
Abstract
City events are being organized more frequently, and with larger crowds, in urban areas. There is an increased need for novel methods and tools that can provide information on the sentiments of crowds as an input for crowd management. Previous work has explored sentiment analysis and a large number of methods have been proposed relating to various contexts. None of them, however, aimed at deriving the sentiments of crowds using social media in city events, and no existing event-based dataset is available for such studies. This paper investigates how social media can be used to estimate the sentiments of crowds in city events. First, some lexicon-based and machine learning-based methods were selected to perform sentiment analyses, then an event-based sentiment annotated dataset was constructed. The performance of the selected methods was trained and tested in an experiment using common and event-based datasets. Results show that the machine learning method LinearSVC achieves the lowest estimation error for sentiment analysis on social media in city events. The proposed event-based dataset is essential for training methods to reduce estimation error in such contexts.
As cities compete for global attractiveness and community quality, city-scale public events become more and more popular to boost tourism and promote economic growth. Thematic exhibitions, sports competitions, and national celebrations are instances of city events that take place in urban areas, and may attract a large amount of people during a short time period. The scale and intensity of these events require technical solutions that support stakeholders (e.g., event organizers and public and safety authorities) to manage the crowd.
During such events, the crowd is managed by public authorities to reduce the risk of incidents as a result of internal and external threats. This is usually achieved by exerting predefined measures based on qualitative interpretations of the crowd by stewards, police officers, or event organization employees.
As the efficiency and effectiveness of crowd management measures depend on pedestrian behavior ( 1 , 2 ), it is beneficial for stakeholders to obtain information about the behavior of the crowd. The sentiment of people in the crowd is one of the factors affecting crowd behavior ( 3 ). Together with other information such as crowd density and demographics, it may help crowd managers estimate and predict (negative) behaviors that can be inferred from the sentiment of people in the crowd, such as risky behaviors. Therefore, deriving the sentiment of people in the crowd could be valuable to crowd management.
The sentiment of crowds is difficult to acquire, however. In conventional approaches this information is captured manually by stewards or staff members ( 4 ), a practice that is costly and subject to bias. Traditional crowd observation techniques are based on sensors (e.g., counting systems, GPS trackers, and Wi-Fi sensors) which only provide spatio-temporal information. These solutions do not provide sentiment values. Although crowd sentiment could be extracted from image or video clips provided by cameras through image recognition techniques ( 5 , 6 ), accessing the images or video recordings of a public area is computationally intensive, and often restricted because of privacy issues.
The advance of web-based technologies provides new data sources which could be applied to understand and analyze pedestrian behavior ( 7 – 10 ). Several social media networks, such as Twitter and Instagram, are widely used. Time-stamped social media posts, such as text content, are often geo-tagged. More importantly, these posts intrinsically embrace rich semantic information which could be employed for deriving sentiments in a crowd. Therefore, social media data can be used to derive the sentiments of crowds during events.
A large number of works studied sentiment estimation of crowds using social media data. Jiang et al. ( 11 ) introduced a method to estimate sentiment of tweets considering multiple strategies and including context information (i.e., related tweets). Zhang et al. ( 12 ) demonstrated a machine-learning method incorporating syntactic and context information from social media to estimate users’ sentiments. Ortigosa et al. ( 13 ) presented a method to estimate sentiment of users based on their Facebook texts which integrated lexicon-based, machine-learning techniques.
Yu et al. ( 14 ) applied sentiment analysis to the financial sector, deriving the sentiment of traders from social networks, and exploring its relationship with short-term stock market performance. Surveys about sentiment analysis ( 15 , 16 ) reviewed more than 20 methods and 30 works on estimating sentiment from social media. The methods can be categorized into three types: lexicon-based methods, machine learning (ML)-based methods, and hybrid methods. Lexicon-based methods assign each consecutive combination of words of a text a sentiment score according to a dictionary and calculate the weighted average sentiment score. ML-based methods train the model with a sentiment annotated dataset and estimate the sentiment of a test dataset through the model. Hybrid methods are a combination of lexicon- and ML-based methods. With respect to the context, sentiment analysis in the context of city events for crowd management differs from other contexts (e.g., E-learning, marketing, stock market prediction) in a set of characteristics, such as the specific topic of the event, its location, popularity, and time of occurrence. Consequently, sentiment analysis methods suitable for other contexts may differ from methods fit for the context of city events. While showing the utility of social media data in sentiment analysis studies, no previous work has aimed at deriving the sentiments of crowds in the context of city events. Moreover, the sentiment annotated dataset for a specific context is significant in sentiment analysis. It can be used for evaluating sentiment estimation results from various methods. It can also be used for ML-based or hybrid methods to train their models for sentiment estimation. However, none of the previous works proposed sentiment annotated datasets in such a context. There is a lack of an in-depth understanding of which methods are most effective in this context, and whether their performance will be affected by the diversity of the events or the urban areas in which they take place.
These research gaps lead to the following research question: Which methods are suitable to derive sentiments of crowds from social media texts in city events?
To answer this research question, a number of methods were selected. To compare and assess their performance in the context of city events, an event-based sentiment annotated dataset was required as ground truth. As no annotated event-based datasets existed, the authors constructed one. Using this dataset, the authors tested the performance of candidate methods and selected the most promising method.
The next section presents a literature review, followed by the research methodology to examine the performance of candidate methods. In the fourth section, the methods for comparison are selected, followed by a description of the data collection. The fifth section introduces the experimental setting, followed by the findings and analysis and discussion of the results. Conclusions and proposals for future work are presented at the end of the paper.
Literature Review
The present work compares the sentiment analysis performance of various methods and proposes an event-based sentiment dataset. This section briefly reviews previous works about comparison of sentiment analysis methods and the proposed sentiment datasets.
Previous works have performed experiments in certain contexts or for certain purposes, such as for document classification, e-learning, and brand marketing. They select a set of methods for comparison, use datasets to train their model, and evaluate the results. Therefore, three elements are involved: the context for comparing methods, the selected methods for comparison, and the datasets for training and testing. The following literature review is structured with regard to these three elements.
Sentiment analysis has been applied in various contexts. Pang et al. ( 15 ) investigated a set of methods to estimate sentiment for classifying documents. They compared the sentiment analysis performance of several ML methods based on public reviews collected from the internet, such as movie reviews from IMDb (an online database of information related to films, television programs, home videos and video games, and internet streams and fan reviews and ratings: https://www.imdb.com/). The methods selected for comparison were Naive Bayes (NB), support vector machines (SVMs), and maximum entropy (ME). The results showed that SVM outperformed other methods in their experiment. Boiy and Moens ( 17 ) applied sentiment analysis for opinion mining on multilingual web texts. They analyzed the performance of ML methods including NB, SVM, and ME to estimate sentiment in public reviews about cars and movies. Their findings showed that SVM outperformed other methods.
Li and Li ( 18 ) estimated sentiment on social media for marketing purposes. They derived market intelligence through sentiment analysis based on product reviews on Twitter, such as reviews for Microsoft and Sony products, iPhone, iPad, and Macbook. They compared the performance of NB and SVM with various settings and found that SVM achieved the best performance in their experiment. Ortigosa et al. ( 13 ) analyzed sentiment in the context of e-learning based on social media data. A set of ML methods including a hybrid method were compared for sentiment analysis of text from Facebook. In contrast to other works, they found that NB outperformed other methods, including SVM, in this context. Bravo-Marquez et al. ( 19 ) studied sentiment analysis on big social data. They compared sentiment through various methods with different configurations based on a large volume of non-topic specific posts on Twitter (“tweets”). They also found NB to perform better than SVM in their experiment.
