
Abstract
Artificial intelligence (AI) software in radiology is becoming increasingly prevalent and performance is improving rapidly with new applications for given use cases being developed continuously, oftentimes with development and validation occurring in parallel. Several guidelines have provided reporting standards for publications of AI-based research in medicine and radiology. Yet, there is an unmet need for recommendations on the assessment of AI software before adoption and after commercialization. As the radiology AI ecosystem continues to grow and mature, a formalization of system assessment and evaluation is paramount to ensure patient safety, relevance and support to clinical workflows, and optimal allocation of limited AI development and validation resources before broader implementation into clinical practice. To fulfil these needs, we provide a glossary for AI software types, use cases and roles within the clinical workflow; list healthcare needs, key performance indicators and required information about software prior to assessment; and lay out examples of software performance metrics per software category. This conceptual framework is intended to streamline communication with the AI software industry and provide healthcare decision makers and radiologists with tools to assess the potential use of these software. The proposed software evaluation framework lays the foundation for a radiologist-led prospective validation network of radiology AI software. Learning Points: The rapid expansion of AI applications in radiology requires standardization of AI software specification, classification, and evaluation. The Canadian Association of Radiologists' AI Tech & Apps Working Group Proposes an AI Specification document format and supports the implementation of a clinical expert evaluation process for Radiology AI software.
Introduction
The increasing variety of radiology artificial intelligence (AI) software offers numerous opportunities to improve detection, diagnosis, and prediction of patient outcomes and increase quality and operational efficiencies. Numerous regulatory body approved AI software solutions have been announced in radiology, with greater than 241 FDA-approved solutions alone as of the time of writing, the vast majority of which were approved since 2017. 1 Independent research supports estimate the global market for medical imaging AI applications will reach $1.2 billion by 2024. 2
Despite this, as radiology AI software has been deployed clinically, limitations of real-world effectiveness and weaknesses of radiology AI have now been observed. Many of these weaknesses primarily concern the inability of contemporary AI to adapt to novel inputs that may differ from training datasets by disease sub-type, imaging parameters or imaging artifacts. Standardized methods for external validation and performance evaluation, and mechanisms for prospective post-market system reliability monitoring still remain elusive and inconsistent throughout the field. Improving the state of evaluation is particularly urgent, given that in a recent survey conducted by the ACR Data Science Institute, approximately 30% of radiologists are currently using AI as a part of their practice with 20% of practices not currently using AI but planning to purchase AI tools in the next 1 to 5 years. 3
To help guide this growth in AI development and deployment, several guidelines have provided reporting standards for publications of AI-based research in medicine and radiology.4-7 Yet, in a large systematic review of COVID-19 detection algorithms, 258 of 320 publications screened using the Checklist for Artificial Intelligence in Medical Imaging (CLAIM) and Radiomics Quality Score (RQS) failed quality control, with insufficient documentation of model selection, image pre-processing and algorithm training approach as the most common causes for rejection. 8 A recent systematic review on AI algorithms that have undergone external validation has shown that only 13% of 86 studies stated adherence to a reporting quality guideline. 9 Additionally, although many AI algorithms report performance metrics, fewer solutions have undergone multi-centric or external validation or evaluation, comprising only 6% of 516 medical imaging algorithms reviewed in a 2019 systematic review of publications investigating AI software performance in medical imaging analysis. 10 Multiple recently published external validation studies of AI algorithms showed at least some decrease in performance between the training and external datasets, with 24% of 86 studies showing a substantial decrease. This loss of generalizability is commonly attributed to differences between the training and validation/test populations and limited interpretability of neural networks.9,11
As the radiology AI ecosystem continues to grow and mature, there is a need for a formal approach to evaluation of AI software to ensure patient safety and user acceptance, both pre- and post-deployment. This paper seeks to provide a comprehensive formal format for regulators, healthcare organizations or clinical radiology practices to evaluate AI models before deployment. Complementary to that of the recent guidelines for evaluation of commercial AI solutions proposed by the ECLAIR guidelines, 12 the paper takes a format of standardized evaluation forms that can be utilized as is, or further modified and built upon, for structured evaluation of candidate AI solutions. These forms propose a systematic approach to the evaluation of a radiology AI product: from both accurately specifying and describing clinical radiology AI software through standards for single- or multi-centre pre-deployment evaluation and post-deployment monitoring.
