
Abstract
Regional perimeter control based on the existence of macroscopic fundamental diagrams has been widely studied as an effective tool to regulate traffic and prevent oversaturation in dense urban areas. Significant research efforts have been performed concerning the modeling aspects of perimeter control. More recently, data-driven techniques for perimeter control have shown remarkable promise; however, few studies have examined the transferability of these techniques. While it is surely of the highest priority to devise effective perimeter control methods, the ability of such methods to transfer the learned knowledge and quickly adapt control policies to a new setting is critical, particularly in real-life situations where training a method from scratch is intractable. This work seeks to bridge this research gap by comprehensively examining the effectiveness and transferability of a reinforcement-learning-based perimeter control method for a two-region urban network in a microsimulation setting. The results suggest: 1) the presented data-driven method demonstrates promising control effectiveness in comparison with no perimeter control and an extended greedy controller and 2) the method can readily transfer its learned knowledge and adapt its control policy with newly collected data to simulation settings with different traffic demands, driving behaviors, or both.
Keywords
Urban traffic signal control has been a heated research topic in the transportation community owing to its potential to alleviate congestion and reduce accidents. Classical signal control systems such as SCATS and SCOOT make the utilization of existing transportation infrastructures more efficient ( 1 , 2 ). However, these systems are microscopic and localized ones that concentrate on intersection- or link-level performances yet disregard network-level effects such as congestion propagation. Further, their applicability and effectiveness may be in question under oversaturated traffic conditions where severe queue spillbacks occur. Historically, there have been continued efforts on aggregate modeling of traffic dynamics to facilitate the development of network-level traffic control schemes, with the notion of macroscopic fundamental diagram (MFD) receiving extensive research interest over the past 15 years. Initially proposed in ( 3 ) and recently verified with analytical and empirical evidence ( 4 , 5 ), MFD describes a well-defined relationship between network usage (e.g., vehicle accumulation) and production (e.g., space-mean traffic flow or trip completion rate). The existence of MFD has been observed in homogeneously loaded traffic networks with low spatial variation of traffic flows ( 5 , 6 ). In the presence of heterogeneous vehicle distributions, undesirable phenomena such as instability, hysteresis, and bifurcation may arise ( 7 – 10 ). In such scenarios, network partitioning methods can be applied to divide a heterogeneous network into several smaller regions so as to maintain the feasibility of MFD-based aggregate modeling of traffic dynamics ( 11 , 12 ).
Ever since its conceptualization, MFD has served as a theoretical foundation in the construction of numerous regional-level traffic control schemes. Among these, perimeter control, which involves the regulation of transfer flows between neighboring regions, is perhaps the most intensively studied. Adopting a gating concept, perimeter control aims to regulate the regional accumulations to predefined critical levels that are associated with the maximum productions. This control scheme is particularly helpful in scenarios with strong directional traffic demands into a protected region where the resultant congestion cannot be mitigated by intra-regional traffic control alone. Numerous works have been presented in the literature, with perimeter control applications spanning single-region, two-region, and multi-region urban networks ( 4 , 13–19). Different aspects of perimeter control have also been examined, for example the integration with route guidance, robust control, and boundary queue dynamics ( 18 , 20–24).
Over the years, various techniques have been presented for perimeter control problems. These range from classical proportional–integral regulator to more advanced model predictive control (MPC) ( 15 , 18 , 21 , 25 ). Recent times have witnessed an increasing trend to develop data-driven methods for perimeter control, which are particularly helpful as a network’s traffic dynamics or MFD functions are often unknown or hard to calibrate accurately. Even more so, the modeling of network traffic dynamics may need to be adjusted continuously as it is prone to exogeneous disturbances (e.g., vehicle rerouting and demand stochasticity). These modeling difficulties thus highlight the prospect of data-driven perimeter control methods, in contrast to the model-based counterparts. On this note, the modeling difficulties also highlight the need to evaluate perimeter control methods in a more realistic environment that does not rely on the explicit modeling of traffic dynamics (e.g., microsimulation rather than numerical simulation) as, otherwise, comparisons using inaccurate models may not truthfully reflect the real efficacy of the methods.
Despite still being in the early stage, the development of data-driven methods for perimeter control has seen some notable research works; for example, data-driven adaptive control methods, adaptive dynamic programming methods, and reinforcement learning (RL)-based approaches ( 26 – 33 ). The current paper follows the lines of these works to present an RL-based perimeter controller and evaluate its effectiveness and transferability using microsimulation. Note, most data-driven methods are evaluated using numerical experiments with explicit models of network macroscopic traffic dynamics. However, these models are merely estimates; more realistic evaluations and impartial comparisons can only be established with microsimulation. To the best knowledge of the authors, ( 29 , 30 ) are the only works that have presented and evaluated data-driven perimeter control methods using microsimulation. In ( 29 ), numerical experiments and microsimulations were adopted for a comprehensive validation, while in ( 30 ) the perimeter controller is evaluated in combination with the max pressure method ( 34 ). However, only a single-region network was simulated there, where boundary queue impacts were largely overlooked. Importantly, neither work considered the transferability aspects of their methods.
While it is surely of the highest priority to devise an effective perimeter control method, the ability of the method to transfer to unencountered traffic conditions is also critical, especially in real-life scenarios where training the method from scratch may be costly or even infeasible. Moreover, in practical applications of perimeter control, the scenarios where the data-driven methods are to be applied (i.e., reality) may differ from where they are initially trained (i.e., simulation). In such cases, the ability of the methods to transfer the learned knowledge and even to continue their learning trajectories is crucial, as this would significantly reduce the training time thus facilitating fast application on the new scenarios. In this regard, note that, while transferability has been considered in ( 31 , 33 ), only numerical experiments were adopted, and the ability of the proposed agents to keep learning in another setting with continuous data feed is not examined ( 31 , 33 ). Further, the current work focuses on examining the effectiveness and transferability of a RL-based two-region perimeter controller in microsimulation and seeks to bridge several research gaps previously outlined, while acknowledging that perimeter control is merely part of the urban traffic control framework ( 31 – 33 ). Combining this regional-level control with intra-regional traffic signal control will potentially increase the control benefits and lead to a more complete paradigm of urban traffic control, as previously demonstrated in, but this exceeds the scope of the present work ( 30 , 35 , 36 ). The significance of this work is to show that the RL controller, when pretrained in one setting, can transfer its knowledge and more quickly adapt its action-taking policy (compared to training from scratch) with newly collected data in a different setting with demand patterns, driving behaviors, or both, that are more indicative of reality.
The remainder of the paper is structured as follows. The next section provides the specification of the simulated two-region network. The methodology is then explained, followed by the simulation results on the evaluation of effectiveness and transferability. Concluding remarks are provided in the last section.
Two-Region Urban Network Set-Up
In this work, a two-region urban network is simulated using the Eclipse SUMO software ( 37 ), where a larger periphery encompasses a smaller city center (see Figure 1). The periphery shaded in blue is denoted as Region 1 while the city center in gray is denoted as Region 2. The two regions are assumed to be homogeneous and connected by two-directional linking roads where perimeter control can be enforced (see ( 28 ) for a similar structure). Figure 1 also presents the detailed layouts of three types of intersections in the network: four-leg (circled in orange), T-shaped (circled in blue), and the perimeter control intersections (circled in green). Each street in the network assumes a length of 500 m with three lanes in each travel direction. The free flow speed of each lane is set to 50 km/h while the saturation flow is 1,800 vehicles per hour per lane.
