
Abstract
As the world rapidly urbanizes in pace with economic growth, the rising demand for products and services in cities is putting a strain on the existing road infrastructure, leading to traffic congestion and other negative externalities. To mitigate the impacts of freight movement within commercial areas, city planners have begun focusing their attention on the parking behaviors of commercial vehicles. Unfortunately, there is a general lack of information on such activities because of the heterogeneity of practices and the complex nature of urban goods movement. Furthermore, field surveys and observations of truck parking behavior are often faced with significant challenges, resulting in the collection of sparse and incomplete data. The objective of this study is to develop a regression model to predict the parking duration of commercial vehicles at the loading bays of retail malls and identify significant factors that contribute to this dwell time. The dataset used in this study originates from a truck parking and observation survey conducted at the loading bays of nine retail malls in Singapore, containing information about the trucks’ and drivers’ activities. However, because of the presence of incomplete fields found in the dataset, the authors propose the use of a generative adversarial multiple imputation networks algorithm to impute the incomplete fields before developing the regression model using the imputed dataset. Through the parking duration model, the activity type, parking location, and volume of goods delivered (or picked up) were identified as significant features influencing vehicle dwell time, corroborating with findings in the literature.
As the world rapidly urbanizes in pace with economic growth, major cities are becoming increasingly dense with large urban freight traffic generators such as retail malls producing and attracting many daily truck trips to the area ( 1 ). The constant flow of freight activities concentrated at these localized sites leads to the issue of traffic congestion which may propagate to other parts of the road network, leading to system gridlocks and other negative externalities ( 2 ). With the continuing growth in demand for retail products and services, city planners and urban authorities have begun shifting their attention to the parking behaviors of commercial vehicles ( 3 ) and exploring various logistics initiatives aimed at reducing freight-driven congestion (4–7).
The general lack of information on the conduct of logistics delivery activities, caused by the heterogeneity of practices between multiple stakeholders and the complex nature of freight transportation, has led to a limited understanding of the factors that contribute to the dwell time of commercial vehicles and the resulting congestion issues caused ( 8 ). As a result, only a handful of studies have attempted to develop duration models to explore the factors influencing commercial vehicle parking duration (9, 10). In an attempt to shed light on this growing problem, past field surveys conducted at the loading bays of urban retail malls are often faced with significant challenges, while relying heavily on traditional data collection methods such as observational studies and on-site interviews ( 10 ). As these methods are often labor-intensive, error-prone, and subject to the consent of the interviewee, this often leads to the collection of sparse and incomplete data, thus limiting the validity of the post-data analysis conducted.
The issue with incomplete and sparse data is not just limited to freight studies but is also encountered in other fields such as the medical and social studies where participants may choose to omit certain personal information in their survey response because of privacy issues (11–13). Therefore, various imputation methods have been proposed in the past by researchers to deal with the issue of incomplete data to facilitate a more meaningful analysis.
García-Laencina et al. ( 14 ) attempted to categorize the different methods of data imputation into two groups, whereby the first group involved the use of statistical analysis to perform imputation, while the second group relied on machine learning approaches. Out of all of the statistical methods of dealing with missing data, one of the most successful methods was that proposed by Rubin ( 15 ) with the concept of multiple imputation (MI). In MI, the procedure attempts to replace each missing component with a set of possible values to capture accurately the variability in the feature containing missing fields. By generating multiple completed datasets from the original dataset, the former can be analyzed using standard methods before combining their results for further inference. A particular imputation method that uses the concept of MI is the multivariate imputation by chain equations (MICE) algorithm ( 16 ). In MICE, a series of regression models are used to impute the missing data sequentially by conditioning on the other variables that are both observed initially and previously imputed. This process is repeated in a round-robin fashion over multiple iterations until the parameters governing the imputation converges.
On the other hand, imputation methods based on machine learning approaches generally consist of a data-driven approach to perform estimations of the missing components based on the observed data. Under this category, the most popular approach is the K-nearest neighbor (K-NN) method whereby a missing component is estimated from a set of its K-nearest neighbors (determined according to a distance metric) containing the complete feature set. Two other approaches that fall under this category are the multi-layer perceptron imputation ( 17 ) and the autoencoder ( 18 ). Both of these approaches use a similar idea of performing imputation whereby a multi-layer network is trained on a complete dataset with the observed data introduced into the network as input features and produces the missing data as output. Different loss functions are selected to ensure that the distribution of the imputed values approaches the true distribution of the missing data. The limitation of these approaches is that they need to be trained initially on a complete dataset which may not be available. With the recent successes in the application of generative adversarial networks (GANs) to many real-life problems, Yoon et al. ( 19 ) proposed the generative adversarial imputation network (GAIN) algorithm to overcome these limitations encountered by other imputation approaches. The GAIN algorithm works by training two neural networks, a discriminator and a generator, pitted against each other in an adversarial relationship. By passing the incomplete data vector into the generator, imputation is performed based on the observed components to output a complete dataset. This dataset is subsequently passed into the discriminator where it will attempt to differentiate between the observed components against those that are imputed. As the objective of the generator is to impute the missing components such that the discriminator is unable to differentiate between the imputed and the observed components, both neural networks possess opposing objective functions. A theoretical analysis has also been conducted to prove that the generator can replicate the joint distribution of the original data. This approach has been tested on various benchmarking datasets and was shown to outperform many state-of-the-art imputation methods.
