
Abstract
This article demonstrates that Australian equity returns and factors are strongly non-normal and that non-normality seems to be adequately modelled as a jointly multivariate t random variable with 7 degrees of freedom. When means and alphas are estimated using maximum likelihood estimation under the multivariate t case, we find dramatic changes in the estimates of the mean of the test assets, and find that the sign of the price of SMB risk flips from positive to negative (though insignificant). The evidence against asset pricing models is larger when returns are non-normal. This methodology can be viewed as a robust estimator, and its results suggest caution should be applied in interpreting estimates of risk premia and alphas obtained using non-robust methods.
Keywords
1. Introduction
Over the past several decades, our understanding of the cross-sectional behaviour of equity returns has improved markedly. Research has shown that exposure to risk factors, including size, value, asset growth, and profitability are cross-sectionally related to expected returns. At the same time, evidence that stock returns do not follow a normal distribution has grown (see, among many others, Fama (1965), Affleck-Graves and McDonald (1989), and Richardson and Smith (1993)). Despite this evidence, the vast majority of tests of asset pricing models either assume multivariate normality explicitly or base their inference on sample average returns, which is the maximum likelihood estimator of means if returns are normal, or ordinary least squares estimates, which are also consistent with maximum likelihood under normality. Of course, standard errors and critical values of test statistics can be constructed accounting for non-normality. However, if returns are not normally distributed, then sample averages are not statistically efficient as an estimate of the mean since it is not the maximum likelihood estimator, which, according to the Rao-Blackwell theorem, is asymptotically efficient. Indeed, the current literature (e.g. MacKinlay and Richardson, 1991 and Zhou, 1993) shows that tests based on normality, including the seemingly ubiquitous Gibbons-Ross-Shanken test (Gibbons et al., 1989), are biased towards over-rejection when returns are fat-tailed. However, there has been little work that explicitly accounts for the non-normality of returns by estimating factor model alphas under alternative return distributional assumptions, which we now do using Australian equity returns.
The recent Australian asset pricing research has focused on the Fama and French (1993, 2015) asset pricing models, and the literature is a little mixed in how relevant factors other than the market return are in pricing Australian stock returns. Halliwell et al. (1999) find that the HML factor marginally improves the performance of asset pricing models in Australia over the CAPM. Gaunt (2004) finds that the three-factor model of Fama and French (1993) improves pricing over the CAPM, but much of the heavy lifting is done by SMB, the size factor, not the value factor HML. Brailsford et al. (2011) use a portfolio formation strategy as in Brailsford et al. (2012) that acknowledges the significant differences between the Australian and US equity markets and tweaks the traditional definition of the size portfolios, and they find that size and value factors are significant and priced in the cross-section and improve asset pricing over the single-factor CAPM. Chiah et al. (2016) and Huynh (2018) consider the five-factor model of Fama and French (2015) and find that the profitability and asset growth factors are significant and provide an improvement over the basic three-factor model. In particular Huynh (2018) compares how the 3 factor and 5 factor Fama-French models perform in explaining a set of 16 anomalies previously documented in the Australian market, finding that the five-factor model does a much better job at rendering alphas statistically indistinguishable from zero at a range of significance level, and he shows that the absolute value of alpha decreases for 15 out of the 16 anomalies when using the five-factor model as opposed to the one-factor model. Gharghori et al. (2007) find that default risk is not priced in Australia, and the Fama-French factors aren’t proxying for default risk. Durand et al. (2016) reject a four-factor model that includes momentum. 1 Chai et al. (2013) find that while liquidity explains some variability in returns above the standard three-factor model plus momentum, its contribution to explanatory power is marginal.
Much of the Australian literature has focused on estimates of asset pricing models using ordinary least squares, which is consistent with maximum likelihood when residuals are normally distributed. However, it is well known that equity returns, including in Australia, exhibit nonnormality, including more frequent tail returns that generate leptokurtosis. There is a large literature on non-normality in portfolio returns, including Richardson and Smith (1993), Zhou (1993), Tu and Zhou (2004), and Kan and Zhou (2017). There are a number of ways to deal with the non-normality. One approach is to conduct inference using OLS estimates that account for the non-normality of returns, including using GMM or constructing test statistics that explicitly adjust the standard errors of the alphas for non-normality. Examples of this second approach are MacKinlay and Richardson (1991), who construct a GMM-based Wald test of the zero alpha restriction, including an explicit example where returns are multivariate t. The test continues to use the OLS estimates of the alphas, which we have seen from Zhou (1993) and Kan and Zhou (2017), are inefficient when the data is not multivariate t.
Zhou (1993) shows how to adjust critical values for the Wald-type tests, accounting for non-normal elliptical residuals that account for uncertainty in the distribution of the factor realizations. He finds that after accounting for plausible distributions, the CAPM can no longer be rejected in some cases in which inference based on the normality assumption rejects the efficiency of the market return. Finally, Kan and Zhou (2017) present an alternative approach that directly estimates factor model parameters using maximum likelihood that accounts for the non-normality of returns and factors and constructs a likelihood ratio test for asset pricing models.
Given the strong evidence of non-normality and the peculiarities of asset pricing models in Australia, it seems useful to assess the extent to which results depend on the use of inefficient statistical methods. This article conducts an empirical analysis of the multivariate t distribution in Australian equity returns and explore the impact of testing the five-factor asset pricing model of Fama and French (2015) on Australian returns, accounting for leptokurtosis in returns using the multivariate t distribution. The student t distribution has been in favour for quite some time. For example, more than 50 years ago, Praetz (1972) and Blattberg and Gonedes (1974) suggested it, and it has a wide history in applications to modelling financial returns, including in GARCH models by Bollerslev (1987). In this article, we follow Kan and Zhou (2017) and consider the multivariate t distribution to model the joint distribution of returns and factors. Maximum likelihood estimates of complex models of large-scale distributions is, in general, not a trivial exercise. In the case of the multivariate normal distribution, the sample mean and covariance matrix are the maximum likelihood estimates. The multivariate t distribution is only marginally more complex, given the expectation-maximization algorithm of Dempster et al. (1977) with a particular application by Liu and Rubin (1995).
We find that the use of OLS as opposed to the more efficient multivariate t-based maximum likelihood has a massive impact on returns. We find that the size effect, which is somewhat marginal even under the assumption of normality, with a point estimate of 19 basis points per month, which is about 1 standard error from zero; yet when the price of SMB risk is estimated using the non-normality assumption, it flips sign and is about −11 basis points per month. The size of the market risk premium also drops slightly. The estimates of the means and alphas of the test assets also change markedly when non-normality is accounted for, with the largest changes occurring, perhaps unsurprisingly, among small-cap and growth stocks. Interestingly, estimates of the standard deviation of returns and their betas are much less dependent on distribution assumptions than means and alphas. We also find that the three- and five-factor models are unable to be rejected by a likelihood ratio test applied to 16 size and book-to-market sorted portfolios if returns are assumed to be normally distributed (though they are rejected when we form test assets by sorting on size and asset growth and size and profitability) but we do reject all asset pricing models when we allow returns to come from a multivariate t distribution.
