
Abstract
Correspondence analysis (CA) is a popular technique to visualize the relationship between two categorical variables. CA uses the data from a two-way contingency table and is affected by the presence of outliers. The supplementary points method is a popular method to handle outliers. Its disadvantage is that the information from entire rows or columns is removed. However, outliers can be caused by cells only. In this paper, a reconstitution algorithm is introduced to cope with such cells. This algorithm can reduce the contribution of cells in CA instead of deleting entire rows or columns. Thus the remaining information in the row and column involved can be used in the analysis. The reconstitution algorithm is compared with two alternative methods for handling outliers, the supplementary points method and MacroPCA. It is shown that the proposed strategy works well.
Introduction
Correspondence analysis (CA) is an exploratory data analysis method which visualizes the dependence of the two categorical variables in a two-way contingency table using a two-dimensional plot (Gower & Hand, 1996; Greenacre, 1984, 2017, 2018; Greenacre & Hastie, 1987). CA has received considerable attention in a variety of areas such as education (Kienstra & Van der Heijden, 2015), marketing (Pitt et al., 2020), psychology (Kim et al., 2021), and text categorization and authorship attribution (Qi et al., 2024). However, relatively little attention has been given to CA in the presence of outliers (Riani et al., 2022).
Outliers may be errors or unexpected observations which could shed new light on the researched phenomenon (Sripriya & Srinivasan, 2018). In general data structures, not contingency tables, the data are arranged in a matrix where rows correspond to the individual observations and columns are variables (Grubbs, 1969; Hubert et al., 2019; Raymaekers & Rousseeuw, 2024; Rousseeuw & Van Den Bossche, 2018). The term outlier typically refers to an individual observation that deviates markedly from other members of the sample in which it occurs (Andersen & Mayerl, 2017; Robette, 2022).
However, in a contingency table, the definition of an outlier is different (Kuhnt et al., 2014; Sripriya & Srinivasan, 2018). An entry in the table represents the number of individuals that occurs jointly in a category of one variable and a category of the other. Thus, in the contingency table, a row does not correspond to a single observation but to a number of joint sample frequencies of individual observations. Here, extreme counts that do not follow the general pattern in the table are viewed as outliers.
In the context of CA, an outlier can be defined in different ways and the procedure to detect outliers depends on the definition of an outlier. Two detection procedures stand out. On the one hand, Greenacre (2013, 2017) uses visual inspecting of CA plots to detect outliers. Greenacre (2013, 2017) considers a row or column point as an outlier when it clearly lies far from other points in the CA plot. In addition to large absolute coordinates, Hoffman and Franke (1986) and Bendixen (1996) define a row or column point as an outlier if the row or column point has a high contribution to an axis. The contribution of a point to an axis is determined not only by the position of the point in the CA plot but also by the marginal proportion of the point. According to Hoffman and Franke (1986) and Bendixen (1996), if the marginal proportion of a point is very small, it may not be an outlier, even though, following Greenacre’s definition, it is an outlier in the sense that it lies far from other points in the CA plot.
On the other hand, Riani et al. (2022) and Raymaekers and Rousseeuw (2024) detect outliers making use of distributional assumptions. Riani et al. (2022: 8) state “an outlier is a row which does not agree with the multiplicative model assuming independence fitted to the data.” This outlier detection procedure is less attractive, because, in interesting applications, the independence model assumption would be rejected almost always (De Leeuw et al., 1990), and thus, in this situation, this procedure tends to detect too many rows as outlying points. Raymaekers and Rousseeuw (2024) use MacroPCA to detect outliers. MacroPCA is originally proposed by Rousseeuw and Van Den Bossche (2018) for principal component analysis (PCA) and subsequently used in CA by Raymaekers and Rousseeuw (2024). MacroPCA assumes that the data are generated from a multivariate Gaussian distribution. However, the two variables in the contingency table are categorical variables, and therefore the normality assumption for the input matrix of MacroPCA may be not appropriate for CA.
Hoffman and Franke (1986), Bendixen (1996), Greenacre (2017) and Riani et al. (2022) detect outlying rows or columns, and, after detecting the outliers, they cope with the outliers by the supplementary points method. That is, CA is performed on the contingency table without the outlying rows and columns. Afterwards, the outliers are projected into the CA solution of the reduced table. Therefore, the outliers cannot determine the CA solution.
In contrast, Raymaekers and Rousseeuw (2024) detect outlying cells and outlying rows and handle the outliers in the same step. The basic idea is to impute the outlying cells by an iterative PCA algorithm while excluding outlying rows. Their method does not have a good fit with the theory of CA, and important properties of CA, such as that Euclidean distances in a CA display can be interpreted as approximations of chi-squared distances between rows and between columns of contingency table, are lost. Moreover, this method seems to flag a lot more rows as outliers than necessary.
The supplementary points method and MacroPCA delete outlying rows or columns completely, and therefore, also remove information from these rows or columns that is not related to this outlying problem. So, the removal of an entire row or column causes a unnecessary loss of information.
According to Bendixen (1996), a cell frequency that causes its row to be identified as an outlier might also cause its column to be identified as an outlier, and vice versa. Thus, an outlying row or column may be caused by a specific joint frequency. This suggests that we only need to deal with the specific cell and do not need to delete the entire row or column.
In this paper, the focus is on cell-wise outliers. To detect outlying cells, we follow Greenacre’s definition and use visual inspection of the CA plot. This is because (1) a main aim of CA is to summarize the structure of data via a two-dimensional plot; (2) such outliers cause the other points to be tightly clustered; (3) thus such outliers reduce the readability of a CA plot. A cell is an outlying cell if the corresponding row and column points of this cell lie far from other points. Here, once a cell is identified as an outlier, the cell is not removed but its contribution is reduced. For reducing the contribution of an outlying cell, the reconstitution algorithm is proposed. The reconstitution algorithm has been proposed originally by Nora-Chouteau (1974) and has later been used by Greenacre (1984) and De Leeuw and Van der Heijden (1988) to handle missing values in cells.
The paper is built up as follows. We start with a description of CA background. The next section “Methods to handle outliers” presents the reconstitution algorithm to handle cell-wise outliers and describes MacroPCA and the supplementary points method. Section “Experimental Studies” compares these three methods in simulated data. The next empirical section compares these three methods on a contingency table, the brands of cars dataset, and compares the reconstitution algorithm and the supplementary points method on an incidence table, the ocean plastic dataset. Finally, we discuss and conclude this paper; the last section introduces the implementation of code.