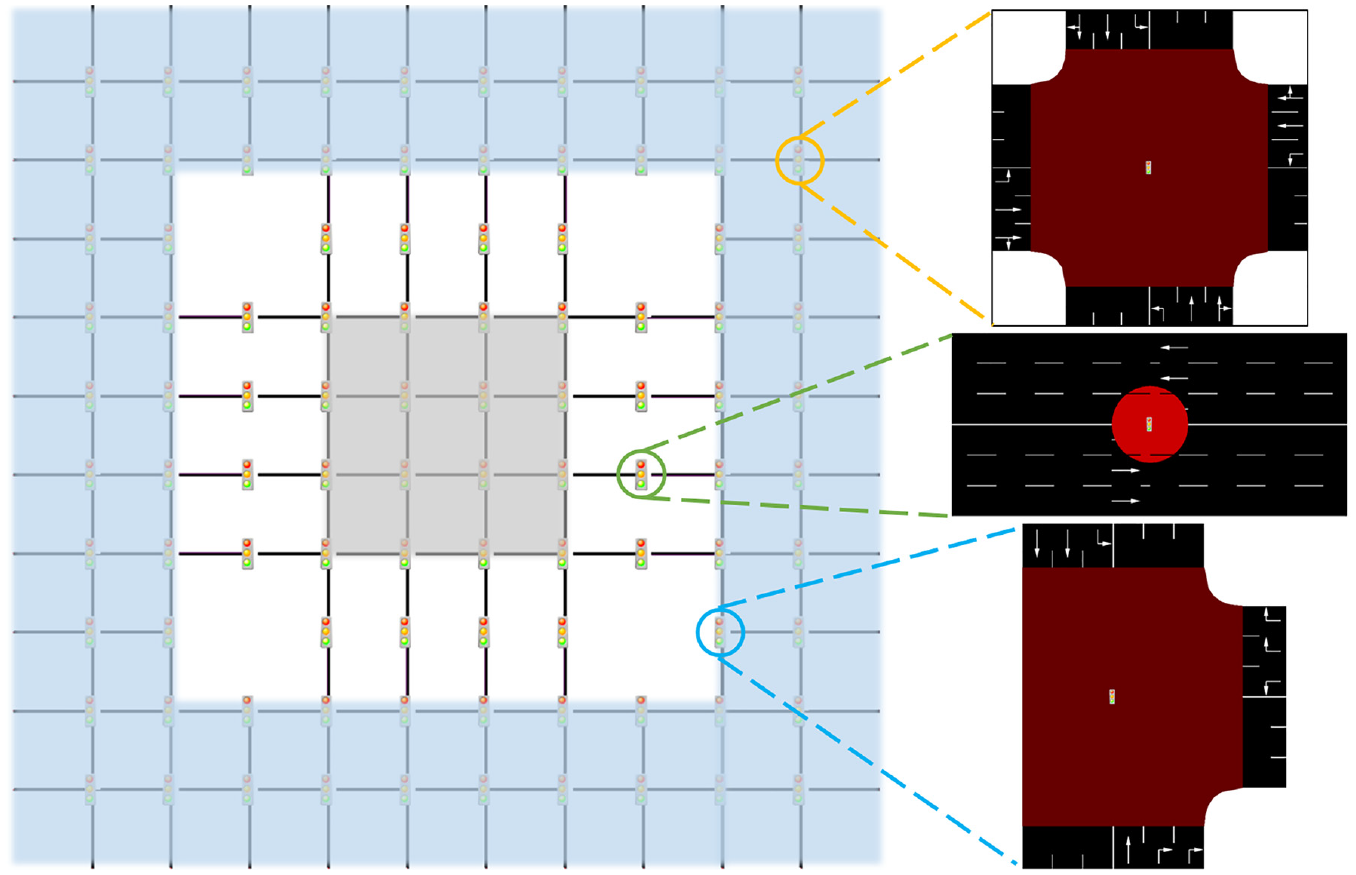
The simulated two-region urban network.
All intersections in the network are signalized, where the non-perimeter control intersections adopt a fixed multiphase signal plan with a shared cycle length of 90 s. In contrast, the 16 perimeter control intersections assume a common cycle length of 30 s so that they can adapt faster to the prevailing traffic. All left-turn movements are treated as protected, as permitted movements form long queues and were observed to be a source of inhomogeneity. No offset is assumed, as it is shown to be inconsequential to the network-level performances in grid networks ( 38 ). The simulation step is set to 1 s.
Origin and destination locations are evenly distributed within each region. To simulate scenarios where perimeter control is the most helpful—that is, to protect destination-loaded regions from over-saturation—strong directional demand from the periphery to the city center is assumed; see Figure 2 for the baseline demand profile where strong inbound traffic flows last for 60 min followed by a recovery period of 30 min. Each of the total demands (e.g., from Region 1 to 2) is evenly assigned to all associated origin-destination pairs. Note that, while the traffic demands in Figure 2 appear to be constant, the realized traffic demands will exhibit variability during each simulation instance; for example, the exact times when vehicles are inserted into the network, the initial routes of the vehicles, and/or the vehicle speeds may differ in each simulation instance depending on the random number generation process. For this reason, multiple random seeds were used to enhance realism for the traffic demands. Moreover, different demand profiles will be adopted in subsequent sections. The simulated vehicles are initially routed using the stochastic C-logit route choice model ( 39 ). A subset of the vehicles (60%) were assumed to be able to adaptively reroute themselves based on prevailing traffic to mimic more realistic driving patterns (which, other than rerouting, also include car-following and lane-changing behaviors). This adaptive rerouting has been shown to be helpful to network-wide operational performances ( 7 , 8 ). In this work, it happens at regular intervals of 3 min.
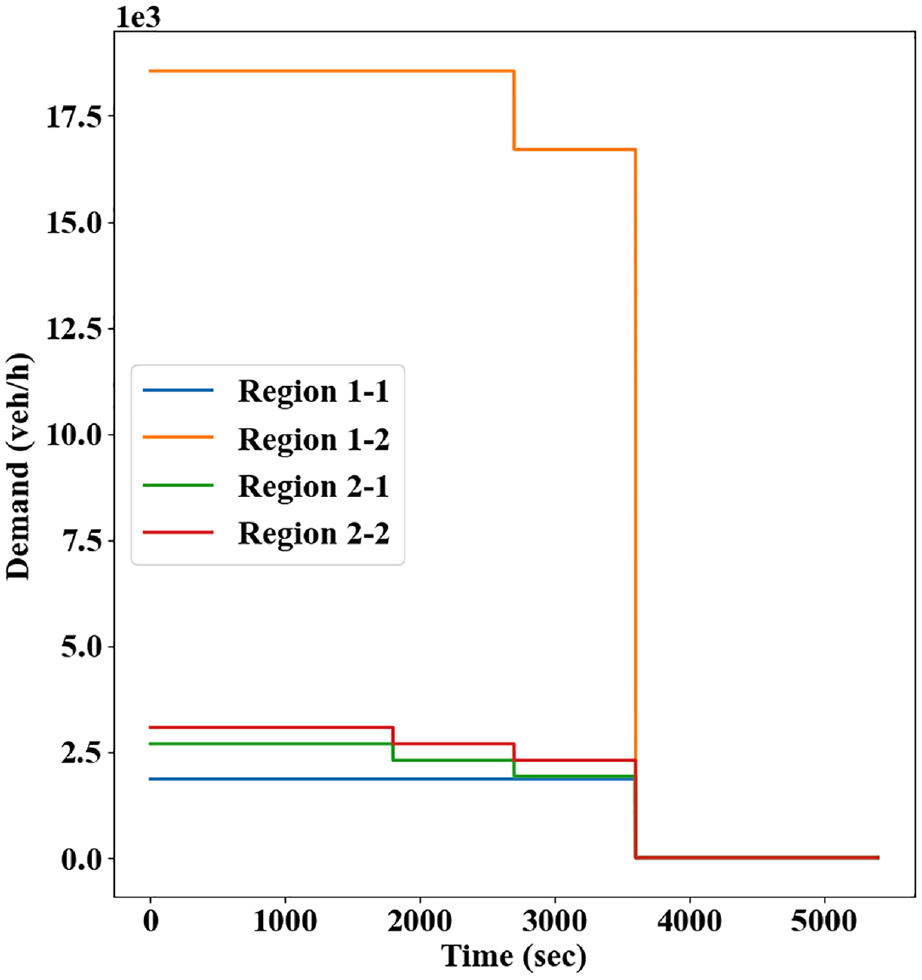
The baseline traffic demand profile.
Methodology
This section first presents designs of a comparative method, that is, an improved greedy controller (I-GC). Adopting similar design ideas, the RL-based two-region perimeter controller is explained. Lastly, transfer learning—a technique that enables the transferring of learned knowledge and policies to a new setting—is discussed. Note, in this work the MPC method is not applied for comparison, as consistent with existing works that evaluate data-driven perimeter control methods using microsimulation ( 29 , 30 ). The reasons are multifold. For one, the MPC method has tremendous data requirement, such as detailed traffic demand information throughout the whole simulation. However, such information is specific to the environment (microsimulation or reality) and often not made available to the controller beforehand. For another, applying MPC necessitates the estimation of the MFD functions so as to describe the traffic evolutions using dynamic equations in the prediction model. Yet, such estimation (and therefore the resultant prediction model) is prone to significant errors, which would make the MPC application particularly challenging ( 8 – 10 ). In contrast, I-GC can serve as an effective comparative baseline for perimeter control in a microsimulation environment, as will be explained shortly.
