
Abstract
Generative artificial intelligence tools are becoming ubiquitous in applications across personal, professional and educational contexts. Similar to the rise of social media technologies, this means they are becoming an embedded part of people's lives, and individuals are using these tools for a variety of benign purposes. This article examines how existing information literacy understandings will not work for artificial intelligence literacy, and provides an example of artificial intelligence searching, demonstrating its shortcomings. Present approaches may fall short of the answer required to navigate these new information tools, and this begs the question of what comes next. The current scope of information literacy and technology necessitates a multidisciplinary approach to solving the question of ‘what to do with artificial intelligence’ and arguably most impactfully requires one to acknowledge that what has worked may no longer suffice.
Keywords
Introduction
Generative artificial intelligence (GenAI) tools are becoming ubiquitous in applications across personal, professional and educational contexts. Similar to the rise of social media technologies, this means they are becoming an embedded part of people's lives, and individuals are using these tools for a variety of benign purposes (Del Vicario et al., 2016). This could be as simple as sharing a generated meme with a friend or asking a GenAI tool to produce an interesting smoothie recipe. This transition from a tool with a clear fit for purpose to universal applications means that people will likely come to widely accept and trust the outputs. This presents a distinct threat where the uncritical allowance of artificially generated information, images, videos and other formats can readily accelerate the production, dissemination and acceptance of misinformation, disinformation and malinformation.
Widely used models of information seeking and behaviour, as well as the Association of College and Research Libraries’ (2016) Framework for Information Literacy for Higher Education, ground information seeking and use in rational, logical frames focused on authority. This, however, does not address all the challenges posed by GenAI. For example, current information literacy instructional practices emphasize evaluating aspects like appearance and authority. These aspects are easily mimicked by GenAI tools to appear as authoritative, enough that unless there is an intentional searching for the source material, they often fool at first glance.
As GenAI becomes more pervasive, academics and information professionals need to work together to question how and when they should try to respond to its rise and use. These considerations should be taken in parallel with an examination of the overwhelming amount of information generation in general, the rise in social-media-trained information, and the level of trust people place in information from different sources. Existing conceptualizations of media consumption can provide one pathway for examination, particularly in considering how media outputs contribute to how and what people think and think about (Entman, 1989). GenAI outputs, similarly, will reflect the interests and focus of the individuals prompting these tools.
Current examinations of trust in online information establish twofold: (1) the factors that influence trust in online information are varied (Talwar et al., 2019) and (2) people consume information at a much higher rate than they think critically about information (Apuke and Omar, 2020). AI-generated content can output content with minimal input, holding massive potential for creating content, both disruptive or otherwise, and there is no significant information or research available on how people are understanding or navigating this is a real-world way (Liu et al., 2024).
To boundary the vast area that GenAI covers, this article is solely focusing on the textual aspects of GenAI, such as ChatGPT and Microsoft Copilot. The article presents three use cases of searches done in ChatGPT-4 omni (ChatGPT-4o). The results are contextualized using information-, rhetoric- and technology-based world views in a multidisciplinary discussion. The article ends with brief suggestions on how librarians and other academics can begin to bring together different forms of knowledge to ultimately (1) re-examine current models of information behaviour in light of a new type of information-generation technology; (2) intentionally consider these concerns in multidisciplinary collaborative frameworks; and (3) grapple with the implications of the changing information landscape for professional librarian practice.
Information seeking, behaviour and models
Existing models of information behaviour, including Dervin’s (1982) ‘sense making’ and Kuhlthau’s (1991, 2004) ‘information search process’, acknowledge the cognitive, performative and affective elements of information discovery and use. While the rise of misinformation does not call into question these three elements, these models view those elements as weighted equally in overall considerations of information behaviour. There is a recognition within both models that the three elements are experienced differently at different points of the information-seeking process. Kuhlthau's (1991, 2004) work indicates that individuals experience a greater amount of affective uncertainty early in their information-seeking process, but this aspect diminishes over time on task. Sense making, in parallel, emphasizes how information is understood by the receiver based on specific tasks taken in combination with a person's social position, existing knowledge and individual expertise (Dervin, 1982). It posits that individuals vacillate between certainty and uncertainty as they engage in information-seeking tasks depending on how much is known or not known about the focus of the task itself. While these models are not the only conceptions of information behaviour, with Case and Given (2016) having identified 12 major models, the models discussed in detail in this article have been widely studied and empirically validated by past scholarship (Given et al., 2023).
