
Abstract
Same-day delivery (SDD) services have become increasingly popular in recent years. These have been usually modeled by previous studies as a certain class of dynamic vehicle routing problem (DVRP) where goods must be delivered from a depot to a set of customers in the same day that the orders were placed. Adaptive exact solution methods for DVRPs can become intractable even for small problem instances. In this paper, the same-day delivery problem (SDDP) is formulated as a Markov decision process (MDP) and it is solved using a parameter-sharing Deep Q-Network, which corresponds to a decentralised multi-agent reinforcement learning (MARL) approach. For this, a multi-agent grid-based SDD environment is created, consisting of multiple vehicles, a central depot, and dynamic order generation. In addition, zone-specific order generation and reward probabilities are introduced. The performance of the proposed MARL approach is compared against a mixed-integer programming (MIP) solution. Results show that the proposed MARL framework performs on par with MIP-based policy when the number of orders is relatively low. For problem instances with higher order arrival rates, computational results show that the MARL approach underperforms MIP by up to 30%. The performance gap between both methods becomes smaller when zone-specific parameters are employed. The gap is reduced from 30% to 3% for a 5 × 5 grid scenario with 30 orders. Execution time results indicate that the MARL approach is, on average, 65 times faster than the MIP-based policy, and therefore may be more advantageous for real-time control, at least for small-sized instances.
Keywords
Same-day delivery (SDD) services as used by online retailers seek to deliver goods to customers less than 24 h after the order is placed. SDD services play an integral part in e-commerce by allowing online retailers to offer the immediacy of in-person shopping to their consumers. In fact, SDD market size is predicted to grow from $4.7 billion to $9.6 billion in 2022 in the U.S. alone ( 1 ). This increase in demand is likely to have accelerated even more because of consumers massively adopting online shopping during the COVID-19 pandemic.
However, this upward trend in SDD services has led to new challenges related to sustainability, costs, and aging workforce. According to Boysen et al., an increase in delivery vans entering city centers negatively affects the environment, human health, and road safety ( 2 ). Labour costs associated with traditional van deliveries are high and an aging workforce in many industrialised countries exacerbates the problem of labour shortage for such a physically demanding job ( 3 ). Furthermore, SDD may reduce efficiencies by diminishing the chance for consolidated deliveries with a full load. This worsens the impact of last-mile delivery on the environment. Therefore, as the SDD market continues to grow, it becomes increasingly important to optimise its operations.
Since SDD services have only recently been widely adopted, the literature in the context of the dynamic vehicle routing problem (DVRP) is relatively scarce. A few of the recent approaches in the literature include a sample-scenario planning approach, a dynamic dispatch waves approach, and mixed-integer programming (MIP). These studies will be further analysed in the Literature Review.
Exact solution methods for DVRPs rarely scale past a few vehicles ( 4 ). Reinforcement learning (RL), on the other hand, has arisen as a powerful method that can potentially scale to thousands of vehicles and orders. Recently, the combination of deep neural networks (DNNs) with RL has shown to achieve superior performance against MIP solvers in similar fleet management problems ( 6 ). In addition, DNNs allow for offline training and real-time execution, which is crucial for the same-day delivery problem (SDDP).
To the best of the authors’ knowledge, only Chen et al. have implemented RL to solve an SDDP involving heterogeneous fleets of drones and vehicles ( 5 ). However, the RL developed only solves the assignment part of the problem of whether an order is assigned to a drone or a vehicle. Other decisions, such as route planning and pre-emptive depot return, are solved using separate heuristics and algorithms which may lead to sub-optimal policies. Outside the SDD literature, RL has been used to solve a similar on-demand pick-up and delivery (ODPD) problem. Balaji et al. showed that RL outperforms a MIP solution approach to the ODPD problem, for a single vehicle scenario ( 6 ).
This paper makes an important contribution to the SDD literature by exploring the implementation of a state-of-the-art decentralised multi-agent deep RL approach. More specifically, a multi-agent version of the well-known Deep Q-Network (DQN) method, called parameter-sharing DQN, is adopted. The main advantage of this method over MIP-based solvers is the real-time execution (after offline training), which is particularly important in SDD to meet customers’ expectation of immediate response. In addition, the MARL formulation gives extra flexibility by allowing agents to determine policies about which deliveries can strategically wait at the depot or pre-emptively return to depot, reject services, or execute unconventional routes in anticipation of future orders. These flexibilities have been shown to significantly improve performance ( 7 – 9 ). Nevertheless, one of the biggest challenges of RL for vehicle routing problem (VRP)-related problems is the large action space, which can limit algorithm scalability.
In short, this paper aims to further explore and fill in the gaps in the SDD literature with the following step-by-step objectives:
To model SDDP as a Markov decision process (MDP) with an action space that allows for different agent strategies, such as the ones described above.
To develop a virtual environment based on the MDP model as a simulator for the MARL framework.
To implement a state-of-the-art MIP solution approach for SDDP as a benchmark for the MARL approach.
To assess the performance and scalability of the proposed MARL approach.
The rest of the paper is structured as follows. First, the literature related to SDDP and the RL solution approach is discussed. Then, a general description of SDDP is given, along with a general MDP model formulation, followed by a presentation of the RL solution approach, or, more specifically, the parameter-sharing DQN algorithm. The results section describes the set-up of the experiments, the implementation of DQN, the benchmark algorithm, and, lastly, the results of the experiments. Finally, the paper is concluded and the potential directions for future work are discussed.
Same-Day Delivery Problem (SDDP) and Vehicle Routing Problem (VRP)
Same-Day Delivery Problem (SDDP): General Background
SDDP involves the delivery of goods from a depot to customers, with customer requests coming in over the course of a day. The goods must be picked up from a depot before delivery can occur and must be delivered within the same day. SDD-specific literature is relatively scarce as it is very recent, although it is becoming an increasingly popular service in the real world.
