
Abstract
This article builds upon a proiminent definition of construct validity that focuses on variation in attributes causing variation in measurement outcomes. This article synthesizes the defintion and uses Rasch measurement modeling to explicate a modified conceptualization of construct validity for assessments of developmental attributes. If attributes are conceived as developmental, hypotheses about how new knowledge builds cumulatively upon the cognitive capacity afforded by prior knowledge can be developed. This cumulative ordering of knowledge required to accomplish test items constitutes evidence of a specific form of construct validity. Examples of cumulative ordering appear in the extant literature, but they are rare and confined to the early literature. Furthermore, cumulative ordering has never been explicated, especially its relationship to construct validity. This article describes three of the most complete examples of cumulative ordering in the literature. These examples are used to synthesize a method for assessing cumulative ordering, in which the Rasch model is used to assess the progression of item difficulties which are, in turn, used to review developmental theories and hypotheses, and the tests themselves. We discuss how this conceptualization of construct validity can lead to a more direct relationship between developmental theories and tests which, for practitioners, should result in a clearer understanding of what tests results actually mean. Finally, we discuss how cumulative ordering can be used to facilitate decisions about consequential validity.
Keywords
In human measurement, the word validity has been redefined numerous times since the 1920s. Kelley's (1927) oft-cited definition plainly states that “the problem of validity is that of whether a test really measures what it purports to measure” (p. 14). Kelley also noted that isolating the causal relations of an attribute to establish validity in the first instance is the most difficult problem confronting test developers. Kane (2016) recently made the same observation. In their definition of construct validity, Borsboom et al. (2004) acknowledged the importance of the causal relations of an attribute, stating that a test is valid “if (a) the attribute exists and (b) variations in the attribute causally produce variations in the outcomes of the measurement procedure” (p. 1061). This definition partially represents the basis of the cumulative ordering of assessments for developmental attributes. In this article we extend this definition to explicitly encompass patterns within person-item outcomes.
The first aim is to extend Borsboom et al.’s (2004) definition of construct validity by adding a third criterion designed to isolate the causal relations of developmental attributes. It states that “(c) person-item level outcomes conform with specified hypotheses of cumulative development in the attribute.” In their definition, Borsboom et al. (2004) focus on the attribute affecting outcomes at the level of total scores; we extend this to focus on the attribute affecting the pattern of scores across items. The third criterion is designed for tests of developmental attributes, in which new knowledge and skills are hypothesized to build on prior knowledge and skills. Hence, this third criterion is based on the notion that people with less knowledge tend to answer only simple questions correctly. And with increasing knowledge, people tend to answer simple plus increasingly difficult questions correctly in a way that proceeds developmentally. We do not believe this to be a simple linear relationship, but a cumulative one, whereby knowledge builds on the cognitive capacity underpinned by prior knowledge acquisition in a way that parallels multiplicative cell growth in biological structures (for a discussion, see Humphry, 2017). Here, cognitive capacity represents the potential of an individual to acquire new knowledge and develop further, and this potential is directly proportional to the magnitude of that underlying capacity.
Our conceptualization of cumulative ordering contributes to the ongoing debate about the need for substantive theory in human measurement (see Borsboom & Mellenbergh, 2004; Humphry, 2017; Michell, 2019; Sijtsma, 2012; Sijtsma & Emons, 2013), which was perhaps most clearly stipulated by Duncan (1984): As I see it, a measurement model worthy of the name must make explicit some conceptualization—at least a rudimentary one—of what goes on when an examinee solves test problems or a respondent answers opinion questions; and it must incorporate a rigorous argument about what it means to measure an ability or attitude with a collection of discrete and somewhat heterogenous items (p. 217, emphasis in original).
The second aim is to synthesize a method for assessing cumulative ordering. We have found very little evidence of the explication of cumulative ordering in the literature and its relationship to construct validity. The examples that do exist, which we will explore in depth later, were either applied prior to the introduction of modern test theory (see Thurstone, 1928) or confined to earlier literature in Rasch measurement modeling (see Bond & Bunting, 1995; Wright & Masters, 1982). As such, cumulative ordering as a concept, for the most part, must be inferred by the reader. To use an early example, Guttman (1944) explained that one reason for attaining Guttman-like data is to measure developmental progress in each person. It might be inferred here that a further stipulation implied in Guttman’s work is that people attain item level outcomes in a manner that corresponds with some developmental hypothesis. But it is not guaranteed that the reader will make any such inference, even though it is a logical extension to Guttman’s position. In a similarly way, Rasch (1980) originally referred to the “ordering of items simply by the number of persons who solved each item correctly” (p. 65, italics in original), but he did not discuss the relationship between such ordering, nor did he hypothesize why skills and knowledge develop progressively.