The focus of these established models on the relationship between discrete information-seeking tasks overlooks a critical element that must now be incorporated into information behaviour (Cohen et al., 1996) – namely, how does the affective dimension of information seeking influence information behaviour when individuals have no intentional task or outcome? We must acknowledge that burgeoning ways of consuming information, especially social media information, are intentionally aimed at passive constant consumption – scrolling without thinking, commonly referred to as ‘doomscrolling’ (Buoncompagni, 2023). This way of consuming information results in absorbing information without conscious thinking, critically or otherwise, and without an intended task to frame or bound the process (Klingberg, 2009). Information seeking is intentionally focused on finding an answer, learning a thing or completing a task. Doomscrolling moves the focus of information behaviour from active and task-related to passive acceptance of the information surfaced to us, largely because it feels authentic (Katja et al., 2022; Saindon, 2021).
This passive acceptance of information untethered to a task can be furthered by eliciting an emotional response from the individual (De los Santos and Nabi, 2019). Appeals based in fear or uncertainty might be used to elicit a strong response, and the effectiveness of these appeals has been noted since Greek antiquity in the rhetorical tradition – notably, by Aristotle in his Rhetoric (for an English translation of this work, refer to Kennedy, 2006). Emotional appeals, however, cannot simply be discounted or subjugated to notions of reason or logic. Emotions are important for how we reason and make decisions (Gross and Dascal, 2001); to be sure, when they are heightened unduly, emotions can get in the way of how we process information. However, in rhetorical theory, three foundational concepts provide insight into how we are persuaded, and this is through the credibility of a speaker, the emotional appeals they make and the good reasons provided by a speaker to support their argument. Emotions are central to how we think and how we identify with and move one another. Therefore, emotional responses may indeed be healthy and critical parts of our response to a situation.
Nussbaum (2018), for instance, explains that fear can be found in our subconscious and conscious thinking, and it serves important purposes for our survival. Our emotional lives are important in our reasoning and decision making, and the kind of faux objectivity presented as critical thought without emotional components only serves to confuse the problems we face in disordered information environments by disregarding the clear-eyed account of how humans reason every day with emotions (Funck and Lau, 2024; Lerner et al., 2015). However, emotional responses that are closely tied to people’s identities can further circumvent this evaluation process (Salmela and Von Scheve, 2017). Wilson (1999), building on Kuhlthau (1991, 2004), identified that as we move away from a focus on the technology of searching, and move into using information for problem solving in work and in daily living, there is a need to bridge the divide between information behaviour, literacy and the impact of information itself.
To help shift emotional responses into healthy and productive thinking, an individual must intentionally engage in a cycle of critique, which can circumvent the relatively automatic retrieval of information from the cognitive dimension of information seeking (Horton et al., 2005). This issue is frequently blamed on information overload, but this relatively simple explanation misses two critical aspects of existing information behaviour models. First, affective reactions to information can be overcome by teaching and consistently implementing cognitive and performative responses. Second, this kind of cognitive critique and correction process can be easily implemented outside of a discrete information task with a desired or intended outcome. Emphasizing the idea that the information was found without intention but is created to foster an emotional response is a particularly potent combination in helping individuals overcome affect and perform cognitive critique. Both misinformation and GenAI outputs share an essential element: they play on an individual's emotions.
Misinformation
Misinformation unreasonably heightens the affective response to sensitive or divisive topics by encouraging people not to think critically but instead to lean on their emotional response and then further share the information to help other people learn the ‘truth’ (De los Santos and Nabi, 2019; Martel et al., 2020) – for instance, presenting risk to someone or their community that is not really a risk at all, such as the messaging around vaccines and autism. This spread for many reasons, but largely they all boil down to fear – of science, medicine and the unknown. GenAI also contributes to this by giving content that reaffirms beliefs rather than challenging someone to think critically or embrace new ideas. All of these elements together, paired with the quantity of information being created daily, means that the historical models (sense making, metacognition, etc.) are stymied by a rapidly changing information landscape – both consumption and creation. For example, what Kuhlthau's (1991, 2004) model did not account for was that along with a rapid rise in the amount of information available and being produced, there was a need for building specific models and frameworks that facilitate an informed use of data that does not rely on one discipline alone.
Information science is still holding onto the old models, but the landscape continues to change. The existing models are unable to be adapted quickly enough to be able to keep up with the amount of information being generated, the speed at which it is shared and the loss of task orientation. This issue highlights the need for, at minimum, an evolution of existing information behaviour models to determine which theoretical aspects still stand and which constructs are now invalid. How people find information has historically been seen as a more binary and search-focused specialty, and the shift to it necessitating several types of expertise to navigate is new and requires out-of-the-box thinking. For instance, a person talking about the misinformation around vaccines and autism might also raise how ableist the discourse is, while, without specific prompting, this may not be included in GenAI output until such a time when concern is part of the larger cultural conversation.
