
Abstract
Safe railway operation is vital for public safety, the environment, and property. Concurrent with climbing amounts of rail traffic on the Canadian rail network are increases in the last decade in the annual crash counts for derailment, collision, and highway railroad grade crossings (HRGCs). HRGCs are important spatial areas of the rail network, and the development of community areas near railway tracks increases the risk of HRGC crashes between highway vehicles and moving trains, resulting in consequences varying from property damage to injuries and fatalities. This research aims to identify major factors that cause HRGC crashes and affect the severity of associated casualties. Using these causal factors and ensemble algorithms, machine learning models were developed to analyze HRGC crashes and the severity of associated casualties between 2001 and 2022 in Canada. Furthermore, spatial autocorrelation and optimized hotspot analysis tools from ArcGIS software were used to identify hotspot locations of HRGC crashes. The optimized hotspot analysis shows the clustering of HRGC crashes around major Canadian cities. The analysis of cluster characteristics supports the results obtained for causal factors of HRGC crashes. These research outcomes help one to better understand the major causal factors and hotspot locations of HRGC crashes and assist authorities in implementing countermeasures to improve the safety of HRGCs across the rail network.
Keywords
The railway industry of Canada is a major contributor to the country’s economy. The safety of the rail network is crucial, as crashes on the railway network can seriously harm the system environment and result in numerous fatalities ( 1 , 2 ). Canada’s rail network is the third largest in the world, with more than 41,700 km of rail tracks featuring 25,155 highway railroad grade crossings (HRGCs) ( 3 , 4 ). A HRGC is an intersection of railway tracks and roads at the same grade level ( 4 ). Crashes at HRGCs are a safety concern and have attracted the attention of transport authorities, the public, and the railway sector ( 5 ). The expansion of municipalities and the development of high-population areas near railway lines pose a greater risk of crashes that can result in fatalities, injuries, extensive property damage, and delays in railway and highway traffic, making HRGCs spatial areas paramount for transportation safety ( 2 , 6 , 7 ). Between 2011 and 2020, 10,705 railway crashes were recorded in Canada, with the leading categories being non-main-track derailments (49.3%), followed by HRGC crashes (15.4%) (Table 1) ( 8 ). A non-main-track derailment is when one or more railcar wheels come off the rail surface on non-main tracks (such as yard rail lines). These crashes usually happen at speeds below 10 mph and are considered low-consequence crashes ( 8 ). On the other hand, crashes at HRGCs that include trains and highway vehicles are known as HRGC crashes ( 9 ). These crashes usually happen at track speed between vehicles and a moving train and are considered high-consequence. According to the data in Table 1, the number of HRGC crashes (1648) is less than the number of non-main-track derailment crashes (5278), but the fatality counts for HRGC crashes is far higher (227 versus 1). Thus, HRGC crashes are considered higher risk than non-main-track derailments and can result in more fatalities ( 10 ).
Rail Crashes Based on Crash Type (2011–2020) ( 8 )
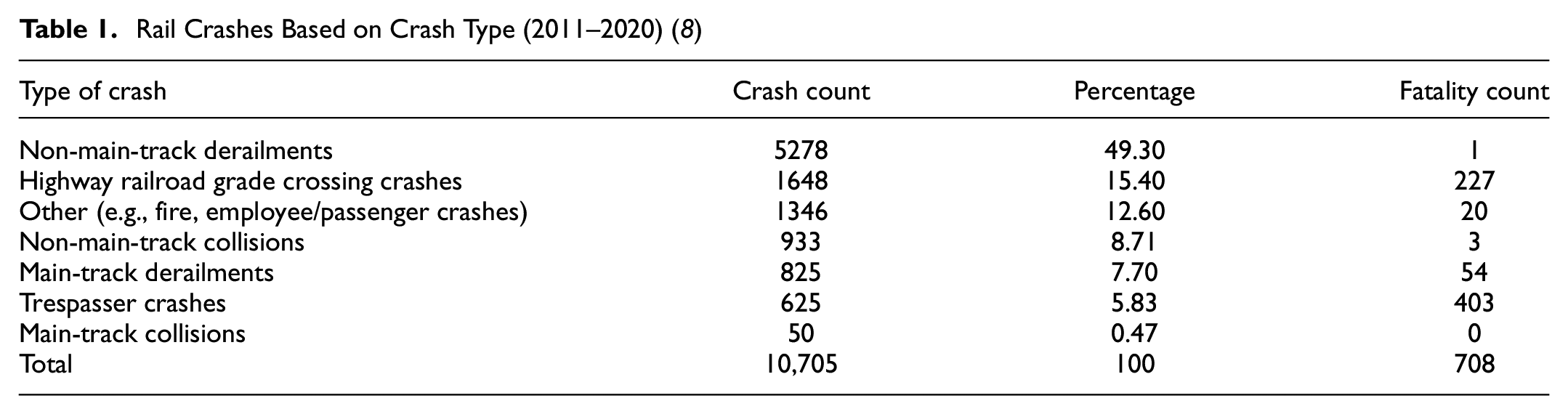
Figure 1 shows the time-trend analysis of HRGC crashes and associated casualties in Canada from 2011 to 2020. The analysis used crash and casualty counts from the Transportation Safety Board of Canada (TSB) dataset. These counts were normalized for comparison using million train miles (MTM) data for each year. HRGC crash counts per MTM have not changed much over the last decade (Figure 1a); however, fatality and serious injury counts per MTM have fluctuated. Fatality and serious injury percentages for HRGC crashes have shown an overall decreasing trend in the last decade; yet, the percentage of fatalities (Figure 1b) and serious injuries (Figure 1c) caused by HRGC crashes is high, at ~30% in 2020. HRGC crashes were the second-highest contributor to railway fatalities after trespasser crashes from 2011 to 2020; however, HRGC crashes have been the highest contributor to serious injuries on the Canadian railway in the last decade ( 8 ).
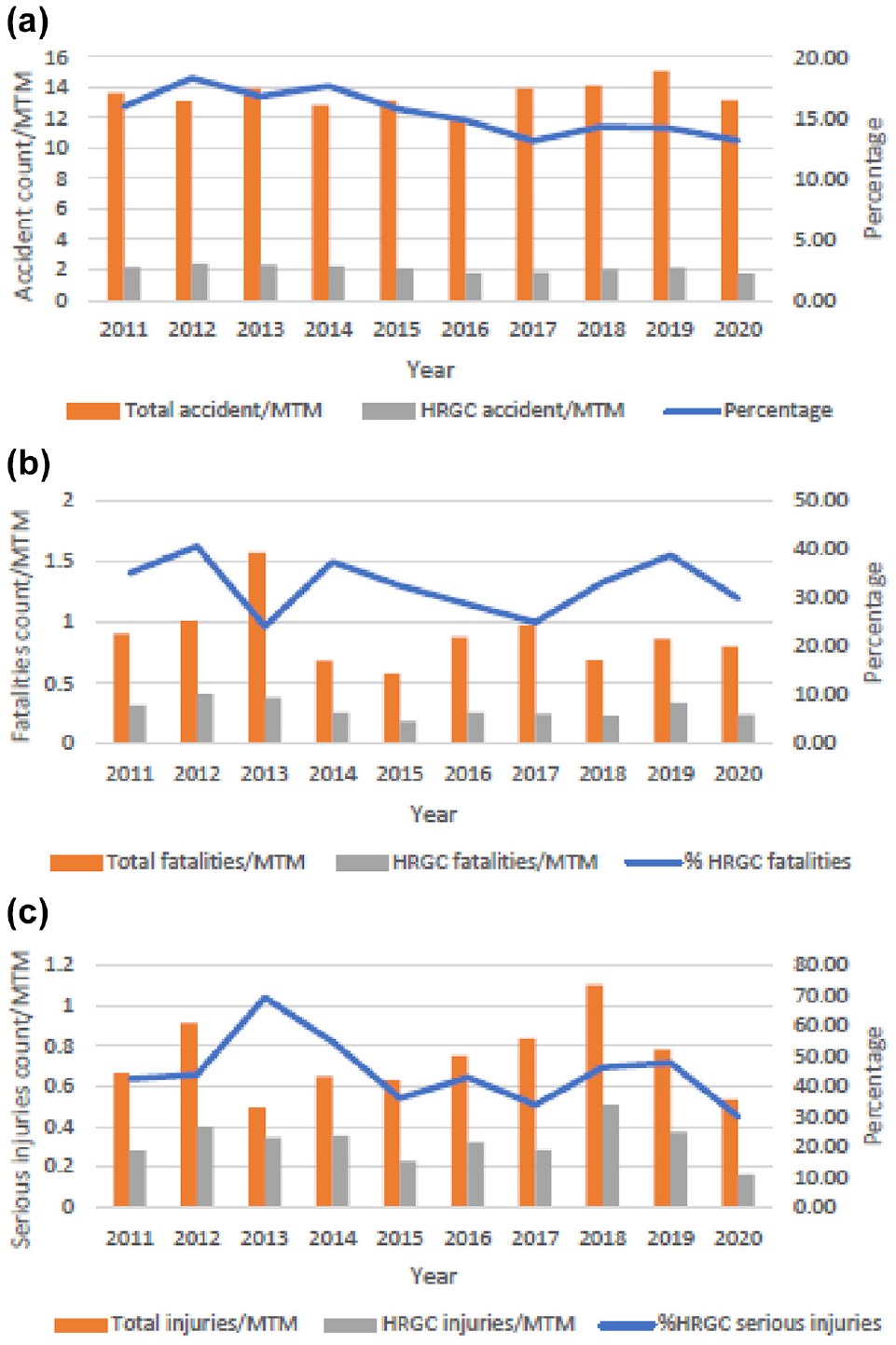
Trends in (a) highway railroad grade crossing (HRGC) crashes, (b) fatalities, and (c) serious injuries (2011–2020) ( 8 ).
Figure 1b shows a sudden drop in 2013 concerning %HRGC fatalities. In 2013, 47 fatalities were reported in the “main-track derailment” category because of a crash in Lac-Mégantic, Quebec, which resulted in a lower % of HRGC fatalities. Thus, the %HRGC fatalities value is considered an outlier for fatality data 2013. Figure 1c shows that the %HRGC serious injuries experienced a sudden rise in 2013. The total serious injury count was 39 in 2013, and fewer injuries were reported in other categories. This resulted in an unusually large contribution of HRGC crashes to the total. Thus, the 2013 value is considered an outlier for serious injury data ( 8 ).