Correspondence analysis background
Let X be a contingency table having I rows and J columns with non-negative entries
CA can be introduced in many ways. We introduce CA here using the concept of total inertia (Greenacre, 2017), i.e., the well-known Pearson
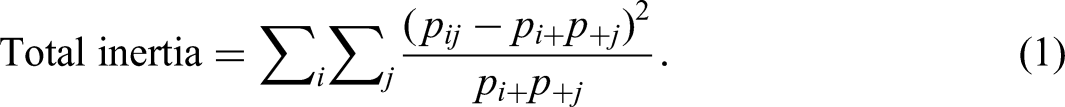
The aim of CA is to provide a multidimensional representation of the matrix X where the total inertia is projected as much as possible onto a low-dimensional space. The computational procedure to obtain the solution makes use of the singular value decomposition (SVD). In the first step the matrix X is transformed into the matrix of standardized residuals
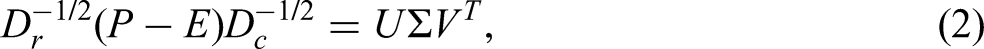
where
If we pre-multiply and post-multiply both sides of Equation (2) by
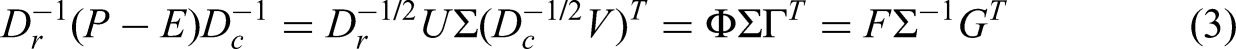


Euclidean distances between rows of F (
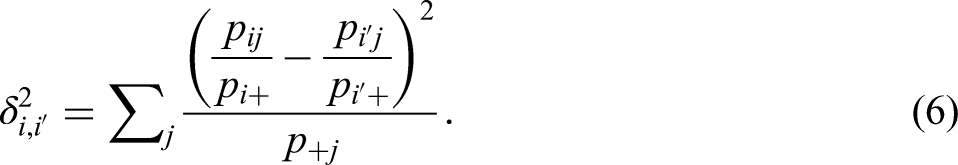
The
Joint graphic displays of row points and column points are usually made to study the relationship between the rows and the columns in the matrix P. For this asymmetric and symmetric maps are used. In an asymmetric map rows of P can be displayed as points in a multidimensional space using principle coordinates, and columns as points using standard coordinates. Thus, in full-dimensional space the dot products of row points F and column points
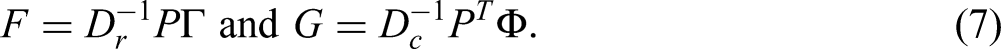
The points for the average row profile and the average column profile fall in the origin. Thus, for the combination of F and
Asymmetric maps have drawbacks. For example, when the pair F and
The total inertia can be expressed as a weighted sum of squared
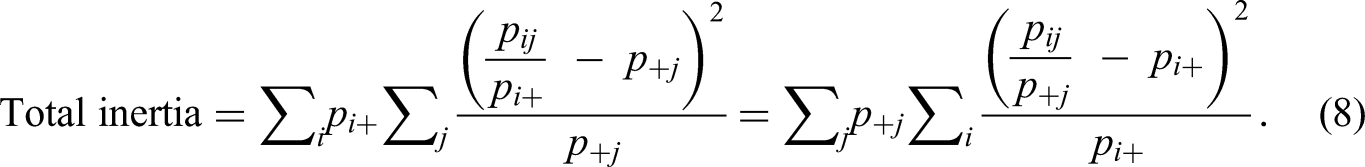
This shows that the total inertia can be split up over the rows and over the columns. The inertia of the row point i and the column point j in dimension k are
The total inertia can also be split up over cells. The inertia of each cell in the matrix
By rewriting Equation (3), the correspondence matrix P can be decomposed as follows:
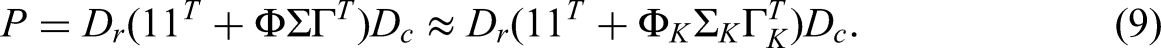
Equation (9) is called the reconstitution formula and is the foundation of the reconstitution algorithm, discussed in Section “Methods to handle outliers”.
Similar to Equation (7), an additional row can be projected as a supplementary point in an existing CA plot. Let the extra row (supplementary) point be the vector

To summarize how to obtain CA solution, there are three steps (Qi et al., 2024). Step 1: compute the matrix of standardized residuals
We now analyze the attributes of brands of cars dataset to illustrate CA. The dataset has been analysed before in Raymaekers and Rousseeuw (2024); Riani et al. (2022). This dataset is a part of the R package cellWise (Raymaekers, Rousseeuw, Van den Bossche, & Hubert, 2023). See Table 1 for the data. The contingency table consists of 39 rows and 7 columns. The rows represent 39 brands of cars, such as Jeep, Porsche, and Volvo. The seven columns represent the attributes: Fuel Economy, Innovation, Performance, Quality, Safety, Style, and Value. In total 1,578 participants were asked what they considered attributes for the 39 different vehicle brands. They selected all attributes in the list which they felt applied to a brand. An entry in the table represents the number of respondents that chose the attribute for a car. In total this led to 11,713 scorings. We note that this is not a typical contingency table as in a typical table the total count is identical to the number of respondents.
Car data matrix
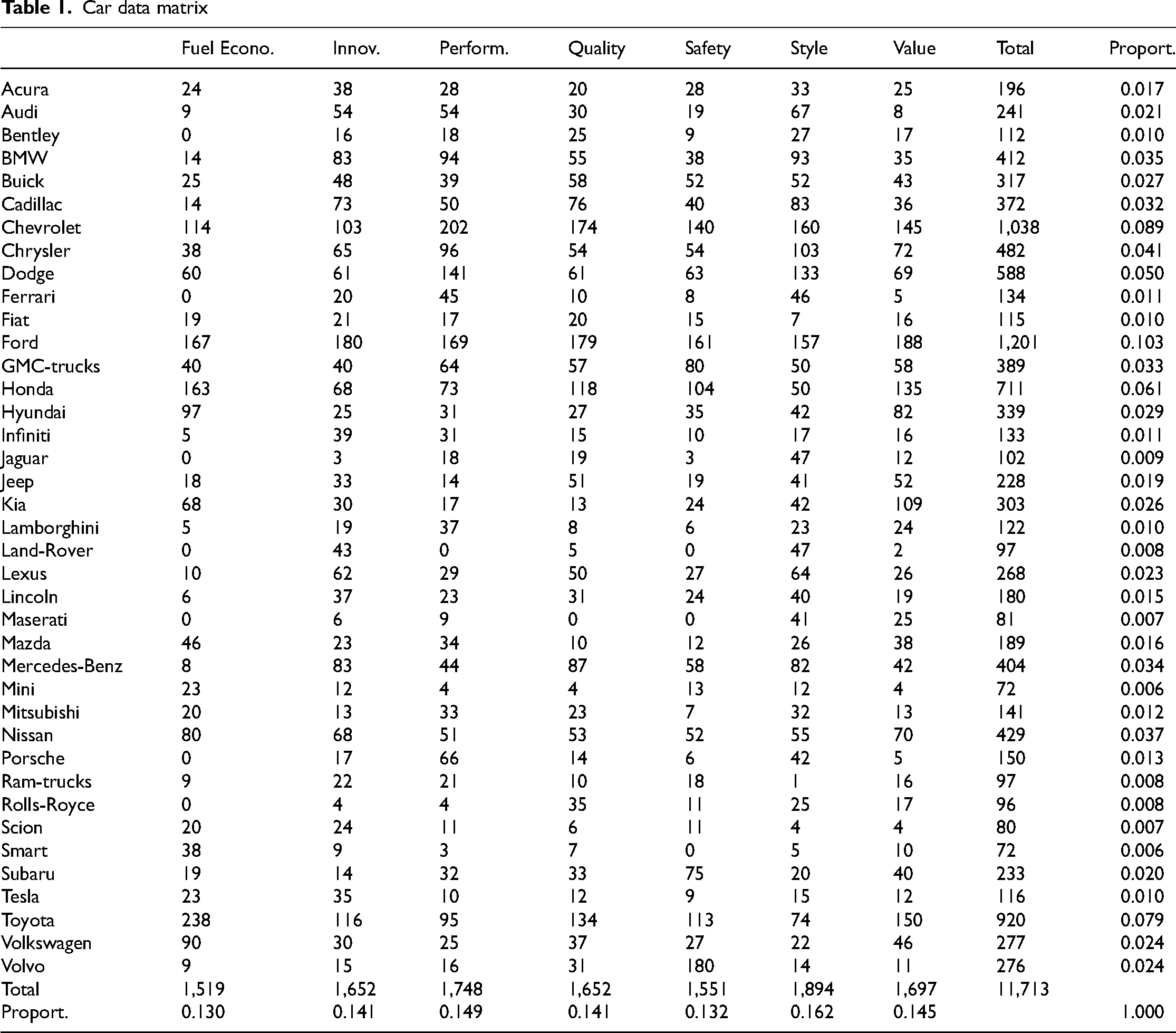
Figure 1 shows the symmetric plot of CA, having
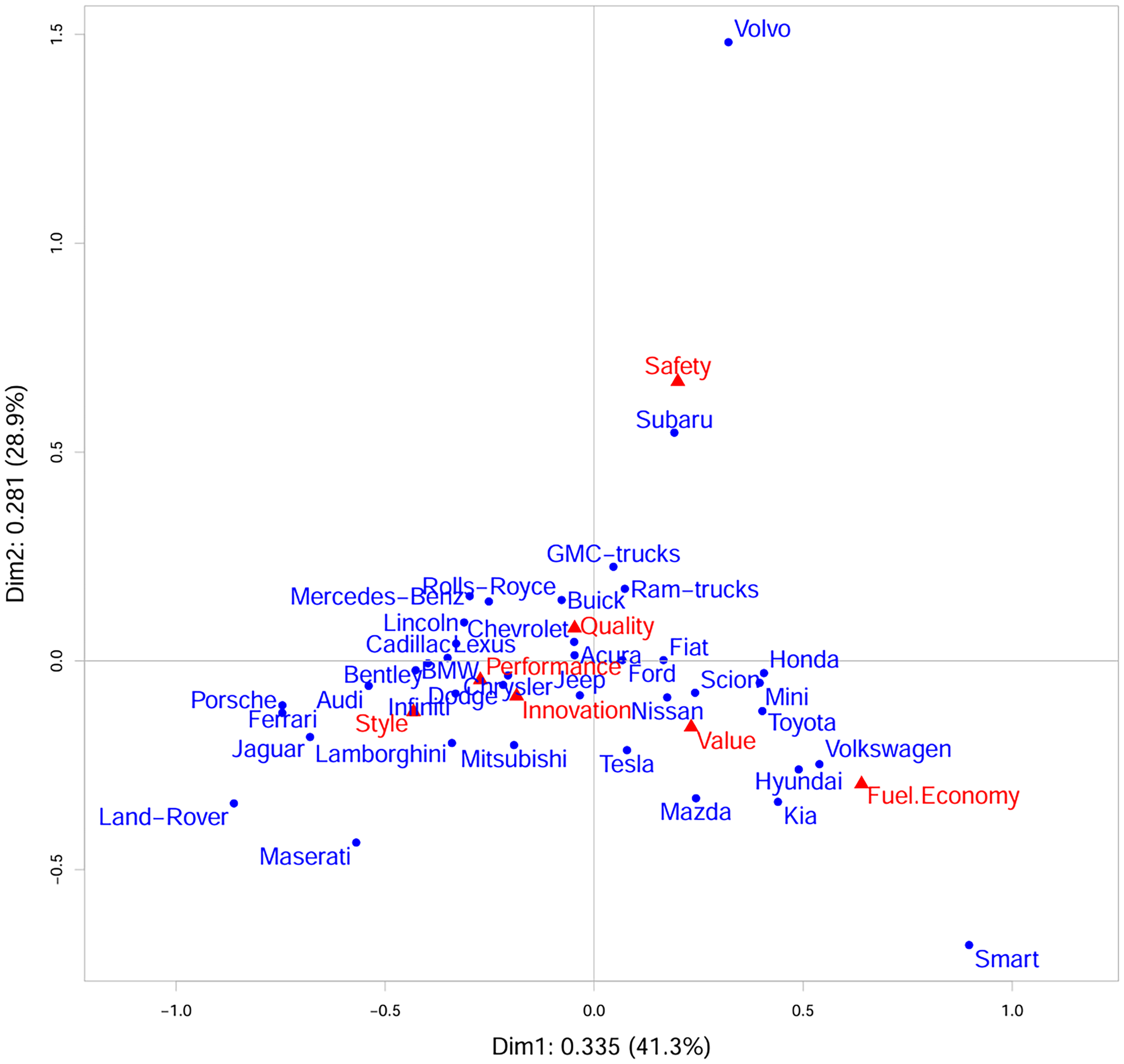
CA plot of Table 1
Methods to handle outliers
We discuss three methods to handle outliers. Two methods are cell-wise outlier methods: reconstitution of order h and MacroPCA. The third is the supplementary points method. It is worth noting that reconstitution of order h has been used to handle missing data, but has not been proposed to handle outliers.
Reconstitution of order
