
Abstract
The study investigates how Chinese English-as-a-foreign-language (EFL) learners construct translanguaging space via multimodal orchestration in collaborative English-language YouTube videos introducing Chinese culture. By triangulating multimodal analysis of videos and students’ interview responses, the current research maps translanguaging space construction within and across modes and identifies four multimodal translanguaging space patterns. Meanwhile, learners’ understanding of modal affordances, their intents, their perceptions of the intended audience, and their experiences with relevant (multimodal) texts were found to influence their multimodal orchestration in translanguaging space construction. Digital multimodal composing (DMC) provides EFL learners with opportunities to draw upon their expanded multimodal repertoires, to combine multiple modes for meaning-making creatively, and to transcend the boundaries of languages and modalities critically. Pedagogical suggestions are provided regarding integrating DMC tasks into multilingual learning environments.
Keywords
Introduction
Writing has been increasingly viewed as a form of multimodal design, with the emergence of new communication forms that combine different modes (Belcher, 2017; Hafner, 2018). New literacy practices of using digital tools to create multimodal artifacts through digital multimodal composing (DMC) have been considerably incorporated in multilingual learners’ classrooms for language teaching and learning (e.g., Hafner, 2014, 2015; Jiang, 2017; Liu et al., 2024) and subject knowledge consolidation (e.g., Ho, 2022). As a consequence, multilingual learners’ ways of orchestrating multiple modes for meaning-making is one foci in second language (L2) and foreign language (FL) DMC research (M. Li, 2022). For example, researchers have studied DMC projects as academic assignments or classroom activities (e.g., Hafner, 2014, 2015; Ho, 2022; Tan, 2023).
Multilingual-Multimodal Composing and Second/Foreign Language DMC
With the “multilingual turn” in language education (May, 2013), power differentials among languages have been increasingly deconstructed through innovative practices, for example, translanguaging (Cenoz & Gorter, 2013; García & Lin, 2017; W. Li, 2018; Zhang, 2022a). From the translanguaging perspective, learners’ multilingual resources are viewed as assets (García et al., 2017; Zhang, 2022b). In this view, multilingual learners critically and creatively draw on their holistic repertoires for meaning-making across linguistic, cultural, and geographical boundaries (Pontier & Gort, 2016) without strict adherence to the socially and politically defined borders of named (and usually national and state) languages (W. Li, 2018). In the increasingly digital and multimodal communication landscape (Jewitt, 2009), scholars have argued for an expanded definition of writing as design (G. Kress & Van Leeuwen, 1996/2006/2021; The New London Group, 1996) and emphasized the value and ubiquitousness of composing with multiple modes (Selfe, 2009). Considering the multimodal and multilingual nature of texts and composing, writing and rhetoric scholars like Fraiberg (2010) and Gonzales (2018) have called for attention to understanding multilingual-multimodal literacy practices, which they see as crucial for moving composition into the 21st-century realities (Gonzales, 2018). In Fraiberg’s (2010) situated framework of multilingual-multimodal composing, writers are conceptualized as knotworkers who are “negotiating complex arrays of languages, texts, tools, objects, symbols and tropes” (p. 107), and are “interlocking social, material and semiotic relationships and practices” (p. 105) in their composing. Multilingual-multimodal composing is, therefore, deeply rooted in the configuration of social, cultural, economic, historical, and ideological factors.
Digital multimodal composing (DMC) refers to literacy practices in which multiple modes (e.g., texts, images, and audio) are integrated with the help of digital technologies (M. Li & Akoto, 2021). This approach provides multilingual learners with new opportunities for their second or foreign language identity and agency expression (e.g., Cimasko & Shin, 2017; Hafner & Miller, 2011), and their holistic meaning-making via bridging the lived experience into composition (de los Ríos, 2020, 2022). For example, Olga, an English-as-second-language (ESL) undergraduate writer studied by Cimasko and Shin (2017), expressed and adjusted her authorial intentions for her perceived audience by making specific mode choices. To attract audiences beyond ESL students, Olga attempted to perform an L2 identity as an English native speaker by using the device voice instead of her natural voice in her argumentative video. De los Ríos (2020) illustrated the value of DMC practice as a research approach and a reflection means for uncovering multilinguals’ meaning-making more holistically. De los Ríos (2020) involved a Latino American participant, Marisela, in photovoice journal composing in which Marisela was invited to take photos inside Chicanx/Latinx studies classrooms and then write her associated reflections with the photos in a Google Doc. As de los Ríos (2020) argues, participants’ photovoice journals offer researchers and educators a new window to investigate students’ histories and their understanding of social justice and empowerment behind their composing choices.
Previous research on multilingual learners’ L2/FL DMC practices also reveals the complexity of composing and uncovers several influential factors toward designers’ multimodal orchestration practices, such as the understanding of the audience (Hafner, 2014; Ho, 2022), designers’ discoursal identities (Hafner, 2014; Tan, 2020), designers’ agency and intents (Hafner, 2015; Yang, 2012) and their experience with media (Cimasko & Shin, 2017). It is worth noting that in previous research, the L2/FL DMC projects primarily served as academic assignments or classroom activities for multilingual learners (e.g., Hafner, 2014, 2015; Ho, 2022; Tan, 2023). Although in very few studies (e.g., Ho, 2022), students were asked to post their videos in public for a broader audience, the DMC task was still an assignment from learners’ lecturers, the nature of which could influence students’ DMC practices. There is a paucity of studies on how multilingual learners deal with the L2/FL DMC projects that are composed for the audience mostly initiated outside of their classrooms and serve for non-academic purposes.
Translanguaging Space Construction in Multilinguals’ L2/FL DMC Projects
As discussed previously, translanguaging offers a perspective for understanding the fluidity of multilingual and multimodal resources in multilingual learners’ repertoires (W. Li, 2011a, 2018). Translanguaging space is a social space created by and for translanguaging practices (W. Li, 2018). When constructing translanguaging space, multilingual learners can “bring together different dimensions of their personal history, experience, and environment; their attitude, belief and ideology; their cognitive and physical capacity, into one coordinated and meaningful performance” (W. Li, 2011a, p. 1223). In translanguaging spaces, multilingual learners break the boundaries between languages and between language varieties—a process that requires creativity—and they use evidence to question, problematize, and express ideas—a process that affords criticality (W. Li, 2011a, 2011b; W. Li & Zhu, 2013). Several translanguaging studies have documented how multilinguals employed their full linguistic and semiotic resources creatively and critically to create new meanings and new language practices in online foreign language teaching videos (e.g., Ho & Tai, 2021), everyday interactions (e.g., Choi, 2020), and English medium instruction (EMI) classrooms for content subject teaching among EFL students (e.g., Pun & Tai, 2021; Tai & Li, 2021). For example, in Tai and Li’s (2021) study in a Hong Kong secondary school setting, the EMI mathematics teacher creatively and critically used his multilingual resources, including Cantonese rhyming words, repetition, and an English technical term, to form a mnemonic, and then visualize the meaning of the mnemonic to students by his gestures.
By allowing designers to mobilize diverse modes with the assistance of digital tools, DMC alters the conditions of composing, creating opportunities for multimodal translanguaging space construction. Designers of the L2/FL DMC projects were found to transcend the boundaries of languages and modalities and to deploy resources in their holistic repertoires to achieve a coordinated and meaningful performance with a real or imagined audience (e.g., Ho, 2022; Ho & Feng, 2022). Pacheco and Smith (2015) termed students’ translanguaging practices in composing multimodal texts as multimodal codemeshing. Pacheco and Smith (2015) were particularly interested in the multimodal aspect of translanguaging spaces and highlighted the importance of understanding students’ multimodal codemeshing practices and the meaning-making affordances of those practices.
Previous research has attempted to map out how translanguaging space was constructed within or across modes in multimodal composing projects and what functions were achieved through multimodal codemeshing. Pacheco et al. (2022) systematically reviewed 35 studies on emergent bilingual students’ (EBs’) translanguaging practices in multimodal composition products and composing processes, and they found that EBs orchestrated semiotic resources coded in multiple languages to express their identities, to add nuanced meanings, and to engage the audience in composing products. For instance, students in the Pacheco and Smith (2015) study meshed audio recordings (e.g., accompanying non-English interview voice recordings with orally recorded English translation), texts (e.g., presenting both English and Spanish phrases on the screen), and images (e.g., including the map of the characters’ hometown) when they composed PowerPoint presentation projects. Translanguaging space was built to engage different audiences simultaneously, to convey multidimensional and nuanced meanings, and to revoice the subjects. For example, students kept voice recordings in their heritage languages to address an audience from their cultural backgrounds and to express their emotions, and they presented English subtitles to cater to an audience, their classmates and lecturers, who cannot communicate with the designers in languages other than English. De los Ríos (2018) also found that audios were meshed to construct translanguaging space in Latinx bilingual youth’s video projects, explaining their ethnic, racial, and gender identification. Students deliberately used multiple languages, dialects, and registers in their speech. Ho’s (2022) research on Hong Kong EFL undergraduate students’ instructional video-making unveiled another way of translanguaging space construction: transcending genre conventions of academic writing and instructional videos. Students re-created a new genre of academic instructional video by drawing on the linguistic and cultural capitals established in their Cantonese and English learning contexts. Out of the considerations that the video task was a course assignment, students included citations in their videos to show their alignment with the academic discourse community consisting of their course instructors.
As Zhu et al. (2020) mention, more research efforts are still needed to understand the multimodal nature of translanguaging space, and DMC is a good place in which translanguaging space could be constructed multimodally (Ho, 2022; Ho & Tai, 2021). As discussed above, the multilingual learners’ practices in L2/FL DMC projects to the audience mainly from the out-of-classroom contexts are still under-researched, so the current study would investigate how Chinese EFL learners construct the translanguaging spaces multimodally in their collaborative English-language YouTube videos designed for introducing Chinese cultural artifacts and events to a global audience, and it also attempts to understand what could impact designers’ translanguaging space construction.