The dataset used in this study originates from a truck parking and observation survey conducted at the loading bays of nine urban retail malls in Singapore, containing visual information about the delivery activity as well as the drivers’ delivery patterns. Given the presence of incomplete fields found in the dataset, the primary objective of this study is to develop a regression model to predict the parking duration of each commercial vehicle using the incomplete data and to identify significant factors related to dwell time during delivery activities. The regression model is developed using a two-step process whereby the presence of incomplete fields found in the dataset is addressed during the imputation step through the introduction of a generative adversarial multiple imputation networks (GAMIN) algorithm. The GAMIN algorithm is an extension of the GAIN algorithm proposed by ( 19 ), which reduces the implementation complexity and allows for MI. By generating multiple imputed versions of the original dataset, these datasets will be passed through separate regression models in the regression step to produce multiple predictions and will be combined through averaging to output the final prediction.
Through this study, the significant factors related to the dwell time of commercial vehicles can be identified, allowing city planners and building management to review the effectiveness of existing and future logistic management schemes. Future extensions of this study can also include the proposal of more effective parking management policies at existing loading bays to lessen the impacts of congestion during delivery peak hours.
Data Description
The dataset used in this study originates from a commercial vehicle parking and observation survey that was conducted at nine urban retail malls in Singapore over 12 separate weekdays between 2015 and 2018 ( 10 ). For the first two urban retail malls, a combination of road-side video recordings, a loading bay observation survey, and electronic parking records was used to capture a comprehensive view of the activities occurring at both retail malls under observation.
Road-Side Video Recordings
Video cameras were placed at several strategic locations around the shopping mall to capture the flow of delivery traffic. These locations include the entrance and exit of the service road as well as the entrances and exits to various parking facilities such as the loading bay and the customer car park. The video recordings were subsequently post-processed using a license plate recognition algorithm to create a sequence of timestamps describing different phases of each delivery. These timestamps include the time of arrival and departure from the retail mall, the amount of time spent queuing at the service road, as well as the amount of time spent parked at the loading bay.
Driver Survey and Vehicle Observation
