
Abstract
Analysis of stresses in components of even modestly complex geometries often require the use of finite element analysis (FEA). For testing a large number of design options quickly, FEA can be time consuming and provides more accuracy than required. In this project, a machine learning-based system is developed to provide quick and approximate solutions to stress analysis problems in parametrised compressor disc geometries. Simple mechanics problems were completed preliminarily to test the practicality of machine learning approaches for this application. This included applying instance selection by the
Introduction
During the early design stages of a component, it is often necessary to gain an approximate idea of whether a design could withstand the operating stresses before developing it further. A designer frequently desires to test a range of design options of different geometries quickly. Using FEA at each of these design steps is time consuming and provides an unnecessary level of accuracy. Therefore, there is a need for an approach which can quickly provide approximate answers. A machine learning-based system can provide approximate analysis in seconds, where FEA may take a number of hours. 1 Machine learning provides a great advantage when analysing designs of similar geometries. In this study, machine learning has been used to predict the stresses in an axial compressor disc. This problem was considered suitable for a machine learning problem because of the simplicity in parameterising the compressor disc geometry. Additionally, the boundary conditions and loads on a compressor disc are simple to approximate.
The work of Javadi et al. 2 substitutes the constitutive material model for a neural network incorporated in the finite element programme. The neural network was trained using data representing the stress, strain and displacement response to an applied load. The overall system was effective at estimating the deflection of an end-loaded cantilever formed of nine quadratic quadrilateral elements. The system was trained to find the relationship between stress and strain for non-linear systems. An additional benefit of the model was its ability to incorporate experimental data into the model to more accurately predict the complex behaviours of materials such as soil. The drawback of this approach is the inability to generalise the model for more complex problems.
For irregular 2D geometries, the approach of Nie et al.
3
provided a method which was versatile for however less accurate (10.4% error) due to over-simplification of geometries. Cantilever shapes were formed from rectangular elements arranged in a
Physics informed neural networks (PINNs) have been found to help reduce the required training data in simple geometries. 6 However, the improvements to performance and accuracy from physics informing have only been found in nonlinear elastoplasticity. 7
The complex geometries of aortas were analysed using a machine learning-based process by Liang et al. 1 This was achieved by meshing each aorta by mapping it from a uniform rectangular grid, allowing convolution operations to be used. Before predicting stresses from the shape and internal pressure of the aorta, the input shape data was passed into a shape encoder. The shape encoding process used principal component analysis to represent the 15,000 inputs (5000 nodes located in 3D space) with three scalar values. The stress output was decoded from 64 values up to 15,000 values across the aortic wall.
Madani et al. 8 approximated stress analysis of artery walls using five different neural networks. The FEA model that data was drawn from analysed 2D cross-sections and simplified blocked arteries into ideal shapes. In general, the networks were trained to predict the maximum von Mises stress and its position in the cross-section. Two of the networks received a set of parameters as inputs and three received an arterial image input for convolutional operations. Some networks also predicted other intermediary outputs, such as heatmaps and prediction of the parameters from an image input. The most accurate von Mises stress prediction (9.86% error) came from mapping the parameters to the stress directly.
Overall, the literature provided examples of machine learning applied to 2D FEA problems and 3D problems which could be solved in a 2D space. CNNs have produced accurate surrogate models for thin 3D geometries which are mappable to a 2D rectangular grid. If a stress field output is required, a truly 3D problem will require significantly more data than a 2D problem. However, if calculating a single maximum stress value and its location from parameters, as carried out by Madani et al., 8 3D problems are feasible for problems which can be defined in a reasonable number of parameters.
Machine learning approaches for mechanical problems
Dimensionality
It was expected that the training data set for the final model would be very large due the large number of inputs. Such data sets are susceptible to the ‘curse of dimensionality’. This refers to problems which arise when training data has high number of dimensions. In order to collect a reasonable amount of data for all combinations of input variables in a high-dimensional feature space, an excessive amount of training data is required. This leads to the opposing problems of having a considerable number of samples or having sparse data in each dimension. Another problem is that the Euclidean distances between all samples in high-dimensional space have significantly less variance. This is problematic for clustering algorithms which attempt to group similar samples to create dissimilar groups. Feature importance techniques (further explained in Section 5.3.2) can help in the process of reducing dimensionality. Inputs with lower importance scores can be removed without significantly impacting the accuracy of predictions.
Minimum redundancy maximum relevance algorithm
Dimensionality reduction is an effective solution to the curse of dimensionality in many regression applications. In this project, dimensionality reduction through mininum-redundancy-maximum-relevance (mRMR) has been explored. mRMR is a feature selection process which ranks input variables by importance. In MATLAB, mRMR is applied through the algorithm proposed by Peng et al.
9
where starting from a feature set
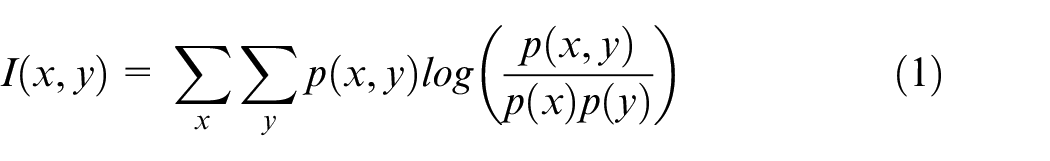
The relevance of the optimal feature set

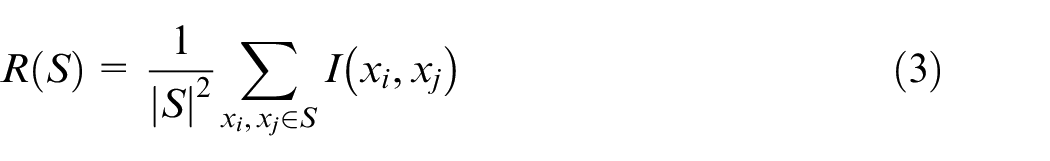
In order to rank features by importance, the relevance and redundancy of each feature is calculated using equations (4) and (5). The ratio
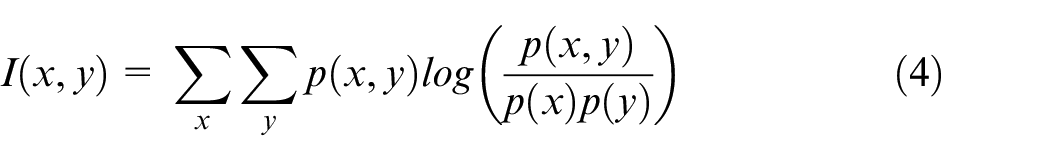
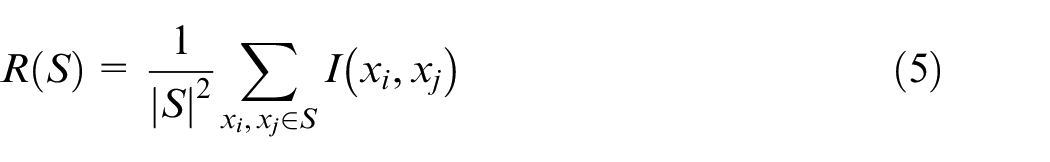
Instance selection algorithms
Instance selection aims to reduce the size of a training data set to a smaller representative set with minimal increase in training error. Many efforts have been made to apply clustering algorithms to instance selection, however these have mainly been focused on classification.
