
Abstract
Over the past few decades, numerous adaptive traffic signal control (ATSC) algorithms have been proposed to alleviate traffic congestion and optimize traffic mobility using real-time traffic data, such as data from connected vehicles (CVs). However, most of the existing ATSC algorithms do not consider optimizing traffic safety, likely because of the lack of tools to evaluate safety in real time. In this paper, we propose a novel ATSC algorithm for real-time safety optimization. The algorithm utilizes a traditional Reinforcement Learning approach (i.e., Q-learning) as well as recently developed extreme value theory (EVT) real-time crash prediction models. The algorithm was validated using real-world traffic video data collected from two signalized intersections in British Columbia. The results indicated that, compared with an existing fully actuated signal controller, the developed algorithm can significantly reduce the real-time crash risk by 43% to 45% at the intersection’s approaches even at low CVs market penetration rates.
Keywords
Adaptive traffic signal control (ATSC) systems have been receiving considerable interest in recent years. This interest is expected to grow with the availability of real-time traffic data from emerging connected vehicles (CVs) and advances in sensing technologies. ATSC systems use real-time traffic data to optimize traffic efficiency and minimize traffic delay. The mobility-oriented ATSC techniques have demonstrated considerable benefits in enhancing traffic efficiency at signalized intersections ( 1 – 9 ). However, the safety impact of ATSC systems was not considered in many of these evaluation studies. Only a few studies considered evaluating the safety impact of mobility-oriented ATSC algorithms, producing inconsistent results ( 10 – 15 ). Some studies have shown that ATSC systems can have considerable safety benefits. The safety improvements were represented by either a reduction in the number of crashes ( 10 , 11 , 13 , 16 ) or traffic conflicts ( 15 , 17 ). On the other hand, other studies showed little impact on crashes or even an increase in surrogate safety measures, such as traffic conflicts, after the implementation of ATSC systems ( 12 , 18 ). This may be because ATSC systems focusing on only optimizing traffic flow and maximizing traffic efficiency may not provide improved traffic safety ( 19 ).
There has been some previous work on optimizing the safety of signalized intersections using microsimulation models and the Surrogate Safety Assessment Model (SSAM) ( 19 – 21 ). The optimization process described in these studies includes tuning parameters such as the cycle length, splits, offsets, and left-turn phase sequence at signalized intersections. Then, several signal designs were proposed and evaluated offline, and the safety level of each design was investigated using SSAM. However, using SSAM to evaluate safety has many limitations and may not produce valid results ( 22 , 23 ). Moreover, it is important to evaluate real-time control strategies using real-time traffic data. In this case, self-learning ATSC optimization techniques can be more effective and reliable than offline methods. They can adapt quickly to real-time traffic changes and cover all possible traffic states. The real-time safety optimization of traffic signals has not been generally considered in existing ATSC systems. This is possibly because of the unavailability of adequate real-time safety evaluation tools.
Recently, prediction models for real-time safety evaluation have been developed and validated ( 24 – 26 ). These models predict the number of traffic conflicts (as a safety surrogate) for a short time period (i.e., signal cycles) using several dynamic traffic variables (e.g., traffic volume, shock wave area, shock wave speed, queue length, and platoon ratio). The models can quantitatively assess the safety level of dynamic traffic conditions per signal cycle. Although these models are useful for real-time safety evaluation, the use of traffic conflicts as a safety measure is generally associated with two main shortcomings. First, as reducing crashes is the ultimate goal of safety improvements, measures based on crash risk should be used in the real-time safety evaluation of signalized intersections. Second, to identify a severe conflict event, a threshold for a conflict indicator (e.g., time-to-collision of 1.5 s) should be defined; the results of the safety evaluation can vary depending on the selection of this threshold.
Acknowledging the above-noted limitations of using traffic conflicts, researchers have proposed use of extreme value theory (EVT) for conflict-based crash-risk estimation ( 27 – 31 ). In the EVT approach, traffic crashes can be estimated from the extreme value distribution of traffic conflicts. Recent research has applied the EVT approach to develop an advanced method for real-time safety evaluation of signalized intersections ( 32 , 33 ). In this method, safety indices (e.g., the risk of collision) can be obtained and related to dynamic traffic parameters, reflecting the real-time safety level of the signalized intersection ( 32 , 33 ). Such a method enables development of new ATSC strategies to directly minimize crash risk and optimize safety of signalized intersections in real time.
In this paper, we propose a Q-learning-based adaptive signal control algorithm for real-time safety optimization (QASCS) to minimize crash risk. EVT-based real-time crash prediction models for signalized intersections ( 33 ) were applied to define the reward and evaluate safety. Using these EVT models, two real-time safety measures, the risk of collision (ROC) and the return level of a cycle (RLC), can be extracted to estimate the safety level of each signal cycle based on dynamic traffic parameters. Real-time data from CVs and dynamic traffic changes were considered in the algorithm. Moreover, validation of the trained algorithm was performed using real-world video data collected from two signalized intersections in the city of Surrey, British Columbia, Canada. The novel contribution of this study is the real-time safety optimization of traffic signals using direct crash-risk measures.
Literature Review
Real-Time Crash Prediction Models
Recently, considerable research has been conducted in modeling real-time crash risk to manage and evaluate traffic safety proactively. For example, Abdel-Aty and Abdalla developed a model to predict daytime crashes on a freeway using real-time roadway geometric features and traffic flow characteristics ( 34 ). Other studies introduced real-time safety performance functions for signalized intersections to evaluate traffic safety ( 35 , 36 ). In these studies, crash risk was related to several traffic parameters in a period of less than 1 h. Considering a shorter time period, other studies related the number of traffic conflicts to dynamic traffic parameters (volume, shock wave area, shock wave speed, queue length) at the signal cycle level ( 24 , 25 ). A comprehensive review of the existing real-time crash prediction models was conducted by Hossain et al. ( 37 ).
EVT Models
There has been significant interest in using traffic conflicts to estimate crashes and develop crash-risk measures from observable non-extreme frequent events (i.e., conflicts). This can be realized by applying the EVT, in which models can be developed to enable extrapolation from observed levels to unobserved levels of a stochastic phenomenon. The application of EVT for road safety was first proposed by Campbell et al. and Songchitruksa and Tarko ( 38 , 39 ), who developed several EVT models which were the foundation for most of the subsequent EVT studies in road safety. Other important studies can be found elsewhere (27–31, 40–42).
Recently, the use of EVT models in safety analysis has witnessed considerable advances, including new methods and applications. New applications included the use of EVT models to conduct before–after safety evaluations ( 42 – 44 ). New methods included the development of bivariate EVT models to integrate more than one conflict indicator ( 32 , 45 , 46 ), and developing Bayesian hierarchical extreme value models to combine conflicts from several sites to account for non-stationarity and unobserved heterogeneity in conflict extremes ( 32 , 47 ).
Zheng and Sayed proposed an approach for real-time crash-risk prediction at signalized intersections within the EVT framework ( 33 ). Generalized extreme value (GEV) models were developed based on conflict extremes. A Bayesian hierarchical model (BHM) that combines traffic conflict extremes from different sites, incorporating the influence of dynamic traffic parameters, was developed and used to estimate real-time safety indices to measure the safety level of signalized intersections at the signal cycle level. These indices include the ROC and RLC. The ROC can directly identify the cycles with crash-prone traffic conditions when it exceeds zero, whereas the RLC can characterize and differentiate the safety levels even for safe cycles (i.e., ROC = 0).
ATSC Algorithms
ATSC algorithms have recently been implemented in many jurisdictions worldwide to alleviate traffic congestion and reduce delays. The Sydney coordinated adaptive traffic system was the earliest ATSC algorithm (SCATS) ( 1 ). Earlier ATSC examples include the split, cycle and offset optimization technique (SCOOT) ( 48 ) and the real-time demand-responsive traffic signal control framework “Optimization Policies for Adaptive Control” (OPAC) ( 49 ). More recently, a cost-effective solution for applying adaptive control system (ACS-Lite) was proposed by the Federal Highway Administration ( 2 ). All the previously mentioned ATSC techniques aim to address the same objective of improving traffic efficiency and mobility by reducing delays and congestions, even though they use different operations. Although ATSC algorithms provide performance improvements over pre-timed and actuated signals, they experience several operational limitations ( 7 ). These include the difficulty of obtaining adequate microscopic data from available sensors such as loop detectors, and accounting for the large variations in traffic. Another main limitation of existing ATSCs is that they do not consider optimizing traffic safety in relation to crash-risk reduction.
Traffic Signal Optimization Using CV data
With the increasing emergence of CV technology, numerous traffic signal control algorithms have recently been proposed to optimize traffic efficiency using real-time data from CVs. Some studies, for example, proposed various algorithms to optimize and coordinate traffic movement in road intersections without using any traffic lights, assuming that all vehicles are connected and autonomous ( 50 – 53 ). More realistically, other studies assumed various market penetration rates (MPRs) of CVs to develop and test ATSC algorithms. The developed algorithms generally aim at minimizing the total delay ( 54 – 58 ). Several studies have also considered multiple objectives, such as minimizing the total delay and the number of stops ( 59 ), or minimizing the total delay and the queue length ( 60 ). Most of the existing algorithms optimize the traffic signal timing based on real-time vehicle information, assuming one-way vehicle-to-infrastructure (V2I) communications. Some algorithms, however, optimize both the traffic signal timing and vehicle trajectories, assuming a specific percentage of autonomous vehicles and bidirectional V2I communications (56, 61–64). Although the majority of previous studies have mainly focused on adapting traffic signals to improve mobility, a limited number of studies have considered optimizing traffic signals to reduce traffic emissions and fuel consumption ( 62 – 64 ). On the other hand, optimizing traffic safety has generally been disregarded. More details and a systematic review of research on using real-time CV data for urban traffic signal control can be found in a recent study by Guo et al. ( 65 ).
Use of Reinforcement Learning for Traffic Control
Reinforcement learning (RL) is a machine learning approach that analyzes how agents can take actions to maximize their cumulative reward. RL techniques have been proposed in the literature for signal control as they are suited to the stochastic and dynamic traffic environments. These techniques can learn the control policy by interacting with the environment directly without the need of a model of the traffic environment or human intervention ( 66 – 68 ). Several studies were conducted to evaluate ATSC systems using RL with the objective of organizing traffic movements and reducing delays and congestions. Self-learning ATSCs were implemented using different techniques and methods, including model-based Q-learning and multi-agent self-learning ( 6 , 69 ), Q-learning (3–5, 70–73) and Deep Q-Network methodology ( 8 , 9 ). The primary objective of all the above-mentioned studies is minimizing traffic delays and travel times to optimize mobility. Safety optimization was not included in previous RL-ATSC techniques. However, these techniques have demonstrated substantial traffic mobility improvements.
