
Abstract
Introduction
Interest in artificial intelligence (AI) in radiology is growing exponentially, with currently over 180 radiology AI algorithms approved by the Food and Drug Administration. 1 Academic publications and marketing materials state that AI and radiologists can deliver better care together. For instance, O’Neil et al found that using AI to triage head CT scans reduced the wait time to reporting on cases with AI-identified intracranial hemorrhage by 22%. 2 Brown et al. 3 also showed that using a computer-assisted detection software for lung nodule detection on CT scans reduced radiologists’ reading time by up to 44% without decreasing the number of nodules identified.
However, multiple challenges prevent AI from becoming more widely used in radiology. From a deployment perspective, AI uptake requires safe and efficient integration into pre-existing clinical workflows.4,5 On a user level, radiologists must also anticipate worthwhile gains in reporting quality and efficiency.6,7 Simultaneously, fundamental concerns toward AI, such as the risk of automation bias and medicolegal consequences of incorrect diagnoses, must be addressed. From a safety perspective, as the airline industry has learned, a software system intended to improve quality can cause unintended harm and warrants testing of the combined human-software system. 8
Although some authors have provided suggestions to meet these demands, few studies have directly examined the user interaction of radiologists with AI software.5,8 Among these studies, Gaube et al. 9 found that even expert radiologists are susceptible to incorrect advice from AI, but their short web-based experiment did not closely mimic clinical practice and was enriched with trainees. Unfortunately, there remains a wide gap in the literature describing how experienced radiologists interact with AI systems and its impact on clinical workflow and decision-making.
In this study, we perform in-depth experimentation applying methods from software usability testing to examine how experienced staff radiologists interact with a commercially available, regulatory approved chest x-ray AI software tool. We collected feedback on the tool and used time-stamped video recordings to assess the tool’s impact on reporting times.
Materials and Methods
Ethics Approval
The study protocol was approved by the Trillium Health Partners (THP) Research Ethics Board. All participating radiologists provided informed consent prior to participating. Patient consent was waived as anonymized images were used.