Specifically, the research deals with the following research questions:
Research Question 1: How was the translanguaging space constructed through multimodal orchestration in Chinese EFL learners’ YouTube English-language videos?
Research Question 2: Which factors might influence translanguaging space construction through multimodal orchestration in Chinese EFL learners’ YouTube English-language videos?
Theoretical Framework
The social semiotic approach informs the analysis of translanguaging space construction patterns and the identification of the influential factors for students’ multimodal orchestration practices in translanguaging space construction. From the social semiotic perspective, linguistic signs are part of sign makers’ modal repertoire for meaning-making, and the modal resources at designers’ disposals carry particular sociohistorical and political associations, the idea of which translanguaging also embraces (W. Li, 2018). Therefore, a multimodal lens is taken in the current research to understand how translanguaging space is constructed within and across modes in videos. Translanguaging space is viewed as not only constructed within linguistic modes but also within and across other modes.
The social semiotics approach views “sign” as motivated and “made—not used—by a sign-maker who brings meaning into an apt conjunction with a form, a selection/choice shaped by the sign maker’s interest” (G. Kress, 2010, p. 62). Sign makers’ interest refers to their momentary considerations of the social experience and is generated to respond to the social environment in which signs are made. Therefore, designers’ sign choices for meaning-making are socially situated and influenced by diverse contextual factors, such as the audience (Hafner, 2014; Ho, 2022) and the media on which designers work (Cimasko & Shin, 2017). Designers are agentive in shaping and reshaping ways of presenting messages by utilizing and mingling semiotic resources with a focus on the intended meanings, instead of just utilizing the available resources in predefined conventions (Hafner, 2014). A socially situated view, hence, is applied to examine the influential factors to participants’ modal decisions in translanguaging space construction in videos.
Social semiotics provides diverse insights into how designers’ decisions are impacted. However, this approach is circumscribed to the composing context(s) and could be complemented by linking to the design decisions at other times and places. Witte’s (1992) concept of intertext from constructive semiotics highlights the mechanisms through which designers build up their current text(s) by referring to other text(s) within and beyond the context of production, therefore providing a lens through which we can investigate how factors outside the immediate context of composing influence designers’ sign decisions. This intertextual perspective complements the social semiotics approach, which focuses on the socially situated nature of sign-making, by accounting for the broader textual networks and prior textual experiences that shape and inform the meaning-making process. The idea of text is understood in this study as “a cohesive entity that can be disseminated in a number of ways” (Serafini, 2014, p. 13), such as, a picture book, a journal article, and a video. As Todorov (1984) argued, any text intersects with another, therefore, designers’ use of particular modes in their videos for translanguaging space construction could also be informed by other (multimodal) text construction practices. By integrating social semiotics with the concept of intertext from constructive semiotics (Witte, 1992), a nuanced analysis could be conducted to understand how participants’ multimodal orchestration practices will be influenced by factors within and beyond the context of production.
Methodology
Participants and Context
The five participants included in this study were undergraduate English-major students from the faculty of foreign languages at a comprehensive university in Southern China. The faculty is affiliated with several research centers on intercultural communication and translation. The centers conduct research projects regularly with student volunteers with an aim of providing students with chances to deal with real-life problems regarding intercultural communication. Recruitment advertisements for student volunteers are posted on the faculty website by research centers and in WeChat groups where students are active. Participants in the current research were voluntarily involved in an extracurricular project that introduced Chinese traditional culture to the international audience via YouTube videos. As the extracurricular research projects did not offer any credits and were unrelated to any coursework, students’ engagement conditions in those projects would not influence their academic benefits. At the beginning of the project, the project leader, who was also one of the course instructors from the faculty, introduced the project’s purposes and gave some general tips on video making, such as understanding the audience’s preferences and utilizing accessible resources (e.g., video or image databases). Participants were expected to work collaboratively on video making, and they had much authority in the project implementation and could decide the specific topic of each video and work arrangement. The project leader had several group meetings to give comments on the video drafts that participants finished. The videos were revised by participants based on the feedback. No extra training was provided. The five participants played different roles in the video composition group work (Table 1).
Participants’ Information.
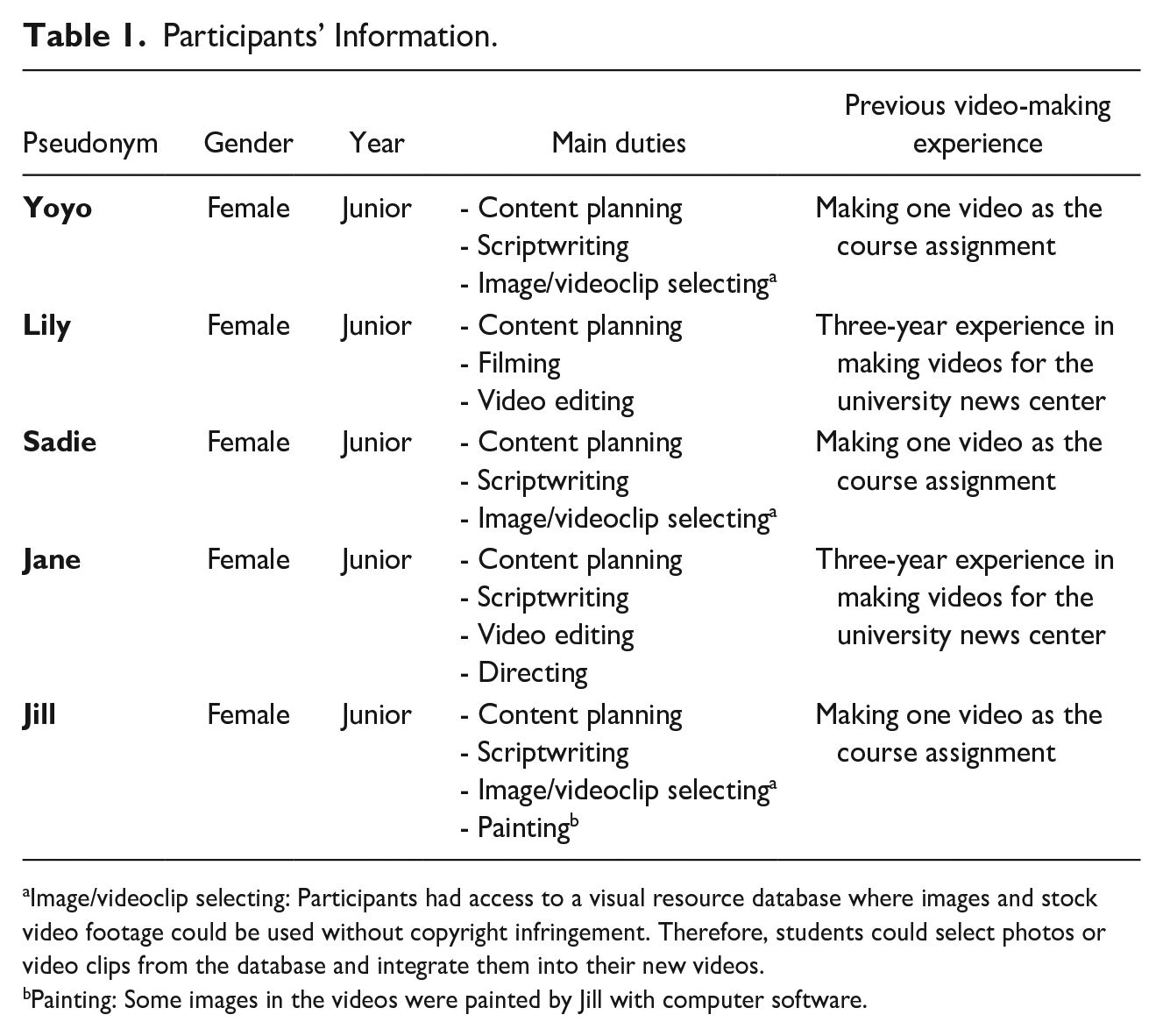
Image/videoclip selecting: Participants had access to a visual resource database where images and stock video footage could be used without copyright infringement. Therefore, students could select photos or video clips from the database and integrate them into their new videos.
Painting: Some images in the videos were painted by Jill with computer software.
Procedures
The five participants collaboratively finished 10 videos in total. The first author contacted each participant via email for a 45-minute discourse-based semi-structured interview (Odell et al., 1983) conducted in Chinese, the participants’ first language. Invitation letters and informed consent letters were attached to the emails. Participants were informed that all information would be kept confidential and that they could withdraw from the research without any adverse consequences. In the consent letters, students were asked to indicate their preferences for the use of audio recording, video recording, and photographing. Detailed descriptions of three recording methods were provided to give participants as much control over their data as possible (Olinger, 2020). Participants were also invited to indicate their favorite video in the reply email. All of them indicated their agreement to the audio-recorded-only interviews in the signed informed consent letters which they sent back to the researchers. Interviews were conducted on Zoom two weeks after the participants’ email responses. Five participants indicated their favorite videos in the emails, and two of them selected the same one. Therefore, four videos in total were finally taken as participants’ favorite works (see Table 2 for video details).
Video Details.
