
Abstract
Adaptive cruise control (ACC) systems are increasingly offered in new vehicles in the market today, and they form a core building block for future full autonomous driving. ACC systems allow vehicles to maintain a desired headway to a leading vehicle automatically. Recent research demonstrates that (1) shorter headways lead to higher throughput, and (2) the effective use of ACC can improve traffic flow by adapting the desired time headway in response to changing traffic conditions. In this paper we show that, although shorter headways result in higher capacity, flow breakdown still occurs if traffic densities at bottlenecks are allowed to exceed the critical density. Therefore, dynamic traffic control near bottlenecks is still necessary to avoid bottleneck activation and capacity loss. We propose an adaptive reinforcement learning (RL) headway controller that uses ACC headways to optimize traffic flow and minimize delay. Based on state measurements, the controller dynamically assigns an optimal headway value for each freeway section within a control cycle. In a freeway simulation example, we first demonstrate that different nondynamic headway assignment strategies failed to avoid congestion and traffic breakdown. We then present a dynamic headway control strategy based on deep reinforcement learning (DRL) that adapts the desired headway according to the changing traffic conditions on both the freeway and the ramp to effectively maximize traffic flow and minimize system delay. We quantitatively demonstrate that our DRL dynamic headway control strategy improved traffic and reduced system delay by up to 57% compared with the examined nondynamic headways.
Adaptive cruise control (ACC) is an advanced driver assistance system (ADAS) that uses headway sensors to continuously measure the spacing to the vehicle ahead and adjusts the vehicle speed to ensure this headway is maintained close to a desired value. When the road ahead is clear, ACC automatically accelerates to a desired preset speed. ACC is a major component and precursor of fully autonomous vehicles (AVs). According to the Society of Automotive Engineers, Level 1 automation systems have at least one ADAS that provides either steering or braking/acceleration assistance, whereas Level 2 automation systems provide drivers with both steering and braking/acceleration assistance. Therefore, ACC on its own is a Level 1 automation system, but when combined with another ADAS such as lane centering, the vehicle reaches Level 2 on the driving automation scale, which is a step closer to fully autonomous driving. ACC is one of the key driving automation subsystems that will significantly affect traffic flow dynamics as their market penetration increases. The use of conservative desired headway values may enhance the driver’s convenience and safety, which were prime motivators for their development, but at the same time, could adversely affect transportation network performance ( 1 ).
According to ACC literature ( 2 – 5 ), such systems have the potential to improve transportation network performance. However, if conservative values are set for ACC parameters (e.g., accelerations, headways) for comfort and safety reasons, deterioration in the transportation network performance is likely to happen. This is a possibility if the recommended ACC system settings by auto manufacturers are on the conservative side (i.e., leaving larger gaps between the vehicle ahead) or if ACC users choose more conservative settings than those employed in manual driving for safety concerns, which is likely, especially in the early adoption phase of such systems when users may be more cautious. This possible negative effect, therefore, emphasizes the need for traffic control to maximize the potential benefit and reduce the deterioration that these systems may cause. Most importantly, the desired headway setting in ACC systems has a significant impact on traffic performance. Ntousakis et al. examined the effect of the desired time headway setting in ideal noninterrupted flow conditions in which the network used for simulations was a single-lane stretch without any bottlenecks ( 2 ). The study demonstrated that as the ACC penetration rate increases, the capacity further expands if the time headway is less than 1.2 s, whereas capacity decreases with longer time headways (≥1.2 s) and increased ACC penetration rates. Makridis et al. ( 3 ) and Mattas et al. ( 4 ) analyzed the effect of ACC users adopting conservative time headways on a real freeway stretch, showing that this will lead to significant deterioration in a network’s performance. In research by Elmorshedy et al., the effects of adopting different headway settings in the context of a long and congested urban freeway corridor with multiple bottlenecks and hotspots were investigated ( 5 ). The results of this study quantified that shorter time headway settings result in greater improvements, whereas adopting long headways leads to performance deterioration, which worsens as the penetration rate increases. This highlights the need for implementing ACC control strategies to reduce the deterioration that can be caused by such systems to the greatest extent possible.
Headway control strategies can be implemented to reduce the deterioration caused by adopting conservative headway settings, as well as to increase the improvements that could be achieved by adopting shorter headways in case there is room for further improvement. We started this line of work by implementing a simple headway control strategy that varies the time headway according to the traffic situation ( 5 ). This has proven to be a promising solution to enhancing the performance of ACC systems and reducing the deterioration caused by their conservative behavior or, ideally, turning them into improvements. There are a few other studies in the literature that try to optimize ACC settings to maximize traffic flow. For example, Liu et al. studied the optimization of ACC system parameters, however, this study is based on an offline optimization technique that does not cope well with dynamically changing traffic conditions ( 6 ). Other studies address this limitation by adjusting the ACC system settings adaptively in real time according to dynamic traffic conditions (e.g., Elmorshedy et al. [ 5 ], Kesting et al. [ 7 ], and Spiliopoulou et al. [ 8 , 9 ]). However, these latter studies mainly rely on historical observations in selecting the control parameters, which may not guarantee optimal behavior of these systems in real time.
To address this limitation, several reinforcement learning (RL) AV control studies have recently been undertaken. Das and Won proposed a dynamic ACC system for a highway section with an on-ramp based on deep reinforcement learning (DRL) that adapts the headway according to changing traffic conditions for both the main road and ramp to optimize traffic flow ( 10 ). In a subsequent study, Das and Won went a step further by training the RL agent to control the optimal headway to maximize the combination of traffic flow, driving safety, and driving comfort ( 11 ). However, control in the studies by Das and Won was undertaken at the vehicle level for equipped vehicles on highway segments only, that is, each equipped vehicle updates its headway every control cycle in response to dynamically changing traffic conditions, which increases the complexity of the problem and its real-life implementation ( 10 , 11 ). This may also have a negative effect on traffic stability if neighboring vehicles are assigned different headways. Moreover, the reward in these studies seeks to minimize the average delay based on their knowledge of the congestion speed, which is obtained from historical data. Other RL control studies (e.g., Zhu et al. [ 12 ] and Yen et al. [ 13 ]) look into this problem from a car-following perspective, for which there are two vehicles, a leading and a following vehicle, both keeping their lateral positions in a lane, with the following vehicle adjusting its longitudinal speed to maintain a safe following distance. The action in these RL-car-following studies is the acceleration command, whereas the reward considers the performance of the agent to be based on comfort and safety. Human driving data are used to train the RL model and the results demonstrated that the proposed model has the capability for safe, efficient, and comfortable driving, outperforming human drivers.
In this paper, we specifically show that, although shorter headways result in higher capacity, as previously proven in the literature, flow breakdown still occurs if traffic densities at bottlenecks are allowed to exceed the critical density corresponding to the new higher capacity, regardless of how short the target headways might be. Therefore, dynamic traffic control near bottlenecks is still necessary to avoid bottleneck activation and capacity loss. We propose an adaptive RL headway controller that uses AV headways to optimize traffic flow and minimize delay. The controller dynamically assigns an optimal headway value for each freeway section within a control cycle, based on state measurements. Therefore, the main objective of this work focuses on developing a traffic control strategy based on real-time measurements of the traffic conditions to configure the headway parameter accordingly for improved network performance. To enable vehicles to adapt to the headway setting more effectively in a fine-grained manner according to the current traffic conditions, we adopt DRL, which is known to enable effective decision making in such a complex environment especially for AVs ( 14 ). We formulate the problem of determining the optimal desired headway setting based on the traffic condition information received via vehicle-to-everything communication (V2X) as a Markov decision process (MDP) ( 15 ). We then solve the problem by training an agent using the proximal policy optimization (PPO) algorithm ( 16 , 17 ). The PPO algorithm is suited for continuous state and action space. Considering that merging traffic is one of the major causes of traffic perturbations on freeways ( 18 ), we demonstrate the impact of our proposed control strategy on a general freeway scenario with a bottleneck represented by an on-ramp.
Microscopic simulations are conducted using a combination of Aimsun, a microscopic road traffic simulator ( 19 ), and a modified and extended version of the computational flow framework ( 20 ) in addition to the Reinforcement Learning Library (RLLib) ( 21 ) to train an RL agent and evaluate the performance of the proposed control strategy. We demonstrate that the RL-based headway control strategy improves traffic and the total system delay compared with the other examined headway scenarios. The contributions of this paper are summarized as follows:
We propose a novel RL-based headway control system that adaptively configures the ACC desired time headway settings in response to dynamically changing traffic conditions. In the proposed control concept, ACC vehicles communicate with a traffic management center that imposes appropriate values for the time-gap parameter to the ACC vehicles on a road segment-by-segment basis.
We formulate the problem of the dynamic headway adaptation from the traffic management center as an MDP. An RL agent is trained to periodically issue ACC time headway settings to minimize average system delay (by maximizing outflow through a bottleneck).
Microscopic simulations are conducted under a general highway scenario with a bottleneck represented by an on-ramp. We demonstrate that the proposed headway control strategy outperforms ACC systems with the other examined headway settings by reducing the congestion through demand pacing, which is found to be achievable via headway control. To the best of the authors’ knowledge this is the first study that attempts demand pacing through headway control.
This paper is organized as follows. The next section presents the concept of closed-loop optimal control, RL, and the PPO algorithm used in this work. We then conduct a motivational study to demonstrate that traffic breakdown can occur under all examined headway scenarios, justifying the need for further control, followed by the details of the proposed headway control system, including the MDP design and our agent for optimizing traffic flow. The simulation settings and results are subsequently presented and discussed, and our conclusions and future research directions are outlined.
Methodology
Traffic Control Strategies
Control strategies are classified as closed- or open-loop, depending on whether the control decision is based on real-time measurements or historical data, respectively ( 22 ). The open-loop optimal controller determines the control variable by solving an optimal control problem such that the control strategy achieves optimum system performance. However, this requires accurate models of the environment and accurate detailed data trajectories, which may not be available, as well as requiring huge computational power, which may not be suitable for large-scale, real-time applications. On the other hand, some control strategies seek decisions yielding the optimum process output, whereas others only aim to regulate the output at a certain exogenously defined level, which is not necessarily optimal. In the regulator-based control approach, the controller automatically adjusts the traffic flow to keep the controlled variable at a desired level, for example, maintaining traffic density at or slightly below critical density (at capacity), therefore the optimality of the solution may not be guaranteed. For this, the closed-loop optimal approach is the preferred control method, since it learns a control law or policy (i.e., the brain of the system), which is solvable by methods such as dynamic programming and RL control. RL approaches have been gaining popularity in traffic control over the last decade ( 23 ), especially model-free RL approaches (i.e., that do not require a model of the controlled environment). Rather, they learn to map the state of the system to optimal action by direct interactions with the environment. In relation to using a traffic model to control the environment, it can be argued that, in general, a good model is better than no model and no model is better that an inaccurate one. Traffic models, although abundant, are useful but not superb. Therefore, a model-free RL is a plausible option for traffic control.