10
Rodríguez-Fdez et al.
11
proposed an instance selection algorithm composed of three modules which begun with a
Plate geometry and loads.
The neural network trained for this problem used a structure of (6/12/12/1). The stress at a location (
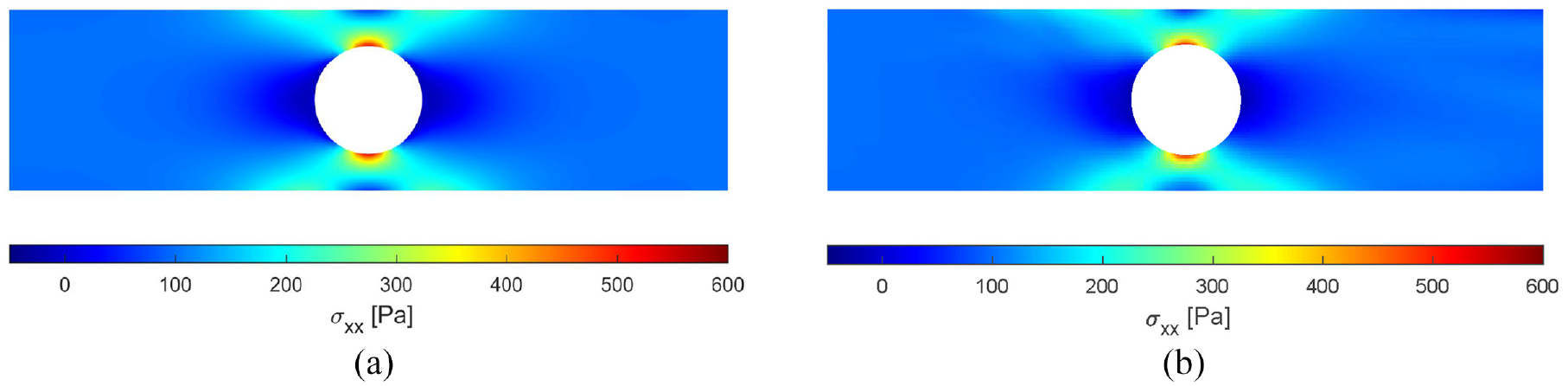
Predicted distributions of
To reduce the amount of redundant training data, a
In this application, it was sought to reduce the number of data points in areas of low stress variation. Stress concentrations around the hole would require more samples for accurate regression. The simulations were repeated with
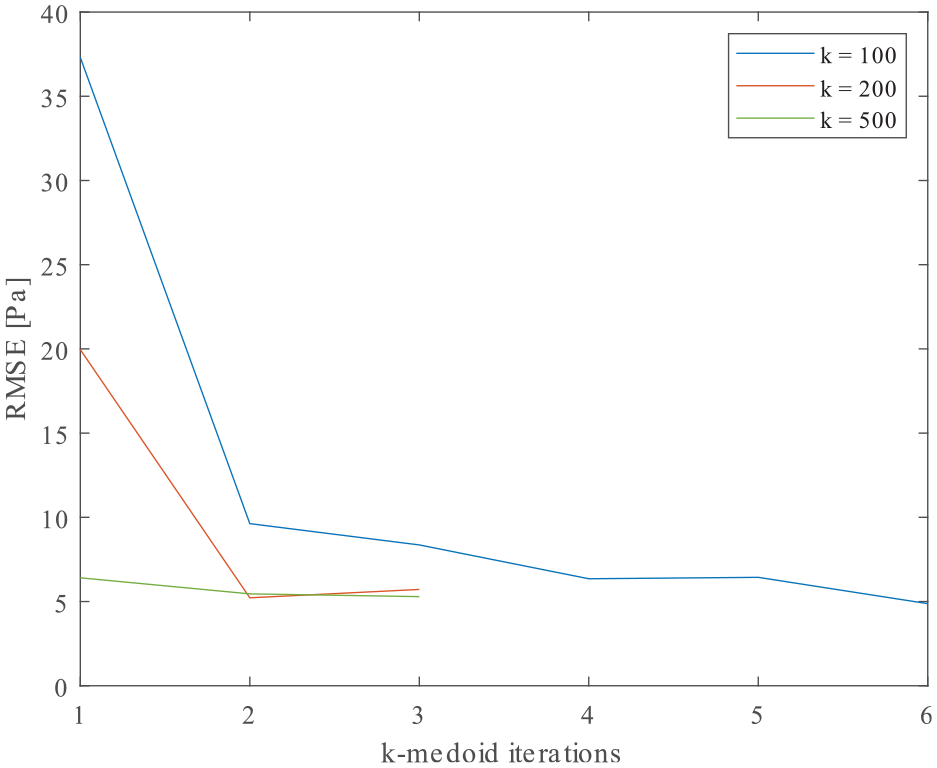
RMSE of NNs trained on downsampled data sets.
