
Abstract
Geoscientists frequently are interested in defining the overall trend in x-y data clouds using techniques such as least-squares regression. Yet often the sample data exhibits considerable spread of y-values for given x-values, which is itself of interest. In some cases, the data may exhibit a distinct visual upper (or lower) ‘limit’ to a broad spread of y-values for a given x-value, defined by a marked reduction in concentration of y-values. As a function of x-value, the locus of this ‘limit’ defines a ‘limit line’, with no (or few) points lying above (or below) it. Despite numerous examples of such situations in geoscience, there has been little consideration within the general geoenvironmental literature of methods used to define limit lines (sometimes termed ‘envelope curves’ when they enclose all data of interest). In this work, methods to fit limit lines are reviewed. Many commonly applied methods are ad-hoc and statistically not well founded, often because the data sample available is small and noisy. Other methods are considered which correspond to specific statistical models offering more objective and reproducible estimation. The strengths and weaknesses of methods are considered by application to real geoscience data sets. Wider adoption of statistical models would enhance confidence in the utility of fitted limits and promote statistical developments in limit fitting methodologies which are likely to be transformative in the interpretation of limits. Supplements, a spreadsheet and references to software are provided for ready application by geoscientists.
Keywords
1. Introduction
Ordinary least-squares regression analysis commonly is used to define the statistical relationship between one or more explanatory variables
Often interest lies not with identifying the central trend to the x-y data, but with whether the x-y data tend to indicate that maximum values of
1.1. Overarching objective of the data analysis
Herein we review various methods that have been used to fit limit lines. Although sometimes theory has informed the fitting of limit lines in the literature, oftentimes such consideration is lacking. The researcher should consider what are the known or expected key characteristics of the expected limit lines in terms of the likely effect on the decisions that might arise from the analysis. Thus, it is beneficial if the form of the likely limit line can be specified or parameterised from theory. Where theory is lacking, logical reasoning can be applied, informed by previous considerations of empirical x-y data pairs similar to the target set of observations. These two approaches may involve writing down the options for the form of the equations relating
II Approaches to limit line estimation – a statistician view
This section seeks to provide an intuitive but rational framework within which the fitting of limit lines can be discussed, motivated by elementary statistical thinking. Thereafter in Section III, the relative merits of different approaches to estimation of limit lines, known to be used by practitioners and reported in the literature, are considered with respect to this framework.
It is assumed that the researcher has a data set or sample of pairs of points
2.1. Inspection
Where the scatter of
2.2. Theoretical limit
In some situations, a theoretical function defining an expected limit line can be considered along with the data plot and the relationship between this function and the empirical data can be considered. Such an approach is related to defining tolerance limits or a specification, which can be completely independent of the distribution of the plotted sample statistic.
2.3. Joint statistical models
Joint statistical models, like their conditional counterparts discussed in Section 2.4, are attractive since they introduce a degree of objectivity into the estimation of limit lines (certainly in contrast to
Joint statistical modelling treats both
More generally appropriate models might be used to describe the marginal characteristics of variable
The joint statistical model therefore can be rather complex. In contrast, conditional statistical models (discussed next) characterise the distribution of
2.4. Conditional statistical models for
The data can be used to estimate a statistical model for
2.4.1. Linear regression
An initial assumption might be a
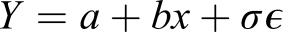
2.4.2. Parametric model
Generalising linear regression, it might be assumed that the probability distribution of
2.4.3. Non-parametric model
Extending Section 2.4.2, there is no need to assume a parametric form for the parameters of the distribution of
2.4.4. Mixture model
Another approach which can be considered non-parametric is a
2.4.5. Conditional models for
Because the focus of interest is in the largest values of
III Approaches to limit line estimation – a practitioner view
This section lists some of the methods used by practitioners, and reported in the literature, for estimation of limit lines. With reference to Section II, this section also provides an outline of the strengths and weakness of the various approaches. Methods are listed in approximate order of increasing complexity.