In this study, we developed a traffic control strategy using closed-loop RL-based optimal control methods. The proposed control methods include algorithms and software systems for RL-based headway control in which the headway of the ACC-equipped vehicles is controlled upstream of bottlenecks on a section-by-section basis. The optimal control approach and methods mainly focused on the integration of deep neural networks (NNs) operating directly on detailed sensory inputs and feeding them into the RL-based optimal control method known as DRL. Traffic control with optimal ACC system parameters (e.g., headway) was accordingly developed for improved network performance. Analysis of the performance of this model was then conducted with a 100% ACC-equipped vehicles traffic population operating in dense traffic conditions. The advantage of the proposed traffic control strategy is that it can explicitly consider several objectives rather than efficiency alone, such as safety, traffic breakdown avoidance, and stability to impose headways achieving a certain objective or a balance between several objectives. In this work we proposed a traffic control strategy such that traffic breakdown is avoided at bottlenecks and congestion is reduced to the greatest extent possible by dynamically changing the desired headways. The freeway under study was divided into sections and the infrastructure-based optimal control strategy was applied via a traffic management center at every section independently or cooperatively, as illustrated in Figure 1.
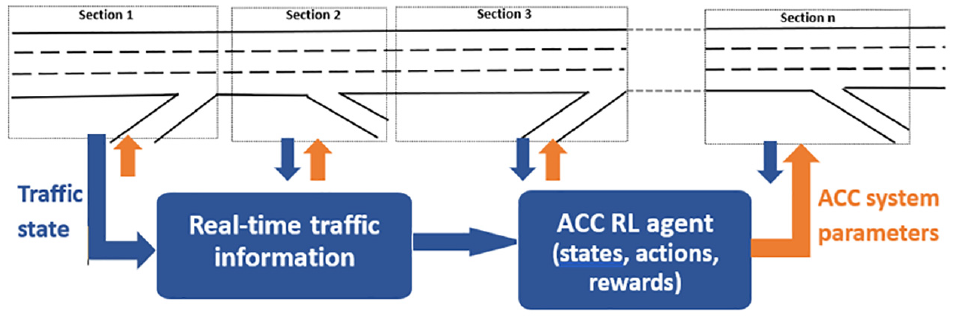
Proposed RL-based headway control system.
Reinforcement Learning and Proximal Policy Optimization
RL is an area of machine learning that approaches control problems by training artificial agents that iteratively learn to solve the control task by using feedback in the form of rewards obtained from the agent’s environment. The process of an agent interacting with its environment is formalized as an MDP, that is, the tuple
where
In the literature, it is common to define the reward function as having a dependence on the current state,
An agent’s policy is a function,
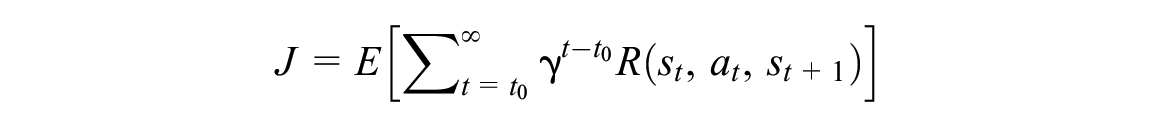
where the action at timestep
DRL is a collection of algorithms such as deep Q-learning (DQN), proximal policy optimization (PPO), and soft actor-critic (SAC) (
25
) that combines RL ideas with the recent advances in the representational power of and the training techniques for deep NNs. PPO is a type of policy gradient algorithm. In general, policy gradient algorithms represent the agent’s policy by a function,
PPO Details
In this subsection, we provide a succinct description of the PPO algorithm and its hyperparameters. The reader who is not interested in a detailed description of the PPO algorithm may prefer to skip ahead to the Experiment Setup section. We begin by recalling several basic concepts from RL (
15
). Recall that the state value,
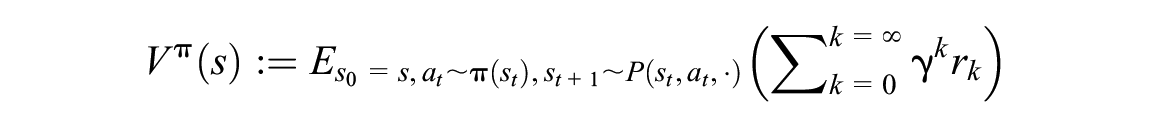
where
whereas the state–action value,
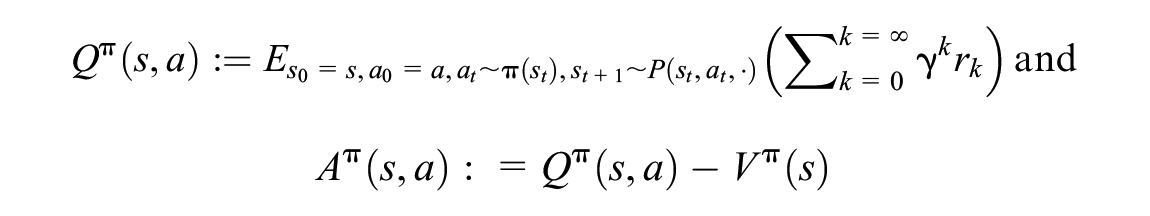
We interpret
The PPO algorithm uses two deep NNs (we used dense feedforward NNs in our experiments) to represent (1) the current policy,
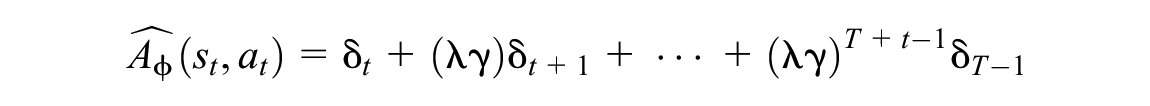
and the empirical return over the same trajectory is given by
We can now describe the PPO algorithm. During each iteration of the training loop, the PPO algorithm collects a trajectory of experience by interacting with the environment and sampling actions using the current policy,
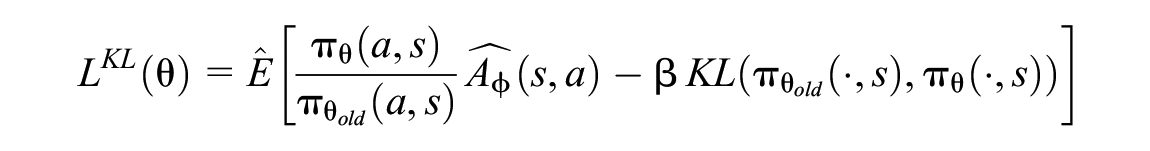
where
Then, the parameters,
Experiment Setup
Quantitatively Demonstrating Our Motivation
As concluded from the previously cited literature studies, shorter headways will yield better network performance compared with longer headways. In this section, however, we demonstrate that despite superior performance of ACC systems with short headways compared with their counterparts with long headways, traffic breakdown can still occur. Consider the network in Figure 2, which consists of a three-lane mainline and one ramp. We simulated ACC car-following in Aimsun Next 20, which uses the car-following model presented in the research by Milanés and Shladover ( 26 ). We examined the case of having 100% ACC vehicles. We investigated three scenarios in which the time headways were (1) 0.8 s (representing aggressive AVs), (2) 2.0 s (representing cautious AVs and considered the common default value recommended by manufacturers), and (3) a normally distributed headway ranging between 0.8 and 2.0 s with an average of 1.2 s (representing a range of settings selected by different drivers).

Case study network.
Figure 3 shows the average network throughput for the different headway settings considered for the freeway stretch illustrated in Figure 2. The results in Figure 3 show that the throughput decreased as the time headway adopted by the ACC users increased, which implies that the 0.8-s time headway scenario yielded the highest throughput. This result was intuitive, expected, and has been demonstrated previously in the literature. However, on examining the corresponding fundamental diagrams in Figure 4 of the bottleneck section, that is, the merge section highlighted in red in Figure 2, we clearly see the occurrence of traffic breakdown for all headway scenarios even for the 0.8-s headway, despite achieving the highest throughput among the considered headway scenarios. The black dashed lines in Figure 4 are the regression lines of the flow-density points of each headway scenario, in which we plotted the free-flow and congested lines separately to highlight the capacity loss resulting from the traffic breakdown. Consequently, the main motivator of our study was to investigate whether this breakdown could be avoided or reduced through more elaborate dynamic headway control.
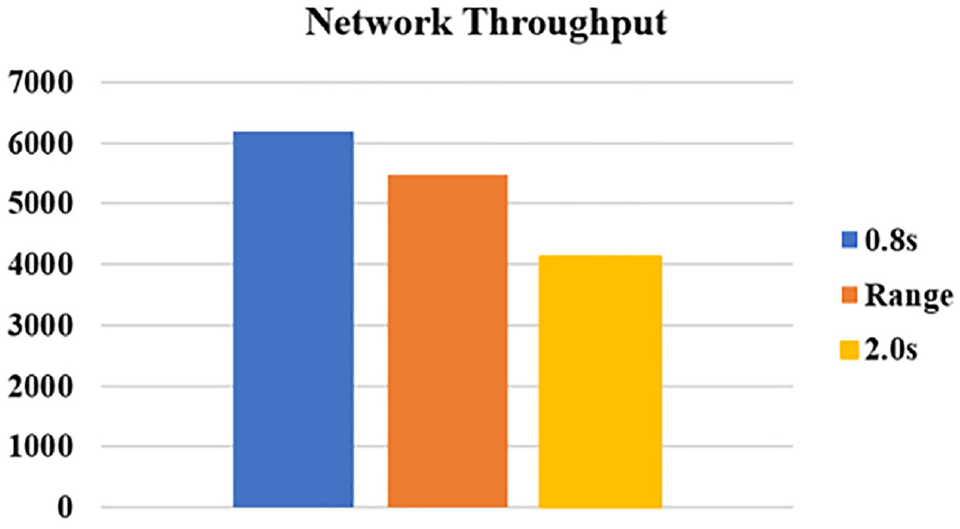
Network throughput for the different headway scenarios considered for the network in Figure 2.