We find marked differences in conclusions about the five-factor pricing model in Australia when we allow returns to be multivariate Student t rather than normal. We find that the size effect flips sign from positive to negative. Since most Australian asset pricing tests typically find a robust size effect, this result is surprising; but it is not without precedent in Australia. Faff (2001) constructs novel proxies for the size and value factors using ‘off-the-shelf’ style returns and finds a negative premium on the size factor, in contrast to US results, in which size is remarkably robust. Indeed, using a novel approach to testing the explanatory power of asset pricing models using a firm-level bootstrap-based analysis, Harvey and Liu (2021) find that only the market return and the size factor (SMB) are priced in US returns. Hoang et al. (2019) show, using the same methodology in Australian equity returns, that only the market return is reliably concluded as providing valid pricing of returns when the problem of data mining is accounted for. We also find that the evidence against asset pricing models is generally stronger when we use multivariate t returns. Given the marked differences between the estimated risk premia under the standard and robust estimation methods and the dramatic loss of efficiency in standard sample estimates, these results have implications for investors, regulators and portfolio managers.
The remainder of the article proceeds as follows. Section 2 presents a discussion of the data we use. Section 3 presents empirical tests of non-normality in the portfolio and factor returns. The estimation methodology that we use is described in Section 4. The empirical results are presented in Section 5, some robustness and simulation results are presented in Section 7, and we conclude in Section 8.
2. Data
To construct portfolio returns for Australian stocks, we use stock and accounting data sourced from the Securities in Research Centre Asia-Pacific (SIRCA), as it has the widest coverage for historical Australian equity returns. A significant problem with Australian equity returns is non-trading, which occurs because of the very large number of extraordinarily small stocks. To address this, we apply a number of filters. To illustrate the magnitude of the problem, before any screening of the data 11.15% of monthly return observations represent months where a return could not be recorded due to non-trading (either the current or previous month's price record is missing). This decreases to 6.45% and 3.39% when focusing on the top 1000 and 500 firms by market capitalization, respectively. And because we are constructing portfolio and factor returns by sorting stocks based on accounting data, we have to drop stocks that don’t have accounting data, and larger, more liquid stocks are far more likely to have accounting data. Accounting data is sourced from company annual reports from the SIRCA fundamental files. This data extracts over 600 individual items from the financial reports of Australian firms.
The final sample includes only ordinary stocks (Share Code ‘01’) of non-financial firms that are listed on the Australian Stock Exchange. Returns are calculated using SIRCA’s price relative series, which adjusts returns for dividends and capital adjustments such as stock splits. When a stock doesn’t trade in the present or previous month, a price-relative isn’t available, and we treat the returns as missing. When a return of over 300% is observed, that reverses the following month, both months’ returns are treated as an error and set to missing. There were only 24 pairs of monthly observations that were revised from this procedure. Although we only keep stocks with an ordinary share code of ‘01’, we also search for and exclude any firms whose company name includes the words ‘Fund’ or ‘ETF’. There are roughly 5000 monthly observations that are removed. In line with previous studies, and to ensure a fair comparison, we only keep stocks that have all of the following accounting variables: BM (Shareholders Equity), MBM (requires Operating Expenses), AG (total assets), profitability (NPBT) and market capitalization. Firms must therefore be at least 2 years old as AG requires 2 years of accounting data to calculate.
Stock and accounting data are available from July of 1984; however, the number of firms with coverage in these early years is rather low. We thus restrict our attention to returns starting January 1991 onwards. Our final sample contains 2794 unique firms over the period January 1991 to December 2023, with a total of 395,694 firm-month observations combining valid monthly stock and annual accounting data.
2.1. Test assets
Brailsford et al. (2012) argue quite convincingly that the Australian market has some peculiarities compared with the US markets. The quintile of the largest stocks in Australia accounts for 95% of the total market capitalization of all stocks. The smallest 60% of stocks is only 1.6% of the total market capitalization. In the United States, the largest size quintile accounts for about 75% of the total market capitalization and the smallest 60% of stocks account for 13% of the total market capitalization. In light of this, they suggest defining large stocks as the top 50 stocks by market cap, the second portfolio as stocks ranked 51–200. The number 200 is chosen to correspond to the number of stocks in the ASX200 index, which is the main index used in the Australian market. The third portfolio is the next 100. The fourth portfolio contains stocks ranked 301–500. The fifth is everything after that.
The procedure for forming test assets following Fama and French (1992) involves forming portfolios based on independent sorts on size and some other characteristic, and then allocating stocks based on those independently formed breakpoints.
Inspired by this approach, we construct portfolios by sorting stocks into four portfolios every year. The smallest 50% of stocks are small, the second smallest portfolio consists of all stocks between the 50th and 75th percentile. The second largest portfolio stocks are those stocks between the 75th and 90th percentile by market cap. The largest portfolios are the largest 10% of stocks. We then form portfolios by sorting on characteristics like value, profitability and asset growth by sorting within these bins. By using dependent sorts, we avoid problems that arise with zero stocks in some months in some portfolios when using two-dimensional independent sorts. The Australian market has significantly fewer stocks than the US data typically studied, so using independent two-way sorts finds many fewer stocks in some portfolios. In several cases, we find that some of our portfolios have zero stocks in them if we sort independently. If we do independent sorts and define the largest stock portfolio as the top 10% of firms by market cap, then in all three bivariate sorts, there are many portfolios with either zero or one stock. And significant heterogeneity in the number of stocks in portfolios results in significant variation in the amount of diversification across portfolios, which in turn results in dramatic variation in variance across portfolios. On the other hand, running independent sorts facilitates cross-portfolio comparison – if the sorts are independent, a small-value stock might will be markedly different from a large-value stock. So caution must be exercised in comparing portfolio returns from the non-size characteristics.
Ranking is done at the end of the calendar year to allow six months to elapse to ensure all annual reports released during the June-ending Australian financial year are publicly available. The typical US reporting cycle ends in December, and the United States studies use a June 30 ranking date. Because the Australian financial year is offset by 6 months, so too are our portfolio-formation dates.
2.2. Factor construction
We construct five factors. The first is the value-weighted market portfolio return on all stocks in excess of the 13-week treasury note rate obtained from the Share Price and Price Relative database from SIRCA. The other four factors from Fama and French (1993, 2015) are formed by a 2 × 3 sort on market capitalization (size) and one of four other characteristics: value factor based on High-minus-Low (HML) book-to-market ratios, the Robust-minus-Weak profitability (RMW) factor where profitability is defined as annual revenue less the sum of cost of goods sold, selling general and administrative expenses and interest expense scaled by book value of equity; and the investment factor Conservative-minus-Aggressive (CMA) sorting stocks based on the year-on-year growth rate in total assets. And following Fama and French (2015), the size factor SMB (Small-minus-Big) are formed to be neutral with respect to all three of the other factors.
Following Fama and French (1992), in the United States, factors are formed using breakpoints for, say, the book-to-market ratio using only the NYSE stocks, which are larger than the stocks on AMEX and NASDAQ. So, the US factors are constructed by forming breakpoints based on a subset of the universe of stocks (i.e. those that trade on the New York Stock Exchange (NYSE)) and form breakpoints on size using the median market capitalization, and independently forming breakpoints at the 30th and 70th percentiles for the value, profitability and investment characteristics. Inspired by this, we follow Brailsford et al. (2012) and Huynh (2018) and adapt this idea to the rather peculiar context that the Australian market presents. We define a small and a large stock for the purpose of the SMB factor on the basis of whether or not it is in the top 200 stocks ranked by market capitalization on December 31 of each year. The value, profitability and investment breakpoints are also defined using percentiles from an independent ranking of those factors.
3. Testing for multivariate normality?
We follow Kan and Zhou (2017) and model the joint distribution of both test asset and factor returns. In particular, we have the K–vector of factor returns denoted by Ft and the N-vector of returns on the test asset by Rt. There are T observations indexed by t = 1,…,T. We are interested in jointly determining whether the joint portfolio and factor return vector
To conduct a multivariate test of normality, we apply the tests of Mardia (1970), who proposed to test for normality based on the multivariate skewness and multivariate kurtosis statistics defined by

