
Abstract
Over the last decade, there has been rising interest in automated driving systems and adaptive cruise control (ACC). Controllers based on reinforcement learning (RL) are particularly promising for autonomous driving, being able to optimize a combination of criteria such as efficiency, stability, and comfort. However, RL-based controllers typically offer no safety guarantees. In this paper, we propose SECRM (the Safe, Efficient, and Comfortable RL-based car-following Model) for autonomous car-following that balances traffic efficiency maximization and jerk minimization, subject to a hard analytic safety constraint on acceleration. The acceleration constraint is derived from the criterion that the follower vehicle must have sufficient headway to be able to avoid a crash if the leader vehicle brakes suddenly. We critique safety criteria based on the time-to-collision (TTC) threshold (commonly used for RL controllers), and confirm in simulator experiments that a representative previous TTC-threshold-based RL autonomous-vehicle controller may crash (in both training and testing). In contrast, we verify that our controller SECRM is safe, in training scenarios with a wide range of leader behaviors, and in both regular-driving and emergency-braking test scenarios. We find that SECRM compares favorably in efficiency, comfort, and speed-following to both classical (non-learned) car-following controllers (intelligent driver model, Shladover, Gipps) and a representative RL-based car-following controller.
Keywords
Autonomous driving started to come to reality with the development of sensors and artificial intelligence (AI). One of the main advantages of autonomous vehicles (AVs) is their ability to overcome the inherent system randomness in human driving behavior that creates instability in the traffic system ( 1 ) resulting in traffic jams ( 2 ). Furthermore, AVs could potentially learn to outperform human driving in safety, efficiency (tight headways), and comfort (low jerk) ( 3 ).
A car-following controller is the component of an AV system that sets the longitudinal (within-lane) acceleration of a vehicle. Achieving safe, efficient, and comfortable car-following is crucial in autonomous driving. In traffic flow theory, classic car-following models (CFMs) are based on physical knowledge and human driving behaviors. Several standard CFMs have been developed to mimic human driving behavior. For example, the Gipps model ( 4 ) imitates human driving by considering both speed-following mode (without leading vehicle) and leader-following mode (with the leading vehicle) and takes the smaller of the two velocities as the target to decide whether to apply acceleration or deceleration. The target speed is also affected by some safety constraints ( 4 ). Another example is the intelligent driver model (IDM) ( 5 ), in which the applied acceleration depends on the desired velocity, desired headway, relative velocity, and true headway.
Recently, different applications that depend on deep learning (DL)/deep neural networks (DNNs) have outperformed human experts in different fields, motivating many researchers to adopt these methods in the area of AVs ( 3 , 6–8). The deep reinforcement learning (DRL) technique is the use of reinforcement learning (RL) with DNNs to learn the optimization of certain metrics such as safety, efficiency, and comfort in autonomous driving. The model interacts with the controlled environment and learns from experience to optimize the given set of metrics (formalized as a reward signal). Isele et al. ( 9 ) utilized DRL to optimize lane-changing maneuvers. In Isele et al. ( 9 ), Gong et al. ( 10 ), and Zhou et al. ( 11 ), DRL is applied to optimize safety and efficiency. Only a few research papers tried to design a safe, efficient, and comfortable car-following model using DRL ( 3 , 12–14).
There are some limitations that have not been considered by the previously mentioned DRL-based CFMs. First, all the existing DRL-based CFMs design their optimal behavior (e.g., desired headway) using real-life data sets such as the HighD data set ( 15 ), NGSIM data ( 16 ), and data from Shanghai Naturalistic Driving Study ( 17 ). That results in a model that tries to mimic human driver behavior which is not the optimal driving behavior; that is, these models have no potential to produce better-than-human performance. Second, all the existing DRL-based CFMs neglect to train and test on some common but safety-critical driving scenarios where the leader suddenly decelerates to a complete stop, and which may result in a collision. Third, DRL CFMs often focus on car-following mode, ignore speed-following mode, or do not offer a seamless switch between car-following mode and speed-following mode when the leader is no longer present ( 3 , 14 ). According to Treiber and Kesting ( 1 ), a complete car-following model must be able to seamlessly deal with such different situations as driving in free traffic, following the leader in both stationary and non-stationary situations, emergency situations when full braking is required, and approaching slow traffic caused by congestion or red traffic lights. Fourth, most of the existing DRL-based CFMs depend on time-to-collision (TTC) as a metric for safety. However, according to Vogel ( 18 ), following TTC-based safety criteria cannot guarantee safety and can lead to very dangerous situations and accidents in some cases. Fifth, generalization is missing in most of the existing DRL-based CFMs. In Packer et al. ( 19 ), generalization is defined as the ability of the model to preserve a good performance in different environments even if these environments were not seen before. Training and testing of RL models are often done in the same environment with the same parameters, which can lead to overfitting. The work ( 20 ) conducted a performance comparison between DRL and model predictive control for adaptive cruise control (ACC); DRL showed very good performance until the researchers conducted an out-of-distribution validation, where it was found that a substantial degradation in performance happened.
To overcome the limitations and fill in the mentioned gaps in literature, in this paper we propose a complete autonomous driving DRL-based car-following model that:
- Optimizes efficiency (unlike some previous RL CFMs partly based on human driving data), while preserving safe and comfortable driving behavior;
- Can handle all driving scenarios, such as speed-following scenarios (with different speed limits) as well as leader-following driving scenarios (normal driving with different speed limits and leader emergency-braking scenarios);
- Uses a newly designed reward function that depends on the proximity of the vehicle’s speed to the maximal safe speed for safety, efficiency, and speed-following, and the vehicle’s jerk for comfort;
- Uses a randomized environment during training to help improve generalizability to various car-following scenarios, such as regular driving with different speed limits, sudden speed change in emergency braking, and speed-following with different speed limits.
This paper is structured as follows. In the “Methods” section, we begin by briefly defining the RL problem and its formalization in finding an optimal policy for a Markov decision process (MDP). Then, we discuss adding safety constraints to an RL agent and provide a brief description of the area of safe RL. We then formulate a hard safety constraint that will be used for our agent and justify using a worst-case-based safety criterion instead of a TTC-threshold-based safety criterion for the constraint. Following this, we formally introduce the observations, actions, and rewards of SECRM (the Safe, Efficient, and Comfortable RL-based car-following Model), the training algorithm (deep deterministic policy gradient [DDPG]), and our training and evaluation scenarios. In the “Results” section, we describe experimental results obtained in the five evaluation scenarios (two regular-driving scenarios, two emergency-braking scenarios, and one speed-following scenario). We conclude by discussing several aspects of our agent.
Methods
Notation and Conventions
In this paper, we propose a controller for the longitudinal (within-lane) acceleration of AVs. We call the controlled vehicle the follower vehicle F, and the vehicle immediately in front of the follower vehicle (if such a vehicle exists) the leader vehicle L. The velocity of the follower is denoted by
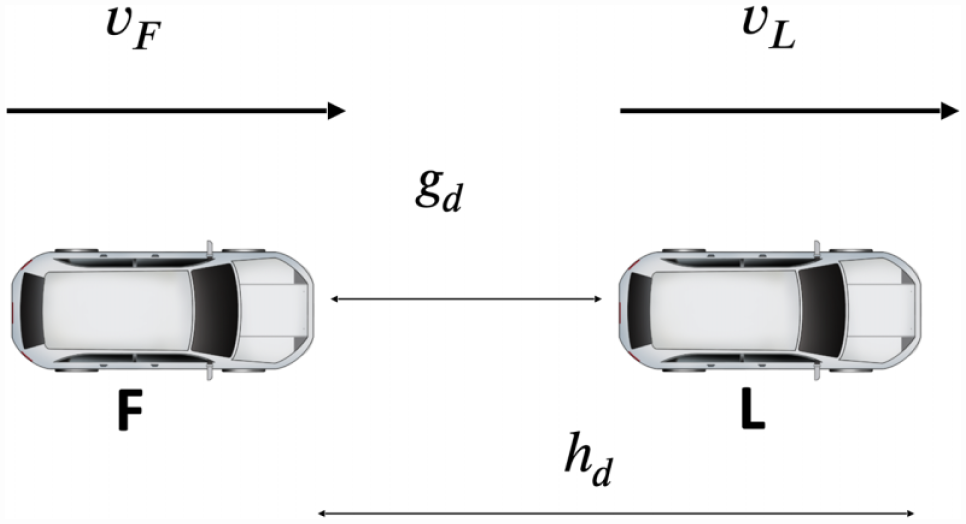
The distance gap
The time gap between the follower and the leader is defined as
We denote the speed limits of the road section that the follower and (if it exists) the leader is driving on by
By a follower–leader configuration (with respect to fixed parameters
We use
Reinforcement Learning and Markov Decision Processes
RL is a subfield of machine learning that studies methods for training intelligent controllers (agents) using reward signals obtained by the agent’s interaction with its environment ( 21 ). The agent’s decision-making process is frequently formalized in the concept of an MDP (or a variant, for example partially observable MDP [ 22 ] and constrained MDP [CMDP] [ 23 ]).
An (infinite-horizon) MDP is a five-tuple
The agent iteratively interacts with the environment, at time t starting at state
A policy
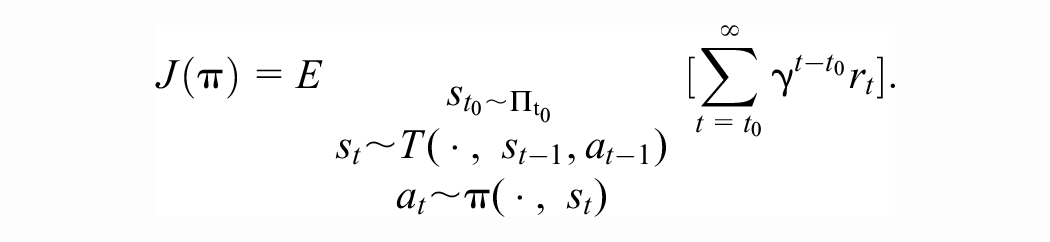
Multiple algorithms are known for approaching the RL problem. For example, classical algorithms include dynamic programming, Monte Carlo methods and Q-learning, and more recent deep RL algorithms include deep Q-learning (DQN) ( 24 ), DDPG ( 25 ), proximal policy optimization (PPO) ( 26 ), and soft actor-critic ( 27 ). Classical algorithms are theoretically relatively well understood (with proven convergence properties) but can have difficulties in scaling to larger problems (with a richer state representation and more complex actions). In recent years, there has been success in using neural networks as function approximators for representing the policy function and other auxiliary objects involved in RL algorithms (such as the state value function, and the state-action value function); collectively, the resulting new family of algorithms is known as deep RL (DRL). DRL algorithms are less well understood theoretically but often offer gains in performance over RL. In this paper, we use the DDPG algorithm, which is a deep RL algorithm. We choose DDPG because of its sample-efficiency (being an off-policy algorithm), and for easier comparison with previous RL CFMs, many of which (for example, Zhu et al. [ 3 ], Shi et al. [ 14 ], Lin et al. [ 28 ]) use DDPG. We provide more description of DDPG below, in the “Training” section.
Safe RL and the Worst-Case Action Bound
Safety of Previous RL Car-Following Controllers
In general, RL car-following controllers rely on reward alone for safety. Typically, the reward is a linear combination of several terms including safety, efficiency, comfort, speed-following, energy consumption, and so forth, with one of the terms in the reward function being a safety reward. The safety term is often either a large penalty (negative reward) for a crash (or a very small gap) in training ( 28 ), or a large penalty whenever the follower has a low TTC with respect to the leader ( 3 , 14 ). In either case, for agents trained using reward alone, the satisfaction of safety constraints is not guaranteed. One reason for this is that RL agents see only a finite part of the observation space in training; even a well-trained agent may find itself in a part of the observation space in testing that was not sufficiently well explored in training. Despite having some capacity for generalization, agents can fail in such situations. In support of the claim that reward alone may not be sufficient for satisfying safety constraints, as described in the “Experiments” section, we found that RL CFMs whose safety relies on reward alone (and that learn not to crash in training) may collide when the leader vehicle starts decelerating suddenly (i.e., in an emergency-braking scenario).
Because safety is paramount for autonomous driving systems, we find it necessary to place additional restrictions on an RL car-following controller to guarantee safety.
Safe RL
The question of how to impose safety criteria on RL agents gives rise to a subfield of reinforcement learning called safe RL. A wide variety of approaches to safe RL have been proposed. Please see for example Gu et al. ( 29 ) or Brunke et al. ( 30 ) for surveys of the field.
We find that we can formulate our safety constraint in the relatively simple form of an explicit analytic state-dependent acceleration upper bound
Therefore, we can avoid the complications of passing to a framework such as CMDPs and algorithms appropriate to it, as is frequently required in safe RL, and instead directly modify the formulation of our basic MDP, placing an upper bound on the acceleration of the controlled vehicle, so that the set of actions at state
Worst-Case Safety Criterion
In this paragraph, we formulate the hard constraint on our controller’s actions.