Methodology
RL Formulation
RL is an area of machine learning that analyzes how an agent is interacting with the surrounding environment to realize a goal ( 74 ). The agent discovers by guided trial and error how to react to acquire the most reward, instead of giving it explicit examples of the desired actions such as in the supervised machine learning approach. In this study, RL is applied to develop the proposed algorithm for signal control to reduce the risk of crashes. The agent or the decision maker in this application is represented by the signal control unit, and the surrounding environment is represented by dynamic traffic environment changes in the intersection area. During the learning process, the agent selects randomly from a set of actions (i.e., signal phases) given a specific state of the surrounding environment, then it learns by receiving reward or penalty for the selected action. The agent iteratively seeks to maximize the total reward it receives over time. Therefore, the outputs that maximize the received rewards over time are being selectively retrained by the RL algorithm (Figure 1). The control policy is defined in the algorithm as a mapping of the perceived states of the environment to the pre-defined possible actions corresponding to these states. Thus, the agent learns the control policy over time by trial and error to maximize the total cumulative reward in the long run by performing appropriate actions. Subsequently, the selected actions are not only affecting the immediate reward, but they are affecting the future rewards as well ( 74 ).
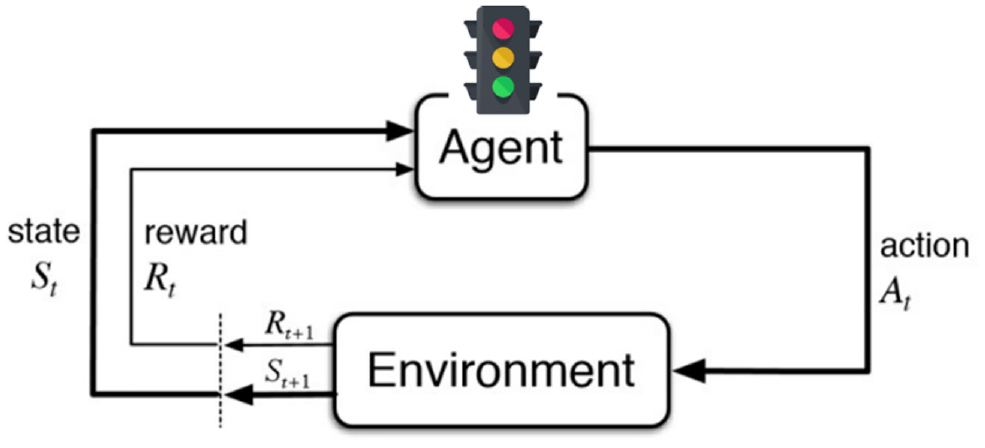
Reinforcement learning framework.
Modeling the Environment
A signalized intersection in Surrey, British Columbia was simulated in this study using the microsimulation platform (VISSIM 7) ( 76 ) to mimic the CVs environment and to investigate the performance of the proposed QASCS algorithm. The modeled intersection consists of four approaches with each approach having two through lanes and one left-turn lane. In the QASCS algorithm, the decision maker (i.e., the agent) receives real-time information (i.e., V2I) from all CVs located within a pre-defined distance from the stop lines. This distance defines the standard V2I dedicated short-range communication (DSRC) zone. The typical value of the DSRC is less than 1,000 m ( 77 ). Previous research on CV-based applications has used DSRC values between 150 and 300 m. We selected the average of this range (i.e., 225 m). To simulate CVs in VISSIM, a new vehicle class (i.e., Connected Vehicle) was created. Various traffic composition percentages were defined, representing the market penetration rates of CVs. For the non-connected vehicles, loop detectors were installed to provide real-time information to the traffic controller about traffic counting of all lanes.
Q-Learning
There are three main methods for formulating the RL algorithms and learning the optimal policy: dynamic programming (DP), Monte Carlo techniques (MC), and temporal difference (TD) learning. The three methods share some similarities and distinctions. For example, the DP method requires a model of the environment to be defined, whereas in the MC and TD methods, the RL algorithm can learn directly from interacting with the surrounding environment. Likewise, the DP and TD methods share an advantage of updating the estimates at each time step without waiting for the final outcome such as in the MC method (
66
,
75
). TD methods are the most convenient for solving the ATSC control problem (
7
,
66
). There are two main types of TD methods: the on-policy SARSA method and the off-policy Q-learning method. In this study, the 1-step off-policy Q-learning method was selected. This method uses the experience of each state to update one element in the Q-table. This entry in the table is a Q-value for a specific state–action pair
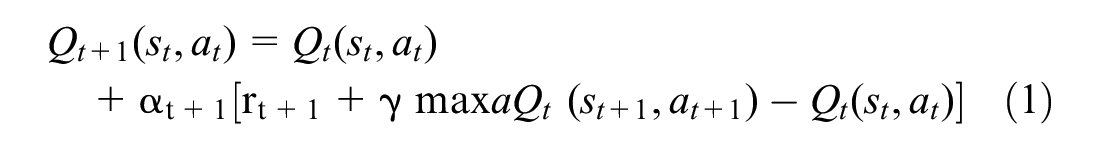
The learning rate (
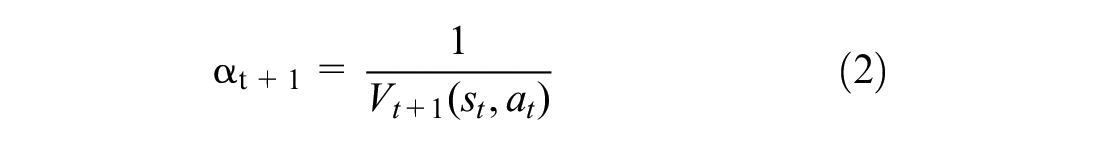
where
γ: a discount factor, a value of 0.5 is chosen.
State Definition
In Q-learning, a tabular form is usually used to represent all state–action pairs. This approach of storing the states in a look-up table is questionable, especially when RL is applied to stochastic environments that possibly include an infinite number of states. Including many states in the Q-matrix will result in most states not being experienced by the agent. Potentially, a generalization from the states that were visited previously to the ones that have never been experienced (i.e., function approximation) may be helpful to solve this issue. Popular methods of generalization include artificial neural networks and statistical curve fitting ( 66 , 75 ). However, there are many negative consequences of the imperfect value estimations by the generalization of the states, such as the divergence of Q-estimates ( 66 ). A simpler discrete table (i.e., the Q-table) can be created to define the possible states of the environment. In addition, the states can then be divided into ranges and defined in the Q-matrix. This discretization of the states might solve the problem of having an infinite number of states. A Q-matrix with discretized ranges of states was successfully introduced in several previous studies (3, 4, 7, 69, 70, 72). The discretization method was applied in this study for state representation.
The state is represented by the current green phase and the status of the total number of vehicles within a range (i.e., DSRC = 225 m) on its incoming approaches upstream of the stop line. The overall objective of the proposed algorithm in this research is to optimize traffic safety. Therefore, an arrival-queue factor that represents positions and speeds of vehicles and the real-time traffic condition is introduced. The arrival-queue factor of an approach is a weighted sum of the number of vehicles that exist at this approach. This weighted sum considers the position and speed of every vehicle. If the vehicle is stopping or moving at speed less than 5 km/h (i.e., vehicle is in a queue), it is counted as one vehicle. Otherwise, it is counted as a fraction (i.e., between zero and one). The value of this fraction depends on the distance from the vehicle position to the end of the queue or to the stop line, whichever is shorter. To cover most of the possible states of the environment, the value of the arrival-queue factor is divided into 15 ranges to create a Q-matrix. The factor for each approach is calculated as follows:
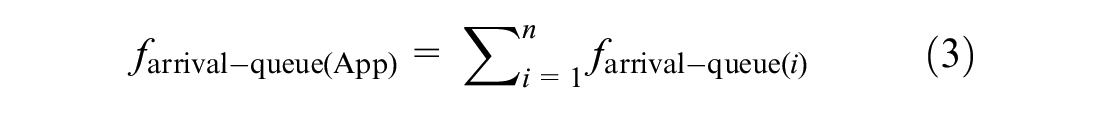
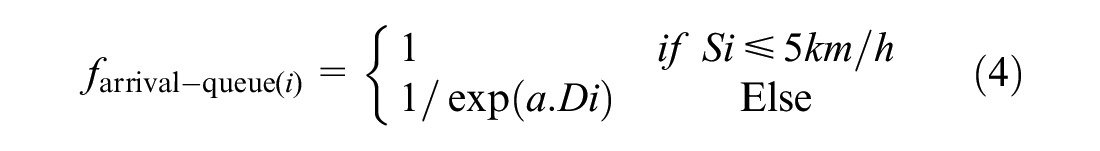
where
n: the number of vehicles that exist on the approach;
Di: the distance from the stop line or the end of the queue to vehicle i;
Si: the speed of vehicle i;
a: constant.
Action Definition
In RL-ATSC algorithms, defining the next green phase is the action that is taken by the signal controller. The number of possible actions that the signal controller can choose from varies depending on the phasing sequence scheme. Two phasing sequence schemes were defined in the literature: the fixed phasing sequence ( 3 , 4 , 7 , 70 , 72 ) and the variable phasing sequence (5, 7–9, 69, 73, 78). If the phasing sequence is fixed, there are only two actions in the action space, either extending the green time for the current green phase or switching the green light to the next phase. In the variable phasing sequence, the action space consists of N actions, where N is the number of phases. In this paper, the fixed phasing sequence was adopted for the proposed algorithm.
At each time step, the agent of the proposed algorithm implements one of two actions, either extending the green time (A1) or switching the green light to the next phase (A2). In the case in which the agent selects A1, the current green phase of the through movements is extended by a time (t). If A2 is selected, the green light will be switched to the next phase and its minimum green time (
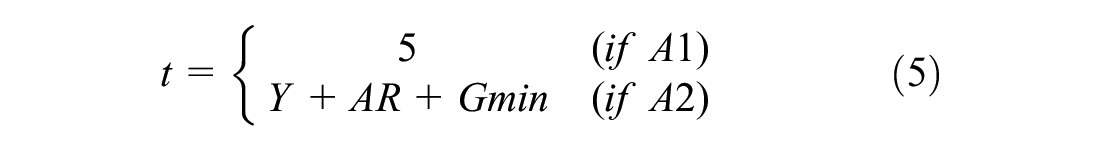
where
t: the time interval between the decision points in seconds;
Y: the yellow time in seconds;
AR: the all-red time in seconds;
Gmin: the minimum green time in seconds.
Following the standard signal timing manual (
79
), standard constraint values for minimum green, all-red, and yellow times are applied in the QASCS algorithm to ensure its feasibility to be implemented in the real world. The assumed values of
It is worth noting that selecting the update time interval (t) was relatively tricky. With too short an update time interval, it will be difficult to estimate the immediate reward of the applied action, as the new state of the environment will be almost the same as the old state. On the other side, a relatively long update time interval does not enable the algorithm to capture the variation in the environment’s state between consecutive actions, making the algorithm less adaptive to real-time traffic conditions. Therefore, after several preliminary trials, we assumed a reasonable value of 5 s for the update time interval (if A1 is selected). However, investigating the results’ sensitivity to the update time interval value is a recommended area of future research.