In this paper we propose to deal with an outlier or outliers by changing the data. Specifically, we assume that specific cells in a matrix are outlying cells if they cause row and column points to be outliers. We propose to make such cells in the data matrix missing. We use visual inspection of the CA plot to define outlying cells. In a second step, we apply an algorithm that imputes a new value for each missing value. For this, we use the reconstitution algorithm, originally proposed by Nora-Chouteau (1974) and revisited by Greenacre (1984), De Leeuw and Van der Heijden (1988), and Josse et al., (2012).
We assume for the moment that there is only a single cell causing a row and a column to be outliers, but the procedure that we describe can be applied to multiple outlying cells simultaneously. The idea is to adjust the value in this single cell in such a way that it is perfectly reconstituted in a
Since the margins vary as the missing cell is iteratively imputed, it is easier to describe the method using the raw data 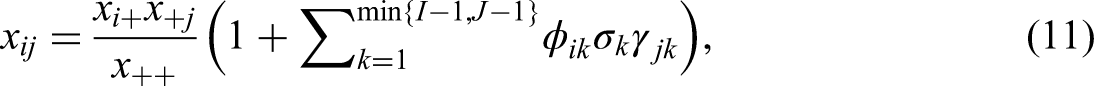
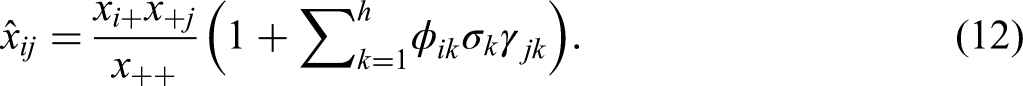
We first explain reconstitution of order 0, meaning that no CA dimensions are used in the reconstitution. Assume that cell 
After convergence, we have the converged value
However, as the residual for cell 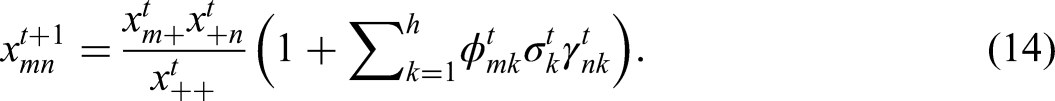
Thus the first h dimensions of CA for row m and column n are given by
As far as we know, there is no R package in which reconstitution of order h is implemented, where
MacroPCA
MacroPCA was originally proposed for PCA (Hubert et al., 2019) and subsequently adjusted for CA (Raymaekers & Rousseeuw, 2024). MacroPCA is quite involved and detects outliers and handles outliers at the same time. It includes two parts. The first part of MacroPCA is a multivariate method called DetectDeviatingCells (DDC) (Hubert et al., 2019; Rousseeuw & Van Den Bossche, 2018) that assumes that data are generated from a multivariate Gaussian distribution but some cells were corrupted. DDC detects cellwise outliers, and provides these cellwise outliers with initial values. It also detects initial row-wise outliers. In the second part, the set of outlying rows will be improved. Low-dimensional representations are obtained in a way that is similar but not identical to the reconstitution algorithm. The low-dimensional representations of MacroPCA are not nested. That is, for example, the two-dimensional representation is not a subset of three-dimensional representations. We refer to Hubert et al. (2019); Rousseeuw and Van Den Bossche (2018) for details.
MacroPCA is modified to handle missing data and outlier problems in the context of CA (Raymaekers & Rousseeuw, 2024). For CA the original matrix is replaced with the matrix of standardized residuals. As in CA the standardized residuals are only a starting point in finding the CA solution, the modification is close to but different from CA. Also, in the DCC step of MacroPCA where outlying cells are detected, the algorithm makes the assumption of a Gaussian distribution, for which there is no clear rationale in the context of CA.
Supplementary points method
The supplementary points method is a well-known method to deal with row-wise outliers or column-wise outliers. That is, after noticing outlying points, for which we use visual inspection, a new CA is performed on the data matrix where these row-wise or column-wise outliers are removed. Then, as a second step, these outliers are projected as supplementary points into the existing CA solution. Using Equation (10) in CA background section, if an outlier a is a row point, its coordinates in the
The supplementary points method is a standard method to deal with outliers in CA, see, for example, Hoffman and Franke (1986), Bendixen (1996), Greenacre (2017), and Riani et al. (2022). However, as we argued in Section Introduction, outliers may be caused by a single cell in the data matrix, and deleting an entire row or column where cell-wise outliers occur from the contingency table leads to a loss of the entire category, including outlying and non-outlying cells. In contrast, reconstitution of order h eliminates the effect of only the outlying cells, thus keeping as much information as possible in the analysis.
