
Abstract
Airlines face significant challenges when building flight schedules, particularly because of unpredictable operations caused by factors such as adverse weather, airport congestion, mechanical problems, and so forth. One of the major components of flight scheduling is block time; accurately estimating block time is crucial for optimizing resource utilization and effective planning (on the scale of minutes). Given that flight scheduling takes place months in advance, accurately predicting block time is a challenging task. This is largely a result of the limited availability of features affecting operations on a specific day, such as the weather, at the time of planning. Consequently, current literature suggests that popular machine learning models are not suitable and recommends the use of statistical historical metrics. However, these methods (a) do not capture the complex latent relationships between factors affecting block time, (b) do not effectively handle high-cardinality categorical data and temporal variations, and (c) only consider a very small number of flights in their conclusions. We conduct, to the best of our knowledge, the first large-scale study of the airline on-time performance database for 2018 from the Bureau of Transportation Statistics (BTS), a public dataset. Specifically, our work introduces an entity-embedding-based representation learning model to efficiently incorporate high-cardinality categorical features and improve the long-term predictive capabilities of the model. These entity embeddings also encapsulate richer feature representations and their interactions. Complementary to these, we conduct rigorous experimental evaluations across 10 baselines and significance tests to demonstrate the advantages of using our entity-embedding-based model to increase long-term forecast accuracy for planning. For reproducibility, the code has been made available at https://github.com/criticalml-uw/Embeddings-for-Block-Time-Prediction.
Keywords
Flight schedule planning involves complex decision-making at extended time horizons, typically 4–6 months before the actual day of operations. This stage in operations planning is critical since it directly affects resource requirements, revenues, and costs. Central to building an efficient schedule is the allocation of correct time estimates for each operational segment of a flight. By accurately estimating these durations, airlines aim to align the planned schedules closely with the actual time taken on the day of operations. Here, even a 1- to 2-min reduction in prediction error is critical, as it can determine whether a flight can connect seamlessly with the next. Achieving this level of accuracy is essential for maximizing the on-time performance, a key metric that airlines use to demonstrate the timeliness and reliability of their operations.
An essential aspect of schedule building is determining the (SBT) of a flight, which is the time interval between the scheduled departure and scheduled arrival of a flight; see Figure 1, based on Deshpande and Arıkan ( 1 ), which shows various segments of flight operations that can affect block time. This contrasts with the actual block time (ABT), which is the measure of time duration between blocks off and blocks in, as observed on the day of the flight. SBT serves as an estimate of ABT, informing the setting of departure and arrival times. The discrepancy between SBT and ABT can lead to departure and arrival delays and is crucial for robust planning and maximizing OTP.
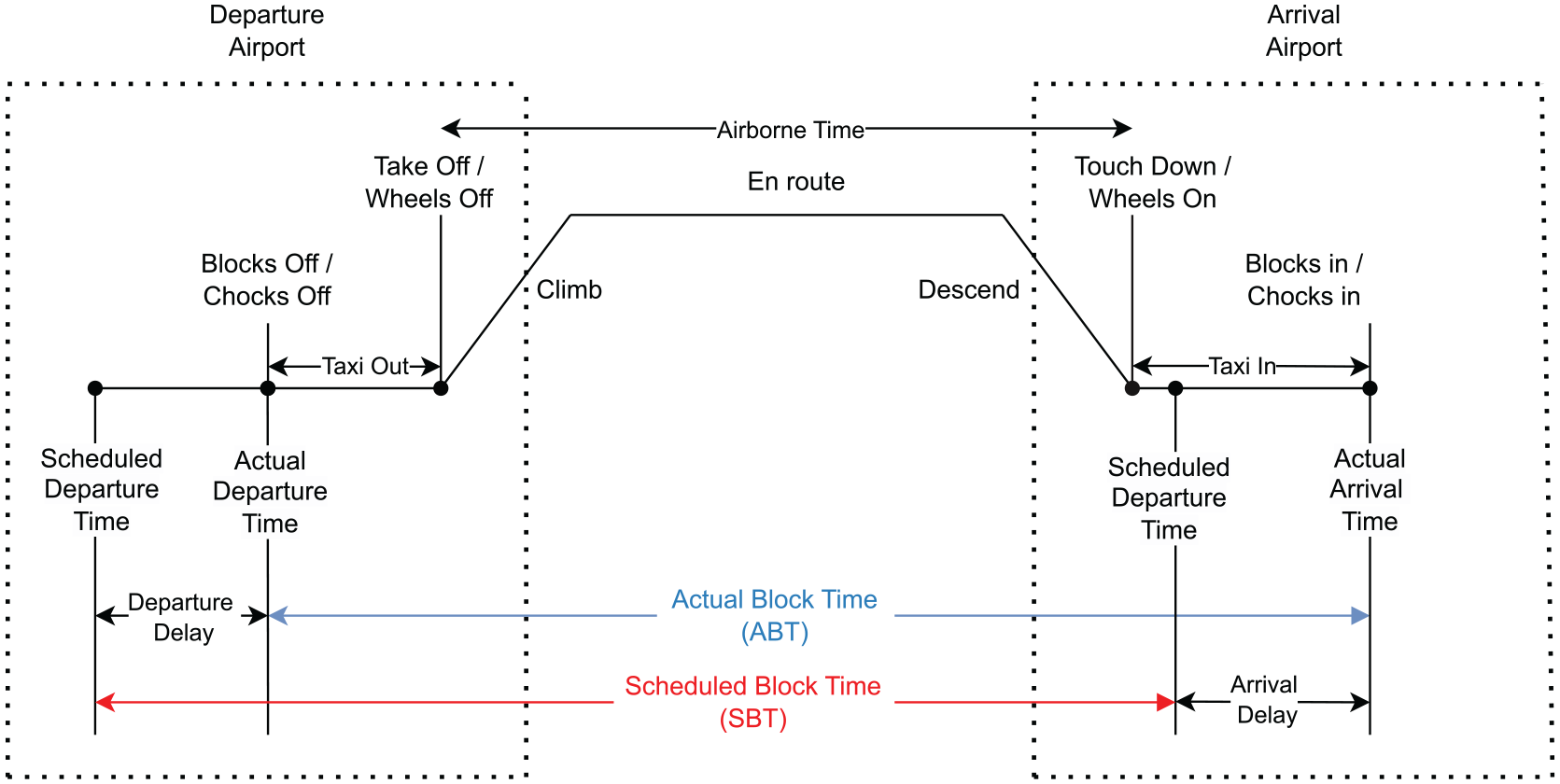
Segments of the flight operations.
Several challenges are encountered in SBT estimation because of the long-term prediction horizon and the dynamic nature of airline operations. Prediction takes place months in advance, making it impossible to accurately anticipate factors such as wind, weather, air traffic, and aircraft load ( 2 – 4 ). As a result, only factors that are known a few months in advance, such as the origin and destination airports, along with time-based features (day, week, month, etc.), can be utilized in any prediction modeling. Moreover, airlines make adjustments closer to flight departure to accommodate real-time changes, and these often go unrecorded. When planning, airlines typically lack information on what affects operations on the actual flight day. This limited availability of explanatory variables in the data makes achieving accurate predictability extremely challenging. Another challenge comes from the nature of the explanatory variables. Many features such as the departure and arrival airports and time-based features are categorical, are of high cardinality, and have spatiotemporal effects that are not well captured by traditional encoding schemes in machine learning. This complexity demands advanced methods for effective modeling and prediction.
Both the over- and underestimation of SBT is undesirable. With a shorter block time, the possibility of delayed arrival arises, leading to disruption of flight sequences, crew displacement, and additional expenses like food and lodging. In contrast, introducing buffers into block time may cause early arrivals, potentially resulting in the inefficient utilization of resources such as crew allocation, thus leading to suboptimal outcomes ( 5 – 8 ). To optimize scheduling and maximize resource utilization, airlines strive to find the most accurate SBT estimate that closely aligns with the ABT.
A broad spectrum of approaches have been employed to estimate flight block times, their components (such as taxi and flight times), and delays. These methodologies range from machine learning techniques, including random forest and XGBoost, to deep-learning models, which have been applied to predict short-term delays ( 9 – 13 ). However, much of this work tends to focus on short-term predictions made typically hours or a day before the day of operations, and it often excludes certain links or routes, suggesting a gap in broader applicability across the airline industry. There is a notable absence in the literature concerning long-term SBT prediction modeling. A recent work by Abdelghany et al. ( 8 ) concluded that machine learning models, specifically regression tree, random forest, and XGBoost, have limited capability in predicting ABT. They show that these models were outperformed by historical median-based estimates of ABT. Moreover, this study only considered a very limited set of routes (seven), which necessitates a large-scale analysis and the investigation and development of more sophisticated neural-network-based approaches for this critical task to effectively exploit the information available at the planning stage and enhance the predictive capabilities of the models.
Adding to the complexity of modeling is the inherent problem with traditional encoding schemes. Although straightforward and commonly used, encoding schemes like one-hot encoding have significant drawbacks. Primarily, since it adds a variable for each unique category of a feature, the model’s dimensionality increases proportionally to the cardinality of the categorical variables. This escalation poses a challenge known as the curse of dimensionality, which demands exponentially more data for the model to remain accurate ( 14 ). Another issue with one-hot encoding is that it assumes that categories are mutually exclusive and unrelated, leading to representations that are orthogonal and equidistant. This fails to capture any natural similarity between categories, overlooking their potential associative or semantic connections ( 15 ). For instance, consider the scenario where we are analyzing a dataset related to days of the month in airline operations. For a human observer, it is clear that the last day of a month and the first day of the following month are close, but once this feature is one-hot encoded we lose this natural progression. Moreover, while circular transformations to encode this closeness between days can be useful, these cannot capture additional complex relationships and similarities. Therefore, learning these latent relationships is key to improving long-term forecasting, especially for a very limited feature set.
To bridge these gaps, our study adopts entity-embedding-based representation learning to discern intricate nonlinear relationships through a neural network framework. Specifically, entity embeddings are task-dependent relationships that the model learns to help the downstream task ( 16 ). This methodology efficiently addresses the challenge of encoding categorical features with high cardinality, a task that is often challenging with traditional encoding schemes. Embedding techniques have significantly evolved to capture complex data relationships in various domains. Starting with RESCAL ( 17 ) and TransE ( 18 ) for knowledge graphs, these methodologies have laid the groundwork for advanced representations. DeViSE ( 19 ) further extended embeddings to map images into semantic spaces. Subsequently, methods like DeepWalk ( 20 ) and Node2Vec ( 21 ) have been developed for graph representations. The most recent work on the use of embeddings for transportation research by Arkoudi et al. ( 22 ) introduces embedding encoding for socio-characteristic variables, aligning latent representations with individuals’ travel behavior choices. This progression highlights the versatility and importance of embedding models in capturing nuanced data relationships across a spectrum of applications.