It is a scientific hypothesis that if a given developmental attribute exists, it has a cumulative nature in which people normally build knowledge cumulatively. The hypothesis may be derived from a broader theory of learning in a domain such as language acquisition. In testing specific hypotheses pertaining to such theory, researchers can (i) formulate hypotheses about the order in which new knowledge builds upon prior knowledge, with specific consideration given to the potential for exponential growth in cognitive capacity, (ii) construct items that assess this knowledge along the developmental continuum, (iii) administer the instrument to groups of persons, and (iv) use the Rasch model to examine the degree to which item difficulties conform to the hypotheses. To the degree that the item ordering follows these hypotheses, the hypotheses are supported or refuted. To the degree that they are supported, the construct validity of the instrument is strengthened via the empirical ordering of the progression of knowledge. Other psychometric models can be used to assess cumulative ordering, but different considerations will be required depending on which model is chosen.
Background
In this article, we sketch a brief history of the definition of instrument validity in human measurement, followed by a short discussion about the definition of the term in the physical sciences. We then provide an illustration of cumulative ordering as evidence of construct validity in instruments of developmental attributes. Next, we synthesize a simple method for assessing cumulative ordering, based on three rare, and incomplete, examples in the extant literature (see Bond & Bunting, 1995; Thurstone, 1928; Wright & Masters, 1982). In the discussion, we describe how cumulative ordering can be used to refine developmental theories and, in turn, revise instruments. We discuss how cumulative ordering can strengthen the link between theories and instruments, leading to less ambiguity about what these instruments actually measure. Finally, we discuss how a clearer understanding of what an instrument measures can lead to better-informed decisions about consequential validity.
In the early 1950s, a joint committee of the American Psychological Association, American Educational Research Association, and the National Council on Measurements in Education (1954) wrote a series of technical recommendations to standardize psychological and educational test manuals. The aim was to help practitioners better understand the purpose and results of the instruments they used. In particular, the recommendations introduced the term construct validity which, like Kelley’s (1927) definition, was described as the degree to which an instrument measures the attribute it intends to measure. The recommendations stated that construct validity must be evaluated using a “logical and empirical attack” (p. 14), whereby an instrument is said to measure what it intends to measure if its results are correlated with those of another instrument measuring a related attribute. As such, the joint committee effectively claimed that an instrument is valid if it measures some other attribute, the instrument for which could itself have been validated using the same oblique method. In this context, the question of whether an instrument measures the attribute it purports to measure, and whether the observed behavior is a manifestation of the attribute itself, is never directly addressed.
Cronbach and Meehl (1955) elaborated on this definition of construct validity, asserting that attributes are characterized by laws that position them within complex systems of interrelated attributes called nomological networks. Once again, here the construct validity of an instrument depends on the degree to which its results are correlated with those of other instruments in the network. Cronbach and Meehl explained that this chain of inference is “very complicated” (p. 294), and that to increase the degree of validity an instrument must “send out roots in many directions, which attach it to more and more…constructs” (p. 291). We agree with Borsboom et al.’s (2004) conclusion that this method is problematic because in human measurement there are only loosely specified theories of how two or more attributes relate to each other, but also because nomological networks are themselves theoretical constructions without empirical basis. Much like the method proposed by the joint committee of the APA, AERA, and NCME (1954), this approach did not recognize the causal effect of variations in the attribute on the measurement outcome, making it difficult to know what is being measured.
Until the 1970s, the Standards for Psychological and Educational Testing (APA, AERA, & NCME, 1974) recommended a method for establishing construct validity that was closely aligned with Cronbach and Meehl’s (1955) approach. It was Cronbach (1971) who once again contributed to validity theory when he asserted that tests themselves should not be validated, but that instead the interpretation of the results should be validated. Cronbach (1988) believed that validation involves more than test accuracy. This represented a critical shift in validity theory. The idea was developed further by Messick (1989) in his unified concept of validity, in which he explained that interpretations of test results must be validated, inferences about test results must be validated, and the resulting ethical implications must be validated. Messick highlighted the ethical implications of test results as central to construct validity, and recommended that practitioners ask, “Should the test scores be interpreted and used in the manner proposed?” (p. 11, emphasis in original). Messick went as far as to assert that such considerations are as important as empirical evidence of construct validity.
