
Abstract
Abrégé
Objectif
L’objectif de l’étude est d’évaluer la structure factorielle et les qualités psychométriques de l’Échelle de Fatigue Pandémique parmi la population adulte québécoise.
Méthode
Les données analysées proviennent d’une enquête Web réalisée en octobre 2021 auprès de 10 368 adultes résidant au Québec. La structure factorielle de l’échelle et l’invariance selon le sexe, l’âge et la langue utilisée pour le questionnaire ont été testées à l’aide d’analyses factorielles confirmatoires. La validité convergente et divergente ont aussi été évaluées. Enfin, la fidélité de l’échelle a été estimée à partir des coefficients alpha et oméga total.
Résultats
Les analyses suggèrent la présence d’une structure bidimensionnelle dans l’échantillon d’adultes québécois avec la fatigue informationnelle et la fatigue comportementale. L’invariance de la mesure est notée pour le sexe, pour les groupes d’âge et pour la langue utilisée pour la complétion du questionnaire. Les résultats de la validité convergente et divergente apportent des preuves supplémentaires à la validité de l’échelle. Enfin, la fidélité des scores de l’échelle est excellente.
Conclusion
Les résultats appuient la présence d’une structure bidimensionnelle comme dans les travaux initiaux de Lilleholt et coll. Ils permettent également d’affirmer que l’échelle possède de bonnes qualités psychométriques et qu’elle peut être utilisée parmi la population adulte québécoise.
Introduction
Au cours des dernières années, plusieurs instruments de mesure ont été élaborés ou adaptés afin de mieux comprendre l’impact de la pandémie de COVID-19 dans de nombreuses sphères psychosociales. Les sphères étudiées ont porté notamment sur la peur, 1 le stress, 2 l’anxiété,3,4 la phobie, 5 la détresse psychologique, 6 les ruminations, 7 le deuil, 8 le burn-out 9 et la fatigue.10–13
En ce qui concerne la fatigue pandémique (FP), Lilleholt et coll. 11 et Cuadrado et coll. 13 ont élaboré des questionnaires composés de six questions comprenant deux sous-échelles de trois questions chacune, qui mesurent la fatigue informationnelle (FI) et la fatigue comportementale (FC). La FI est une composante importante de la FP car elle permet d’évaluer le degré de saturation des individus lorsqu’ils sont confrontés à une surabondance d’informations sur la pandémie de COVID-19. L’autre dimension, la FC, mesure la démotivation à se conformer aux mesures sanitaires. L’importance de cette dernière dimension avait été mise en évidence par l’Organisation mondiale de la santé (OMS). 14
L’échelle de fatigue pandémique (ÉFP) la plus utilisée est celle de Lilleholt et coll. 11 Elle a été testée au Danemark et en Allemagne, et par la suite aux États-Unis. 12 L’échelle a été conçue pour mesurer deux dimensions, la FI et la FC. Les analyses de Lilleholt et coll. 11 confirment la présence des deux dimensions. Cet instrument a souvent été utilisé sans que sa structure factorielle et ses qualités psychométriques soient évaluées.15–25
Peu d’analyses ont été effectuées pour déterminer la structure de l’ÉFP depuis la publication de Lilleholt et coll. 11 Dans un article récent, Asimakopoulou et coll. 26 ont collecté des données dans une université située sur l’île de Chypre avec l’ÉFP. Une analyse factorielle confirmatoire (AFC) a montré qu’elles s’ajustaient bien à un modèle hiérarchique de second ordre. Une autre étude, réalisée en Espagne, 27 a par contre révélé, grâce à une AFC, qu’une structure unidimensionnelle représentait bien les données sur la FP. Enfin, une étude de Kyprianidou et coll., 28 par le biais d’analyses factorielles exploratoires (AFE), a suggéré que l’échelle est constituée de deux facteurs, qui expliqueraient entre 41% et 49% de la variance totale des données collectées dans quatre pays (Chypre, Italie, Pologne et Espagne). Récemment, Kurt et coll. 29 ont confirmé également la présence d’une structure bidimensionnelle en Turquie (à partir d’une AFC). Ainsi, les résultats concernant la structure factorielle de l’ÉFP sont contradictoires.
L’objectif premier de cette étude est de déterminer, à partir d’un échantillon d’adultes québécois, la structure factorielle et les qualités psychométriques de l’ÉFP. Il est important de pouvoir statuer que les données collectées parmi la population adulte québécoise représentent bien une structure bidimensionnelle, telle que conceptualisée dans les travaux initiaux. Le second objectif est de tester l’invariance du modèle retenu selon le sexe, l’âge et la langue utilisée pour compléter le questionnaire. Il est nécessaire de tester l’invariance de cette mesure afin de pouvoir conclure que la moyenne des scores totaux, des deux dimensions et de chacune des questions peuvent être utilisées sans biais, dans la comparaison des hommes et des femmes, des répondants des différents groupes d’âge et selon la langue utilisée, soit le français ou l’anglais. L’atteinte de ces objectifs est nécessaire avant de statuer que l’ÉFP est un outil utile et pertinent afin de mesurer la FI et la FC au sein de la population adulte québécoise.