Experimental studies
Here, we show the results of some experimental studies to evaluate different outlier handling methods. To create a contingency table, we first specify the marginal probabilities and CA dimensions and then use the reconstitution formula (9). For the cell-wise outlier, we set an element in the table to be large. We study three scenarios. Namely, we create a contingency table based on Equation (9) where the dimensionality K of the CA solution is 0, 1 and 2. All tables (Table B.1, Table B.2, and Table B.3) for this Section can be found in the Supplementary materials.
Dimensionality is 0
A contingency table with dimensionality 0 is created by the marginal probabilities
For our experimental studies we take
A cell-wise outlier in cell (1,a)
To create a contingency table with a cell-wise outlier, we set the element
The CA solution only has one dimension. Figure 2 shows the symmetric plot of CA based on Table B.1b. In Figure 1, row 1 and column a, where the outlying cell is located, are far from other points. The singular value, with percentage of inertia displayed between brackets, is 0.603 (100%). We analyze the contribution of row 1 and column a to the first dimension. The marginal proportion of row 1 is 0.260, yet its contribution to the first dimension is 74.0%; the marginal proportion of column a is 0.408, yet its contribution to the first dimension is 59.2%. The contribution of cell (1, a) to the total inertia is 43.8%.
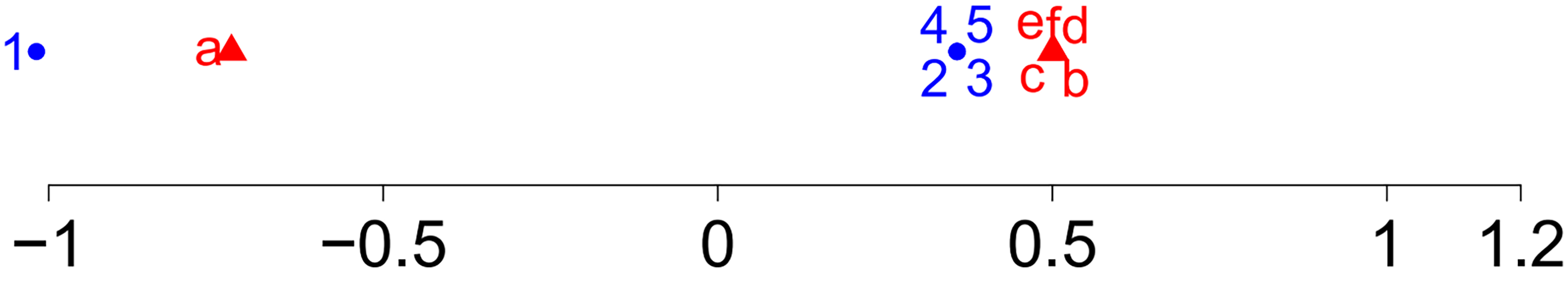
CA plot about Table B.1b with outlier (1,a)
Dimensionality is 1
A contingency table is created by the marginal probabilities, row scores
The matrix of joint probabilities is given in Table B.2a. We perform CA on this matrix and obtain Figure 3a. As intended, the CA solution only has one dimension. Row points are ordered from 1 to 5, column points from a to f.
(a) CA of Table B.2a, (b) CA of table with outlier, (c) Reconstitution of order 0, (d) MacroPCA, and (e) Supplementary points
A cell-wise outlier in cell (1,a)
To create a contingency table with a cell-wise outlier, we let the element
The CA solution has two dimensions. Figure 3b shows the symmetric plot of CA based on Table B.2b. Compared with Figure 3a, the first dimension in Figure 3b shows that the order of row points and column points remains the same. However, the outliers row 1 and column a are far from other points and lie on one side of the origin, and a second dimension is needed. The first two singular values, with percentage of inertia displayed between brackets, are 0.74970 (95.2%) and 0.16883 (4.8%).
We perform CA on this matrix and obtain Figure 3c, whose first dimension is similar with the first dimension of Figure 3a except that row 1 is larger than row 2. We note that, as the reconstituted value in cell (1, a) is the product of the row and column margins
Now we use the reconstitution of order 1 to handle the cell-wise outlier. Using the reconstitution algorithm, the value 0.48060 in (1, a) becomes 0.02196, which is the same as the value in Table B.2a. So here the reconstitution algorithm works as intended.
We also use reconstitution of order 2, and the imputed value is the same as the initial in the reconstitution algorithm. This is because the CA solution has two dimensions. The outlier in cell (1, a) in Table B.2b is perfectly reconstituted by order 2. So if h is taken too large, the reconstitution algorithm is not able to eliminate the impact of the outlier.
Figure 3d is the corresponding symmetric CA-type plot based on MacroPCA. MacroPCA does not work well, as in the first dimension the order of the columns is not reproduced. For more details, see the Supplementary materials B.2.1.
Figure 3e shows a symmetric CA plot, where 1 and a are added as supplementary points. The order of row and column points is the same as the order in the original Figure 2a. So here the supplementary points method works well.
Dimensionality is 2
We use the same matrix as the matrix for dimensionality is 1, but now we add a second dimension. I.e. we take row scores
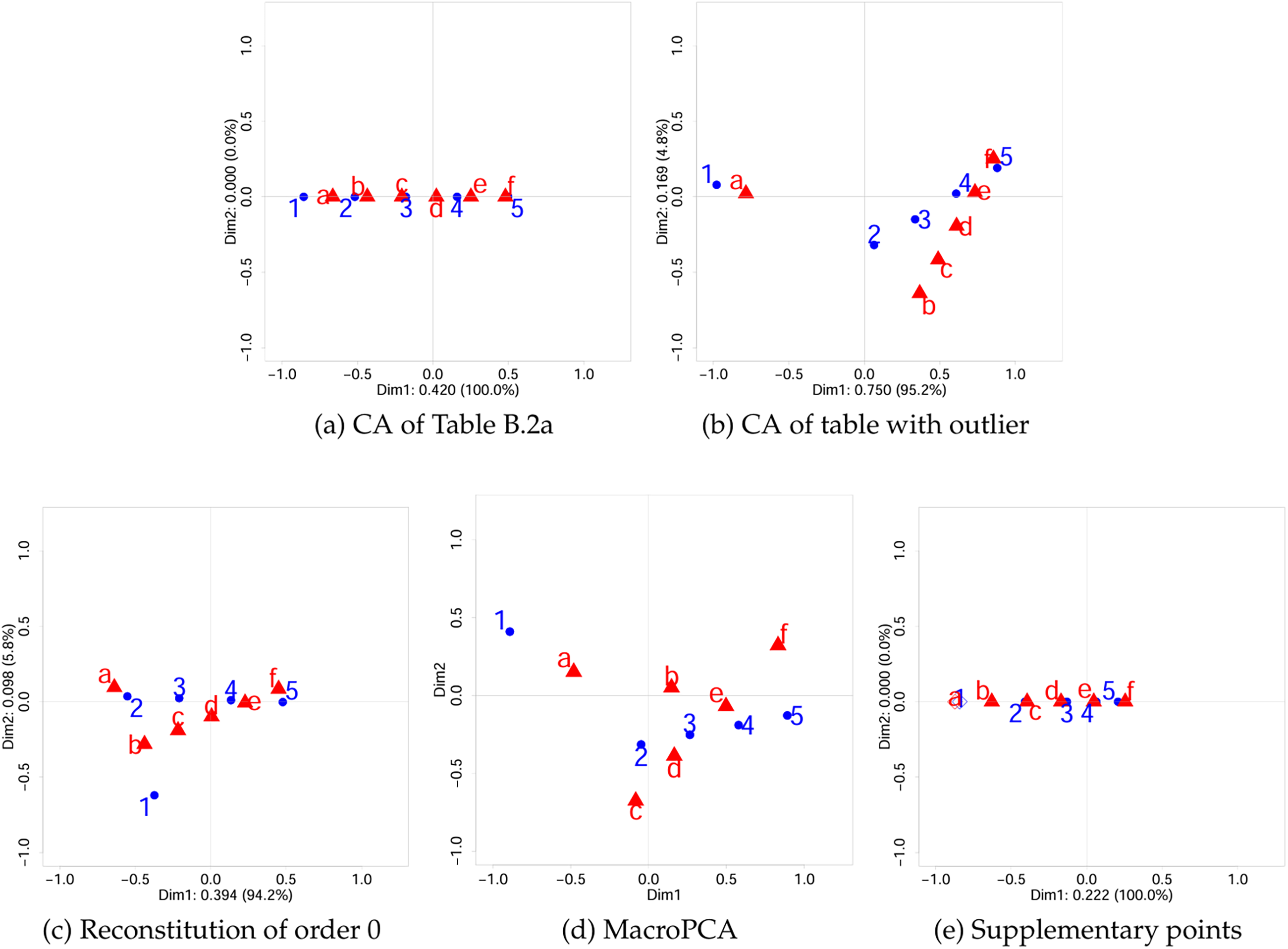
(a) CA of Table B.3a, (b) CA of table with outlier, (c) Reconstitution of order 0, (d) Reconstitution of order 1 (e) MacroPCA, and (f) Supplementary points
A cell-wise outlier in cell (1, a)
To create a contingency table with a cell-wise outlier, again, we let the element
The CA solution has three dimensions. Figure 4b shows the symmetric plot of CA based on Table B.3b. In the first dimension, the outliers row 1 and column a are far from other points. The first three singular values, with percentage of inertia displayed between brackets, are 0.76415 (90.2%), 0.25057 (9.7%), and 0.02844 (0.1%).
