
Abstract
In-vehicle infotainment systems can increase cognitive load and impair driving performance. These effects can be alleviated through interfaces that can assess cognitive load and adapt accordingly. Eye-tracking and physiological measures that are sensitive to cognitive load, such as pupil diameter, gaze dispersion, heart rate (HR), and galvanic skin response (GSR), can enable cognitive load estimation. The advancement in cost-effective and nonintrusive sensors in wearable devices provides an opportunity to enhance driver state detection by fusing eye-tracking and physiological measures. As a preliminary investigation of the added benefits of utilizing physiological data along with eye-tracking data in driver cognitive load detection, this paper explores the performance of several machine learning models in classifying three levels of cognitive load imposed on 33 drivers in a driving simulator study: no external load, lower difficulty 1-back task, and higher difficulty 2-back task. We built five machine learning models, including k-nearest neighbor, support vector machine, feedforward neural network, recurrent neural network, and random forest (RF) on (1) eye-tracking data only, (2) HR and GSR, (3) eye-tracking and HR, (4) eye-tracking and GSR, and (5) eye-tracking, HR, and GSR. Although physiological data provided 1%–15% lower classification accuracies compared with eye-tracking data, adding physiological data to eye-tracking data increased model accuracies, with an RF classifier achieving 97.8% accuracy. GSR led to a larger boost in accuracy (29.3%) over HR (17.9%), with the combination of the two factors boosting accuracy by 34.5%. Overall, utilizing both physiological and eye-tracking measures shows promise for driver state detection applications.
Factors such as road environment (i.e., high traffic conditions), bad weather, and the usage of in-vehicle technologies (e.g., cellphones and infotainment systems) can increase the cognitive load experienced by drivers. Both simulator and on-road studies have shown that high cognitive load can impair driving performance and visual scanning behaviors (1, 2). Real-time assessment of cognitive load can enable vehicle manufacturers to provide preventative warnings and develop adaptive interfaces that can support drivers, for example, by actively limiting functionality on menu interfaces ( 3 ) and automatically filtering information when high levels of cognitive load is detected ( 4 ). Automated vehicle systems can also utilize cognitive load estimates to intelligently transfer vehicle control to the driver ( 5 ).
As summarized in Table 1, a variety of measures were found to be responsive to varying levels of external cognitive load experienced by drivers, including: (i) eye-tracking measures, such as pupil diameter (2, 6), blink rate ( 7 ), and standard deviation (SD) of horizontal gaze position (7, 8); (ii) physiological measures, such as heart rate (HR) (8–10), galvanic skin response (GSR) (8, 9), and electroencephalography (EEG) (11, 12); (iii) driving performance measures, such as vehicle speed ( 8 ); and (iv) subjective measures, such as NASA-Task Load Index (NASA-TLX) ( 1 ).
Example Cognitive Load Measurements

Note: EEG = electroencephalography; GSR = galvanic skin response; HR = heart rate; SD = standard deviation.
It is widely acknowledged that no single measure alone can provide sufficient information to estimate cognitive load (9, 11). Indeed, multiple measures have been combined in previous research to estimate the cognitive load experienced by drivers. For example, Solovey et al. ( 14 ) reached 89% accuracy in classifying 2 levels of cognitive load (no-task versus an auditory recall 2-back task) using driving performance, GSR, and HR data collected in an on-road study. Liang et al. ( 15 ) reached 81.1% accuracy in identifying 2 levels of cognitive load (no-task versus an auditory stock ticker task) using driving performance and eye-tracking data collected in a simulator study. In general, driving performance measures used in these earlier studies (e.g., speed and lane position) are highly sensitive to traffic conditions and may require additional driving context-assessment to improve their utility in driver state detection ( 16 ). This need for additional information can be a barrier for the use of driving performance measures in driver state detection.
The fusion of eye-tracking and physiological measures seems to be more promising for real-time assessment of driver cognitive load, yet research is lacking in this area. Eye-tracking measures have been adopted in several production cars for detecting visual distraction (e.g., Cadillac [ 17 ]) and drowsiness (e.g., Khan and Lee [ 18 ]). They have not yet been adopted for cognitive load detection, although pupil diameter (e.g., Recarte and Nunes [2, 6]), blink rate (e.g., Liang and Lee [ 7 ]), and gaze dispersion (e.g., Liang and Lee [ 7 ], Mehler et al. [ 8 ]) are known to be sensitive to cognitive load variation. Physiological measures, such as HR (e.g., Mehler et al. [8, 9], Brookhuis et al. [ 10 ]) and GSR (e.g., Mehler et al. [8, 9]), also react well to variations in cognitive demand and can now be collected through cost-effective and nonintrusive sensors, for example, in wearable devices such as the Apple Watch ( 19 ) and FitBit ( 20 ). Thus, combining eye-tracking with HR and GSR data is now a feasible solution for in-car applications, yet it is unknown what level of performance enhancement this combination may provide in driver cognitive load detection.