and

where


are the sample mean vector and the sample covariance matrix of Xt respectively. There are several reasons why the statistics D1 and D2 are desirable. When Xt is a scalar; the test statistics correspond to β1 and β2 Pearson’s measure of skewness and kurtosis, and the well-known Bera-Jarque test statistic, can be expressed as

where Y is a random variable independent of X but which has the same probability distribution as X. When X is a multivariate normal random vector with dimension n then E(D1) = 0 and E(D2) = n(n + 2). Zhou (1993) showed that asymptotically
Another useful property of the test statistics is that they are invariant to nonsingular transformations. The test statistics are standardized by the sample mean and sample covariance matrices, so the distribution of the test statistics is the same for the entire multivariate location-scale family of variables. This makes constructing the exact distribution of the test statistics quite easy using Monte Carlo simulation methods.
Although Mardia (1970) used asymptotic standard errors of the two measures to conduct inference, Zhou (1993) showed that the invariance property could be used to construct the exact distribution in quite a straightforward manner. Because the test is invariant to nonsingular transformations, the distribution doesn’t depend on the mean or covariance matrix of the distribution. So simulating n independent normally distributed random variables that have zero mean and unit variance give the finite sample distribution of the test statistics for any normal random vector with any mean and any full rank covariance matrix.
Tu and Zhou (2004) apply this approach to construct an exact test for multivariate normality. We follow their example and simulate the exact distribution of D1 and D2 using a multivariate normal random variable and a student t random variables with 6, 7 and 8 degrees of freedom. The exact p-values are then constructed as the fraction of simulated values greater than the estimated D1, and a two-tailed comparison of D2 with its simulated counterparts.
In our empirical work, we consider the multivariate t-distribution with v degrees of freedom. The density function for the multivariate t is given by

where ψ is a scale matrix that, when v > 2 is related to the covariance matrix of Xt by
To demonstrate the need to account for non-normality, Table 1 reports the tests for normality. As noted above, the statistic D1 is the square of the skewness coefficient, and both the normal and multivariate t distributions are symmetric, so we are interested in testing for non-zero skewness, which is equivalent to testing the null that D1 is zero against the alternative that it is positive. We therefore use a right-tailed one-sided p-value. On the other hand, we are interested in testing if we have the right degree of kurtosis in the data. To achieve this, we report two-tailed p-values for D2 by comparing the fraction of simulated values that are either greater than or less than its observed sample value, simulating under a range of null values. For the univariate data, we report the sample skewness coefficient, which is the signed square root of D1 to indicate the direction of the skewness, but the p-values reported are in relation to D1 itself, though this won’t matter.
Multivariate skewness and kurtosis tests.
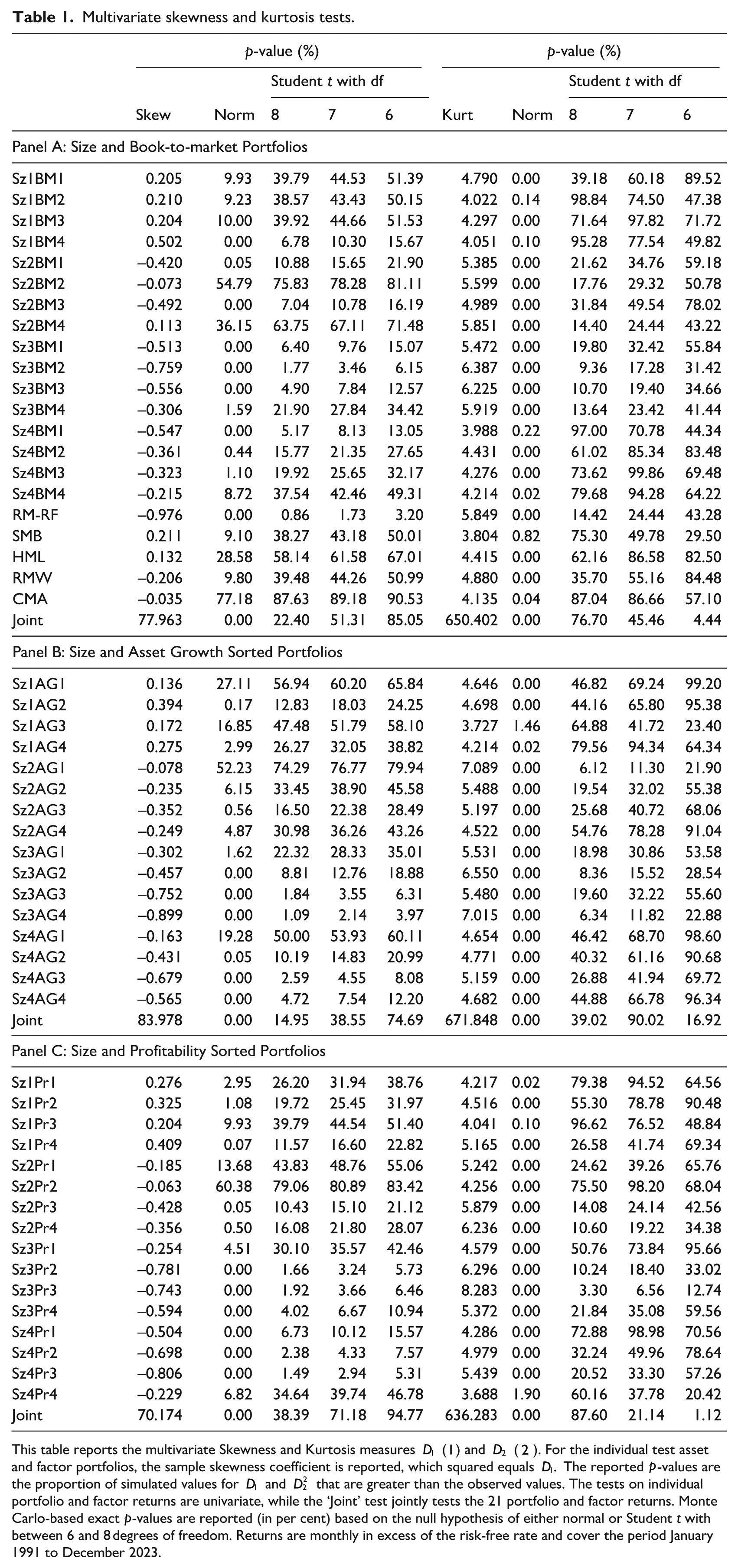
This table reports the multivariate Skewness and Kurtosis measures D1 (1) and D2 (2). For the individual test asset and factor portfolios, the sample skewness coefficient is reported, which squared equals D1. The reported p-values are the proportion of simulated values for D1 and
Panel A of Table 1 shows very strong evidence of non-normality, and the evidence against normality is strongest in the kurtosis statistic D2. The largest p-value for the kurtosis test D2 is only 0.82%. For the size and book-to-market portfolio, the largest p-value is only 0.22% for the large-growth portfolio – 11 of the 16 portfolios are zero to four decimal places. If the data is normally distributed, the kurtosis statistic should equal three, but we see that every portfolio is greater than three by a large margin. Even the factors, with the exception of SMB, are well above four. The joint kurtosis test has a p-value that is smaller than one hundredth of 1%. The p-value of the test for kurtosis consistent with a multivariate Student t distribution with 6 degrees of freedom is also rejected (just) at the 5% level, but we are unable to reject the null that the size and book-to-market portfolios come from a multivariate t distribution with 7 or 8 degrees of freedom. Looking at the skewness tests, we find that small stocks are generally positively skewed, but larger stocks tend to be negatively skewed. Interestingly, the size and value factors are also positively skewed, but the profitability, asset growth, and market return factors are all negatively skewed too. Six of the 16 size and book-to-market portfolios have skewness that is not statistically different from zero at the 5% level, but of course we must be cautious about interpreting multiple comparisons and the multivariate tests. As Richardson and Smith (1993) note, when returns are highly correlated, as our portfolio returns are, misleading conclusions can be reached by focusing on univariate tests. The evidence against normality from observing two independent variables that have statistically significant univariate kurtosis is much less significant if the two variables are highly correlated, as a few extremely large returns that may occur by chance, leading to one asset’s return having large sample skewness, will also affect the other stock because of this correlation. Thus, inference should focus on joint tests. The joint test for kurtosis is reported in the final row and is 650. Since the statistic is computed using 21 test assets and 396 monthly observations, if returns and factors were really jointly normally distributed, the test statistic would be normally distributed with a mean of 483 and a standard deviation of 3.1. The multivariate kurtosis test statistic is thus 53.5 standard errors from zero for the size and book-to-market returns!
Interestingly, the four small stock portfolios tend to have smaller kurtosis than larger stock portfolios. An important reason for this is that the number of stocks used in the small portfolio is significantly larger. The four smallest stock portfolios average around 125 stocks each, while the four largest stock portfolios average around 25 stocks. If we construct portfolios by ranking stocks into four size bins with equal numbers of stocks and then into four book-to-market portfolios independently, the number of stocks in the Sz1BM1 portfolio is significantly lower, and the Kurtosis statistic jumps to 6.7. All four Sz1 portfolios’ skewness jumps markedly too, with the Sz1BM1 with independent homogeneous sorts having a skewness statistic of 0.881, which is much higher than 0.205 in the dependent heterogeneous size bins. Of course, the Sz1Bm1 homogeneous independent sort is $7 million. Indeed, if the small portfolio is defined as the 25% smallest stocks by market cap, the average firm size for all value portfolios is only around $7 million.
The joint skewness test convincingly rejects the null hypothesis that returns are normally distributed (p-value of 0.0001), but is unable to reject the null of a Student’s t distribution with between 6 and 8 degrees of freedom. Since the Student t, like the normal, are symmetric distribution, this suggests a lack of power in skewness to reject the student t distribution.
4. Asset pricing with fat tails
If the n-dimensional vector Xt is distributed as a multivariate t random variable, its probability density function is given by