This review of the literature shows that NB and SVM are the most popular ML methods for sentiment analysis ( 13 , 15 , 17 – 21 ). Public reviews and social media data are widely used for deriving sentiment. Some investigations ( 13 , 15 , 17 , 18 ) have also been performed with data related to certain topics, such as reviews of movies or cars, as well as brands such as Microsoft, Sony, and Google, while other studies (19–21) were performed with common-based datasets. None of these works, however, was performed in the context of a city event with respect to crowd management, and none of them investigated the impact of using different datasets, that is, common-based or a certain topic based, on the performance of sentiment analysis.
Regarding the construction of datasets, Kouloumpis et al. ( 22 ) published a dataset including 222,570 sentences annotated with three sentiment categories: positive, neutral, and negative. The sentences were collected from Twitter with no specific topic. Costa et al. ( 23 ) published a comprehensive dataset containing 400 deceptive and 400 truthful reviews in positive and negative categories. These datasets have been widely used in several sentiment analysis works ( 24 – 28 ). There are also datasets proposed related to certain topics. For instance, Hu and Liu ( 29 ) presented a dataset with 6,800 opinion words on 10 different products. Cruz et al. ( 30 ) proposed a sentiment annotated database of reviews with different topics: 587 reviews of headphones, 988 reviews of hotels, and 972 reviews of cars. Similarly Blitzer et al. ( 31 ) proposed a sentiment annotated dataset including Amazon reviews in four domains: books, DVDs, electronics, and kitchen appliances. However, there is no dataset proposed for sentiment analysis in the context of city events.
Research Approach
This section elaborates the research approach for testing the sentiment estimation performance of candidate methods in the context of city events using social media.
The research approach is illustrated in Figure 1. It consists of three major steps: (i) estimate the sentiment using different methods and different datasets, (ii) evaluate the estimation error per method, and (iii) compare the estimation error between methods. It involves two different types of datasets: common-based datasets and an event-based dataset. The common-based datasets in this research cover a wide variety of situations and have no domain knowledge or context information about city events. Moreover, these datasets are well known in the research area of sentiment analysis. Event-based datasets refers to datasets of social media posts collected during events and annotated with sentiments. The event-based dataset used was generated in the course of this research. In the first step, lexicon-based methods estimate the sentiment of each text in both common and event-based datasets. The ML-based methods train their models using part of the common and event-based datasets. Then both trained models estimate the sentiments of the remaining texts in the common and event-based datasets, respectively. In this step, both methods yield estimated sentiment. In the second step, to verify whether the estimated sentiment is correct, the estimation result is compared with the sentiment ground truth of the test dataset using the metrics introduced in the next paragraph. N-round testing is then performed to reduce the random error. In each round, a subset is selected, and the sentiment of each text is identified and compared with the ground truth. Finally, the performance of the methods across different datasets is compared. The analysis results also provide feedback on the research methodology, such as how best to adjust the sample size of the training and testing dataset, select feasible candidate methods, and choose suitable comparison metrics.
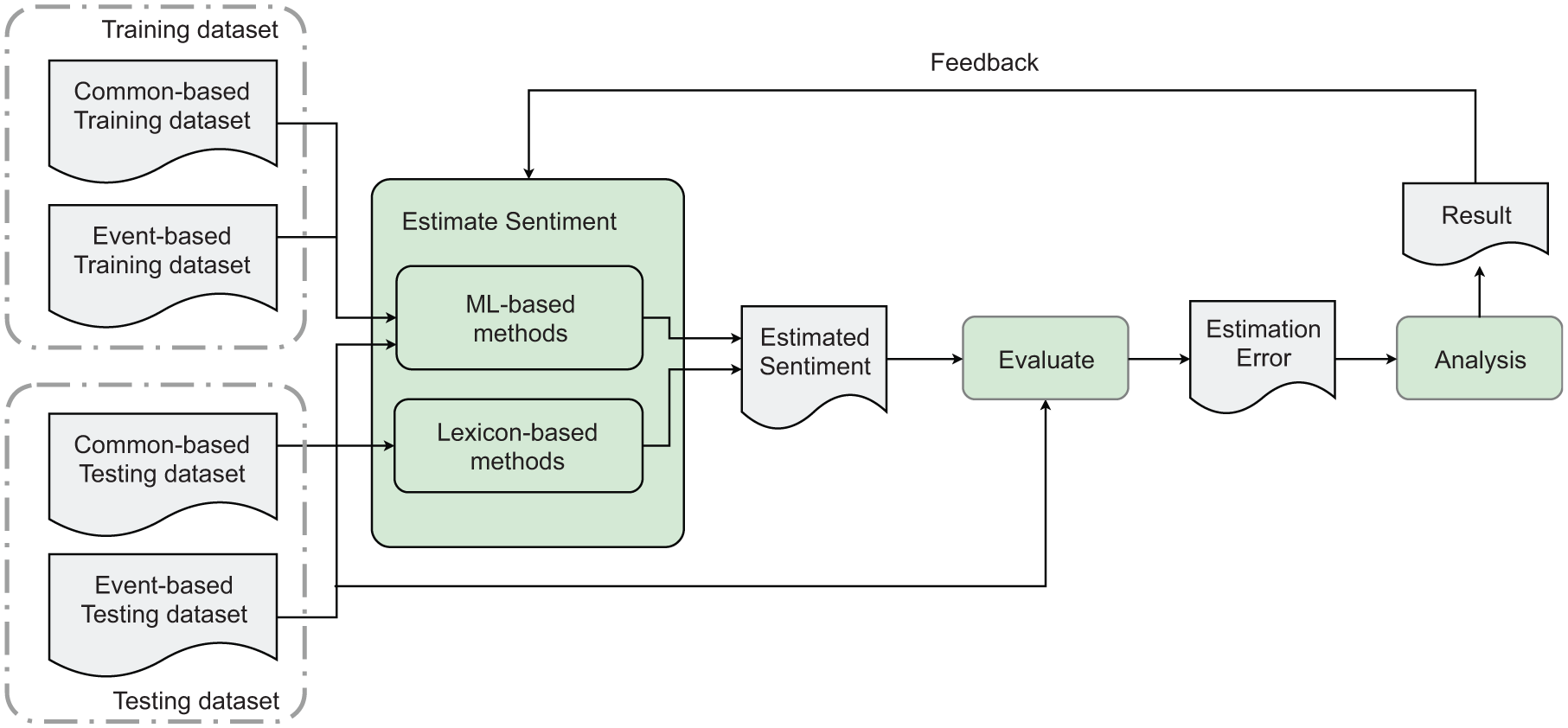
The process of investigating sentiment estimation performance of selected methods on social media text in city events. The green symbols denote three major steps: estimate the sentiment using different methods with different datasets; evaluate the estimation error per method; and analyze the estimation error between methods. The gray symbols denote documents input and output.
Comparison Metrics
The sentiment estimation performance is assessed using the estimation error, which is calculated for each repetition of sentiment estimation. This estimation error per repetition Ei is calculated by the amount of false identifications

Selection of Candidate Methods from Literature
This section presents the selection of a set of candidate methods to perform sentiment analysis on social media data. As indicated above, there is no existing literature comparing the performance of sentiment analysis methods using social media in the context of large-scale city events. Thus, the sentiment analysis methods reviewed were those applied to generic situations.
Deriving sentiments from social media text is not a novel problem. Many authors have discussed this topic and proposed methods to solve it ( 16 , 32 , 33 ). Ravi and Ravi ( 16 ) reviewed 161 studies of which about 30 discussed sentiment analysis on social media networks. As mentioned in the introductory section above, sentiment analysis methods can be categorized into three types: lexicon-based, ML-based, and hybrid methods. Hybrid methods are a combination of lexicon- and ML-based methods. The performance of hybrid methods is therefore influenced by the quality of the lexicon- and ML-based methods they combine. Understanding the performance of lexicon- and ML-based methods is necessary to investigate hybrid methods. Therefore, this research focuses on lexicon- and ML-based methods, and leaves hybrid methods for future work.