In
In selective linear regression Examples of limit line fits. (a) Central tendency in the relationship between the size to pebbles and the energy required to break them is defined by least-squares regression (blue curve). Uncertainty in the energy required increases as a function of the pebble size. Limit lines (red) are defined using Inspection (explained in text); (b) Lichen growth curve: Central tendency defined by zero-intercept (blue) regression curve; Limit line (grey) defined by simple linear regression with adjusted intercept (explained in text) to enclose all data points. (c) Significant wave height as a function of wind speed at a location in the north-east Atlantic, with piecewise linear quantile regressions at the 0.9 quantile level fitted independently to the data below and above the median x-value of 10 ms−1; Pebble data from Tuitz et al. (2012); Lichen data from Carling (1987); wave data from Reistad et al. (2011).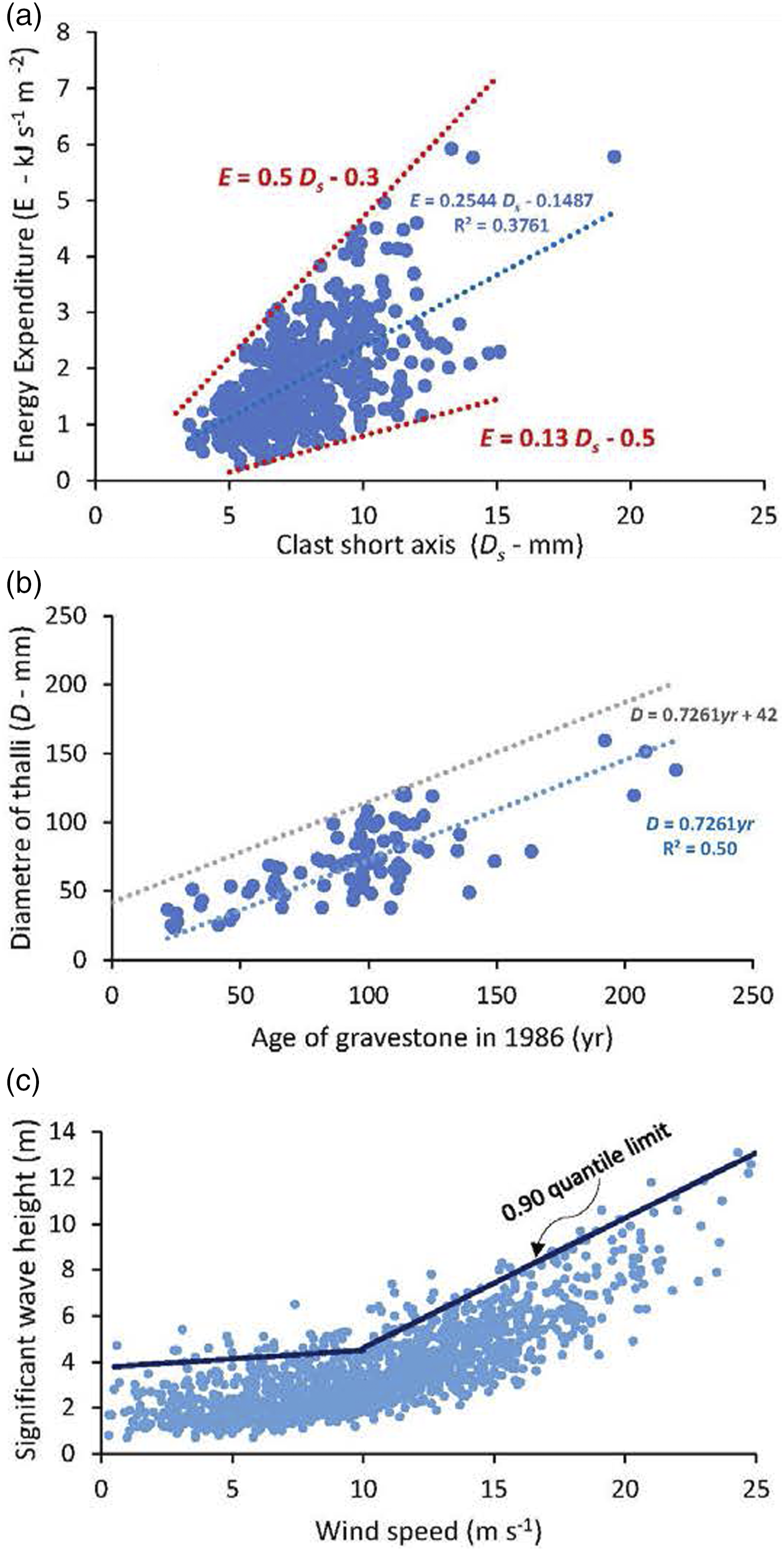
The
Parametric model fitting (see Section 2.4.2) is widespread in environmental sciences. Once the parameters of the model have been estimated by fitting to the complete sample, the limit line can be specified and easily calculated, for example in terms of a quantile of the conditional distribution
Eberhardt and Thomas (1991), considering environmental systems, recommend the Box and Lucas method to obtain optimal parameter estimates of response surfaces; thus, effectively defining limit lines. Box and Lucas is a relatively robust approach but implementation needs a higher level of statistical competency, although software is available to fit a selection of functions (e.g. Originlab®). The original use was to define a complex curve through few data points which are believed to be the optimal (or in our case maximal) values of
Quantile regression (see Section 2.4.3) is capable of modelling any specific quantile of the conditional distribution
The mixture model of Maller et al., (1983; Kaiser et al., 1994, and see Section 2.4.4) needs a reasonably high level of statistical competency. In outline, values of
Extreme value analysis (see Section 2.4.5) is used widely in environmental science to define return values for processes such as rainfall, temperature, storm, wildfire and earthquake severity, extreme occurrences of which are hazardous. The
IV. Practical issues
A number of practical issues arise in attempting to estimate limit lines from a sample of data. In this section, we provide an overview of some of the issues that are likely to be of concern to the practitioner. These include identification of outliers, breakpoints and mixed samples, and the quantification of uncertainty of inference.
4.1. Identifying outliers
In regression modelling (Section 2.4), observations with large residuals (outliers) or high leverage are problematic, since they may violate the assumptions underlying the model and cast doubt on the outcome of a regression. Outlier detection and regression diagnostics naturally have a large statistical literature; the works of Wetherill et al. (1986) and Cook and Weisberg (1982) provide introductions. Traditionally when assessing a dataset before conducting linear regression, outliers were identified by eye from inspection of the x-y scatterplots. Objectively identified outliers likely lie above any proposed limit line so their identification is critical when fitting limit lines.
Unusually large values of
For joint modelling of bivariate data (Section 2.3), Mahalanobis distance and similar metrics can be used to identify data points which are unusual with respect to that metric. In a regression context, when the occurrence of outliers can be attributed to one or more additional data-generating processes (over and above those responsible for the bulk of the sample), then more sophisticated techniques including mixture modelling can be used to simultaneously estimate ‘bulk’ and ‘outliers’ (e.g. Aitkin and Tunnicliffe Wilson 1980; Yu et al. 2015).