A feature of the multivariate t (MVT) density is that the tail probabilities decline at a polynomial rate rather than the exponential decay rate in the normal distribution, which means that the multivariate t distribution is fat-tailed. Because of this feature, the MVT distribution is used in the context of robust estimation and robust regression (Lange et al., 1989). It is well-known that MVT random variables can be expressed as a chi-square mixture of normal random variables

where Zt in an n-dimensional standard normal random variable and
If returns and factors are distributed as multivariate t then parameter estimates that maximize the log-likelihood function based on that density will outperform estimates based on, for example, the normal density. In particular, when Xt is multivariate t log-likelihood function is given by

A disadvantage of the non-normal distributions is that closed-form expressions for the maximum likelihood estimators are generally not available, requiring numerical optimization for estimating parameters. Indeed, the number of parameters involved, even for modest n can be quite daunting since there are n parameters for the mean vector and n(n + 1)/2 unique elements in Ψ. Further complicating numerical optimization is the need to impose the constraint that the scale matrix Ψ is positive definite.
However, for the multivariate t distribution the EM algorithm of Dempster et al. (1977) can be applied (Liu and Rubin, 1995) to provide a rapid iterative approach that converges monotonically to the optimal parameter estimates. The algorithm takes an initial guess for the mean vector and scale matrix, say



The conditional mean is thus a weighted average of the sample returns, where the weights are

where using the Mahalanobis distance between Xt and

we can write

so the maximum likelihood estimator of the mean under a multivariate t distribution places less weight on more extreme observations, since ut is a decreasing function of δt.
As an aside, the estimation algorithm works by casting the multivariate t as an inverted Gamma mixture of normal distributions, and then ut is the expected value of this mixing scale conditional on Xt and the mean and scale matrix. Heuristically, we can motivate it by taking the derivative of (6) with respect to μ setting equal to zero, multiplying both sides by Ψ and simplifying gives

So when the Mahalanobis distance of Xt from the mean is large, those observations are given a smaller weight. When the data is normal, the weight on each observation is constant and thus independent of the size of the Xt s. However, when returns are from a multivariate t distribution with finite degrees of freedom, then outliers occur more frequently than they would if the data were normal, and the sample average performs less efficiently than the maximum likelihood estimator because it is adversely affected by such outliers. The sample average in this case will be consistent and asymptotically normal, but it will be less efficient than maximum likelihood estimates because these optimally place less weight on extreme values, resulting in improved efficiency. Indeed, Lange et al. (1989) discuss using the multivariate t distribution as an explicit way to construct robust estimates of multivariate means and covariance matrices and multiple regressions in the presence of outliers.
Proposition 4 of Lange et al. (1989) shows that the asymptotic covariance matrix of

The asymptotic covariance matrix of the sample mean when the data are iid, equals its covariance matrix V. When the data is multivariate t then if v > 2 then V = v/(v − 2)Ψ, giving

In each case, we consider there are 16 test assets and 5 factors, so n = 21 and if v = 7, which seems to fit the data reasonably well, then the asymptotic standard errors for the sample average will be 14.3% larger than the standard errors for the maximum likelihood estimates, which is quite significant.
An advantage of allowing for non-normality by using the multivariate t distribution is that the standard Capital Asset Pricing Model (CAPM) of Sharpe (1964) and Lintner (1965) because it is a member of the broader class of elliptical distributions and the standard CAPM will hold for this class of multivariate distributions (Chamberlain, 1983; Owen and Rabinovitch, 1983). This enables us to test the performance of asset pricing models using a conditional distribution that is both tractable and justifiable theoretically, and yet can also account for the significant departures from multivariate normality we see in equity returns. And the Australian stock market is no different from other markets, and indeed, the large number of very small stocks suggests that non-normality is particularly relevant to the Australian empirical experience.
The components of Xt consist of rt, the N-vector of asset returns; and ft, the K-vector of factor returns, and we let εt be an N-vector of zero mean regression errors with nonsingular covariance matrix ∑ giving the factor structure

The parameters of the regression model are related to the moment for

When both ft and εt are normally distributed then rt and ft are jointly normal, and the conditional distribution of rt given ft is well-known, having a conditional mean

and covariance matrix

And we also have

As Kan and Zhou (2017) note, when returns and factors are multivariate normal, then ∑ is the covariance matrix of εt conditional on ft, but when both rt and ft is a jointly multivariate t random variable

showing that the conditional variance of rt given ft is not constant but is rather heteroscedastic. This is in contrast to the standard approach of modelling a regression in which the errors follow a student t distribution conditional on the regressors. As such, the regressors and the errors are independent. This class of models has been used in robust estimation because it downweights extreme observations (see, for example, Lange et al. (1989)). In cases where the exogenous variables are chosen by the researcher, this specification makes sense. In the context of asset pricing factor models, jointly modelling factors and returns as jointly multivariate t random variables arguably makes more sense. As noted above one can view the multivariate t as an inverse chi-square mixture of normals, so the leptokurtosis arises because on some days there is much less information than normal resulting in observations clustered around the mean, while on other days the amount of information, and hence variance, is much greater and this results in too many returns far from the mean (Blattberg and Gonedes, 1974). (Too many is measured relative to the normal distribution with the same mean and covariance matrix.) The joint multivariate t specification can be motivated as the volume of information flow affects all portfolio and factor returns, as they are all simply portfolios of component stock returns. Using this information flow interpretation to have regressors that are multivariate t random variables independent of the regression errors that are also multivariate t requires that the amount of systematic information (that affects factor returns) on any given day be independent of the amount of common idiosyncratic information (affecting the errors). This, while possible, is harder to motivate conceptually.
The key distinction between these two specifications is the conditional heteroscedasticity, and this heteroscedasticity has a specific functional form. In Appendix A, we present a GMM-test of the overidentifying moment condition
Alternatively, we can test between the two using a likelihood ratio type test. Unfortunately, the two models are non-nested, meaning that one model cannot be expressed as a restriction on the parameters of the more general model. When models are nested, then twice the difference in the log-likelihoods follows a chi-square distribution with degrees of freedom equal to the number of restrictions. However, Vuong (1999) shows that when two models, 1 and 2, are non-nested (as in the case of multivariate t errors versus multivariate t returns), then the test statistic

where Li is the log-likelihood of the model i, Ki is the number of parameters in the model i and ω is an estimate of the variance of the difference in the log densities of models 1 and 2, and can be used to conduct inference. In particular, under the null hypothesis that both models are equivalent (the expected value of the log-likelihoods is equal), the test statistic V will be asymptotically distributed as a standard normal random variable. When model 1 fits the data better, V will diverge V → ∞, while model 2 fits the data better then V → −∞.
When returns are multivariate t and we have the estimates

and

Kan and Zhou (2017) show that the asymptotic covariance matrix of the least squares and maximum likelihood estimates of the alphas and betas when the returns and factors are jointly multivariate t random variables with v degrees of freedom are:

and

respectively.
The ratio of the asymptotic variance of the two β estimates are given by

and thus the standard errors of

clearly showing this dependence on the squared Sharpe ratio. We can gauge the possible improvement in efficiency by noting that the ratio is bounded between
This raises the question of how to test the efficiency of the factors ft when returns are non-normal. The standard approach to testing asset pricing models follows Gibbons et al. (1989), who test the parametric restriction

