
Abstract
In this paper, we examine the practical problem of minimizing the delay in traffic networks that are controlled at each intersection independently, without a centralized supervisory computer and with limited communication bandwidth. We find that existing learning algorithms have lackluster performance or are too computationally complex to be implemented in the field. Instead, we introduce a simple yet efficient and effective approach using multi-agent reinforcement learning (MARL) that applies the Deep Q-Network (DQN) learning algorithm in a fully decentralized setting. First, we decouple the DQN into per-intersection Q-networks and then transmit the output of each Q-network’s hidden layer to its intersection neighbors. We show that our method is computationally efficient compared with other MARL methods, with minimal additional overhead compared with a naive isolated learning approach with no communication. This property enables our method to be implemented in real-world scenarios with less computation power. Finally, we conduct experiments for both synthetic and real-world scenarios and show that our method achieves better performance in minimizing intersection delay than other methods.
Keywords
Urbanization and population growth pose a significant challenge to modern urban traffic networks. While the number of vehicles on the road increases, road capacity stays the same, resulting in growing congestion in densely populated areas. This places a heavy burden on society with respect to waste of fuel and time, greenhouse gas emissions, and other factors ( 1 ). Road network infrastructure modifications help and can provide better accessibility, but they are commonly limited by land use. The expansion of road networks also induces higher emissions, imposing a heavier burden on the environment and potentially being harmful to public health ( 2 ). Traffic signal control (TSC) systems aim to maximize the utility of existing networks by managing traffic-light timing plans to improve intersection efficiency, for example by reducing traffic delay time.
Fixed-Time, Actuated, and Adaptive Control
TSCs have been studied for more than half a century and can be categorized into three domains: fixed-time control ( 3 ), actuated control ( 4 ), and adaptive TSC (ATSC) ( 5 , 6 ). Fixed-time controls collect historical traffic demand profiles, compute and assign right-of-way (ROW) and green light to phases that consist of movements (turnings), and apply timing plans without online modifications. Some of them, such as MAXBAND ( 7 ) and MULTIBAND ( 8 ), optimize bidirectional green-wave bandwidths with mixed-integer linear programming (MILP), while others minimize system delay according to macroscopic delay-estimation models, such as TRANSYT ( 9 ).
Actuated controls ( 4 ) set timing constraints using techniques similar to those used for fixed-time controls but have the ability to skip phases or extend phase durations online based on detector readings. Pedestrians can be be incorporated into actuated control schemes by pushing a button, thus affecting the priorities. Actuated control also enables Transit Signal Priority (TSP) control ( 10 ), which benefits the operation of public transits.
Adaptive methods are the third type of approach, focusing on dynamically adjusting timing plans according to real-time sensed traffic conditions to be more adaptive to traffic fluctuations. This is presently the most popular type of approach in TSC research. Well-established examples include model-based optimization methods such as SCOOT ( 11 ), SCATS ( 12 ), and SURTRAC ( 13 ), which have been broadly deployed across the world. These methods rely highly on the precision of their pre-calibrated traffic models. More recently, reinforcement learning (RL) as a data-driven approach has received attention from traffic researchers, in part because of its astonishing achievements in playing games ( 14 ). Model-free deep RL has been applied to ATSC problems using deep neural networks (DNNs) as function approximators to handle more complex decisions and input features ( 15 , 16 ). ATSCs also facilitate an integrated approach to the design of TSP ( 17 ), where the optimization of travel time allows giving priority to the service provided to public transit vehicles.
Levels of Control
Network control can be carried out at several levels: centralized, hierarchical, and fully decentralized. Centralized methods (e.g., SCOOT) have a single global controller, which sends control decisions down to individual intersections. It is typically assumed that centralized controllers have access to the state of each controlled intersection. Hierarchical methods (e.g., SCATS) divide the control decisions into a hierarchy, with levels of control spanning from the network-wide level down to the intersection level; some of the control decisions are made by higher-level controllers, and some are left to lower-level controllers. In SCATS, the high-level controller coordinates agents by offsets and provides timing plan constraints, while low-level controllers determine exact time splits similar to actuated controllers. In fully decentralized methods (e.g., SURTRAC, MARLIN [ 5 ]), each intersection is controlled independently of the others, although the intersections may have access to some part (or even all) of the global state.
As the size of the controlled network increases, the number of possible system configurations and control actions grows combinatorially fast, and centralized controllers quickly fall under the curse of dimensionality. This is further exacerbated by practical requirements of sparse communication, as well as other computational constraints.
Because they often carry out the training and execution stages separately, RL methods can design agents to couple in different forms at different stages. Decentralized agents that make decisions locally can thereby be trained with more (even global) information. This approach is referred to as “centralized training and decentralized execution” (CTDE). In Wei et al. ( 18 ), Oroojlooy et al. ( 19 ), and Devailly et al. ( 20 ), Graph Attention Networks (GATs) were used to encode one-hop regional information in each layer by using their characteristic of parameter sharing.
However, the CTDE framework requires a risky assumption. The training process is solely completed offline, and no more policy updates will be done after deployment. Policies learned with model-free RL are often not robust against an issue called “distributional shift,” meaning that the deployment environment behaves and shows dynamics that are different from the training environment. Specifically, in the context of TSCs, distributional shift has two possible causes: differences in system dynamics between traffic simulators and the real world, and in patterns between the training demand profiles and the actual demands. The work ( 21 ) has shown that model-free RL may not generalize well if traffic demand patterns shift considerably from the training demand. It suggests that keeping policies updated with data reflecting real dynamics after in-field deployment is desired. Compared with CTDE, methods that do not require centralized training support distributed online policy updates without relying on expensive centralized communication infrastructure. Therefore, in this work, we develop a fully decentralized control method.
Related Works
Our method is a fully decentralized controller in which an intersection communicates with its one-hop neighborhood. SURTRAC is one of the decentralized controllers with one-hop information sharing that uses model-based optimization methods. SURTRAC enhances agents’ coordination by sharing an intersection’s recently released flow profile data (tens of seconds) to reveal incoming demands flowing toward neighbors. To our knowledge, there are only a few RL-based ATSC that fit into our category. MARLIN and its variants ( 5 , 22 ) coordinate agents by sharing their local full observation and actions with immediate neighbors. To stabilize learning, each agent in MARLIN also maintains a set of policy estimators for its neighbors, which significantly increases the complexity of such a type of approach. In addition, some other fully decentralized approaches enhance the capability of ATSC by augmenting the sensing ability. Zhou et al. ( 23 ) introduces an edge computing enabled approach that utilizes Internet of vehicle (IoV) data in a efficient way. On the other hand, Wang et al. ( 24 ) enriches decentralized agents’ observation with a generative adversarial network to complement the global state.
