
Abstract
With the evolution of digital platforms, ordinary users have gained the opportunity to participate in the organization of digital knowledge. This has given rise to folksonomies or social indexing, and the duty of information services to integrate user participation in the organization of their digital collections, and thus incorporate folksonomies in their information organization practices. This article presents a case study of the involvement of users of an academic museum and archive in the indexing of a set of resources within a project on digital preservation. The main objective of this study was to analyse the labels or tags suggested by a group of six students from several scientific areas who participated in the experience, and explain the criteria they used to choose and assign the terms to represent the content of the documents. The responses were categorized based on content analysis. The labels assigned by the students were also compared with the indexing terms used by information professionals. Although the students were not familiar with the methods of information professionals, they gained enough sensitivity to understand the need for term validation and recognize that term selection is a subjective choice.
Introduction
The digital age is characterized by rapid technological innovations that enable individuals to perform different tasks with regard to the production and organization of information. Users’ information behaviour has changed, as they have become more active and more involved in the processes of the production, description, consumption and sharing of information in digital environments. Regarding the description of information resources on digital platforms, social tagging, folksonomies, social bookmarking and social indexing have generated new ways of creating metadata content, helping users to share, store, organize and retrieve the resources they are interested in.
Information services (libraries, archives and museums) need to take advantage of the potential offered by digital technologies in order to facilitate the participation of their users in the organization of their collections’ resources. Thus, the use of tagging created by users has been incorporated in some libraries as a new and complementary approach to the indexing and knowledge organization of their information resources (Yu and Chen, 2020). Folksonomies have become a knowledge organization system similar to others used by libraries, such as thesauruses and subject heading lists.
This article presents a case study on the creation of a folksonomy by the users of the academic museum and archive of the University of Aveiro, Portugal. Through the Digital Preservation project being developed by the Library, Document Management and Museology Services (Serviços de Biblioteca, Informação Documental e Museologia or SBIDM) of the University of Aveiro within the scope of the university’s 50th anniversary, user involvement in the indexing of a set of resources is presented.
The main objective is to analyse the tags indicated by the common user (social indexing) in the context of the Digital Preservation project being developed by SBIDM. Specifically, it is intended to identify and explain the users’ criteria for choosing and attributing terms that illustrate the content of each document. At the same time, the controlled terms used by information professionals for the same set of documents are highlighted. The intention to carry out this work arose from personal and professional curiosity around the theme and because of the wish to contribute to reflection on this topic in Portuguese information services. In addition, an interest in understanding if there could be some collaboration between the information professional and the user in the identification of terms/tags representing the information content emerged. The study offers an example of the reality in Portugal regarding the application of folksonomy by the user of an academic museum and archive, and could serve as a comparative approach for other international settings.
The search terms used were folksonomy, folksonomies, social indexing, information professional and information systems. These terms were combined through the use of Boolean operators, and compound terms were fixed with quotation marks. The information search was carried out mainly in the Open Access Scientific Repositories of Portugal (Repositórios Científicos de Acesso Aberto de Portugal or RCAAP) and other specialized databases. The selected bibliography mostly comprises scientific articles and corresponds to the time period between 2007 and 2021. A focus on the Portuguese language was chosen to understand how this topic has been included in the scientific literature published in that language. However, due to the dearth of literature in Portuguese, and also due to their relevance, texts in English were included in the literature review.
Origin of folksonomy in the Web 2.0 context and its usefulness in Web 3.0
The progress of information and communications technologies, associated with the growth of the World Wide Web, has allowed the increasing and continuous production of information. Created by Tim Berners-Lee in the 1980s, the World Wide Web has not only allowed the publication of and access to information, but has also fostered the active role of people in these processes.
Web 2.0 emerged with the creation of new services and functionalities due to technological advances and the evolution of the sociological context. Coined in 2005 by Tim O’Reilly, Web 2.0 is defined as a ‘platform where all connected devices are shared’ (O’Reilly, 2005). According to Catarino and Baptista (2007), Web 2.0 reinforces the Internet concept of enabling its users to collaborate effectively to make virtual services and content organization available. The main characteristic of Web 2.0 is collaboration because, according to Blattmann and Silva (2007), the actions are performed by the users themselves in a collective way. Attending to their needs, each user collaborates in the implementation of the content available on the Internet.