Action Selection Strategy
In RL, the agent is accumulating the maximum reward through exploiting the best rewarding actions. Moreover, it needs to explore new actions, to make better action selections in the future. Exploration enables the agent to visit more state–action pairs to converge the optimal policy ( 7 ). The agent should exploit and explore new actions at the same time to obtain the optimal policy. Therefore, an action selection strategy should be applied to balance the exploration and the exploitation. Typically, ∈-greedy and SoftMax algorithms were adopted as action selection strategies in most previous research ( 75 ).
In this study, the ∈-greedy method was employed as the action selection strategy. In this method, the greedy action is selected most of the time except for ∈-time when a random action is selected uniformly. At the beginning of the learning process, the rate of exploration is higher than the rate of exploitation, as the agent does not know much about the environment. Then, the agent exploits more until the end of the learning process as it converges to the optimal policy ( 75 ). Thus, the exploration rate was assumed to be decreasing gradually using an exponentially decreasing function ( 7 ) as follows:

where E is a constant, and n is the age of the agent (i.e., the iteration number).
Real-Time Collision Prediction Models
The real-time collision prediction models developed by Zheng and Sayed ( 33 ) are utilized in this research for reward definition and for evaluating the safety effectiveness of the proposed QASCS algorithm. These real-time collision prediction models are Bayesian hierarchal EVT models developed using traffic conflicts as intermediate for real-time crash prediction ( 32 , 47 ) (Figure 2). The models can be used to predict the ROC using cycle-level dynamic traffic parameters (i.e., traffic volume, shock wave area, and platoon ratio) as covariates. The EVT models were originally developed using real-world video data from four signalized intersections in the city of Surrey, British Columbia, Canada. Traffic conflicts were identified by the MTTC conflict indicator ( 80 ). The cycle-level dynamic traffic variables (i.e., traffic volume [V], shock wave area [A], and platoon ratio [P]) were extracted from the real-world video data using computer vision techniques. Three Bayesian hierarchal GEV models (BHM_GEV) were developed in Zheng and Sayed ( 33 ), considering the three dynamic traffic covariates added to location paramater, scale paramater, and both location and scale paramaters, respectively. Furthermore, the ROC and RLC measures were obtained from the GEV distribution. The model parameters are estimated as follows:
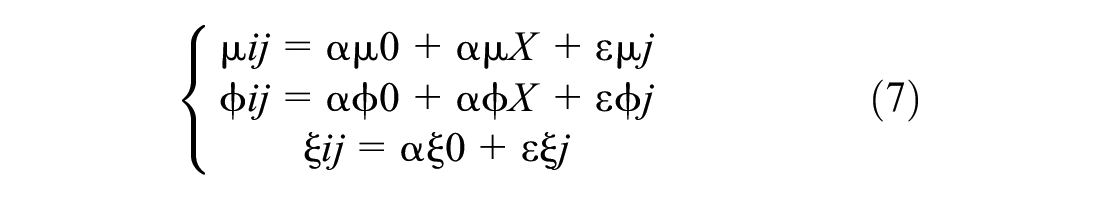
where αμ0, αϕ0 and αξ0 are the three intercept terms corresponding to the three model parameters location, scale, and shape, respectively. εμj, εϕj, and εξj are random error terms to account for additional heterogeneity that is not directly addressed by the covariates. X is the vector of covariates,
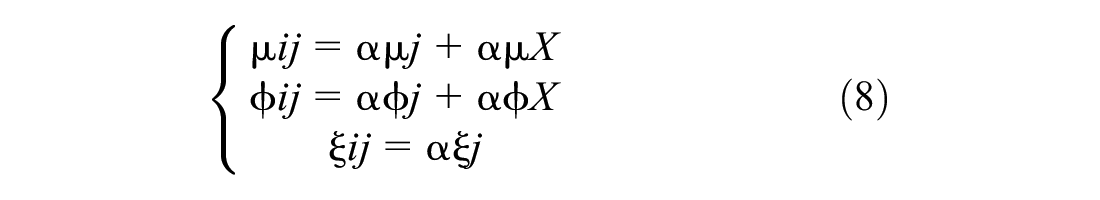
The parameters of the utilized best-fitted model are shown in Table 1.
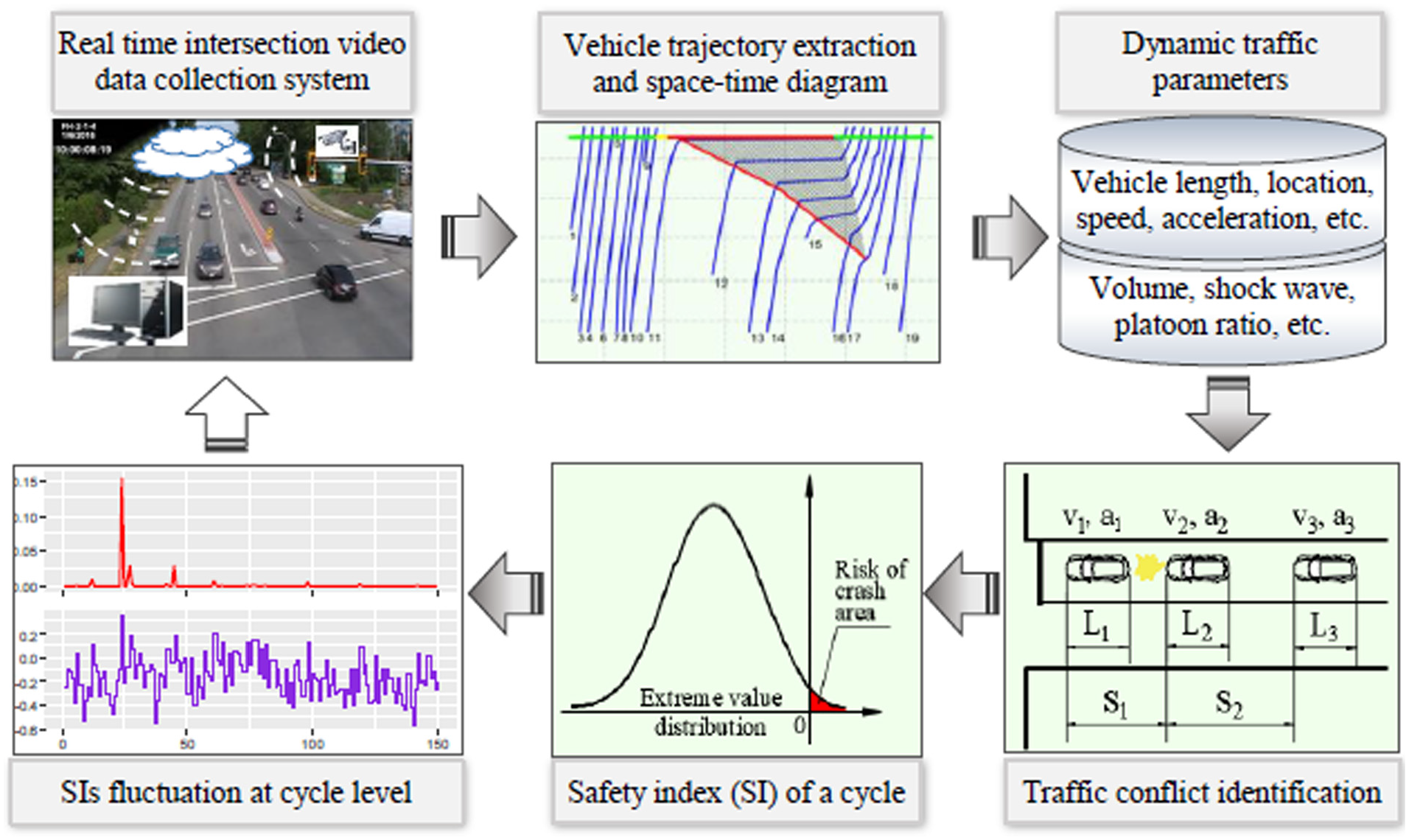
Real-time Bayesian Hierarchical Models (BHM) at the cycle level.
Parameters of the Best-Fitted Model ( 33 )
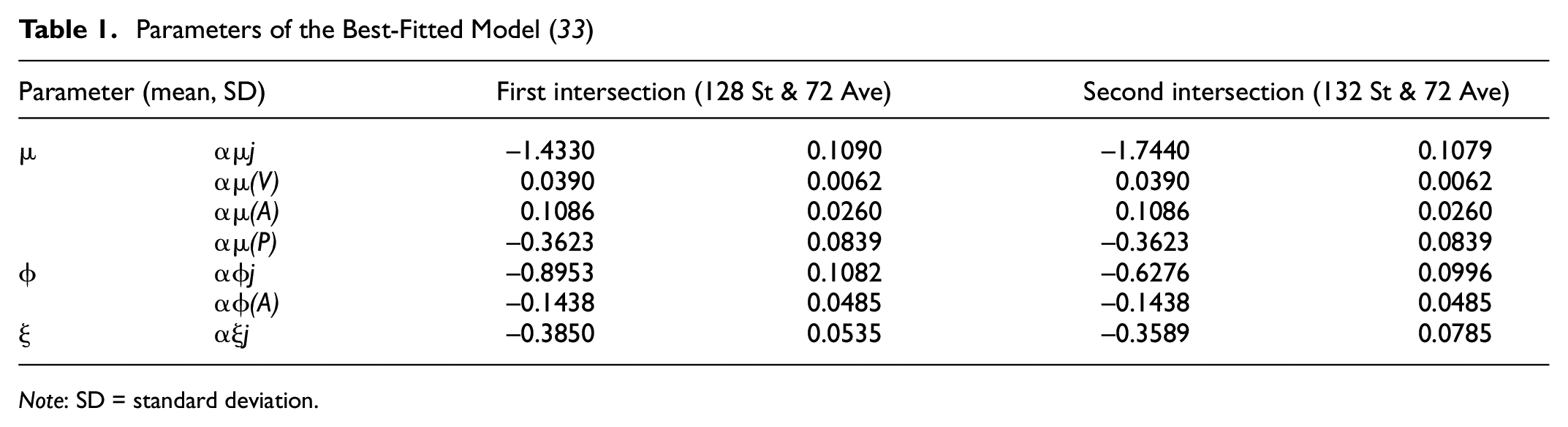
Note: SD = standard deviation.
Reward Definition
The main objective of this research is to optimize the safety of signalized intersections by minimizing the ROC in real time. Therefore, there was a need of quantitative measures that can reflect the fluctuating safety levels of dynamic traffic conditions cycle-by-cycle, to represent the algorithm’s reward or penalty. The ROC and RLC were selected as two RL rewards. In the proposed QASCS algorithm, the ROC and RLC were estimated from real-time collision prediction models ( 28 , 33 ) using cycle-level dynamic traffic parameters (i.e., traffic volume, shock wave area, and platoon ratio) as covariates. Although two safety indices were used as rewards in this study, each indicator was introduced to the algorithm separately.