An overview of the methods selected for sentiment estimation on social media texts in the context of city events is shown in Table 1. More details on the selected methods are given below.
Selected Methods for Deriving Sentiment of Crowd on Social Media in City Events

Note: na = not applicable; ML-based = machine learning-based; SVM = support vector machines; SVC = support vector classifier.
For reference numbers, see References section.
Lexicon-Based Methods
Lexicon-based, or dictionary based, approaches are widely applied in the field of sentiment analysis ( 16 , 34 ). Given a text from a social media post, lexicon-based methods assign each n-gram (i.e., consecutive combination of words) a sentiment score according to its attached dictionary and calculate the weighted average sentiment score as a performance indicator after filtering out stop words and reducing other noises. More than 41 studies explore lexicon-based methods in sentiment analysis ( 16 ). Among these, SentiStrength and SentiWordNet are two popular lexicon-based methods used for deriving sentiment from social media data.
SentiStrength
SentiStrength was created by identifying sentiments expressed in the texts on MySpace, a social media platform. It estimates the strength of negative, neutral, and positive sentiment in short texts. It was originally developed for the English language and optimized for short social media texts ( 20 ). SentiStrength reports three sentiment values with a range of strengths: −5 to −1 as negative, 0 as neutral, and 1 to 5 as positive. It has been applied and investigated in many papers in which it shows significant performance ( 21 , 35 – 37 ).
SentiWordNet
SentiWordNet is a lexical resource for opinion mining. Instead of constructing its sentiment dictionary from a corpus (e.g., MySpace data) as SentiStrength does, it assigns to each syncset of WordNet one of three sentiment values: positive, negative, or objective ( 38 ). It is widely used in estimating sentiment from social media networks ( 20 , 25 , 39 , 40 ).
ML-Based Methods
ML-based methods train the model with a sentiment annotated dataset and estimate the sentiment of a test dataset through the model. Numerous ML-based methods have been proposed and investigated in recent studies in various situations ( 16 ). Among these methods, NB and SVM are widely tested and outperform most other methods in deriving sentiments from social media texts ( 15 , 16 , 33 ). In the following these methods are described in more detail.
Naive Bayes (NB)
NB is a supervised linear ML algorithm which is popular for classifying text. It is a simple probabilistic classifier based on applying Bayes’s theorem ( 41 ). It is widely used to estimate sentiments from social media texts ( 13 , 19 , 42 ). Although its mechanism is fairly straightforward, it often performs as well as much more complicated solutions ( 14 , 43 ).
Support Vector Machines (SVMs)
SVMs are a family of supervised learning models used for linear and nonlinear classification analysis. SVMs are widely used in text categorization for sentiment analysis ( 15 , 16 ). In this research, the four most popular SVM models are tested, namely: stochastic gradient descent classifier fitted SVM (SGDClassifier or SGDC), linear support vector classifier (LinearSVC), Nu-support vector classifier (NuSVC), and support vector classifier (SVC). SGDClassifier is a linear SVM classifier fitted with stochastic gradient descent learning. LinearSVC is an implementation of SVC in case of a linear kernel. SVC and NuSVC apply the statistics of support vectors developed in the SVM algorithm. SVC and NuSVC are similar methods, but accept slightly different sets of parameters and have different mathematical formulations. These methods are explored in a large number of papers on deriving sentiment from social media ( 11 , 13 , 19 , 20 , 42 – 47 ).
Sentiment Estimation Result Scheme
This research aims to compare the performance of sentiment analysis methods. However, the various methods selected result in different sentiment schemes. For instance, the lexicon-based method SentiStrength outputs sentiment values as an integer between −5 and 5, while the SentiWordNet results in values of negative, neutral, and positive. For other methods, the output schemes are listed in Table 2. To compare the performance of these selected methods, it is necessary to define a unified output scheme and map schemes of all the selected methods to the unified output scheme.
Sentiment Estimation Output Schema Transformation Rules
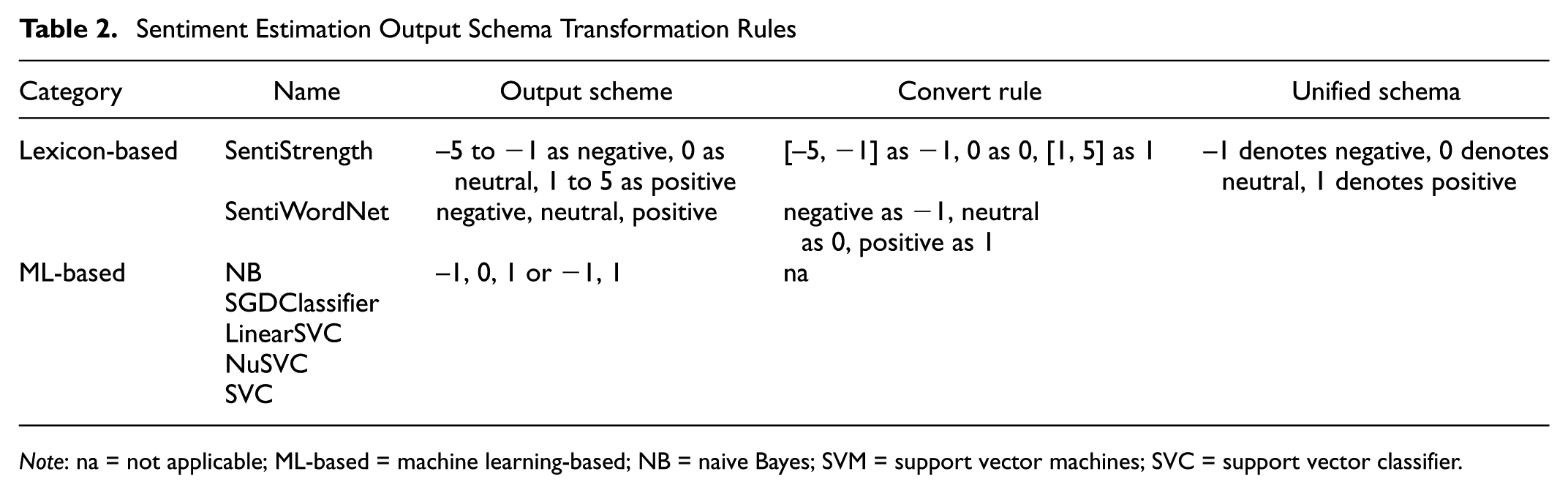
Note: na = not applicable; ML-based = machine learning-based; NB = naive Bayes; SVM = support vector machines; SVC = support vector classifier.
According to Table 2, there are two types of sentiment scheme: simplified or detailed. “Simplified” in this research refers to a sentiment scheme featuring only three categories: positive (1), neutral (0), and negative (−1). A detailed sentiment scheme, in contrast, has more sentiment categories, for example: extremely negative, very negative, negative, slightly negative, neutral, slightly positive, positive, very positive, extremely positive.
For lexicon-based methods, SentiStrength supports a detailed sentiment scheme, while SentiWordNet results in the simplified scheme. For ML-based methods, the supported sentiment scheme depends on the training data. Namely, if the training dataset is annotated with a detailed sentiment scheme, the ML-based methods trained with such a dataset also yield sentiment scores in the same scheme.
