
Abstract
Computational thinking (CT) is an emerging and multifaceted competence important to the computing era. However, despite the growing consensus that CT is a competence domain, its theoretical and empirical account remain scarce in the current literature. To address this issue, rigorous psychometric evaluation procedures were adopted to investigate the structure of CT competency, as measured by Computational Thinking Challenge (Lai, 2021a), in a large sample of 1,130 British secondary school students (M age = 14.14 years, SD age = 1.45). Based on model comparison from an exploratory multidimensional item response theory approach, the results supported the multidimensional operationalization of CT competency. A confirmatory bi-factor item response theory model further suggested CT competency is comprised of a general CT competency factor and two specific factors for programming and non-programming problem-solving. Despite the multidimensionality, the common variance is largely explained by a primary general factor of CT competency, thus the use of a single scale score is recommended. Psychometric evaluation from the bi-factor model indicated good psychometric properties of the assessment tool. Overall, the bi-factor model provides a useful approach to investigating CT competency and serves as a robust test validation tool.
Keywords
Introduction
Computational Thinking (CT) encompasses diverse cognitive skills that can be expressed in multiple contexts. As such, it is an important multifaced construct in education and learning sciences. Its relevance is especially crucial in the 21st century, often called the century of computing, where even children are encouraged to grasp the principles of computing and tackle complex problems. However, the domain-specific account that views CT equating to or overlapping with programming (e.g., programming-centric CT skills) does not sufficiently encapsulate other generalized skills that are equally valuable to solving cross-disciplinary problems—problems of the 21st century (McCuddy et al., 2007). This concern has led to the growing view that CT should be considered as a competence domain that reflects both domain-specific and domain-general skills (Yadav, Good, Voogt, & Fisser, 2017a; Grover & Pea, 2018). Domain-specific CT skills emphasize knowledge and skills in the programming context whereas domain-general CT skills highlight cognitive and non-programming problem-solving skills that can be applied in the real-world (Lai, 2021a). Collectively, these CT skills contribute to CT competency as an effective approach to general problem-solving (Grover & Pea, 2018; Yadav et al., 2017a; Webb et al., 2017; Lai, 2021a).
The combination of domain-specific and domain-general CT skills has the potential to equipping learners to solve multidisciplinary problems in the 21st century. Moreover, the integration of these skills in the conceptualization of CT competency can better reflect the diversity and complexity of the construct (Basso et al., 2018; Grover, 2015; Wiebe et al., 2019; Lai, 2021a). Hence, there are educational and theoretical reasons to view CT competency as a broader competence domain, and potentially an umbrella term. In other words, to perceive it as a construct that does not only entail programming-centric CT skills but also non-programming problem-solving CT skills. This conceptualization distinguishes CT competency from the general construct of CT. However, despite this emerging conceptualization, a compelling or unified theory for CT competency remains scarce in the current literature. For example, the contexts in which CT competency can be expressed is still not well understood.
Competence is multifaceted and includes an integrated set of knowledge, skills, and capabilities (Hager et al., 1994). Emerging views conceptualize CT as a competence domain that includes cognitive skills that are important for programming and beyond (Wing, 2006; Yadav et al., 2017a; Grover & Pea, 2018; Labusch, Eickelmann, & Vennemann, 2019). For example, Grover & Pea (2013, 2018) argue that programming is an appropriate platform to develop students’ CT competency. However, as the nature of general competencies necessitate multiple knowledge, skills, strategies, and performances (Koeppen et al., 2008), programming alone may be too narrowed to reflect the diversity of CT competency. As such, many researchers have included domain-general and non-programming problem-solving approaches, strategies, and skills to the conceptualization (e.g., Wing, 2006; Cuny et al., 2010; NRC, 2010; Chen et al., 2017). For instance, Wing (2006) suggests that CT, as a general analytical ability, includes attitudes and skillsets that are universally applicable. As it exhibits various skills, the conceptualization of CT competency extends from programming to problem-solving processes, useful in multiple domains and contexts. Aho (2012) refers CT as an algorithmic thought process in problem-solving and Webb et al. (2017) argue that CT should be applied more generally as a problem-solving strategy. In general, Kalelioglu et al. (2016) argue that CT is, by and large, a complex and higher-order thinking skill relevant to problem-solving processes. Although these researchers did not use the term competency to describe CT, they recognize its importance extends from programming to problem-solving contexts for non-programming problems.
The above theoretical views seem to be agreed by educators. For example, Lai (2021b) adopted a text mining approach to summarize teachers’ views regarding CT. Two key clusters were extracted from the teachers’ responses. More than half of the teachers (53.60%) considered CT as a problem-solving domain and close to half (42.26%) considered it as a transferrable cross-disciplinary skills that require computing knowledge. This finding is similar to other studies that focus on teachers’ perspectives and found problem-solving to be an important domain in which CT is manifested in (see Bower & Falkner, 2015; Good et al., 2017; Yadav et al., 2018; Fessakis & Prantsoudi, 2019). Given these previous findings, there are at least two contexts that researchers and educators agree to be relevant for CT competency: programming and non-programming problem-solving.
Despite this consensus, the theoretical account and empirical evidence for the construct remain ambiguous. This leads to challenges in CT measurements. One reason may be due to the predominate focus on the lower-order CT cognitive skills (e.g., algorithmic thinking, abstraction, problem-decomposition, generalization, and debugging) in the literature, rather than on the context(s) in which CT competency is expressed. Extensive works have evaluated these cognitive skills in CT frameworks and models, such as in Brennan & Resnick (2012) and Shute et al. (2017). However, little emphasis has been paid to exploring how these skills are applied in different contexts. Yet, context is crucial as it influences what and how we consider CT competency (Lai, 2021b). Another reason may be due to the complexities in measuring CT competency in more than one context (traditionally and commonly, it is assessed in the programming context). For these reasons, it is imperative to further investigate how to tackle issues related to the measurement of a multidimensional CT competency that can be expressed in more than one context.
Literature Review
Measuring a Multidimensional CT Competency
Reliable and valid measurements of CT competency necessitate a broad coverage of relevant tasks and contents to increase construct representativeness. That is, to cover the spectrum of skills, knowledge, strategies, and contexts where CT competency is used (Frederiksen & Collins, 1989). Tedre & Denning (2016) suggest that researchers distinguish between assessing CT skills and competency. They contend that students might demonstrate the former in knowledge-based assessments yet reflect little competence in CT when actually applying it. Regarding this, Denning (2017) advocate the need to directly measure CT competency.