High occurrences and consequences of HRGC crashes have raised concern, resulting in many studies aimed at improving the safety of HRGCs. For instance, a study by Lu et al. ( 11 ) uses generalized linear models, such as the Poisson, Bernoulli, and hurdle Poisson models, to predict HRGC crash frequency. The dataset contained crossing, highway, and rail traffic variables of HRGC crashes in North Dakota, U.S.A., between 1996 and 2014. The study highlights variables such as average daily vehicle traffic, daily train traffic, warning system, nighttime through-train traffic, train maximum speed, and the number of traffic lanes on the highway as contributors to HRGC crashes. Moke and Savage ( 12 ) use negative binomial regression on HRGC crash data from the U.S.A. from 1975 to 2001. Two separate models are developed in their study, one for predicting the number of HRGC crashes and another for predicting the number of casualties that occurred in HRGC crashes. The results indicate that daily train and vehicle traffic increases the risk of HRGC crashes and fatality counts, while an active warning system, locomotives with ditch lights, and safety campaigns reduce the risk. Another study by Brod and Gillen ( 13 ) developed two models for HRGC risk assessment. The authors use the zero-inflated negative binomial model to predict HRGC crashes and the multinomial regression model to find the severity probability (fatal, injury, and no injury). The study shows significant relations among HRGC characteristics, warning devices, and traffic exposure in HRGC crashes. Brabb et al. ( 14 ) studied HRGC crash data to analyze various factors in injuries and fatalities caused by HRGC crashes. The report identifies the effects of traffic, driver demography, environment, and crossing characteristics on the severity of casualties in HRGC crashes. Soleimani et al. ( 15 ) use Federal Railroad Administration (FRA) data to develop a HRGC consolidation model for public crossings using text mining, spatial analysis, and an extreme gradient boosting (XGBoost) algorithm to identify possible HRGCs that can be considered for closure in the future.
Several recent studies employ machine learning (ML) models to improve the safety of HRGCs. For instance, Zheng et al. ( 16 ) used ML to identify HRGC crashes based on crash risk in the U.S.A. between 1996 and 2014. The classification model was developed using a decision tree (DT) and gradient-boosting (GB) algorithm and obtained good classification accuracies (0.7705) for crashes and no crash cases at HRGCs. The authors found factors such as daytime train movement, nighttime train movement, daily train traffic, train speed, and highway speed are the most important factors related to HRGC crashes. Another study by Lasisi et al. ( 17 ) uses various ML classifiers, such as the support vector machine (SVM), random forest (RF), Gaussian naïve Bayes (GNB), multi-layer perceptron-neural network (MLP-NN), and logistic regression (LR), to predict casualties resulting from HRGC crashes using HRGC casualty data from California, U.S.A. High prediction accuracy (0.989) is achieved with the SVM. A total of 15 features are considered, including features related to railway and highway traffic and crossing characteristics that revealed train speed, average daily train, and vehicle traffic are essential factors affecting casualties in HRGC crashes.
The spatial distribution and hotspot locations of HRGC crashes have been assessed using spatial autocorrelation and optimized hotspot analysis using ArcGIS software. These tools generate significant and valuable spatial analysis results by employing crash counts/rates and geographic data as inputs. The results of spatial autocorrelations and optimized hotspot analysis show the statistically significant locations on maps called hotspot locations of crashes. Various studies have been conducted to analyze aviation crashes and road crashes using different ArcGIS software. Li and Liang ( 18 ) studied aviation crashes in Florida, U.S.A., using hotspot analysis tools and data from the National Transportation Safety Board (NTSB) from 2002 to 2017 and reported 75 hotspot locations for aviation crashes. Prasannakumar et al. ( 19 ) studied spatial clustering of road crashes in India and Mulugeta Tola and Gebissa ( 20 ) in Ethiopia using ArcGIS. The results of these studies give information on hotspot and coldspot locations, which provide insights for traffic management and crash reduction.
To the authors’ knowledge, limited research has been conducted on HRGC crashes in Canada’s rail network. Many contributing factors are involved in HRGC crashes, including highway and railway factors. The study by Heydari and Fu ( 21 ) uses Canadian railway HRGC data (2008–2013) to assess the effects of HRGC location attributes. The study only investigates a few factors, such as train speed, road speed, daily train traffic, daily vehicle traffic, and the number of highway lanes. Furthermore, a study by researchers at the University of Waterloo developed a tool called GradeX to assess HRGCs in Canada ( 4 ). It supports decision-making so authorities can identify high-risk HRGCs. The tool uses factors such as daily traffic of trains and vehicles, speed of trains and vehicles, location, and warning system at HRGCs. However, in both studies, important factors such as visibility, season, type of vehicle, and driver actions were not included. To address this research gap, all of these variables were considered in this research. This study focuses on identifying the most significant causal factors for HRGC crashes and the severity of casualties and helps minimize the chances and consequences of HRGC crashes. These causal factors are used with ensemble classifiers to analyze HRGC crashes based on crash risk and severity of associated casualties. The results can inform the implementation of strategies to increase HRGC safety in Canada. However, targeting all HRGCs within a rail network concerning the implementation of safety strategies is a very wide-scope and highly capital-intensive task. Thus, locating the hotspots of HRGC crash locations is beneficial in allocating appropriate resources. ArcGIS software helps not only visualize the spatial distribution of HRGC crash locations but also locate hotspot locations. Information about hotspot locations and causes of HRGC crashes will contribute to quicker implementation of safety strategies and enhanced safety at HRGCs.
The main objectives of this research are as follows:
identify the causal factors of HRGC crashes and the severity of associated casualties using a feature selection technique (ExtraTree classifier);
apply ensemble-supervised ML algorithms (RF, AdaBoost, and XGBoost) to analyze HRGC crashes;
apply ensemble-supervised ML algorithms (RF, AdaBoost, and XGBoost) to analyze casualty severity in HRGC crashes; and
determine HRGC crash hotspot locations using ArcGIS software for Canada’s rail network.
Methods
Data for the ML Model
The HRGC crossing information and crash data were taken from two public sources. The HRGC inventory data, which was collected from the Government of Canada website ( 4 ), was used in the analysis of HRGC crashes. The dataset contained information about HRGC crashes at every HRGC in the Canadian rail network. The original HRGC inventory dataset ( 4 ) contained 25,155 samples with 26 feature columns, such as the number of daily vehicles, number of daily trains, maximum road speed, maximum train speed, type of protection, and number of tracks at the HRGC.
The data containing information about the severity of casualties associated with HRGC crashes were taken from the TSB’s Railway Occurrences Database System (RODS) ( 22 ) and were used in the severity of casualty analysis using the ML model. The dataset included information about casualties reported in HRGC crashes. The original dataset contained information on 6581 HRGC crashes with 348 features, such as rank, HRGC-ID, railway owner, region, province, and number of daily vehicles. Figure 2 shows the methodology for this research.
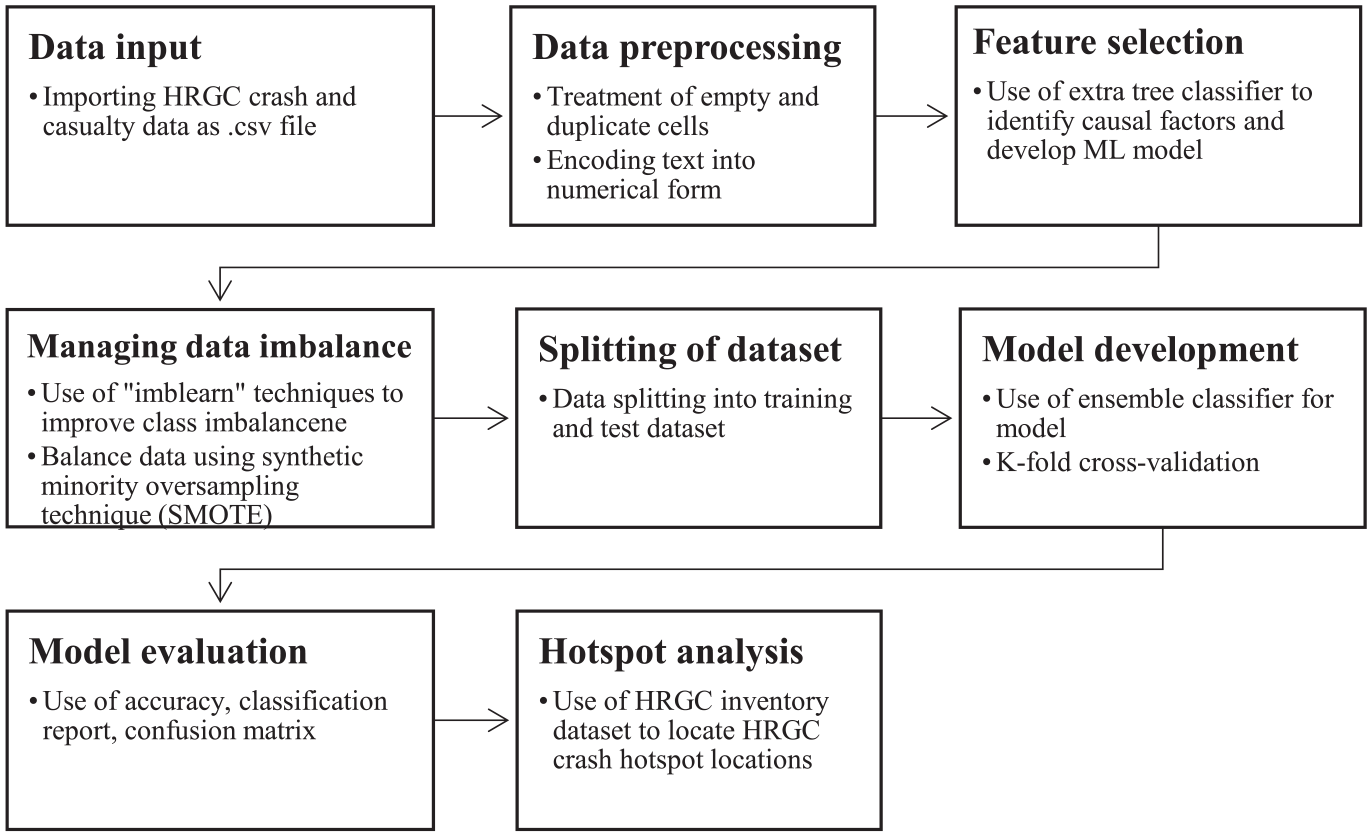
Methodology for the supervised classification machine learning (ML) model.
Data Preprocessing
The raw datasets from the data sources need preprocessing to address missing cell entries, duplicate rows, and categorical variables ( 23 , 24 ). If not treated beforehand, these missing cell entries and duplicate rows in datasets cause biased performance estimation for the ML model. Techniques such as deleting rows with missing cells or entering arbitrary or mean values of the feature are commonly used to manage missing cell entries ( 25 ). The datasets used in the present study contain many feature columns, including location, highway, railway, and environmental factors. However, some of the feature columns in the dataset had empty cells and therefore were excluded. In addition, duplicate row entries and feature columns with less important information were manually removed from the datasets.