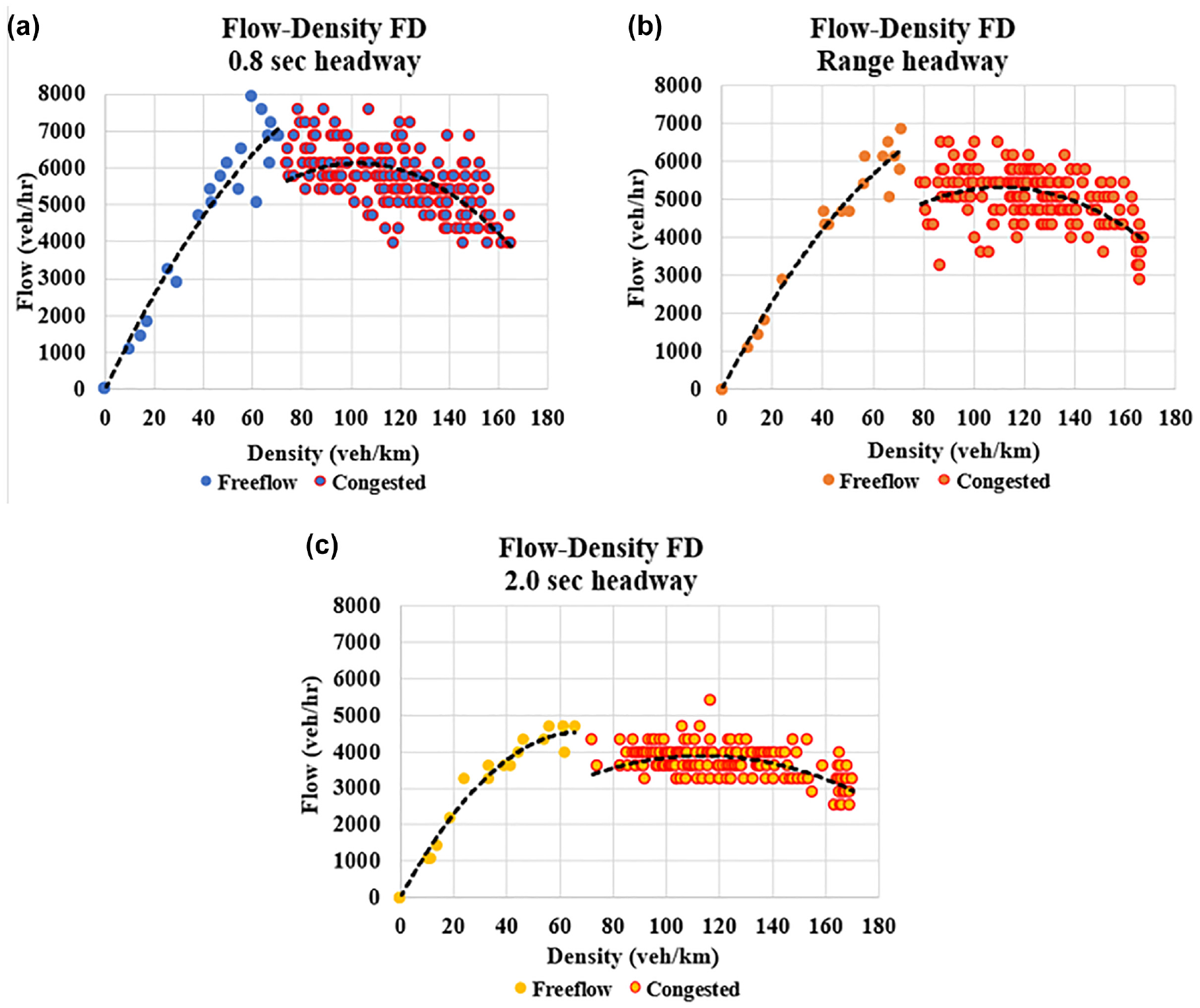
Flow-density fundamental diagram (FD) of the bottleneck section (merge section) for the different headway scenarios: (a) 0.8 s, (b) range headway, and (c) 2.0 s.
In our previous work, we demonstrated that in light traffic we could allow headways to be chosen by the driver, even if their choice was a long headway, because the impact on traffic was insignificant ( 5 ). However, in denser traffic, a simple on-off headway control strategy was demonstrated to improve freeway traffic performance significantly and transform the significant deterioration caused by adopting conservative headway settings into improvements by implementing the proposed control strategy ( 5 ). The simple headway control strategy implemented intervenes and imposes minimum headways in critical and near-critical traffic situations, aiming to maximize road capacities and overcome the deterioration that may be caused by the conservative behavior of ACC systems. In this paper, we further demonstrate that although tighter headways improve traffic, a breakdown still occurs at higher densities, which require further attention and more elaborate dynamic optimal headway control. We then propose and develop a closed-loop RL optimal headway controller that maximizes traffic performance and prevent flow breakdown.
Proposed Control Strategy
An overview of the RL headway control strategy is depicted in Figure 1. It is built on a feedback loop comprised of an RL agent that is used to control the desired time headway in response to dynamically changing traffic conditions to maximize network performance. This section explains the details of the MDP for the headway agent. The network under consideration is the same as the network in Figure 2, consisting of a three-lane mainline and a ramp, which was adopted from the geometry of the existing Churchill ramp in Toronto, ON, Canada. We divided the mainline into shorter segments/sections ranging between ∼300- and 500-m lengths, such that each segment/section received a headway action based on the state and reward, which we will discuss shortly. The mainline entry section denoted by 4304 and the ramp entry sections denoted by 4253 and 4254 were elongated to avoid the problem of queuing vehicles outside of the network by the end of the simulation (i.e., virtual queues in the simulation), thereby serving the whole traffic demand and having comparable performance metrics among the scenarios considered in this study. We had six mainline sections in total and three ramp sections, as illustrated in Figure 5.

Case study network divided into sections.
The RL-based headway agent was used to adjust the desired time headway in each section dynamically in response to the current traffic conditions. The details of the MDP for the headway agent were as follows:
A single environment step was a single control cycle, which for our experiment was equal to 10.0 s.
State space: The state space was designed to represent the current traffic conditions. The state space consists of the average flow and speed of vehicles on each network section over the previous control cycle, as measured by a detector placed near the middle of each segment. The observations are normalized by a constant to fit into the interval [−10, 10] to improve training ( 27 ).
Action space: Since the goal of the RL agent was to find the optimal desired headway and adapt it dynamically depending on the real-time traffic conditions, the action space was primarily designed to control the headway of each segment, such that all vehicles on the same segment were assigned the same desired headway. A total of 20 actions were defined for the time headway, which were chosen to be between 0.8 and 2.7 s with an interval of 0.1 for vehicles on the mainline, and between 1.0 and 20.0 s with an interval of 1.0 for vehicles on the ramp. The agent applied the headway settings to the vehicles in the network once at the beginning of the control cycle. The reasons for choosing different headway ranges for the mainline and ramp vehicles were (1) traffic breakdown was not avoided when the same ranges were assumed for mainline and ramp vehicles, since the ramp demand was quite high and found to be the main reason for congestion and traffic breakdown on the merge section, and (2) longer headways on the ramp created a ramp metering effect, which is an established traffic control method.
Remark (1): Our learning algorithm PPO can be applied with both discrete and continuous action spaces. Since the headway parameter is a continuous variable, it is natural to try to use PPO with a continuous distribution as the output of the policy network. After trying both continuous and discretized action spaces in our initial experiments, we saw no substantial differences in performance, but somewhat faster learning for the agent with discretized actions.
Remark (2): PPO learns a stochastic policy that maps an agent state to a probability distribution over actions in that state. After the training is complete, one may either sample actions according to the policy probability distribution, or always deterministically draw the action with the highest probability in a given state. We found that sampling actions stochastically even at test time gave better results.
Reward function: The design of the reward function is focused on maximizing the traffic flow, which in turn may yield a reduction in the average network delay if congested traffic states are avoided. Our choice of flow as the reward feature was to make sure that the chosen feature was measurable in real time and could be implemented in field test scenarios. It is worth mentioning that the whole traffic demand was served, and all vehicles entered the network by the end of the simulation in the considered control scenarios, that is, no vehicles were waiting outside of the network. This was done to ensure comparable performance metrics between the controlled and uncontrolled scenarios. We also wanted to investigate the effect of avoiding traffic breakdown on system delay and network throughput in line with the findings of Papageorgiou et al. that minimization of the total time spent in a traffic network is equivalent to maximization of the exit flows, given that the whole demand is served ( 28 ). Thus, the immediate reward is equal to the flow of the merge section, that is, Section 4258, received from the detector placed on that section, over the previous control cycle. The rewards were normalized by a constant to fit into the interval [−10, 10] to improve training ( 27 ).
Simulation Results
Microscopic simulations were conducted using the traffic simulator Aimsun Next 20. RL agents were trained using a modified and extended version of the computational flow framework ( 20 ) in combination with RLLib, version 1.8.0 ( 21 ). We considered a high demand scenario in this study such that we had a mainline demand of 6,000 vehicles per hour (vph) and a ramp demand of 1,260 vph following a constant distribution. The speed limit was assumed to be 120 km/h on the mainline and 50 km/h on the ramps. Note that the whole demand (7,260 vph) was tested first on the same network with no ramp demand to ensure that breakdown did not occur, which was confirmed. After that we attempted to divide the demand between the mainline and the ramp by a ratio analogous to that found in the real observed data. Our base-case uncontrolled scenario considered that the demand was made up of 100% ACC vehicles with headways ranging between minimum and maximum admissible ranges. We considered another base-case scenario in which all ACC users adopted the 0.8-s headway. The 0.8-s headway scenario yielded the best performance among longer headways, yet led to traffic breakdown and congestion on bottleneck Section 4258 (as previously shown in Figures 3 and 4), which our goal was to avoid by using the RL controller.
Vehicle length was assumed to be 5-m long. Each vehicle was laterally controlled according to the default lane-changing model in Aimsun ( 19 ) and was longitudinally controlled according to the target headway from our RL control model and the ACC car-following model developed by Milanés and Shladover ( 26 ), which was Aimsun’s default ACC car-following model. The simulated time was 33 min and 20.0 s, and the ACC-equipped vehicles updated their desired time headway every 10.0 s based on the segment they were on, in response to the changing traffic conditions, yielding 200 actions per rollout since the control cycle was equal to 10.0 s, and four rollouts per training iteration. In increasing or decreasing the headway, an acceleration of up to 2.0 m/s2 and a deceleration of up to 3.0 m/s2 were used. All traffic parameters and their default values used for this simulation study are summarized in Table 1, whereas the RL parameters are listed in Table 2.