When constructing such dataset, however, the agreement reached on a sentiment category from a detailed scheme, for example, “extremely negative,” is less than on a category from the simplified scheme, for example, “negative.” Moreover, subjective errors introduced by human agents in the annotation process is also increased when using the detailed scheme. Thus, a dataset annotated with a detailed sentiment scheme is difficult to construct, less reliable, and therefore more rare. Most of the existing sentiment datasets are annotated with a simplified scheme, that is: negative, neutral, and positive. ML-based methods trained with such a dataset also result in a simplified sentiment scheme.
With regard to the impact of a simplified sentiment scheme on the estimation error of the models, compared with a detailed sentiment scheme, a simplified one indeed may lose the detailed sentiment strength information, but it still reports the same sentiment polarity; for example, in a detailed scheme, either “very positive” or “slightly positive” will be reported as “positive” in a simplified scheme.
As the simplified sentiment scheme is widely supported by both lexicon- and ML-based methods, the simplified sentiment score is applied in this research. The following three sentiment values are assigned: −1, 0, or 1, denoting negative, neutral, and positive, respectively. The mapping of all the selected methods is shown in Table 2.
Data Collection
Investigating the performance of candidate methods in the context of city events requires ground truth data, both for testing purposes and, in case of ML-based methods, to train their model. This research, required both common-based and event-based sentiment annotated social media data. Annotation in this respect means that, for each text, its sentiment is known. Common-based datasets cover a wide variety of situations and have no domain knowledge or context information about city events, while event-based datasets focus on posts which have been collected during events. As indicated above, annotated common-based datasets are available from previous research, but annotated event-based datasets are not yet available. To fill this research gap, the authors constructed such an event-based dataset.
Both the common and event-based sentiment datasets were annotated with sentiment polarities: Positive, Neutral, and Negative. Activities in city events, for example, celebrations and riots, tend to stimulate attendees’ sentiments. The sentiments of crowds in the context of city events are stronger than in a normal context, meaning that they generate more extreme (positive or negative) expressions than neutral ones. Thus, it is valuable to explore the distinction of sentiment estimation with and without neutral polarity. This research considers sentiment polarity in two sets: one consists of Positive and Negative (PN) and the other Positive, Neutral, and Negative (PNN). Sentiment analysis with and without other individual polarities will be kept for future research.
The following subsections describe the selection of the common-based datasets and the construction of an annotated event-based dataset.
Common-Based Dataset
There is no official definition for a common-based dataset. In this research, it refers to datasets which cover a wide variety of situations, and contain no domain knowledge or context information about city events. Several papers have proposed sentiment annotated datasets consisting of texts collected from social media. The most comprehensive review ( 16 ) listed 32 public datasets used for sentiment analysis, six of which are social media datasets.
These datasets vary in relation to topic, sentiment polarity, and annotation approaches. Social media posts contained in these datasets may cover diverse topics, such as digital brands, sports, and technology. With regard to sentiment polarity, some datasets contain posts with Positive, Neutral, and Negative polarities, while others only have Positive and Negative posts. There are two major annotation approaches: by the researchers themselves or through crowd-sourcing. For the common-based ground truth in this research, the authors chose two social media datasets based on their large amount of texts, the fact that they are widely used in other research, and their diverse sentiment polarities and topics. The first one is the dataset for the University of Michigan Sentiment Analysis competition, which consists of more than 1.5 million social media posts annotated as Positive or Negative. It is applied several times as the ground truth for this competition. The second dataset is an extended version of Niek Sanders’s sentiment dataset series which is widely used in sentiment analysis studies ( 48 – 51 ). This dataset contains more than 55,000 social media posts, each of which is annotated with Positive, Neutral, or Negative. The posts in both datasets cover random topics.
Event-Based Dataset
Event-based datasets in this research refers to sentiment annotated datasets consisting of social media posts posted during both city-scale events and local events. They should be sufficiently large to be used as ground truth for testing candidate methods, but also serve as training data for ML-based methods. To construct such an event-based dataset, the first step was to estimate the required size of the dataset. The authors then collected social media posts and annotated them with sentiment scores. This process is elaborated upon in the following.
The size of an event-based dataset should meet two criteria. First, it should be sufficient as a training dataset for ML-based candidate methods to reach stabilized performance for sentiment analysis. Second, it should be as small as possible given the efforts and costs involved in performing the sentiment annotation. To estimate the sample size, a common-based dataset was used to investigate the estimation performance variance for different sample sizes using different ML-based methods, as shown in Figure 2. Figure 2a shows the variance of mean estimation error with respect to the size of the training sample. As expected, the mean error of linear ML-based methods decreases when the training sample is increased. However, the nonlinear ML-based methods show unexpected increases with increasing sample size, which may be caused by their nonlinear nature. To present the variation pattern of the linear method more clearly, an error is highlighted in Figure 2b. The figure shows that the mean estimation errors of linear ML-based methods decrease considerably when the training sample is less than 2,000 posts, after which the decrease in error becomes less sharp and gradually flattens after a sample size of 6,000 posts. Taking a training sample size of 6,000, increasing the sample with another 2,000 posts only reduces the mean estimation error by less than 0.01. This also holds for the decrease of the standard deviation of estimation error, shown in Figure 2c and d . It can thus be concluded that the estimation error of linear ML-based methods stabilizes when the training sample is higher than 6,000, while a training sample with more than 6,000 posts does not reduce the estimation error significantly. Thus, 6,000 was chosen as the training sample size. In addition, around 15% of the dataset is needed to test the method performance, so the event-based dataset should contain around 8,000 posts.
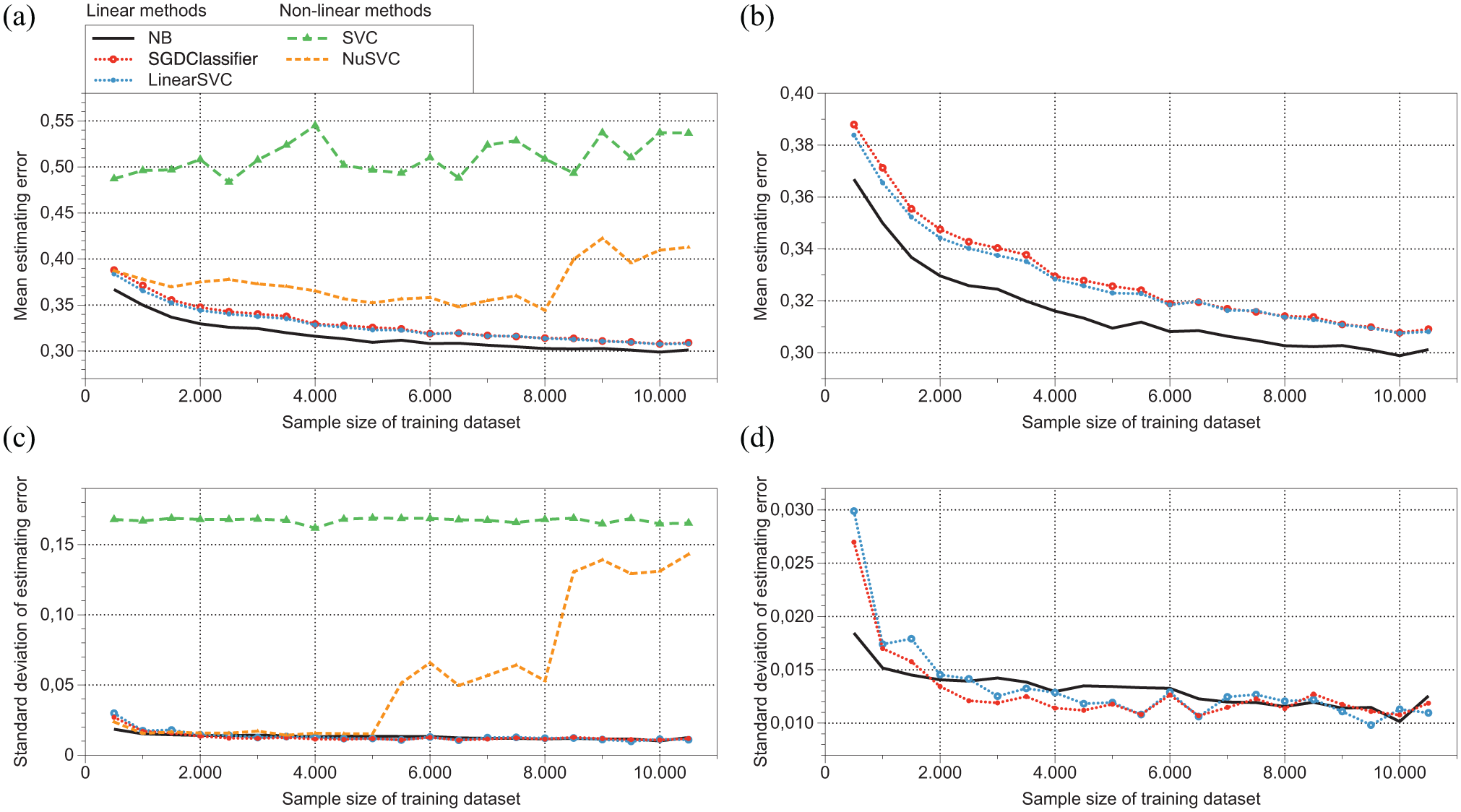
Mean and standard deviation of estimation error when increasing the training data sample size for ML-based methods. (a) Mean estimating error; (b) mean estimating error-linear methods; (c) standard deviation estimating error; and (d) standard deviation estimating error–linear methods. (b) and (d) zoom in linear ML-based methods to present the variation pattern of linear methods more clearly. The estimation error of linear ML-based methods stabilizes when the training sample size is higher than 6,000.