Improved Greedy Controller (I-GC)
Greedy control, a two-region extension of the bang-bang policy, seeks to protect the more congested region by minimizing the transfer flow into it, and it has often been adopted as a comparative baseline ( 4 ). However, despite its relatively wide usage involved in numerical experiments, its effectiveness has not been examined in microsimulation environments ( 15 , 40 ). The greedy control policy considers two levels of congestion in the MFDs (with accumulations below or over the critical values) and could alternate its action abruptly around the critical values. Nevertheless, the regions are operating roughly around the maximum production level in the proximity of the critical values, and such abrupt alternation may cause irregularities in the traffic patterns that would disrupt the congestion distribution and evolution. While such impacts may be negligible in numerical simulations where vehicle dynamics are not modeled, they could greatly manifest themselves in a microsimulation environment and cause local pockets of congestion that cannot recover.
Microsimulation experiments are used in this work; thus, the greedy control policy is extended with consideration of three levels of congestion in the MFDs: free flow, critical flow, and congestion flow. A similar categorization of the regional congestion levels can also be found in (
32
,
41
). Specifically, when a region operates in free flow, traffic flows into the region should not be metered, and green times at the perimeter control intersections should be set at the maximum value (
Improved Greedy Control (I-GC) Policy

Note: na = not applicable. *This case is not considered, as perimeter control will be of little help.
A few remarks are provided here on the I-GC policy. First, the cutoff points generally adopt values higher than the critical accumulations to avoid excessively long queues at the perimeter control intersections that may be highly disruptive to the network operations. In such manner, the critical flow range
Reinforcement Learning (RL)-Based Two-Region Perimeter Controller
To better compare with the I-GC policy, the RL controller utilizes the same actions; that is, it selects among
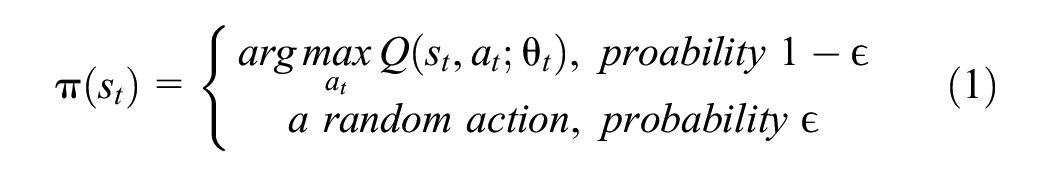
where
Clearly, larger values of
The actions taken by the RL controller, which inform the green time settings at the perimeter control intersections, are then implemented in the microsimulation for a time step, which in this work has the same duration as the cycle length of the perimeter control intersections (i.e., 30 s). At the end of a time step, the microsimulation arrives at a new state and returns a reward to the controller as an evaluation for the action taken. The reward is characterized by the weighted sum of average flows in both regions, and a larger weight (0.7) is placed on the average flow of the inner region (i.e., Region 2, the simulated city center) since it is the region to protect from oversaturated traffic conditions. With this reward, the RL controller proceeds to take another action based on the new state. This action-taking process is executed sequentially until termination, that is, until the simulation ends in 90 min.
The learning goal of the RL controller is to accumulate as many rewards as possible in a simulation run. To balance the importance of rewards with respect to the time they are received, a discount factor is employed which decays the value of the rewards received at a delayed time. Thus, the learning goal amounts to maximizing the cumulative discounted reward in a simulation, as termed by return
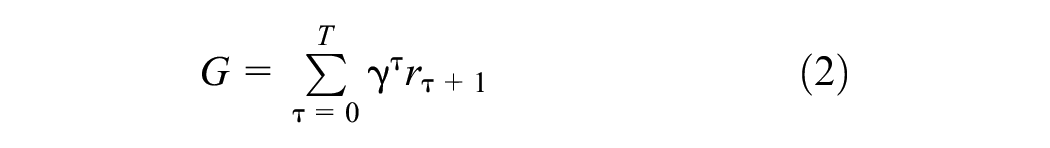
where
Note, the action value
To carry out the learning process in a principled manner, the double DQN method is adopted (
43
). Specifically, after each visit to a state-action pair (
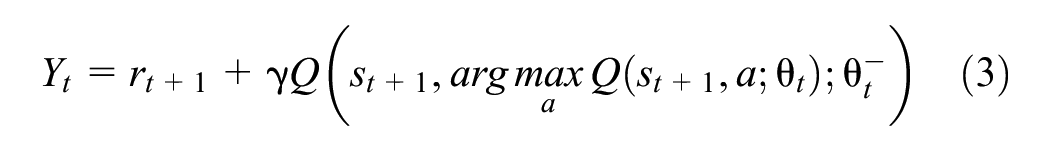
where
The learning target embeds in the Bellman Equation for solving Markov decision processes and also decouples the action selection from evaluation to mitigate the overestimation of action values ( 43 , 45 , 46 ). Then, the RL controller updates its parameters toward the learning targets by minimizing the loss:
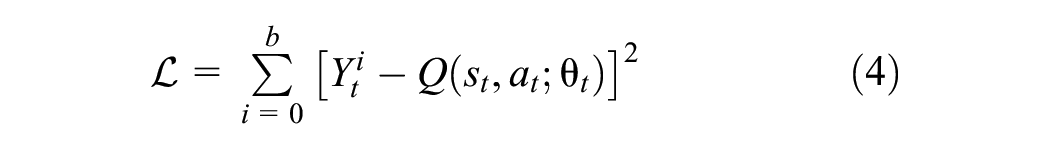
where
Note, utilizing a replay buffer improves sample efficiency as it allows reusing the transitions multiple times; also, it enhances training stability by reducing correlations between the transitions via random sampling (47).
In this work, the parameters
Transfer Learning
Transferability is an important methodological aspect for a perimeter control method to have the potential to be applied in the real world. While training a perimeter control method from scratch can be conveniently done using numerical experiments or microsimulation, this is hardly feasible in real networks. Further, the training process can be rather time-consuming, even under microsimulation. As such, the ability of a method to transfer its learned knowledge and continue the learning course becomes increasingly crucial. Though transferability of a perimeter control method has been investigated by ( 31 , 33 ), only numerical experiments were considered and the ability of the methods to continue learning with online data feed was neglected. This work thus bridges a few research gaps outlined there.
In the present work, the examination of transferability is enabled by transfer learning, a technique that helps speed up fast application of knowledge gained from one problem to another. Typically, transfer learning is applied on deep learning tasks (such as computer vision) where there is a lack of sufficient data (e.g., labeled images) on a new problem, in which case the general features learned from a relevant problem can be reused. In this work, instead of transferring the learned features, the mapping from state-action pairs to action values (i.e.,
This work considers only homogeneous transfer learning ( 53 ) applied to perimeter control; that is, the source and target problems share the same network settings such as intersection layouts and speed limit, while the traffic patterns (e.g., travel demands and driver rerouting behaviors) are allowed to differ. In the case of notable differences between the source and target problems (e.g., when there are numerous road closures in the target problem), negative transfer might occur, that is, the reused knowledge is not helpful to the target problem and ends up hampering the learning process rather than accelerating it. As such, transferring the agent might perform even worse than training the agent from scratch. On the other hand, homogeneous transfer learning allows the RL controller to adapt quickly to unseen traffic patterns where there may be travel demands, driving behaviors, or both, different from microsimulation and more representative of reality.
To sum up, in this work, transferability is evaluated by transferring the learned action value function of a pretrained RL controller to a target problem and adapting the function with continued data feed. With this type of intra-agent transfer ( 51 ), the RL controller could learn better initial control policies and improve the control performances more efficiently with reduced learning and exploration, compared with training the controller from scratch.
Microsimulation Experiments
In this section, the effectiveness and transferability of the RL controller is evaluated on a simulated two-region network. The experiment setups are first provided, followed by simulation results.
Experiment Setup
Initially, to investigate the regional productions (MFD), a strong traffic demand is used to fill up the network. The MFDs (reflected by regional trip completion rate versus accumulation relationships) are presented in Figure 3, where each symbol represents a random seed in the simulation. Note, trip completion refers to a trip ended within the region or transferred to the neighboring region; also, the term MFD is used interchangeably as the network exit function ( 15 , 28 , 29 ). Each point in Figure 3 represents average measurements of trip completion and vehicle accumulation within an interval of 180 s. As can be observed, both regions exhibit relatively low-scatter MFDs, and the regional trip completion rate peaks at accumulations around 5,000 vehicles and 1,000 vehicles for Region 1 and 2, respectively. The macroscopic traffic dynamics are not modeled as they are neither utilized in the microsimulation nor the control algorithm, so the MFD functions are not estimated. The critical accumulation information, however, provides guidance on how the comparative benchmarking methods should be implemented (but not needed for the RL method).