Using a dataset collected in a driving simulator study, this paper investigates the benefits of fusing eye-tracking and physiological data for driver cognitive load classification. It is hypothesized that increasing the number of features in the dataset by fusing different measure types would improve classification performance. In the simulator study, three levels of cognitive load (no external load, 1-back task, and 2-back task) were imposed by an audio-verbal cognitive task, the modified n-back task ( 21 ), while participants drove through an urban environment. A variety of machine learning methods used in earlier studies were explored on this three-class driver state estimation problem, including k-nearest neighbor (KNN, e.g., Solovey et al. [ 14 ]), support vector machine (SVM, e.g., Wang et al. [ 22 ]), feedforward neural network (FNN, e.g., Solovey et al. [ 14 ]), recurrent neural network (RNN, e.g., Shimizu et al. [23]), and random forest (RF, e.g., Barua et al. [ 24 ]). The models were built and compared using the following measures to investigate the benefits of fusing eye-tracking and different physiological data (in particular, HR and GSR):
• eye-tracking data only, including eye closure (i.e., fraction of the iris covered by the upper and lower eye lid), pupil diameter, and gaze rotation angle (i.e., the orientation of the eye gaze with respect to the world coordinate system);
• physiological data only, including HR and GSR;
• eye-tracking data and HR combined;
• eye-tracking data and GSR combined;
• eye-tracking data, HR, and GSR combined.
Data Source
The data utilized in this paper was collected from 33 participants in a driving simulator study originally reported by He et al. (21, 25), which investigated the effects of different levels of external cognitive demand on drivers’ physiological, eye-tracking, and driving performance. In a within subject design, participants completed three counterbalanced conditions (in three drives total): no external task, and two difficulty levels of an external cognitive task (i.e., a secondary task). Eye-tracking measures, including the level of eye closure, pupil diameter, and gaze rotation angle, as well as physiological measures, including Electrocardiography (ECG) and GSR, were collected. In the following, we provide an overview of the experimental methods, but a more detailed description of the methods can be found in He et al. ( 21 ). He et al. ( 26 ) also utilized physiological measures from this dataset for a preliminary machine learning application, but only with relatively simple machine learning models and without using eye-tracking data.
Participants
A total of 33 drivers (18 males and 15 females), recruited through campus and online posts, completed this driving simulator study. Participants were required to drive at least several times per month, to hold a full driver’s license (G license in Ontario, Canada or equivalent) for at least 3 years, and to be under 35 years old (average age: 27.6; SD: 4.45). The compensation was C$12 per hour, and the participants were told that they could receive a bonus of up to C$14 based on their secondary task performance as an incentive for engaging in the secondary task.
Apparatus
The study was conducted on a NADS miniSim™ driving simulator (Figure 1a). This fixed-based simulator has three 42-inch screens, creating a 130° horizontal and 24° vertical field at a 48-inch viewing distance. The center screen displays the left and center parts of the windshield; the right screen displays the rest of the windshield, the rear-view mirror, and the right-side window and mirror, whereas the left screen displays the left-side window and mirror.
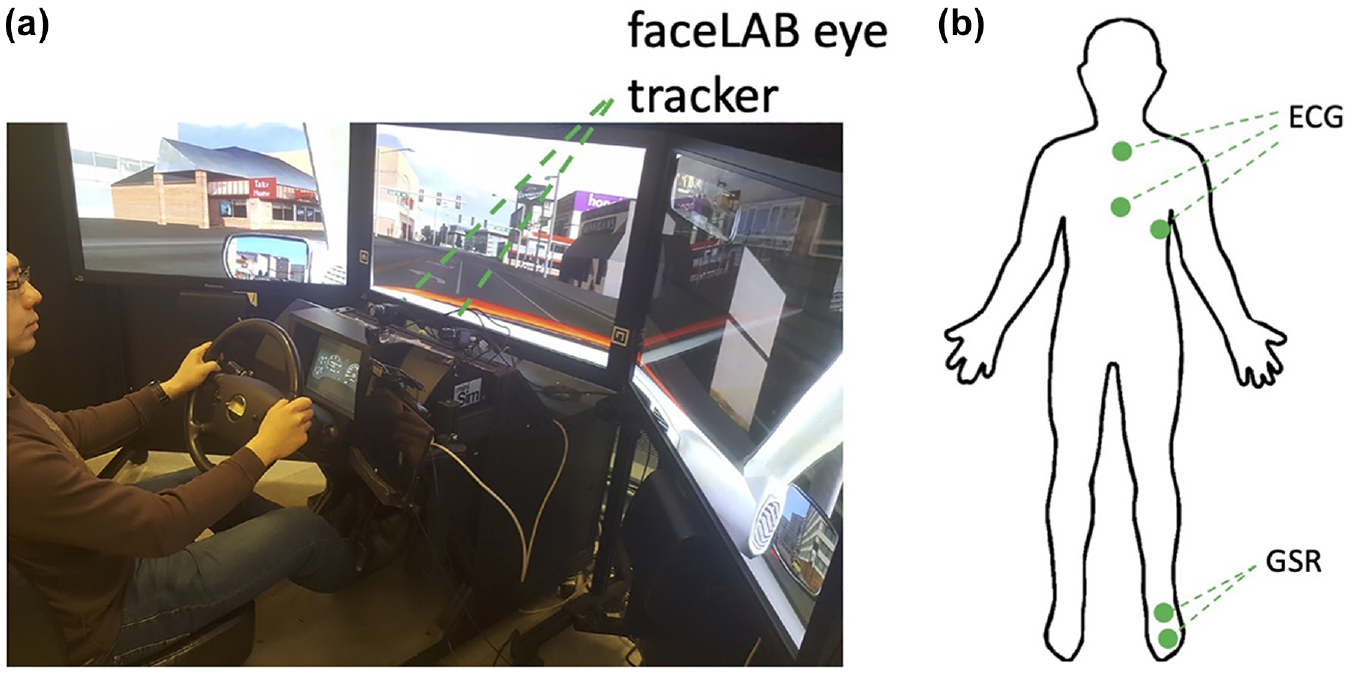
Apparatus: (a) driving simulator, the NADS miniSim and faceLAB 5.0 eye-tracking system and (b) placement of ECG and GSR sensors.