Proposed Method
We propose an embedding communicated multi-agent reinforcement learning for integrated network of ATSC algorithm (eMARLIN). We design our agents with two modules: an encoder and an executor. Each agent’s encoder encodes the corresponding raw observation into a latent space, which we name the “observation embedding.” Agents then broadcast their own embedding to one-hop neighbors rather than the raw observation, collect and concatenate embedding vectors from neighbors, and feed them as the input of the executor. The executor plays the role of Q-network, estimates the Q-value of each candidate action, and makes decisions. Each agent trains its encoder together with its executor by the Deep Q-Network (DQN) algorithm in an end-to-end manner. In such an approach, the encoder is regulated by the gradient from the downstream task in which neighbors’ embedding is mixed in. Therefore, the embedding in eMARLIN has the advantage of not only being a compact representation of the raw observation, but also containing extra implicit information granted by the special design of the training loop. The agent executor treats the embedding shared from neighbors as constant inputs, and will not affect their encoders, which reduces the stress on both the communication and computation system. Compared with MARLIN, the method that is the most related to our work, the proposed eMARLIN retains a high efficiency in coordination while requiring fewer computation resources.
We evaluate the proposed method and compare its performance to other baselines in simulation environments, including both synthetic and real-world scenarios. As the base case, we compare with not only fixed-time plans as broadly used in related works but also a set of semi-actuated control plans ( 4 ) based on the standard dual-ring NEMA scheme that is working in the field in North York, Toronto, Canada. Empirical results show that our approach achieves better performance across scenarios while exhibiting a faster convergence speed and stabler multi-agent learning.
We summarize this paper’s contributions as follows:
We model the problem of distributed ATSC with a restriction on agent-level communication power that better describes the real-world implementable scenarios.
We propose a lightweight learning algorithm for the distributed ATSC problem, with unique agent design that conserves the communication bandwidth by compressing and sharing necessary information across only one-hop neighbors.
We provide experiments and comparisons for several baselines, on both synthetic networks and a real-world test bed, validating and showing the effectiveness and efficiency of our algorithm.
Preliminaries
Markov Decision Processes and RL
The Markov Decision Process (MDP) is a widely adopted approach for modeling sequential decision-making processes in discrete time. In this practice, the controlling agent observes the environment and subsequently makes decisions on how to act within it (
25
). An infinite-horizon MDP is a tuple
A policy
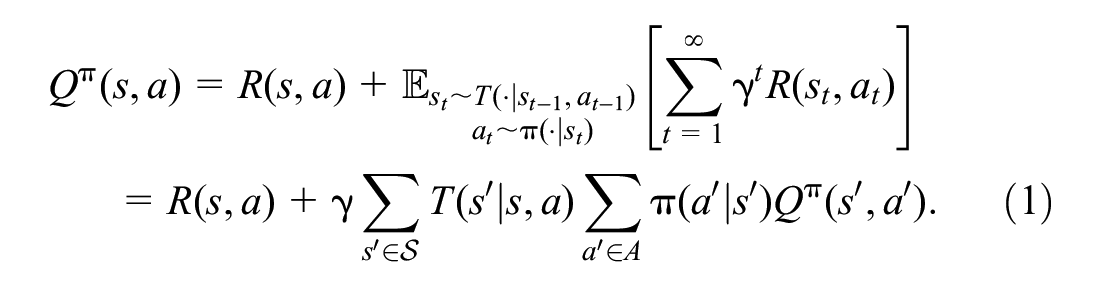
If the system model
Among model-free RL methods, value-based approaches such as Q-learning try to find the optimal policy by fitting the Q-function with temporal difference (TD) learning (that during each training iteration perturbs the Q-function toward the one-step bootstrapped estimation that is identified by the Bellman function):
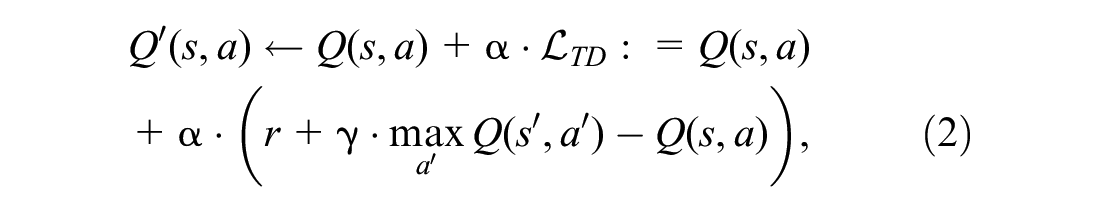
where
After learning is finished, the agent’s policy at state
Coordinated ATSC as Decentralized MDP and the Relaxation
An MDP can also describe a system with multiple intersections. The complexity of solving an MDP grows exponentially with the scale of the system. Modeling the traffic network as a whole and training a single centralized RL agent is intractable for large-scale networks. For simplifying the representation, we assume that the joint of intersections’ local observation can describe the full system dynamics, that is, the system is fully observable. Therefore, we formalize the multi-agent ATSC problem as decentralized MDPs (Dec-MDPs). Dec-MDP extends the MDP to represent the scenarios where multiple agents in a single system take control of different system components. Agents act jointly and influence the system synchronously, such that agents are coupled. A Dec-MDP is defined as a tuple
Solving Dec-MDPs has been proven to be NEXP complete (
27
). We have to relax the problem and decouple it into multiple MDPs, each of which is only P complete (
28
). The problem turns into a stochastic game, where each of the group of agents control a single intersection and learns its own policy. As we stated in the Introduction, limited by the one-hop communication constraint, agent
Methodology
We address the ATSC problem over a network of
Modeling
The number of queued vehicles (number of vehicles driving below a predefined threshold speed) in each lane within the sensors’ detection range. The number of vehicles in each lane within the sensors’ detection range. The index of the current phase. The elapsed duration of the current phase, with respect to the proportion to the minimum/maximum allowed green time.
The full state of the problem then can be viewed as a factored space composed of all local observations
EXTEND the current phase at intersection CHANGE the phase at intersection
The permitted phase transitions are determined by the agent’s current phase. For example, if from a certain phase the agent can choose to change to one of two possible phases, then there will be three actions from that phase (extend current phase, change to first possible phase, or change to second possible phase).
We call a phasing scheme in which the set of permitted phase transitions depends on the source phase a “constrained variable phasing scheme” (CVPS). A CVPS may alternatively be defined by a directed graph with no multiple edges or self-edges, where the vertices of the graph are identified with the phases, and there is a directed edge between two vertices if and only if the corresponding phase transition is permitted.
If arbitrary phase transitions are permitted (i.e., all phases except the current phase are permitted as the next phase), we obtain the variable phasing scheme (VPS) as a special case of CVPS. If from every phase there is only one possible transition, we call this a “FPS,” which is a special case where the phase order is fixed and, in practice, the agent only controls the duration of each phase. The corresponding graph of a VPS is the complete directed graph, and that of an FPS is a directed cycle.
In the ATSC literature, VPS is a common phasing scheme choice ( 15 , 29 ). However, with VPS, there is a danger that one or more turning movements of the intersection is starved of green time, that is, does not get served any green time in a cycle. In this work, we use phasing schemes that are not allowed to skip any major movements in a cycle. Please see the Experiments section for more detailed descriptions.
Following standard practice, phase durations are subject to minimum and maximum time constraints. When the phase time is less than the minimum time, the agent only has the EXTEND action available; when the phase time is equal to the maximum time, the agent only has the CHANGE actions available. Once the agent selects a CHANGE action, the traffic light undergoes a yellow phase followed by a red phase, during both of which EXTEND is the only action available to the agent.
