
Abstract
With the increasing importance of Computational Thinking (CT) at all levels of education, it is essential to have valid and reliable assessments. Currently, there is a lack of such assessments in upper primary school. That is why we present the development and validation of the competent CT test (cCTt), an unplugged CT test targeting 7–9 year-old students. In the first phase, 37 experts evaluated the validity of the cCTt through a survey and focus group. In the second phase, the test was administered to 1519 students. We employed Classical Test Theory, Item Response Theory, and Confirmatory Factor Analysis to assess the instruments’ psychometric properties. The expert evaluation indicates that the cCTt shows good face, construct, and content validity. Furthermore, the psychometric analysis of the student data demonstrates adequate reliability, difficulty, and discriminability for the target age groups. Finally, shortened variants of the test are established through Confirmatory Factor Analysis. To conclude, the proposed cCTt is a valid and reliable instrument, for use by researchers and educators alike, which expands the portfolio of validated CT assessments across compulsory education. Future assessments looking at capturing CT in a more exhaustive manner might consider combining the cCTt with other forms of assessments.
Introduction and Related Work
The Increasing Position of CT in Research and Formal Education
An international debate sparked with Wing (2006)’s article presenting Computational Thinking (CT) as a universally applicable attitude and skill set, as important as reading, writing and arithmetic. While a consensus has not been reached on the definition of CT, nor on where its boundaries lie, one prominent definition is the one by Brennan and Resnick (2012). Brennan and Resnick (2012) decompose CT into: (i) computational concepts (the concepts most closely related to computer science and programming, that is, “sequences, loops, parallelism, events, conditionals, operators, and data”), (ii) computational practices (the strategies and practices required to be apply said concepts), and (iii) computational perspectives (“the perspectives designers form about the world around them and about themselves”). While CT is traditionally considered to be the “thought processes that facilitate framing and solving problems using computers and other technologies” (Relkin & Bers, 2021), more and more researchers argue that CT is not specific to “those interested in computer science and mathematics”. These researchers consider that CT has a “multi-faceted theoretical nature” and can be considered more generally as an example of “models of thinking” (Li et al., 2020). Under this new light, CT is envisioned to have a broader role to play in education, from STEM-related disciplines (Li et al., 2020; Peel et al., 2020; Weintrop, 2016), to languages (Rottenhofer et al., 2021), and transversal competences 1 such as “creative problem solving” (Grover et al., 2017; Chevalier et al., 2020). Some researchers thus consider CT to be one of the fundamental competences that every citizen must acquire in the 21st century (Li et al., 2020). The growing importance of CT as a transversal competence has led, in the past decade, to an increase in the research around CT (Ilic et al., 2018; Li et al., 2020; Tang et al., 2020) as well as in the initiatives seeking to equip K-12 students with CT competences (Basu et al., 2020). Such initiatives operate through informal education (Weintrop et al., 2021), extra-curriculars, and formal education settings (Weintrop et al., 2021), some even starting at the level of kindergarten (Bocconi et al., 2016).
The Need for CT Assessments at all Levels of Education
With this “tremendous growth in curricula, learning environments, and innovations around CT education” (Weintrop et al., 2021), the design of tools to assess CT competences in a developmentally appropriate and reliable way throughout compulsory education becomes crucial (Hsu et al., 2018). Indeed, “CT assessment is important [to document] learning progress, [measure] lesson effectiveness, [assist] in curriculum development and [help] identify students in need of greater assistance or enrichment” (Relkin & Bers, 2021). As CT is also becoming popular among K-9 educators (Chen et al., 2017; Mannila et al., 2014), it is also paramount to develop assessments for that age range. Indeed, as mentioned by Relkin and Bers (2021), “one of the greatest challenges to integrating CT into early elementary school education has been a lack of validated, developmentally appropriate assessments to measure young students’ CT skills in classroom and online settings” (Lockwood & Mooney, 2017; Román-González et al., 2019). Assessment tools should therefore be adapted for use, not only by researchers looking to design CT learning experiences (Weintrop et al., 2021) and investigate how best to foster CT competences (Chevalier et al., 2020), but also by teachers aiming to ensure that their students are acquiring the desired competences, and this starting from kindergarten onward (Zapata-Cáceres et al., 2020). Provided the pressing need to clarify the question about how best to assess CT competences (Tang et al., 2020; Lockwood & Mooney, 2017; Hsu et al., 2018), it is not surprising to find that CT assessment “is at the forefront of CT research [and] gathering the greatest interest of researchers” (Tikva & Tambouris, 2021). However, as stated by Zapata-Cáceres et al. (2020) and Román-González et al. (2019), most efforts to develop assessments for CT have focused on secondary school and tertiary education.
The Importance of Validated and Reliable Instruments Which Do Not Conflate with Programming Abilities
Developing CT assessments must consider, in addition to the developmental appropriateness for the target age group, the different assessment formats which exist, their use cases, and their scalability. From a design perspective, four main formats have been used to assess CT (Tang et al., 2020): traditional tests (often used in combination with other assessment methods), portfolios (to “[situate] CT assessment in a real-world context and further allows teachers and researchers to provide formative feedback”), interviews (“to support or elaborate on the results of traditional or portfolio assessment by specifying students’ thinking processes”) and surveys (to assess dispositions and attitudes towards CT). The most common approach seems to consist in the use of portfolios to “analys[e] projects performed by students in specific programming environments” (Tang et al., 2020). Unfortunately, assessment tools following this approach carry the risk of “conflating CT with coding abilities” (Relkin & Bers, 2021), which may limit their use in (i) pre-post test designs (Chen et al., 2017), (ii) when validating new learning environments, and (iii) in cases where Computer Science (CS) unplugged activities (Bell & Vahrenhold, 2018) are employed to develop students’ CT competences
2
. Because of the transversal nature of Computational Thinking and the “variety of methods by which CT is taught and contexts in which students learn CT” (Weintrop et al., 2021), researchers advocate the development of CT tests that go beyond self-reporting, and are more general (Tikva & Tambouris, 2021). Such assessments should be agnostic of the specific content of the study and the programming environments. The past few years have thus seen a rise in age appropriate unplugged CT assessments targeting CT skills
3
which i) Can be administered without employing screens (referring to the definition of Unplugged provided by Bell & Vahrenhold, 2018) and can thus be easily deployed in various settings and at a large scale, ii) Do not require any prior knowledge pertaining to programming or coding (including that of a specific programming language) and are therefore adapted for use in pre-post test experimental designs, iii) Put a strong emphasis on the reliability and validity said instruments (Chen et al., 2017; Relkin et al., 2020; Román-González et al., 2017, 2018, 2019; Zapata-Cáceres et al., 2020; Wiebe et al., 2019), something which has been identified so far as lacking in the CT assessment literature (Tang et al., 2020).
The Lack of Existing Validated and Reliable CT Assessments Spanning Compulsory Education
Synthesis of decontextualised unplugged CT assessments and corresponding validation processes.
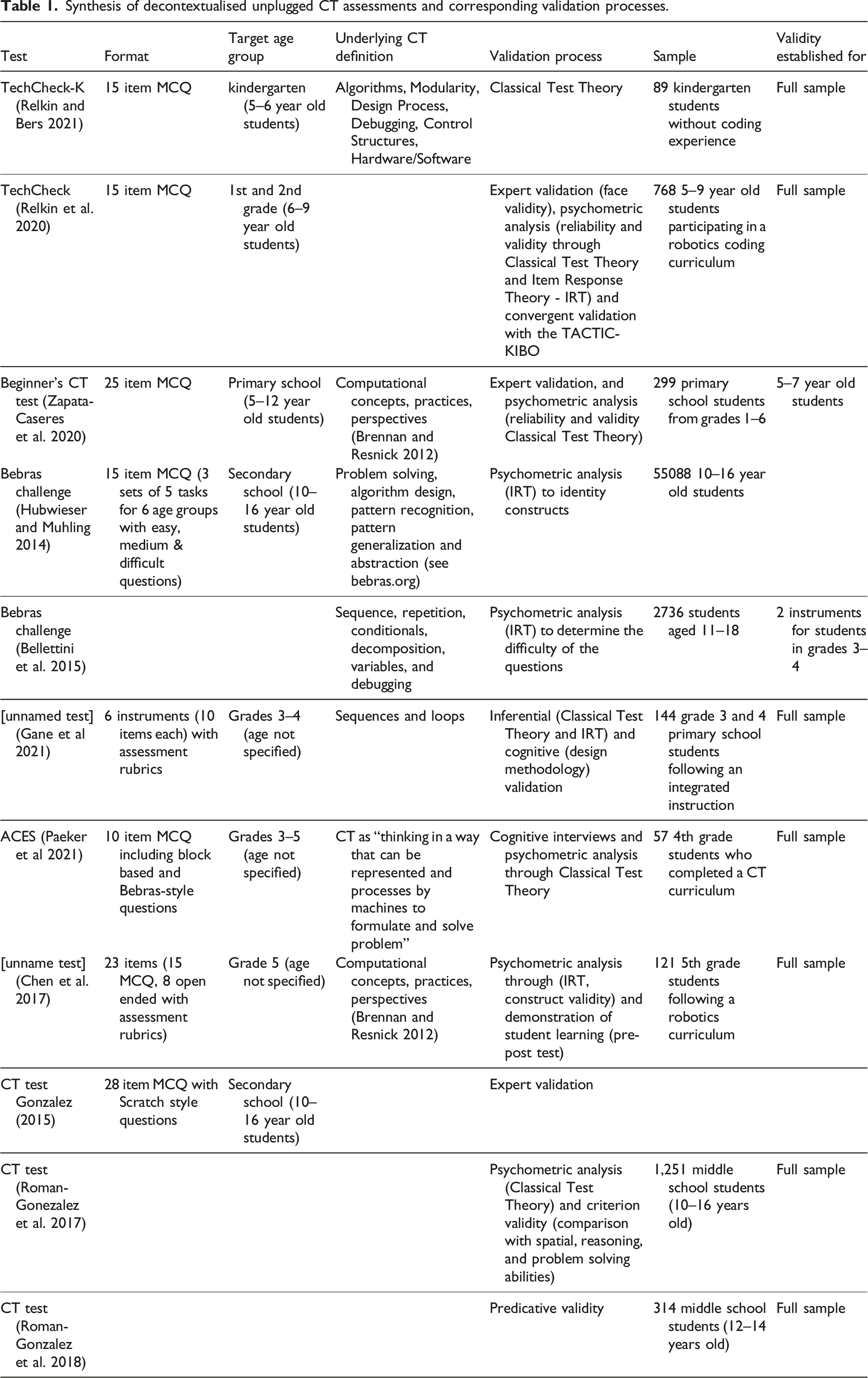
Starting from the lower end of the spectrum, the TechCheck-K was recently developed by Relkin and Bers (2021) to assess CT at the level of kindergarten, considering the requirements of that age group in terms of cognitive, literacy and motor development.
Two assessment tools exist for lower primary school: the TechCheck (Relkin et al., 2020) and the Beginner’s CT test (BCTt, Zapata-Cáceres et al., 2020). The TechCheck (Relkin et al., 2020) was developed for grades 1–2 and proved reliable through Classical Test Theory and Item Response Theory and valid in comparison with the original TACTIC-KIBO instrument (Relkin et al., 2020), thus speaking to the instruments’ convergent validity. The BCTt draws inspiration from the CT test (CTt, Román-González et al., 2017; 2019), specifically adapting the original CTt in terms of format and content to take into account students’ limited reading and understanding skills (Tikva & Tambouris, 2021; Zhang & Nouri, 2019) and ensure the use of “developmentally appropriate language and tasks to assure that factors such as literacy and fine motor skills are not limiting” (Relkin et al., 2021). The instrument, which follows a multiple choice format, was validated with both experts and primary school students (ages 5–10) without prior coding experience, but showed a ceiling effect for students aged 7–10, with the developmental appropriateness in regards to the length of the test (45 minutes) for lower primary being put into question by (Relkin et al., 2021). Indeed, provided the objective of having developmentally appropriate instruments, which can also be used in a diverse range of settings, including researchers in pre-post intervention study designs, and practitioners evaluating the impact of educational reforms (notably digital and computing education), length of administration also becomes a major factor of adoption.
While certain researchers have looked into developing assessments for upper primary school (Gane et al., 2021; Parker et al., 2021), they suffer from numerous limitations. The Bebras challenge (Román-González et al., 2017), for example, is an international competition for students throughout compulsory school. While it is sometimes used to assess CT skills, it has undergone limited psychometric validation (Hubwieser & Mühling, 2014; Bellettini et al., 2015). At the same time, the assessment by Gane et al. (2021) requires manual grading and multiple annotators, limiting the test’s scalability. Finally, the assessment by Parker et al. (2021), which relies on a combination of block-based and Bebras-style questions, has been piloted with just 57 4th graders.
Lastly, we find the CTt by Román-González et al. (2017, 2018, 2019), a multiple choice test designed and adapted for secondary school (ages 10–16). The CTt has undergone several stages of validation (including reliability, criterion validity in relation to other cognitive tests Román-González et al., 2017, predictive validity Román-González et al., 2018, and convergent validity Román-González et al., 2019).