The eye-tracking information was collected at 60 Hz by using the faceLAB 5.0, a dashboard mounted eye-tracker by Seeing Machines. ECG was collected with three solid gel foam electrodes placed on participants’ chest; and GSR was collected with one solid gel foam electrode beneath the bare left foot and the other under the heel (Figure 1b). Both ECG and GSR sensors were from Becker Meditec and the data was collected at 240 Hz using the D-Lab software developed by Ergoneers.
Experimental Tasks
The secondary task used in this study was a modified version of an auditory-verbal n-back task widely used in driving research (e.g., Mehler et al. [8, 9]), and was validated to impose graded levels of cognitive load on drivers (21, 25). The modification was performed to minimize physiological signal interference because of speech. In each n-back task, participants listened to a prerecorded series of 10 letters, separated by approximately 2.5-second intervals, for an overall duration of approximately 25 s. For the 1-back task (lower cognitive load), participants were asked to silently count the number of times two identical letters appeared back-to-back (e.g., PP). For the 2-back task (higher cognitive load), participants were asked to silently count the number of times two identical letters appeared in pairs separated by one letter in between (e.g., DTD). Participants were asked to verbally provide their answer at the end of each n-back task. Figure 2 offers examples of auditory input provided to participants with the target instances highlighted with different colors.
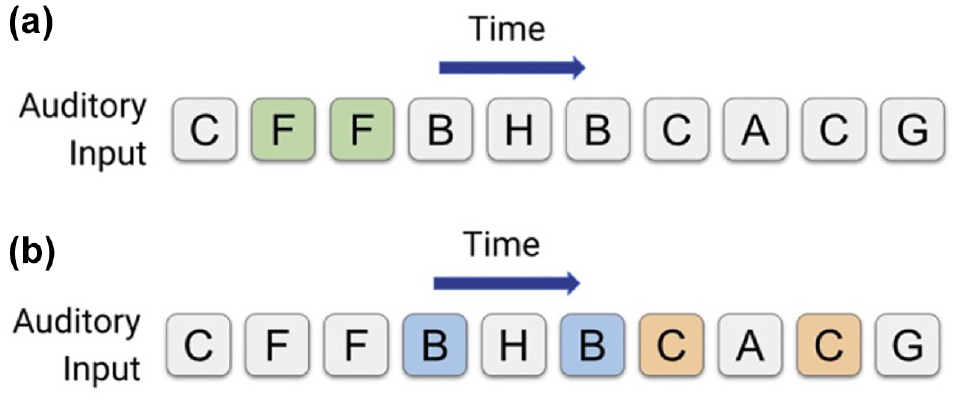
Visualization of the modified n-back task: (a) example 1-back task, the correct answer is “1” and (b) example 2-back task, the correct answer is “2.”
The driving scenarios were designed to involve mainly operational driving, without tactical decisions (e.g., navigation or passing a vehicle). Participants were asked to follow a lead vehicle at a speed of 40 mph (around 64.4 km/h) and a comfortable headway on a 4-lane urban road. In addition to training drives, each participant completed three driving tasks with different levels of the modified n-back task: baseline with no task, lower cognitive load with 1-back task, and higher cognitive load with 2-back task. The order of these three taskload levels was counterbalanced across participants. For machine learning models presented in this paper, data from four n-back tasks (a series of 10 letters for each n-back task) per drive were utilized. Participants had completed another two n-back tasks in each drive, but these corresponded to lead vehicle braking event response, which could affect physiological measures and was deemed to be outside the scope of the current analysis. In each n-back drive, the participants spent 100 s performing the four n-back tasks. This 100-s period for each n-back drive (i.e., 1-back and 2-back) and a corresponding 100-s period for the no-task drive were used in model building, leading to 300 s of data per participant being used in the machine learning models.
Procedures
After verifying their eligibility, participants were asked to sign a consent form. All participants completed a practice drive that was identical to the route used in the three experimental driving tasks. Participants were then provided written and oral instructions on the modified n-back task and practiced it without driving to ensure that they fully understood the secondary task. The eye-tracking system was then calibrated and the physiological sensors were placed on participants. Then, participants completed another practice drive while performing the secondary task. Participants went on to complete the three experimental driving tasks (no-task, 1-back, and 2-back).
Data Processing and Model Training
A three-class classification problem was pursued in our analysis: no-task versus 1-back task versus 2-back task. We fitted KNN, SVM, FNN, RNN, and RF models to different combinations of eye-tracking and physiological data. Overall, five different datasets were created as described in the following section.