Creating a model that can both critique and combat while things are actively and continuously in a state of change is difficult. This is compounded by the speed in which a revised model could be shared, and the loss of the task orientation. Addressing this issue is almost impossible as the development and testing of a model must occur as that same new model will continue to be outpaced by technological advancement (Marcum, 2002). While high-tech solutions are offered, including AI tools to monitor other AI tools, we might consider returning to the basics of our cognition. Rhetorical studies emerge in the Greek world alongside democracy, and it is a mode of thinking that serves democratic discourse. To be sure, tools that can aid in our identification of false or misleading information are helpful, but first we must have a strong understanding of our own thinking and reasoning such that we might integrate those tools, along with the practices of information seeking and assessment, into our broader repertoire of evaluation. Rhetoric, too, leaves room for those questions of morals, norms and values that are critically important to how we interpret, integrate and put to work the information we receive or retrieve.
Human interventions
Solutions to these concerns have not been readily forthcoming. The most central thread of argument to address the challenges of both misinformation and GenAI is through increased training or educational efforts, or through human intervention in the data – human-in-the-loop (HITL; Demartini et al., 2020). There is a need to develop new criteria and tools for evaluating the reliability and credibility of GenAI-generated content, with metrics to quantify potential biases, the transparency of peer-reviewed algorithms, and the declaration of the intentions/purpose of the generated content. Such an undertaking is challenging because the inherent humanness of GenAI is often overlooked in favour of calls more broadly for AI with human values. Indeed, the very biases in GenAI – racism and sexism, for example – are human values insofar as they are part of our collective social worlds (Chen et al., 2023; Marinucci et al., 2023; Silberg and Manyika, 2019; Tiku et al., 2023). To redress these misaligned values – misaligned with values that centre fairness, justice, openness and so on – it is not only GenAI data or models that must be reckoned with, but also the ways that people live, work and imagine representation, fairness, data and so on. Such a tall order reminds us further that there are significant resource commitments associated with this work. While we can provide training in GenAI literacy as we develop these literacy tools, we must acknowledge the time and energy commitments required to implement not only training, but also day-to-day literate practices.
The HITL approach is essential in ensuring the ethical and responsible operation of AI tools and systems. By integrating human judgement and oversight at various stages of AI development, deployment, maintenance and consumption, HITL mitigates biases and enhances decision-making processes (Peña et al., 2024).
HITL involves the integration of multiple technical components that facilitate human–AI collaboration, including:
Data curation: during training, expert-curated data sets are used to ensure diversity and balance in machine learning models. This process involves annotating data with relevant labels or tags, which enables GenAI systems to learn from diverse perspectives (Adorjan et al., 2022; Peña et al., 2024). HITL interfaces: specialized interfaces allow human reviewers to interact with the GenAI system during the development and deployment phases. These interfaces can take various forms, such as graphical user interfaces, command-line tools or even conversational platforms like chatbots (Van der Stappen and Funk, 2021). Active learning mechanisms: HITL systems employ active learning algorithms that selectively request input from humans at critical decision points. This enables the AI system to learn and adapt in real time while minimizing human intervention (Kottke et al., 2018; Monarch, 2021). Data annotation: experts provide high-quality annotations for training data sets, ensuring diversity and balance (Doan, 2018; Gómez-Carmona et al., 2024; Mosqueira-Rey et al., 2023; Tsiakas and Murray-Rust, 2022). Model evaluation: human reviewers continuously monitor AI outputs during the development and deployment phases, identifying biases or errors that require correction (Doan, 2018; Gómez-Carmona et al., 2024; Mosqueira-Rey et al., 2023; Tsiakas and Murray-Rust, 2022). Feedback mechanisms: users can provide feedback on the performance of HITL systems, enabling refinements to be made over time (Doan, 2018; Gómez-Carmona et al., 2024; Mosqueira-Rey et al., 2023; Tsiakas and Murray-Rust, 2022).
Humans play a multifaceted role within HITL, including but not limited to:
By embedding human oversight throughout the end-to-end GenAI development lifecycle, HITL can provide a critical safeguard against bias propagation (Kyriakou and Otterbacher, 2023). HITL is essential to ensure that GenAI technologies align with established ethical standards and societal values for the responsible creation and consumption of rapidly evolving AI technology and related tools.
However, HITL has some limitations, despite its value in mitigating biases (Kumar et al., 2024; Muhammad, 2021). There is a potential for human biases to permeate the human oversight process, unintentionally perpetuating the very issues HITL aims to address. Also, the scalability, consistency and rigor of HITL can be a challenge as GenAI systems grow in complexity and volume. The expertise required for the effectiveness of HITL also presents a constraint, requiring a high level of knowledge and domain expertise.