Messick’s (1989) approach became known as consequential validity because of its strong focus on the social consequences of test use. It received both criticism and praise. For example, Wiley (1991) explained that how a test is used is important, but beyond the scope of validity. Popham (1997) added that conflating the analysis of what an instrument measures with the social consequences of how results are interpreted is counterproductive and risks detracting from the aim of examining validity, which is to determine the accuracy of score-based inferences. Furthermore, Mehrens (1997) warned that in consequential validity a test may be considered invalid for making an inference, even though the instrument itself measures changes in the attribute accurately. His point here was clear, “If validity is everything, then validity is nothing” (p. 18). Borsboom (2006) later added that this “black hole” of construct validity mystifies the “question of whether a test measures a certain attribute or not” (p. 431). Despite this kind of criticism, Messick (1995, 1998) defended his position and stated that “it is not possible to separate score meaning from the consequences of legitimate interpretation and use because these consequences are an inherent part of score meaning” (1998, p. 42). Messick added that the consequences of test use are integral to construct validity because they can signal shortcomings such as construct underrepresentation and construct-irrelevant variance.
Others agreed with Messick. For example, Linn (1997) viewed consequential validity as an evolution of a “primitive” question about the truth (p. 15). Linn believed that separating empirical validity from the consequences of test use is equivalent to relegating consequences to a lower priority. More recently, Kane (2001) defended the approach using a medical analogy. He stated that an accurate diagnostic test that causes serious side-effects might be valid in limited studies in search of treatments, but not in everyday clinical settings. The method for establishing construct validity reported in the most recent edition of the Standards (AERA, APA, & NCME, 2014) also closely resembles Messick’s approach, and places strong emphasis on score interpretations: It is the interpretations of test scores for proposed uses that are evaluated, not the test itself. When test scores are interpreted in more than one way (e.g., both to describe a test taker’s current level of an attribute being measured and to make a prediction about a future outcome), each intended interpretation must be validated. Statements about validity should refer to particular interpretations for specific uses. It is incorrect to use the unqualified phrase “the validity of the test” (p. 11).
In this brief historical review, we have shown that since the 1950s the approach to construct validity has gradually shifted away from directly addressing whether an instrument measures what it intends to measure. We do not intend to argue whether the consequentialist approach is an appropriate conception of validity. However, we do intend to illustrate that cumulative ordering improves the accuracy of what an instrument intends to measure. This may have a number of advantages. In cumulative ordering, the instrument represents a kind of framework of the underlying theory; a device intentionally designed to capture variations across the continuum. We believe this link between theory and instrument will lead a clearer understanding of what an instrument actually does, and that this will, in turn, lead to better-informed decisions about consequential validity. Ethical considerations may indeed be as important as empirical evidence of construct validity (Messick, 1998), but such considerations depend, primarily, on the accuracy of the empirical evidence. That is, the consequences of how a test is interpreted cannot be fully known until what the test measures is understood. Hence, even if “it is the interpretations of test scores for proposed uses that are evaluated, not the test itself” (AERA, APA, & NCME, 2014, p. 11), the nature of such interpretations depends on knowledge of what the test measures. Stated slightly differently, we do not disagree with Kane’s (2001) medical analogy. But we do believe that the analogy only works if the clinician understands precisely what the test itself measures.
Therefore, we agree with Borsboom et al.’s (2004) definition of construct validity because it attempts to address whether an instrument measures what it intends to measure. We see this as fundamental to any serious attempt to establish construct validity and, by extension, consequential validity. Our third criterion for cumulative ordering adds specificity to Borsboom et al.’s definition, connecting it to the Rasch model. Implicit here is the need to structure instruments using theories that describe the cumulative development of capacity, whereby knowledge builds on cognitive capacity underpinned by prior knowledge. Hence, our third criterion assesses if the progression of item difficulties in an instrument corresponds with the hypotheses used to construct it. As such, evidence of cumulative ordering allows practitioners to better answer the critical question, “what are we measuring, anyway?” More formally, it is evidence that (a) the attribute exists, (b) variations in it causally produce variations in the outcomes of the procedure, and (c) person-item level outcomes conform with specified hypotheses of cumulative development in the attribute. To the degree cumulative ordering is obtained, the functioning of the instrument across the developmental continuum is validated. To the degree that it is not obtained, the true functioning of the instrument cannot be known. Nor can the consequential validity of the instrument.