4.2. Identifying breakpoints
It is possible that an attempt to estimate a limit line with given characteristics (e.g. linearity) through x-y data does not yield satisfactory results. If the limit line is estimated using a statistical procedure, then lack of fit can be quantified. In such cases, more general models for the limit line should be sought. The relative performance of different models for the limit line can then be compared, and the best model adopted (e.g. Wetherill et al. 1986). Sometimes it may be appropriate to consider: (1) whether the data might exhibit breakpoints or change-points in the x-y relationship, or; (2) whether a model admitting a non-linear relationship between variates is appropriate (e.g. Zanini et al. 2020). Figure 1(c) illustrates this issue. Here, the slope of the limit line clearly changes at wind speed around 10 ms−1; it might therefore be appropriate to fit a piecewise linear limit line as illustrated. However, physically we know that water waves are generated by the wind via frictional drag forcing, which implies alternative approaches including a linear limit line for y on the square of x, or a quadratic quantile regression limit line might be appropriate. However, the relationship observed at a specific location is unlikely to follow the quadratic form exactly, due to various effects including fetch-limitation, wind-field non-stationarity, bathymetric effects in shallower water etc. For this reason, fitting a piecewise linear form for a limit line is a pragmatically sound way to proceed; in practice, a larger number of piecewise segments might probably be used. In fact, exactly this approach is frequently used in ocean engineering to specify an extreme value threshold, and amounts to an approximate non-parametric quantile regression (see Section 2.4.3).
In general, identifying breakpoints or changepoints in a sample can be important in the interpretation of a physical process (e.g. Ryan et al., 2002). The modelling challenge is to identify one or more breakpoints in
Identification of breakpoints also can be achieved as part of the statistical inference. For example, optimal partitioning of the x-domain into
4.3. Identifying mixed samples
Sometimes, it is possible that the sample for analysis corresponds to observations of a mixture of different data-generating processes. In this situation, we might expect that limit lines would be more appropriately estimated for the individual processes from which the mixture is composed. It might therefore be useful to perform prior partitioning of the sample into two or more groups using data for both
4.4. Quantifying uncertainty
Quantifying the uncertainty of estimates of limit lines is generally important if those estimates are to be trusted. Some of the approaches described in Sections II and III do not involve an explicit quantitative model for the relationship between
Sources of model uncertainty can be considered aleatory (due to the inherent natural variation of the process we are modelling, which will always be present) or epistemic (due to inadequate data, measurement procedures, model specification, etc., the effects of which we could in principle eliminate with enough effort).
When a regression-type model for
The second approach to uncertainty quantification is based on assessing the variability of inferences from models estimated using resamples of the original data sample. Different resampling techniques, including cross-validation, bootstrapping and randomised permutation testing provide relatively simple pragmatic approaches to estimate the performance of statistical models, to estimate uncertainties of predictions, and perform significance tests. Resampling approaches are widespread in the applied literature, especially when there is some ambiguity about the appropriateness of the model being used. However, some might claim that resampling approaches lack the overall coherence and elegance provided by the Bayesian approach. There is a huge literature on resampling methods; Good (2006) provides an introduction. The works of Molinaro et al. (2005), Hesterberg (2015) and Lehr and Ohm (2017) provide useful practitioner perspectives.
4.5. Measurement error and heteroscedasticity
In many data sets, measurements of both
In a simple linear regression model, we make the assumption that the variance of
4.6. Model selection
Model selection is a procedure to select one among many candidate models. Typically, we select a model with the best performance for the task at hand. However, there may be many competing issues relevant for good model selection other than quantitative performance, such as model complexity and interpretability. In many practical situations, a model which is straightforward to estimate, interpretable and gives reasonable performance, is preferrable over a considerably more complex model which is less interpretable and gives only slightly improved performance.
There are essentially two approaches to model selection. In general, probably the wisest approach is based on the assessment of predictive performance of the model, preferring the candidate model with best predictive performance. Predictive performance is assessed by quantifying out‐of‐sample error; that is how well a model performs on data that were not used to fit the model in the first place. There are many approaches to quantifying predictive performance, including (1) partitioning the original data into two groups, using one group to fit a model, and the other group as an unseen test set to estimate predictive performance, and (2) cross-validation, in which the original sample is partitioned into a number of sub-sets which are withheld one at a time, serving as test sets for models estimated using all the remaining sets; an estimate of predictive performance is then accumulated over all the test sets. The second approach to model selection attempts to quantify model performance using fitting performance of the model. However, because fitting performance is typically an over-optimistic assessment of predictive performance, the fitting performance score is usually penalised by a measure of model complexity; more complex models receive higher penalties. A number of related performance measures, including the Akaike Information Criterion (AIC). Bayesian Information Criterion (BIC), and Minimum Description Length (MDL) are available. Pawitan (2001, Sections 13.5–13.6), Davison (2003, Section 4.7) and Kuhn and Johnson (2018, Section 4.8) provide a useful discussion.
V. Examples of current fitting procedures
In this section we make use of three different data sets to illustrate the strengths and weaknesses of fitting limit lines using some of the simpler methods introduced above. For conciseness, we have focussed on those simpler methods. The issues that arise using simpler methods also apply to, and would inform the application of, more advanced statistical procedures. The application here of simpler methods does not imply that more sophisticated approaches could not be explored beneficially in the case of these examples.
