
Abstract
Predicting the bicycle flow capacity at signalized intersections of various characteristics is crucial for urban infrastructure design and traffic management. However, it is also a difficult task because of the large heterogeneity in cycling behavior and several limitations of traditional capacity estimation methods. This paper proposes several methodological improvements, illustrates them using high-resolution trajectory data collected at a busy signalized intersection in the Netherlands, and investigates the influence of key variables of capacity estimation. More specifically, it shows that the (virtual) sublane width has a significant effect on the shape of the headway distribution at the stop line. Furthermore, a new method is proposed to calculate the saturation headway (a key variable determining capacity), which excludes the cyclists initially located close to the stop line using a distance-based rule instead of a fixed number (as is usually done in practice). It is also shown that the saturation headway is quite sensitive to the sublane width. Moreover, a new, empirically based method is proposed to identify the number of sublanes that can be accommodated in a given cycle path, which is another key influencing variable. This method yields considerably lower estimates of the number of sublanes than traditional methods, which rely solely on the (available) cycle path width. Finally, the authors show that methodological choices such as the sublane width and the method used to estimate the number of sublanes have a considerable effect on capacity estimates. Therefore, this paper highlights the need to define a sound methodology to estimate bicycle flow capacity at signalized intersections and proposes some steps to move toward that direction.
The ability to predict the bicycle flow capacity of cycle paths at signalized intersections is crucial for urban infrastructure design and traffic management. Capacity (maximum hourly rate at which bicycles can pass the stop line of cycle paths) depends on various key variables, such as the geometric characteristics of cycle paths, the interference with other traffic modes (e.g., car traffic), the traffic control schemes, and the cyclist headway distributions. Estimation of the latter is a difficult task because of the large heterogeneity in cycling behavior. Previous studies on headway distribution models mainly focus on motorized vehicles, and can be split into two categories. The first states that all the headways can be modeled from a single distribution. Examples are the normal distribution ( 1 ), the exponential distribution ( 2 ), the gamma distribution ( 3 ), and the lognormal distribution ( 4 ). The second category consists of composite headway models. In this case, the total headway distribution is made up of two different headway distributions, resulting from whether the vehicle/bicycle is following the vehicle/bicycle in front or moving freely. Examples of composite headway models are a semi-Poisson model ( 5 ), a generalized queueing model ( 6 ), and a distribution-free approach ( 7 ). Applications of headway distribution models on cyclist data are rare. A distribution-free (or rather, non-parametric) model estimation approach following the theory of composite headways has been performed on a cyclist intersection in the Netherlands ( 8 ).
Another key variable of capacity estimation is the saturation flow, which is often calculated as the inverse of the average headway observed between cyclists and their leaders once the queue is moving in a stable manner, multiplied by the number of cyclist sublanes that the cycle path can accommodate. There are multiple examples of empirically derived saturation flows, and various values of saturation flows have been reported. A study in the Netherlands reported 3,000–3,500 cyclists per hour for a 0.78 m-wide cyclist lane ( 9 ). An empirical analysis in California and Colorado suggested a maximum flow rate of 4,500 cyclists per hour on a 2.43 m-wide cycle path, and it concluded that cyclist saturation headway started at the sixth cyclist in a queue ( 10 ). A case study in Beijing, China found 1,836–2,088 cyclists per hour for a 1.25 m-wide path ( 11 ). A 2 m-wide cycle-track in Santiago de Chile was reported to have a saturation flow of 4,657 cyclists per hour, whereas for Tavistock Square in London the saturation flow was equal to 4,320 cyclists per hour for a path with the width of 1 m ( 12 ). Another point of interest related to saturation flow calculation is the cycle path width. Usually, cyclists can form multiple queues as the “sublane” of a bicycle path is not fixed; this is different from the lane usage of motorized vehicles. In the literature, many different sublane widths have been suggested, for example, 0.78 m in the Netherlands ( 9 ), 1.00 m in Germany ( 13 ) and even 1.60 m in Norway ( 14 ). However, there is a lack of a unified paradigm to compute saturation flow rate and thus the bicycle flow capacity. Besides, there are several limitations in traditional calculation methods. For instance, the calculation of the number of sublanes in Botma and Papendrecht was solely based on the available cycle path width, and ignored leader–follower relations in queue discharge processes ( 9 ); the calculation of saturation headway in Raksuntorn and Khan suffered from the problem of headways close to zero, because leader–follower pairs were not clearly identified ( 10 ).
Generally, the capacity of a cycle path at a signalized intersection (

where:

and:

In Equations 1–3:
The rest of this paper is structured as follows. the next section first describes the data set used in this study, and then illustrates the calculations of several key variables of capacity estimation. The results of the analyses are then presented. The final section contains the conclusions of this study and some suggestions for future research.
Data and Methods
This section describes the empirical trajectory data set analyzed in this study, and then it describes the method used to measure cyclist headways at the stop line as well as the methods proposed to estimate the saturation headway, the saturation flow, the start-up lost time and thus the capacity of cycle paths at signalized intersections. For clarification and easy reference purposes, all the variables introduced in this work and their definitions are listed in Table 1.
Variables and Their Definitions (in Alphabetical Order of the Notation Names)

