
Abstract
This work aims to assess the occlusion of traffic signs for autonomous vehicles (AVs) using point cloud data, while addressing the limitations and recommendations of previous studies. Dense point cloud data are used to create a digital twin of existing roads and simulate a set of AV sensors within this environment. Convex polyhedrons or hulls with an octree data structure and semantic segmentation were used to assess traffic sign occlusion. Using the developed method, several case studies are presented to identify locations with occluded traffic signs for AVs. This work can help infrastructure operators and AV professionals make data-driven decisions about smart physical infrastructure investments for AVs.
Keywords
Significant progress has been made in autonomous vehicle (AV) development over recent years ( 1 , 2 ). While there is a lot of interest in, and research on, such technologies in the AV market, government bodies have been slow to assess the ability of current road infrastructure to accommodate these vehicles. In the United States, the Department of Transportation has conducted assessments of highways to prepare for the mass deployment of AVs ( 3 ). Similarly, Transport Canada has funded research on the effect of driverless vehicles on road infrastructure ( 4 ). The complete deployment of AVs will be gradual over the years. A classification of automation levels was created ( 5 ) to identify the transition from no driving automation (Level 0) to full driving automation (Level 5). Given that current roads are designed based on human driver constraints, it might be necessary to adjust them for vehicles with different automation levels as technology evolves ( 6 – 8 ). During the transition to Level 5, standard designs must be revised to consider adequate parameters for different types of driver ( 6 – 8 ).
From the literature, it is possible to identify highway features, such as horizontal curves, vertical curves, intersections, and traffic signs, that are designed based on the capabilities of human drivers ( 6 , 7 , 9–12). Traffic signs, which represent a means of communication between traffic flow engineers and road users ( 13 , 14 ), present a challenge of potential poor visibility ( 15 , 16 ). However, current studies on the topic do not consider the parameters of AVs when defining the visibility of a traffic sign. Therefore, it is crucial to investigate whether the current placement of traffic signs is adequate for an AV to process and react to highway sign information ( 17 , 18 ). The importance of traffic sign visibility becomes more evident when considering AV sensors, as they differ from the human eye in operation, range, and resolution. AV sensors usually consist of some combination of radar, cameras, and lidar ( 1 ).
Lawson ( 19 ) discussed the importance of traffic signs in avoiding collisions during the transition period to fully AVs. Such activities as speed limit compliance, lane-keeping, and hazard warning will be dependent on traffic signs until technology provides complete support for that information. Also, even in a time when such a resource is supported, a road with well-placed visible signs can help mitigate the risk of an accident if access to the information platform is lost ( 8 , 19 ).
Lawson ( 19 ) also emphasized that both human beings and AVs can only properly read a traffic sign when it is correctly placed, oriented, and unobstructed by vegetation. In addition, Zhang et al. ( 15 ) considered occlusions by road facilities and buildings when defining elements that might cause visibility problems to traffic signs. As the verification for possible occluded traffic signs still depends on manual efforts made by traffic departments ( 15 ), an automated method capable of identifying traffic sign occlusions in complex situations is imperative to enhance the highway infrastructure for AVs.
Transportation agencies follow the Manual on Uniform Traffic Control Devices for Streets and Highways for the design and placement of traffic signs ( 20 ). This manual is designed based on human constraints. Severe weather conditions, changes in the surrounding environment, accidents, and maintenance, among other reasons, lead to changes in traffic sign placement. Therefore, traditional surveying methods are performed to build traffic sign inventories (TSIs) to maintain traffic signs. Traditional methods are time-consuming, labor-intensive, inaccurate, and limited, compared with the large size of existing transportation networks.
This paper presents a simulation-based method to assess the occlusion of highway traffic sign placement considering parameters related to AV sensors using dense point cloud data. The proposed methodology seeks to extract occluded traffic signs using lidar data. Lidar utilizes laser scanning, the Global Positioning System (GPS), and navigation technologies to provide positional and intensity information that can be used to create virtual high-density 3D point cloud representations of the scanned environment ( 21 ). As an automated method, it replaces the tedious and time-consuming process of manually creating and analyzing TSIs using traditional methods and manual surveying ( 13 ). Recent research and practice has gravitated toward the use of lidar data for infrastructure asset management and maintenance applications ( 9 , 21–26).
Literature Review
Much of the existing research on AV sign detection has been focused on image processing algorithms rather than the optimal positioning of the signs themselves. This literature review, therefore, focuses on existing research on traditional detection methods to better understand potential difficulties faced by these algorithms with respect to sign positioning. In addition, state-of-the-art research on traffic sign occlusion detection is presented.
Shladover and Bishop ( 27 ) presented a paper addressing predicted future issues related to the introduction of AVs. One topic mentioned was the importance of traffic signs for connected AVs (CAVs). Shladover and Bishop ( 27 ) explained how traffic sign recognition is necessary for vehicles in areas with a high sign density, such as construction zones, or while they are disconnected from the CAV network and cannot receive road information digitally, such as during times of poor connectivity, owing to hacking, adverse weather conditions, and so forth. In these cases, sign recognition is essential as a reliable source of real-time information. Sign data from individual vehicles can then also be uploaded to the network and aggregated to update digital sign inventories in real time. Shladover and Bishop ( 27 ) concluded that accurate AV sign recognition is critical for CAV deployment as the vehicles, by design or circumstance, might not always be connected to a network and, therefore, will rely on vehicle sensors for information.
Wahyono et al. ( 28 ) investigated a method of traffic sign recognition by AVs from visual data using cascade support vector machines (SVMs). Signs were identified by segmenting images by color, isolating known sign shapes, and identifying differentiating patterns on the faces of signs. Segmentation was primarily handled using a histogram of oriented gradients. The completed program was run on a database of 300 images, with sign recognition and detection rates of 90.82% and 89.12%, respectively. Wahyono et al. ( 28 ) also noted how rotation and occlusion of traffic signs complicated the image processing techniques used.
Walters et al. ( 29 ) reviewed the difficulties faced by CAVs in rural areas. They noted how, in these areas, CAVs are prone to disconnection from the vehicle-to-infrastructure (V2I) network and are entirely reliant on onboard sensor systems and global navigation satellite systems (GNSSs) for navigation. In these cases, the identification of road signs allows CAVs to collect road regulatory information and make positional adjustments during so-called blind time, when GNSS signals are temporarily interrupted. Walters et al. ( 29 ) pointed out how the development of robust sign detection programs is required to ensure safety during times of extreme weather conditions, which generally reduce the accuracy of existing sign identification techniques. Walters et al. ( 29 ) recommended regular inspection and cleaning of rural road signs to improve their visibility and identification by CAVs.
Chen et al. ( 30 ) investigated multi-sensor system design for AV environmental perception. They noted how sensors with high contrast improve sign recognition, as most existing detection algorithms rely heavily on color matching. This was tested by constructing a multi-sensor array of visual and laser scanners on a sports utility vehicle, then processing the sign data using a detector and descriptor for speeded-up robust features (SURF). Their algorithm operated by identifying regions of interest (ROIs) in the images (ROI locking), and then segmenting out the individual colors. Detection rates for signs were 94.3%, taking 50 ms per frame.
Geese et al. ( 31 ) investigated sensor performance in AVs and advanced driver assistance systems. Their study focused on a comparison between human observers and visual sensors. They recognized that the human eye has much better contrast detection abilities than existing image processing techniques and can better adapt to non-ideal conditions. The paper found that digital sensors and image processing algorithms struggled to find which parts of an image should be denoised, especially when analyzing dark images.
Wali et al. ( 32 ) investigated current difficulties with vision-based sign detection systems. They demonstrated that the traditional analysis methods of detection, tracking, and classification could be improved by merging steps and allowing, for instance, the classification of a sign to be used to update the detected shape of a sign. They also examined environmental effects on sign detection. Inconsistent lighting, sign clustering, and sign rotation, among other factors, generally decreased the accuracy of detection algorithms. It was also identified that color and shape remain the most common metrics used by detection algorithms and that convolutional neural networks appear to produce the most accurate results.
Wu et al. ( 16 ) investigated traffic sign visibility using retro-reflectivity and ground plane proximity. Signs were ranked based on vertical driver view angle, planarity with respect to the travel direction, and view distance, among other factors. Rankings were awarded based on sign visibility. Test sign data were collected using a mobile laser scanning (MLS) system utilizing laser scanners, digital cameras, and a wheel-mounted distance measurement indicator. A sample of 100 sign images was tested by both the proposed algorithm and a human reviewer. Signs were categorized by visibility rankings; the discrepancy between human and computer rankings observed was less than 5%
Hirt et al. ( 33 ) investigated detection using lidar data and 3D city models of occlusion of traffic lights and signs caused by vegetation. Their models included the location and orientation of streets, traffic lights, and traffic signs. They used ray-tracing in an occupancy grid generated by the voxelization of the lidar data to identify occluded traffic signs. Hirt et al. ( 33 ) found that their method is feasible for the detection of occlusion by vegetation in an urban street scenario. Kilani et al. ( 10 ) and Gouda et al. ( 24 , 25 ) used voxel-based raycasting for sight distance analysis and obstruction detection on urban and rural roads. Huang et al. ( 34 ) detected occluded traffic signs using 3D point clouds and trajectory data acquired by MLS. Sign extraction was based on both the reflectance and geometric features of signs. A hidden point removal algorithm was adopted to detect occlusion using the trajectory and traffic sign data.
In conclusion, sign recognition is important for the safe deployment and operation of AVs. Additionally, several factors, including obstruction, rotation, color condition, shape consistency, lighting, and weather conditions, affect the performance of sign detection. The placement of signs influences occlusion and rotation and is relatively independent of the detection systems and algorithms used by AVs. There is a lack of prior research on physical sign visibility that considers AV sensor characteristics, despite the recommendations of previous studies. The aim in this study is to develop a simulation-based method to assess the occlusion of existing traffic sign infrastructure for AV deployment using lidar data. In addition, our proposed method is compared with a redesigned state-of-the-art voxel-based raycasting approach to account for AV sensors.
Methodology
Two different methodologies were used in this study to analyze the visibility of the signs along several road segments. The methodologies were validated and compared, to determine the more accurate method. The first method involved using a voxelization and raycasting technique, whereas the second method utilized an octree organization and convex hull view frustum to determine visibility. The following subsections describe the shared and varying processes that each of these methods uses. Figure 1 is a high-level flowchart of the methodologies.
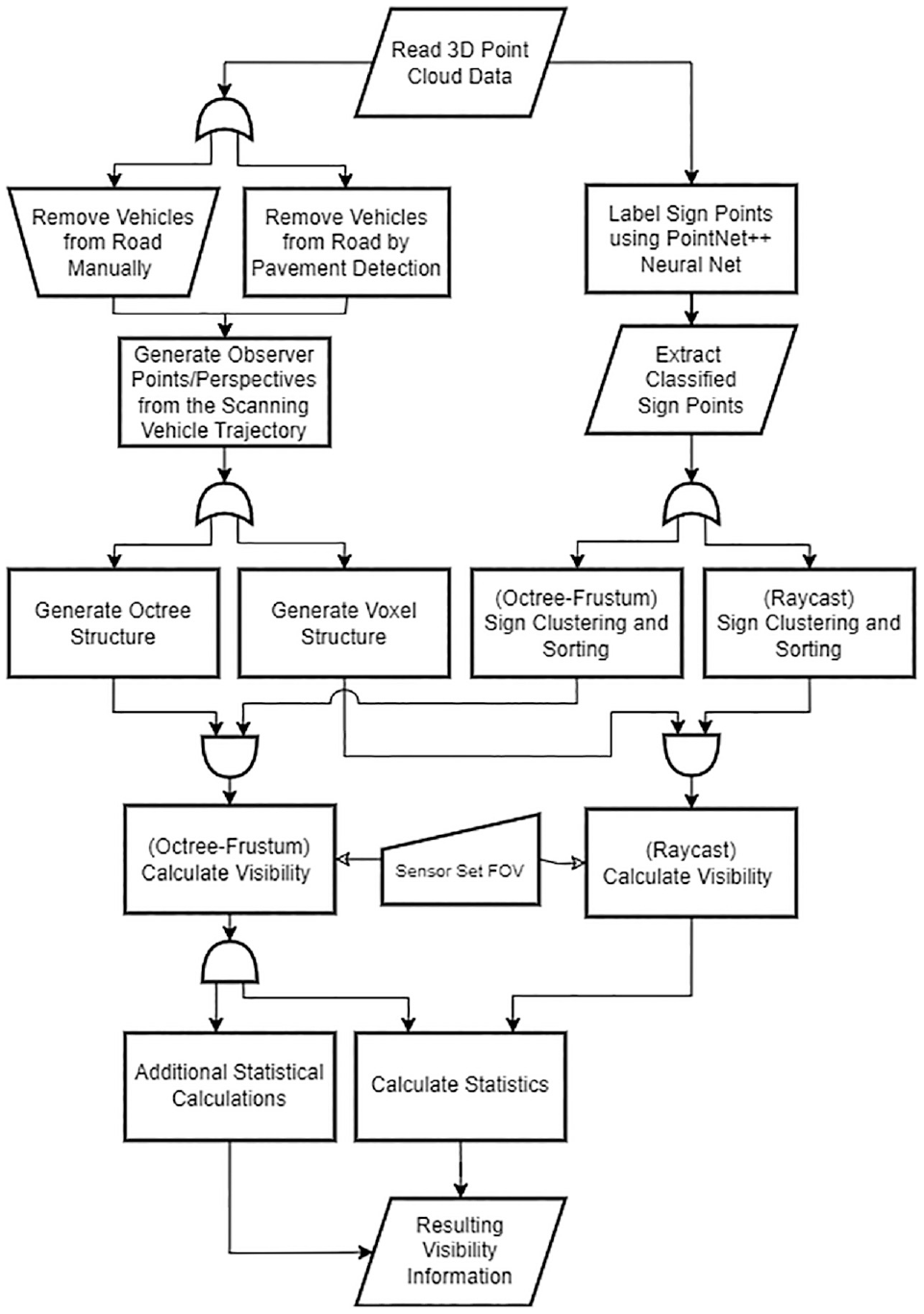
Methodology flowchart (comparing both methods).
Preprocessing
Before using the proposed method, the input point cloud (
Defining Observers
In this work, an observer is defined as a set of points following a vehicle’s trajectory that simulates the visibility positions for an AV. First, the car’s trajectory was extracted from lidar data by taking points with zero scan angle and sorting them by GPS time. All selected points were then smoothed using a window to create a curve describing the car’s trajectory. Along the curve, points were sampled every 1 m and shifted up by 1.2 m, leading to a set of observers (
To explore the full potential of a point cloud, a second set of observers (