When the factor model residuals εt are normally distributed, this hypothesis is tested using the GRS statistics

However, when returns and factors are multivariate t random variables, the GRS test is not appropriate. Zhou (1993) shows that the distribution of the GRS test statistic and the distribution of the OLS estimates vary only slightly when residuals are assumed to be either normally or multivariate t random variables. However, when the distribution of the market returns is taken into account, allowing returns to be multivariate t the distribution of the test statistics and the estimates of the GRS statistic and the regression parameter estimates are markedly different. He also shows that accounting for non-normality leads to higher p-values for the GRS test statistic, indicating that failing to account for non-normality biases the GRS test into rejecting asset pricing models. Indeed, Zhou (1993) shows that assuming normality when constructing critical values rejects the CAPM, but allowing for non-normality results in the GRS test no longer rejecting the CAPM in some situations.
MacKinlay and Richardson (1991) construct a GMM-based Wald test of the zero alpha restriction that doesn’t place distributional assumptions like normality. It is the asymptotic version of the GRS statistic, leading to a chi-square rather than F distribution under the null hypothesis. They also allow returns to be multivariate t random variables, noting the residual heteroscedasticity that this entails, and quantifying the bias in the GRS statistic that arises by erroneously assuming normality. The test continues to use the OLS estimates of the alphas, which we have seen from Zhou (1993) and Kan and Zhou (2017), are inefficient when the data is not multivariate t.
Kan and Zhou (2017) developed a likelihood ratio test to replace the GRS test when returns and factors are multivariate t random variables. They develop an EM algorithm to estimate the other model parameters while imposing the restrictions of the null hypothesis that α = 0 the null hypothesis using the following mapping


where Ψ
ε
= (v − 2)/v∑. Appendix

where
5. Results
We use the portfolio and factor returns to estimate and test multiple factor models using Australian returns that assume normality or a multivariate t distribution for factors and returns. Table 2 reports the maximum likelihood estimates of the means and standard deviations of the test assets and factors under these two distributional assumptions. The sample mean is the maximum likelihood estimate of the mean under the assumption of normality. The results are largely as expected. Within each size bin, we see sample excess returns increasing as portfolios move from growth to value (BM1 to BM4); decreasing, but not monotonically, from conservative to aggressive asset growth (AG1 to AG4); and increasing from weak to robust profitability (Pr1 to Pr4). We also find that standard deviations decrease within each size bucket as we increase all three non-size characteristics.
Maximum likelihood estimates of means and standard deviations under alternative distributional assumptions.
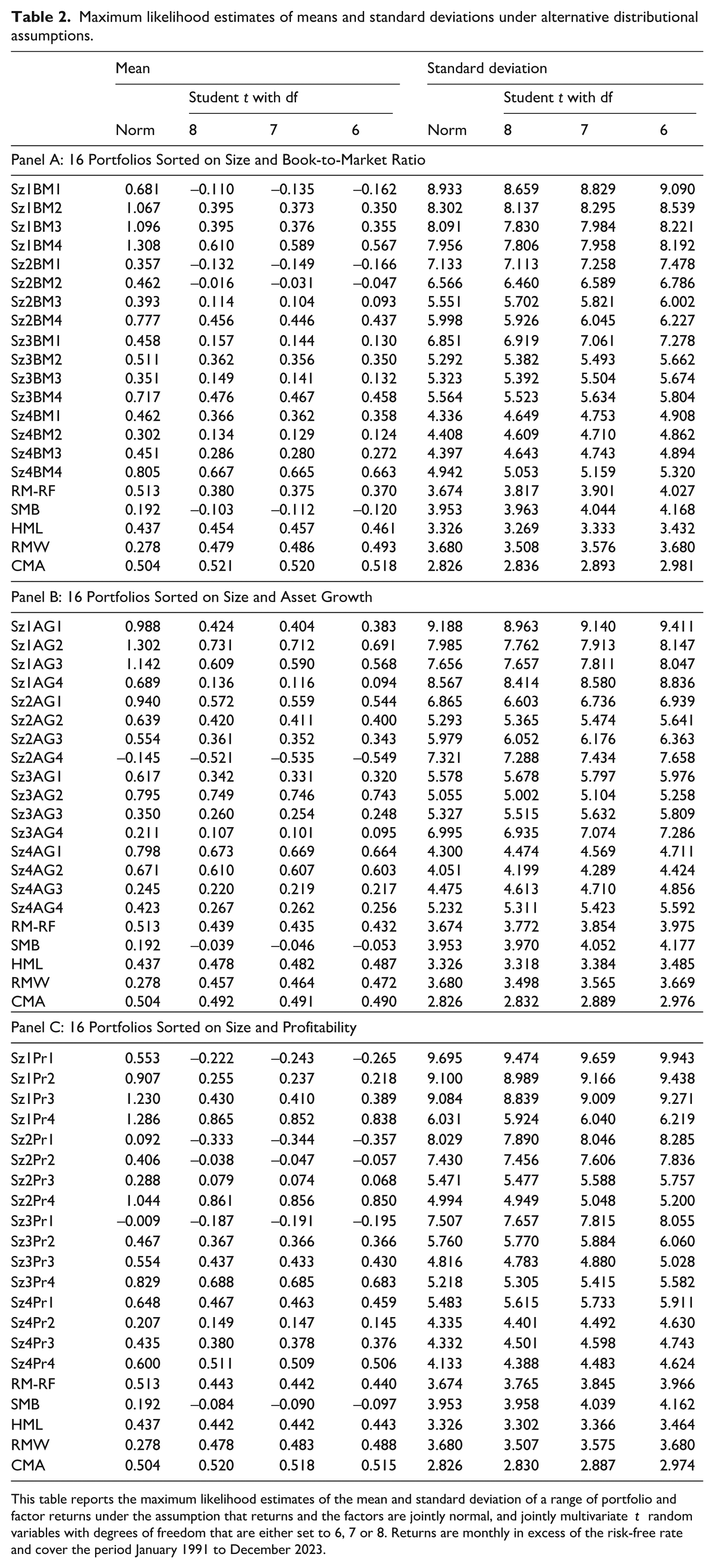
This table reports the maximum likelihood estimates of the mean and standard deviation of a range of portfolio and factor returns under the assumption that returns and the factors are jointly normal, and jointly multivariate t random variables with degrees of freedom that are either set to 6, 7 or 8. Returns are monthly in excess of the risk-free rate and cover the period January 1991 to December 2023.
These results are only statistically efficient if returns are normally distributed, because the sample average is not the maximum likelihood estimator of the mean when returns are non-normal. We can relax this assumption by estimating the means and standard deviations when returns and factors are jointly distributed as a multivariate t random variable. We also report those results in Table 2. We consider three different degrees of freedom: 6, 7 and 8. We find that 7 degrees of freedom seem to fit the data best based on the multivariate skewness and kurtosis tests discussed earlier, and considering values slightly higher and slightly lower allows us to gauge how robust the results are to varying the degrees of freedom. Relaxing the normality assumption on expected returns has a remarkable impact on the size and book-to-market sorted portfolios. The mean return on the small growth stock portfolio (Sz1Bm1) decreases from 68 basis points per month to -14 basis points per month – a change of over 0.8% per month or about 10% per year! The decrease in expected returns among the four largest portfolios only drops 0.1% to 0.2% per month. The value effect is still strongly observable. For example, among the smallest stocks, the spread between the extreme value and growth portfolios is over 0.6% per month if returns are assumed to be normal and over 0.7% if returns are student t with 7 degrees of freedom. The spread for the largest four portfolios drops from 0.34% to 0.30%, with all returns being at a slightly lower level.
All portfolio mean returns are lower when student t distributions are used rather than normal returns because the most extreme positive returns are when the Mahalanobis distance δt is largest. And it is especially true that returns on small-cap stocks tend to be much higher during months that are more extreme. If we calculate the average return on the 5% days with the largest δt, which are when δt > 65, the average monthly percentage return on the small growth stock is 7.64% per month. On months where δt ≤ 64 the mean excess return was 0.29% per month. That is a difference of 25 times! This pattern is similar for the other small stock portfolios, all having average returns of between 5% and 7% per month during the months where the Mahalanobis distance is greatest. The quadratic loss function that comes with the normality assumption places too much weight on these extreme observations, because such extreme outcomes simply don’t arise frequently when returns are normal, but happen relatively frequently when returns exhibit fat tails, as in the multivariate t distribution. These effects are seen also in the scatter plot of the Mahalanobis distance against the returns for the Small-Growth portfolio, the market and SMB factor returns in Figure 1. We see a large number of observations with high returns when δt is between 80 to 100. And for the SMB, the ratio of positive to negative returns when δt is above about 75 looks to be roughly two-to-one. When all these larger returns are down-weighted, the estimates of the means are moderated. Again, this is statistically optimal because the sample average places far too much weight on extreme outcomes because if the data truly is normal, such large outcomes simply don’t occur, however, outliers are common when dealing with leptokurtic distributions such as the multivariate t distribution.