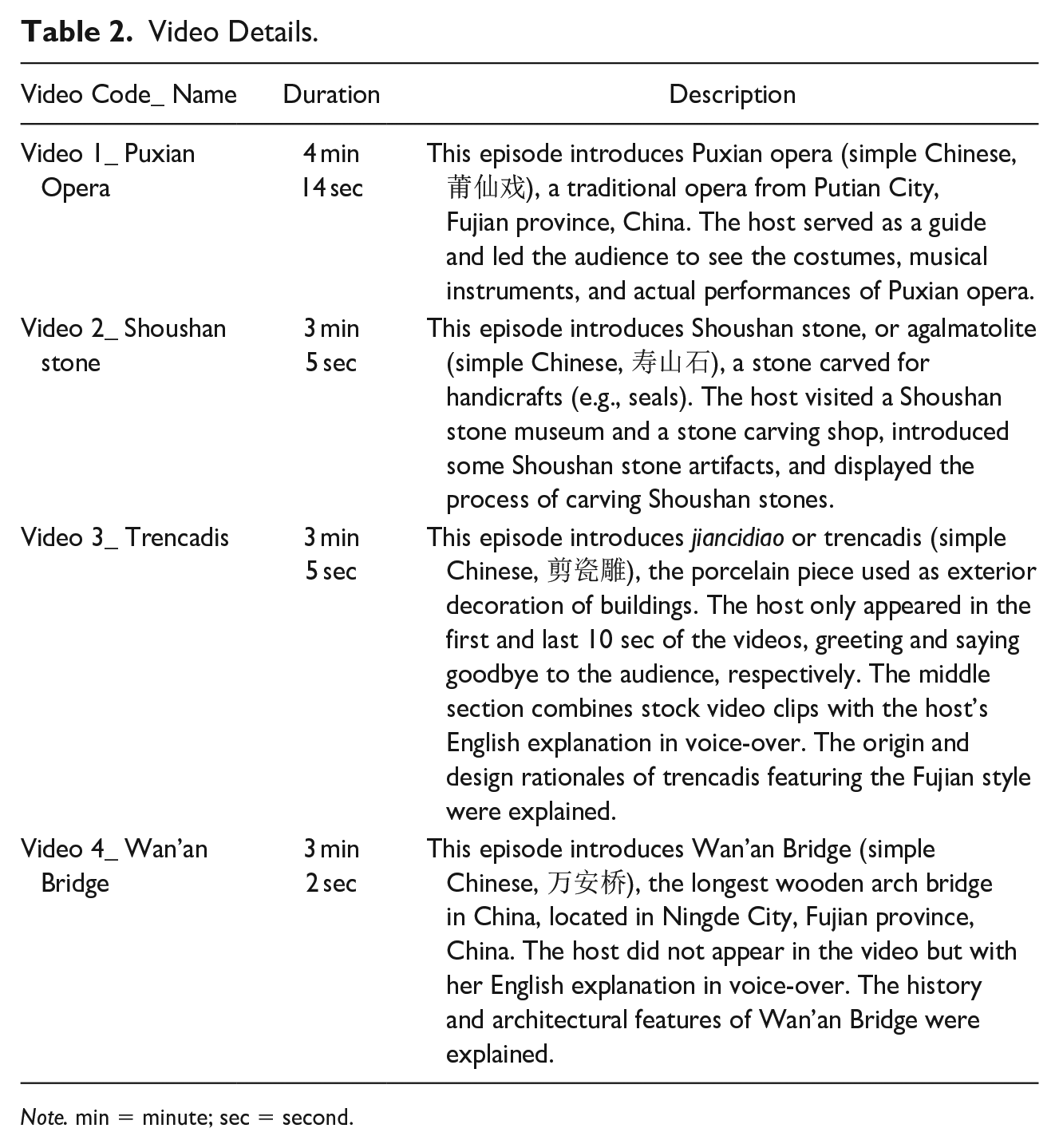
Note. min = minute; sec = second.
Before discourse-based semi-structured interviews, the researchers selected representative clips, in which translanguaging space was established multimodally. The selection of representative clips (translanguaging-in-multimodal-orchestration episodes) is discussed more in Step 2 in the subsequent section, Data Analysis. Ten video clips were finally collected as visual prompts for the interviews, during which students rewatched selected shots and reflected on their decision-making process in composing. The interview protocol can be seen in Appendix 1.
Data Analysis
Two research questions were addressed simultaneously via the triangulation of two data sources: participants’ videos and their interview responses regarding the decision-making process in constructing translanguaging spaces in the selected video clips. Data analysis at this stage was divided into four steps, informed by Bezemer and Jewitt’s (2010) model of multimodal data analysis, including (a) data familiarization, (b) identification of translanguaging-in-multimodal-orchestration episodes in videos, (c) multimodal transcription of selected shots, and (d) qualitative coding by triangulating interview results.
Step 1. Data familiarization
Four videos were first imported into ATLAS.ti, a qualitative data analysis software providing functional analysis tools in academic and professional research (Hwang, 2008). Researchers then watched the videos and made notes about the video topics and creative video segments in video logs by using the “comment” function in the software.
Step 2. Identification of translanguaging-in-multimodal-orchestration episodes in videos
Translanguaging spaces are regarded as existing in those episodes where multiple semiotic resources in different named languages are used for meaning making. In the selected episodes, multiple semiotic resources were used potentially for specific purposes, which would be verified in the interviews. The selection and orchestration of specific semiotic modes were driven by designers’ personal history, experience and environment, attitude, belief, and ideology. An example can be seen in a clip from video 2 (Figure 1). In this clip, the original sound of Chinese conversation was kept, the practice of which was not seen in the rest of this video and seemed unusual to the team based on their experience with English-language videos and, therefore, was assumed to have been designed with specific purposes. The use of Chinese dialogue (audio mode) was drawn from the designers’ first language learning experience, and the inclusion of English caption (linguistic mode) could be informed by their English learning and perhaps their previous media experience.

Selected video clip example.
Step 3. Multimodal transcription of selected clips
Selected clips were transcribed in terms of the modes that were used for translanguaging space construction, following the New London Group’s (1996) mode categorization, including (a) linguistic modes (e.g., vocabulary and metaphor, delivery, local coherence relations, and global coherence relations); (b) visual modes (e.g., images, colors); (c) audio modes (e.g., voice-over, music, and sound effects); (d) gestural modes (e.g., body language); and (e) spatial modes (the meaning of environmental spaces and architectural spaces). The interview results would also inform the multimodal transcription of selected clips, the process of which is discussed in the subsequent Step 4.
Step 4. Qualitative coding by triangulating interview results
As mentioned previously, the selected translanguaging space episodes were used as visual prompts in interviews, inquiring about participants’ decision-making process in constructing translanguaging space via multimodal orchestration. Audio-recorded interviewees’ responses to those questions were transcribed verbatim and within Olinger’s (2020) adapted transcription conventions from Hepburn and Bolden’s (2017) research (Appendix 2) to capture interviewees’ nonverbal vocal qualities, part of participants’ embodied actions that could shed more light on their affective (regarding personal attitudes and emotions) and epistemic (regarding the certainty or authority over a proposition) stances (Gray & Biber, 2012) over the translanguaging space construction. Those interview response episodes were located and triangulated with multimodal transcription of selected clips to understand students’ translanguaging practices and to identify the influential factors on their multimodal orchestration in translanguaging space construction. A translanguaging-space-multimodal-orchestration template (Table 3) was developed to depict (a) what modes were used in constructing translanguaging spaces in the column “Multimodal orchestration regarding translanguaging space construction,” and (b) why students orchestrated modes in specific ways in the column “Translanguaging space.” Transcribed episodes were imported into MAXQDA and coded inductively using the constant comparative method (Glaser, 1965). Multiple rounds of coding were conducted. At the initial stage, the researchers compared individual translanguaging space episodes with each other to identify translanguaging space multimodal construction patterns (e.g., translanguaging space in linguistic-visual modal interaction). Then, the rest of the translanguaging space practices were grouped into the existing categories, and the classification was constantly adjusted. To address the second research question on the influential factors to students’ translanguaging space via multimodal orchestration, interview data from the “interview response” column were analyzed following thematic analysis procedures (Braun & Clarke, 2016) and an inductive approach. A tentative coding scheme emerged with themes. Each theme was defined, revised, and cross-checked with video data for high trustworthiness in interpretation. The exploration of possible connections between themes was informed by previous translanguaging research, for instance, Pacheco et al.’s (2022) systematic review of the functions of translanguaging practices in composing multimodal texts, including expressing identity, adding nuance to and augmenting meaning, and engaging audiences. The refined themes were further interpreted through the lens of social semiotics and the concept of intertext to understand how participants’ mode choices were influenced by the social and cultural contexts of the video production and by the references and connections to other (multimodal) texts.
Translanguaging-Space-Multimodal-Orchestration Template.
Results
This section presents results on how translanguaging spaces were constructed multimodally in four videos and what influenced participants’ ways of orchestrating multiple modes in translanguaging spaces. As discussed previously, designers’ mode choices are understood as socially situated in the context of production from the social semiotic perspective and as linked to other design decisions in a broader textual network from Witte’s (1992) idea of intertext. The current research complemented the analysis of translanguaging space construction patterns with designers’ explanations of what they considered behind the specific mode choices. This complementation aims to provide a comprehensive understanding of translanguaging space construction patterns, as some mode choices could be too implicit to be noticed without the designers’ explanations. It also provides contextual information for the influential factors that emerged from designers’ explanations regarding their decision-making processes in mode choices. The dynamic interactions among the identified influential factors are also presented.
Translanguaging Space Construction via Multimodal Orchestration
Translanguaging space was mapped within and across modes in participants’ videos, and four translanguaging space construction patterns were identified as (a) within linguistic mode, (b) in linguistic-audio modal interaction, (c) in linguistic-visual modal interaction, and (d) in linguistic-spatial modal interaction. Because of the space limit, only one case was presented for each translanguaging space illustration. Designers’ considerations regarding their choices of specific semiotics resources were explained for each case.
