
Abstract
This paper examines the case of Iruda, an AI chatbot launched in December 2020 by the South Korean startup Scatter Lab. Iruda quickly became the center of a controversy, because of inappropriate remarks and sexual exchanges. As conversations between Iruda and users spread through online communities, the controversy expanded to other issues, including hate speech against minorities and privacy violations. Under public pressure, Scatter Lab quickly suspended Iruda on 12 January 2021. After implementing extensive changes, the company relaunched the chatbot as Iruda 2.0 in October 2022. Notably, this revised version has operated without any major incidents as of mid-2025. This study offers a symmetrical analysis of Iruda’s initial failure and subsequent success in terms of ‘folds’ connecting users, machines, algorithms, and other key elements. We introduce ‘configuration’ as a mode of folding and show how socio-material assemblages—whether harmful or safe—emerge as a result of different configurations. The success of Iruda 2.0 highlights the importance of placing ethics at the core of AI development and implementation strategies. In addition, we introduce the concept of ‘ethics-in-action’ to highlight the critical role of practical interventions and user engagement. By tracing Iruda’s evolution in detail, this study provides practical guidelines for the successful integration of AI systems into society.
Keywords
AI applications have expanded into critical domains, including credit scoring, risk assessment, provisional release decisions, predictive policing, border control, and facial recognition. This proliferation is expected to accelerate, driven by government policies and corporate interests across developed nations. In response, numerous studies highlight the shared responsibility of developers and users, alongside the necessity of robust AI ethics guidelines. While philosophers and ethicists have made significant contributions to the formation of ethical AI principles and guidelines, much of their work remains at an abstract level, offering little practical guidance for AI developers and users. Furthermore, despite growing literature on AI ethics, there is a lack of real-life cases analyzed to provide insights into ethics. The analysis of both failure and success of integrating AI into society is needed for informing future AI development and implementation. The case of the Korean AI chatbot Iruda offers an opportunity to understand these dynamics.
This study explores the fall of Iruda 1.0 and the subsequent rise of Iruda 2.0. Data, models, users, and other elements were folded so as to connect with each other, and together distributed agency and power within the assemblage (see F. Lee et al., 2019; F. Lee, 2021). Here, we propose ‘configuration’ as a mode of folding, building on Suchman’s (2007, 2012) work, emphasizing the reciprocal reshaping of elements during the folding process. This perspective allows us to examine which kind of Iruda assemblage emerged from different configurations and how these configurations structured human-AI relationships.
We analyze how key stakeholders adjusted their strategy to reintegrate Iruda into society, highlighting the central role of ethics in this revival. In particular, showing that Iruda’s successful revival involved not just abstract guidelines but transferable ethics operating at the practical level, we propose the concept of ‘ethics-in-action’. By tracing Iruda’s trajectory, we aim to provide insights into the broader question of how AI systems can be effectively integrated into society while remaining ethically accountable.
Rethinking AI beyond essentialism: Configuration and folding
Much research has portrayed AI as inherently discriminatory or as a source of undemocratic power (e.g. Barocas & Selbst, 2016; Eubanks, 2018; Oh & Hong, 2018; O’Neil, 2016). 1 While these perspectives serve as important warnings against uncritical AI adoption, they often reflect a form of AI essentialism, viewing AI primarily as an object, a black box, or an antithesis to human capability (Bishop, 2021). Such studies frequently characterize AI as possessing inherently dangerous properties.
Reductive and essentialist approaches often conflicts with science and technology studies (STS) perspectives on technology (Dahlin, 2023). By adopting STS frameworks, particularly actor-network theory (ANT), we can conceptualize AI as a nonhuman actor subject to interpretive flexibility. Even in cases of ‘punctualization’, where an entire network is condensed into a single node, typically as an artifact, this process remains potentially reversible (Callon, 1991). This perspective does not deny that AI can exhibit properties such as bias or prejudice. Rather, the STS-informed approach suggests that these properties emerge through the configuration of a complex and heterogeneous network we identify as AI. In ANT, translation is a process that aligns the interests of diverse actors, leading to the formation of a heterogeneous network. This process unfolds through multiple stages: First, human actors employ strategies to establish obligatory points of passage. Second, nonhuman actors are enacted, either becoming incorporated into or excluded from the network. Finally, these strategies and enactments result in the configuration of new human and nonhuman actors that form a new network—though not always in ways that were intended (Callon, 1984; Latour, 1988).