There thus appears to be a gap in validated unplugged assessments for students in upper primary school (ages 7–9, Román-González et al., 2017).
Research Questions
Therefore, to expand the portfolio of validated CT tests across compulsory education, specifically filling the gap in upper primary school, in this article we present the competent CT test (cCTt), the steps undertaken to develop it on the basis of the BCT test, and its psychometric validation with 37 experts and 1519 students. In the following, we specifically consider the following research questions: • RQ1: Is the cCTt a valid measure of CT skills for students in third and fourth grade (aged 7–9)? • RQ2: Is the cCTt a reliable measure of CT skills for students in third and fourth grade (aged 7–9)? • RQ3: Is the length of the cCTt developmentally appropriate for students in third and fourth grade? If not, can it be shortened?
Methodology
The objective of the study was to design a CT assessment adapted for students in upper primary school, with adequate psychometric properties: the competent CT test (cCTt). In section The competent Computational Thinking Test, we describe the format of the cCTt and its development, before presenting its validation in section Validation of the competent Computational Thinking Test. Validation was done in two stages. First, the cCTt underwent an expert evaluation (see section Expert evaluation). Subsequent adjustments were made based on their recommendations before administering the cCTt to 1519 students to evaluate the psychometric properties of the test (see section Psychometric reliability and construct validation from student data).
The competent Computational Thinking Test
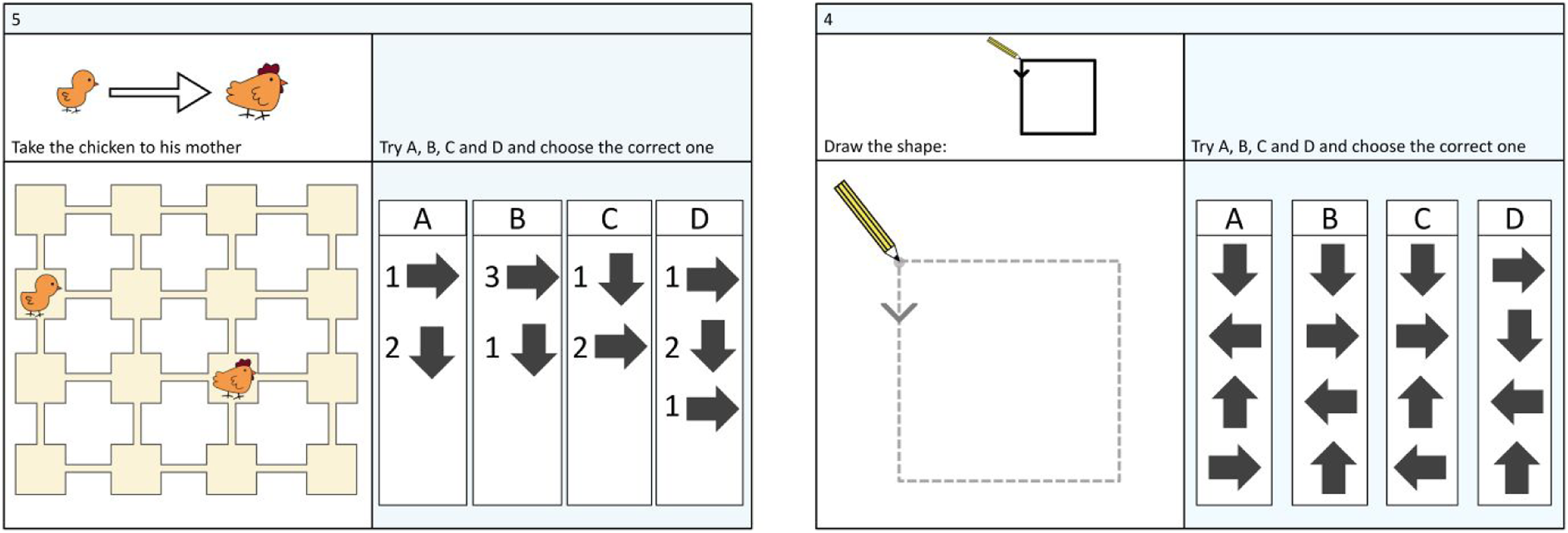
The cCTt was developed by adapting the BCTt in terms of format and content to the target age group, as was done by researchers to develop the TechCheck-K from the TechCheck (Relkin et al., 2021) and to develop the BCT test from the CT test (Zapata-Cáceres et al., 2020). Both the BCTt and the cCTt are unplugged (i.e., paper-based) multiple choice exams composed of 25 questions of progressive difficulty which employ questions in two formats (see Figure 1). The majority of questions (21 out of 25) use a 3×3 or a 4×4 grid that a chick must navigate to reach a hen, possibly satisfying side-goals as well, such as picking up a flower or avoiding a cat. The remaining questions are canvas-type questions where students have to replicate a drawing pattern. In both formats, each question presents itself with four possible answers from which the students must choose from. As shown in Table 2, both tests address CT concepts, as defined by Brennan and Resnick (2012), by successively assessing notions of sequences, simple loops, nested loops, conditionals (if-then and if-then-else), and while statements, but with varying number of questions per concept. While designing the cCTt, adaptations in terms of content aimed at rendering the test more complex by i) Mainly employing 4 × 4 grids, ii) Removing questions of low difficulty (i.e., which exhibited notable ceiling effects in Zapata-Cáceres et al., 2020, in particular questions on 3 × 3 grids and questions involving sequences and simple loops) iii) Adding more questions related to complex concepts (e.g., while statements) iv) Creating a new subset of questions which looks to determine whether students had assimilated the range of concepts addressed in the test (referred to as “combinations”) v) Altering the disposition of objects (starting point, targets and or obstacles) on the grid, and/or the selection of responses students could choose from, so that identifying the correct response requires more reflection on the students’ part. The two main question formats of the cCTt: grid (left) and canvas (right). Comparison between the BCTt and the cCTt in terms of question concepts and question types.
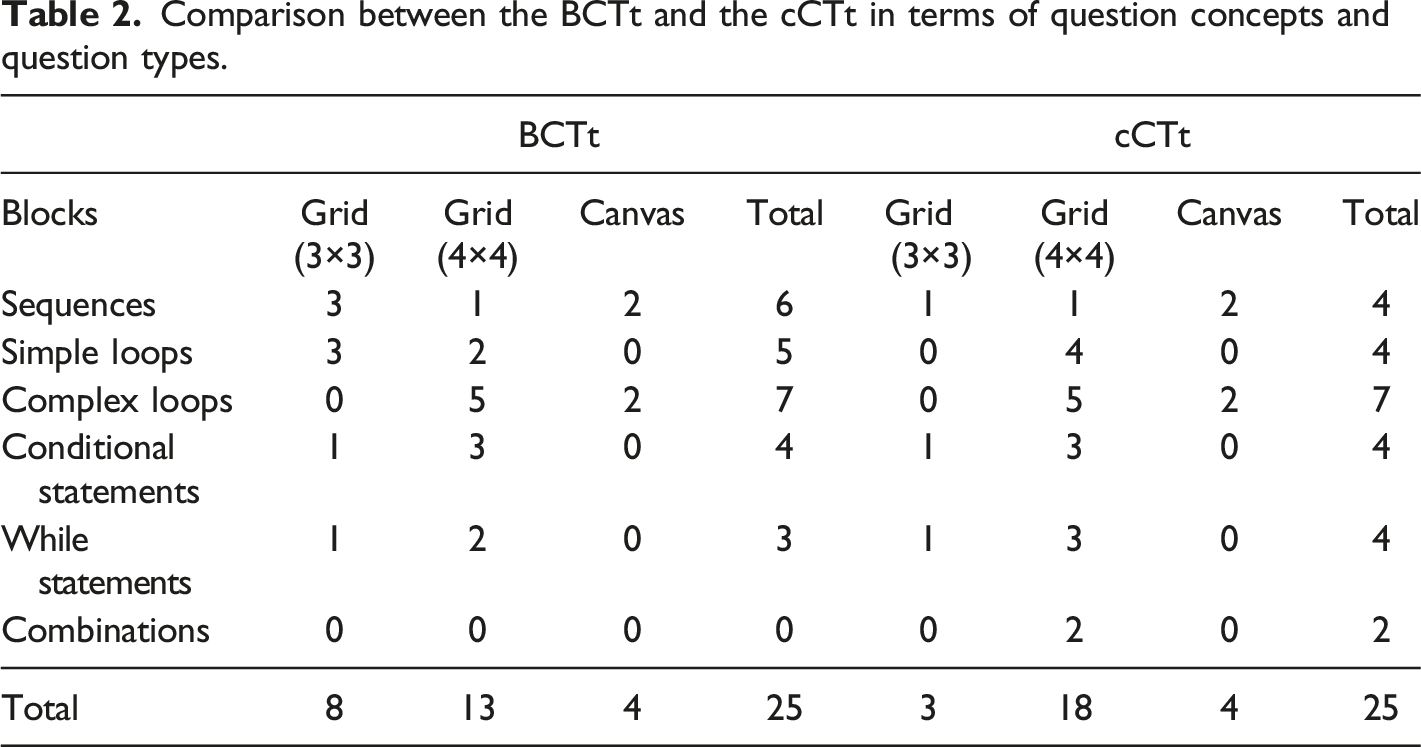
Adaptations in terms of format primarily concerned the while statements: to convey the notion of repetition, and to make the statement more clearly distinct from the simple sequences, the symbols were adapted as shown in Figure 2. Example of a format and content adaptation (Q24 in the BCTt on the left, which became Q21 in the cCTt on the right), including the recommendations made by the experts.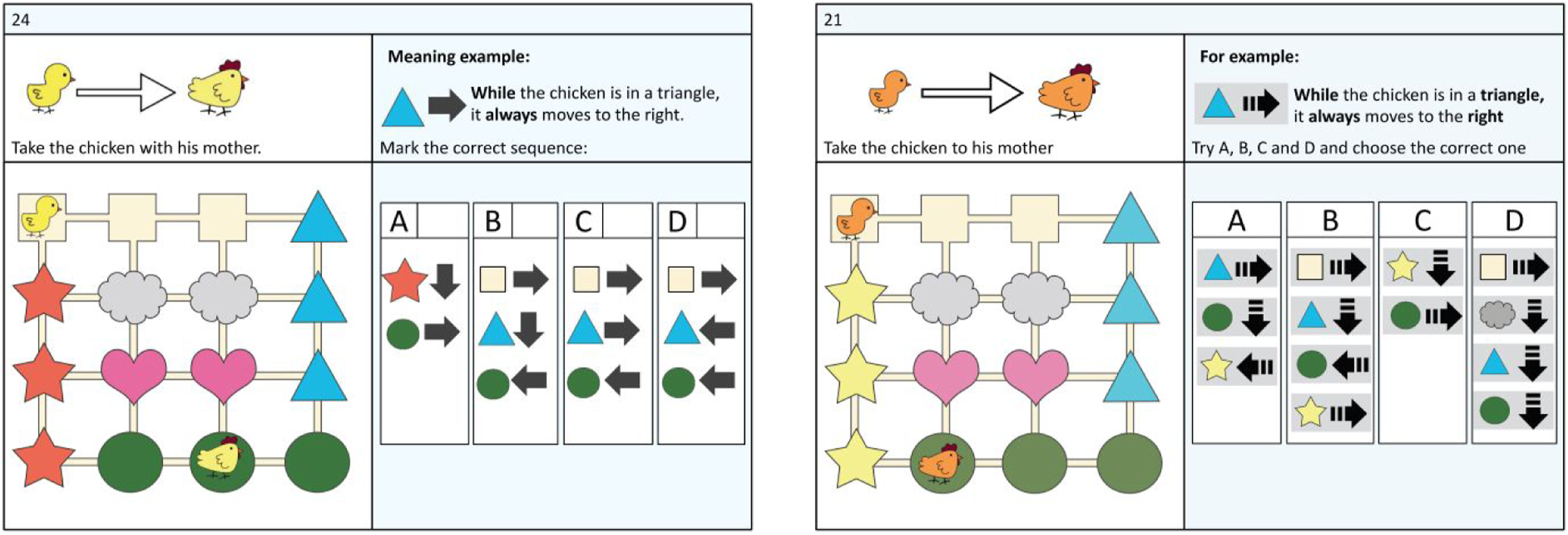
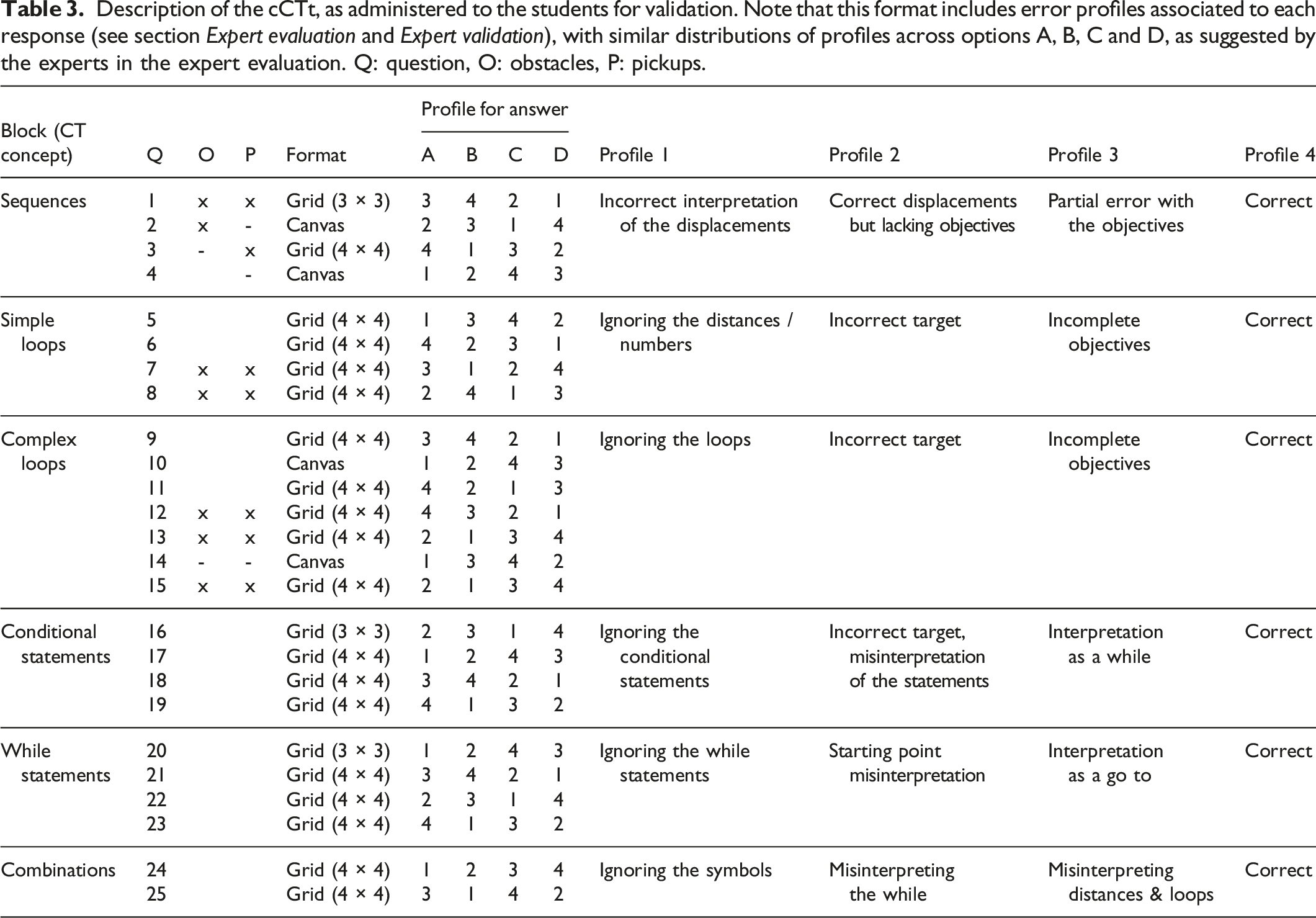
Description of the cCTt, as administered to the students for validation. Note that this format includes error profiles associated to each response (see section Expert evaluation and Expert validation), with similar distributions of profiles across options A, B, C and D, as suggested by the experts in the expert evaluation. Q: question, O: obstacles, P: pickups.