Azi et al. considered SDDP for a fleet of vehicles and approached the problem by considering multiple scenarios for future requests to make decisions on whether to accept a request or not ( 7 ). Similarly, Voccia et al. solved the same problem with the same sample-scenario planning approach, but it differs in that it allows vehicles to strategically wait at the depot in anticipation of future requests that can fit into the current planned route ( 8 ). This additional flexibility is particularly useful when orders are heterogeneously spaced in time. In contrast to waiting, Ulmer et al. investigated a strategy that allows vehicles to pre-emptively return to depot before serving all customers ( 9 ). They found that this strategy increases the number of customers served per workday using a combination of routing heuristic together with approximate dynamic programming methods.
Several studies have approached SDDP by formulating it as a dynamic dispatch waves problem (DDWP) ( 10 – 12 ). DDWP only allows starting of routes at certain dispatch epochs, in this case, every hour. The first two mentioned papers consider only a single delivery vehicle and implement an a priori policy which applies the rollout algorithm to decide when to leave the depot and which customers to serve. On the other hand, Heeswijk et al. formulate an MDP model ( 12 ). For large spaces, they solve the problem using an integer linear program together with linear value function approximation.
Ming et al. considered SDDP with a focus on local small retail stores as depots with crowd-shippers as the delivery vehicle ( 13 ). Assignment decisions are made based on a mixed-integer linear programming (MILP) model with a rolling horizon structure to consider future requests. Liu explored on-demand meal delivery with drones ( 14 ). Similarly, a MILP model is also devised to represent the problem while using heuristics to solve the dynamic part of the problem.
All previous papers explore only homogenous fleets, but there are a few recent papers dedicated to studying SDDP with heterogenous fleets (SDDPHF). Liu is the first to study the incorporation of drones into a fleet of vehicles in the context of SDD, applying a parametric policy function approximation (PFA) approach ( 14 ). Balaji et al. improved on this by using a deep Q-learning approach, which demonstrated superior performance when compared with PFA ( 6 ). They attributed this improvement to DQN’s ability to incorporate more information into its decision-making process, such as availability of resources and demands. Furthermore, both papers used a technique novel to the SDD order assignment problem—the minimum cost insertion heuristic.
Multi-Agent Reinforcement Learning (MARL) in the Vehicle Routing Problem (VRP)
MARL refers to multiple learnable agents that take actions and receive back rewards from the same environment ( 15 ). Agents in the same environment can be trained independently or cooperatively ( 16 ), where the latter allows communication between agents. Busoniu et al. showed that cooperative Q-learning can significantly outperform independent Q-learning in many distinct settings if it can be used efficiently ( 15 ). Cooperative training benefits from the additional observations from other agents and results in a faster learning speed, but at a cost of communication. Tampuu et al. applied DQN in a MARL setting which showed the potential of DQN as a tool in decentralised learning of multi-agent systems ( 17 ).
In the context of SDD, decentralised MARL has yet to be explored, but in the broader literature of DVRP, there are more relevant works exploring decentralised MARL. Balaji et al. implemented DQN to optimise the route of a single delivery driver in a stochastic and dynamic and environment ( 6 ). Their work has shown that the RL agent can consistently outperform a state-of-the-art MIP. However, the training time was roughly 3 days for a single vehicle in an 8 × 8 grid map with 10 maximum orders. This may lead to unacceptable training time for scenarios with larger fleets. Lin et al. showed that careful design of the simulator can allow scalability to large-scale fleet management systems ( 18 ). Contextual deep Q-learning and contextual multi-agent actor critic algorithms are used to achieve explicit coordination between agents, which also outperformed state-of-the-art approaches in empirical studies. In contrast to the former paper, the latter successfully scaled up to a 504 hexagonal grid with thousands of orders. Nevertheless, it is still important to note that the problems solved by these two authors are significantly different. The latter studied the fleet repositioning problem, which has a smaller state-action space when compared the former which studied the ODPD problem with a much larger state-action space.
In summary, DQN has been shown to be useful in decentralised learning of multi-agent systems. However, scalability to city-sized instances has only been attempted for problems where the RL agents’ actions are limited. For flexible policies in which agents have flexible action choices, only a single-vehicle scenario has been tested ( 6 ). This paper will first test the solution approach by Balaji et al. on SDDP for a single agent and then attempt to scale it up by utilizing a decentralised multi-agent system, the parameter-sharing DQN ( 6 ).
The solution proposed in this paper also aims to take advantage of many of the strategies employed by the SDD literatures discussed earlier, which has yet to be done, possibly because of the complexity in implementing multiple flexibilities using only heuristics. For example, in Voccia et al. vehicles are allowed to strategically wait at the depot but a pre-emptive depot return is not allowed ( 8 ). RL methods can easily implement these strategies by designing a flexible action space such that it can anticipate future requests and strategically wait at the depot, as well as pre-emptively return to the depot. However, it is worth noting that these added flexibilities do not guarantee that the RL agent can learn to exploit all of them in an effective manner.
Methodology
Problem Description
The problem involves a fleet of vehicles to deliver parcels from a depot to customers whose requests are stochastic and dynamic across the period of a day. Although the probability distribution of where and when a customer will appear is known, the actual location and time of the customer request are unknown until revealed.
When a request comes in, each vehicle in the environment is required to accept or reject the request. The vehicle must make this decision within the next time step to simulate real-world SDD service providers, which give immediate feedback to the customers on whether an SDD service is available.
On order acceptance, the parcel must be delivered within a fixed deadline, and missing a deadline will result in a penalty. Penalties will be given to any accepted but missed orders because this will mean customer expectation is not being met, resulting in low customer satisfaction. If more than one vehicle accepts the order at the same time step, the order will be assigned to the agent with the minimum insertion cost. This assignment is made irreversible, since the process of packaging and loading onto a specific vehicle would have begun.
Among the assigned orders, the vehicle can also decide the route plan for which orders to serve first. In addition, the vehicles can choose to wait strategically at the depot in anticipation of future requests. While en route, agents are also allowed to pre-emptively return to the depot to consolidate the delivery route. If an order is rejected by all vehicles, no penalty or reward will be given, as it is assumed that the order is simply assigned to another delivery service such as next-day delivery.