Setting
Located in Mississauga, Ontario, THP is the largest community hospital system in Canada providing approximately 600 000 imaging examinations per year to a globally diverse catchment area of over 1 000 000 people. The data collection occurred within August 2021.
AI System
We conducted usability testing on an AI algorithm for chest x-rays (referred to as “x-ray classification tool” hereafter) provisionally approved by Health Canada in the context of COVID-19. The software’s AI component is a deep learning-based classifier which analyses posteroanterior chest x-ray DICOM images for the absence or presence of abnormalities and returns a binary prediction (“normal” or “abnormal”) along with a confidence level. According to vendor materials, a 35% confidence level was preselected by the vendor as the output threshold for abnormal classification, and a 5%–35% confidence level was considered a low probability of abnormality. Furthermore, the software produces a scrollable heatmap in a DICOM series (maximum 30 images for a single x-ray study) highlighting the suspected area of abnormality in a red overlay (Figure 1). Binary label and heatmap. (A) 1 layer of the heatmap overlay highlights a small area over a cavitary lesion and has a confidence level of 95%. (B) Another layer of the heatmap for the same case highlights a larger area but has a smaller corresponding confidence level of 58%.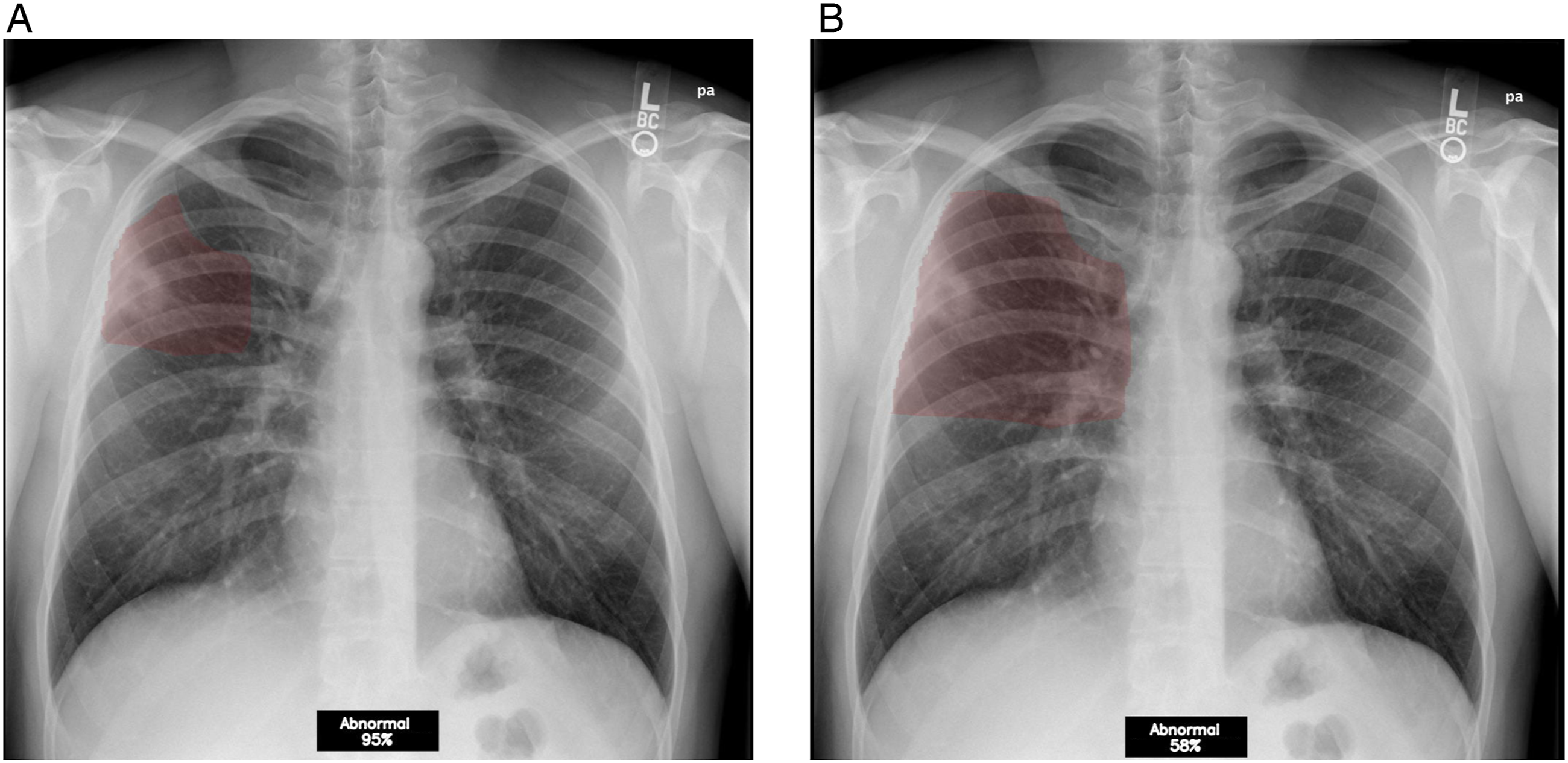
In this study, to facilitate radiologist users’ interactions, the results were integrated into a research PACS environment (Sectra IDS7) with (a) the ability to triage worklists by binary label and confidence score (Figure 2) and (b) a custom-developed discordance button for radiologists to report disagreements with the AI. Triaged worklist. Worklists could be triaged such that AI-labeled abnormal scans with a higher confidence level were placed higher on the user’s worklist (red outlined box).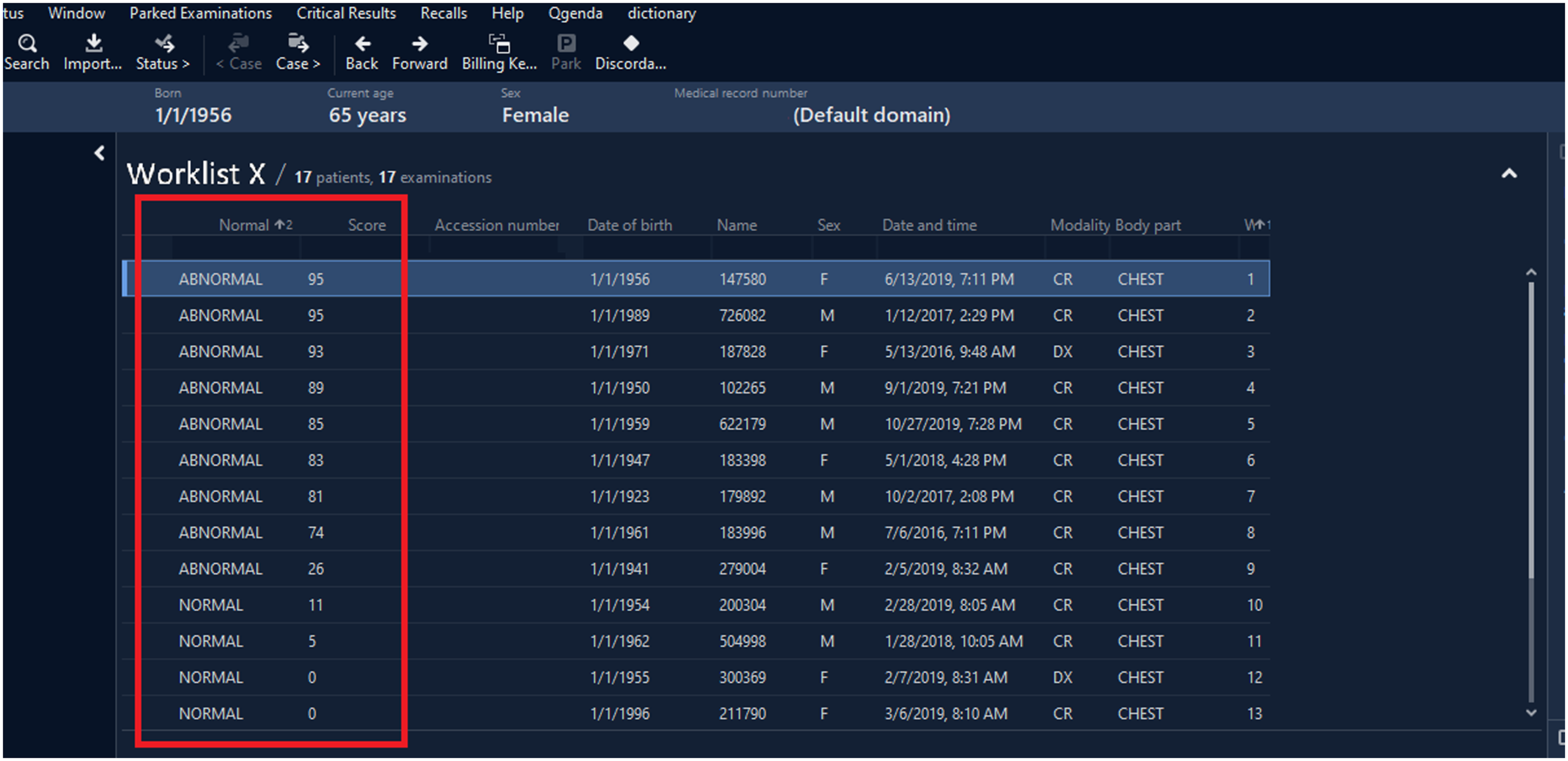
Imaging data were anonymized from the PACS production system and stored in a research PACS environment. Studies were routed for analysis by third party software application running the x-ray classification tool, and AI results (DICOM images) were added as a series to the matching PACS study for review by radiologists on a PACS workstation. Voice recognition integrated within the PACS workstation software was used for this study.