The ROC is a non-negative indicator. A value of zero indicates a safe cycle with no risk of crash, whereas a ROC greater than zero indicates a positive crash risk. The RLC is a standard prediction in extreme value analysis that also reflects the safety level of a cycle. A value greater than or equal to zero for RLC indicates positive ROC of the cycle, and RLC less than zero implies that no crash risk is predicted. It is worth mentioning that the ROC and RLC are positively correlated (
28
,
33
). Also, smaller values of ROC and RLC indicate safer signal cycles. Thus, the reward function for each state–action pair is defined by ROC and RLC as penalty. The ROC was estimated at each lane of the four approaches, and the sum of all the lanes of all the approaches was then obtained for each cycle. For the other safety indicator, a value of RLC was obtained for each lane of each approach, then a weighted average of RLC for all lanes of all the approaches was estimated cycle-by-cycle. Both indicators were then input to the algorithm as penalty at the end of each cycle. Eventually, the reward was distributed equally as a delayed penalty
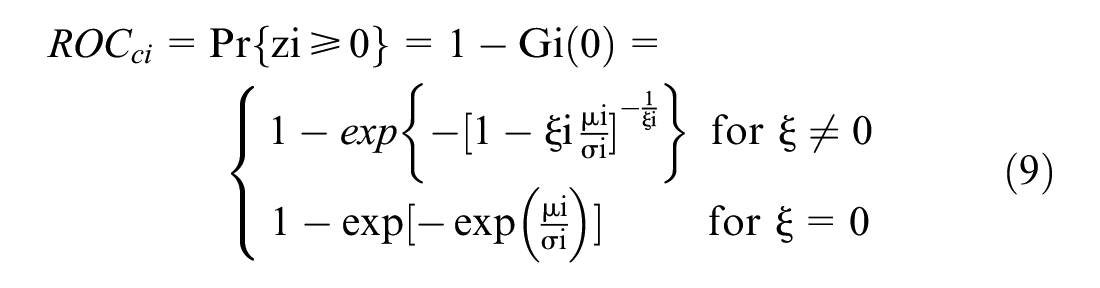
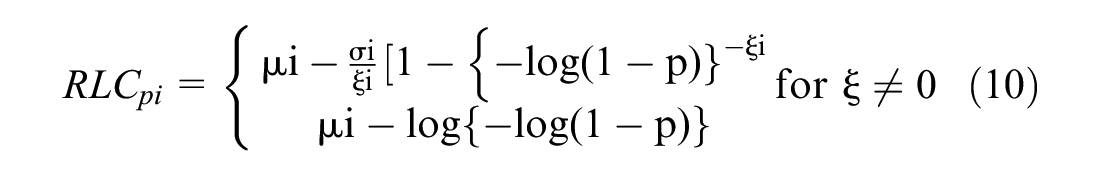
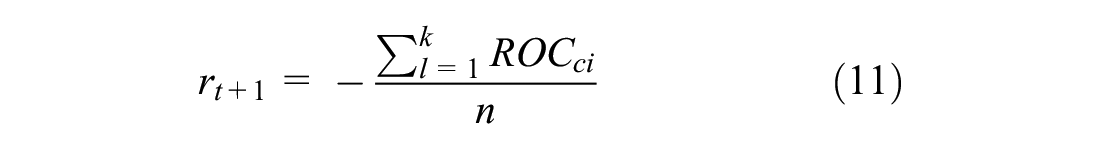
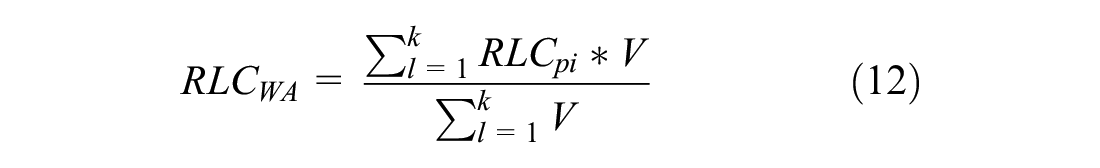
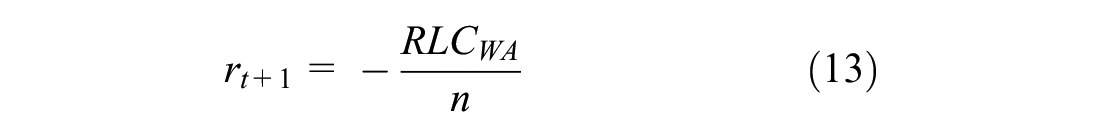
where
n: the number of cycle actions.
k: the number of lanes.
X: the vector of model covariates.
Training the Algorithm
The proposed QASCS algorithm was trained using the simulation platform VISSIM to find the optimal policy. The simulation was run for 500 iterations for both safety indices (i.e., ROC, RLC). Each iteration was divided into a 1,000-s warming-up period, a 500-s cooling-down period, and a 3,600-s (i.e., an hour) training period. The total training time for each safety index was more than two million seconds. It was observed that after 400 iterations, the proposed algorithm converged to the optimal policy. At each time interval (t) as shown in Equation 5, a new state of the environment is defined after pausing the simulation, the agent selects the best action and applies it, and finally the Q-value is updated. Afterwards, a reward is received at the end of each cycle as a delayed reward and divided backward equally to the cycle actions. For each signal controller, 10 different random seeds were applied, and the results were then averaged. The minimum required number of random seeds to compare the performance measures of the two alternatives (i.e., the proposed QASCS and the ASC benchmark) was estimated, following the methodology provided in Dowling et al. ( 81 ). The statistical analysis showed that 10 simulation runs are sufficient to reject the null hypothesis at 95% confidence level. This means the differences in the performance measures are caused by using two different alternatives and not just a result of using different random seeds. As well, to enable the algorithm to visit more states, the traffic volume at each approach was defined as a random volume between 200 and 1,600 vehicles/hour. It should be noted that although the traffic microsimulation VISSIM was used to train the algorithm, the ROC in this research is not based on the driving behavior in the simulation model. Rather, the previously mentioned EVT models are used for the crash-risk prediction. These EVT models include cycle-level dynamic traffic parameters (i.e., traffic volume, shock wave area, and platoon ratio) as covariates. Previous research has shown that these dynamic traffic parameters can be estimated from traffic simulation with a reasonable accuracy ( 23 ). Traffic conflicts from VISSIM are not used in the analysis because of the simulation model’s inability to capture the actual driving behavior and to simulate drivers’ mistakes.
Validation of the Proposed Algorithm
Real-world traffic data from two signalized intersections in the city of Surrey, British Columbia, Canada, were used to validate the proposed algorithm. The first intersection is 72nd Avenue and 128 Street, and the second intersection is 72nd Avenue and 132 Street. Figure 3 shows the two signalized intersections and the studied approaches. Both intersections are urban signalized intersections and are controlled by a typical fully actuated signal control (ASC). The trained QASCS algorithm and the existing ASC were both simulated in a VISSIM model for each intersection.
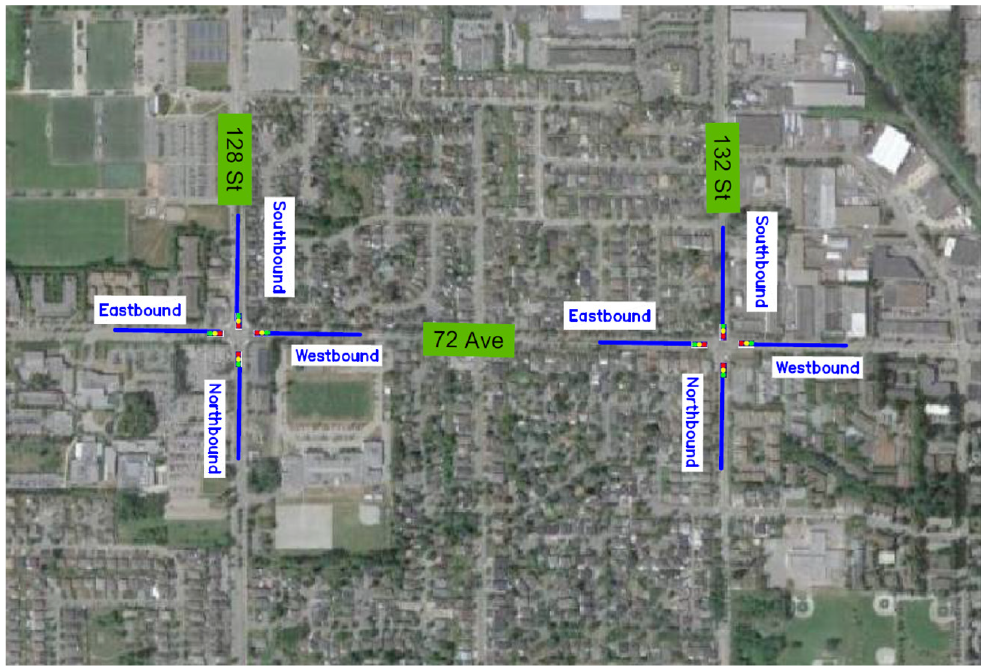
Study intersections and approaches.
VISSIM models of the two selected intersections came from previous studies ( 22 , 82 ). The VISSIM models were built to accurately match actual field conditions in relation to intersection geometry, traffic volumes, traffic composition, and traffic signal settings (i.e., the actuated signal controller). The real-world ASC was defined in VISSIM using the Ring Barrier Controller (RBC) module. Visual inspection was also performed to ensure that there are no abnormal movements of the simulated vehicles. In addition, the VISSIM models were precisely calibrated in Essa and Sayed ( 22 , 82 ) using a comprehensive two-step calibration procedure. The first calibration step aimed to match the simulated delay times with the field-observed delay times. This was achieved by matching the arrival pattern and the desired speed to the field conditions. The second calibration step aimed at enhancing the correlation between field-observed and simulated traffic conflicts by calibrating the VISSIM parameters. First, important VISSIM parameters that had the most significant effect on the simulated conflicts were determined through a sensitivity analysis. Subsequently, a Genetic Algorithm was applied to estimate the best values of these parameters with the objective of enhancing the correlation between field-observed and simulated conflicts. Table 2 shows the selected VISSIM parameters and their calibrated values at each intersection ( 22 , 82 ).