The event-based dataset was constructed following the process shown in Figure 3. After estimating the size of the dataset, the authors identified the requirements regarding the events and activities considering diversity in cities, event characteristics, and their major activities.
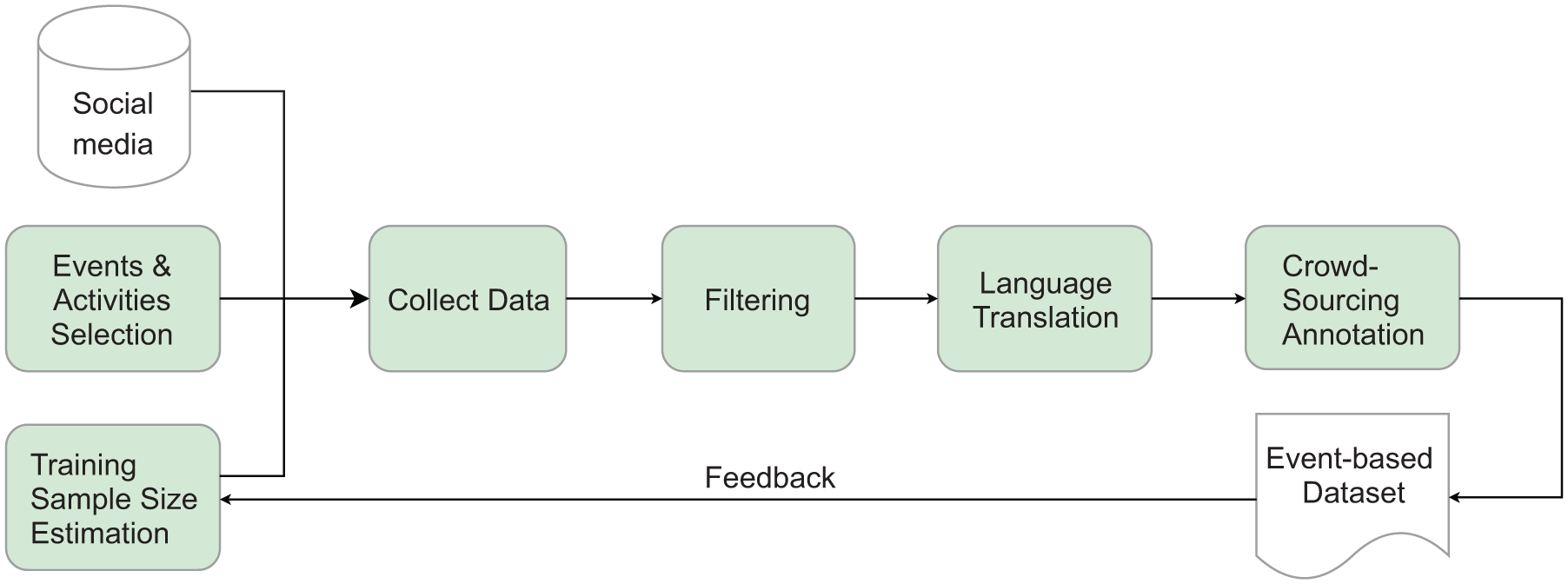
The process of constructing the annotated event-based social media sentiment dataset.
To select the cities and activities, several criteria were identified, as listed below.
Different cities. The authors decided to use social media posts from the two biggest cities in the Netherlands, Amsterdam and Rotterdam, as they would provide sufficient posts and cover slightly different populations as well.
Different event characteristics. Four events were selected, as listed in Table 3.
A large nautical event (Sail 2015)
An annual national holiday (Koningsdag, or King’s Day, 2016)
An annual celebration including a canal parade and parties (Europride 2017)
Football riots and championship celebration (Feyenoord 2017)
Different activities take place during these events, including:
Canal parade
Street parties
Flea market
Fireworks
Riots
Different areas in the city. The selected events include both events with activities that spread out over the whole inner city and events that are located in a smaller area.