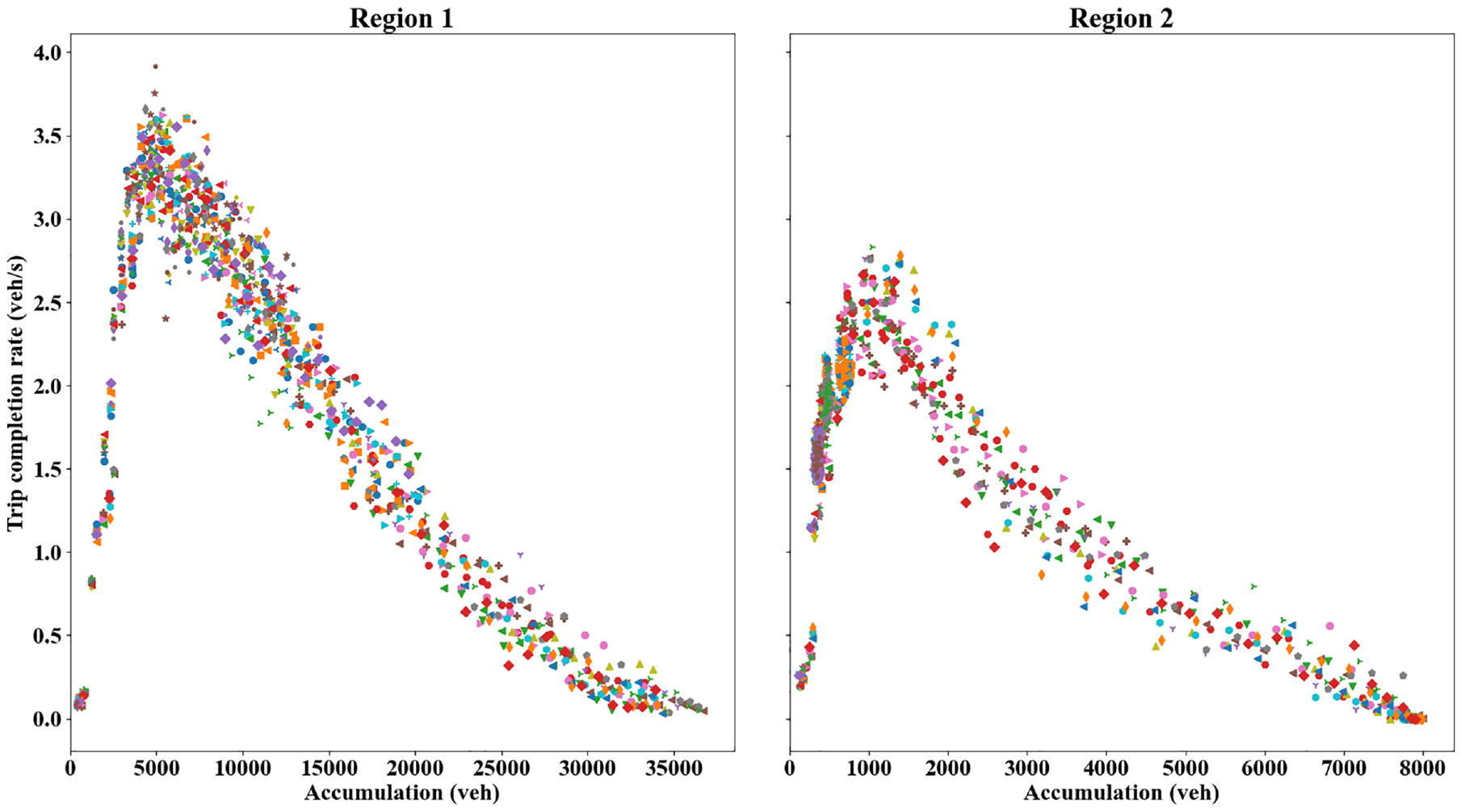
Regional trip completion rate-accumulation relationships (macroscopic fundamental diagram): Region 1 (left) and Region 2 (right).
Two benchmarking methods are considered, that is, no control (NC) and the I-GC policy. In the case of NC, fixed time signal plans are applied, which simulates the status quo. I-GC is the baseline perimeter controller and used to show perimeter control can alleviate oversaturated traffic conditions even without an advanced solution mechanism. As previously noted, the cutoff points used by I-GC are higher than the critical accumulations and set to
In this work, multiple random seeds are used in the simulation to enhance realism where each seed corresponds to a specific traffic pattern (e.g., vehicle routing, speed distribution, times of vehicle insertion). These seeds are used both by the benchmarking methods and the RL controller. Concretely, for the RL controller, a seed will be randomly picked every time a simulation is run during the training process so that it can learn a robust policy against simulation randomness. In contrast, the benchmarking methods are directly applied to the simulation with all seeds, as they are not learning-based approaches and adopt fixed policies. As such, each random seed is associated with a constant control outcome for these methods, and their performances among multiple random seeds will be expressed as narrow horizontal bands.
Simulation Results: Effectiveness
This section presents the simulation results on evaluating the effectiveness of the RL method. Adopting the baseline demands in Figure 2, the simulation starts from an empty network and the first 90 s is used as a warmup period during which the network operations are not recorded. The presented RL method, as well as the benchmarking I-GC and NC policies, are applied, and the realized cumulative trip completion (CTC) is shown in Figure 4, where the solid line and shaded area separately indicate the mean and 95% confidence interval. Note, the benchmarking methods are not learning-based approaches and adopt fixed policies based on the environment information (e.g., regional accumulations for I-GC). Therefore, their “learning curves” appear as horizontal bands and do not exhibit an upward trend, while the shaded areas represent the variation over random seeds.
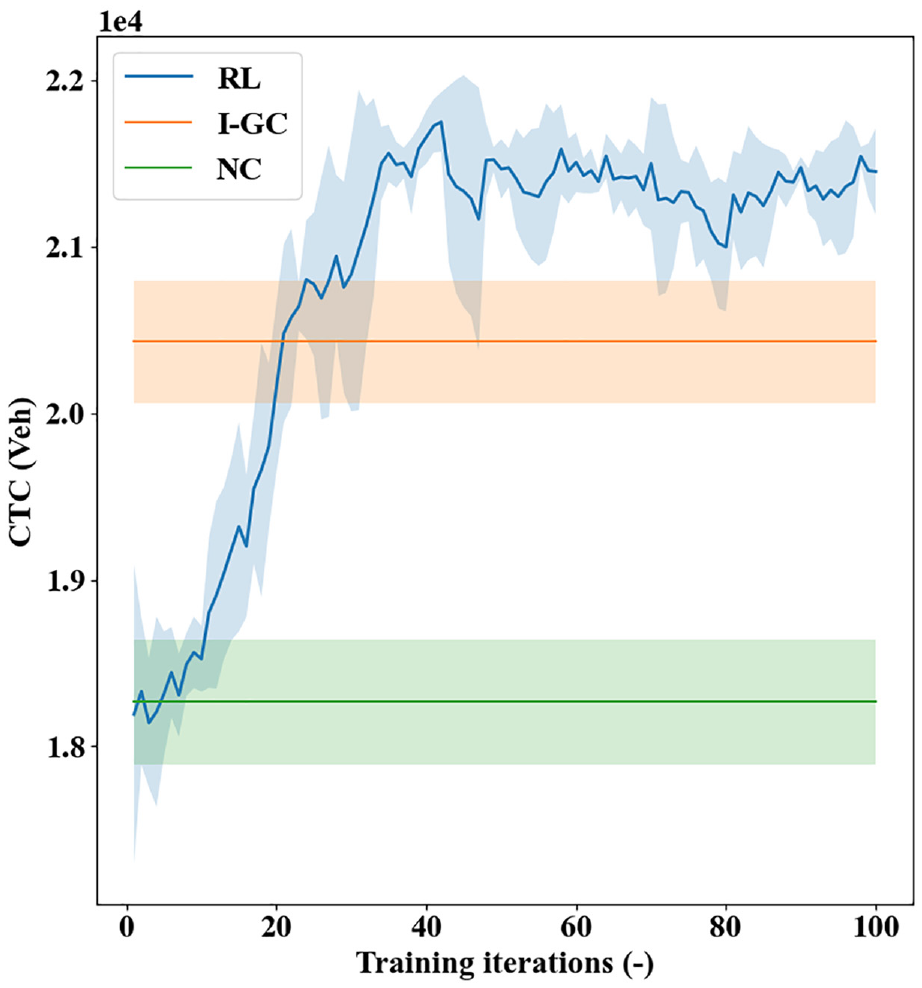
Cumulative trip completion (CTC) realized by different methods under the baseline demand.