Signal Processing and Feature Extraction
Table 2 summarizes our signal processing steps. In total, two physiological features were generated (HR and GSR) along with six eye-tracking features, including eye closure (EC) raw data, blink duration (BD), blink frequency (BF), pupil diameter (PD), eyeball rotation speed (eyeRS), and percentage of time at least 75% of iris is covered by eyelids (PERCLOS). These features were selected based on previous studies, which showed relationships between BF, PD, gaze dispersion and cognitive load, as summarized in Table 1. In place of SD of gaze position and periphery/mirror/instrument check rate reported in Table 1, we used eyeRS, which captures gaze dispersion and can be calculated independently of the driving scene (e.g., extracted through video of driver’s face only). Although no clear relationship has been found between BD and cognitive load (e.g., Tsai et al. [ 27 ]) and PERCLOS is primarily a measure of drowsiness (e.g., Khan and Lee [ 18 ]), we opted to include these features, as they can be readily available from eye closure data. All eye-tracking features were calculated for each eye and were then averaged across the two eyes.
Processing of Eye-Tracking and Physiological Measures to Obtain Machine Learning Features (i.e., Inputs)

Note: BD = blink duration; BF = blink frequency; EC = eye closure; ECG = electrocardiography; eyeRS = eyeball rotation speed; GSR = galvanic skin response; HR = heart rate; PD = pupil diameter; PERCLOS = percentage of time at least 75% of iris is covered by eyelids; SD = standard deviation.
The measures that were originally sampled at a rate higher than 60 Hz (i.e., physiological measures) were downsampled to 60 Hz in order have equal number of data points across all features. All features, except EC, GSR, and PD, were calculated within a moving window. With a step size of 1/60 s (i.e., 60 Hz), a window size of 10 s was used for the eye-tracking features and a window size of 5 s was used for HR. The ECG data is noisy and, thus, is commonly converted into interbeat interval (ibi) data after R-peak detection (e.g., Solovey et al. [ 14 ]) and a running window procedure is necessary for this conversion. The 5-s window was adopted for HR based on our preliminary work on the same data investigating cognitive load detection ( 26 ). A longer time window was deemed necessary for eye-tracking measures given that, for example, the average blink frequency was recorded to be around 10 times/minute in De Padova et al. ( 29 ) and 24 times/minute in our dataset. Thus, a 10-s window size was chosen to provide a long enough period for reliable eye-tracking data extraction, but not too long compared with the entire data extraction period for each level of cognitive load (100 s), although earlier research used a longer time window for PERCLOS (30 s in Cardone et al. [ 30 ] and 1 min in Rodríguez-Ibáñez et al. [ 31 ]).
All features were extracted at 60 Hz leading to 594,000 rows of data (sampling frequency of 60 Hz × 25 s of data for each n-back task × 4 n-back tasks in each drive × 3 drives per participant × 33 participants). We built five datasets to train and evaluate our machine learning models:
Data Partition
As shown in Figure 3, a within-driver data partition approach was adopted, aiming to represent all participants in the training, validation, and test datasets. This data partition was selected over a between-drivers data partition method (which allocates some participants to the test dataset and the remaining to the training dataset), as we did not have a large enough sample to capture individual differences across participants that would be required for a between-drivers data partition. Hyperparameters were tuned using a 10-fold cross-validation on 90% of the data from each cognitive load level from each participant. The last 10% of the data from each level of cognitive load from each participant was used as the test dataset. Ten different splits (see Figure 3) were generated for the 10-fold cross-validation, each for one fold, with the training conducted on 81% of the data and the validation on 9%. A random split of training and test datasets was not appropriate for this data given its temporal nature and the resulting correlation over time.