The first example consists of a complex of several data sets which, taken together, define a visual upper limit line for which an upper limit is expected from theory. This example is used to demonstrate the use of three relatively simpler methods together with fitting of a theoretical function that makes use of the empirical data.
The second example consists of a single data sets that is inadequate to clearly define a visual upper limit line, although a limit is reasonably expected from prior studies. This example is used to demonstrate the use of three relatively statistically robust methods.
The third example consists of a single data set for which the variance in y increases rapidly as the value of x increases, and both upper and lower limit lines are required. Solutions derived using a simple robust method are contrasted to inspection functions.
Catastrophic outburst floods from dammed lakes Figure 2 serves as an example of the issues that arise from fitting limit lines using Inspection, Selective Regression and application of a data-informed Theoretical Limit. The data sets collectively represent the relationship between measured volumes of released lake water (V) and the estimates of the peak discharge (Q
p
) downstream due to catastrophic lake failure (O’Connor et al., 2013). It may be expected that variation in breaching mechanisms, channel geometry and roughness (amongst other controls) will mediate the downstream translation of the flood wave so that different peak discharge values might be obtained for the same initial lake volumes. However, if the discharge from the lake is constrained by the initial geometry of the eroding breach (e.g. critical flow control), or by the way the flood translates down system, there should be an upper limit to the scatter of peak discharge values. The data in Figure 2 considered collectively, or as separate data sets, provide some support for the critical flow control as is detailed below. Inspection and selective regression: The green curve is fitted by inspection Selective regression with optimal a*: A least-squares regression of the ‘physical model’ data defines the trend of that data set which, when extrapolated forwards (not shown) passes through the centre of the mass of other data sets. This consilience between the two groups of data suggest that the small-scale model results reproduce well the central tendency of behaviour of large natural dam failures across several orders of magnitude. Interestingly, such an extrapolation might define an upper limit line for ‘Ice dams – subglacial tunnelling’, although we do not explore the implications herein. However, to define a limit line for the majority of data, the trend of the ‘physical model’ data can be adjusted by adding increments to the intercept value, a∗, until sufficient data points fall below the limit. In the example provided, the intercept value is increased (Selective regression with optimal a∗) by a factor of ten such that although ten data points lie outside the limit, the black line provides a reasonably satisfactory visible limit to the data spread, notably that of the ‘constructed group’ and ‘moraine group’ data sets. A small increase in the intercept value would readily include seven more data points leaving only three as outliers. By adjusting the intercept value, the exponent of the trend line is preserved, implying that the central tendency growth function for ‘physical model’ data also can define the behaviour of data at the upper limit to the larger-scale dam-break data. By such systematic exploration of central tendency and limits, consideration can be given to (i) the relationship of one data set to another; and (ii) the consistency of data point plotting positions within the individual data sets. Further, (iii) the positions of some individual data points come under scrutiny and; (iv) possible theoretical constraints on the data plotting positions may become evident. Theoretical Limit: A theoretical critical flow control might be considered to provide an upper limit to the data spread in Figure 2. The theoretical derivation is provided as Supplement 1 but the basic facts are as follows. Failure of earthen and ice dams often is associated with initial establishment of a critical-flow depth (h
c
) at the breach that determines the peak outflow discharge (Walder and O’Connor, 1997; O’Connor and Beebee, 2009). Larger volume (V) lakes tend to have greater depths (h) and so have the propensity to develop rapid failures with greater critical flow depths; thus, h
c
The V-data in Figure 2 are used to calculate

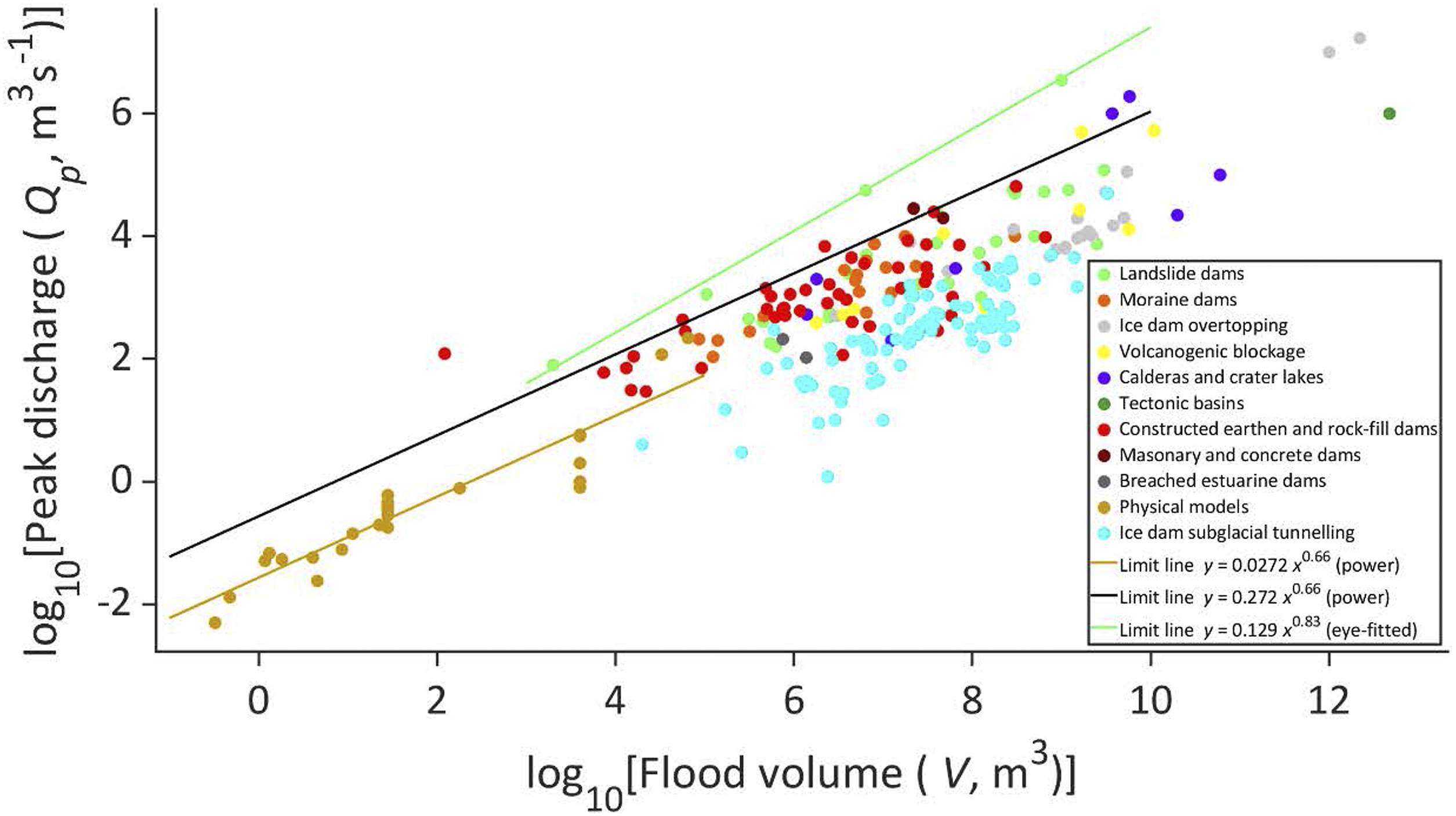