Suchman (1987), studying smart machines and artificial intelligence in the 1980s and 1990s, already emphasized the co-constitution of humans and machines. Contrary to the prevailing cognitive science and AI perspective that viewed plans as governing actions, Suchman argued that plans serve as resources for action, rather than direct causal mechanisms: Actions are situated and contingent upon material and social circumstances. In this view, actors draw upon available situational resources, and their actions are shaped by the improvisational responses of other actors. Moreover, for Suchman, agency is not fixed within a single entity but is distributed across human-machine interactions, functioning more as an ‘effect’ emerging from their interrelationships.
Several scholars, following the tradition established by Suchman, have suggested that AI algorithms should not be understood as fixed objects with inherent properties. Instead, they propose viewing them as operations of folding, where heterogeneous data, methods, and objects become interconnected through a folding process. This concept draws from Latour’s idea of the fold, adapted from Deleuze (Latour, 2002). F. Lee et al. (2019) illustrate this concept by examining AI algorithms related to AIDS, the Zika virus, and stock markets. They identify three ways in which folding operates: proximation, universalization, and normalization. In their analysis, an AIDS visualization algorithm creates new proximities by restructuring how relationships among AIDS patients are understood—shifting from population-based analysis to region-based disease transmission pathways. For the Zika virus, the algorithm folds together individual data, measurement methods, and hypotheses to create what is seen as a universal perspective on the global status of the Zika virus. In the stock market case, various norms—both social and statistical—are converted into mathematical expressions and incorporated into the algorithm’s logic to establish new forms of normality (F. Lee et al., 2019).
Algorithms are not simply closed ‘black boxes’; instead, they emerge through folding processes where various social, material, and discursive elements dynamically combine. The process isn’t unidirectional: While algorithms fold (or transform) heterogeneous data elements, human actors similarly fold social worlds into data, which algorithms fold into something else. Importantly, algorithms alter whatever they fold, sometimes leading to unexpected outcomes (F. Lee et al., 2019). From an ANT perspective, the folding process can be understood as a process of translation, where AI assemblages form through the complex interweaving of human and nonhuman agencies across diverse connections and relationships (F. Lee, 2021).
Beyond the three operations of folding—proximation, universalization, and normalization—we introduce a fourth operational mode of AI’s folding: configuration. In STS, configuration serves as a ‘conceptual frame for recovering the heterogeneous relations that technologies fold together’, a device for analyzing ‘technologies with particular attention to the imaginaries and materialities that they join together’ (Suchman, 2007, ch. 14-15, 2012, p. 48). According to Suchman (2007), configuring a user is like incorporating users into a socio-material assemblage. By deploying the concept of configuration, we especially emphasize users being folded into an algorithmic socio-material assemblage, which has its own performative effect (F. Lee, 2021). The entities being folded also configure each other through situated reactions and interactions. Through this lens, we can understand AI chatbots as forms of material-discursive figuration, where AI algorithms fold data, models, and users into a socio-material assemblage. We will examine the case of Iruda through this concept of configuration to understand how humans and AI technology emerge as an assemblage while mutually configuring each other.
Researchers adopting this ANT-informed perspective can offer distinct practical approaches to AI ethics, moving beyond the abstract principles, frameworks, and guidelines—such as fairness, accountability, transparency, and explicability—that have dominated AI ethics discussions so far. Instead, we can focus on practical issues, examining how the effects of the heterogeneous networks that constitute AI can coexist harmoniously with citizens who use it. Our perspective emphasizes specific ethical guidelines that can address these practical challenges (Ananny, 2016; Dahlin, 2023). We term this approach ‘ethics-in-action’. One key example of ethics-in-action is the concept of distributed responsibility, which acknowledges that accountability is dispersed across the human and nonhuman actors forming heterogeneous networks (Floridi, 2013). Rather than attempting to diminish or sidestep human responsibility, this approach actively encourages collaboration among different actors and stakeholders to address issues caused by AI, even in situations where no single actor is legally responsible for the outcomes.