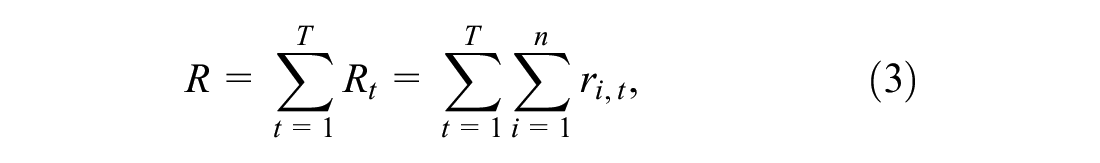
which is equal to the total number of time steps all vehicles have been stopped in the system.
Solution Approach
Our approach utilizes deep reinforcement learning tools, specifically DQN (
30
). We denote our method as eMARLIN. An illustrating figure of the method on a one-dimensional scenario is given in Figure 1. Each agent trains its own Q-network. The output is the Q-value of the actions, and the inputs of the network are the observation
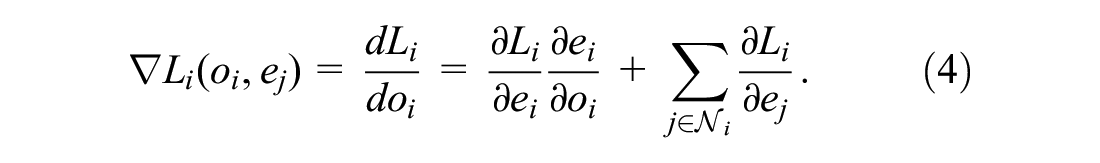
That is, the neighbors embedding are treated as constant inputs so they affect the Q-values (decisions and loss). Thus, the executor learns to consider them, but the embedding of a neighboring agent
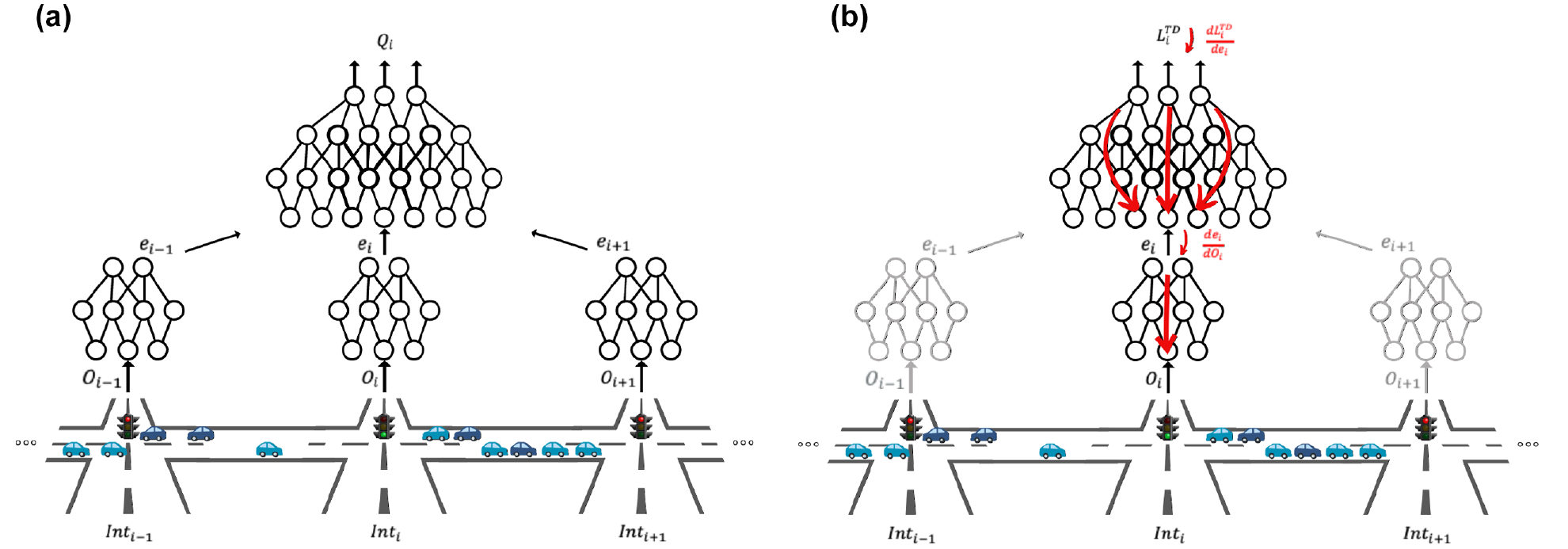
Forward and backward passes of the eMARLIN Q-network from the perspective of the ith intersection. The mappings
Approach Motivation
A simple scenario motivated our work. It is possible that at a specific time, two intersections, one in the middle of the network and one close to the border, may obtain the same set of self and neighbors observations. Yet, it is clear their roles in the larger scheme are different. They are affected differently by what happens in the network and have different impacts on congestion. So, it is clear some information is missing in the raw observation of the network’s topology and the intersections’ role. The proposed learned embedding approach was meant to capture at least part of that information and use it for decision making. Furthermore, we considered the following properties during the design of our method:
Learning stability and reliability—fast convergence rate with consistent results.
Architectural simplicity—minimal amount of concurrently learning components, which affect each other’s performances.
Scalability—in both the number of intersections and the complexity of the phasing scheme (the cardinality of the action space).
Computational and communication lightness—not posing too heavy a burden on the communication network and lighter amount of computation than existing methods, allowing for lighter controllers that cannot handle multiple large neural networks.
Experiments
Here, we perform empirical experiments to test our method. We evaluate our method on two types of scenarios, synthetic and real world, each with unique properties, both in simulation. We compare our results to several baselines and state-of-the-art methods in the field and show the validity of our approach. All experiments are conducted on a server equipped with an AMD Ryzen 3990X CPU and 256 GB RAM.
Test Scenarios
Synthetic Grid Networks
We build synthetic grid networks of different scales in the Simulation of Urban MObility (SUMO) simulator ( 31 ). All intersections in the grid networks are signalized and controlled by external agents. Each of them have four single-lane approaches, four straight movements (no left, right, or U turns), and two phases (NS-through, EW-through). Each of the intersections uses a FPS (the single permitted phase transition is to the other phase). All approaches are classified as major approaches. The intersections are 300–1,500 m away from each other, depending on the specific scenario, as shown in Figure 2. All source and sink sections are 1,000 m long. The traffic demand is generated randomly with a time-varying probability on each of the source sections. The probability of spawning a vehicle per second on each of the source sections is sampled every 20 s from approach-dependent Gaussian distributions, as shown in Table 1. In all synthetic scenarios, horizontal origin–destination pairs are treated as corridors and are assigned higher demand compared with the vertical ones. The U.S. Department of Transportation Federal Highway Administration suggests a common range of saturation flow rate of 1,500–2,000 vehicles per hour per lane ( 32 ). Therefore, our synthetic networks cover a variety of traffic volume settings. We also test different algorithms on a time-varying environment, which is the Toronto network that covers light to medium traffic in a 4 h demand profile, to be discussed below.

Illustration of synthetic grid networks modeled in Simulation of Urban MObility (SUMO): (a) Benchmark 0, 1 × 2; (b) Benchmark 1, 1 × 3; (c) Benchmark 2, 2 × 4; and (d) Benchmark 3, 4 × 5.