This study aims to leverage entity-embedding-based representation learning in a neural network to improve flight-scheduling predictions. By learning embeddings, the proposed neural network architecture is intrinsically aware of the task it is being trained for and concurrently learns the multidimensional relationships as the model trains. Henceforth, we refer to entity embeddings ( 16 ) as embeddings, unless otherwise specified. To ensure the robustness of our approach, we conducted ablation studies, leading us to the best-suited neural network architecture. Additionally, we benchmarked our approach against 10 baseline ML models for a thorough comparison using Monte Carlo simulations. Furthermore, we employ t-distributed stochastic neighbor embedding (t-SNE) on the learned embeddings to visualize the high-dimensional representations, revealing patterns learned by the proposed model.
Contributions
In the sections that follow, we present a literature review on block time and delay prediction, followed by a detailed description of the methodologies applied in this study. Subsequently, we assess the performance of our predictive models and conduct sensitivity analysis.
Literature Review
Through an extensive literature review, we uncovered a diverse range of models that address the estimation of block time, its components (i.e., taxi time, flight time), and delays. While the broader scope of this paper encompasses the long-term prediction of ABT, delays, taxi times, and other related downstream tasks to aid airline operational planning in the long term, our experimental focus and demonstrated results center on the prediction of ABT. In this section, we review the literature on the prediction modeling of time segments of the flight operations, focusing on block time and delay, which seem to have attracted most of the work. We begin by examining the efforts made to estimate block time. Then, we review the modeling of delay propagation and prediction while making the distinction between short-term and long-term prediction.
Block Time Prediction
The prediction of ABT has been the focus of two studies by Wang et al. (
23
) and Abdelghany et al. (
8
). Wang et al. (
23
) proposed a stacking model that demonstrates promising generalization for the prediction of block time for various spatial–temporal instances. Abdelghany et al. (
8
) used three machine learning (ML) models—namely, regression tree (RT), random forest regression (RFR), and extreme gradient boosting (XGBoost) regression—to know of when planning their schedules several months in advance. They found that the performance of the ML models was poorer when evaluated against a benchmarking scenario where the median value of historical actual block times was used as an estimate. The analysis employed Bureau of Transportation Statistics (BTS) data from 2019, focusing on seven airport pairs. For the flights along these routes, the study employed outlier filtering by applying a lenient approach using a lower bound =
To enhance the understanding of SBT estimation, previous studies have undertaken various analytical approaches. Coy ( 24 ) developed two-stage statistical models corresponding to six U.S. airlines to predict SBT. The approach involved estimating an initial block time by averaging the previous year’s similar flights and using it as a prediction variable in a second-stage regression model. The models are claimed to capture over 95% of the variance, indicating a strong fit. However, their approach relied on a subset of data obtained by dropping the less frequented routes, avoiding the challenges of the long-tailed distribution of block time. In contrast, our approach harnesses the entirety of the data. Moreover, their reliance on variables such as traffic and weather conditions, which are not readily available during the planning phase, potentially limits the practical application of their model for long-term predictions.
Sohoni et al. (
25
) note that airlines typically determine SBT based on fixed percentiles of historical data. Expanding on this, Hao and Hansen (
26
) suggest that airlines commonly adopt an SBT ranging from the 65th to the 75th percentile of ABT. However, Sohoni et al. (
25
) argued that these approaches have not yielded substantial improvements in OTP. Building on this critique, our study introduces a machine learning framework that is not solely dependent on historical trends; it is also capable of learning from available explanatory variables. Deshpande and Arıkan (
1
) analyzed flight buffer selection using the newsvendor problem as an analogy, where early or late flight arrivals equate to newspaper vendors experiencing a surplus or shortage. Their study revealed that buffer decisions are notably influenced by carrier types, route market shares, and specific route attributes. Kang and Hansen (
27
) modeled how airlines adjust SBT to balance OTP. They analyzed five U.S. domestic airlines and found that schedulers are inclined to extend SBT by
Instead of relying on block time prediction, Gui et al. ( 28 ) propose a data-driven three-stage method to enhance the estimation of expected arrival time. Their method involves identifying aircraft arrival patterns (clustering), classification (XGBoost), and estimating flight time (XGBoost). This approach primarily focuses on short-term prediction since it relies on real-time radar trajectory data, including current, historical, and traffic situation information. As a result, it is more suitable for operational use rather than long-term planning, which is the focus of this paper.
Delay Prediction
Flight delay prediction has been extensively researched in the literature ( 29 , 30 ). A significant differentiation can be observed in the practical application of these predictions. In the long term, such predictions are employed for planning and scheduling purposes, including activities like booking slots at the airport, which are done several months in advance of the flight departure. On the other hand, in the short term, predictions are utilized to optimize and enhance the operational efficiency of airlines in real time.
One of the first studies that incorporated the spatiotemporal aspect into the prediction of delay was by Rebollo and Balakrishnan (
9
). They defined a NAS (National Airspace System) delay state at time
Deep-learning models, on the other hand, have excelled in capturing complex nonlinear relationships in space and time (
10
,
12
). Researchers have transformed the multi-airport flight delay prediction into a graph representation learning task (
13
). Several other efforts have also been made to develop tree-based and neural network-based models to predict delays at the individual flight, airport, link, and network levels with prediction horizons of minutes, hours, and days (
10
–
12
). Another formulation that is frequently seen is the classification problem, which focuses on classifying delay in an OD link, departure/arrival at an airport, or individual flights based on predetermined delay thresholds. Alonso and Loureiro (
33
) define the intervals as
Interestingly, most of the research around delay prediction has been restricted to the last hours or days before departure, when data sources are abundant. For example, weather data and information on the state of the airline network, both strongly associated with delay, are typically used. However, in a long-term context, only a couple of studies have addressed this challenge. Lambelho et al. ( 34 ) proposed a generic approach to assess strategic flight schedules (arrival/departure slots several months before execution) based on flight delay and cancellation predictions. Their analysis showed that LightGBM outperformed other models in delay prediction, emphasizing key factors like airlines and seats in forecasting arrival delay with high accuracy and Area under the curve (AUC) metrics. Kafle and Zou ( 7 ) presented an analytical model to quantify the propagated and newly formed delays. Wong and Tsai ( 6 ) used survival analysis to find key contributing factors for departure and arrival delays. Their results indicate that key factors affecting departure delays include turnaround buffer time, aircraft type, logistics, and weather, while arrival delays are primarily influenced by block buffer time and weather conditions.
Proposed Approach
Our objective is to develop a predictive model equipped to process high-dimensional categorical variables and intricate relationships between them for predicting delays, block time, taxi-in and taxi-out times, and other critical operational parameters. The predictive model for such tasks can be formulated the bold variables are vectors as
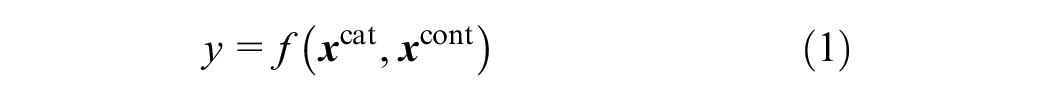
where
The features
The nondeterministic nature of these factors presents challenges when incorporating domain expertise into prediction models. To effectively capture these multifaceted interactions, we undertake a representation learning task.
To leverage the latent information encoded within the data, we enrich our feature set by learning the embedding (
16
)
Now, introducing

Given this, we train a mapping
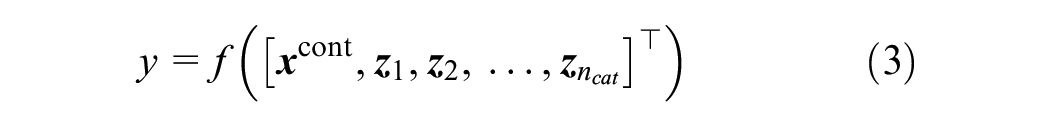
The action of the first layer of such a neural network can be written as follows (see also Figure 2):
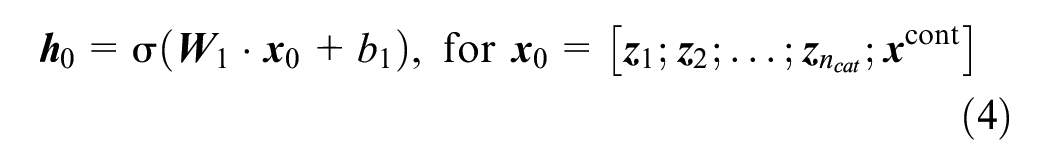
Here, the function
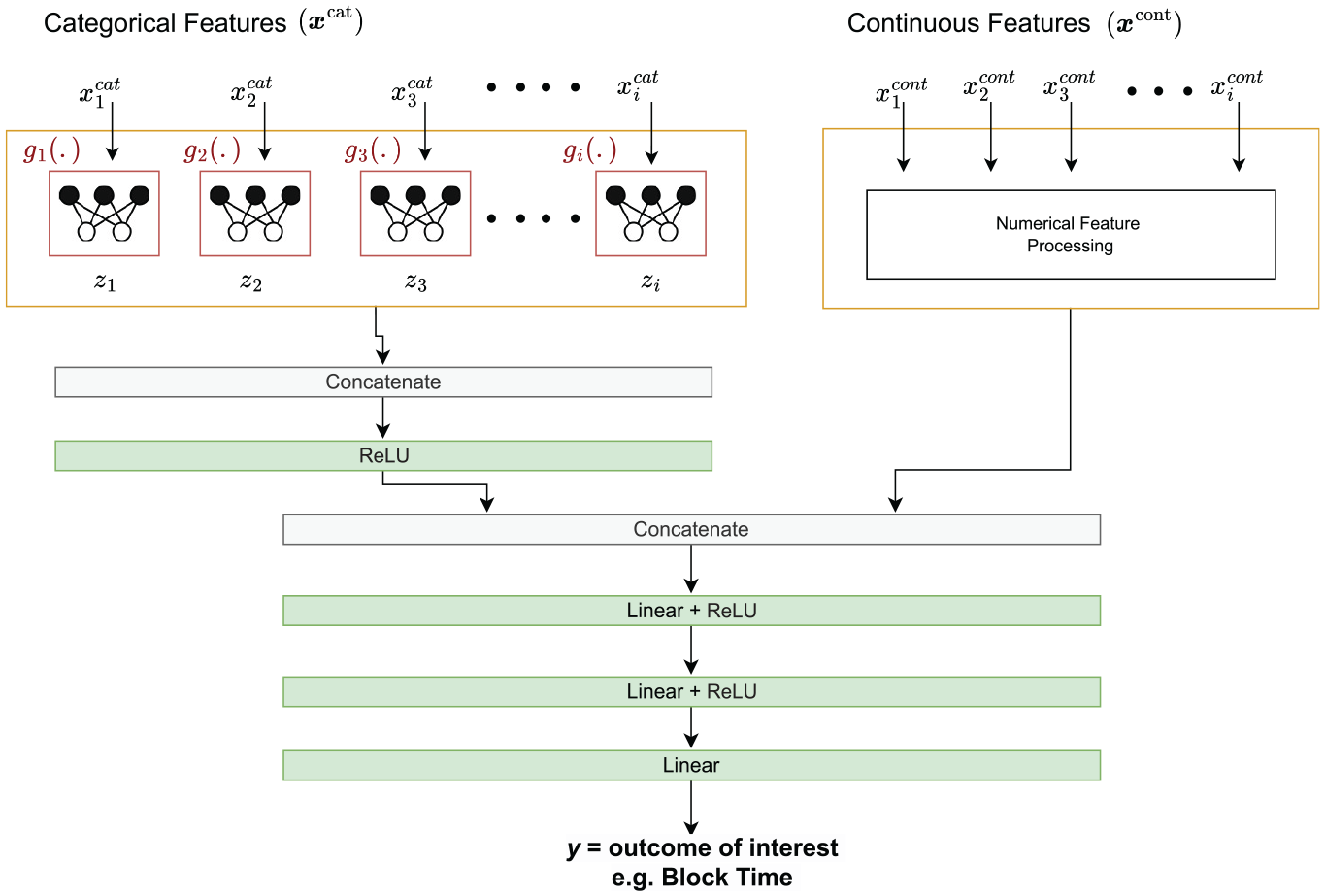
Block diagram: harnessing categorical embeddings and continuous features for specific tasks.