Méthodologie
Population à l’étude
L’échantillon provient d’une enquête Web réalisée par le groupe Léger à partir des membres de leur panel, résidant au Québec. Ce projet s’inscrivait dans un plus vaste projet international visant à obtenir de l’information sur la réponse psychologique et comportementale des adultes à la pandémie de COVID-19. L’enquête a eu lieu du 1er au 17 octobre 2021. Au total, 10 368 adultes ont répondu à un questionnaire. Un objectif de recrutement de 750 à 2000 participants était visé pour les régions sociosanitaires les plus peuplées.
L’Échelle de Fatigue Pandémique
L’échelle de Lilleholt et coll. 11 est composée de six questions. Les trois premières questions mesurent le concept de FI et les trois autres évaluent le concept de FC. L’échelle a été traduite de l’anglais au français par la firme de sondage Léger puis vérifiée par les chercheurs responsables de l’enquête. Chaque question est répondue à l’aide d’une échelle de Likert à sept choix de réponses où 1 = totalement en désaccord et 7 = totalement en accord. Le score total des répondants varie donc entre 6 et 42, un score élevé indiquant une FP élevée. Pour chacune des deux dimensions, les scores varient entre 3 et 21. Les travaux publiés lors des quatre dernières années indiquent que la fidélité de l’ÉFP, estimée avec le coefficient alpha de Cronbach, variait entre 0,74 et 0,89.
Analyses statistiques
Dans un premier temps, les statistiques descriptives seront présentées pour chacune des questions, ainsi que pour les deux sous-échelles et le score total. Par la suite, les corrélations entre les scores des questions avec le score total et celles entre les scores des questions de l’échelle seront présentées.
La normalité des données sera testée en se basant sur les valeurs d’asymétrie et d’aplatissement afin de déterminer si l’on doit utiliser une matrice de corrélation polychorique ou de Pearson pour la suite des analyses. Dans le cas où les valeurs d’asymétrie et d’aplatissement des questions sont inférieures à 2 en nombre absolu, une matrice de corrélation de Pearson serait alors utilisée pour les analyses subséquentes. 30
Par la suite, des AFE en facteurs communs et des AFC seront effectuées. Il n’est pas recommandé d’utiliser le même échantillon pour faire les deux formes d’analyses. C’est pourquoi l’échantillon a été scindé en deux avec la technique de SOLOMON, 31 ce qui a permis d’obtenir deux échantillons équivalents de 5184 personnes, identiques au niveau de la variabilité. L’équivalence fait référence au fait que la distribution des réponses des questions des deux échantillons est similaire.
Les AFE ont été réalisées à partir du premier échantillon et visent à déterminer la présence de facteurs communs latents. Ces analyses cherchent à expliquer la variance commune entre les variables mesurées. Avant de procéder aux analyses, la qualité d’échantillonnage a été vérifiée avec le coefficient de Kaiser-Meyer-Olkin (KMO). Un coefficient élevé permet de statuer qu'il existe une solution factorielle statistiquement acceptable, qui représente bien les relations entre les questions. Ensuite, le test de sphéricité de Bartlett a été effectué afin de vérifier que toutes les corrélations ne soient pas égales à zéro. Un résultat significatif (p ≤ 0,05) permet de conclure que cela n’est pas le cas.
Le nombre de facteurs a été estimé grâce à l’analyse parallèle, une méthode considérée supérieure au graphique de l’éboulis (scree test) et au critère de Kaiser (une valeur propre (eigenvalue) supérieure à 1). La méthode employée est celle de Timmerman et Lorenzo-Seva, 32 qui est une modification de la technique de Horn. 33
Ce type d’analyse permet de comparer les valeurs propres des données de l’échantillon avec la moyenne de 500 échantillons aléatoires, se composant d’un nombre semblable de répondants et d’items. Le nombre de facteurs retenus correspond au nombre de valeurs propres empiriques supérieures à la moyenne des valeurs propres simulées. La méthode d’extraction s’appuie sur une analyse robuste fondée sur la technique des moindres carrés pondérés avec une statistique ajustée sur la moyenne et la variance (Robust diagonally weighted least squares (RDWLS)). Enfin, les coefficients de saturation ont été calculés en considérant deux structures, soit une structure unidimensionnelle (AFE1) et une structure bidimensionnelle (AFE2).
Certains indices seront également présentés afin d’évaluer le degré de proximité des données de l’échantillon avec une structure factorielle unidimensionnelle, soit le coefficient de congruence unidimensionelle (CCU) et la variance commune expliquée (VCE). Les seuils minimaux retenus pour affirmer la présence d’une structure essentiellement unidimensionnelle sont de 0,95 pour le CCU et de 0,85 pour la VCE. 34 Les AFE en facteurs communs, le CCU et la VCE ont été obtenus à partir du logiciel FACTOR 12.01.02.
Des AFC ont été ensuite réalisées avec le second échantillon afin de déterminer si la structure des données représente bien la structure identifiée dans les travaux antérieurs. Trois structures seront testées. Le premier modèle vérifiera la validité théorique du modèle unidimensionnel (AFC1). Deux autres modèles seront éprouvés, soit le modèle à structure bidimensionnelle (AFC2) et le modèle à structure hiérarchique de second ordre (AFC3).