We adopt the following criterion to distinguish between safe and unsafe follower–leader configurations: (Worst-case criterion) A follower–leader configuration is safe if and only if, in the event the leader brakes with maximal deceleration
Based on the above criterion, we define the unsafe region as the set of gaps that are unsafe (the gap is not large enough for the follower to be able to stop), and the safe region as the set of gaps that are safe. The maximal safe speed is the highest follower speed in the following time step such that the follower does not cross into the unsafe region.
The worst-case criterion for safe driving is not new, appearing in multiple prior works, such as Gipps ( 4 ) and the General Motors (GM) model ( 31 ). It is the safety criterion adopted in the Vienna Convention on Road Traffic ( 32 ). We provide a justification for our preference for the worst-case criterion over another common safety criterion, based on a TTC threshold, later in the text. Note that although our model uses worst-case scenario for safety like the above-mentioned models, it is not an RL replica of the prior models, as our model includes other criteria such as concurrently balancing traffic efficiency (minimizing headways) and comfort (minimizing jerk), as will be discussed later in the text as well.
Derivation of the Maximal Safe Speed
Although our derivation of the maximal safe speed is based on similar principles to the well-known Gipps and GM models ( 4 , 31 ), for completeness and the convenience of the reader, we include the derivation details here.
Our goal is to find an upper bound for
We begin by deriving a criterion for a safe gap, assuming that
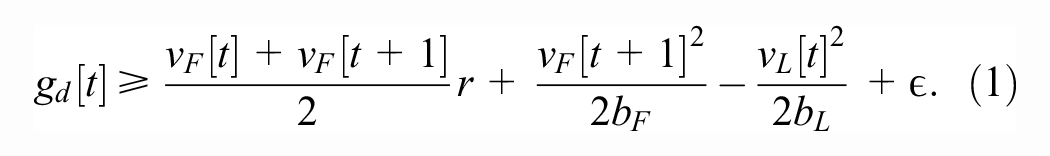
Next, assuming all quantities at time t (including the gap
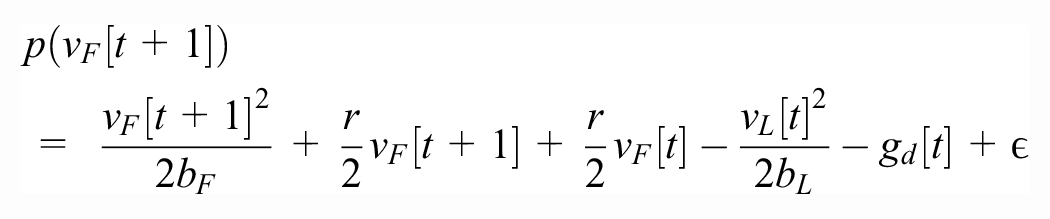
(please see Figure 2). Using the quadratic formula, we find that the maximal safe speed is given by
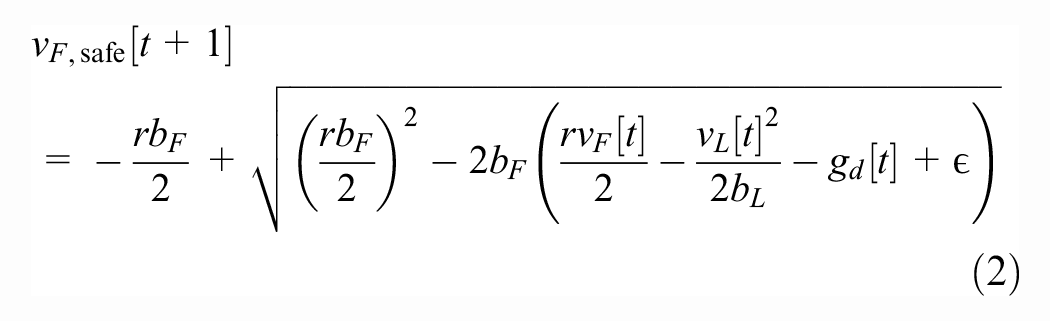
Please see Figures 3 and 4 for two heatmaps of the value of
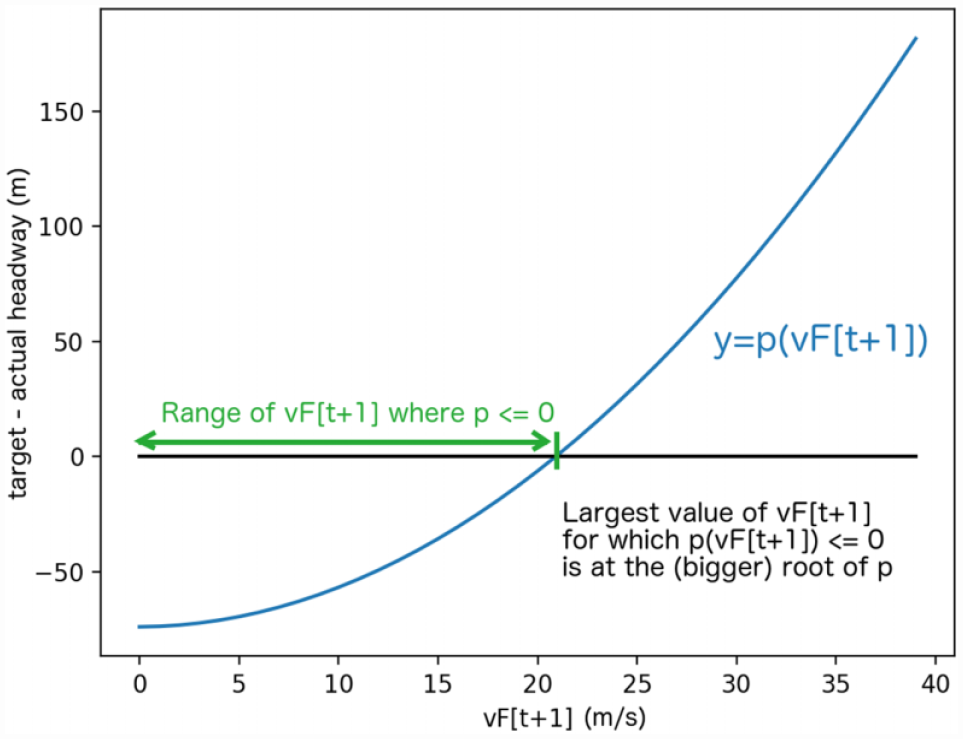
Deriving the maximal safe next speed
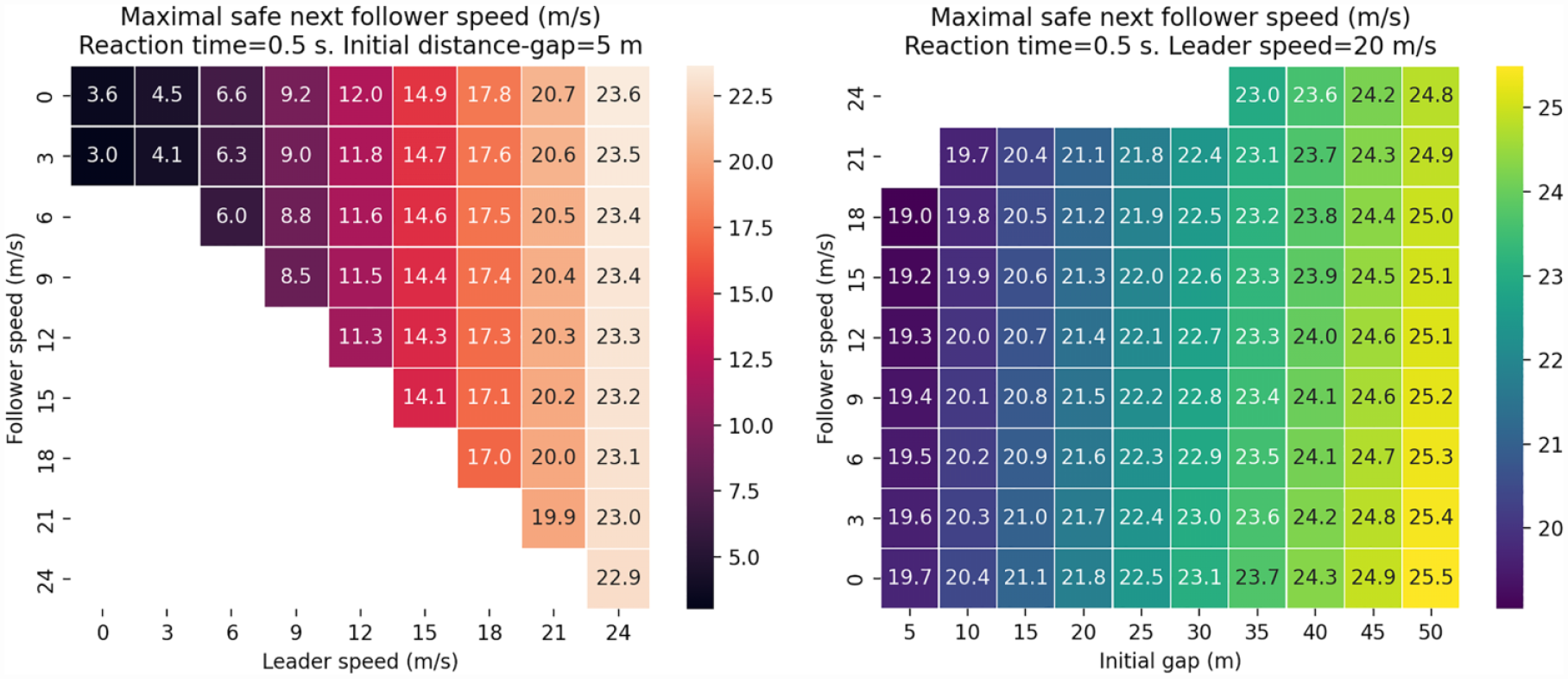
Heatmaps of
Critique of Safety Criteria That Are Based on a TTC Threshold
We recall that the TTC of a follower–leader configuration is given by
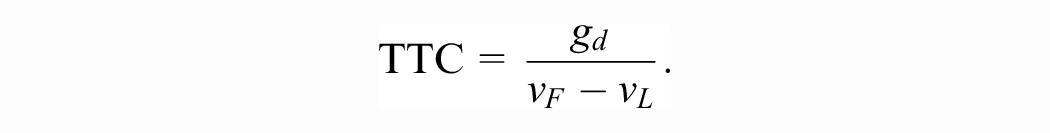
A safety criterion that is commonly used for RL approaches to longitudinal car-following takes the form (TTC-threshold criterion) A follower–leader configuration is safe if and only if
For example,
There exist follower–leader configurations that are safe according to any TTC-threshold criterion (i.e., any choice of constant c), yet unsafe according to the worst-case criterion.For example, consider the case when
TTC-threshold safety criteria do not depend on the follower’s reaction time
The article ( 18 ) is devoted to analyzing the relative advantages and disadvantages of distance gap and TTC as safety indicators. The author’s thesis is that small gaps represent “potential or actual danger” whereas small TTC represents “actual danger.” For example, in the situation when the follower is tailgating the leader, with approximately equal speeds, the gap is small, yet the TTC is large (identifying the configuration as safe). If the leader suddenly decelerates, the TTC will become small, but the follower will not be able to avoid a crash. Staying safe according to the worst-case criterion may thus be seen as avoiding potential (and therefore actual) danger in the categories of Vogel ( 18 ). Using a TTC-threshold safety criterion is not sufficient for formulating hard constraints that provide safety guarantees.
Safety in Low-Visibility Conditions
In low-visibility conditions (for example, fog or heavy snowfall), it is necessary to add another (but conceptually similar) speed constraint. We assume that the system can determine its detection range at time t as
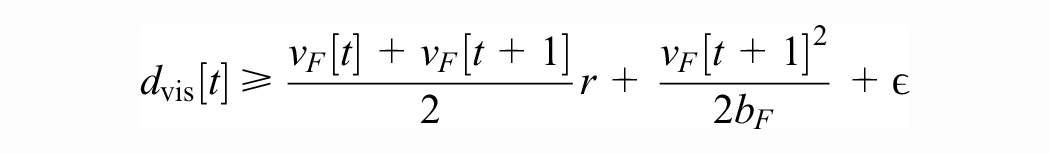
and obtain the maximal safe speed in low-visibility conditions,
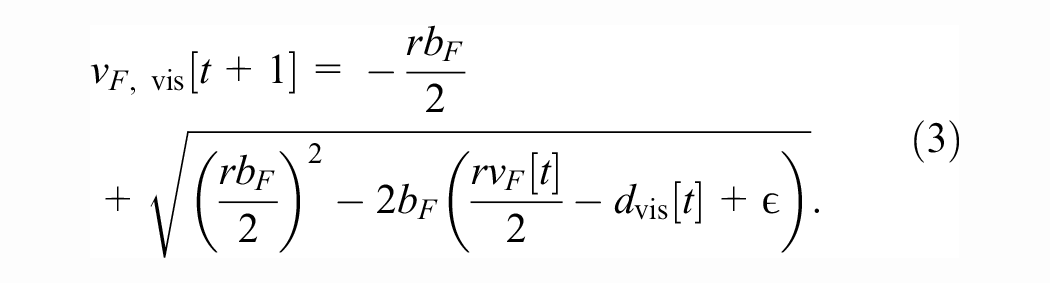
Alternatively, we could have reduced the derivation to the previous case by imagining a virtual stopped leader vehicle at the edge of the detection range.