Assessing CT competency might need a different approach to traditional educational assessments that usually measure performance in a single, specific context. Given its complexity, measuring CT competency might benefit from an integrative approach to assessment by including diverse skills, knowledge, and contexts. This integrative approach has been advocated by several researchers. For example, Grover (2015) suggests the inclusion of various complementary assessment tools that tap cognitive and non-cognitive skills by using “systems of assessments.” Likewise, Kong (2019) recommends the use of multiple-choice questions, programming projects, and questionnaires to measure CT holistically. Similarly, Weintrop & Wilensky (2017) included both block-based and text-based programming tasks in their assessment for high school computer science students. All of these approaches integrate multiple tasks and tools but are focused on the programming context.
Several integrative assessment approaches include both programming and non-programming tasks. For example, Basso et al. (2018) proposed a comprehensive framework that extends from assessing domain-specific skills of CT to more general and transferrable CT skills. Wiebe et al. (2019) explored the feasibility of developing a “lean” set of items from the Computational Thinking Test (Román-González et al., 2017) and Bebras® (Dagienė & Stupuriene, 2016). They evaluated the psychometric properties of the items and concluded these two tools can be used together to evidence CT. Taking a similar approach, Román-González et al. (2019) included a comprehensive evaluation model using three validated assessments in an intervention study – the Computational Thinking Test, Bebras®, and Dr Scratch (Moreno-León et al., 2016). Despite the fact that each tool focuses on a different context—the Bebras® emphasizing problem-solving and the other two on programming concepts— they have been shown to complement each other in measuring CT. The methods used in Wiebe et al. (2019) and Román-González et al. (2019) indicate the feasibility of using several different assessment tools to comprehensively assess CT in both programming and non-programming contexts. However, the majority of the tools used by these authors still have a larger focus on programming items.
Highlighted above are two larger approaches in measuring CT. One approach is to use a combination of different programming tasks (e.g., Grover, 2015; Kong, 2019; Weintrop & Wilensky, 2017). Another approach is to use different assessment tools that focus on both programming and non-programming problem-solving tasks (e.g., Román-González et al., 2019; Wiebe et al., 2019). The increasing use of more than one assessment tool illustrates that researchers are beginning to consider CT as a multidimensional construct as well as a competency otherwise a single assessment is sufficient. While the former approach allows for fine-grained analyses of programming proficiency, other aspects of CT competency could be disregarded. Outside of the programming context, the former approach could limit construct representativeness in assessment, particularly in competency-based CT assessments. That is, the multidimensionality of CT competency would still be conceptualized within the scope of programming. The latter approach might holistically measure different aspects of CT competency thereby enhancing construct validity. However, it may be time/resource consuming to administer all tools in a single study, especially for large-scale research. Hence, an alternative approach may be to include programming and non-programming problem-solving tasks that measure CT competency in a single assessment while encapsulating its multidimensionality. However, this approach could also pose several challenges in assessment design. We discuss these challenges below and potential ways to resolve the issues in measuring a multidimensional CT competency that can be expressed in more than one context.
Challenges in Evaluating a Multidimensional CT and The Way Forward
If CT competency includes programming and non-programming problem-solving skills, then it seems reasonable to conceptualize it as a multidimensional construct. One possible explanation for why its internal structure has not been more actively explored by researchers may be attributed by the challenges in evaluating a multidimensional CT.
Firstly, measuring a multidimensional CT may require heterogenous items that measure different domains/contexts of CT, with items grouped into several testlets. A testlet is a group of items related to a specific domain/context that is developed as a unit (Wainer & Kiely, 1987). Testlets are useful for assessment validity because they incorporate interrelated sets of items measuring a different aspect of a complex construct. As such, testlets can enhance content validity and construct representativeness. However, items that are nested within testlets often violate local dependence (an assumption of traditional item response theory models - IRT) as they are associated with a secondary factor or domain trait. Violating local dependence can cause an overestimation of reliability, an underestimation of standard error of the ability estimates, and a misestimation of difficulty and discrimination parameters (Wainer, 1995; Wainer & Wang, 2000; DeMars, 2006).
Secondly, related to testlet dependencies is the long-standing challenge of modeling and assessing multidimensional constructs due to the dichotomy between choosing a composite versus individual score. The composite score approach includes the use of a total (or summed) score from the individual factors of the testlets. The individual score approach involves the analysis of each factor of the construct individually. The composite score approach accounts for the shared variances, but not the unique variance of the factors within the construct. As such, the variances contributed by the programming and non-programming problem-solving skills that might make up CT competency cannot be disentangled. In contrast, analyzing the specific factors alone sheds light on their unique contributions but the specific factor could be confounded by the effects of the general CT competency construct (Chen et al., 2012). Given this, both approaches have been criticized for their respective issues that could result in conceptual ambiguity (Chen et al., 2012).
With the advancement in psychometrics, multidimensional IRT models can alleviate the challenges associated with measuring multidimensional constructs. For example, the bi-factor model, a multidimensional IRT model, was used in intelligence research to help develop the Spearman-Holzginer Model (1993) by providing empirical support for a general factor of intelligence (i.e., the ‘g’ factor) and the five specific factors (i.e., verbal, recognition, associative memory, perceptual speed, spatial relations). Hence, the bi-factor model can be a useful approach to evaluate general versus specific skills. Despite its history and usefulness, the bi-factor model is underutilized in educational psychology and only recently has it been used to model other dynamic and multidimensional constructs (Immekus et al., 2019). For instance, Kong & Wang (2021) adopted the bi-factor model in evaluating CT practices in a visual programming context. The authors have shown the potential of the bi-factor model in test validation from a psychometric approach by comparing competing IRT models and evaluating the dimensionality of the CT practices test.
Other than test validation, the bi-factor model incorporates two hypotheses that accommodate the complexity of multidimensional constructs. As such, it is particularly useful for investigating the structure of CT competency for two key reasons. First, a general factor accounts for the common variance shared by the factors. Second, there are multiple specific factors, each accounting for unique contribution over and above the general factor. In this scenario, the general factor of interest is the broader construct of CT competency and the specific factors are programming and non-programming problem-solving CT skills. Adopting this approach in modeling CT competency can provide equally good content validity as with the composite score approach. At the same time, it can prevent the limitations of the individual score approach by examining the unique contributions of programming and non-programming problem-solving (Chen et al., 2011). Hence, the bi-factor model could facilitate both test validation and theory development for CT competency.