Data Set Characteristics
The data set analyzed in this study consists of the trajectories of 691 cyclists moving along a cycle path that leads to a signalized intersection in Amsterdam (the Netherlands). The cycle path is 2 m wide, unidirectional, and segregated from car traffic. Traffic demand for this cycle path is relatively high in peak hours, and consists of people riding both bicycles and scooters. In this data set the percentage of scooters is very low; hereafter we refer to these as cyclists in both cases with an assumption that there is no effect on the analysis results. Access to the intersection is regulated by a traffic light.
The trajectories were derived from top-view video images using the methodology described in Goñi-Ros et al. ( 15 ). The video images were obtained using two cameras mounted on a 10 m pole, which was placed next to the cycle path (more details about this type of installation can be found in Duives [ 16 ]). The two camera views can be seen in Figure 1 in ( 15 ). The two camera views combined covered 20 m of cycle path upstream of the traffic light. The frame rate varied between 5 and 10 fps during the video recordings.

Illustration of the methods used to calculate different variables. (a) Illustration of the method used to calculate the time headways (w = 1.0 m). The numbers assigned to (ti, yi) points correspond to the cyclist indices i. Green phase starts from time tG; (b) Example of piecewise-linear function fit to determine the distance threshold ds (w = 1.0 m); (c) Illustration of the method used to calculate the saturation headway (hs) and the headway increment tc, once the distance threshold ds has been identified (w = 1.0 m); (d) Linear relation between
Traffic along this cycle path stretch was recorded between 12:45 and 19:00 h on June 6, 2016. By looking at the video footage, the queue discharge periods that met the following criteria were selected (see also Goñi-Ros et al. [ 15 ]): (a) the queue is formed by at least seven cyclists; (b) no more than two cyclists within the queue are riding scooters; (c) all cyclists move toward the stop line and pass it without getting out of the path; (d) no pedestrian crosses the cycle path during the queue discharge process; (e) the discharge process is not affected by downstream traffic conditions; and (f) all cyclists pass the stop line before the end of the green phase.
The total number of selected queue discharge periods was 57, with an average queue size of 12.12 cyclists, 2% of which were scooters (see also Goñi-Ros et al. [ 15 ]). For every selected period, the trajectories of all cyclists forming part of the queue were derived using a procedure that comprises six steps: (1) video clip decomposition; (2) manual cyclist tracking; (3) height transformation; (4) orthorectification and scaling; (5) time coding; and (6) trajectory merging. Please refer to Goñi-Ros et al. ( 15 ) for a full description of this procedure.
Definition of Headway of a Cyclist
In road traffic, the (gross) time headway—or simply headway—of a vehicle
To overcome this issue, headways can be defined based on the concept of virtual sublane, as proposed, for example, by Hoogendoorn and Daamen (
8
) and Botma and Papendrecht (
9
). For a given queue discharge period, let us assign an index
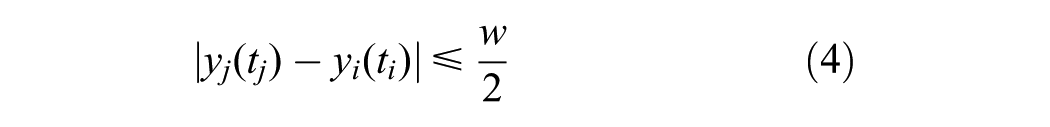
where
Parameter
Here, the leader of cyclist

Note that using the method described above, it is not possible to assign a leader to some cyclists, particularly those who are initially located close to the stop line (because no cyclist passes the stop line before them within their virtual lane). For these cyclists, it is assumed that
Headway Distribution Modeling
Using the method described in above, the headways of cyclists at the intersection stop line (i.e.,
A histogram of the headways of all cyclists who have a leader (all following headways) was built. Three different functions were fitted to the headway data to determine the shape of the distribution: (a) normal distribution function,
Note that a critical influencing factor of the headway calculation method (see “Definition of Headway of a Cyclist”) is the virtual sublane width (
Calculation of Saturation Headway
Similarly to road traffic ( 19 ), the saturation headway for cyclists can be defined as the average headway between cyclists and their leaders once the queue is moving in a stable manner. Like in road traffic, the first group of cyclists in a queue generally have longer headways than cyclists located more upstream ( 10 ). The main reason is that they generally lose time reacting to the traffic light ( 15 ) and they pass the stop line when still accelerating to their desired speed, whereas the other cyclists pass the stop line at more or less constant speed. For this reason, in practice, the headways of the first group of cyclists are excluded when calculating the saturation headway ( 10 ).
As mentioned above, when calculating the saturation headway, the basic assumption is that once the queue moves in a stable manner, the average headway stays constant, whereas the average headway of the first group of cyclists is longer. Therefore, the main challenge is to determine which headways need to be excluded from the calculation. For example, Raksuntorn and Khan analyzed the discharge process on a 2.43 m-wide cycle path and estimated that the headways of the first five cyclists in the queue need to be excluded (
10
); note, however, that they did not calculate the headways based on the concept of virtual sublane (see “Definition of Headway of a Cyclist”), so their headways are not necessarily the difference in passing times between follower–leader pairs. Here, the authors propose to exclude not a fixed number of cyclists (like in Raksuntorn and Khan [
10
]), but those cyclists who are initially closer than a certain distance to the stop line (
To determine the distance threshold

which has three parameters:
Once the distance threshold

Note that the distance threshold
Calculation of Start-Up Lost Time
As discussed in “Calculation of Saturation Headway”, the first group of cyclists in the queue (more specifically, those located closer to the stop line than
The average headway of the first group of cyclists in the queue (both with and without a leader) can be decomposed into two elements: the saturation headway (