Simulation Parameters
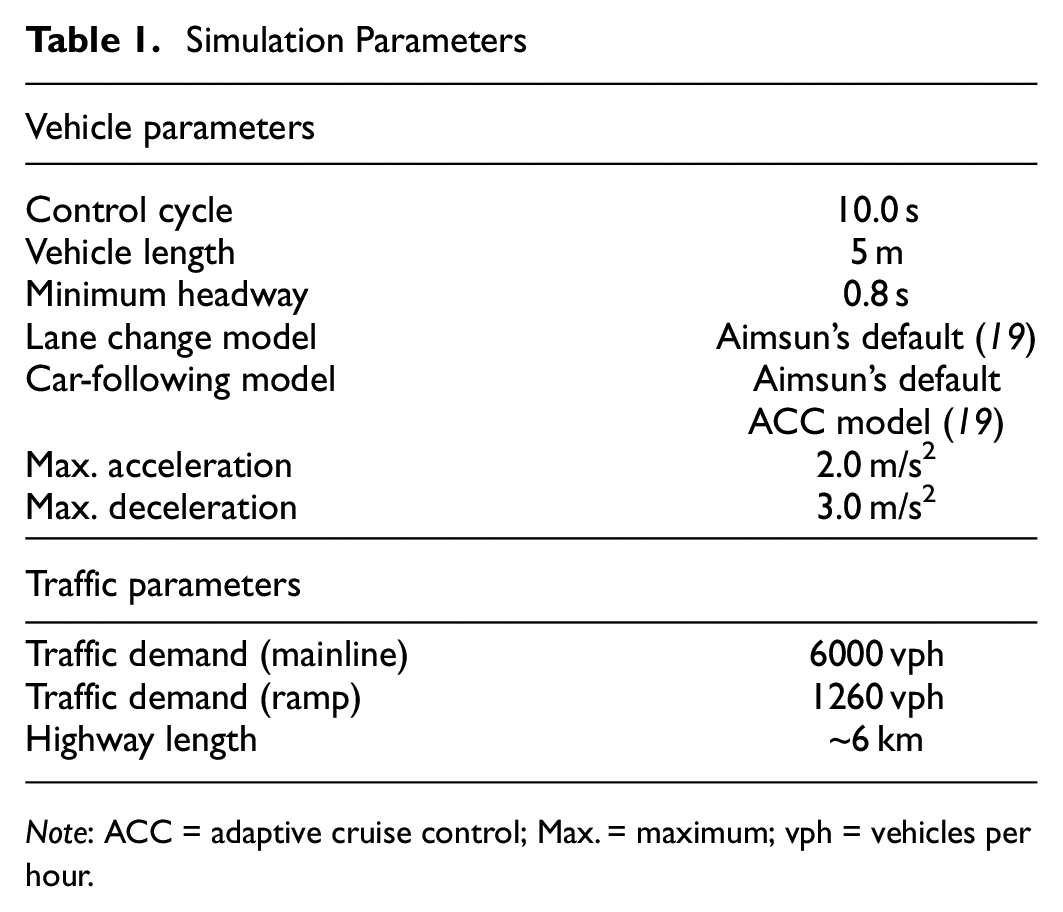
Note: ACC = adaptive cruise control; Max. = maximum; vph = vehicles per hour.
RL Parameters
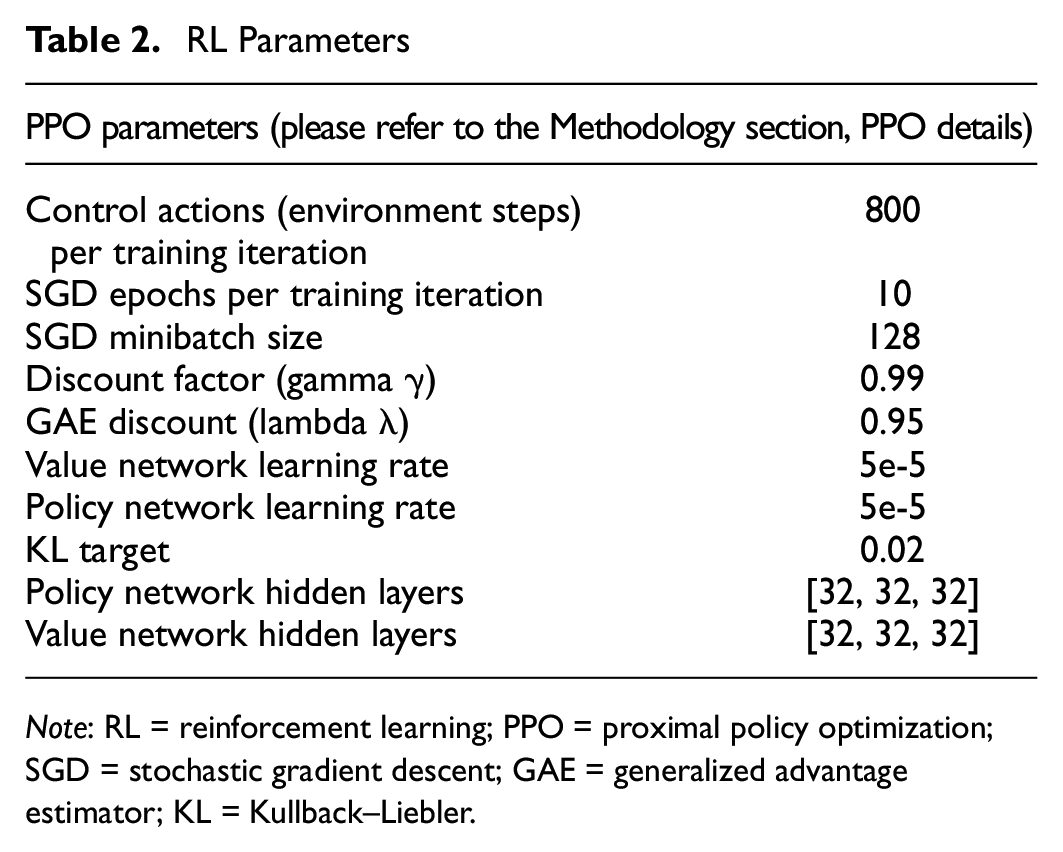
Note
The main performance metric considered in this simulation study was the average network delay of all vehicles in the given highway segment. This metric was chosen to effectively represent the traffic flow and the flow-density fundamental diagram of the bottleneck section to identify whether congestion was avoided or reduced via the RL-based headway control strategy. We compared the performance to the case when ACC users choose a headway between the minimum and maximum admissible ranges, that is, uncontrolled ACC, as well as when all ACC users adopt the minimum 0.8-s headway, which results in the best performance, yet leads to traffic breakdown on the bottleneck. We only controlled the segments upstream of the bottleneck, that is, four mainline segments and the ramp segment, whereas the remaining segments, that is, the bottleneck section and the one downstream of it, as well as the two sections generating the ramp demand, were assigned a 0.8-s desired time headway. The reason we assigned a 0.8-s desired time headway on those segments was that we aimed to achieve an improvement in the network performance compared with the 0.8-s headway scenario that achieved the best performance compared with longer headway scenarios.
We varied the controlled segments for the RL experiment such that we had three different control scenarios as follows: (1) controlling the mainline segments upstream of the bottleneck and ramp segment simultaneously, (2) controlling the ramp segment only, and (3) controlling the mainline segments upstream of the bottleneck only. This was done to understand the effect of controlling the segments on the mainline versus the on-ramp on avoiding traffic breakdown and reducing congestion. We ensured that the time headway did not fall below 0.8 s in any of the control scenarios to ensure safety. The number of training iterations performed was around 800 for Scenarios 1 and 3, and 400 iterations for Scenario 2. Figure 6 displays the results of our reward function with the number of iterations for all control scenarios, demonstrating the convergence of the reward function. Note the faster convergence of Scenario 2, because one segment was being controlled compared with five segments in Scenario 1 and four segments in Scenario 3, leading to easier training in Scenario 2.
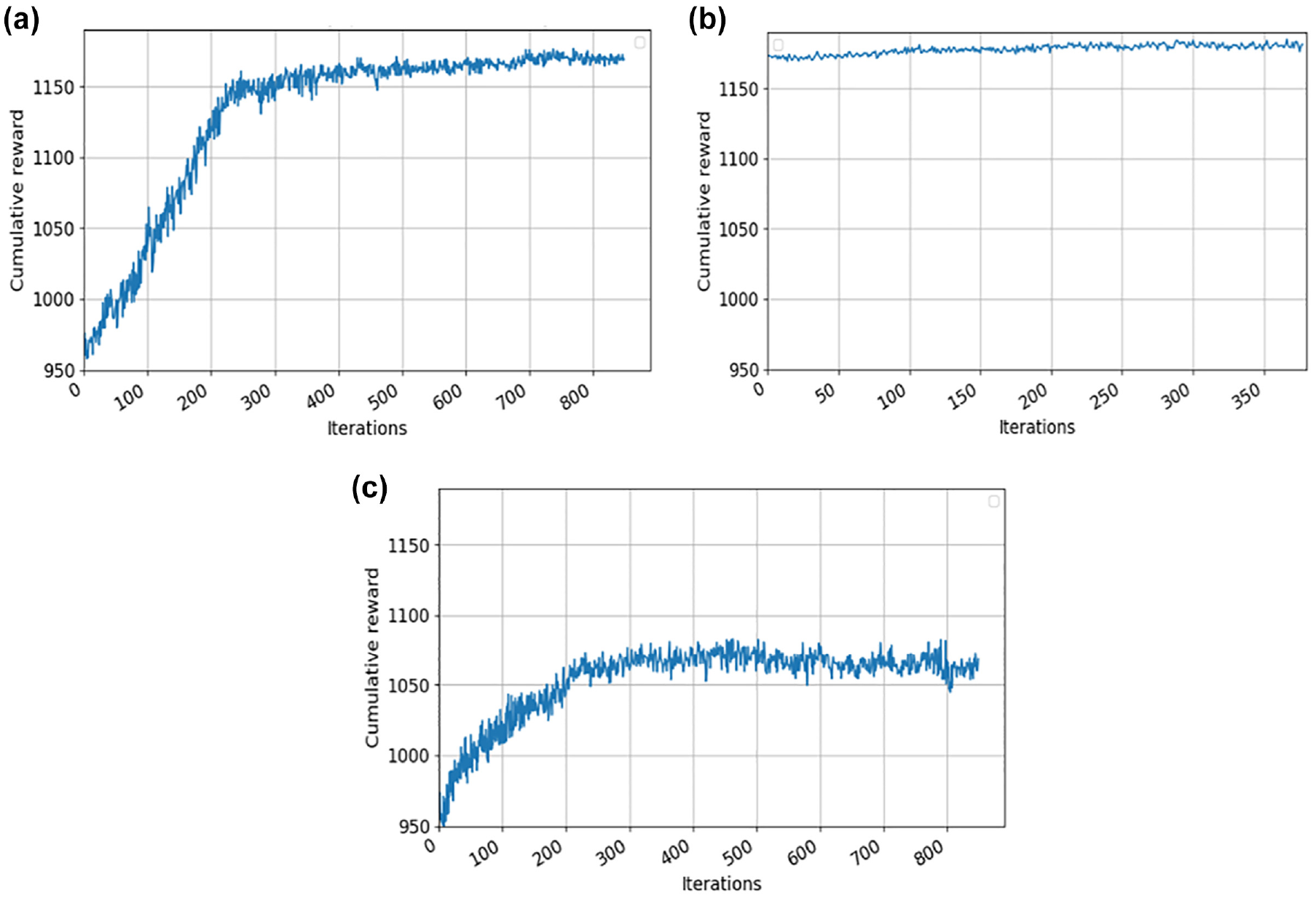
Reward function for (a) Scenario 1, (b) Scenario 2, and (c) Scenario 3.