Scatter plot of small-growth stocks, market and size factor returns against δt.
This dramatic change in signs is even larger than that observed in the United States returns. For example, Kan and Zhou (2017) note that the smallest size and book-to-market portfolio’s conditional mean decreases by 2% annually when estimated by maximum likelihood using a Student t rather than a normal. In Australia, the difference in estimates is closer to 9% annually. This is because the smallest stocks in the Australian market are microscopic relative to US firms. However, the difference in the size and book-to-market portfolio for growth stocks that are between the 75th and 90th percentiles by market capitalization (Sz3Bm1), the difference between the normal and t maximum likelihood estimates of the mean are over 3.5% annually.
Similar results hold for the other sorting strategies. To illustrate, for the profitability-sorted stocks, the drop in estimated mean returns when using a multivariate t distribution with finite degrees of freedom is marked. The average decrease in mean returns for the four small-size portfolios is about 70 basis points per month. The profitability effect is still amplified: under normal returns, the spread Sz1Pr4-Sz1Pr1 is about 75 basis points, but for a student t distribution with 7 degrees of freedom, the same spread is 110 basis points per month.
Interestingly, the estimates of the factor prices of risk, other than the size factor SMB, don’t change dramatically when excess kurtosis is accounted for. The excess returns to the market, HML and CMA are all about, or for HML slightly below, 50 basis points per month when returns are normal, and they are all between 44 and 48 basis points if we assume a Student t distribution with 7 degrees of freedom and estimate them jointly with the Profitability sorted portfolios. And RMW’s price of risk increases from 28 to 48 basis points. However, the size factor drops from 19 basis points to negative 10 basis points. A 30 basis point swing flipping the sign is the most striking result that we find. Note also that the maximum likelihood estimates of the factor means under the multivariate t assumption vary as the assets change because although the estimates are a weighted average of that factor’s returns, varying the asset portfolio returns will cause variations in the weights and result in small variations across specifications.
Interestingly, the standard deviations don’t change appreciably when fat tails are accounted for. Table 3 reports the fitted maximum likelihood estimates of the betas for the three-factor model for all three portfolio formation strategies. Interestingly, we find that the distributional assumptions have very little impact on the betas, which stands in stark contrast to the profound impact on the estimates of alpha. This is consistent with the results in Table 2 that find very little impact on the estimates of the standard deviations.
Portfolio betas from the three-factor model for 16 size and book-to-market portfolios.

This table reports the maximum likelihood estimates of the slope coefficients or betas from the Fama and French (1993) three-factor model for portfolios sorted based on size and Book-to-Market ratios under the assumption that returns are normally distributed and that returns and the factors are jointly multivariate t random variables with 7 degrees of freedom. Returns are monthly in excess of the risk-free rate and cover the period January 1991 to December 2023.
Table 4 reports the alphas for four models: the one-factor Capital Asset Pricing Model, the three-factor model of Fama and French (1993), the five-factor model of Fama and French (2015) that adds profitability and asset growth to the three-factor model, and a four-factor model (labelled as FF4) that is inspired by the Hou et al. (2015) 2 that includes a market, size, profitability and investment factor. As the table shows the magnitudes of the alphas vary remarkably depending on whether one uses simple sample moments, which are only MLEs if returns are normal, or if we assume returns and factors exhibit kurtosis following the multivariate t distribution with 7 degrees of freedom. For the size and book-to-market sorted portfolios, the Sz1Bm1 portfolio goes from trivially negative (−0.036) to a much larger negative alpha (−0.645) in the CAPM and FF3 models, and in the FF5, the alphas switch signs from 0.107 to −0.131. The evidence against the CAPM is stronger if one imposes normality.
Portfolio alphas.

This table reports the alpha from four asset pricing models: the basic CAPM, the Fama and French (1993) three-factor model, and the four- and five-factor models of Fama and French (2015). Returns are monthly in excess of the risk-free rate and cover the period January 1991 to December 2023.
Of course, this is only one of the 16 test asset portfolios that we consider. The entire results are summarized in Table 5 using the summary statistics suggested by Fama and French (2016), including the likelihood ratio test statistic for zero alpha (where Fama and French (2016) report the GRS statistic), and the average absolute alpha, the average absolute alpha scaled by the average deviation of estimated mean from the grand estimated means, and the mean squared alpha scaled by the average deviation of squared deviation of means from the grand mean. The FF3 model does the best when returns are normal when portfolios are formed by sorting stocks on Size and Book-to-Market ratio, while if returns and factors are assumed to be drawn from a multivariate t distribution with 7 degrees of freedom, the FF5 model produces the smallest alphas on average. However, the FF5 model does better when stocks are formed by sorting on Size and Asset Growth and a bivariate sort of Size and Operating Profitability.
Summary statistics of asset pricing tests under various distributional assumptions.

This table reports likelihood ratio tests of four different asset pricing models: the CAPM, Fama-French Three-, Four- and Five-Factor models. Three different sets of test assets are used: 16 portfolios formed by sorting stocks into four portfolios based on Size, and then four portfolios for each size quartile based on Book-to-Market Ratio, Asset Growth, and finally Profitability. Likelihood Ratio Tests under normal, and student t returns (with 6,7, 8 and estimated degrees of freedom) are estimated, and the average absolute alpha, average absolute alpha scaled by average absolute deviation of estimated means from grand mean, and the average squared alpha scaled by average squared deviation of estimated means from grand mean. Returns are monthly in excess of the risk-free rate and cover the period January 1991 to December 2023.
Significance is denoted by * at the 10% level, ** at the 5% level, and *** at the 1% level.
The evidence against all four asset pricing models is greater when returns are multivariate t than when they are assumed to be normal, with the size of the LR statistics being higher in the three t LR tests than in the Norm LR test for the size and book-to-market portfolios and the size and asset growth portfolios, though the magnitudes of the LR statistics are similar for normal and t distributions in the size and profitability sorted assets. A similar result is seen in the US returns in Kan and Zhou (2017). Looking at the likelihood ratio tests when we assume normality to test the size and book-to-market portfolios, we can reject only the basic CAPM, but none of the multiple factor models. However, when accounting for student t returns all cannot reject either the three- or five-factor models, but the CAPM and FF4 models are both rejected. However, all four models except the full five-factor model are rejected if the leptokurtosis of the return distribution is accounted for by using a student t distribution. The alternative portfolio sorts are all rejected by the data. The average squared alphas scaled by squared de-meaned means under the t distributions are larger than under the normal distribution, with the increase being largest for the CAPM.
6. Robustness and simulations
A natural question that arises is how robust and important the assumption that returns are heteroscedastic. To address this issue, we have discussed the Vuong non-nested Likelihood Ratio test and a GMM-based specification test in Table 6. The Vuong test will be large and positive if the joint multivariate t model fits the data better than the homoscedastic multivariate t error model, it will be large and negative if the homoscedastic errors are more appropriate, and it will be close to zero if the models are indistinguishable. Interestingly, the CAPM errors are unable to be separated in the three data sets, while the Vuong test statistics are greater than three for all multifactor asset pricing models in all three portfolio formation contexts. To explore the performance of these tests, we undertake a Monte Carlo simulation experiment in Table 7. The left half of the table reports the percentiles of the Vuong test statistic when the homoscedastic multivariate t error model is true, and the right half of the table reports the percentiles of the Vuong test when the heteroscedastic joint multivariate t model is true. The true parameters correspond to the maximum likelihood parameter estimates estimated under that model. We find that the test doesn’t do particularly well in differentiating the two alternative models when there is a single factor, as the upper tail of the homoscedastic model and the lower tail of the heteroscedastic models are both close to zero (and cross for the size and profitability sorted returns). However for all the multiple factor models the right 99th percentile (95th percentile for the three-factor model) of the test when the data is homoscedastic (regression errors are t) are statistically significant at the 5% central critical value of −1.96, and when the data are heteroscedastic (returns and factors jointly t) the left 1st percentile (5th percentile for the three-factor model) are statistically significantly greater than the 5% central critical value of 1.96. The more factors there are, the more information about the latent volatility mixing parameter there is, causing a greater difference between the two alternative multivariate t specifications and the more useful accounting for the error heteroscedasticity that the joint multivariate t distribution produces.
Model specification tests.

