
Abstract
With the increasing availability of big, transport-related datasets, detailed data-driven mobility analysis is becoming possible. Trips with their origins, destinations, and travel times are now collected in publicly available databases, allowing for detailed demand forecasting with methods exploiting big and accurate data. In this paper, we predict the demand pattern of New York City bikes with a low-dimensional approach utilizing three-level data clustering. We use historical demand data along with temperature and precipitation to first aggregate and then decompose data to obtain meaningful clusters. The core of this approach lies in the proposed clustering technique, which reduces the dimension of the problem and, differently from other machine learning techniques, requires limited assumptions on the model or its parameters. The proposed method allows, for the given temperature and precipitation method, to obtain expected vector of movement (mean number and direction of trips) for each zone. In this paper, we synthesize more than 17 million trips into daily and zonal vectors of movement, which combined with weather data allow forecasting of the trip demand. The method allows us to predict the demand with over 75% accuracy, as shown in series of experiments in which various settings and parameterizations are validated against 25% holdout data.
Since the first tentative program in 1965 in Amsterdam ( 1 ), public bike-sharing systems (BSS) have long been eclipsed by traditional transport modes, such as public transit and motored cars ( 2 ). The main reason was the intrinsic inefficiency of the system, as first and second generations were usually small in size. The Bycyklen program, born in 1995 in Copenhagen, is the first large-scale BSS ever launched. However, as a result of user anonymity, vandalism issues remained ( 3 ). The role of BSS in transportation drastically changed only in 1996, when a small bike-sharing program (Bikebout) was first launched at Portsmouth University in England. For the first time ever, users were provided with a magnetic card to rent a bike. The end of anonymity marks the end of the second generation, and the beginning of the third-generation BSS. Following this pioneering work, BSS have been flourishing around the globe and today represent an essential element of our transport networks. Modern BSS are characterized by a variety of technological improvements which allow for a seamless integration with traditional transport modes. Usually associated with reductions in greenhouse gases, health benefits, and reduction of on-road vehicles, recent studies show that BSS also bring huge economic benefits for the urban economy (3, 4). Recent improvements, such as free-floating services and mobile phone access, allow for an improved spatial connectivity of transport systems and deliver time-savings that far exceed commonly claimed benefits ( 4 ). The side-effects of those improvements are publicly available datasets, which we exploit in this study.
This paper contributes to the existing research on this topic by introducing a novel low-dimensional approach to forecast the expected BSS demand. First, docking stations are spatially clustered, then mobility data—bike-sharing trips—are synthesized into a compressed form (named Vector of Movements (VM) in the rest of the paper) to identify similar daily mobility patterns. Finally, we use contextual data (weather and precipitation data) to further refine this classification. Under this assumption, the proposed framework identifies recursive behavior from historical observations and predicts daily BSS trip rates.
The three main contributions of this paper can then be summarized as follows. First, it is a low-dimensional approach. This means that the number of parameters to be calibrated to achieve a good estimation is limited. Second, we show that contextual data complement Vector of Movements, as they explain fluctuations in the number of trips that cannot be explained with the proposed synthesized representation. Finally, although the model can provide city-level and cluster-level estimations, we show that, if a reasonable clustering is available, predictions at a cluster level are more accurate. We illustrate the method with publicly available trip data from the New York public bike system. We use the publicly available trip data to collect and synthesize over 17 million bike trips made in 2018, and show that the proposed approach provides accurate predictions of the daily demand for BSS service while keeping the computational time low (a few minutes).
The remainder of this paper is structured as follows. The next section introduces related work, which is separated into two main streams: Effects of weather and climate on BSS and Demand forecasting techniques. Then, we introduce our methodology for demand forecasting. Finally, the case study and results are shown.
Related Work
Effects of Weather and Climate on BSS
In a study from 1999, Nankervis studied the effect of climate and weather conditions on bicycle commuting ( 2 ). After investigating both short and long-term (seasonal) variations, the author concluded that a correlation between demand and weather data exists, but it is not as strong as originally assumed. However, more recent studies showed not only that a correlation exists, but that weather is more likely to influence occasional cyclists rather the frequent ones (5, 6), meaning that this correlation becomes stronger for BSS users.
Following this intuition, there has been quite some research on investigating which elements influence BSS demand (7, 8). An analytic approach was formulated to measure the influence of weather conditions and special events on origin–destination demand flows ( 9 ). Although the approach shows that a high correlation between variables exists, building these maps is computationally demanding, if not even unfeasible in some cases. An et al. analyzed data from the public BSS in New York (Citi Bike), currently the largest in the United States, finding that weather affects BSS demand more than topography, infrastructure, land-use mix, and calendar events ( 10 ). Finally, studies show that demand flows depend not only on weather, but that weather during the previous 3 h influences user decisions ( 11 ). These analyses suggest that a strong relationship between BSS demand and weather patterns exists.
Demand Forecasting Techniques
Successful deployment of BSS stations (or bikes) depends on an optimal balance between supply and demand. As rental rates are characterized by temporal and spatial fluctuations, the main challenge to handle BSS efficiently is to understand the underlying structure of its demand, avoiding supply imbalances (12, 13). BSS are often divided into station-based and free-floating categories. In the station-based systems, users pick the bike at a certain station and deliver it to a different one belonging to the same operator. In the second case, users are free to choose where to drop their bike, removing the need for a specific station/infrastructure (12, 14).
Concerning the demand, models can be grouped into two main categories: demand rebalancing and demand forecasting techniques. The former is highly related to the level of service of the system. Operators need to ensure a certain distribution of bikes among different docking stations. However, during the day, these bikes move on the network following the main demand flows. As these changes influence and usually lower the level of service of the system, a redistribution operation is required to re-establish optimality ( 15 ). From the strategic point of view, this problem can be solved by properly designing the number and location of dock stations in the BSS (16, 17). From a management perspective, rebalancing strategies are divided into user-based or operator-based approaches. In the first case, incentives are adopted to self-balance the system, whereas in the second case the operator deploys a fleet of vehicles that physically redistributes bikes ( 14 ). Lastly, rebalancing strategies can be further divided into static and dynamic. In the former case, the redistribution operation is performed when the system is not operating (for instance at night) whereas the latter is performed in real time ( 13 ).
Finally, models for demand forecasting are often classified based on their spatial granularity according to three main groups: City-level, Cluster-level and Station-level ( 12 )
City-level: The goal of these models is to estimate the demand for an entire city. In 2014, Kaggle, an online community of data scientists and machine learners with more than 1,000,000 users, proposed a competition for city-level demand forecasting. In the competition, participants were asked to combine historical trip data with weather data to forecast bike rental demand in the Capital Bikeshare program in Washington, D.C. (12, 18). Giot et al. tested various regressor models, concluding that although some perform better than others (Ridge Regression and Adaboost Regression), these models tend to overfit the data ( 19 ). To overcome this limitation, the authors proposed a low-dimensional model that leverages Vector of Movements – (VM) and weather data to forecast BSS demand at the city level ( 20 ). Preliminary results on New York City showed the potential of this approach, which, however, cannot be directly applied at a cluster level. As this work builds on and extends our previous research ( 20 ), these issues will be discussed in the conclusions and methodology sections.