Definitions of Efficiency and Comfort
In addition to safety, our controller aims to maximize efficiency and comfort.
Efficiency
We define the target speed of the follower at time
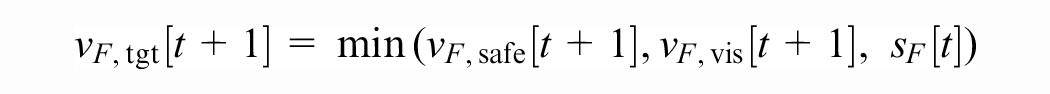
where
We then define the follower inefficiency over a trajectory
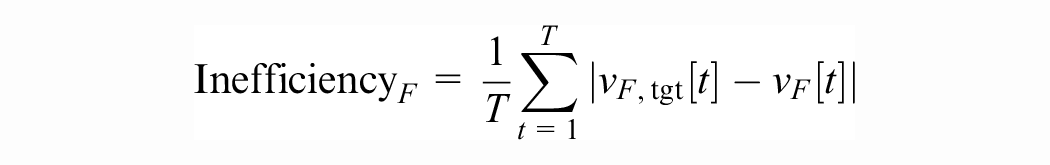
where
We discuss three separate cases to justify our definition of efficiency.
In the case where there is a close leader vehicle (
Minimizing gaps between consequent pairs of vehicles in a system leads to a higher system capacity. Suppose, for example, that the average vehicle length is 5 m; then, in a steady-state stream of vehicles at common speed v and time gap
From Figure 5 we can observe that with a smaller time gap, the flow capacity will be larger. This calculation is highly idealized, but it illustrates clearly the effect that decreasing vehicle gaps has on system capacity.
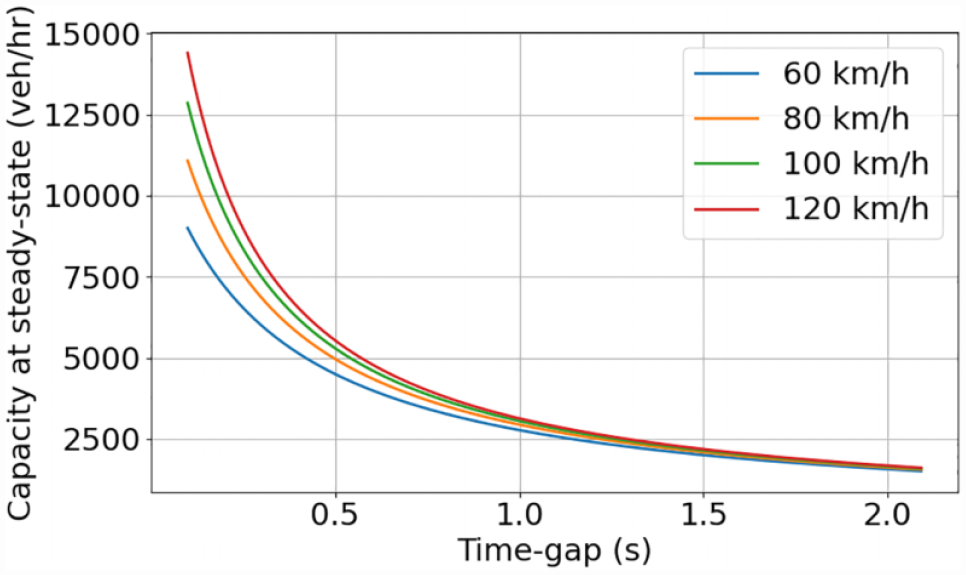
The motivation for decreasing time gaps between vehicles (maximizing efficiency) is the resulting increase of system capacity.
The case when the speed is constrained by low-visibility conditions (
Finally, the case in which the speed is constrained by the speed limit (
Comfort
We define the follower discomfort over a trajectory
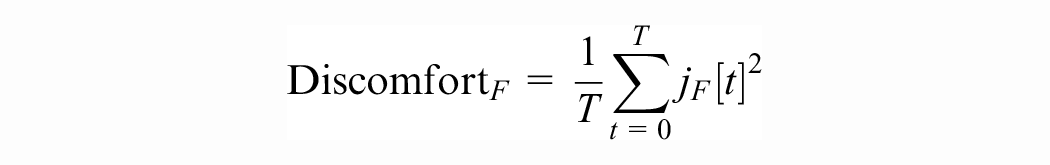
where the follower jerk (rate of change of acceleration) at time t is given by
SECRM
In this section, we introduce our reinforcement-learning-based car-following model, which we call SECRM. The core idea is to constrain the acceleration of the controlled vehicle so that the speed is always below the maximal safe speed. Subject to this constraint, the controller learns to take actions that bring the speed as close to the maximal safe speed as possible, maintaining safety and maximizing efficiency while minimizing jerk.
MDP Formulation
The MDP models the follower’s decision-making. The controller controls the follower’s longitudinal acceleration.
State: The follower receives the following tuple as the observation of the state of the environment at time t (cf. the “Notation” section;
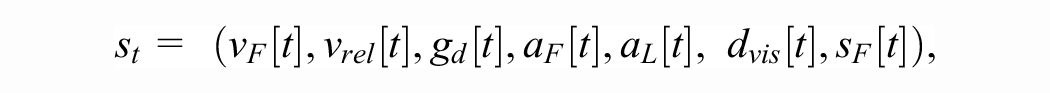
and in cases when there is no leader, or the leader is beyond the detection range, we set
• Actions: Given the observation at time t, the follower computes
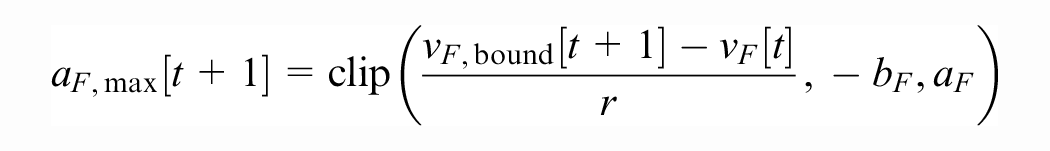
where
The follower may apply any action in
Rewards: The reward is the linear combination of two separate parts.
Efficiency (and speed-following): We formulate the efficiency reward following the target speed
This choice allows us to control the cases when the follower’s speed is constrained by (1) its proximity to the leading vehicle (leader-following mode), (2) low-visibility conditions, and (3) the speed limit (speed-following mode), with the same RL model. The minimum function dynamically switches between the three objectives, based on which of the three speeds is lower.
The efficiency/speed-following reward is piecewise-linear, based on how close the actual velocity is to the target (writing
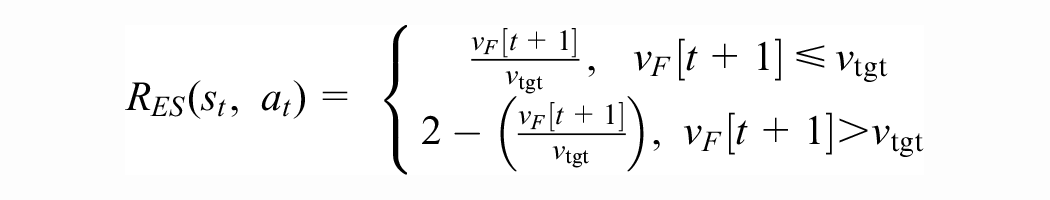
Please see Figure 6. Notice that in the car-following and poor-visibility cases, the acceleration constraint ensures that
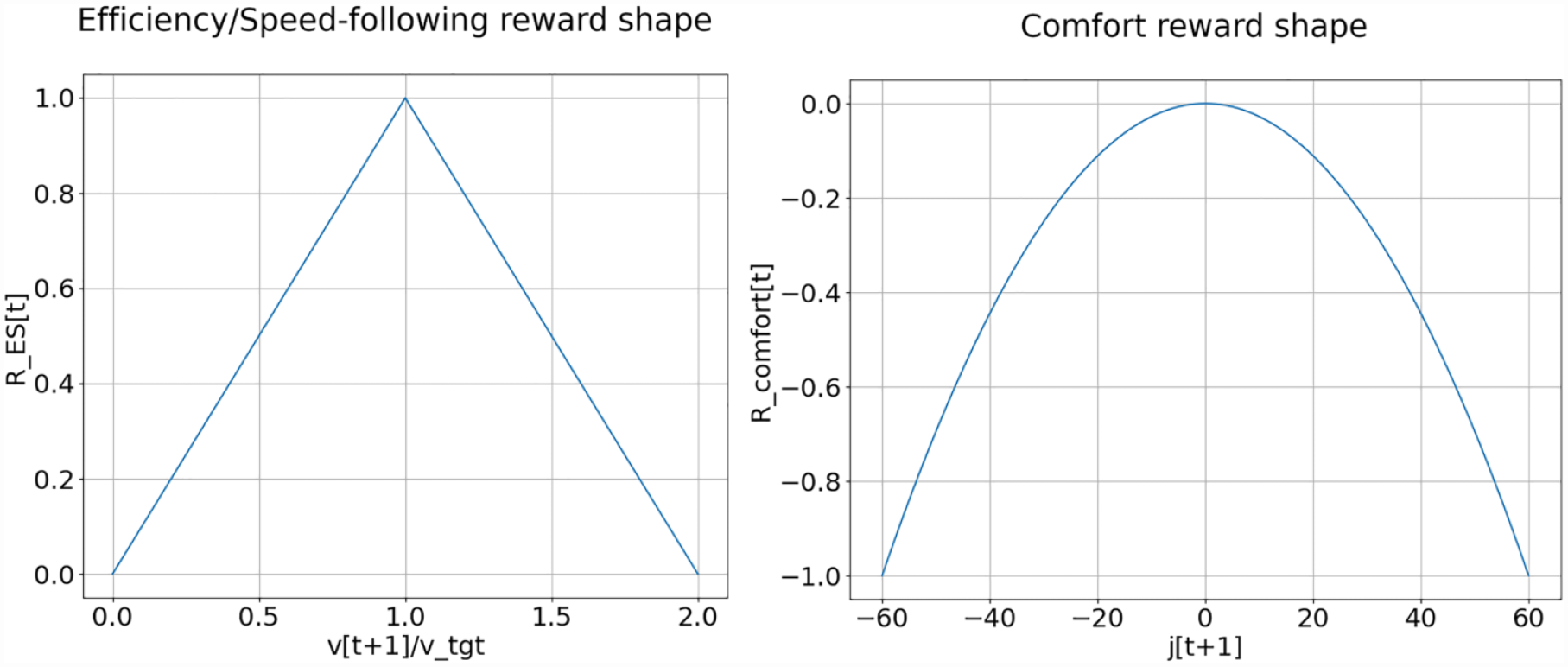
Shapes of the reward functions. The efficiency/speed-following reward function is displayed on the left, and the comfort reward function on the right. For the comfort reward example,
Comfort: The comfort reward is formulated to penalize large jerk. The value is normalized to lie between −1 and 0. Thus,
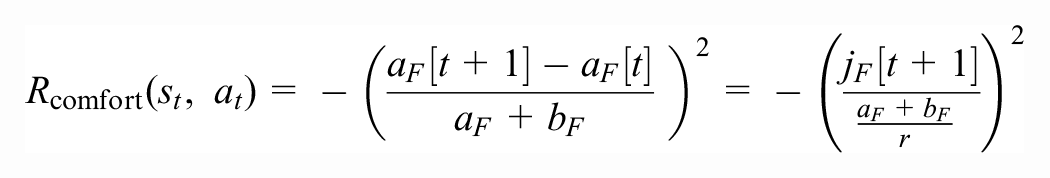
where
The full reward is then given by
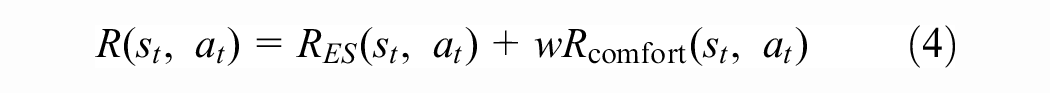
for some parameter
We experimented with
We remark that in safety-critical situations the action of the controller is highly constrained by the bound
Importance of Using a Target Speed Instead of a Target Gap
It is common (for example Zhu et al. [ 3 ], Shi et al. [ 14 ], Lin et al. [ 28 ]) to formulate the efficiency part of the RL car-following reward as following a set target gap. In our work, we instead formulate efficiency as following the dynamic maximal safe next speed. We find that our formulation has the following three advantages.
There is no target gap setting that is optimal for all follower–leader configurations. Usually, a given gap will either be inefficient or unsafe. We use a dynamic target speed, effectively following a dynamic target gap.
As mentioned above, formulating efficiency as speed-following allows us to uniformly treat the cases when the follower’s speed is constrained by the leader (car-following mode), poor visibility conditions, and by the speed limit (no leader present and sufficient visibility).