During the conduct of the driver survey, surveyors were stationed at various parking locations around the retail mall, such as the customer car park, the loading bay, and on the streets to capture illegal on-street parking. The surveyors were also trained to observe and record specific details about the activity conducted, including the activity type, commodity type, volume of goods picked up or delivered, vehicle type, and vehicle stop duration, among other visual information. Next, the surveyors were instructed to approach the delivery crew to conduct a short face-to-face interview to gain more information about their delivery patterns. This information includes the number of tours made daily, the number of stores they serve in the retail mall, as well as the number of retail malls they serve in the vicinity among other details. However, because of their busy schedules, it was not uncommon for the delivery crew to refuse to participate in the interview portion of the survey, resulting in incomplete fields found in the dataset.
Electronic Parking Records
The parking facilities in Singapore’s retail malls are also equipped with an electronic gantry system that recognizes and records the entry and exit times of every vehicle via its in-vehicle unit. Vehicle owners will be charged based on the amount of time spend in these parking facilities when exiting through the gantry. By accessing these electronic records, it is possible to obtain detailed information about the vehicles’ arrival and departure times, parking duration, and parking location (i.e., customer car park or loading bay).
For the remaining seven urban retail malls, data collection was mainly concentrated at the loading bay where only the driver survey and vehicle observation were conducted. Table 1 presents a short description of each feature captured in the dataset, together with its respective missing rate.
Description of Data Features and Their Respective Missing Rates
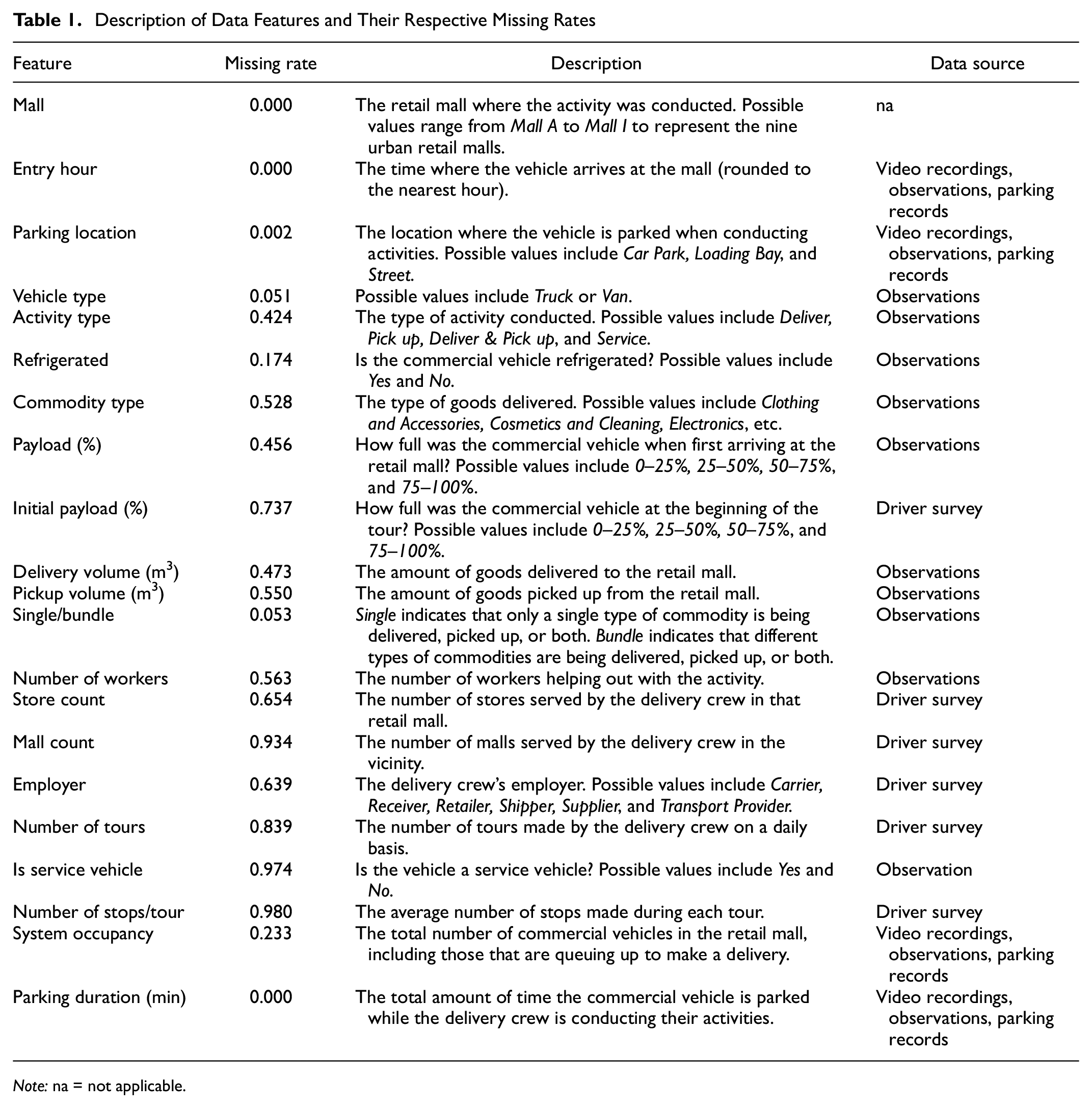
Note: na = not applicable.
Methodology
Because of the presence of incomplete fields found in the dataset, the development of the parking duration model follows a two-step approach. The first step involves the imputation of missing values found in the dataset by implementing the GAMIN algorithm to obtain a complete dataset. The dataset is subsequently passed through a regression algorithm to develop the final parking duration model in a supervised fashion.
Notation Definition
The following set of notation will follow the same notation used by Yoon et al. ( 19 ) for ease of comparison between the two algorithms for the interested reader.
Consider a d-dimensional space
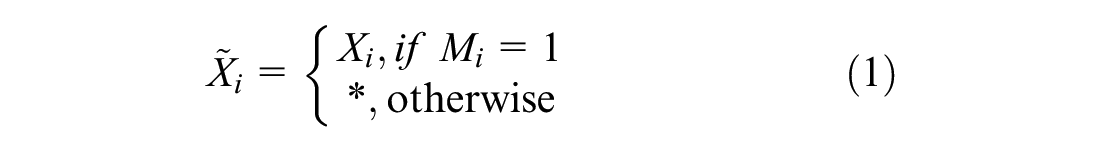
Therefore mask matrix
Throughout the remainder of the paper, lower-case letters will denote the realization of a random variable. For instance, n independent and identically distributed (i.i.d.) copies of
Imputation: GAMIN Algorithm
The imputation of the missing values found in dataset
Generator
The generator network
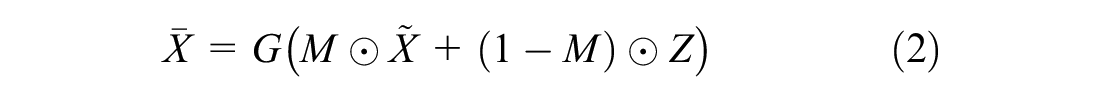
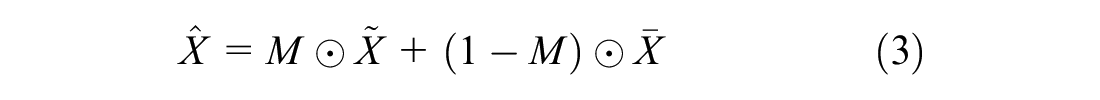
where the symbol ⊙ denotes element-wise multiplication.