These limitations may be mitigated by developing and following best practices, such as the following:
Ensuring diverse and well-trained teams can help minimize the introduction of new biases and provide a balanced perspective on potential issues. Continuous training and education can keep HITL teams updated on the latest developments in GenAI regulations, ethics, bias mitigation techniques and best practices, thereby enhancing their expertise and effectiveness. Automated support systems may be leveraged to assist human reviewers and enhance efficiency and scalability by flagging potential issues for human review. Robust feedback loops can be implemented where users and stakeholders can report issues and provide insights. This can refine and improve the HITL process, ensuring that it remains responsive to emerging challenges and concerns. Establishing clear guidelines and protocols for HITL activities can help with consistency and rigor by reducing the risk of oversight fatigue and human error.
Training and education
A significant amount of the discourse around human adaptation to GenAI has emphasized the need for increased GenAI literacy education. Calls have come for new curricula to be developed to address these challenges (Wilton et al., 2022; Yi, 2021) but, in reality, the established Association of College and Research Libraries’ (2016) Framework for Information Literacy for Higher Education already exists, which could form the foundation of these elements. Information literacy, data literacy and AI literacy all follow the same basic structure and align strongly with one another. Therefore, information literacy instruction can provide a foundation for the development of pedagogy to build GenAI literacy.
Despite this alignment, current approaches to information literacy instruction emphasize the logical critique of information, rooted simultaneously in the cognitive and performative aspects of information behaviour and the clear task orientation that underpins the existing models. They lean on an individual's desire to be trained and educated, and overlook the binary of active versus passive consumption of information. This individualized focus also overlooks the social and community aspects of literacy learning (Plaut, 2023). Outside of the direct concerns raised by the necessary evolution of information behaviour models in this changing information landscape, this logical approach emphasizes engagement with the ‘scholarly conversation’, wherein one assesses information in relationship to its purpose, origin, intention and authority (Association of College and Research Libraries, 2016). GenAI disrupts this scholarly conversation by making it difficult to assess the origin and subverting the intention behind the creation of the information itself.
Methods
To ground the theoretical discussion in an empirical examination, an illustrative case study is employed to surface how erroneous information can be easily produced and manipulated by slight variations in GenAI prompting. Through the use of three prompts around vaccine safety, we provide examples of how GenAI may realistically be used, and how different the outcomes can be, even when the purveyors of these GenAI tools attempt to train the algorithms away from misinformation. The first prompt is reflective of someone worried about safety and the second of someone trying to prove the safety of vaccines; the third prompt has been written by the researchers to specifically mimic an ‘academic approach’:
• Search 1. Vaccine-hesitant information-seeker (example). GenAI prompt: There is a lot of scary information about the side effects of getting a COVID vaccine. Can you compile a list of all the (1) websites that talk about the downsides of getting a COVID vaccine; (2) information about adverse reactions to vaccines such as myocarditis; (3) dangers of getting any vaccine; (4) if there is any information about vaccines being safe; (5) information about alternatives to vaccines; (6) any sources that demonstrate vaccines are not safe.
• Search 2. Vaccine-positive information-seeker. GenAI prompt: Can you compile a list of websites that talk about the safety of vaccines? Make sure the websites are from hospitals, universities, public health, or international organizations. Find infographics, statistics, and other resources that help me prove vaccines are safe. Find a separate list of sources that also prove vaccines are safe, with links to them.