This table reports the Vuong non-nested Likelihood Ratio test of the null hypothesis that the heteroscedastic multivariate t model is no better than the homoscedastic t error model. This test statistic is distributed standard normal under the null that the two non-nested models are equivalent, and is positive when the heteroscedastic model is better, and negative when the homoscedastic model is better. Significance is denoted by * at the 10% level, ** at the 5% level, and *** at the 1% level. The final two columns report the GMM-based test of the null hypothesis that the conditional variance of the factor model residuals is unrelated to the Mahalanobis distance of the factors from their mean and a bootstrapped p-value. Returns are monthly in excess of the risk-free rate and cover the period January 1991 to December 2023.
Percentiles of Vuong’s non-nested likelihood ratio test.

This table reports the five quantiles of simulated values of the Vuong non-nested Likelihood Ratio test when the true model is a regression model with factor distribution as multivariate t random variables independent of the regression errors that are also multivariate t (left half), and when both factor and test asset returns are jointly multivariate t random variables. Hypothetical data is simulated using true parameter values set to the maximum likelihood estimates of each corresponding model and portfolio formation strategy. Returns are monthly in excess of the risk-free rate and cover the period January 1991 to December 2023.
The right panel of Table 6 reports the GMM specification test presented in Appendix A. The middle column reports the size of the test statistic, and the right column reports the bootstrapped p-value. In all cases, we cannot statistically reject the null hypothesis of homoscedasticity at the 5% level for the CAPM, but we are able to reject the null hypothesis of homoscedasticity for all multiple factor models for all test asset portfolio formation strategies. The size and power of the test are explored using a simulation experiment presented in Table 8. The first two columns report the rejection frequency using the asymptotic critical value 26.3 (chi-square distribution with 16 degrees of freedom) when returns are generated first from the homoscedastic multivariate t error model and then from the heteroscedastic joint multivariate t model. The results show that the rejection frequency under the null is far too high, rejecting between 16% and 30% when it should only reject in 5% of samples. To address this, we construct the critical value by bootstrapping the residuals. In particular, we estimate the GMM parameters (coinciding with the OLS coefficients) and then resample from those residuals with replacement 500 times, generating returns using the regression alphas and betas, which results in multivariate t errors that are independent of the regressors. The p-value of the test statistic is then given by the fraction of the bootstrapped sample greater than the estimated quantity. When the true data is homoscedastic, these bootstrapped critical values reject between 3.8% and 4.9% of samples, quite close to the theoretical 5%. The test also has remarkable power when the data is heteroscedastic, being rejected in roughly 90% of samples when there are three factors and 99% of samples when four or five factors, but only 10% of samples when the CAPM is true.
Monte Carlo rejection frequencies of the multivariate t heteroscedasticity test.

This table reports the rejection frequencies of the Vuong non-nested Likelihood Ratio test of the null hypothesis that the heteroscedastic multivariate t model is no better than the homoscedastic t error model. This test statistic is distributed standard normal under the null that the two non-nested models are equivalent, and is positive when the heteroscedastic model is better, and negative when the homoscedastic model is better. Significance is denoted by * at the 10% level, ** at the 5% level, and *** at the 1% level. The final two columns are a GMM-based test of the null hypothesis that the conditional variance of the factor model residuals is unrelated to the Mahalanobis distance of the factors from their mean and a bootstrapped p-value. Returns are monthly in excess of the risk-free rate and cover the period January 1991 to December 2023.
Another question is the importance of accounting for fat tails. The efficiency gains discussed above are asymptotic in nature. To explore the size of efficiency gains that accrue to using the robust estimation methods in finite samples, we undertake a small Monte Carlo experiment. In particular we simulate 10,000 replications of a range of six data generating processes and estimate the sample average return and the maximum likelihood estimates of the mean assuming returns and factors are jointly multivariate t random variables (MLE-t), and the ordinary least squares and MLE-t alphas and report the percentage increase in average mean-squared errors for the sample average mean returns over the maximum likelihood estimates of the means in Table 9 and alphas in Table 10. In particular, the statistics we report, for example, for the means, as

where μi is the assumed true mean for portfolio i’s return,
Normal returns,
Multivariate t returns with 7 and 10 degrees of freedom,
Multivariate t errors are independent of multivariate t factors,
Mixture of normal distributions with three different mixing probabilities.
Mean squared error of means.
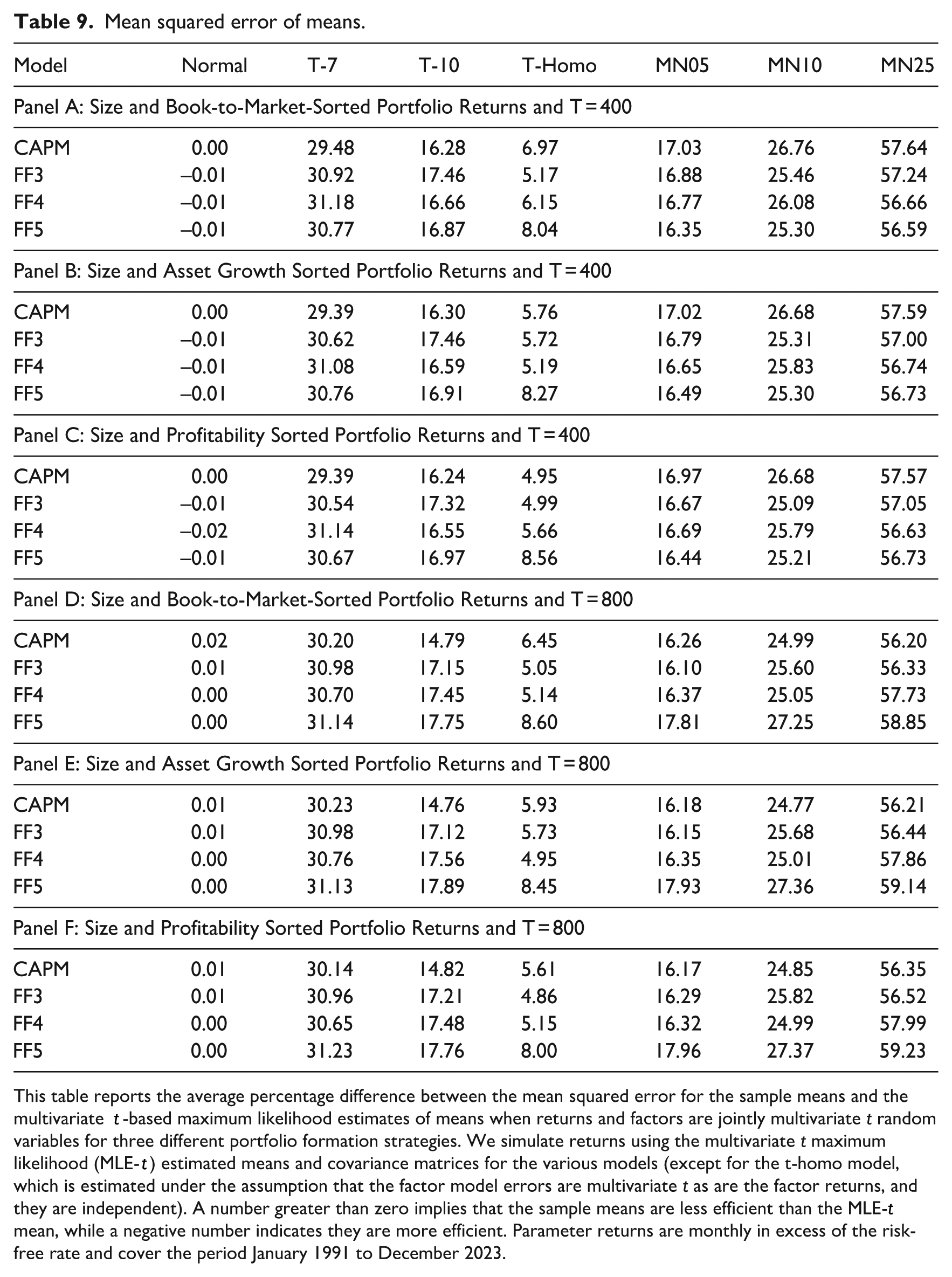
This table reports the average percentage difference between the mean squared error for the sample means and the multivariate t-based maximum likelihood estimates of means when returns and factors are jointly multivariate t random variables for three different portfolio formation strategies. We simulate returns using the multivariate t maximum likelihood (MLE-t) estimated means and covariance matrices for the various models (except for the t-homo model, which is estimated under the assumption that the factor model errors are multivariate t as are the factor returns, and they are independent). A number greater than zero implies that the sample means are less efficient than the MLE-t mean, while a negative number indicates they are more efficient. Parameter returns are monthly in excess of the risk-free rate and cover the period January 1991 to December 2023.
Mean squared errors of alphas.