City Events and Activities for Constructing Event-Based Dataset
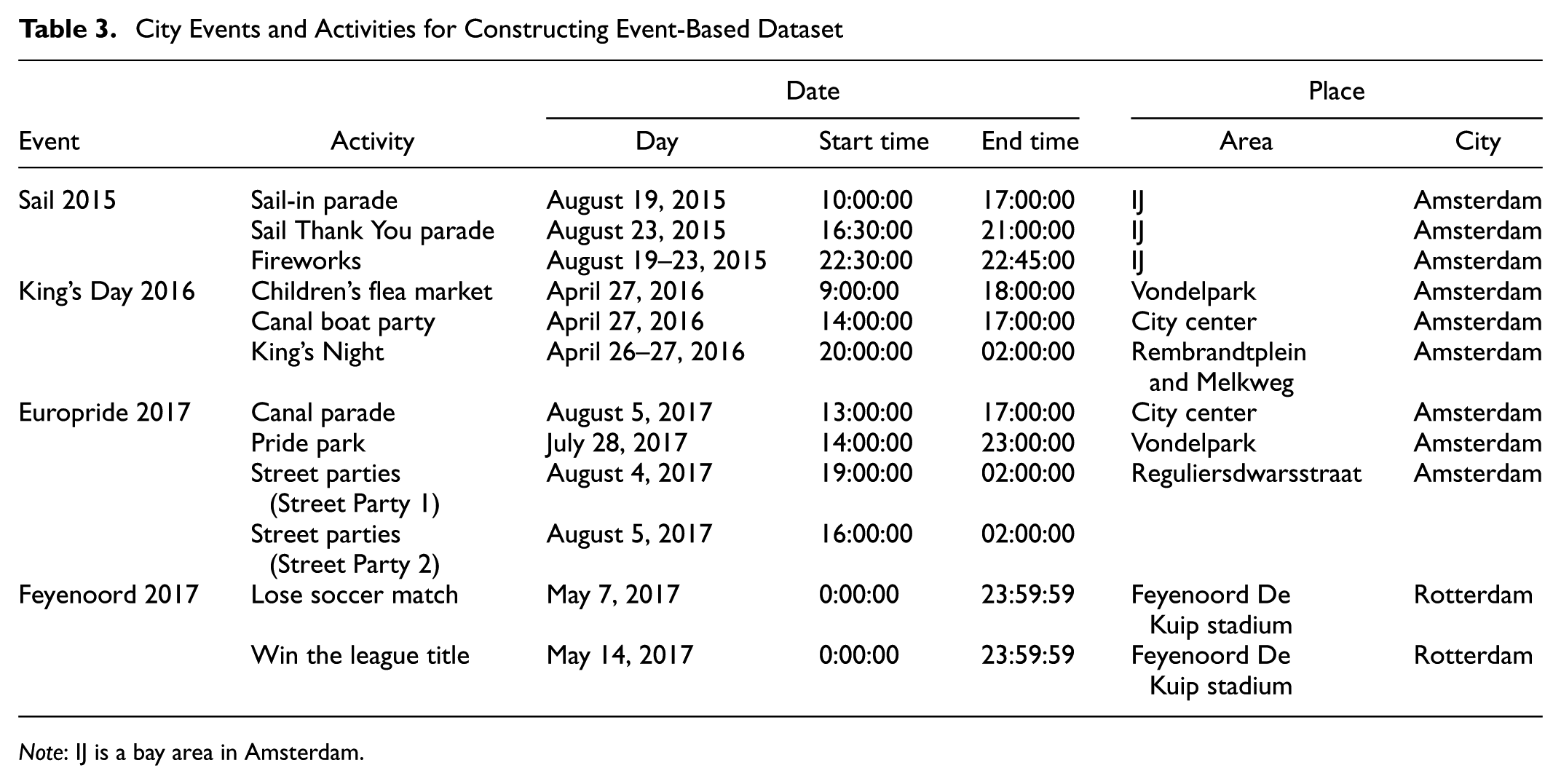
Note: IJ is a bay area in Amsterdam.
Geo-referenced tweets and Instagram posts were then collected from selected city events according to the estimated sample size. The collection of social media posts during these events was performed through the API of social media platforms with the help of SocialGlass (http://social-glass.tudelft.nl/), an integrated system for collecting and processing social media data. The next step was to filter out spam accounts and short posts (i.e., length smaller than 30 characters) which may contain useless or insufficient information for sentiment analysis. As city events attract many foreigners, posts may contain various languages, rather than only English. To determine the sentiments of those posts, all posts were translated into English using the Google Translate API (https://cloud.google.com/translate/) which provides acceptable results compared with other translation services ( 52 ). The sentiment of each post was then annotated through crowd-sourcing where the sentiment of each post was determined by multiple people and the majority judgement taken as the ground truth. The crowd-sourcing operation was performed using Figure Eight (https://www.figure-eight.com/), a popular crowd-sourcing platform. Each post wass annotated using one of the terms: positive, neutral, or negative.
The characteristics of the common and event-based datasets used in this study are presented in Table 4. For each category there are two datasets: one with sentiment polarity of Positive and Negative, the other with the polarities Positive, Neutral, and Negative.
Common and Event-Based Datasets for Sentiment Estimation
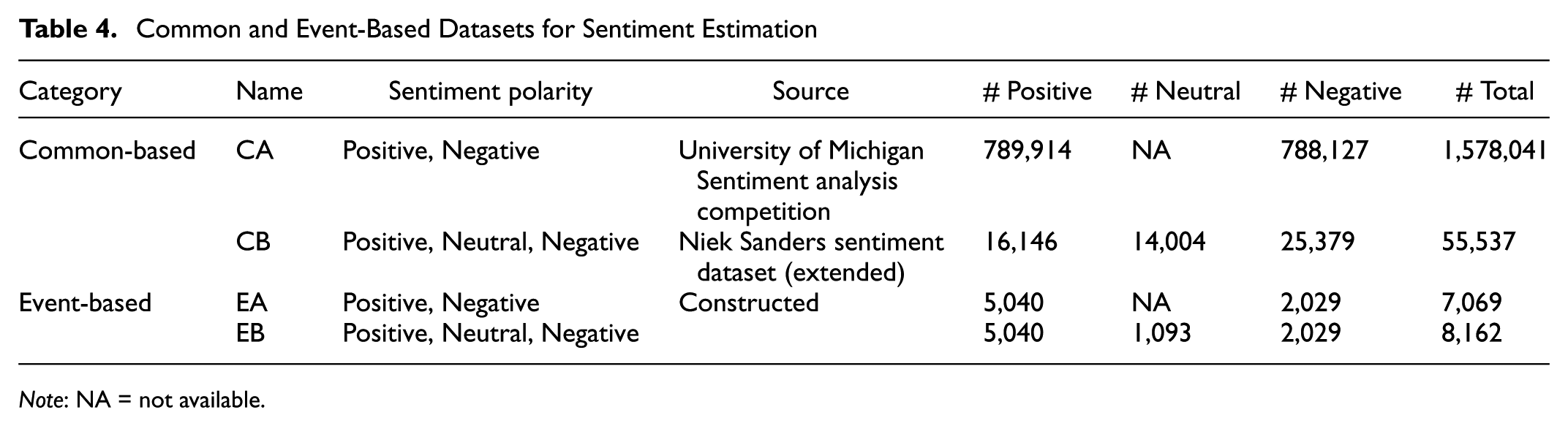
Note: NA = not available.
Experimental Setting
This section describes the set up of the experiment to test the sentiment estimation of crowds in city events using the selected methods using social media. The experiment involves multiple control variables. The following subsections first describe the values of each control variable, then introduce the experimental scenarios which combine the variable values. The final subsection describes the experiment setting applied in this experiment, that is, the training and testing sample size, the number of rounds for N-round testing.
Control Variable
The experiment is designed to test the sentiment estimation performance of selected methods when applied to city events. It therefore consists of methods and testing datasets as variables. ML-based methods also require training datasets. Thus, the training dataset acts as another variable. Moreover, as indicated in the data collection section above, two polarity sets are applied: Positive and Negative (PN), and Positive, Neutral, and Negative (PNN). Hence the sentiment polarity is also a variable for this experiment. In summary, the experiment involves control variables including: sentiment polarity, selected methods, the training data, and the testing data.
With regard to the candidate methods, two lexicon-based methods and five ML-based methods were selected, as shown in Table 2. In relation to data, both common-based and event-based datasets are used for both training and testing. The details of these datasets have already been given in Table 4.
Scenario Design
To explore the estimation performance under different variable values, a set of scenarios was designed which combine values of those variables, as shown in Table 5 for PN polarities and Table 6 for PNN polarities.