The Current Study
The goal of this study is two-fold. First, to provide an empirical basis for the hypothesized structure of CT competency as measured by the Computational Thinking Challenge (CTC) (Lai, 2021a). Second, to evaluate the psychometric properties of the tool. Specifically, the study seeks to understand the dimensionality of the construct. With the emerging view that CT resembles a competence domain, and that CT competency is a multidimensional concept, it is important to disentangle the extent to its multidimensionality. Ultimately, addressing this question requires an in-depth psychometric evaluation of CT competency. Doing so will clarify the conceptualization of the construct. For this reason, the following research questions are addressed using the CTC: 1. Can the assessment be refined based on internal-consistency reliability? 2. Which IRT model best fit the data: 1-, 2-, or 3-parameter logistic (1PL, 2PL, 3PL) model? 3. What is the dimensionality of CT competency? 4. Does a bi-factor model explain the structure of CT? Is a single score or sub-scale scores more reliable?
Materials and Methods
Computational Thinking Challenge (CTC)
The CTC is a validated online tool that measures CT competency in the programming and non-programming problem-solving contexts (Lai, 2021a). A prior study using a Rasch model suggests good quality of the assessment and provided evidence of reliability and validity (e.g., item fit and item difficulty) (Lai, 2021a). Programming-centric CT skills are measured using Parson’s problems (Parsons & Haden, 2006) and multiple-choice questions. Both formats use generic languages (in English) that do not require prior programming skills (i.e., move, turn, pick). In the Parson’s problem format, participants arrange blocks of code to formulate an accurate solution. In the multiple-choice format, they select the most efficient and correct algorithms for more advanced programming questions. The non-programming problem-solving items use a multiple-choice questions format, with a focus on authentic and real-world scenarios. All multiple-choice questions have four answer options.
In the CTC, items are assumed to tap five CT cognitive skills (e.g., algorithmic thinking, abstraction, problem-decomposition, generalization, and debugging) though the weight for each skill may differ in each item. In other words, the skills are not parsed as it is unlikely that they are individual and non-interactive processes that are separable (Dagienė et al., 2017). Indeed, recent findings suggest that these cognitive skills could be indistinguishable in CT tasks, such as in the Bebras® (Araujo et al., 2019). Similarly, although not looking specifically at cognitive skills, a recent neuroscience finding highlights CT may not be parallel cognitive processes that can be divided, but a composite process integrated as a whole (Xu et al., 2021). These findings illustrate the possibility that CT cognitive skills may be overlapped, interconnected, or interdependent. Hence, the current article focuses on the two contexts for which CT cognitive skills can be applied to and to investigate whether these two contexts could encapsulate CT competency appropriately.
Sample and Procedure
The sample includes 1,030 Year 7–13 secondary school students (M age = 14.14, SD age =1.45) from 15 schools in the United Kingdom (n = 240 Year 7, n = 172 Year 8, n = 270 Year 9, n = 110 Year 10, n = 73 Year 11, n = 92 Year 12, n = 23 Year 13, n = 50 non-responses for year group). There were more boys (n = 591) than girls (n = 439). Except for 124 non-responses, the majority of the participants had a variety of coding/programming experiences (n = 307 with no experience, n = 94 over 1 week, n = 81 over 1 month, n = 99 over 6 months, n = 128 over a year, n = 128 over 2 years, and n = 68 over 3 years).
This age group was targeted for two reasons. First, previous studies of CT assessment have focused predominately on primary to upper primary school students (e.g., Grover, 2015; Román-González et al., 2018; Kong & Wang, 2021). Second, competency is reflected better in older age groups (Bishop, 1994). In our preliminary analysis, age was positively correlated with performance in programming sub-score (r = .49, p < .001), non-programming problem-solving sub-score (r = .41, p < .001), and the total test score on CT competency (r = .52, p < .001).
The CTC was administrated by classroom teachers to students during computer science class. The teachers in the schools provided the link to the online assessment, read the instructions script to the students at the start, and gave technical support during the task without interfering with students’ responses. Each teacher received a standardized protocol on the procedure and followed the given steps to minimize variabilities in test administration. The students could write notes using a paper and a pen. All items were score automatically and dichotomously (0 = incorrect; 1 = correct). The data was downloaded as a csv file.
Statistical Procedure and Calculation
Data and analyses scripts are available from https://osf.io/pf6zq/?view_only=5a9f0d05f2104c62851616a8a283aaac (Lai & Ellefson, 2021c). The analyses were conducted in four stages using R (R Core Team, 2021): (1) internal-consistency reliability (using the psych package; Revelle, 2018); (2) IRT model comparison (using the TAM package; Robitzsch et al., 2018); (3) exploratory multidimensional IRT modeling (using the MIRT package; Chalmers, 2012); and (4) confirmatory bi-factor model (also using MIRT).
Internal-consistency reliability analyses were conducted using Cronbach’s α (Cronbach, 1951), McDonald’s ω (McDonald, 1999) and Guttmann’s λ6 (Guttman, 1945). As part of the test construction process, the aim was to identify items that are too heterogeneous such that the assessment can be improved (Zijlmans et al., 2019). Based on the item-total correlation, items that exhibited negative correlation or low correlation coefficients were removed and the assessment was refined for further analyses.
Three dichotomous 1PL, 2PL, and 3PL IRT models were compared and tested using the log likelihood ratio function (lmmekus et al., 2019). Key fit indices were used to identify the most appropriate parsimonious model (Reise, 1990). Amongst the three models, the 1PL model is the most parsimonious as it only accounts for the one parameter of item difficulty. The 2PL model extends from that to account for item discrimination, while the 3PL model includes an additional pseudo-guessing parameter. Hence, the 3PL model is the most complex model. As these models are nested, the likelihood ratio test is used for model comparison. The likelihood-ratio statistic is the test statistic with degree of freedom equal to the difference between the number of parameters between the models being tested.
Using an exploratory multidimensional item response theory approach, one-dimensional and two-dimensional theoretical models were compared based on the results of the last stage. The basis of the former model is linked to the traditional IRT assumption that test items measure one single latent trait, a unidimensional CT competency. This was tested against the theoretical model, which hypothesizes that CT competency is composed of subsets of items in programming and non-programming problem-solving domains. That is, the latter model evaluates the operationalization that CT is a multidimensional construct. Model fit indices were evaluated against the recommended thresholds (Hu & Bentler, 1999).