Constructing translanguaging spaces within linguistic modes
Captions or subtitles are the places where different linguistic resources are remixed, and translanguaging space is constructed. Despite English being the primary language of four videos, designers deliberately added Chinese pinyin (i.e., the phonetic symbols or Romanized spelling of Chinese characters) and Chinese characters for specific terms (e.g., the names of cultural artifacts and events introduced in videos) in the English captions or subtitles. For example, in Case 1 (Table 4), Chinese pinyin Shoushanshi and Chinese characters 寿山石 in parentheses were added, referring to agalmatolite in English, in the caption.
An Example of Translanguaging Space Within Linguistic Modes.

Note. The column “Multimodal orchestration in translanguaging space” only includes the sub-column(s) for the modes existing in the reported case.
As Jane explained in the interview (Extract 1, Figure 2), Chinese pinyin and characters for the name of agalmatolite were kept after her serious consideration regarding the redundancy of term use and with the intention to emphasize the cultural identification of the introduced cultural artifact. Jane acknowledged that there was a translated name of Shoushanshi, that is, agalmatolite, which might already be familiar to the foreign audience. However, very quickly, she switched and mentioned that she identified agalmatolite as “>a symbol of Chinese culture<” and, therefore, the necessity of including the Chinese name of this cultural artifact. She paused three times when saying, “so it was needed (.) to give it a (.) Chinese name (.)”, and stressed the necessity of letting the audience know the Chinese name of agalmatolite by saying, “which should be known by foreign audience.” Therefore, the designers’ intent to emphasize the cultural identification of agalmatolite was one primary driving force toward the selection of specific linguistic signs (e.g., Chinese pinyin) in this case.

Transcript of interview, Extract 1.
Constructing translanguaging space in linguistic-audio modal interaction
Translanguaging space could also be constructed in the interaction of multiple modes. One of the interaction patterns was linguistic-audio, which was evidenced in Case 2 (Table 5). The conversation between Speaker 1 (a stone-crafting expert) and Speaker 2 (video host) was conducted in Chinese, the speakers’ first language. Speaker 1 was illustrating the carving techniques of Shoushan stone (agalmatolite) to Speaker 2 in a local Chinese museum. The Chinese dialogue was not dubbed into English, and an English subtitle was provided.
An Example of Translanguaging Space in Linguistic-Audio Modal Interaction.

Note. The column “Multimodal orchestration in translanguaging space” only includes the subcolumn(s) for the modes existing in the reported case.
When explaining why Speaker 1’s Chinese narration was kept, Lily termed it “a very ridiculous idea” and “not that professional” to let “the craftsman (Speaker 1) speak English (h)” or “someone do the interpretation besides him (h),” as she thought that this practice might entail a possibility that the audience thought video producers “just ask someone on the street (h), who can speak English, to read the text” (Extract 2, Figure 3). Therefore, Chinese dialogue was kept to show that the stone carving techniques of Shoushan stone (agalmatolite) were illustrated by a Chinese stone specialist (Speaker 1), and also to increase the professionalism of video content.

Transcript of interview, Extract 2.
On the other hand, speech in the audio mode was regarded by participants as being related to the authenticity of the scene. When questioned by the interviewer regarding why English dubbing was not provided (Extract 3, Figure 4), Jane raised her voice and stated with a relatively affirmative tone that English subtitles were efficient enough to deliver messages to the international audience. She emphasized that the status of being “more authentic” could be entailed by the original Chinese dialogue, which acted as an indicator that the filming was conducted in real-life Chinese EFL scenes where not everyone can speak English.

Transcript of interview, Extract 3.
Meanwhile, Jane’s experience with media (e.g., news broadcasting and YouTube videos) also gave her the assumption that providing English dubbing in audio mode could make videos as formal as CGTN news, which, as Jane emphasized (Extract 4, Figue 5), was against the designers’ expectations that the video could be interpreted as a light-hearted travel vlog with “casual” style. She compared the form-style relationships of two kinds of videos, formal CGTN news and videos of casual style, which were outside the immediate context of their YouTube video production. Jance then took the stylistic reference to the latter video to create her expected viewer interpretations.

Transcript of interview, Extract 4.
Constructing translanguaging space in linguistic-visual modal interaction
Similar to Ho’s (2022) research, designers in the current study mobilized linguistic and visual modes in translanguaging space to exemplify the meaning of keywords, such as the name of the cultural artifact. Case 3 in Table 6 is a good example. This video episode was taken from the beginning of Video 3, in which video designers introduced the idea of “trencadis featuring in Fujian style” or cut porcelain carving (jiancidiao in Chinese pinyin, 剪瓷雕 in simple Chinese). Trencadis is a Catalan word that means “broken up” and is commonly used to refer to a technique of covering structures with a mosaic, usually abstract, of irregular pieces of ceramic, glass, or marble tiles. The word trencadis was selected instead of the literally translated term “cut porcelain carving” presented in some Chinese official documents (e.g., Xiamen Market Supervision Administration [Intellectual Property Office], 2021).
An Example of Translanguaging Space in Linguistic-Visual Modal Interaction.
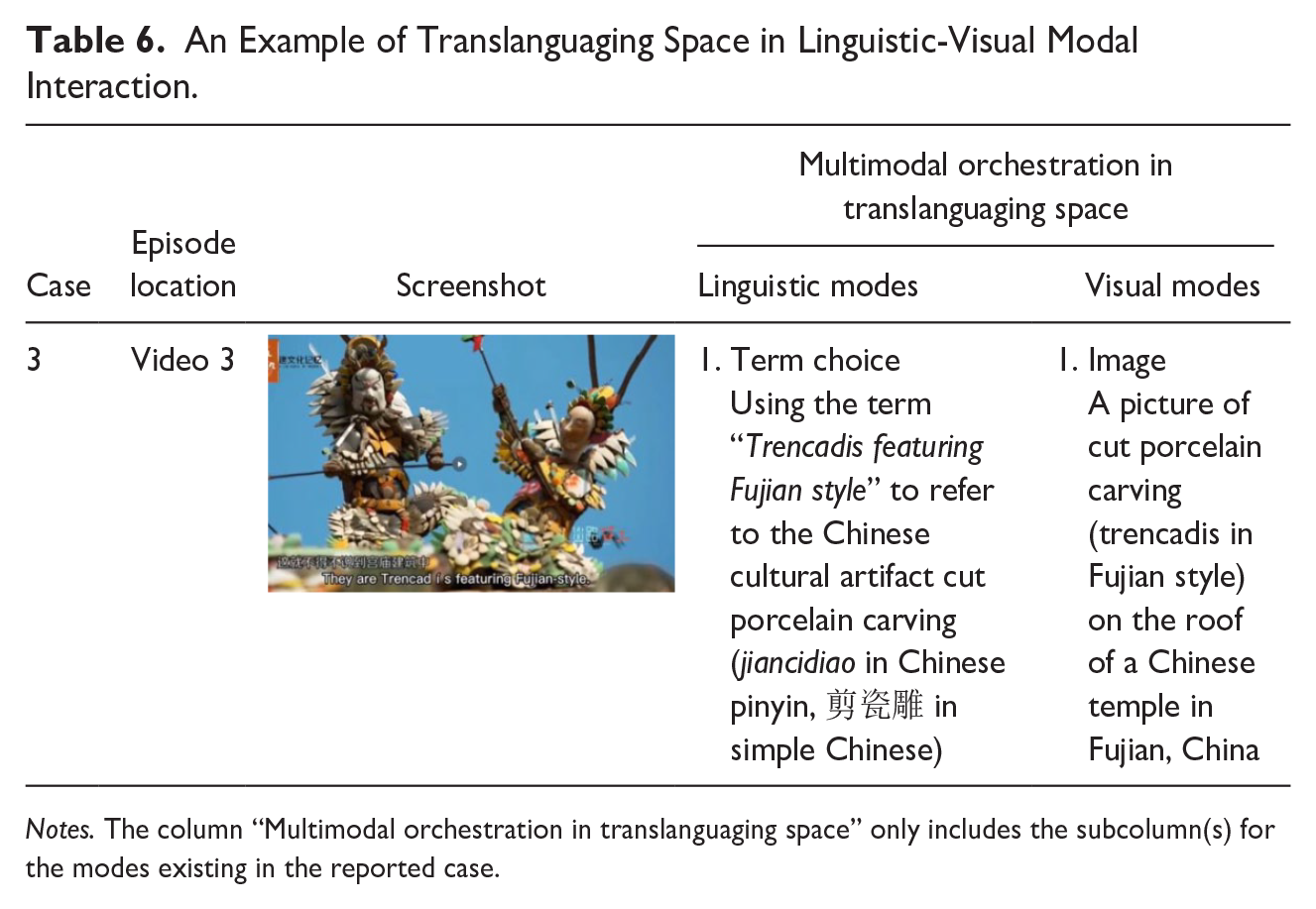
Notes. The column “Multimodal orchestration in translanguaging space” only includes the subcolumn(s) for the modes existing in the reported case.
In linguistic modes, designers tried to relate the Chinese cut porcelain carving to the concept of “trencadis,” which was assumed to be familiar to the intended audience. As seen in Extract 5, designers held the view that the intended audience might understand the crafting techniques better when hearing “trencadis” instead of Chinese pinyin jiancidiao. In the visual modes, designers presented a photo of a cut porcelain carving (trencadis in Fujian style) filmed in China to exemplify what it looked like and to visually show the differences between trencadis and the cut porcelain carving (trencadis in Fujian style) (e.g., the choice of character). Sadie explained in the interview (Figure 6, Extract 5) that she strategically decided the order of pictures and the term for naming the target cultural artifact to “have something they (audience) are familiar with appear first and then something about China” which could “to some extent meet the audience’s expectation.” Translanguaging space was constructed through the linguistic modes, which were externally connected to the intended audience from diverse cultural backgrounds, and visual modes, which complemented the meaning-making at the linguistic level and provided the actualization of linguistic terms in (Chinese) local cultural context. Therefore, it could indicate that designers’ mode choice and orchestration were underpinned by their understanding of the intended audience and their intent to ease the comprehension load for their audience.