Model Preparation
SDDP is modeled as an MDP. The fleet of
Markov Decision Process (MDP) Model Formulation
SDDP was modeled as in Ulmer et al. and Ulmer and Thomas (
9
,
19
). There are five main components to an MDP—decision point, state space, action space, rewards, and transition. The decision point is defined as the time at which a decision is made. For this problem, a decision is required at every time step. Therefore, the time step representing the
The state contains all the information needed to make the decision at a particular decision point. The state at time,
The order status has the following values:
The state is mathematically defined as:
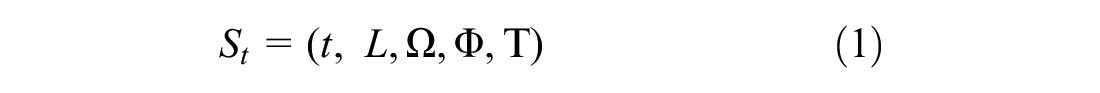
At each decision point, an action within the action space is to be selected. Each vehicle in the set
Therefore, the number of available actions is
The reward for a state-action pair is denoted as
Once the decision is made, the environment transitions to the post-decision state,
Reinforcement Learning (RL) Solution Approach
DQN is a modified version of the simpler Q-learning algorithm, which is an RL method that learns the value of a state-action pair, known as Q-values. Each Q-value is an estimate of the expected future reward for taking an action in any given state. A table containing the Q-values of all possible state-action pairs is known as a Q-table.
However, it is virtually impossible to exhaustively explore all the possible Q-values for tabulation in complex environments with multiple agents. Therefore, a DNN is used to approximate Q-values, using a given set of features from the state space as inputs. This is known as DQN and it is based on the following loss function:
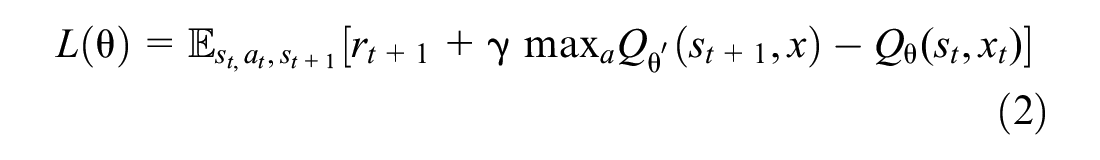
where
A parameter-sharing DQN framework is used, that is, each agent can learn an independent policy, but all agents share the parameters of the network. This makes training more scalable than the fully decentralized approach, because the number of trainable parameters does not depend on the number of agents.
Experiments
The experiments were run on a grid world environment, where agents can only move north, south, east, or west. Each episode consists of 144 time steps (
The default depot location is set at the center of the grid. If the grid map is an even number and there are four center locations, then the depot will be set to any one of the center grids. For example, the depot location can be at (5,5) or (6,6) in a 10 × 10 grid map. A representation of the grid world is shown in Figure 1.
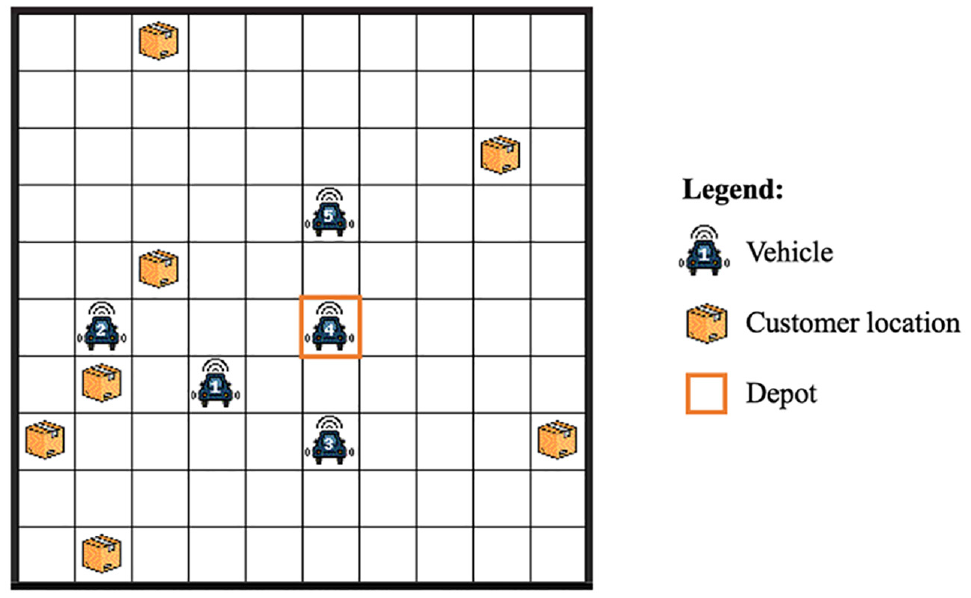
Illustration of a 10 × 10 gridworld environment with five vehicles.
The deadline of the order,
The same DQN architecture is used for all experiments in this paper. A neural network architecture consists of three hidden layers, consisting of 256, 256, and 128 nodes, respectively. The input layer receives a set of features from the environment, that is, the state observation described in the MDP formulation. The number of nodes in the output layer corresponds to the number of possible actions in the environment.
A flowchart of each step is presented in Figure 2. The full state is retrieved from the environment and passed to the parameter-sharing DQN, which then outputs the individual Q values for each vehicle. Based on the Q values, the policy outputs the action, which is then passed to the environment to perform vehicle movements.