Now we use reconstitution of order 1. Using the reconstitution algorithm, the value 0.53025 in (1, a) becomes 0.00252, similar but not identical to 0.02633 in Table B.3a. We perform CA on this matrix and obtain Figure 4d, which is similar with Figure 4c.
Last, we use reconstitution of order 2 to handle the cell-wise outlier (1, a). Now the value 0.53025 in (1, a) becomes 0.02633, which is the same value as in Table B.3a. Therefore, the reconstitution of order 2 works perfectly.
Conclusion
In this section, we performed some experimental studies. We explored the choice of the parameter h in the reconstitution algorithm. It appears that an optimal choice of h depends on how a contingency table is constructed. If a contingency table is constructed by the h dimensions of CA and then cells in the table are contaminated as outliers, reconstitution of order h works perfectly.
Reconstitution of order h clearly outperforms MacroPCA. In the examples we studied, reconstitution of order h did better than the supplementary points method where dimensionality is 2. In the examples where dimensionality is 1, reconstitution of order 0 is less appealing than the supplementary points method in terms of the order of row points, but the reconstitution of order 1 works perfectly.
Yet more study is needed to better understand the behavior of reconstitution of order h. The choice for the experimental data is quite limited. In the Supplementary materials more results can be found, for the situation that cell (1,c) is an outlier.
Empirical studies
We consider two datasets, the attributes of brands of cars (analysed before in CA background section) and ocean plastic datasets. The attributes of brands of cars dataset is a classic dataset to study the problem of outliers in the context of CA (Raymaekers & Rousseeuw, 2024; Riani et al., 2022). For example, Raymaekers and Rousseeuw (2024) use the dataset to explore the usefulness of MacroPCA in terms of outliers in CA. Therefore we compare reconstitution of order h, MacroPCA, and the supplementary points method on this dataset.
The ocean plastic dataset is an incidence dataset created by Vonk et al. (2024). We use this dataset to show that the reconstitution algorithm is appropriate for incidence data as well. However, we do not discuss MacroPCA for this example, as MacroPCA applied to this dataset yielded a degenerate solution (See Supplementary C in the Supplementary materials). The reason for this is not clear to us, but we notice that assumptions underlying MacroPCA are severely violated by the matrix of standardized residuals. Therefore, for this dataset, we only compare reconstitution of order h and the supplementary points method.
The attributes of brands of cars data
As a first dataset, we use the attributes of brands of cars dataset to illustrate our method. We analysed this dataset before in CA background section. From this section, we concluded that the cell (Volvo, Safety) is a cell-wise outlier, leading to outlying points for Volvo and Safety on dimension 2.
Reconstitution algorithm
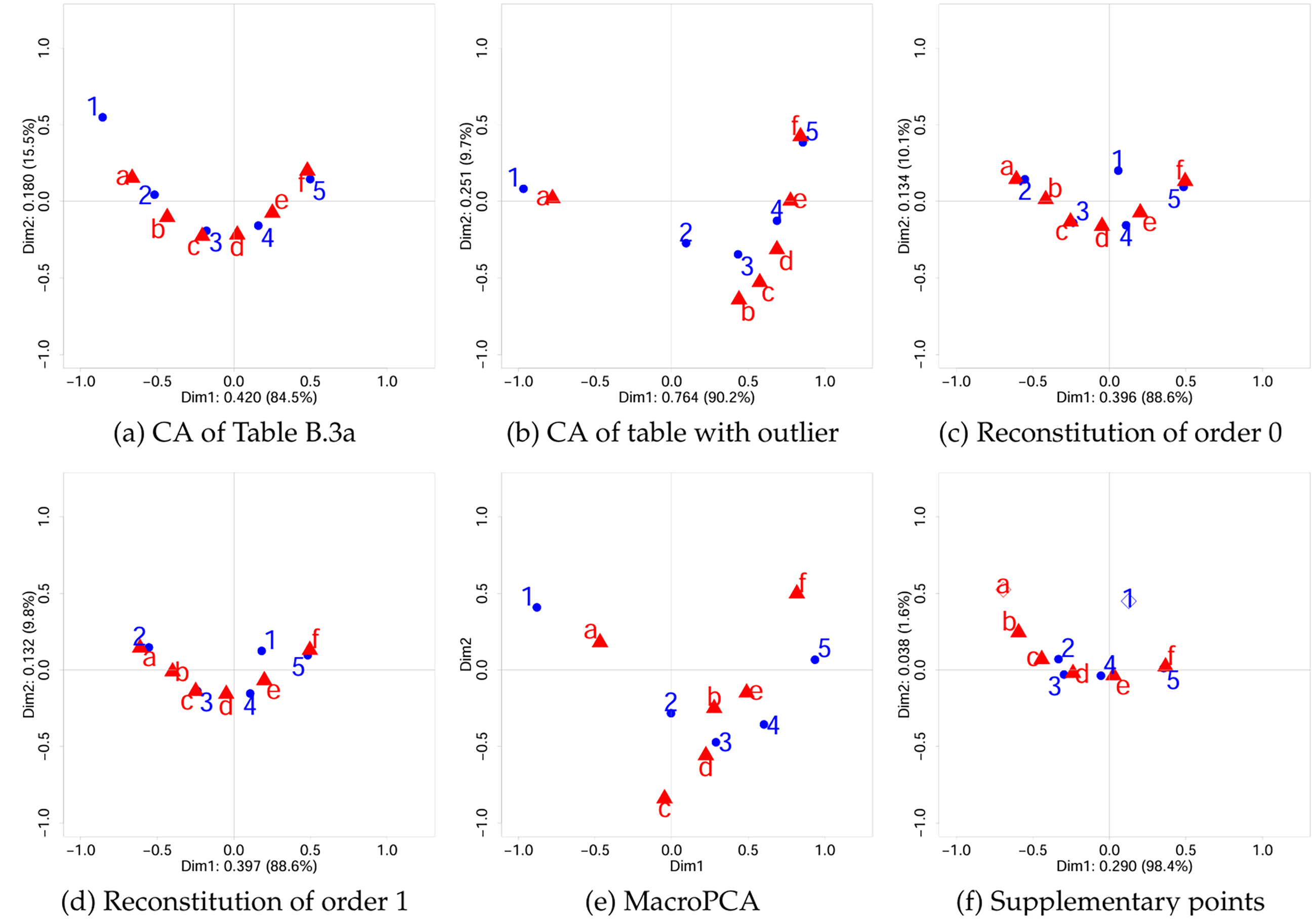
Here we use reconstitution algorithm of order 2 to handle the cell-wise outlier (Volvo, Safety). Using the reconstitution algorithm, the value 180 in (Volvo, Safety) becomes 27.0 (Reconstitution of order 0 leads an imputed value of 13.1, but the graphic results are similar). The contribution of cell (Volvo, Safety) to the total inertia went down from 17.7% to 0.4%. The first four singular values become 0.334 (51.0%), 0.186 (15.8%), 0.170 (13.2%), and 0.156 (11.1%). It is clear that the second dimension now is less important, the proportion of inertia went down from 28.9% to 15.8%. The singular values of dimensions 2, 3 and 4 do not differ much, and using the elbow criterion, we decide only to study the first dimension. Also, since in a contingency table the singular value can be interpreted as the canonical correlation between the row variable and the column variable, with 0.186 the second singular value is quite small.