The follower’s action directly controls the speed, whereas the gap depends additionally on the (uncontrolled) acceleration of the leader. Consequently, we find that learning with a target speed is simpler than learning with a target gap.
Training
Deep Deterministic Policy Gradient
We use the DDPG algorithm ( 25 ) to train our controller. DDPG is a model-free, off-policy actor-critic algorithm. DDPG is an analog of the DQN algorithm that works with continuous action spaces.
To describe more details, we recall that the state-action value function of policy
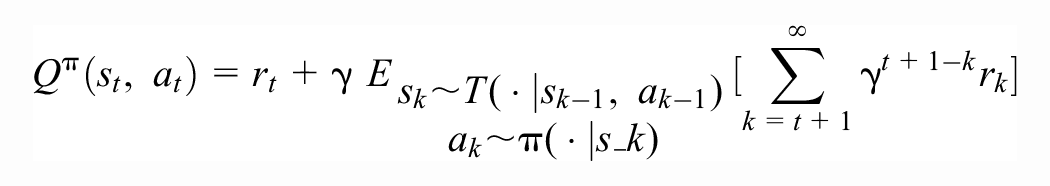
The state-action value function
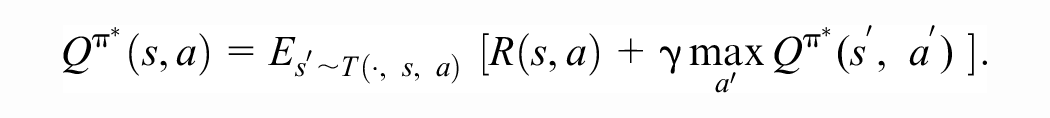
Motivated by the Bellman equation, the classical Q-learning algorithm creates a sequence
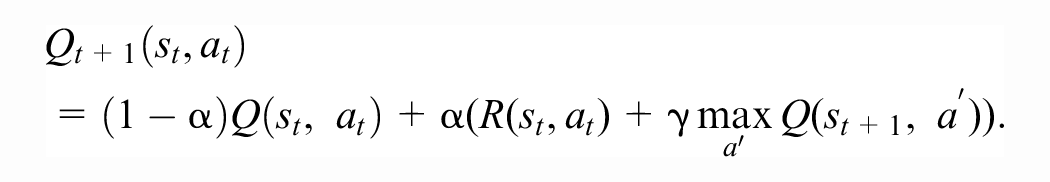
In deep RL, the iterative Q-function approximations are replaced by a neural network with parameters
In Q-learning (both tabular and deep), the agent chooses the action that maximizes its current Q-value estimates, during both training and deployment. Because maximizing the Q-value over all possible actions can be a difficult problem in itself when the action space is continuous, DDPG trains a deterministic policy function (the actor) in addition to learning the (estimate of the) Q-value function (the critic). The actor’s decisions are also computed using a neural network with parameters
The DDPG algorithm keeps a replay buffer of recent experience by storing tuples
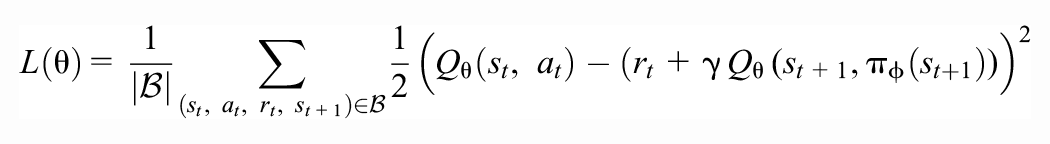
where
The critic network is not used for deciding the agent actions, but it is used for updating the actor network by maximizing the current estimates of the cumulative return provided by the critic, using minibatch stochastic gradient ascent with respect to
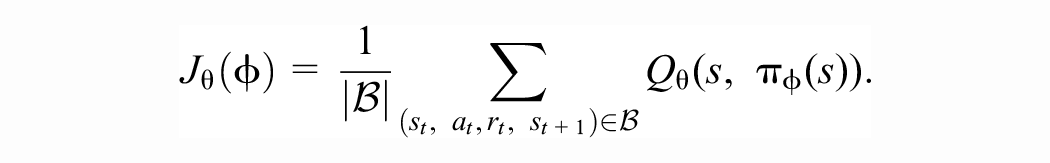
To stabilize learning, target copies of the actor and critic are kept, whose weights are updated by taking an exponential moving average of the most recent and previous target weights. To encourage exploration, a noise term in the form of an Ornstein–Uhlenbeck process is added to the actor. For full details of the DDPG algorithm, please see the original paper ( 25 ).
The hyperparameter settings for the DDPG algorithm are listed in Table 1.
DDPG Parameter Settings
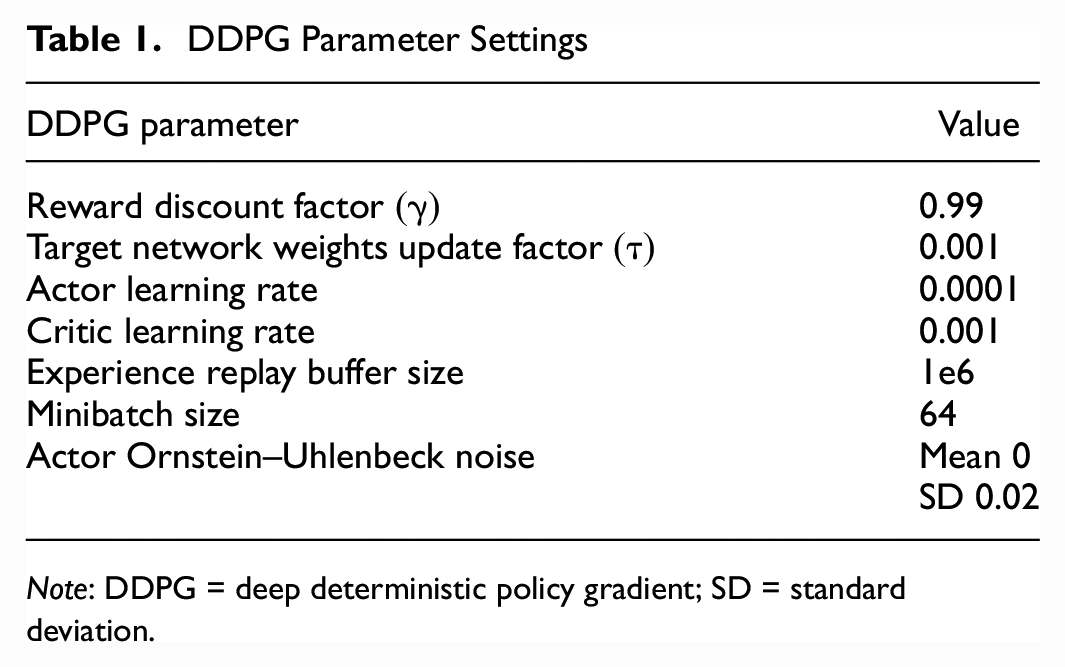
Note: DDPG = deep deterministic policy gradient; SD = standard deviation.
Training Details
During training, we use a loop road network (please see Figure 8). We train for 200 episodes with a horizon of 3000 time steps per episode (except that in the event of a crash, an episode is prematurely terminated). Every 10 episodes, we assign new speed limits to each section of the loop. To allow the agent to gather more experience (avoid initial crashes), we use curriculum learning strategy; during the first 20 episodes we sample speed limits uniformly from
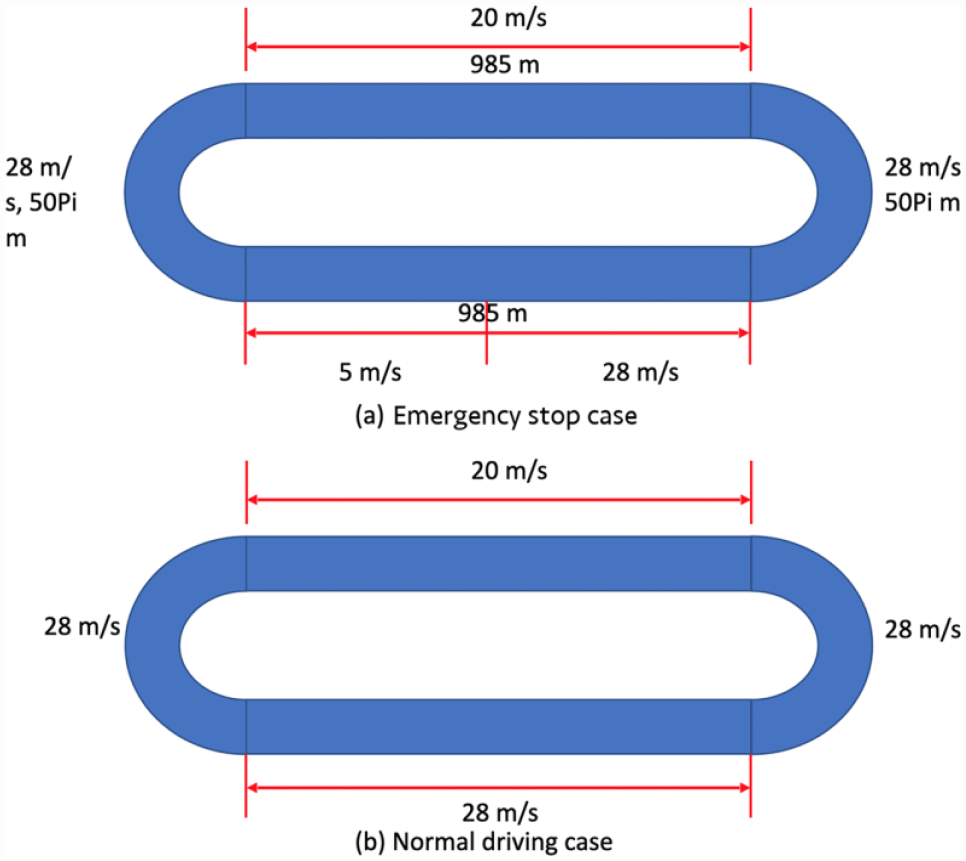
Network geometry for the emergency-braking (top) and regular-driving (bottom) test scenarios.
Evaluation Scenarios
Regular Driving and Emergency Braking
In the regular-driving and emergency-braking scenarios, there are two vehicles driving in the loop network with a single lane. Please see Figure 8 for the network geometry. The difference between the two scenarios is that in the emergency-braking scenario, one of the loop sections has a speed limit of 5 m/s, with the immediate upstream section’s speed limit equal to 28 m/s which forces the leader to aggressively decelerate, emulating emergency slowdown.
The follower vehicle is controlled by SECRM in both scenarios. In regular driving, the leader is controlled by IDM (described in the “Baselines” section); in emergency braking, the leader is also controlled by IDM, except that on the emergency-braking section the leader’s action is overridden to the maximal deceleration
Speed-Following Test
In the speed-following test, there is a single vehicle on a straight segment with varying speed limits, with no leader. Please see Figure 9 for the geometry and the specific speed limits. We created this straight network to allow the vehicle to drive a longer distance with no leader vehicle and without any curvature that might affect following the target speed.

Network geometry for the speed-following test scenario.