As shown in Figure 4, the I-GC and RL controller can achieve significantly higher CTCs than NC. While the design ideas are intuitive, the I-GC policy can effectively prevent oversaturation in the city center and realize a more productive congestion distribution within the network. The RL controller, with the ability to learn from interactions with the microsimulation, can also yield control policies that lead to increasing CTCs over its learning course. This learning ability is even more notable given that multiple random seeds are used which can affect the realized demand patterns and vehicle behaviors. As a side effect, though, the abundance of simulation randomness also leads to noticeable fluctuations in its learning curves.
To see how perimeter control improves the regional level traffic operations, the accumulations and average speeds are compared among the control methods. The accumulations are obtained by counting the number of vehicles in both regions, while the average speed is the average of lane-level speed weighted by their lengths. The profiles of (regional or network) accumulations and average speed are presented in Figures 5 and 6, respectively, where the cutoff points used by I-GC are also plotted in Figure 5a. As can be seen, under NC, the demands from the periphery would enter the city center almost unrestrictedly. As such, the Region 2 accumulation increases rapidly, and the congestion leads to a consistently decreasing average speed that plateaus around 3,000 s. Even in the recovery period (3,600–5,400 s), Region 2 cannot restore its operations from such congestion when there is no new traffic demand, which suggests the formation of traffic gridlock. In comparison, under the I-GC policy, Region 2 accumulation is well regulated between the two cutoff points adopted, whereas Region 1 is significantly more congested than under NC. This metering policy considerably improves the average speed of Region 2 at the cost of decreased average speed in Region 1. In addition, the strictness in metering also leads to fewer trips completed in the network (see Figures 4 and 5b where the peak value of network accumulation is smaller under RL than I-GC). On the other hand, the RL method achieves a middle ground between NC and I-GC in that it effectively mitigates congestion in the city center compared with NC while, in the meantime, not hindering vehicle transfer too much, to realize the highest trip completion. Furthermore, Figure 5 indicates that perimeter control (RL or I-GC) can produce a congestion distribution where both regions are trending toward clearance of vehicles at the end of the simulation, while the network (in particular Region 2) remains severely congested under NC.
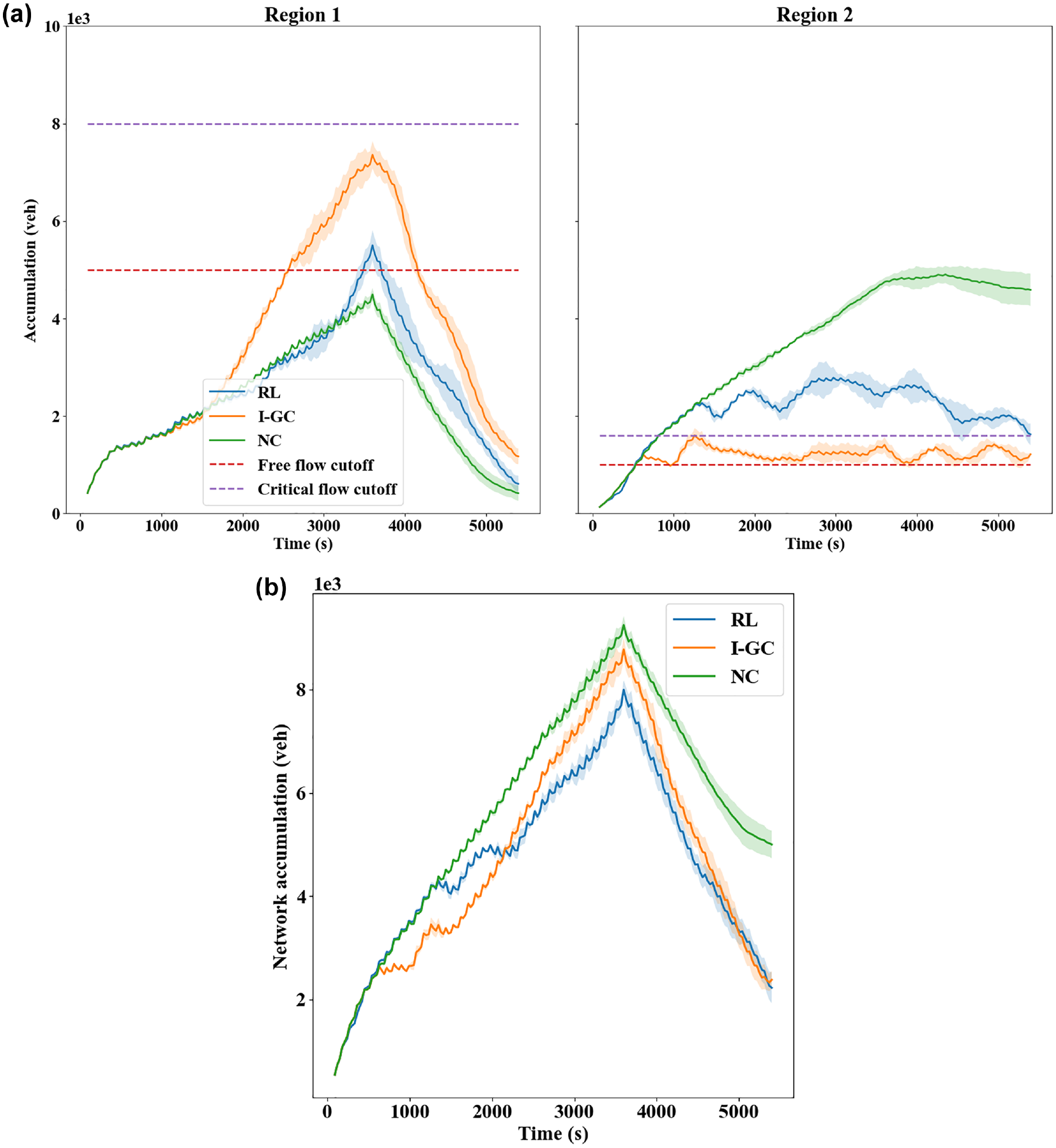
(a) Evolution of accumulations in Region 1 (left) and Region 2 (right) and (b) Evolution of accumulations in the network.
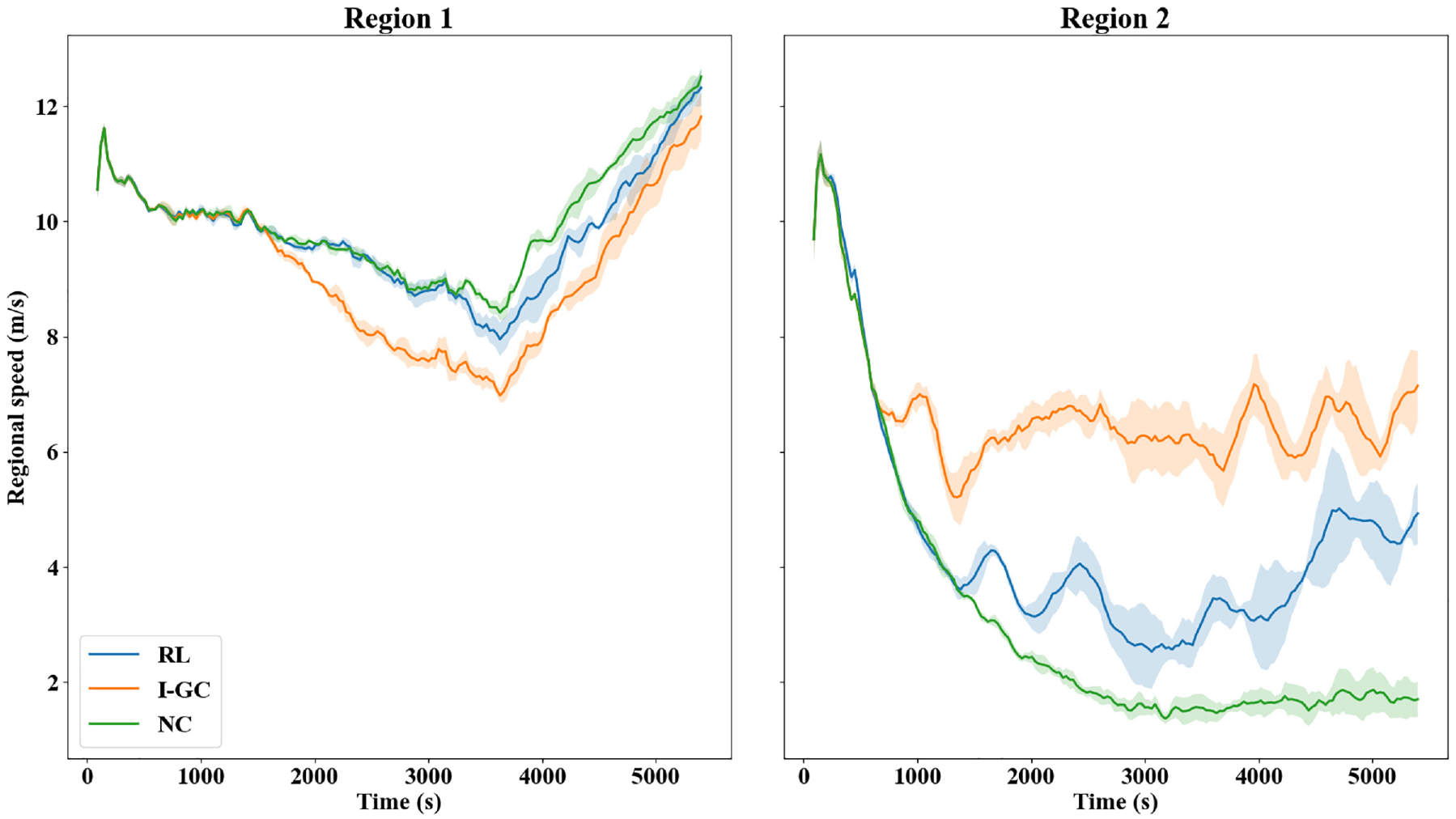
Average speed: Region 1 (left) and Region 2 (right).