Synthetic Grid Network Traffic Demands
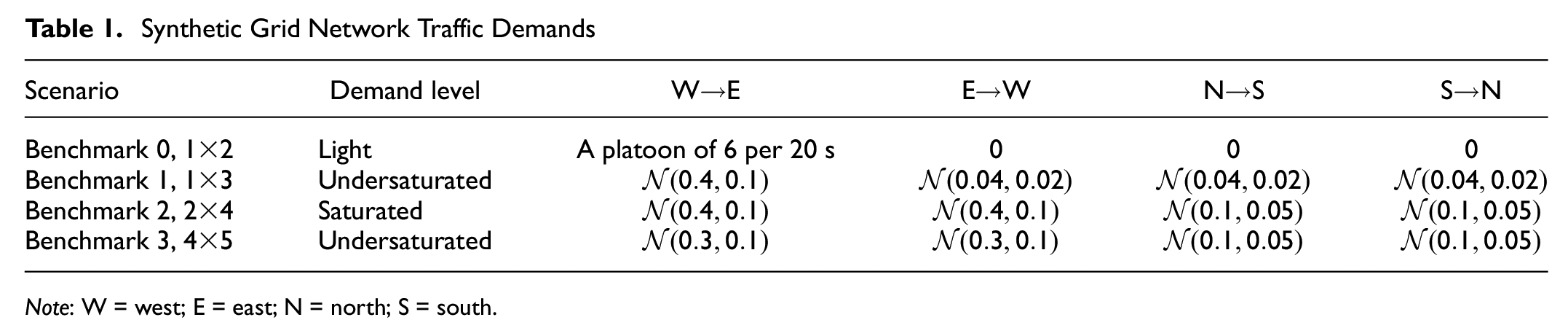
Note: W = west; E = east; N = north; S = south.
Toronto Network
We model a neighborhood of the intersection of Yonge Street and Steeles Avenue in Toronto, Canada, in the Aimsun simulator ( 33 ) (Figure 3). The network geometry is manually traced from a reference satellite image in the UTM-17 coordinate system. The modeled neighborhood consists of eight signalized intersections: Yonge–Steeles is an intersection of two major arterials, while the remaining seven intersections are intersections of a major arterial and a minor road. The distances between the signalized intersections vary between approximately 150 and 450 m.
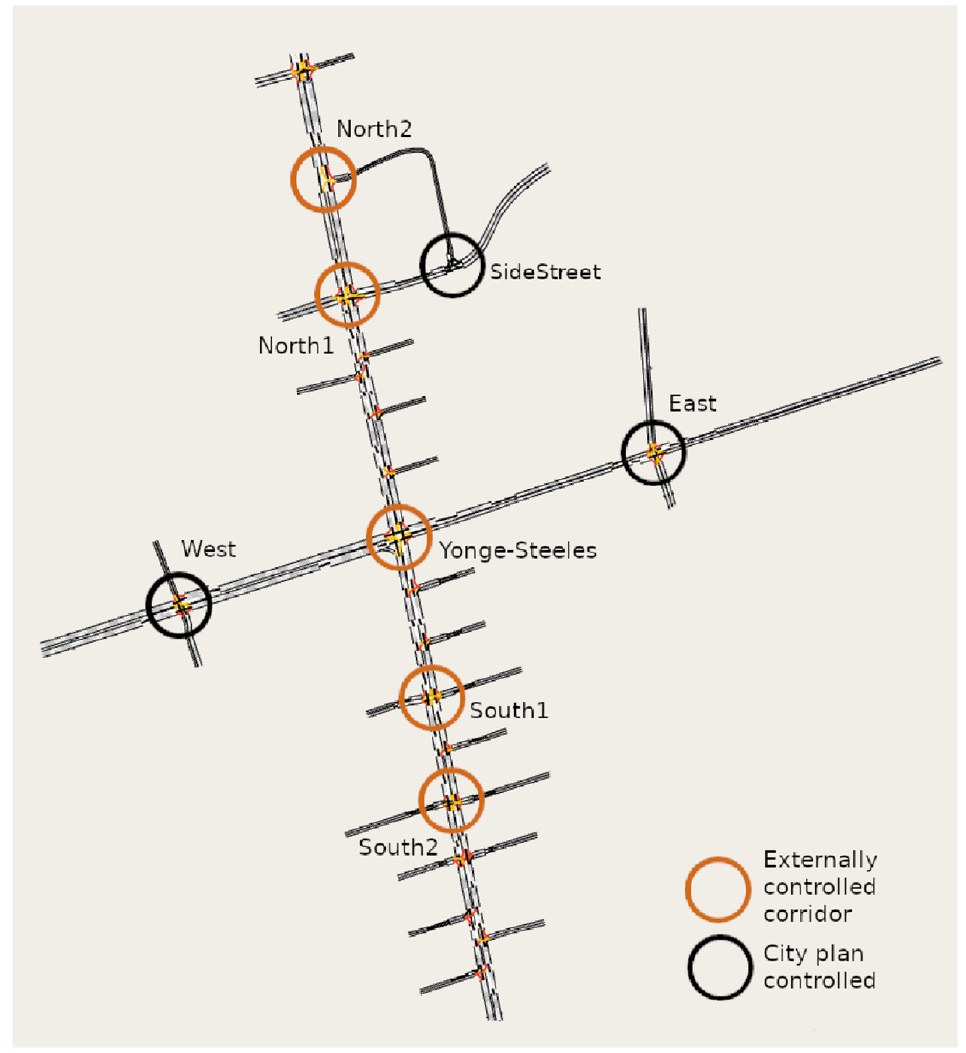
The Toronto network, with the signalized intersections circled and labeled.
The city signal timing plans (obtained from the city of Toronto) follow the standard NEMA phasing diagram, with semi-actuated control ( 4 ). The major through phases have a fixed duration and cannot be skipped, while the minor through phases and all phases that include a protected left turn are callable and extendable by loop detectors.
When evaluating eMARLIN, five intersections along Yonge Street (a north–south direction corridor) are controlled by external agents, and the remaining three intersections follow the city signal timing plans (Figure 4). The phasing scheme of the external agents is a CVPS, with a phase transition permitted in the phasing scheme if and only if the phase transition is possible under the city plan. This ensures a fair comparison of the RL controllers with the city plan.