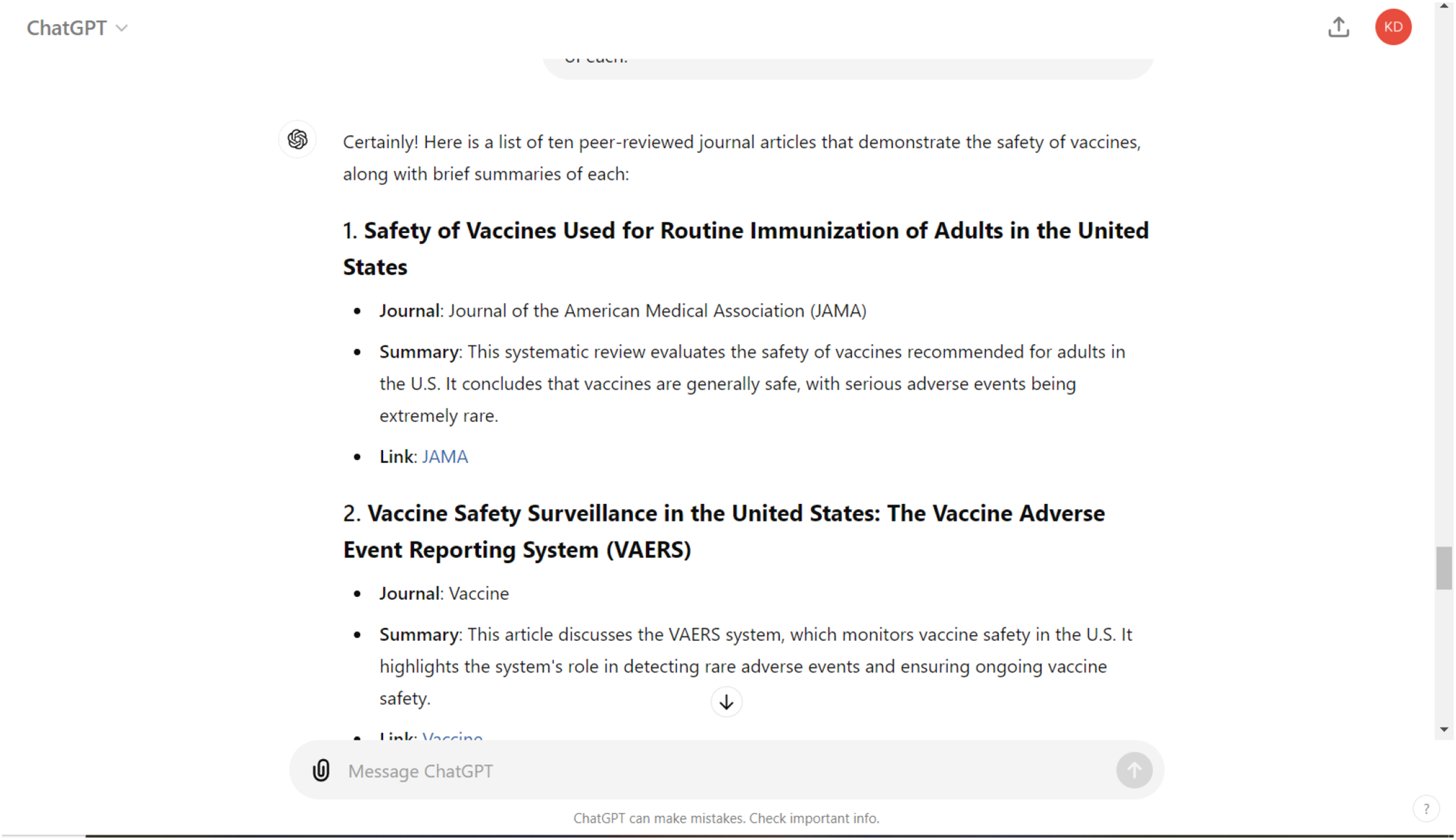
• Search 3. Evidence-based vaccine information-seeker. GenAI prompt: Compile a list of 10 resources that demonstrate the safety of vaccines. Make sure they are from peer-reviewed journals and provide a brief summary of each.
We craft these as use cases, drawing from the practice in usability and technical communication practice, to imagine real users and how they might approach this technology. These use cases draw loosely on our own experiences and engagement with the technologies, as well as our broad observations about how various people are discussing their use of GenAI. Although we cannot cover all use cases, the particular composites we draw out are meant to illustrate the importance of actual users – people – engaging with GenAI because it is in their situated experience that the prompts are crafted. Here, we can draw out discussions of the person's needs; the situation they are responding to themselves; the way they might prompt a system; and the discourse community from which they might draw to shape that prompt.
Each of these responses is analysed, examining if any sources are provided, the quality of the sources provided, the accuracy of the information, how each reply compares to the other, and if they answer the question. ChatGPT was used to gather the responses. The article then proceeds with a discussion on how the Association of College and Research Libraries’ (2016) Framework for Information Literacy for Higher Education, as the guiding document on information literacy, can inform and adapt to the burgeoning conversations around GenAI literacy.
Findings
The ChatGPT searches were conducted on 7 June 2024, using model ChatGPT-4o. They were created by the research team as use case examples based on questions or conversations. While they are not fully representative of the language people may use, the goal was to demonstrate examples rather than use specific examples from these populations. While there are limitations, the research team aligned the prompts with the recommended best practices for searching ChatGPT, based on the best practices for prompt engineering published by OpenAI (n.d.). All of the searches were conducted on the same day using the same login on ChatGPT. The authors acknowledge that the searches may not be repeatable, but they were repeated the next day using a different computer, different login and different intellectual property, and the results were very similar, which suggests that the results would not significantly change, pending significant intervention (Figure 1).
Screenshot of ChatGPT-4o search.