Scenario Setting of Sentiment Estimation in Polarities of Positive and Negative
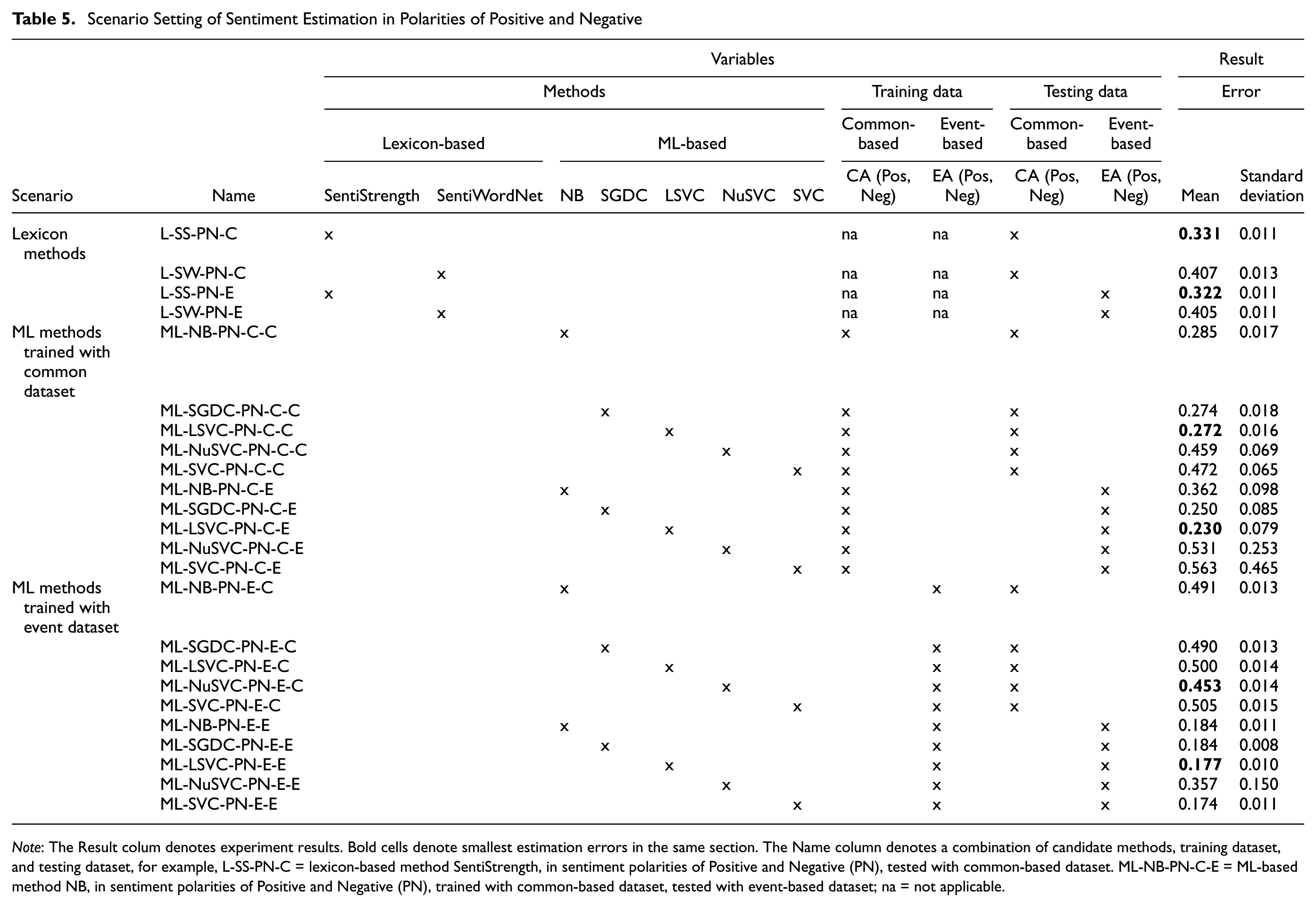
Note: The Result colum denotes experiment results. Bold cells denote smallest estimation errors in the same section. The Name column denotes a combination of candidate methods, training dataset, and testing dataset, for example, L-SS-PN-C = lexicon-based method SentiStrength, in sentiment polarities of Positive and Negative (PN), tested with common-based dataset. ML-NB-PN-C-E = ML-based method NB, in sentiment polarities of Positive and Negative (PN), trained with common-based dataset, tested with event-based dataset; na = not applicable.
Scenario Setting of Sentiment Estimation in Polarities of Positive, Neutral, and Negative
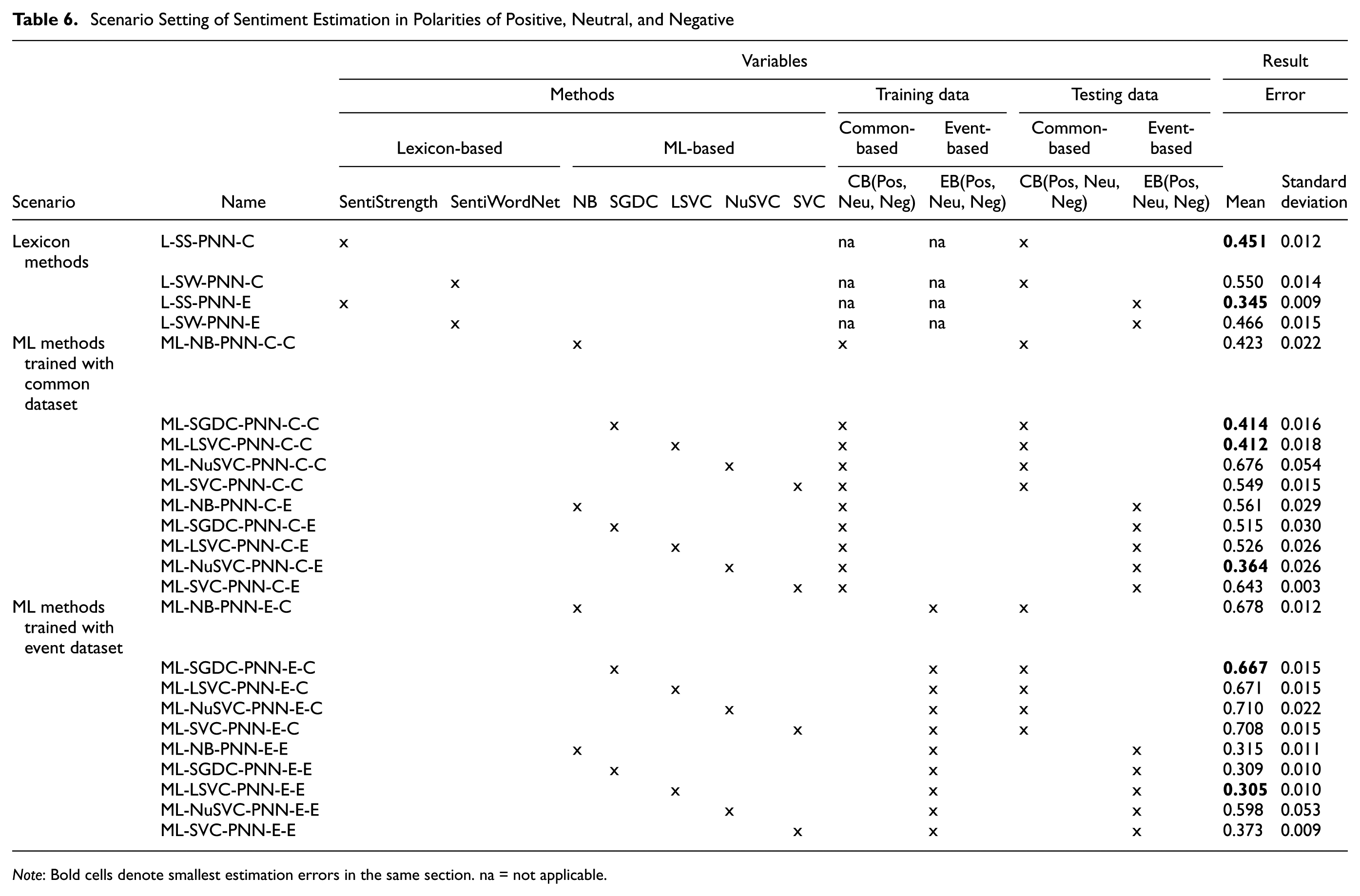
Note: Bold cells denote smallest estimation errors in the same section. na = not applicable.
Both Tables 5 and 6 consist of three sections (see Scenario column), investigating lexicon-based methods, ML-based methods trained using common-based data, and ML-based methods trained with event-based data, respectively. The Result column lists estimation results of each scenario, which will be discussed in the next section.