Cluster-level: These models assume that groups of stations are geographically correlated. Consequently, the demand prediction model estimates trip rates for each cluster by assuming that the demand within the cluster will self-equilibrate—that is, users will find at least one station with an available bike ( 21 ). A hierarchical procedure was introduced to forecast the demand at a cluster level that combines weather data, events, and spatial correlation between stations ( 22 ). Specifically, this first clusters docking stations into groups and then uses a gradient-boosting regression tree to predict the time-dependent demand. On a similar line, BSS stations were clustered based on a spatial, temporal, and weather factors ( 21 ). Then, the average rental rate is obtained as the average of the cluster.
Station-level: Supposedly the most precise, these models estimate the demand for every single station in the system ( 23 ). Also in this case, common approaches are linear regression models ( 24 ) and machine learning (12, 25). The downside of these approaches is that they are not applicable to free-floating BSS.
To conclude, empirical and methodological studies support the idea that a strong correlation between BSS demand and weather/contextual data exists. However, to the best of the authors’ knowledge, there is no method to integrate these data sources while minimizing the number of inputs. The closest works to ours are those of Giot et al., Chen et al., and Li et al., (19, 21, 22 ), in which the authors indeed combine weather and trip data. However, these studies focus on the methodological aspect of finding the most advanced algorithm to learn these correlations. We argue that simply adding data is likely to create issues when new contextual data are included and, finally, overfitting issues ( 19 ). Instead, we propose to leverage these correlations to process the data compactly, reduce problem complexity, and keep computational times low.
Methodology
The Methodology at a Glance
To build the proposed low-dimensional approach, we adopt the two frameworks introduced in Chen et al. ( 21 ) and Li et al. ( 22 ), meaning that we use a hierarchical procedure that first clusters all BSS stations in groups of geographical correlated stations (spatial clustering); then, for each group, observations are clustered based on their temporal similarities (temporal clustering). Finally, the prediction for each cluster is obtained as the average rental rate. However, with respect to the existing work, we add two more phases, named Aggregation and Decomposition (Figure 1).
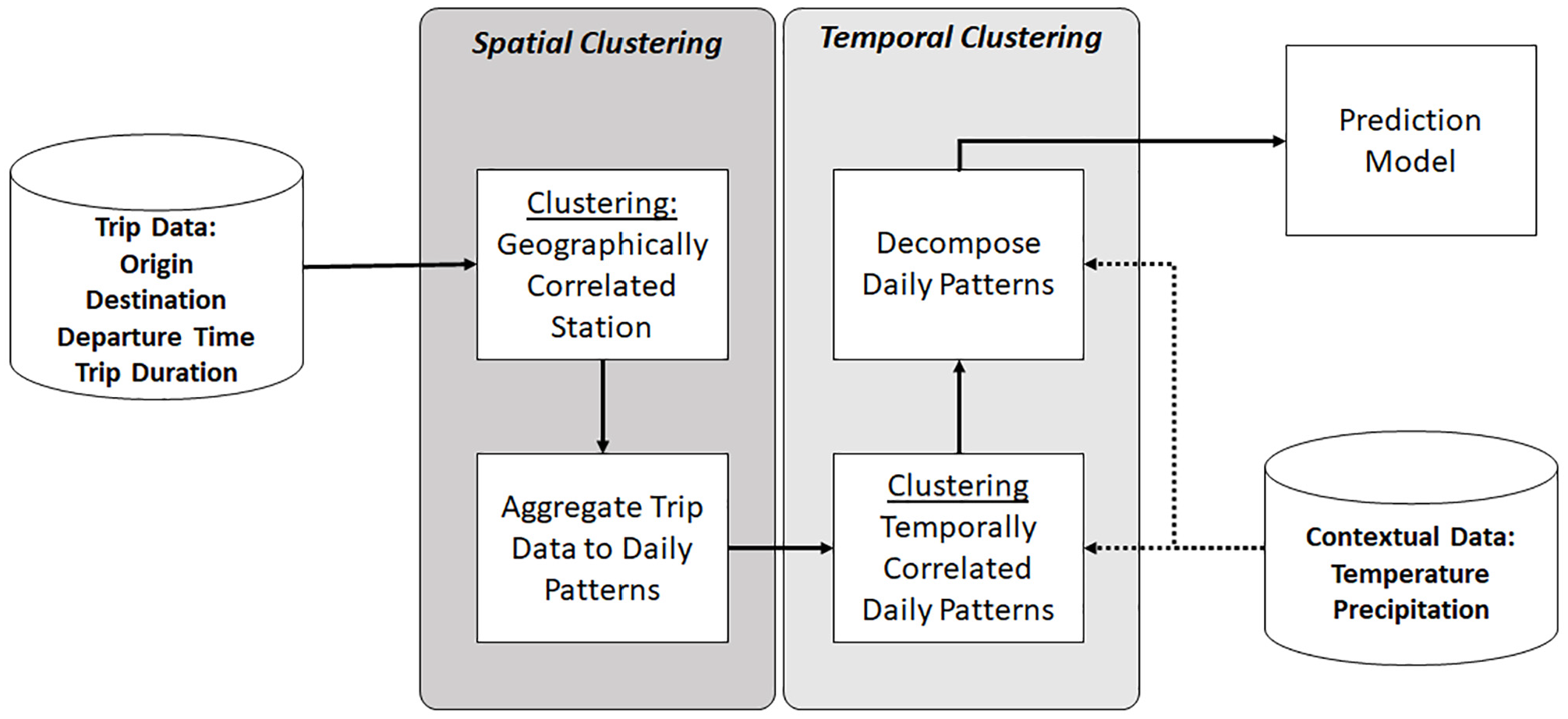
Methodological framework of the proposed low-dimensional approach.
First, trip origins and destinations are clustered in groups of geographically correlated stations. Then, for each cluster, trip data are aggregated—or synthesized—into Vector of Movements. The mathematical details about the process are shown in the next subsection; the difference is that all observations for a specific time interval, such as morning or evening commute, are grouped in one compact vector form (spanned between two spatial points). Temporal clustering will then group them under the assumption that similar vectors lead to similar daily patterns/day type. However, for the same day type, different demand values can be observed. As a consequence, the decomposition process leverages contextual data to find vectors that are consistent across different contextual data, such as precipitation or temperature. Finally, we stress that, if multiple contextual data are available, some of them might be explicitly included within the clustering procedure and the remaining will only be adopted within the decomposition process. In this paper, both options are explored.
In the next subsections, we first describe the two databases (Trip data and Weather data) and then we introduce the four phases of the model.
Data Structure
Trip Data
In this paper, a generic record in the mobility pattern is a trip
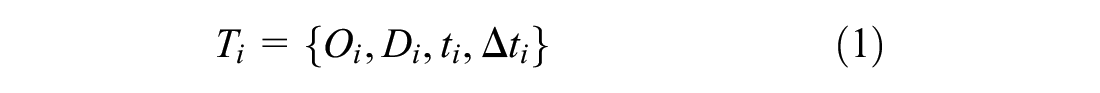
Trips recorded over a given time period (day, hour, or week) form a set of observations (Equation 2). Equations 1–2 represent the input for the proposed low-dimensional framework.