To introduce the concept of MI into the algorithm, multiple noise matrices
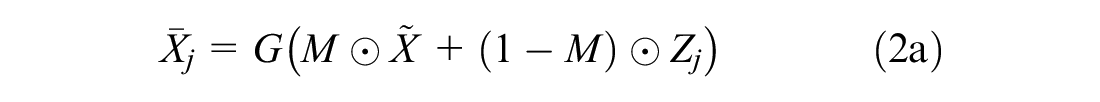
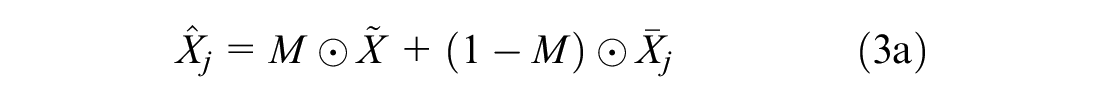
Note that for each noise matrix
Discriminator
By passing the imputed data vector
Hint Mechanism
Yoon et al. (
19
) proposed in the original paper that it was necessary to pass a random variable
However, it will be shown in the subsequent sections that the introduction of
Objective Function
As the objective of discriminator
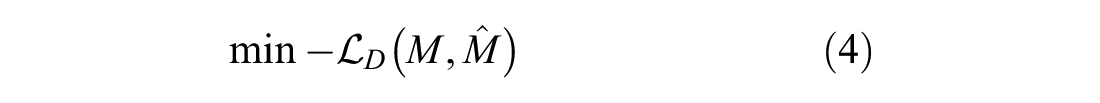
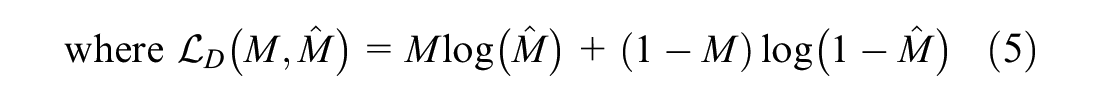
On the other hand, generator
The first loss function
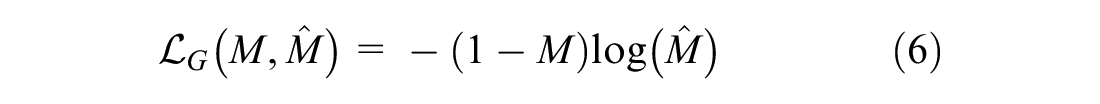
While the second loss function,
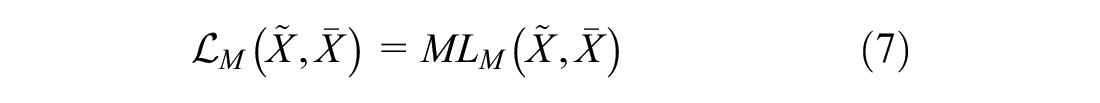
In the original GAIN algorithm,
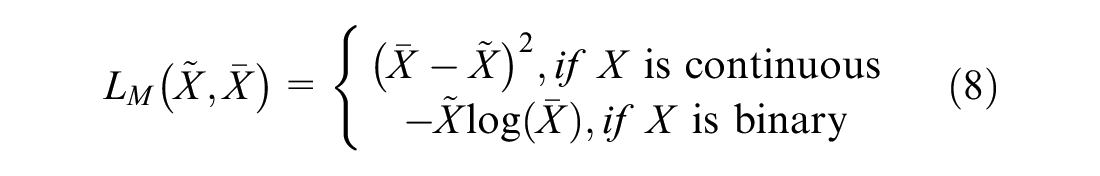
In the case where
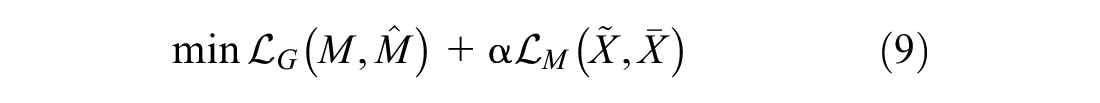
However, it is challenging to define an appropriate
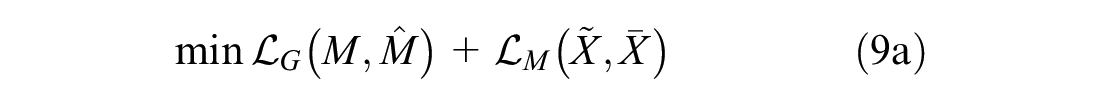
Regression
The imputed data vector
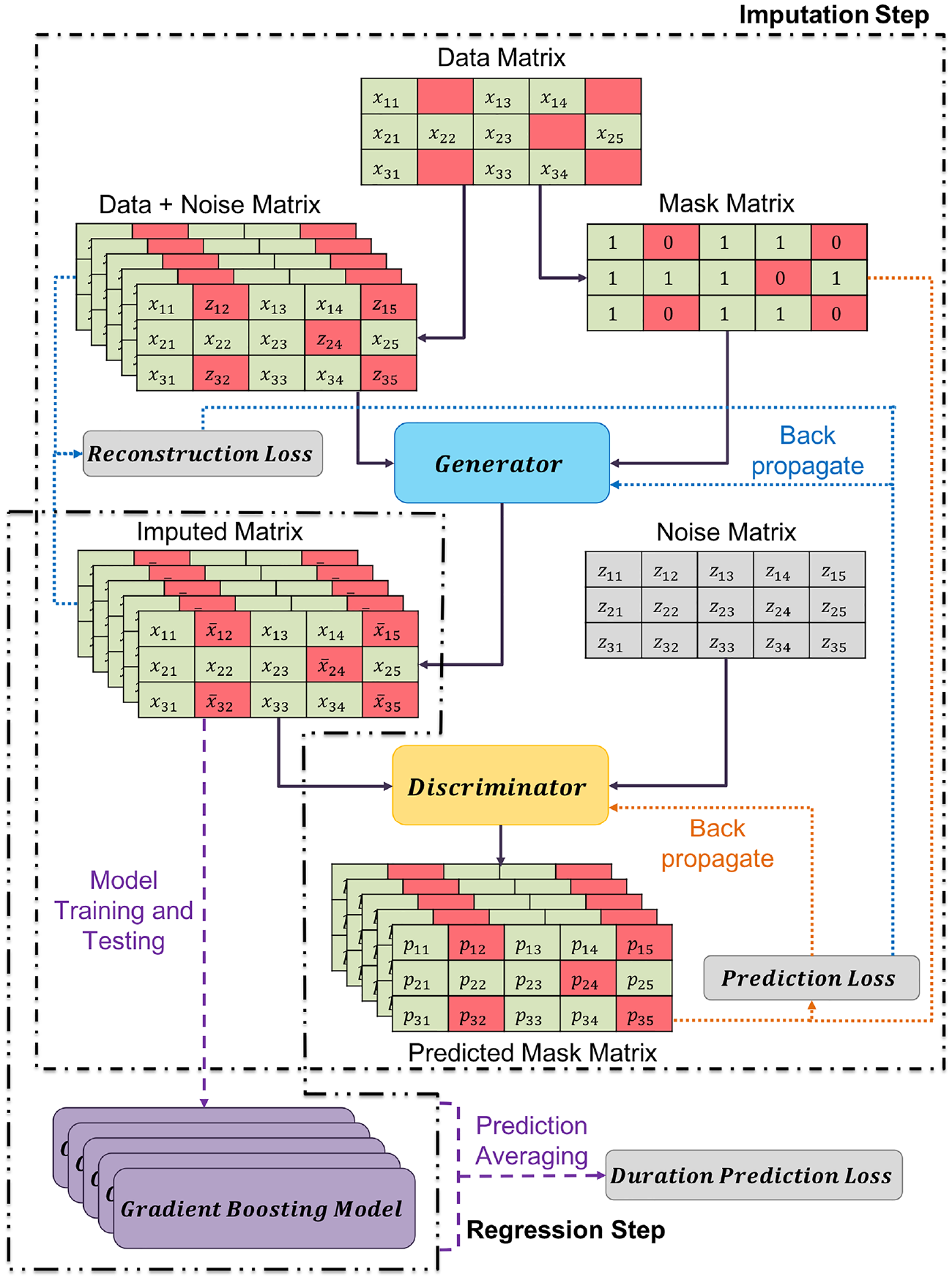
Graphical representation of methodology of this study.
Implementation
Data Preprocessing