Scenario 1: Simultaneously Controlling the Mainline and Ramp
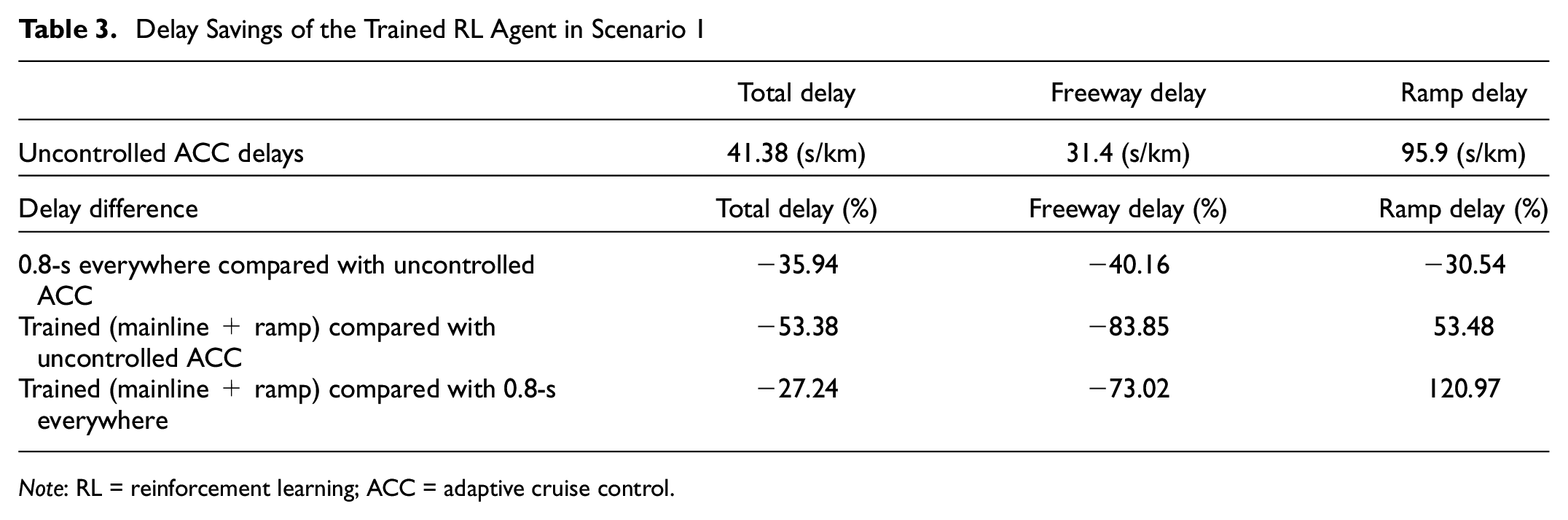
In this scenario, the RL agent controlled the mainline sections upstream of the bottleneck in addition to the ramp section (highlighted in yellow in Figure 7); the remaining segments were assigned a 0.8-s headway (highlighted in gray). First, we noted the delay differences of the 0.8-s headway everywhere scenario compared with the case of the range headway, that is, desired headways ranging between 0.8 and 2.0 s, which we refer to as uncontrolled ACC throughout this paper (see Table 3). We present mainline delay (i.e., the result of the delay of all vehicles on only the mainline sections), ramp delay (i.e., the result of the delay of all vehicles on the ramp sections only), as well as total delay, which takes into account delays from both the mainline and ramp vehicles. As expected, the 0.8-s everywhere scenario achieved a delay enhancement compared with the uncontrolled ACC case such that the total-, freeway-, and ramp delay all improved by 35.94%, 40.16%, and 30.54%, respectively. However, despite the 0.8-s headway scenario achieving an enhanced delay performance (see Table 3), congestion still occurred on the merge section (i.e., Section 4258), as previously outlined in the flow-density fundamental diagram (Figure 4). Our goal is to enhance the fundamental diagram through the proposed RL headway control strategy and examine its impact on the network delay compared to the 0.8-s headway scenario.
Delay Savings of the Trained RL Agent in Scenario 1
Note

Controlled section(s) in Scenario 1.
The delay differences of the trained RL agent in Scenario 1 compared with the uncontrolled ACC, as well as the 0.8-s headway everywhere (which our aim is to improve further), are presented in Table 3. By observing the delay difference for the trained RL agent compared with the uncontrolled ACC we found that total delay and freeway delay improved by 53.38% and 83.85%, respectively, which were significant improvements over the 0.8-s everywhere scenario, whereas ramp delay increased by 53.48%. This translated to a total delay improvement over the 0.8-s everywhere scenario of 27.24% and a freeway delay improvement of 73.02%, whereas ramp delay increased by 120.97% compared with the 0.8-s everywhere scenario.
The flow-density fundamental diagram of the bottleneck section (i.e., Section 4258) for the 0.8-s headway versus the trained RL agent in Scenario 1 is shown in Figure 8. It can be observed that the fundamental diagram of the trained RL agent is mostly in the free-flow regime as opposed to that of the 0.8-s headway, which is primarily in the congested regime, thereby leading to traffic breakdown and increased total delay. This explained the total delay improvement achieved with the RL-based headway control strategy as opposed to the 0.8-s scenario outlined in Table 3, which is a result of the headway control leading to a shift in the fundamental diagram, to be operating mainly in free flow.
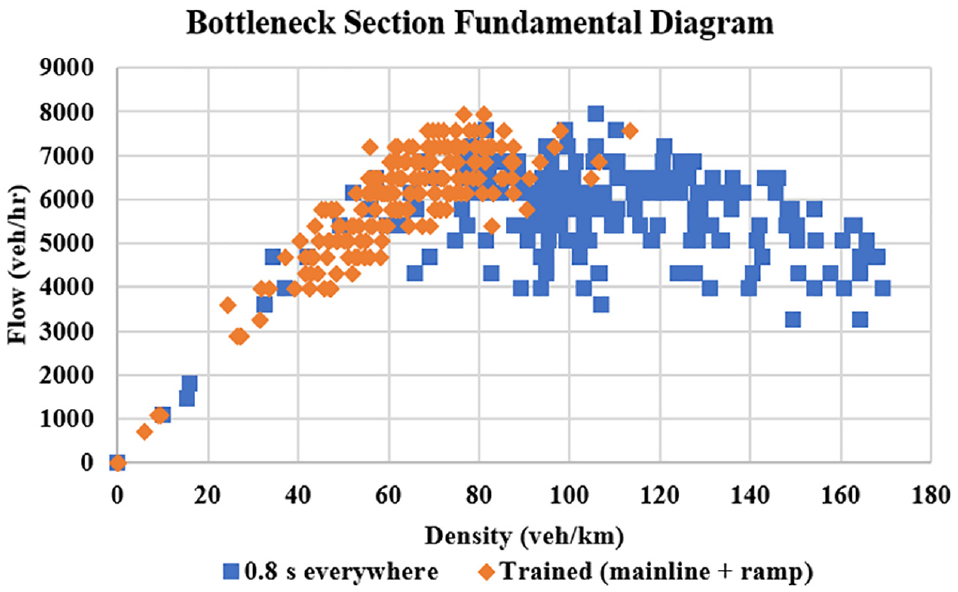
Flow-density fundamental diagram of bottleneck section (Section 4258) in Scenario 1 versus that of 0.8-s everywhere.
Conversely, the trained RL agent actions led to an increase in ramp delay, which motivated us to look further into the trained agent’s actions. In Figure 9 we present a histogram of the trained agent’s actions for one simulation after training completion: the y-axis represents the number of times an action is chosen, whereas the x-axis represents the desired time headway action selected by the agent. The agent’s actions for each controlled segment are presented separately, thus there are five separate histograms, each representing one of the five controlled segments in Scenario 1. The mean and median values were used as representations of the trained actions, but we have only presented the median values because both were found to be within similar ranges. By looking at the headway actions on the ramp section, Section 4255, we noted that 4.0 s was the headway action chosen by the agent most of the time whereas the median headway was found to be around 7.0 s. This explained the increase in the ramp delay for the RL agent compared with the uncontrolled ACC scenario, as well as the 0.8-s headway scenario, which could be considered the price paid for avoiding congestion leading to traffic breakdown, thereby yielding delay savings at a network level. The headway actions on the mainline sections seemed to be mostly chosen from the short headway range, in which the median headway actions were found to be around ∼1.0 s. This implies that to achieve a free-flow regime for this network, given the controlled segments outlined earlier, short headways should be imposed on the mainline to maximize network capacity, whereas long headways should be imposed on the ramp to limit the inflow, which seemed to be the main cause of traffic disturbance. In a sense, the agent was learning to slightly meter the mainline with headway control in a way that was analogous in its effect to dynamic speed limit control, as found in research by Papageorgiou et al. ( 29 ), Jin and Jin ( 30 ), and Yang et al. ( 31 ), while metering the ramp with headway control in a way that was analogous in its effect to traditional ramp metering, as presented in Papageorgiou and Kotsialos ( 32 ), Rezaee et al. ( 33 ), and Davarynejad et al. ( 34 ).