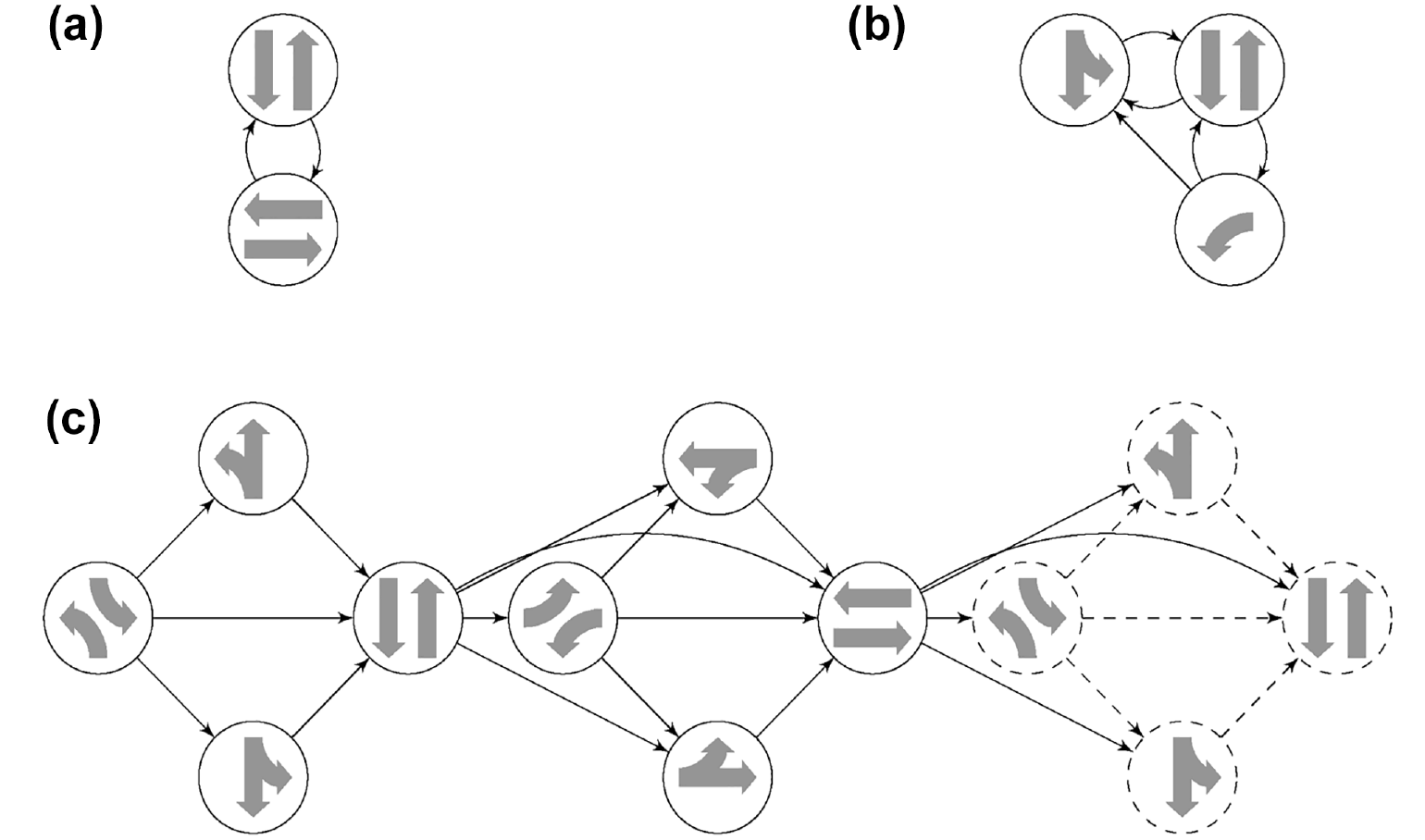
Constrained variable phasing schemes used in the test scenarios. Although not indicated in the figures, left turns are always permitted on through movements (when present), and right turns are always permitted (when present): (a) phasing scheme used for the synthetic grid networks, (b) phasing scheme used for the North2 intersection, which is a three-legged major-minor intersection, and (c) phasing scheme used for the Yonge–Steeles intersection. The leftmost four phases are duplicated on the right (the dashed nodes) to make the graph drawing clearer. The phasing scheme used for the remaining intersections (North1, South1, and South2) is similar, except the transitions from the North–South through phase to the other three North–South phases become permitted (North–South being the major and East–West the minor direction at these intersections, the East–West phases may be skipped by the controller).
The scenario traffic demand spans the morning peak period of 6–10 a.m. The demand is calibrated in several steps. First, the results of the 2016 Transportation Tomorrow Survey (TTS) ( 34 ) (origin–destination matrices between traffic analysis zones) are used to create the demand of a larger hybrid mesoscopic-microscopic model of the Greater Toronto and Hamilton Area (GTHA). The TTS traffic analysis zones that intersect our smaller subnetwork are kept as origins and destinations, each incoming link into the subnetwork gets assigned a new origin, and each outgoing link gets assigned a new destination. The incoming vehicle origin–destination pairs are accumulated in 15 min intervals from a simulation of the larger GTHA network. Then, the resulting origin–destination counts are adjusted using the techniques described in Aimsun ( 33 ) (“Integrating Macro, Meso, Micro, and Hybrid Simulations” tutorial), using turning movement counts at the subnetwork intersections (which are publicly available from the city of Toronto, accumulated in 15 min intervals). The turning movement counts of the final calibrated demand are a good fit to the city turning movement counts; the linear regression coefficient of determination (R2) is equal to 0.933.
Compared Baselines
We compare the proposed method to the following baselines (see also Figures 5 and 6):
City plan (Toronto network only): a standard NEMA phasing diagram with semi-actuated control activated ( 4 ).
MaxPressure ( 35 ): a decentralized heuristic method that greedily assigns right of way to the phase with the highest pressure.
PressLight ( 36 ): a decentralized DRL method that learns to minimize intersection pressure to balance queues in a traffic network.
Independent DQN (iDQN) ( 30 ): separate DQN agents for each of the controlled intersections without parameter sharing or any form of observation sharing.
iDQN-shareObs: iDQN agents taking one-hop neighbors’ observation as additional inputs.
Deep MARLIN ( 22 ): the DRL variant of MARLIN.
Note that different agents may operate on different state spaces. Specifically, iDQN-shareObs, Deep MARLIN, and eMARLIN consider the combination of the local observation space and all neighboring observation spaces as the state space for an agent. Conversely, Max-pressure defines the state space as the queue counts on all incoming and outgoing lanes. Additionally, PressLight defines the state space as the traffic status on all partitioned incoming and outgoing lanes, without any limitations with regard to detection ranges. We reproduce PressLight according to the description in the original paper. It uses the a variation of the pressure metric (based on vehicle counts rather than queued vehicle counts) as reward function.