Before the dataset was passed through the GAMIN algorithm to perform the imputation step, several data preprocessing steps were taken in the following order. By plotting the distribution of the parking duration, it is observed from Figure 2 that the dataset suffers from a “long tail” problem whereby a tiny percentage of the vehicles reported unusually large values for their parking durations. These extreme cases, if left in the dataset, could potentially prevent generator
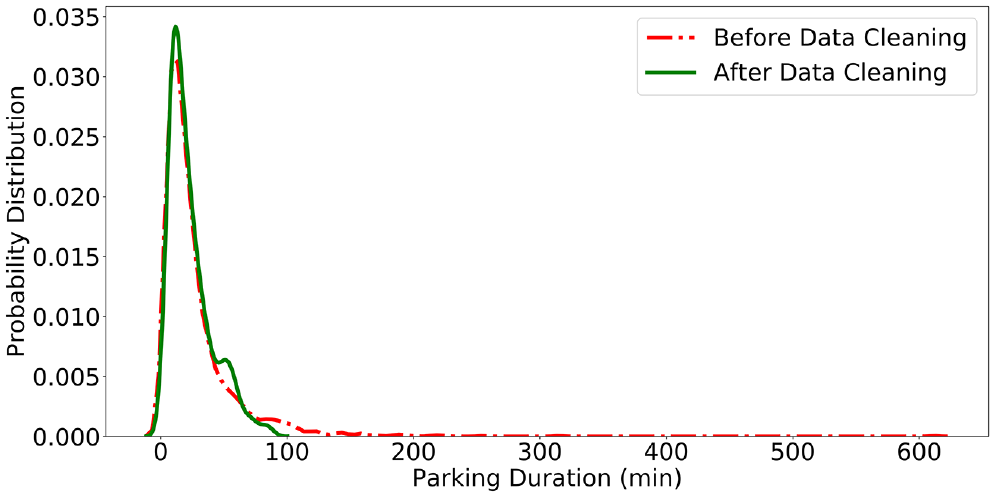
Distribution of parking duration before and after data cleaning.
Next, given that the GAMIN algorithm assumes that
Although the implementation of the discretization step was deemed necessary to obey the assumption of the GAMIN algorithm, the second reason for discretizing the dataset stems from the data collection approach adopted in this study. Given that most of the features are obtained via traditional data collection approaches, the observation and response errors that come with the visual observation of the activity and face-to-face interviews can be reduced if these features take on a range of values (through discretization) instead of an absolute numerical value. Therefore, by reducing the precision of the numerical features, we are also attempting to improve the accuracy of the information captured in the dataset, which will improve the performance of the parking duration model.