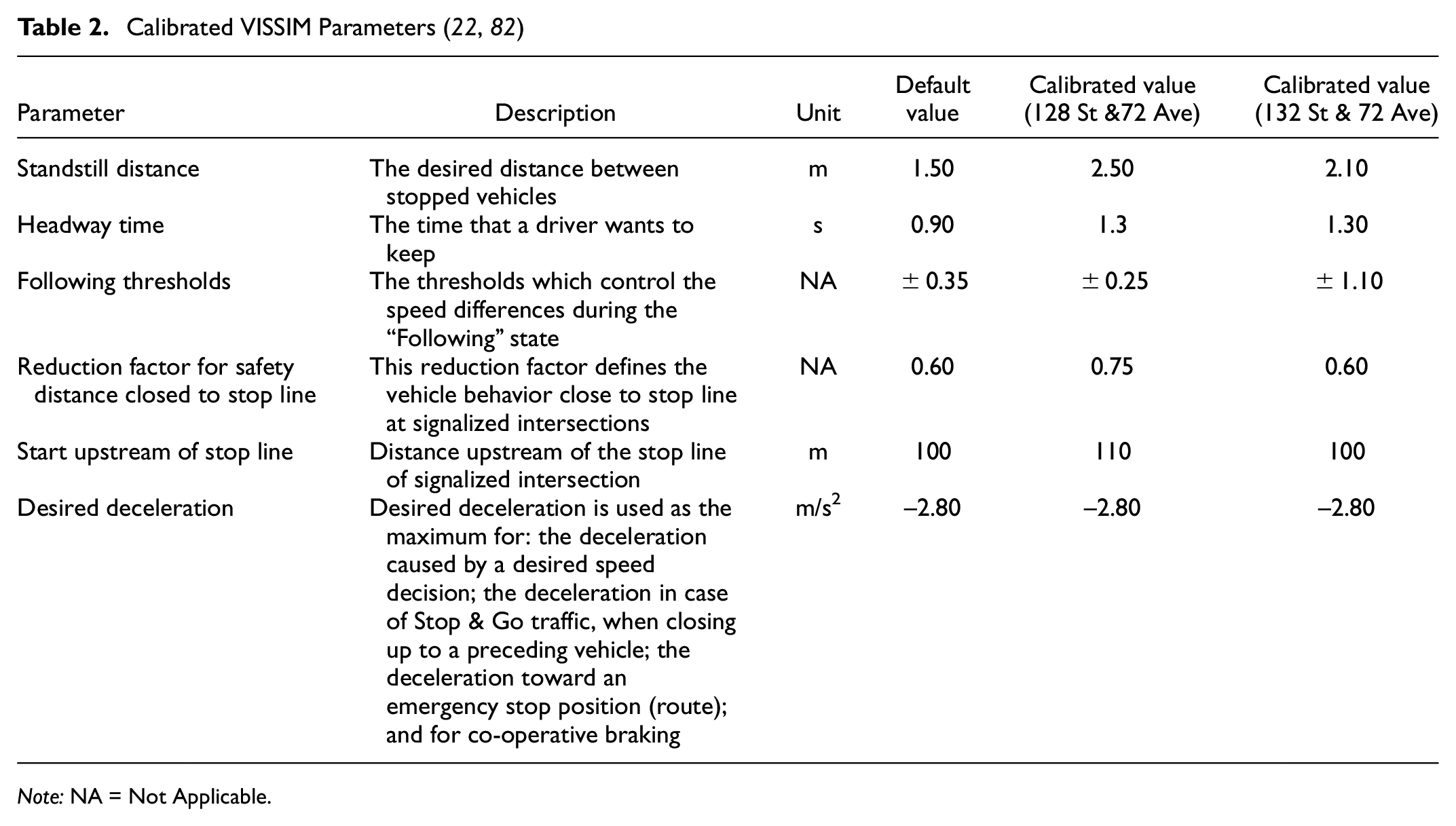
Note: NA = Not Applicable.
After developing the simulation models for both intersections using ASC and QASCS algorithm, the two measures ROC and RLC were estimated and compared for both signal controllers. The calibrated simulation models were run separately for each signal controller for 9 h (i.e., the available real-world video data are from 9:00 a.m. to 6:00 p.m.). Table 3 shows the location, date of the video data collection, number of lanes, and traffic volume statistics for each intersection. The ASC was simulated using the RBC module, whereas the QASCS algorithm was represented by an external supporting code. Simulated traffic data were constantly extracted and saved for each simulation run, such as position and speed of each vehicle crossing the intersection, the vehicle type (e.g., connected or non-connected), and the indication of all signal heads.
Study Intersections and Camera Scenes
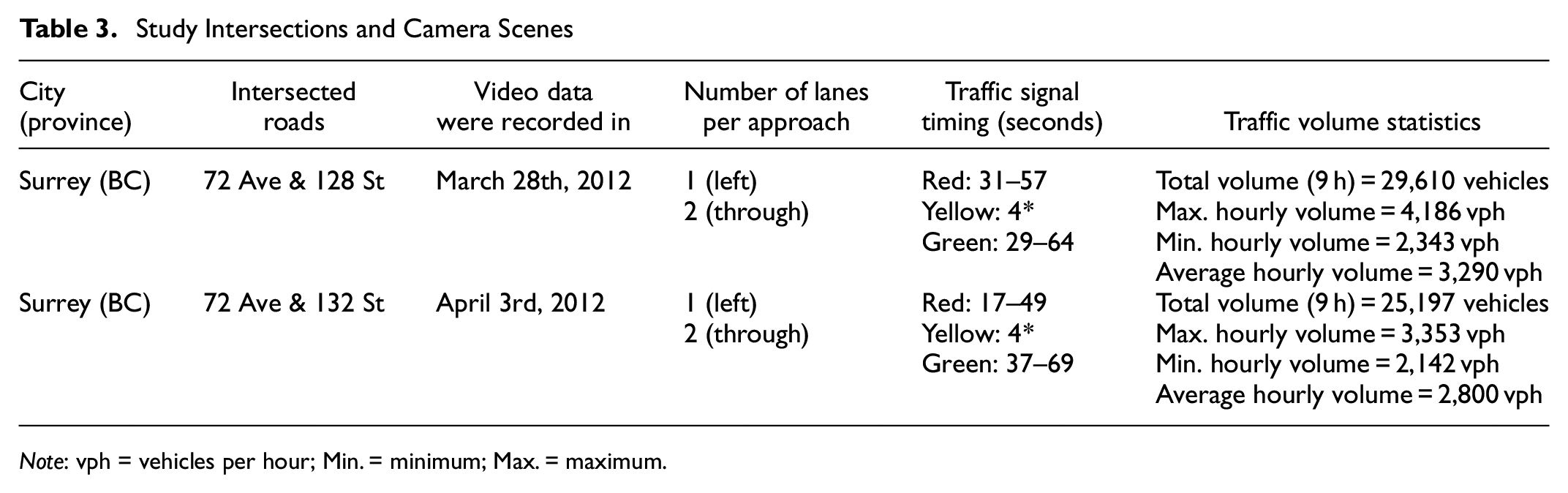
Note: vph = vehicles per hour; Min. = minimum; Max. = maximum.
Dynamic traffic parameters were extracted for each signal cycle (e.g., shock wave area, platoon ratio, traffic volume). These dynamic parameters were then used in the EVT model (
33
) shown in Table 1 and Equations 9 and 10 to estimate the ROC, and RLC for each cycle. Furthermore, the annual frequency of crashes and severe conflicts for the whole intersection were obtained. Equations 9 and 14 were used to calculate the annual crash frequency, and Equations 9 and 15 were employed to estimate the number of extreme conflicts per year. The value of
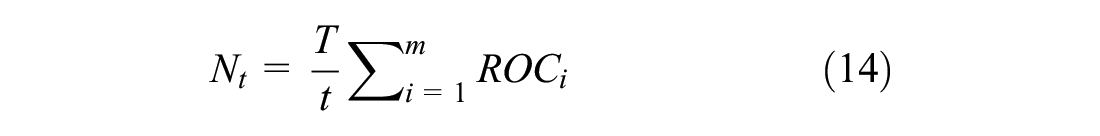
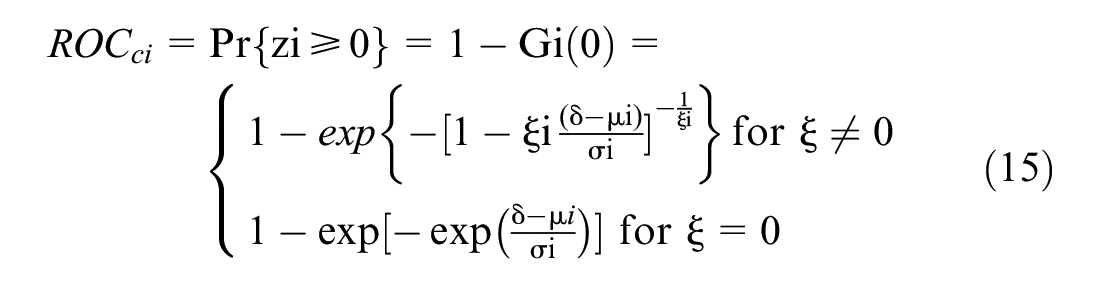
where
t: the conflict observation period (daytime hours only);
m: the number of blocks (cycles) corresponding to the observation period;
T: a long period (a year);
Validation Results
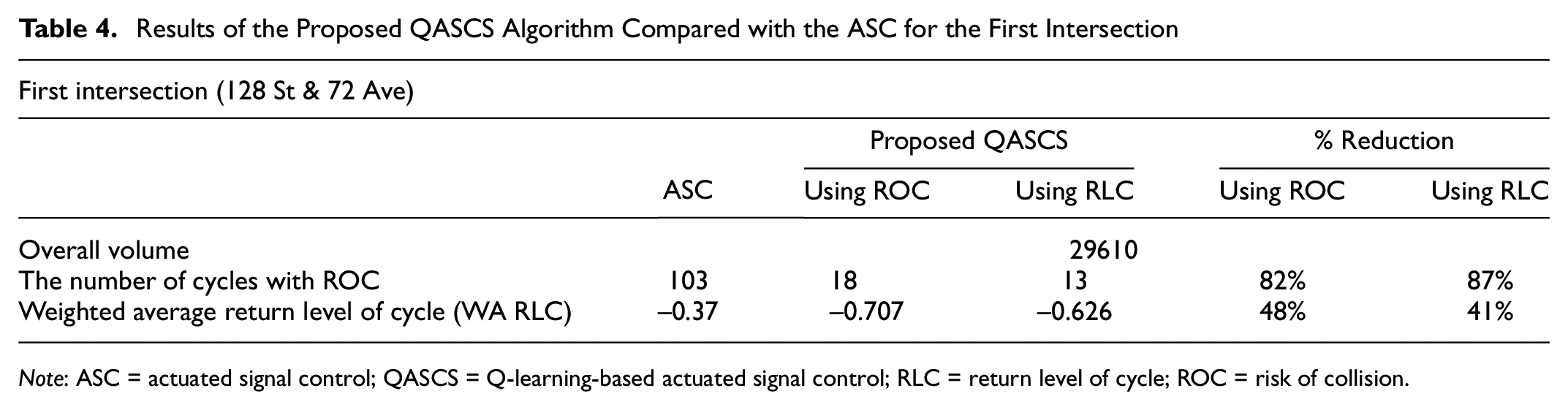
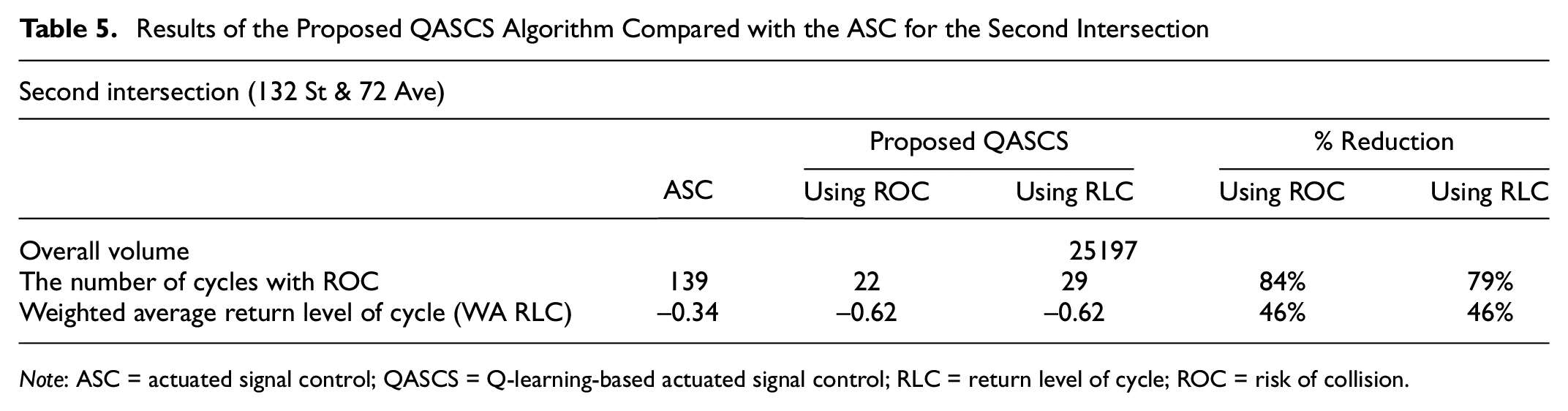
A comparison between the existing real-world ASC and the trained QASCS algorithm was conducted. The results indicated that the proposed algorithm improved traffic safety considerably at both intersections. The number of cycles with ROC as estimated using Equation 9 was reduced from 103 cycles to 18 and 13 cycles for the first intersection using ROC and RLC as reward functions, respectively. For the second intersection, the number of cycles with ROC was reduced from 139 cycles to 22 and 29 cycles using ROC and RLC as reward functions, respectively. Furthermore, taking into consideration the strong correlation between ROC and RLC, the weighted average RLC was estimated using Equation 12 and compared for each hour of the day for the ASC and the proposed QASCS (Figures 4 and 5). Reduction values of 48% and 41% in the weighted average RLC were observed at the first intersection when using ROC and RLC as reward functions, respectively. For the second intersection, 46% reduction was obtained after using both reward functions (i.e., ROC and RLC) separately.