With low numbers of clusters and iterations, centroids were distributed highly asymmetrically and stress distributions appeared skewed. Figure 4(a) displays an arrangement of 100 centroids after one iteration of
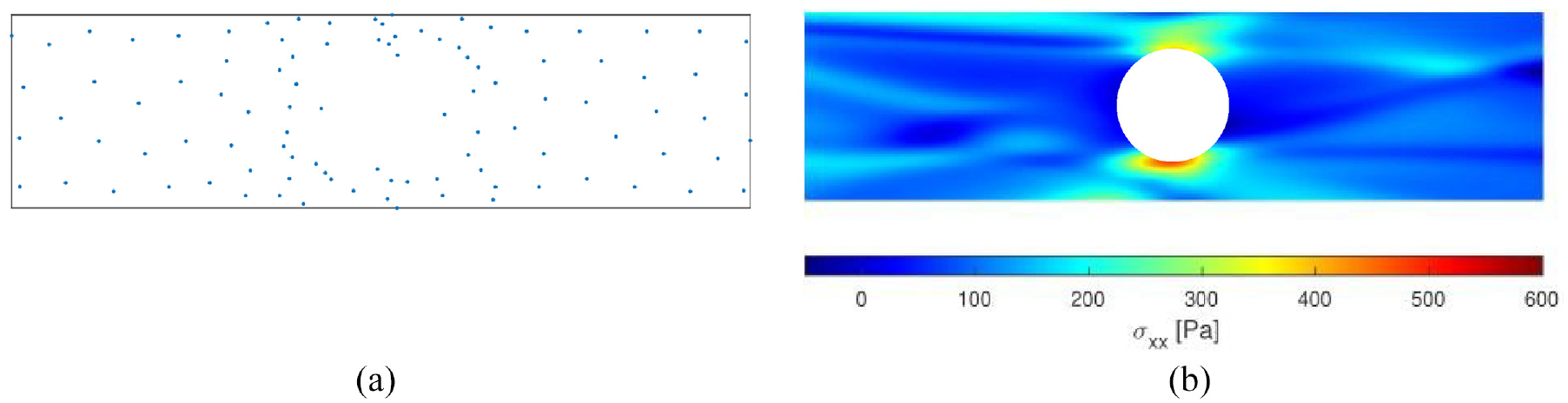
Data sampling and network performance with
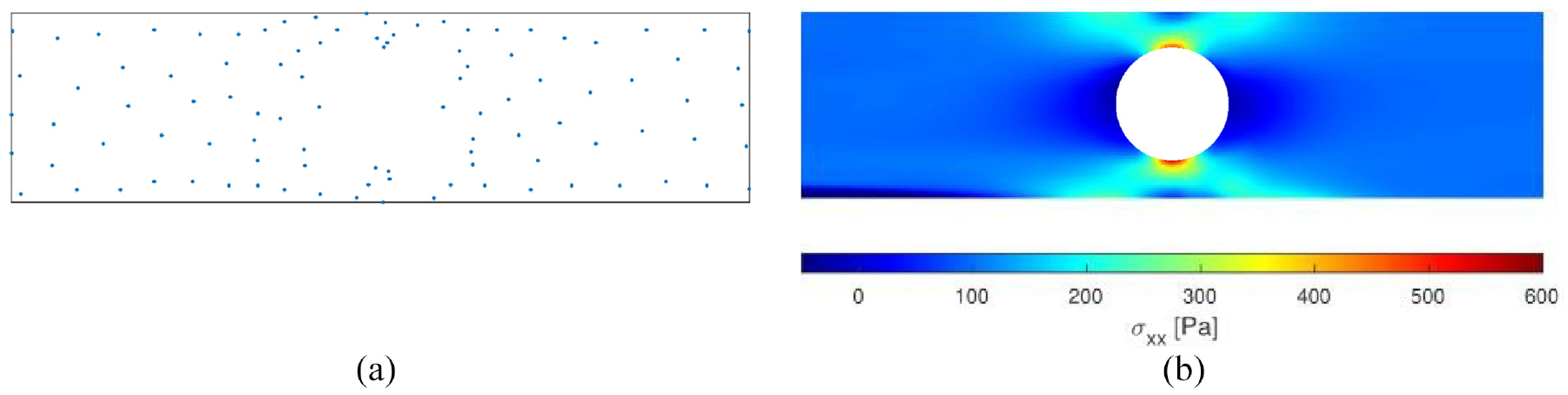
Data sampling and network performance with k = 100 and six iteration of k-medoids: (a) centroid locations and(b) predicted distribution of
Completing four iterations of
Compressor disc model
Model geometry
A simplified model of a compressor disc was devised to define the stress analysis problem. First, loading schemes and boundary conditions were identified. Then the geometry was parametrised so that FEA simulations in Abaqus could be automated. The training data set was built using FEA data from automated simulations using different combinations of parameters. The simplified axial compressor profile in Figure 6 is based on previously used models for fatigue analysis in compressor discs.14,15 Table 1 lists a range of example values that were modelled.
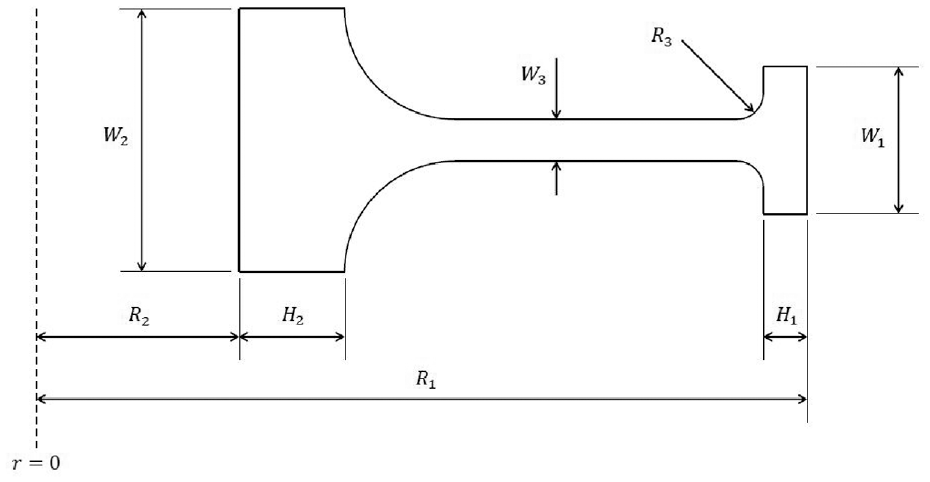
Compressor disc profile dimensions.
Dimension ranges.
An axisymmetric model was chosen to simplify the problem to 2D. This approximation is more suitable for an assembly which uses circumferentially orientated dovetail joints between the disc and blades. Although the local stress concentrations produced at axially orientated dovetails are not axisymmetric, the local stress effects are assumed to diminish away from the joints by Saint-Venant’s principle to a degree that they can be ignored for first-pass stress analysis of the overall disc geometry.
Finite Element Model
Applying the previously mentioned assumptions yields the model set up in Figure 7. The model considers the distributed body-force due to disc rotation together with the radial force due to the blades, which is modelled as a negative pressure on the outer rim. These loads are modelled separately for each geometry so that they may be adjusted independently in the final machine learning-based system.