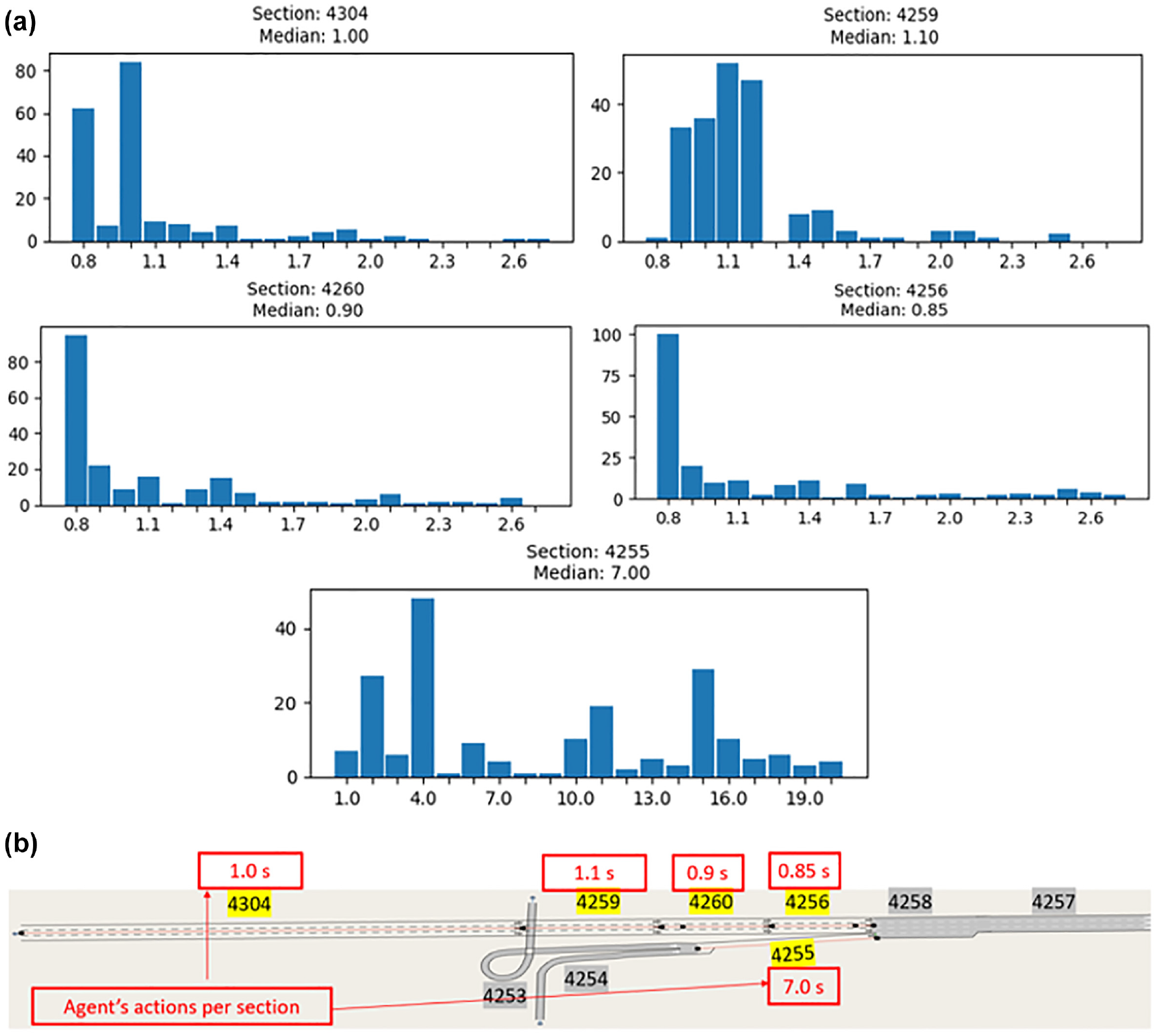
Trained actions for Scenario 1 shown via: (a) Histograms and (b) Median headway values denoted above each controlled section.
Scenario 2: Controlling the Ramp Segment Only
In this scenario, the RL agent controls only the ramp section (highlighted in yellow in Figure 10). All remaining segments were assigned a 0.8-s headway (highlighted in gray), that is, all vehicles on those segments were assigned a 0.8-s desired time headway.

Controlled section(s) in Scenario 2.
The delay differences with respect to the case of uncontrolled ACC, and as compared to the 0.8-s headway scenario are presented in Table 4. By observing the delay difference for the trained RL agent compared with the uncontrolled ACC we found that total delay and freeway delay improved by 56.71% and 88.99%, respectively, whereas ramp delay increased by 49.75%. The delay differences between the trained RL agent in Scenario 2 and the 0.8-s headway scenario shown in Table 4 illustrated that the total delay and freeway delay improved by 32.43% and 81.61%, respectively, whereas ramp delay increased by 115.60%. These improvements/deterioration are in line with the delay savings in Scenario 1 (Table 3): total delay and freeway delay improved whereas ramp delay worsened. However, the main differences were that the improvements were slightly higher, and the deterioration slightly less in Scenario 2, which implies superior performance compared with the trained RL agent in Scenario 1.
Delay Savings of the Trained RL Agent in Scenario 2

Note
The flow-density fundamental diagram of the bottleneck section, that is, Section 4258, for the 0.8-s headway versus the trained RL agent in Scenario 2 are shown in Figure 11. It can be observed that the fundamental diagram of the trained RL agent is mainly in the free-flow regime with very few points in the congested regime, as opposed to the fundamental diagram of the 0.8-s headway, which is mostly in the congested regime. This is again in line with the fundamental diagram of the bottleneck section resulting from the trained agent in Scenario 1 (Figure 8), although in Scenario 2 we only controlled the ramp section. This implies that the merging demand was the main reason for traffic breakdown and congestion and to address this behavior, demand should be regulated via headway control.
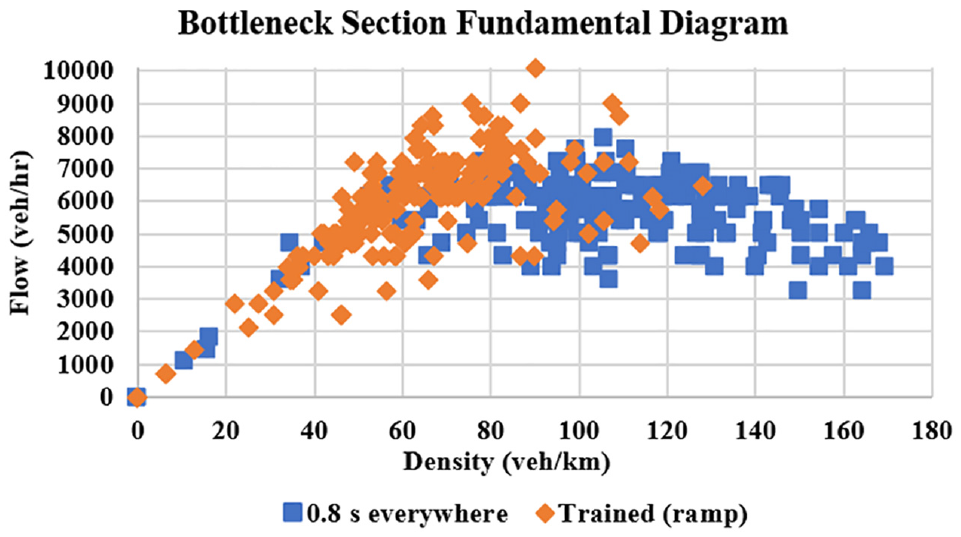
Flow-density fundamental diagram of bottleneck section (Section 4258) in Scenario 2 versus that of 0.8 s everywhere.
The histogram of the trained agent’s actions in Scenario 2 is presented in Figure 12. By looking at the headway actions on the ramp section—the only controlled section in this scenario—we noted that 4.0 s was the headway action chosen by the agent most of the time, whereas the median headway was 5.0 s. This again justified the increase in the ramp delay for the RL agent compared with the uncontrolled ACC scenario, as well as the 0.8-s headway scenario. However, the ramp delay increase in Scenario 2 is considered to be less than that in Scenario 1 because of the shorter median headway imposed on the ramp, that is, 5.0 s median headway in Scenario 2 as opposed to 7.0 s median headway in Scenario 1. Therefore, the improvement in Scenario 2 over Scenario 1 is most likely because of the shorter median headway imposed on the ramp compared to the median headway imposed in Scenario 1, which may be because of easier/faster training since one section is trained in Scenario 2 as opposed to five sections in Scenario 1. In a sense, the agent in Scenario 2 is learning to meter the ramp with headway control in a way analogous in effect to traditional ramp metering as in Papageorgiou and Kotsialos ( 32 ), Rezaee et al. ( 33 ), and Davarynejad et al. ( 34 ), without resorting to controlling the mainline. We speculate that because the mainline demand is high, attempting to control the mainline together with controlling the ramp as in Scenario 1 is less successful compared to controlling the ramp only in Scenario 2.