Observer points in both directions along a two-way two-lane road.
Data Structures
Raycast Method: Voxelated Point Cloud
The raycast method involved using a voxelated point cloud to determine obstructions and reduce processing time. The input point cloud
Octree-Frustum Method: Octrees and Half-Spaces
The convex hull method uses an octree, which is a space-portioning data structure effective in storing 3D data. Octrees, like their 2D counterpart, binary trees, enable spatial searching and queries in logarithmic time. This is done by dividing space into eight octants or cuboidal nodes and grouping points in each octant according to their position, up to a maximum number of points. Beyond this maximum, any arbitrary node is recursively subdivided into eight smaller child octants until none of the child nodes of the octree contains more than the maximum number of points per node. Queries into the octree search for points in a volume bounded by a set of constraints. Such constraints are represented by the intersection of half-spaces, given as
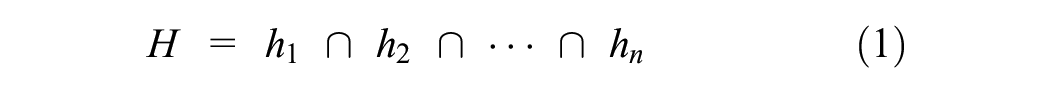
A half-space is either of the two subspaces obtained when a hyperplane divides affine space. In three dimensions, this refers to the two volumes on either side of an infinite plane. A half-space is given by
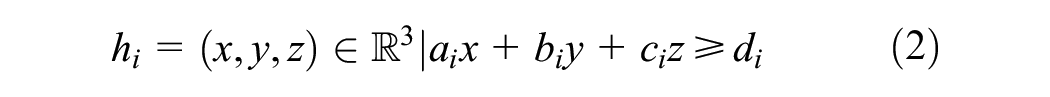
with constants
The intersection of a set of half-spaces in three dimensions forms a convex polyhedron. If the volume of the intersection is finite, or bounded, the constraints may be used as an input into the octree for query or search purposes. Figure 3 shows what this may look like in three dimensions.
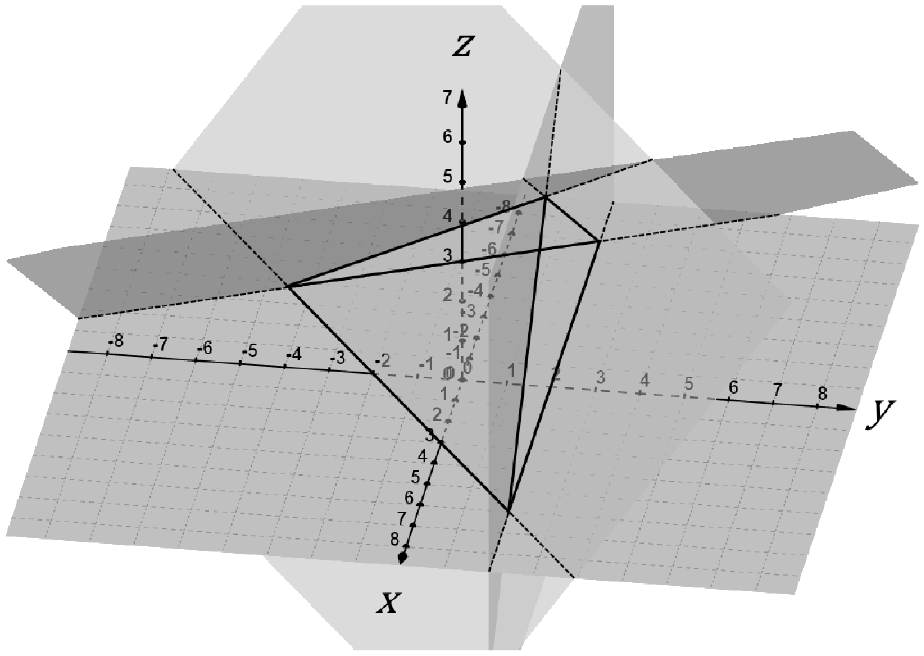
Example intersection of four half-spaces forming bounded volume:
The equation of a half-space can be found with three non-colinear points (
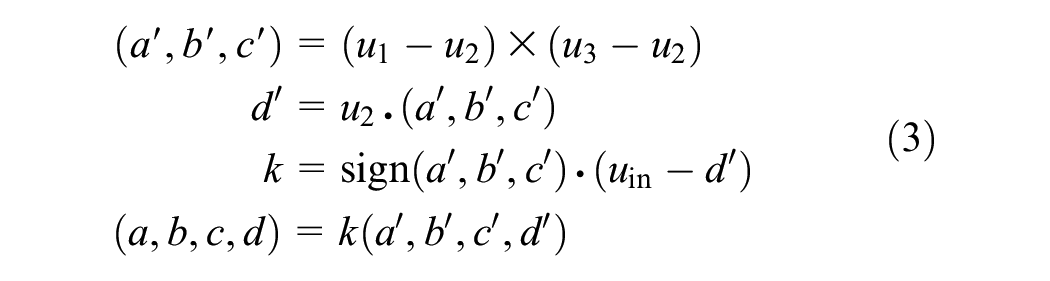
Sign Clustering and Sorting
Raycast Method
In the raycast method, signs were clustered based strictly on proximity to each other. Points were clustered such that no two clusters were within 0.5 m of each other. After defining these separate clusters as individual signs, their mean center points were calculated. Using the center points of these sign clusters, the closest observer to the sign was calculated and used to determine the sign’s distance from the road. Signs beyond 20 m from the road were not considered, and such clusters were removed from the sign set. The remaining sign center points formed the set
A set of signs
Then, the observer’s index that led to the minimum value of the dot product
To consider observers driving in both directions for the same point cloud,
The orientation angle