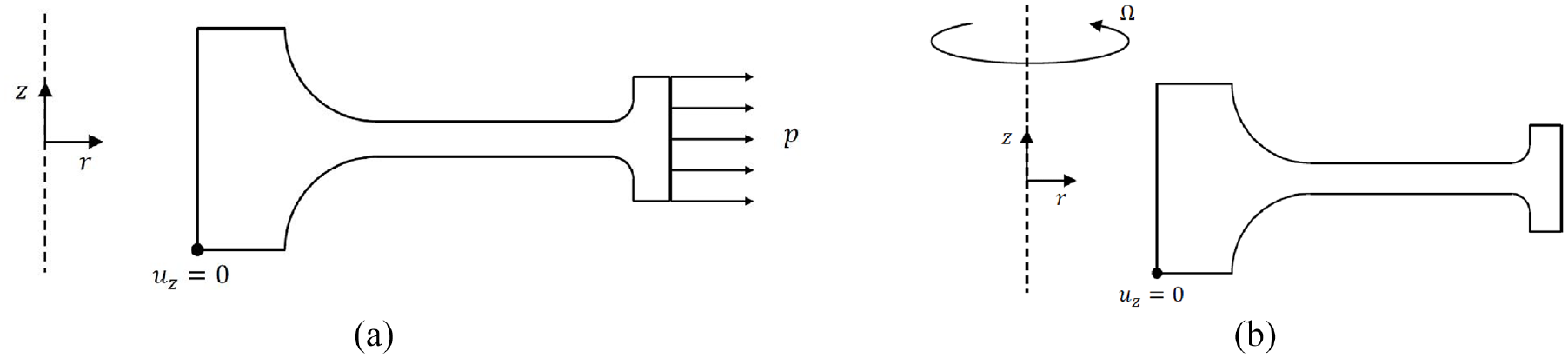
Loading schemes of the compressor disc: (a) radial load from blades and (b) rotational body force.
To reduce both computation times and the size of the output data, the minimum required mesh refinement was determined using a mesh refinement study. The model used for the study had dimensions in the middle of each range in Table 1. A study was performed separately for both loading schemes. The study showed that for this model, a mesh refinement which generated 129 four-node reduced-integration axisymmetric solid elements (CAX4R) was required for the maximum tangential stresses to be within 10% of the converged solutions. This level of mesh refinement was used to build the training data set. Results from the neural network were later compared to FEA results from a refined mesh of 7537 elements, which provided results within 1% of the converged solutions. The stress from the rotational body force was significantly less mesh dependent than the stress from the blades. The stress fields due to the blades (discussed below in Section Results) show greater stress concentration at internal corners. The high mesh dependency of the stress from the blades is a result of stress concentration features only being resolved at higher mesh refinements than the rest of the stress field.
Parameter selection
As seen in Table 1, the geometry of the profile of the compressor disc is defined by eight dimensions. Additionally, the rotational body force is dependent on the angular velocity
Rotational body force scaling
Analysing the loads on a volume element of a thin rotating disc of thickness
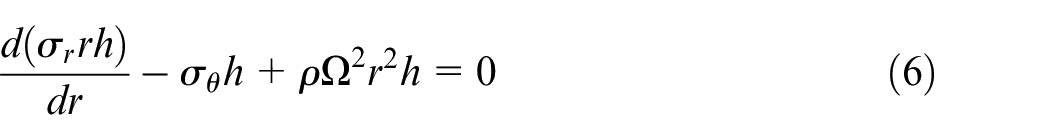
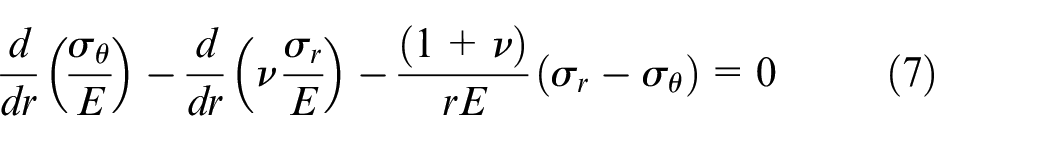
Radial load scaling
The pressure load applied on the rim is expressed in terms of the resultant radial stress in equation (8) where


Model parameters
Since stresses from the body force and the blade load scale with the model size, stress distributions can be calculated from the FEA results of a scale model. Therefore, dimensions of the model can be normalised with respect to a chosen dimension, which reduces the number of dimensional parameters by one. Normalisation was accomplished by dividing all dimensions by
Data collection
Training data was collected from FEA simulations in the Abaqus software suite. In each simulation, the position and tangential stress
A Python script was used in conjunction with Abaqus to complete stress simulations at three values of each of the seven parameters. The applied loads were
Machine learning model
In many stress analysis applications, the information of most importance is a maximum stress value and its location. An approach which calculated only this information would have been suitable with one loading scheme. However, with two independently adjustable loading schemes, the total stress at any point must be calculated by superimposing the stress fields. The overall maximum stress may not be located at the maxima of either of the separate stress fields. Thus, stresses must be computed at a range of locations and the machine learning-based system becomes a substitute for FEA.
Data pre-processing
Results from the simulations were read into MATLAB and compiled into one data set with 495,338 samples with nine inputs and two outputs. Although the inputs were varied in orders of magnitude, normalisation of inputs, which often scales the values of inputs into a range [0, 1], was not required for regression because any necessary rescaling could be accomplished with the weights and biases. Since the outputs varied greatly with the rotational stress being approximately four orders of magnitude greater than the stress from the blades, a second version of the training set was produced with normalised output variables. Values of each output in the training data were mapped to the range [0, 1]. Normalising data to the same scale speeds up the training of a feed-forward network. 16
Neural network designs
As previously stated, an initial network was designed to follow the assumption that two hidden layers of
The data was split into training, validation and test data sets in a 70:15:15 ratio. Training was stopped if a network had not converged after being trained for at least 1000 epochs and for 1 h. While training with the original training data set, convergence was not achieved within these conditions so the training was paused. To check whether a network of a smaller capacity would suffice, a 9/10/10/2 network was also trained. Similarly, convergence was not achieved in a reasonable time using the original data set, however the network passed the validation criteria within 677 epochs using the normalised data set.
Data post-processing
Values of the tangential stress were produced by selecting values for the disc profile dimensions, angular velocity
In order to produce a stress distribution, the stress had to be plotted queried at several points. When the dimensions of the model being queried belonged to the training set, a simple approach was to query at the same points stress had been measured from. The MATLAB function ‘griddata’ was used to linearly interpolate between integration points in a manner similar to that for FEA postprocessor. Originally, queries were made at an evenly spaced grid of points where some were located outside the disc profile. This approach to querying increased the error between the predicted stress field and the stress field produced by the corresponding FEA data in the training data set. So, points were initially selected only within the bounds of the geometry. This result is further discussed in Section ‘Sampling accuracy’.