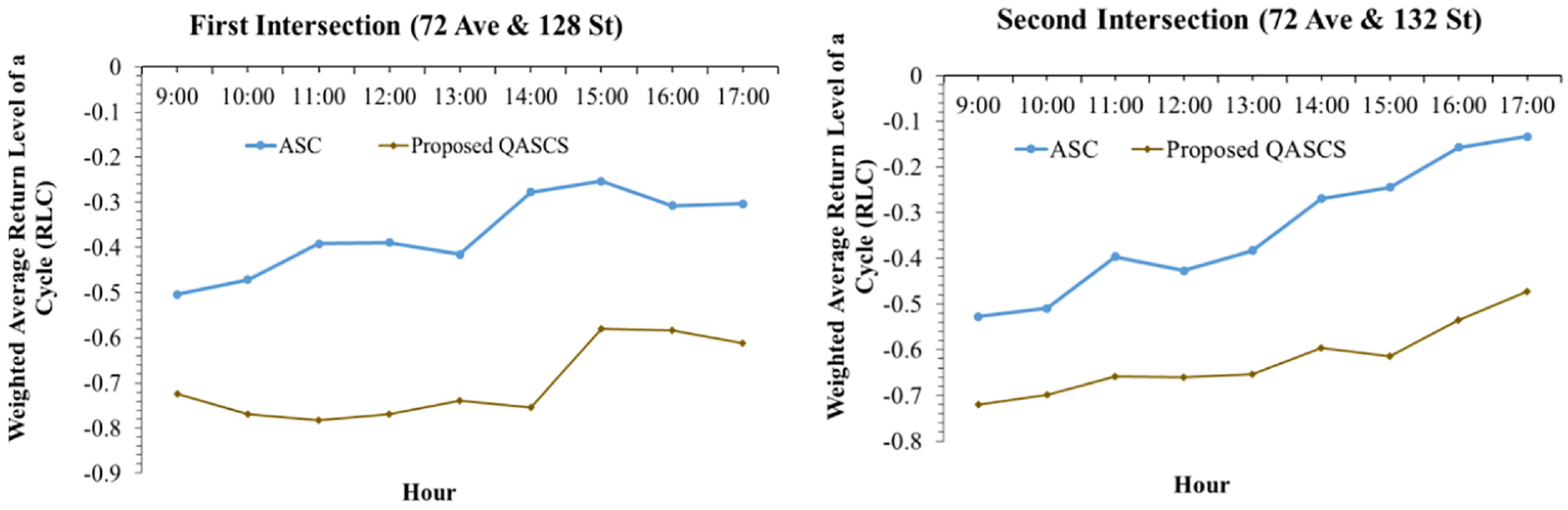
Weighted average return level of a cycle (RLC) at the two studied locations before and after implementing the proposed algorithm with risk of collision (ROC) as a reward.
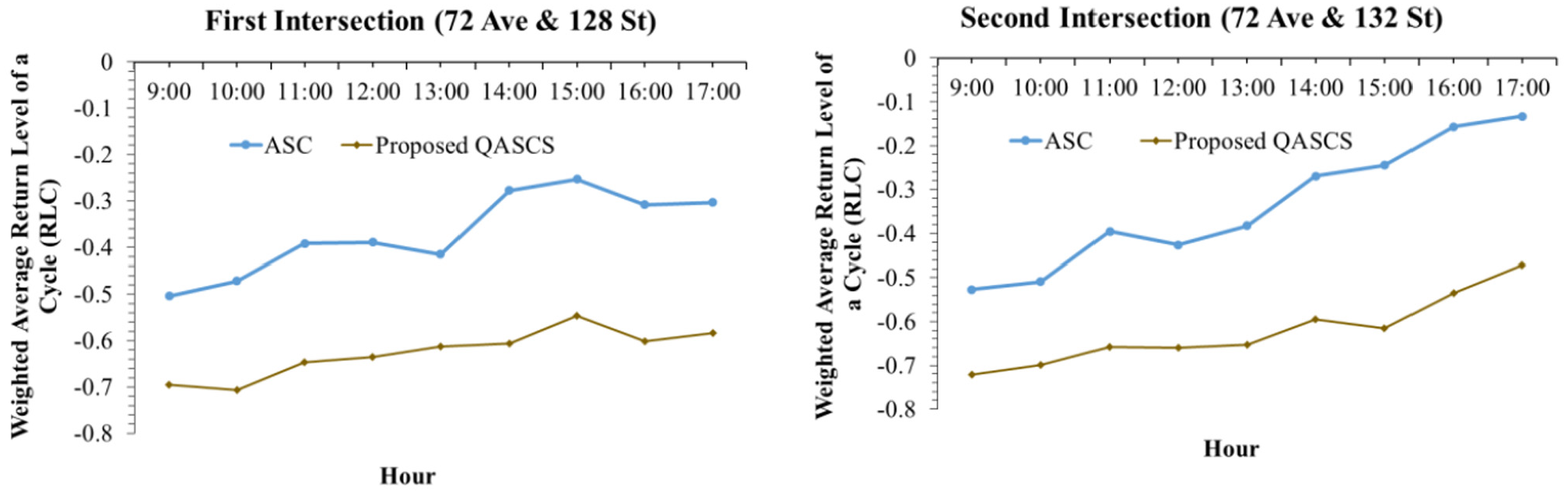
Weighted average return level of a cycle (RLC) at the two studied locations before and after implementing the proposed algorithm with RLC as a reward.
The real-time variation of RLC is shown in Figures 6–9 for both locations and both safety rewards. These values were calculated using Equation 10; positive RLC values imply that positive crash frequency is expected, whereas negative RLC values indicate that the cycle is safe and lower values of RLC represent safer signal cycles. As shown in the following figures, a reduction in RLC was observed after applying the proposed QASCS algorithm in most of the approaches and for both reward functions. Although the value of RLC has not improved significantly for some cycles, they are still safe as RLC remains below zero.
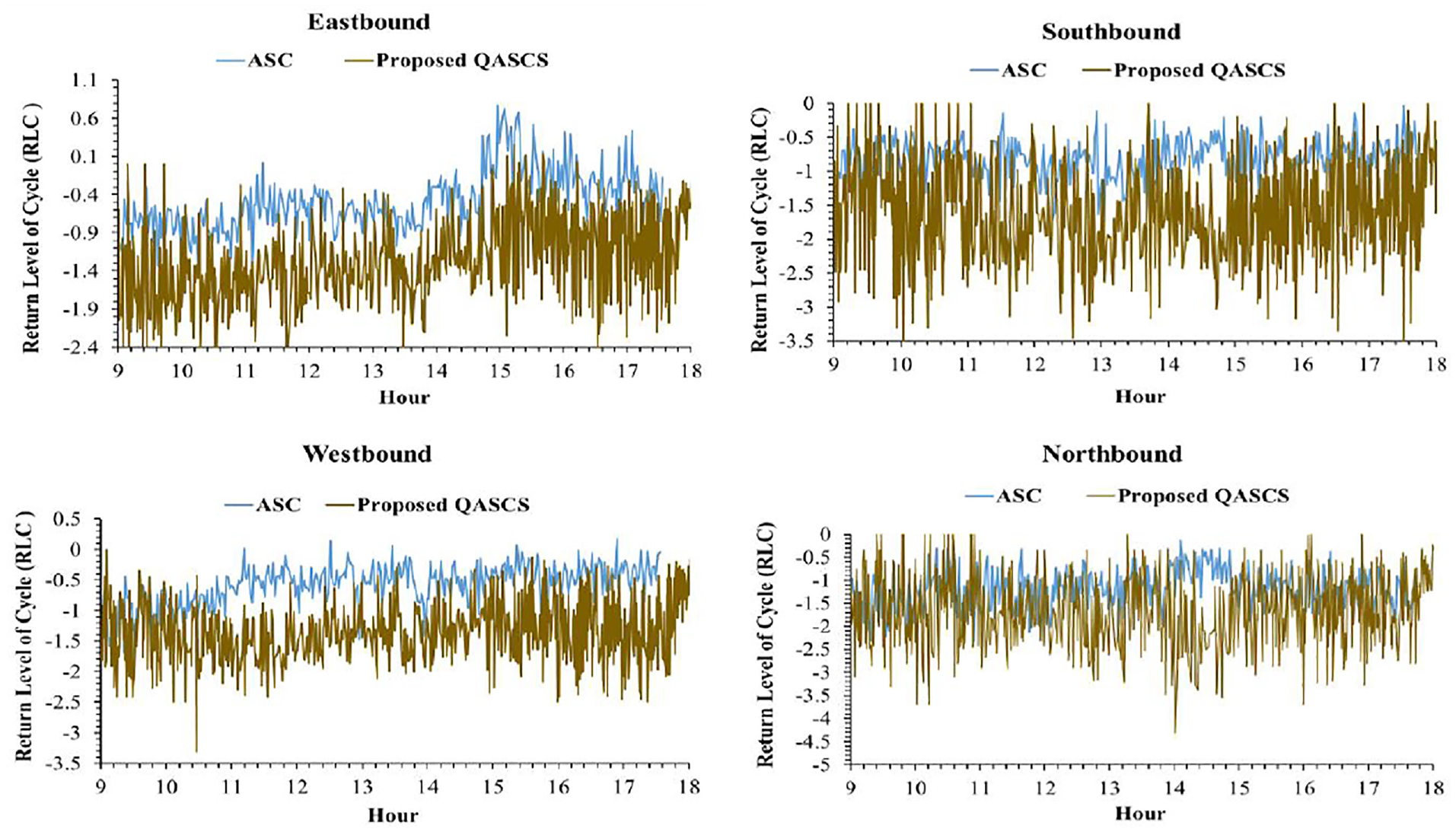
Cycle-by-cycle fluctuation of RLC at each approach of the first intersection (72 Ave and 128 St) before and after implementing the QASCS algorithm using ROC reward.