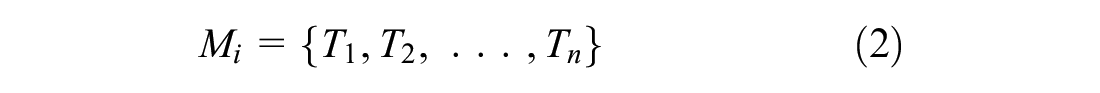
Weather Data
In this paper, the term contextual data refers to all data sources that can be used to classify events. These include, but are not limited to, data about weather conditions, special events, public transportation strikes and any information that can be used to understand typical and atypical behaviors in the system. As different contextual data might have different structures, this subsection only describes how to process weather-related databases. Yet, other data could be used with the proposed approach.
In this work, we use daily statistics about precipitation levels and temperature to estimate the demand for BSS. We average and classify the data and assign each observation with its temperature and precipitation class, as shown in Equation 3:
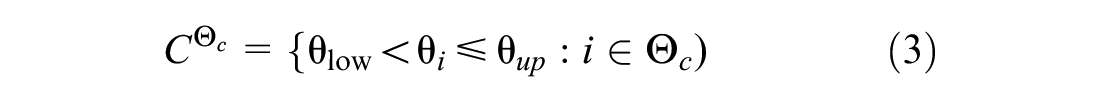
where
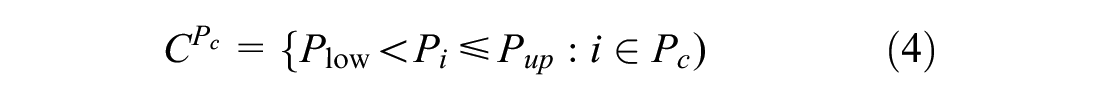
where
Spatial Clustering
As mentioned in the introduction, this study aims at predicting the demand for a certain cluster of BSS stations. Generalizing, we want to identify BSS trips that are spatially correlated and use them to approximate traffic analysis zones (TAZs). Demand from one TAZ to all the others can then be estimated through the framework presented in Figure 1. To do so, we use the Euclidean distance between coordinates to measure the similarity between trip origins coordinates. This creates sub-optimal solutions, as it does not consider accessibility barriers such as rivers or motorways. However, this approach represents the worst-case scenario, as a more realistic similarity measure will generate better clusters and thus better estimations. To this end, we tested the following techniques: Affinity Propagation, Agglomerative Clustering, Gaussian Mixture, and Mean Shift. We exploited the implementation proposed in Scikit-learn, which is an open-source library developed in Python ( 26 ). For the propose of this study, the Gaussian Mixture model clearly outperformed all other models and provides more realistic TAZs when only the Euclidean distance is used as a similarity measure. The procedure returns the following result:
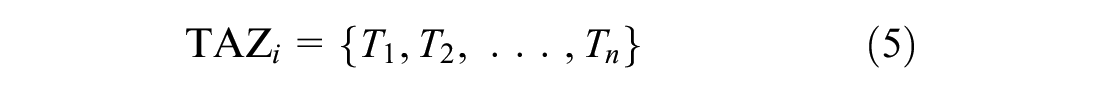
where
Aggregate Trip Data: Vectors of Movements
Daily mobility patterns are composed of thousands of trips per day, each of them characterized by various data including trip origin, destination, and duration. It is far from obvious when two mobility patterns present similar characteristics.
We presume that fundamental set features such as trip duration and cardinality are not sufficient to identify mobility pattern similarities. In addition, if all these features were to be explicitly modeled the dimension of the BSS demand forecasting problem would quickly increase. Therefore, we propose a new way of representing mobility patterns. We start from the concept of gravity center (mass center), an arithmetic mean of trip origins, destinations, or both. Then we introduce Vector of Movements spanning between them. Because of the particular meaning of peak hours in the mobility patterns, we introduce a vector for AM and PM peak hours.
For a generic traffic zone
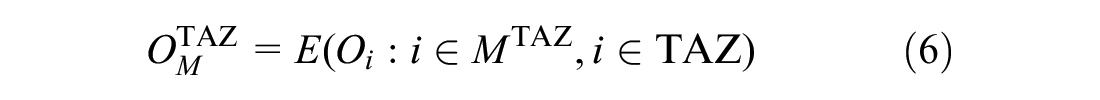
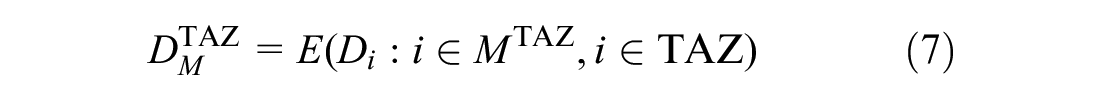
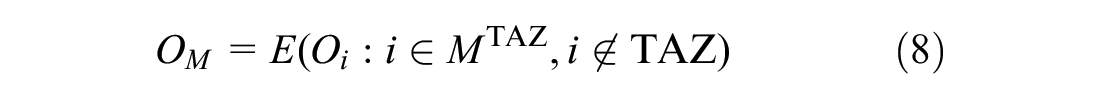
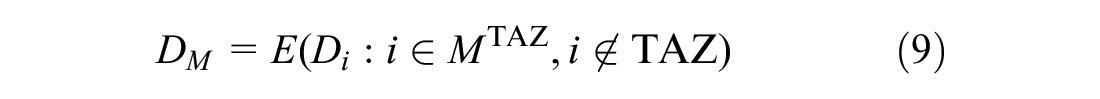
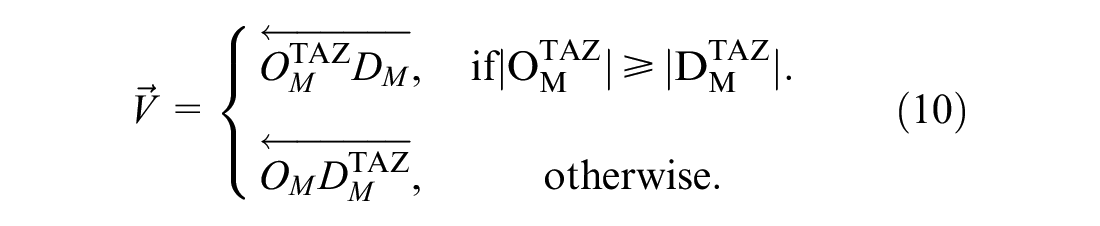
From the daily mobility, we analyze trips of the
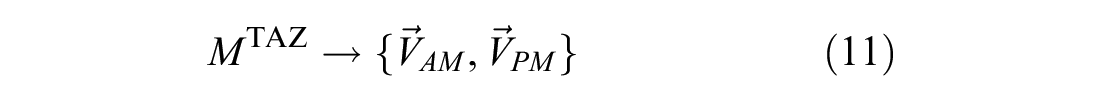
Note that, in the case of station-based BSS, the clustering is performed on the station ID, so (Equation 10) is calculated by taking into account the direction of the demand (there are more trips generated or attracted in the zone). In the case of free-floating services, in which the spatial clustering is performed on the trip ID, the two vectors are the same and are calculated under the assumption that
Temporal Clustering
To cluster Vectors of Movements and Weather Data, we need to specify proper similarity measures and a clustering technique. Both are described in this subsection.