Next, the homogeneous transformation matrix (
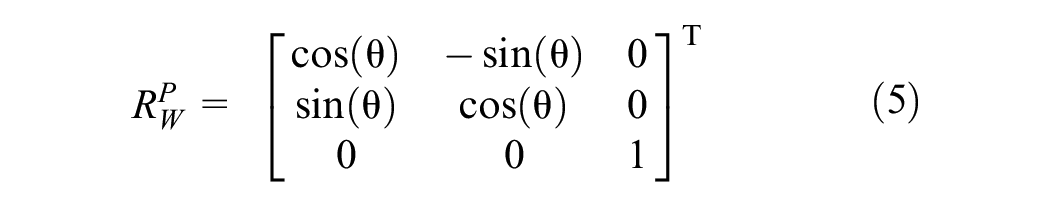
Defining
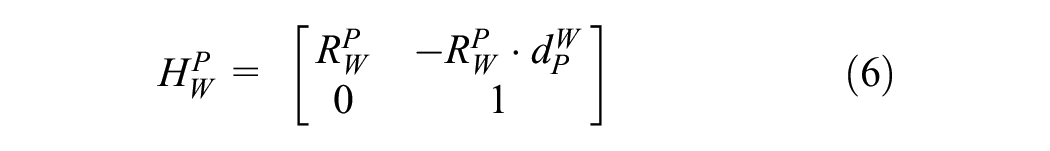
The matrix
Octree-Frustum Method
In the octree-frustum method, signs were obtained by clustering points in