User Testing
We conducted two rounds of usability testing, an observational technique where intended end-users trial a system in a simulated environment to assesses its appropriateness and usability. 10 Round 1 aimed to gather detailed feedback on the x-ray classification tool and identify layout changes to be implemented prior to Round 2. Round 2 focused on assessing the user experience and the tool’s impact on workflow efficiency during a simulated real-world deployment scenario. Using a convenience sample, a total of 10 radiologists (5–33 years of staff experience) were recruited and sent a short email description of the AI tool. The only inclusion criterion required participants to be a staff radiologist. There were no exclusion criteria. Self-reported comfort with technology and trust in AI were provided by users before the sessions.
All sessions were conducted remotely using GoToMeeting (LogMeIn, USA) with multi-monitor screensharing enabled (Figure 3). Video and audio were recorded with users’ permission. Multi-monitor screensharing. In this scenario, the radiologist user had access to 3 monitors. In the top-left monitor, the user displayed the x-ray worklist and their dictation note. In the bottom-left monitor, the user displayed the frontal and lateral x-ray images. In the rightmost monitor, the user displayed the x-ray classification tool’s output. The hanging protocol was arranged so that the frontal and lateral x-rays would display by default, but the heatmap only displayed if it was manually opened by pressing the “layout” button or scrolling through the lateral x-ray.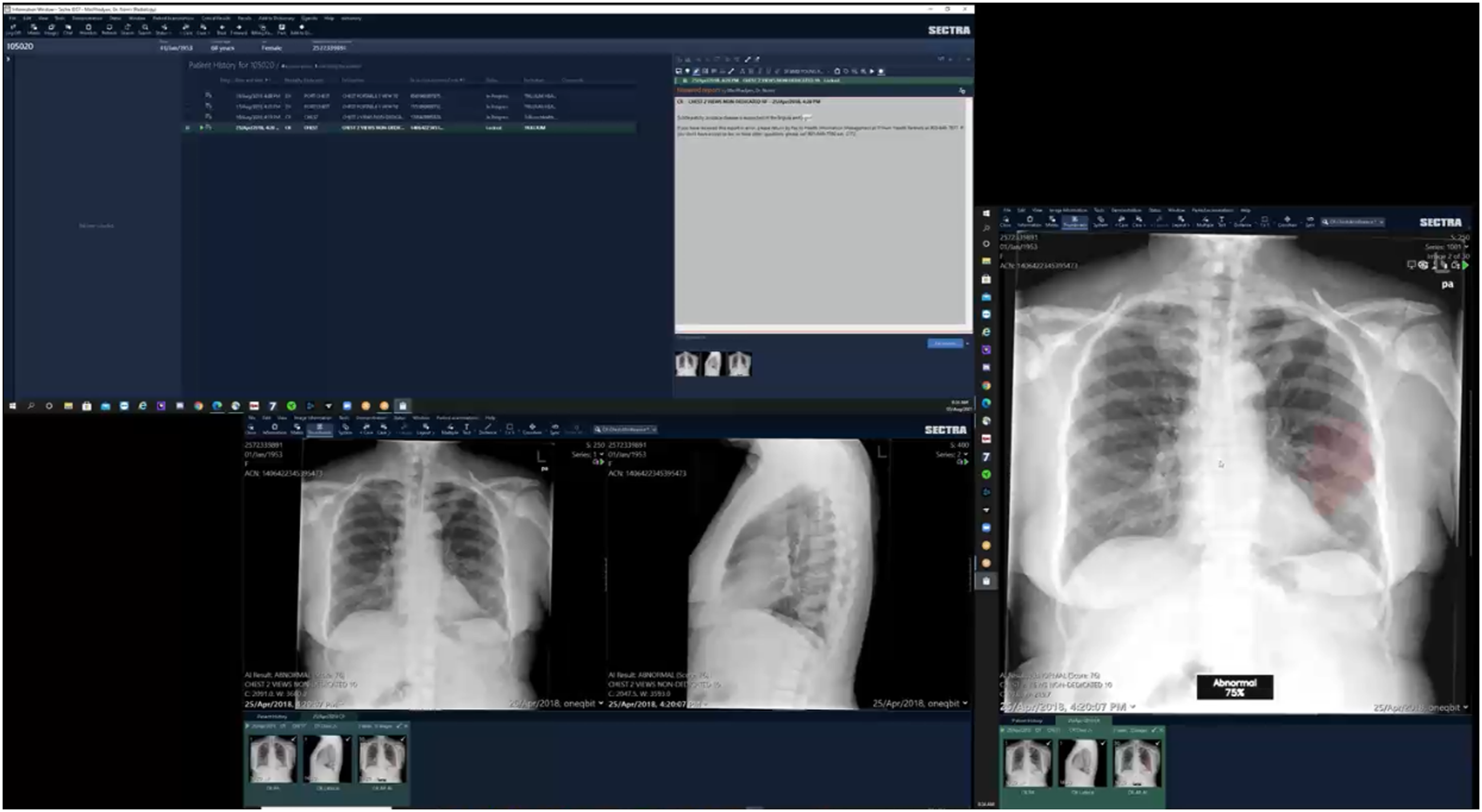
Round 1
We recruited 3 radiologists who each reviewed 3 worklists (I, II, and III). Each worklist contained 8 cases (3 normal and 5 abnormal cases), to provide sufficient exposure to the x-ray classification tool in different scenarios without fatiguing users. Abnormal cases were selected to reflect the types of cases encountered during an emergency shift (e.g., pneumothorax, pneumonia, and atelectasis) where such a tool might be used clinically. All worklists were vetted by the principal investigator (BF), a musculoskeletal radiologist with five years of staff experience.