The main advantage of synthesizing trips in vectors is that VM allows for pairwise comparison of days/observations, which is troublesome for a set of recorded trips. We propose to compare two generic vectors
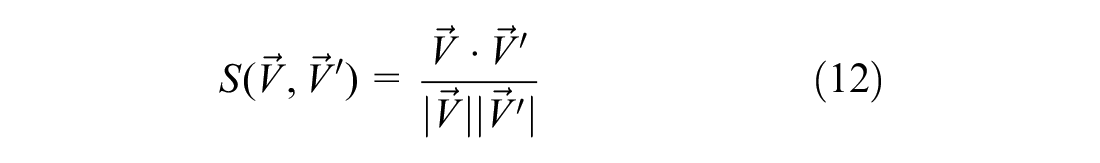
The cosine similarity shown in Equation 12 could directly be used on the VM introduced in the previous subsection. However, this procedure would only measure the similarity in relation to direction. Instead, we propose to calculate the similarity in a three-dimensional space, thus introducing the following modified vector:
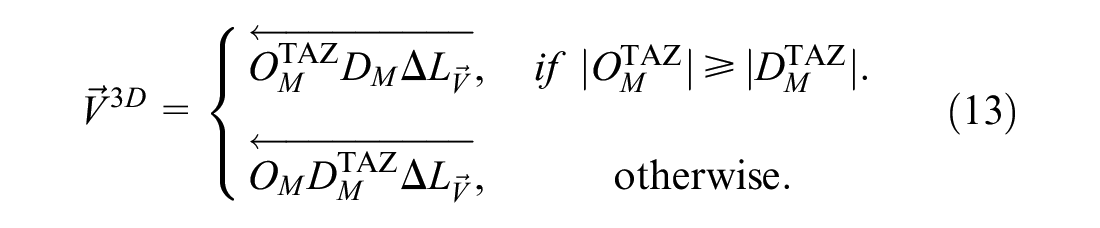
where
Consequently, we can introduce the pairwise distance measure between two days N and M. Given the Vectors of Movements for the morning and evening commute, calculated as in Equations 10, 11, and 13, the similarity between the two days is given by:
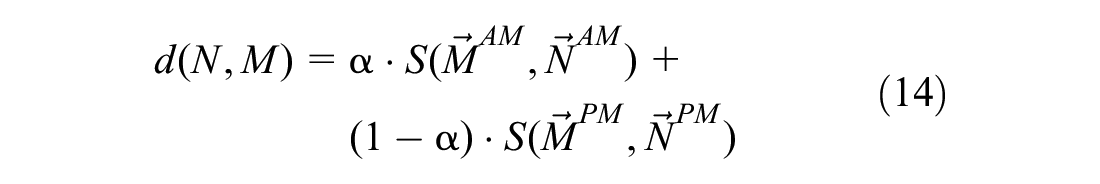
where
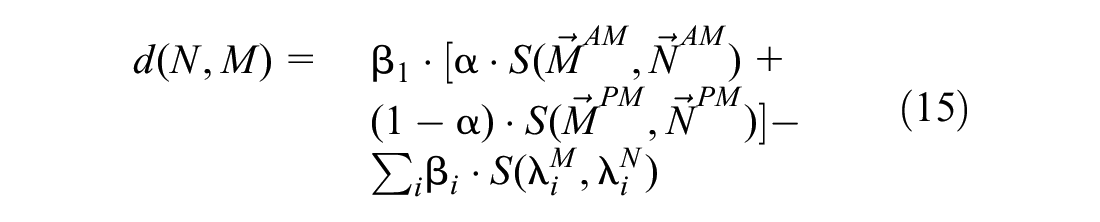
where
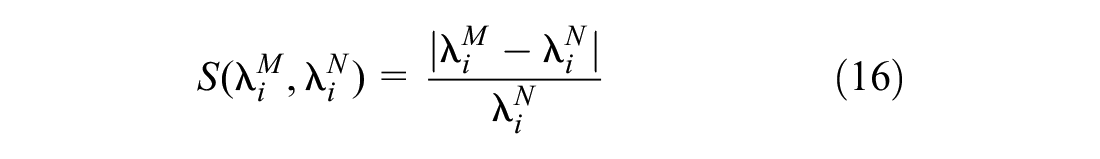
Such metric can be applied to most clustering methods. Note that a 0 value means a perfect match, whereas errors return positive values. This is why
Decomposition
If a sufficient number of observations is available, results from the clustering procedure can be adopted to forecast the mobility demand
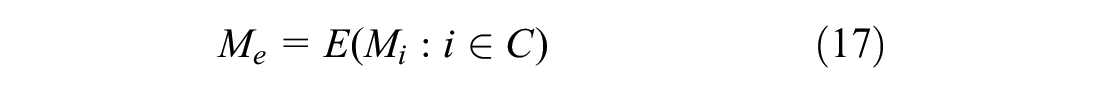
However, if not all information has been included within Equation 15, the model is likely to provide a biased estimation
To account for the contextual information, we exploit the classes already introduced in the subsection Data Structure: Weather Data. As each day is associated with a specific temperature/precipitation class, the input data are already divided into subsets of homogeneous observations
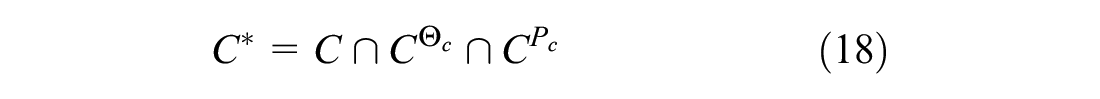
with
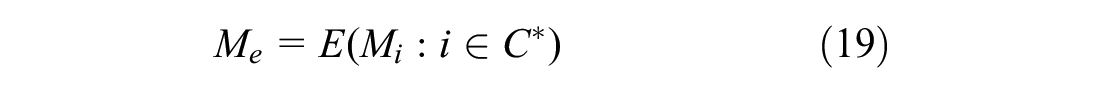
which provides the most likely mobility pattern for a given cluster and temperature. In particular, for each TAZ we obtain the expected vector
Remarks
As we will show in the next section, this methodology performs particularly well in combining contextual and trip data (Vectors of Movements) to identify recurrent mobility patterns. However, the ultimate goal is to forecast hourly rental rates at a zonal level. The hourly prediction for a certain cluster of observations can be obtained as the average rental rate of the observations belonging to the cluster ( 21 ). However, as our data are divided into two parts—training and test points—we also need to associate each test point to a cluster. This is a crucial aspect, as associating training points to the wrong cluster would provide highly inaccurate predictions. To avoid this problem, we use categorical variables to label our data before the clustering. For instance, each day is labeled as “working day” or “holiday,”“warm” or “cold.” These labels are used to match each test point to a unique cluster.
Concerning the generality of the model, the proposed methodology can be applied to both free-floating and dock-based systems. However, the main difference between the two systems lies in the spatial-clustering phase. Creating TAZ from station IDs is a relatively trivial task. However, creating TAZ for a free-floating system might call for another clustering itself, in which exact bicycle locations are clustered spatially. In both cases, a poor spatial clustering would result in poor model performances.