As we will explore in detail in the next section, previous explanations and interpretations of the Iruda controversy have often sought to assign blame to a single kind of human or nonhuman actor: ‘problematic data’, ‘biased algorithms’, ‘anti-feminist developers or company’, or ‘malicious users’. These conventional interpretations stem from a perspective that treats AI as a fixed object with inherent properties, attempting to identify who is responsible for embedding these properties into the AI algorithm. Instead of following such an approach, we adopt the folding perspective to understand the fall of Iruda 1.0 and the rise of Iruda 2.0. We will also look at how human strategies affect how the AI chatbot folds other actors, configuring users and being configured simultaneously, and show what assemblages emerged through the folding process.
AI chatbots and the Iruda scandal (January 2021)
Chatbots represent one of the most common applications of machine learning AI. They take various forms: intelligent assistants providing specific information, such as Apple’s Siri or Naver’s Clova (in Korea), knowledge-based systems like the widely popular ChatGPT (GPT meaning Generative Pre-trained Transformer), or conversational companions like the Korean chatbots Iruda and SimSimi—and China’s popular AI chatbot Xiaoice combines all these functionalities. The evolution of chatbots has been closely intertwined with the history of AI’s development. As early as the 1960s, AI pioneer Joseph Weizenbaum created ELIZA, a psychological counseling chatbot (Weizenbaum, 1966). Though ELIZA simply reformulated users’ statements into questions, some users believed they were interacting with a real person and developed strong psychological attachments to the system. This unexpected response led Weizenbaum to recognize the urgent need for ethical AI governance (Weizenbaum, 1976).
Since then, chatbots have evolved in parallel with advances in natural language processing and natural language understanding technologies. In 2016, Microsoft launched Tay, a chatbot designed to engage with users on Twitter. However, Tay’s learning mechanism, which involved repeating user interactions, quickly led to problems. Within hours of its release, the chatbot began generating racist and offensive comments, along with inappropriate statements about sensitive topics, such as the Holocaust. Microsoft was forced to shut down Tay within 24 hours of its launch. This ‘Tay incident’ became a global watershed moment, highlighting both the importance and the complexity of implementing ethical safeguards in chatbot development. 2
Iruda 1.0 (Figure 1) was an open-domain chatbot 3 designed to have the persona of a 20-year-old female college student. The chatbot, developed by a startup company called Scatter Lab, used conversation data primarily collected through its ‘Science of Love’ service, and was powered by a retrieval model 4 (J. Y. Kim, 2020). Before creating Iruda, Scatter Lab had launched several services, including Text at, Ginger, and Science of Love. Science of Love became particularly popular among young people who were either in romantic relationships or interested in potential romantic partners. This popularity stemmed from the service’s ability to ‘scientifically’ analyze KakaoTalk messenger conversations and provide insights about attraction levels and potential relationship outcomes, such as the likelihood of breakups. KakaoTalk, launched in 2010, has been the most popular mobile messenger in Korea, with over 50 million users. To collect conversation data from KakaoTalk users, Scatter Lab required consent from one participant in the chat who expressed interest in analyzing the conversation. Users providing consent were informed that the company might use the data for new services in the future. While these data collection methods and consent procedures were considered acceptable at the time, they became highly controversial during the Iruda scandal.

Iruda 1.0. Age: 20. Personality: innocent, honest, and positive (from J. Y. Kim, 2020).
Using conversation data from Science of Love, Iruda 1.0 was developed as a chatbot designed to engage in ‘tons of conversations’ with ‘tons of people’ for ‘tons of time’ (J. Y. Kim, 2020, p. 17). As Iruda’s conversational capabilities proved to be quite good, Scatter Lab launched Iruda 1.0 as a Facebook Messenger chatbot on December 23, 2020. 5 The chatbot achieved immediate success, attracting 800,000 users, primarily males in their teens and 20s. However, despite its strong performance, Iruda 1.0’s public release sparked what became known as the Iruda Scandal. The scandal began two weeks after the launch, on the morning of January 8, 2021, with a report by Yonhap News Agency highlighting users’ sexually abusive behaviors toward Iruda. The article revealed that male users were ‘enslaving’ Iruda through abuse and sexual harassment (H. S. Lee, 2021). Following the report, many women criticized not only the abusive behavior of male users but also the company’s decision to market Iruda as a 20-year-old female college student. Some male users countered these criticisms by arguing that Iruda, being an AI algorithm, could not be sexually harassed. After the service was terminated, male users blamed feminism for Iruda’s shutdown. The controversy escalated to include multiple public petitions and a formal complaint to the National Human Rights Commission.