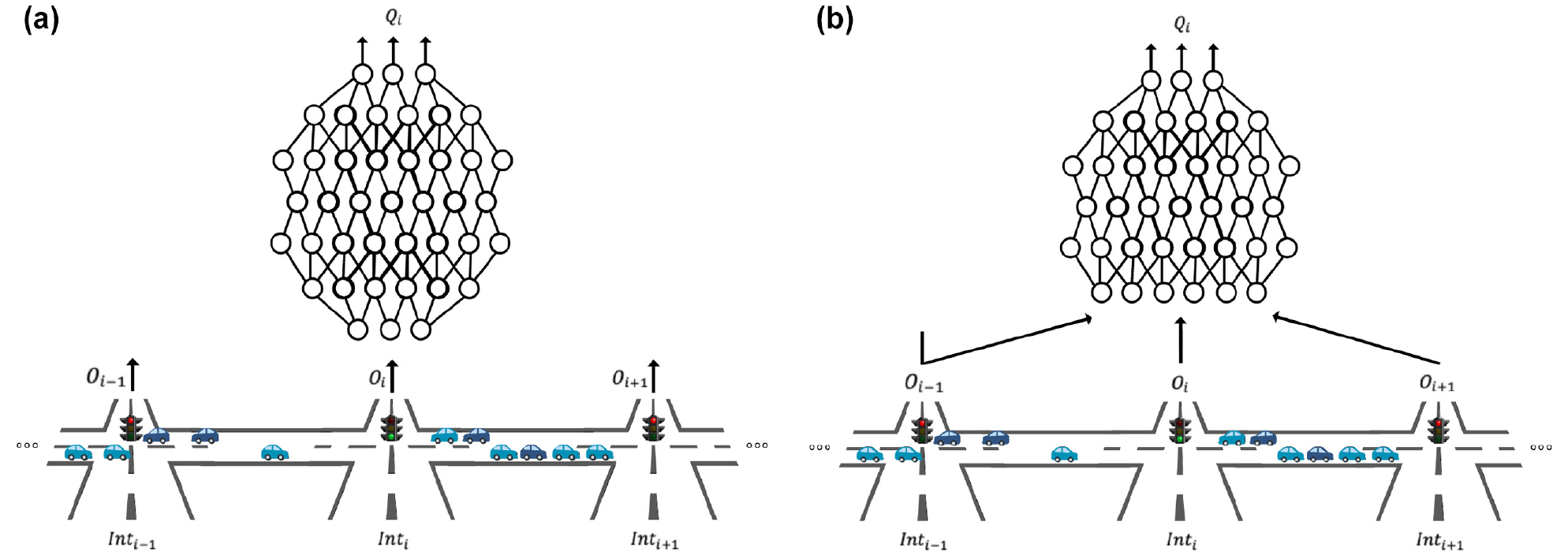
Forward pass for independent Deep Q-Network (iDQN) and iDQN-shareObs from the perspective of the
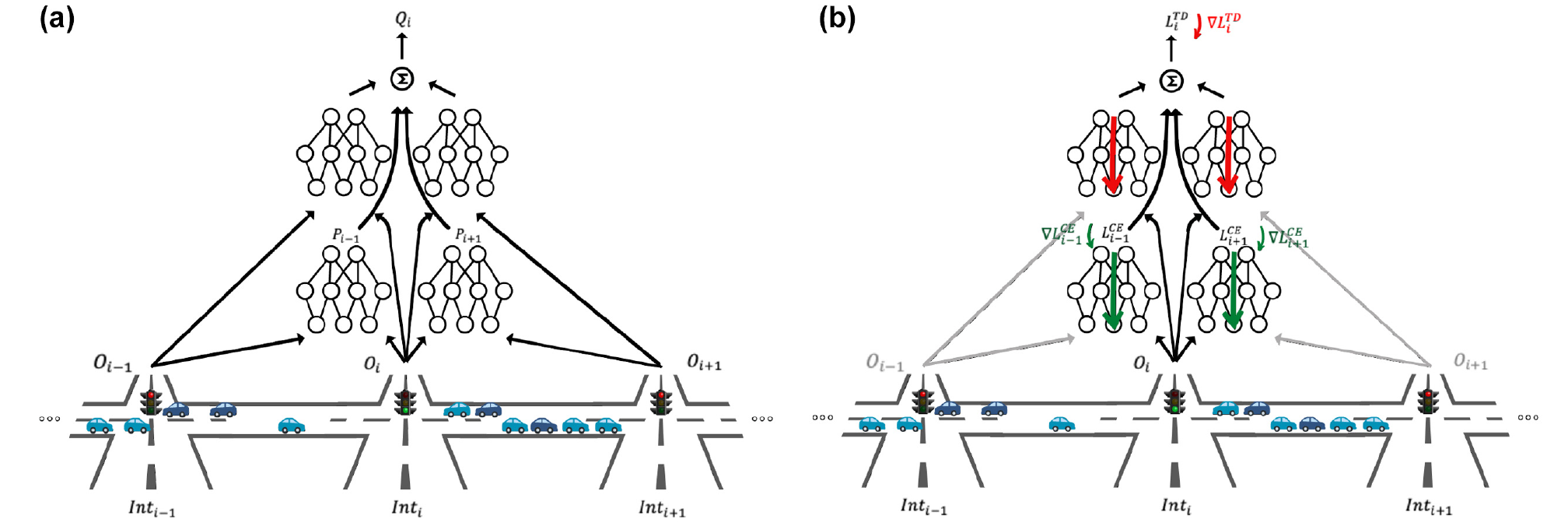
Forward and backward passes for Deep-MARLIN from the perspective of the
Evaluation Metrics
We evaluate the algorithm performance with a few metrics:
Episodic total delay (stopped time): the total time vehicles driving below the threshold speed (2 m/s) within all controlled intersections’ detection range (300 m).
Episodic average delay (AD): the average delay (stopped time) over all vehicles that have finished their trips.
Episodic average travel time (ATT): the average travel time over all vehicles that have finished their trips.
Training time: the world-clock time spent for finishing certain steps of training.
Neural Network Configuration
The observations are normalized before being input into a neural network. Vehicle counts (both queue and total counts on each lane) are normalized by passing them through the
Neural Network Configurations for Reinforcement Learning Algorithms
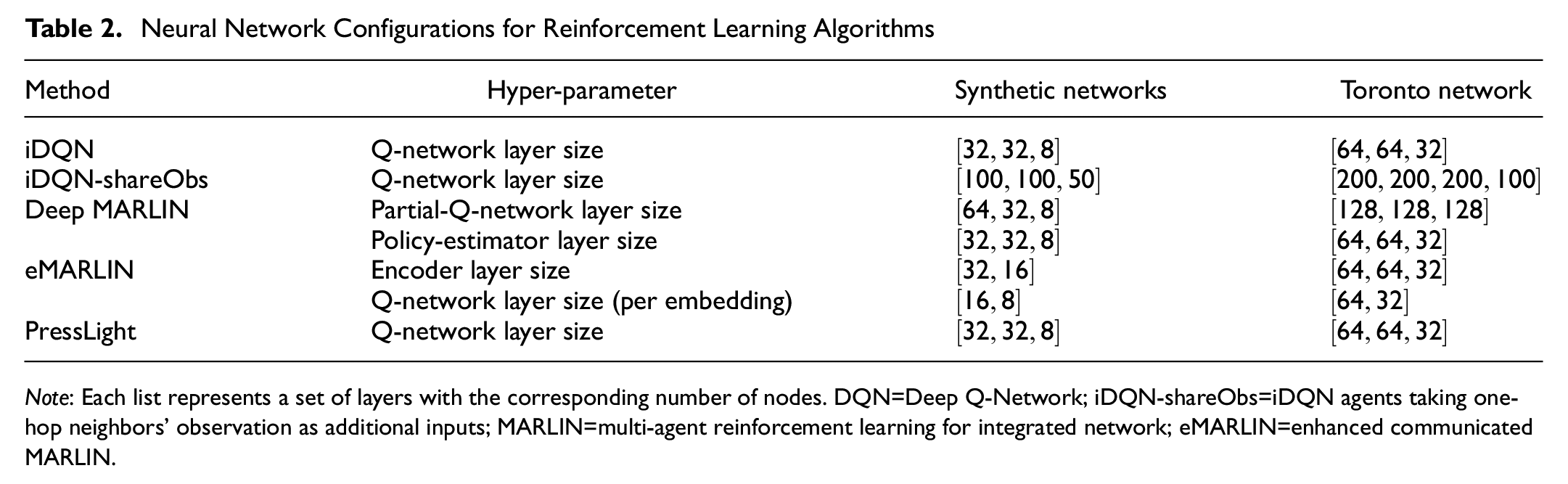
Note: Each list represents a set of layers with the corresponding number of nodes. DQN=Deep Q-Network; iDQN-shareObs=iDQN agents taking one-hop neighbors’ observation as additional inputs; MARLIN=multi-agent reinforcement learning for integrated network; eMARLIN=enhanced communicated MARLIN.