Algorithm
The GAMIN algorithm follows the usual GAN approach of iteratively training the discriminator and generator by sampling mini-batches of size
Next, generator
MI is achieved by generating multiple
A preliminary implementation of the GAMIN algorithm described up to this point showed a rapid convergence in the performance of discriminator

Comparison of Results
The performance of the imputation algorithm is evaluated by randomly removing 10% of the initially observed information from the commercial vehicle parking and observation survey dataset and calculating the imputation error. Since
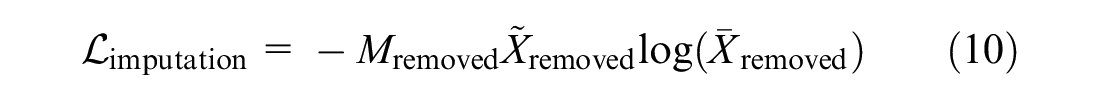
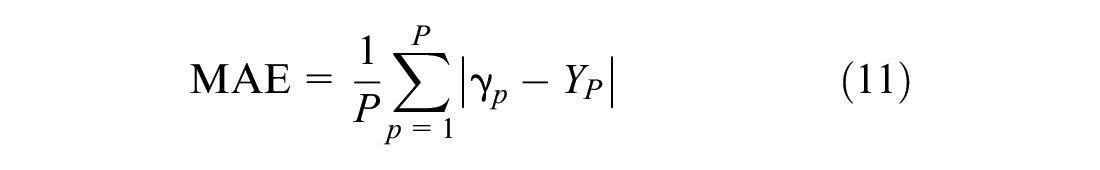
where
The performance of the GAMIN algorithm is evaluated against other baseline imputation algorithms by passing the same training and test datasets through the K-NN algorithm, the MICE algorithm, as well as the original GAIN algorithm before using the imputed datasets to perform model development. Each gradient boosting model uses an identical set of hyperparameters to ensure a fair comparison between the different imputation methods. On top of the proposed GAMIN algorithm, GAMIN (Noise), we have also included the evaluation results for different variants of the GAMIN algorithm. The second variant, GAMIN (Hint), involves replacing the proposed noise matrix
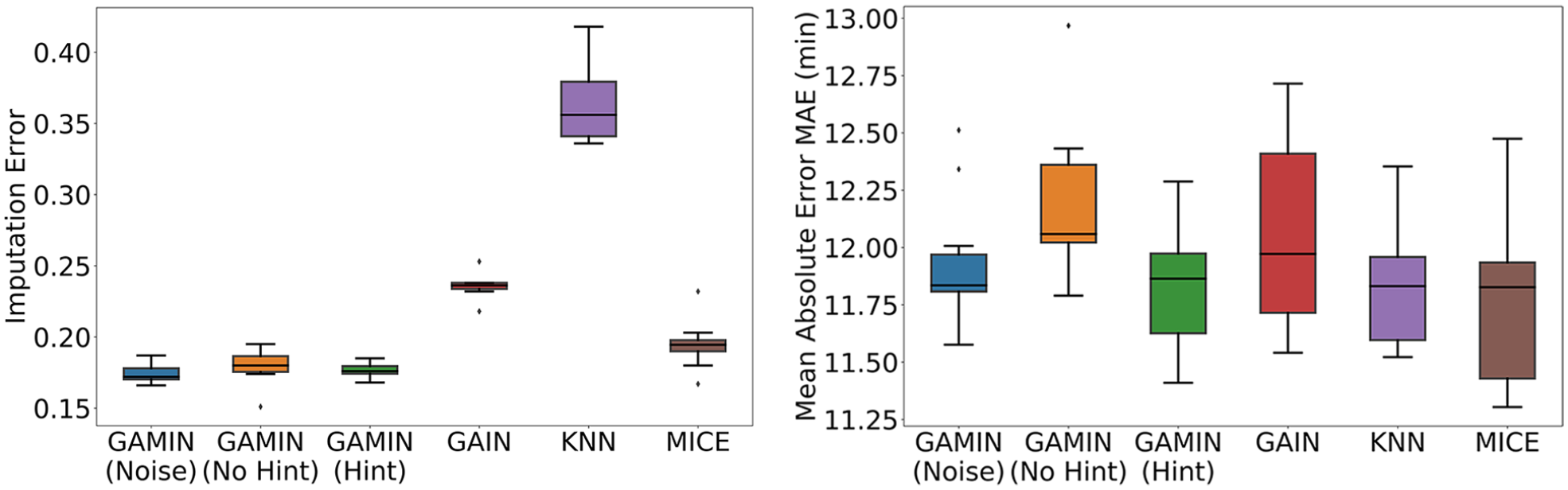
Performance comparison between different imputation methods. The figure on the left shows the imputation error of each method, where the lower the imputation error, the better the imputation performance. The figure on the right shows the performance of the resulting parking duration models that were developed based on the same dataset imputed using different imputation methods.
As shown in Figure 3, the GAMIN (Noise) algorithm was able to outperform the baseline imputation algorithms, such as K-NN, MICE, and the original GAIN algorithm, by producing a lower imputation error but also producing a parking duration model that is more robust to changes in the training dataset. These results can be attributed to the GAMIN algorithm’s better ability to represent the variability in the missing features through the generation of multiple completed datasets from the original dataset.