The HRGC inventory dataset contained feature columns such as rank, Transport Canada (TC) number, railway owner, region, and province; these were removed because they added little value to the analysis (n = 15). Some sample entries were removed afterward as they had empty cell entries (n = 6001). Categorical features such as “Access,”“Protection,”“Regulator,” and “IsUrban” were converted to numeric variables using “LabelEncoder,” which generated the matrix of data for the classification. Finally, 10 input features and one output feature were selected, with 19,154 samples for feature selection. The output feature is a binary class feature, where 0 (zero) indicates a HRGC with no crash in history and 1 (one) indicates a HRGC with at least one crash reported in the history. Definitions of each feature of the model are given in Appendix A.
The HRGC casualty dataset from the RODS contained features such as railway owner, region, province, and subdivision that were not useful for the supervised classification model and, therefore, were removed from the dataset. In addition, some of the feature columns (such as dangerous goods released cars, ballast type, and temperature) were reported with many empty cell entries and therefore were also removed from the dataset (n = 330). Furthermore, duplicate sample entries were removed from the dataset (n = 174). Finally, after the data preprocessing, 17 input features and one output feature with 555 samples were selected. In addition, three more features were incorporated into the dataset to examine the effect of season, hour of the day, and train speed. The features named “Season” and “OccHour” were extracted using the time and date for given crashes from the dataset. The time was reported in “hhmm” format in the “OccTime” column. Thus, “OccHour” is extracted as “hh” from the “OccTime” column. “Season” is extracted from the “OccDate” feature column. The season of a crash was given a categorical variable, with 1 for winter (December to February), 2 for spring (March to May), 3 for summer (June to August), and 4 for fall (September to November). The “Train_Speed_MPH” feature was extracted using the HRGC-ID number for the effect of train speed on casualties associated with HRGC crashes. The HRGC inventory dataset was used to extract train speed values based on the HRGC-ID for the RODS dataset. The output feature is a multi-class feature, where 0 (zero) indicates a HRGC crash with no serious injury, 1 (one) indicates a HRGC crash with at least one serious injury, and 2 (two) indicates a HRGC crash with at least one fatality. The final classification dataset had 20 input features and one output feature with 555 samples. Definitions of features are given in Appendix B.
Feature Importance by the ExtraTrees Classifier
An ExtraTrees classifier is an ensemble method that helps identify the most important features for obtaining the classifier’s output ( 26 ). As a part of the ExtraTrees classifier, initial training samples are used to build each DT in the extra tree forest. Then, each tree is given a random sample of k features from the features at each test node. It must choose the best feature to divide the data according to a criterion (Gini index or entropy). The feature importance value ranges from zero to one, with higher feature importance values indicating features with a higher pertinence for predicting the output ( 27 ).
Based on the output of the ExtraTrees classifier, the optimum number of features is selected from the dataset for the classification model. According to the ranking of features in the ExtraTree classifier, an optimum number of features can be selected by assessing the accuracy value of the classification model for different numbers of features ( 28 ). When less than an optimum number of features is selected, the model gives a low accuracy value for the classification model. When the number of features increases, the accuracy value increases. However, the accuracy value will not significantly improve after the optimal number of features is reached. To determine the optimal number of features for developing the classification model of HRGC crashes and severity of casualty, a comparison of accuracy values was conducted using different feature subsets ranked by the results of the ExtraTree classifier. The goal was to identify the subset of features that achieved the highest accuracy in the classification model. This approach ensured the classification model was built using the most relevant and influential features, improving performance ( 29 ). The classification model takes a long time to train and test a dataset and can be computationally expensive when more than optimum features are selected ( 30 ).
Data Balancing
Initial analysis of the datasets showed an imbalance in class distribution (i.e., one class label has many observations, and the other has a small number of observations [ 24 ]). Imbalanced datasets cannot be used for conventional classification algorithms because such algorithms are based on three main assumptions: (i) the use of the precision of the model for assessment criteria; (ii) a nearly equal distribution of classes in the dataset; and (iii) the consequences of incorrect prediction of the class are identical for every class ( 31 ). These assumptions are not valid for most real-world datasets, which often have an imbalanced distribution of classes ( 32 ). High-performance classification models are built with a balanced dataset, which has near-equal sample counts for every class ( 33 ). To balance the class distribution, advanced techniques from the “imblearn” package in Python, such as the oversampling technique, undersampling technique, and synthetic minority oversampling technique (SMOTE), are available ( 34 ).
The oversampling technique increases the minority class samples by duplication and equalizes the class distribution but raises concerns about overfitting. On the other hand, the undersampling technique reduces the number of majority class samples, which leads to the omission of helpful information about a dataset ( 35 ). Another applicable technique is the introduction of synthetic samples around the existing samples, called the SMOTE, which creates minority samples by linear interpolating two identical classes using Equation 1 and adding them to the dataset ( 31 ):
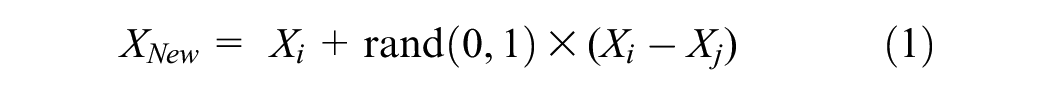
The SMOTE approach uses sample Xi of a given class from the dataset and calculates the distance from neighboring identical classes. The neighboring sample Xj will be randomly selected to populate new XNew using Equation 1. Therefore, the SMOTE can reduce overfitting and improve the classification model performance ( 31 ). Therefore, the SMOTE technique was used in our study. Data balancing is performed after the feature selection process because the SMOTE algorithm is applied to address a class imbalance in the dataset. Performing feature selection before data balancing ensures that the selected features are based on the original distribution of the data, which helps preserve the intrinsic information and relationships present in the original dataset and allows for more accurate and meaningful feature evaluation ( 36 ).
Splitting of the Dataset
For supervised ML, datasets are divided into training and testing datasets using the “test_train_split” method with stratified parameters. This method divides the dataset according to the input ratio from the user, and stratify parameter splits the dataset with an identical output class ratio in both the training and testing datasets. In this research, an 80:20 split ratio was used, meaning 80% of the data were partitioned into a training dataset and 20% into a testing dataset. In supervised ML, a training dataset is used to train the model, which allows the model to learn. After training, model performance is evaluated using the testing dataset ( 37 ).
Classification Model Development
Ensemble classification algorithms were used in research to implement ML models. An ensemble classifier method is a meta-approach for improving the predictive performance of the ML model ( 38 ). Ensemble classifiers generate one optimal ML model by combining multiple base models. The ensemble method is advantageous because it guarantees the prediction and provides a ML model with high stability and resilience. Vijaya and Sivasankar ( 39 ) compared ensemble and conventional classifiers to predict telecommunication customer churn. The outcome supported that the accuracy of ensemble classifiers, such as boosting and bagging, is greater than traditional classifiers. Therefore, this research utilizes several ensemble-supervised ML classification models, such as RF, AdaBoost, and XGBoost.
The RF classifier employs DTs as individual models and uses bagging as an ensemble method ( 40 ). Bagging is fitting several models to various samples of the same dataset and averaging the resulting predictions. The algorithm develops many trees, which happens in parallel, and then these trees vote for the most popular class ( 41 ). The algorithm has two phases: the first is the development of the RF, and the second is the prediction of results from the RF developed in earlier stages. As the RF uses the bagging method, it helps to reduce overall variance by combining the results of several classifiers trained on various training data samples. The RF classifier requires considerable computational power and time for training the model, as it creates several DTs to integrate their outputs. For the RF, the greater the number of trees, the better the result of the model. One fundamental problem that can worsen the results of the RF algorithm is overfitting. However, when the RF classifier has sufficient trees for the model, then the model’s outcome is not prone to overfitting ( 42 ). For the RF classifier, all the hyperparameters were selected with their default values.
The AdaBoost classifier employs DTs as individual models and uses boosting as an ensemble method. Boosting is the repetitive application of a weak learning algorithm to different distributions over the training data and then merging the weak learner’s classifiers into a single composite classifier. AdaBoost is a popular ensemble ML method that targets misclassified instances in a previous weak classifier while training a new weak classifier. Obtaining high accuracy in the classification model is a primary objective; however, achieving high accuracy with only one classifier may not be possible. This problem can be rectified when multiple weak classifiers are employed, as each one gradually learns from the misclassified samples of the previous classifier. When training a new weak classifier, the weights of training samples are changed to improve learning. The weights are increased (decreased) for training samples that are incorrectly (correctly) classified in weak classifiers ( 43 ). The AdaBoost algorithm is easy to implement, flexible, and prone to overfitting. However, it is sensitive to noisy data and outliers and takes longer to train as it trains the weak classifiers individually ( 44 ). For the AdaBoost Classifier, n_estimator = 500 was selected, and the rest of the hyperparameters were selected with their default values.
XGBoost is a supervised ensemble ML algorithm that uses the gradient-boosted DT as a model and boosting as an ensemble method. The input variables are assigned weight factors used by the gradient-boosted DT to predict the results. Variables that the previous weak learners incorrectly anticipated are given more weight before being placed into the following DT. The models trained with this approach provide a more accurate and potent model for ML applications ( 45 ). The model is popular because of its ability to manage sparse data and parallel and distributed computing while handling large samples ( 46 ). By incorporating regularization parameters, the learning rate, and column subsampling, XGBoost lessens overfitting and improves speed and performance. Compared to AdaBoost and the RF, XGBoost is more challenging to comprehend, visualize, and tune. The XGBoost model requires significant resources to train and tune the model to get significant results ( 47 ). For the XGBoost classifier, all the hyperparameters were selected with their default values.
Performance Assessment Using Evaluation Metrics
Classifier models were evaluated using performance metrics, such as a confusion matrix, classification reports, and accuracy. The confusion matrix is a table frequently used to describe how a classification model performed on the test data. The confusion matrix provides the counts for true positive, false positive, false negative, and true negative (Figure 3) ( 48 ).