Results
Synthetic Grid Networks
With synthetic grid networks, we evaluate the coordination capability and the scalability of the proposed method. The results are shown in Table 3. We assign synthetic benchmark environments with high traffic volume to examine the capability of long-term planning. For a fair comparison across different experiments, we fix the seed for sampling vehicle-spawning probabilities during the evaluation stage. The proposed eMARLIN outperforms the iDQN consistently over scenarios with different scales under different demand levels, which indicates the positive effect of the information propagation mechanism. On the other hand, eMARLIN gives competitive results compared with deep MARLIN while having a lighter structure and lower computational requirements, as indicated by the running time of finishing
Performance Comparison of all Methods on Synthetic Grid Networks
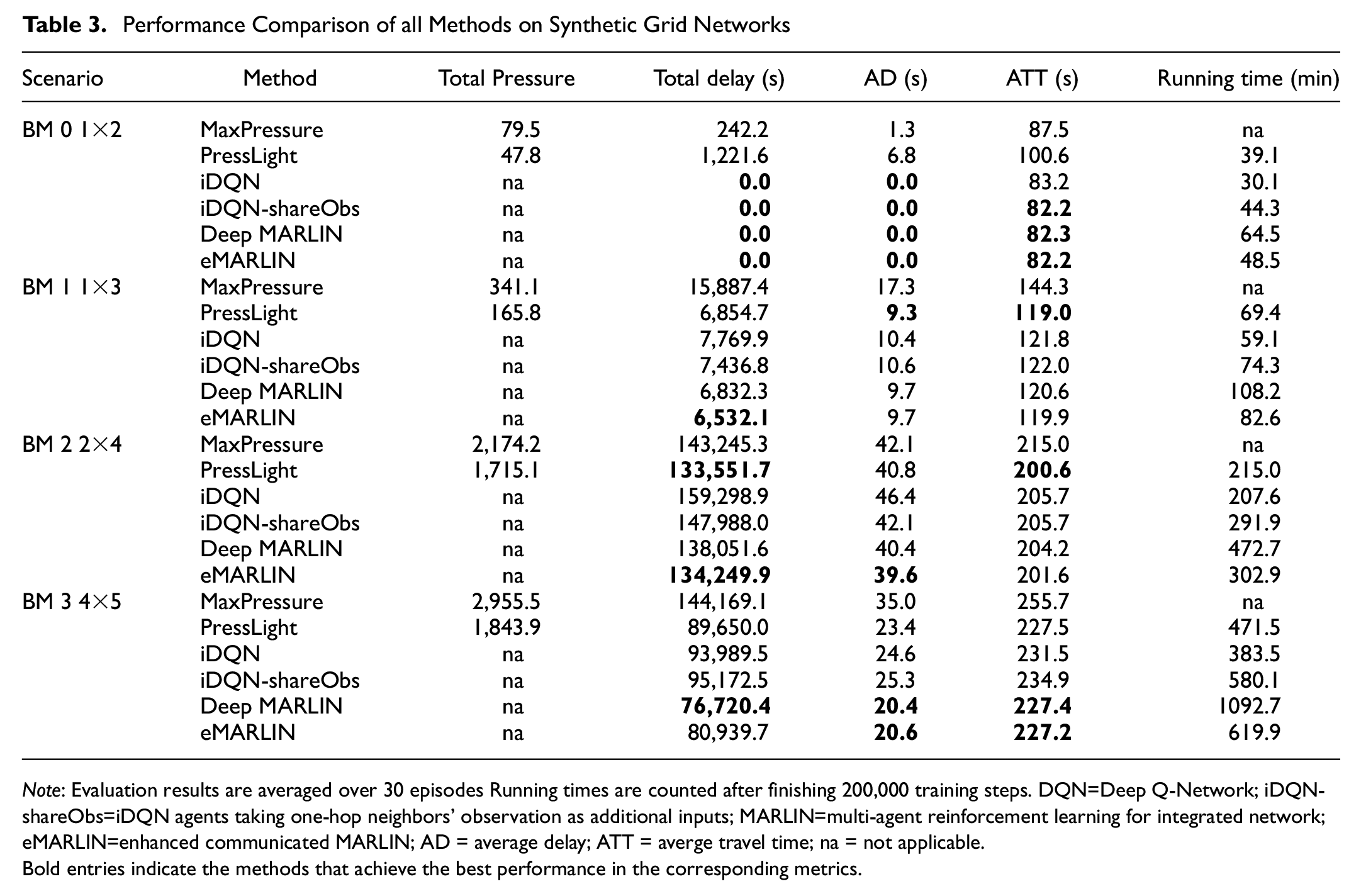
Note: Evaluation results are averaged over 30 episodes Running times are counted after finishing 200,000 training steps. DQN=Deep Q-Network; iDQN-shareObs=iDQN agents taking one-hop neighbors’ observation as additional inputs; MARLIN=multi-agent reinforcement learning for integrated network; eMARLIN=enhanced communicated MARLIN; AD = average delay; ATT = averge travel time; na = not applicable.
Bold entries indicate the methods that achieve the best performance in the corresponding metrics.
As for pressure-based methods, there is a clear trend in the results. PressLight works better under heavy traffic demand but suffers in light scenarios. Specifically, in benchmark
Toronto Network
Table 4 summarizes the experiment results under a realistic environment, the Toronto network. It shows that eMARLIN outperforms all baseline methods by a visible margin:
Performance Comparison on the Toronto Test Bed.