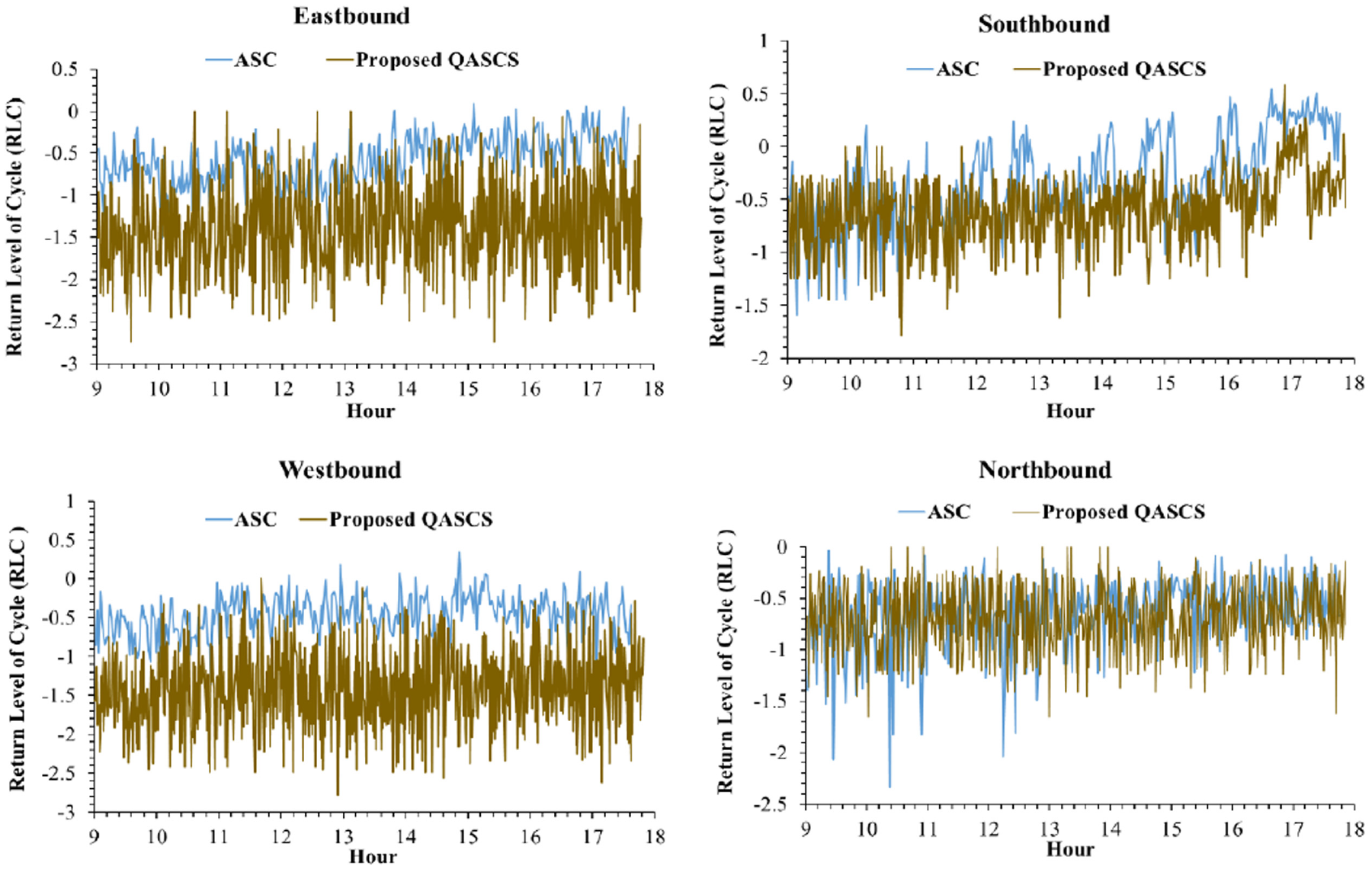
Cycle-by-cycle fluctuation of RLC at each approach of the second intersection (72 Ave and 132 St) before and after implementing the QASCS algorithm using ROC reward.
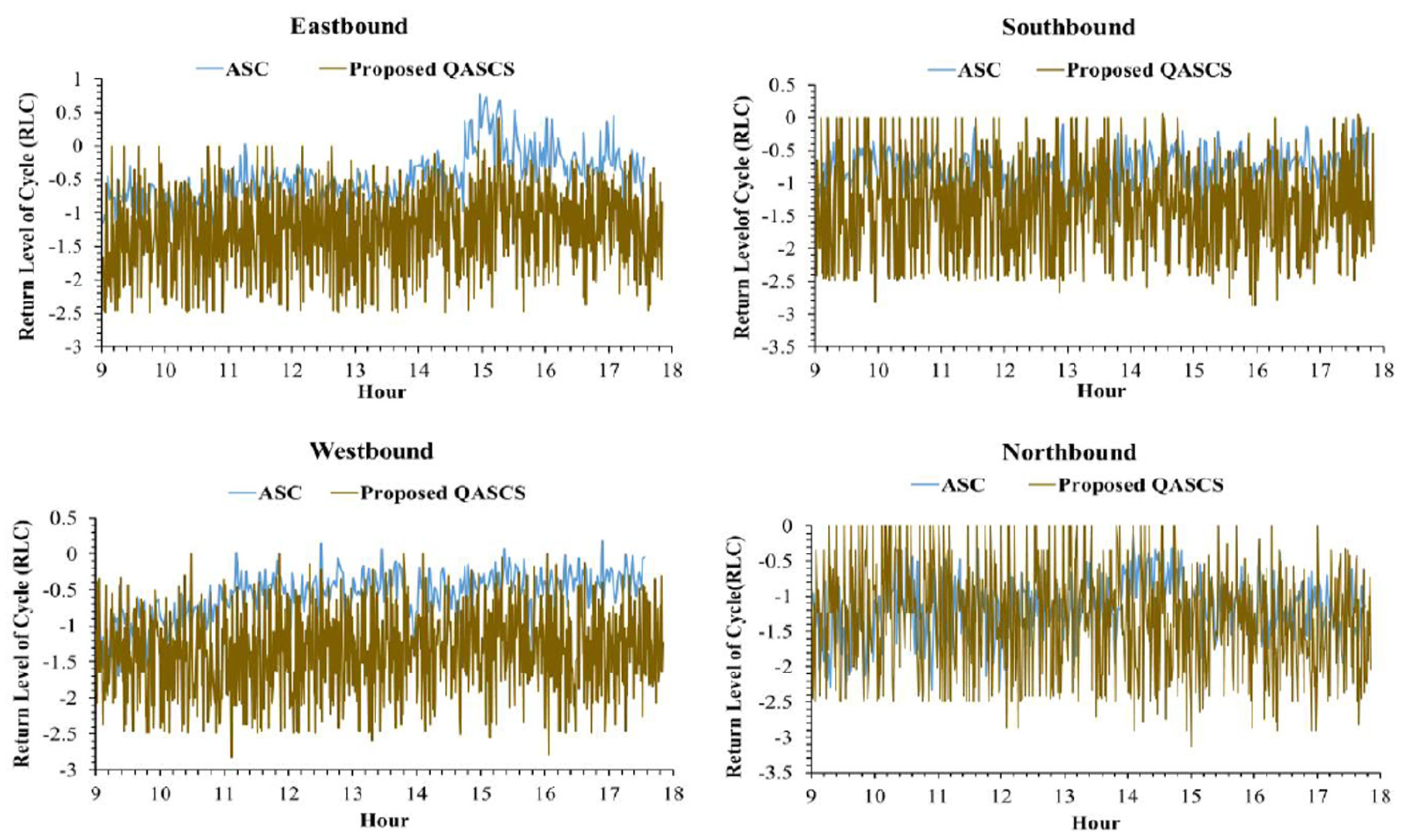
Cycle-by-cycle fluctuation of RLC at each approach of the first intersection (72 Ave and 128 St) before and after implementing the QASCS algorithm using RLC reward.
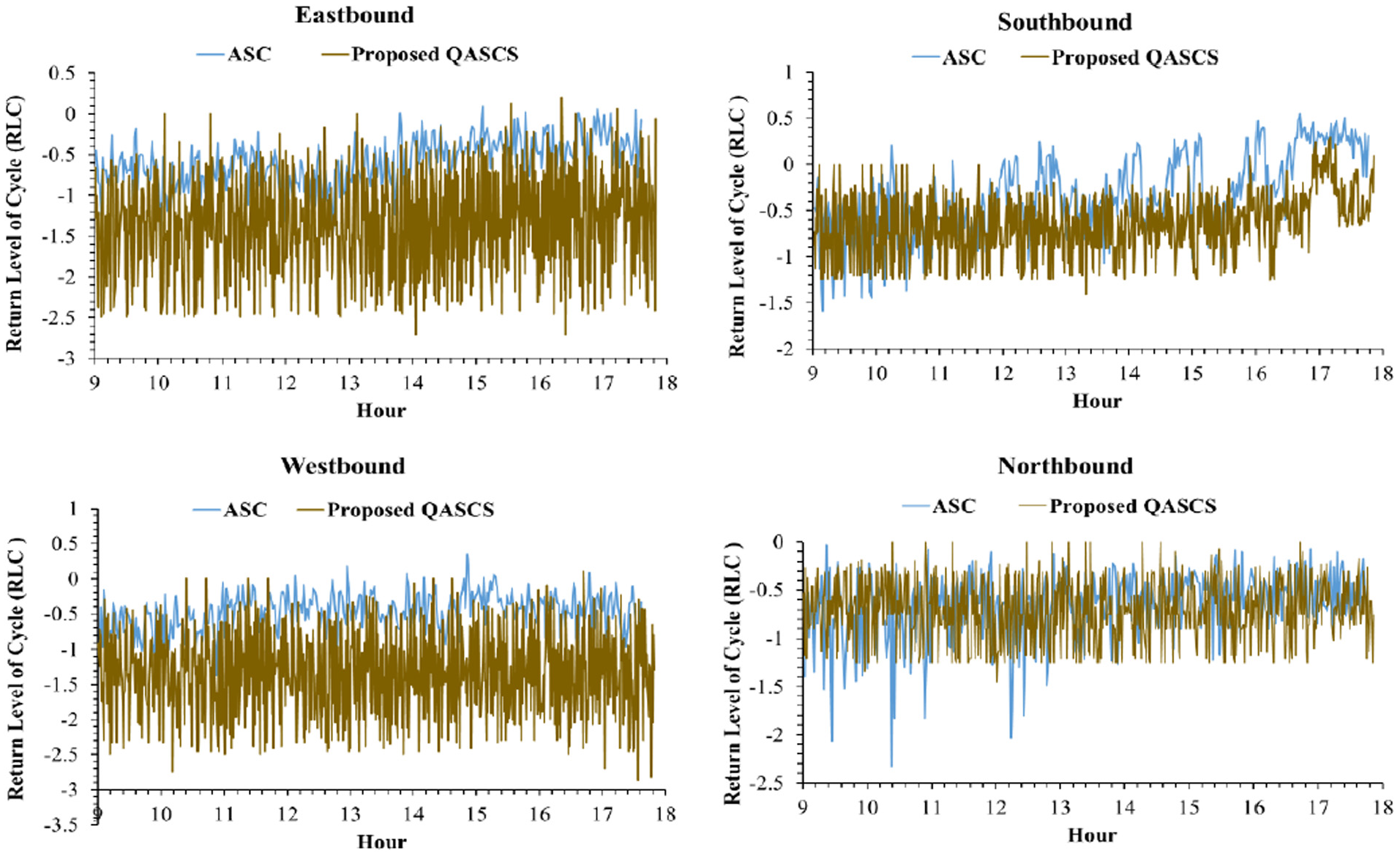
Cycle-by-cycle fluctuation of RLC at each approach of the second intersection (72 Ave and 132 St) before and after implementing the QASCS algorithm using RLC reward.