L'ajustement des modèles (autant pour les AFE que les AFC) sera évalué en utilisant les indices d’ajustement suivants : l’indice d’ajustement comparatif (CFI : Comparative Fit Index), l’indice de Tucker-Lewis (TLI : Tucker-Lewis Index), l’erreur quadratique moyenne de l'approximation (RMSEA : Root Mean Square Error of Approximation) et la valeur moyenne quadratique pondérée (SRMR : Standardized Root Mean Square Residual). Le modèle sera considéré adéquat si CFI> 0,90; TLI> 0,90; SRMR< 0,06; RMSEA< 0,08. 35 La méthode d’extraction des facteurs s’appuie sur une analyse robuste basée sur la technique des moindres carrés pondérées (Diagonally weighted least squares (DWLS)).
Après avoir sélectionné le meilleur modèle, l’invariance de l’ÉFP sera examinée pour le sexe (femme ou homme), pour l’âge (18 à 34 ans, 35 à 49 ans, 50 à 64 ans ou 65 ans et plus) et pour la langue du questionnaire (français ou anglais) à l’aide d’une séquence d’analyses comprenant quatre modèles augmentant en sévérité de contraintes, mesurant l’invariance configurationnelle, métrique (faible), scalaire (forte) et résiduelle (stricte). Le premier modèle ne contient aucune contrainte. Le deuxième modèle, l’invariance métrique, contraint les coefficients de saturation à être égaux. Le troisième modèle, l’invariance scalaire, contraint l’égalité des intercepts et le dernier modèle, l’invariance résiduelle, force l’égalité des termes d’erreurs. L’invariance configurationnelle sera statuée si les critères des indices d’ajustements sont rencontrés. L’invariance métrique, scalaire et résiduelle seront assumées si Δ CFI ≤ 0,01 et Δ RMSEA ≤ 0,015 en nombre absolu, lorsque comparé au modèle précédent. 36 Les analyses d’invariance ont été réalisées à l’aide d’analyses factorielles confirmatoires multi-groupes. Les AFC ont été produites grâce au logiciel JASP 0.16.2.
La fidélité des données sera estimée à partir des coefficients alpha et oméga total. Le coefficient G-H de Lorenzo-Seva 34 sera également estimé; il permet d’évaluer la réplicabilité de la fidélité de l’échelle. Une valeur supérieure à 0,80 suggère que les construits sont bien définis et qu’ils sont susceptibles d’être stables d’une étude à l’autre.
Enfin, deux formes de validité critériée seront analysées : la validité convergente et la validité divergente. La validité convergente sera évaluée à l’aide d’une corrélation entre les scores de l’ÉFP et ceux d’une échelle pour mesurer la fatigue face aux changements climatiques. Pour y arriver, le terme COVID-19 dans l’ÉFP a été remplacé par changements climatiques. Les corrélations entre les dimensions mesurant la FI et la FC, et l’échelle évaluant la fatigue climatique seront également estimées. La validité divergente sera examinée par une corrélation évaluant l’association entre les scores de l’ÉFP et les scores obtenus au Questionnaire sur la santé du patient (PHQ-9 : Patient Health Questionnaire). Les corrélations entre les deux dimensions et les scores du PHQ-9 seront aussi calculés. Il est attendu que les corrélations de la validité convergente soient positives et de force modérée (r = 0,40 à 0,60) à forte (r = 0,70 à 0,90). À l’inverse, il est attendu que les corrélations pour la validité divergente soient faibles (r = 0,10 à 0,30) ou non significative. 37
Résultats
Description de l’échantillon
L’échantillon total est composé de 10 368 répondants âgés de 18 ans et plus, dont environ 57% sont des femmes et près de 53% sont des adultes âgés de 50 ans et plus (Tableau 1). Environ 24% des répondants rapportent avoir obtenu un diplôme de secondaire 5 ou moins, et près de 21% des ménages gagnent moins de 40 000 $ avant impôt.
Caractéristiques sociodémographiques de l’échantillon total et des deux échantillons utilisés pour les analyses factorielles.