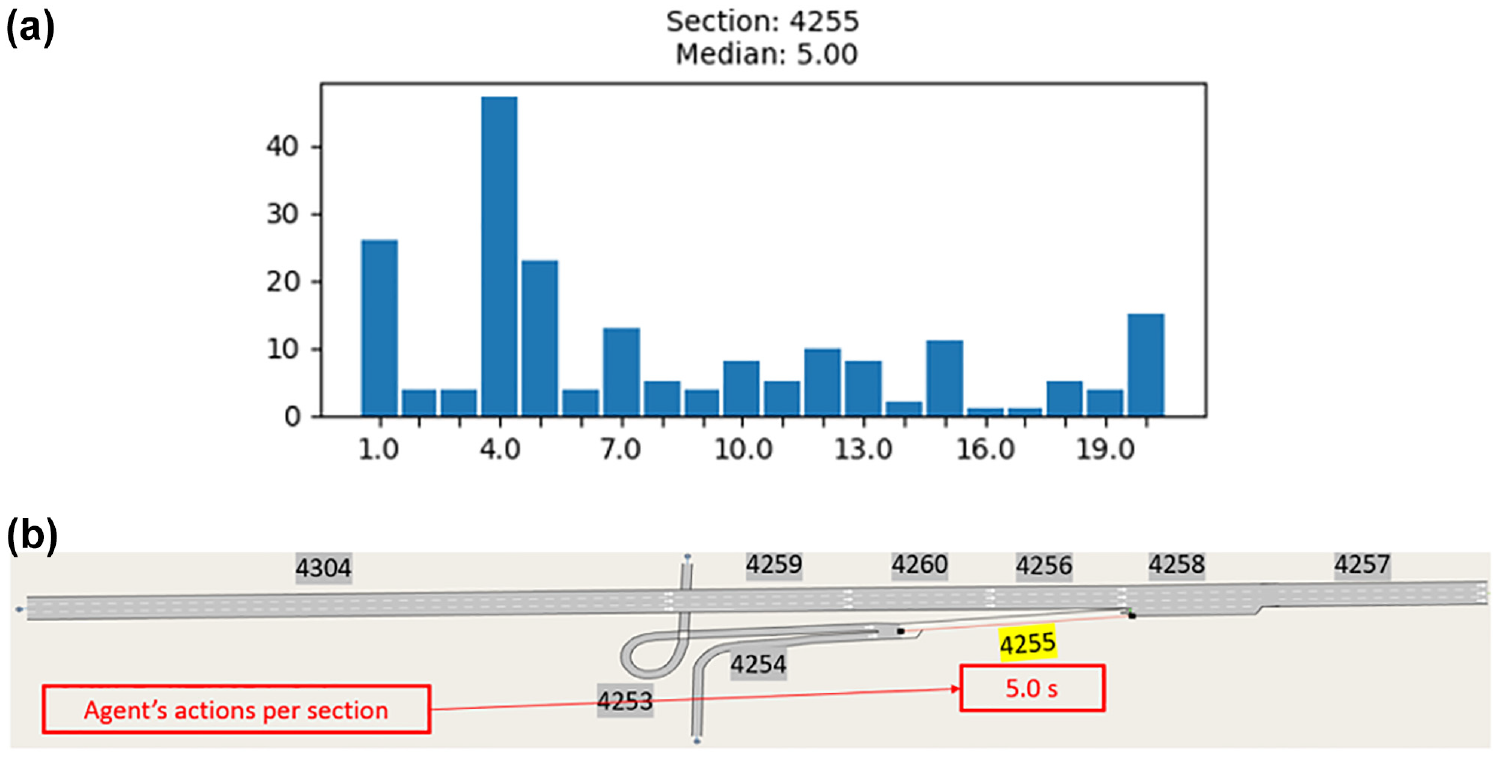
Trained actions for Scenario 2 shown via: (a) Histograms and (b) Median headway value denoted above the controlled section.
Scenario 3: Controlling the Mainline Only
In Scenario 3, the RL agent attempted to control only the mainline sections upstream of the bottleneck: Sections 4304, 4259, 4260, and 4256 (highlighted in yellow in Figure 13; all remaining sections, in gray, were assigned a 0.8-s headway).

Controlled section(s) in Scenario 3.
The delay differences between Scenario 3 and the uncontrolled ACC scenario as well as the 0.8-s headway scenario are presented in Table 5. By observing the delay difference for the trained RL agent compared with the uncontrolled ACC we found that total-, freeway-, and ramp delay improved by 45.51%, 32.66%, and 69.59%, respectively. It is worth mentioning that ramp delay in Scenario 3 improved as opposed to increasing in both Scenarios 1 and 2, which was expected because the ramp section was always assigned a 0.8-s headway in this scenario whereas it was controlled in Scenarios 1 and 2 with long headways if needed. Total- and freeway delay also improved in this scenario, however, the improvement was found to be much smaller than that achieved in Scenarios 1 and 2: freeway delay improved by 32.66% in Scenario 3 as opposed to improving by 83.85% and 88.99% in Scenarios 1 and 2, respectively.
Delay Savings of the Trained RL Agent in Scenario 3

Note
Moreover, the delay differences between the trained RL agent in Scenario 3 and that of the 0.8-s headway scenario shown in Table 5 illustrated that total- and ramp delay improved by 14.95% and 56.21%, respectively, whereas freeway delay increased by 12.53%. Total delay improvement over the 0.8-s headway in Scenario 3 was much smaller than that achieved in Scenarios 1 and 2: total delay improved by 14.95% in Scenario 3 as opposed to improving by 27.24% and 32.43% in Scenarios 1 and 2, respectively. This can be explained by demand being paced in this scenario via the mainline sections, which yielded a delay improvement for the ramp vehicles since they were merging more easily, however, this also led to an increase in delay for the mainline vehicles because longer headways may have been imposed to pace mainline demand. The difference here is that the enhancement in ramp delay did not lead to a significant enhancement in the total delay owing to the increase in the mainline delay, which most likely made a greater contribution to the total delay as it represents the bulk of the traffic demand compared with ramp demand.
The flow-density fundamental diagram of the bottleneck section (Section 4258) of the 0.8-s headway versus the trained RL agent in Scenario 3 is shown in Figure 14. It can be observed that traffic breakdown was not avoided via headway control when controlling the mainline sections only, since the fundamental diagram had points in both the free-flow and congested regimes, which was almost similar to the fundamental diagram of the 0.8-s headway but with slightly more points in free flow owing to pacing the demand on the mainline. This again implies that the merging demand was the main reason for traffic breakdown and congestion in this study and to enhance this behavior, this demand should be regulated via headway control.
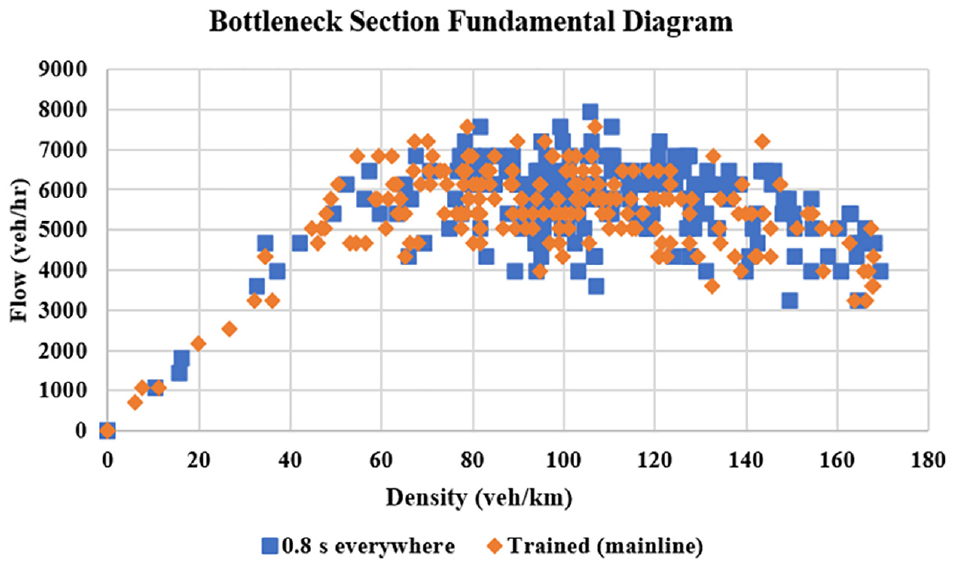
Flow-density fundamental diagram of bottleneck section (Section 4258) in Scenario 3 versus that of 0.8 s everywhere.
The trained agent’s actions in Scenario 3 are illustrated in the histograms presented in Figure 15. The headway actions on the early upstream mainline sections—Sections 4304 and 4259—had a median headway of 1.4 and 1.6 s, respectively. It is worth mentioning here that a shorter median headway was imposed on the mainline entry section (i.e., 4304) to avoid vehicle queuing outside the network and achieve maximum flow within the bottleneck section according to the reward definition. However, the headway actions on the mainline sections approaching the bottleneck—Sections 4260 and 4256—seemed to be shorter since they had a median headway of 1.2 and 0.9 s, respectively. It can be observed from the trained agent’s actions that demand was being paced by imposing longer headways on the early upstream mainline sections, while the headways were being tightened as we approached the bottleneck to maximize the flow there and, at the same time, avoid or at least reduce congestion. This was also observed when pacing mainline demand in Scenario 1 and was conceptually analogous to how variable speed limits are implemented in conventional traffic control ( 30 ). The agent was able to slightly enhance total delay compared with the 0.8-s headway everywhere by pacing mainline demand and improving ramp delay, however freeway delay increased and traffic breakdown was not avoided. Therefore, it was evident that the merging demand was the main source of disturbance in this problem, which would be the main demand regulated if we were seeking to avoid congestion and operate in a free-flow regime.