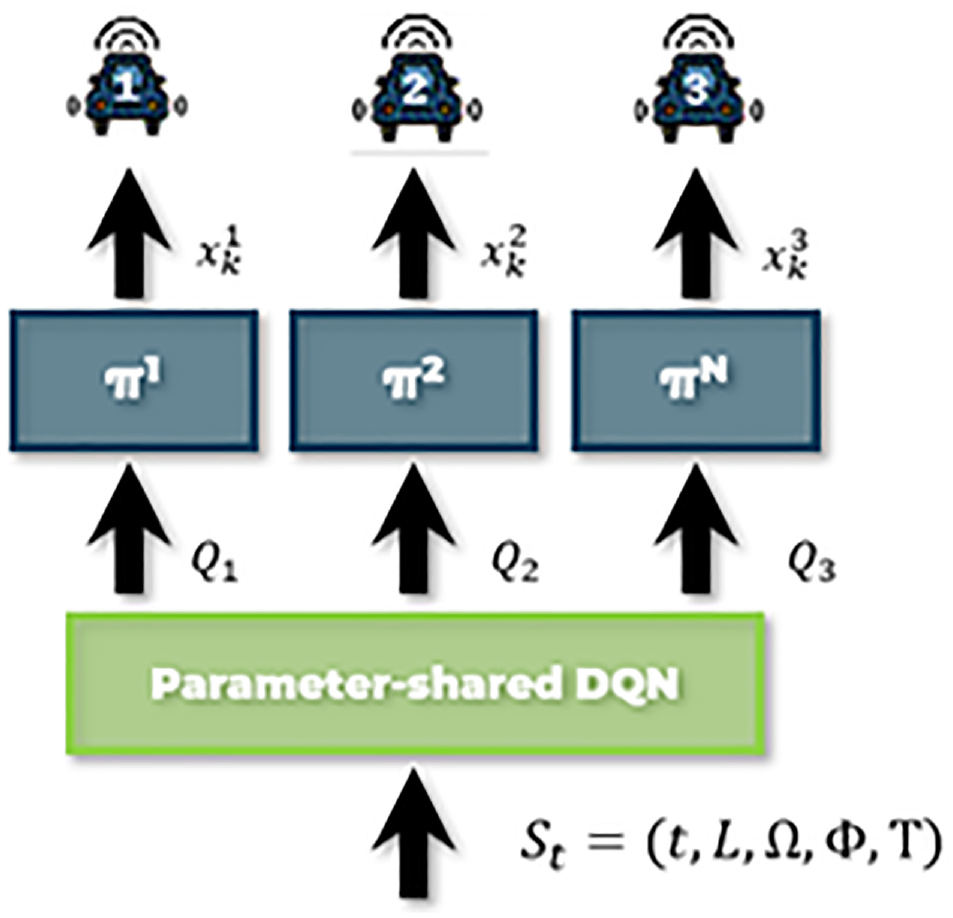
Flowchart of a step of the proposed solution algorithm.
Baseline Algorithm
The proposed DQN approach is compared against a baseline model consisting of a deterministic MIP solution approach. Balaji et al. also used MIP as a baseline model for the dynamic and stochastic pick-up and delivery problem ( 6 ).
Whenever a new order arrives, a solution from the deterministic MIP is obtained for the current available orders in the environment. MIP can either accept or reject the order and will execute a route plan such that it can serve all the currently assigned orders in the shortest possible time.
A near-optimal solution, instead of the optimal solution, can be accepted if the runtime for MIP exceeds the set maximum optimisation time. This is because finding a solution to MIP can become computationally intractable for more complex scenarios. However, the maximum optimisation time is set such that this occurs in less than 10% of tested episodes.
It is worth noting that it is difficult to directly compare the performance of algorithms from different papers in the literature review section even though they all solve seemingly similar SDDP. This is because of differences in different papers’ set-up and definition of SDDP, and, besides, it is difficult to accurately reproduce the exact problem formulation from another paper because problem descriptions can often possess some ambiguities ( 9 ). Therefore, the solution approaches from other papers will need to be reproduced to fairly compare the different methods. This is one of the main reasons the MIP model is used as a benchmark solution instead of directly comparing results to other SDD papers. Comparison of DQN with anticipatory models described earlier is left for future works.
The mathematical model for MIP is now presented:
Sets:
V: Current vehicle location, V = {0}
P: Pick-up location (depot location, associated with orders that are not in transit)
D: Delivery locations representing all orders that are not in transit
A: Delivery locations representing the orders that are accepted by driver, but not in transit
T: Delivery locations representing orders that are accepted by driver, but in transit
R: Return location (depot location, used for final return)
N: Set of all nodes/locations in the graph,
E: Set of all edges,
Decision variables:
Parameters:
n: number of orders available to pick up, n = |D|
cij: Symmetric Manhattan distance matrix between node i and j;
li: Remaining time to deliver order i,
m: Travel cost per mile