To further compare the capability of the methods on maximizing the network throughput, the trip completion plot is provided in Figure 7, where the total travel time (TTT) difference can be calculated as the areas between the curves. As can be seen, both RL and I-GC realize higher CTCs than FT, where the mean improvements are, respectively, 16.9% and 11.8%. However, despite the higher trip completion, the I-GC policy results in a large TTT than FT (by
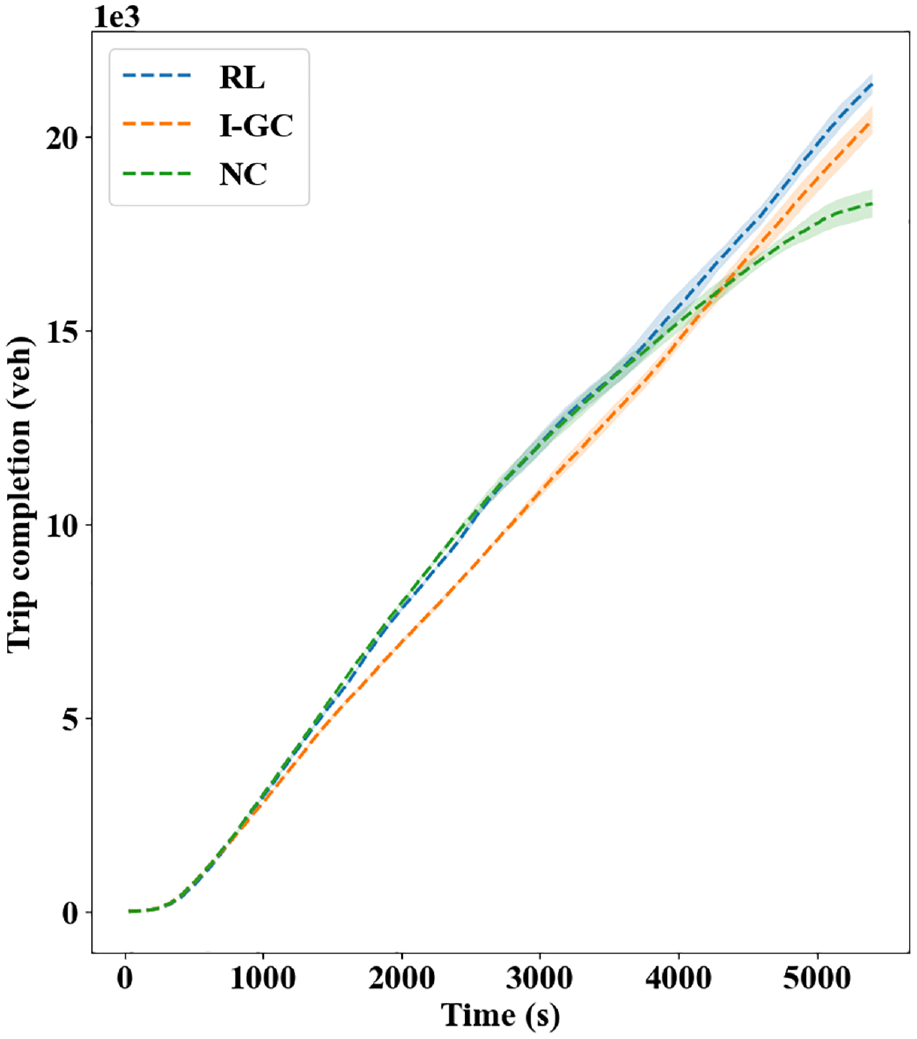
Trip completion plot.
A few additional remarks are provided here. First, the city center is destination-loaded with large traffic demands from the periphery area. Therefore, perimeter control is the most helpful if it helps prevent Region 2 from becoming oversaturated. In this regard, both the I-GC and the RL controller can effectively realize this control objective, in that Region 2 has substantially improved operational performance compared with NC. Second, the RL controller presented in this paper can effectively regulate traffic and consistently achieve higher CTC than the I-GC policy, despite differences in the control outcomes. Third, the RL controller adopts the same action designs as I-GC to fairly compare the two methods. As a result, the simulation outcomes could exhibit noticeable fluctuations over time (see Figure 6). Foreseeably, a more flexible action space design could potentially yield smoother network operations, as demonstrated in ( 30 ).
Real-life measurements of traffic states (e.g., vehicle accumulation) are often subject to noises because of factors such as sensor malfunction. Thus, to evaluate the learning robustness of the presented RL controller, measurement noise of regional accumulations is examined. Here, the form of measurement noise considered is (similar to ( 27 , 33 ):
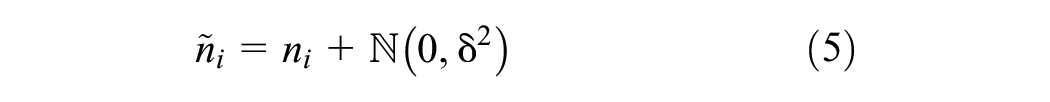
where
The control methods receive inaccurately measured accumulations, while the microsimulation environment maintains the accurate accumulation values. Therefore, a mismatch exists between the actual congestion level and the controller’s perception, which would affect the control policy should the controllers act on accumulation information. In other words, the RL method and I-GC policy are subject to the measurement noise, while NC is not. As such, the realized control outcomes remain the same under NC.
In this work, two levels of measurement noise with standard deviation of 25 and 50 are examined: the realized CTC curves during the training processes are presented in Figure 8. As can be confirmed, the NC method has performances invariant to the measurement noise, as its policy does not build on any accumulation information. The performances of I-GC are affected, but it still significantly outperforms NC with increased CTC. More importantly, the presented RL method can learn to achieve higher CTCs than I-GC in both levels of measurement noise. As the level of noise increases, the fluctuations in the learning curves also increase. Further, the average CTC improvement of RL over I-GC is higher with noise 50 than under noise 25, which showcases the RL controller’s robustness to learn against increasingly noisy measurements. However, note that the measurement noise cannot be overly high as it may disrupt the controller’s ability to regulate traffic (e.g., the controller might over-perceive the congestion in the environment heavily and meter the transfer flows needlessly, thus reducing trip completion). Overall, these results suggest that the presented RL controller is effective and robust, even with sizable measurement noise.