Experimental Setting
As indicated above, 1,000 samples were selected from the testing dataset for each scenario to perform 100-round testing. For ML-based methods, the training sample size was 6,000 in each round, as indicated in data collection section.
Sentiment Analysis: Findings of the Experiment
This section shows the findings and analysis of the results. They are presented and compared with and without sentiment polarity of Neutral, respectively. Within each, the discussion starts with lexicon-based methods, followed by ML-based methods. Finally, the performance of all the methods is compared.
Table 5 lists sentiment estimation results with sentiment polarity of Positive and Negative (PN). With regard to lexicon-based methods, SentiStrength reaches a similar estimation error when tested with both common-based and event-based data (mean error 0.331 and 0.322, respectively) which is better than SentiWordNet (mean error 0.407 and 0.405). Unexpectedly, ML-based methods, when trained with a common-based dataset, and tested with the event-based dataset achieved a lower minimal estimation error (mean error 0.230) than when tested with the common-based dataset (mean error 0.272). The best ML-based method appears to be LinearSVC. When ML-based methods were trained with the event-based dataset, performance tests with the event-based dataset also reach a lower minimal estimation error (LinearSVC, mean error 0.177) than when tested with a common-based dataset (NuSVC, mean error 0.453).
Likewise, Table 6 shows results for the sentiment polarity Positive, Neutral, and Negative (PNN). According to the results, the lexicon-based method SentiStrength again achieved lower estimation errors than SentiWordNet. In particular, it performed better with event-based testing dataset (mean error 0.345) than with the common testing dataset (mean error 0.451). ML-based methods showed similar patterns with the Neutral polarity (PNN) as with PN. Specifically, when trained with a common-based dataset, tests with the event-based dataset (NuSVC, mean error 0.364) performed better than when tested with a common-based dataset (LinearSVC, mean error 0.412). When trained with the event-based dataset, this pattern also holds, namely, when tested with event-based dataset (LinearSVC, mean error 0.305) the results were better than when tested with common-based dataset (SGDC, mean error 0.667.). LinearSVC reaches the lowest estimation error when both trained and tested with the event-based dataset (mean error 0.305).
When comparing all methods, ML-based methods achieved lower minimal estimation errors (when tested with event-based dataset) than lexicon-based methods. In lexicon-based methods, SentiStrength had a weaker estimation performance than SentiWordNet. For all ML-based methods, linear methods achieved more consistent results. LinearSVC reached the lowest estimation error in most scenarios, except when trained with event-based dataset and tested with common dataset, as well as vice versa, including with Neutral polarity.
When comparing sentiment estimation with and without Neutral sentiment polarity, it was found that all methods achieved lower estimation errors without Neutral polarity (PN) than with Neutral polarity (PNN).
Discussion
This section presents discussion of the results of the sentiment analysis experiment in relation to different sentiment polarities and different training and testing datasets.
With regard to different sentiment polarities, all methods show lower sentiment estimation errors when estimating the sentiments of crowds with PN, rather than using three polarities (PNN). In city events, posts sent by crowds may contain more expressions of sentiment, and stronger expressions of sentiment towards positive and negative polarities, and there may be fewer neutral posts, than in an ordinary context. This is confirmed by the distribution of sentiment in the event-based dataset constructed in this research (see data collection section, above). Therefore, estimating sentiment with PNN from these posts is more difficult, and consequently the estimation errors increase.
Following a similar reasoning, the lowest estimation error was achieved by ML-based methods trained with event-based data and tested with event-based data annotated with PN sentiment polarities (LinearSVC, mean error 0.177), followed by the same method trained with common-based data and tested with event-based data with PN (i.e., LinearSVC, mean error 0.230). These observations may indicate that similarities between training and testing datasets in relation to content and context information may considerably affect the estimation performance. For instance, when training and testing data are both from events, even from different events, the texture characteristics, such as words, phrases, hashtags, emojis, and punctuation marks, may be similar, thus producing lower estimation error than training with common-based data and testing with event-based data, which are less similar.
With regard to the training dataset, with sentiment polarity of PN, the estimation error appears to be significantly distinct when ML-based methods trained with common-based or event-based data. This may also be explained by the (dis)similarity between the training and the testing dataset. The sentiments of posts in a common-based dataset are more equally distributed, while the event-based dataset contains posts with more positive or negative sentiments. Thus, the ML-based methods trained with common-based models are less biased in sentiment estimation than when trained with an event-based dataset.
Lexicon-based methods tested on both common and event-based data showed a similar error, which was worse than for the ML-based methods: lexicon-based methods take no or limited context information (e.g., weighted lexicon-based methods) into consideration, so the estimation error is increased. This is in line with the findings of Ravi and Ravi ( 16 ) who reviewed 161 sentiment analysis works and concluded that ML-based methods result in better accuracy than lexicon-based methods because semantic orientation provides better generality. For instance, a post such as “We are having beer on the boat! #Kingsday” is identified as a neutral post by lexicon-based methods as it is interpreted as describing a fact, but it is identified as a positive post by ML-based methods because of the context of the King’s Day boat parade. This may also indicate the reason why the estimation error for lexicon-based methods tested on common and event-based data is similar; the context differences between common-based and event-based scenario data do not affect their decision.
Conclusion
City events are becoming more and more popular. Information on the sentiments of crowds is valuable when it comes to crowd management. Conventional solutions to derive such information depend on manual observations, which are expensive, prone to observation biases, and not suitable for global observations.
This paper investigates the effectiveness of methods to estimate the sentiments of crowds using social media text in the context of city events. The authors created an event-based sentiment dataset consisting of social media posts from various events and major activities. Each post was annotated with sentiment polarity of Positive, Neutral, or Negative using crowd-sourcing. This dataset has been used for the training and testing of several methods. The main objective of the research was to investigate the performance of the candidate methods using different datasets.
It was found that all candidate methods show lower estimation error with sentiment polarity of Positive and Negative, without Neutral. ML-based methods show better performance than lexicon-based methods in most situations. Specifically, the ML-based LinearSVC method reaches the minimal estimation error when trained and tested with event-based data. The findings indicate that, to predict sentiments in a crowd using social media, it is best to use ML-based method LinearSVC trained with event-based data, which achieved a mean estimation error of 0.177 approximately.
The results may be influenced by the construction bias of the event-based dataset, which are introduced by the various characteristics of selected events, and the unbalanced numbers of positive, neutral, and negative social media posts. Likewise, the bias in the common-based dataset used in this research may affect the result. Moreover, in the construction of the event-based dataset, we used the Google Translate API to translate posts in other languages into English for crowd-sourcing annotation. The accuracy of translation may introduce errors into the sentiment estimation, as posts do not follow the common way of spelling words.
In future work, the authors plan to explore more methods deriving sentiment from social media, for example, hybrid methods that integrate the lexicon-based and ML-based methods. The authors also intend to enlarge the event-based dataset by adding more diverse events and activities, and to examine the sentiment estimation performance of candidate methods across different events, or the same events in different versions. Last but not least, the sentiment estimation performance with different sentiment schemes, for example, a detailed sentiment scheme, will be investigated.
Footnotes
Acknowledgements
The research leading to these results has received funding from the European Research Council under the European Union Horizon 2020 Framework Programme for Research and Innovation. It is established by the Scientific Council of the ERC Grant Agreement no. 669792 (Allegro).
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: all authors; data collection: VXG; analysis and interpretation of results: VXG, WD; draft manuscript preparation: VXG, WD, AB; study supervision: SPH. All authors reviewed the results and approved the final version of the manuscript.
The Standing Committee on Traffic Flow Theory and Characteristics (AHB45) peer-reviewed this paper (19-04989).