Testing was consistent and structured across users. Radiologists received a maximum of 5 min to review Worklist I which lacked outputs from the x-ray classification tool and acted as a control to ensure that users were comfortable using the research PACS. Next, users had a maximum of 20 min each to review Worklists II and III, which both included the x-ray classification tool’s core features: a binary label and confidence level. To assess whether users preferred to see a heatmap concurrently with the binary label, Worklist III included the scrollable heatmap. Finally, to gather feedback on a triage function, either Worklist II or III was randomized to have AI-identified abnormal cases with higher confidence levels ordered higher on the list (Figure 2).
As Round 1 focused on user feedback, radiologists did not dictate reports and were simply asked to verbalize whether they thought cases were normal or abnormal (and to describe any perceived abnormalities). Participants were also instructed to think-aloud during testing. Facilitators only spoke to remind participants to share their thoughts if they remained silent for >15 seconds, 11 or if the participant needed reminders of how to access the tool’s features. To ensure that all users had the same description of the x-ray classification tool, if users asked about the tool beyond the scope of the initial introduction, facilitators used standardized responses to explain that these questions could not be addressed, and facilitators encouraged the users to continue vocalizing their thoughts.
Round 2
We recruited 10 radiologists who were assigned (by simple randomization) to one of two groups (A or B). To assess whether the presence of the x-ray classification tool impacted an individual user’s performance, each radiologist reviewed 2 worklists (X and Y), and only one worklist included the AI output, based on group assignment.
To minimize the effect of case selection on reading times, Worklists X and Y were intended to have the same baseline difficulty by having the same number of cases and same types of pathologies. Both worklists included 17 cases (9 normal and 8 abnormal) to expose users to a variety of cases, and prior trials with the principal investigator suggested that most users could comfortably complete the caseload in the allotted time of 25 min per worklist. Like Round 1, abnormal cases were intended to reflect cases encountered during an emergency shift. To assess how users would react to prediction errors, we included one case that the x-ray classification tool falsely labeled as abnormal and one case that was falsely labeled as normal in each worklist. All worklists were vetted by the principal investigator.
To simulate a real-world workflow, radiologists were asked to dictate reports on the x-rays as if it was their regular clinical duties (to mimic macros templates for normal cases, users could report “Normal chest x-ray” if there were no remarkable findings).
All previously described features of the x-ray classification tool were available in Round 2. The default hanging protocol was modified according to Round 1 feedback such that the heatmap would only display after the user pressed the “next layout” button or scrolled over the lateral x-ray image (Figure 3) to reveal the AI result series.
Post Testing Interview
Following Rounds 1 and 2, we conducted semi-structured interviews with the users. A standard set of questions was created a priori with the intent to explore radiologists’ thoughts and attitudes toward the features of the x-ray classification tool and its impact on clinical performance. When radiologists provided vague responses (e.g., only responding “yes” or “no”) or introduced new concepts (e.g., automation bias), we used off-script questions to elicit further details.
Qualitative User Feedback
We collected feedback by recording comments from the think-aloud method, where users were asked to verbalize their thought process and any questions arising while using the system 11 (Round 1 only), and post-testing interview (Rounds 1 and 2). Audio recordings were transcribed and scrutinized by three reviewers (AA, JLSC, MA). Using thematic analysis, reviewers independently listed all identified themes then convened to group the themes using a bottom-up method. 12 Discussions were held until a consensus was reached on the categorizations.
Quantitative Workflow Assessment
One author (JLSC) manually reviewed Round 2’s video recordings and time-stamped when: (1) cases were opened, (2) dictations began, and (3) cases were completed (when the case was closed as some radiologists continued examining scans after finishing their dictation). Only the reports completed in the 25-minute time limit for each worklist were analyzed. Statistical analysis was performed in Microsoft Excel, and P-values were two-tailed and considered significant at P < .05.
As described previously, radiologists in Round 2 dictated cases from two worklists where only one included the x-ray classification tool output. To determine impact on workflow, a student’s paired t-test was used to compare the average time each user took to begin dictating (with vs without AI assistance) and to completely read a single x-ray (with vs without AI assistance).13-15 To account for a learning curve, a sensitivity analysis was performed by removing the first case from the worklist with the AI output. A second sensitivity analysis was performed by removing results from user P4, who was an outlier (only radiologist who did not finish reporting all the cases in the allotted time).
Finally, we sought to assess whether triaging, which could only be used when the AI output was present, impacted the time to reach a critical finding for a given worklist. To achieve this, we included a tension pneumothorax case in both Worklists X and Y, as this diagnosis is a clinical emergency requiring immediate care. For each user, the worklist with the AI output was then randomly selected to either include or omit the triage function. Without triaging, cases were sorted by their accession number to maintain the same order across users. For a given worklist (X or Y), we measured the time each user took to reach the tension pneumothorax case (when the x-ray classification tool was used), and a student’s unpaired t-test was used to compare the time to reach the same tension pneumothorax case (with vs without triaging).
Results
Participant Demographics.