Causal Relations
Borsboom et al. (2004) emphasized the need to establish that variations in an attribute causally produce variations in measurement outcomes. This is how measurement in the physical sciences functions. For example, variations in the quantity of a physical phenomenon, such as atmospheric temperature, cause commensurate quantifiable change in the measurement outcome, such as the volume of mercury in the partial vacuum of a mercury-in-glass thermometer. In this example, changes in the volume of mercury are not changes in the atmospheric temperature itself, but rather a manifestation of such changes, which can be observed and used for hypothesis testing in scale development (for historical discussions, see Barnett, 1956; Sherry, 2011). As such, Humphry (2017) observed that in the physical sciences: It has proven possible to measure a given physical attribute in different ways because principles of both the design and operation of measurement instruments are based on substantive, quantitative theory. The relevant quantitative theory encompasses a number of specific, causal relations between quantities. Instruments and procedures are designed to: (a) isolate one causal relation from other causal relations and (b) minimize the effect of extraneous variables on the outcomes of the procedures (p. 417).
Psychometrics does not deal with the kinds of deterministic phenomena found in the physical sciences, hence “psychometric laws” that serve as analogs of the physical laws underlying measurement do not exist at this time (for discussions, see Duncan, 1984; Humphry, 2011, 2017; Michell, 2014; Sijtsma & Emons, 2013). Nevertheless, the attributes measured in psychometrics are theoretical attributes hypothesized to manifest as behaviors, and insights to the development of these attributes can have significant implications in practice (Briggs, 2017). Consideration of physical measurement brings us back to Kelley’s (1927) acknowledgment of the difficulty of isolating the causal relations of an attribute, and Kane’s (2016) statement that “causal inferences are notoriously hard to establish” (p. 200). Cumulative ordering is not intended to be a psychometric law, but it is intended to represent a generalized approach to framing probabilistic relations in human measurement, forming an important step in the overall consideration of construct validity.
Without a body of quantitative psychological theory and law, it is difficult to isolate causal relations as a foundation for the measurement of attributes as it occurs in the physical sciences. Nonetheless it is still possible to investigate the specific item level causal relations of an attribute on item responses to ascertain whether cumulative ordering accords with developmental hypotheses. Evidence that shows developmental data conform reasonably to the Rasch model (Bond & Bunting, 1995) also indicates that developmental phenomena may progress exponentially to a point, so that cognitive capacity builds on itself at a rate proportional to current capacity, rather than at a linear rate independent of capacity (Humphry, 2017). In this way, we can respond to Duncan’s (1984) query about “what goes on when an examinee solves test problems” (p. 217), by postulating how different stages of development represent the building of knowledge, with specific reference to how knowledge builds upon existing cognitive capacity at each stage. With reference to cumulative ordering, if an individual is early in the development process, what specific cognitive capacity exists which leads to relatively small incremental gains in knowledge? And if an individual is more advanced, what are the broader cognitive bases from which greater absolute gains in knowledge develop, and how is this capacity specifically recruited to achieve multiplicate gains?
Finally, theory-based attempts to empirically minimize construct-irrelevant variance are analogous to isolating one physical relation from other relations known to be relevant to the measurement of a physical quantity. That is, just as Anders Celsius used mercury because it is relatively easy to expel impurities from it (Sherry, 2011), we intend to explicate cumulative ordering as a conceptualization of construct validity because it is an effective way to identify and reduce construct-irrelevant variance in developmental attributes. That is, where item difficulties do not accord with the underling hypothesis for development, an iterative process can begin in which the hypotheses, or broader theory, are revisited and perhaps the instrument is itself modified or rewritten. It is this kind of improvement in construct validity that could increase the likelihood of measuring what was intended. More formally, this process could be incorporated into the development of Kane’s (2013, 2016) interpretation and use arguments (IUAs) for instruments. In his discussions of argument-based validity, Kane explained that test validity requires an explicit network of inferences and assumptions linking test results to conclusions about the attribute. We agree, and would add that cumulative ordering could be used to inform IUA refinements, which may, in turn, lead to better-informed decisions about consequential validity.