The uncontrolled amount of information produced and available on the Internet endorsed users themselves to also participate in the organization of these contents and, consequently, to index the digital resources on the Web. Thus, tagging practices and the creation of folksonomies emerged. This was a new approach to describing resources grounded in shared metadata and social tagging, and it allows a more dialogic communicative practice where creators, readers, listeners and viewers of documents are encouraged to add tags representing their own vision of the information items (Rafferty, 2018).
Although there is no consensus on the definition of ‘folksonomy’, it is known that the term was coined by Thomas Vander Wal in 2004, and that it represents the combination of the terms ‘folk’ (from the Germanic ‘people’ or ‘group of people’) and ‘taxonomy’ (from the Greek ‘science or technique of classification’). Translated literally, we are talking about classification by people. Wal defines folksonomy as the result of personal free tagging of information and objects (anything with a URL [Uniform Resource Locator]) for one’s own retrieval. The tagging is done in a social environment (usually shared and open to others). Folksonomy is created from the act of tagging by the person consuming the information. (Wal, 2007) this external tagging is derived from people using their own vocabulary and adding explicit meaning, which may come from inferred understanding of the information/object as well…The people are not so much categorizing as providing a means to connect items and to provide their meaning in their own understanding. (Wal, 2005)
From these definitions, it is important to emphasize that folksonomy derives from the need to organize the information and knowledge produced and available on the Internet. Folksonomies are a product of tagging practice, which is characterized by the assignment of tags in the classification of online documents, regardless of their format. The average user is the main actor, and the way each user organizes and classifies information depends on the level of their general culture and personal characteristics. This means that users are free to decide what to use their tags for, and tags are not necessarily informational or subject-related keywords as they might be purpose-related or even quite random (Rafferty, 2018).
Folksonomy has several characteristics that can be seen as advantages or disadvantages. In a broad sense, and according to Kato and Silva, folksonomy is characterized by flexibility, pattern identification, social collaboration and the anarchic way in which information is born (Silva, 2010: 9). Catarino and Baptista (2007) agree with this and develop these characteristics, stating that the main feature is the social collaborative approach. Furthermore, the attribution of tags by the prosumer to documents previously handled by an information professional demonstrates the possibility of collaboration between them. Folksonomy allows the formation of communities around subjects that represent common interests among different users. This can be seen by the attribution of the same tag to the same document by different individuals. Another characteristic is the absence of people in charge or any kind of control over language and tag assignment. The user has total freedom over the number of tags to assign, the criteria adopted and the writing of tags. In terms of digital information organization and retrieval, accessibility to tagged content is another characteristic. Finally, and most worrisome, is the poor precision in information retrieval caused by the user’s total freedom in the tagging process. Total freedom promotes ambiguous, synonymous, homonymous and polysemic terms that make it difficult to retrieve information that was previously classified in an controlled manner.
Guy and Tonkin (2006) refer to ‘sloppy’ tags and enumerate the main instances that reflect this: misspelt tags (e.g. museum, musum); badly encoded tags resulting from word groupings (e.g. PaulOtlet); tags that do not follow the rules with regard to issues such as case and number or singular versus plural (cake, cakes); personal tags that are without meaning to the wider community (e.g. my dog); compound words consisting of a mixture of languages; and single-use tags that appear only once in the database. To be of more social value in terms of information organization and retrieval, tag creation needs to become much more proficient.
Noruzi (2006) identifies the four main problems of folksonomies as polysemy (which dilutes query results by returning related but potentially inapplicable items); synonymy (as an item can be identified by several words with the same meaning, it is difficult for users to be consistent in the terms chosen for tags); plural (with inconsistent use of singular and plural); and the depth specificity of tagging (which refers to how many tags there are relative to an item; also different users may consider terms at different levels of specificity to be most useful or appropriate to describe the same item). Because of this, as Noruzi (2006: 202) underlines, folksonomy tagging has the potential to exacerbate the problems associated with the fuzziness of linguistic and cognitive boundaries. Incorporating computational tag recommendation mechanisms can contribute to improving the process of finding good tags for a resource, also helping to consolidate the vocabulary across the users and reminding a user what a resource is about (Jaschke et al., 2007). Another alternative is to implement a human judgement that is designed to produce structured folksonomies that aggregate tags created by users as a starting point and use expert or collective decision-making to solve problems like synonymy and homographs. This is what Bullard (2018) calls a ‘curated folksonomy’, which is able to address some of the major shortcomings of folksonomies, thus providing a new option for knowledge organization and improving recall and precision in information retrieval with a high degree of success within large user-generated collections.