The results shown in Figures 6–9 indicate that the RLC values of the QASCS generally have higher variability than that of the ASC. The reason is that the two controllers are completely different in relation to the operation mechanism. The QASCS utilizes dense and detailed traffic data from CVs, whereas the ASC relies on relatively limited traffic information captured by loop detectors. Thus, the QASCS is more adaptive to the real-time variation in traffic conditions, and it results in higher variability among consecutive signal cycles in relation to the optimized signal-timing plan (e.g., cycle length) and, subsequently, the RLC value.
Tables 4 and 5 summarize the validation results. It was also noted that the number of extreme conflicts and the number of crashes can be calculated and compared for QASCS and the ASC algorithms. In this case, the results would show reductions in extreme conflicts and crashes reaching more than 95%. However, given the short time period (limited number of hours), the calculation of these values is subject to very large uncertainty and therefore not reported in Tables 1 and 2.
Results of the Proposed QASCS Algorithm Compared with the ASC for the First Intersection
Note: ASC = actuated signal control; QASCS = Q-learning-based actuated signal control; RLC = return level of cycle; ROC = risk of collision.
Results of the Proposed QASCS Algorithm Compared with the ASC for the Second Intersection
Note: ASC = actuated signal control; QASCS = Q-learning-based actuated signal control; RLC = return level of cycle; ROC = risk of collision.
In addition to the safety impact of the proposed algorithm, the algorithm’s effect on mobility was also evaluated. Even though the delay/travel time was not the primary objective function, the proposed algorithm improved mobility and reduced the total travel time at both intersections. The results indicated that the total travel time per vehicle was decreased by an average of 16% after applying QASCS using the ROC as an objective function for the two intersections. A reduction of 7% in the total travel time per vehicle was observed for the two intersections after using the RLC as a reward. Other performance metrics were also improved, including the queue length and the number of stops. Specifically, the maximum queue length, the 95th percentile of queue length, and the number of stops were reduced by 14%, 39%, and 32% using ROC as a reward, and by 16%, 40%, and 10% using RLC as a reward, respectively.
Thus, the proposed algorithm improves both the safety and operational performance. In other words, the algorithm optimizes safety (i.e., minimizes ROC and RLC) without deteriorating mobility. No doubt that traffic delays are an essential issue as congestion occurs more frequently and leads to significant economic and environmental cost. Traffic safety as well is a fundamental issue because of high collision frequencies and severities at signalized intersections and their enormous associated social and economic costs. Therefore, both traffic safety and mobility are fundamental optimization objectives. As previous research has been focused on optimizing delays (i.e., mobility) ( 1 – 9 ), the main contribution of this paper is to present a new algorithm that optimizes safety without deteriorating mobility (without increasing delays). The developed algorithm can further be modified to incorporate both safety and mobility in a multi-objective optimization problem. In such a problem, a weight can be assigned to each objective based on its associated cost (e.g., savings resulted from decreasing delays or collisions). These weights can vary among different locations and jurisdictions. These issues are potential areas of future research.
Effect of CV MPRs
The prevalence of CV technology is expected to increase gradually over the coming years. Before the full deployment of this technology, CVs will constitute a percentage of the total number of vehicles. Therefore, the validation of the proposed algorithm should be conducted based on various MPRs of CVs. The performance of the proposed algorithm was evaluated and compared using various MPRs of CVs at both intersections. The investigated MPRs range from 10% to 100%. Various MPRs of CVs were represented in the VISSIM model by creating a new vehicle class called “connected vehicle” and varying traffic composition percentages of each traffic input point. When implementing the algorithm with a specific MPR value, instantaneous vehicle information was captured from vehicles with the “connected vehicle” class only. The arrival-queue factor of each approach was estimated from CVs data. To determine the real-time state for the algorithm, the estimated arrival-queue factor was multiplied by a correction factor (i.e., magnification factor) to represent all vehicle classes (CVs and conventional vehicles). This factor equals the reciprocal of the MPR value. The exact MPR value is estimated in real time, given the number of CVs from the V2I communications and the total traffic counts from the counting detectors upstream of each approach of the intersection.
The results showed that the proposed QASCS algorithm can lead to considerable safety improvements even under lower MPRs of CVs. For example, compared with the benchmark ASC, a reduction of 43% in the weighted average RLC was achieved when the QASCS is applied with MPR of 50%. Generally, the higher the MPR value, the more the safety effectiveness of the algorithm. It should also be noted that MPR values less than 20% may not lead to significant safety benefits, as the algorithm cannot define the environment state with a reasonable accuracy because of the lack of real-time information on vehicle positions and speeds.
Summary and Conclusions
This study introduces an ATSC algorithm (i.e., QASCS) to optimize traffic safety in real time by directly minimizing crash risk. Reward representation and safety evaluation of the algorithm were based on real-time crash prediction models for signalized intersections developed in a recent study ( 33 ). The models used traffic conflicts extracted from vehicle trajectories and considered cycle-level traffic parameters (e.g., shock wave area, shock wave speed, traffic volume, and platoon ratio) as covariates for crash prediction within the EVT framework. Using these models, two real-time crash-risk measures, the ROC and the RLC, can be obtained using the GEV distribution. The RL framework was applied to formulate the proposed QASCS algorithm. Moreover, real-time data from CVs and variables representing traffic dynamic changes were considered in the analysis. To the best of the authors’ knowledge, this is the first study that applies ATSC for real-time safety optimization by reducing crash risk at signalized intersections.
The TD RL method, (particularly, the Q-learning off-policy method) was used in this study. In this method, the environment was simulated using VISSIM model. The state of the environment was represented by the position and the speed of each vehicle approaching the intersection within the DSRC range (i.e., 225 m). The fixed phasing sequence for action definition was adopted. This includes two actions, either extending the green time to the phase in effect or switching it to the next phase. Moreover, two real-time crash-risk measures, ROC and RLC, were employed to define the reward function as a penalty, separately. Constraints such as the yellow, the minimum green, the maximum green, and the all-red times were considered to ensure the feasibility of implementing the proposed technique in the real world.
The algorithm was trained using a real-world intersection modeled and simulated by VISSIM to learn the optimal policy. Traffic volumes at each intersection were randomized to run the simulation model for 500 iterations for both reward functions (i.e., ROC, RLC). Each iteration was divided into a 1,000-s warming-up period, a 500-s cooling-down period, and a 3,600-s training period. It was observed that after 400 iterations, the proposed algorithm converged to the optimal policy.
Validation of the trained algorithm was investigated using two separate signalized intersections in the city of Surrey, British Columbia, Canada. Additionally, the safety performance of the proposed QASCS algorithm and the field fully actuated traffic signal controller was compared. Important safety performance measures were evaluated for the two algorithms, including the number of cycles with ROC, and the weighted average RLC. Generally, the validation results showed that the proposed QASCS algorithm reduced ROC at the two signalized intersections significantly compared with the existing ASC. A drop of 82% and 87% in the number of cycles with ROC was obtained after implementing the QASCS algorithm at the first intersection using ROC and RLC as reward functions, respectively. For the second intersection, the number of cycles was reduced from 139 cycles to 22 and 29 for ROC and RLC as reward functions, respectively. The findings also illustrated that the weighted average RLC was reduced by 48% using ROC and 41% using RLC for the first intersection, whereas it was reduced by 46% for both reward functions at the second intersection.
Furthermore, the algorithm’s effect on mobility was evaluated at the two intersections. Despite the delay/travel time not being the primary objective function, the proposed algorithm improved mobility and reduced the total travel time at both intersections. The results indicated that the total travel time per vehicle was decreased by an average of 16% after applying QASCS using the ROC as an objective function for the two intersections. When using the RLC as a reward, a reduction of 7% in the total travel time per vehicle was observed for the two intersections. This reduction cannot be considered the optimal outcome for mobility improvement, as the primary objective of the proposed QASCS algorithm is optimizing traffic safety by reducing the ROC.
Additionally, the performance of the proposed algorithm was investigated under various MPRs of CVs. Results indicated that reasonable safety improvements can be realized at MPR values lower than 100%. Approximately 43% reduction in the weighted average RLC was obtained at MPR of 50%, compared with the existing ASC system.
Several areas of future research can be applied to improve the effectiveness of the proposed QASCS algorithm and address the study limitations. First, this study used only two intersections for validation. Future studies may consider a larger number of intersections to investigate the safety and mobility performance of the proposed algorithm. Second, future research may consider replacing the discrete Q-table that defines the possible states to a continuous state space by using a deep neural network to describe the infinite possible states of the environment. Third, investigating the sensitivity of the results to the assumed parameters such as the discount factor, the update time interval, and the V2I DSRC domain is recommended. Fourth, the improvement in the safety performance in this research was achieved by using the CVs technology and the RL technique combined. Investigating the separate effect of each of them is an interesting area of research that deserves future investigation. Fifth, it is suggested to test the algorithm’s performance in other jurisdictions (e.g., developing countries) with different traffic conditions and driving cultures as well as to compare the algorithm’s performance with other ATSC algorithms. Most importantly, safety and mobility can be considered in the algorithm as two primary objectives for a multi-objective real-time traffic signal optimization.
Footnotes
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: P. Reyad, T. Sayed; data collection: P. Reyad, M. Essa; analysis and interpretation of results: P. Reyad, M. Essa, L. Zheng; draft manuscript preparation: P. Reyad, T. Sayed. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.