Results and discussion
Results
Table 2 summarises the results of the four networks detailed in Section ‘Neural network designs’, which have been labelled networks (a) – (d). Although all networks were trained to minimise MSE, the results cannot be used to compare networks which have used different training sets. An RMSE for each output has been provided separately for the networks (a) and (b). For networks (c) and (d), the RMSE values have been scaled to reverse the scaling which was used to normalise the data set, so that RMSE values are comparable across data sets. The RMSEs show that the normalised data sets allowed networks (c) and (d) to optimise themselves to map to each output more equally. The normalised data also allowed network (c) to converge within the stopping criteria for training.
Summary of NN generated results.

In order to analyse the distribution of stresses more closely, a geometry with one set of dimensions has been selected for analysis. This geometry has dimensions at the midpoint of their range specified in Table 1 and will be referred to as the ‘average disc geometry’. The stress plot in Figure 8(a) shows the total circumferential stress in the average disc profile from values calculated by FEA. The stress from the blades and rotational body force have been scaled and superimposed using the example parameters:
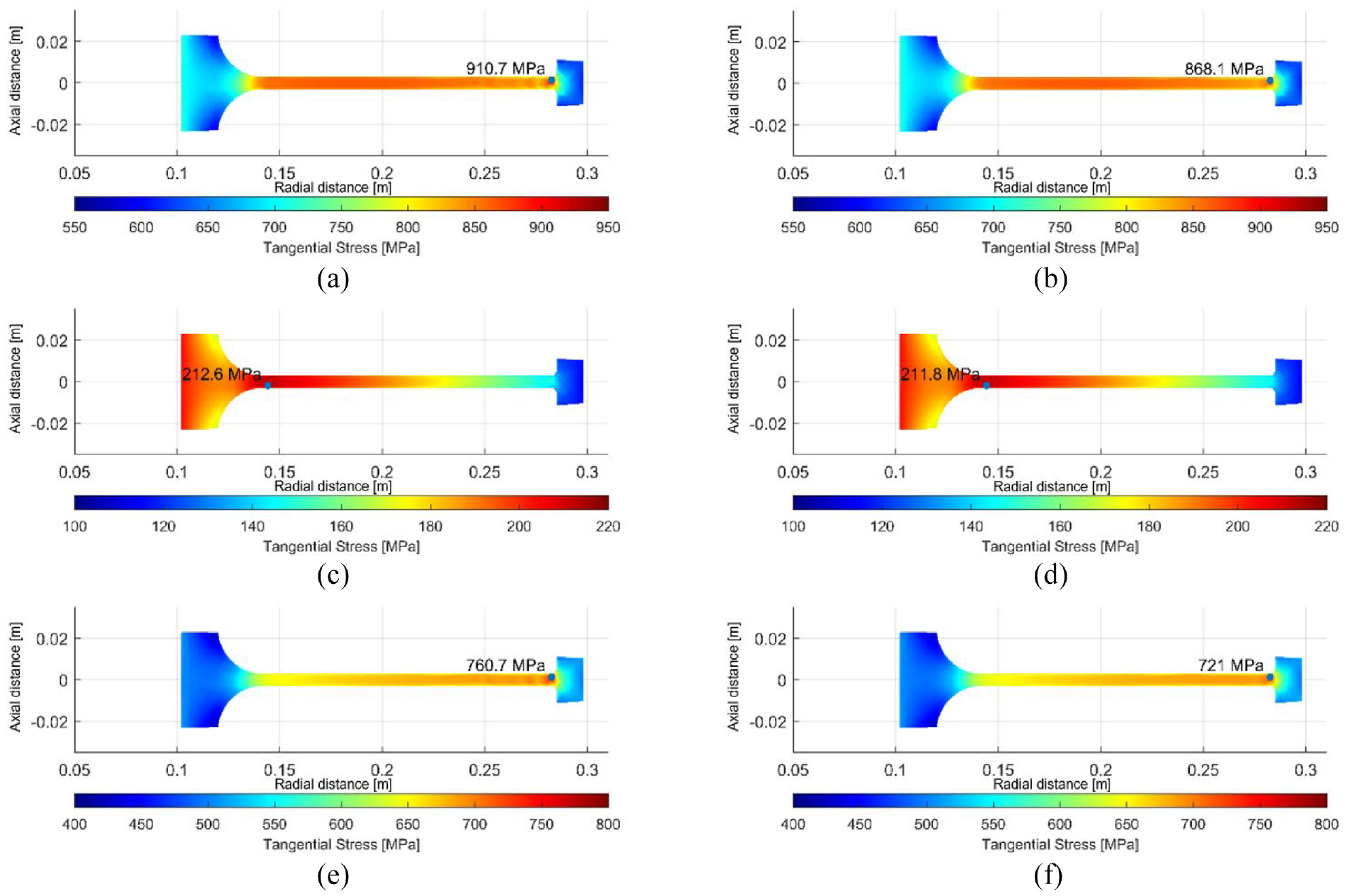
Tangential stresses computed by FEA and the neural network model: (a) total tangential stress, FEA, (b) total tangential stress, NN, (c) total tangential due to rotation, FEA, (d) total tangential due to rotation, NN, (e) total tangential due to blades, FEA and (f) total tangential due to blades, NN.
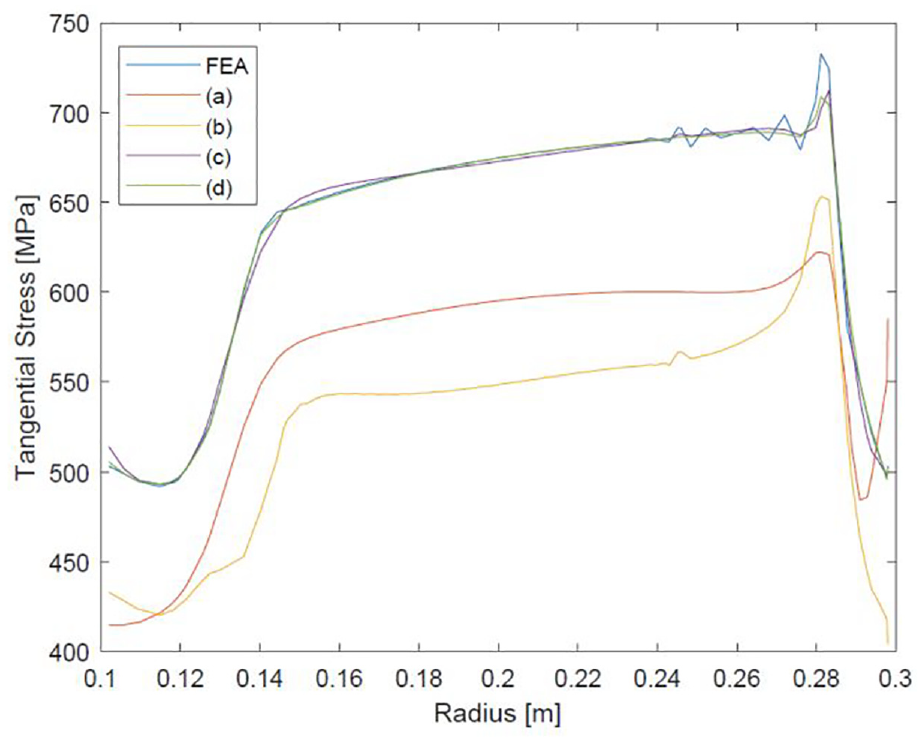
The four networks detailed in Section 10 were first tested with this geometry. The input dimensions were part of the training data set, meaning that an overfitted network would be able to map the values accurately. However, underfitting was suspected of being more likely than overfitting due to difficulty in reaching convergence in training and the large quantity of data. Results are recorded in Table 3. The circumferential stresses along the radius at the midplane
Accuracy of NN generated results for the average disc geometry.