Web 2.0 presents as a limitation the fact that the terms read and produced solely and exclusively by the user do not have an associated context, which thus becomes another difficulty in information retrieval. In turn, Web 3.0 (also called the Semantic Web), supported by the use of machines, has allowed information, which was previously produced and shared by users through Web 2.0 to be related and reused (Eis, 2017). It also allows for overcoming the challenge of integrating representations in a linked data web in order to achieve a global database. According to the Library of Congress (2012) ‘the ultimate goal of linked data is to provide a seamless browsing experience in a “web of trust” where users can make their own contribution' (quoted in Cagnazzo, 2019: 12). From this input, Google, for example, will be able to distinguish and separate the different contexts of the same term (Eis, 2017). Thus, the practice of tagging and the creation of folksonomies, even if they originate from and are typical of Web 2.0, present themselves as important contributions to the construction of the Semantic Web. On the other hand, one way to improve the potential of tagging from the point of view of knowledge organization and information retrieval is by the application of Semantic Web principles to Web 2.0 sites. The main example is semantic tagging, which implies tagging content with URIs (Uniform Resource Identifiers) and thus helping to solve the issue of ambiguity, as the tags are linked to unambiguous URIs. Moreover, semantic tagging permits the reuse of tags across different applications, allowing for the exchange and sharing of data (Cagnazzo, 2019).
In addition to this broad contribution to the Semantic Web, tagging and folksonomies can improve interactivity and community participation in library services, helping information professionals to create better information representation and knowledge organization instruments. In the following, a case study is presented and these aspects are underlined.
Research methods
How would folksonomy be incorporated in the knowledge organization of SBIDM at the University of Aveiro? This was the question that motivated this research. The methodology adopted translates into a qualitative or interpretative paradigm represented by a criterial non-probability sample composed of two sets of stakeholders – information professionals and students.
Before preparing the experiment to identify how common users create tags to identify information items, a bibliographic search was performed to understand better critical aspects related to folksonomies. The case study was carried out within the scope of the Digital Preservation project and counted on the collaboration of the four information professionals from SBIDM who are developing this project, with the support of six University of Aveiro students who collaborate with SBIDM under a merit scholarship. In June 2022, the information professionals selected a set of five documents of varied typologies without imposing any requirements. These documents were analysed and labelled by the students. Afterwards, through an individualized interview with each student, they explained the criteria chosen to assign the tags to each document by answering the following questions: Describe the steps of your tagging process. What was the most difficult document to tag? Why? Have you resorted to other sources of information? How easy was it in the tagging process? If not, why? Do you think that some characteristics of your personality are present in the way you assigned tags to documents? Did you give any logical order to the tags? What is your opinion on the implementation of folksonomy in the SBIDM information system platforms? Do you think this process of tagging would have been easier if the documents analysed were related to your field of study?
These questions are partially aligned with a suggestion made by Guy and Tonkin (2006), who note that it is important to understand users and why they submit certain tags. Furthermore, they recommended that a useful approach will include examining users’ motivations when adding tags and seeing why they decide on particular words. From this observation, it will be possible to understand the number of tags they have added and compare how the same items are represented by different users.
The student interviews took place at the SBIDM facilities and were guided by one of the authors of this study, who recorded their responses manually. The amount of time taken to analyse and label the documents was managed by each student. From the analysis of the interviews, each student took, on average, an hour. The students had no previous knowledge of information science but have since acquired sensibility to some of the technical issues that the information professionals have passed on to them.
The strength of a folksonomy approach is often described as its openness – the ability of any user to describe the world as they see it. Thus, the limitations of this study are related to the diversity of cultures and cognitive abilities of the students, which influenced the perception of what was intended by this study. Equally limiting was the lack of sensitivity shown by some of the students in the document analysis, which later influenced the answers given in the interviews.