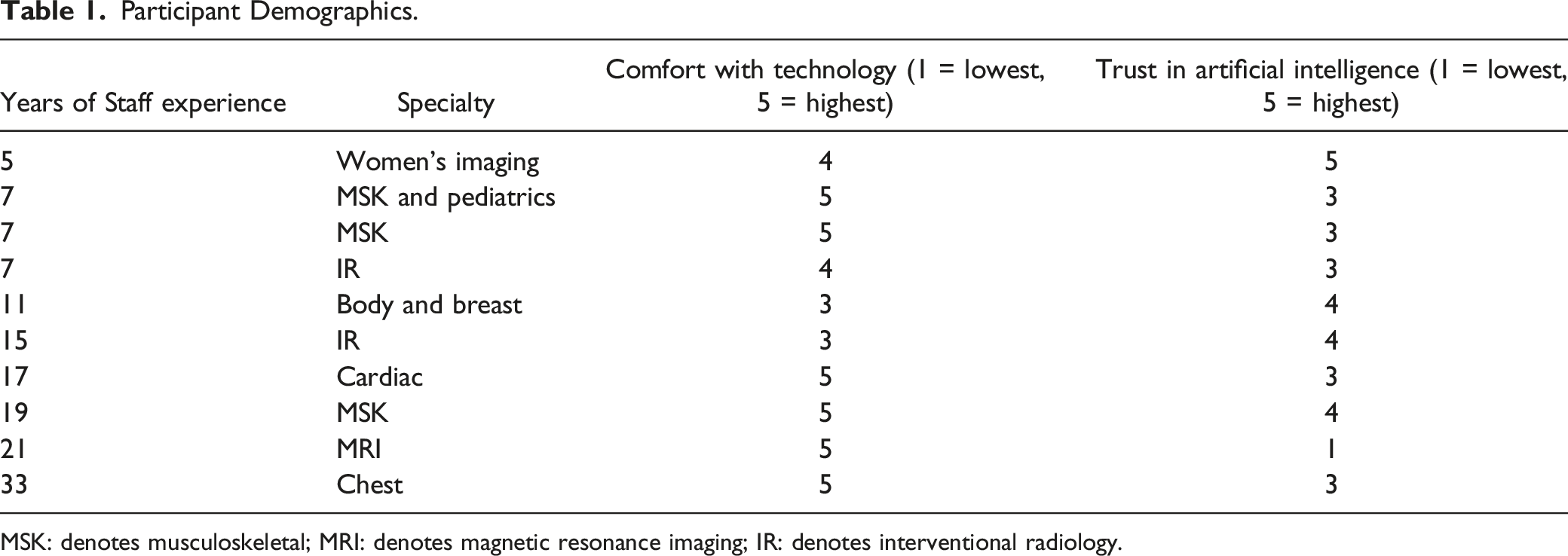
MSK: denotes musculoskeletal; MRI: denotes magnetic resonance imaging; IR: denotes interventional radiology.
Qualitative User Feedback Results
Qualitative Thematic Analysis of User Feedback.

Category 1. Features of the X-ray Classification Tool
Users appreciated simple features, such as the binary label (7 users voiced this opinion), and considered the heatmap necessary to understand what the tool considered abnormal (7 users).
Users were sometimes unsure of how to interpret confidence levels (6 users). Some users also hoped this tool would include additional features such as providing diagnoses for abnormal cases (3 users). “If the algorithm tells me that the x-ray is abnormal and says that there’s a 94% chance that the pattern represents edema and only a 6% chance that the pattern represents pneumonia, that would be very helpful.” (P1)
Category 2: Considerations for Deploying the Trialed Tool
Users shared mixed opinions on the tool’s impact on reading efficiency, report accuracy, and clinical confidence. However, many users believed that this tool’s main clinical value was assisting with detecting subtle, easily overlooked abnormalities (8 users).
Supposing that the x-ray classification tool was available in their clinical practice, users had mixed thoughts on whether they would use it for triaging. Some users noted there may be clinical scenarios, such as busy emergency shifts, where triaging may improve efficiency (5 users). Others questioned the accuracy of the triage function and worried about automation bias (3 users). “If I have a whole group of normals, I don’t want to be biased in thinking they’re normal or abnormal beforehand.” (P8)
Finally, many users suggested that the trialed tool should be deployed in hospitals with understaffed radiology departments or used by trainees and non-radiologist specialties instead (7 users). “[The x-ray classification tool is] more useful for emerge docs or medical trainees or residents or people who don’t do this every day. For us, I don’t think it’s very useful.” (P9)
Category 3: General Human-AI Interaction
Radiologists appreciated that different AI tools may specialize in detecting certain pathologies and thus accomplish different goals (7 users). For example, radiologists identified patient safety improvement as a potential goal for AI (3 users). “I can imagine a scenario where I was really rushed and maybe I would miss those. So, that was one case that I thought maybe it would have helped.” (P5)