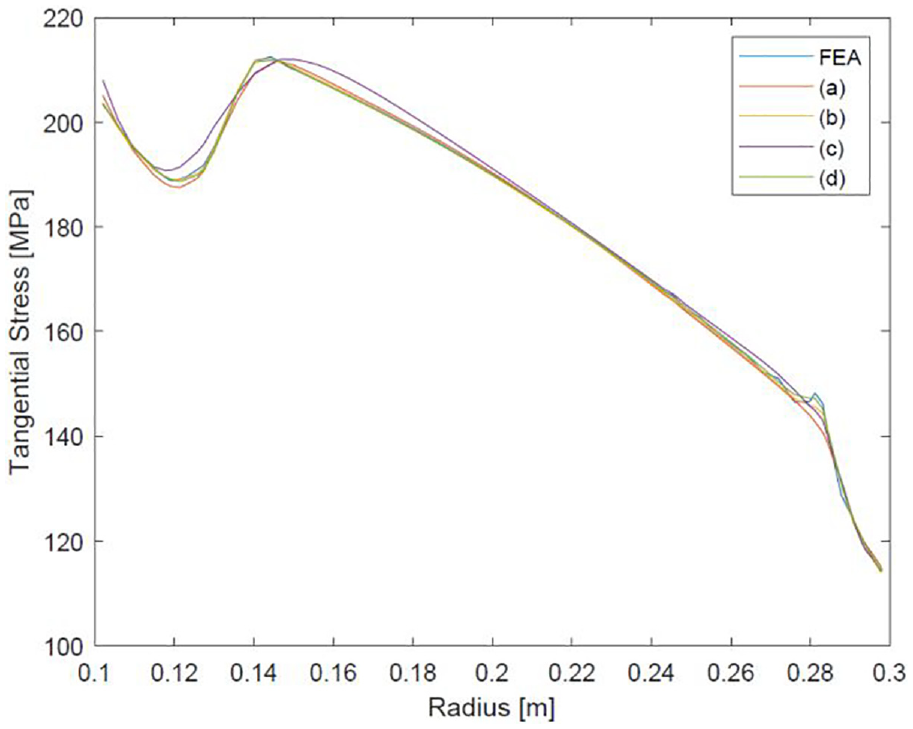
Stress across the disc midplane due to rotational loads.
Stress across the disc midplane due to radial loads from the blades.
Accuracy
It is clear from the overall stress plots that all networks were accurate in regions of gradual stress variation. Maximum stresses were calculated with mixed accuracy and all predictions were underestimates. In the stress fields of some geometries not displayed here, the maximum stress was located nearer to the bore where the stress varied more gradually. In these cases, the maximum stress prediction was more accurate.
Rotational body force
The stress from the body force was predicted very accurately from all networks and is reflected in the low error values. This is likely due to the mostly linear nature of stress variation radially, with only a minor outlying stress concentration at
Radial load
The midplane stresses from the radial load in Figure 10 show large variation in accuracy between the networks. The networks trained from the original data set are offset from the FEA result by
approximately
If there were only one loading scheme, a solution to this problem would be to introduce a separate output for the maximum stress in a geometry. This output would only require the seven inputs corresponding to the disc dimensions without needing locations of integration points. With two superimposed loading schemes a maximum stress can be predicted for each scheme which is then added to the stress caused from the other loading scheme at that location. Even with accurate predictions of the maximum stress, inaccuracies will still remain at smaller local stress maxima.
Sampling accuracy
As mentioned in Section ‘Data post-processing’, sampling the stresses at points led to results which differed from the FEA data. It is common practice to not query a network outside of the range of the training data, however the integration points in the training data were located within the edges of the profile. Since stress concentrations are often located on edges, the stress data required extrapolation to the edges. Extrapolation could be done either linearly in MATLAB (similarly to a FEA package) or by querying stresses outside the geometry and interpolating. As seen in Figure 10, the internal corner of the rim is a stress concentration under radial loading. In the mesh refinement study, a relatively large error of 10% was settled upon. This resulted in the mesh in Figure 11(a) being used to produce training data for the average disc geometry. From this mesh, no stress concentration effect is visible and Abaqus measured a maximum stress of
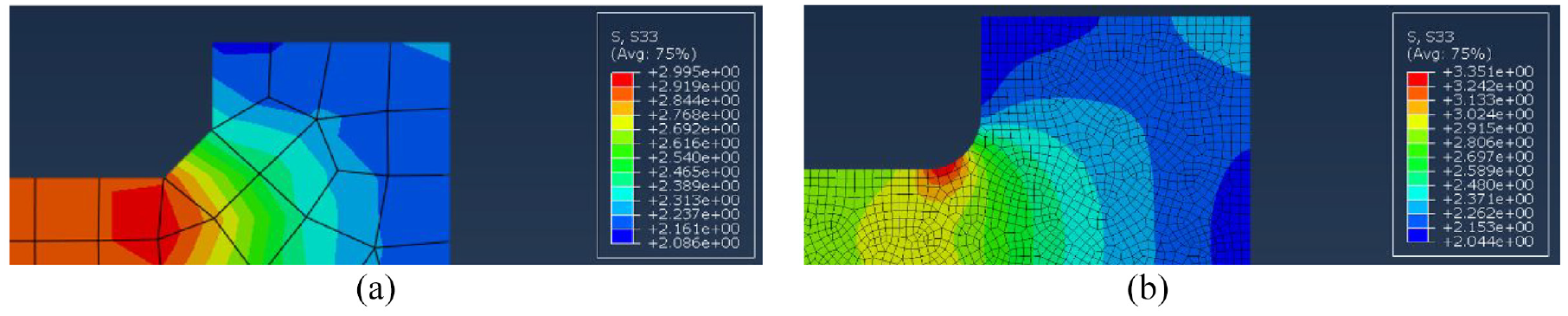
Results of mesh convergence study – tangential stress under a 1 Pa radial load: (a) coarse mesh and (b) refined mesh.