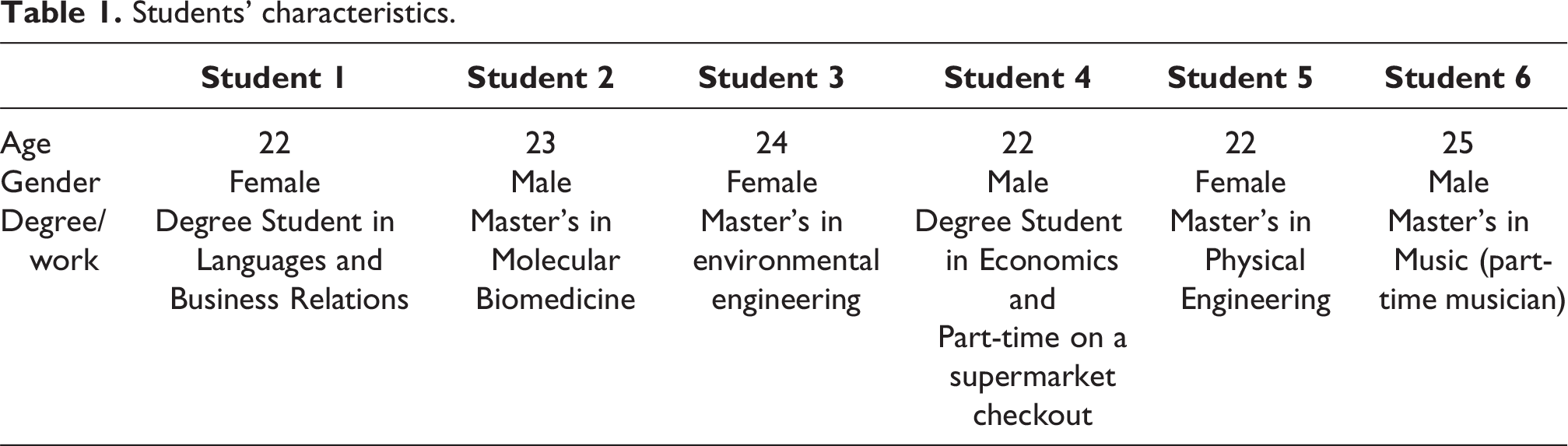
All of the students were in their twenties. They were students in the areas of Languages and Business Relations, Molecular Biomedicine, Environmental Engineering, Economics, Physical Engineering and Music. Three were male and two worked part-time. One of the students was from Mozambique and the others were from the centre-north of Portugal. All of them were diligent users of social media and the Web in general, and all experienced some difficulty in tagging the requested documents. Thus, the data collection was performed through indirect observation at the time of the document analysis by the students and, later, through individual interviews with them for a better perception of the results obtained.
The objective was to establish a comparison between the creation of folksonomies by the user and the use of controlled vocabulary by the information professional in the context of SBIDM at the University of Aveiro. More specifically, the intention was to identify and explain the criteria that the users applied in the choice and assignment of terms to represent the content of each document.
The analysis of the interviews respected the personal characteristics of each student (see Table 1) and the relationship they established among themselves by the way they analysed the documents, according to age, gender, training and professional experience. The questions were designed according to the bibliography consulted and in order not only to understand the students’ opinion about the labelling process, but also to make them aware of the relevance of information management, even if not controlled.
Students’ characteristics.
The analysis of the results was presented in comparative tables and the conclusions drawn were supported by the literature review.
This work is presented as further support for the study of folksonomy. It is a practical example of the collaborative relationship that can exist between information professionals and prosumers in the creation of information content and the adoption of solutions that avoid the disadvantages of folksonomy.
Findings: folksonomy in the context of the Digital Preservation project at the University of Aveiro
As part of the University of Aveiro’s 50th anniversary celebrations, SBIDM is developing (in collaboration with other departments and services at the university) a project called Digital Preservation. The project consists in defining a digital preservation plan for the digitization of collections to preserve the physical objects and provide access to them, as well as the preservation of resources created in digital format that are at risk of becoming obsolete, lost, corrupted and illegible if they are not properly organized and preserved. The technical team is made up of four information professionals. Since November 2021, this team has had the collaboration of six merit scholarship students, who perform several functions within the project – namely, the cleansing, digitization and description of the information items in the Collective Access platform.