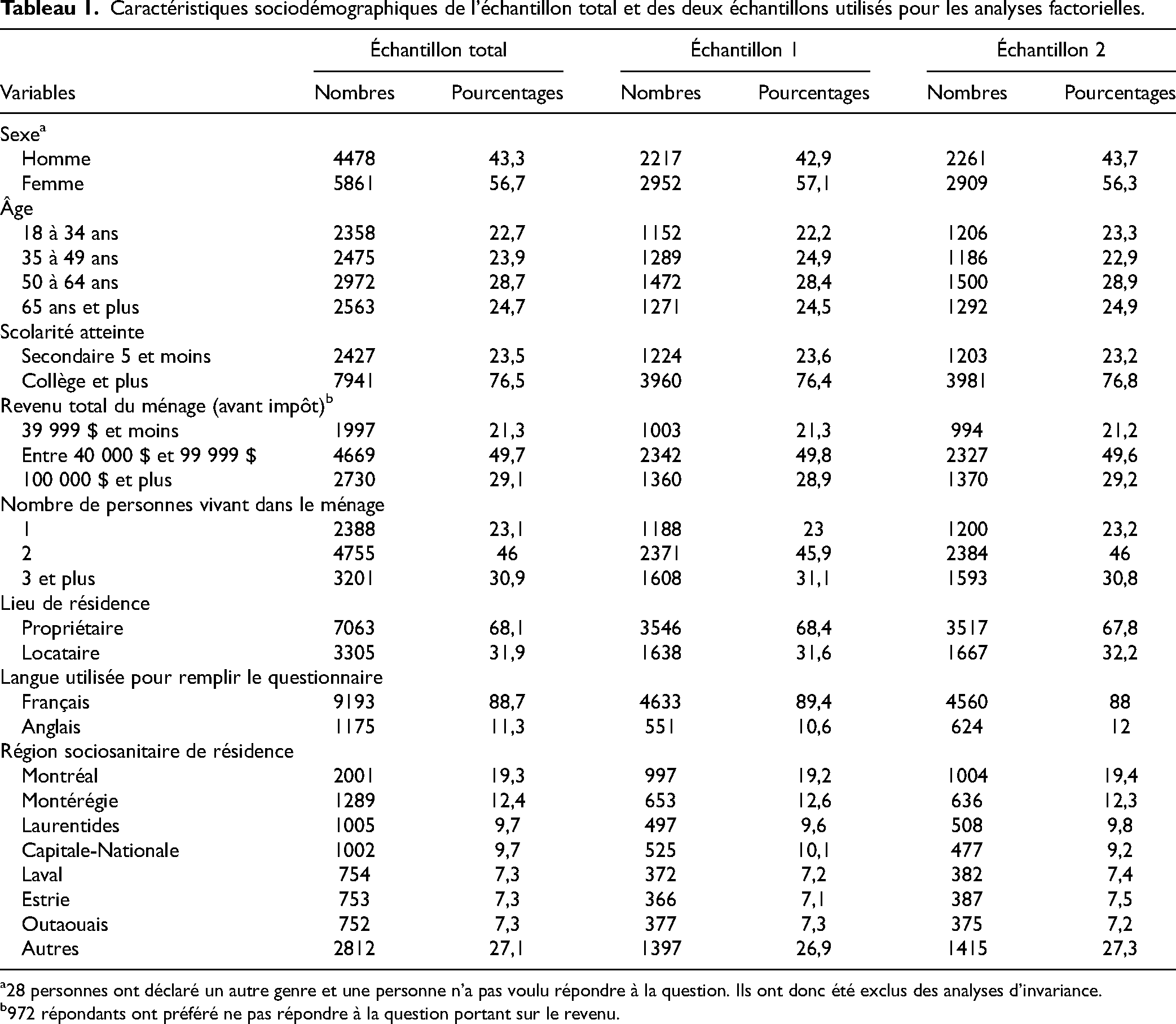
28 personnes ont déclaré un autre genre et une personne n’a pas voulu répondre à la question. Ils ont donc été exclus des analyses d’invariance.
972 répondants ont préféré ne pas répondre à la question portant sur le revenu.
Analyses descriptives et corrélations
Les données de l’ensemble de l’échantillon indiquent que les moyennes des questions varient entre 3 et 5,1. (Tableau 2). Les mesures visant à évaluer la normalité des données, soit l’asymétrie et l’aplatissement, sont inférieures à 2 en valeur absolue. Il est donc approprié d’utiliser une matrice de corrélation de Pearson pour les analyses.
Statistiques descriptives de l’ÉFP.
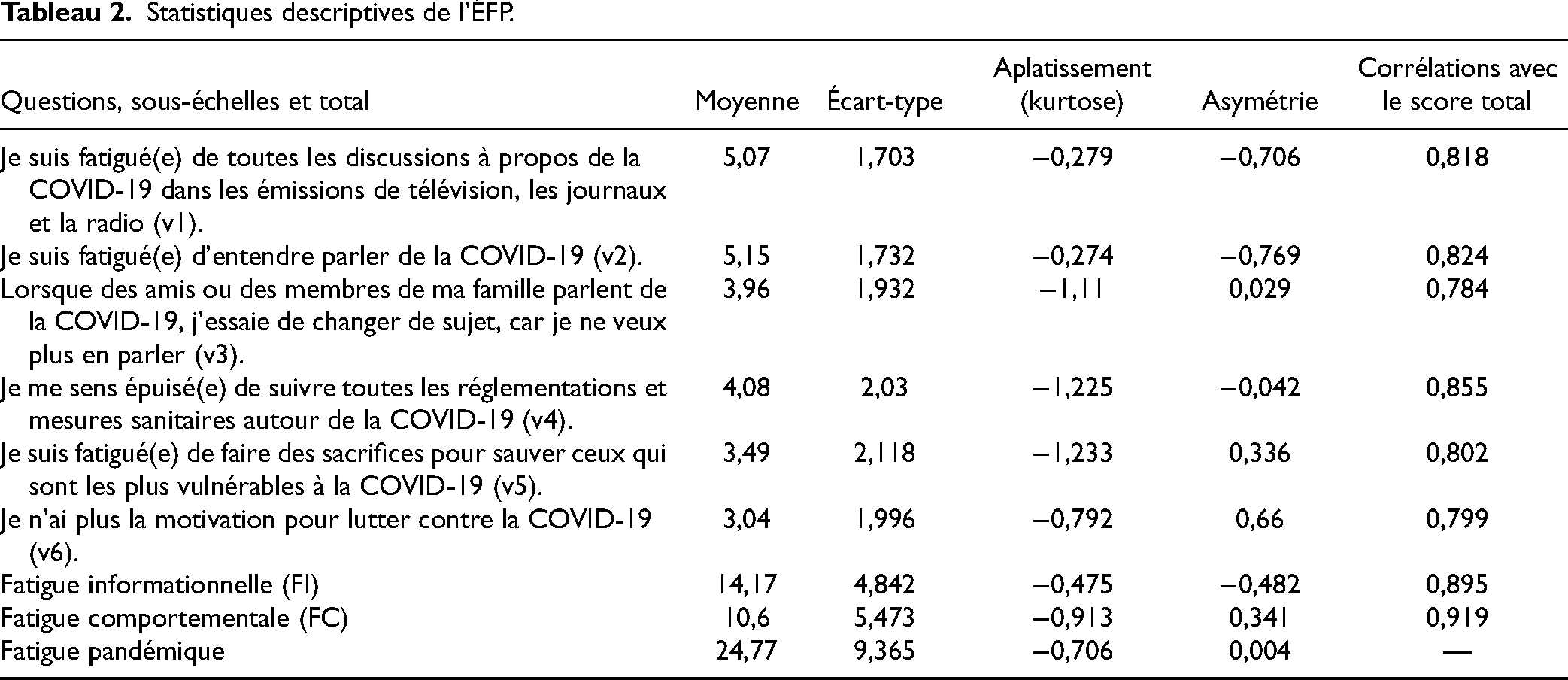
Les données montrent des corrélations élevées entre le score de tous les items et le score total, variant entre 0,784 et 0,855 (Tableau 2). Toutes les corrélations sont significatives à 0,01. Les corrélations entre les scores des items varient entre 0,469 et 0,920 et sont également toutes significatives à 0,01. La corrélation entre les deux dimensions est de 0,647 (p ˂ 0,01).
Analyses factorielles exploratoires
L’indice KMO est égal à 0,824 et le test de Bartlett est significatif (χ2 = 23404,7; ddl = 15; p = 0,0001). Ces résultats indiquent que le recours à l’analyse factorielle est approprié. L’AFE pour la solution à