Validation of the competent Computational Thinking Test
The validation of instruments generally falls under the field of psychometrics, which we briefly introduce here before detailing the approach undertaken for the cCTt.
Psychometric theories are part of a field which seeks to understand the structure of intelligence and “portrays intelligence as a composite of abilities measured by mental tests”
4
. Psychometric theories help evaluate the quality of assessments through two main properties: validity and reliability. Reliability is “the ability to reproduce a result consistently in time and space”. Validity on the other hand “refers to the property of an instrument to measure exactly what it proposes” (Souza et al., 2017) and is typically presented under four forms (Taherdoost, 2016): • Construct validity, or the “extent to which there is evidence consistent with the assumption of a construct of concern being manifested in subjects’ observed performance of the instrument” (Raykov & Marcoulides, 2011). Simply put, does our test measure the skills/abilities it intends to measure? • Content validity, or the “degree to which test components represent adequately a performance domain or construct of interest” (Raykov & Marcoulides, 2011), that is, “whether the particular items in the test adequately represent the domain of possible items one could construct” (Raykov & Marcoulides, 2011). Simply put, is the test fully representative of the content it aims to measure? • Criterion validity, or how closely the results of the test correspond to the results of a different test. • Face validity, or the extent to which the content of the test appears to be suitable to its aims.
Both validity and reliability must be considered to adequately validate an assessment instrument. As such, we employ expert evaluation to look into the face, construct and content validity of the test (see section Expert evaluation) and analyse student performance to establish both construct validity and reliability of the cCTt (see section Psychometric reliability and construct validation from student data). Criterion validity, generally established by comparing the assessment with other validated instruments (Román-González et al., 2017, 2019), is lacking in the present study.
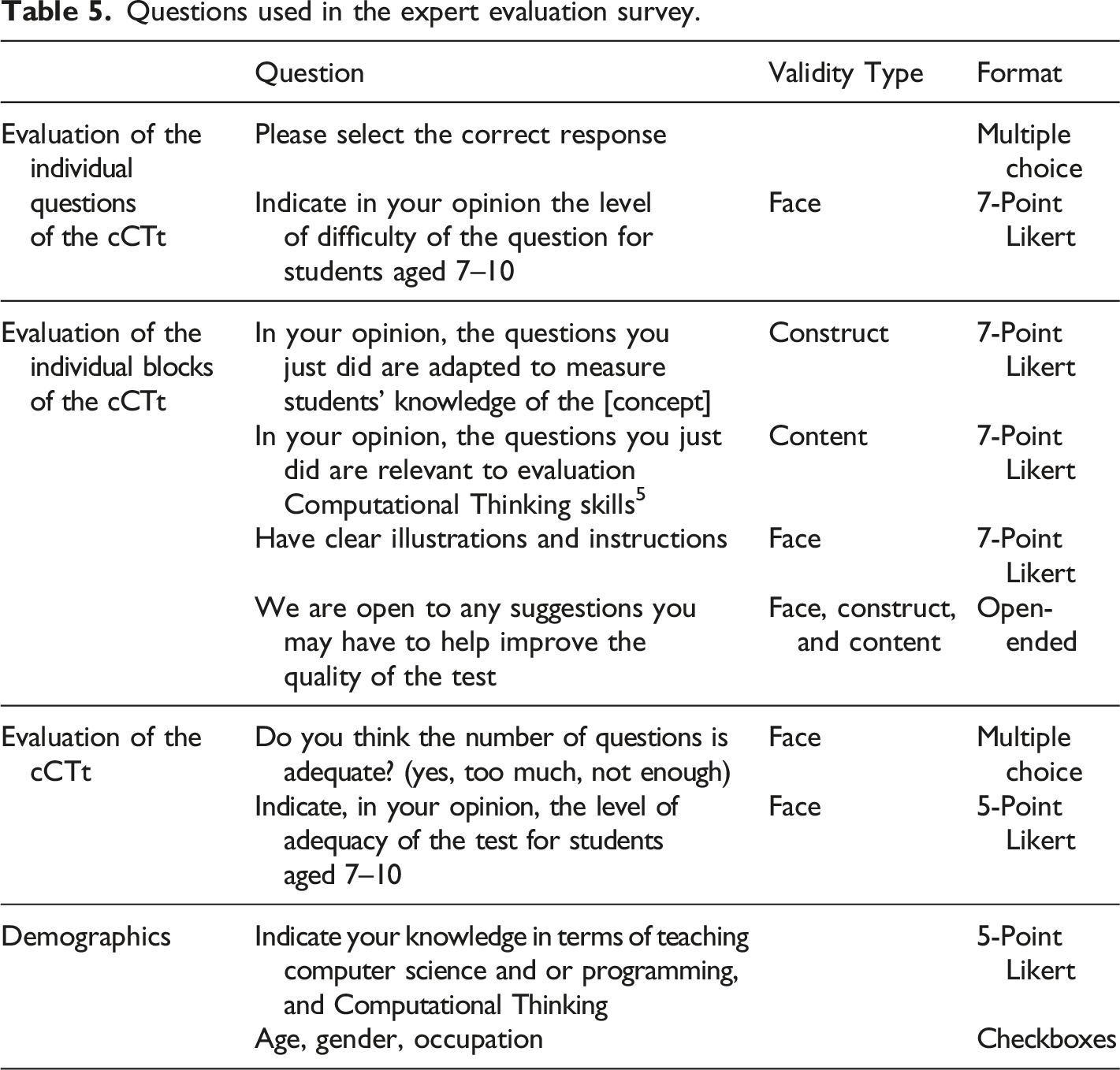
Expert evaluation is an approach that has been used by many researchers to validate CT assessments (Djambong et al., 2018; Zapata-Cáceres et al., 2020; Relkin et al., 2021). That is why, prior to administering the test to the students, a panel of experts was organized to (i) “evaluate if the test [content corresponds] to the intended constructs” (Tang et al., 2020, construct validity), (ii) if the test is an adequate measurement of CT competence (content validity), and (iii) whether the test appears adequate for students in upper primary school (face validity). In total, 37 experts of diverse backgrounds participated in the evaluation of the cCTt (see Table 4). The experts were recruited from: 1. The panel of experts having participated in the validation of the BCTt (Zapata-Cáceres et al., 2020). 2. Researchers in education and computer science working on the question of fostering and/or assessing CT. 3. Practitioners involved in the local digital education reform to gain additional insight into the developmental appropriateness of the instrument. These included (a) experts in assessment from the department of education, (b) professors from the university of teacher education, and (c) teachers having been trained to introduce digital education (including computer science and CT) and presently teaching said concepts to students in the target age group. Experts’ profiles. Note that the experts had the possibility to select multiple occupations. Two early childhood education teachers were part of the experts who have been teaching CT to their students for years and participated in the evaluation of the BCTt (Zapata-Cáceres et al., 2020), while the other one is a former primary school teacher who is presently working as a teacher trainer and doing a PhD in a CT-related field.
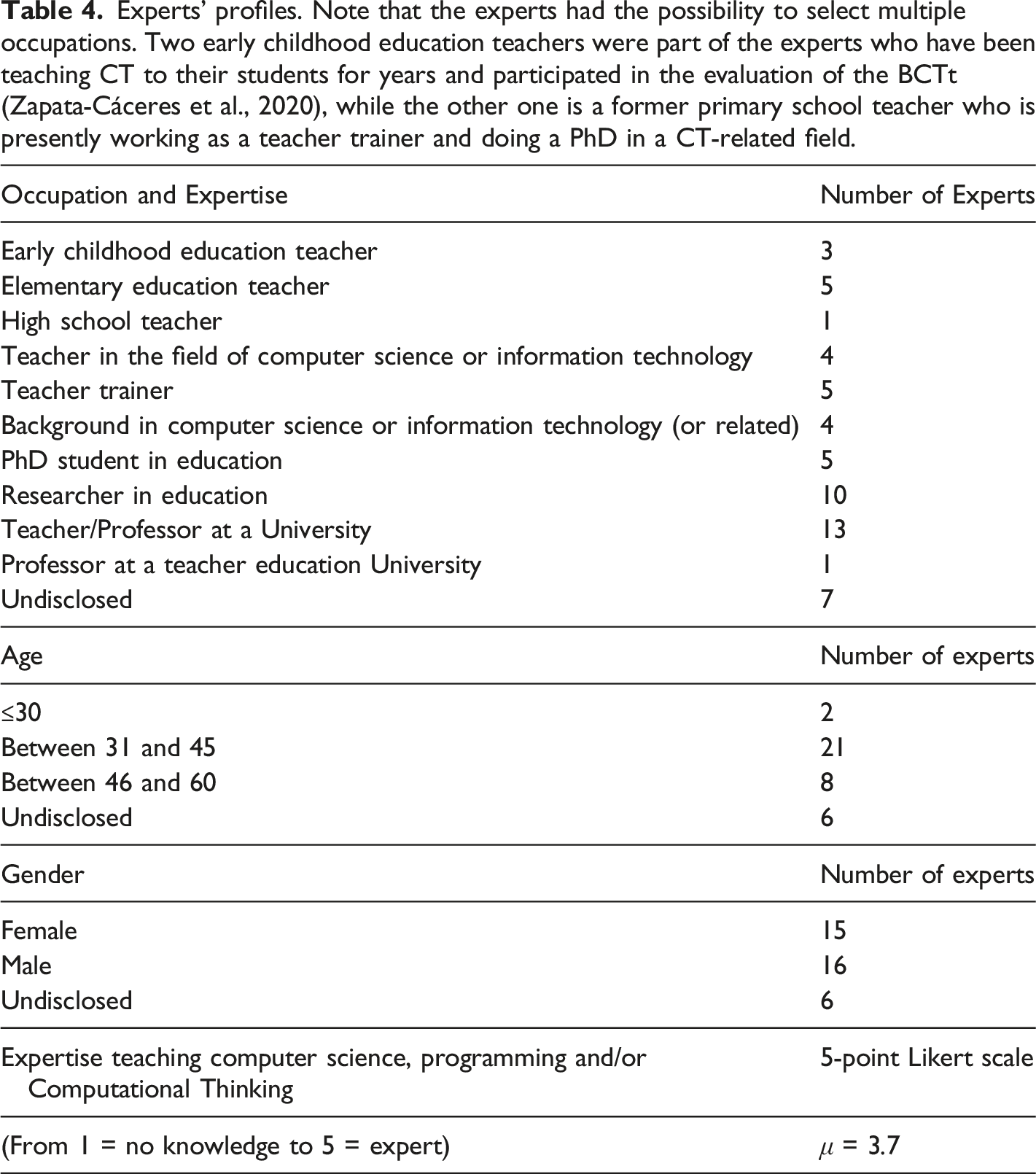
Questions used in the expert evaluation survey.