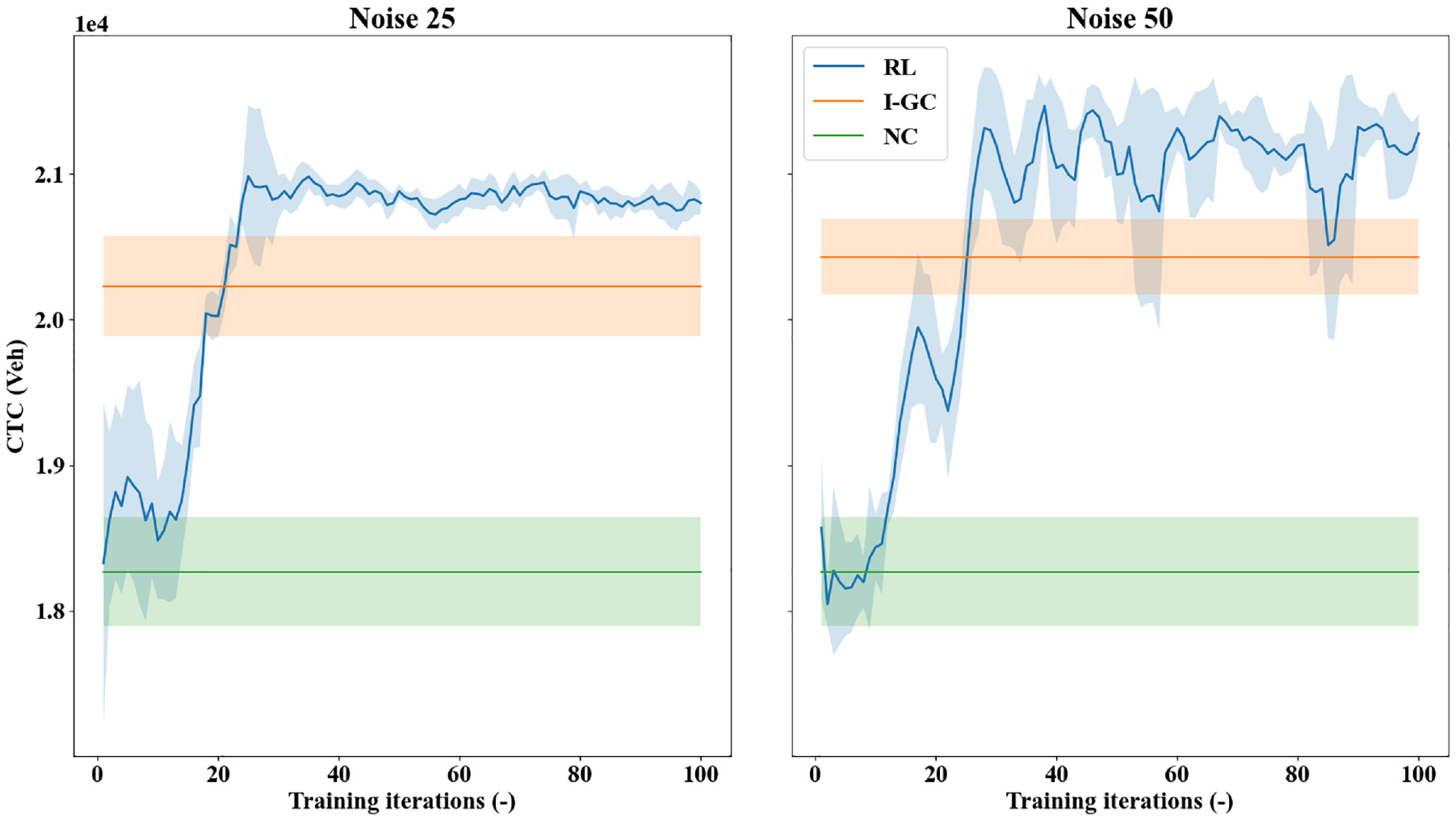
Realized cumulative trip completion (CTC) curves by different methods under noisy measurements: noise 25 (left) and noise 50 (right).
Simulation Results: Transferability
Transferability is examined here by applying the pretrained RL controller with the baseline demand to different demand scenarios, driving behaviors, or both. Note that homogeneous transfer learning is considered to avoid negative transfer, so the network settings are not altered (as the dynamics underlying the problem would otherwise be significantly affected). Also, the premise of transfer learning is the source and target problems share adequate commonalities (as opposed to, say, models trained for image classification applied to natural language processing). It should thus be expected that the more different the two scenarios are, the less promising the transferred performances will be, though control benefits may still be achievable. Further, the controller has already internalized knowledge on how to conduct perimeter control based on the traffic conditions; therefore, during adaptation, less learning and exploration are needed. Finally, it is worth reiterating that these tests are meant to showcase the ability of the RL controller to quickly adapt its policy to unseen traffic patterns by utilizing its knowledge learned from the source problem and continuing its learning with online data feed. This is important for real-life applications where training the controller from scratch may be expensive or even prohibitive.
The first scenario considers a non-uniform demand pattern from the periphery to the city center, while the other demands remain unchanged. This demand simulates a commute pattern where one side of the periphery area is more populous than the other. As an example, the west side of the periphery is assumed to have the most traffic demands into the city center (see Figure 9a). Further, this demand change is coupled with worse driving behaviors (e.g., less adaptive routing and higher driver imperfection), which was done to mimic real-world driving conditions where human drivers exhibit more variation in their driving performance than is typically modeled in simulation ( 54 ). For this traffic scenario, NC and I-GC are applied with numerous random seeds and, to better demonstrate transferability, an RL controller is also trained from scratch (with same parameters as used for the baseline demand) to compare with the transferred RL controller. The CTC achieved by different methods are provided in Figure 9b, where the transferred RL controller is denoted by “RL (Transfer).” The transferred RL controller is only trained for 50 iterations, as it is merely adapting its pretrained action value function. As can be seen, the RL controller, when trained from scratch, can still realize promising control benefits that are generally better than the I-GC policy. This indicates the applicability of the RL controller to different scenarios, more so considering the same parameters are used. Comparatively, the RL controller transferred with pretrained action value function learns at a faster rate from a substantially better starting point and achieves promising control performances within 20 iterations. With newly collected experiences, it can quickly adapt its action value functions to the different traffic scenario, even with less exploration of the environment and learning update. Importantly, these results indicate the RL controller, despite trained in an environment with better simulated driving behavior, can transfer its knowledge and quickly adapt its action-taking policy to a setting that is more representative of reality, which showcases its significant potential for practical application.
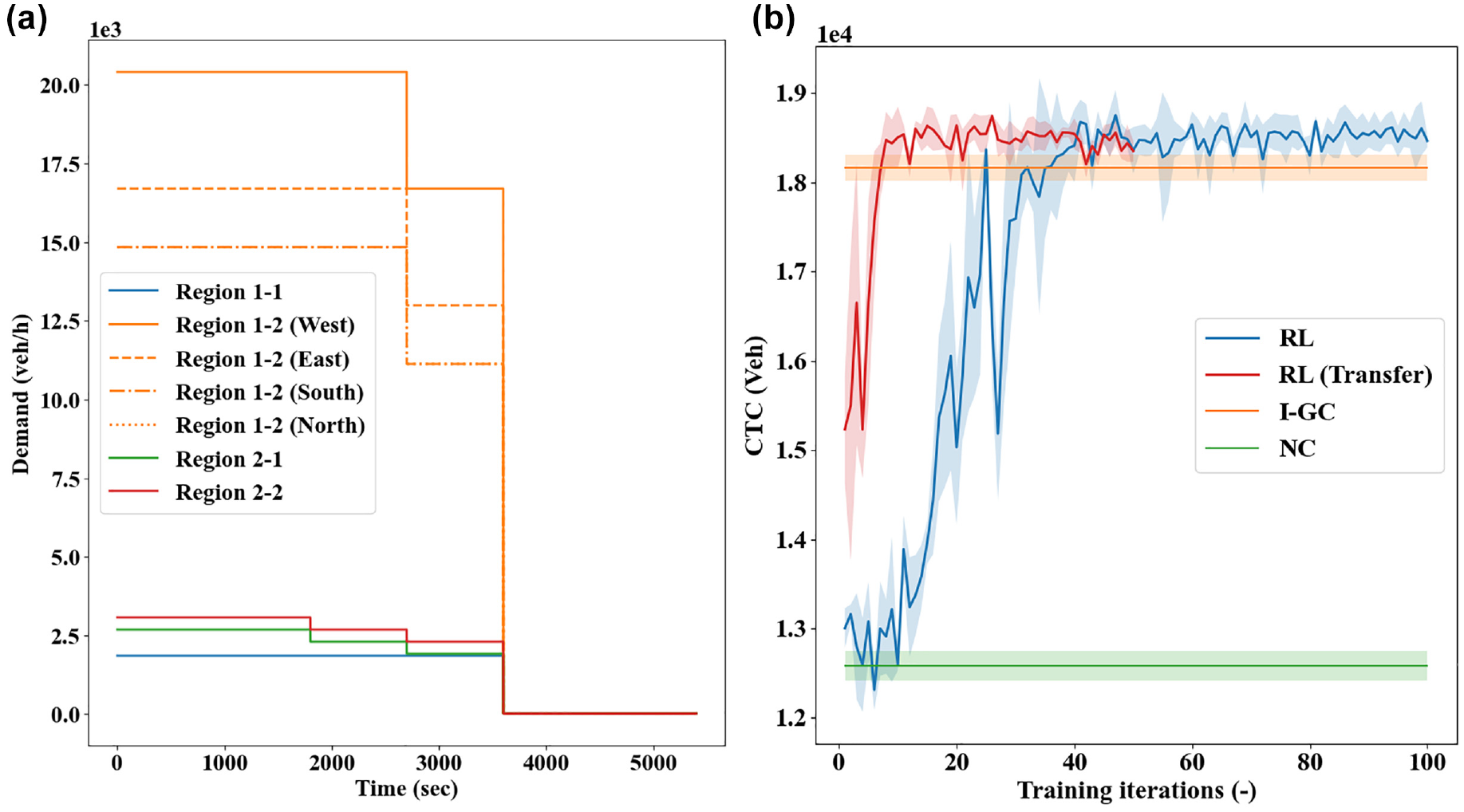
Transferability scenario 1: (a) demand profile and (b) realized cumulative trip completion (CTC) curves.