A confirmatory bi-factor model was specified using the marginal maximum likelihood estimation method. The bi-factor model is ideal in this research for two reasons. First, it can be used to address the question of the amount of variance each item can be accounted for by the general factor as well as the partial correlations between the specific domains after accounting for the general CT competency factor. Partitioning item response variance can be used to evaluate whether it is appropriate to discuss CT competency in a general form compared to specific factors (e.g., programming-centric CT skills), as well as how reliable it is to use a single score to represent a multidimensional CT competency. Second, a bi-factor model can help avoid overestimation when measuring testlet-based assessments, thus achieving higher accuracy in item parameter estimation (Wang & Wilson, 2005). Moreover, it is a useful framework and informative psychometric tool to measure heterogenous items as a single construct (Reise et al., 2010).
Ancillary bi-factor indices were inspected for the bi-factor model: the explained common variance and percentage uncontaminated correlations illustrated if the test score was better explained by the general factor or the specific factors (Rodriguez et al., 2016). In addition, the ω-hierarchical estimated the reliability of the total score from the general factor despite the multidimensional nature of the items (Flora, 2020). Lastly, the construct reliability and factor determinacy were calculated to investigate how well the set of items represent a latent variable. Here, higher values (closer to 1) indicate that a factor is appropriately specified by the given set of items.
Results
Descriptive statistics and Internal-Consistency Reliability Statistics
Mean Accuracy and Standard Deviation for Each Item.
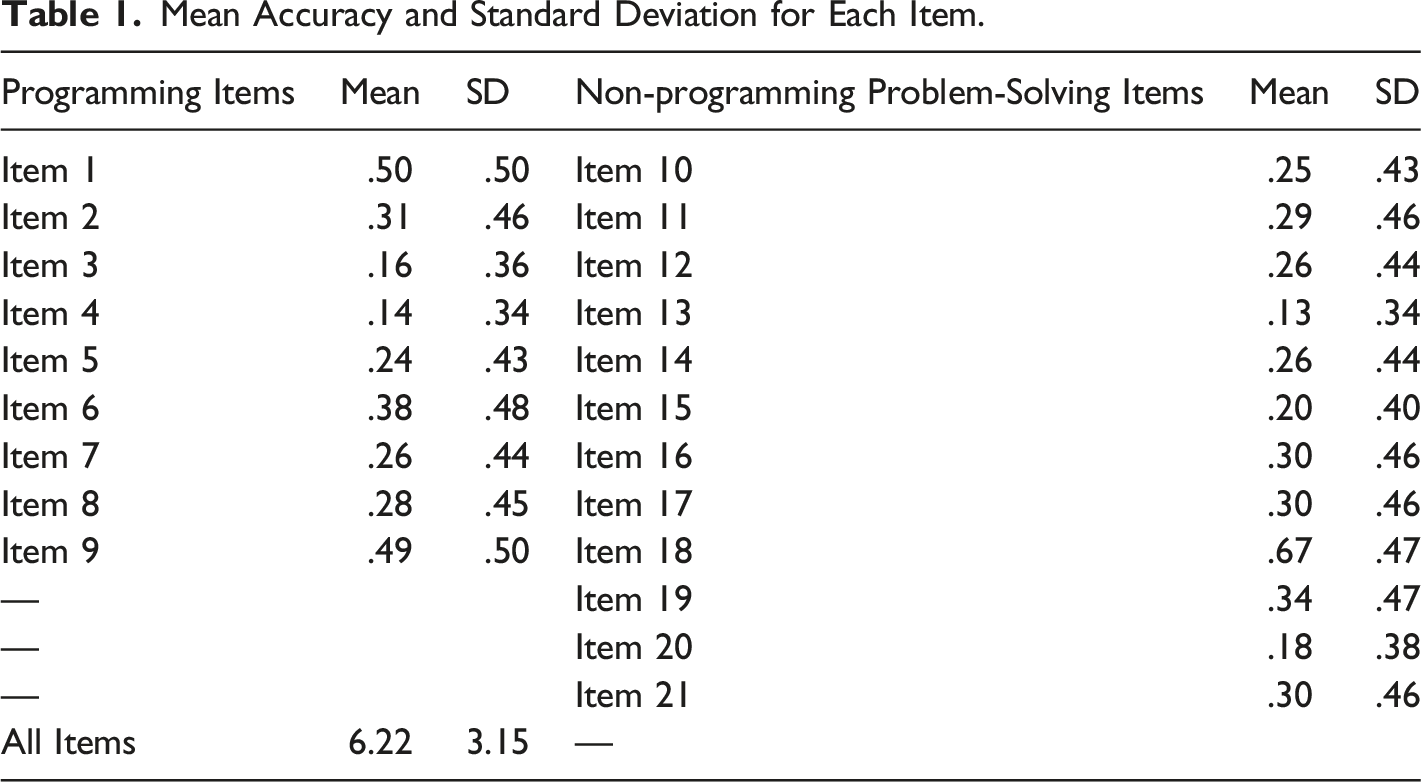
Internal-Consistency Reliability Statistics for the Original and Refined Versions.

Model Comparison
1- 2- and 3PL Model Comparisons.