This table reports the average percentage difference between the mean squared error for the sample alphas and the multivariate t-based maximum likelihood estimates of alphas when returns and factors are jointly multivariate t random variables for three different portfolio formation strategies. We simulate returns using the multivariate t maximum likelihood (MLE-t) estimated means and covariance matrices for the various models (except for the t-homo model, which is estimated under the assumption that the factor model errors are multivariate t as are the factor returns, and they are independent). A number greater than zero implies that the OLS alphas are less efficient than the MLE-t alphas, while a negative number indicates they are more efficient. Parameter returns are monthly in excess of the risk-free rate and cover the period January 1991 to December 2023.
The multivariate t error model has regression errors distributed as multivariate t independent of ft and is estimated using the EM algorithm outlined in Appendix B and simulated as discussed in Appendix D.
The mixture of normal distribution, in which Xt ~ N(μ,V1) with probability p and Xt ~ N(μ,V2) with probability 1 − p, is an elliptical distribution (as is the multivariate t) that exhibits fat tails. However, it is interesting to consider because in this case, the multivariate t distribution is misspecified, and yet the maximum likelihood estimates based on it may outperform the sample average because it is robust and downweights extreme returns. To keep parameterization manageable, we introduce a single parameter γ (that depends on p) and let V1 = γ/(1 + p(1 − γ))V and V2 = γ/(1 + p(1 − γ))V, so that, coupled with the fact that the means are state-invariant, the covariance matrix of Xt is V = pV1 + (1 − p)V2 since pγ/(1 + p(1 − γ)) + (1 − p)/(1 + p(1 − γ)) = 1. To ensure the kurtosis of the variables is plausible, we consider 3 cases: pA = 0.005 and γA = 6.2981, pB = 0.10 with γB = 5.3738, and pC = 0.25 and γA = 5.4575. Appendix D describes how we simulate returns in all these cases.
Table 9 reports the average percentage increase in mean squared error across the mean parameters for the six models considered above, with two different sample sizes: 400 observations consistent with our current sample size, and 800, corresponding to a little over 66 years of monthly returns. When returns are normal, the robust multivariate t-based maximum likelihood estimator of the means performs about as well as the optimal ordinary least squares estimator. However, the multivariate t-based maximum likelihood estimator performs better than the least squares whenever there is excess kurtosis relative to the normal distribution, such as when returns and factors are jointly multivariate t random variables, when the factor model errors are multivariate t independent of the factors, or when returns and factors come from a fat-tailed distribution other than the multivariate t distribution. When the multivariate t distribution with 7 degrees of freedom, the sample mean has, on average, a MSE 30% higher, and when the degree of freedom is 10, the gains drop to about 17% when using 400 monthly observations and 15% when the sample size is doubled to 800. The T-Homo results refer to the homoscedastic multivariate t error model considered above. This model has returns with fat tails, but the heteroscedastic error joint multivariate t maximum likelihood estimator is misspecified. However, the sample average returns have an MSE that is still on average 5% larger than the (misspecified) maximum likelihood-based estimator. Finally, when we simulate returns from any of the three mixture of normal distributions that are elliptical random variables that exhibit excess kurtosis and produce heteroscedastic factor model errors but are not from the multivariate t distribution so the t-based maximum likelihood estimators are inefficient, but provide impressive improvements over the sample mean that on average have MSEs larger than our robust estimator of between 16% and 60% depending on parameterizations. This provides strong evidence that the MLE-t estimator is a useful robust estimator: even when returns are normal is doesn’t markedly underperform the optimal sample average because the normal case is a special case of the robust estimator when the degree of freedom parameter increases without bound. The only downside is one irrelevant parameter. However, when there are fat tails, even when these are drawn from a different distribution, and even when the factor model errors are homoscedastic, the robust multivariate t-based maximum likelihood estimator dramatically outperforms the sample average return. Table 10 repeats the experiment for alphas, and the same picture emerges: the robust multivariate t-based maximum likelihood estimator does no worse than the least-squares estimator when that is optimal and provides significant efficiency gains when returns exhibit fat tails, even when the multivariate t distribution is misspecified.
7. Conclusion
We explore the impact of relaxing the normality assumption and estimate means, alphas, and betas using methods other than least squares. We provide strong evidence against the multivariate normality assumption using tests of multivariate skewness and kurtosis, but we cannot reject the null hypothesis that returns and factors are jointly multivariate t random variables with 7 degrees of freedom. This approach is different from the case where the multivariate regressions are estimated assuming that the residuals are multivariate t conditional on the factors, which means that the residuals are conditionally heteroscedastic.
Although estimates of standard deviations and betas are similar when returns are estimated using maximum likelihood under normality and the multivariate t distribution, estimates of means and alphas change dramatically. We find that the mean excess return for the small growth portfolio decreases by more than 0.8% per month, the mean estimate of the size SMB factor flips from positive to negative, and the average squared alphas are typically higher after accounting for fat tails. The evidence against asset pricing models are higher using the likelihood ratio test under the multivariate t distribution than under the normal, showing the importance of accounting for non-normality.
Key practical and research applications
Extreme returns are common stock returns, and traditional estimates of key features of asset pricing models, such as the price of factor risk, are adversely affected by such outliers.
Estimating models using robust measures provides practitioners with more reliable parameter estimates. Simulation results show that the robust estimation method based on the multivariate t distribution performs much better even when returns have extreme returns from a range of fat-tailed distributions, and it shows that the sign of the size effect changes relative to the sample average factor return.
The robust methods provide practitioners and researchers alike with improved estimation tools.
Footnotes
Appendix 1
Acknowledgements
I thank two anonymous referees for their feedback and Richard Colthurst for very useful conversations and help with constructing the portfolio and factor returns.
Final transcript accepted 27 November 2025 by Philip Gharghori (AE Accounting).
Funding
The author received no financial support for the research, authorship and/or publication of this article.