un facteur indique la présence d’une seule dimension expliquant près de 76% de la variance observée. Les indices d’ajustement révèlent des valeurs plus élevées que les seuils usuels (CFI : 0,962 et TLI : 0,937), mais la valeur du RMSEA (0,278) est trop haute par rapport au seuil de 0,08. La solution à deux facteurs produit un CFI (0,997) et un TLI (0,988) plus élevé, mais un RMSEA encore trop élevé (0,122). Les valeurs du CCU et de la VCE sont respectivement de 0,977 et de 0,837. Ces deux dernières valeurs suggèrent que les données présentent une certaine proximité avec une structure unidimensionnelle.
Analyses factorielles confirmatoires
Plusieurs indices d’ajustement du modèle unidimensionnel (AFC1) n’atteignent pas les seuils mentionnés précédemment (RMSEA : 0,127 et SRMR : 0,094) (Tableau 3). Par contre, les seuils de tous les indices d’ajustement sont atteints pour les deux autres modèles, soit pour la structure bidimensionnelle (AFC2) (CFI : 0,993; TLI : 0,986; RMSEA : 0,069; SRMR : 0,048) et pour la structure hiérarchique de second ordre (AFC3) (CFI : 0,993; TLI : 0,984; RMSEA : 0,074; SRMR : 0,048).
Indices d’ajustement des modèles testés par AFC.
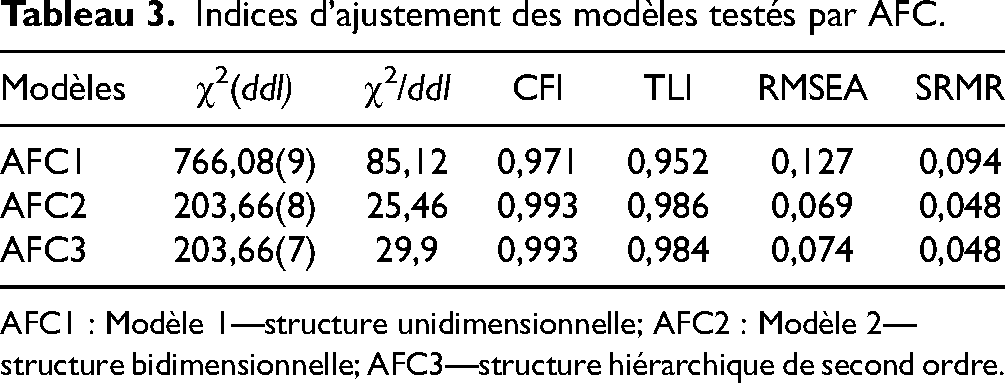
AFC1 : Modèle 1—structure unidimensionnelle; AFC2 : Modèle 2—structure bidimensionnelle; AFC3—structure hiérarchique de second ordre.