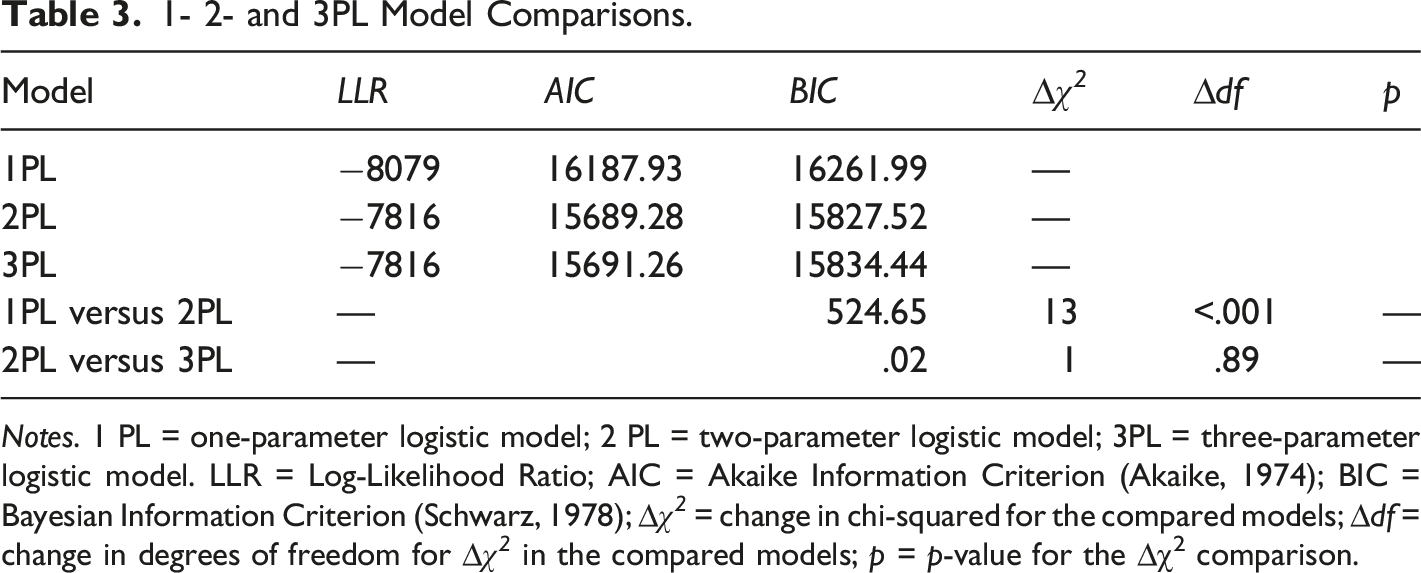
Notes. 1 PL = one-parameter logistic model; 2 PL = two-parameter logistic model; 3PL = three-parameter logistic model. LLR = Log-Likelihood Ratio; AIC = Akaike Information Criterion (Akaike, 1974); BIC = Bayesian Information Criterion (Schwarz, 1978); ∆χ 2 = change in chi-squared for the compared models; ∆df = change in degrees of freedom for ∆χ 2 in the compared models; p = p-value for the ∆χ2 comparison.
Multidimensional Item Response Theory Analysis
Fit Indices for the One- and Two-dimensional 2PL Models.
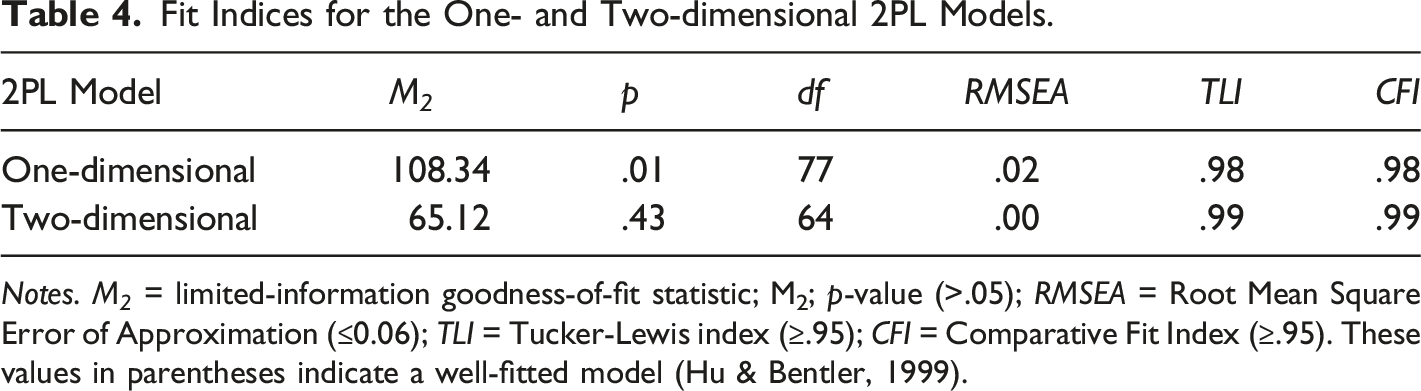
Notes. M 2 = limited-information goodness-of-fit statistic; M2; p-value (>.05); RMSEA = Root Mean Square Error of Approximation (≤0.06); TLI = Tucker-Lewis index (≥.95); CFI = Comparative Fit Index (≥.95). These values in parentheses indicate a well-fitted model (Hu & Bentler, 1999).
Log-Likelihood Ratio Test for the Competing 2PL Models.
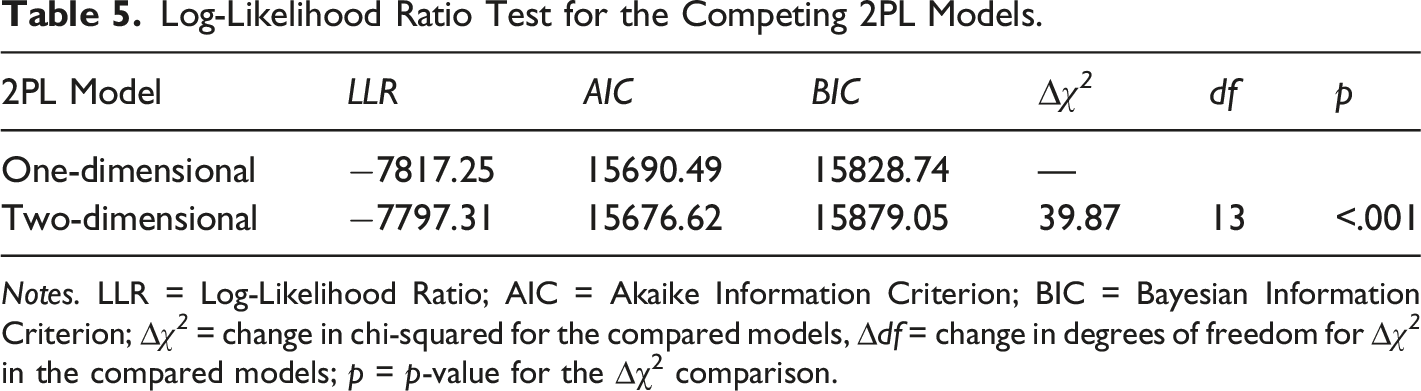
Notes. LLR = Log-Likelihood Ratio; AIC = Akaike Information Criterion; BIC = Bayesian Information Criterion; ∆χ 2 = change in chi-squared for the compared models, ∆df = change in degrees of freedom for ∆χ 2 in the compared models; p = p-value for the ∆χ2 comparison.