ri: Reward for orders associated with deliveries that are not in transit, D
M: A big real number
t: Time to travel 1 mi
d: A constant service time spent on accept, pick-up and drop-off
Model:
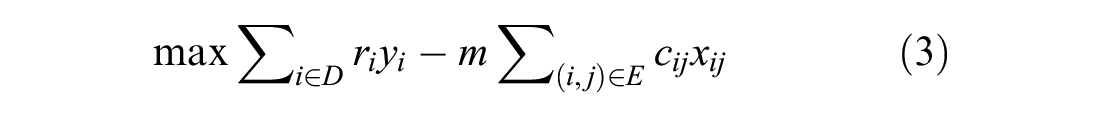
Subject to:
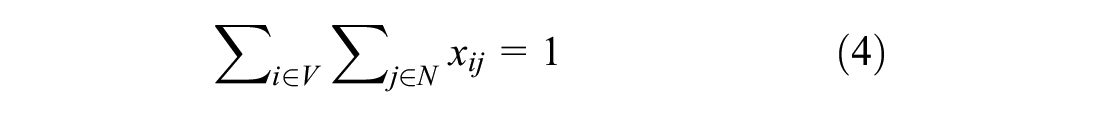
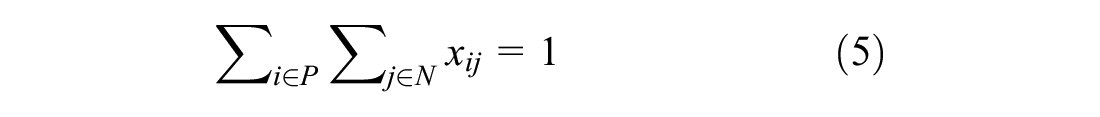
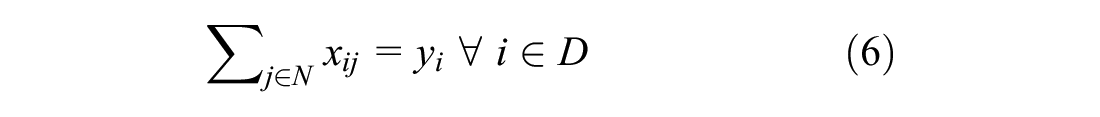
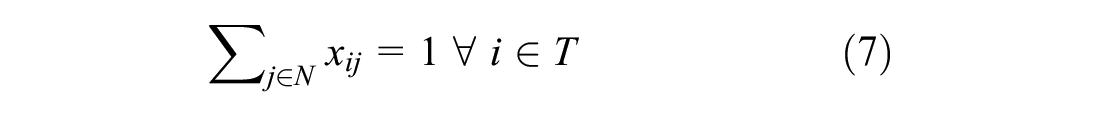
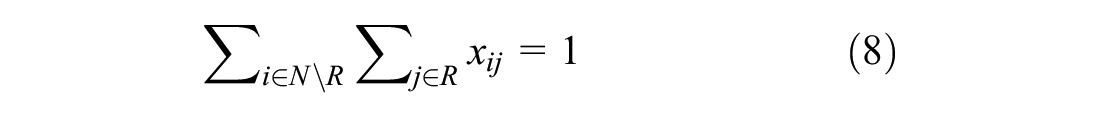
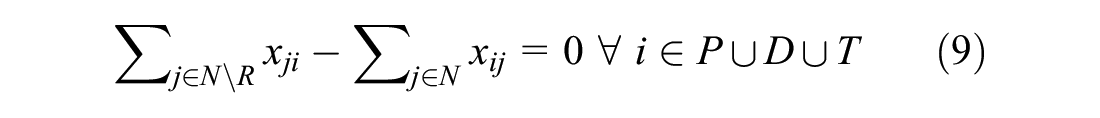

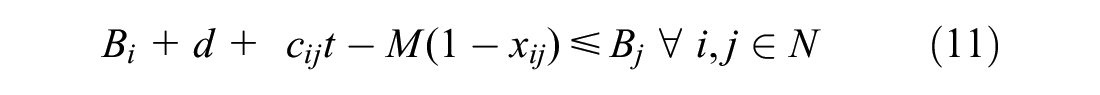
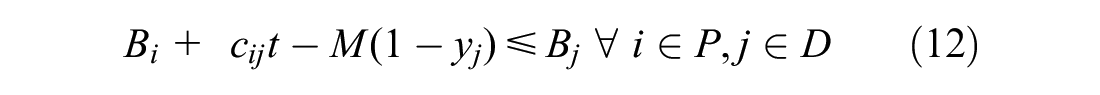
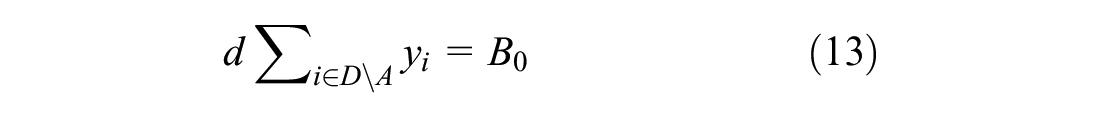

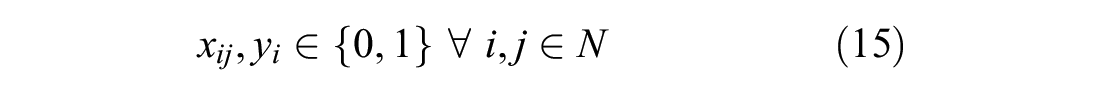
Constraints 4 to 7 restrict the flow of vehicles. Constraint 4 ensures the vehicle leaves its current location only once. Constraint 5 ensures vehicle leaves the depot only once for pick-up. Constraints 6 and 7 ensure vehicle leaves the delivery destinations only once. Lastly, constraint 8 ensures the vehicle return to the depot. Constraint 9 ties everything together by enforcing a zero net flow through the nodes, therefore ensuring that sets P, D, and T are visited once and only once.
Constraint 10 ensures that all previously accepted orders are included in the route. Constraints 11 to 15 are time constraints. Constraint 11 ensures that time window is met. Constraint 12 sets the priority that orders not-in-transit must be picked up at the depot before being delivered. These two constraint were originally non-linear, and were both linearised using the big M method ( 20 ). Constraint 13 ensures times required to accept and deliver orders are accounted for. Equation 14 ensures order to be delivered before expiry. Lastly, Constraint 15 ensures decision variable x and y are binary. It should be noted that the capacity of the vehicle in this problem formulation is unconstrained. This is reasonable for small order sizes, which results in vehicles only taking a limited amount of orders, but would not be realistic for bigger order sizes.
Results
For each set of experiments, DQN was trained over 150,000 episodes and then tested over 100 episodes, while the MIP method was executed over 100 random episodes. Moreover, because of the stochasticity of the environment, three independent training rounds were obtained for the DQN algorithm. The total episodic reward is used as the performance measure for each method. It is worth noting that both methods were assessed on the exact same environment, with the same reward function. For training, a workstation was used with an Intel Core i9-10900X CPU processor and a NVIDIA RTX 3090 GPU.