Radiologists expressed concerns for automation bias, especially when discussing the tool’s triage function (3 users). As an extension, one radiologist also worried about the medico-legal consequences of misinterpreting AI software results. “One of the legal fears that I would have using this is the algorithm says abnormal. I disagree. I call it normal, and I missed the tumor, for example. Three years later, it comes back. I’ll be like, well, the algorithm said it was abnormal. And I’m like, yeah, I thought the algorithm saw there were old rib fractures.” (P1)
Quantitative Workflow Assessment Results
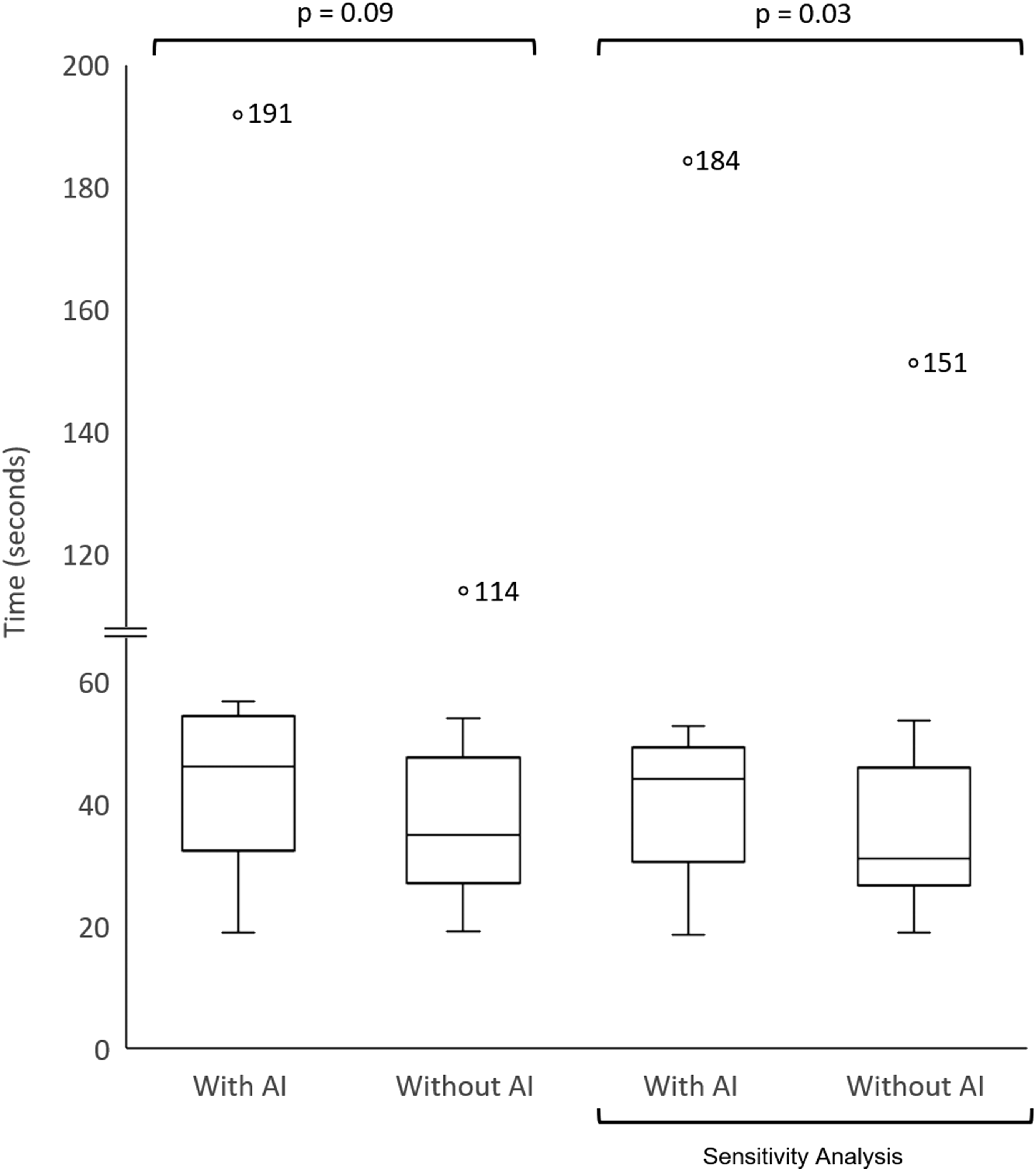
On average, participants started dictating 5 seconds later (42% increase) with AI assistance (P = .02) and took 14 seconds longer (33% increase) to complete cases with AI assistance (P = .09) (Figures 4 and 5). Results were consistent regardless of the worklist (X or Y) that had the AI output (Appendix 1). After accounting for a learning curve, participants started dictating 5 seconds later (42% increase) with AI assistance (P = .02) and took 9 seconds longer (19% increase) to complete cases with AI assistance (P = .03) (Figures 4 and 5). When results from P4 were excluded, participants started dictating 6 seconds later (55% increase) with AI assistance (P = .01) and took 7 seconds longer (19% increase) to complete cases with AI assistance (P < .01). Impact on decision-making time. Box-plots are used to compare the time it took radiologists to begin dictating cases with and without using the x-ray classification tool. The 2 box-plots on the right represent results from a sensitivity analysis to account for a learning curve by removing the first case from the Worklist with the AI output. Outliers are represented with a circle. Impact on total reading time. Box-plots are used to compare the total time it took radiologists to read an x-ray case with and without using the x-ray classification tool. The 2 box-plots on the right represent results from a sensitivity analysis to account for a learning curve by removing the first case from the Worklist with the AI output. Outliers are represented with a circle, and the corresponding value is listed adjacent.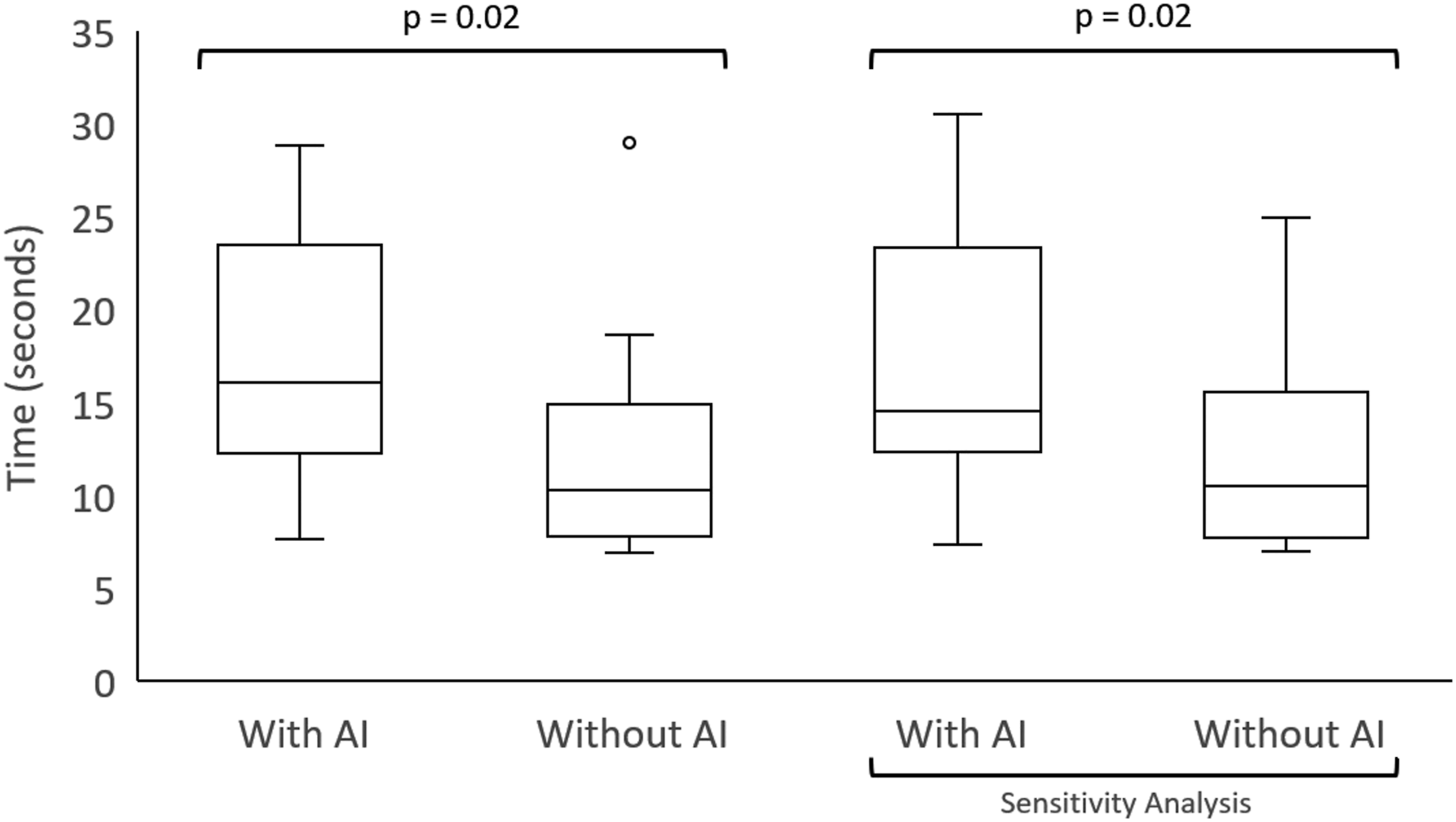