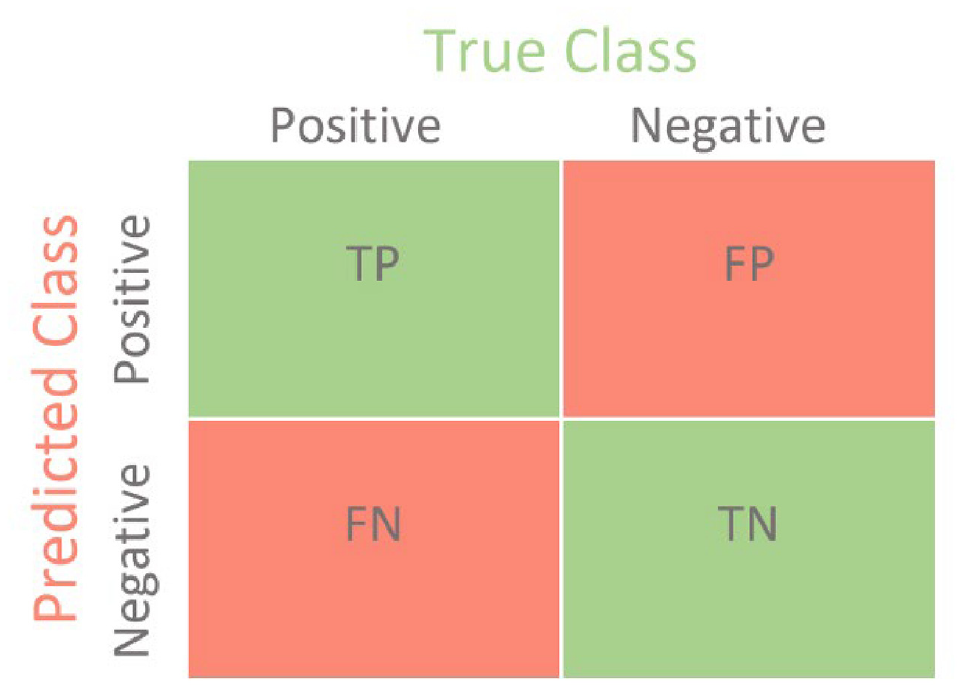
Confusion matrix for binary classification ( 48 ).
A classification report is simply a consolidated representation of precision, recall, F1-score, and support values of the testing dataset for the classifier model. The equations for precision, recall, and F1-score are given in Equations 2–4. The macro average in the classification report indicates the mean value of the evaluation parameters (precision, recall, and F1-score). However, the weighted average in the classification report indicates the weighted value of the evaluation parameter by multiplying the respective proportion of each class in the test dataset. Accuracy is a ratio of correctly predicted observations to total observations (Equation 5). In this research, the K-fold cross-validation technique is used with K = 10. The use of cross-validation helps to eliminate overfitting and underfitting scenarios. It also generalizes the model accuracy for any independent data ( 49 ). A classification model must have high accuracy, high precision, high recall, and high F1-score values to be called a high-performance classifier ( 48 ).
The algorithms described above were implemented using Python version 3.9.7:
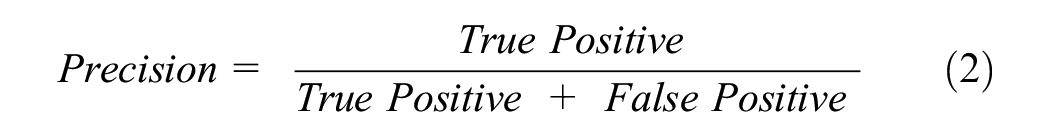
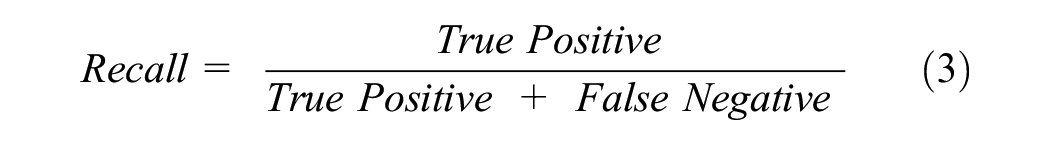
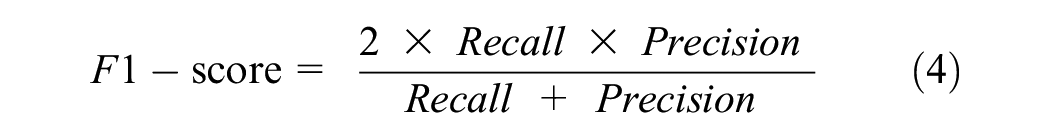
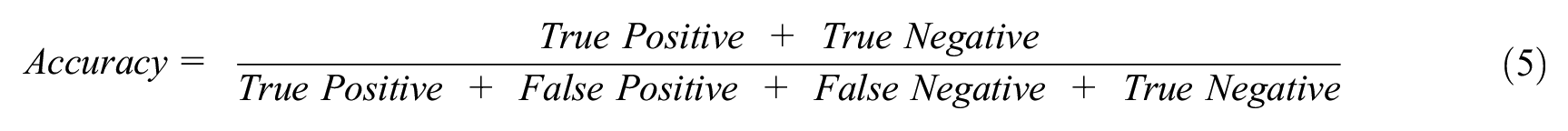
Hotspot Analysis of HRGC Crashes
Hotspot analysis is an advanced technique to identify hotspot locations using incident/crash data. This approach is superior to existing techniques for identifying crash frequency, rate, and density. In this research, hotspot analysis was conducted by incorporating two tools included in ArcGIS software: (i) spatial autocorrelation (Moran’s I method) and (ii) optimized hotspot analysis.
Spatial Autocorrelation (Moran’s I Method)
The spatial autocorrelation method uses global Moran’s I statistics, which consider feature values and location coordinates. Moran’s I was one of the earliest measures of spatial autocorrelation globally and is still used to assess spatial autocorrelation (Equation 6). The spatial autocorrelation tool provides results that include Moran’s I, Z-score, p-value, and so forth ( 50 ). Moran’s I helps identify spatial patterns such as random, dispersed, or clustered, while the Z-score and p-value help determine statistical significance and reject or accept the null hypothesis ( 19 ). Moran’s I can be calculated using the following equation:
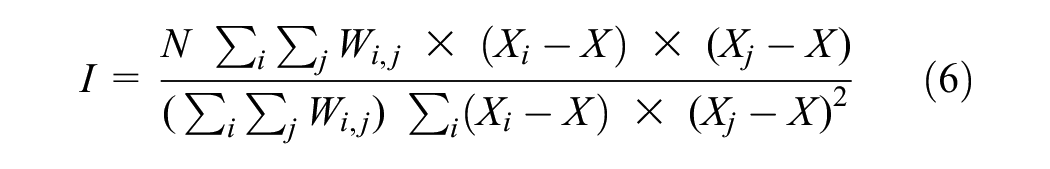
where N is the number of samples, Xi is the variable value at one location, Xj is the variable value at another location, X is the variable’s mean, and Wij is a weight that compares locations i and j.
A Moran’s I value near +1 indicates clustering (positive spatial autocorrelation), and that near −1 indicates dispersion (negative spatial autocorrelation); a value of zero indicates a random (no spatial autocorrelation) distribution. In some cases, when the Z-score is extensive, but the significance value indicates rejection of the null hypothesis, Moran’s I needs to be assessed. The result displays a clustered pattern if the Moran’s I value is greater than 0 and a dispersed pattern if the Moran’s I value is less than 0 ( 19 ).
Optimized Hotspot Analysis
Optimized hotspot analysis is an ArcGIS software tool that helps search for the region with a high concentration of occurrences within a defined limit ( 19 ). Optimized hotspot analysis is similar to the hotspot analysis tool but uses a parameter from the input data to run Getis-Ord Gi* statistics, such as counts of crashes and counts of fatalities. The results provide statistically significant spatial clusters of the hotspots (high-value points) and coldspots (low-value points). This tool operates by examining each characteristic and considering its surrounding feature points. The outcome of optimized hotspot analysis gives a GiZScore and GiPValue for every sample of the dataset. These values help analyze the statistical significance and spatial clustering of the samples using Equations 7–9. The features with a high GiZScore and a low GiPValue indicate hotspots or high-value clustering locations, while features with a low GiZScore and low GiPValue indicate coldspots or low-value clustering locations ( 19 , 51 ):
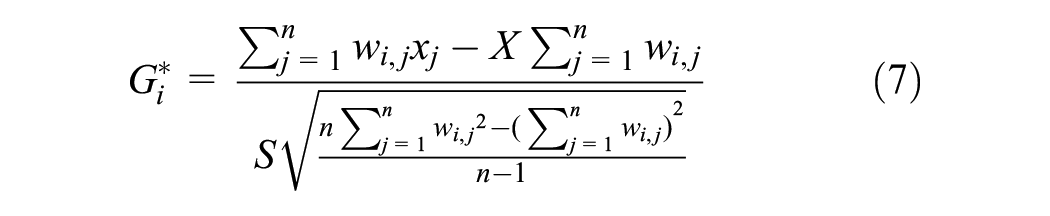
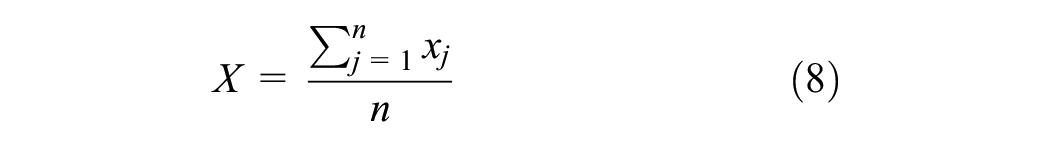
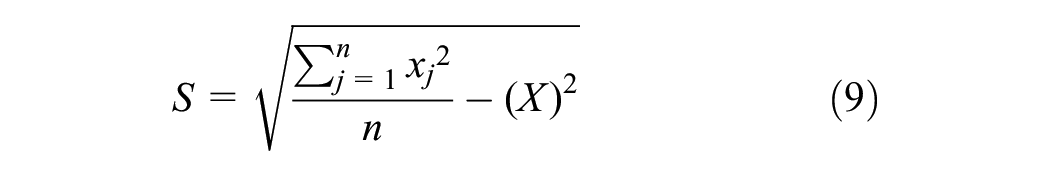
where
Results
Feature Selection for HRGC Crash Data
Figure 4 shows the importance of each feature of the HRGC crash dataset generated by the ExtraTrees classifier. “Vehicles_Daily” emerges as the most influential feature, while “Access” exhibits the least impact on predicting the HRGC crashes using the classifier. The results shows similarity with the results of previously conducted studies ( 11 , 12 ).