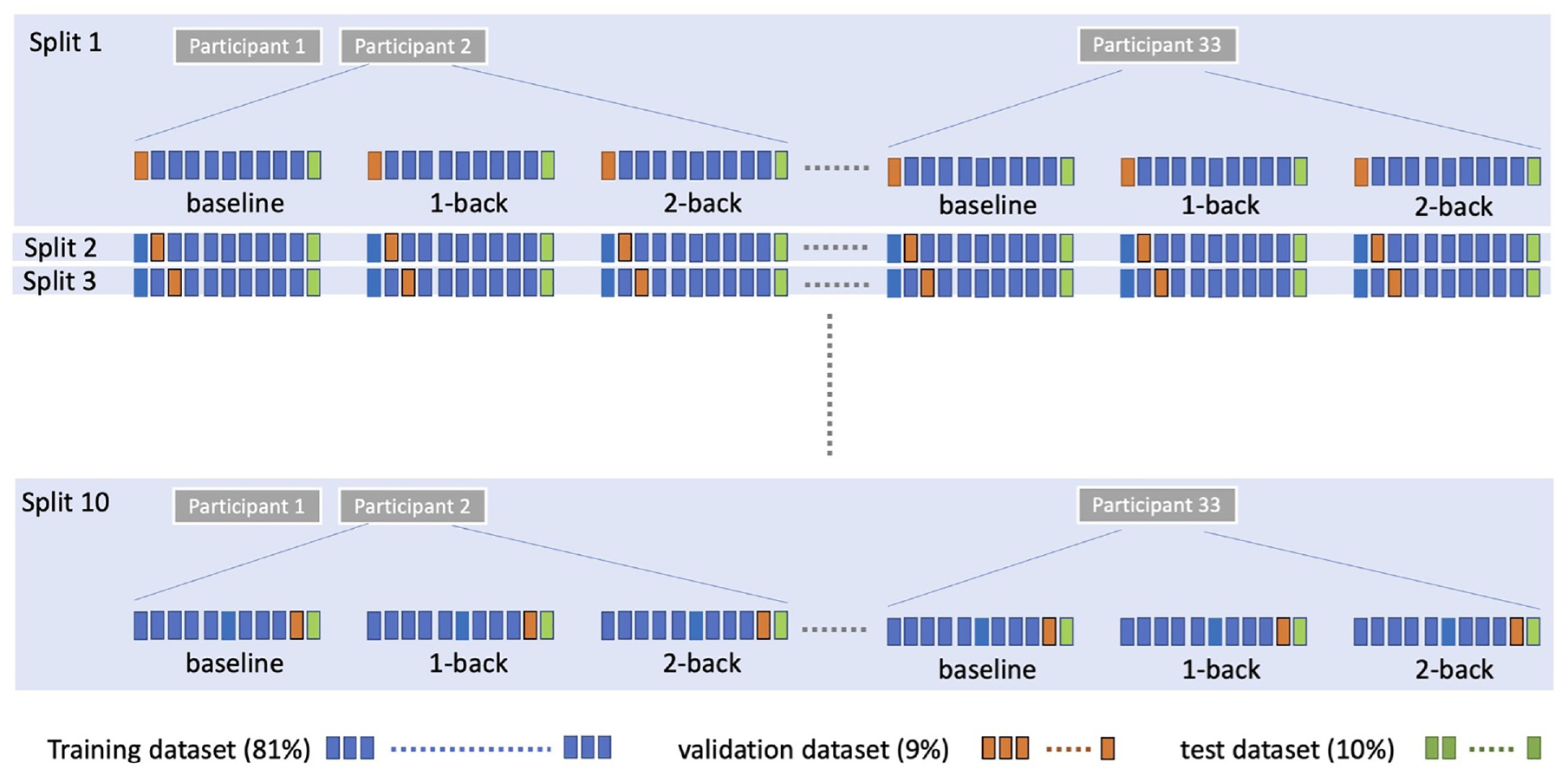
Visualization of data splits for cross-validation and testing. Note that the boxes are arranged to fall on a timeline for each cognitive load level and represent 10 s of data (with 100 s for each level of cognitive load and 300 s in total for each participant). Each blue and orange box represents 9% (i.e., 540 consecutive samples) and each green box represents 10% (i.e., 600 consecutive samples) of the total samples for each cognitive load level for each participant.
Data Preparation
Previous work has shown that individual differences among drivers influence the accuracy of driver state classification when eye-tracking and physiological data are used (32, 33). To minimize this effect, each participant’s data were normalized with respect to their no-task responses in the training dataset as
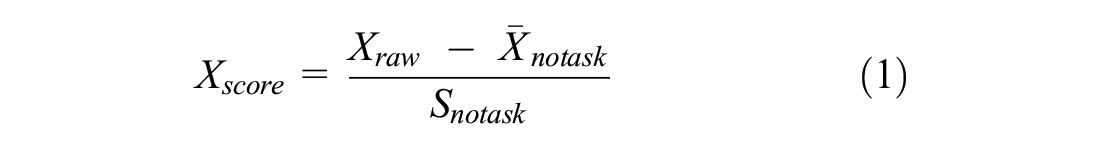
where
Further, each feature was also standardized using the scale of the features from the training dataset. Data standardization can control for scale differences across features and has been shown to improve the overall model accuracy in models such as KNN ( 34 ) and neural networks ( 35 ). Feature standardization was performed as in

where
Model Training
All machine learning models were built in Python. Modules from the Scikit-Learn Library ( 36 ) were used to train and test SVM, FNN, KNN, and RF, whereas Keras ( 37 ) was used for RNN. The specific functions used are documented in Table 3. Hyperparameters were tuned through a grid-search approach using cross-validation (i.e., iterating over combinations of parameters and selecting those that resulted in the highest average accuracy on validation datasets). All models were trained on an Apple MacBook Pro (16 in., 2019) with 2.6 GHz 6-Core Intel i7 CPU and 16 GB 2667 MHz DDR4 RAM. Graphical processing units were not used in the training of the neural network models.
Overview of Model Fitting and Hyperparameters Explored. The Best Combinations of Hyperparameters for Each Model are Indicated With the Following Superscripts: eeyeSet, pphysioSet, eheyeHRset, egeyeGSRset, epeyePhysioSet

Note: FNN = feedforward neural network; KNN = k-nearest neighbor; RF = random forest; RNN = recurrent neural network; SVM = support vector machine.