Similar to the work in Raksuntorn and Khan (
10
), the start-up lost time (
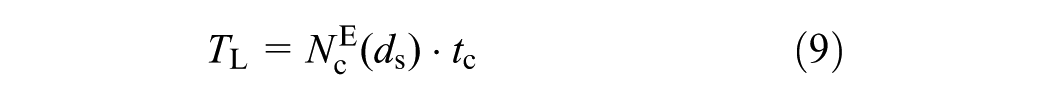
Variable

where:
As shown in Figure 1d, variable
Calculation of the Number of Sublanes
The number of virtual sublanes (

where

From this definition of available cycle path width, it follows that in some sites
This theoretical definition of
The number of virtual sublanes of a given discharge period can then be defined as follows:

and the number of virtual sublanes (
The saturation flow (
Results
This section presents the results of the previously described analyses, which have been performed using the empirical trajectory data set described in the same section.
Headway Distribution Functions and Influence of Virtual Sublane Width
The histograms shown in Figure 2, a–d provide an overview of the empirical headway distributions at the stop line with different virtual sublane widths (

Headway distributions and negative log likelihood with three distribution functions with respect to different sublane widths. Note only the headways of cyclists who have a leader (following headways) have been included in this analysis. (a) Headway distribution with w = 0.80 m; (b) headway distribution with w = 1.00 m; (c) headway distribution with w = 1.20 m; (d) headway distribution with w = 1.40 m; (e) negative log likelihood of three distribution functions with different sublane widths.
Values of Different Variables with Respect to the Sublane Width

Distance Threshold, Saturation Headway and Start-Up Lost Time
The distance threshold

Relations of distance threshold, saturation headway, start-up lost time, number of sublanes, saturation flow and capacity with respect to the sublane width chosen to calculate the headways at the stop line. (a) relation between sublane width and distance threshold; (b) relation between sublane width and saturation headway; (c) relation between sublane width and start-up lost time; (d) relation between sublane width and number of sublanes; (e) relation between sublane width and saturation flow; (f) relation between sublane width and capacity (TG = 20 s, and TYG = 4 s).
The saturation headway decreases with the increasing sublane width (see Figure 3b and Table 2), as expected. More specifically, the saturation headway decreases from 1.72 to 1.10 s if
The start-up lost time, instead, seems to increase for
Saturation Flow and Capacity Estimation
Clearly, the proposed empirical method to calculate the average number of virtual sublanes
The fact that the observed number of sublanes is much lower than the theoretically assumed number of sublanes has enormous implications for the calculation of the saturation flow (and thus the capacity). As shown in Figure 3e and Table 2, the saturation flow calculated using the mean empirical estimates of
Conclusions
The ability to predict the bicycle flow capacity at signalized intersections of various characteristics is crucial for urban infrastructure design and traffic management. However, it is also a difficult task because of the large heterogeneity in cycling behavior as well as several limitations of traditional capacity estimation methods (e.g., the ignorance of leader–follower relations). This study presented an improved methodology to estimate the saturation flow and the capacity of cycle paths at signalized intersections. More specifically, this methodology includes a method to measure headways between leader–follower pairs using the concept of virtual sublane, an improved method to calculate the saturation headway and the start-up lost time (using a distance-based rule), as well as a new empirically based method to estimate the number of virtual sublanes that the cycle path can accommodate. Estimates of these variables were derived from cyclist trajectory data of a busy intersection in Amsterdam (the Netherlands). One of the main findings is that saturation headway, start-up lost time, and number of virtual sublanes are highly stochastic variables. This needs to be taken into account when interpreting the saturation flow and capacity estimates calculated using the means of these variables. For a reasonable range of
Further research is necessary to identify the lateral influencing area of cyclists and to define the virtual sublane width based on empirical evidence. Moreover, it is necessary to analyze more sites with various cycle path widths (
Footnotes
Acknowledgements
This research was supported by the ALLEGRO project (Unravelling slow mode traveling and traffic: with innovative data to create a new transportation and traffic theory for pedestrians and bicycles), which is funded by the European Research Council (Grant Agreement No. 669792), and the Amsterdam Institute for Advanced Metropolitan Solutions.
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: BG-R, YY, MP; data collection: BG-R, WD; analysis and interpretation of results: YY, BG-R; manuscript preparation: YY, BG-R, MP; comments to draft manuscript: WD, SPH. All authors reviewed the results and approved the final version of the manuscript.
The Standing Committee on Bicycle Transportation (ANF20) peer-reviewed this paper (19-04329).