Transcript of interview, Extract 5.
Constructing translanguaging space in linguistic-spatial modal interaction
Spatial meanings are denoted through environmental spaces and architectural spaces (The New London Group, 1996). In digital multimodal composing, the spatial design could be expressed in the layout of components on the screen, such as writing and images (Shin & Cimasko, 2008). Though not common among the four videos, the spatial relationship among visual elements was creatively used to construct a translanguaging space with elements in linguistic modes. A typical example can be seen in Case 4 (Table 7). A researcher on the Chinese trencadis study explained the design rationale of images on the Chinese trencadis; that is, images are intentionally designed for good fortune (图必有意, 意必吉祥 in Chinese). Two Chinese terms, 图必有意 and 意必吉祥, were vertically presented from right to left on the screen (Figure 7), the spatial relationship of which is typical in Chinese traditional literature and calligraphy. In the Chinese caption, these two Chinese terms were displayed horizontally, indicating an uncommon spatial relationship realized in two on-screen terms (Figure 7). English subtitles were also provided to present the meaning of two terms to the audience in English (Table 7). It is worth noting that the last word of the first term, 图必有意, is the first one of the second term, 意必吉祥, which is the application of anadiplosis, a common rhetorical device used in Chinese literature (e.g., poetry). The spatial relationship of Chinese terms and the rhetorical device, anadiplosis, applied in the video were drawn upon from the literal practices in the designers’ Chinese language learning situations, which were beyond the immediate context of production.
An Example of Translanguaging Space in Linguistic-Spatial Modal Interaction.

Note. The column “Multimodal orchestration in translanguaging space” only includes the subcolumn(s) for the modes existing in the reported case.

Spatial arrangement of two Chinese terms in Table 7.
Except for English subtitles, the aforementioned semiotic resources from both linguistic and spatial modes were chosen with (a) the designers’ intent of maximizing possibilities of including more Chinese cultural elements in addition to the introduced cultural artifact, and (b) their assumption that the audiences were relatively familiar with the added elements. Sadie described the audience as those who “have already known these stuff (Chinese four-character-term and horizontal word order)” (Extract 6, Figure 8). Presenting those elements in videos was to verify the assumed audience’s previous understanding of some Chinese culture, or, in Sadie’s words, to “let them see four-Chinese-character terms really exist in China.” Though certainly saying “Ye:::s?” to the question regarding whether additional culture-related elements were integrated with the intention to promote Chinese culture in Extract 7 (Figure 9), Sadie raised a concern regarding the audience and indicated that those elements might not have been added if the audience did not know them since they were “not the most important thing.” Therefore, it could be observed that designers’ assumptions about their audience could influence their decisions on whether specific semiotic resources related to Chinese culture should be included. To be more specific, participants appeared to include those Chinese culture-related elements only if the inclusion of those components would not decrease the comprehensibility of the designers’ introduction of the target cultural artifact.

Transcript of interview, Extract 6.

Transcript of interview, Extract 7.
Factors Influencing Designers’ Translanguaging Space Construction
The investigation of the influential factors to designers’ decision-making process in translanguaging space construction is informed by the social semiotics approach and Witte’s (1992) concept of intertext. Therefore, we understand designers’ mode decisions as socially situated practices influenced by factors in the immediate context of production and, at the same time, shaped by the broader textual networks and prior textual experiences. Four factors were recognized as influential to designers’ decision-making during translanguaging space construction via multimodal orchestration, including (a) designers’ experience with relevant (multimodal) texts (Cases 2 and 4), (b) designers’ understanding of modal affordances in video making (Case 2), (c) designers’ intents (Case 1, 2, 3, 4), and (d) designers’ perceptions of the intended audience (Cases 3 and 4). Figure 10 depicts the decision-making process regarding sign choice in translanguaging space construction and how the identified influential factors interacted and impacted the process.
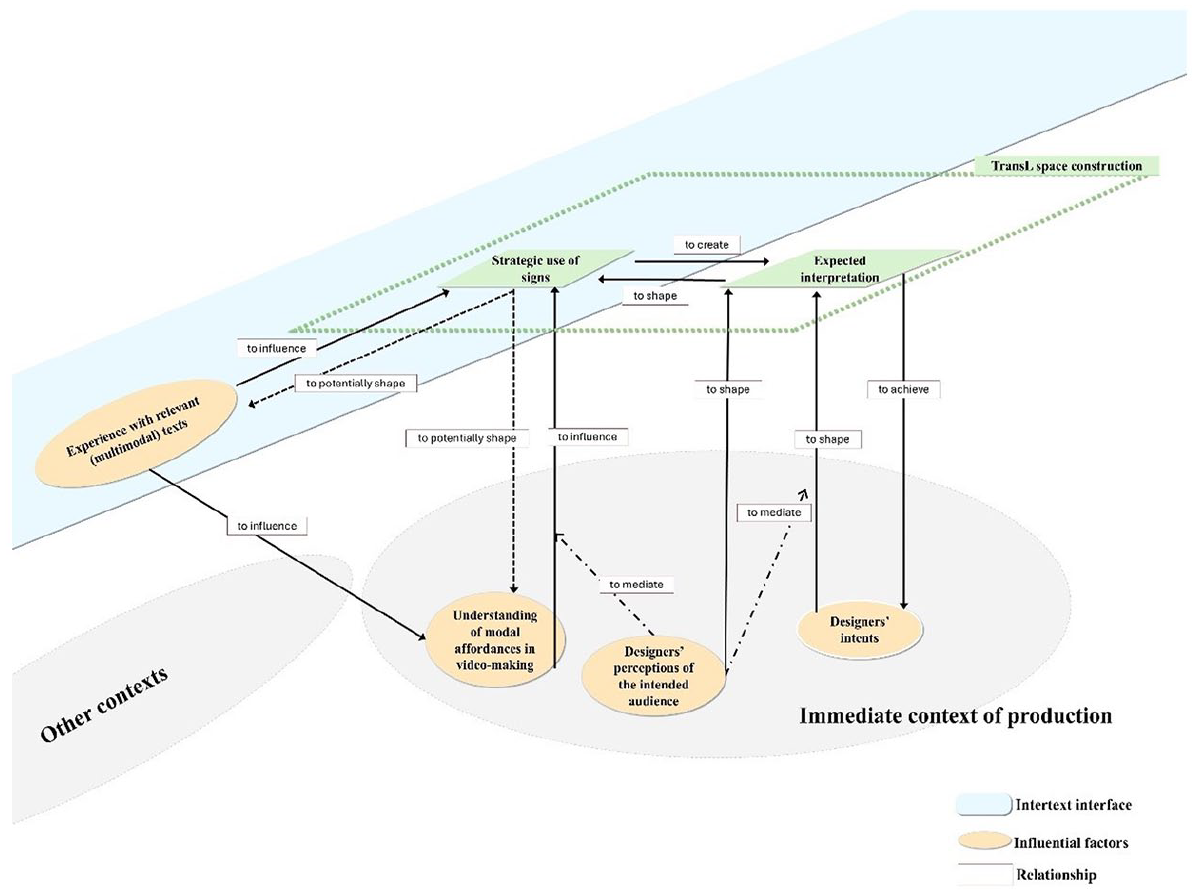
Translanguaging space construction and influential factors.
Experience with relevant (multimodal) texts
Informed by Witte’s (1992) concept of intertext, the current research identified designers’ experience with the relevant (multimodal) texts as one of the influential factors in their mode decisions (Figure 11 refr). For instance, participants compared the form-style relationships from several videos they had watched (Case 2, Extract 4) and adapted the features (e.g., original sound of Chinese dialogue) in their video, with the expectations that the video could be interpreted in the way that the reference videos were interpreted. Participants also drew upon literal practices from monomodal texts, the Chinese four-character terms, and the typical spatial relationship of Chinese characters commonly seen in Chinese traditional literature and calligraphy (Case 4, Extract 6), and then integrated those features into videos for creating their expected interpretations. Those expected interpretations were further driven by designers’ intent of maximizing possibilities of including other Chinese cultural elements. Therefore, translanguaging space construction could occur during the course of intertext; designers’ experience and understanding of relevant (multimodal) texts (e.g., videos) could influence their decisions regarding what features they should adopt and adapt in their videos. Designers’ mode decisions in the current video-making are also viewed as being part of their experience with multimodal texts and potentially shaping their future intertext practices.