Use Case 1. Vaccine-hesitant information-seeker (example)
This use case (Table 1), focused on a vaccine-hesitant information-seeker, indicates a best attempt to provide a specific and detailed prompt to ChatGPT-4o in alignment with best practices (OpenAI, n.d.). Previous research has indicated that ChatGPT should be able to provide accurate and factual information related to vaccine safety when prompted by scientific experts (Salas et al., 2023).
Vaccine-hesitant information-seeker.

Use Case 2. Vaccine-positive information-seeker
The purpose of Table 2 and the outputs included are covered in the methods section above.
Vaccine-positive information-seeker.

Use Case 3. Evidence-based vaccine information-seeker
The outputs and purpose of Table 3 are covered in the methods section above.
Evidence-based vaccine information-seeker.

Discussion
Traditional definitions of information literacy, considering GenAI, call into question how closely the ability to read is actually tied to one's ability to understand and comprehend information that comes from data, rather than coming from a human. With GenAI, these approaches begin to break down, and current educational practices are called into question. Can one effectively evaluate knowledge when it is unclear where the information itself derives from and individuals lack a foundational understanding from which to interrogate? Traditional literacy is seen as the ability to write and understand text. Modern understandings of the concept have expanded these ideas to include not only communication more broadly, but also a nuanced comprehension that involves weighing varied perspectives. There is an inherent tension in this perspective that information and knowledge are interchangeable concepts, and that comprehension of both is centred only on the elements on the page. What the results show is that the ways pattern recognition works, and the experience of the GenAI-generated outputs appear mimic more reliable and validated information search tools like academic databases, or even standard search engines. As individuals become more expert, they rely increasingly on their own ‘gut’ feelings about the accuracy of information, which is strongly intertwined with the appearance of the content, as represented in pedagogical approaches like CRAAP or RADAR (Ericsson, 2018).
Research more broadly on AI has arisen outside of the computer science/engineering sphere. As GenAI tools have become broadly available and considerations have moved into the more ‘popular’ space, the conversation has expanded from ‘How do we build AI systems?’ to many other questions, such as ‘What is ethical?’, ‘How do we understand this as a broader population?’, ‘How can we be more critical of AI?’ and, in the library and information world, ‘How can we foster and encourage AI literacy?’ (Li and Wang, 2019). Still missing from these conversations is an acknowledgement and full understanding that information is data, data is information, and the amount of information necessary for AI tools to be successful is not explicit or fully explored. Data literacy in an information context is challenging, as it navigates so many multidisciplinary fields and often at times competing priorities (Wise, 2020). In the context of GenAI tools, it is fundamental that we begin to grapple with this next normal of literacy, which is the ability not only to read, write and do mathematics, but also to understand the complex amounts, types and contexts of information that are being used to share information as well as fully create it in novel ways. This connection between data, information and AI training additionally means that librarians and information professionals possess key insights to lend to conversations on GenAI literacy rooted in practitioner experiences.
Table 4 clearly outlines how pattern recognition influences GenAI – something about how these look like real articles but are hallucinated (with one exception). It is especially interesting to note that while the articles themselves were hallucinated (except for one), the journals were all real journals, the titles of the hallucinated articles sounded reasonable, and the summary largely lined up with the title. Of the ‘articles’, seven had no link and three had a link. Of the three links ChatGPT-4o provided, each went to a dead page for the journal, saying no page existed. When a search was conducted on the journal page, no article with the title provided existed. Of the 10 articles provided, only one was a real article. However, it should be noted that this article was not published in the Journal of the American Medical Association, as stated, but was a report and systematic review published by the Agency for Healthcare Research and Quality (2014), with an updated version as of 2021 published in Vaccine.
Article details from ChatGPT-4o list.

This article does not exist in JAMA, but a similar article does exist in Vaccine: ‘Safety of vaccines used for routine immunization in the United States: An updated systematic review and meta-analysis’ (DOI: 10.1016/j.vaccine.2021.03.079).
Links to Nature but is a dead link.
This article does not exist in the Lancet Oncology, but a similar article does exist in the Journal of Immunology Research: ‘Safety of human papillomavirus 9-valent vaccine: A meta-analysis of randomized trials’ (DOI: 10.1155/2017/3736201).