Table 3 summarizes the candidate hyperparameters we tested and the best for each dataset and for each machine learning model. For KNN, the number of neighbors specifies the number of training data samples that can vote for the prediction of a given test data point. The weight function dictates how the voting samples are weighted. The distance metric dictates how the distances between the unknown sample and the voting samples are calculated. For SVM, a radial basis function (RBF) kernel was used, as it yielded the best performance in most of the previous attempts in classifying levels of cognitive load with SVM (e.g., Liang et al. [ 15 ], Wang et al. [ 22 ], He et al. [ 26 ]). Two additional hyperparameters were tuned for SVM. The regularization parameter trades off model complexity for training accuracy and the kernel coefficient defines how far the influence of a single training example reaches ( 36 ). For FNN, the activation function defines the (nonlinear) output of the neuron in the network given a set of inputs, the learning rate controls how quickly the model is adapted to the problem and the L2 regularization rate decides how much the model is regularized to reduce the likelihood of overfitting.
Traditional RNNs may suffer from the exploding or vanishing gradient problems, that is, if the input sequence is too long, the RNN model might be unstable (38, 39). A long short-term memory (LSTM) architecture solves this problem by adding three gates to the network (40, 41), and has been found to perform well in time-sequence classification ( 42 ). For this reason, we used LSTM in our RNN architecture. Further, the use of a sliding window has been shown to improve the performance of neural networks for time-series prediction ( 43 ). Thus, we explored several combinations of moving window size and step size. Our RNN consisted of two LSTM layers, each followed by a dropout layer, which prevents the model from overfitting by randomly setting the input units to 0. The dropout rate defines the frequency of the input units being ignored (i.e., set to 0). Then, 1 to 5 layers of fully connected layers were used, each followed by a dropout layer as well. The last fully connected layer outputs the classification of the estimated cognitive load into one of the three classes. For RF, if bootstrap is true, the whole dataset is used to build each tree; otherwise, bootstrap samples are used when building trees, which means a subset of the samples was used for the training of each tree.
Results
Figure 4 shows the classification accuracy on the test dataset for each machine learning model for the different combinations of features. Figure 5 provides confusion matrices on the test dataset. The average accuracies on cross-validation were comparable to the test accuracies and, thus, are not reported; this indicates that overfitting or underfitting are unlikely to have occurred.
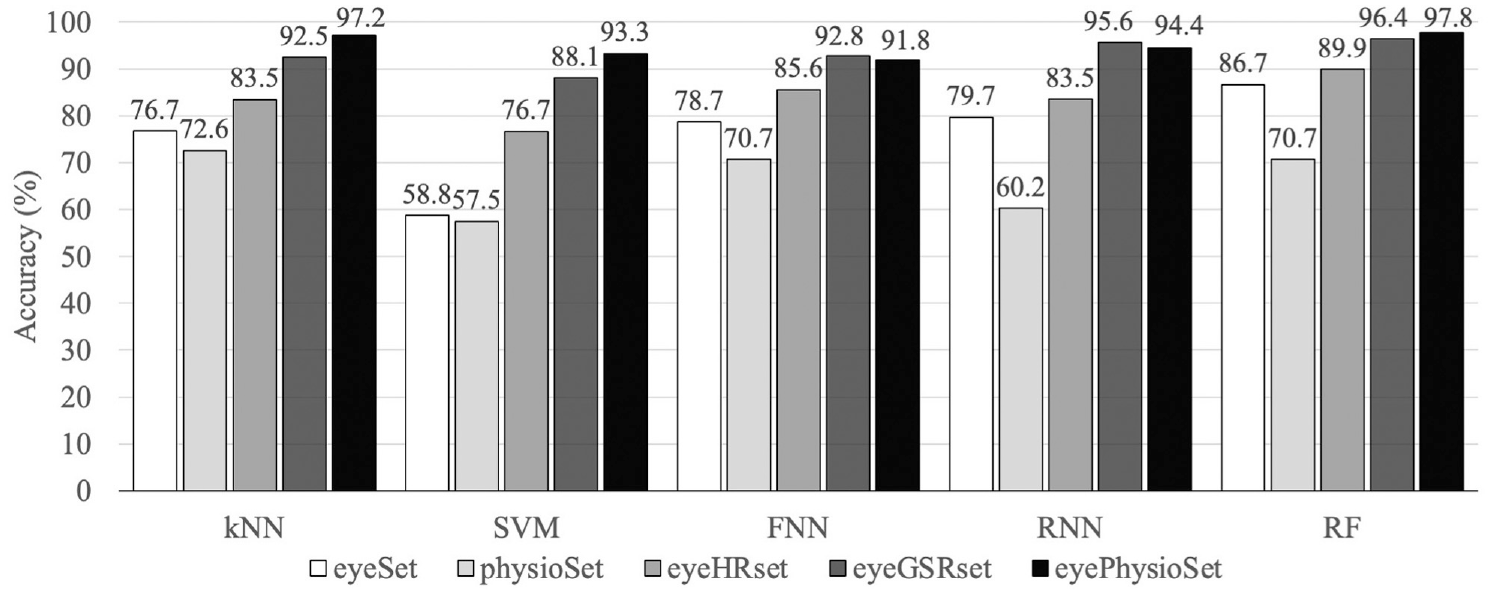
Classification accuracies in identifying three levels of cognitive load on test dataset.