Figure 4 illustrates how this fit is applied to a point cluster.
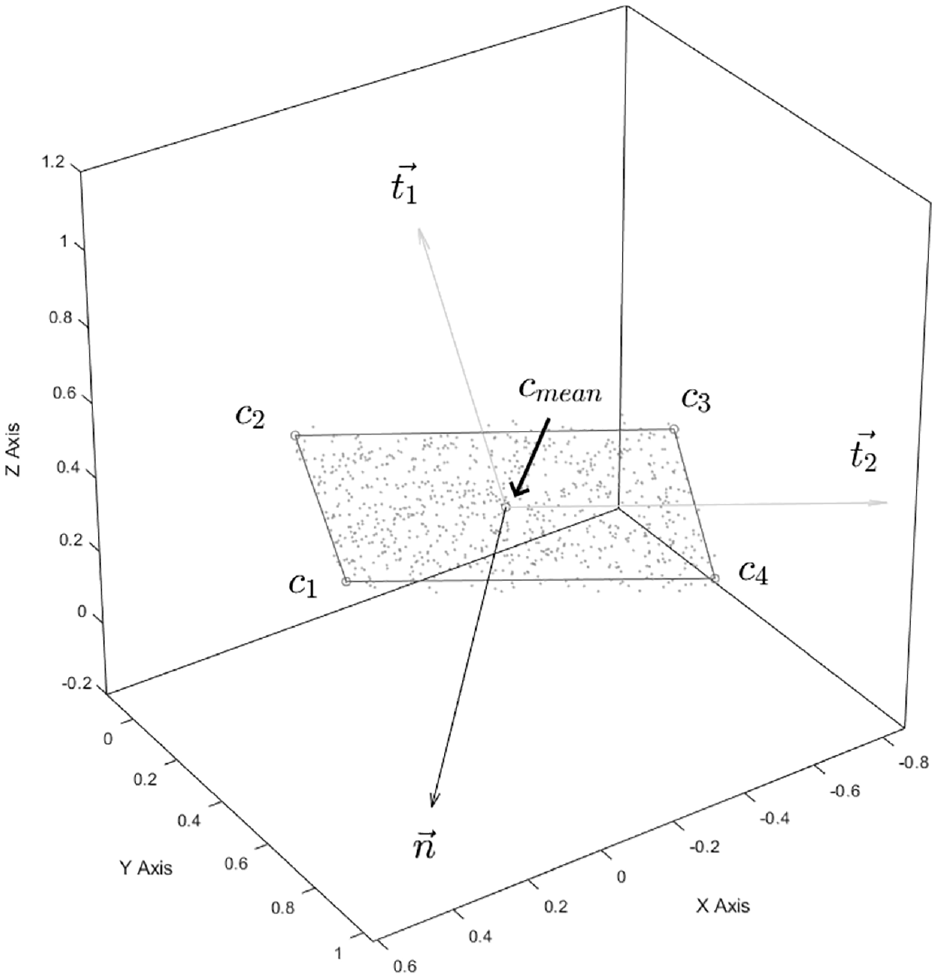
Sign point cluster fit, displaying corner points, mean point, and corresponding computed vectors.
Additionally, shifted corner points can be calculated using two scaling factors (
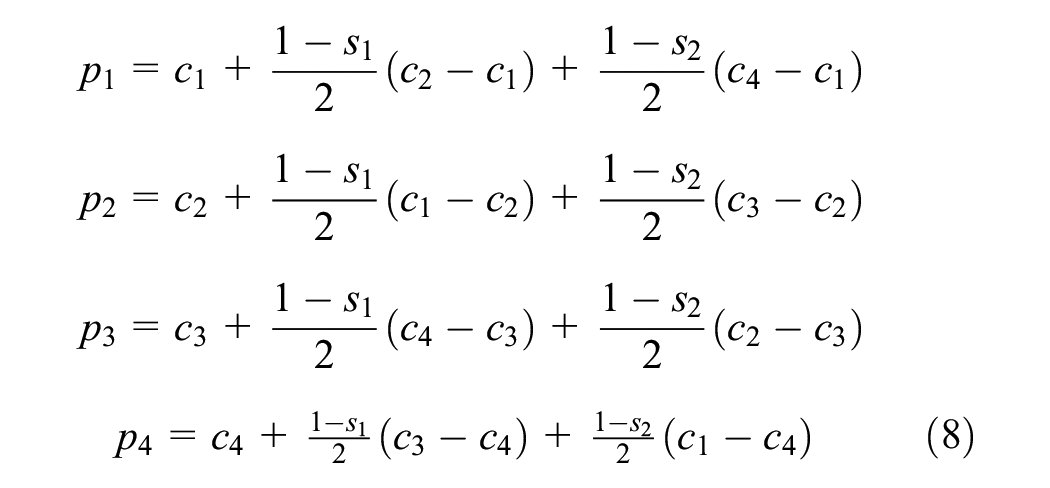
These formulas stretch the border around the sign by a ratio of
The clusters were filtered so that only clusters with center points within 20 m of their closest observer were considered, to filter out distant signs from the road. The filtered center points form a set
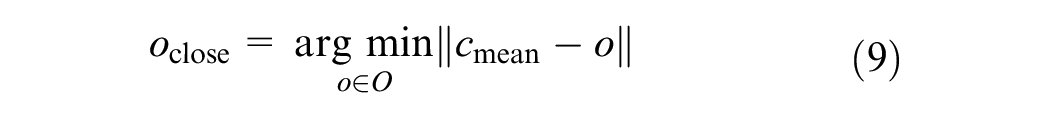
Additionally, each sign is either on the left or the right side of the road. This is determined based on the dot product of the vector from its closest observer to the sign and the leftward vector for that observer:
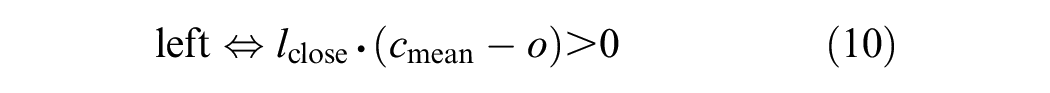
Identifying which side of the road the sign is on allows the signs to be filtered, so that one side of the road can be analyzed later by splitting
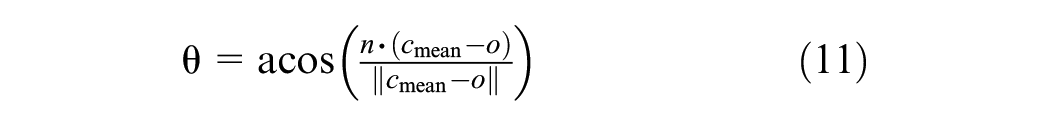
The created set of signs,
Defining Sensor Sets
The analysis of visibility by an AV is strongly dependent on the number of sensors and their field of view. This can vary between vehicles, which is why a simulation-based approach with configurable sensor characteristics is valuable. The number of sensors, the description of the vertical and horizontal limits, and the range for each sensor used forms a sensor set. Figure 5 shows how the individual sensor boundaries are defined.
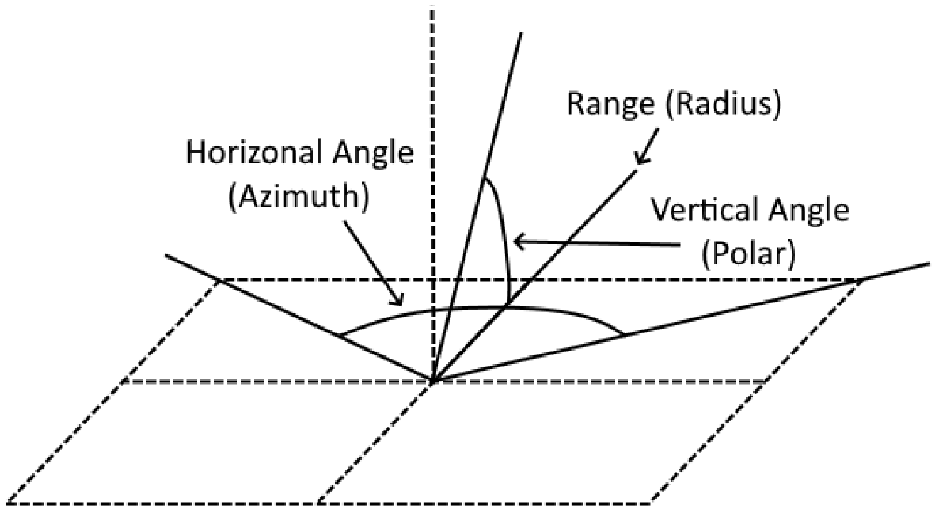
Sensor angles using spherical coordinates.
Generally, sensors are defined using spherical coordinates. This suggests that the horizontal and vertical limits or boundaries are given as azimuthal or polar angles, respectively, with the forward vector being 0° at any given observer. Therefore, each sensor has a minimum and maximum angle in each of these directions, with upwards and clockwise from the forward vector considered as the positive directions for these angles. The ranges of sensors also vary, bounding the distance of the individual sensor field of vision (FOV) arcs created by these angles and causing the FOV to appear as a section from a sphere, with the range as the radius. Figure 6 shows what this looks like for the sensors described in Table 1 ( 2 ).