Psychometric reliability and construct validation from student data
Student demographics.

Construct validity was assessed through factor analysis, a technique which groups “observed variables [(here, the questions of the test)] into latent [variables, (here, the associated concept)] based on commonalities within the data” (Atkinson et al., 2011). Two main approaches exist for factorial analyses (exploratory and confirmatory). Confirmatory Factor Analysis (CFA) is used when there is an assumption about the underlying structure of the data and to “confirm the structural model of an instrument” (de Souza et al., 2019), while exploratory factor analysis is usually used to explore the dimensionality of the data at hand. In our case, the objective being to evaluate whether the blocks of questions presented in Table 3 constitute coherent groups of questions (i.e., factors, or latent variables which cannot be directly observed—e.g., intelligence, motivation, happiness—but are inferred from others), we employed CFA. When conducting CFA one must employ multiple fit indices as they provide “a more holistic view of goodness of fit, accounting for sample size, model complexity, and other considerations relevant to the particular study” (Alavi et al., 2020). Two types of fit indices exist and must be employed in parallel: (i) global model fit indices assess “how far a hypothesized model is from a perfect model” (Xia & Yang, 2019) (such as the chi-square χ2 statistic, the root mean square error of approximation or RMSEA, and standardized root mean square residual or SRMR), while (ii) local or incremental fit indices “compare the fit of a hypothesized model with that of a baseline model (i.e., a model with the worst fit)” (Xia & Yang, 2019) (such as the comparative fit index CFI and the Tucker-Lewis index TLI). Cutoffs frequently employed for these metrics are (Hu & Bentler, 1999; Xia & Yang, 2019) CFI and TLI > 0.95, RMSEA < 0.06, SRMR < 0.08 p x 2 > 0.05. It is important to point out that these thresholds are conventional and were established in a specific context, thus meaning that they should be considered as indicative of levels of miss-specification, rather than absolute judges of bad model fit (Xia & Yang, 2019). Additionally, the χ2 statistic is sensitive to sample size, with larger samples decreasing the p-value (Alavi et al., 2020; Prudon, 2015), and should thus not be considered as “the final word in assessing fit” (Alavi et al., 2020). Some authors therefore suggest employing the ratio between the χ2 statistic and the degrees of freedom with a cutoff at χ2 /df ≤ 3 (Kyriazos, 2018). Finally, as the input data is binary (with a score of 0 or 1 per question), the CFA analysis is conducted using an estimator which is adapted to non-normal data and employs diagonally weighted least squared to estimate the model parameters and tetrachoric correlations (Rosseel, 2020; Schweizer et al., 2015).
Reliability was evaluated through two means: Classical Test Theory and Item Response Theory (IRT), as recommended in the context of instrument validation (Cappelleri et al., 2014; Embretson & Reise, 2000; Relkin et al., 2020). Classical Test Theory “comprises a set of principles that allow us to determine how successful our proxy indicators are at estimating the unobservable variables of interest” (DeVellis, 2006) and focuses on test scores (Hambleton & Jones, 1993). Main metrics include (i) difficulty (proportion of students responding correctly), (ii) reliability (proportion of the item’s variation that was shared with the true score, often computed using Cronbach’s alpha when considering scale reliability), and (iii) discrimination (i.e., to what extent the question helps distinguish between the top performers and the low performers, estimated using the Point-biserial correlation). Unfortunately, Classical Test Theory suffers from several limitations. As its focus is at the test level, the observed scores and true scores are test-dependent, and sample-dependent (Hambleton & Jones, 1993). In other words, “different samples with different variances will not yield equivalent data or data that can easily be compared across samples” (DeVellis, 2006). While Classical Test Theory can be used to compare groups against one another, this can also put into question the reliability of the test. Moreover, “a score value on one item should mean the same thing as the same score value on another item of the same scale” (DeVellis, 2006), which is not necessarily true when we consider assessments that have questions of increasing difficulty. That is why researchers have advocated the use of ability scores which are test independent. Item Response Theory (IRT) addresses this limitation, as it helps estimate the ability of an examinee, which is test independent. IRT is based on latent trait theory and assumes that there is an underlying student ability which leads to consistent performance, that is, that the probability of a student getting a given item correct is a function of said students’ ability. IRT thus operates at the item level and estimates parameters for the population (and not just the sample), but is based on high assumptions which are often hard to meet (Hambleton & Jones, 1993).
The data analysis was conducted in R (version 3.6.0, R Core Team 2019) using R Studio (version 1.2) with the lavaan (version 0.6–7, Rosseel, 2012), CTT (version 2.3.3, Sheng, 2019), psych (version 2.1.3, Revelle, 2021) and ltm (version 1.1.1, Rizopoulos, 2006) packages.
Shortening the competent Computational Thinking Test
A further objective of our work is to determine whether the length of the test if developmentally appropriate through the expert evaluation and by gathering feedback from teachers in the field having participated in the test’s administration. Provided their responses, if inadequate, the objective is to propose several versions of the cCT test which can be selected according to researchers’ and/or practitioners’ needs. To that effect, Confirmatory Factor Analysis will be employed once more, this time not to validate the underlying structure of the test, but to identify questions exhibiting high correlations with other factors or other questions. Indeed, CFA fit indices tend to improve with parsimonious models, that is, which are less complex (Alavi et al., 2020).
Results
RQ1: Validity of the competent Computational Thinking Test
As anticipated, we establish the validity of the cCTt through two means: expert validation, reported in section Expert validation, and Confirmatory Factor Analysis, detailed in section Confirmatory Factor Analysis for construct validity. Considering the validity measures, the experts appear in agreement on the face and content validity of the test, and both the expert validation and the factor analysis point to adequate construct validity. While content validity is evaluated positively, the experts highlight that the test is best suited for computational concepts and does not measure the full range of competences related to CT, notably computational practices (i.e., thought processes) and computational perspectives (i.e., perception). This is indeed an identified limitations of summative assessments (Román-González et al., 2019), which, if one desires a more exhaustive CT assessment, may be addressed by combining multiple assessment methods (Grover et al., 2015; Román-González et al., 2019).