Empirical data define the relationship between the flood volume and the peak discharge of water released from catastrophic failures of dammed lakes. Brown curve is the least-squares fit to the physical model data; Limit line (black) fitted to all the data using selective regression with optimal a*; Limit line (green) fitted by inspection of a data sub-set. The equivalent theoretical equation,
Lichen growth curve to date flood deposits Figure 3 serves as an example of the issues that arise from fitting limit lines using parametric mixture modelling. The data considered (Carling, 1987) define the relationship between the diameter of the largest lichen thalli on dated gravestones in Teesdale, northern England (Figure 1(b)). Such lichen growth curves can be used to date the surface of rocks that have been transported by floods or glaciers in the same region for which the calibration data were obtained. The supposition is that geophysical flows transport, abrade and destroy any pre-existing lichens, such that lichen growth only occurs once the rocks are stable in a deposit. In this manner, flood gravel bars can be dated. The species of lichen (Huilia albocaerulescens) used by Carling (1987) tends to produce circular thalli which, after an initial rapid growth phase of a few years only, tend to steadily increase linearly in size with age. Eventually lichens reach senescence, at which time lichen thalli cease to grow, grow more slowly, or being to break-up. Consequently, any maximum linear growth function can only be extended to a given x:y breakpoint value beyond which maximum growth does not apply (Cooley et al. 2006). Beyond this point, either a separate lower-gradient function is fitted for the senescence phase, or, if a single function is fitted it must account for the growth and senescence phases (Innes, 1983). In ideal growth conditions, lichens will achieve a maximum diameter during the rapid growth phase. Data scatter occurs below an expected upper limit to the x:y data pairs occurs for a number of reasons, including: pollution, the date on the gravestone being added some time after erection; differences in the rock type, aspect, and occasional cleaning of gravestones. Box and Lucas: The data shown in Figure 3 produces an upper limit line (blue curve) when using the Originlab® procedure, that is of the same form as a conventional least-squares exponential fit (orange curve) through all the data. Both curves are constrained to have an origin at T equals zero, although other intercepts could be specified. A linear least-squares zero-intercept fit to all the T ≤ 190 data pairs (not shown), to represent only the growth phase, statistically would be a less good fit (r2 = 0.31) than the orange curve. The fitted limit is that which maximises the r2 value for eight outer points, so other curves could be selected if desired. The points that lie just above the D
max
exponential solution were determined to do so by the final choice of the curved fitted. The fitted line intuitively is acceptable as it encloses 93% of the data points, but a higher curve could equally be obtained to enclose more data points. Mixture modelling: An expectation–maximisation (EM) algorithm was used to fit the red curve in Figure 3 following the mixture model of Maller et al. (1983). The least-squares trimming method of Maller et al. (1983) leads to a solution (green curve) that is similar to selective regression (which fits a least-squares function to an arbitrary selection of data points), but the degree of objectivity in curve fitting is greater using mixture modelling. The solution is not uniquely determined, but the accepted fitted line usually is taken to be the solution that includes the greatest number of data points. In the case of the data in Figure 3, a limit was derived after eight iterations which enclosed 95% of all data points and which passes through a further 4% leaving two points just above the curve. The fitted curve: D
max
= 0.815T + 24.33 lies slightly below the red curve fitted using EM algorithm which enclosed all data points. As lichens often exhibit initial rapid growth, followed by a linear growth phase, followed by an exponential decline during senescence (Cooley et al. 2006), a bipartite or tripartite limit line might be preferable, although in the case of the data in Figure 3 there are inadequate data to define a separate senescence phase. However, it would be more satisfying if recourse was made to biologically based theoretical models of lichen growth (Childress and Keller, 1980) to determine what form of function should be fitted that mimics the growth of lichens.