Experiments
This section outlines the dataset, the preprocessing steps, the baseline models used for comparison, and the various neural network architectures explored in our study.
Data Overview
The data used for this study were obtained from the airline on-time performance database. This database comprises scheduled actual departure and arrival times recorded by certified U.S. air carriers, which account for a sizable share of the domestic scheduled passenger revenue. This database is compiled by the Office of Airline Information of the Bureau of Transportation Statistics (BTS). It provides complete details on on-time arrival and departure dates, flight cancellations and diversions, taxi-out and taxi-in times, causes of delay and cancellation, air times, and non-stop distances.
For the purpose of block time prediction, we use the 2018 data, comprising more than 6 million flights operated by 17 airlines. Table 1 provides a detailed breakdown of each airline’s percentage of short-, medium-, and long-haul flights based on block time alongside their International Air Transport Association (IATA) code, names, regional or international classification (R/I), and operational model (HS or P2P). The table is sorted in decreasing order of the percentage of short-haul flights (%S).
Airlines and Their Percentages of Short-Haul (%S; <3 h), Medium-Haul (%M; 3–6 h), and Long-Haul (%L; >6 h) Flights in 2018, Based on Block Time (Airlines Are Sorted in Decreasing Order of %S)
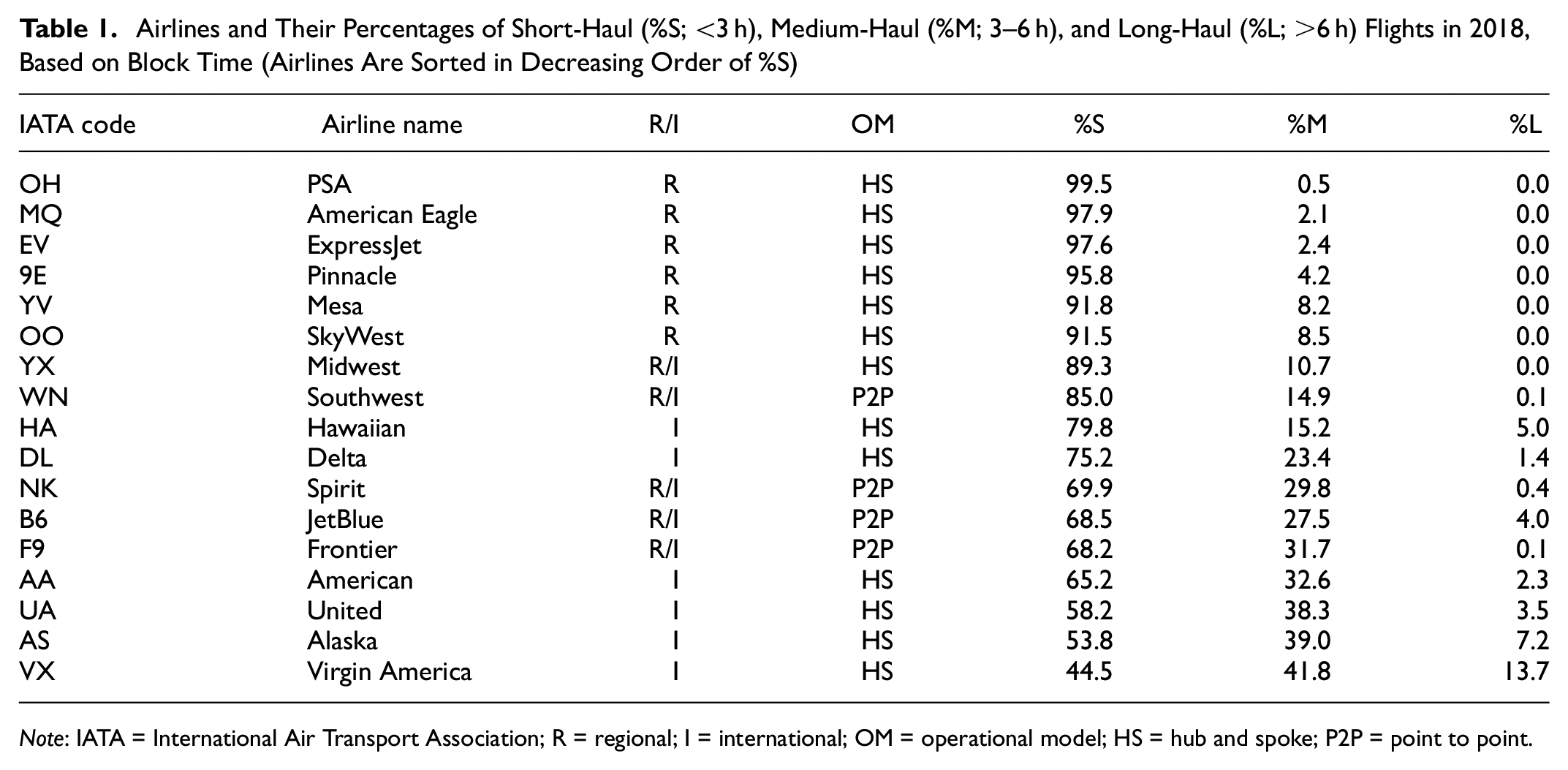
Note: IATA = International Air Transport Association; R = regional; I = international; OM = operational model; HS = hub and spoke; P2P = point to point.
Figure 3 provides a comprehensive visualization of the ABT distributions. The primary plot at the top of the grid depicts the overall distribution across all airlines, revealing a right-skewed pattern with a pronounced long tail. The subsequent plots, each labeled with an IATA code, represent the block time distributions of 17 individual airlines. The differences in these distributions are quite pronounced, reflecting the varied operational profiles of the airlines as described in Table 2. Some airlines, potentially those servicing shorter routes, showcase a more centered distribution, while others exhibit broader spreads, suggesting a mix of short- and long-haul flights. For instance, regional airlines like ExpressJet Airlines (EV) often operated multiple short hops per day, where delays can accumulate with each subsequent flight. In contrast, medium- and long-haul flights operated by airlines such as Alaska Airlines (AS) experience more variability from weather conditions, such as sustained headwinds at cruise altitudes. Additionally, Figure 4 illustrates the block time variation across the top 10 busiest origin–destination (OD) pairs, highlighting the variability that occurs not only across routes but also within each route and arises from the operating conditions, different airline practices, and other factors, further emphasizing the complex nature of predicting block times accurately.