Baselines
Intelligent Driver Model ( 5 )
The IDM was proposed to study the phase transition between free-flow traffic and stop-and-go traffic on freeways. It is commonly used to model both human drivers and AVs. Translating into the notation of our paper, the action of the IDM is given by
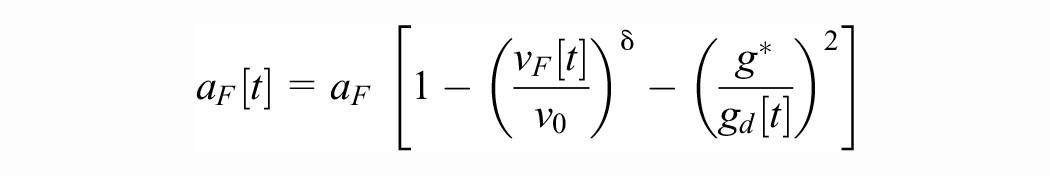
where
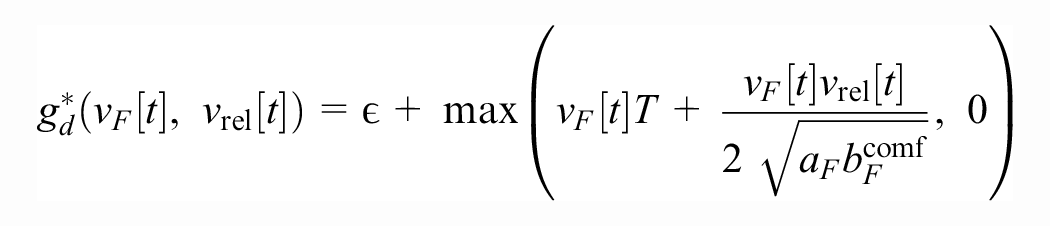
where
In free-flow traffic (
Shladover’s ACC Model ( 33 )
We use the unilateral ACC model proposed in the paper, and not the collaborative ACC, for a fair comparison with the other tested models. The paper proposes a simple model of ACC vehicles that is based and tested on experimental data gathered from commercial ACC vehicles. The model (translating into our notation) is
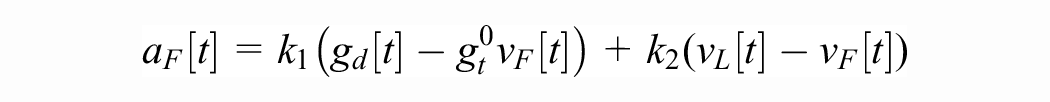
where
Car-Following Model-RL ( 3 )
The car-following model-RL (CFM-RL) is an RL-based longitudinal car-following model. We use the unilateral (not bilateral) version of the controller, for a fair comparison with the other tested models. The reward is given by (translating to our notation)
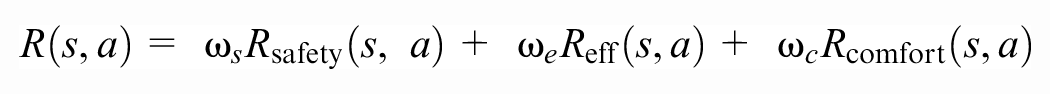
where
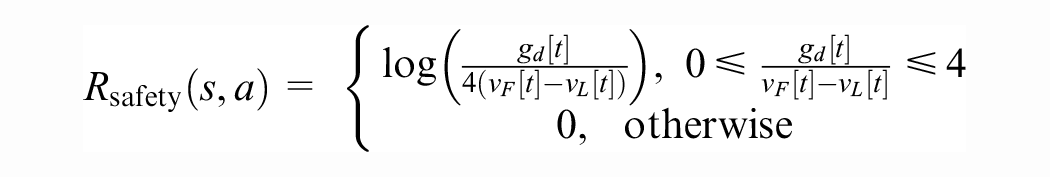
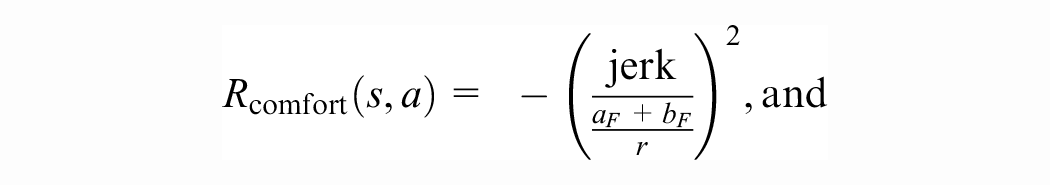
The efficiency reward is given by the probability density function of the log-normal distribution with parameters
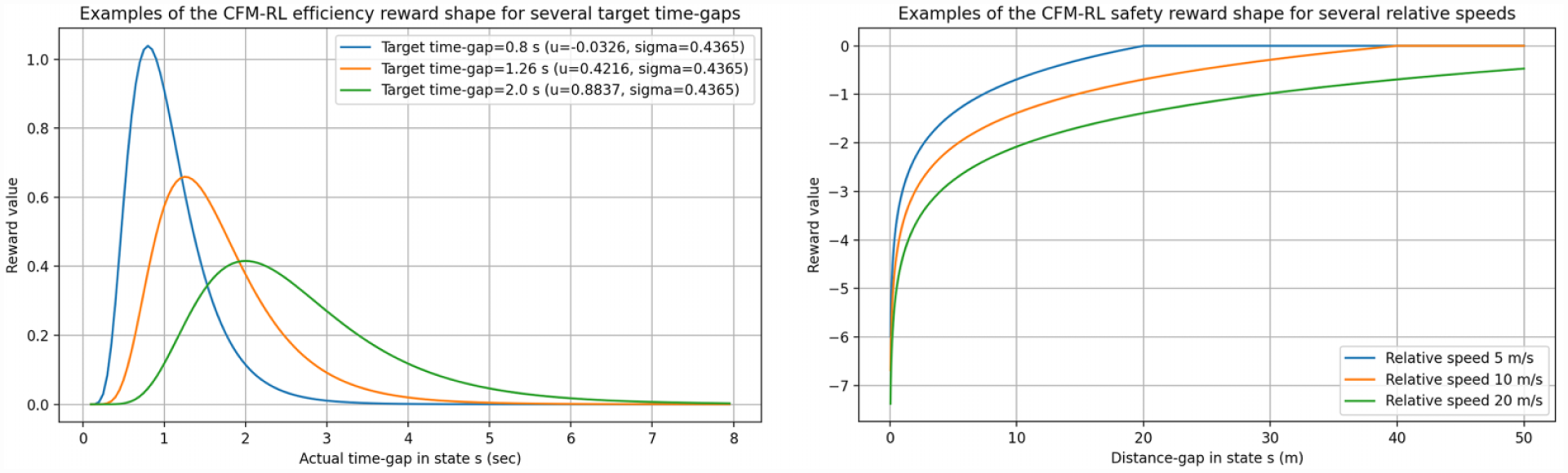
Examples of the shape of the CFM-RL efficiency (left) and safety (right) rewards.
The paper (
3
) sets the weights to
In the CFM-RL training phase, we use the exact same network to train our model as SECRM. As for SECRM, we also tried the curriculum learning framework to gradually increase the learning difficulties, that is, adding smaller speed-limit change in the first few episodes but changing to larger speed-limit change in the following few episodes. However, we found that if we have smaller headway in emergency stop cases, the CFM-RL model cannot converge well.
Gipps Model ( 4 )
When the leader vehicle is sufficiently close to the follower, the Gipps model’s acceleration is based on the worst-case criterion, just like SECRM (as we have discovered after independently formulating the criterion and deriving the action bound). In this case, Gipps follows the maximal safe speed
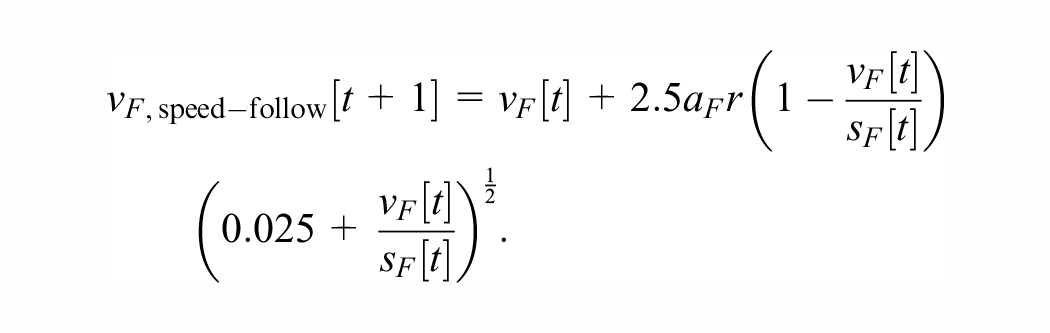
According to Gipps ( 4 ), this function was derived by fitting a curve to a plot of instantaneous speeds and accelerations from a sensor-equipped vehicle with a human driver on an arterial road in moderate traffic. The complete Gipps model is
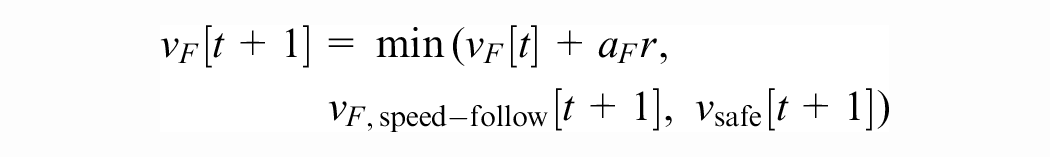
Advantages of SECRM over the Gipps Model
Because the SECRM maximal safe speed
In leader-following mode: In the presence of a leader, the Gipps model always takes on the maximal safe speed. This means the motion of the vehicle is quite jerky, with large second-to-second variance in accelerations. In Treiber and Kesting ( 1 ), large jerk is said to be one of the main disadvantages of the Gipps model. Because we additionally optimize a comfort term that rewards the controller for minimizing the cumulative (normalized square of) the jerk, SECRM is significantly better than Gipps for comfort, and therefore more practical.
In speed-following mode: To formulate the speed-following model, Gipps relied on experimental data obtained from a sensor-equipped vehicle with a human driver, fitting an ad hoc function to the data. Because of this, the behavior of the Gipps controller in speed-following mode is human-like and inefficient.
In leader-following mode, SECRM can be thought of as trading in a bit of efficiency for smaller jerk, while in speed-following mode, SECRM is both more efficient and less jerky than Gipps. Both advantages are verified by our experiments described below.
Simulator
We perform the experiments in the Simulation Of Urban Mobility (SUMO) microsimulator ( 34 ). To interface between the simulator and our implementation of the DDPG algorithm, we use an augmented version of the middleware Flow ( 35 ) to which we have added features useful for our experiments. In turn, Flow uses SUMO’s TraCI API to interact and control the simulator.
Experimental Results
In the regular-driving and emergency-braking scenarios, we select two desired time-gap configurations as follows. First, since models with a target gap need a gap value as an input, we test each model with a target time gap equal to SECRM’s average time gap in that scenario for fair comparison (except Gipps, which does not have a target time gap). Second, we perform a “smallest safe time gap comparison.” Namely, by incrementing the desired time gap by 0.1 s, we find the smallest target time gap that does not crash in the emergency-braking scenario for each model. Then, we compare the safe models in normal driving.
The smallest safe time-gap setting is the one we would use in practice. On the other hand, the smallest safe time gap is in general quite high across all models, and we found it valuable to also test each model in regular driving with the target time gap equal to SECRM’s average gap because based on our previous proof we can assume this is the most efficient and safe time gap.
For all experiments, we use
Regular-Driving Scenario
In this section, we want to test the model in regular car-following scenario (no sudden leader accelerations or decelerations).
Regular Driving—SECRM’s Average Time Gap
With the target gap equal to SECRM’s average, CFM-RL and Gipps will have slightly smaller average time gap than SECRM, but higher average jerk by approximately an order of magnitude than SECRM. This makes sense, because SECRM’s reward is formulated to smooth out the high jerk characteristic of the Gipps model, at some expense of efficiency.
Please see Figures 12 and 13 for the time- and distance-gap comparisons, Figure 14 for the jerk comparison, and Table 2 for the average result over the simulation. From the results, we can see that the average time gap of Gipps is the smallest one; on the other hand, SECRM has a very similar average gap to that of Gipps. However, Gipps’s jerk is much higher than SECRM.
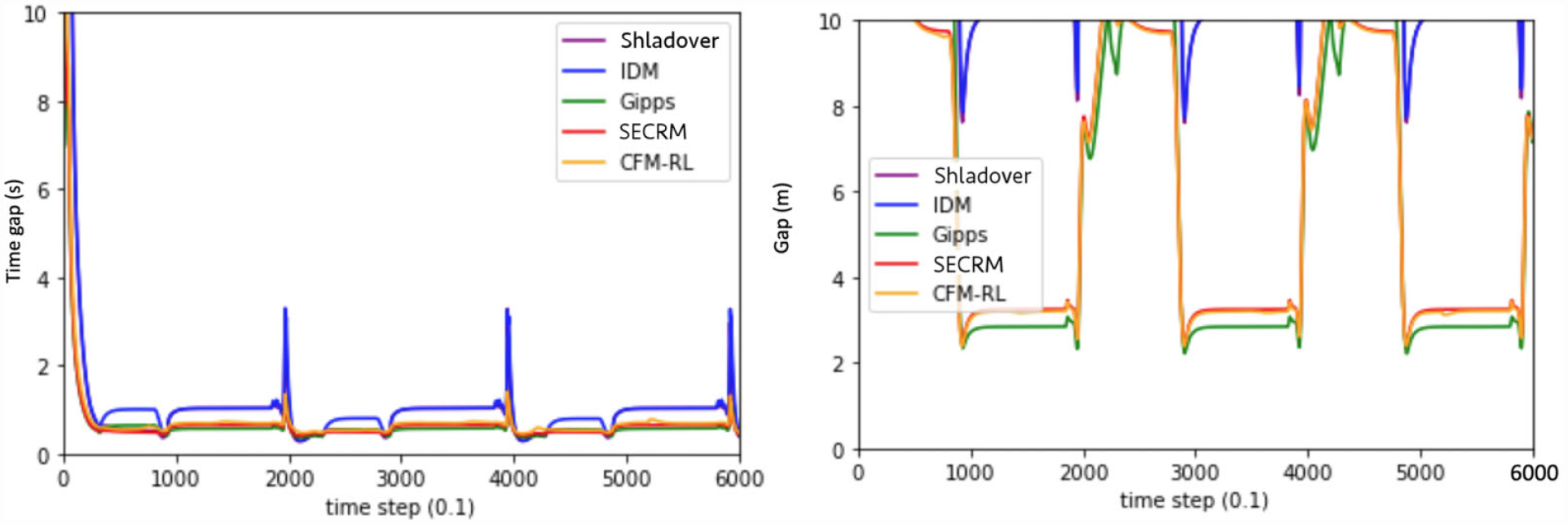
Time gap (left) and distance gap (right) for the regular-driving scenario. Target time gap = SECRM’s average time gap.