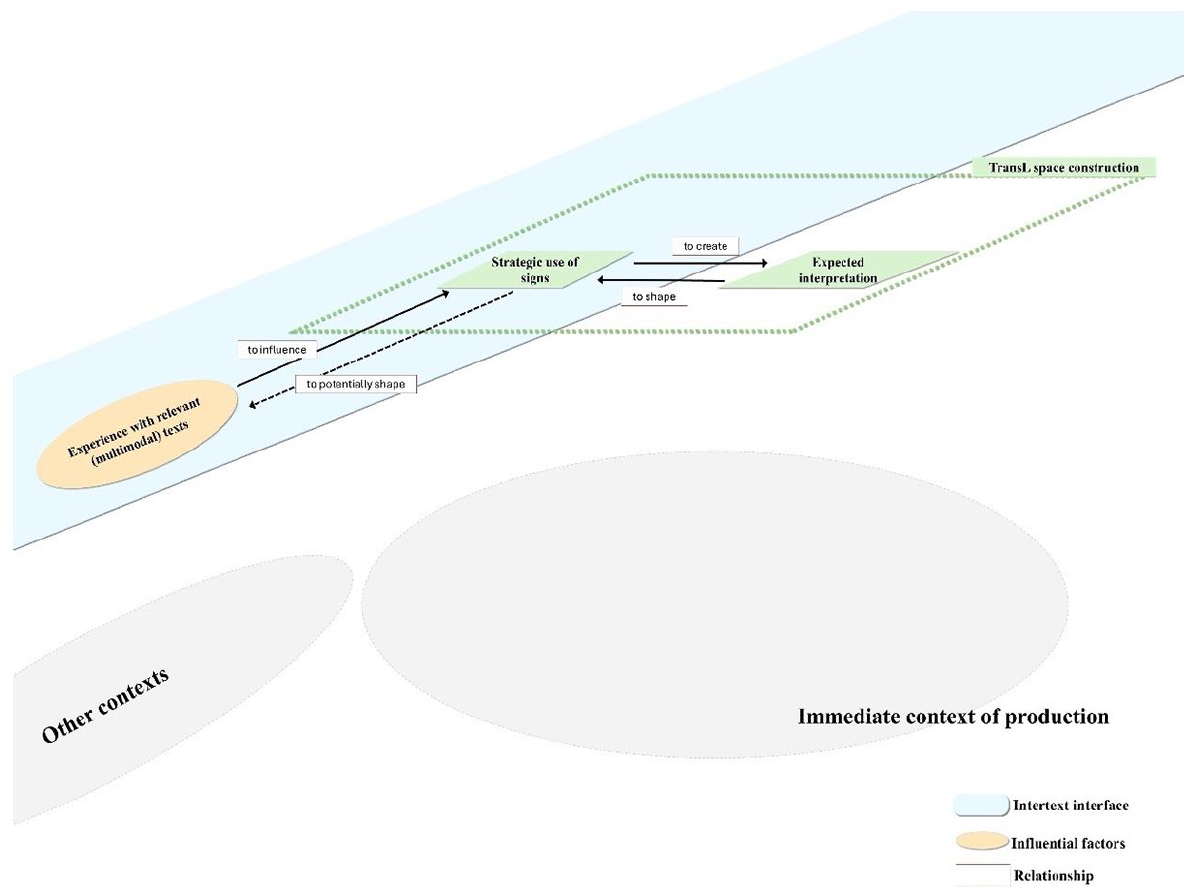
Experience with (multimodal) texts and translanguaging space construction.
Understanding of modal affordances in video-making
Modes have different potentials for meaning-making, in other words, modal affordances, which could influence sign makers’ choice of modes (Jewitt et al., 2016). Designers’ understanding of the modal affordances could be developed through their experience with relevant (multimodal) texts, and designers’ perceptions of the audience could “mediate” the influence of their knowledge of modal affordances in video making on their decisions regarding the actualization of modes in their videos (Figure 12). For instance, in Case 2, participants regarded the audio mode as related to scene authenticity and formality, and by picturing the effects of different modal realization for the audience based on their experience with media, they decided to keep the original sound of Chinese dialogue in their videos. Participants’ perceived relation between the original voice of the speakers and the “casual” style of video was built upon their experience with other YouTube videos and news broadcasting.
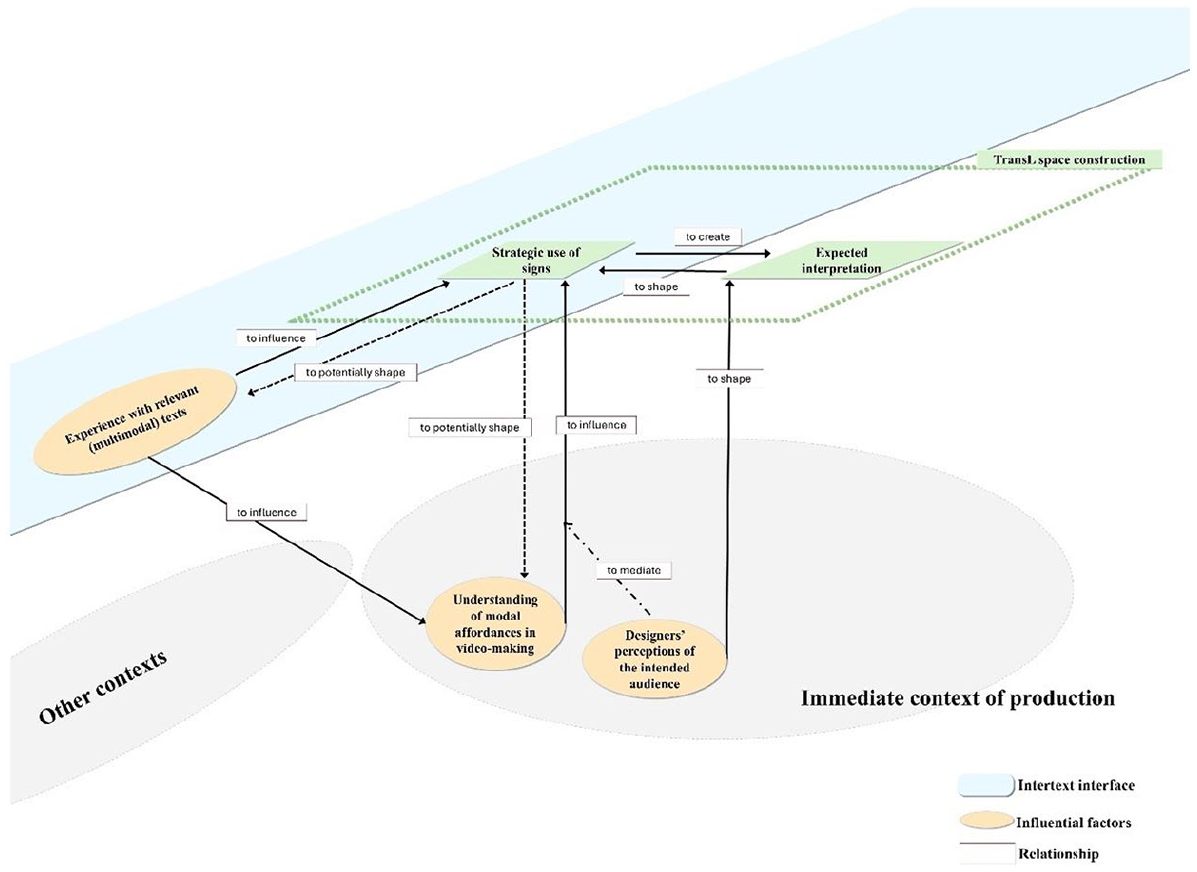
Understanding of modal affordances in video making and translanguaging space construction.
Designers’ intents
Another influential factor is identified as designers’ intents, which in the current study involve (i) emphasizing cultural identification of the introduced artifacts (Case 1), (ii) increasing the professionality of the video content (Case 2), (iii) maximizing possibilities of including other Chinese cultural elements (Case 4), and (iv) ensuring the comprehensibility of the introduction of target cultural artifacts (Case 3, 4). Designers’ intents could shape how they expect their videos to be interpreted by their audience and then further influence their modal use in videos. For instance, participants added semiotic resources specific to the Chinese context, such as Chinese pinyin and Chinese characters, in videos with the expectation that the audience could also perceive the introduced artifacts as part of Chinese culture. It should be mentioned that designers’ intent to include additional Chinese cultural elements was negotiated by the interaction between designers’ perceptions of the audience and their intent to ensure that the target cultural artifact was clearly introduced (see Figure 13 for the interactional relation). The perceptions of the imagined audience could guide video designers in navigating through the selection and orchestration of semiotic resources to the end of presenting the cultural artifact in an easily comprehensible manner, which designers prioritized. If designers perceived the semiotic resources related to Chinese culture (e.g., Chinese four-character terms) as unfamiliar to the audience, they would neglect their goal of maximizing possibilities of including other Chinese cultural elements and remove those semiotic resources to ensure the overall content comprehensibility of the target cultural artifact to the audience.