Expert validation
Face Validity of the cCTt was evaluated based on several criteria (see Figure 3). The evaluation of each individual question’s difficulty points to a progressive increase in difficulty as intended, with an average overall difficulty of −0.4 ±1.0% (between “neither easy nor difficult” and “somewhat difficult” on a scale of −3 to +3). The experts, unaware that there was a protocol with examples that was provided to teachers at the time of the survey administration, believed that the symbolism would be difficult to understand without prior explanations, notably in the case of the for loops, the if-else statements, while statements and their combinations. This accounts for the more negative ratings obtained in terms of illustrations for those blocks of questions, and confirms the importance of providing examples to the students beforehand to grasp the key mechanics of the test. As for the test length, 52% of respondents believed it was adequate, 41% that it was too long, and 7% that it was not enough. All in all, 63% believed the test was adequate to measure upper primary school students’ CT skills, 26% were neutral, and just 11% were in disagreement. Face Validity of the cCTt.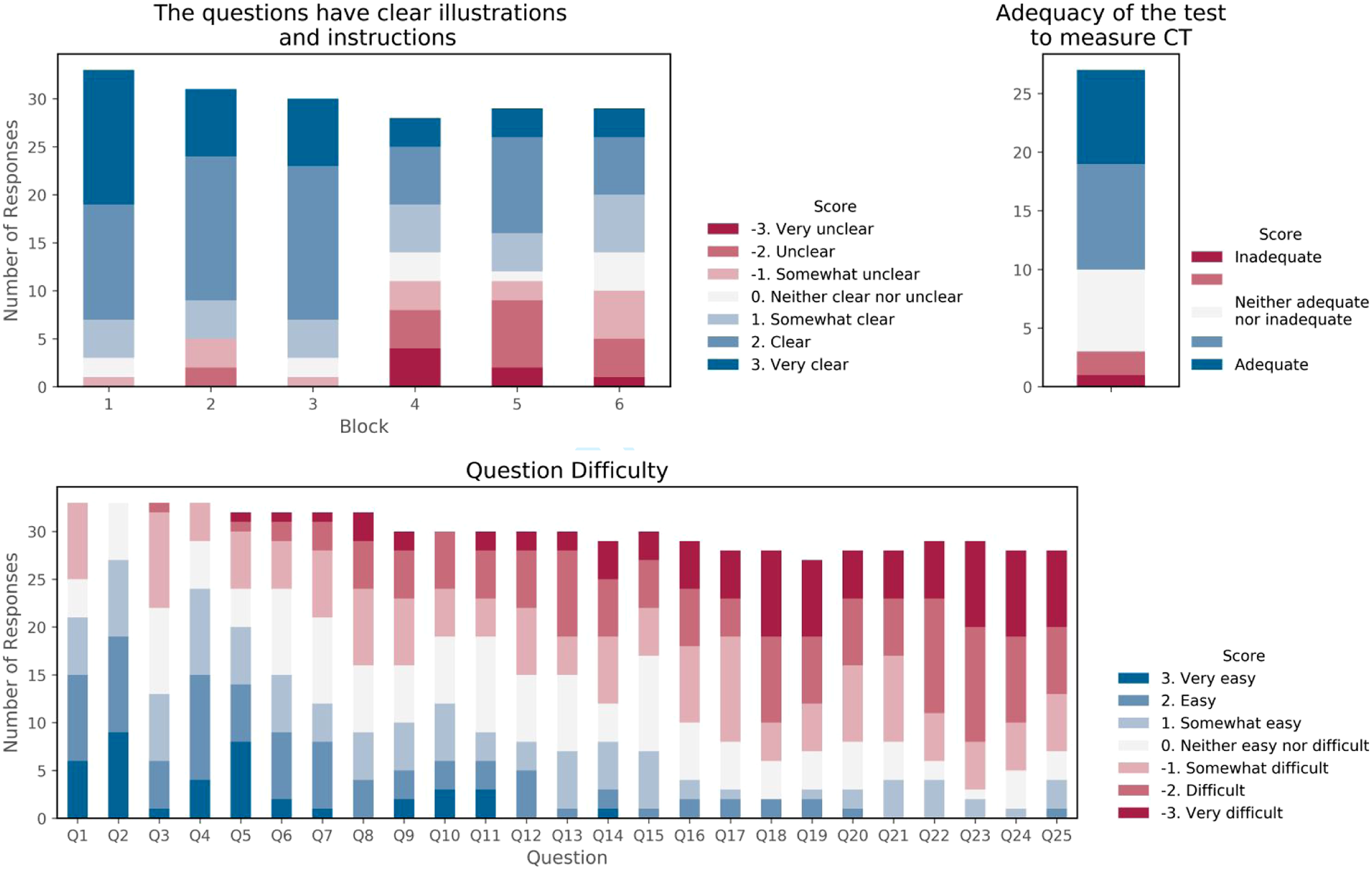
Construct validity is established in Figure 4. The experts were asked to what extent they believed the blocks of questions adequately measure the concepts defined in Table 3. In the worst case, that is, for the while statements, 76% of the experts agreed that the block of questions adequately measures the targeted concept, with an average agreement of 1.2 ± 0.4% (between “agree” and “totally agree” on a scale of −3 to +3). This seems to point to an adequate construct validity. Construct and content validity of the cCTt.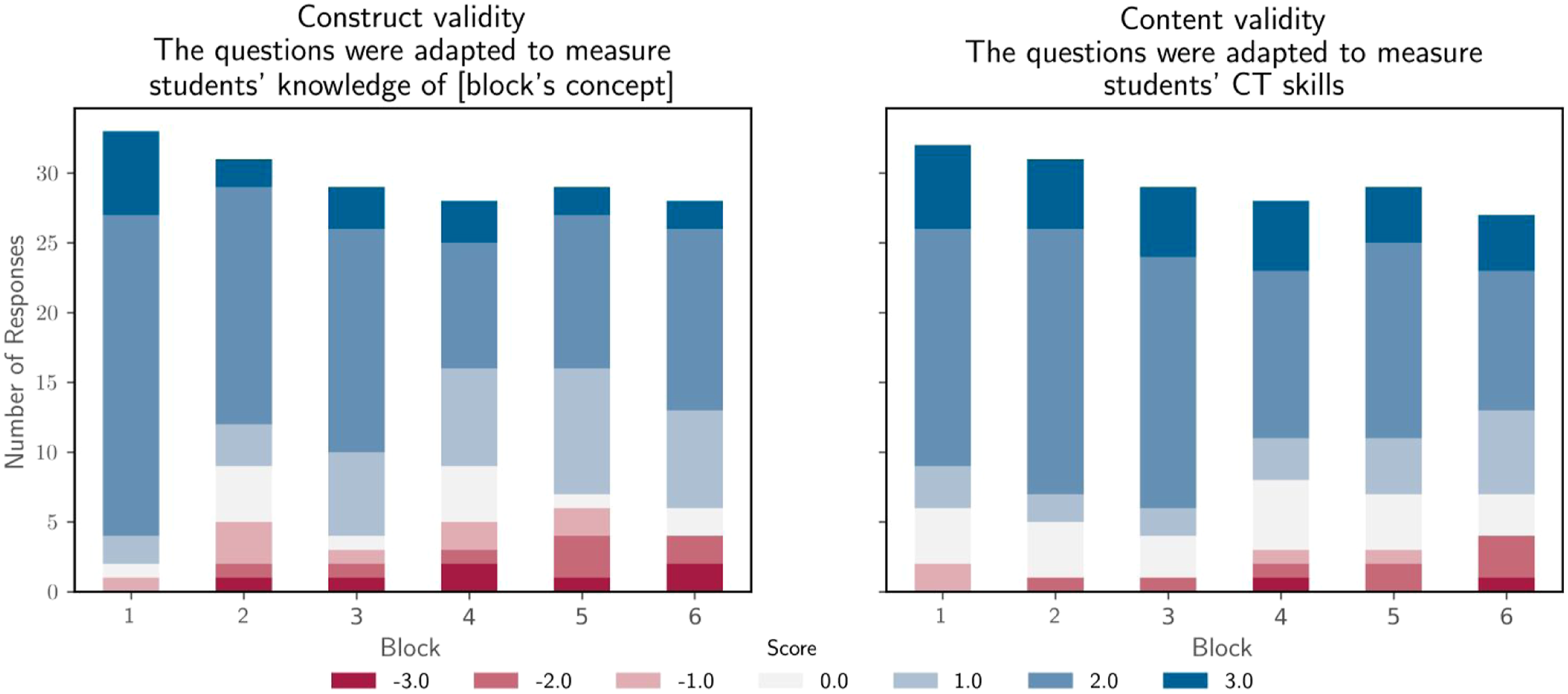
Content validity was assessed on the basis of whether the experts believed each block of questions was an adequate representation of CT skills. Results were mainly positive with an average approval rating of 1.5 ± 0.3% (on a scale of −3 to +3). In the worst case, a 71% approval was obtained for the conditional statements (see Figure 4). The experts provided additional insight into their perception of the content validity of the test through the open comments, and in particular in the focus group. The latter, which was unstructured, was primarily focused on what it entails to assess CT considering the fact that (i) CT highly multi-dimensional, (ii) suffers from a lack of consensus around what CT encompasses, and (ii) can be considered both in disciplinary and non-disciplinary contexts. For the experts, the cCTt, although it assesses adequately computational concepts, it does not assess CT in all its dimensions. The cCTt, like the CTt and the BCTt before it, mainly focuses on computational concepts and while it includes certain notions of computational practices, it disregards computational perspectives. Indeed, the cCTt does not provide insight into students’ thought processes when engaged in CT-related problem solving tasks (Chevalier et al., 2020), their transversal competences (both inter-personal and intrapersonal), and their perception of “of themselves and their relationships with others and the technological world” (Lye & Koh, 2014). This is a limitation of most summative assessments (Román-González et al., 2019) which, despite having excellent adequacy for computational concepts and little adequacy for computational practices, are considered inadequate for computational perspectives. Indeed, both the literature and the experts highlighted the importance of combining the cCTt with other instruments in a system of assessments to get a comprehensive evaluation of CT interventions (Grover et al., 2015; Román-González et al., 2019). Multiple assessment methods help provide complementary information on the acquisition of CT competences. In particular, computational practices relate to processes and are best assessed through direct observations as in the case of the study by Chevalier et al. (2020) who looked into the students’ thought processes using the Creative Computational Problem Solving model.
Other suggestions, both in terms of format and content, emerged from the focus group discussion and open questions of the survey. While we will not detail the format related suggestions that were implemented, we present the remaining content related suggestions that were provided. A primary school educator recommended adding an “I don’t know” option so students would not feel pressured into selecting a response. Such an addition also helps distinguish between students who did not have time to answer the question and those who did not know what the correct answer was. Another expert with experience in didactics, pedagogy, research and teacher training also emphasized the importance of establishing error profiles in the selection of responses. Concretely, the idea is that each response should correspond to a type of error, so teachers may also use the test to identify specific learning difficulties and intervene accordingly. Ideally, a teacher would like to know where the students are struggling in order to remedy the situation. Both suggestions were included in the version of the cCTt that was administered to the students (see Table 3 for the error profile attributed to each response).
Confirmatory Factor Analysis for construct validity
Confirmatory Factor Analysis for the cCTt-25, with latent variables and observed variables corresponding to the distribution in Table 3.
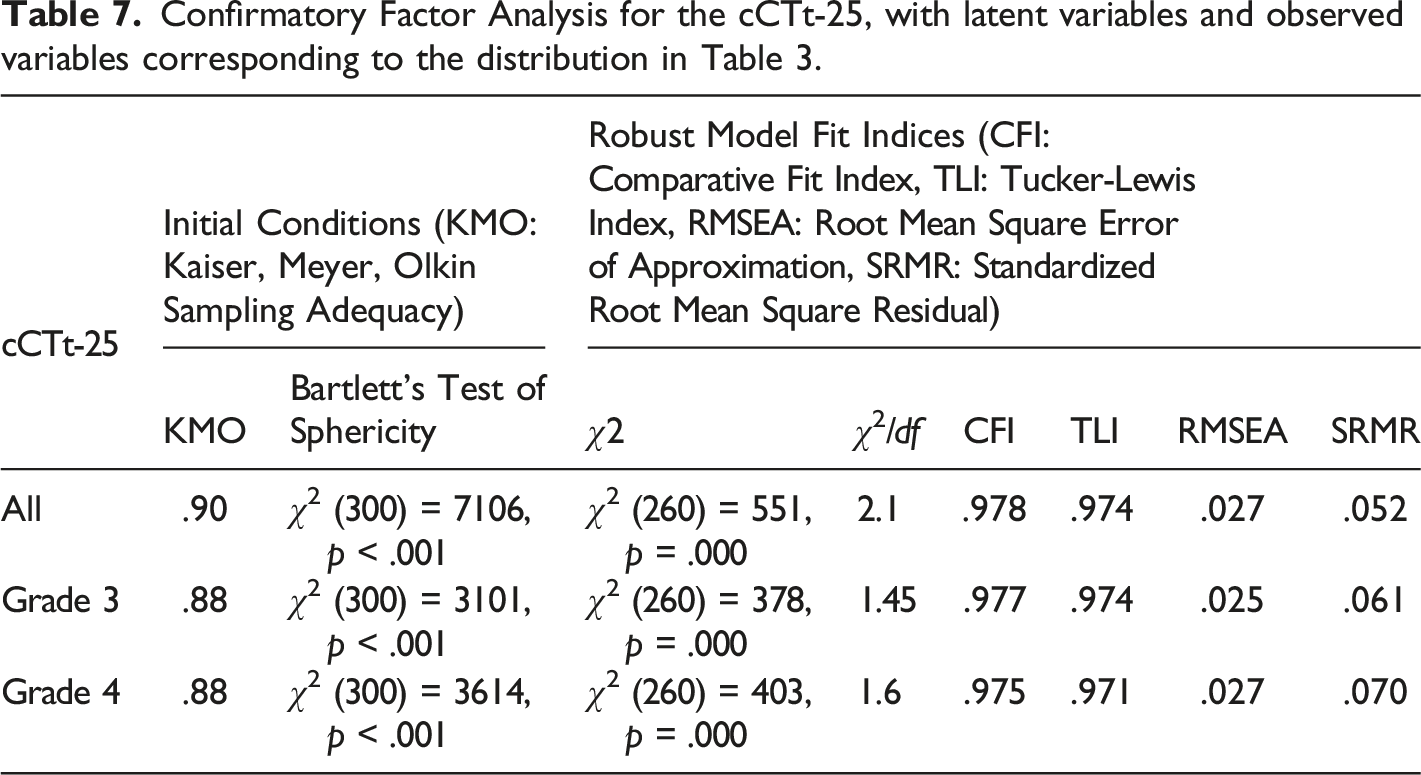
cCTt-25 Factor Loadings for CFA on the full dataset.
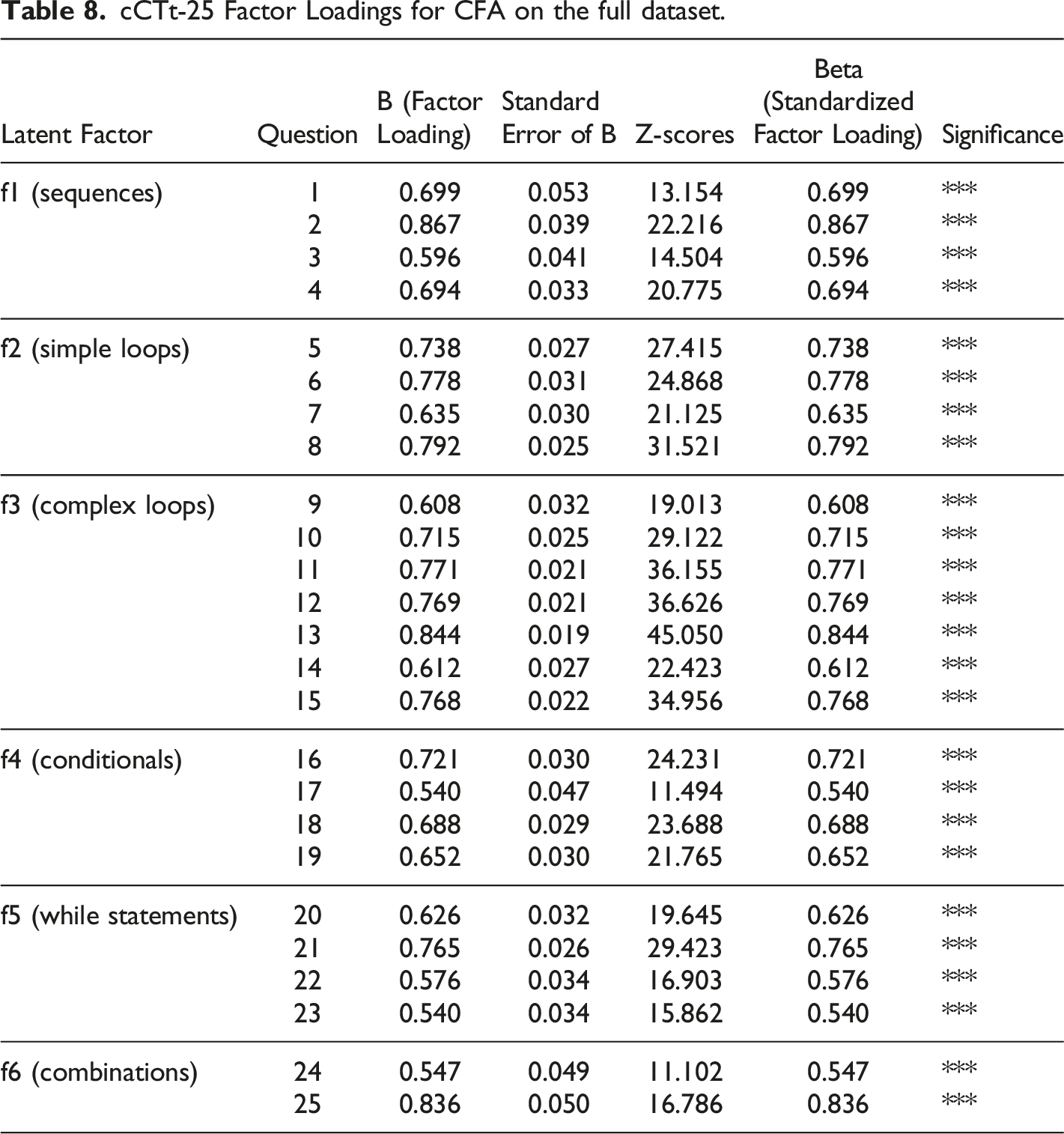
cCTt-25 Latent Factor Correlations for CFA on the full dataset.

These results indicate that the cCTt-25 fits well, and that the blocks are representative of the CT concepts they intend to measure.
RQ2: Reliability of the cCTt
Reliability of the cCTt was established through two means which are considered complimentary: Classical Test Theory (see section Reliability through Classical Test Theory and item analysis) and Item Response Theory (see section Reliability through item response theory). Both approaches appear to indicate that the test has a wide range of question difficulties and adequately discriminates between students. The IRT contributes to this by showing that the test is best suited to discriminate between students with low and medium abilities, while Classical Test Theory adds that the cCTt has a good level of internal consistency and exhibits no clear ceiling or flooring effects, with students in grade 4 scoring significantly better than students in grade 3.