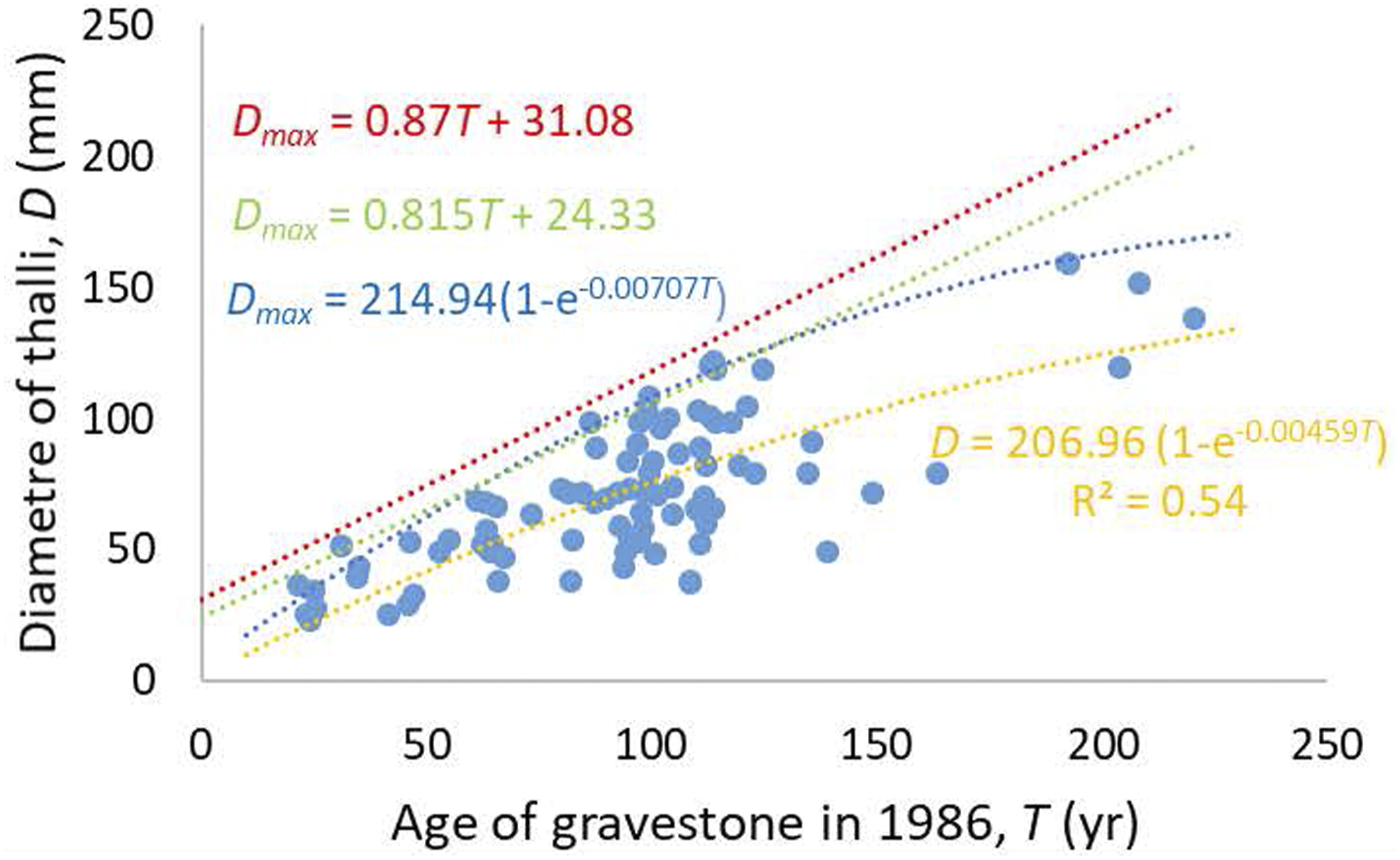
Empirical relationship between the date on gravestones and the diameter of lichen thalli in 1986. Data from Carling (1986). The red curve was fitted using an EM algorithm. The green curve was fitted using the Maller et al. (1983) trimming method. The blue curve was fitted using the Box and Lucas (1959) method. The orange curve was fitted to all the data using a least-squares exponential fit.
Variation in energy expenditure required to fracture pebbles Figure 4 serves as an example of the issues that arise from fitting limit lines using Inspection and Iterative Selective Regression. Figure 4 reproduces the data shown in Figure 1(a), with additional limit lines fitted. The data published originally by Tuitz et al. (2012) were presented in this graphical context by Carling and Fan (2020). The data represent the variation in experimentally derived energy expenditures recorded using a laboratory point-load test to fracture river pebbles. It is known from theory and empirical measurements in prior published studies of facture processes that the energy should increase in a linear manner for the range of pebble sizes considered here. However, as pebble size increases the number and complexity of flaws in the pebbles also increases such that the variance in the y data increases as a function of x. Carling and Fan (2020) only wished to draw attention to the data spread and eye-fitted the red-dotted lines to delimit the data spread. The lower and upper blue fitted limit lines were obtained after seven and nine iterations respectively using iterative selective regression.