In rhetorical studies, the study of genre provides critical tools for understanding and responding to GenAI. Genre is the study of how typified forms are invoked in response to recurrent rhetorical situations (Miller, 1984). A rhetorical situation might, for example, be a visit to an urgent care centre, and the genre response might be the patient intake form. The genre serves a function to help the medical personnel understand your reason for a visit and systematize information that might be diagnostically useful. In other words, genre describes a wide range of real-world discourse activities, not just categories one might scroll through while looking for the next streaming programme to watch. In a rhetorical sense, genre can also help us understand the complexities of what GenAI systems are doing to our informational environment. Genre-ing activities are situated within particular discourse communities, particular organizations with their attendant norms and values, within particular media environments, for example. Genre-ing activities – both the invocation and interpretation – are contextual. Although GenAI outputs appear to replicate genre features (Mehlenbacher et al., 2024), such as the ability of GenAI to produce what appears to be a research article introduction, the contextual elements that shape the forms of knowledge produced have been removed and replaced with a statistical simulacrum. Features that help us understand the, for instance, textual elements of an output are no longer rhetorical in the sense of rhetoric being a relationship between the rhetor and audience. Instead, the intermediate effect of GenAI technologies decontextualizes information, which makes its later rendering as knowledge a novel challenge.
When prompted to provide a list of reputable websites from hospitals, universities, public health organizations and international entities, the outputs seem reasonably informed and provide sources in line with the request. A list of such information is not without its antecedent genres, and we might look to various patient-information genres, for instance, or to websites providing health information from hospitals, universities and public health organizations themselves. Linking to good sources of information is an important function of such websites, and their credibility is indeed established through the proxies for expertise that GenAI suggests are criteria for evaluation (e.g. authority and credibility, transparency and accountability, peer review and evidence-based information). But such criteria are not how GenAI produces outputs.
Consider the prompt to identify 10 peer-reviewed journal articles that demonstrate the safety of vaccines, and how trained experts were not able to identify original sources through academic library databases. The research-article genre is a well-defined research-process genre (Swales, 1990, 2004) that has been studied by genre scholars, charting its early evolution through the needs of researchers (Bazerman, 1988), its digital transformations (Gross and Harmon, 2016) and its continued evolution in response to the replication crisis (Mehlenbacher, 2019). Research articles function within the research-process-genre ecology, or the spaces where research findings are shared, but they also have considerable credibility outside of research spaces. This manner of prompting is also consistent with commonly found assignment instructions that librarians are encouraged to design their information literacy efforts around within their teaching practice (Saines et al., 2019). During the COVID-19 pandemic, not only the credibility but also the complexity of research articles, peer review and research processes became part of public discussion of science, including the challenges of a research environment where preprints appear in repositories that are publicly accessible (Lauria, 2023). Put simply, research articles present a complex enough genre problem without making them up, which is precisely what GenAI has done.
In addition to matters of a legitimate research article's contribution to the advancement of scientific knowledge, one must be cautious of completely hallucinated articles. The hallucinated articles in Table 4 illustrate that there seems to be a typified response (a bibliography of peer-reviewed research articles) to a recurrent rhetorical situation (here, the need for research on a subject), but the response ignores important norms and values of science. The reported articles are neither peer-reviewed nor articles at all.
GenAI, in these examples, echoes an older problem. In an information environment rich with complex scientific and technical information, which describes much of the information we consume related to public health, people rely on experts. Expertise is not simply knowledge of a specific area of specialization, however, and instead is a highly social (Collins et al., 2007) and rhetorical enterprise (Mehlenbacher, 2019). Where GenAI does add novel challenges is in how it is interpreted as an expert agent (we use the term ‘expert’ as an attributional one here, meaning that someone might believe the technology can make expert assessments or provide expert-like knowledge). Considering how these changes impact established information evaluation practices would be a beginning for many librarians, but this effort is convoluted by the fact that it is not yet clear how such systems will be assessed, and it can be difficult to distinguish between expert-produced text and GenAI-generated text. Understanding the socio-rhetorical ways in which we access, interpret and integrate knowledge in an era of GenAI requires that we are mindful of information seeking, like information sharing, as a happening within social spaces and discourse communities, and as fundamentally governed by what rhetorician Kenneth Burke (1966) calls our ‘terministic screens’, or the terms through which we understand the world.
We are putting an existing tool to work, and we do not have strategies for addressing all the emotions we impart on AI. We need to stop pretending that our existing tools and frameworks work. They do not work and we do not understand what to do, in part because we do not understand the tools, but, more critically, because we do not understand how people use information anymore. Within tech, a lot of models are on trained on data that does not include recent social changes. As a consequence, such models are working in a paradigm that no longer exists. People need to understand that the seemingly futuristic tools of GenAI are, in fact, anachronistic in their understanding. There is a false perception that people care about the truth – people often search for information that agrees with what they think and feel. The current modes of information complicate the landscape in two ways: (1) people are more easily able to find information, real or false, which contributes to an echo chamber, not a search for understanding, and (2) there is an easily useable platform in GenAI that amplifies this. The solutions to these issues are not found within the practices and theories of information science alone. They will need to be created through deep cross-disciplinary collaboration, including, as has been integrated here, health, science, education, technology and rhetoric. In future iterations, the Association of College and Research Libraries’ (2016) Framework for Information Literacy for Higher Education could be reviewed and revised, incorporating such multidisciplinary perspectives, and doing so would allow the development of instructional best practices to intentionally incorporate the different types of knowledge.