Figure 5a is a symmetric CA plot of the reconstituted table. On the first dimension the configuration of row and column points is similar to the configuration of the original Figure 1, except for the change of location of Volvo. Safety is still in a similar position, and the reason for this difference between Volvo and Safety is that bringing down the value of 180 to 27 has a much larger impact on the profile of Volvo, that originally had a marginal total of 276, than the marginal total of Safety, that originally was 1,551. Note that by eliminating the impact of a single cell the new figure is much better readable than Figure 1.
CA plots about Car dataset
By eliminating the influence of a single cell the reconstitution method allows us to arrive at the simple conclusion that (i) there is a single outlying cell for Volvo and Safety, as Safety is chosen as the outstanding characteristic of Volvo (180 out of 276 scores for Volvo come from Safety), and (ii) there is largely a one-dimensional structure for the cars and features going from Land-Rover, Ferrari and Porsche on the left, scoring higher than average on Style and Performance, to Smart, Volkswagen, Hyundai and Kia, on the right, scoring higher on Fuel Economy, with the other car types and features ordered in between.
MacroPCA
We obtain the results of MacroPCA by applying the MacroPCA function in the R package cellWise (Raymaekers et al., 2023). We use the same parameter setting as in Raymaekers and Rousseeuw (2024) and Raymaekers et al. (2023), except for
The results from the first step in MacroPCA, DCC, provides a cellmap. See Figure 6. The red or blue cells indicate cellwise outliers. Specifically, red cells indicate that the observed values are much larger than the predicted values, and for blue cells the opposite holds. Thus DDC finds 19 cellwise outliers, including the cellwise outlier (Volvo, Safety) found using the visual inspection employed in precedent “Reconstitution algorithm” Section.
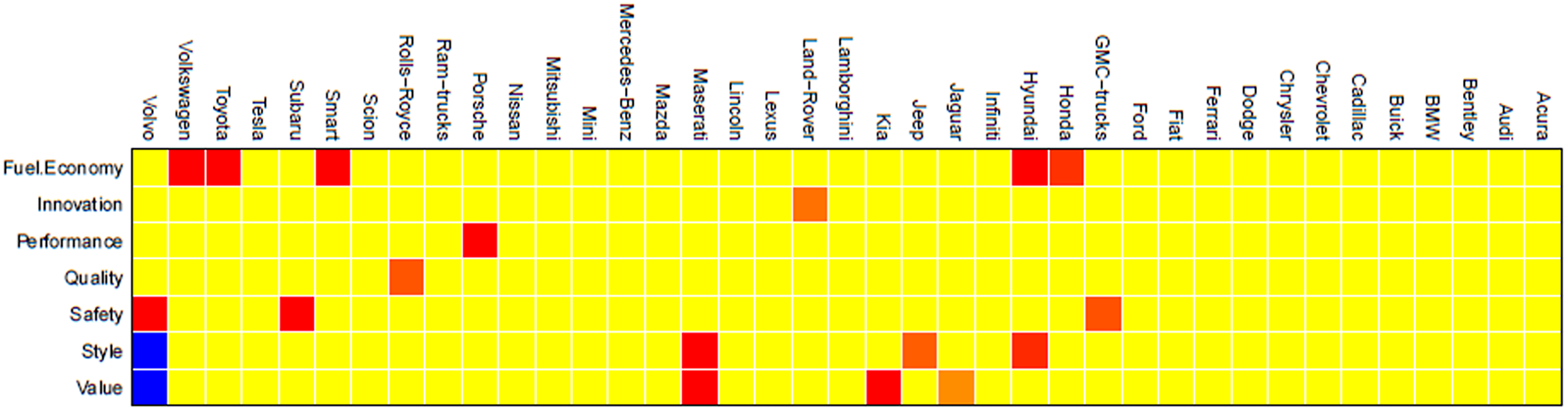
Cellmap from DDC of MacroPCA about Car dataset to detect cell-wise outliers
Figure 5b is the corresponding symmetric CA-type plot. On the first dimension, the configuration of row and column points is similar to the original Figure 1.
Supplementary points method
From CA background section, we concluded that Volvo and Safety are far from other points and coined Volvo and Safety outliers. Therefore, we handle Volvo and Safety as supplementary points. Thus the table analysed has size
Figure 5c shows a symmetric CA plot, where Volvo and Safety are added as supplementary points. On the first dimension the configuration of row and column points is similar to the original Figure 1, except for Volvo. Again, Safety is still in a similar position. For this dataset the interpretation using the supplementary points method is very similar to the interpretation using the reconstitution approach.
The ocean plastic data
The ocean plastic dataset is created by Vonk et al. (2024) to analyze how scientific studies on ocean plastic are communicated in press releases. The study analyzed press releases published on EurekAlert! between January 2017 and December 2021. In the analysis, variables defining the four frame elements of Entman (1993), namely causal interpretation, problem definition, moral evaluation, and treatment recommendation were noted, resulting in 21 frame variables. Table 2 summarizes these framing variables, while a more detailed description can be found in Appendix 1 of Vonk et al. (2024).