Reliability through Classical Test Theory and item analysis
The distribution of scores obtained by the students is shown in Figure 5. Students score on average 14.14 ± 5.22 out of a total of 25, with no evident ceiling effect, and 8% of students scoring below chance (i.e., < 25/4). Considering the minimum effect size that can be considered in the study to achieve a power of 0.8 (Cohen’s D = 0.14), significant differences are observed between grades (p < 0.001, +2.9pt in grade 4, Cohen’s D = 0.57), and gender (p = 0.013, +0.6pt for boys, Cohen’s D = 0.15). Although the effect size for gender is small, this brings up the question of when (and why) gender differences arise in STEM and disciplines related to Computer Science (CS), and the need to effectively addressed them in ongoing CS and CT curricular reforms (El-Hamamsy, Chessel-Lazzarotto, et al., 2021). Provided the small effect size for gender, we only distinguish between grades in the rest of the Classical Test Theory analysis. Score distribution per grade and gender.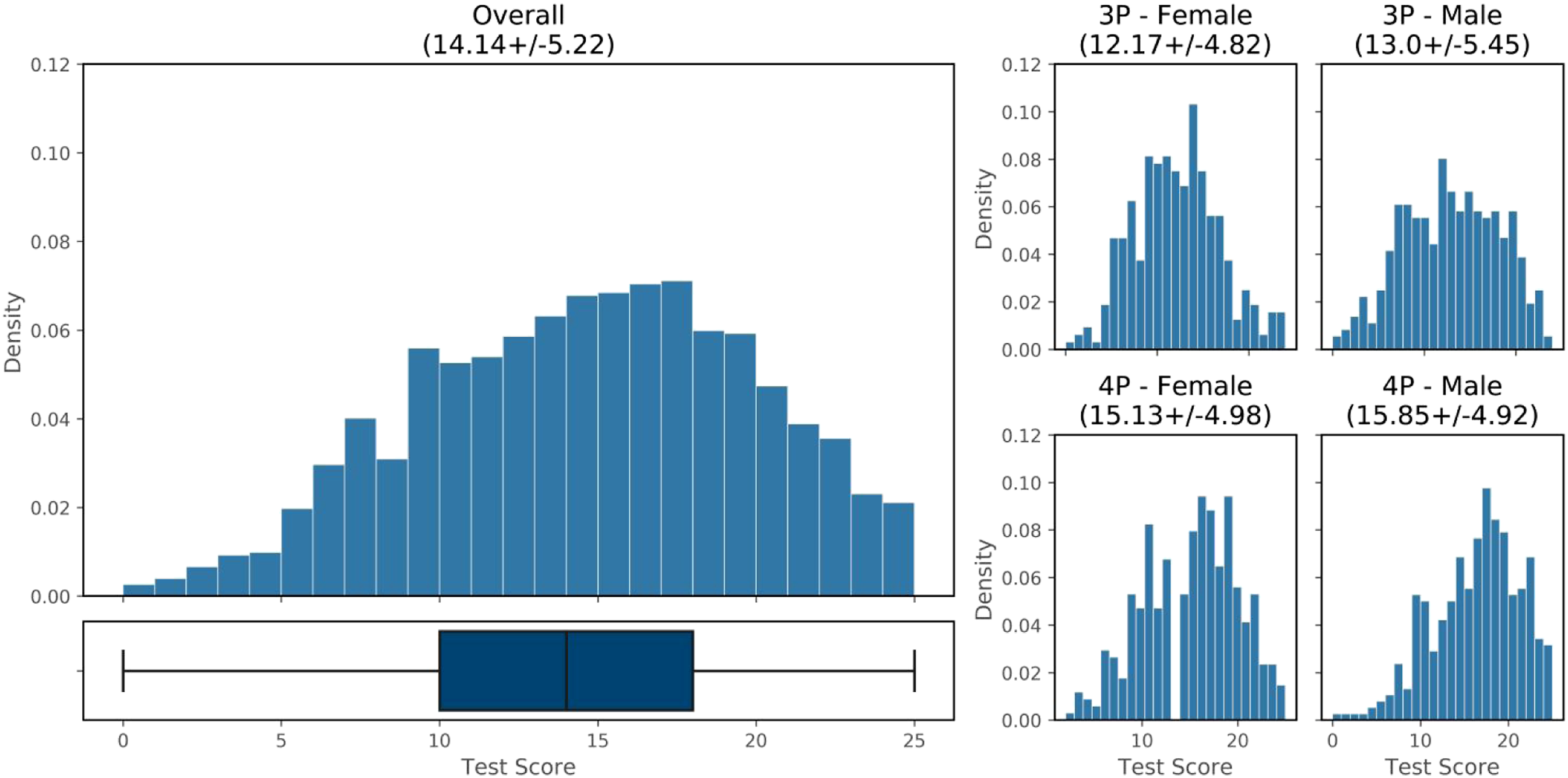
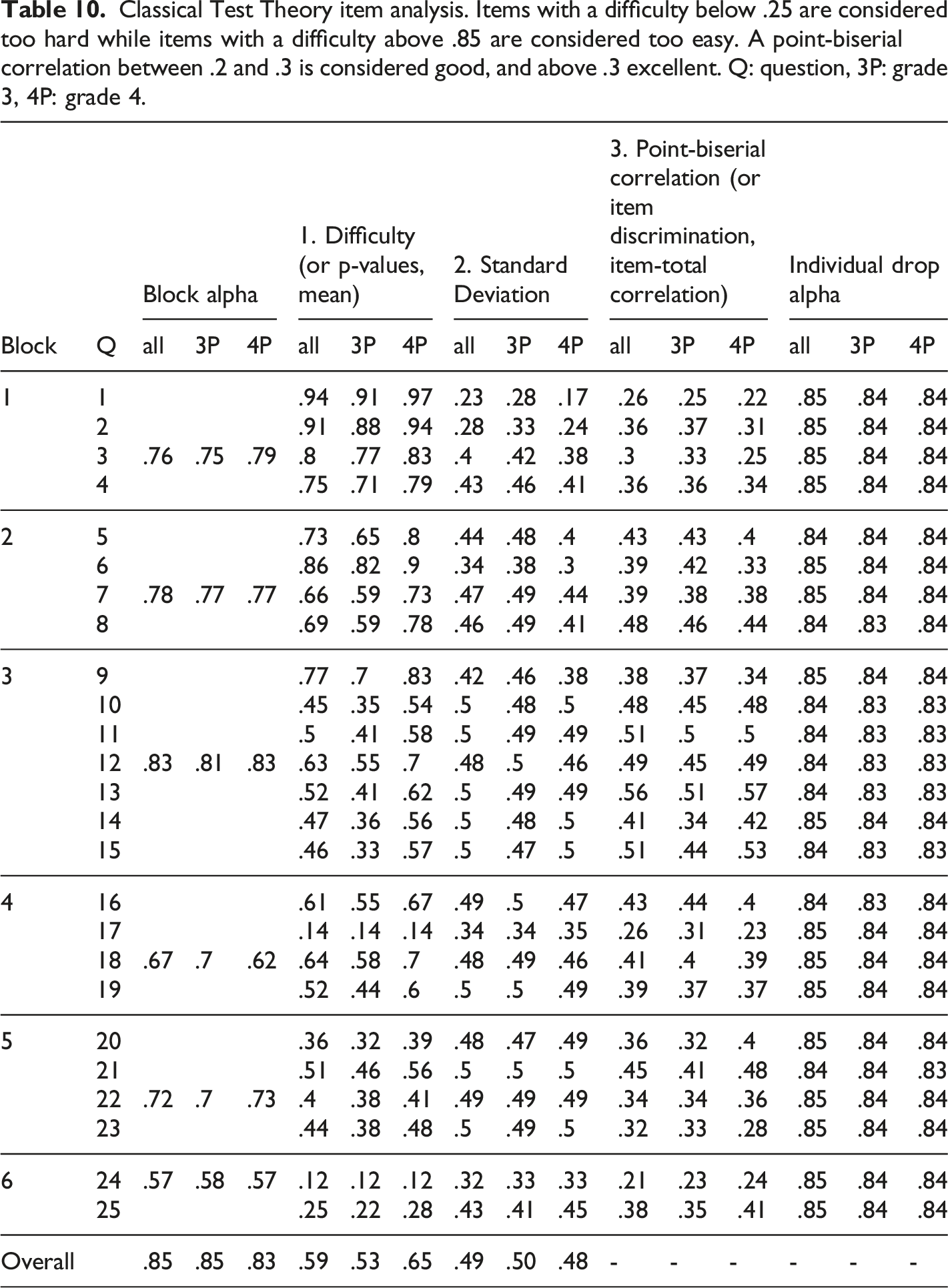
Figure 6 shows the proportion of correct responses for students in grade 3, grade 4 and for the full sample. The questions appear to be increasingly difficult with certain earlier questions being too easy (difficulty index > 0.85 for questions 1 and 2 for all, and question 6 for grade 4), and later questions being too hard (difficulty index < 0.25 for question 17 and 24 for all, and question 25 for grade 3). Students in grade 4 appear to score consistently better than students in grade 3 over all questions. Looking at the point-biserial correlation, which is the difference between the high scorers and the low scorers of the sample population, all questions score above 0.2 which is considered acceptable. Question difficulty and point-biserial correlation distribution per question. Items with a difficulty below .25 are considered too hard while items with a difficulty above .85 are considered too easy. A point-biserial correlation between .2 and .3 is considered good, and above .3 excellent.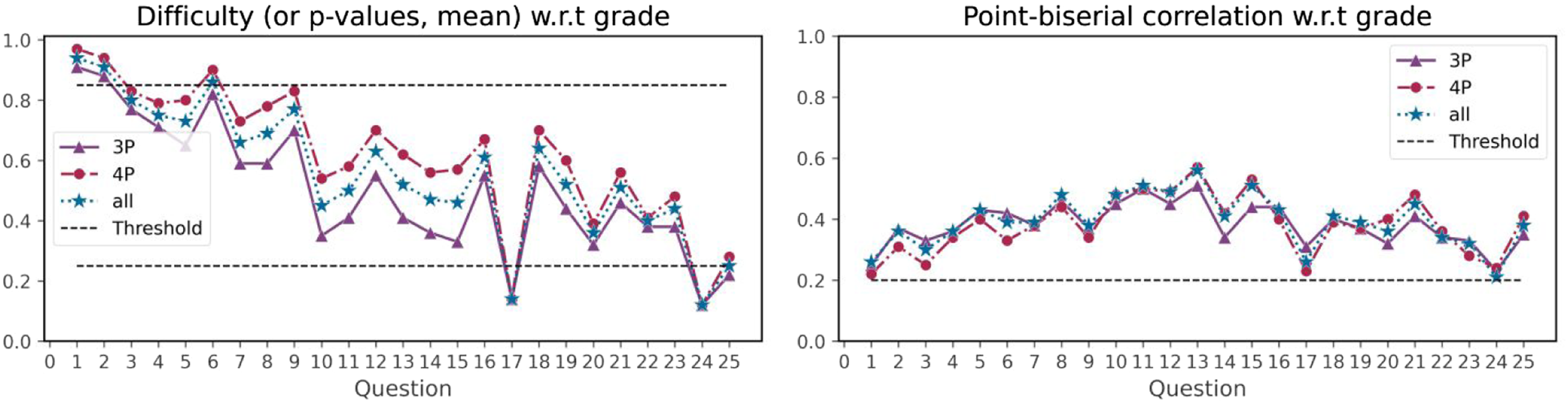
Classical Test Theory item analysis. Items with a difficulty below .25 are considered too hard while items with a difficulty above .85 are considered too easy. A point-biserial correlation between .2 and .3 is considered good, and above .3 excellent. Q: question, 3P: grade 3, 4P: grade 4.
Reliability through Item Response Theory
Comparison of the 1-PL and 2-PL model.