Single-Agent Scenario
The proposed parameter-sharing DQN method is first compared with the MIP baseline on a single-agent environment. Different environment parameters were experimented with, considering two grid map sizes (5 × 5 and 10 × 10) and two expected number of orders (5 and 30). These values were chosen to show how the size of the grid world and the number of orders affect the performance of MIP. The results are shown in Table 1, where there are two sections referring to a homogenous and a heterogenous scenario. Scenarios marked with an asterisk in Table 1 are trained over a larger number of episodes to achieve more consistent results over the three independent runs. The homogenous scenario corresponds to an environment where order generation and rewards are the same across the whole map, whereas in the heterogenous scenario, order generation and rewards are given by a random probability distribution. For the heterogenous scenario, the grid map was divided into four zones with relative order probabilities of {0.3, 0.4, 0.2, 0.1}, with each zone respectively generating orders with maximum and minimum rewards of {[12,8], [8,6], [5,3], [3,1]}.
Comparison of Reinforcement Learning (RL) Performance versus Mixed-Integer Programming (MIP) for a Single-Agent Scenario
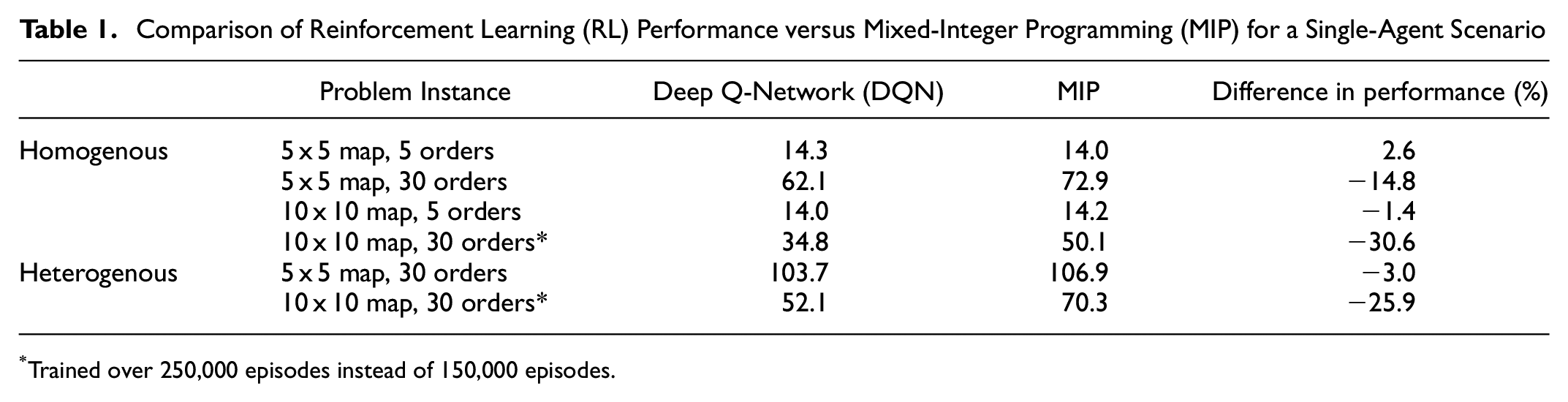
*Trained over 250,000 episodes instead of 150,000 episodes.
Table 1 shows that the proposed DQN method can achieve similar final rewards as MIP when the order number is small. However, for the problem instance with a high number of orders (30), MIP significantly outperforms DQN. This is likely because of the DQN method converging to a policy that takes a sub-optimal route. Furthermore, the lower reward obtained by DQN is also a result of some missed orders and failure to return to the depot by the end of episode. In the heterogenous scenario, the DQN approach still underperformed MIP, but performed more closely to the MIP benchmark. This is especially true for the smaller 5 x 5 map with 30 orders scenario where DQN only underperforms MIP by 3% in the heterogenous scenario as compared with 15% in the homogenous scenario. Note that a higher number of episodes was needed to achieve convergence for the scenarios consisting of a 10 x 10 map and 30 orders. This is mainly because the higher environment complexity of having more orders.
Figure 3 shows the DQN training curve for the 5 x 5 map with 30 heterogenous orders distribution shown in Table 1. The graph shows that the DQN method has large inter-episode variance, and some of the episodes outperform the MIP benchmark. Furthermore, the DQN method occasionally incurs in large penalties of up to −150, which negatively affects the average performance. This is likely because of the active exploration of state-action space by the DQN algorithm.
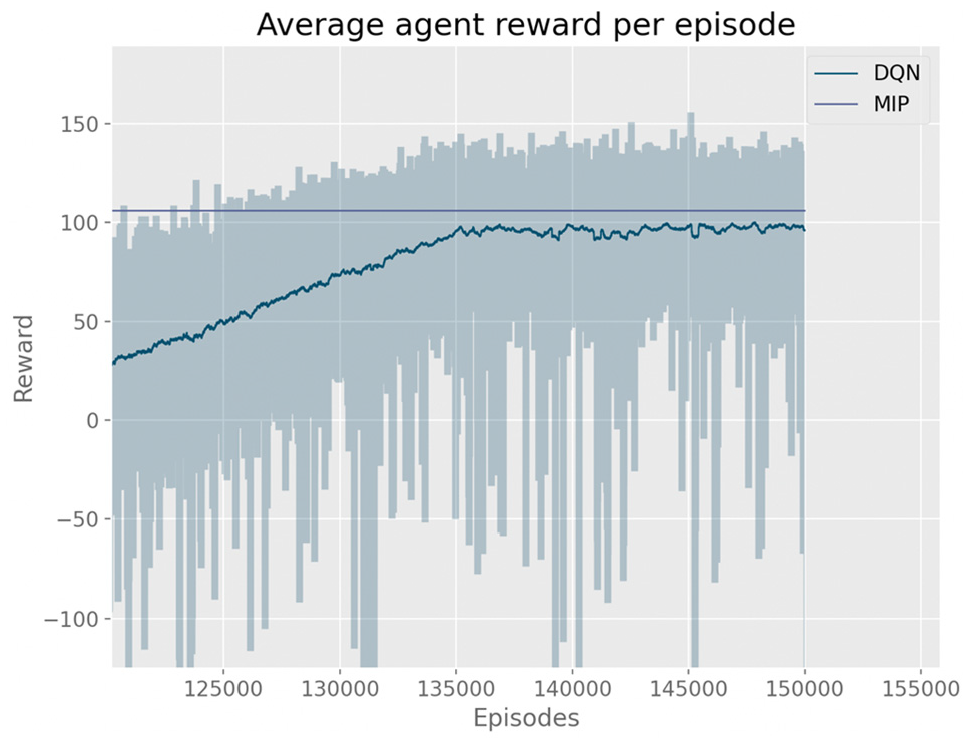
Training curve for the Deep Q-Network (DQN) algorithm, considering a 5 × 5 grid map with 30 heterogeneously distributed orders.