Limitations
There are clear interdisciplinary tensions around who studies GenAI, who develops GenAI, who navigates GenAI and whose work helps people navigate GenAI. The place of librarians and other information professionals in this new landscape is often tense at best, and loaded by disciplinary silos and perceived expertise. We acknowledge that this tension is an important part of this discussion and will look to future work to better and more fully examine, understand and find avenues for better communication and collaboration between information professionals, AI researchers and every discipline seeking to navigate this rapidly growing source of information.
AI researchers also are missing fundamental understandings and evidence-based background around the level of literacy in data and AI (Wise, 2020). Additionally, AI literacy is frequently mentioned as another key answer to the concerns over GenAI shortcomings (Long and Magerko, 2020). As GenAI tools are developed rapidly, including new features of the technologies such as video generation, anticipating the forms of awareness and literacy is likely to miss key features. Our remarks, then, are constrained to current publicly accessible versions of GenAI technologies. Furthermore, because of the rapid development and integration of GenAI, it is difficult to provide a comprehensive account of user actions in our use-case scenarios. As prompt engineering, for instance, becomes more widespread, user behaviours will change. As we are concerned with the outputs, not the skill of users in interacting with GenAI systems, we are mindful of this limitation with an eye towards how outputs are shaped by prompts.
Conclusion
There are current attempts to combat bias in algorithms, such as HITL, but many of these are labour- and time-intensive, expensive and often not able to address concerns around bias. It is important to note that AI tools are what we train them to be – when they are racist and sexist, it is because that is what they were built and designed to be. Tech is built with the biases of a largely male, predominantly white workforce. Whether internal biases are realized or not, they have been noted to come out in the tech they create. Human values are already embedded in AI, for better or worse. Developing information literacy tools to navigate this has the added challenge of having to work with biases that are often unrealized and then exaggerated using a rapidly growing tool and librarian access to engagement with these broader multidisciplinary discussions.
New strategies are needed to address the nuances introduced by GenAI. Educational institutions need to equip students with the skills necessary to critically navigate the emergent GenAI ecosystem. Strategies could include teaching information-source verification and evaluation, using cross-referencing, using fact-checking tools and resources, and highlighting the differences between the information generated by humans and AI. The difficulty in these approaches is that the quantity of information and time inherent in information critique can, and does, disrupt these learned behaviours, even for experts. People do pay more attention and give more weight to negative information (Buoncompagni, 2023). Considering information seeking as a community or social activity may also inform the development of future pedagogical designs for this work.
This article provides several examples of how existing interventions for AI literacy, informed by the work in data and information literacy education, may fall short of the answer required to navigate these new information tools. While we focus on GenAI, this discussion can, and should, be more broadly brought into the holistic AI conversation. Going forward, there must be a fulsome discussion of the ways in which human intervention and the relationship between HITL methods and information literacy pedagogy will help to provide the initial steps towards building a framework for all AI-generated information and learning needs that is trustworthy, accurate and evidence-based. Such conversations might include looking to those traditions, such as rhetorical studies, that have reflected on how we, as humans, think, reason, argue and persuade. Finally, we must openly grapple with the fact that the information landscape has changed in a world of GenAI, and we will need to reassess our understanding of information behaviour. The first step is admitting that we do not know what to do next, but we do know that things have changed and more things will have to change. We do know that the solutions likely lie in our own humanity and, by collaborating with other experts across multiple fields, a solution may come from the least likely place.
Footnotes
Acknowledgements
We would like to thank our fellow Trust in Research Undertaken in Science and Technology (TRuST) Scholarly Network members at the University of Waterloo and beyond. We are excited to be part of a group that is working to engage with new ideas, understandings, technologies, challenges and responsibilities through exciting collaborations. We would also like to thank the University of Waterloo Libraries for its continued support of learning, research and innovation while transforming approaches to the creation, discovery, use, sharing and preservation of information.
AI disclosure statement
Artificial Intelligence Tool(s): ChatGPT v. 4omni, accessed 7 June 2024; Methodology: ChatGPT was used in the design of the methods for testing initial prompts to ensure the validity of the method from a rhetorical and information behaviour perspective prior to the finalization of the prompts used in the manuscript; Data Collection Method: ChatGPT was used directly to collect data analysed in this study as described in the methods and discussion of the manuscript.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The authors received no financial support for the research, authorship and/or publication of this article.