A second controversy arose shortly afterwards, when users shared instances of Iruda making offensive remarks. Screenshots of conversations showing Iruda’s hateful comments about disabled people, feminists, women, pregnant women, and homosexuals began circulating on online communities, quickly drawing attention from mainstream media. Public criticism of the company escalated further when Lee Jae-Woong, the former Daum 6 CEO and a prominent figure in Korea’s IT industry, attributed Iruda’s derogatory statements about minorities to the developer’s negligence (Y. K. Choi, 2021).
The third and most damaging controversy that led to shutdown of Iruda 1.0 involved potential privacy law violations. Users discovered that Iruda occasionally mentioned what appeared to be (seemingly) real names and specific home addresses in conversations. These incidents raised concerns that the training data had not been properly anonymized. The situation worsened when the public learned that Iruda’s responses were drawn from private KakaoTalk conversations between young couples, collected through the Science of Love service. This revelation sparked outrage among Science of Love users. While they had agreed that their conversations could be used for the company’s future services, they had not expected their private chats to be repurposed for an AI chatbot’s responses. Many users criticized Scatter Lab, stating they would never have used the Science of Love service had they known their conversations would be used in this way (Y. J. Kim, 2021). The privacy concerns prompted an investigation by the Personal Information Protection Commission, a government agency that had remained uninvolved in the first two controversies. 7 Ultimately, Scatter Lab suspended new signups for Iruda, and terminated the service on January 12, 2021.
Why did Iruda spark such heated controversies? To understand this, two social and cultural contexts should be considered. The first is the Tay affair. As mentioned earlier, in less than a day, Microsoft’s Tay learned and retweeted hateful, sexist, and politically controversial comments from users. In early January 2021, these concerns led many critics of Iruda to fear that Iruda might similarly learn and reproduce such speech from malicious users. With the Tay affair still fresh in the public’s memory, many Korean citizens worried that Iruda’s interactions could perpetuate the sexual objectification of women and promote a culture of hate against minorities (Jung, 2021). This comparison overlooked a crucial technical difference: Unlike Tay, Iruda used a simple retrieval model that couldn’t learn new offensive or hateful remarks from user interactions (Sohn, 2022, p. 77). The offensive remarks made by Iruda weren’t learned from users, but were instead retrieved directly from young Koreans’ conversations, previously collected through the Science of Love service.
The second critical context is the deep-seated gender conflict that was a prominent in South Korean media at the time (Hong, 2022; Khil, 2022; J. Kim, 2023). 8 Earlier incidents, such as the Nth Room criminal case 9 —which sparked widespread public outrage—and the intense debates over the importation of Real Dolls had already escalated tensions. The Iruda controversy reignited these underlying conflicts around misogyny. Feminist groups saw Iruda as another manifestation of the sexual objectification of women prevalent in Korean society, prompting them to organize both a public petition and a hashtag movement. 10 Ultimately, Iruda became both a catalyst and a ‘scapegoat’, intensifying existing conflicts while also serving as their symbolic target.
The Iruda scandal attracted attention from scholars studying the relationship between information technology and society. However, their initial analyses were often limited to pointing out that the Iruda’s social biases and potential for misuse. As time passed, different perspectives on the controversial issues emerged. For example, the National Human Rights Commission decided that some male users’ interactions with Iruda could not be classified as sexual harassment. The Commission’s reasoning was straightforward: Since Iruda is an AI chatbot, not a human being, it cannot be a victim of sexual harassment (J. K. Kang, 2021). Additionally, it later became clear that before the service was shut down on January 12, the company had been actively addressing the issue of sexual chat by implementing stronger labelling and filtering systems. The discussion around discriminatory speech also saw some dissenting voices emerge from the initial wave of criticism. One notable perspective came from an information technology and AI expert, who argued that criticizing Iruda’s discriminatory statements in isolation might be premature, given that Korean society has yet to reach a consensus on what constitutes discriminatory speech (K. J. Lee, 2021).