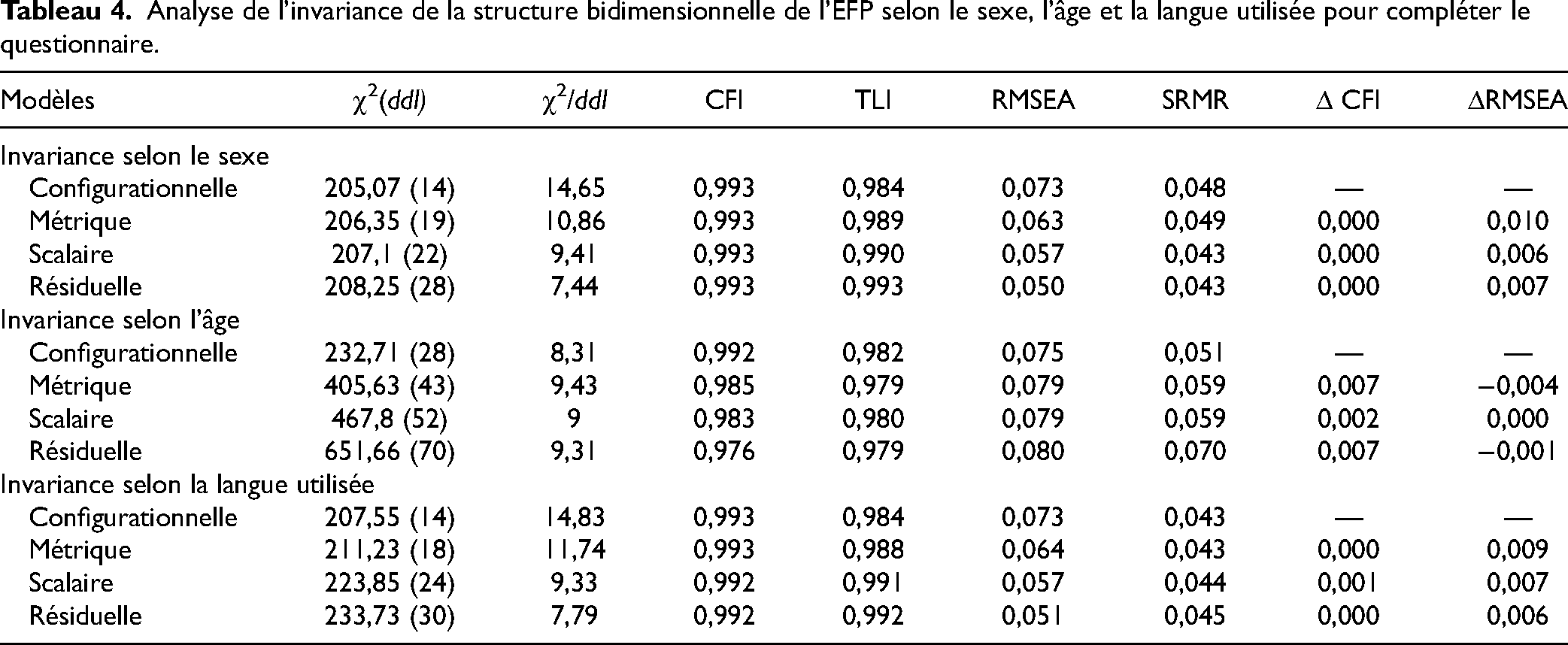
Le modèle sélectionné pour les analyses d’invariance est la structure bidimensionnelle puisque les indices d’ajustement sont tous adéquats et qu’ils s’ajustent le mieux aux données empiriques (Figure 1). L’invariance des données selon le sexe, selon l’âge et selon la langue utilisée est attestée par les valeurs de CFI, Δ CFI, RMSEA et Δ RMSEA de tous les modèles évalués (Tableau 4).
Analyse de l’invariance de la structure bidimensionnelle de l’ÉFP selon le sexe, l’âge et la langue utilisée pour compléter le questionnaire.