Jerk comparison for the regular-driving scenario. For non-SECRM models, target gap = SECRM’s average time gap.
Method Comparison for Regular Driving (for Non-SECRM Models, Target Gap = SECRM’s Average Time Gap)
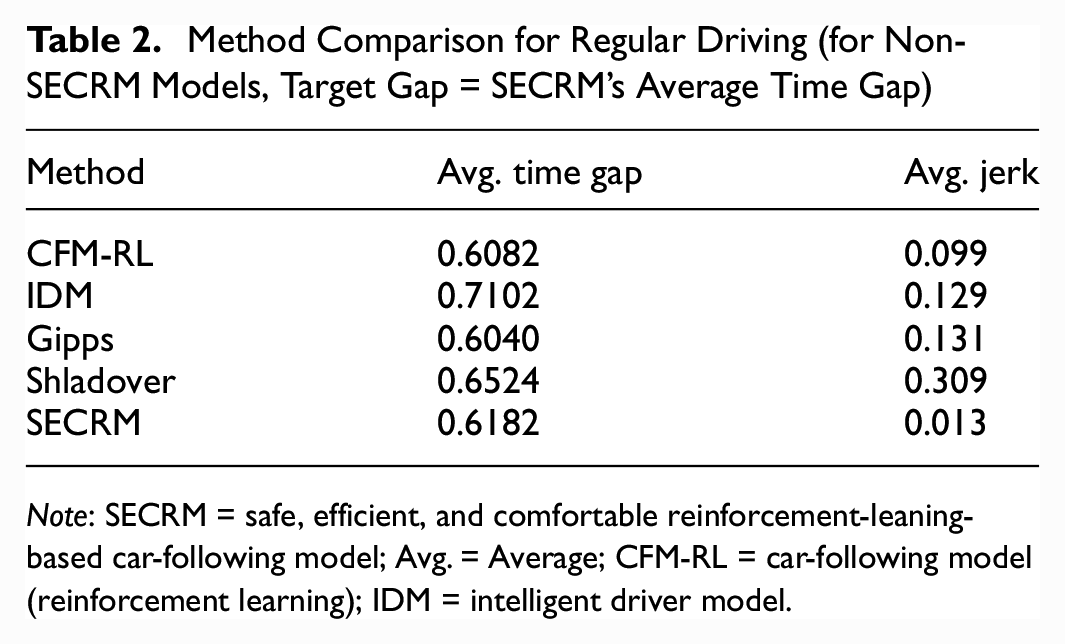
Note: SECRM = safe, efficient, and comfortable reinforcement-leaning-based car-following model; Avg. = Average; CFM-RL = car-following model (reinforcement learning); IDM = intelligent driver model.
Regular Driving—Smallest Safe Time Gap
The time gap of each model (except Gipps and SECRM) is set to the smallest safe time gap (as measured by the emergency test scenario). Unsurprisingly, each human-driving-based model, including CFM-RL, IDM, Shladover will have larger average time gap.
Please see Figures 15 and 16 for the time- and distance-gap comparisons, Figure 17 for the jerk comparison, and Table 3 for the average result over the simulation.
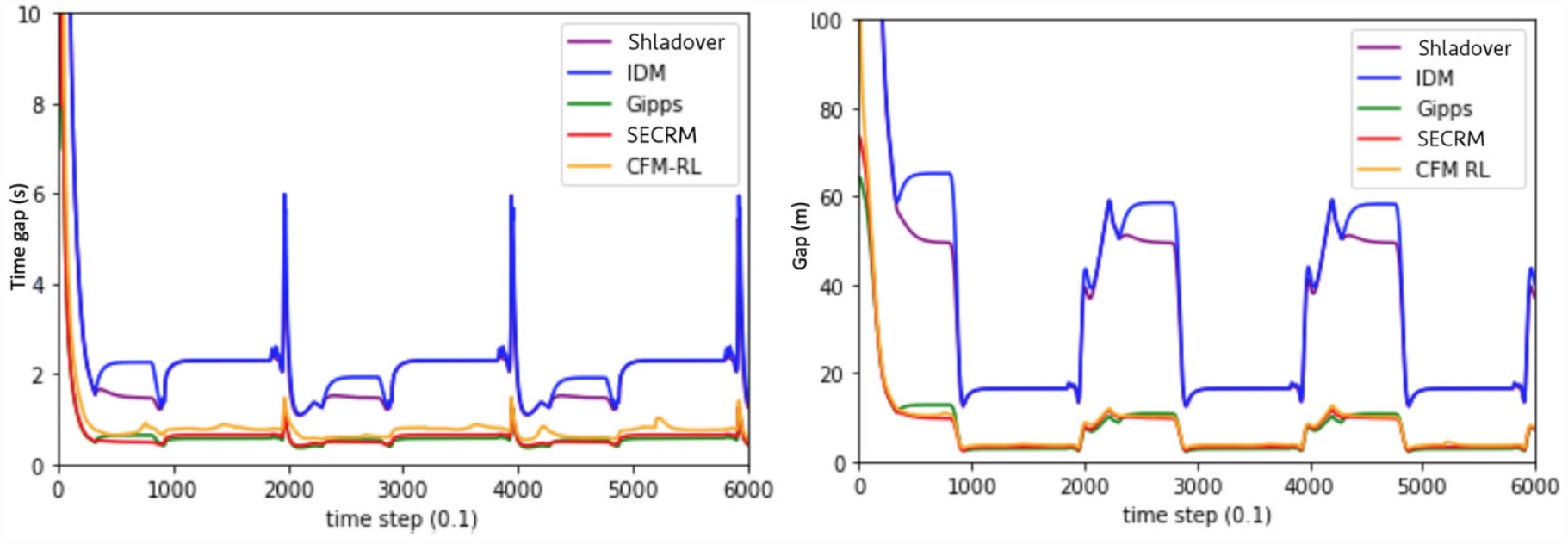
Time gap (left) and distance gap (right) for the regular-driving scenario. Target gap = smallest safe gap.
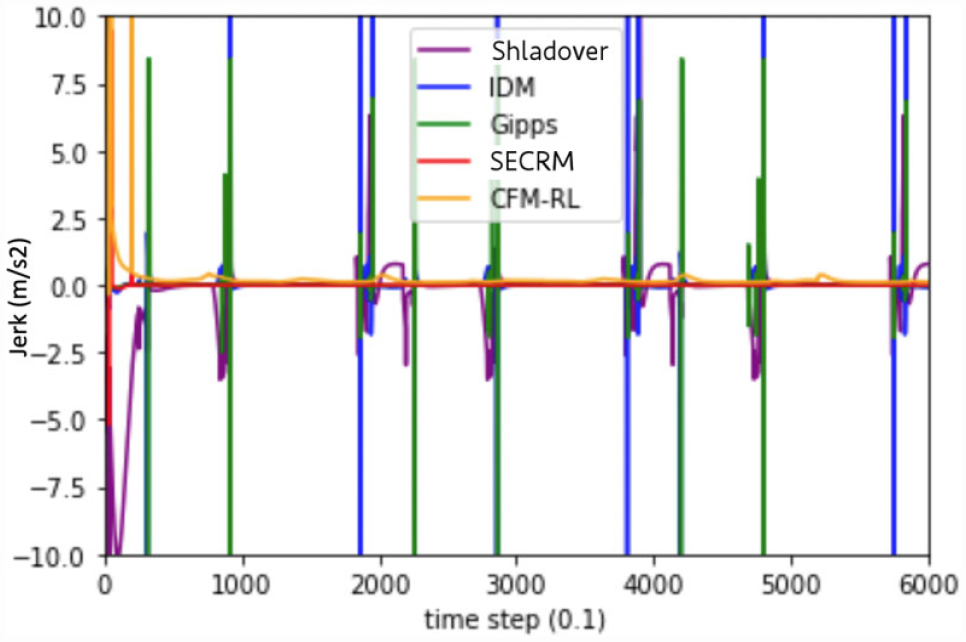
Jerk comparison for regular driving. For non-SECRM models, target gap = SECRM’s average time gap.
Method Comparison for Regular Driving (for Non-SECRM Models, Target Time Gap = Smallest Safe Time Gap)
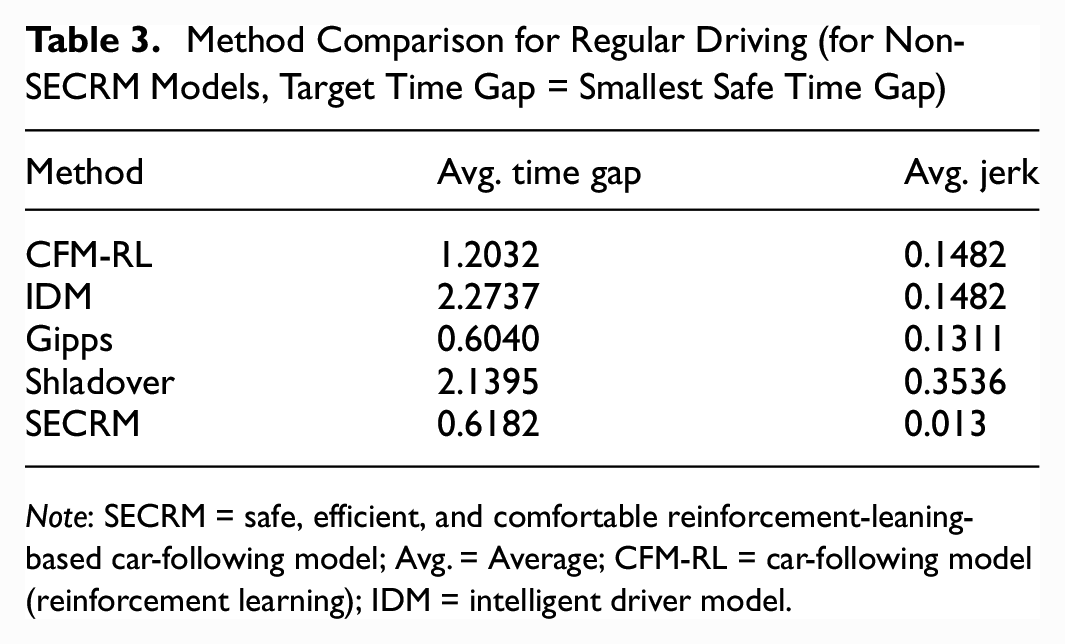
Note: SECRM = safe, efficient, and comfortable reinforcement-leaning-based car-following model; Avg. = Average; CFM-RL = car-following model (reinforcement learning); IDM = intelligent driver model.
Emergency-Braking Scenario
In this section, we test each model in a scenario in which the leader undergoes a sudden maximal deceleration from 28 m/s to 5 m/s which is the emergency stop network from Figure 8.
Emergency Stop—SECRM’s Average Time Gap
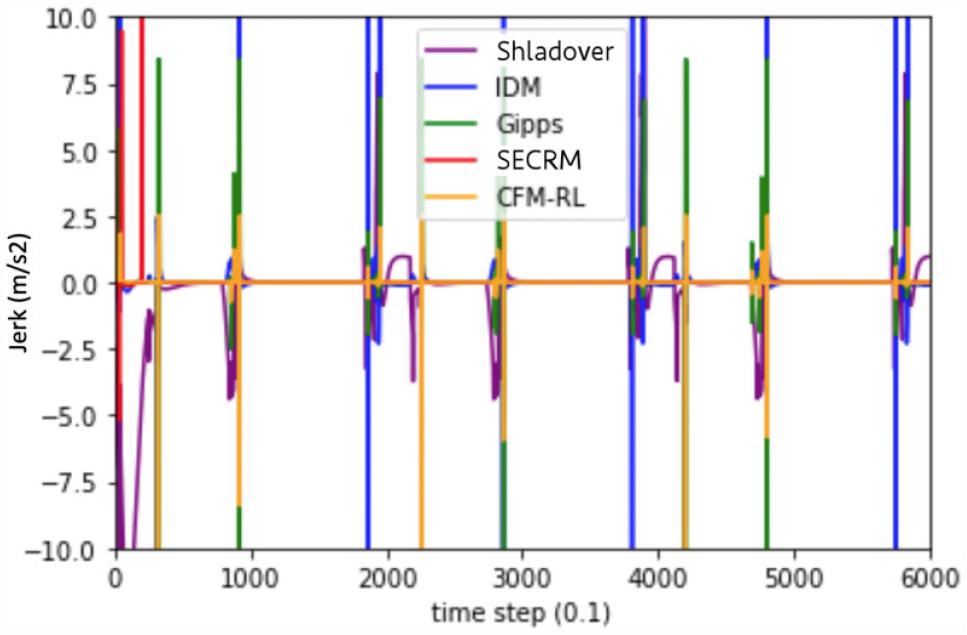
Based on our findings, we observe that the models with fixed target time gap will be more likely to crash given a smaller target time gap. SECRM outdoes Gipps in both the average time gap and average jerk, while the other models crash. Because the CFM-RL crashes in this scenario, while it does not crash in training, we verify our claim that RL models that rely on reward alone for safety may not generalize sufficiently to avoid unsafe situations like crashes.