Multi-Agent Scenario
In the following set of experiments, a 10 × 10 grid map with 30 orders was used, and the agent number was increased to five. Results are summarized in Table 2. As shown, positive rewards for all cases were achieved by the MARL approach after 150 k training episodes. Furthermore, when the number of agents reached four, the rewards plateau as the agents can virtually deliver all 30 orders. The DQN method performed worse than the MIP-based method for one, two, and three agents. However, when the number of agents is increased to four and five, DQN achieved better results than MIP. This suggests that the DQN approach may be more advantageous than MIP in environments with a higher number of agents.
Comparison of Reinforcement Learning (RL) Performance for the Multi-Agent Scenario
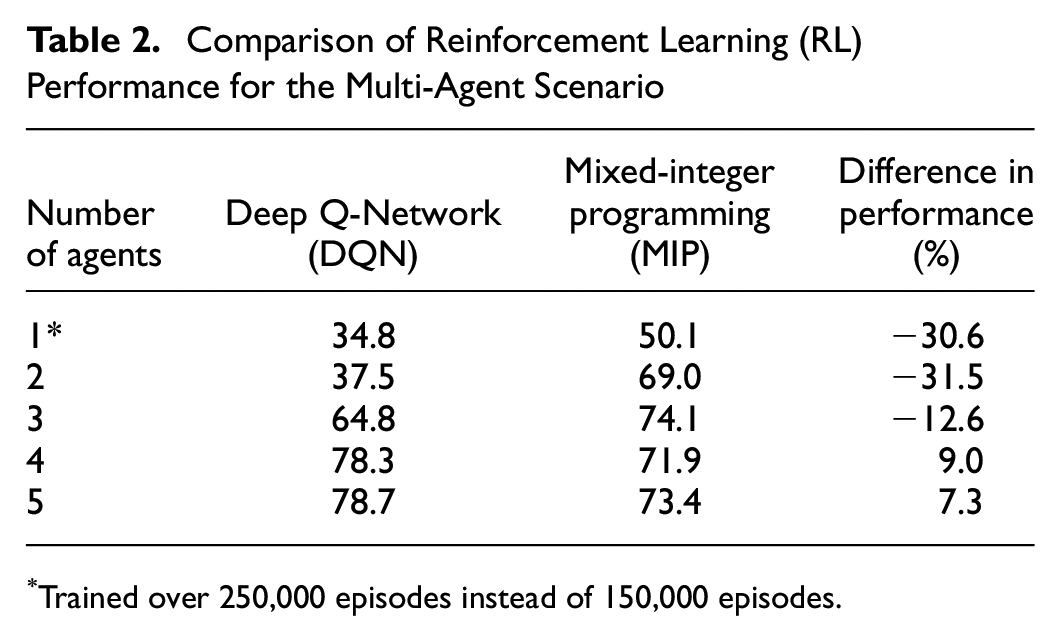
Trained over 250,000 episodes instead of 150,000 episodes.
Execution Time Evaluation
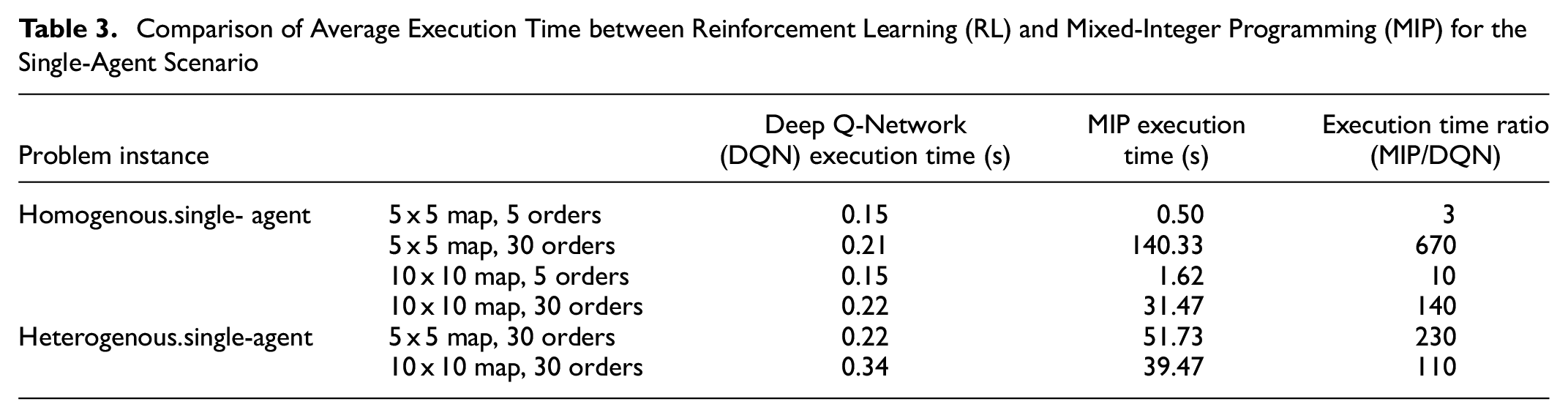
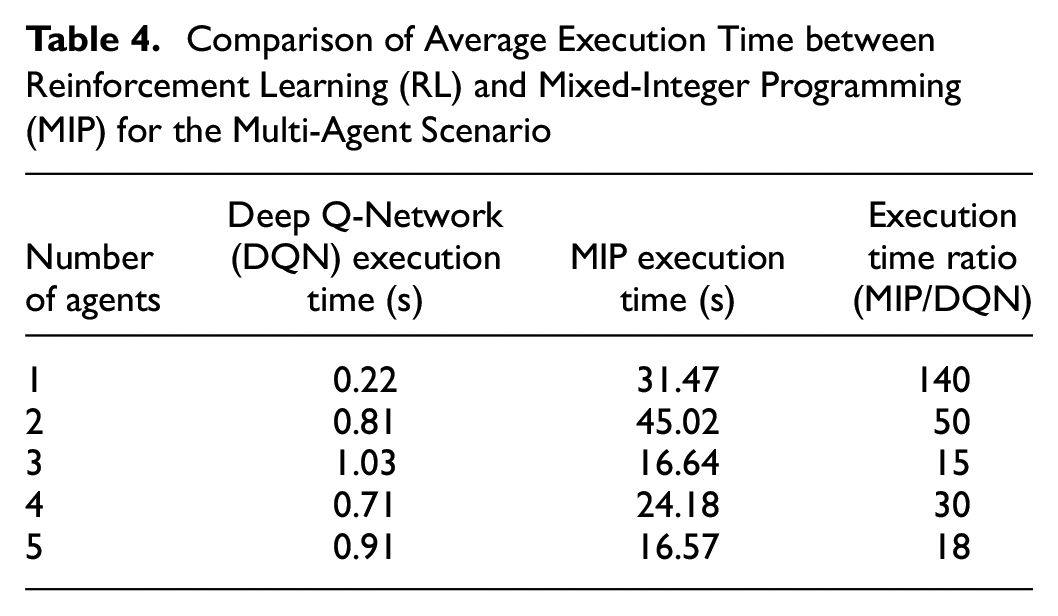
Experiments were performed on execution time to assess the efficiency of each method and their suitability for real-time control. Tables 3 and 4 show the average execution time per episode for each method. Results show that the execution time for the proposed MARL approach is far superior when compared with the MIP-based approach for all scenarios. This is an important advantage, since real-time decisions are essential for real-world SDD services. MIP tends to take much longer when the ratio between the number of orders and the grid size is higher. This is because high orders in a small grid will result in more simultaneous active orders, which means that there are more nodes, edges, and decision variables that need to be considered by MIP.
Comparison of Average Execution Time between Reinforcement Learning (RL) and Mixed-Integer Programming (MIP) for the Single-Agent Scenario
Comparison of Average Execution Time between Reinforcement Learning (RL) and Mixed-Integer Programming (MIP) for the Multi-Agent Scenario
Conclusions and Future Work
In this paper, SDDP was formulated as an MDP and it was solved using a parameter-sharing DQN, which corresponds to a decentralised MARL approach. An established MIP algorithm was used as a benchmark comparison for the proposed MARL approach. To compare both methods, an SDD environment consisting of a central depot, multiple delivery vehicles, and dynamic order generation was designed and implemented. Two different scenarios were then experimented on: single-agent and multi-agent.
For the single-agent scenario, it was shown that, when the order rate is small, the DQN approach is, at least, competitive with the MIP-based method. For problem instances with higher order arrival rates, the computational results showed that the MARL approach underperformed MIP, regardless of the grid size. The reason for this is that the MIP-based solver corresponds to a centralized method where all decisions are made by a single central unit that optimizes the global objective of the system. In contrast, MARL agents are based on the decentralized learning paradigm, that is, they optimize local decisions using a partial observation of the environment which may be more realistic in certain real-world applications. When zone-specific order generation and reward probabilities are introduced, the gap between the two methods is smaller, which may suggest that the DQN approach can be more advantageous in environments with higher complexity.