Confirmatory Bi-factor Model
Model Fit
A confirmatory 2PL bi-factor model was tested in which all items were loaded onto the general factor of CT competency as well as one of the specific domains on programming or non-programming problem-solving. The data fitted the model excellently (χ 2 (63) = 60.17, p = .58, CFI = 1.00 TLI = 1.00, SRMR = .02, RMSEA = .00 (90% CI = [0.00, 0.02]). As the bi-factor model performed better than the two-dimensional 2PL multidimensional IRT model, (∆χ 2 (1) = 9.58, p = .002), factor loading, and ancillary bi-factor indices were inspected to provide more nuanced evidence of dimensionality as well as reliability of the CTC total and subscale scores. Lastly, the bi-factor model was adopted for test validation.
Factor Loading
Factor Loading and Ancillary Bi-factor Indices of the CTC.
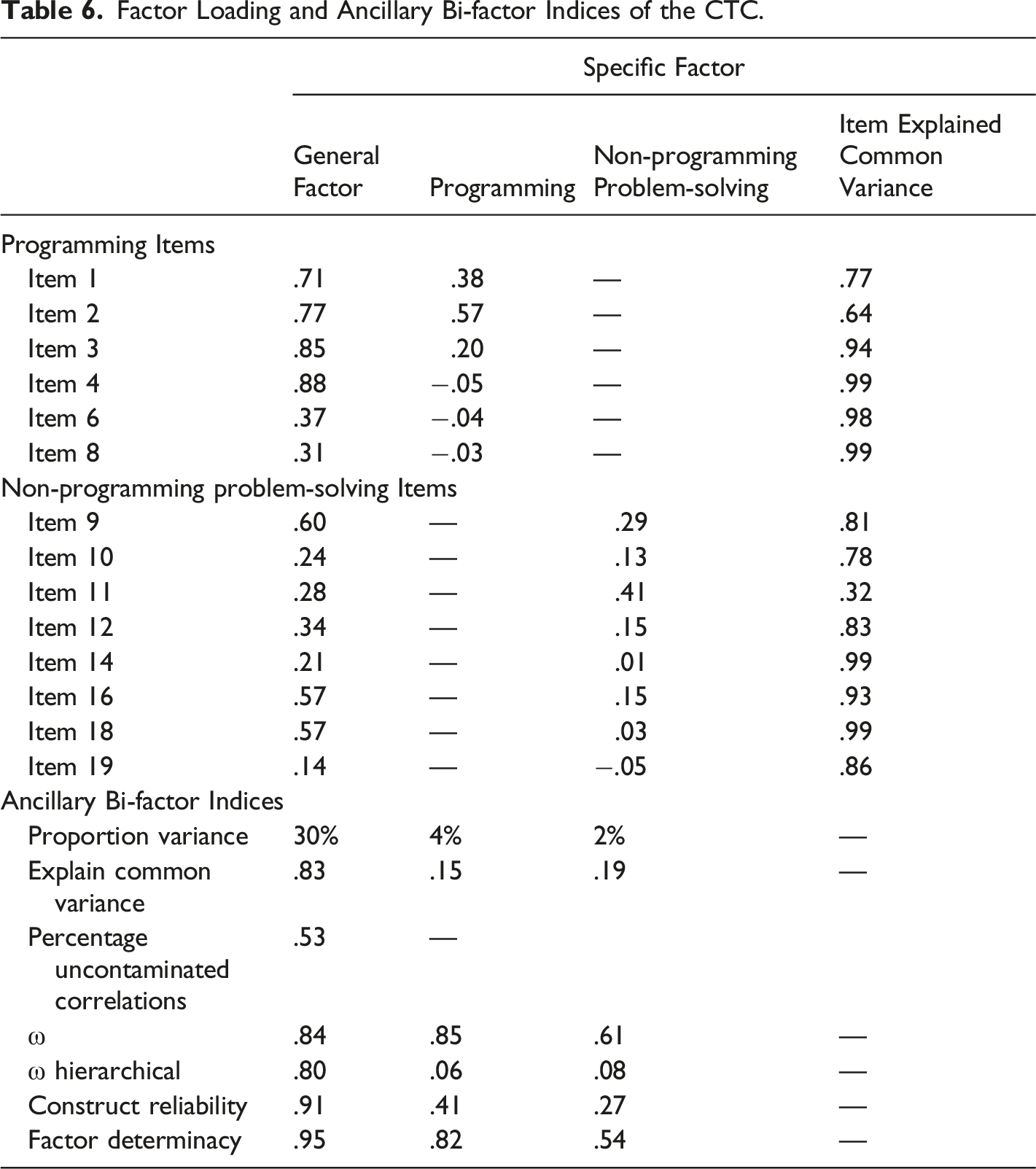
Ancillary Bi-factor Indices
The explained common variance of the general CT factor accounted for most of the common variance (83%) in CT competency and there was a small amount related to the specific factors (15% from programming; 19% from non-programming problem-solving). The percentage uncontaminated correlation was .53, indicating that a large proportion of correlation matrices reflected the general CT factor. Model-based reliability results indicated that the reliable variance in the total scores could be attributed to the general CT factor (ω = .84, and ωH = .80). The general factor had significantly higher construct reliability (H = .91) and factor determinacy (FD = .95) than the specific factors.
Finally, the item explained common variance for each item was computed to identify the degree of item common variance attributed to the general CT factor (Rodriguez et al., 2016). Stucky et al. (2013) suggested that item explained common variance values above .80 can be selected for a unidimensional measure (or when a single score is used). Based on this criterion, 71% of the items have values >.80, and 28.5% have values as high as .99. The results suggested that most items were stronger measures for the general CT competency factor than the specific factors. Overall, the majority of variance extracted was mostly and reliably accounted for by the general factor. Therefore, despite the data being multidimensional, the scores derived from the assessment primarily reflected a single common source – CT competency. That is, CT competency consists of a strong general factor and weak but meaningful specific factors.
Item Fit Statistics and Parameter Estimation
Finally, item fit statistics were computed to demonstrate the compatibility between the data and the model. Each item was inspected using the recommended index of the root mean squared error approximation based on M2, RMSEA2 (Orlando & Thissen, 2003). Maydeu-Olivares & Joe (2014) provided the following recommendations: RMSEA 2 ≤ .089 as adequate fit, RMSEA 2 ≤ .05 as close fit, and RMSEA 2 ≤ .05 as excellent fit. Based on these criteria, most of the items demonstrated close to an excellent fit.
Parameter Estimates and Fit Statistics for Each Item.