Finally, although this procedure returns accurate predictions of daily patterns, it should be stressed that it does not provide insights in relation to policy analysis. On the other hand, contextual data can be used to identify factors influencing the mobility demand. For example, our results from the New York case study show that temperature data should be included within the estimation framework, as they help the model to better explain the demand. This is in line with previous findings ( 10 ), which showed that, in New York, weather affects cycling rates more than topography, infrastructure, land-use mix, calendar events, and peaks.
Validation: The Case of New York City
The procedure illustrated in the previous section is now validated on real-world data to assess its applicability. To this aim, we collected and processed trip data for the year 2018 (over 17 millions bike trips) from Citi Bike (New York City), one of the biggest BSS in the United States. City Bike NYC is a station-based BSS with more than 15,000 bikes in New York City and Jersey City, New Jersey. Basic statistics are presented in Table 1.
Citi Bike Database: 2018.
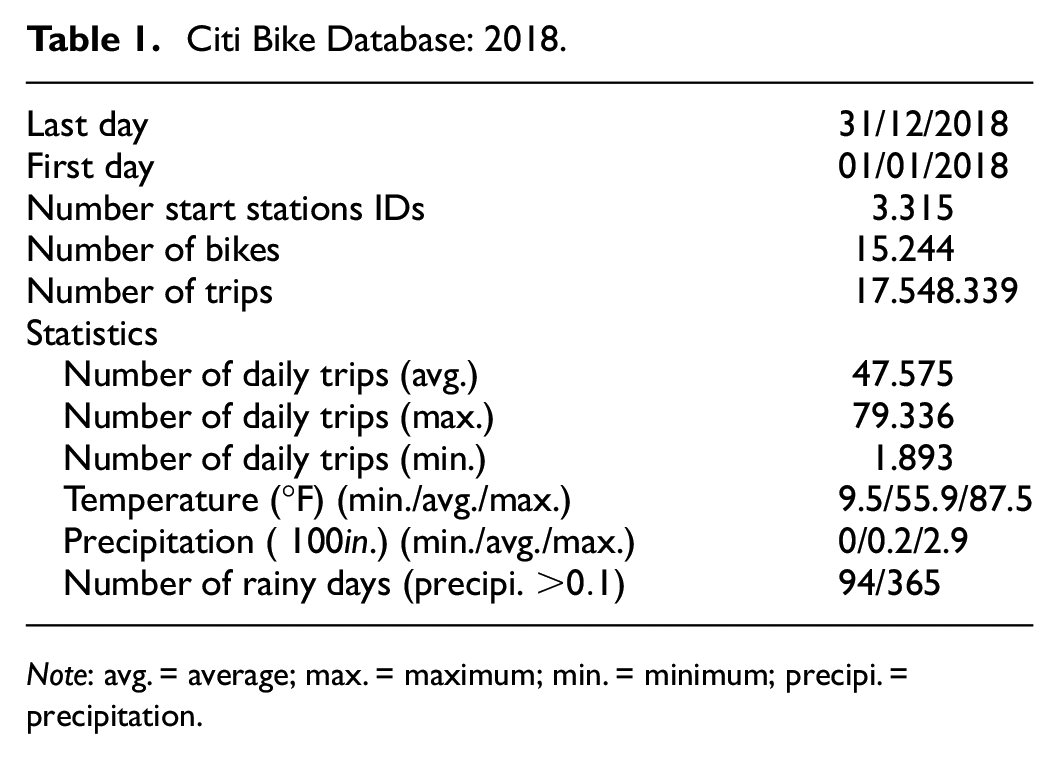
Note: avg. = average; max. = maximum; min. = minimum; precipi. = precipitation.
General statistics show the volume and complexity of the available database. The average daily number is in fact about 45,000 trips, but this number shows a large variance.
Vectors of Movements: A Sensitivity Analysis
To validate the proposed model and to support our claims, we perform in this section a sensitivity analysis for the temporal clustering. Specifically, we use Equations 14 to compare the predictions at a daily and cluster level. We also compare results when using
Internal cluster validation: Evaluates the goodness of a clustering structure without reference to external information. Internal verification should measure cluster Compactness and Separation. The first indicates how closely related are the objects within a cluster, whereas the second indicates how well separated clusters are ( 27 ).
External cluster validation: Evaluates the “purity” of the procedure by comparing it with external information, not available within the clustering procedure.
In this study, we use the Silhouette Index and the Calinski–Harabasz Index for internal validation, which balance compactness and separation performances (
27
). For the external validation, we calculate clusters’ entropy to the validation dataset. Specifically, the Silhouette value ranges from
Finally, to calculate the entropy of the system, we calculate the Shannon entropy index for each cluster:
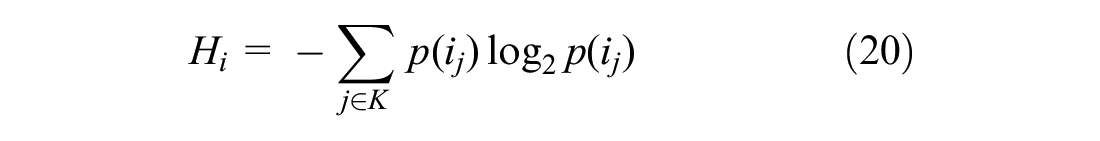
where
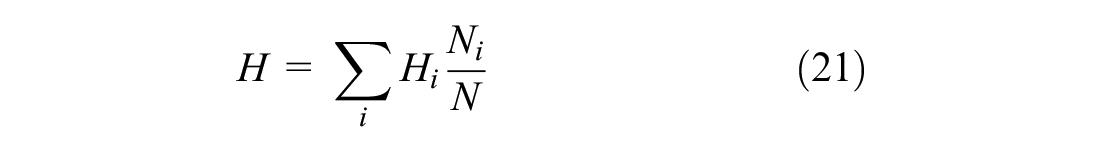
with
Results of the sensitivity analysis are depicted in Figure 2. Specifically, Figure 2,
a
and
b
, show two possible zonal clusterings. As specified in the previous section, we adopted the Gaussian Mixture algorithm as it provides better results. Figure 2,