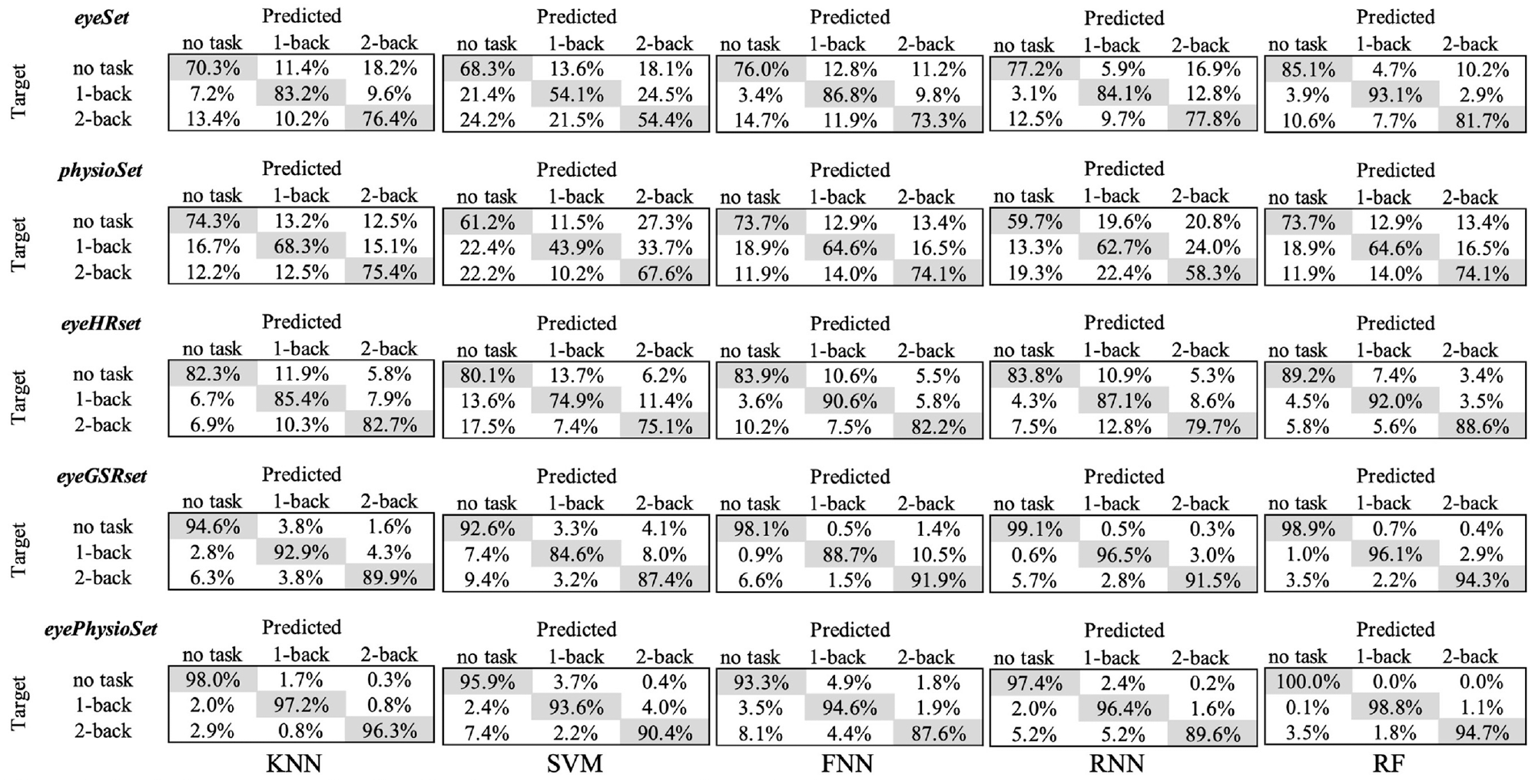
Confusion matrices for classification performance on the test dataset.
It can be observed that RF generated the highest prediction accuracy (97.8%) when all eye-tracking and physiological features were used (eyePhysioSet data). Although using physiological features alone (physioSet) generated worse prediction accuracy (1%–15%) compared with using eye-tracking features alone (eyeSet), adding physiological features in addition to eye-tracking features increased the model prediction accuracies. Among the physiological features, GSR seems to have provided more predictive power compared with HR. When comparisons are made across machine learning models, it can be seen that the discrepancies between different models decreased with the expansion of the feature set. The confusion matrices indicate that different models may be good at identifying different levels of cognitive load, even if the models may be comparable in relation to their overall accuracy. For example, with all features utilized, RF was better at differentiating no task from 1-back task (i.e., lower level of cognitive load) compared with KNN, but KNN was better at differentiating 1-back task from 2-back task (i.e., higher level of cognitive load).
Discussion
This paper revealed the potential for improving cognitive load estimation through combining eye-tracking and physiological measures. Eye-tracking measures are being adopted in production vehicles for distraction (e.g., Cadillac [ 17 ]) and drowsiness (e.g., Khan and Lee [ 18 ]) detection, but also hold promise for cognitive load detection (e.g., Recarte and Nunes [2, 6], Liang and Lee [ 7 ]). Further, physiological measures are also promising for cognitive load detection: earlier studies that used physiological predictors to classify drivers’ cognitive load reported classification accuracies of 85%–96% (14, 22, 26, 44). However, not all physiological measures are suitable for driver state estimation because of the intrusiveness of associated sensors (e.g., EEG). Further, although the fusion of eye-tracking and physiological measures seems to be more promising for real-time assessment of driver cognitive load, research is lacking in this area.
