ while the SB version suggested a ‘sombre meditation’ that is also ‘more introspective’ (George, 2003, p. 33). Contrary to these previous structural analyses of form and content, our lexical analysis based on George’s translation suggests greater continuity at a psychological level between the Sumerian and Old Babylonian texts. Despite the noted shifts in narrative and message, it appears that the story used relatively similar implicit personality concepts to cast the main heroes of the story. The psychological structure of actors and the frequency of terms used to describe characters were more similar across these two versions, even though they used a different language, in contrast to the Old and Standard Babylonian versions which both used Akkadian. Considering the closer proximity in time of the Sumerian and Old Babylonian sources, the psychological make-up of the audience may have remained similar and hence, we found greater continuity in relevant aspects in spite of a complete and creative retelling of the story. For this reason, we propose that a psychological analysis of the terms used in a text, in particular an analysis of the co-occurrence structures of character descriptions, provides an important tool for the analysis of ancient texts.
One central limitation of our analysis is that we used English translation of these texts. At the same time, the mapping onto modern dictionaries requires translation. It could be argued that it is safer to use a high-quality translation that preserves the textual integrity instead of working with the original cuneiform terms, which requires additional work in terms of both computational mapping and subsequent translation without having the textual context. We provided preliminary evidence that translator choices for original terms in the epic are relatively unlikely to have affected the results. Nevertheless, a bottom-up linguistic analysis in Sumerian and Akkadian may provide additional nuances and insights that are missed when using a translation.
Our analyses relied on mixed methods, combining human coding with computational tools from NLP. Considering recent developments in NLP, specifically various transformer models for word and sentence embeddings and their application to personality structure in contemporary corpora (Cutler & Condon, 2022), our approach may appear rather simple, yet straightforward. We treated words as information tokens about linguistic choices to convey information about characters in the epic to an audience. This linguistic assignment of information tokens to characters allowed us to deduce some implicit cognitive models of personality. What terms are being used together to describe a specific character? Do these co-occurrences reveal some underlying dimensionality, similar to the insights that have been gained in personality research using self- or other-report surveys? We stayed as close as possible to the available text which did not require us to rely on additional assumptions about the language or modelling choices, while also preserving some conceptual similarity to canonical research practice in the field of personality research. Using a human coder to assign information tokens to fictional characters, we were also able to utilise all available information from the context in these highly fragmented and sparse texts.
We think our approach has merit in light of the available corpus. Large language models that have started to dominate text analyses in recent years are built and trained on large corpora of mostly contemporary texts (e.g. content from Web pages). To the best of our knowledge, the gold standard of contemporary transformer-based models has not been evaluated against highly fragmented documents which use a poetry structure with both elliptical and complex sentences and employ archaic language constructions.
Psychological analysis can often access the individuals that produced certain texts and obtain, for example, self-report data to cross-validate the textual analyses. This in itself has led to significant debates about the relative validity of survey responses versus textual analyses (Boyd & Pennebaker, 2017). Nevertheless, having access to data from independent methods pertaining to the same individuals allows at least in principle a disentangling of biases inherent in either method. When using historical data, this opportunity for cross-validation does not exist (at least not with the type of data that we are dealing with here), and new avenues for identifying the validity within the specific historical context in which the texts were generated need to be sought. Using large language models that have been pretrained on contemporary language and word usage would mean we may lose precision in tracking culturally and historically meaningful word associations, which represent nuances that may be considered insignificant within the statistical models that aim to predict the next likely word.
We suggest one interesting option for future research may be to pretrain such models on text corpora from specific time periods and then compare the resulting distance metrics from each temporal instance with each other. An interesting computational and statistical challenge is to develop algorithms that allow the identification of nuanced shifts and subtle connotations that change over time and are at the threshold of statistical detection within the distribution of terms in a larger temporal corpus. Diachronic word embeddings (Hamilton et al., 2016) are one line of work that seeks to address this challenge, but even with those methods important theoretical nuances may be pushed towards the boundaries of the trained language models due to the sparsity of the text at hand and the rare occurrence of individual terms. It needs to be investigated whether meaningful results can be produced given the very small corpora available for specific temporal epochs, which may reduce the possibilities to reliably detect subtle changes that are not artefacts of the available source documents.
Current algorithms rely on statistical patterns to predict the next likely word, emphasising form over meaning (Bender & Koller, 2020). We used human coders to identify which information tokens (words) were associated with which character and then analysed the co-occurrences of information tokens to identify patterns of meaning across recurring associations of words with characters within the epic. In this sense our approach is more robust. Yet, even our analysis cannot overcome some general challenges of biased analyses, most importantly our inability to interact with the language users and analyse their ‘lived’ language experience against the power relations in place that are represented in the texts and are incorporated into the statistical models (Blodgett et al., 2020). Furthermore, the identified dimensions in the MDS need to be interpreted, which brings in contemporary bias. Together with our inability to verify the robustness of these dimensions beyond purely statistical replicability, we need to acknowledge that slight changes in the rotated spaces together with our contemporary intuitions about ancient societies may have led to biases.
In closing, we present a first linguistic analysis of the implicit personality structure in the Gilgamesh epic. We found an increasing usage of terms that can be mapped onto modern dictionaries in the later versions of the epic. The analysis of word frequencies and structural analyses suggested subtle temporal shifts in the implicit personality models that our ancestors had in mind when chiselling the epic onto their clay tablets. Examining the structures and changes of character descriptions, analyses of ancient texts using modern psychological and linguistic tools can provide new insights into both the psychology of periods long gone and cultural evolution dynamics.
Supplemental Material
Supplemental Material - Tracing the evolution of personality cognition in early human civilisations: A computational analysis of the Gilgamesh epic
Supplemental Material for Tracing the evolution of personality cognition in early human civilisations: A computational analysis of the Gilgamesh epic by Ronald Fischer, Johannes A. Karl, Velichko Fetvadjiev, Markus Luczak-Roesch, Reinhard Pirngruber, and Amy He Du in European Journal of Personality
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Data accessibility statement
Supplemental Material
Supplemental material for this article is available online.
Note
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.