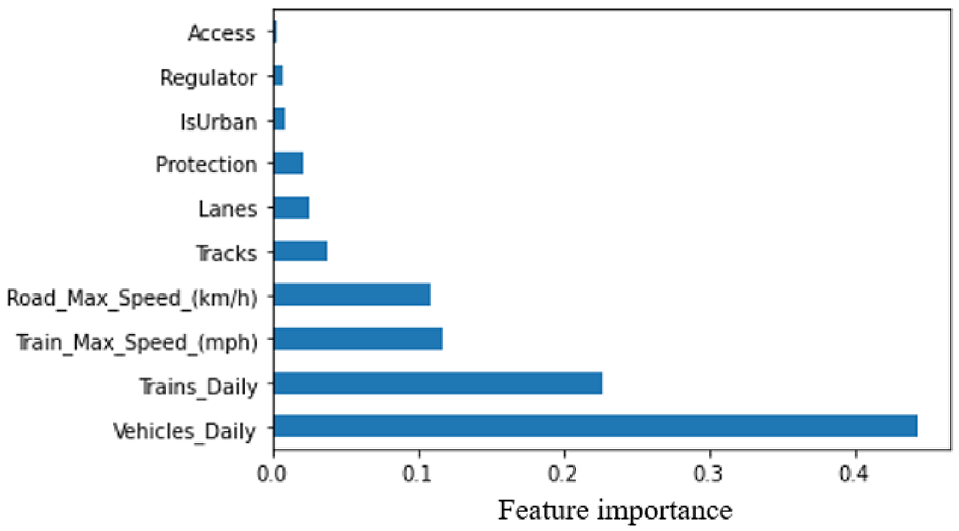
Feature importance for highway railroad grade crossing crash causes.
Feature Selection for Severity of Casualties in HRGC Crash Data
Figure 5 shows the importance for each feature with respect to severity of casualties associated with HRGC crashes as obtained by the extra trees classifier model. “Train_Speed_MPH” emerges as the most influential feature, while “NumberTrainsInvolved” exhibits the least impact on predicting the severity of casualties using the classifier. The results are in alignment with studies that were previously conducted ( 14 , 15 ). Also, the results here unveiled some important factors, such as occurrence hour (OccHour), vehicle type (VehicleTypeID), and season (Season), which were not identified in the previously conducted studies of HRGC safety.
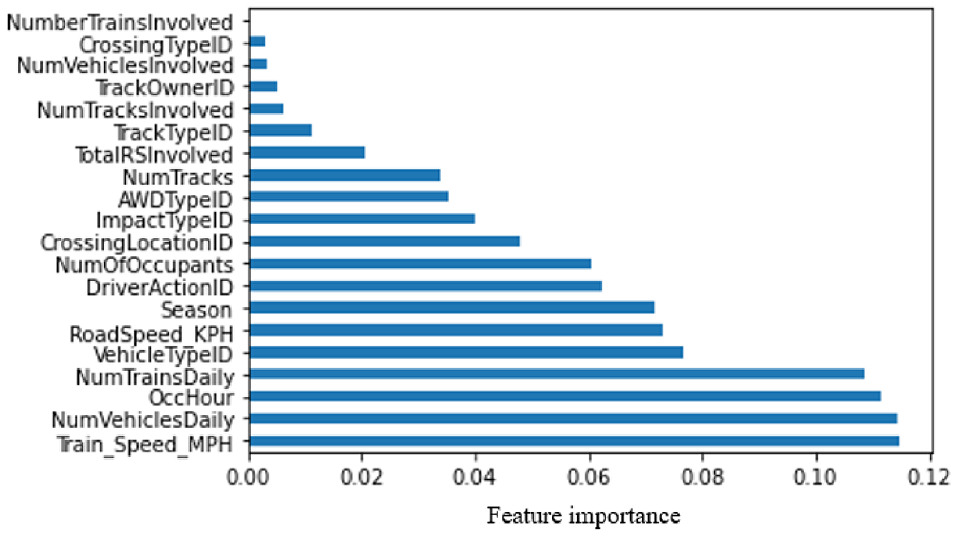
Feature importance for the severity of casualty causes.
Analysis of Results of the Classification Model of HRGC Crashes
The HRGC crashes classification model was developed using features obtained from the feature selections, with the feature importance of each feature (Figure 4) considered in the model. The model accuracies were compared using a different number of features (based on the output of the ExtraTrees classifier) to obtain the optimum number of features for the classification model. The highest accuracy was obtained with the top seven features of the dataset, as reported in Table 2.
Features for the Analysis of Highway Railroad Grade Crossing (HRGC) Crashes

The classifiers were then evaluated using the mean accuracy of the classifier models (value of accuracy after K-fold cross-validation) ( 17 ). The highest mean accuracy value was obtained with XGBoost (0.90), followed by the RF (0.87) and AdaBoost (0.82) classifiers.
Performance parameters (precision, recall, and F1-score) for the XGBoost classifier are reported in Table 3. Both classes (0 and 1) show high accuracy, precision, recall, and F1-score with the XGBoost classifier.
Classification Report for the XGBoost Classifier for Highway Railroad Grade Crossing Crashes
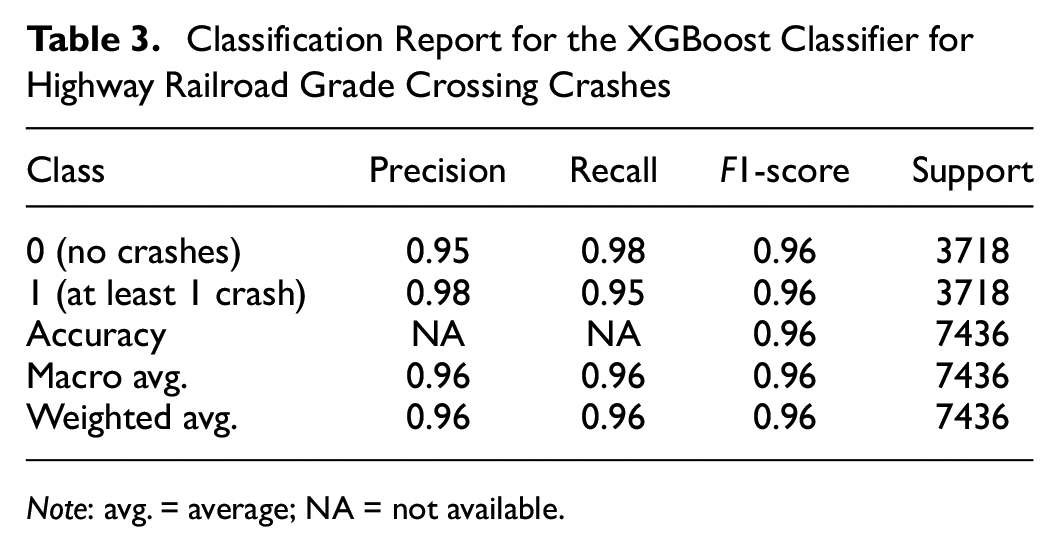
Note: avg. = average; NA = not available.
Analysis of Results of the Classification Model of the Severity of Casualties Associated with HRGC Crashes
The classification model was developed using features obtained from the feature selections, with the feature importance of each feature (Figure 5) considered in the model. The model accuracies were again compared using a different number of features (based on the output of the ExtraTrees classifier) to obtain the optimum number of features for the classification model. The highest accuracy was obtained with the top 11 features of the dataset, as reported in Table 4.
Features for the Analysis of the Severity of Casualties Associated with Highway Railroad Grade Crossing (HRGC) Crashes

The classifiers were then evaluated using the mean accuracy of the classifier models (value of accuracy after K-fold cross-validation) ( 17 ). The highest accuracy was obtained with XGBoost (0.79), followed by the RF (0.75) and AdaBoost (0.53) classifiers.
The performance parameters (precision, recall, and F1-score) for the XGBoost classifier are reported in Table 5. All three classes (0, 1, and 2) show high accuracy, precision, recall, and F1-score with the XGBoost classifier.
Classification Report for XGBoost Classifier for the Severity of Casualties Associated with Highway Railroad Grade Crossing Crashes
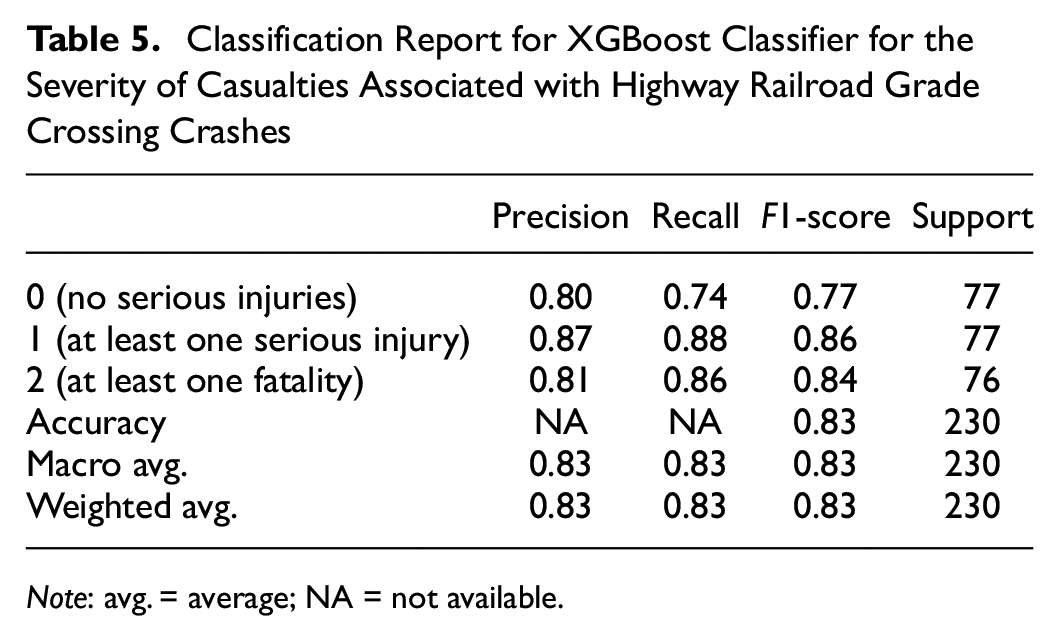
Note: avg. = average; NA = not available.
Results of Hotspot Analysis
The hotspot analysis of the HRGC crashes was conducted using the HRGC inventory dataset. The dataset contained crash counts at different HRGCs across the rail network with Global Positioning System (GPS) coordinates of each HRGC. The spatial autocorrelation of the dataset resulted in a z-score value of 8.1851, a p-value of zero, and Moran’s I more significant than zero (0.0116), which together indicate positive spatial autocorrelation and spatial clustering of HRGC crashes in the rail network ( 52 ). The data are distributed as clusters for the rail network, which can be helpful for further analysis of causal factors of HRGC crashes for each cluster.
After obtaining the clustering distribution of HRGC crashes, optimized hotspot analysis was applied. The results of the optimized hotspot tool identified a total of 1514 hotspot locations (with 99% confidence) of HRGC crashes in Canada’s rail network (Figure 6).