Figure 12(a) displays the FEA data for this study after processing in MATLAB, as well as the predictions from network (d). As expected, the stress results from the neural network in Figure 12(c) did not capture the separate stress concentrations at each corner when using samples from within training data from FEA simulations which themselves did not represent this feature. However, when querying outside of the disc profile, network (d) displayed stress concentrations (Figure 12(d)) similar to those displayed by the refined mesh and predicted a maximum tangential stress of
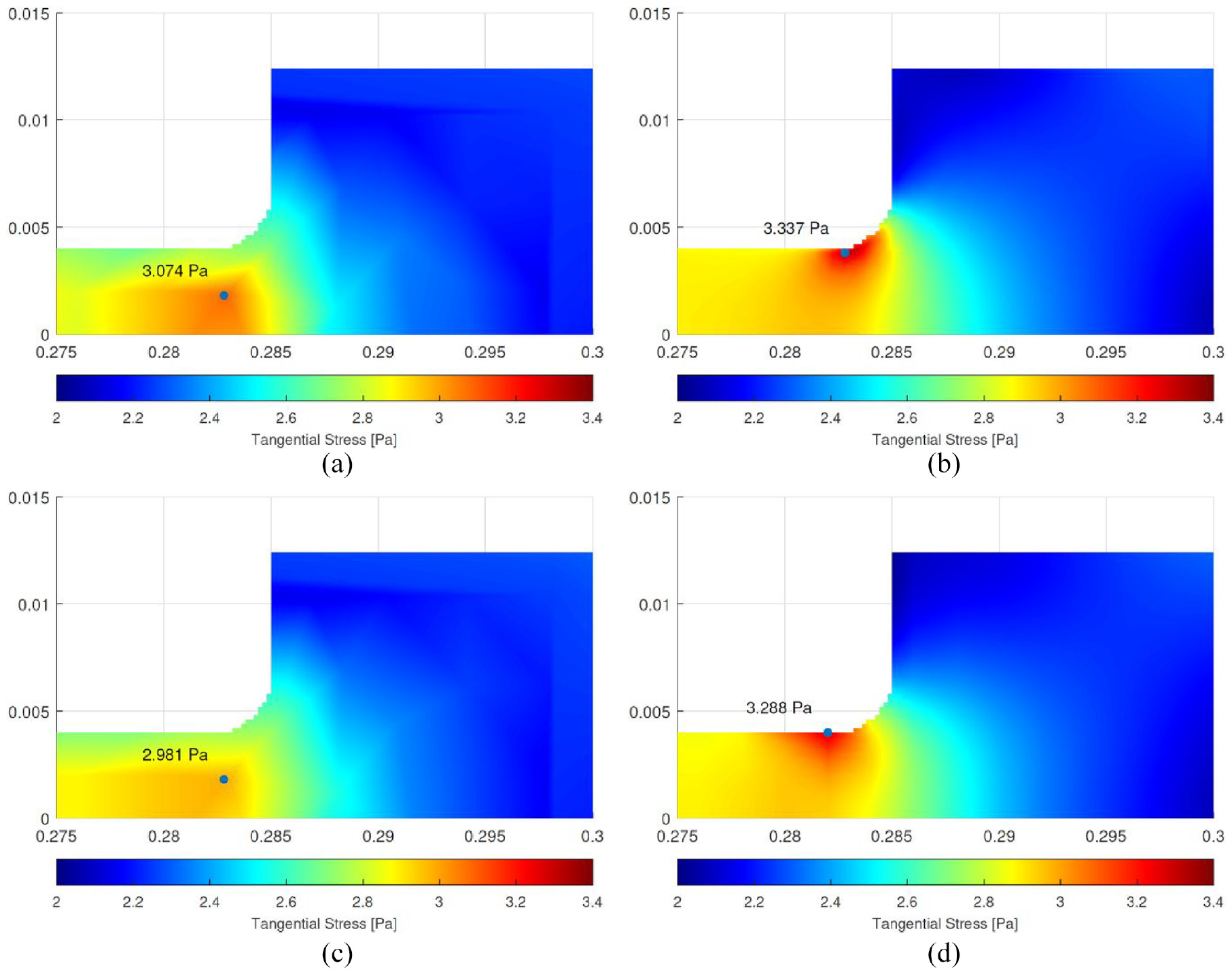
Tangential stress predictions at the rim under a 1 Pa radial load: (a) FEA data from the training data set, (b) FEA data from a refined mesh, (c) NN prediction from queries within the bounds of the integration points and (d) NN prediction from queries outside the bounds of the disc profile.
Errors incurred with querying methods.
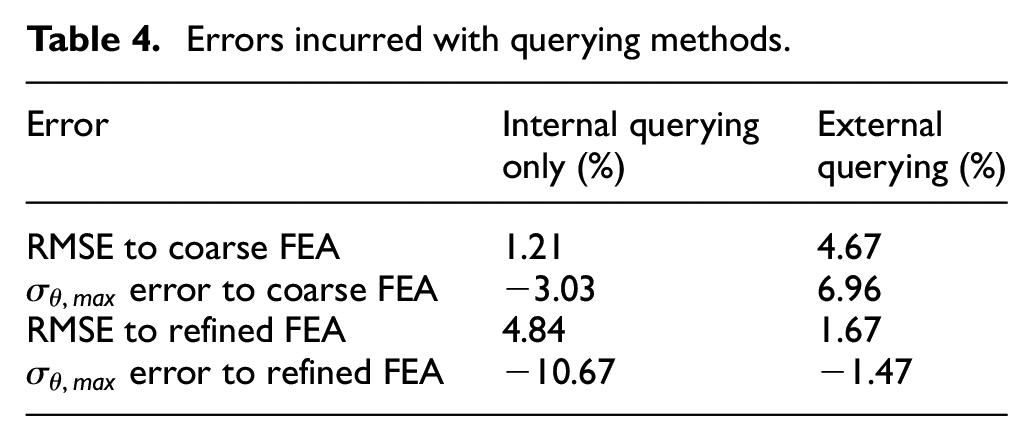
Overall, extrapolation from the integration points is performed more effectively by the NN and the error at the internal corner is reduced to −1.47%. The mean error from this approach is lower than or comparable to typical NN-based FEA surrogate models. Among the models described in Section ‘Introduction’,3,8 an overall error of approximately 10% is commonplace. An advantage of this method is that the training data meshes are of a lower refinement to the desired output stress field. The different meshes and thus different node locations, between training data geometries allow the NN to compute stresses around the internal corner more accurately than FEA can achieve with a single mesh of similar refinement to the training data. Conversely, this approach would be ineffective at solving a problem where the geometry and node position around stress concentration features are constant across all designs, such as a cantilever beam, 2 unless mesh controls around the feature are intentionally varied between training meshes.