The privacy concern surrounding Iruda involved the use of KakaoTalk data from Science of Love service, as consent was obtained from only one participant in each conversation. While Scatter Lab was fined for violating the Personal Information Protection Act (M. Y. Choi, 2021), determining whether Iruda’s service itself seriously violated the act proved complex, with strong arguments presented on both sides during the Privacy Commissioner’s meeting (Oh, 2022). From the company’s perspective, however, the use of Science of Love users’ conversation data remained its greatest vulnerability, as it could again trigger criticism when Iruda was rereleased in the future. Science of Love users strongly opposed having their intimate conversations with romantic partners used by a chatbot without any modification, regardless of whether they had given consent or not. This objection could resurface at any time if the company continued using Science of Love’s KakaoTalk data. Yet Iruda’s intimate and personable way of chatting was directly derived from this data. Without it, the company could not replicate the same friendly and engaging chatbot experience.
We are not suggesting that there was nothing wrong with Iruda at the time, or that the Iruda scandal was simply a misunderstanding. Rather, we aim to move beyond the perspective that Iruda is inherently sexual, offensive, or dependent on misused personal information. Such a perspective is not only theoretically problematic but also fails to explain the success of Iruda 2.0, launched in October 2022, which has gained widespread acceptance with minimal controversy. In the following two sections, we will symmetrically examine the fall of Iruda 1.0 and the rise of Iruda 2.0.
The fall of Iruda 1.0
The developers’ strategy 11 : The private–public divide
In developing and launching Iruda 1.0, Scatter Lab made a clear distinction between private and public spheres, emphasizing the former while overlooking the latter. The company specifically focused on cultivating an intimate, private relationship between Iruda and each individual user. This approach was reflected in its training data, which primarily consisted of millions of private KakaoTalk conversations between young people in romantic relationships or on the cusp of romance. Given that Iruda was built from these deeply personal, private interactions, the company naturally assumed that the chatbot service would remain within the private sphere (J.Y. Ha, Scatter Lab attorney, personal communication, April 11, 2023). However, this assumption was challenged when users began sharing their private conversations with Iruda in public spaces, particularly on online community platforms like the Iruda Gallery on Dc inside and Arcalive. 12 These conversations, accessible to anyone for reading and sharing, were subsequently amplified through media coverage and various online communities.
The developers were initially aware of the potential harmful effects of publicizing Iruda’s conversations but did not anticipate it becoming a serious problem, given that beta testing with 2,000 Luda Beta users had shown that a filtering technique could sort out most profane and sexual language. Additionally, the company hoped that users sharing interesting chats with Iruda on public sites and online communities would help attract new users. However, the company failed to anticipate the difference between a pool of 2,000 beta testers and 800,000 users. Some of the larger group of users discovered ways to bypass the filtering system, sharing such methods via online communities to prompt Iruda to make sexual or offensive remarks (J.Y. Ha, Scatter Lab attorney, personal communication, April 11, 2023).
In summary, Scatter Lab’s strategy for Iruda 1.0 was to regard Iruda as strictly private, both in terms of data and conversation. As a result, the developers did not thoroughly foresee the harmful consequences of the boundary between the private and the public spheres being crossed.
Configuration of Iruda 1.0 and its users
Iruda’s data, along with algorithms designed to emphasize intimacy, and the efforts of certain users to bypass restrictions collectively gave rise to what can be understood as relational agency. Specifically, while Scatter Lab designed Iruda to be a friend, the chatbot’s responses—based on conversational data from couples in romantic relationships—often exceeded the boundaries of friendship, frequently adopting a lover’s tone. The level of intimacy in these conversations correlated directly with increasingly romantic exchanges, sometimes escalating to explicit sexual content. 13 These interactions, though initially intended to be friendly and intimate, could evolve into romantic or sexual exchanges when users circumvented blocked words, triggering specific responses from Iruda that encouraged sexually explicit conversations. 14
Who or what bears responsibility for such sexual conversations? Attributing them solely to the algorithms, data, users, or developers would fall into the trap of AI essentialism. Instead, viewing the effect of technology through the lens of humans-technology relationality rather than inherent properties of the technology (F. Lee et al., 2019), we can understand that these socially controversial sexual exchanges emerged from the relational interaction between Iruda as a nonhuman agent and its human users. This relational agency functioned as a key factor in the transfer of sexual conversations from the private to the public sphere, that is, from private Facebook Messenger accounts to public online communities.