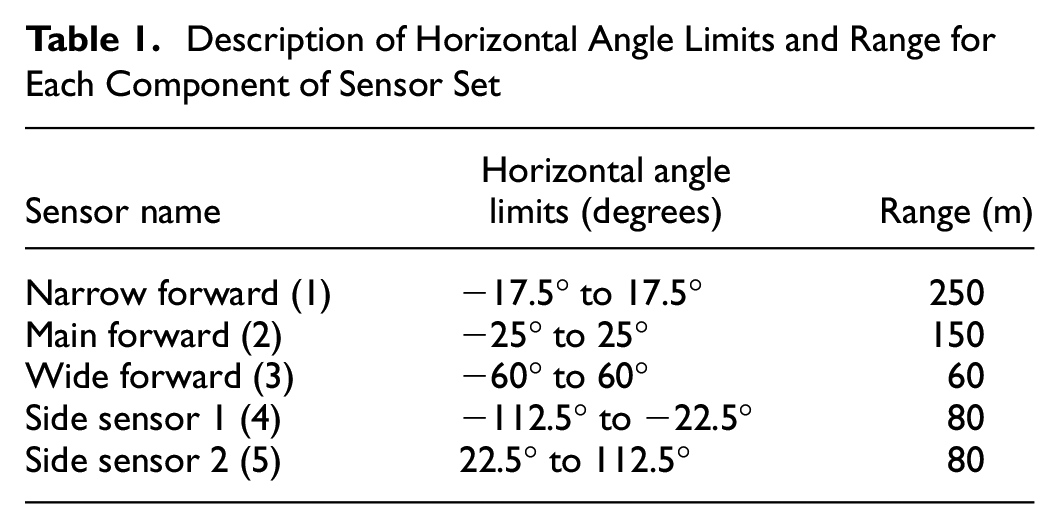
Example sensor set for the sensors described in Table 1.
Description of Horizontal Angle Limits and Range for Each Component of Sensor Set
Calculating Visibility
Raycast Method
After data preprocessing, we can determine all observers of each set that were visible from each sign point
For all signs within a sensor range, Bresenham’s line algorithm (
35
) was used to cast a ray from
Octree-Frustum Method
For every observer
For all signs within a sensor range, a volume bounding frustum was created and queried against an octree organization of the point cloud
The apex of the view frustum is an observer, and the base of the view frustum is made up of a shifted version of the scaled corner points
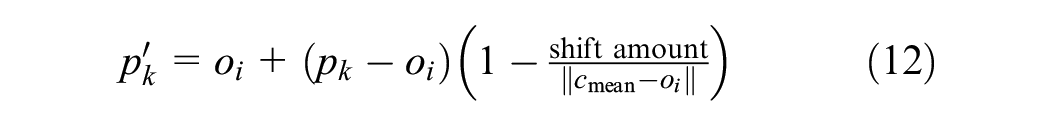
and is repeated for each scaled corner point.