A Method for Cumulative Ordering
We synthesize a simple method for assessing cumulative ordering. Variations of this method have been applied in the extant literature, but this is rare (for examples, see Bond & Bunting, 1995; Thurstone, 1928; Wright & Masters, 1982). The method combines the developmental theory used to construct the instrument with the item difficulty ordering inherent to the Guttman structure and Rasch model. The method tests if the progression of item difficulties in an instrument corresponds with the developmental hypotheses used to construct it. If so, this is evidence that the instrument measures progression in cognitive development. One additional raw score point reflects a progression in development, as measured by the specific item constructed for that developmental position. This is consistent with Guttman’s (1944) stipulation that each additional raw score point should represent an increment in ability, where “a score of 3 means more than a score 2 because the person with a score of 3 knows everything a person with a score of 2 does, and more” (p. 143).
However, in Guttman’s stipulation, the items comprising a particular raw score are not required to be linked to any developmental hypotheses. Therefore, it can be said that in the physical sciences measurement is at least partially achieved via knowledge of physical theory relating to quantities and quantitative relations. On the other hand, in psychometrics, it appears possible to make greater progress in the measurement of developmental attributes if there is conceptual knowledge of the theory of the attribute. This is not an entirely new concept. Piaget (1971) conceived cognitive development as a cumulative process, explaining that cognitive “structures offer a process of integration such that each one is prepared by the preceding one and integrated into the one that follows” (p. 17). As will be shown later, Bond and Bunting (1995) applied a form of cumulative ordering to demonstrate a “remarkable corroboration” (p. 242) between Piaget’s conceptualization of the development of formal operational problem-solving as measured by the pendulum task in the méthode clinique, and the Rasch model.
The method we synthesize here includes three steps. First, hypotheses are developed or the extant literature is referenced to determine the developmental structure of the attribute. In this step researchers consider the nature of the attribute, with specific attention to the way knowledge builds on existing cognitive capacity at different stages of development. Second, items are written to assess specific progressions in development, as described in the hypotheses. This is consistent with Bond’s (Bond, 1995; Bond & Fox, 2015) conceptualization of construct validity. For example, Bond and Fox stated that each item in an instrument “should contribute in a meaningful way to the construct/concept being investigated” (p. 41). Third, the test is administered and analyzed using either the simple Guttman structure or the Rasch model. To the degree that the item ordering is as hypothesized based on developmental hypotheses, cumulative ordering is supported. To this degree, the construct validity of the instrument is demonstrated via a relationship between developmental theory and empirical data. Therefore, to establish cumulative ordering is to confirm a specific aspect of construct validity where ordering has been hypothesized.
Furthermore, when designing an instrument, it is important to control for the extraneous factors that might conflate the results. For example, two common factors in mathematics are the need for working memory and understanding the procedures required to solve equations. Due to these complexities, it is important to develop a clear measurement objective based on the developmental theory underpinning an instrument. This definition must be precise and focus on how the factors, as causal relations, impact the development of the attribute. In this way, extraneous factors can be identified and minimized in the instrument. For example, in a mathematics test, if a certain level of working memory is considered intrinsic to the attribute, it is part of what is being measured. Otherwise, the need to use working memory should be minimized. For this reason, in cumulative ordering, the shortcomings described by Messick (1989), including construct underrepresentation and construct-irrelevant variance, are both addressed before a test can be misused and cause negative social consequences.