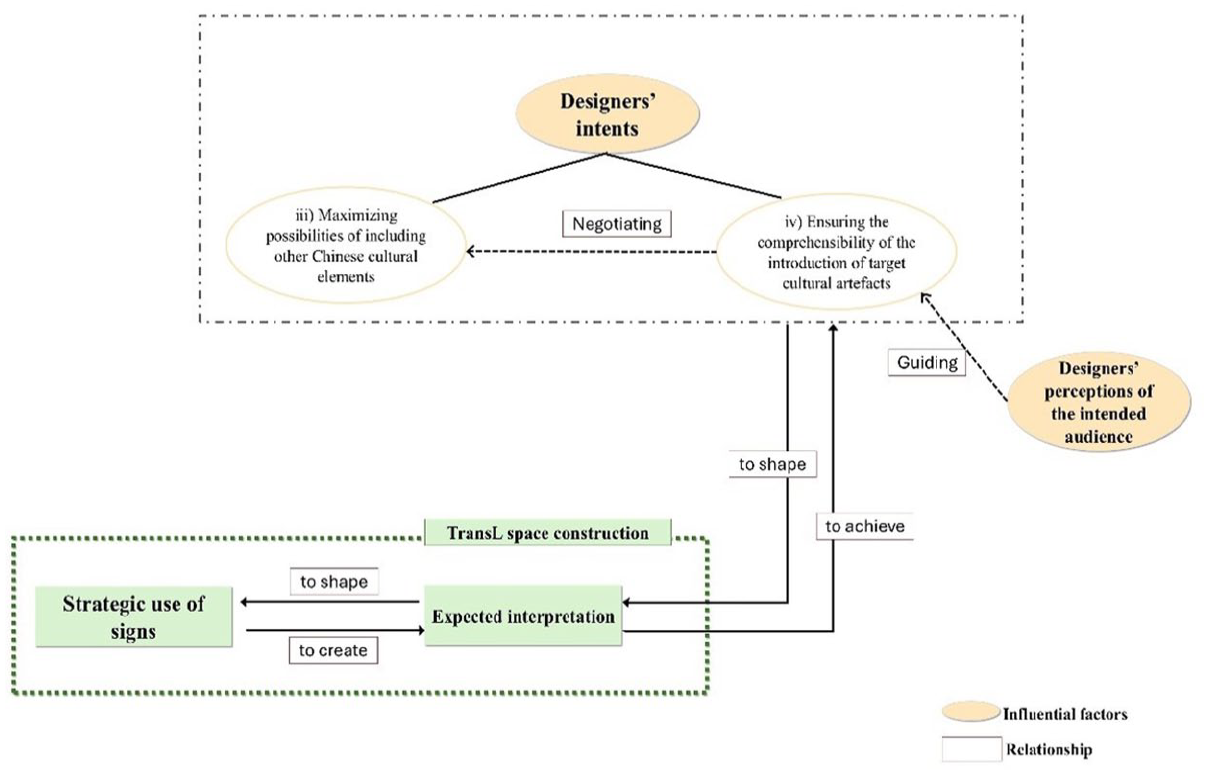
Interaction between two designers’ intents and their perceptions of the intended audience
Designers’ perceptions of the intended audience
As Pacheco et al. (2022) suggest, students could draw on their holistic semiotic repertoires in multimodal composing to negotiate meaning with a real or imagined audience. How the audience was imagined, along with what the author intended to achieve, shaped designers’ expectations regarding how their modal decisions could be interpreted (Figure 14). The audience was perceived (or assumed) by the designers regarding their familiarity with some specific modal elements related to culture. For instance, in Cases 3 and 4, Sadie made several assumptions about the audience’s knowledge and familiarity with some visual and literal elements (e.g., the photo of “foreign trencadis” in Extract 5 and four-Chinese-character terms in Extract 6). These perceptions of the audience shaped designers’ forecasts about whether and how the message delivered through their modal choices could be interpreted.
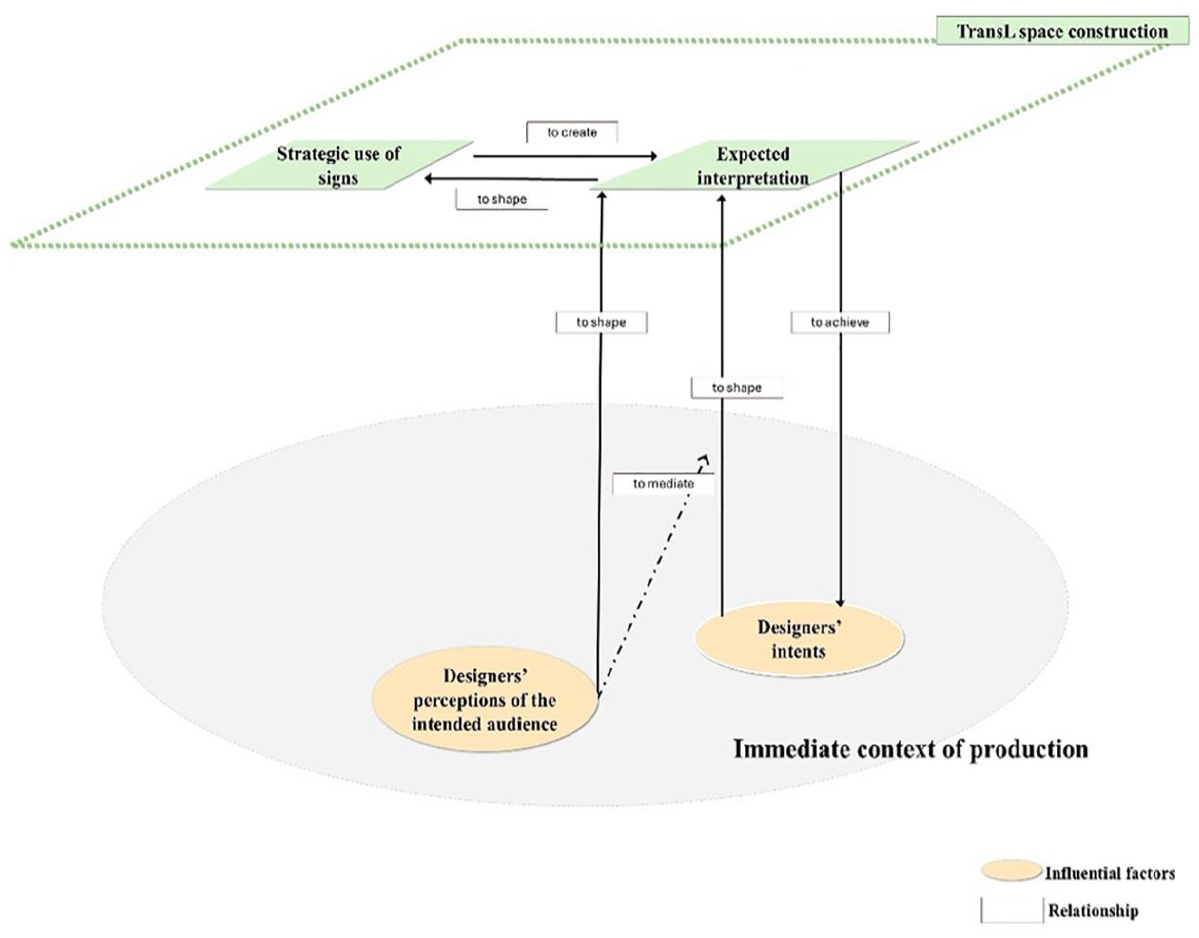
Designers’ understanding of audience and translanguaging space construction.
Discussion and Conclusion
Informed by the social semiotic approach and Witte’s (1992) concept of intertext, this research aims to understand translanguaging space construction via multimodal orchestration in five Chinese EFL designers’ collaborative English-language YouTube videos introducing Chinese culture to the international audience, and the influential factors to designers’ mode choices in translanguaging space construction. As the sample size of videos in the current research is relatively small (N = 4), only four multimodal translanguaging spaces were identified. More translanguaging spaces constructed in other modal interactions (e.g., audio-visual and visual-spatial) might emerge in a larger video database, which could be addressed in future research. Another limitation of this study is that because of interviewees’ unwillingness to be video-recorded, some of their embodied actions (e.g., gestures, facial expressions) were not captured, which might cause the loss of data that represent their ways of decision making in translanguaging space construction.
Despite the limitations, the current research addresses the call to investigate the multimodal nature of translanguaging (W. Li, 2018; Zhu et al., 2020) as well as the integration of DMC and translanguaging (e.g., Ho, 2022). This study mapped out translanguaging space construction within the same mode and across modes in videos to provide a nuanced investigation of the multimodal nature of translanguaging spaces. Video designers actively utilized their “enlarged” multimodal repertoires and creatively constructed translanguaging and transnational spaces (Pacheco & Smith, 2015) within linguistic modes, and in the linguistic-audio, linguistic-spatial, and linguistic-visual modal interactions, moving across local and global contexts. Modes interacted with each other differently in different combinations. In line with Ho’s (2022) research, our participants complemented linguistic modes (e.g., written text) with visual modes (e.g., images) for meaning-making. Images could carry the visual appearance of the cultural artifact (Unsworth, 2007) and, therefore, decrease the potential confusion arising from the linguistic description.
Different from meaning complementation between linguistic and visual modes mentioned above, audio and linguistic modes served distinctive rhetorical functions when meshed in the current study. For example, in one scene of the investigated videos, the original sound of Chinese illustration from the specialist working on the target cultural artifact was kept to augment the scene authenticity and content professionality, and the English translation in the subtitles for that specialist’s illustration was set to deliver the message clearly to the intended global audience who were watching those videos on YouTube. It is different from Pacheco and Smith’s (2015) study on EFL students’ “My Hero” PowerPoint assignments, in which students used different named languages in audio and linguistic modes for addressing multiple audiences, including teachers, peers, and people involved in their multimodal projects (e.g., their heroes), that is, audio recording in the heritage language for expressing emotions to their heroes and English translation in on-screen written text for making sure the content comprehensibility to their English-speaking in-class audience. In the current case, the DMC project was not a classroom assignment for academic credits that primarily served for the in-class audiences. It was mostly a task directly addressing the real-life communication needs, introducing cultural artifacts or events of one country to the global audience, and dealing with out-of-class audiences, people watching videos on YouTube and probably being interested in (Chinese) culture. Therefore, participants paid additional attention to meeting the real-life audience’s needs based on their interpretation of this DMC task when mobilizing available semiotic resources in their design, a situated social sign-making process (G. R. Kress, 2003).
However, it should be acknowledged that participants in the present study were very likely to view the project leader (also the course instructor in the participants’ faculty), who gave feedback on their videos, as their important audience. Participants’ decision-making process could be influenced by the teacher-student relationship and the project leader’s comments, which were not mentioned in the current interview data and could be examined in future research. A unique translanguaging space in the present study is constructed in linguistic-spatial modal interaction. Designers adopted the spatial relationship of word order in Chinese traditional literature and one Chinese rhetoric device when explaining the design rationale of the targeted cultural artifact in English.