The average time (minutes:seconds) to reach the tension pneumothorax case with and without triaging were 0:00 and 6:33, respectively, for worklist X (P = .04) and 1:17 and 1:52, respectively, for worklist Y (P = .50).
Discussion
Despite the increasing development of artificial intelligence (AI) products in radiology, few studies have examined practicing radiologists’ interactions with AI tools. Using remote usability testing, we addressed this gap and collected radiologist’s opinions on effective AI tool features, deployment considerations, and human-AI interactions. We also found that early AI adoption increased reading times.
Qualitative Feedback
All users valued a simple, non-intrusive interface. However, peripherally placed elements, such as the binary label, became increasingly neglected over time due to a lack of conspicuity. This highlights a considerable challenge in user interface design as developers must find balance when creating non-intrusive tools that still capture the user’s attention.
Not surprisingly, unnecessarily complex and non-intuitive features were viewed poorly. For example, some users considered the scrollable heatmap with multiple confidence levels to be cumbersome. Conceptually, users recognized the potential value of the confidence levels, and previous studies have shown that clinicians prefer knowing about the level of uncertainty with advice they receive. 16 However, some users suggested that using a single heatmap image with the highest confidence level would have been clearer and more effective. Some users also wanted more background information on what confidence level could be considered clinically significant for their practice. This reinforces the need for user education and training prior to AI deployment, as other researchers have advocated.8,17,18 Thus, AI tool developers and institutions who purchase AI software should consider creating frequently asked-question documents or holding interactive question-and-answer sessions with users. The associated costs may be a necessary investment to promote optimal use, as simply e-mailing a description of an AI tool and hosting a live demonstration were considered insufficient in our testing.