The Rasch Model Extends the Guttman Structure
The Guttman structure can be used as a simple tool to examine cumulative ordering. The Rasch model can be used as a supplementary tool to examine cumulative ordering in a more detailed way, especially for assessing the underlying cognitive capacity along the scale. The common expression of the model for dichotomous responses is
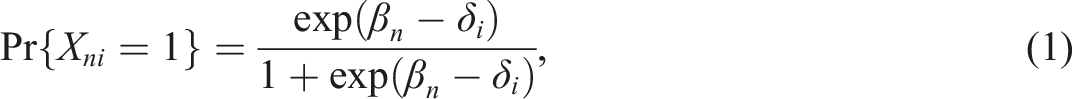
Examples of Applied Cumulative Ordering in the Literature
In the literature, we have found one instance in which a procedure for item ordering was briefly described and applied, although it did not represent cumulative ordering per se (Wright & Masters, 1982). And we have found one instance of applied cumulative ordering (Bond & Bunting, 1995). Prior to Georg Rasch conceiving the dichotomous Rasch model, both Allport and Hartman (1925) and Thurstone (1928) introduced a method for developing attitudinal scales by ordering statements that describe varying magnitudes of an attitude. Thurstone used a fictitious example, in which he described the development of a scale that measured attitudes toward defense policies. Judges rank ordered a series of statements from pacifistic to militaristic, and then sorted the statements into 11 stacks that appeared to represent evenly spaced magnitudes of the attitude. Judges’ decisions were not based on personal attitudes, but rather objective interpretations of the magnitude of the attitude inherent in each statement. Thurstone indicated that scales could be constructed via the direct application of his law of comparative judgment, which he had only recently introduced (see Thurstone, 1927).
Ambiguous statements that judges did not agree on were removed, as were statements that, after initial data were collected, were not endorsed in a manner consistent with their rank order. This latter process, which Thurstone described as an “objective criterion of irrelevance” (p. 549), appears to be the first instance of assessing the concordance of the rank order of statements as a basic kind of item fit analysis. Thurstone took each item on the scale and investigated whether the persons who endorsed it also endorsed any items located at vastly different positions on the scale. Such items were believed to be influenced by factors other than the degree of the attribute being measured. Overall, Thurstone’s aim was to obtain a “valid unit of measurement” (p. 541) through the development of a scale based, first, on the objective rank ordering of statements and subsequent scaling using the law of comparative judgment and, second, on an assessment of whether like-items were endorsed in manner generally consistent with their scale position. Thurstone did not discuss the use of theory to construct statements or inform the rank order of judgments, nor did he recommend using expert judges in his method. Thurstone also focused on attitudinal constructs and not development constructs. Nevertheless, his method was certainly an early precursor to the cumulative ordering we synthesize in this article.
Wright and Masters (1982) provided a general outline for assessing the concordance between the rank order of statements in an attitudinal instrument and subsequent item difficulty estimates derived using the polytomous Rasch model. Wright and Masters did not aim to assess the cumulative acquisition of knowledge within the individual over time, but instead described a procedure for simply assessing the concordance between nine judges’ rank-ordered statements, from least to most representative of the attitude, and subsequent item difficulty estimates. The researchers illustrated the procedure using a 25-item science questionnaire assembled by the Cleveland Museum of Natural History. The questionnaire aimed to measure children’s general attitude towards, or “liking” for, science. Each item was based on a three-point attitudinal scale, from 0, “Dislike,” to 1, “Not sure,” to 2, “Like.” The items described activities like, “Watching birds,” “Reading books on plants,” and “Talking with friends about plants.” Judges ordered the statements by followed the procedure described by Thurstone (1928). They initially ordered statements using an 11-point scaled, from 1, “Easy-to-like” science activity, to 11, “Hard-to-like” science activity, and then placed the ordered items into 11 equally spaced stacks, with the aim of ordering items so that it was “possible to ‘see’ a line of increasing attitude” (p. 12).
Wright and Masters assessed whether the rank-ordered statements, describing “easy-to-like” science activities through to “hard-to-like” science activities, conformed to the item difficulty estimates, which were estimated using the UCON method. Wright and Masters examined the correlations between the hypothesized item order and the actual item difficulties by plotting judges’ median placement of the items against the item difficulties (see p. 94). The researchers did not discuss the purpose of this ordering review at length, other than to say that, to the extent that item difficulties conformed to the judges’ expectations, it affirmed the construct validity of the instrument. Nor did the researchers relate their method to developmental constructs, or the potential to assess whether item locations, as well as clusters of like-item locations, reflected any hypothesized growth in cognitive capacity within the individual over time.