For this particular study, a student team was asked to make the information resources description choosing their own tags. Table 2 shows the terms indicated by the technical team (indexing) and the tags suggested by the students (folksonomy) for the same set of documents.
Folksonomy: terms assigned by the students.
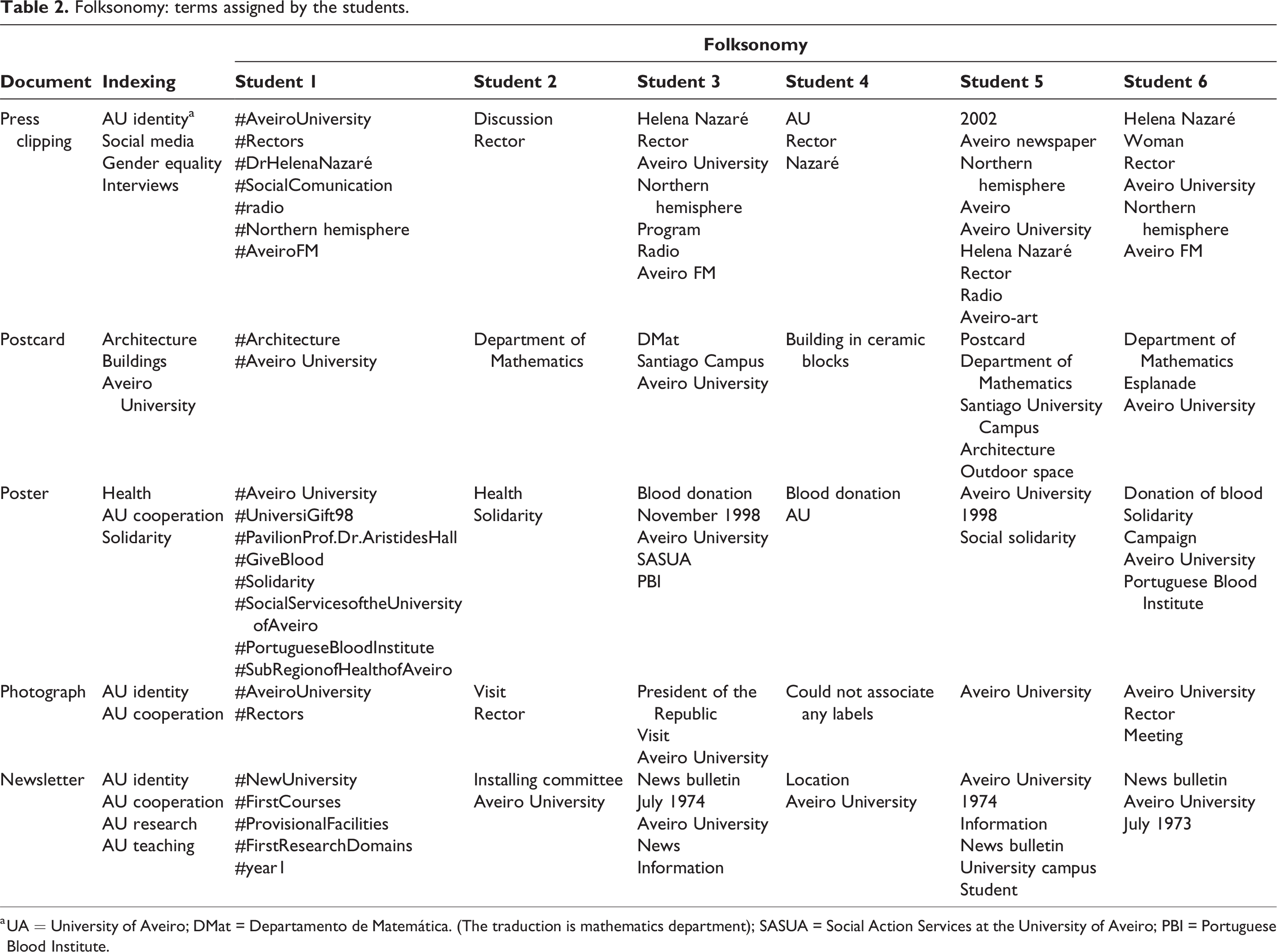
a UA = University of Aveiro; DMat = Departamento de Matemática. (The traduction is mathematics department); SASUA = Social Action Services at the University of Aveiro; PBI = Portuguese Blood Institute.