Designers’ constructing translanguaging spaces via multimodal orchestration is suggested to be fluid and natural to multilingual learners (Horner et al., 2011; Lee, 2014), but moving across languages in the composition, as Pacheco and Smith (2015) argued, is cognitively and socially sophisticated, and the understanding of audience, subject, and semiotic tools could be essential in this process. By complementing the analysis of designers’ translanguaging construction patterns with the explanations of their decision-making processes in mode choice, this research attempts to present the cognitive and social sophistication of translanguaging space construction and to provide contextual information for the identified influential factors. Informed by the social semiotic approach and Witte’s (1992) concept of intertext, this research identified four factors within and outside the immediate context of production as influencing participants’ modal decisions in translanguaging space construction, including designers’ experience with relevant (multimodal) texts, designers’ intents, designers’ perceptions of the intended audience, and their understanding of modal affordances. Four factors interacted and contributed to specific modal orchestration in translanguaging space construction. The integration of social semiotics and the idea of intertext provides a lens to delve into the complexity of and dynamic relationship among the influential factors to multimodal translanguaging space construction in videos. The understanding of both what could influence designers’ meaning-making in multimodal orchestration and how designers negotiate those considerations could provide more insights into the complexity of transcending the languages in composition.
Findings of this study could provide implications for integrating DMC tasks into multilingual learners’ learning environments and suggestions for DMC designers’ research. First, DMC offers a space where designers could draw on their enlarged multimodal repertoire, break the boundaries of named languages and modalities creatively and critically, and reshape their ways of meaning-making by mobilizing multiple semiotic resources with the assistance of digital technologies. Therefore, DMC could be a means of realizing translanguaging pedagogies (e.g., Tao et al., 2022) in which students could “bring the outside in” (Tai & Li, 2020) and utilize their “fund of knowledge” (Moll et al., 1992). Second, designers’ understanding of modal affordances plays a vital role in the design, and teachers could provide the necessary scaffolding to support student designers in learning the meaning potentials of different modes. One of the ways is to provide explicit instruction of metalanguage, that is, “a language for talking about language, images, texts and meaning-making interactions” (The New London Group, 1996, p. 77).
More recently, Lim and Tan-Chia (2023) drew from G. Kress and Van Leeuwen’s (1996/2006/2021) framework of analyzing images and proposed pedagogic metalanguage with aspects to (a) integral features of modes, (b) ways of interaction, (c) presentation of ideas, and (d) interplay of meanings, to support the learning of multimodal literacy. Pedagogic metalanguage has been applied, to name a few, in Lim and Tan’s (2018) film-teaching lessons, Toh and Lim’s (2021) analysis of video games, and Liang and Lim’s (2021) video-making lessons. Third, DMC designers had many intents, some of which were controversial in actualization. It might be interesting to investigate how designers negotiate their intents and what could be influential factors for this negotiation, for example, designers’ perceptions of the intended audience in this case. Lastly, as Adami et al. (2022) mentioned, when they discussed the integration of learning by design perspective (G. Kress, 2010; G. Kress & Selander, 2012) into curriculum and pedagogy, it is essential to give students opportunities to be involved in meaning-design activities. The current DMC project addressing the real-life audience could be an option as it provides opportunities for students to apply multiple semiotic resources at their disposal agentively and creatively for the intended purposes, and it is also a relatively low-stake activity if in the “learning as competence” educational context that values the accurate expression of predetermined knowledge and skills (G. Kress & Selander, 2012). Future research could also look at the possibly different impacts of DMC projects in formal and informal learning contexts on students’ DMC products and processes as well as their learning outcomes.
Footnotes
Appendixes
2. Multimodal transcription convention (Hepburn & Bolden, 2017).
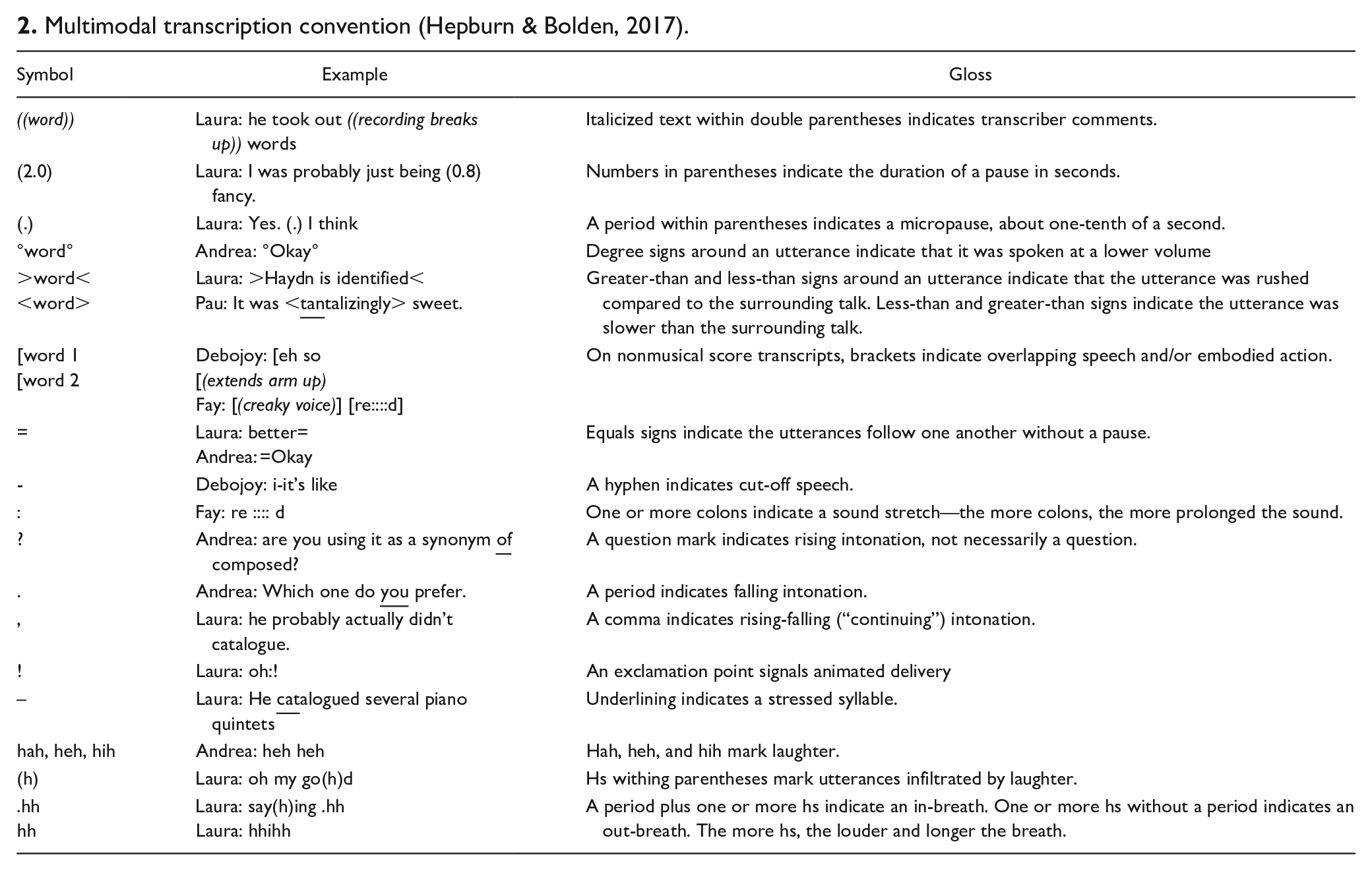
| Symbol | Example | Gloss |
|---|---|---|
| ((word)) | Laura: he took out ((recording breaks up)) words | Italicized text within double parentheses indicates transcriber comments. |
| (2.0) | Laura: I was probably just being (0.8) fancy. | Numbers in parentheses indicate the duration of a pause in seconds. |
| (.) | Laura: Yes. (.) I think | A period within parentheses indicates a micropause, about one-tenth of a second. |
| °word° | Andrea: °Okay° | Degree signs around an utterance indicate that it was spoken at a lower volume |
| >word< <word> |
Laura: >Haydn is identified< Pau: It was < |
Greater-than and less-than signs around an utterance indicate that the utterance was rushed compared to the surrounding talk. Less-than and greater-than signs indicate the utterance was slower than the surrounding talk. |
| [word 1 [word 2 |
Debojoy: [eh so [(extends arm up) Fay: [(creaky voice)] [re::::d] |
On nonmusical score transcripts, brackets indicate overlapping speech and/or embodied action. |
| = | Laura: better= Andrea: =Okay |
Equals signs indicate the utterances follow one another without a pause. |
| - | Debojoy: i-it’s like | A hyphen indicates cut-off speech. |
| : | Fay: re :::: d | One or more colons indicate a sound stretch—the more colons, the more prolonged the sound. |
| ? | Andrea: are you using it as a synonym |
A question mark indicates rising intonation, not necessarily a question. |
| . | Andrea: Which one do |
A period indicates falling intonation. |
| , | Laura: he probably actually didn’t catalogue. | A comma indicates rising-falling (“continuing”) intonation. |
| ! | Laura: oh:! | An exclamation point signals animated delivery |
| – | Laura: He |
Underlining indicates a stressed syllable. |
| hah, heh, hih | Andrea: heh heh | Hah, heh, and hih mark laughter. |
| (h) | Laura: oh my go(h)d | Hs withing parentheses mark utterances infiltrated by laughter. |
| .hh hh |
Laura: say(h)ing .hh Laura: hhihh |
A period plus one or more hs indicate an in-breath. One or more hs without a period indicates an out-breath. The more hs, the louder and longer the breath. |
Acknowledgements
We would like to thank the editor and anonymous reviewers for their thoughtful feedback, and all participants’ collaboration.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Ethical Approval Statement
This research was approved by the University of Auckland Human Participants Ethics Committee (Project ID: 27222). All participants understood and agreed to the anonymity and confidentiality principles that guided the conduct of this study.