c–e
, show instead the internal/external verification of our proposed approach at a city level, at a cluster level, and when the
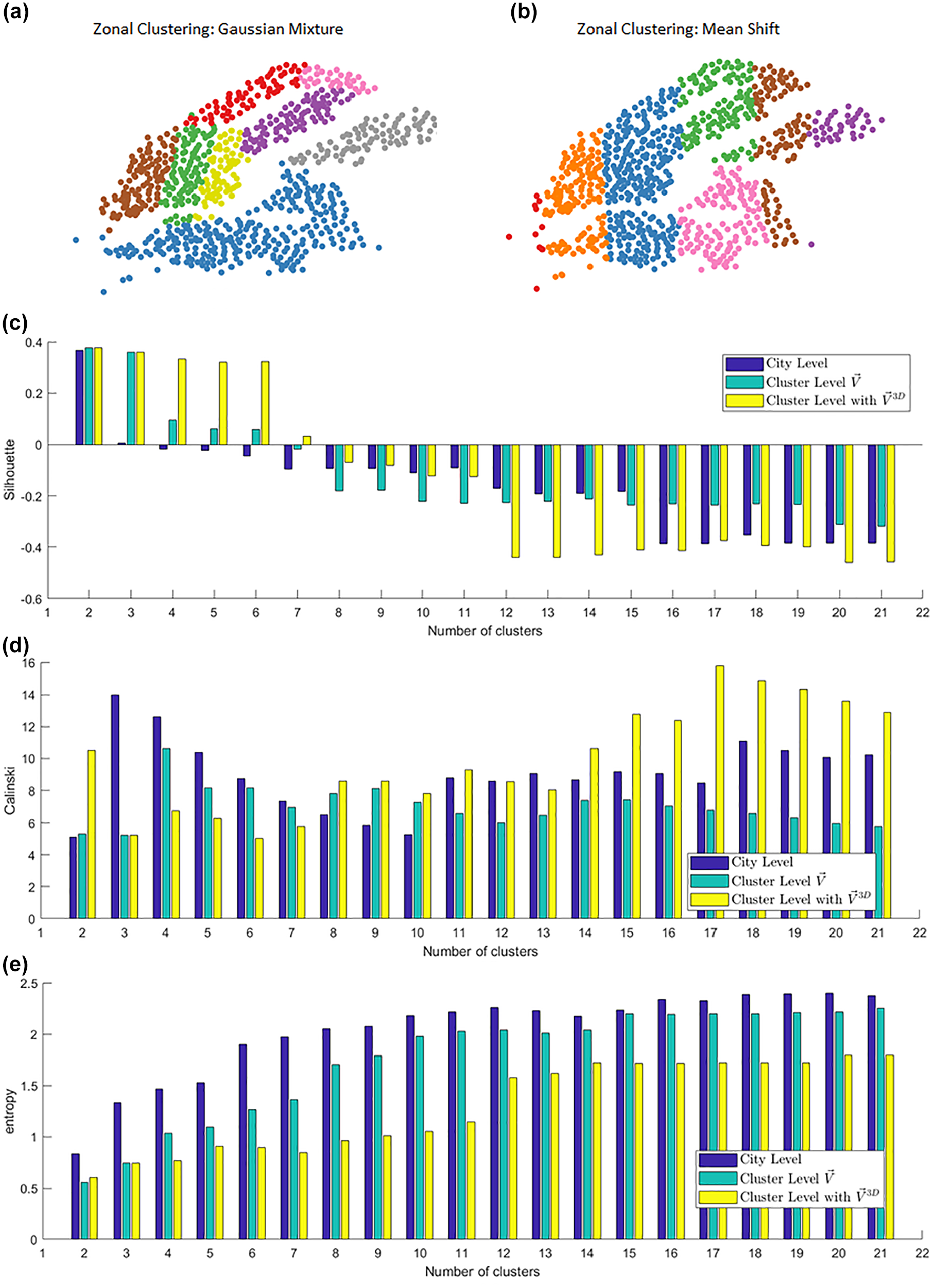
Sensitivity analysis at city level and cluster level: (a) zonal clustering with Gaussian Mixture, (b) zonal clustering with Mean Shift, (c) values of the Silhouette Index, (d) values of the Calinski–Harabasz Index, (e) values for the entropy.
By looking at the difference between city-level predictions and cluster-level predictions, we can see that the model is usually performing better at a cluster level. Specifically, with respect to the entropy—which is the most reliable measure—the model systematically outperforms the city-level one. Concerning the Silhouette and Calinski–Harabasz indexes, the analysis is not straightforward. For the Silhouette, cluster-level predictions usually provide better estimations for a low number of clusters (between 2 and 7) and perform worse for a larger number. On the contrary, the city level works better for a low number of clusters according to the Calinski–Harabasz index. As pointed out in the literature (
27
), the Silhouette index provides biased estimations when many sub-clusters exists (i.e., two different clusters are grouped in a single one). The Calinski–Harabasz is instead very sensitive to noise in the data. As the database at city level aggregates millions of trips in a few clusters, the index still returns a good value even if both entropy and Silhouette point to the opposite solution. This suggests that we need to find clusters that are consistent across the three metrics. This becomes easier when the
Similarly, the entropy is the most reliable measure to compare our results but, in this case, it is not the best measure to calculate the best number of clusters for a given method, as it is more likely to obtain low values when only two clusters are allowed. However, to assume that only two clusters exist means that for the entire database—more than 17 million trips—we are assuming only two daily patterns while assuming that any deviation from these patterns is unpredictable noise. To avoid this last problem, we also calculated the prediction error in relation to normalized mean absolute error (NMAE). Results are shown in Figure 3 where, for a given number of cluster, the boxplot of all NMAE values is shown. We can see that, when the normal vector of movements is adopted (Figure 3b), results are similar for a small number of clusters and decreases when 12 clusters are used. On the other hand, when
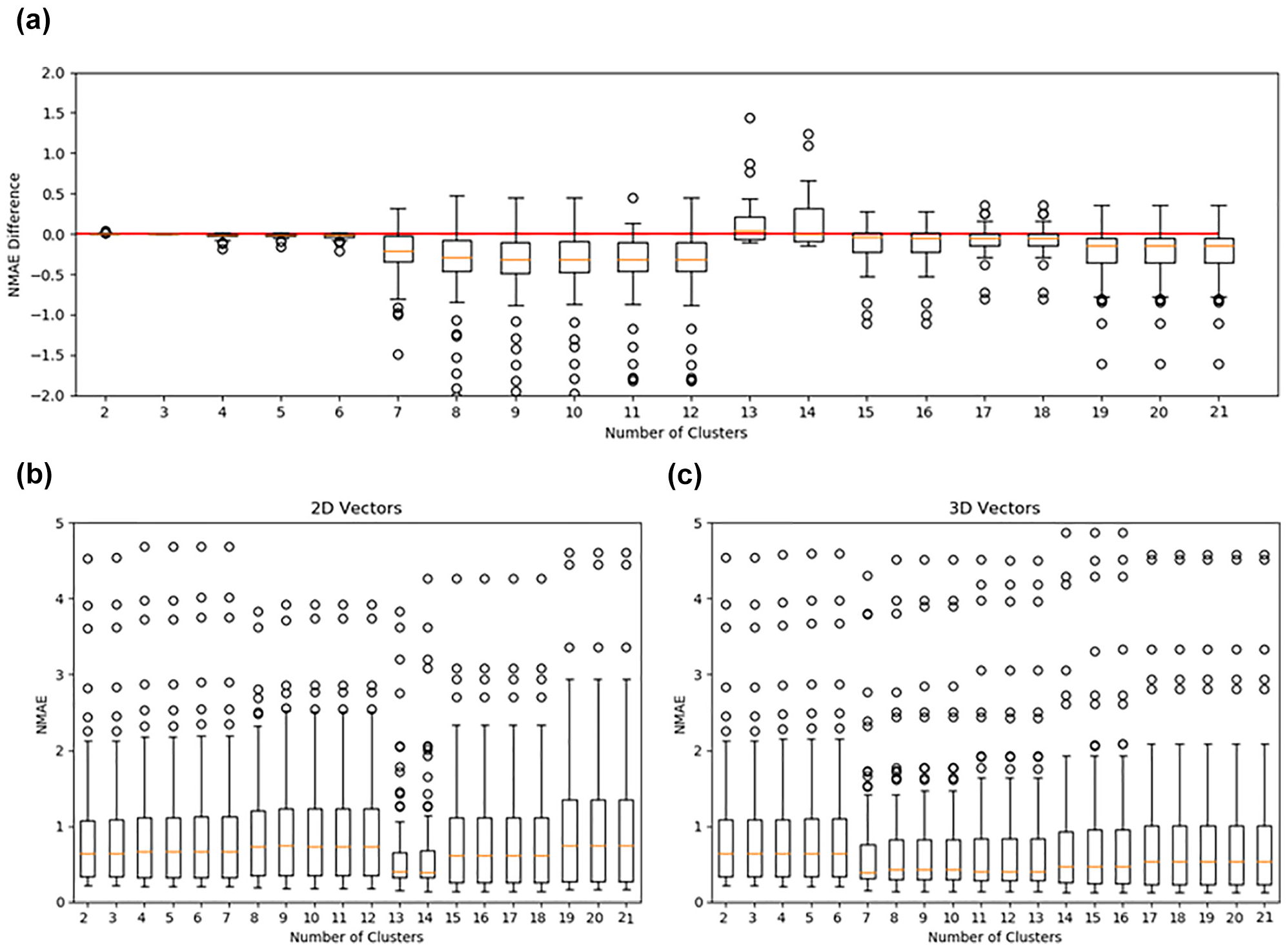
Normalized mean absolute error (NMAE): (a) difference
Temporal Clustering with Contextual Data
In this subsection, we analyze the performances of the model when three-dimensional vectors
Experiment 1: Only
Experiment 2:
Experiment 3:
Experiment 4: All data are used within Equation 15 (Figure 4d).