Computation time
Code profiling
Profiling the code revealed that total time to run the code was highly dependent on the resolution of the grid that queried stresses were interpolated onto. For example, a grid resolution of
Feature importance
If the machine learning-based system were to be streamlined or a similar system were made using less data, it would be beneficial to identify the variables of most importance. The mRMR algorithm explained in Section ‘Minimum redundancy maximum relevance algorithm’ was applied to check the importance of the inputs in predicting each output. Figure 13 displays the predictor importance scores for the stresses from the rotation and blades respectively. Note that
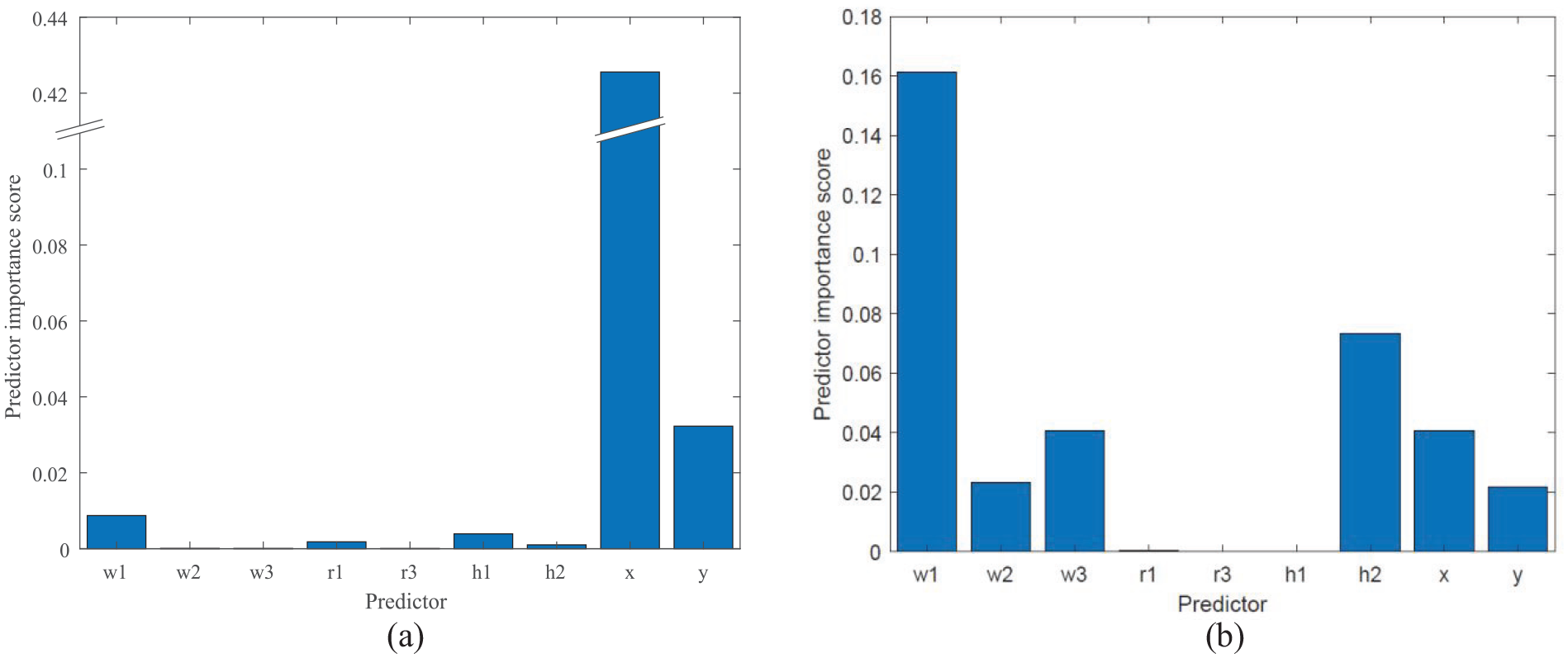
Predictor importance for tangential stress prediction: (a) predictor importance for tangential stress due to rotational load and (b) predictor importance for tangential stress due to blade load.
Figure 13(a) shows that the rotational is most dependent on
Across both loading schemes, the least important parameter was
Conclusions
Machine learning techniques and their application in stress analysis have been investigated. A literature review has been conducted into existing approaches to solving similar mechanical loading problems using neural networks.
Data pre-processing methods were explored to reduce redundancy in the training data. The data reduction method – instance selection was trialled on the 2D stress analysis problem of a plate with a hole under uniaxial tension. Training data was downsampled using
A machine learning-based system was then developed for a parameterised compressor disc geometry. The compressor disc was subject to loading from rotational body forces and from a radial force exerted by the blades. Four thousand three hundred and seventy-four FEA simulations were used to collect training data was collected from integration points leading to 495,338 samples. Four networks were trained to predict the two tangential stress from the loading schemes using inputs which represented the compressor discs dimensions and the location queried at. Overall, the network with a 9/20/20/2 structure, which used normalised training data, was most effective at minimising MSE across both loading schemes. For a disc geometry with dimensions which were averaged across the dimensions which were tested, this network produced the most accurate stress field with a NRMSE of 1.51%.
The querying locations on the accuracy of the stress field was also investigated. Query only within the bounds of the integration points of the training data produced a stress field with a NRMSE to the training data of 1.21%. Querying at points which were also outside the bounds resulted in a greater error of 4.84%. Interestingly, using external querying reduced the error to the FEA results of a finer mesh from 4.67% to 1.67%. The error from this approach is lower than the typical NN-based FEA surrogate models of a similar scope, as discussed in Section ‘Sampling accuracy’.
The inputs of the networks were ranked by importance with respect to each output using the minimum redundancy maximum relevance algorithm. It was found that the fillet radius at the disc rim
Overall, the machine learning-based system appears to serve a specialised role in the design of parameterised parts. The performance advantage of the neural network is greatest for problems which FEA takes longer to solve; however this increases the time required to build a training data set. The accuracy of the networks is this project were adequate. Arguably, the speed of neural network is only of use in an exploratory approach to design. The speed of the system allows results to be updated as inputs are updated by a user making it suitable for an interactive computer program. If slightly less speed is necessary, a user-friendly script/application could be used to interface with a FEA package. In this project, FEA studies took approximately 15 s and only required inputs to be entered into a script. Therefore, the neural network has applications in the initial design stages but is less useful when receiving quick results is less important.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.