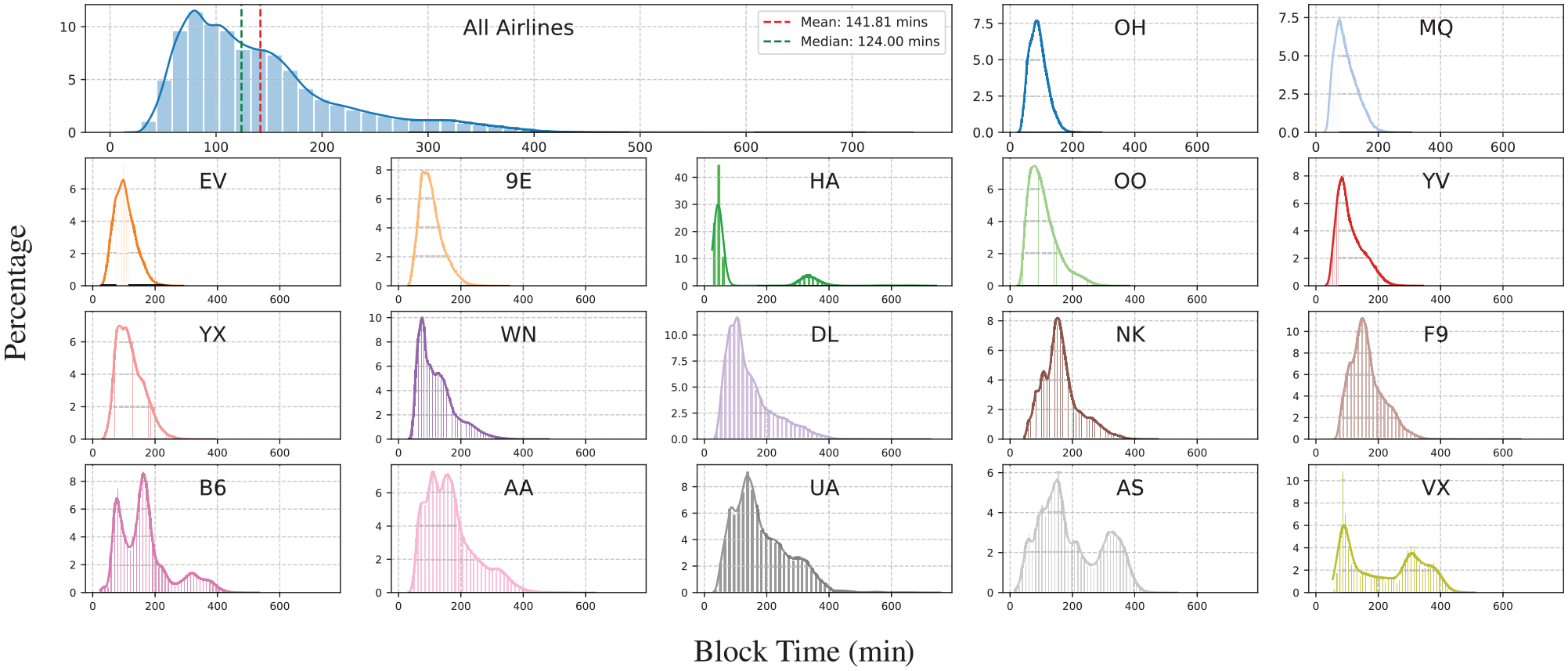
Block time (ABT) distributions for 2018. The main plot illustrates the aggregate distribution, while individual subplots capture airline-specific variations denoted by International Air Transport Association codes. The plots are sorted in decreasing order of %S (% short-haul flights) by airline.
List of Variables
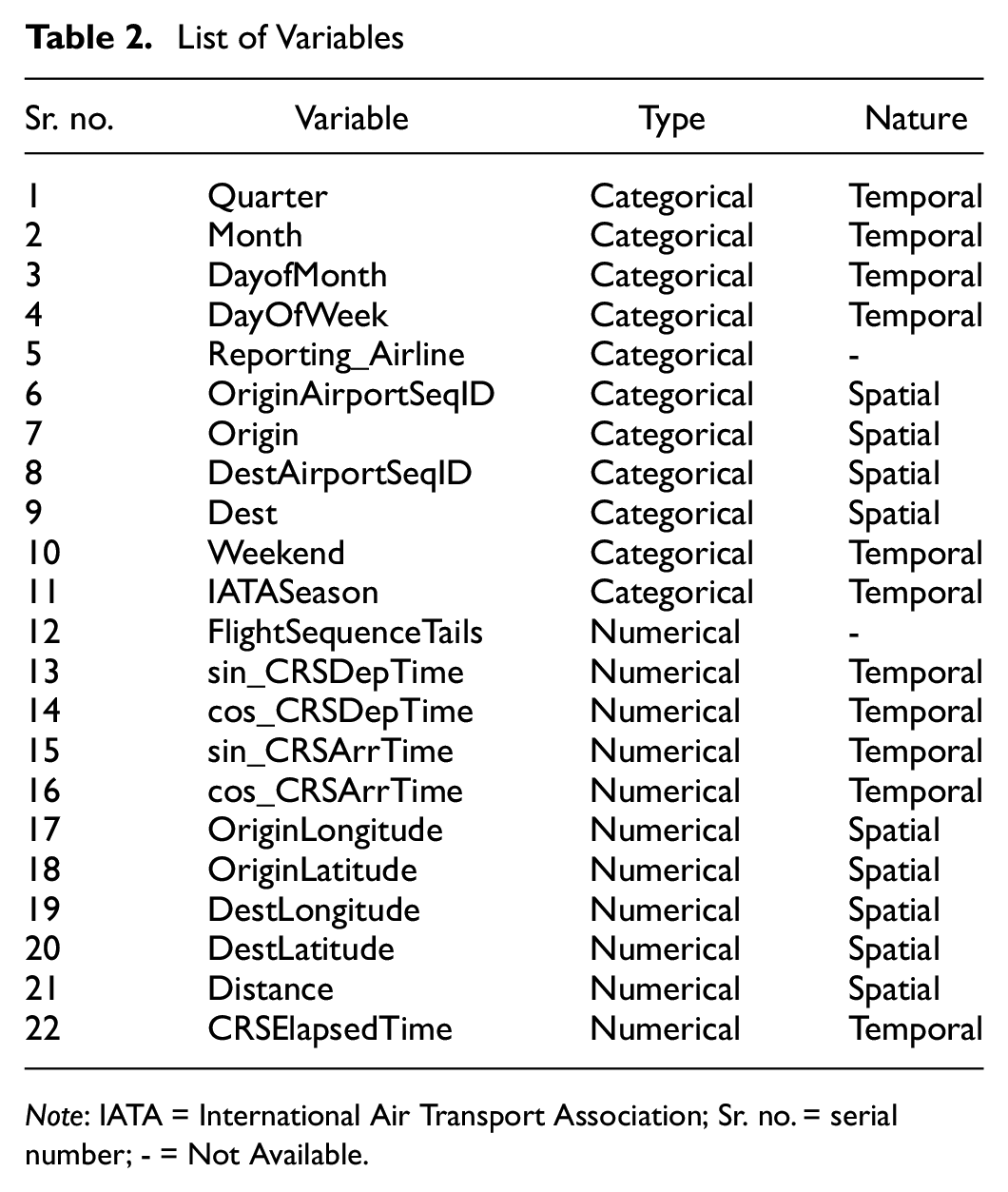
Note: IATA = International Air Transport Association; Sr. no. = serial number; - = Not Available.
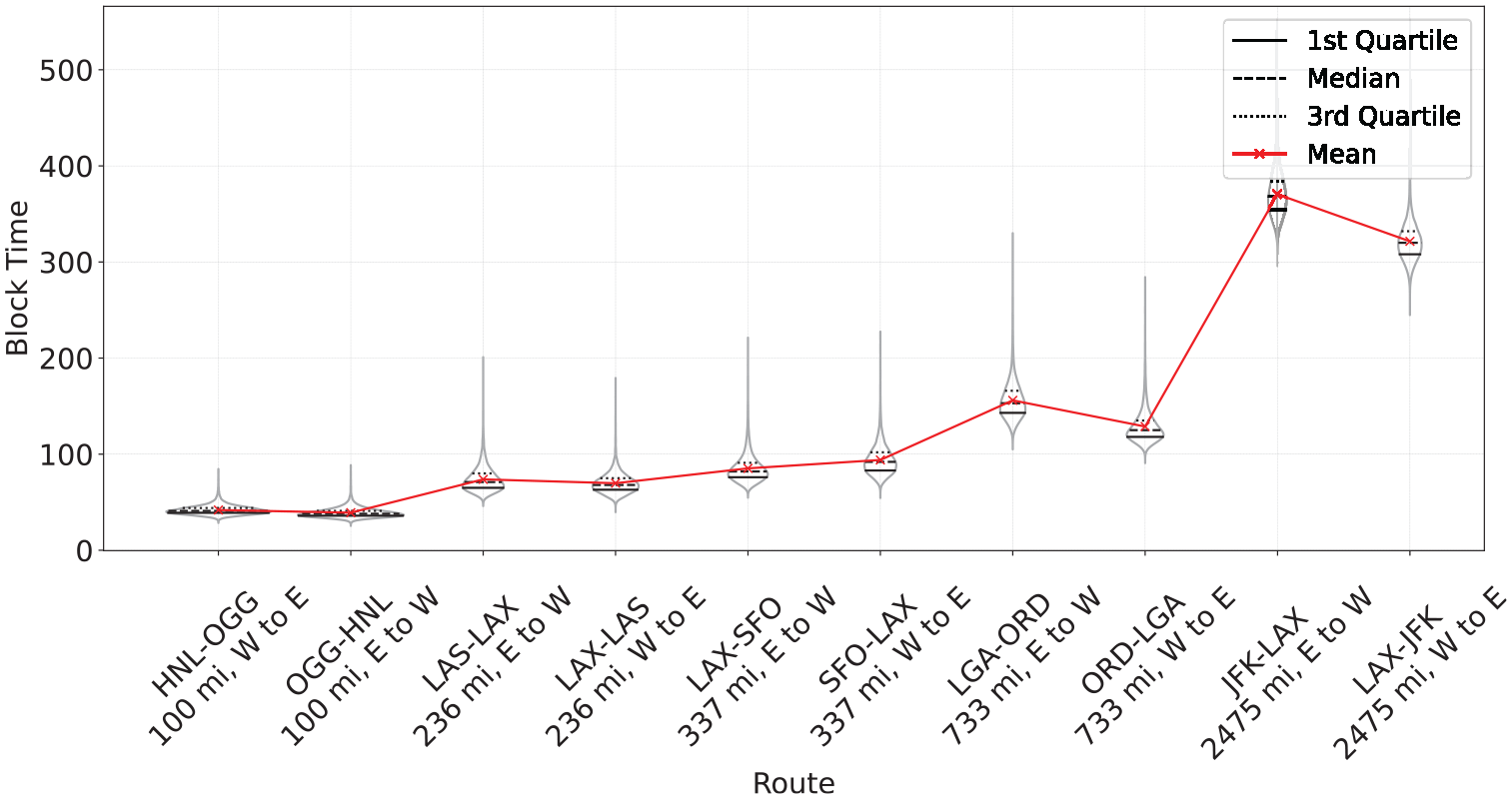
Block time (ABT) variations across the top 10 busiest links (sorted by the distance between the origin and destination airports). Violin plots depict block time variations for the 10 busiest routes (with internal lines indicating quartiles and means), showcasing the within-route variability and providing comparisons across routes.
Data Pre-Processing
Accurately capturing the periodic nature of temporal attributes is critical for modeling the nuances of airline operations. These patterns, especially in the context of timestamps like CRSArrTime and CRSDepTime, influence metrics like block times in airline operations. Table 3 provides comprehensive summary statistics of the temporal categorical features, highlighting the variability of ABT for flights across different time frames. To encode the cyclical pattern in time, we circularly transformed timestamps through the application of sine and cosine functions, enabling them to be represented as angles within a circular space. This approach ensures continuity between the endpoints of a cycle, allowing the subsequent models to recognize and leverage these cyclical dependencies. Recognizing the interdependencies of flights in a sequence and to capture the compounding delays, we also introduce FlightSequenceTails, which is a numerical attribute that encodes the order of flights based on their flight dates and tail numbers, providing insights into the cascading delays.