After each student had assigned one or more tags to each of the documents, a short interview was conducted with each student in order to understand their information behaviour in the process of tag assignment. The aim of the questions was to understand the information behaviour that underpinned the choice of the students’ tags.
Students' information behavior when assigning tags
The answers to the question ‘Describe the steps of your tagging process’ were very similar. In general, all of the students analysed each document and tried to assign tags through the content. Student 2 answered: ‘I started by analysing the documents with textual content and through the text assigned tags’. Student 1 responded in a similar way. Student 6 commented on the importance of the format of the document: ‘I observed the documents and looked for prominent elements, such as words, the format, and assigned the tags’.
Regarding the answers to the second question – ‘What was the most difficult document to tag? Why?’ – all of the students shared the same opinion about the high degree of difficulty in tagging the photograph because, besides not having a caption, none of the students knew the people represented. All of them confirmed that it was much simpler to label textual documents where, through the text, they could understand the content and retrieve some keywords. Student 6 concluded: ‘the most difficult thing was to assign tags to the picture because I don’t know the actors. That’s why, in visual documents, every word counts, however few’.
Given some of the difficulties in labelling and in response to the third and fourth questions – ‘Have you resorted to other sources of information?’ and ‘How easy was it in the tagging process? If not, why?’ – only Students 1 and 2 made additional searches on Wikipedia and Google, respectively, stating that these searches helped in tagging the photograph.
Replying to the fifth question – ‘Do you think that some characteristics of your personality are present in the way you assigned tags to documents?’ – Student 1 said, ‘I am a detailed person and I think it is important to label everything’, and Student 2 commented, ‘I am a curious person and my ability to interconnect information in different media was reflected in the way I labelled the documents’. In turn, Students 4 and 6 mentioned their general culture as a positive characteristic for the labelling process.
In response to the sixth question – ‘Did you give any logical order to the tags?’ – Students 1 and 4 answered that they did not think it was relevant to assign any sort of organization to the labels. More specifically, Student 3 answered: ‘I labelled so spontaneously that at the moment I didn’t realize that I was organizing them according to the logic “what, when and where”‘. Student 6, who typically organized information from the general to the particular, stated: ‘I assigned tags as they came up. However, I found that I identified them from the most explicit to the least explicit’.
In general, in answer to the question ‘What is your opinion on the implementation of folksonomy in the SBIDM information system platforms?’, all of the students were of the opinion that it would be helpful to apply social tagging to the SBIDM information system. We highlight two responses: It would be a good initiative to implement folksonomy in the SBIDM because it would allow an initial screening of the information that is wanted. It would be a similar measure that exists in Scopus in the search for scientific articles, in which it allows the search to be carried out according to keywords. (Student 2) Folksonomy should be applied in the SBIDM but with filtering/validation. It cannot be anything goes. (Student 6)
Finally, regarding the eighth question – ‘Do you think this process of tagging would have been easier if the documents analysed were related to your field of study?’ – only Student 1 disregarded this hypothesis in answering: ‘If the selected documents were from my field of study, my way of labelling would not be different’. Conversely, Student 3 replied: ‘I believe that if the documents were from my field of study, it would have been easier to identify the labels. Still, it would always depend on my degree of knowledge of the information that the document addressed’. Similarly, Student 6 commented: ‘If the documents were from my area of specialization, it would have been easier to tag them since I would be familiar with their contents’. He added: ‘When there is text, even if I don’t know the subject, the tags appear. With images, you need to pay more attention and focus on the details’.
In analysing Table 2, the controlled terms used by the information professionals based on indexing terms that are searchable in the library’s online catalogue and opac.ua.pt were identified. In SBIDM, the indexing process is carried out by consulting the Universal Decimal Classification manual and by searching the online catalogues of the Portuguese National Library and the Library of Congress. To each of the documents, the librarians assigned between two and four terms.