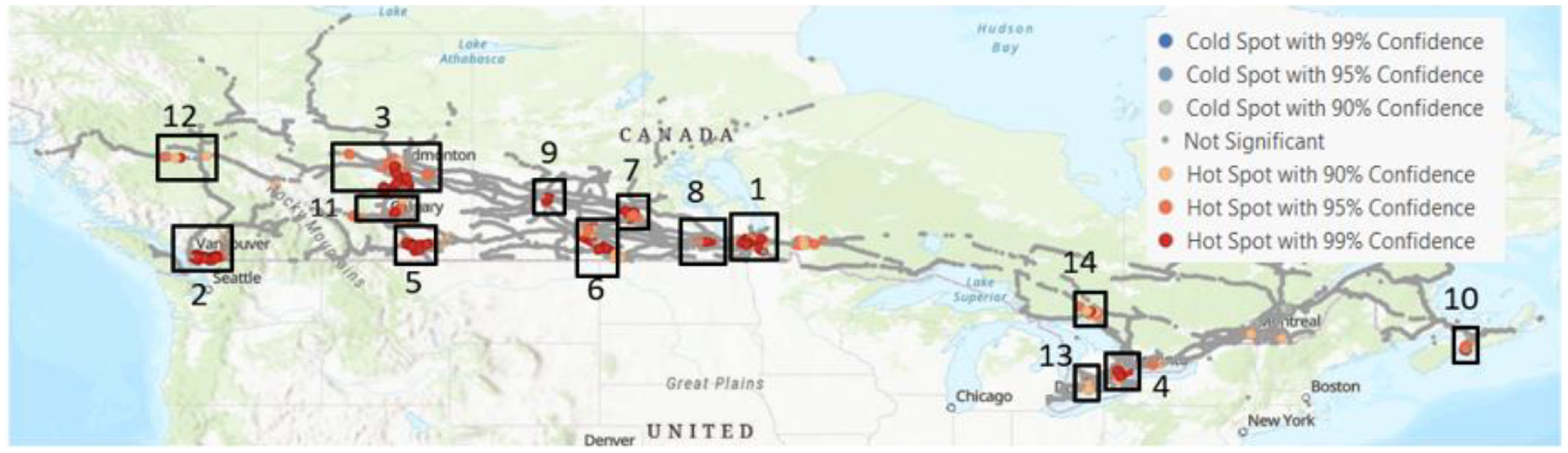
Hotspot locations for highway railroad grade crossing crashes with cluster number.
The details of hotspot locations were used to define different clusters based on their location across the rail network (Table 6).
Highway Railroad Grade Crossing crash Cluster Details

Discussion of Results
Causes of HRGC Crashes
According to Figure 4, the most important causal factor of HRGC crashes is “Vehicles_Daily,” which is the number of road vehicles per day over a given HRGC. An assessment of crossing inventory data shows that the probability of HRGC crashes increases as the number of daily vehicles increases for a given HRGC. The second most influential factor for HRGC crashes is “Trains_Daily,” the number of trains per day over a given HRGC. Table 7 shows the probability of HRGC crashes for different daily train counts and indicates a positive relation with daily train counts. The probability of a HRGC crash is determined by dividing the number of HRGCs with a crash history within a specific range of causal factors by the total number of HRGCs within that same range. The increased probability of HRGC crashes with higher traffic can be attributed to the more frequent meet up of vehicles and trains on the HRGC sites.
Effect of Factors of Highway Railroad Grade Crossing crash Probability
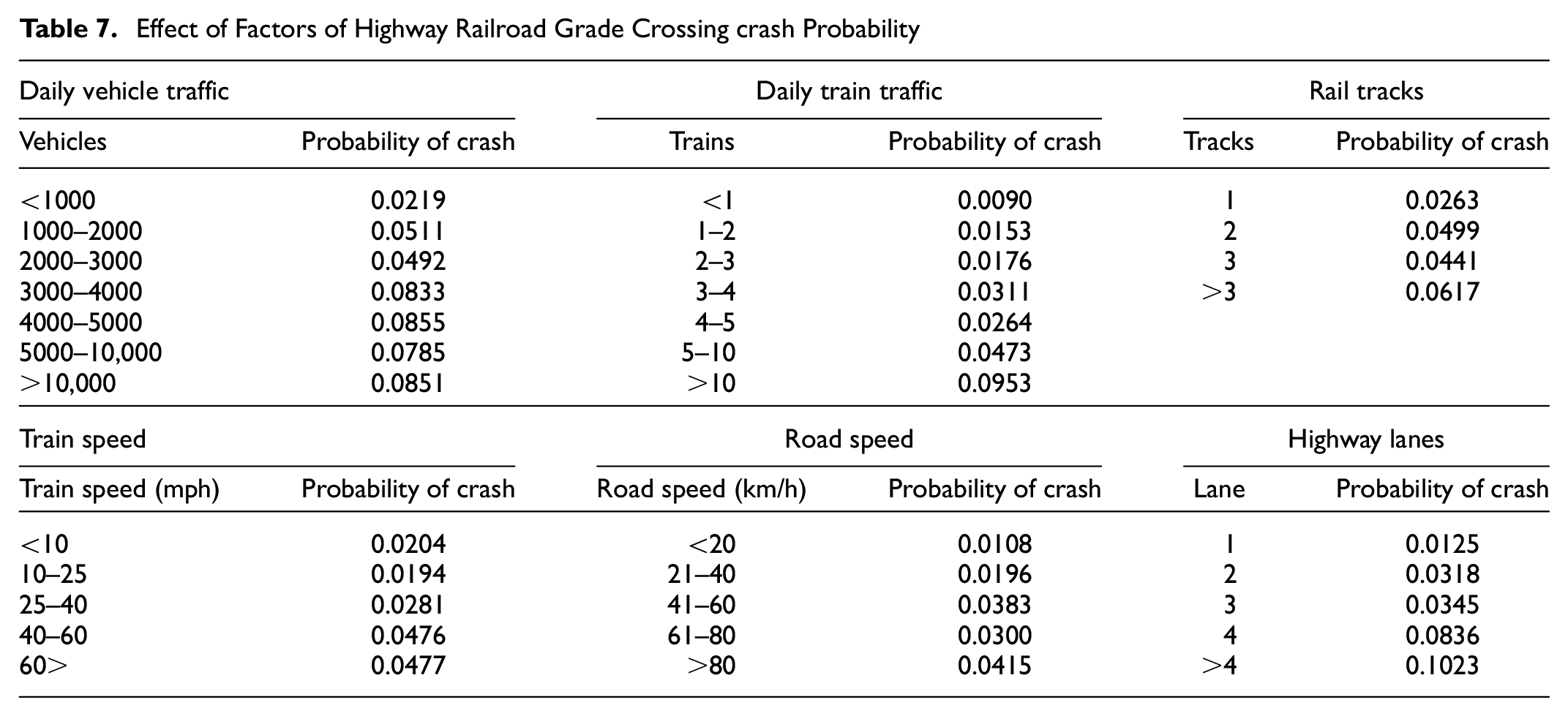
Train_Max_Speed_(mph) is the third most influential causal factor for HRGC crashes. The fourth most important causal factor for HRGC crashes is Road_Speed_(km/h). On assessment of HRGC inventory data, the probability of HRGC crashes increases with increased train speed and road speed. The shorter time available for evaluating the HRGC site’s conditions and making safe decisions about the HRGC’s crossover can be attributed to the increased probability of HRGC crashes at higher speeds (Table 7).
The fifth most important causal factor of HRGC crashes is “Tracks,” which means the number of rail tracks at a HRGC. Table 7 shows that the probability of HRGC crashes rises with an increase in track numbers at HRGCs. “Lanes” on the highway are the sixth most important cause of HRGC crashes. Similar to the number of rail tracks, the probability of HRGC crashes increases with an increase in the number of lanes at HRGCs. The longer time required for vehicles to traverse the HRGC can be attributed for the greater likelihood of HRGC crashes with a higher track number ( 53 ). Similar to this, more vehicles are exposed on the HRGCs with more highway lanes than in those with fewer highway lanes, which increases the probability of HRGC crashes (Table 7).
“Protection” is the seventh most important causal factor for HRGC crashes, and refers to the type of protection device installed at a given HRGC. The data from Canadian railways show 45% of HRGC crashes happen at passive crossings, followed by 30% at crossings equipped with flashlights, gates, and bells, and 25% at crossings equipped with flashlights and gates. These data indicate that protection devices at a given HRGC help to reduce the number of HRGC crashes.
Causes of Severe Casualties Associated with HRGC Crashes
The most important causal factor for the severity of casualties associated with HRGC crashes is “Train_Speed_MPH.”Figure 7 shows that the probability of crashes at HRGCs with fatalities and serious injuries increases with train speed. The figure also shows the probability of a serious injury crash is less at higher train speeds compared to the probability of a fatal crash, likely because of higher train speeds resulting in more fatalities.
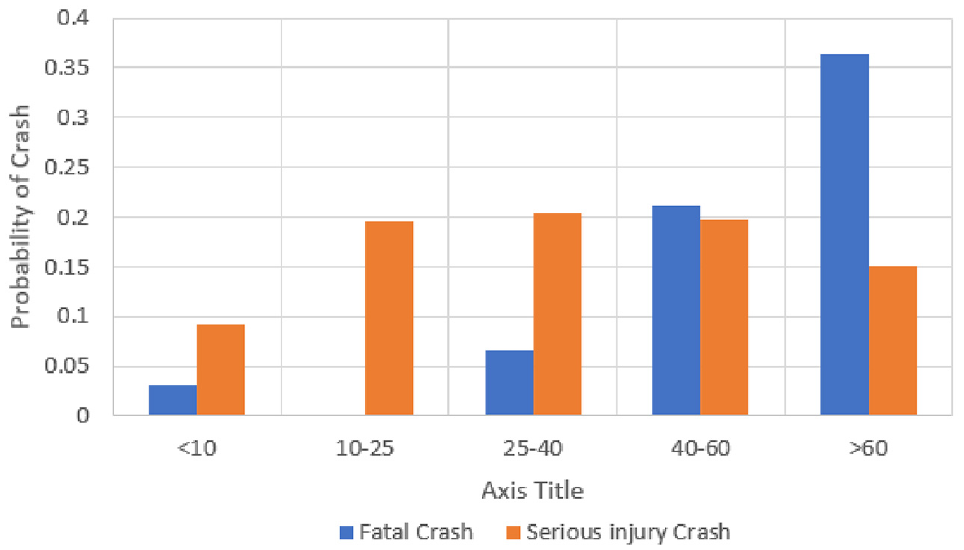
Effect of train speed on the probability of severe injury or fatality associated with a highway railroad grade crossing crash.