Please see Figures 18 and 19 for the time- and distance-gap comparisons, Figure 20 for the jerk comparison, and Table 4 for the average result over the simulation.
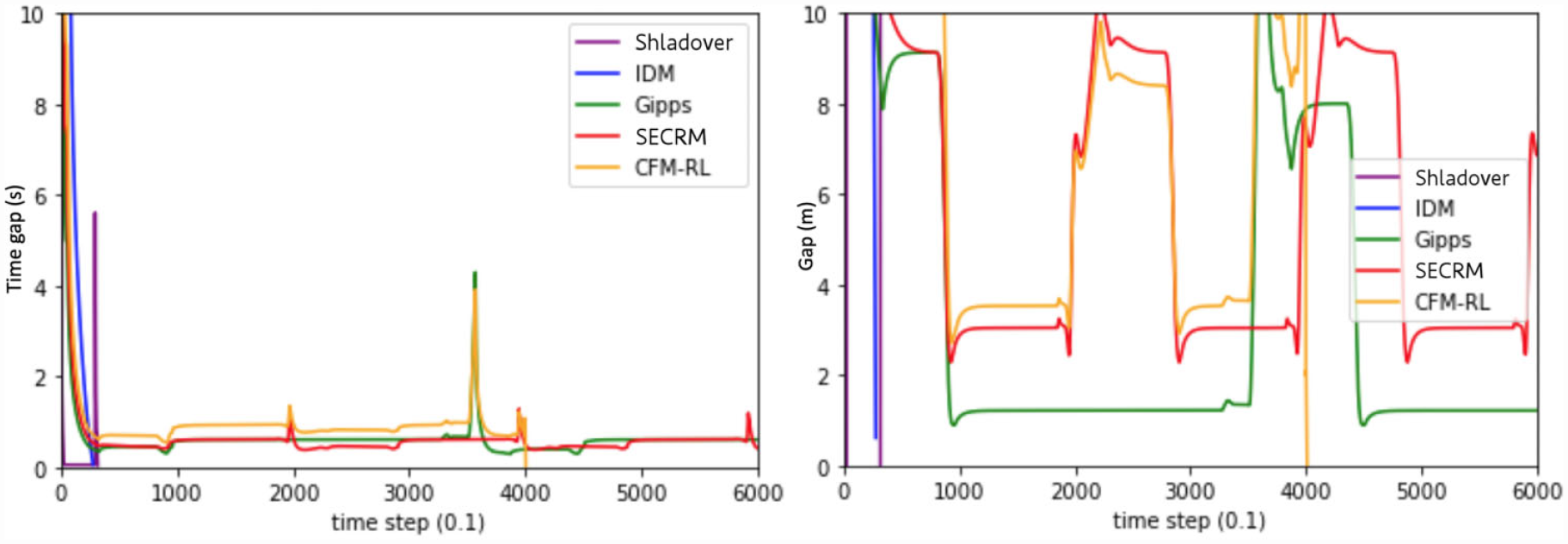
Time gap (left) and distance gap (right) for the emergency-braking scenario. Target gap = SECRM’s average time gap.
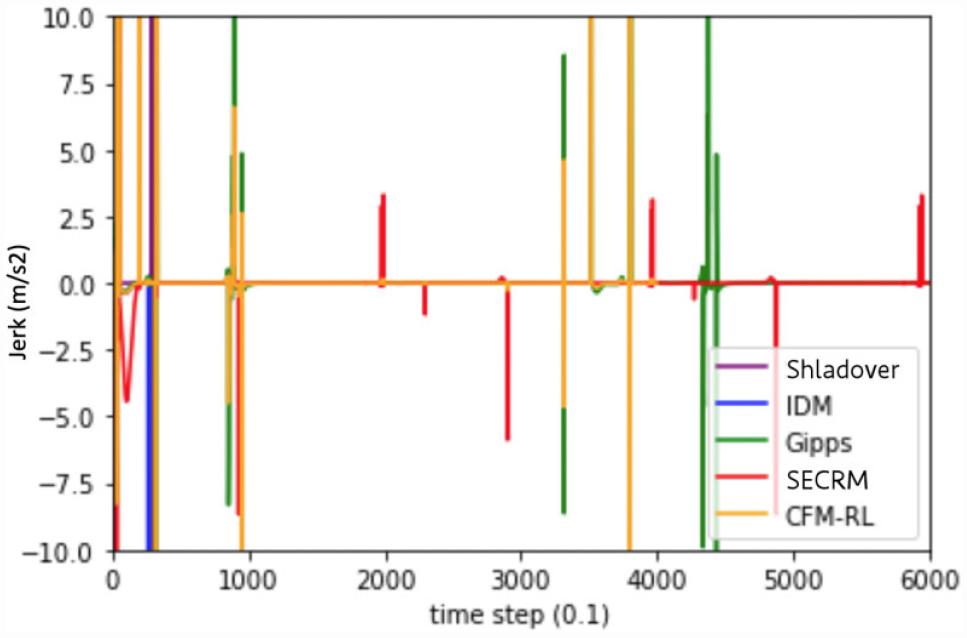
Jerk comparison for the emergency-braking scenario. Target gap = SECRM’s average time gap.
Method Comparison for Emergency Braking (for Non-SECRM Models, Target Time Gap = SECRM’s Average Time Gap)
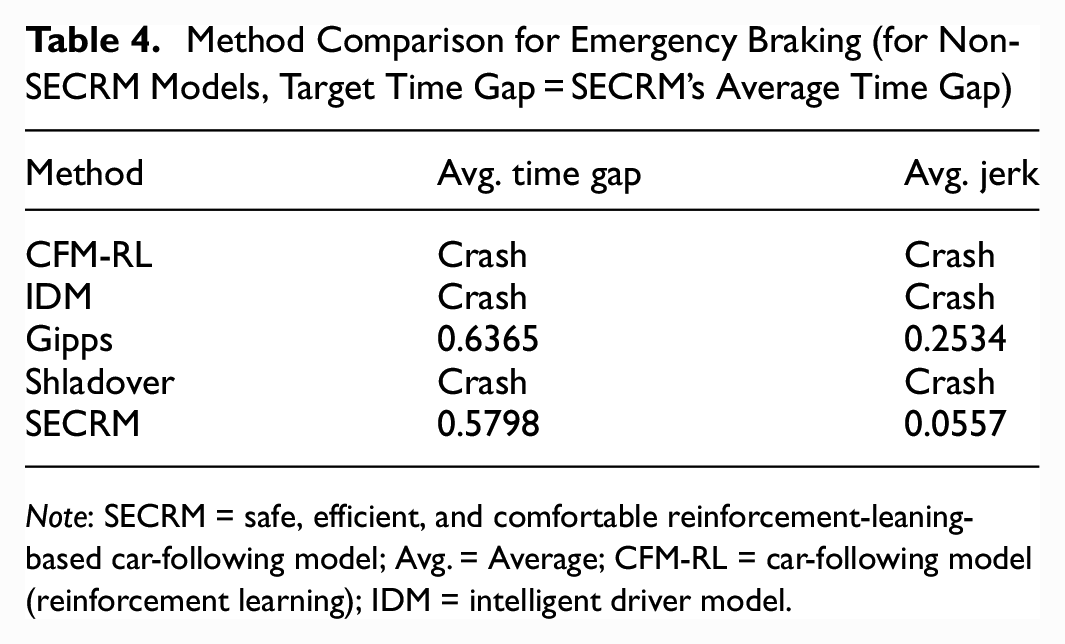
Note: SECRM = safe, efficient, and comfortable reinforcement-leaning-based car-following model; Avg. = Average; CFM-RL = car-following model (reinforcement learning); IDM = intelligent driver model.
Emergency Braking—Smallest Safe Time Gap
We find that all models except Gipps require a significantly higher safe target time gap to safely pass the emergency-braking scenario. IDM and CFM-RL are comparable to SECRM in jerk, but have significantly higher average time gap, indicating loss of efficiency.
Please see Figures 21 and 22 for the time- and distance-gap comparisons, Figure 23 for the jerk comparison, and Table 5 for the average result over the simulation.
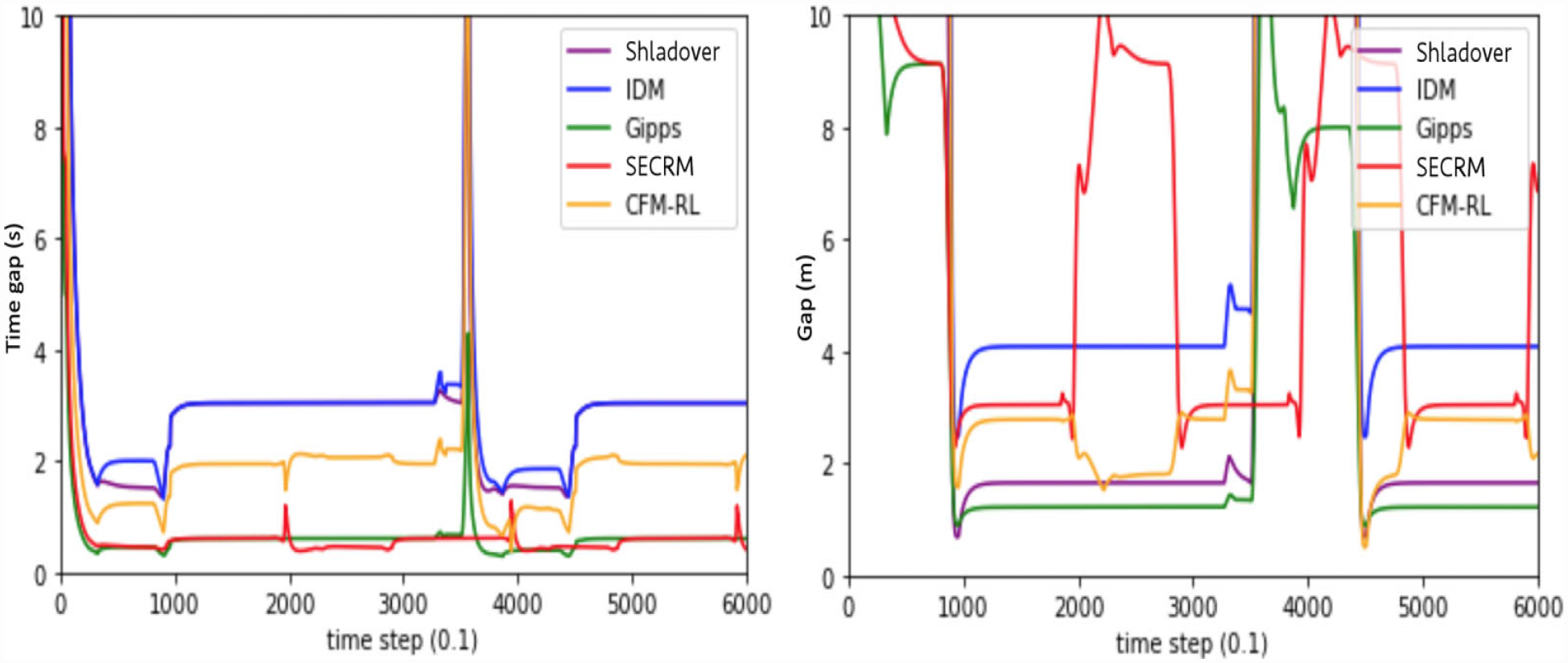
Time gap (left) and distance gap (right) for the emergency-braking scenario. Target time gap = smallest safe time gap.
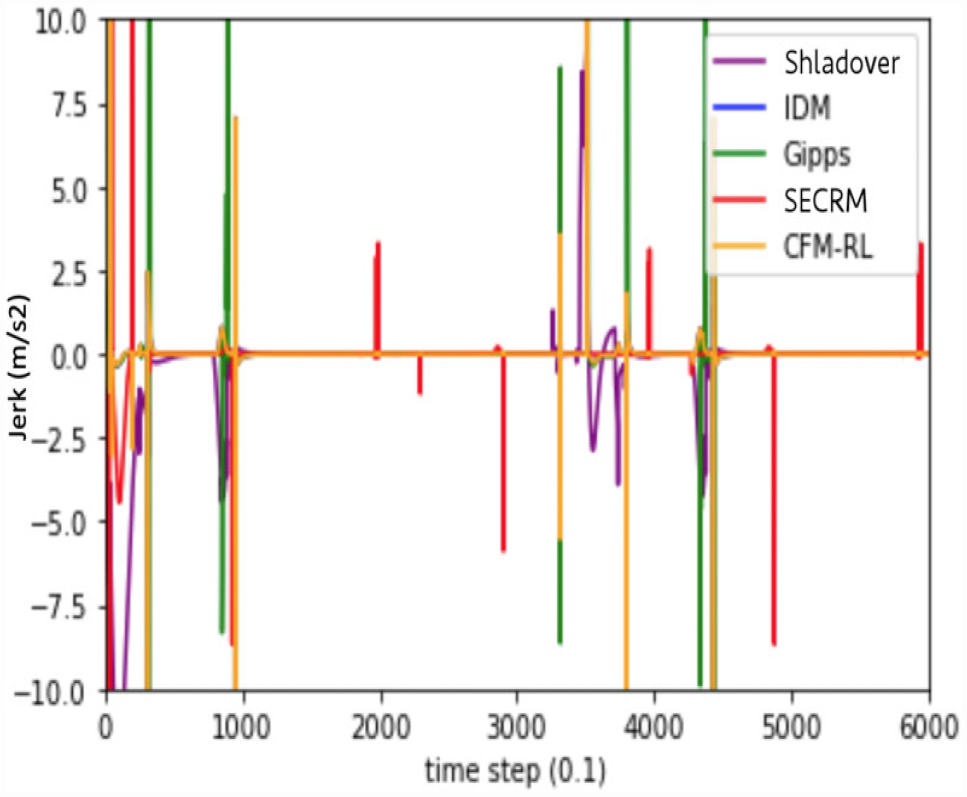
Jerk comparison for the emergency-braking scenario. Target time gap = smallest safe time gap.