Artificial Intelligence Software Overview
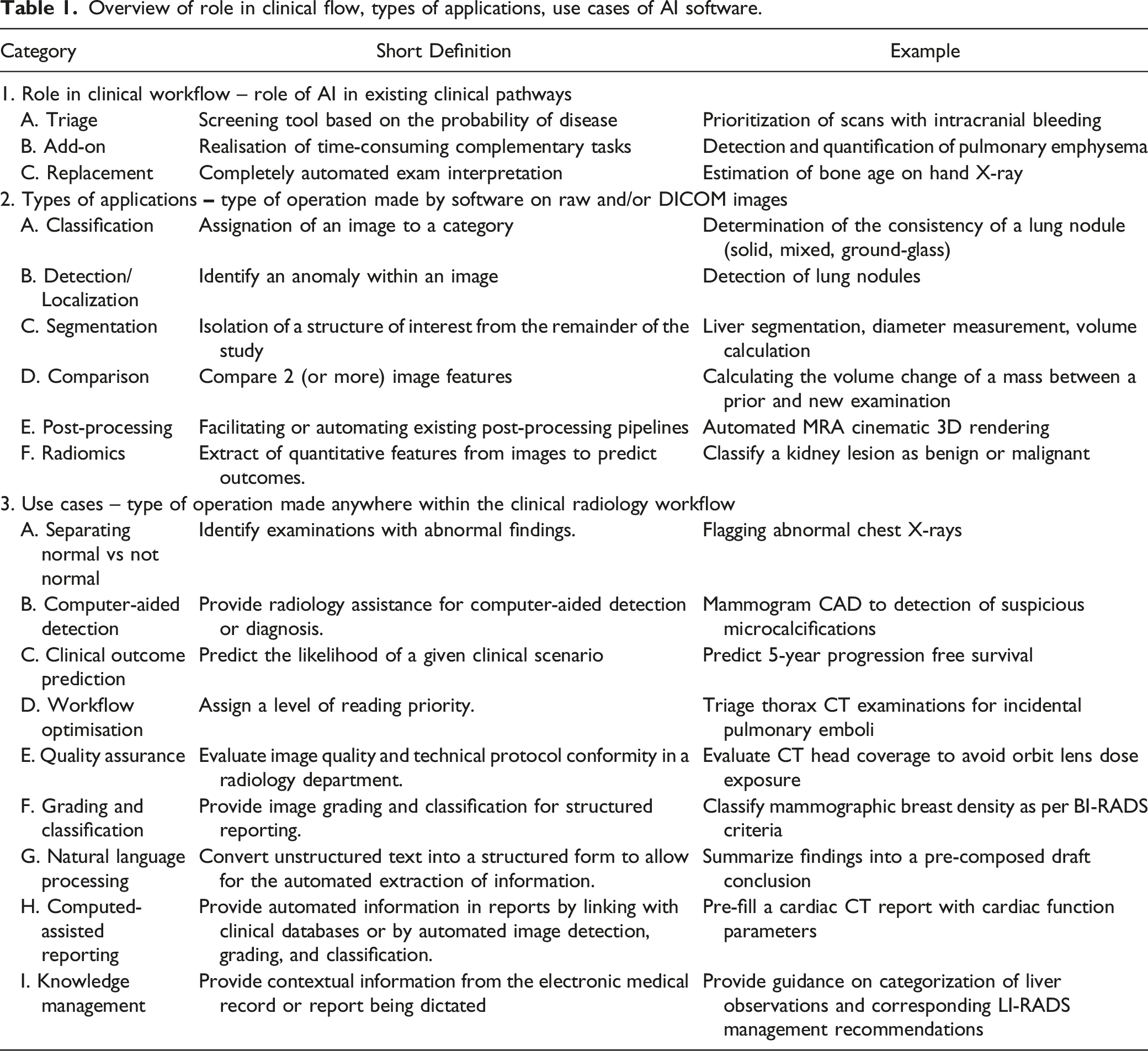
As per the Canadian Association of Radiologists (CAR) White Paper on AI in Radiology, 13 radiology AI software can be categorized according to their role in the clinical workflow, type of application or classes of use cases. This typology is expected to evolve following advances in the field.