For the multi-agent case, it was shown that the proposed approach achieves similar performance as the MIP-based method, while being up to 65 times faster during execution, on average. This is a crucial advantage for SDDP, as decisions must be made in real-time. Moreover, real-world problem instances can scale to hundreds of independent drivers and thousands of order requests within a day. It should be noted that the DQN was trained offline, and the trained model was used to develop the real-time control policies. Training times for the DQN approach for all instances took from a few hours up to a day.
The main limitation of this study is that the performance of the MARL approach was evaluated for a small number of agents. The authors believe that the method should be assessed on a real-sized instance, where stability issues may arise because of agents learning independently. Thus, the next step would be to implement DQN on a large-scale SDDP environment. Real-world instances will inevitably result in higher environment complexity, and, therefore, new methods for faster training should be evaluated. Recent efforts in this domain include the use of curriculum learning (CL) and the use of policy ensembles ( 21 , 22 ).
It is worth noting that both models can easily incorporate extra constraints, such as vehicle capacity, although adding constraints to MIP will likely increase the complexity of the problem, and consequently the execution time. In contrast, adding constraints to the MARL formulation will probably not affect execution time, although an additional number of episodes may be required to achieve convergence. This is because adding constraints to the MARL formulation is directly related to the environment complexity.
Another potential direction for future research is to explore different combinations of input features. For example, some of the information, such as distance from orders, is implicitly derived from the state space. It is possible that explicit inclusion of such information as input features can improve the DQN’s solution. The authors believe it is also worth exploring the use of different neural network architectures to account for different features of the state space, for instance, using convolutional neural networks, recurrent neural networks, or both.
Footnotes
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: P. Angeloudis, L. Parada, J. Escribano; data collection: E. Ngu, L. Parada; analysis and interpretation of results: E. Ngu; draft manuscript preparation: E. Ngu, L. Parada, J. Escribano. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was partially supported by the Chilean National Agency for Research and Development (ANID) through the “BECAS DOCTORADO EN EXTRANJERO” programme, Grant No. 72210279.