To evaluate the transferability of the RL controller to a setting with more dissimilar travel demands, a second traffic scenario is tested that considers an abrupt demand increase, as also examined in ( 15 , 29 ). In this scenario, the traffic demands from the periphery to the city center have increased intensity from the baseline demand for a duration of 15 min (see Figure 10a). The RL controller pretrained with the baseline demand is applied to this scenario, in comparison with the NC, I-GC, and an RL controller trained from scratch. The CTC curves are presented in Figure 10b. As can be seen, the RL controller, when trained from scratch, can still learn control policies that are notably better than the I-GC, despite increased demand dissimilarity. The transferred RL controller with pretrained action value function can also achieve higher CTC than the I-GC policy, yet its learning performances are not as desirable as in the previous case (the CTC curves are noisier than in Figure 9). This, however, is expected, as increased difference between the pretrained and applied scenarios would require more learning and exploration, which may not be achievable within 50 iterations. Nevertheless, the CTC obtained by the transferred RL controller increases more rapidly than the one trained from scratch in the first 50 iterations, which again exemplifies its transferability.
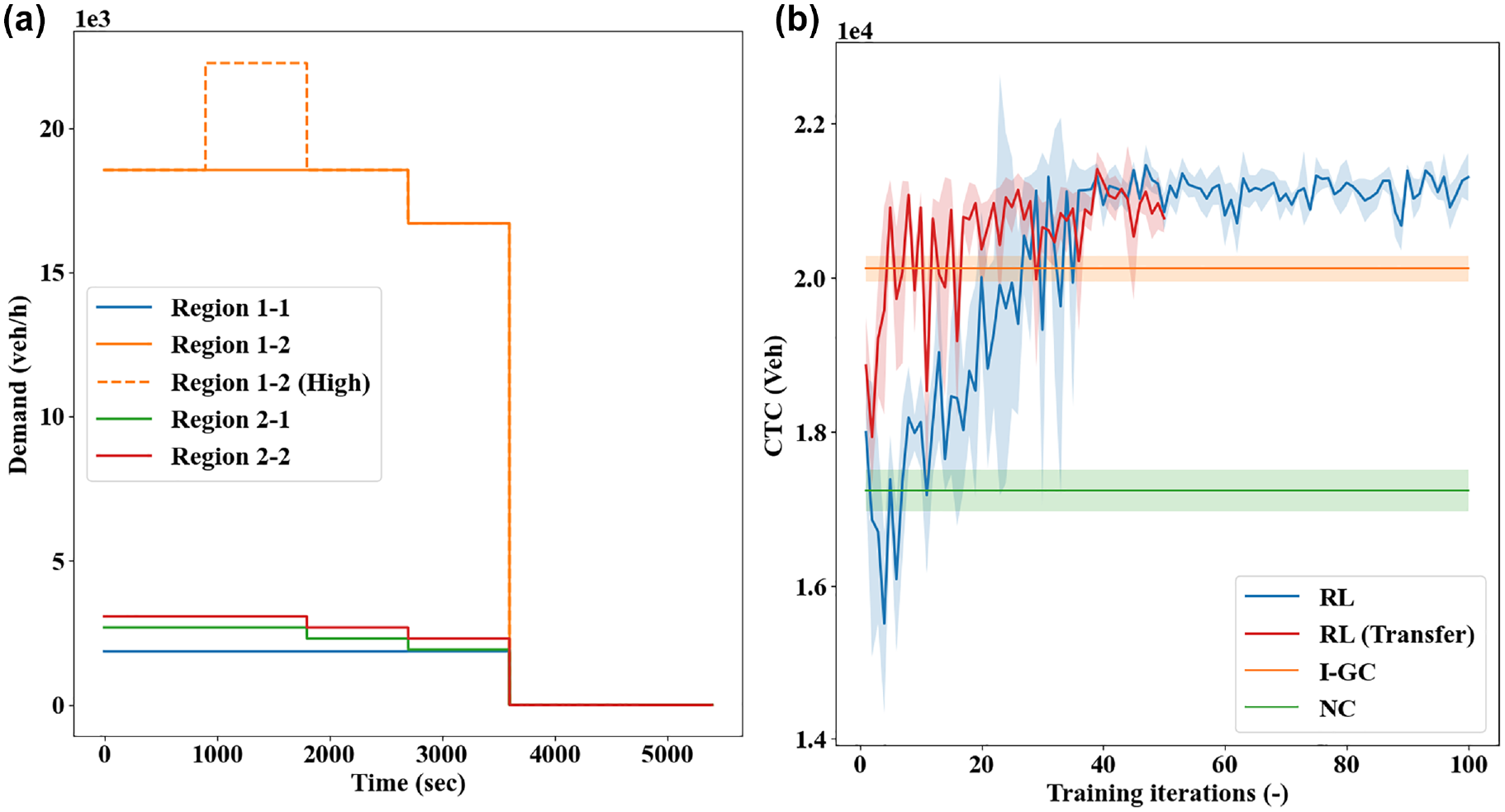
Transferability scenario 2: (a) demand profile and (b) realized cumulative trip completion (CTC) curves.
Concluding Remarks
This paper studies the classical two-region perimeter control problem in a microsimulation environment. An RL-based perimeter controller is presented, with its effectiveness and transferability comprehensively demonstrated in a microsimulation environment. Importantly, the ability of a data-driven perimeter control method to transfer its learned knowledge from one setting to another and to quickly adapt its control policy with newly collected data is critical in real life applications, where training a controller from scratch may be costly or even impossible. Transferability of perimeter control methods has long been neglected, and the few recent works that considered transferring the learned policies have not examined the ability of the methods to keep learning with continued data feed. Further, no other studies that considered transferability have utilized the more realistic microsimulation environment but, instead, adopted simpler numerical simulations. This work thus bridges several research gaps and strengthens the existing literature on data-driven methods for perimeter control.
The simulation results provided in this work suggest the presented RL controller can consistently learn control policies that are superior to I-GC. More importantly, it can readily transfer its learned knowledge to simulation settings with different traffic demands, driving behaviors, or both, and keep learning from newly collected data to produce more promising control strategies. These results showcase the real-world application potential of data-driven methods for perimeter control. In particular, the RL controller can be trained offline in a microsimulation environment with an estimate of the real traffic demands, assuming proper driving behaviors; then, at the time of application, continued streams of traffic data can be collected and fed to the controller to adjust its policy. In this manner, a smaller amount of data will be needed (as the controller has already internalized knowledge in the pretrain process) whereas the controller can adapt at a faster rate than if trained from scratch. Note that the application process can be carried out in real time as the action-taking only involves a forward pass using the parameters
Opportunities for future extensions exist. First, different forms of perimeter control implementation should be investigated, for example setting the green ratios or the allowable ratios of transfer flows ( 17 , 19 , 29 , 30 ). Also, it is worth examining if a more flexible action space could further improve the control benefits. Moreover, it is a research priority to evaluate RL-based perimeter control methods using a larger-scale urban network with microsimulation.
Footnotes
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: D. Zhou, V. Gayah; data collection: D. Zhou, V. Gayah; analysis and interpretation of results: D. Zhou, V. Gayah; draft manuscript preparation: D. Zhou, V. Gayah. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by NSF Grant CMMI-1749200.