View frustum with shift of 1 m and stretch factors
To determine the intersection of half-spaces that constrain this frustum, a point inside it must be found; in turn, this would be inside all the half-spaces required to define the constraints of this volume. A point that is guaranteed to be inside this frustum is the average of the five points that make up the corners, given by
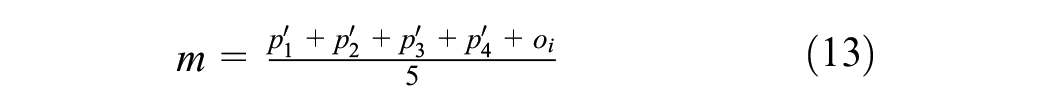
Therefore, the intersection of half-spaces defining the constraints of the view frustum is given by
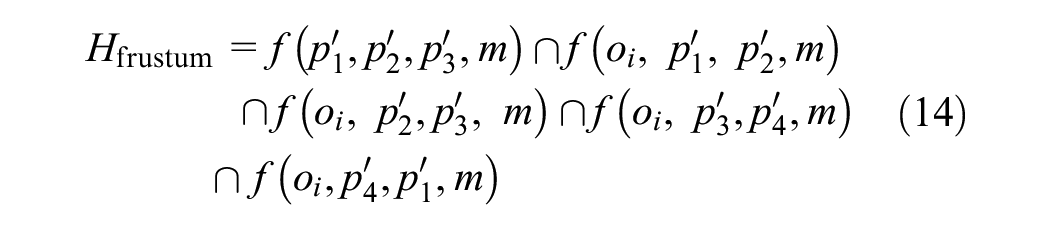
Then Hfrustum can be passed to the octree of
Calculating Visibility Measures
The calculated visibility score matrices were used to generate various measures, such as total visible distance and time, for each sign. If the sum of visibility scores for all observers in relation to a sign
To calculate the measures for a sign, the first visible observer
Octree-Frustum Method: Continuous Sight Distance (Alternative Sight Distance)
In the octree-frustum method, the sight distance was calculated in the same way as in the raycast method, as the sum of observers that had an unobstructed view frustum of the sign given by the visibility matrix
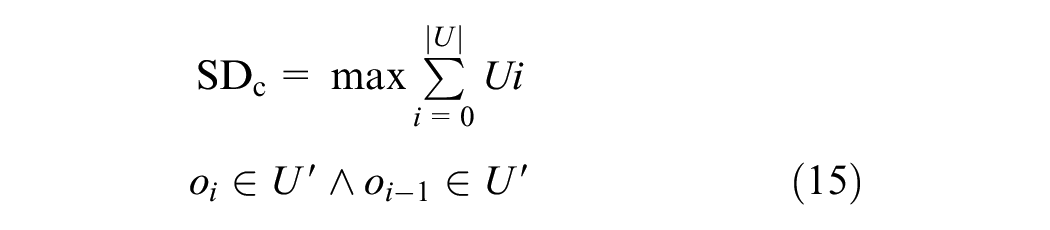
Results and Discussion
Test Segments
The proposed method was applied to three segments of Highway 01A in Alberta, Canada. First, a segment from 12 km to 16 km along the road (Segment 1) was selected because it has a high number of signs. Two other segments were considered: one from 0 km to 4 km) along the road (Segment 2), and one from 8 km to 12 km along the road (Segment 3). Since each 4-km segment was analyzed for both possible directions, the segments generated results for 24 km. All test segments were collected in 2020 by Alberta Transportation using a REIGL VMX 450 lidar system capable of collecting 360° point cloud data. Point cloud densities ranged between 150 points/m2 and 1,000 points/m2, depending on the survey speed and the distance from the scanner.
Sensor Set Used
For all types of sensor analyzed, an angular resolution of 0.1° was adopted for both vertical and horizontal ranges. This work also considered vertical angles ranging from−60° .to 30° .for all sensors. The reference adopted for orientation was the
The set was a representation of a combination of different sensors ( 2 ). Table 1 gives a description of the sensor set, and Figure 8 shows a representation of an observer field of view using the sensor set.

Sensor set: each sensor field of view is represented in a different color.
Comparison of Methods
Each of the raycast and octree methods was used to analyze the sight distance to signs along a roadway segment. These methods were then compared against each other to determine inaccuracies that might have caused discrepancies in the results. This section presents and discusses several figures, comparing the different results of each method in one direction for the same 4 km segment from Highway 1A (Segment 1). Figure 9 is a comparison of sight distances on Segment 1, set
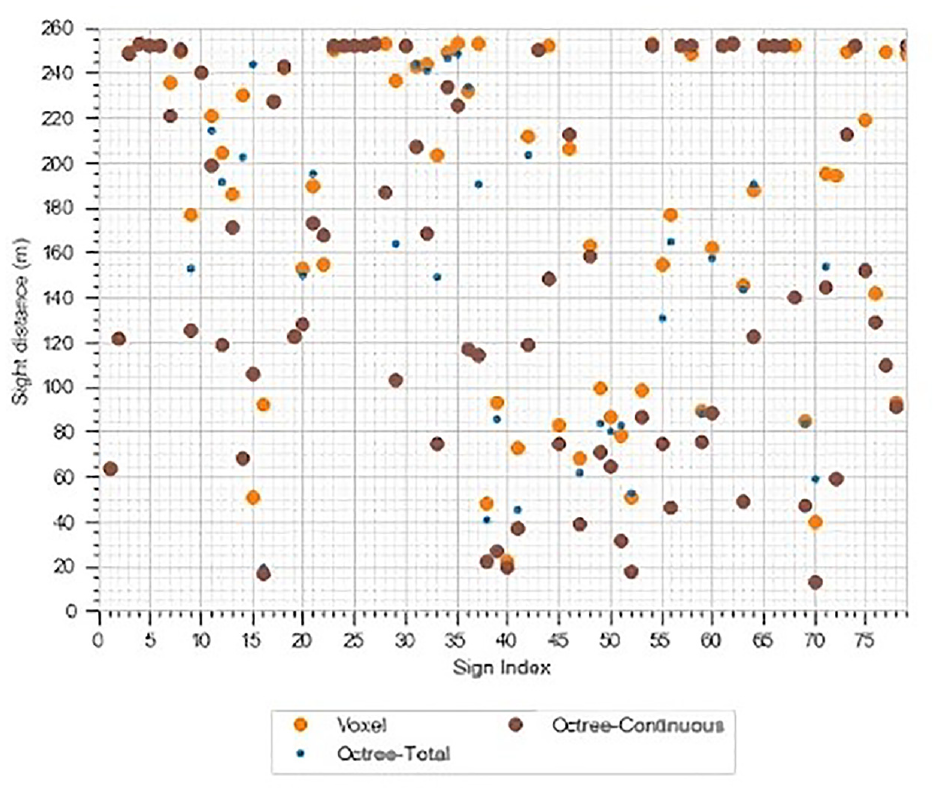
Octree versus voxel sight distance comparison for Segment 1, set C.
Three distinct types of dot can be seen in Figure 9, representing the raycast method, the octree method with continuous sight distance, and the octree method with total sight distance. The total sight distance determines for how long an observer can continuously see a traffic sign without any obstruction. Most of the discrepancies between the two octree methods are of lesser importance, as they operate differently. It is possible that the continuous sight distance to some arbitrary sign equals 1 m, while the total sight distance equals half of the maximum sensor range, 125 m, giving a difference of 124 m, in the case where consecutive observers alternate between obstructed and unobstructed. This could occur if a sign were viewed through a fence line. The discrepancies of concern are between the total sight distance of the raycast method and that of the octree method, as these results are expected to be the same.
Some of the results with large differences between the two methods were excluded. For example, Sign 33 was excluded as it was not a traffic sign and was distanced from the road, and Sign 41 was excluded as it was for a perpendicularly connecting road.
The first sign analyzed from set

Highway 1A, Segment 1, Sign 21.
The obstructions for Sign 21 are mostly applicable to Sign 22 as well, as it is positioned approximately 75 m behind Sign 21. Additionally, Sign 21 blocks the view of Sign 22, justifying the lower sight distance calculated using both methods.
Sign 21 is blocked by several obstacles, including a guardrail, a pole, and some other points along the roadside. These points are displayed in Figure 11; Figure 12 shows a section of the raycasts, as well as a section of the octree frustums obstructed by them.