Clinical Applications of AI in Radiology: Workflow Roles, Application Types and Use Cases
The existing clinical pathway includes image acquisition followed by the radiologist’s interpretation and report creation, readily available to the clinician. Artificial intelligence software can be embedded in the clinical workflow for triage
14
(e.g. screening tool), add-on (complementary tasks) or replacement of existing tasks (Figure 1). Alternatively, software may be defined according to the tasks performed such as which for computer vision tasks could include: classification, detection or segmentation or for natural language processing tasks could include: sentiment classification or summarization. Finally, software may also be divided by use cases: separating normal vs not normal, computer-aided detection, radiomics, workflow optimization, quality assurance, grading and classification, natural language processing, computer-assisted reporting and knowledge management. Some clinical use scenarios may target specific scenarios such as computer-aided detection of pneumothorax. Table 1 provides an overview of AI software categorized according to their role in the clinical workflow, types of applications and use cases, along with short definitions and companion examples. It is critical that radiology providers spend time up front clearly deciding on the intended clinical use to guide effective evaluation. Role of radiology AI software in the clinical radiology workflow. In the standard scenario, the clinician requests an imaging procedure, to which a protocol is assigned either by the radiologist or imaging technologist. The imaging data is acquired from the patient, processed, formatted to DICOM images, read and interpreted by the radiologist who then generates a radiological report. Clinicians can then use the information contained in the radiological report to guide their diagnosis and use existing tools to estimate the patient’s health outcome and prognosis. AI software tools complement radiologists by fulfilling different roles incorporated to their clinical workflow (blue). AI software tools can use DICOM images as input and accomplish a variety of task types (green). Many AI software use cases (black) improve the existing scenario. Overview of role in clinical flow, types of applications, use cases of AI software.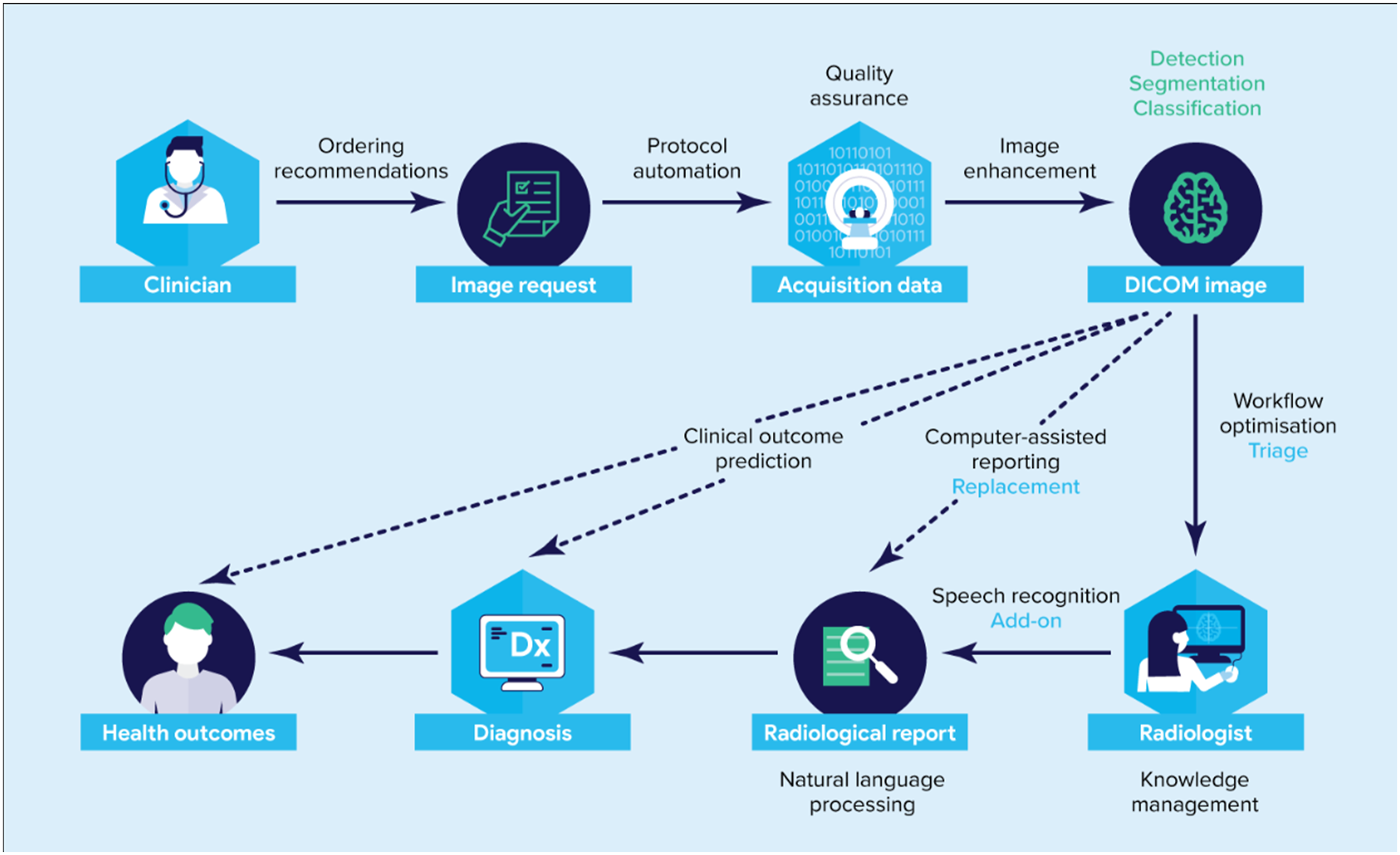
Framework
Radiological Practice Health Needs Assessment
Appropriate evaluation of radiology AI software requires a clear description of the target clinical problem in terms of unmet need and technical specifications to operate. Developers should define the healthcare needs addressed by their software (e.g. quality of radiological care, healthcare network integration, patient perspective, employee experience, efficiency and costs), the applicable clinical domain (e.g. mammography and chest radiograph) and task (e.g. breast density evaluation and pneumothorax detection) and describe the expected positive impact on these needs and patient outcomes. New initiatives which help standardize radiological AI use cases are emerging, most notably the ACR Data Science Institute’s (DSI) comprehensive catalogue of AI use case documents providing a description of a clinical need potentially addressed by an AI algorithm, specifying technical details about the expected inputs needed by the AI algorithm, and the outputs produced. 15