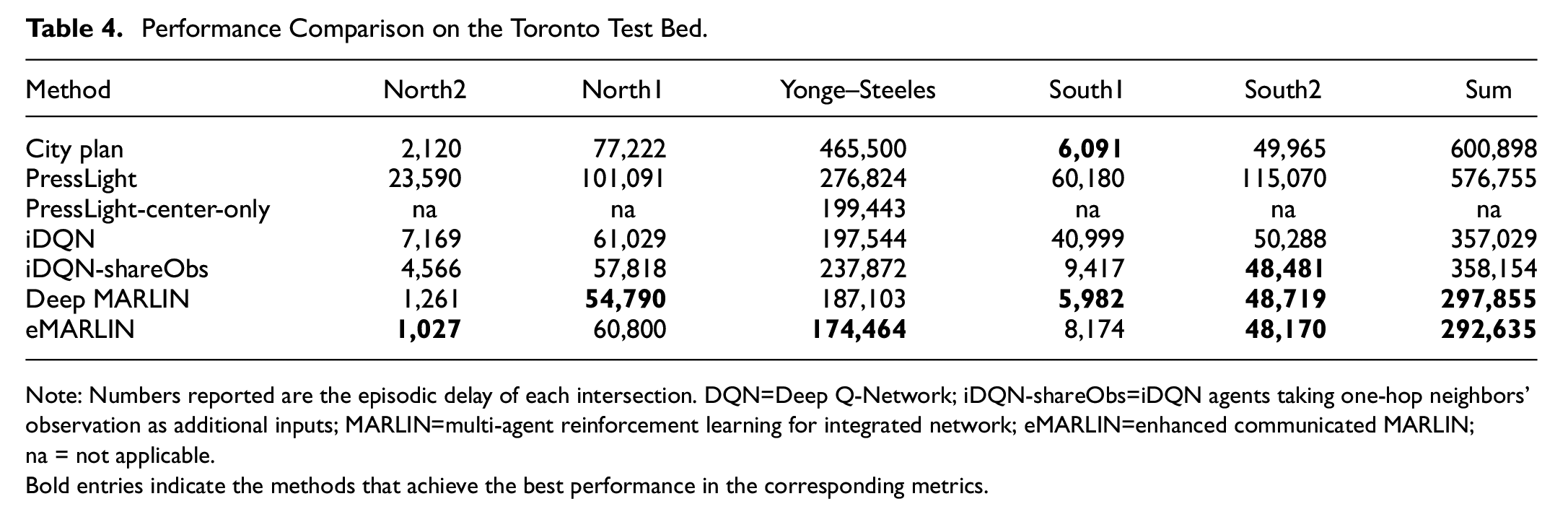
Note: Numbers reported are the episodic delay of each intersection. DQN=Deep Q-Network; iDQN-shareObs=iDQN agents taking one-hop neighbors’ observation as additional inputs; MARLIN=multi-agent reinforcement learning for integrated network; eMARLIN=enhanced communicated MARLIN; na = not applicable.
Bold entries indicate the methods that achieve the best performance in the corresponding metrics.
The max-pressure policy is not tested under the Toronto network, since it requires greedy change to the phase with the largest pressure, which implies a VPS phasing scheme. Following NEMA constraints, we adhere to the CVPS phasing scheme. Thus, the comparison of max-pressure to the other controllers is incompatible.
Although PressLight agents converge on the pressure reward, since the pressure is not always positively correlated with other traffic metrics, as we have shown in the previous result discussion, PressLight fails to learn a proper policy on the Toronto network, which has a light-to-medium volume and time-varying demand profile. In particular, PressLight performs significantly worse than the city plan at the four peripheral intersections, since there are light but dominating north-/southbound flows, which are similar to benchmark
Last, we present the TD loss of all approaches as a measure of learning stability and the convergence rate in Figure 7. The results are given for BM1 and BM2 as representative scenarios, where all methods showed the ability to cope and learn meaningful policies. Results are presented consistently for the most central intersection only. As expected, iDQN as an isolated method learns fast, but the loss is not stable. iDQN-shareObs is able to learn something useful, but once again, the heavy architecture results in a slow learning rate. Deep-MARLIN, the heaviest of them all, requires the policy to stabilize before the Q part can converge and exhibits the slowest learning. eMARLIN performs as desired. It learns fast, and the TD loss is quite stable at a low value.
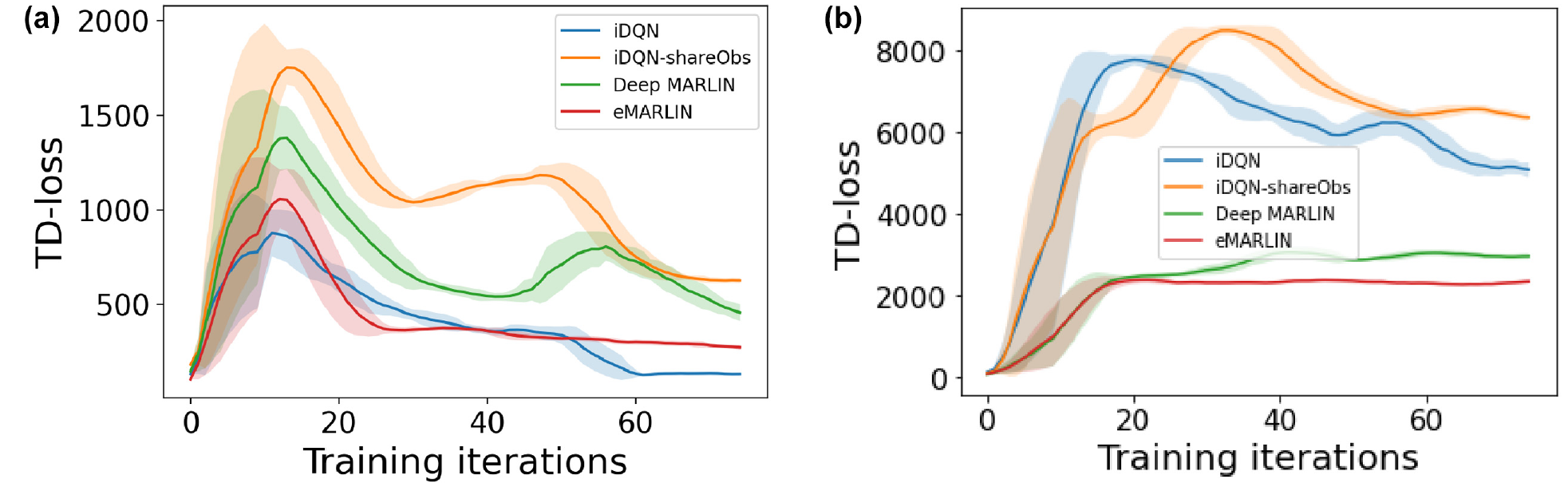
Illustration of the training progress of different methods with respect to the temporal difference (TD) losses: (a) Benchmark 1 TD loss and (b) Benchmark 2 TD loss.
Discussion and Conclusion
We have addressed the problem of reducing traffic delays in urban traffic networks. A decentralized learning method has been presented based on the DQN algorithm in a multi-agent reinforcement learning setting. Our method decouples the Q-network into two components: encoder and executor. Intersections encode their local raw observations into an embedding latent space, with corresponding encoders, and then share this embedding with their one-hop neighbors. The intersections’ executors play the role of Q-networks, taking self and neighbors’ embedding as input and making decisions. Encoders are jointly trained with executors within each private intersection such that no gradient back-propagation across agents is required. Such a strategy ensures the minimum communication bandwidth requirement after deployment, while maintaining the capability of conducting policy updates online. Empirical experiments demonstrate the strong performance and learning stability of the proposed method compared with related decentralized learning algorithms. Future studies should investigate the information transferred within the embedding, and whether information of longer than one-hop distance is being propagated by the embedding.
Footnotes
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: Xiaoyu Wang, Ayal Taitler, Ilia Smirnov, Scott Sanner, and Baher Abdulhai; data collection: Ilia Smirnov; analysis and interpretation of results: Xiaoyu Wang; draft manuscript preparation: Xiaoyu Wang, Ayal Taitler, and Ilia Smirnov. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.