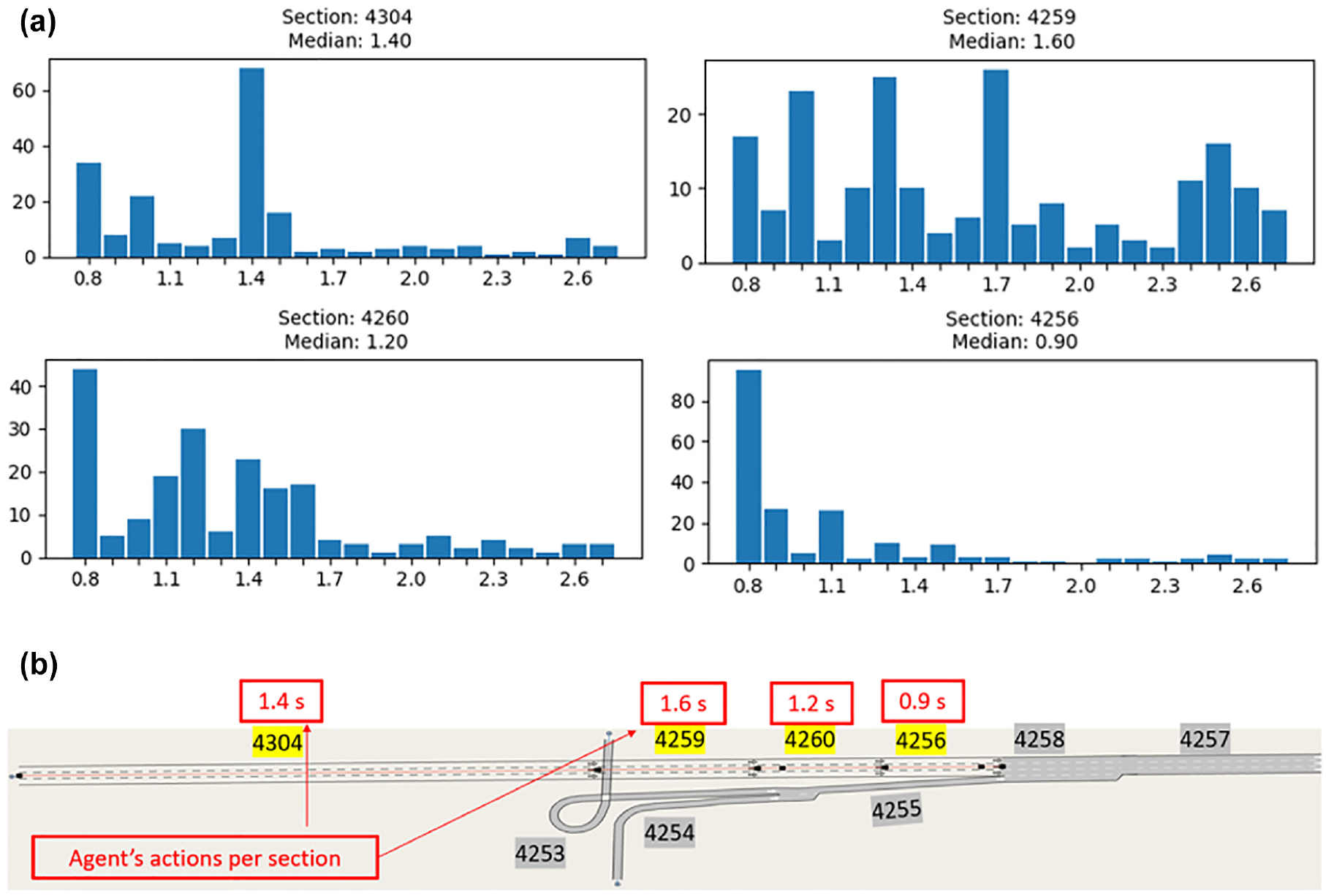
Trained actions for Scenario 3 shown via: (a) Histograms and (b) Median headway values denoted above each controlled section.
Finally, we would like to emphasize that no vehicles were outside of the network waiting to enter by the end of the simulation in all control scenarios considered in this study. Therefore, it was anticipated that the proposed control strategy would maximize traffic flow as a result of the enhanced fundamental diagrams as well as the reduced delays. This was confirmed by plotting the network throughput as well as the cumulative flow on the bottleneck section (i.e., the sum of all flows at every control cycle on that section, as shown in Figure 16). The figure shows that the cumulative flow on the bottleneck section as well as the network throughput of the trained agent in Scenarios 1 and 2 were higher than those of the uncontrolled ACC and 0.8-s scenarios. Note that Scenarios 1 and 2 demonstrated the best delay improvements as a result of enhancing the bottleneck’s fundamental diagram through headway control. The trained agent in Scenario 3, on the other hand, had a slightly lower cumulative flow within the bottleneck section and a slightly lower throughput than the 0.8-s scenario. This can be explained by the slight enhancement in the system delay compared with the 0.8 s scenario, since the agent in Scenario 3 failed to avoid breakdown in the bottleneck section.
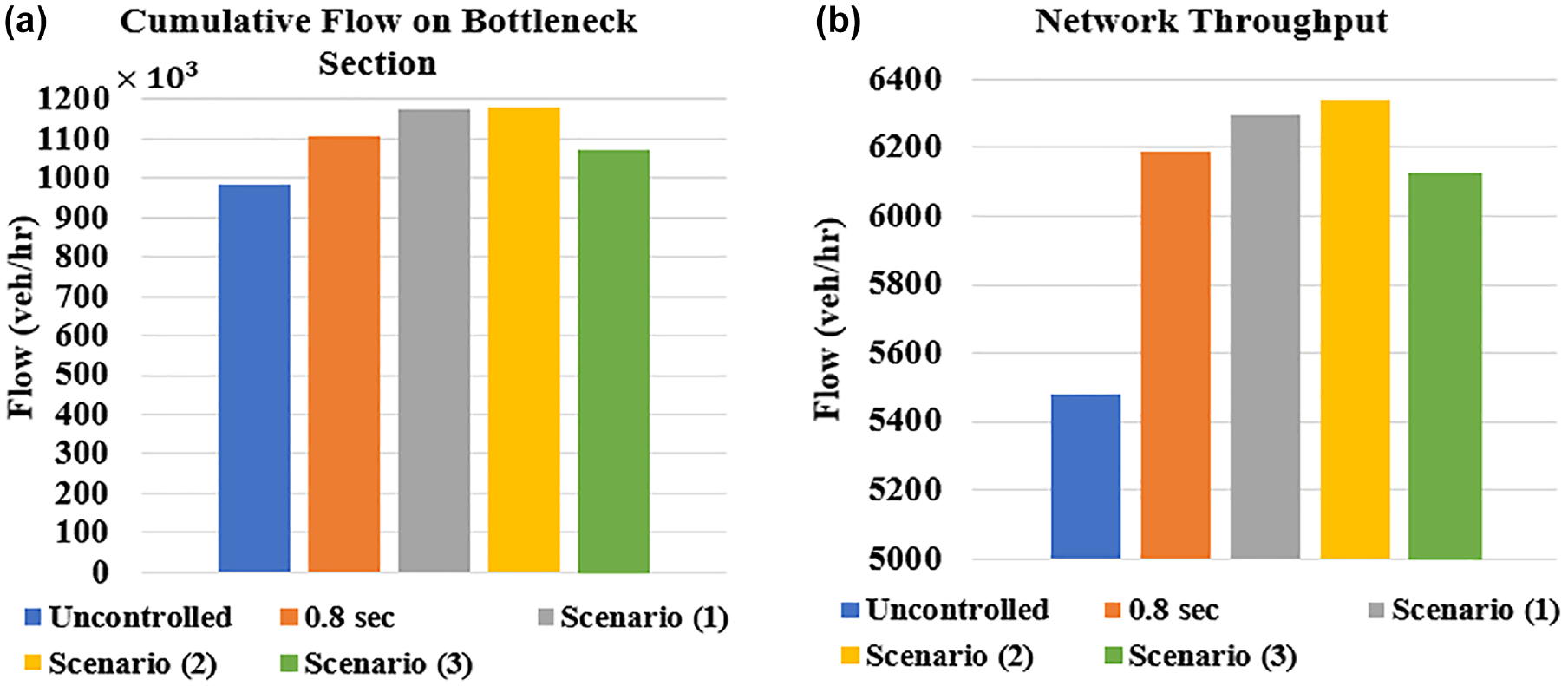
(a) Cumulative flow on the bottleneck section, and (b) network throughput for the considered control- and base-case scenarios.
Discussion
Based on the research presented in this paper, we provide the following observations and key findings:
The desired time headway has a significant impact on network performance: It is well known that desired time headway has a direct impact on the efficiency of a transportation network, and has been shown in several studies that, as the time headway decreases, the capacity of the network increases and its efficiency is enhanced. Therefore, the shortest headway will almost always yield the best network performance, notwithstanding congestion could still be occurring, thereby activating bottlenecks and leading to traffic breakdown, as illustrated earlier in our work. This implies that, in addition to generally tightening headways, there is room for further improvement via dynamic headway control on an infrastructural level, especially with the advent of AVs and vehicle-to-infrastructure communication.
Traffic breakdown can be avoided via headway control: Our results on a short network consisting of a three-lane mainline and a ramp representing the bottleneck showed that, although the minimum 0.8-s headway (assumed in this work) yielded the best performance, compared with the maximum 2.0-s headway and the headway distribution ranging between those two values, traffic breakdown still occurred on the bottleneck section and traveled to the upstream sections, causing congestion. This traffic breakdown could be avoided through segment-level dynamic headway control via RL techniques, found to be effective approaches to pacing demand, and resulting in an enhancement in the total network delay when compared with the minimum headway everywhere scenario. The dynamic controller acts in a manner similar to either ramp metering alone, dynamic speed limit control alone, or a combination of the two. The best performance in this study resulted from controlling the ramp only, by increasing the desired headway on the ramp (and therefore decreasing ramp flow) when necessary to avoid breakdown of the mainline flow.
Choosing which sections to control upstream of the bottleneck for optimum performance depends on the demand profile: It is worth mentioning that traffic breakdown was avoided in Scenario 1 in which the mainline sections upstream of the bottleneck were controlled in addition to the ramp section, and in Scenario 2 in which only the ramp section was controlled; it was not avoided in Scenario 3 in which only the mainline sections upstream of the bottleneck were controlled. Because of high demand on the mainline as well as from the on-ramp, ramp control only or ramp control and some light mainline control were found to be best for addressing system delay. Mainline control only was not found to be as beneficial because any slowing down of the mainline caused an increase in delay that outweighed any ramp delay improvements.
As the number of controlled segments increase, training may be slower, and the optimal solution could be more difficult to achieve for a single agent. It was also observed that Scenario 2 in which only the ramp was controlled achieved a slightly better delay performance than Scenario 1 (i.e., mainline and ramp were controlled together). This may have resulted from slower training, when more segments were being controlled. In future research we will attempt to tackle longer freeways using multiagent RL control; our aim will be to identify an efficient solution compared with a single agent that may have training difficulties because of the dimensionality of the control problem. We aim to investigate independent- and coordinated multiagent RL configurations on a larger network to compare their performances and outline their advantages over a single global agent configuration.
Summary and Conclusions
This paper presents a headway control system designed to adapt the desired time headway using RL in response to dynamically changing traffic conditions to enhance traffic flow efficiency. The proposed control strategy was assessed through microscopic simulation using a freeway stretch, in which congestion was created via an on-ramp bottleneck. The control strategy was implemented on an infrastructural level on a segment-by-segment basis, such that all vehicles on the same segment received a certain desired headway action. Our goal was to reduce congestion by avoiding traffic breakdown at the bottleneck and achieve enhanced performance over short but nondynamic headways of 0.8 s. The simulation results showed that the implemented control strategy improved traffic flow and enhanced total system delay by pacing the demand through headway control and shifting the fundamental diagram to be operating in a free-flow regime. Our future work will involve implementing the headway control strategy on a larger network with multiple bottlenecks/ramps and investigating network performance in a multiagent RL setting.
Footnotes
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: L. Elmorshedy, I. Smirnov, B. Abdulhai; analysis and interpretation of results: L. Elmorshedy; draft manuscript preparation: L. Elmorshedy. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is funded by the Natural Sciences and Engineering Research Council of Canada and Huawei Canada Research Centre.