Healthcare Needs and Key Performance Indicators.

Radiology AI Software Specifications
Required information about each software solution prior to assessment.

Independent Evaluation Performance Assessment
Once a radiology AI software is appropriately specified, evaluation would greatly benefit from expert review, wherein a radiologist reviewer could evaluate hands-on a trial or demonstration of a solution to assess clinical relevance and integration with expected clinical workflow, and have the opportunity to challenge a system with sample cases, for face validation of software solution performance claims. 18 This is especially relevant to AI-driven software, where there may be significant model generalization difficulties due to systematic differences between training datasets vs an end-user’s own clinical population.
This evaluation can be done either retrospectively by running the AI software on previously reported cases or prospectively if the software is applied to cases while the radiologist is reading them. A unique advantage of the latter validation period is that the direct effect of AI software on a reader’s clinical workflow and user interface can be directly assessed, an important practical consideration rarely characterized in scientific literature. However, prospective evaluation may not adequately assess performance for rare diseases.
Independent external test cases should be chosen to reflect the actual patient population on which the system is expected to be applied, with a disease prevalence replicating that which is encountered in a clinical radiologist’s practice. Appropriate test case sample composition sizes can be estimated by sample proportion (p) calculation methods. 15 The size of the test set will depend on many factors, particularly the number of output classes and the frequency of relevant disease presentations. Ground truth would then be established for each test case, ideally with multi-rater consensus to establish inter-rater diagnostic variability, or if reference standards are defined from ground truth derived from clinical or pathology references, obtained appropriately. There is ongoing work to determine statistical power calculation methods to estimate appropriate sample sizes in AI software validation.19,20 Some authors have suggested 50–100 cases may be sufficient when testing lesion detection or segmentation, whereas at least 200 cases for binary classification diagnostic software may be necessary. 15 Such minimums are not exhaustive but could be used as general guidelines and may vary by clinical application and AI technique being evaluated.