Summary Statistics Across Temporal Categorical Features
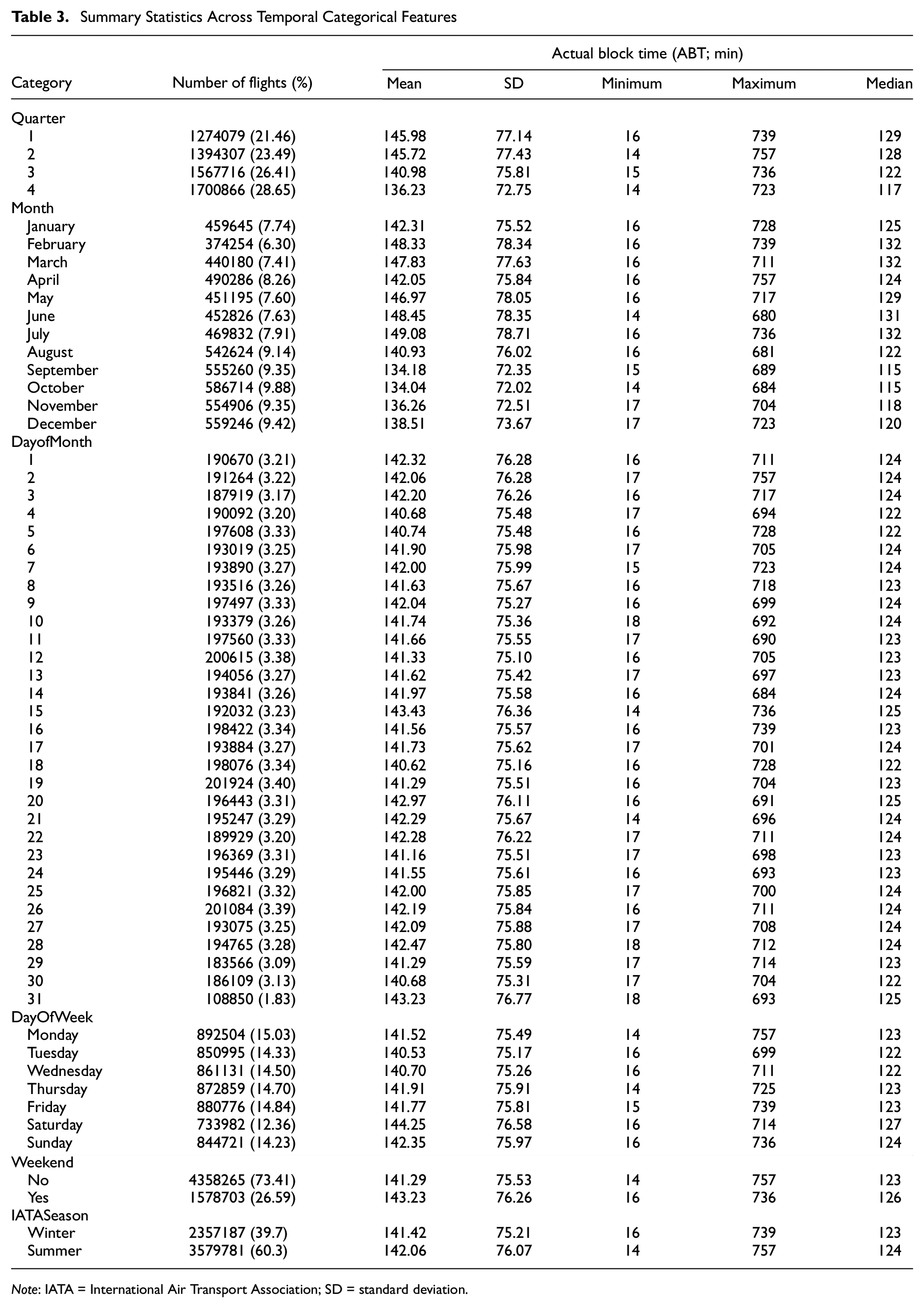
Note: IATA = International Air Transport Association; SD = standard deviation.
Baseline Models
In predictive modeling, especially when dealing with tabular datasets comprising categorical and continuous features, the choice of algorithm plays a pivotal role in predictive performance. Our choice of baseline models reflects a spectrum of algorithms that have traditionally demonstrated robust performance on tabular data, and they were selected to encompass both linear and nonlinear complexities inherent to the data ( 35 – 41 ). Additionally, these models range from ones that directly handle regularization to counteract potential overfitting to the ensemble and boosting methods known for their high accuracy in diverse scenarios. The models presented in Table 4 were considered.
Baseline Models

For handling the categorical features, one-hot encoding is employed. In the context of generalized linear models (GLMs), this encoding allows each category to be treated distinctly, with models fitting specific coefficients for each category. For tree-based models, the encoding directly affects the decision-making process. Tree splits will be determined based on the presence or absence of the encoded categorical variables, thus influencing how the model interprets and acts on the data. Having experimented with the traditional modeling approaches, we now set our sights on the vast potential of neural-network-based architectures.
Neural Network (NN) Architectures
Baselines Using One-Hot Encoding NN_OHE_25
We analyze various configurations of neural network architectures. First, we consider architectures that do not include an embedding layer. For these models, we begin with one-hot encodings of the categorical variables as described in the “Proposed Approach” section, and we directly feed these into the neural network without the embedding layer for the categorical variables. Since the embedding layer is a linear layer, we also choose this to be a linear layer for a fair comparison. Here, the dimension that the first layer maps to becomes an important parameter. To analyze the impact of compression caused by the action of the first layer, we analyze the following variants.
NN_OHE_25
This variant introduces a compression to keep
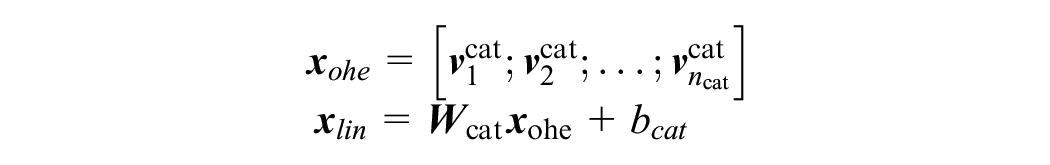
where

Then,
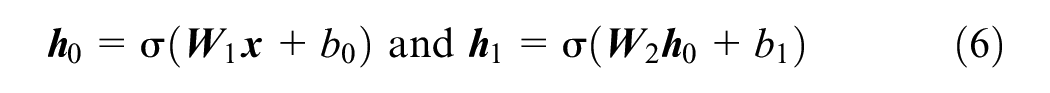
where

where
NN_OHE_50
Building on NN_OHE_25, we experimented with a more aggressive compression strategy, retaining 50% of the initial dimensions after one-hot encoding. The objective was to extract crucial features.
Using embeddings
Embeddings provide a dense representation of categorical variables. Instead of using a sparse matrix as in one-hot encoding, embeddings map each category to a point in a continuous vector space. This allows the model to place similar categories closer together, learning the relationships between categories during training.
NN_EMB
Drawing inspiration from the structure set by the NN_OHE _50 architecture, where categorical data were initially represented using one-hot encoding, in NN_EMB_D_B, we pivot to a more sophisticated approach by replacing the one-hot encoded layer with an embedding layer. Given the input feature vector,
NN_EMB_CORE
Expanding on the NN_EMB framework, this architecture introduces two key modifications: batch normalization and dropout layers. These changes are aimed at optimizing the learning process and enhancing the model’s generalization capabilities.
NN_EMB_D_B
This architecture removes the nonlinearity immediately following the embedding layer in NN_EMB_CORE. This approach is used to ascertain if the initial nonlinearity was perhaps preemptively capturing or distorting the relationships within the data.
Evaluation Metrics
The primary metric used for the evaluation of model performance is the root mean square error (RMSE), defined as
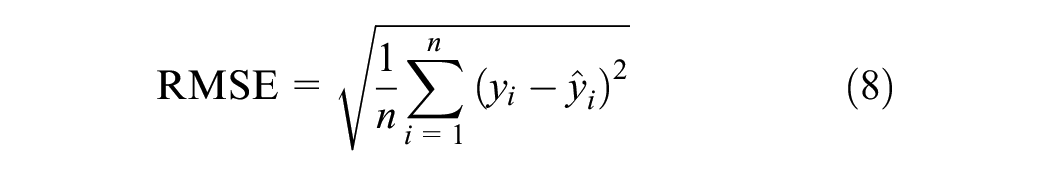
where
Further, to ascertain the statistical significance of the differences observed in the performance of the multiple models, an analysis of variance (ANOVA) was employed. We make use of p-values and confidence intervals to determine whether the observed differences could have occurred by chance, with p-values below 0.05 indicating statistically significant differences.
In addition to the RMSE, the mean absolute error (MAE) was utilized for the sensitivity analysis. This is defined as
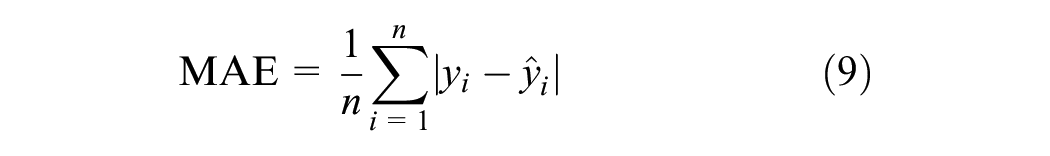
Unlike the RMSE, the MAE does not square the errors, thus providing a direct average error magnitude without unduly penalizing larger errors. This metric is useful for evaluating model performance in practical scenarios, reflecting the operational impact of prediction inaccuracies.
Results and Discussion
In this section, we present and discuss the results of block time prediction models. Both the baselines and the neural network models were subjected to an identical experimental framework. The data were distributed into training, validation, and testing subsets, taking 64%, 16%, and 20% of the total, respectively. Each model underwent training, validation, and testing across three distinct random seeds.