Sign

Sign
The voxels, represented by the cubes, are those obstructing raycasts (bottom row of Figure 12); the red points are those obstructing the frustums (top row of Figure 12). Although they seem to overlap almost identically, five more raycasts are obstructed than frustums, causing a small difference in the calculated sight distances. This provides evidence of the difference in precision between the two methods.
The raycast method uses voxels and Bresenham’s line algorithm, an incremental error algorithm, to detect obstructions, based on the best approximation. When the points aggregated into a voxel group exist near one boundary of the voxel, and the raycast passes through or near an opposite boundary of that voxel, Bresenham’s line algorithm might calculate such a voxel as being in the trajectory of the raycast, when the points inside the voxel did not actually intersect the ray and were in fact a small distance away from it. This shall be referred to as clipping, because the ray clipped a voxel that contains empty space adjacent to and or near the ray.
In the octree method, clipping does not occur. The octree method bounds a specific volume independent of the point cloud itself, allowing for a precise point query into the octree against a set of equalities. By detecting possible obstructions against a set of equalities, the accuracy of the results is strictly dependent on the precision of the input point cloud.
Sign 44 was also analyzed, as shown in Figure 13. Using, the raycast method, no obstruction was calculated and a maximum total sight distance of 252 m was recorded. With the octree method, the total and continuous sight distances were recorded as 150 m and 148 m, respectively. The difference in total sight distance of 102 m was caused because of Sign 43, which blocked a small portion of Sign 44. The difference between the two methods is shown in Figure 13. Figure 13a shows the raycast from potential observers to Sign 44.

Sign
A similar problem was encountered for the last few signs of set

Sign
In many cases, the results of the two methods overlapped, with a mean percentage difference of only 1.2%, but it can be seen from the preceding examples that a large discrepancy in the results is observed in some cases, owing to the limitations of the voxel-based raycast method.
Most of the sign information needs to be visible for a certain amount of time to allow the driver to process the information and possibly take some form of action. Therefore, the octree method should be considered a more realistic representation of sign visibility as it encompasses a better majority of sign information. Because of the precision of lidar data in depicting a road environment in three dimensions, the proposed octree-based evaluation method surpasses the state-of-the-art raycast method used in previous studies in accuracy and provides a more realistic and practical result for sight distances.
Case Study for Segment 1
Figure 15 shows the results of the proportion of in-range observers for Highway 01A using the sensor set and analyzing the sets
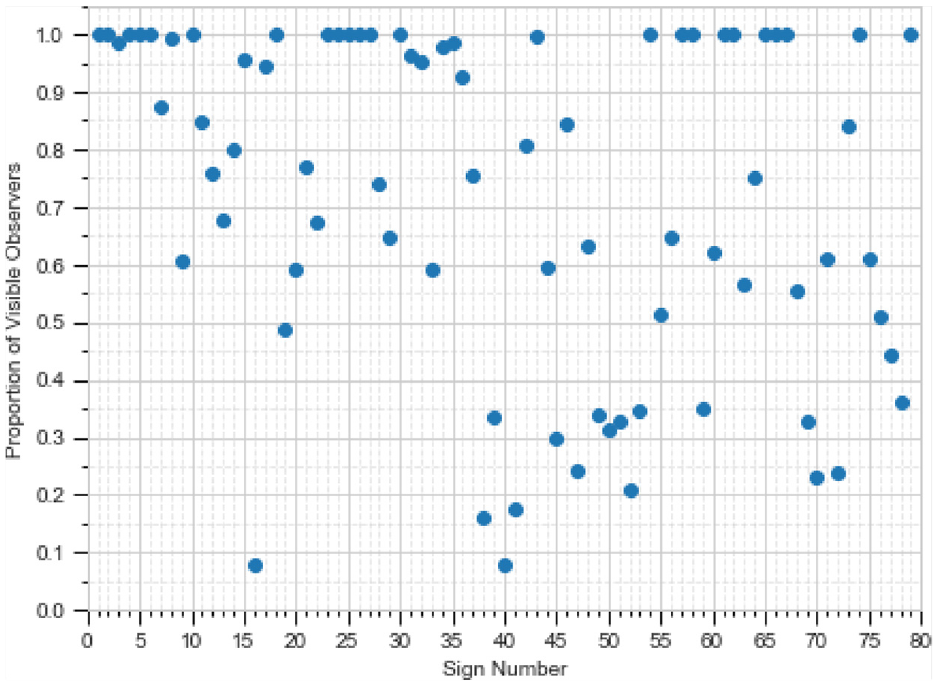
Proportion of visible observers for each sign number using the sensor set, considering sets
Using the number of visible observers, the sight distances were calculated, as shown in Figure 16. To calculate the reaction distance, the regions from Sign 1 to Sign 26 and from Sign 71 to Sign 79 were categorized as rural, while the region from Sign 27 to Sign 70 was in an urban area.
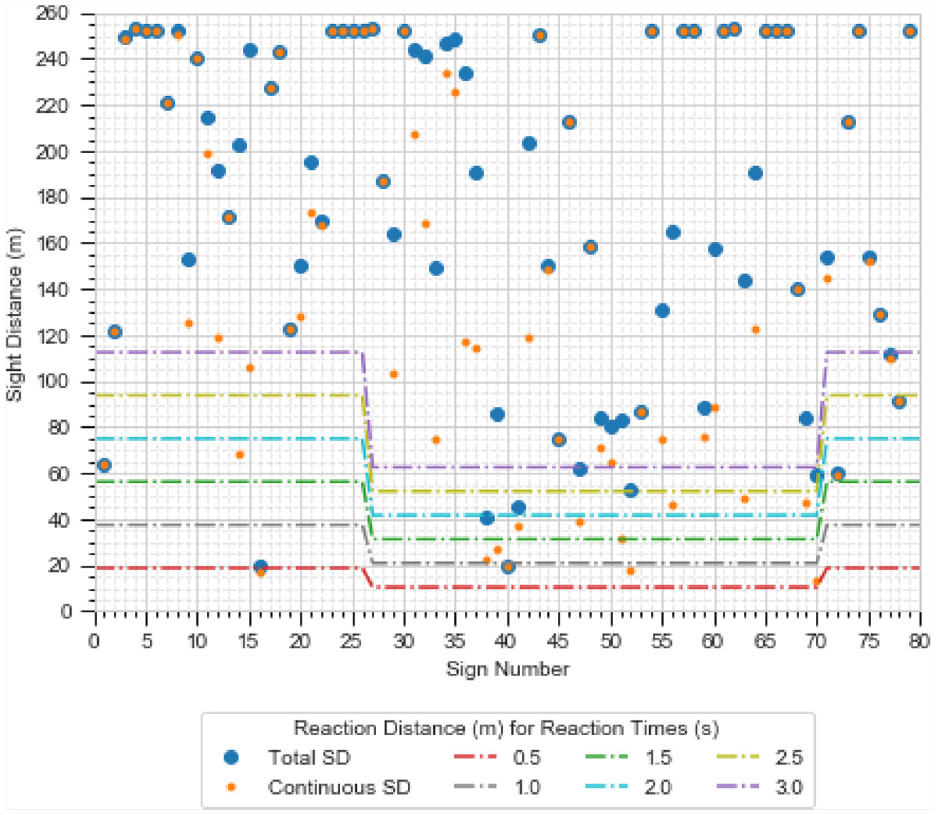
Total visible distance for each sign calculated using the sensor set.
A few signs along the segment were not visible for a sufficiently long distance to be analyzed by a road user for certain reaction times at the given speeds. Signs for which low sight distances are given in both Figures 15 and 16 would be of concern. The total visible time was computed, and the results are shown in Figure 17. Using Figures 15 to 17, a manual search was conducted for signs with poor visibility, in comparison with other signs.
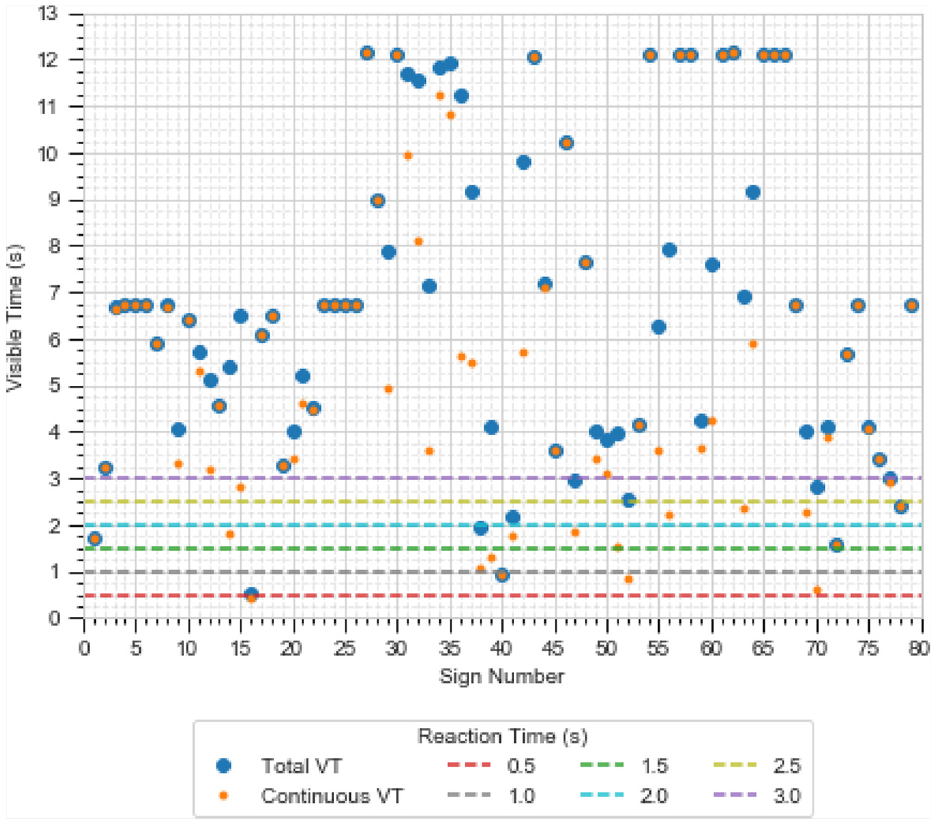
Total visible time for each sign calculated using the sensor set.
Figure 18 shows a comparison for Signs 77 and 78 along the trajectory of a vehicle. The left panel shows the point cloud for Sign 77 (green) covering parts of Sign 78 (pink) from the perspective of an observer. The middle panel of Figure 18 shows the same location, showing the same situation that was identified using the point cloud. Finally, the right panel of Figure 18 shows the same location after Sign 77 was removed and Sign 78 was replaced. This example shows the proposed methodology, in which the position of a sign replaced by Alberta Transportation is automatically extracted. Several other cases for the rest of the data are presented in Figures 19 to 22. Image data in Figures 18 to 22 were collected from Google Street View ( 36 ).