The second most important causal factor for the severity of casualties associated with HRGC crashes is “NumTrainsDaily,” which indicates the number of trains passing over a given HRGC. Figure 8 indicates that the probability of a fatal crash increases with an increase in daily trains, with the highest probability of a fatal crash associated with >25 daily trains. The probability of serious injury crashes varies with daily train count, with the highest probability associated with 5–10 daily trains at HRGCs.
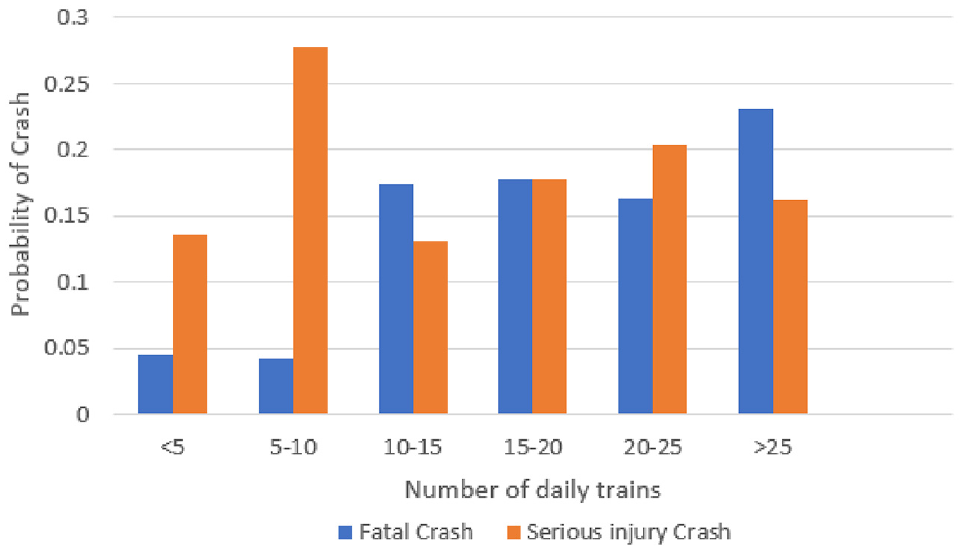
Effect of the number of daily trains on the probability of severe injury or fatality associated with a crash at a highway railroad grade crossing.
“NumVehiclesDaily” is the third influential causal factor for the severity of casualties associated with HRGC crashes and refers to the number of vehicles crossing over a given HRGC. Figure 9 shows the probabilities of fatal and serious injury crashes, which both vary over the range of daily vehicles. The highest probability of a fatal crash is observed for <1000 daily vehicles, and the highest probability of serious injury crashes is observed for 1000–2000 daily vehicles.
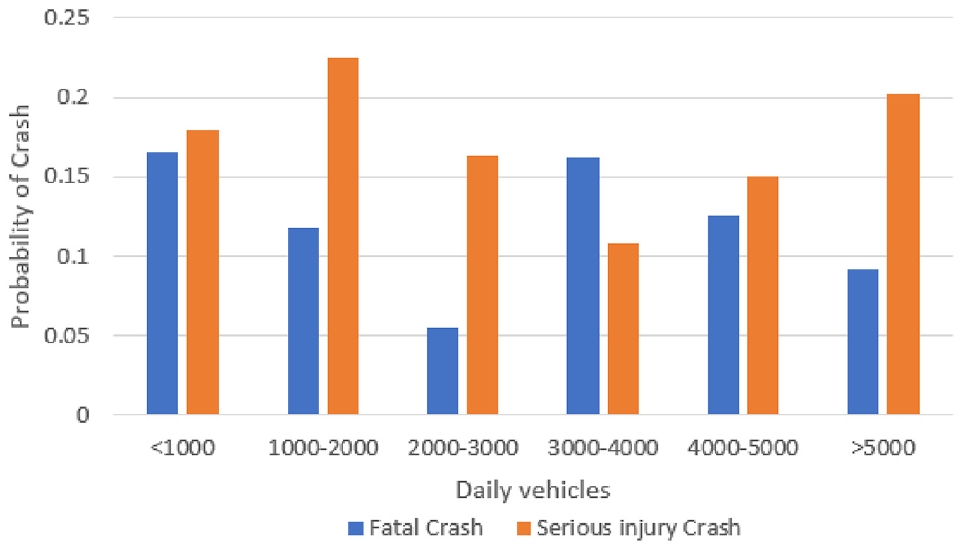
Effect of number of daily vehicles on the probability of severe injury or fatality associated with a highway railroad grade crossing crash.
“OccHour,” the hour of the day when a crash occurred, is the fourth most important causal factor for the severity of casualties associated with HRGC crashes. Figure 10 shows that the probability of fatal and serious injury crashes varies with the time of day, and is highest between 06:00 and 18:00. This is likely because of factors such as high volumes of commuter traffic, traffic jams/impatience, and sleepiness in the late afternoon. A high probability of fatal and serious injury crashes is observed between 18:00 and 23:00, which is likely because of factors such as low visibility, slower reaction time, and tiredness ( 54 ).
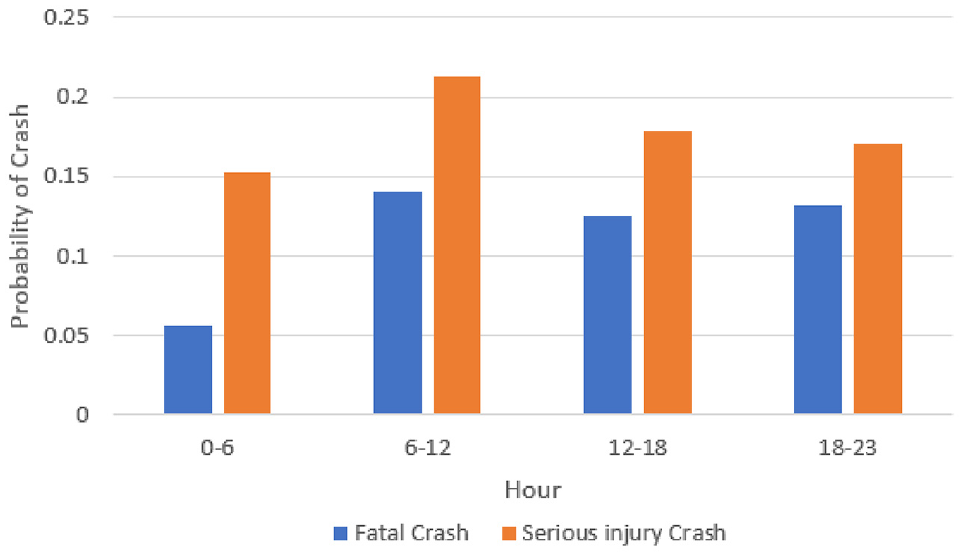
Effect of hour of the day on the probability of severe injury or fatality associated with a highway railroad grade crossing crash.
The fifth most influential causal factor is “VehicleTypeID,” which refers to the type of vehicle involved in the crash. Figure 11 shows the probability of a fatal crash is highest for motorcycles, followed by bicycles and automobiles, and the probability of a serious injury crash is highest for motorcycles, followed by heavy trucks and bicycles.
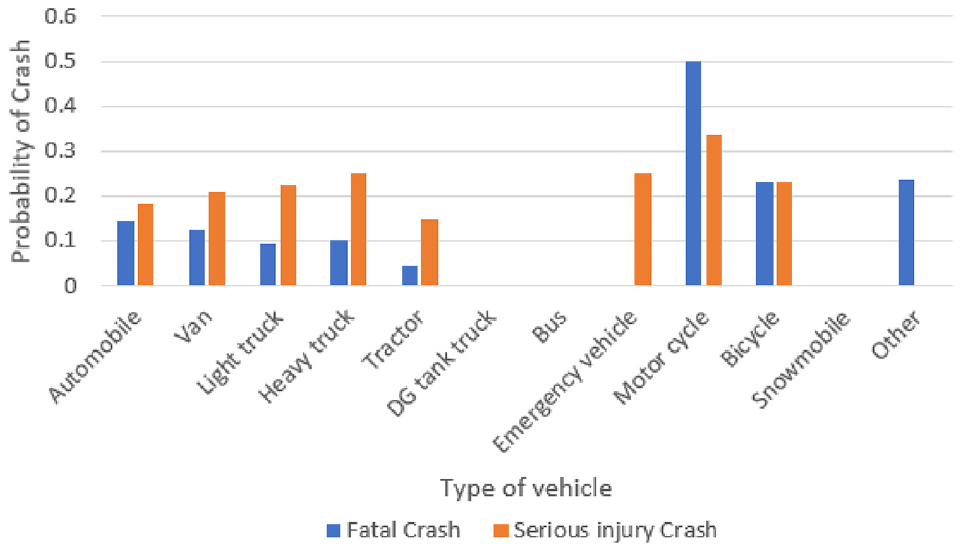
Effect of vehicle type on the probability of severe injury or fatality associated with a highway railroad grade crossing crash.
“RoadSpeed_KPH” is the sixth most important feature and refers to the maximum road speed at a HRGC. Figure 12 indicates that the probability of both fatal and serious injury crashes increases with maximum road speed.
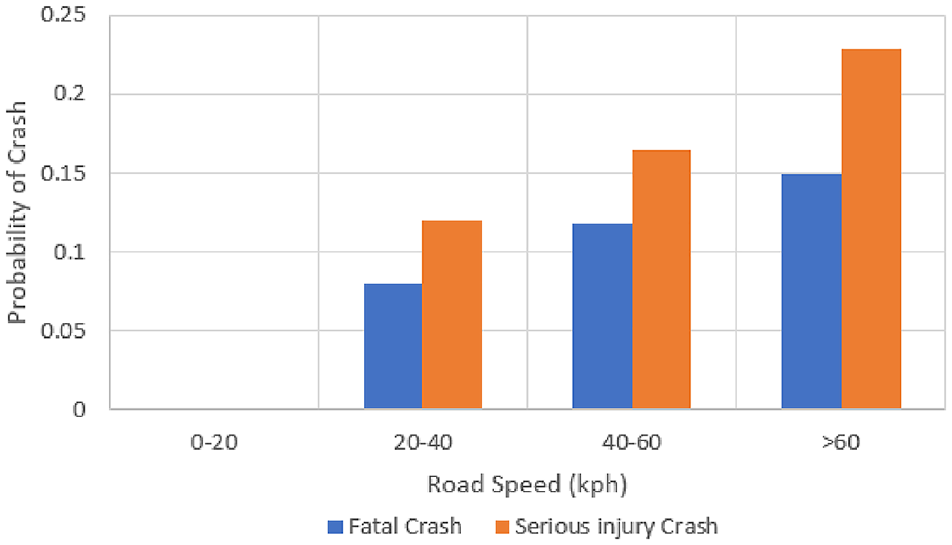
Effect of road speed on the probability of severe injury or fatality associated with a highway railroad grade crossing crash.