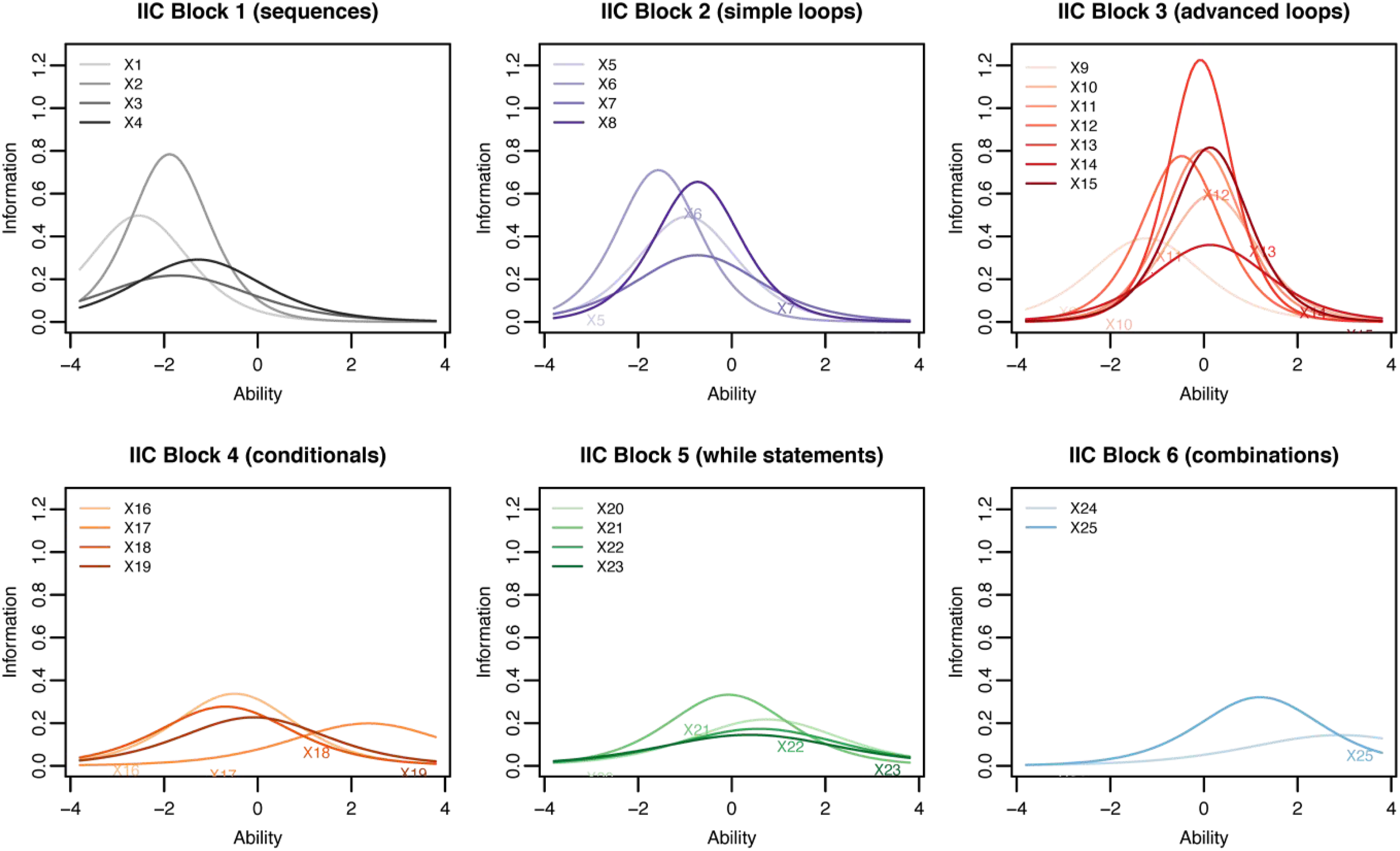
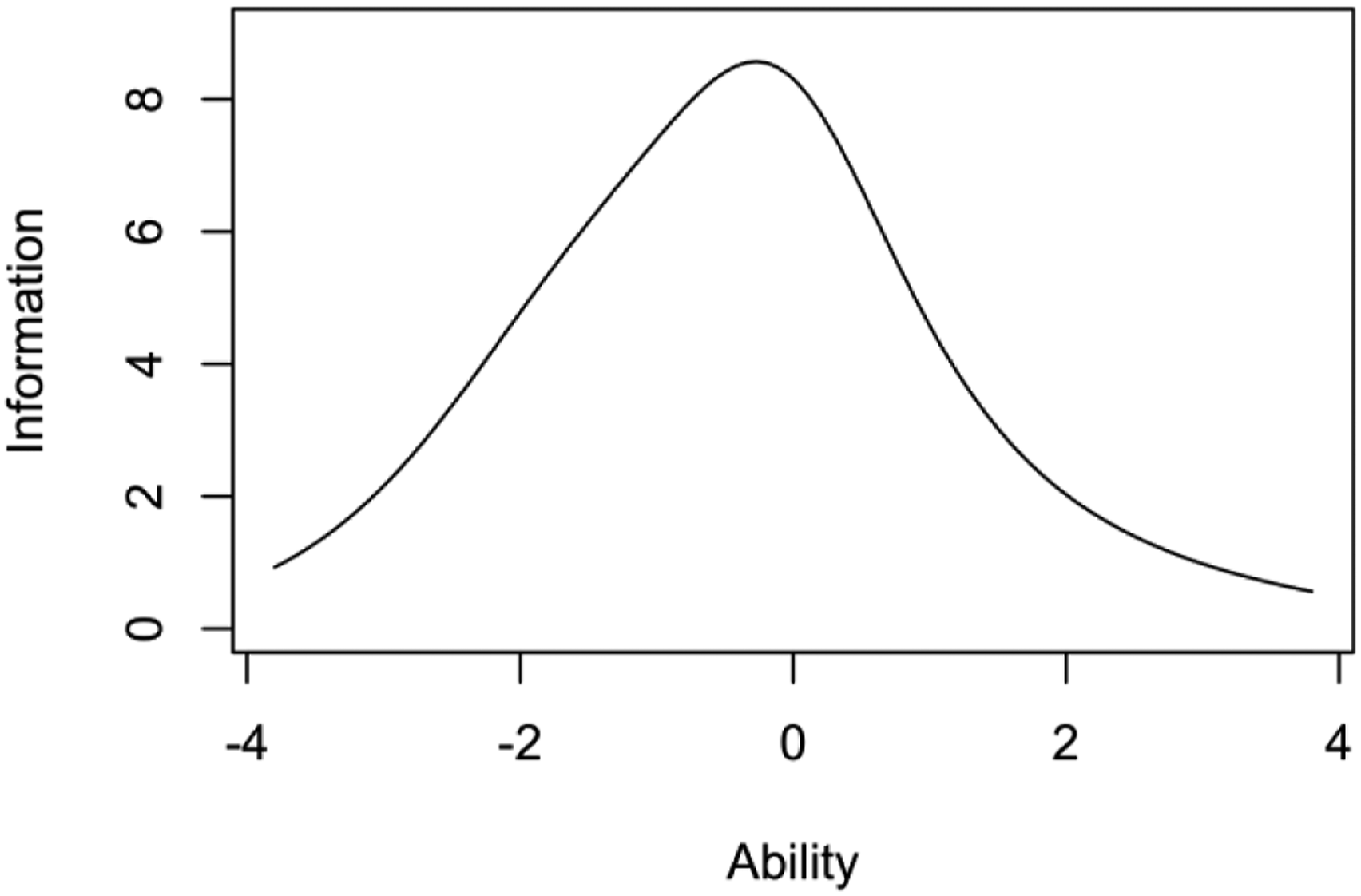
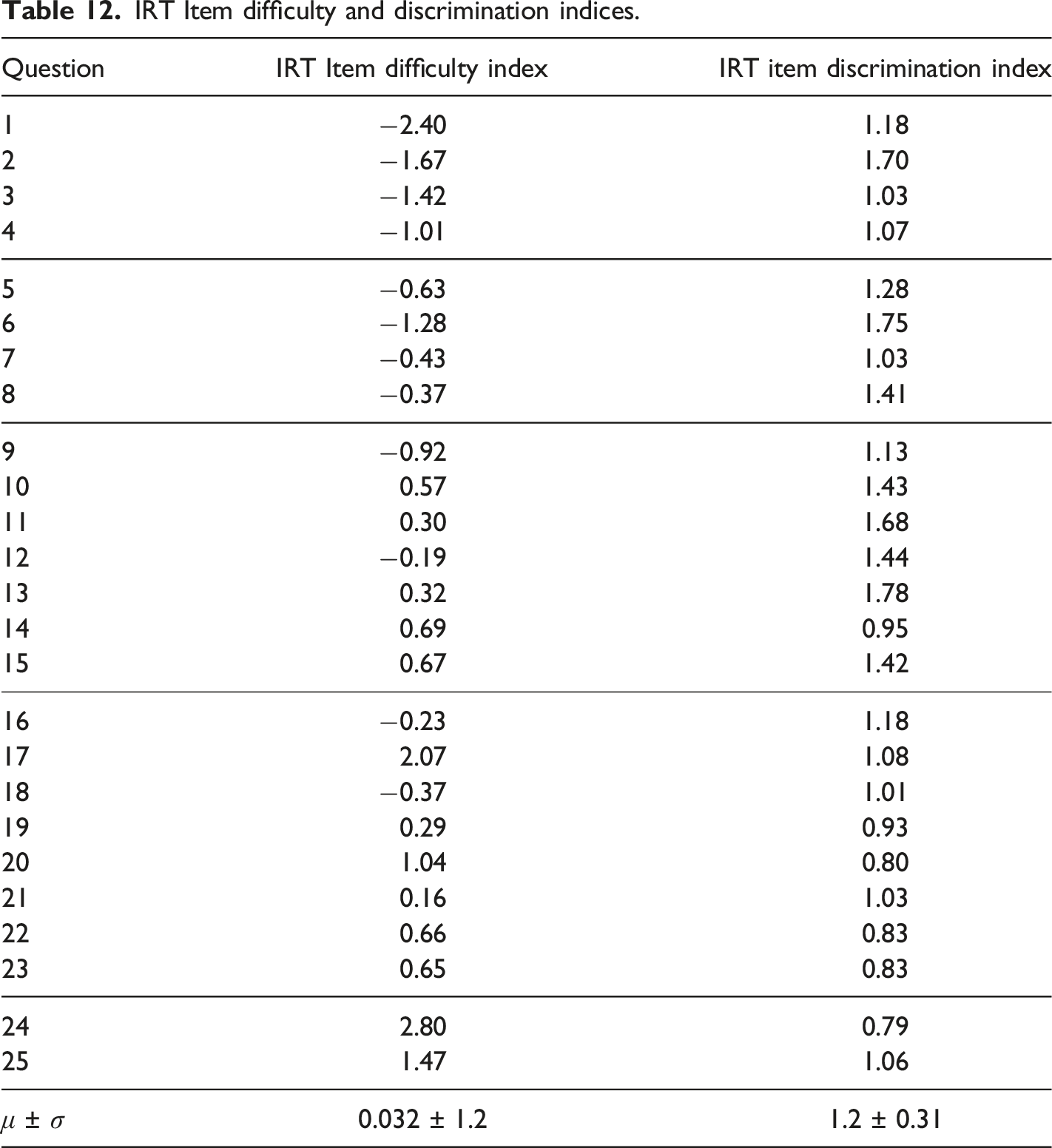
The IRT analysis results with the 2-PL model are shown in Figure 7, 8 and 9. The Item Characteristic Curves (or ICC) show the probability of selecting the correct response for a given question of the cCTt with respect to the students’ ability. In Figure 7, easier questions are those with a curve which begins to increase already at lower abilities. Additionally, questions which better discriminate between students with high and low ability are those with a steeper slope. The objective is to have a test that is composed of questions with varying degrees of difficulty, thus covering a wide spectrum of abilities, and which discriminate well (steep slopes). The ICCs in Figure 7 show curves at varying levels of ability, with easy and medium questions discriminating better than harder ones. Indeed the average test difficulty is equal to 0.032 ± 1.2 on the logit scale, with the easiest question yielding a difficulty index of −2.4 and the hardest a difficulty index of 2.8 (see Table 12). The Item Information Curves (IIC) in Figure 8 offer complementary information by indicating the amount of information that each question provides for a given ability. This means that more precise items at a given ability level are higher on the IIC scale. As higher peaks appear in the low to medium ability range, the test would appear to be better suited to discriminate between students at that level. This is confirmed by the Test Information Function (TIF, sum of the IICs, Hambleton & Jones, 1993) in Fig. 9 which is centered around 0 (medium ability) and slightly higher on the left than on the right, thus providing more information about students with lower abilities than with higher abilities. 2-PL model IRT Item Characteristic Curves (ICC). 2-PL model IRT Item Information Curves (IIC). 2-PL model IRT Test Information Function (TIF). IRT Item difficulty and discrimination indices.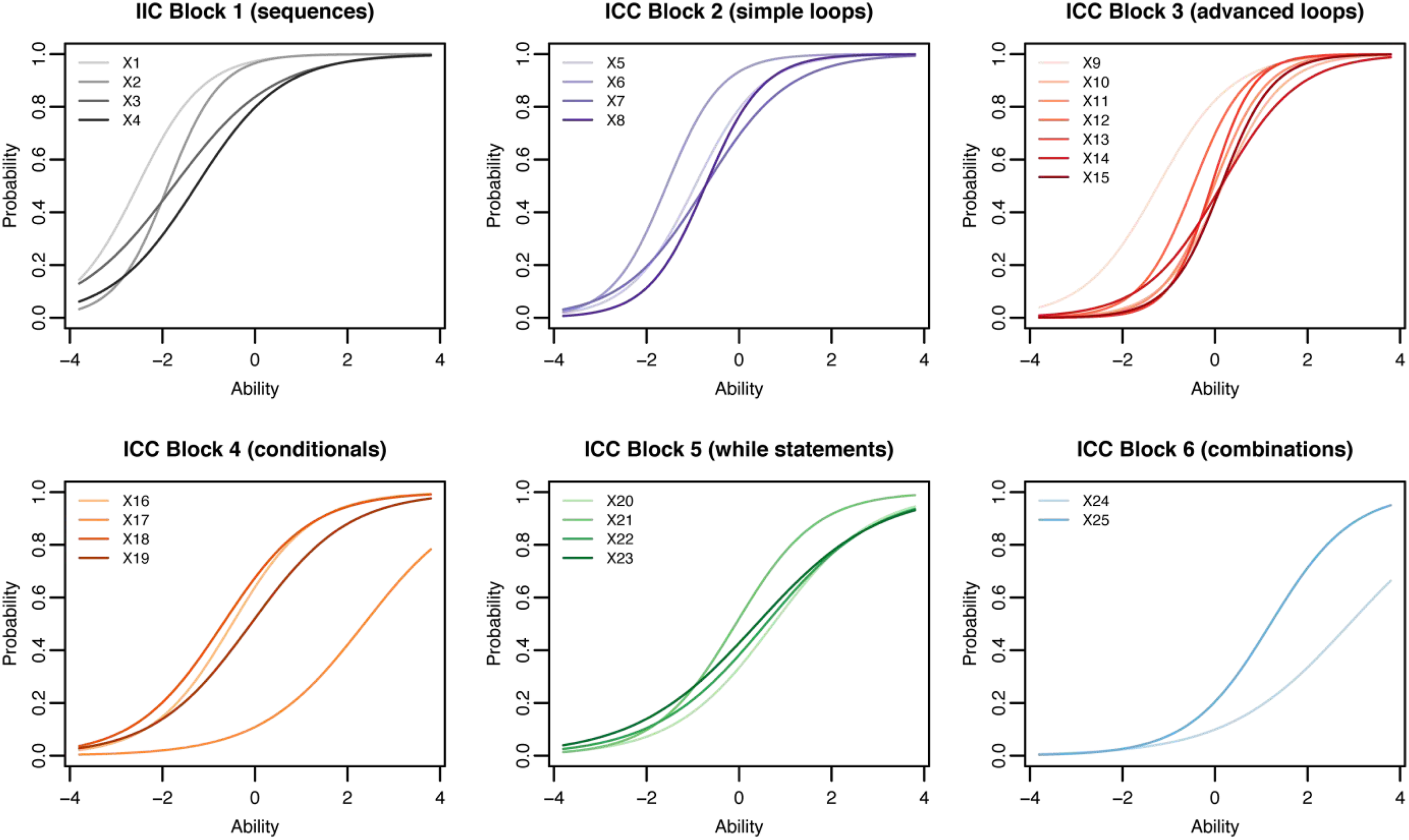
RQ3: Shortening the cCTt through Confirmatory Factor Analysis
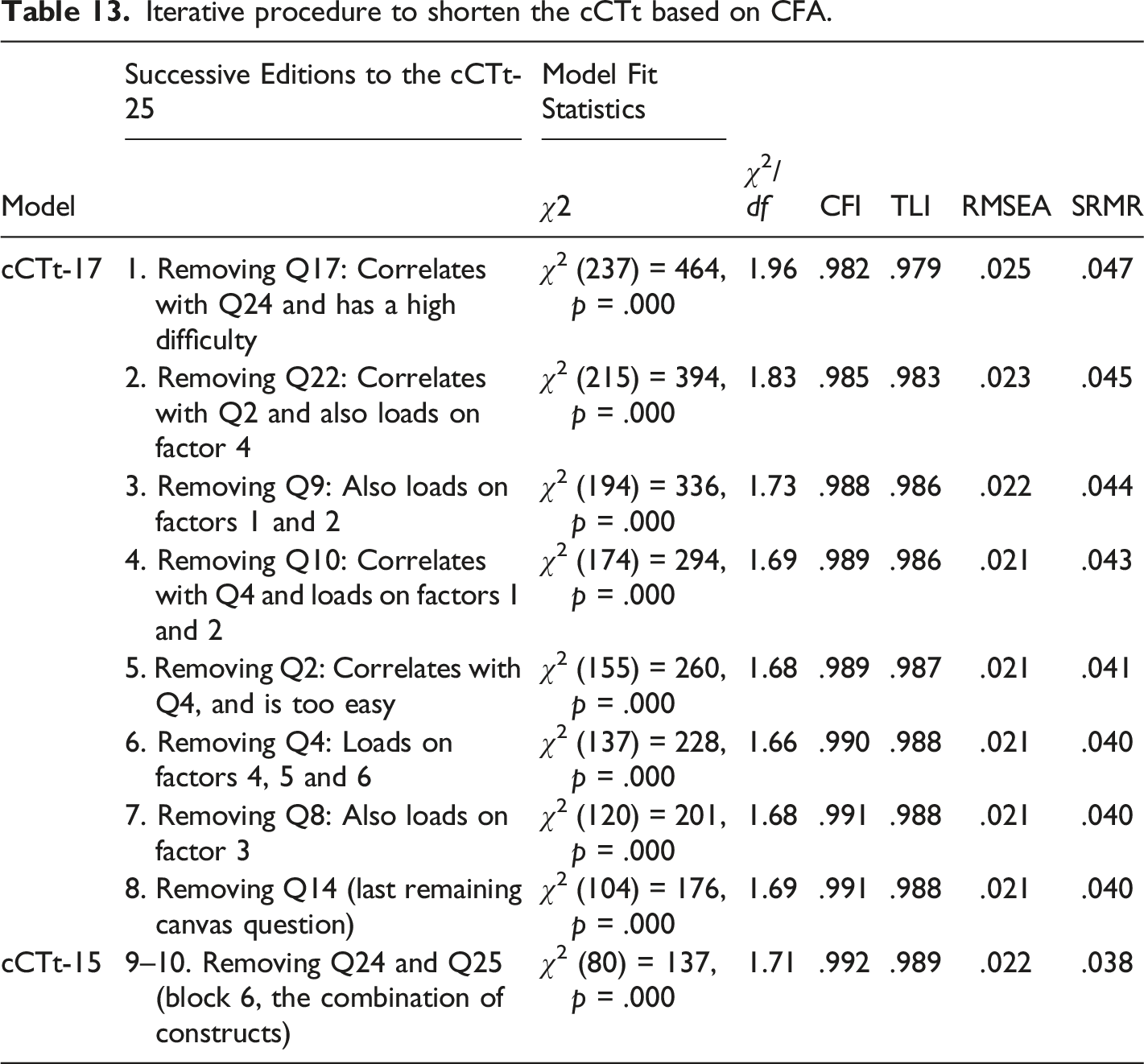
Administration times lasted on average 35 minutes for students in grade 3 and 30 minutes for students in grade 4, according to an estimation with 453 grade 3 students and 680 grade 4 students. Teachers reported having taken a an average of 65 ± 35 minutes (minimum 25 minutes, median of 50 minutes, and a maximum of 4 sessions) to administer the test, including explanations, examples provided to students and breaks. Provided the expert evaluation where 41% of experts considered that the test was too long, as well as the teachers’ feedback following the test administration, in addition to the reported duration of administration, it is important to consider how the test may be shortened. Since the results of the Classical Test Theory analysis (see section Reliability through Classical Test Theory and item analysis) showed that the problematic questions were the same for students in grade 3 and grade 4 alike (despite students in grade 3 scoring less), we believe that there is not enough difference to justify having an ad-hoc test for each grade. That is why we chose to apply the same shortening procedure, independently of the students’ grade, to propose several shorter versions of the cCTt which we validate on the full dataset. The chosen approach is Confirmatory Factor Analysis, more specifically using the provided modification indices (i.e., the amount by which the χ2 statistic would improve) to identify questions which are highly correlated and thus redundant, or load on other factors (and thus reduce the model’s fit). Therefore, taking into consideration that we would like to have blocks which are somewhat balanced in length, we iteratively removed questions as described in Table 13. The resulting variants of the test are presented in Table 14: • The cCTt-25, the longest version of the test which meets all the traditional thresholds for the model fit statistics. • The cCTt-17, which covers the same breadth of constructs of the cCTt-25 but lacks a certain number of redundancies over the different blocks of questions. • The cCTt-15, the fastest and most focused test, which does not include the final block of questions that evaluate the combination of concepts and were the most difficult for students. Iterative procedure to shorten the cCTt based on CFA. Questions in the variants of the cCTt.

Discussion and Conclusion
With the introduction of CT in curricula worldwide, there is a pressing need to have validated and reliable instruments to assess Computational Thinking throughout mandatory schooling. It is not surprising to see that CT assessment is one of the most prominent topics in CT research (Tikva & Tambouris, 2021), with researchers working to develop instruments from kindergarten (Relkin et al., 2021), through primary school (Relkin et al., 2020; Zapata-Cáceres et al., 2020) and up to middle school (Román-González et al., 2017, 2019). However, and to the best of our knowledge, none have proven to be both valid and reliable measurements of CT in upper primary school. Therefore, building up on the CT test (Román-González et al., 2017, 2019) designed for middle school, and the subsequent BCT test which adapted the CT test and validated it for use in lower primary school, we developed the cCT test to pally the lack of validated instruments in upper primary school.