Comparison for locations of Signs 77 and 78: (a) point cloud data, (b) location before signs were changed, and (c) same location after removal of Sign 77.

Sign obstructed by roadside tree.

Comparison of locations of Signs 10, 9, and 8: (a) point cloud data, (b) location before signs were changed, and (c) same location after the change.

Comparison for location of Sign 31: (a) point cloud data, (b) sign after change and (c) sign before change.

Sign 37 occluded by Sign 36; (a) point cloud data and (b) road.
Figure 20 (a) shows the point cloud data. In this image, Sign 10 (pink) is occluded by Sign 8. Figure 20 (b) and ( c ) show the same location before and after Sign 8 was changed to improve the sight distance.
Conclusions
The introduction of and support for AVs is becoming more widespread as manufacturers race to release high-level AVs to consumers. Despite this, government agencies have been slow to assess whether the existing road infrastructure can safely handle these vehicles. Although this is the case, research has demonstrated that AVs will rely on signs for road and safety information, in the same way as human drivers. This paper proposes a novel automated approach to assess the visibility of signs in a road environment based on AV characteristics. Although the methodology is focused on AVs, the method can be applied to human drivers. The proposed method was applied to lidar data of three different road segments in Alberta, Canada. First, semantic segmentation was used to detect traffic sign points. Visibility was assessed by sampling perspectives from the scanning vehicle’s trajectory and calculating view frustums to signs in the FOV of typical AV sensors. The input cloud was organized into an octree data structure so that the calculated view frustums were spatially queried for obstructions. The visible distance, visible time, and continuous visible distance of a sample of traffic signs were determined.
The proposed method was compared with a state-of-the-art raycasting approach, in which the input cloud is voxelated and obstructions are detected using Bresenham’s line algorithm. It was determined that the octree method is superior as it considers a 3D view perspective and the area of the sign face, whereas the raycasting approach only considers the center point of a sign and thus acts more as a point-to-point view perspective. Additionally, the octree method was found to be more precise than the raycast method. The novel methodology introduced in this study could be used to automatically identify several sign locations that had reduced visibility to AV sensors. Furthermore, three of the identified sign locations had been adjusted by Alberta Transportation since the data were collected, providing evidence of the validity of this method.
Footnotes
Acknowledgements
The authors thank Alberta Transportation for providing the data used in this study.
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: M. Gouda, K. El-Basyouny; data collection: M. Gouda; analysis and interpretation of results: M. Gouda, K. El-Basyouny; draft manuscript preparation: M. Gouda, K. El-Basyouny. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors acknowledge the support of the Natural Sciences and Engineering Research Council of Canada (NSERC) and the support of Alberta Innovates and Killam Laureates. These were PhD student awards and scholarships.
The contents of this paper reflect the views of the authors, who are responsible for the facts and the accuracy of the data presented. The contents do not necessarily reflect the official views or policies of Alberta Transportation.