Method Comparison for Emergency Braking (for Non-SECRM Models, Target Time Gap = Smallest Safe Time Gap)
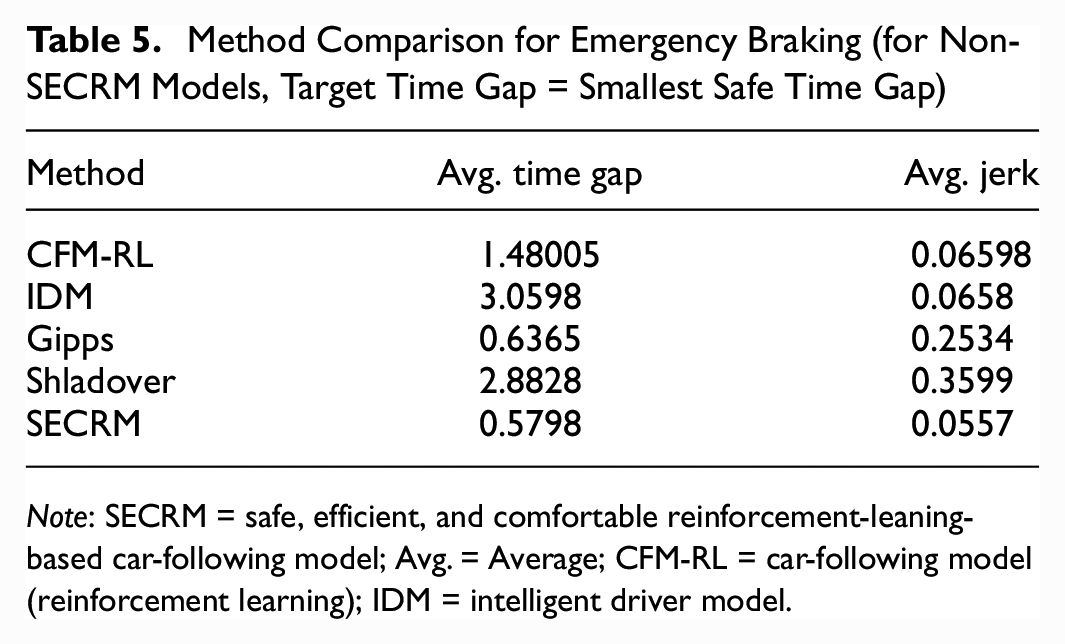
Note: SECRM = safe, efficient, and comfortable reinforcement-leaning-based car-following model; Avg. = Average; CFM-RL = car-following model (reinforcement learning); IDM = intelligent driver model.
Speed-Following Scenario
In the previous section, we analyzed the car-following mode. In this section, we will analyze how the follower vehicle can follow the speed limit in freeway without a leader vehicle. Note that the CFM-RL is not trained with any speed-following reward so we do not include it as a baseline. Meanwhile, because in speed-following scenario, there is no leader, the jerk will be very small, which makes it hard to use for making a comparison, so we use the acceleration for comparison.
First, we use the same baselines as in the previous section.
Please see Figures 24 and 25 for the velocity and acceleration comparisons, and Table 6 for the average result over the simulation. From the results, we find that Gipps cannot follow the target speed very well as a result of the second term of the Gipps equation, which is the safe target speed constraint to avoid sudden acceleration/deceleration incurred by sharp speed change. IDM can better catch up the target speed, but it needs a longer time. The Shladover model will catch up the target speed very fast, but it will end up with the highest jerk. SECRM will catch up soon, but it will not have very high jerk. To summarize, Gipps has two target speeds. One is efficient (car-following), the other is quite inefficient (speed-following). One major advantage of SECRM over Gipps is that it optimizes speed-following too.
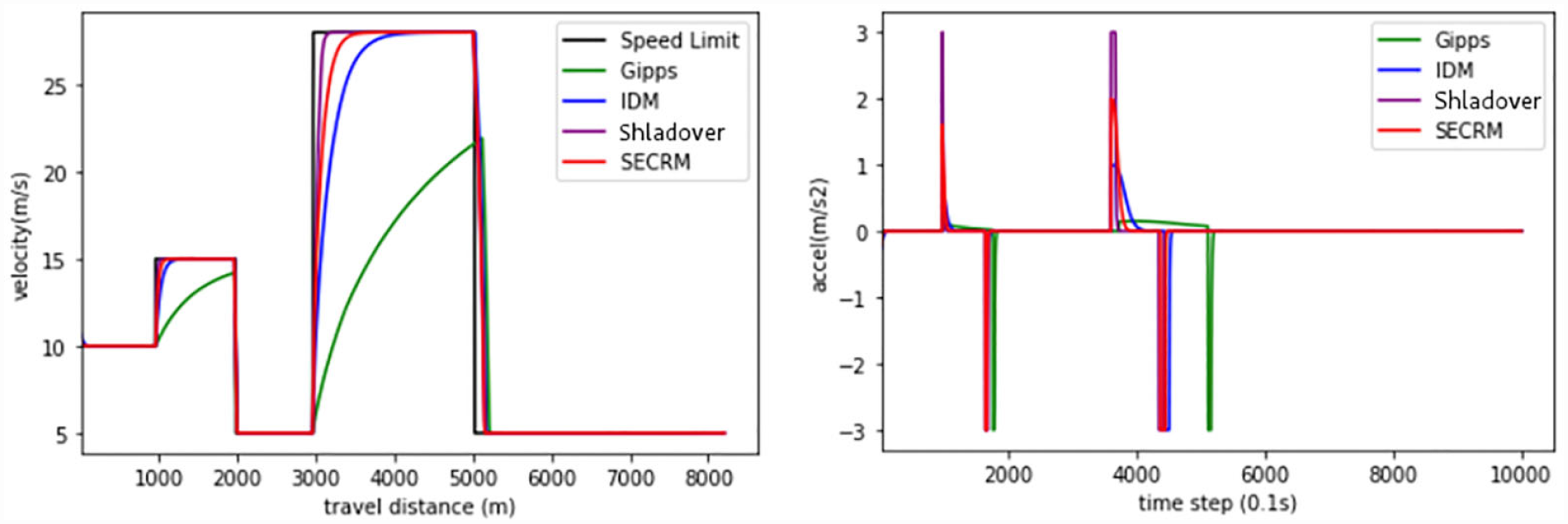
Velocity (left) and acceleration (right) comparison in the speed-following scenario.
Method Comparison for Speed-Following Scenario
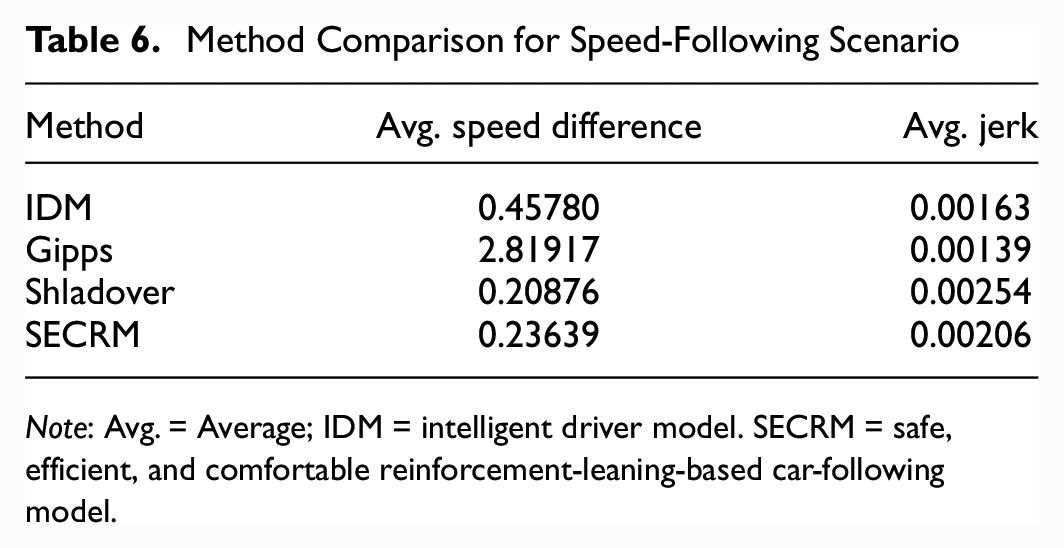
Note: Avg. = Average; IDM = intelligent driver model. SECRM = safe, efficient, and comfortable reinforcement-leaning-based car-following model.
Discussion
Safety, efficiency, and comfort: In our experiments, we find that SECRM is safe and has an efficiency advantage over the models with a fixed target time gap (IDM, Shladover, CFM-RL); for the latter models, a large target time gap is required for the models to avoid a collision in an emergency-braking scenario. Such a large target makes the models inefficient in regular driving. Because SECRM and Gipps have a dynamic target speed (formulated to be safe according to the worst-case criterion), they can drive with more efficiency, while still avoiding collisions in both regular driving and emergency braking. SECRM optimizes an additional comfort term, which solves a major deficiency of the Gipps model—impractically high jerk.
Unification of speed-following and efficiency: Because efficiency is formulated as following the maximal safe speed, we can unify the speed-limit-following and efficiency reward terms, obtaining a single model that works in both speed-following and leader-following scenarios, shifting between the two dynamically (without requiring an ad hoc threshold choice to switch between the two modes).
Generalization and robustness: To ensure that the RL controllers are not overfitting to the training scenarios (and to obtain models that work well in both regular-driving and emergency-braking scenarios), we train on a network whose sections have randomly assigned speed limits that are regularly reassigned during training. The training scenario is different from all three testing scenarios. Nevertheless, the trained models perform well, showing a capacity for generalization, and providing evidence that the trained model is robust.
Extendable framework: By promoting safety from one of the terms of a reward function to a hard action constraint, we obtain a flexible framework for training safe car-following RL models. In this paper, we have focused on optimizing comfort in addition to efficiency, but by modifying the reward function it is possible to add other optimization criteria (for example, cooperative reward function terms for within-platoon optimization, mixed-autonomy scenarios, string stability). Such enhancements will be the subject of future work.
Comfortable vs efficient driving behavior: From our results, we can see that the Gipps model can have slightly smaller headway in a regular-driving scenario than does SECRM; however, SECRM will have more comfortable performance. Generally, if we want to achieve a higher performance of one criterion then we need to sacrifice another criterion.
Conclusion
CFMs have been investigated for decades and have significantly matured. They are heavily used in microscopic traffic system simulation. Over the last decade, there has been renewed and rising interest in improving CFMs because of the rapid emergence of automated driving and ACC.
Autonomous driving systems based on RL have particular promise, being able to optimize a range of desirable features, such as efficiency and comfort, but have several potential drawbacks. In this paper, we have addressed three such potential drawbacks, improving on past work. First, previous RL controllers typically offer no safety guarantees, and the safety reward component is frequently based on a TTC threshold (which we have observed in this work cannot guarantee safety). We improve the system safety characteristics by formulating a hard safety constraint that offers analytic safety guarantees. Second, RL controllers may overfit to the scenarios seen during training. We improve system robustness by including a wide variety of leader vehicle behaviors in training. Third, previous RL controllers typically pass between leader-following and speed-following (free-flow) modes based on an ad hoc threshold. We improve by combining both leader-following and free-flow modes into a single speed target. The resulting agent performs well in our test scenarios, avoiding crashes even in emergency braking (whereas a representative previous RL controller does not), with excellent efficiency, speed-following, and comfort characteristics.
In future work, we plan to extend the controller by including more optimization targets in the reward, including system stability, as well as adding a lane-changing module.
Footnotes
Author Contributions
The authors confirm contribution to the paper as follows: conceptualization, methodology, investigation, software, writing—original draft: T. Shi; conceptualization, investigation, writing—original draft: O. ElSamadisy; methodology, investigation, writing—original draft: I. Smirnov; supervision, writing—review and editing: B. Abdulhai. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.