Beyond the need for better user education, AI developers must also address widespread concerns that radiologists have toward AI. In particular, many of our users expressed concerns for automation bias. Although radiologists tend to rate AI advice as lower quality compared to physicians with less medical imaging expertise, Gaube et al. 9 showed that radiologists are still susceptible to automation bias and experience a decreased in diagnostic accuracy when given inaccurate advice. Consistent with findings from survey studies, our users considered the potential medicolegal consequences and risks to patient safety from automation bias as deterrents to AI use.17,19
One particularly interesting theme warrants mention: the use of AI in difficult clinical cases. Users believed that AI tools may be especially beneficial with diagnosing subtle cases that could otherwise be easily missed. However, most current AI models are trained on datasets with a limited number of labels and without a sufficient number of rare, challenging cases; this area of AI development is currently being investigated by our group (Sanayei et al). This has two important implications. First, AI software should extend beyond identifying grossly normal and abnormal cases, and AI developers must build datasets enriched with subtle/challenging cases in their training data set to develop software with greater clinical value. Second, radiologists need to be informed of potential performance gaps, which could be accomplished using risk communication tools (akin to “drug fact” boxes) such as model fact labels. 20
Impact on Efficiency
There was a significant (P = .02) but small absolute increase in decision-making time (5 seconds, corresponding to a 42% increase) when using the x-ray classification tool. The time increase is largely attributed to time spent reviewing the heatmaps prior to dictating, as P2 noted, “It made me slower… trying to figure out: ok, what is the AI algorithm actually telling me?” There was also an increase in total reporting time (14 seconds, corresponding to a 33% increase) which approached statistical significance (P = .09). The increased decision-making and total reporting times were consistently seen regardless of the worklist with the AI output, a finding seen in other studies examining AI tools for CT scans and breast mammography.21-23 This likely reflects the substitution of typical “fast thinking” interpretation by “slow thinking”—an additional cognitive load provided by a second, potentially counter-intuitive, input from the AI tool—at least early in deployment (see limitations). 24 This interface of radiology AI and neuroscience is worthy of further research.
As expected, we also showed that AI triaging decreased the time to identify a critical result (tension pneumothorax case). The effect was present for Worklist X (P = .04) but not for Worklist Y (P = .50). As has been reported, the benefit of triaging depends on the other cases in a given worklist, and in our study, the critical case was ordered as the ninth and fourth case without triaging for Worklists X and Y, respectively.2,25 Furthermore, the potential temporal benefits of triaging may be partially offset if results are inaccurate. For example, Arbabshirani et al. demonstrated that a machine learning algorithm for CT neuroimaging in real-world practice reduced median time to intracranial hemorrhage identification from 512 to 19 min (P <.01) at the cost of a considerable false positive rate (36.2%). 26 Evidently, triaging worklists is not without challenges, and as our users noted, not all radiologists would resort to using automated triaging in their everyday practice.
Strengths
Our study population included non-academic, subspecialty staff radiologists (with >5 years of experience) as opposed to residents or academic radiologists. Thus, our population well-represents the majority of practicing radiologists across North America.27,28
We also successfully viewed and recorded all monitors that the radiologist testers used, despite performing the usability testing remotely. Additionally, we used a think-aloud method to elicit users’ opinions during testing while their experience was fresh. 11 Thus, we collected detailed information on user preferences and barriers to AI adoption as outlined in Table 2. To our knowledge, this is the first study to describe such a process with radiologists remotely, and this method will become increasingly useful for researchers as teleradiology grows in prevalence. 29
Limitations
Our study was susceptible to sampling bias. We had a small sample size of 10 unique participants from the same hospital network, representing about 25% of all eligible staff radiologists from the 3-site health network. This, however, is still comparable to other radiology AI assessment studies that have included anywhere from 3 to 20 radiologists (often including trainees).13,22,30-32 Participation in this study was also voluntary, and our users may have represented a subset of radiologists who were keen to explore the use of AI in their clinical practice. Radiologists who are averse to adopting AI may have identified more faults with the trialed tool and presented different arguments against incorporating AI in their workflow. Finally, although we consider the inclusion of non-academic community radiologists as a strength, we recognize that our findings may not be generalizable to other geographic locations or academic sites.
Constraints on our study did not allow for to radiologists read the same worklist twice (once with and once without AI use), separated by a washout period which is common methodology.13-15 We instead created two worklists (X and Y) designed to have same baseline difficulty, with each participant completing both a control and AI-intervention worklist. This may limit direct comparison to prior studies, but our results consistently showed that AI use increased reading time independent of worklist (Appendix 1).
Our study also represents an early implementation phase for new AI software. One can reasonably expect that more experience with an AI tool will decrease cognitive load required per case and improve users’ proficiency. This is supported by our sensitivity analysis to account for a learning curve which showed a smaller time increase in total reporting time (19% increase) compared to the preliminary results (42% increase). We, however, recognize that removing only the first case with AI assistance may be considered a short learning period. Long term AI testing may help characterize the duration of a learning period and verify the temporal effects of AI when used by first-time users compared to experienced users.
Conclusion
We demonstrated the application of software usability testing methods to perform in-depth usability testing of the interaction of experienced staff radiologists with AI software (chest x-ray tool). Staff radiologist user feedback indicated radiology AI tools should have a simple design, present confidence levels with clear instruction on their interpretation, and cater toward identifying subtle diagnoses. Early AI adoption also caused increased radiologist reading times, and AI triaging was found to accelerate the detection of critical findings.
Footnotes
Acknowledgments
The authors would like to acknowledge Mohannad Hussain who provided essential technical support during the user testing.
Declaration of Conflicting Interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: B.F. is an advisor and shareholder of PocketHealth and has received consultant fees from Canon Medical.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was funded by Digital Supercluster Canada. The funder and AI vendor had no role in the study design or analysis.
Data Availability
Quantitative Results
In the primary analysis, AI use consistently increased decision-making and total reading times regardless of which worklist had the AI output. When the x-ray classification tool was made available for Worklist X, users took about 3 seconds longer (20% increase) to start dictating (P = 0.02) and 23 seconds longer (45% increase) to complete dictations (P = 0.18). When the x-ray classification tool was made available for Worklist Y, users took about 7 seconds longer (84% increase) to start dictating (P = 0.09) and 5 seconds longer (14% increase) to complete dictations (P = 0.19).