Sometime later, Bond and Bunting (1995) administered Piaget’s pendulum problem to a sample of 58 children (aged 12.5–15.8 years) using the méthode clinique to assess cognitive development in formal operational problem-solving. Their aim was to subject Piaget’s empiricist approach in developmental investigations to the “number crunching” that had characterized American psychology since the early 1900s (p. 251). The pendulum problem was administered using the interview method described by Inhelder and Piaget (1955/1958) in Growth of Logical Thinking from Childhood to Adolescence, or the GLT as it is commonly named. Children were given various lengths of string suspended from fixed points, and weights that could be attached to the string (i.e., 40 g, 80 g, 100 g). They were encouraged to experiment with the stimuli to determine which variables (i.e., string length, weight, force, and/or angle) influenced the oscillation of the pendulum. The experimenters asked probing questions and made minor modifications to conditions to accurately understand each child’s cognitive processes. They assessed performances using a rubric derived from the GLT, which comprised of 18 criteria in the developmental order hypothesized in the GLT. Each criterion, in turn, comprised of statements describing increasingly advanced processes, forming an ordinal scale in each criterion. Overall, the rubric assessed processes from the preoperational (e.g., “able to accurately serially order lengths”) to the late formal operational (e.g., “systematically implements ceteris paribus experimental method”) stages of development.
Using a similar approach to Wright and Masters (1982), Bond and Bunting compared the hypothesized developmental order of each statement to the item difficulties derived from the polytomous Rasch model (i.e., partial credit model). The researchers found a “remarkable corroboration” between the Piagetian hypotheses and item difficulties, which they described as an “unprecedented validation of this aspect of the Piagetian œuvre” (p. 242). However, not all statements conformed to the hypothesized positions derived from the GLT, including a cluster of three statements that were easier than their hypothesized positions in the late formal operational stage (i.e., 7.2, 8.2, and 9.2). The statements referred to children systematically manipulating length, weight, and impetus, respectively, to produce different effects. It is beyond the scope of this article to discuss Piaget’s developmental stages in detail, but it is noteworthy that this cluster of items referred to relatively intuitive behaviors, not behaviors that we would expect to be underpinned by the broad capacity that characterizes the late formal operational stage. In light of their statistical analysis, Bond and Bunting acknowledged that these statements probably belong in the formal operational stage. We agree, but would add that the cluster reflects “easier” items that measure a lower level of cognitive capacity underpinned by fewer integrated structures, compared to statements measuring the late formal operational stage.
Sometime later, reflecting on the role of theory in instrument development, Bond (2004) stated that instrument development in the human sciences is typically characterized by a “bottom-up approach,” whereby instruments are developed, primarily with a focus on statistical parameters, and secondarily on post-hoc considerations about what the results reveal about the construct under investigation. Bond explained that, I am now much more convinced that measurement in the human sciences must be theoretically driven. In common with other quantitative rational sciences, we need theories of measurement of human variables which satisfy the requirements for scientific measurement. On the other hand, we need substantive theories about the human condition that allow us to examine how the responses that candidates make to our collection devices are connected with the human attribute under investigation, (p. 182).
We agree with this statement and with Bond’s perspective that concordance between the hypothesized order of items and item difficulty estimates provides “direct evidence of the validity of the testing procedure” (p. 187). We would, however, like to clarify that a priori considerations about the construct should drive the primary phase of development, in addition to considerations about the degree of the latent trait required for different raw scores (i.e., underlying cognitive capacity within the individual). But as illustrated in Bond and Bunting’s (1995) investigation of Piaget’s pendulum task, instrument development should also be iterative, inasmuch as aberrant statistical results are used to revisit the theories and hypotheses that underpin instruments, which are, in turn, revised to make constructive adjustments to instruments. This kind of iterative approach reifies our proposed third criterion in Borsboom et al.’s (2004) definition of construct validity, which states, “(c) person-item level outcomes conform with specified hypotheses of cumulative development in the attribute.” In light of Bond and Bunting’s formative work, it would seem useful to apply cumulative ordering to modern developmental inventories, such as the Bayley Scales of Infant and Toddler Development-III (Bayley, 2006) and the Brigance Inventory of Early Development-II (Brignance, 2008).