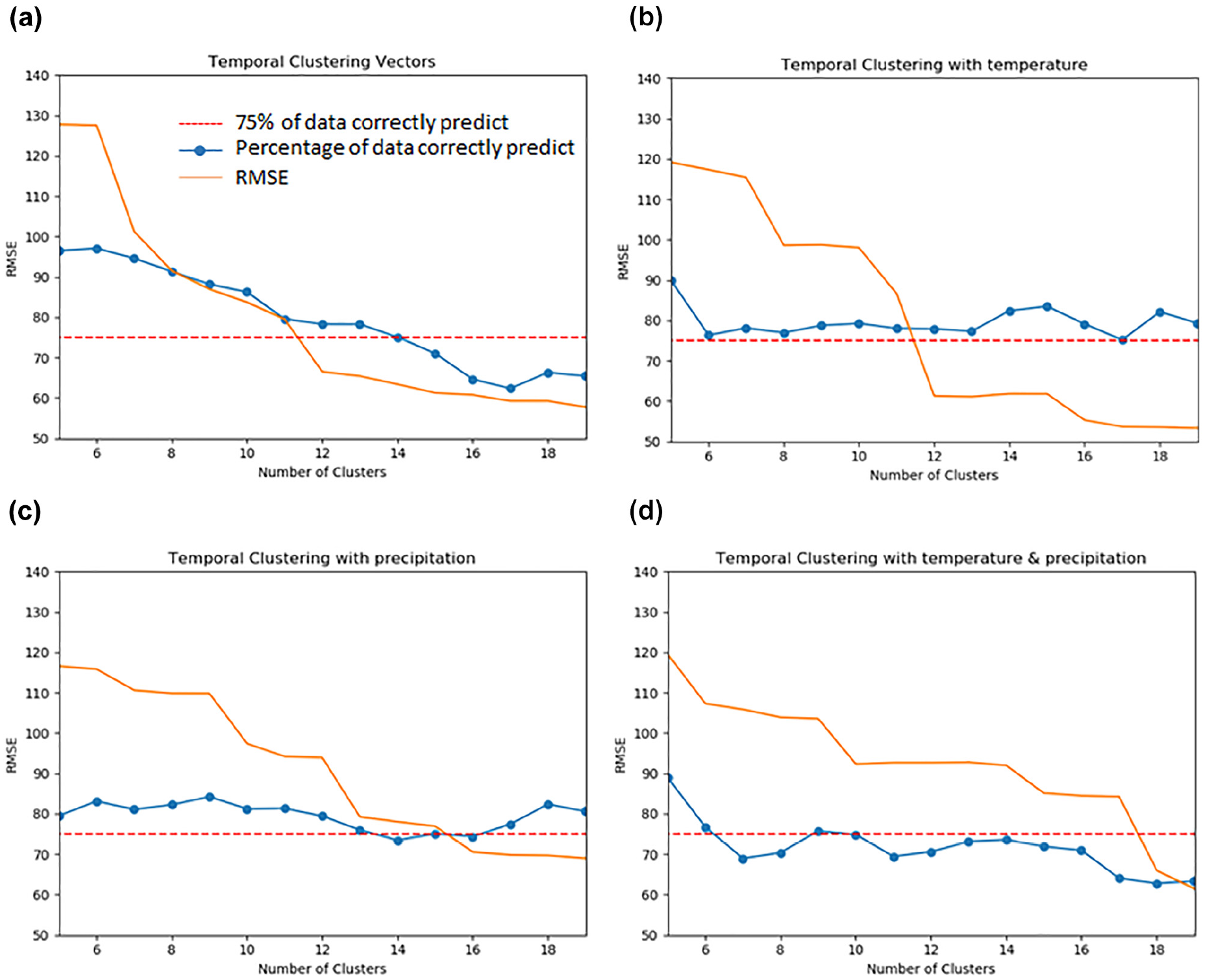
RMSE and precision level for: (a) Experiment 1, (b) Experiment 2, (c) Experiment 3, and (d) Experiment 4.
Results clearly show that best performances are obtained for Experiments 1 and 2. They clearly show a significant reduction of the error and a reasonable precision when increasing the number of clusters. However, for Experiment 1, we can see that the precision decreases almost linearly with the error, meaning that there is a risk of overfitting the data. On the contrary, when weather data are adopted, we can clearly see that the error has a significant reduction for several clusters equal to 12, while the precision of the model stays constant—that is, always above 75%. Similar observations can be done for Experiment 3. However, the RMSE is definitely higher in this case. Finally, Experiment 4 combines all contextual data (weather and precipitations) to forecast the demand (Figure 4d). Both RMSE and precision of the model do not provide satisfactory results, suggesting that—for the current values of
Cluster Decomposition
This is the last building block of the proposed framework, where we adopt Equations 18 and 19 to include all the remaining information in the model. We use the same settings proposed in Experiment 1 and 2 before applying the decomposition scheme, as these provided the best results. Results are depicted in Figure 5. Specifically, Figure 5a represents the results for Experiment 1 and Figure 5b shows the results for Experiment 2. The overall time to perform one estimation of the model is a few minutes on a normal laptop (Intel i7 with 8 GB RAM).