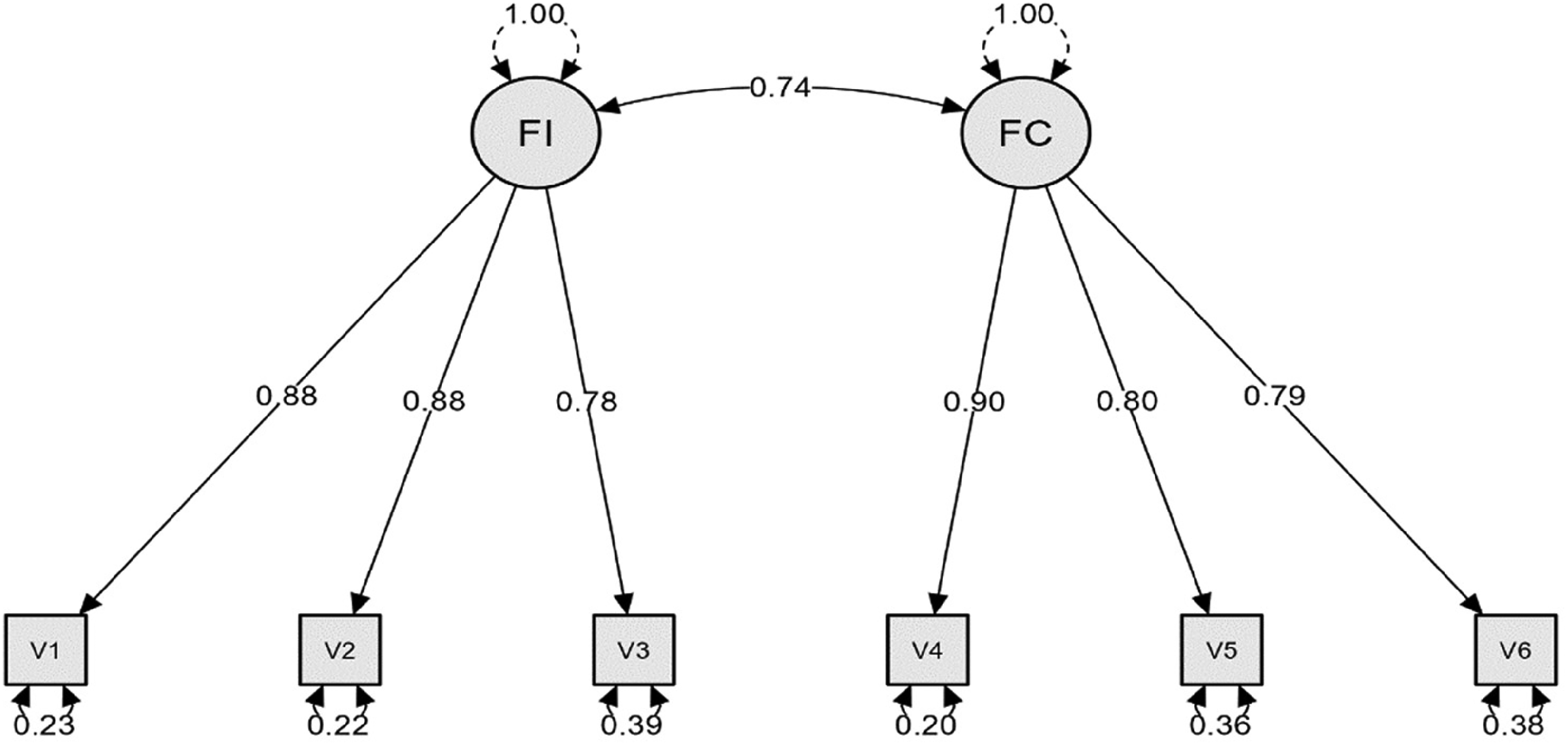
Coefficients standardisés pour le modèle bidimensionnel (FI et FC).
La fidélité
Le coefficient alpha de Cronbach, estimé pour l’ÉFP, est de 0,896. Les coefficients sont respectivement de 0,884 pour la FI et de 0,869 pour la FC. Les coefficients oméga total sont assez similaires, avec des valeurs respectives de 0,899, 0,902 et de 0,869. Le coefficient de réplicabilité de la fidélité, pour l’ensemble des énoncés, est de 0,989. Pour les deux dimensions, les valeurs sont de 0,895 pour la FI et de 0,990 pour la FC.
La validité convergente et divergente
La corrélation entre les scores des deux échelles de fatigue pour l’ensemble de l’échantillon est de 0,456 (p ˂ 0,01). Les corrélations avec les deux dimensions (la FI et la FC) et les scores de fatigue climatique sont respectivement de 0,380 (p ˂ 0,01) et de 0,444 (p ˂ 0,01). Comme anticipé, la corrélation est plus faible entre les scores de FP et ceux du PHQ-9 (r = 0,241; p ˂ 0,01). Les corrélations entre les scores des deux dimensions, la FI et la FC, et les scores du PHQ-9 sont également basses (respectivement de 0,189 (p ˂ 0,01) et de 0,245 (p ˂ 0,01)).
Discussion
Les résultats des AFC révèlent l’adéquation d’une structure bidimensionnelle aux données recueillies à partir de l’ÉFP dans la population adulte québécoise. La structure de l’ÉFP repose donc sur deux dimensions latentes, la FI et la FC. Elles mesurent ainsi des concepts distincts, mais qui sont reliés. Ce résultat corrobore ceux de Lilleholt et coll.,11,12 d’Asimakopoulou et coll. 26 et de Kurt et coll. 29 Seuls les résultats de Rodriguez-Blazquez et coll. 27 soutiennent la présence d’une structure unidimensionnelle pour l’ÉFP. Il est important de mentionner que la structure bidimensionnelle n’a cependant pas été testée dans leur étude, ce qui n’invalide pas son existence.
Les AFC multi-groupes, réalisées à partir du modèle bidimensionnel, ont atteint tous les niveaux d’invariance selon le sexe. À notre connaissance, c’est la première fois que l’invariance selon le sexe est testée à partir de données colligées avec l’ÉFP. Les résultats obtenus permettent de conclure que l’échelle mesure les mêmes construits, de la même façon, chez les hommes et les femmes, ce qui justifie la comparaison de leurs moyennes pour les deux dimensions (la FI et la FC). Une invariance complète de la mesure a aussi été conclue selon l’âge. Ainsi, il est possible de comparer les scores moyens, autant chez les jeunes adultes que chez les personnes plus âgées. Enfin, le même constat peut être dégagé avec la langue utilisée, ce qui confère encore plus de crédibilité à l’utilisation de l’ÉFP.