The cCT test is an unplugged CT assessment adapted from the BCT test in terms of format and content, to be administered to students in the 7–9 age range regardless of their prior coding experience. The test is composed of 25 multiple choice questions of increasing difficulty and addressing notions of sequences, loops, conditionals and while statements. To assess the tests’ validity (face, construct, and content validity) we conducted an expert evaluation with 37 participants. The survey results and focus group indicate that the test has good face, content and construct validity. Then, to validate the psychometric properties of the cCTt (in terms of validity and reliability), the test was administered to 1519 students from 77 classes in grades 3 and 4 (ages 7–9) enrolled in 7 schools of the same region. The analysis of the results involved three stages and the outcomes can be summarized as follows. In the first stage, Confirmatory Factor Analysis confirmed the construct validity of the different blocks of the test. In the second stage, the results from Classical Test Theory showed that there was no evident ceiling or flooring effect, with scores distributed around 14/25, although students in grade 3 score significantly lower than those in grade 4. The Classical Test Theory analysis also indicated adequate reliability with good internal consistency (Cronbach’s α = 0.85), levels of discrimination (Point-biserial correlations > 0.2) and a wide range of question difficulties (proportion of correct responses). In the final stage, the Item Response Theory analysis supported these findings and further indicated that the test was better suited at evaluating and discriminating between students with low and medium abilities. In addition to the psychometric analyses, and to pally the limitations posed by administration time that were brought up both by teachers and experts, several shortened versions of the cCT test are proposed (cCTt-17 and cCTt-15), having been established through an iterative shortening procedure using Confirmatory Factor Analysis.
While the test has adequate face, content, and construct validity, as determined through expert validation, and good psychometric properties, there are two main limitations. Firstly, to achieve a more exhaustive measurement of CT is important to consider combining assessments such as the cCTt with other forms of assessments (Grover et al., 2015; Román-González et al., 2019), thus improving the content validity of the overall assessment scheme. This is because the cCTt, as a paper-based test, does not measure all aspects of CT. The cCTt specifically focuses on computational concepts and practices while lacking computational perspectives (Román-González et al., 2019), and more generally competences (Lye & Koh, 2014), an identified limitation of many summative CT assessments. Secondly, criterion validity needs to be established with respect to a “gold standard”. Three main approaches exist. Typically, researchers make a comparison with other assessment methods (convergent validity, Relkin et al., 2020, 2021; Román-González et al., 2017). More classically however, criterion validity is established through i) Determining the test’s predictive validity (i.e., does the test predict something that it should predict, such as academic performance and coding achievement, as done in Román-González et al., 2018) ii) Determining its concurrent validity (can the test distinguish between two populations that are distinct, for example, can we distinguish between students who partake in CT-related activities and those who don’t?).
Provided that validation is a multi-step process which requires “collect[ing] multiple sources of evidence to support the proposed interpretation and use of assessment result[s]” and “multiple methodologies, sources of data, and types of analysis” (Gane et al., 2021), future work should continue to validate the instrument in consideration of the test’s content and criterion validity, for both the target and older age groups (namely grades 5 and 6).
To conclude, the cCTt appears to be a valid and reliable instrument for CT assessment in grades 3 and 4 (students aged 7–9), which should be combined with other assessments to include computational perspectives and practices. The test is easy to administer and score on a large scale. With this work, we therefore extend the portfolio of CT assessments designed for use by researchers and teachers in formal education. In particular, the BCTt, cCTt, and CTt now jointly cover the range needed for CT assessment throughout primary and secondary school, by means of unplugged tests. It would be desirable, however, to extend the study by applying the cCTt to other populations, and to specifically study the age limits for using one test or the other.
Footnotes
Acknowledgments
We would like to thank all those who were implicated in the expert evaluation, test administration in the schools, as well as the teachers and students who participated in the validation process.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the NCCR Robotics, a National Centre of Competence in Research, funded by the Swiss National Science Foundation (grant number 51NF40_185543), and the Madrid Regional Government, through the project e- Madrid-CM (P2018/TCS-4307) which is also co-financed by the Structural Funds (FSE and FEDER).