The seventh most important causal factor that affects the severity of casualties associated with HRGC crashes is “Season.”Table 8 shows that the highest number of fatal and serious injury crashes happens in winter conditions and the lowest number in the fall. Weather conditions such as low visibility, the presence of snow, and poor road conditions are contributing factors to high-severity crashes in the winter ( 55 ).
Effect of Season on the Severity of Casualties Associated with Highway Railroad Grade Crossing Crashes

Discussion of Hotspot Analysis Results
Figure 6 and Table 6 show major crash-prone clusters near major cities. The top three HRGC crash hotspot clusters are located near Winnipeg (cluster-1), Vancouver (cluster-2), and Edmonton (cluster-3), with 394, 354, and 232 HRGC crash hotspot locations, respectively.
The characteristics of cluster-1 were examined based on the HRGC features examined earlier (Feature Selection for HRGC Crash Data section). This assessment of cluster characteristics shows that of these HRGCs: (1) 50% were equipped with passive protection and 50% with active protection equipment; (2) 22% handle vehicle traffic volumes greater than 5000 vehicles per day; (3) 29% handle more than 10 trains per day; (4) 40% have a road speed of more than 60 km/h; (5) 20% have a train speed of more than 60 mph; (6) 21% have more than one track; and (7) 14% have more than two lanes. Targeting these features from the given analysis can help reduce the crashes at HRGCs in cluster-1.
Recommendations
The ML algorithms highlight how railway, highway, environmental, and human factors contribute to HRGC crashes and the severity of associated casualties. Important railway and road factors discussed above include maximum train speed, number of tracks, daily train volumes, lanes, maximum road speed, and traffic volume. Environmental factors such as season, hour of the day, and visibility also contribute to HRGC crashes and consequences. Human factors include intentional attempts to cross, distracted/confused drivers, visibility obstructions, fatigue, slip of memory/attention, cognitive and emotional distractions, and so forth ( 56 , 57 ).
Based on the results of this study, possible strategies to reduce HRGC crashes and related casualties are as follows.
Installing gates and automatic railway-controlled crossings can restrict vehicles from entering the tracks ( 58 ). Upgrading passive crossings to active crossings by installing flashing lights, bells, and gates can help to reduce HRGC crashes ( 12 ). In addition, installing four-quadrant and median barriers reduce the chances of crashes at HRGCs and reduce severity in the case of crashes ( 59 ). Table 9 shows the effects of crossing features on HRGC crashes and the severity of casualties.
Developing grade separations for crossings that handle high daily vehicle and train traffic is a good solution to reduce the risk of crashes between trains and vehicles ( 60 , 61 ). Grade separation showed a 100% decrease in injuries and fatalities ( 62 ).
Advanced warning devices can be implemented to address the effects of many highway lanes and tracks at HRGCs ( 53 ). Carroll and Warren ( 63 ) recommend an automated photo and video enforcement system to help investigate vehicle users’ compliance with existing warning infrastructure at HRGCs. This system has reduced HRGC-related violations by 34%–92%.
Reduction of train and vehicle speeds during their approach to high-risk HRGCs can reduce HRGC crashes and the severity of associated casualties ( 64 ).
Reduced lighting and/or hindrance to recognizing the incoming train are factors in HRGC crashes. Thus, installing a lighting source and clearing obstructions from the nearby area could reduce the risk of HRGC crashes ( 60 ). The provision of lighting sources at HRGCs resulted in a reduction of nighttime crashes by 52% ( 62 ).
Pavement strips/rumble strips near crossings are noticeable and effective in helping drivers recognize upcoming crossings ( 5 ).
Education through campaigns, for drivers and pedestrians, about traffic discipline and the consequences of HRGC crashes to individuals and the railway can be effective ( 56 ). Awareness campaigns have resulted in a 15% reduction in HRGC crashes and a 19% reduction in fatalities associated with HRGC crashes ( 62 ).
Effect of Crossing Features on Crossing Crashes and Fatalities ( 62 )
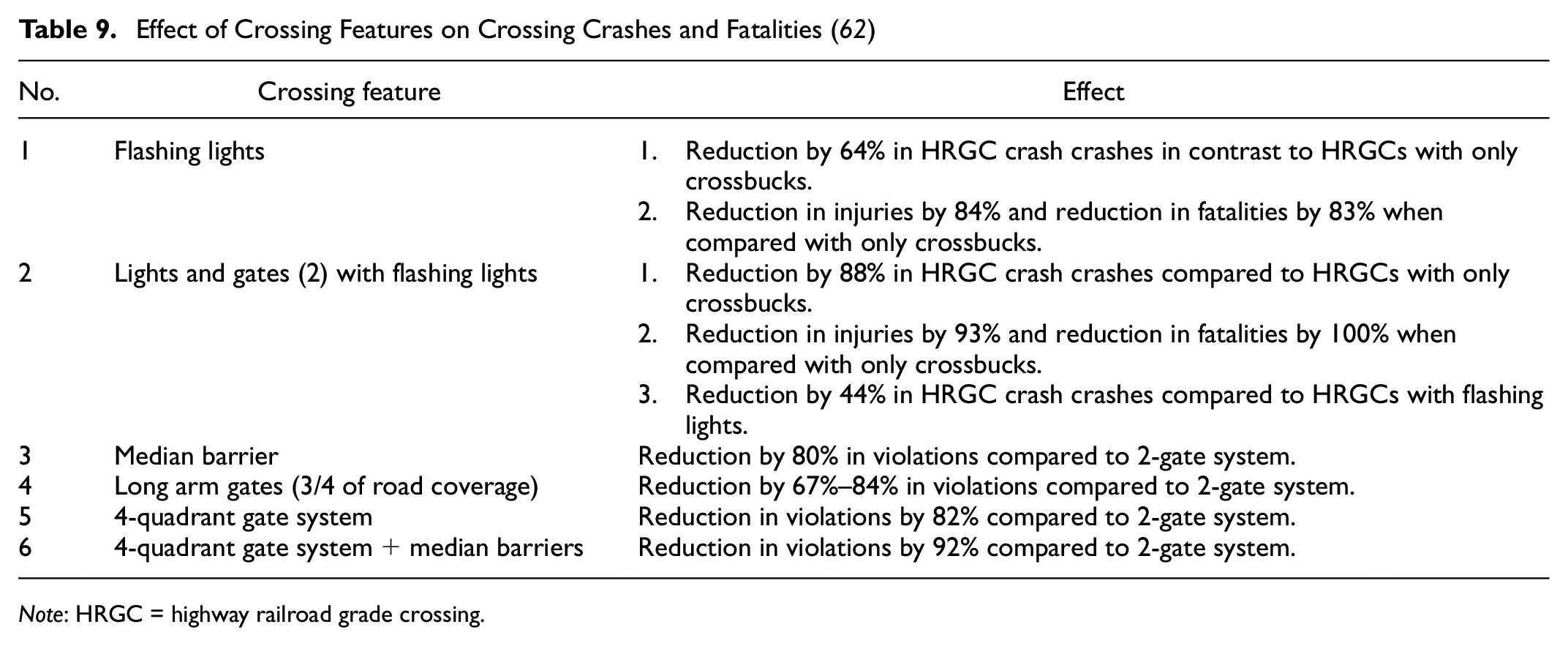
Note: HRGC = highway railroad grade crossing.
Conclusion
HRGCs are regarded as high-risk areas on railway networks because of the catastrophic consequences that can result from HRGC crashes. Thus, transportation authorities place a great focus on safety at HRGCs. This study identified the major causal factors for HRGC crashes and the severity of casualties associated with HRGC crashes in Canada. The results indicate that high train traffic, high vehicle traffic, high highway speed, and high track speed are major factors that contribute to HRGC crashes, while occurrence hour, type of vehicle, high train traffic, high vehicle traffic, high highway speed, and high train speed are major factors that contribute to the severity of casualties associated with HRGC crashes. The use of ensemble classification ML models has provided better prediction results and managed to handle the complex relationship among the variables used for modeling. The ML models help predict HRGC crashes and the associated severity of casualties by employing supervised ML algorithms. These supervised ML models are handy tools for authorities to interpret the data and re-apply using updated data whenever required in the future. The causes identified in this research match with the same study identified in the introduction section. In addition, optimized hotspot analysis using ArcGIS software recognized the spatial patterns of HRGC crashes in Canada’s rail network. Identifying such HRGC crash hotspot locations will allow authorities to target high-risk crash-prone areas of the railway network. Using these findings of high-risk HRGC locations, authorities can assess high-risk HRGC locations, as each HRGC is unique. Subsequently, the authorities will assess the suitability of these recommendations and make informed decisions with respect to the implementation of which recommendation for improving the safety of HRGCs.
The findings of this research can benefit authorities and policymakers concerning decision-making, allocating resources, and implementing countermeasures to reduce the number of HRGC crashes and the severity of associated casualties in Canada’s rail network. The study provided a range of recommendations to enhance HRGC safety; choosing the most suitable recommendation requires careful consideration. Implementing these recommendations necessitates a separate study that assesses the various available options and identifies the most effective approach to reducing risks at HRGCs and improving safety. This could potentially serve as a topic for future research.
However, this study is not without limitations. The source datasets used for this research had many empty features because of poor reporting, and thus were excluded from the datasets used in the analysis. As such, the analysis may not have identified all causal factors for HRGC crashes and the severity of associated casualties. Furthermore, the classification model datasets did not consider human-related features, such as driver experience, state (physical/mental), and gender. Thus, future research should investigate the role of human factors in HRGC crashes and the severity of associated casualties to provide more insight and help improve the safety of HRGCs in the rail network. The HRGC study carried out in this research is specific to the Canadian railway network. The ML models and spatial correlation techniques relied on data pertaining to the Canadian railway network. Therefore, the models in this study are intrinsically tied to the dataset. If a similar study were to be conducted using data from different railway networks, it would be necessary to retrain the models with a new dataset to accurately represent the characteristics of those specific railway networks.
Footnotes
Authors Contributions
The authors confirm contribution to the paper as follows: study conception and design: P. Rana, F. Sattari, L. Lefsrud, M. Hendry; data collection: P. Rana, F. Sattari, L. Lefsrud, M. Hendry; analysis and interpretation of results: P. Rana, F. Sattari, L. Lefsrud, M. Hendry; draft manuscript preparation: P. Rana. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Funding for this study has been provided through the Canadian Rail Research Laboratory at the University of Alberta with funding provided by Transport Canada (T8009-210202), the National Research Council of Canada (989894) and the National Sciences and Engineering Research Council of Canada (IRCPJ 544435).
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.