Comparing Baselines and Neural Networks
Table 5 presents the comparative performances of the baseline models and neural network architectures. The methods can be categorized into three distinct clusters: traditional regression approaches, tree-based algorithms, and neural-network-based models. Linear, lasso, and ridge regressions display nearly identical performances with minimal variations. The elastic net, while similar, shows slightly poorer performance and greater variability. This is reflected in their test error confidence intervals (CIs), which overlap, as shown in Figure 5. Conversely, the decision-tree and random-forest CIs overlap, indicating similar performances, as do the CIs for HGBoost, LightGBM, and XGBoost. However, NN_EMB’s CI does not overlap with those of the other models, suggesting its performance differs significantly.
Test Performance Comparisons (Each Test RMSE Represents the RMSE for the Best Set of Hyperparameters, Averaged Across Three Distinct Random Seeds)

Note: Best performing model - least Test RMSE is is in bold. RMSE = root mean square error; SD = standard deviation.
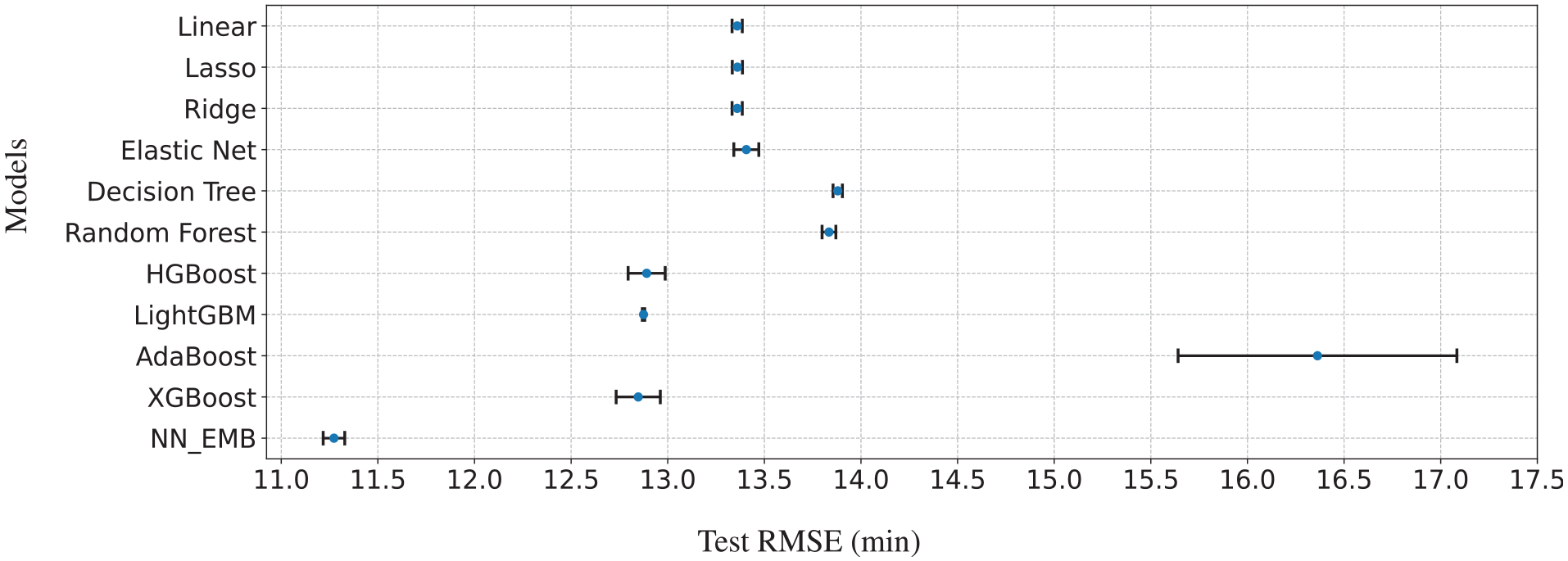
Confidence intervals of test RMSEs for the baseline models and NN_EMB. The blue markers on the graph show the average test RMSEs of the models, while the error bars indicate their 95% confidence intervals.
On the neural network front, both NN_EMB and NN_OHE_50 consistently outperform all the baseline models. It is evident that NN_EMB holds a distinct edge over NN_OHE_50. With a test RMSE of 11.273 min, it not only yields a better prediction accuracy compared with the 12.622 min of NN_OHE_50 but also less variation in performance. Figure 7 compares the train and test performance across baselines and neural networks based models. Consequently, we select NN_EMB as the optimal neural architecture for benchmarking against the baseline models.
To determine the statistical significance of the improvement in prediction error by NN_EMB, an ANOVA was conducted. This ANOVA compared the test RMSE across 10 baseline models and NN_EMB. The results revealed a significant effect of the model on the test RMSE (F-statistic(10, 22) = 535.55, p < 0.0001), indicating marked differences in performance among the evaluated models. On confirming significant differences, Tukey’s Honestly Significant Difference (HSD) post-hoc analysis was applied to perform pairwise comparisons of the means, with the family-wise error rate (FWER) controlled at 0.05. Table 6 details these comparisons, presenting the differences in the mean (
Tukey HSD Post-Hoc Comparisons Based on Mean Test RMSE Differences, 95% CIs, and Adj. P Values, Which Affirm the Statistical Significance of NN_EMB’s Performance Over the Baselines
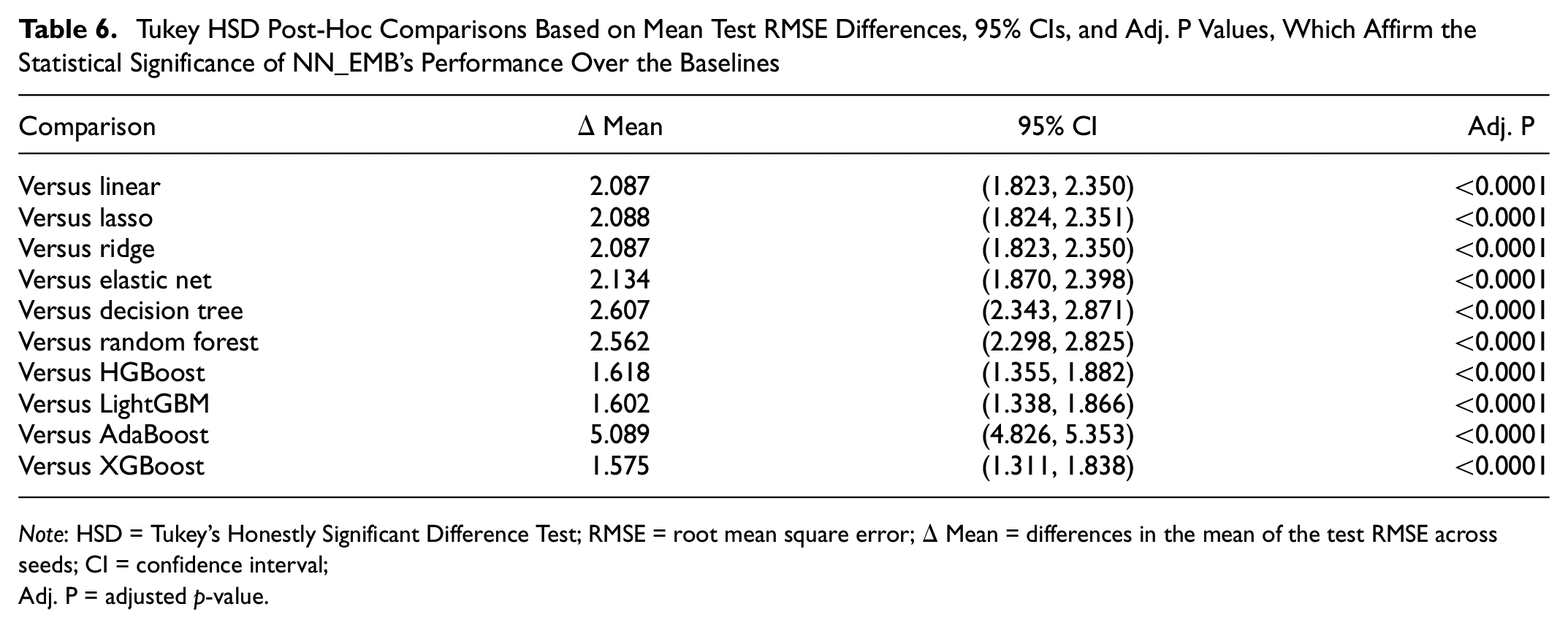
Note: HSD = Tukey's Honestly Significant Difference Test; RMSE = root mean square error;
The better performance of NN_EMB can be attributed to the utilization of embeddings, particularly when tasked with encapsulating features of high cardinality. Traditional encoding schemes often struggle in this regard. Techniques such as one-hot encoding, for instance, operate under the assumption that each category is independent of others, suggesting no inherent similarity between varying categories. This can often be a simplistic and inaccurate representation, as it assumes categories to be orthogonal. Another notable advantage of using embeddings is the adaptability they offer. For instance, if a new airport is incorporated into the dataset, the learned embeddings can be fine-tuned to accommodate these new data, ensuring model robustness and adaptability.
Performance Evaluation and Ablations
We performed a series of modifications of the initial model, employing One-Hot Encoding (OHE) and 25% compression to understand the effects of adding, removing, and replacing elements of the architectures. The outcomes of these variations are summarized in Table 7. It is worth noting that the initial performance of NN_OHE_25 improves significantly when retaining only 50% of the initial dimensions after one-hot encoding. NN_OHE_50 focuses on more critical features, thereby reducing noise and improving performance.
Overview of Architecture Modifications (Each Test RMSE Represents the RMSE for the Best Set of Hyperparameters, Averaged Across Three Distinct Random Seeds)

Note: Best performing method 11.273 (0.022) is in bold. RMSE = root mean square error; SD = standard deviation; OHE = One Hot Encoding; ReLU = Rectified Linear Unit;
Transitioning from OHE to embeddings marked a significant shift, facilitating NN_EMB_D_B with a more nuanced representation of the data. This led to a marked improvement in performance; specifically, the RMSE was enhanced from 12.622 min in NN_OHE_50 to 11.273 min in NN_EMB, highlighting the efficacy of embeddings in capturing intricate data relationships.
However, when further modifications were introduced to NN_EMB (particularly dropouts and batch norms) to form the NN_EMB_CORE architecture, there was a discernible degradation in performance. This suggests that the additional regularizing layers introduce unnecessary complexities that outweigh their benefits for this two-layer network. Notably, on removing the nonlinearity after the embedding layer, the performance of the NN_EMB_D_B architecture improved compared with NN_EMB_CORE, thereby indicating that, in this case, additional nonlinearity does not help.