In this paper, two physiological measures that are available in consumer-grade wearable devices, that is HR and GSR, were fused with eye-tracking measures, leading to 97.8% accuracy with a RF model in classifying three levels of cognitive load (no task, lower difficulty 1-back task, and higher difficulty 2-back task). This result is promising when compared with the accuracies reached in previous research that combined driving performance with eye-tracking measures (e.g., 81.1% in Liang et al. [ 15 ]), and also with the accuracies reached in previous research that combined driving performance measures with physiological measures (e.g., 89% in Solovey et al. [ 14 ]), especially considering that our 3-class classification problem is more challenging than the 2-class problems tackled in these earlier studies. GSR contributed more to the performance of the models compared with HR: when HR was added to eye-tracking data, the model accuracies increased from 3.2% (with RF) to 17.9% (with SVM), whereas with HR, the increases ranged from 9.7% (with RF) to 29.3% (with SVM). Although adding both HR and GSR to eye-tracking data yielded the highest accuracies for most models, the benefit of adding HR on top of GSR was relatively small, with changes in model accuracies ranging from −1.2% (with RNN) to 5.2% (with SVM). Collecting and processing more features may come with monetary and computational costs, and if a choice is to be made, GSR may be preferred over HR.
Our findings reveal that, with the increased number of features, the advantage of using a specific machine learning model becomes less obvious. With only eye-tracking measures, RF yielded the highest accuracy (86.7%) and SVM the lowest (58.8%). When both eye-tracking and physiological measures were used, all models reached over 91% accuracy. It is possible that with more features, the classification problem became easy enough for most models to handle. At the same time, we also note that KNN, which yielded the second highest accuracy (97.2%) on the combined eye-tracking/physiological dataset, took the shortest to train with 7.6 s, and RF, which resulted in the highest accuracy (97.8%), took slightly longer with 61.6 s. The training time for FNN, RNN, and SVM were two orders of magnitude longer (all over 5000s) than that of KNN and RF. Thus, even with the computation cost of model training considered, RF and KNN are preferred over other models for the cognitive load detection problem explored in our study.
Although overall accuracies across models were comparable when all features were utilized, the confusion matrices reveal that different models may be good at identifying different levels of cognitive load. For example, when all features were utilized, RF reached the overall highest accuracy, but KNN performed better than RF in differentiating 2-back from 1-back. Thus, the choice of models may not be based solely on overall accuracies, but also on the specific purpose of the in-vehicle applications, for example, which level of cognitive load is most critical to differentiate from other levels for an alert to be issued.
Individual differences among drivers have been shown to affect the accuracy of driver state classification based on physiological data ( 32 ) and, thus, we used a normalization strategy, which would require the system to have prior data from each driver, or learn from the driver over time. This is a reasonable expectation but prior data may not always be available for each driver. Future research should utilize a larger sample with a more diverse set of drivers to test the generalization of our models by training the models based on a group of participants and predicting the cognitive load of a different group of participants (i.e., between-drivers data partition). It should, however, be noted that if model training/testing is based on a between-drivers data partition, individual differences would have a greater effect on model performance.
Further, although we utilized a validated secondary task to impose cognitive workload on our participants, the task is artificial and there is a need to study more the tasks that drivers normally perform in their vehicles (e.g., talking on a cellphone). In addition, in this paper, we focused on physiological measures (i.e., HR and GSR) that can be collected through wearable devices, but our data came from a research-grade system utilized in a driving simulator study. Further, the eye-tracking measures were collected using an eye-tracker built for the laboratory environment. There are bound to be additional signal noise issues when these measures are collected through wearable devices and cameras, and in a real vehicle. Although our study provided evidence that HR and GSR have the potential to be fused with eye-tracking data to improve driver cognitive load estimation, more research is needed to develop signal processing algorithms for relevant data collected through consumer-grade wearable devices in motion and through in-vehicle eye-tracking systems under varying lighting conditions. As in Fuller et al. ( 45 ), Zhu and Du ( 46 ), and Binaee et al. ( 47 ), there is indeed significant research activity to improve these devices and accompanying algorithms. Finally, the time window sizes used for feature extraction may affect the performance of the models. Future research should explore different time window sizes appropriate for this application.
In summary, physiological and eye-tracking features that can be collected through in-vehicle or wearable devices combined with the algorithms developed in our paper have the potential to support less intrusive driver state detection. Given that our approach excluded driving performance measures, it can also inform driver state detection for automated vehicles where driving performance data may not be indicative of driver state.
Footnotes
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: D. He, B. Donmez; analysis and interpretation of results: D. He, Z. Wang, E. B. Khalil, B. Donmez, and G. Qiao; draft manuscript preparation: D. He, E. B. Khalil, B. Donmez, Z. Wang, and S. Kumar. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The funding for this study was provided by the Natural Sciences and Engineering Research Council of Canada (NSERC) through the Discovery Grant Program [RGPIN-2016-05580] and Hitachi Solutions, Ltd. through a research contract.
Data Accessibility Statement
Data sharing is not applicable to this article as no new data were created in this study.