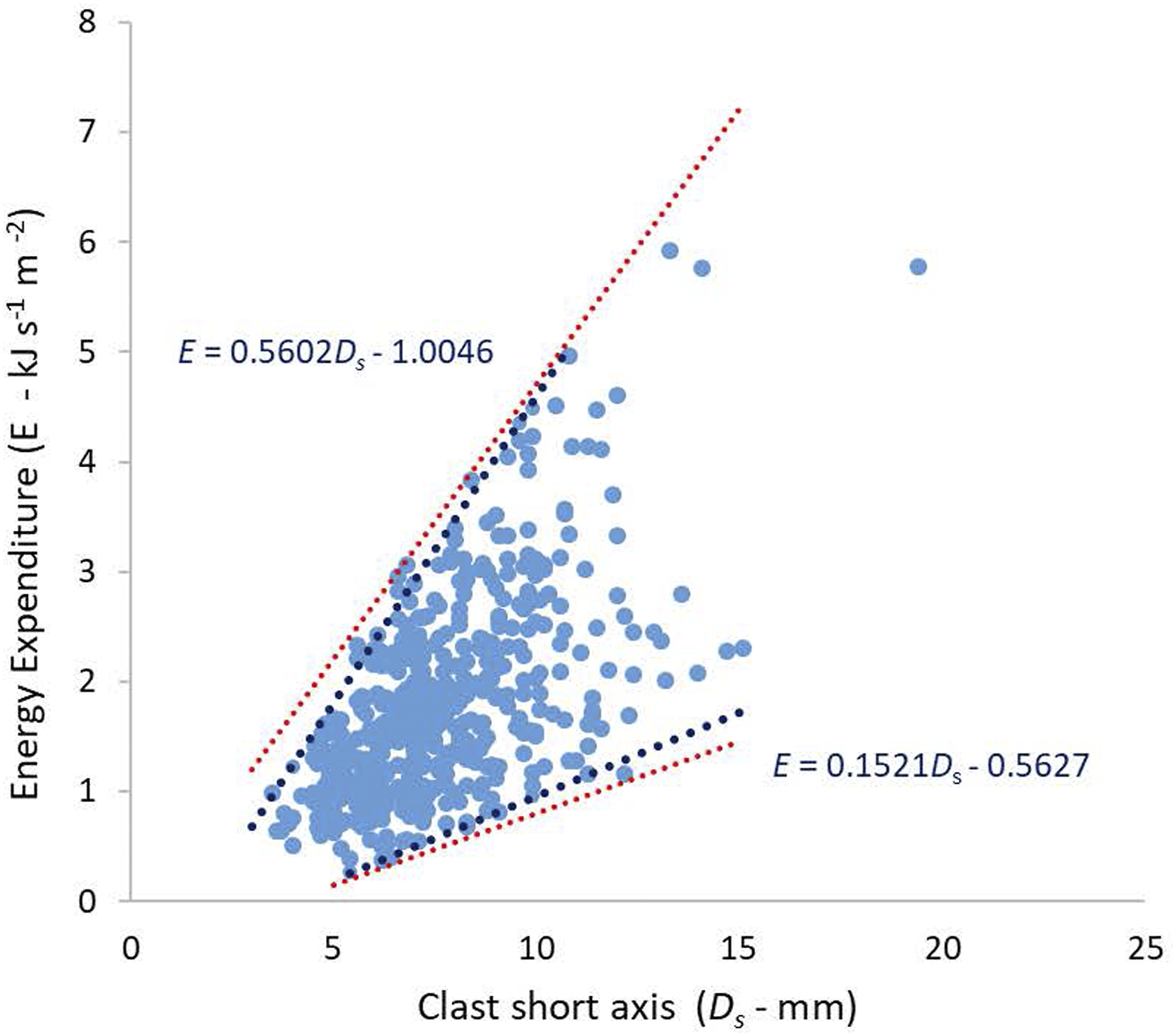
Variation in experimentally derived energy expenditures recorded using point-load test applied to fracture water-worn pebbles. Red curves were fitted by visual inspection. Blue curves were fitted using selective regression.
6. Concluding Discussion
Researchers sometimes wish to define boundaries, upper or lower limits to samples of data, and hence to the distributions from which those samples are drawn. In choosing an approach to achieve this, the researcher should be as specific as possible about the objective of their data analysis. Consideration should be given as to how the inferences derived from the analysis will be used further to inform decisions. In some fields, including hydrology and environmental engineering, there are specific concerns regarding characterisation of extreme values of the data-generating process. In these areas, techniques motivated by extreme value theory are relatively commonplace to quantify the (joint) tails of distributions from samples, and to estimate extreme quantiles including upper bounds for conditional distributions such as
In the absence of theoretical knowledge as to the form of a limit line, the qualitative procedure of inspection is a useful initial means to consider the likely form of a function. Indeed, the intuitive understanding of how the data behaves can assist in statistical model formulation, yet at the same time inspection can lead to false inferences as to the likely behaviour of a limit. The quantitative nature of data allows objective fitting of a statistical function, which can then be compared with the intuitive expectations of the analyst. Given that a variety of statistical models are available, it is important to consider at the outset the purpose of the fitting exercise and to choose the method that is most appropriate to satisfy the objective. Fitting statistically derived limit lines is especially powerful in those cases where the theoretical limit is either well-known or the behaviour is reasonably expected. In these cases, the close agreement of the statistically fitted limit with a theoretically derived line can be confirmatory. In contrast, significant discrepancies between the two curves may indicate deficiencies with the data sample: additional data may be required, or the quality of existing data may be suspect. Discrepancies may also highlight theoretical or model inadequacies: the possibility that other covariates are affecting y- or x-values, or that the theory may need revision.