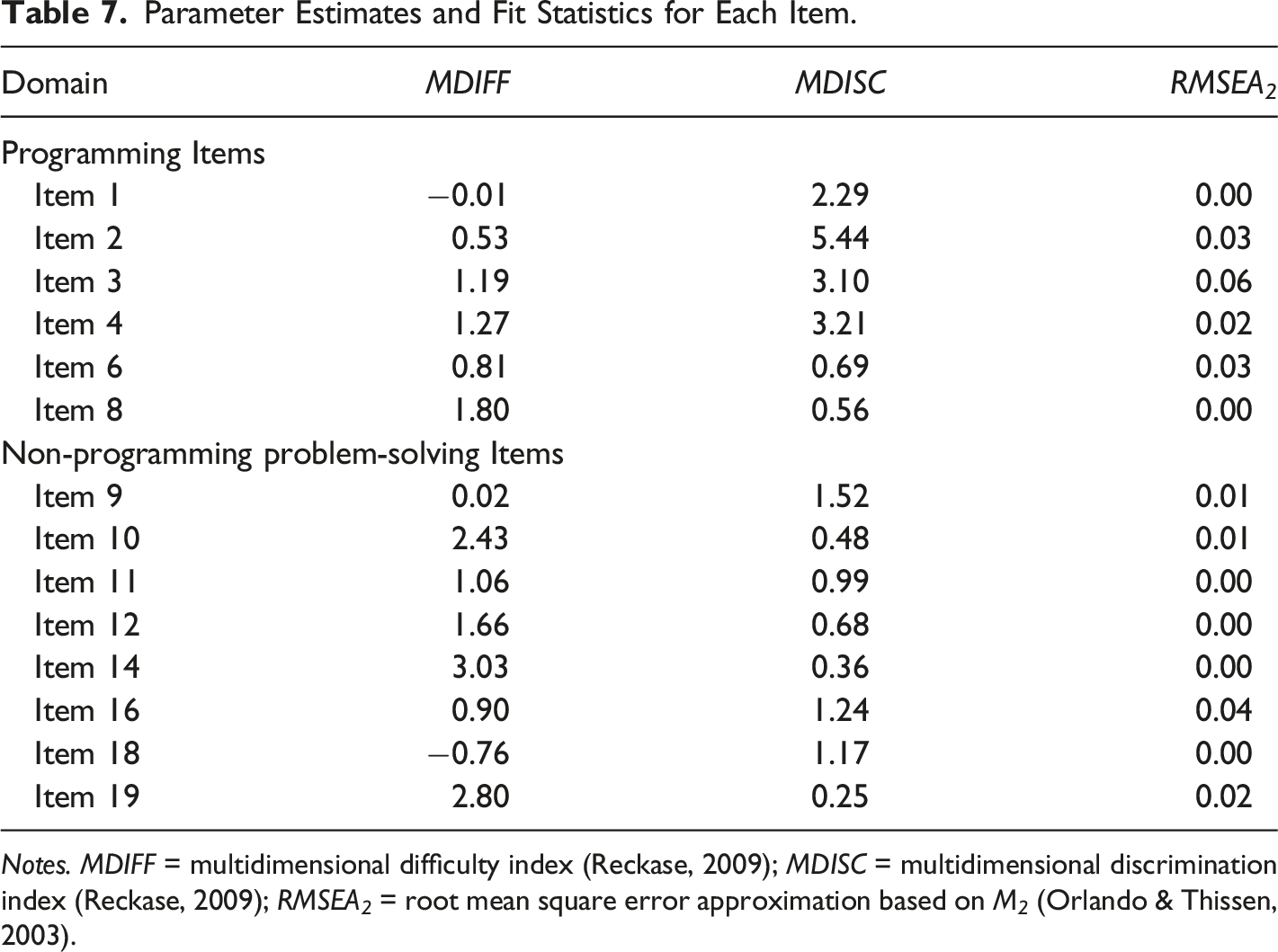
Notes. MDIFF = multidimensional difficulty index (Reckase, 2009); MDISC = multidimensional discrimination index (Reckase, 2009); RMSEA 2 = root mean square error approximation based on M 2 (Orlando & Thissen, 2003).
Discussion
There is a growing consensus that CT resembles a competence domain, important for the current digital, computing era (Grover & Pea, 2018; Yadav et al., 2017a). However, the theoretical and empirical account of CT competency remain scarce in the current literature, especially regarding the dimensionality of CT in general (Kong & Wang, 2021). Addressing this issue, the current study provides empirical evidence for the hypothesized structure of CT competency as measured by the CTC as well as the psychometric properties of the tool.
Theoretical Contribution
The evaluation of CT competency is challenging given its complexity. Previous studies attempted to validate CT assessments through traditional IRT models (e.g., Mindetbay et al., 2019; Alves et al., 2021). However, due to strong assumptions that underlie the models (e.g., local dependency; DeMars, 2010), assessments could be restricted to the design of homogenous items and may potentially narrow the construct representativeness of CT competency. Moreover, traditional item response theory approaches are restricted to unidimensional assessment tools, thus confine the modeling or estimation of complex structures (Immekus et al., 2019). These methodological challenges produce difficulties for evaluating CT competency psychometrically. Using multidimensional item response theory to alleviate these psychometric issues (Reckase, 2009) and building upon Kong & Wang’s (2021) work, this study uniquely addresses those theoretical and methodological gaps with a large sample (N = 1,030). Our bi-factor modeling results suggest both a general factor of CT competency and two specific factors for programming and non-programming problem-solving. More specifically, the findings suggest that the conceptualization of CT competency is a combination of domain-specific and domain-general skills.
Implications
The Dimensionality of CT Competency
Theoretically, it is important to examine the structure of CT competency as its underlying structure provides clarity to its conceptualization. However, the structure measured by the CTC should not be viewed dichotomously; it is not exclusively unidimensional or multidimensional (Gustafsson & Åberg-Bengtsson, 2010; Reise et al., 2010). One implication of these findings is the extent that multidimensionality can be evoked by the comparison of a standard one-dimensional and a theoretical two-dimensional IRT model. Our results extend from Kong & Wang’s (2021) proposition of the multidimensionality of CT practices and support the idea that this theory-driven model provides evidence for the multidimensional operationalization of CT competency. Although Kong & Wang focused on a different operationalization and dimensions of CT, our findings complement theirs in shedding light on the structure of CT in different aspects. Future work should continue building upon these works in delineating the dimensionality of CT.