Les formes de validité évaluées vont dans le sens attendu par rapport au cadre conceptuel. En effet, les corrélations entre les scores de l’ÉFP, de la FI et de la FC, avec les scores de fatigue climatique sont plus élevées que ceux estimées avec les scores de dépression. Ces résultats représentent des preuves supplémentaires de la validité des construits. Aussi, la fidélité des données est établie par les valeurs élevées des coefficients alpha et oméga total, autant pour la FP, la FI et la FC. Ce constat avait également été observé par d’autres auteurs.11,15,19,25,26 Enfin, les valeurs des coefficients G-H suggèrent que les construits de l’ÉFP peuvent être répliqués dans les futures recherches.
Il existe une corrélation importante entre les deux facteurs latents, la FI et la FC. Le même constat est noté dans les écrits de Lilleholt et coll. 11 et Kurt et coll. 29 Ce résultat suggère la présence d’un facteur général de fatigue. 38 De plus, la VCE est égale à 0,837, ce qui indique que le facteur général explique environ 84% de la variance de tous les items. La valeur élevée du coefficient G-H suggère aussi que le construit est bien défini et qu’il devrait être stable et réplicable dans les futures études. Ces résultats suggèrent qu’il pourrait être envisageable d’utiliser le score total 38 afin de mesurer la FP.
L’ensemble des résultats de cette étude permettent d’affirmer que l’ÉFP possède de bonnes qualités psychométriques et qu’elle peut être utilisée parmi la population adulte québécoise. Il est ainsi justifié d’utiliser les scores de FP, de FI et de FC à des fins épidémiologiques afin d’établir la prévalence de chacun des construits. La fatigue pandémique est une réaction naturelle et attendue à l’adversité. Toutefois, des niveaux élevés au sein de la population peuvent engendrer des conséquences néfastes. 14 Le suivi de l’évolution des prévalences est donc une étape centrale pour sonder le pouls de la population à différents moments lors de la pandémie de COVID-19 ou lors d’autres pandémies. Il est important de cerner un niveau élevé de fatigue pandémique au sein de la population puisque celle-ci risque d’engendrer un manque de motivation à adopter des comportements de protection contre la COVID-19 ainsi que de causer de la complaisance, de l’aliénation et du désespoir. 14 Ceci est une réalité pour toute crise prolongée, surtout lorsqu’une trajectoire de communication de crise corrosive est adoptée. 39 L’utilisation des scores permettrait de mieux cibler les caractéristiques démographiques et psychosociales des adultes québécois en situation de FP afin de planifier des stratégies optimales de communication envers les groupes plus enclins à développer de la FP ou certaines formes telles que la FI ou la FC. En effet, parmi les stratégies pour lutter contre la fatigue pandémique de l’OMS, on retrouve « chercher à comprendre les gens, ainsi que « reconnaître leur douleur », 14 deux éléments qui deviennent plus atteignables avec l’habilité de mesurer avec précision la FP au sein d’une population.
Ce travail présente quelques limites. Dans un premier temps, les résultats présentés sont généralisables uniquement aux adultes ayant accès à une connexion électronique. Deuxièmement, le concept de FP portait spécifiquement sur deux dimensions (la FI et la FC). D’autres dimensions n’ont pas été évaluées, telles que la fatigue physique ou mentale ou d’autres formes de fatigue comme celle liée à la distanciation sociale ou celle liée à l’utilisation de plateformes électroniques. Les résultats portant sur la FI et la FC ne peuvent donc pas être généralisés aux autres formes de fatigue mentionnées ci-dessus et les liens entre les formes de fatigue devraient être évalués dans le futur.
En dépit de ses limites, les constats présentés pour l’ÉFP s’appuient sur des analyses utilisant des méthodologies plus appropriées (ex. utilisation de deux échantillons équivalents, de la méthode parallèle, etc.). De plus, des analyses complémentaires aux analyses factorielles ont également été rapportées (ex. VCE, coefficient G-H, etc.) afin de renforcer l’importance des résultats basés sur la structure interne de l’échelle.
Conclusion
L’ÉFP présente de bonnes qualités psychométriques. Une structure bidimensionnelle a été identifiée comme dans les travaux initiaux. De plus, l’invariance de la mesure selon le sexe, l’âge et la langue utilisée pour le questionnaire a été confirmée, ce qui confère plus de crédibilité à son utilisation. Cependant, l’échelle n’a jamais été utilisée auprès de personnes âgées de moins de 18 ans. Ce travail reste à faire pour déterminer si l’instrument peut être utilisé auprès des jeunes. De plus, les différents points de coupure de l’ÉFP retenus dans la littérature n’ont pas toujours été justifiés avec des méthodes psychométriques. Cet enjeu devrait être étudié dans le futur.
Footnotes
Déclaration de conflit d'intérêts
Les auteurs déclarent n'avoir aucun conflit d'intérêts.
Financement
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Instituts de recherche en santé du Canada (grant number OV7-170635).