Figure 6 compares the test performance across different architectures, where individual points on the graph represent distinct runs for each architecture. NN_EMB stands out with its uniform performance, demonstrating a test RMSE of close to 11 min regardless of batch size and learning rate variations. This indicates that it is a robust architecture that generalizes well across different configurations. On the contrary, NN_OHE_25 reveals a more varied performance spectrum.
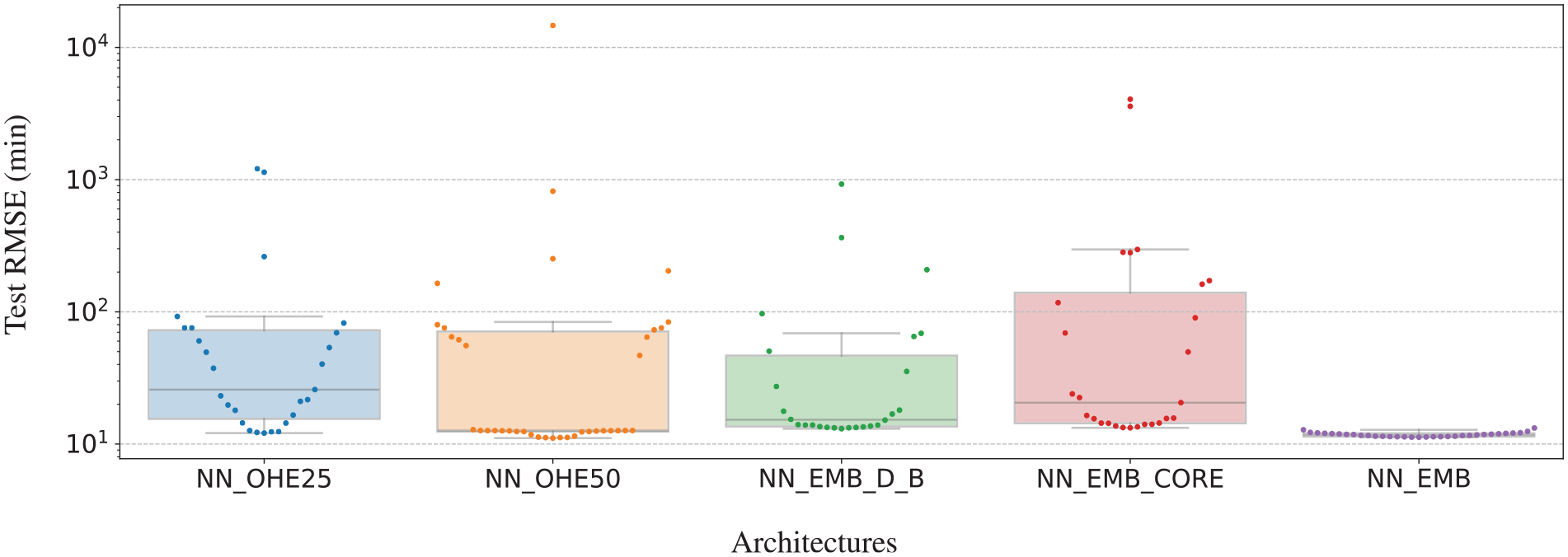
Impact of hyperparameters on the test RMSE. Each point denotes the mean test RMSE for a specific batch size and learning rate combination, averaged over three distinct random seeds. Notably, NN_EMB exhibits consistent performance (an RMSE of approx. 11 min) across various hyperparameter settings.
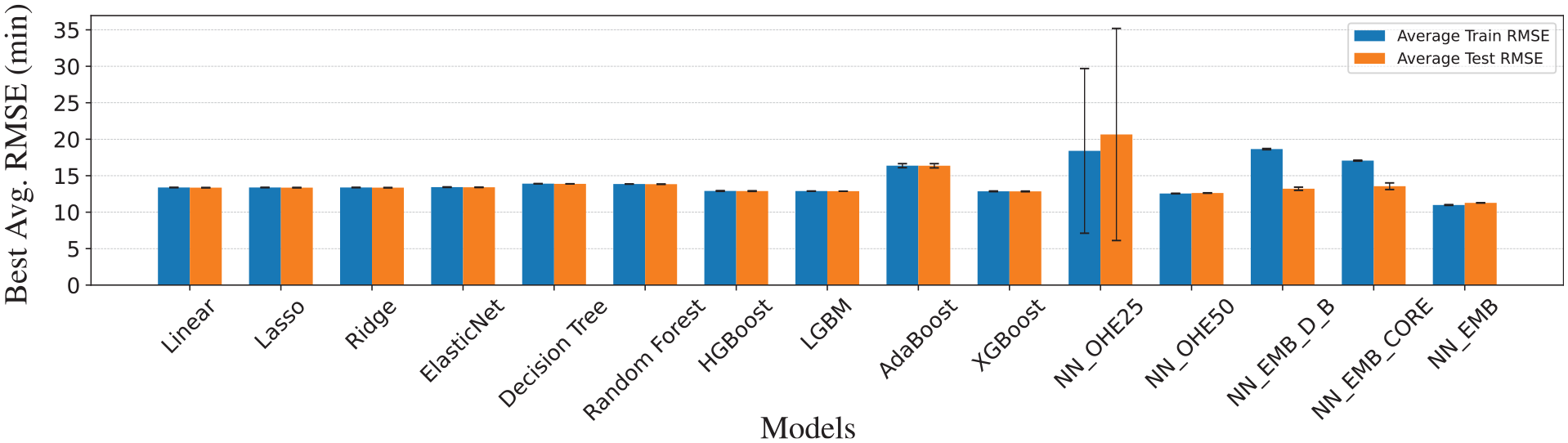
Comparison of the training and test performances of the models.
Meanwhile, NN_EMB_D_B exhibits a notably tighter interquartile range in comparison with NN_OHE_25, NN_OHE_50, and NN_EMB_CORE. This suggests that NN_EMB_D_B offers more consistent performance, with less sensitivity to hyperparameter fluctuations. In contrast, NN_OHE_50 displays a pronounced clustering of data points around its first quartile, indicating inclinations toward a specific performance range. Among all the architectures, NN_EMB stands out not only for its superior performance but also for its remarkable consistency. The data points for this architecture are notably clustered along a line representing the lowest RMSE, indicating that it consistently achieves this performance regardless of minor variations.
Learned Embeddings
In the implemented neural network architectures, NN_EMB_D_B, NN_EMB_CORE, and NN_EMB leverage embedding layers to process categorical variables. As the neural network is trained for block time prediction, these embeddings emerge as rich, multidimensional representations that capture intricate correlations within our dataset. For our visualization, we specifically utilize the embeddings from the best-performing run, notably from NN_EMB. To transform these embeddings into a more interpretable two-dimensional space, we employ t-distributed stochastic neighbor embedding (t-SNE) ( 44 ). Essentially, t-SNE gauges similarities between points in the high-dimensional space and maps them into a lower-dimensional space, ensuring similar data points cluster together. This nonlinear projection technique unveils patterns or clusters that might remain hidden in the original high-dimensional space. Utilizing this technique on our airline embeddings, we obtain a 2-D representation of airlines, as depicted in Figure 8a, which is annotated with IATA labels. We observed that American Airlines (AA), Southwest Airlines (WN), and JetBlue Airways (B6) form a close-knit cluster, revealing shared operational characteristics among them.
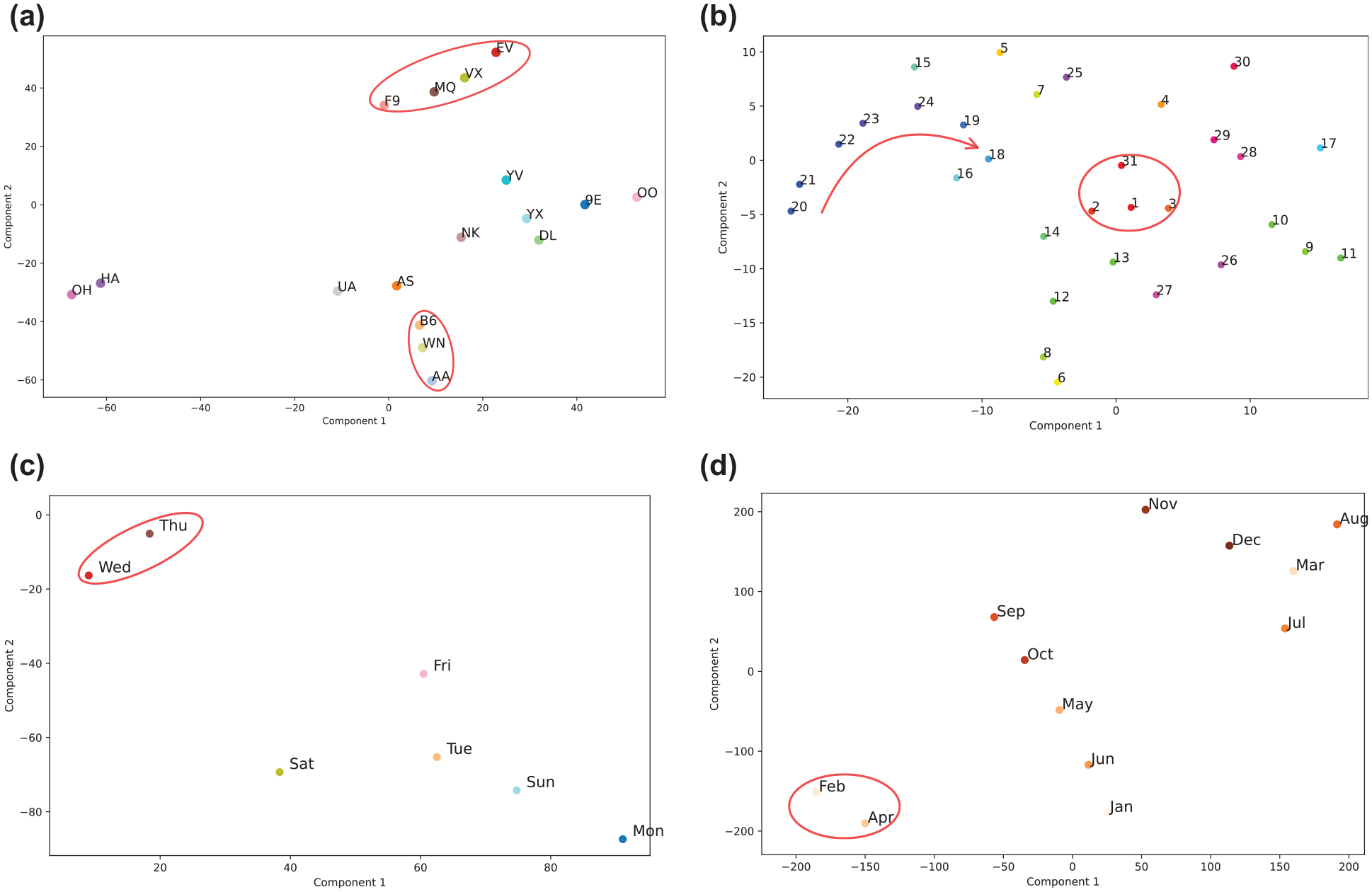
Embeddings from the best-performing NN_EMB run. Red-highlighted clusters and arrows indicate consistent patterns and sequential trends, respectively, across varying learning rates and perplexity values. (a) Airline, (b) DayofMonth, (c) DayofWeek, and (d) Month.