Frame variables
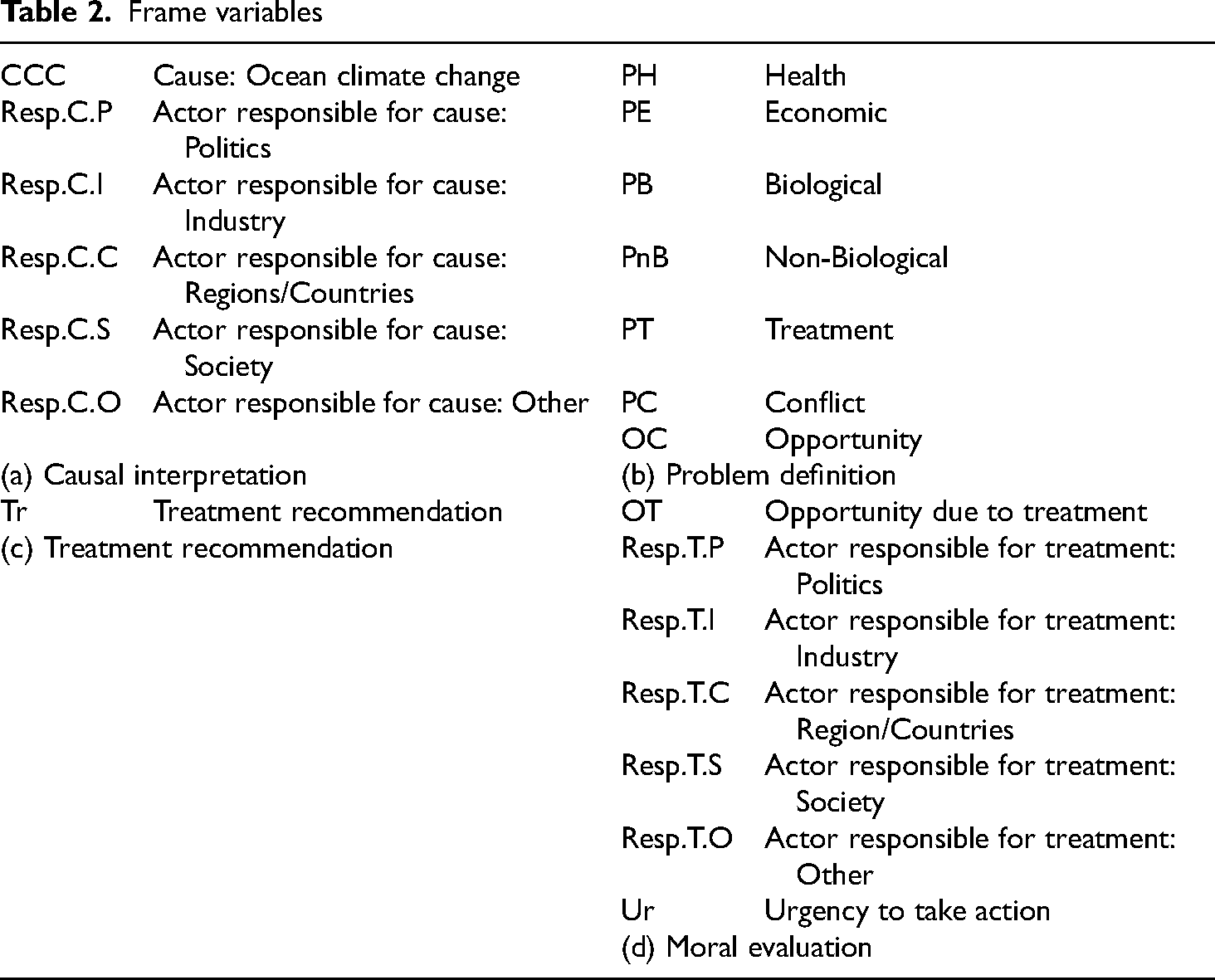
The causal interpretation (a) was coded, when the text referred to climate change (CCC) as a cause of problems. It was coded whether an entity was held responsible for causing climate change, ocean plastics or related problems (Resp.C.P, Resp.C.I, Resp.C.C, Resp.C.S, and Resp.C.O). The problem definition (b) describes different problems (PH, PE, PB, PnB, PT, PC) or opportunities (OC) stated in the text. The moral evaluation (d) was coded when an entity was held responsible for solving problems (Resp.T.P, Resp.T.I, Resp.T.C, Resp.T.S, and Resp.T.O); when opportunities would be named if problems were mitigated (OT); or when the text stated that mitigation of problems was urgently needed (Ur). The treatment recommendation (c) described a solution that reduced or remedied problems or their cause (Tr).
The ocean plastic dataset has 81 press releases in the rows and 21 framing variables in the columns with 0 or 1 in each cell where 1 means the framing variable is present in the text and 0 otherwise (See Table D.1 in Supplementary materials). The table has
Figure 7a is a symmetric plot of the dataset. The first four singular values, with percentages of inertia displayed between brackets, are 0.671 (13.2%), 0.588 (10.2%), 0.570 (9.6%), and 0.544 (8.7%). The closeness of the singular values shows that the dataset cannot be summarized in a small number of dimensions.
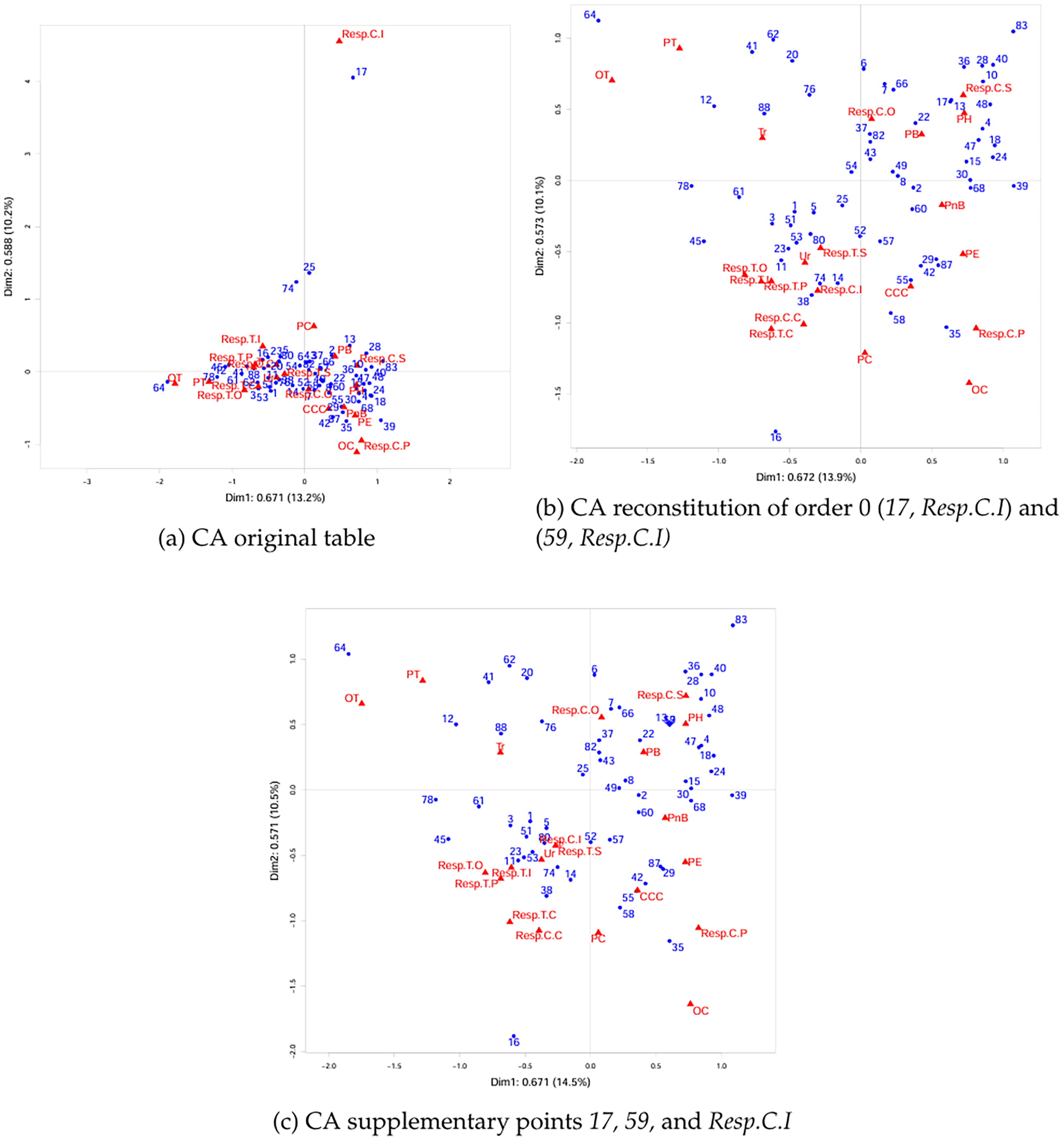
CA plot about Ocean plastic dataset
The first dimension contrasts Opportunity due to treatment (OT), Treatment related problems (PT) and Treatment recommendation (Tr), Responsibility for treatment framings T.O, T.P, T.C and T.I on the left versus responsibility for causes framings C.P, C.S and C.I, and Problem definitions such as Opportunity (OC), Health (PH), Economic (PE), Non-Biological (PnB), and Biological (PB) on the right. On the second dimension, Resp.C.I, i.e. industry is responsible for cause, is far from the origin. The marginal proportion of Resp.C.I is 0.013, and its contribution to the second dimension is 76.9%. Resp.C.I masks the visualisation of the structure in the dataset and reduces the readability of this map. Documents 17, 59, which have identical scores, are far from the origin and are closest to Resp.C.I. The marginal proportion of documents 17/59 jointly is 0.013, yet its contribution to the second dimension is 61.0%. Also, the contribution of the two cells (17/59, Resp.C.I) to the total inertia is 7.0%, which is large (note that there are 81 × 21 cells). Hence the cells (17/59, Resp.C.I) are cell-wise outliers, leading to outlying points for 17, 59 and Resp.C.I on dimension 2.