Analysis of uncontrolled terms
The tags assigned by the six students will now be analysed with deeper, based on the professional experience of Voit (2022), the conclusions of Silva (2010) and Santos and Albuquerque (2021), and the literature review.
When looking at the tags that each of the students attributed to the documents they were asked to identify, it seems that each of the participants selected the aspects from the documents that were most relevant and according to what made sense to them. This idea is in line with Guy and Tonkin (2006), as they noted that items can be categorized with any word that defines the relationship between a document and a concept in the user’s mind. Any number of words may be chosen, some of which are obvious representations, while others make little sense to those outside the context of the tag’s author. Some relevant aspects of the documents were shared by some of the students but were not chosen to identify the content of the documents by the information professionals. The press clipping is a good example, as four students linked it with the idea of ‘radio’ (#AveiroFM, AveiroFM, radio and Aveiro FM) and the information professionals did not choose this concept in relation to the document, instead choosing only a broader representation with the term ‘social media’. Furthermore, the simultaneous use of generic and particular terms stands out, despite the fact that it is advisable to opt for generic terms that allow a greater number of results to be retrieved. The students used generic and specific terms simultaneously. It happened that at least one students simultaneously chose the terms ‘radio’ and ‘media’. If the single term ‘social communication’ had been chosen, a second term would not have been necessary.
The tags that each individual chooses to apply to each document reveal not only the cognitive representation that the individual makes about an item of information but also convey some insights about the person themselves and help us differentiate individuals from each other. This is especially evident when we check the tags from our sample. The number of tags that the students assigned to each document is quite different. Student 2 and Student 4 consistently assigned one or two tags to each document, but the other students tried to be more exhaustive, using more tags for each document. It is also noteworthy that each student did not use a variable number of tags per document, unless difficulties were faced when representing the content of the document. Students 1, 3, 5 and 6 assigned between one and nine tags per document, with the photograph being the item with the least number of tags (one to three). Some students seemed to assign a high number of tags to a document because they intended to go deeper in the level of specificity. For example, Student 5 tagged the postcard with the broad class of ‘architecture’ and then complemented it with the specifics of the context: ‘Santiago University Campus’, ‘Department of Mathematics’ and ‘outdoor space’. Student 6 chose to be more specific, leaving out the generality of the class ‘architecture’ and assigning to the same postcard the labels ‘Department of Mathematics’, ‘esplanade’ and ‘Aveiro University’. Thus, the perspective from which the context was set remained undefined. The ideas behind the representation of the postcard are quite similar from the two students, but they used different words and different levels of depth. This is in line with Noruzi’s (2006) argument that resources can be tagged to varying levels of specificity and with a different numbers of tags, and these choices are strongly influenced by the user’s behaviour and habits.
Another aspect to be underlined is that regardless of the different characteristics of each student, they identified the main concepts in the various documents, thus forming a group that shared terms. The students also demonstrated a tendency to flexibility in the attribution of tags, as is evident in the use of terms taken from the contents of the documents. It is possible to verify terms like ‘northern hemisphere’ and ‘New University’, which were selected from the contents of the documents and reused as tags. Also, the years and terms like ‘woman’, ‘esplanade’ and ‘meeting’ are good examples. Moreover, the students expressed a preference regarding the use of acronyms and abbreviations: terms such as ‘DMat’, ‘IPSS’, ‘UA’ and ‘SASUA’ show a tendency for users to use acronyms and abbreviations that are meaningful for them as tags.
Another interesting aspect of the results is that long words are quite common in this framework. The choice of long words is associated with students who define themselves as attentive to detail and organized. The long words presented were either devised by the students themselves or selected from the contents of the documents. Examples are ‘DrHelenaNazaré’ and ‘SocialServicesoftheUniversityofAveiro’. The longer the word, the greater entropy it will produce in information searches. These results are in line with Guy and Tonkin (2006), who also found a large number of tags using structures other than dictionary words. In these cases, the students concatenated words, formatting each word with an initial upper-case letter to improve readability (camel case). In this regard, Guy and Tonkin (2006) note: ‘The commonness of compound tags, including tags that concatenate more than two words, may suggest that users miss the richness of the sentence structure’.