Furthermore, while a comparison of the resulting imputation error and predictive performance among different variants of the GAMIN algorithm did not produce a clear winner, especially between GAMIN (Noise) and GAMIN (Hint), GAMIN (Noise) was more robust to changes in the training dataset as demonstrated by its smaller variance in predictive performance. This result may be attributed to the introduction of noise matrix
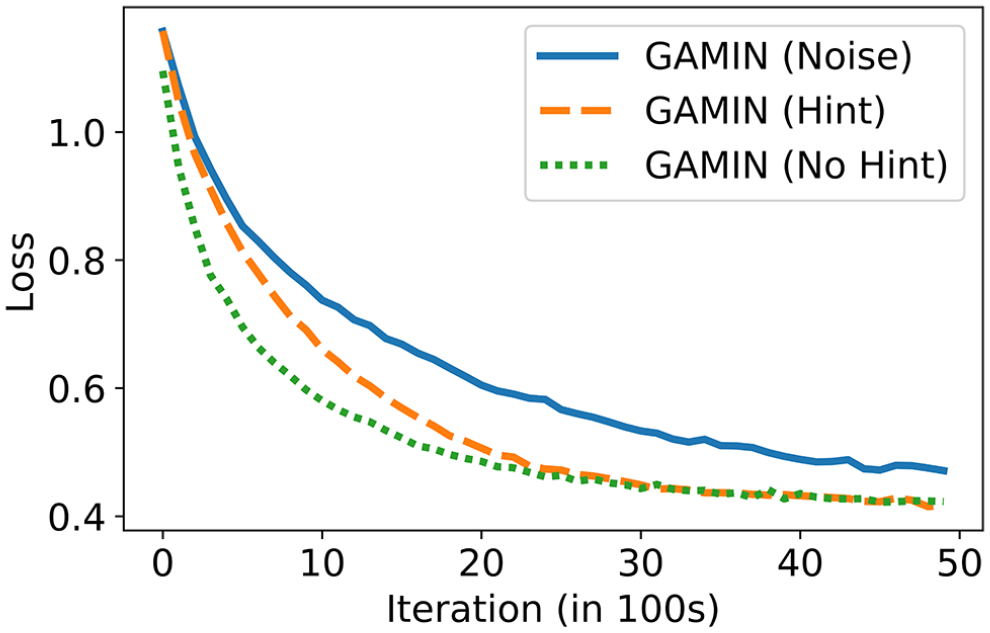
Convergence rate of discriminator D using different variants of the generative adversarial multiple imputation networks (GAMIN) algorithm.
Practical Findings and Applications
After implementing the GAMIN (Noise) algorithm to address the issues of incomplete data and using the gradient boosting algorithm to develop the parking duration model based on the completed datasets, this section will explore the significant factors that are related to vehicle dwell time. This objective is achieved by assigning a numerical value, or feature importance score, to each input feature describing the value of a particular feature in constructing the regression model. In the case of a single decision tree, this feature importance score is defined by the amount of performance improvement achieved by each attribute split point, weighted by the number of samples that are affected by the split. Given that a gradient boosting model, which is made up of an ensemble of decision trees, is adopted in this study, the feature importance score is calculated by averaging over the scores from each decision tree used within the model ( 26 ).
By plotting the feature importance score of each input feature on a Pareto chart arranged in descending order, Figure 5 shows a Pareto chart of the most significant features in the parking duration model responsible for 75% of the total feature importance score (equals to 1.0). While the feature importance score of several of the features changes slightly when the algorithm is repeated on different training and test dataset pairs, features such as the parking location, volume of goods delivered (or picked up), and activity conducted consistently possess the highest feature importance scores among the other features considered in this study.
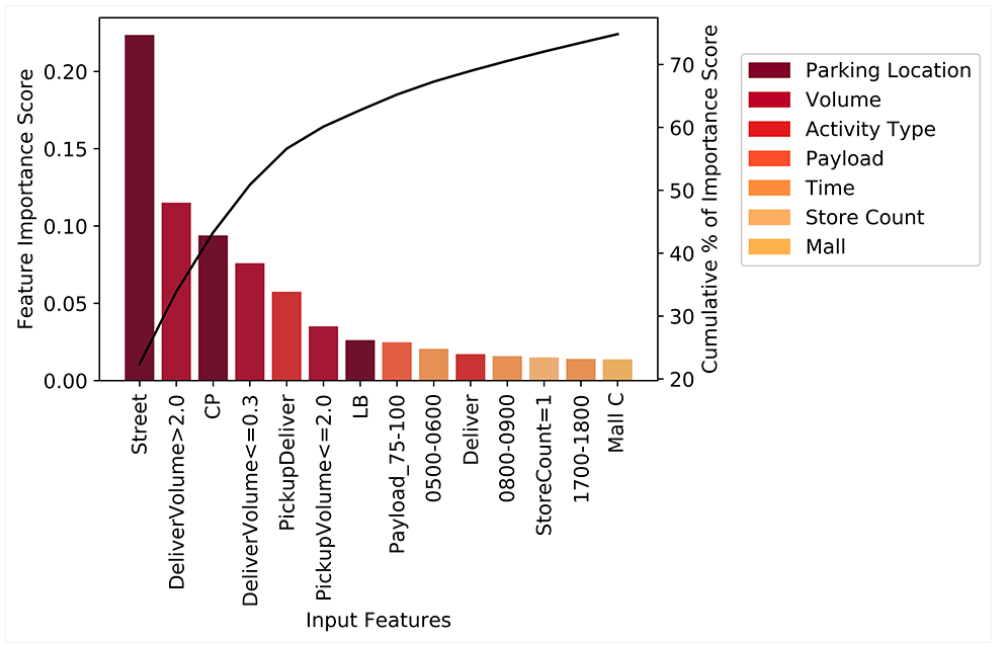
Pareto chart of the feature importance scores for the most significant input features.