In the examples provided herein (section V) it is evident that the application of different methods produces different limit lines. In some applications, these discrepancies may not be significant. As previously noted, the identification of extreme behaviour within environmental systems can be very important for instance in hazard mitigation. In such critical situations, the development of limit lines rationally informed by empirical evidence, statistical and physical theory is preferable. Although this conclusion may seem obvious, there are many examples in the literature of limit lines fitted without consideration of existing theory. For example, surprisingly, limit lines are often fitted to define the relationship between the maximum flood discharges generated from given catchment areas without consideration of the maximum probable flood (MPF). The MPF is the theoretical expectation (e.g. Shalaby, 1994; USFERC, 2001) and it would be informative to compare the statistically derived flood limit lines with the theoretical functions. Where theory is unavailable, consideration should be given as to whether the application of different methods tends to lead to convergence in terms of the form and trend of several limit lines. In general, however, identifying the sub-set of methods that provide consistent estimates of limit lines is likely only to be possible once the details of the problem and data have been understood. Building an appreciation for the relative performance of different methodologies via simulation study for a specific problem type is useful and standard practice in the statistics literature. However, the number of potential problem types is huge, and therefore the specifics of the problem of interest first need to be clearly defined before the simulation study is undertaken.
The use of advanced statistically methods in contrast to simple ones readily can be justified (Jomelli et al. 2010), especially when there is plentiful empirical evidence. Not least, given the inevitable ambiguity in fitting of limit lines, it is important to reason systematically whilst recognising the uncertain evidence that even large data sets offer (e.g. using Bayesian analysis). However, situations occur where the x-y data points are few, or their disposition on the scatter plot render the application of sophisticated methods impracticable or impossible. Such situations usually indicate that additional data are required, or that stronger assumptions about the data-generating process are necessary. Regardless, the procedure used to fit a limit line should be documented sufficiently clearly that limit line estimation given a sample of data can be reproduced with confidence. Fitting a limit by Inspection alone rarely can be justified.
The advantage of a statistical approach in general is that it provides a rational, reproducible basis for inference, and hence a sound basis for learning: different practitioners working independently can be reasonably expected to make the same inference given a sample of data. The performance of a model is dependent on the quality of information used to infer it. It is not reasonable in general to expect that a statistical model provides a ‘better result’ than a visual fit, since a well-informed visual fit may be superior to a badly specified statistical model. However, it is also self-evident than an ill-informed visual fit can lead to spectacularly bad inferences.
The outline taxonomy or road map provided in Section II provides an overview of the range of statistical methodologies available for estimation of limit lines, and references to statistical texts which explain methodologies in more detail. Choice of the appropriate methodology will be problem specific. When dealing with an unfamiliar problem, seeking the advice of a statistician is likely to be beneficial. Given the uncertainty that can pertain to model fitting, we conclude by providing some signposts that may assist in the decision-making process of limit line fitting: • Define the objective of the analysis: for what purpose will the fitted limit line be used? Consider how this informs the analysis to be undertaken • Assess the data to hand, the characteristics of the measurement used to gather data, and likely sources of uncertainty. Are the measurements independent (given covariates)? Are the data representative? What is the potential for gathering further relevant data? • Determine if theory allows the form of the limiting function to be defined • Determine whether a statistical model can be adopted for the data-generating process and fitted to the data. Limit lines may then be estimated using the fitted statistical model. What form of statistical model is likely to be more appropriate? Otherwise consider what form of limit line curve might be appropriate from knowledge of the system behaviour • Assess the appropriate level of sophistication of the statistical model or limit line curve, guided by parsimony. Is it likely that (unknown, unmeasured) covariates are in play? Should breakpoints be considered? • In fitting the statistical model or limit line, always assess fitting performance using diagnostic plots and tools. Assess potential outliers. • Seek to quantify uncertainties in the fitted model (line), and propagate those uncertainties to subsequent decisions made using the fitted model (line)
Supplemental Material
sj-pdf-1-ppg-10.1177_03091333211059995 – Supplemental Material for Fitting limit lines (envelope curves) to spreads of geoenvironmental data
Supplemental Material, sj-pdf-1-ppg-10.1177_03091333211059995 for Fitting limit lines (envelope curves) to spreads of geoenvironmental data by Paul A Carling, Philip Jonathan and Teng Su in Progress in Physical Geography: Earth and Environment
Supplemental Material
sj-jpg-2-ppg-10.1177_03091333211059995 – Supplemental Material for Fitting limit lines (envelope curves) to spreads of geoenvironmental data
Supplemental Material, sj-jpg-2-ppg-10.1177_03091333211059995 for Fitting limit lines (envelope curves) to spreads of geoenvironmental data by Paul A Carling, Philip Jonathan and Teng Su in Progress in Physical Geography: Earth and Environment
Footnotes
Acknowledgements
Teng Su acknowledges the receipt of China Postdoctoral Science Foundation Grant No. 2020M670435. Software for the trimming method of Maller et al. (1983) is provided at Carling et al. (2021), and for simple non-stationary extreme value analysis at ![]() . We are grateful to the Editor, Karen Anderson and two anonymous reviewers for their comments which substantially improved the presentation of the results.
. We are grateful to the Editor, Karen Anderson and two anonymous reviewers for their comments which substantially improved the presentation of the results.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.