The use of the singular form is predominant – all of the students mostly adopted this form. This does not confirm one of the major concerns pointed out in other studies (Guy and Tonkin, 2006; Noruzi, 2006). The exception was student 1 who, despite indicating a set of terms in the singular, also indicated a plural term in the middle of that set. In this case, there was no coherence by the same individual in the use of singular or plural terms. This student differed in some aspects from the others, as he preferred to present information in a disorganized way and the use of plural terms. Moreover, Student 1, in addition to highlighting hashtags (#), was of the opinion that the tags did not need to follow any logical order. On the use of hashtags, it is worth underlining that this reflects a contamination by information behaviour that is typical of social media, as hashtags are used on a variety of social media platforms, such as Twitter, Instagram and YouTube. Moreover, as Spiteri (2019) points out, hashtags have the potential to make positive contributions to library catalogues, as while they serve to describe aspects of information resources, they can extend the resources available to users via library discovery systems. The enhanced use of hashtags raises the concept of a catalogue as a social space because hashtags do not limit this social space to the boundaries of the catalogue but can extend to social networks beyond libraries.
Regarding the grammatical format of the tags, the use of nouns stands out, with no verbs or adjectives included, despite a few uses of dates. The predominance of nouns is in line with other studies (e.g. Guy and Tonkin, 2006).
Conclusion
Folksonomy is a consequence of the emergence of the World Wide Web and its subsequent evolution. The emergence of new services and the development of others in the digital domain has led to increased information production. As a result, the need to organize and retrieve information on the Web has also increased. Folksonomy has given users the freedom and ability to classify the information they produce and intend to retrieve in the future.
Although there is no consensus on the definition of folksonomy, two definitions that complement each other and represent what folksonomy is in practice stand out. First, according to Aquino (2007: 1–18
This study on folksonomy was developed from the perspective of SBIDM users within the Digital Preservation project at the University of Aveiro, whose labels were compared with the controlled terms used by information professionals at the same information services. The analysis of the information behaviour of the group of students, associated with the set of tags attributed by them to various documents, proves that this was a group of individuals who produced information in a disorganized way, assigned a variety of tags and used the same terms, including singular and plural terms, acronyms and abbreviations, long words and, simultaneously, generic and particular terms.
The selected students were in the same age group and had a similar level of education and professional experience, which made a greater variety of responses more difficult. In addition, they were already reasonably familiar with the documents and the purpose of their collaboration in the Digital Preservation project, and had thus acquired certain characteristics and some technical proficiency through the monitoring of the information professionals, making it a possibility that there were some inauthentic results. However, if this study had been carried out with the collaboration of students from outside the project, it would have been equally possible for there to be inauthentic results due to a lack of perception of what was intended. These factors are limitations of the study.
The favourable opinion of the students who collaborated in this study with regard to the adoption of folksonomy in the SBIDM information systems encourages the development of a new study through which to understand what the opinion of the information professionals at SBIDM is and what the professional–user relationship could look like. Even though the students were not familiar with the methods of the professionals, they acquired enough sensitivity to realize the need for validation of the terms and to accept that the selection of terms is subject to different points of view. Since there is already this tendency on the part of users, there is a need to analyse the opinion of information professional on this possibility and evaluate the best way to move forward with such a collaboration.
According to Santos and Albuquerque (2021), there have already been studies on tools that reconcile indexing with folksonomy. To this end, it is suggested that hybrid systems of knowledge organization be explored in future research in order to evaluate the best way to move forward with this collaboration. Future studies may also be directed towards the analysis of collective access software – free and open-source software for cataloguing and publishing museum and archive collections, such as that which has supported the Digital Preservation project being developed by SBIDM.
The analysis and labelling carried out by the group of students collaborating in this project was done manually and theoretically. In other words, the results of this study are not reflected in the practical and technological components of the project. Thus, it would be relevant to understand the level of capacity and acceptance of collective access software regarding uncontrolled information and how information is made available to users.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The authors received no financial support for the research, authorship and/or publication of this article.