The results of this study corroborate the findings of Dalla Chiara and Cheah ( 10 ), which highlighted that the parking duration of commercial vehicles differs significantly depending on their parking location. More specifically, it was reported that the dwell times of commercial vehicles parked illegally along the streets are significantly lower than those parked in the customer car park and loading bay, with the vehicles in the loading bay reporting the most prolonged parking duration. This phenomenon was explained by mentioning that the driver was most likely aware of the expected amount of time that is necessary to complete the delivery. Therefore, in the case where a delivery can be completed within a short period, the delivery crew might choose to park illegally on the streets when performing their activities to avoid the queue at the loading bay and save time.
Parking duration is also found to have a positive correlation with the volume of goods delivered (0.382), with larger volumes of goods requiring a more extended amount of time to be unloaded from the vehicle, and subsequently delivered, and accounted for when the retail staff receive the delivery. A similar argument applies (0.105) when a large volume of goods is picked up by the driver, as an extended amount of time is taken to transport and load the goods onto the vehicle.
Thirdly, the activity type that the driver is conducting also provides valuable information about the dwell time of the commercial vehicle. The parking duration when the driver is conducting a Deliver activity or a Pick up activity takes an average of 18 min, with the former having a higher variance than the latter. When a Deliver & Pick up activity is conducted, the parking duration increases to an average of 32 min with the volume of goods that are being delivered and picked up further increasing the variance in vehicle dwell time. Finally, service vehicles parked at the loading bays have an average dwell time of approximately 17 min and a similarly high variance when compared to the commercial vehicles performing a Deliver & Pick up activity.
Based on the insights gained from this study, a practical application of this work for building managers is to implement a similar model based on the data collected from existing malls to determine the parking duration of each commercial vehicle arriving at the loading bay. By ascertaining the nature of the delivery activity that will be conducted (i.e., activity type, delivery volume) before the vehicle’s arrival, vehicles with shorter delivery times can be assigned to express lots, while vehicles with longer delivery times are assigned to regular lots. An extension of this implementation will involve asking the carriers to provide information about their activities through a mobile application where the estimated dwell time will be passed through a scheduling system to assign a designated parking lot to each commercial vehicle. The objective of the scheduling system could be tuned to maximize the number of commercial vehicles passing through the system (i.e., throughput), thereby ensuring the efficient use of scarce parking resources and reducing congestion during delivery peak hours. Based on the type of parking lot assigned to each commercial vehicle, different parking fees can also be imposed to ensure system integrity. For instance, vehicles that are assigned to the express parking lots might not be charged for the first 30 min but parking fees would then increase exponentially with time beyond the grace period. This measure is aimed at preventing the delivery crew from underreporting their delivery information to enter the express lots. On the other hand, vehicles entering the regular parking lots will be charged with a parking fee that increases linearly with time to provide the delivery crew with more time to conduct their activities. Finally, the installation of dock levellers and belt conveyors at the regular parking lots can assist the delivery crew in loading and unloading their goods, thereby reducing the delivery time for each vehicle.
Conclusion
This study developed a regression model to predict the parking duration of commercial vehicles operating at the loading bays of urban retail malls. The dataset used in this study originates from a truck parking and observation survey in Singapore that contains information about the trucks’ and drivers’ activities. Because of the presence of incomplete fields found in the dataset, an imputation algorithm known as GAMIN was used to fill in the missing fields before developing a gradient boosting model using the imputed dataset. A comparison of the GAMIN algorithm with other baseline imputation methods such as K-NN, MICE, and GAIN showed that the GAMIN algorithm was able to generate datasets that developed better prediction models. Furthermore, by comparing the performance between different variants of the GAMIN algorithm, it was concluded that the introduction of a noise matrix
Footnotes
Acknowledgements
The authors thank Cheung Ngai-Man, Sun Xin, Giacomo Dalla Chiara, Rakhi Manohar Mepparambath, Gabriella Marie Ricart Surribas, IMDA, and the mall operators for supporting and facilitating with the data collection efforts.
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: Raymond Low, Zeynep Duygu Tekler, Lynette Cheah; data collection: Lynette Cheah; analysis and interpretation of results: Raymond Low, Zeynep Duygu Tekler; draft manuscript preparation: Raymond Low, Lynette Cheah. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received the following financial support for the research, authorship, and/or publication of this article. This research is supported in part by the Infocomm Media Development Authority of Singapore (IMDA) and the Singapore-MIT Alliance for Research and Technology. Raymond Low is supported by the SUTD President’s Graduate Fellowship from the Singapore Ministry of Education.
The opinions, findings, and conclusions or recommendations expressed in this paper are those of the authors only.