Conceptualizing a Multidimensional CT Competency
A second implication relates to the extent of multidimensionality as tested by the bi-factor model. Overall, our findings indicate that a bi-factor model with a general CT competency factor and two specific factors for programming and non-programming problem-solving best represented the structure of the construct. This bi-factor model suggests that CT competency is a broad construct tapped by all items, with specific factors tapped by subsets of items. More specifically, CT competency may be an emergent composite of separable and distinguished domain-specific programming and domain-general non-programming problem-solving skills. Indeed, a recent fMRI study investigated the neural correlates of CT and reached a similar conclusion (Xu et al., 2021). A bi-factor conceptualization of CT has relevant implications for future research on CT assessments, particularly when acknowledging the variegated nature of the construct.
Quantifying CT Competency in CTC
The findings lead to the key question of whether CT is multidimensional enough to discard the common use of a single scale or summed score? In other words, how much does the item set reflect a general CT competency that is independent of multidimensionality compared to a more conceptually specific CT that controls for the general CT competency like programming skill? If strong loadings between the items and the specific factors are observed beyond the contribution of the general factor, then sub-scale metrics might be more appropriate. However, the results indicate that a strong general factor dominates the common variance (83%) among items. The two specific factors composed from the unique variance that was uncontaminated by the general CT competency factor were weak (programming = 15%, non-programming problem-solving = 19%.). Hence, there were unique yet small contributions from the specific factors.
Based on the ancillary bi-factor indices, there might be little benefit of using or reporting separate scores for programming and non-programming problem-solving items. Instead, the magnitude and distribution of the loadings suggested greater importance and reliability (ω-hierarchical = .80) for a single score that represents the general CT competency factor. Furthermore, interpreting other indices against Reise et al.'s (2010) recommendations highlighted the appropriateness of using a single score. Overall, the multidimensionality influenced by the specific factors (and heterogenous item content) does not hinder the use of a single scale to measure the common general CT competency factor. By and large, the findings suggest that a single, unidimensional scale is more appropriate.
The Psychometric Properties of the CTC
Many researchers have advocated the need for well-validated CT assessment tools to advance theory (Shute et al., 2017; Román-González et al., 2019; Kong & Wang, 2021). Using the bi-factor model, this study extends Lai (2021a) with a psychometric evaluation of the CTC assessment. Similar to Kong & Wang (2021), our results indicate that the bi-factor model is a good approach for validating CT assessments, especially for assessments that measure a multidimensional CT competency. The fit indices suggested that all 14 items had close to an excellent fit to the bi-factor model and covered a wide and acceptable range of difficulty and discrimination. Similar to Lai (2021a), the four Parson’s problems in the programming domain (Items 1–4) were the most discriminative items, suggesting that items can be used to measure programming-centric CT skills alone or in combination with other tasks to measuring CT competency comprehensively.
Pedagogical Implications for CT Competency
This study addresses an important educational issue at a pedagogical level, which has significant contributions to promoting CT competency in the 21st century. When reflecting on education in the current digital age, it becomes necessary to emphasize skills beyond programming, and to consider non-programming skills that contribute to general problem-solving in the real-world (Fedel, 2008; OECD, 2018). For example, the capability to solve complex problems and use strategies across domain-specific and domain-general contexts is regarded as important in the 21st century (Scherer & Beckmann, 2014; Greiff et al., 2013).
The motivation behind this study as well as the arguments made throughout it help reiterate the importance to expand from a unidimensional understanding of CT competency to integrating diverse tasks in the conceptualization and measurement of the construct. This idea translates into practice, extending to the teaching and learning of CT. In particular, the multidimensionality of CT competency highlights the opportunities to embed it across different subjects because CT may share explicit overlaps with many subjects and can enhance learning in their respective areas, such as STEM (Weintrop et al., 2016; Hutchins et al., 2020). Integrating CT competency across subject is especially promising for teachers to integrate the non-programming problem-solving tasks to foster students’ CT skills, which may evoke interests in non-computer science students. For example, teachers can initiate competency-based activities that link materials and activities to meaningful real-world problems. These problems can be interdisciplinary or transdisciplinary such that it helps widen the interest beyond those who study computer science or have an interest in programming (see Nicolescu, 2005).
Limitations and Future Directions
CT competency is still an emerging concept in a relatively young and new field with plenty of scope for additional investigations. Given the diverse conceptualizations of CT in the literature, there is space for future studies to elucidate the structure of CT and other potential dimensions based on other operationalizations. For example, by examining the similarity/differences between the dimensionality of CT competency (as measured by the CTC) and the dimensionality of other CT models measured by other assessments (e.g., Dagienė & Stupuriene, 2016; Kong & Wang, 2021).
Longitudinal data could be collected in future studies to evaluate the stability/changes that occurs across times for different age groups (e.g., adolescents, young adults, etc.). Such data could help determine how students’ accumulated experiences and knowledge influence the development of their CT competencies.
It would be useful to explore whether gender influences CT competency using differential item function from the item response theory paradigm. The study of gender differences is a key area in computing research and some items could function differently for male students compared to female students, even after controlling for the competency level.
Future research should also include measurements of general cognitive abilities. This will help investigate the extent to which CT competency overlaps with and is distinct from other general cognitive constructs such as intelligence, executive functions, and metacognition.
Although we included a sample with diverse coding/programming experiences, another limitation to note is that convenience sampling was used in this study. Therefore, the results are not generalizable to all 7–13 year-old students in the UK. In other words, the findings should be interpreted with caution and future studies will be benefitted with a more representative sample.
Lastly, it would be useful to explore whether the conceptualization of CT is consistent across different educational contexts (e.g., STEM) or student populations. Many existing CT assessment studies have been conducted in the computing education context and included participants from Western, affluent countries. Future studies should explore whether the conceptualization of CT competency developed with these samples generalize to additional educational contexts and cultural settings.
Conclusions
The emerging view that CT resembles a competence domain calls for sophisticated assessment approaches and evaluation methods. In this study, the conceptualization and structure of CT competency were explored and validated through rigorous psychometric evaluation procedures. Our findings suggest that can serve as a good foundational model a bi-factor model with a general factor and two specific factors for programming and non-programming problem-solving. Moreover, the findings suggest that the CTC assessment has good psychometric properties. As such, as a competency-based assessment, the CTC is a robust tool for evaluating students’ competency in an integrative way. These findings could guide future assessment design and evaluation methods such that knowledge regarding CT competency can be advanced.
Footnotes
Author Contributions
Rina P.Y. Lai: Conceptualization, Methodology, Software, Formal analysis, Investigation, Data curation, Writing – Original draft, Visualization, Project Administration; Michelle R. Ellefson: Methodology, Writing – Review & Editing, Visualization, Supervision.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.