Discussion
This article introduces a scientific approach for gathering specific evidence of construct validity for assessments of developmental attributes. The approach is a conceptualization of construct validity that aims to establish an ideal condition named cumulative ordering. The first aim was to extend Borsboom et al.’s (2004) definition of construct validity by assessing if variations in the outcome of an instrument conform to the developmental theory used to construct it. As stated earlier, Borsboom et al.’s definition stated that an instrument is valid “if (a) the attribute exists and (b) variations in the attribute causally produce variations in the outcomes of the measurement procedure” (p. 1061). We have extended this definition by adding a third criterion, which states that (c) person-item level outcomes conform to the hypotheses regarding cumulative development used to construct the measurement process. This criterion is specifically designed for instruments of developmental attributes, in which new knowledge is hypothesized to build on prior knowledge, sequentially. This criterion operationalizes Borsboom et al.’s definition because it allows researchers to scientifically test whether (a) an attribute exists because (b) variations in it causally produce the hypothesized variations in the outcomes of the measurement procedure in a manner consistent with the hypothesized progression of cognitive capacity.
The second aim was to introduce a simple method for assessing construct validity based on cumulative ordering. The method described in this article uses the Guttman structure or Rasch model in combination with underlying developmental theory. Other psychometric models can be used to assess cumulative ordering, but different considerations will be required depending on which model is chosen. In cumulative ordering, the progression of item difficulties, from easy to difficult, follows the hypothesized progression of knowledge acquisition in a developmental attribute. Therefore, given cumulative ordering, we believe that “a score of 3 means more than a score 2 because the person with a score of 3 knows everything a person with a score of 2 does, and more” (Guttman, 1944, p. 143) because each raw score point in, for example, the probabilistic Guttman structure, reflects a specific developmental position reflected in the underlying hypotheses.
As such, in our conceptualization of construct validity, the continuum produced in the Guttman structure has substantive meaning. Clusters of related performances can be referenced back to specific elements of the developmental theory. For example, students who receive a raw score of 3 on a test can be located at a point on the developmental continuum as being able to perform everything up to, but not beyond, the first three items. Our conceptualization of construct validity is not a remedy for the psychometric problem of the intangibility of attributes. But the relationship between empirical evidence and theory relates behavior and the theorized structure of attributes in a specific manner. Changes measured in behavior reflect developmental theories analogous to the way that changes measured in the physical sciences reflect phenomena summarized using a body of theory and laws.
In this way, our conceptualization of construct validity is closely compatible with Kane’s (2013, 2016) approach to validity, and may foster the development of clearer interpretation and use arguments. In our conceptualization, the very concept of the IUA is implicit to the test development process. The test is the developmental theory, operationalized. As such, users who understand the theory will understand the purpose of the test and be able to make informed decisions about how to interpret and make inferences about results. This naturally removes the need described in the Standards for “each intended interpretation to be validated” (AERA, APA, & NCME, 2014, p. 11). Stated differently, in our conceptualization the interpretation of results are founded in the underlying theory. It is possible that test results could be misinterpreted or even misused, but the intended interpretation is instantiated in the theory itself.
Conclusion
In this article we have presented a nuanced middle-ground amongst existing conceptions of construct validity. Simplistic approaches that emphasize a kind of deterministic “validity of the test” fail to recognize that psychological attributes are not tangible or accessible in the same way as the phenomena measured in the physical sciences. Psychometric tests cannot be validated by simply referencing deterministic manifestations of the attributes they intend to measure because these attributes do not produce readily observable manifestations. On the other hand, consequentialist approaches to validity focus on validating the proposed uses of test results. More than anything else, we do not support validating the interpretations, inferences, and implications of a test that is itself possibly invalid, inasmuch as the test may not measure that attribute that it intends to measure. The danger here is that construct invalid tests are incorrectly considered to have consequential validity, leading to unknown deleterious social consequences arising from fundamentally inaccurate measurement.
The conceptualization that we have presented in this article builds on Borsboom’ et al.’s (2004) definition of construct validity in an attempt to address the inaccessibility of psychological attributes. Whereas instruments in the physical sciences are validated by referencing phenomena summarized using a body of theory and laws, our conceptualization references theories describing attributes. These theories detail the specific causal relations between factors that impact the cumulative progression of attributes. Therefore, in our conceptualization theories are analogous to phenomena in the physical sciences. We acknowledge that in real data sets the Guttman structure, and by extension the Rasch model, are probabilistic and lack deterministic precision. Nevertheless, the conceptualization presented here standardizes the requirement for establishing construct validity for assessments of developmental attributes, potentially improving the consequentialist decisions that test users must follow in documents such as the Standards (see AERA, APA, & NCME, 2014, pp. 11–31).
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.