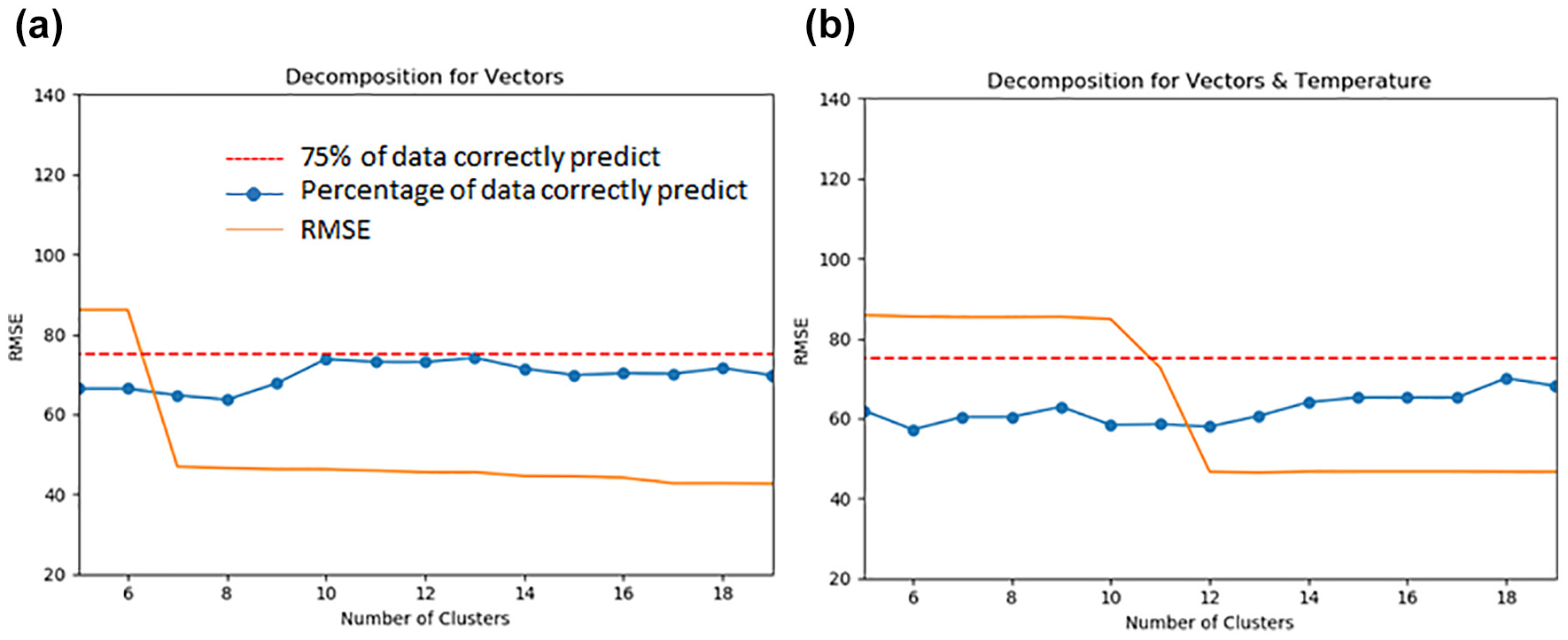
RMSE and precision level when applying the decomposition scheme to: (a) Experiment 1 and (b) Experiment 2.
The first observation that should be reported is that the model shows very stable results in relation to both RMSE and precision. However, both indexes are definitely lower than those obtained in the previous section. This means that the decomposition scheme allows the model to do some overfitting of the data, which might not be an ideal solution. Despite that, the precision results are relatively high (between 60% and 75%) for both models. In addition, the best performances are obtained when only VMs are used within the clustering procedure and all contextual data are adopted in the decomposition phase (number of clusters = 12, precision ≌ 75%). Finally, it is interesting to point out that the decomposition scheme clearly shows different performances with the increasing number of clusters. The difference is observed for several clusters equal to 7 (Experiment 1) and 12 (Experiment 2). According to all metrics adopted, when only vectors of movements are considered, good results can only be obtained for more than seven clusters, meaning that this is the minimum number of cluster to properly identify daily mobility patterns in our study.
However, when we cluster using mobility patterns and weather data, the model needs to classify each daily activity patterns according to two pieces of information, so the optimal number of cluster is almost twice the one of Experiment 1. When the daily patterns have been properly classified, then the decomposition scheme is capable of providing a significant improvement in relation to RMSE.
Finally, we stress that in both cases the proposed decomposition scheme is performing better than Experiment 4, introduced in the previous subsection, in which both precipitation and temperature data were included in the clustering procedure.
Conclusion
In this paper, a low-dimensional model for BSS demand forecasting has been proposed. The framework clusters BSS trips at a spatial and temporal level to predict the mobility demand for a certain cluster/zone. Compared with conventional clustering approaches, our framework includes two additional phases, named Aggregation and Decomposition, which aim at reducing the complexity of the problem. The Aggregation phase synthesizes all trips in a compact form, called Vectors of Movements (VM). This compact form keeps most of the characteristics of the original demand while allowing for simple pairwise comparisons of daily patterns, which was not possible with disaggregated trips. The decomposition scheme allows instead the introduction of contextual data—temperature and precipitation in this study—to achieve more accurate predictions while keeping the overall number of variables low. The work presented in this paper is an extension and generalization of the model presented in Cantelmo et al. ( 20 ), which used VM to estimate the demand at a city level. Contributions of this paper can be summarized as follows:
A generalized version of the Vectors of Movements has been proposed. The new version can be used to estimate hourly rental rates at a cluster/zonal level, and it is sensitive to the attractivity of the zone;
A new procedure to calculate N-Dimensional VMs has been proposed. Each additional dimension represents a new level of information that can be included in the vector;
A general approach to include contextual data has been proposed. The model can use contextual data both within the clustering procedure, as suggested by other authors, or within the decomposition scheme. This allows accounting for more data while avoiding overfitting issues.
The methodology has been applied to publicly available trip data from the New York City bike system (Citi Bike) to forecast BSS demand at a cluster level. In total, 17 million trips have been processed. Several experiments have been proposed, showing that the model provides reliable results.
Future work will focus on three main research directions: First, to investigate new methodologies for both clustering and prediction, including time-series regression. This will allow us to use this methodology for both real-time predictions and rebalancing procedures. Second, to include land-use and socio-demographic information within the demand forecasting for planning purposes. Third, to test the proposed framework with different mobility services, including free-floating BSS and e-scooters.
Finally, we will analyze limits and opportunities of the vectors of movements. In fact, as they approximate the structure of the demand, they might be sensitive to recurrent behavior but provide less accurate predictions for non-recurrent behavior, if this is not properly represented in the training database.
Footnotes
Acknowledgements
We would like to thank three anonymous reviewers for their valuable feedback during the review process.
Author Contributions
The authors confirm contribution to the paper as follows: Study conception: G. Cantelmo, R. Kucharski, C. Antoniou; experiment design, analysis and interpretation of results: G. Cantelmo and R. Kucharski; paper writing: G. Cantelmo, R. Kucharski, C. Antoniou; All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research has been partially sponsored by the European Union’s Horizon 2020 Research and Innovation Programme under the Marie Skłodowska-Curie grant agreement No 754462 and the D-Vanpool; DFG Sino-German 2017 project MOMENTUM - No. 815069.