Additionally, the entities F9, MQ, YX, and EV form a separate group, which is distinctly highlighted in red in the figure. Further, we observed that American Airlines (AA), Southwest Airlines (WN), and JetBlue Airways (B6) form a close-knit cluster. Similarly, the entities Frontier Airlines (F9), American Eagle Airlines (MQ), Mesa Airlines (YX), and ExpressJet Airlines (EV) also form a cluster. Both these clusters are distinctly highlighted in red in the figure, indicative of analogous operational attributes amongst their respective members.
The embeddings for the days of the month, as seen in Figure 8b, reveal distinct cyclical patterns. The days 31, 1, 2, and 3 are closely clustered, with a clear sequential trend observed from days 20 to 24. These patterns are consistent across various t-SNE configurations, highlighting the cyclical nature of block time predictions throughout the month. Thursdays and Wednesdays, as shown in Figure 8c, cluster together across different perplexity values and learning rates, while the other days are spread out, demonstrating a significant deviation from this cluster. February and April cluster together in the month embeddings, as showcased in Figure 8d, suggesting similar flight patterns or operational behaviors during these months. However, there might be seasonal travel demands, holidays, or airline promotional activities that dictate the pattern visible, and one would need to delve deeper into external factors to derive concrete insights.
Sensitivity Analysis
We also carried out a sensitivity analysis for the proposed model NN_EMB, as detailed below.
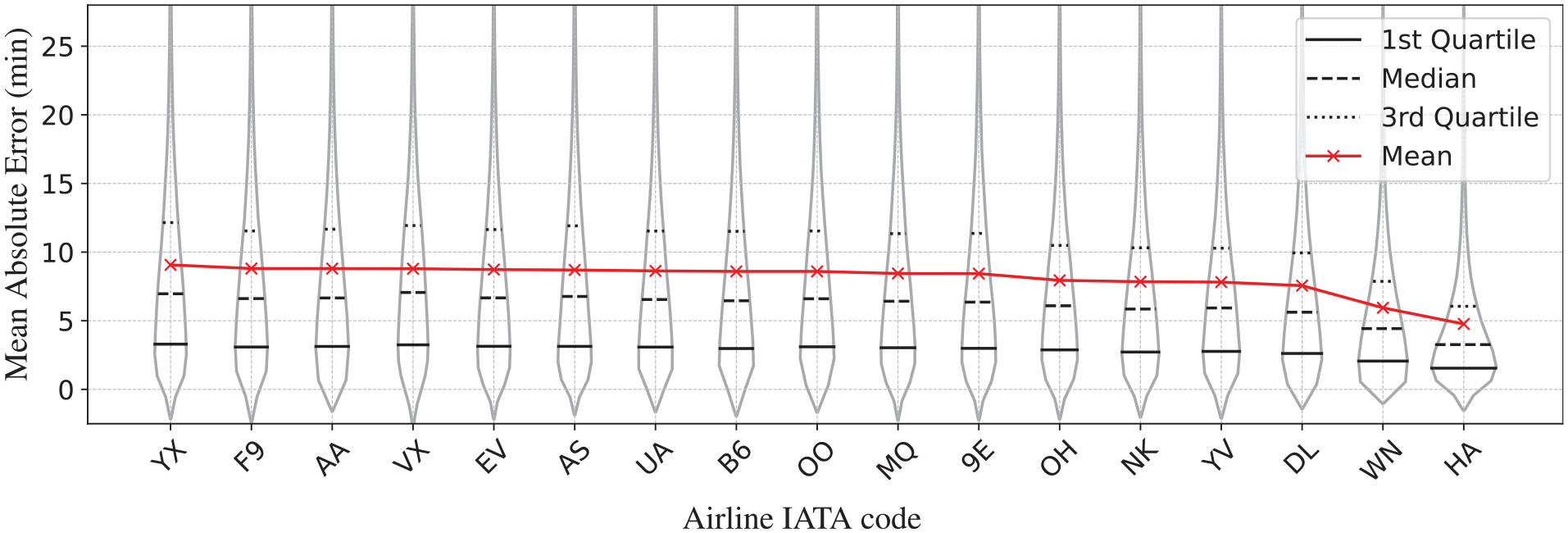
Prediction error across airlines.
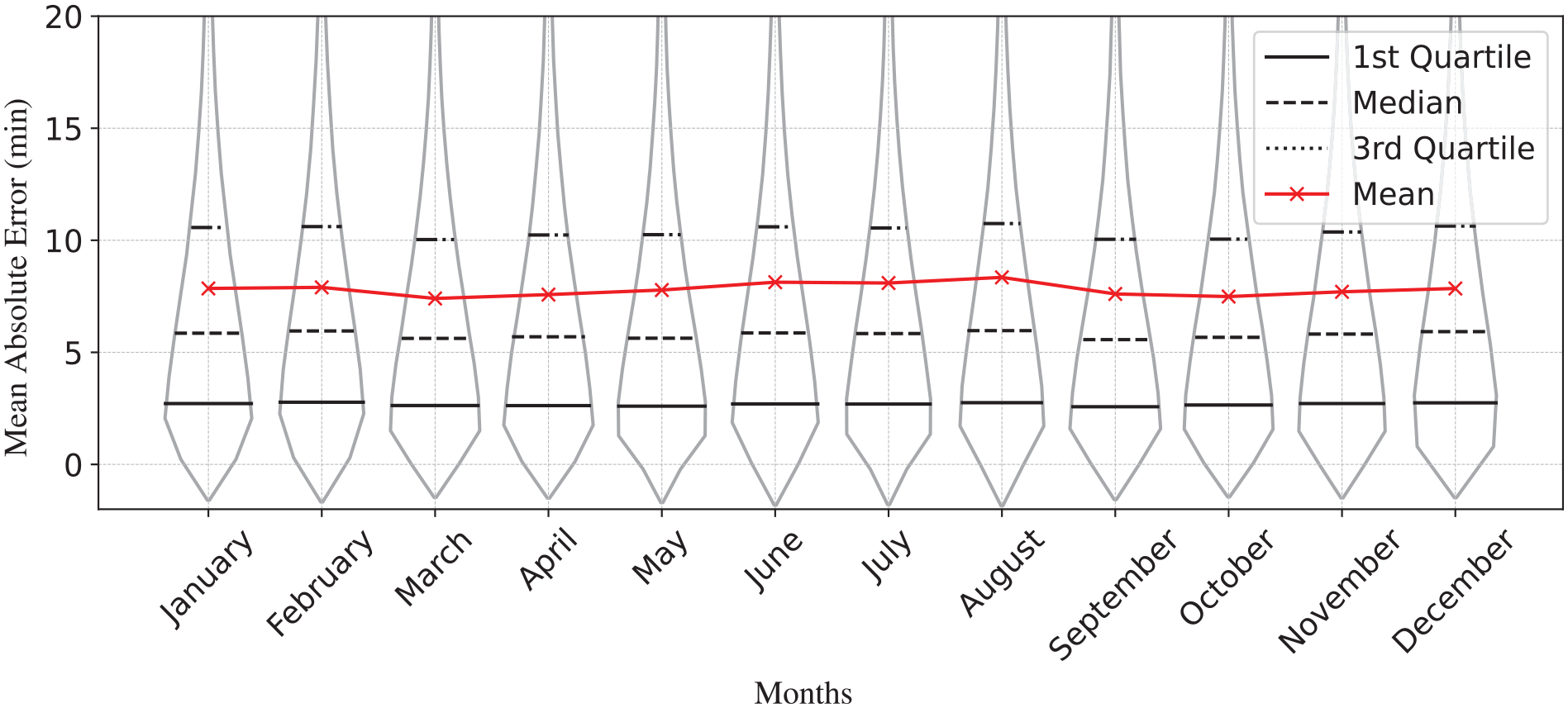
Prediction error across months.
Conclusion
Airline operations, by their very nature, operate under several uncertainties spanning various flight phases. For long-term planning, tasks such as predicting delays, determining block time, and assessing taxi-in and taxi-out durations, among others, take center stage for improving operational efficiencies. To this end, we focused on devising a predictive model tailored to address these challenges for a large-scale dataset (a first, to the best of our knowledge). Our exploration led us to the core insight: traditional encoding methods often fall short when handling the interdependencies and high cardinality of categorical variables. This prompted us to rigorously investigate the role of embeddings in improving forecasting capabilities. Among the neural network architectures explored, an embedding-based neural network architecture (NN_EMB) demonstrated superior performance and consistency properties. In conclusion, our findings emphasize the role of embedding-based representation learning in predictive modeling, especially to capture the complex relationship in high-cardinality features. Future work incorporating additional airline operation priors (aircraft type/age) and diverse data sources remains an exciting possibility to further improve model robustness.
Footnotes
Acknowledgements
The authors would like to acknowledge the NAVBLUE team’s support in providing expert knowledge about the airline industry and feedback on the manuscript.
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: A. Biswal, S. Rambhatla, F. Gzara; data collection: A. Biswal; analysis and interpretation of results: A. Biswal, S. Rambhatla, F. Gzara; draft manuscript preparation: A. Biswal, S. Rambhatla, F. Gzara. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research work was carried out by the authors in collaboration with NAVBLUE Inc. under the Sponsored Research Agreement SRA#04150, jointly funded by the NSERC Alliance grant ALLRP580589-22.