Examples of performance metrics per software category.

Metrics should be intuitive to the end user or clinician and be directly relevant to clinical use. Where possible, AI software evaluation should emphasize clear unambiguous statements of how a solution improves patient outcomes and precisely define quality of care outcomes that complement technical metrics in the performance assessment protocol, to maximize relevance to patient care and value for the healthcare system.
Post-Market Quality Assurance and Quality Control
Software output is subject to change over time, driven either by changes in the population (data drift), changes in the statistical relationship between the fundamental relationship of the input and output data over time (concept drift), or by the nature of the AI software product (e.g. locked vs adaptive algorithms.21,22 Documentation of the software version along with predictions and quality control of software output are essential to detect and remediate any decrease in accuracy. Different strategies have been proposed for performance monitoring and detection of statistical changes in data generating processes, such as ACR assess-AI data registry. 23
As both a practical and technical capability matter, if a solution is not developed in-house, we expect that AI solution vendors themselves would ultimately be most responsible for refreshing a software’s models when concept drift occurs, or decreased performance is noted. There should be a pre-specified strategy for continued quality control established between the developer and end-users, clearly outlined in any service contract or agreement. An adverse event reporting procedure should clearly specify a procedure for reporting and escalating unexpected adverse events.
Future Directions
AI software has the potential to address a large variety of potential use cases. Tremendous intellectual and financial capital has been invested in developing new tools and platforms to further develop these use cases. This has created a steady stream of new products intended, in time, for full-scale clinical use. Despite this large array of imaging software, a standardized method for external validation and performance evaluation, as well as mechanisms for prospective post-market system reliability monitoring are still nascent.
Because of the great variety in applications and tasks, it is inherently difficult to standardize these evaluation processes. Some basic benchmarking protocols can still be adopted to validate products before clinical implementation and purchase by clinical users to benchmark real-world performance and compared with developer-provided specifications, assess for potential bias in algorithm training and risk for systematic errors, as well as unanticipated pitfalls and to ensure continuous quality control of software performance over extended periods of time.
Artificial intelligence software metric development is analogous to benchmarking in the computing hardware industry, with a widening variety of hardware computing products, resulting in a need for application-specific performance metrics. Because it is logistically challenging and in many hospital environments, impractical and prohibitive for individual radiology departments to perform validation of a variety of new AI software, we see a need for a national validation network providing testing cases for multiple clinical use case scenarios and labelled by radiology experts from several Canadian institutions representing a broad range of users from academic and community settings. This would help ensure the external validity and generalizability of performance claims by AI software manufacturers and provide patient, physician and regulator reassurance of system reliability, while also providing an efficient and expedient way for a vendor to demonstrate solution quality to stakeholders.
It is important to acknowledge that due to the dynamic nature of healthcare, performance at the time of deployment does not guarantee continued performance. As real-world deployments expand in reach, post-market surveillance of AI software will prove increasingly critical, akin to the development of pharmacovigilance in the pharmaceutical industry, potentially indicating a future need for standardized radiology AI adverse event reporting. Again, the infrastructure and expertise provided by a national validation network could provide updated testing datasets for dynamic post-market surveillance.
Conclusion
In summary, we have proposed our vision of how Radiology AI validation processes should be performed, inspired by previous work in the field and similar methods in other industries. The responsibility for validation is complex and multi-faceted and will have to draw heavily from the expertise of academic and clinical end-users, industry, regulatory and legal entities to address the variety of challenges ahead. A coordinated approach that balances the priorities of all stakeholders while leveraging each group’s individual strengths will best serve the public and patient’s interests, further grow the burgeoning field of radiology AI, and sustain user trust in these technologies for medical care provision. Delivering on such a robust ecosystem of development and validation will require the right technical infrastructure and strategic investments, but more than this, will require an enthusiastic network of stakeholders and investigators to realize the full potential of radiology AI software.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by a Junior 2 and Senior research scholarship from the Fonds de recherche du Québec — Santé (Awards #26993 and #298509) to An Tang.