Reconstitution algorithm
Again, we used the reconstitution algorithm of order 2 to handle the cell-wise outliers. However, this created a negative imputed value −0.0006 for outlying cells (17/59, Resp.C.I). Negative values are not easy to interpret in an incidence matrix. Therefore, we applied reconstitution of order 0. This yields value 0.0065 for the cells (17/59, Resp.C.I). Now the documents 17/59, having a 1 in the framing variable PB, 0.0065 in Resp.C.I and otherwise 0, are similar to documents 13, 19, 26, 27, 46, 56, 65, 69, 84 which have 1 in PB and 0 otherwise. The first four singular values are 0.672 (13.9%), 0.573 (10.1%), 0.548 (9.3%), and 0.519 (8.3%).
Figure 7b is a symmetric CA plot of the reconstituted table. On the first dimension the configuration of column points is similar to the configuration in Figure 7a, except for Resp.C.I. Resp.C.I is not close to Documents 17/59, and Resp.C.I, 17/59 are not far from the origin. Now, the contributions to the second dimension of Resp.C.I is only 1.2% and of 17/59 jointly 0.6%.
By reducing the influence of cells (17/59, Resp.C.I), the new figure is much better readable than Figure 7a. A full interpretation of the table makes use of the outliers found in standard CA, and the CA solution found with the reconstitution method. The standard CA reveals a strong positive relation between 17/59 and Resp.C.I. We interpret the CA solution found with the reconstitution method by interpreting the four quadrants of Figure 7b.
Press releases in the first quadrant focus on problems related to biology (PB) and human health (PH), and place the responsibility for causes at society (Resp.C.S); The second quadrant represents problems related to treatment (PT) and solutions to these problems in the form of treatment (Tr), and opportunity if treatment is carried out (OT); Press releases in the third quadrant focus on the urgency to treat ocean plastic (Ur) and hold entity responsible for carrying out that treatment (Resp.T.C, Resp.T.P, Resp.T.I, Resp.T.O, Resp.T.S). In some cases they also state the responsibility for cause at industry (Resp.C.I) and specific regions/countries (Resp.C.C); Press releases in the fourth quadrant focus on the interconnections between ocean plastic and climate change (CCC) and they state non-biological (PnB) and economic consequences (PE). The fourth quadrant also represents the responsibility for cause at politics (Resp.C.P) and opportunity due to problems (OC). We note that the marginal frequencies of Resp.C.P and OC are low, namely 1 and 2 respectively.
Supplementary points method
Here we treat 17/59 and Resp.C.I as supplementary points. Thus the size of the table analysed is 79x 20. Now, due to deleting Resp.C.I, documents 25 and 54 are also identical. Rows 17/59 and column Resp.C.I have no effect on the solution of CA but are projected into it afterwards. The first four singular values are 0.671 (14.5%), 0.571 (10.5%), 0.544 (9.6%), and 0.511 (8.4%).
Figure 7c shows the symmetric CA plot for the supplementary points method. Figure 7c is similar to Figure 7b.
Discussion and conclusion
In this paper, we propose to use the reconstitution algorithm of order h to deal with outlying cells in CA. The reconstitution algorithm of order h can reduce the effects of single outlying cells on the CA solution. We compare it with MacroPCA and the supplementary points method.
In comparison to the reconstitution approach, MacroPCA imputes outlying cells in the matrix of standardized residuals instead of in the original matrix. Apart from imputing cell-wise outliers, it can also eliminate complete rows. Yet, MacroPCA is not as transparent and straightforward as the reconstitution approach. One of the reasons is that it is originally proposed for the analysis continuous data and makes distributional assumptions, which do not hold for the reconstitution approach. Due to these distributional assumptions, that do not always fit with how the data originate, in our view it appears to flag too many cells as outlying cells.
The supplementary points method deletes complete rows or columns. In contrast, the reconstitution algorithm only reduces the influence of outlying cells. Thus, the reconstitution algorithm uses more information in the data and is, from this perspective, preferable.
To compare the three methods, we simulated datasets with known properties. We simulated three scenarios: a contingency table with CA dimensionality 0, 1, and 2, each with and without an outlying cell. The experimental results showed that, for these created datasets, reconstitution of order h was able to reproduce the underlying dimensionality structure if the dimensionality h was used with which the table was created. Overall, the supplementary point method also works fine, but it ignores more information than necessary. The MacroPCA does not work well in the simulated data that we created.
We analysed two real data sets to illustrate the use of the reconstitution algorithm and compared the algorithm with the supplementary points method and MacroPCA. For the contingency table car dataset, the three methods yielded similar results. For the ocean plastic dataset, the reconstitution algorithm and the supplementary points method had similar results, but MacroPCA failed.
We are not able to show empirically that the reconstitution method is preferable over the supplementary points method and MacroPCA. However, on theoretical grounds the reconstitution method is preferable: it eliminates only single cells to handle outlier problems, thus it is not necessarily deleting more information than is necessary.
In this paper, to detect cell-wise outliers, we follow Greenacre’s definition using visual inspection of the CA plot. We recognize that it is important to also further develop quantitative approaches to identify outliers in the context of reconstitution of order h (Hawkins, 1980; Riani et al., 2022; Rousseeuw & Hubert, 2011). This is particularly true in this area of big data and data science. We leave this topic for future studies. Likewise, there is also a lack of objective evaluation of the information gain from the reconstitution algorithm, as well as the biases associated with the presented method. We also leave this topic for future studies.
In this paper, we compare reconstitution algorithm with MacroPCA and supplementary points method which are used before to deal with outliers in CA (Greenacre, 2017; Raymaekers & Rousseeuw, 2024; Riani et al., 2022). There are other robust methods about robust CA, such as taxicab CA (Choulakian, 2006b, 2020) or the contribution biplot (Greenacre, 2013). Taxicab CA uses L1 optimization and gives uniform weights to all points. The contribution biplot represents rows or columns by their contribution to axis and thus reduces the influence of row or column margins on the CA plot. Further, robust PCA methods, including L1-norm PCA (Choulakian, 2006a), ROBPCA-AO (Hubert et al., 2009), and PP-PCA (Croux et al., 2007), can be adapted to CA and be used to compare with the reconstitution algorithm. These comparisons are also left for future studies.
Last, we focus on CA with two categorical variables. An extension of CA designed for categorical data with more than two variables is multiple CA (Le Roux & Rouanet, 2010). The application of the reconstitution algorithm to multiple CA is also a study area of interest.
Software
The reconstitution algorithm of order h is implemented by a function reconca both for
The MacroPCA method is performed by the MacroPCA function in R package cellWise. The MacroPCA method is proposed for PCA (Hubert et al., 2019) and adjusted for CA (Raymaekers & Rousseeuw, 2024). To fit CA, the original matrix is replaced with the matrix of standardized residuals.
The code to reproduce the results of this paper is on the GitHub website https://github.com/qianqianqi28/CA-outlier-reconstitution-algorithm/. Specifically, the function reconca is in https://github.com/qianqianqi28/CA-outlier-reconstitution-algorithm/tree/main/R.
Supplemental Material
sj-pdf-1-bms-10.1177_07591063251348789 - Supplemental material for Correspondence analysis: Handling cell-wise outliers via the reconstitution algorithm
Supplemental material, sj-pdf-1-bms-10.1177_07591063251348789 for Correspondence analysis: Handling cell-wise outliers via the reconstitution algorithm by Qianqian Qi, David J. Hessen, Aike N. Vonk and Peter G. M. van der Heijden in Bulletin of Sociological Methodology/Bulletin de Méthodologie Sociologique
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Déclaration de conflits d'intérêts
Les auteurs ont déclaré n'avoir aucun conflit d'intérêt potentiel pour tout ce qui concerne le déroulement de la recherche, les droits d'auteur et/ou la publication de cet article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Qianqian Qi is supported by the China Scholarship Council (CSC202007720017).
Financement
Les auteurs déclarent que Qianqian Qi bénéficie du soutien du China Scholarship Council (CSC202007720017).
Matériel supplémentaire
Des documents supplémentaires sont disponibles en ligne
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.