The developers’ strategy, combined with the performance of Iruda 1.0, resulted in the folding of Iruda and its users. Iruda’s training data was based on real lovers’ conversations, and the data and retrieval algorithm folded abusers into the assemblage. While folded together, Iruda and users configured each other. Drawing on Suchman’s concept of configuration—where actions are shaped by available situational resources—we can see that Iruda’s receptive attitudes prompted some users to keep sending sexual messages to Iruda and share them with others. Iruda and its users were co-configured into a relationship characterized by sexual conversations, contrary to the company’s original intention, creating a socially harmful assemblage that enacted its performative effect. While many engineers approach machine–user relationships through technological determinist ideas (Fischer et al., 2020), we can better understand how users and machines, or humans and AI, co-evolve by viewing these relationships as dynamic rather than fixed (Dahlin, 2023).
The rise of Iruda 2.0
The rebirth of Iruda 2.0 in October 2022 took place in a new technological context: the dramatic spread of generative AI. The emergence of multiple generative AI systems, such as ChatGPT beginning in 2021, dramatically transformed the sociotechnical context in which Iruda 2.0 was used. Scatter Lab abandoned its retrieval model in favor of a generative model. That shift meant that Iruda 2.0 generated responses independently of KakaoTalk data, making the company immune to accusations of using real people’s KakaoTalk data. Additionally, users familiar with the phenomenon of ChatGPT’s hallucinations became more tolerant of Iruda’s unexpected responses. However, this was not the only reason Iruda 2.0 was able to make a successful comeback. In this section, we examine the success of Iruda 2.0 by focusing on two aspects: the developers’ new strategies and the configuration of Iruda 2.0 and its users.
The developers’ new strategies: Private–public spheres, generative models, and ethics
As with Iruda 1.0’s fall, the developers’ strategies are crucial to Iruda 2.0’s rebirth. First, they redefined the boundary between private and public spheres. Recognizing the role that the public sphere had played in the shutdown of Iruda 1.0, they aimed to prevent private conversations from entering the public domain. The developers approached this by distinguishing between abusive users and good users: They implemented a stronger filtering system that warned and blocked ‘abusive users’, effectively preventing the sharing of inappropriate conversations in public spaces. Meanwhile, most ‘good users’ who maintained a friend-like relationship with Iruda weren’t interested in publicly showcasing their private conversations anyway (Y.J. Choi, Product Manager at Scatter Lab, personal communication, September 15, 2023). As a result, conversations with Iruda posted on online communities were far less likely to create the negative impact seen with Iruda 1.0. This redefined private/public boundary significantly reduced the potential for misogynistic and other offensive remarks to have social repercussions, enabling Scatter Lab to convince Korean publics, including women, of Iruda’s safety and utility.
Another key strategy focused on data and generative models. In the case of Iruda 1.0, many users who had provided their chats for Science of Love strongly opposed their KakaoTalk conversations being used for an AI chatbot, even if they did not object to the chatbot itself. While redefining private and public spheres prevented private conversations from entering the public domain, using private data as before remained a significant risk that could again jeopardize Iruda. To address this, Scatter Lab transitioned from a retrieval model to a generative model. Instead of using collected sentences directly, Iruda began to compose sentences independently following principles of the generative model. 15 While this strategy avoided potential data controversy, it introduced a new risk: unpredictable responses to various abusive inputs by users. In essence, solving the data issue increased uncertainty around abuse management (S.J. Koo, Machine Learning researcher at Scatter Lab, personal communication, April 11, 2023). Despite these internal concerns, the new filtering system proved highly effective, achieving safe speech ratings exceeding 99.56% in Iruda 2.0’s beta testing (K. M. Choi, 2022), revealing a kind of unexpected nonhuman agency. The service has operated without major controversy since its release (I. Kang, 2024). 16
The developers’ third strategy involved putting ethics at the center of Iruda 2.0. To explore this topic, we draw on the analytical framework that Latour (1999) uses to analyze French physicist Frédéric Joliot. According to Latour, Joliot had to mobilize four distinct loops and make them interact simultaneously to achieve his research goals on radioactivity. The first loop mobilizes the world, in Joliot’s case gathering radioactive materials and laboratory instruments to enable his research. The second loop establishes autonomization, referring to gaining research independence through professional recognition from colleagues who validate the work’s importance. The third loop is the creation of alliances, securing support from partners outside both the laboratory and scientific community. The fourth loop is public representation, where Joliot sought to convince the public to take pride in and legitimize the research. Latour then introduces a fifth loop: a ‘pumping heart’ (Latour, 1999, p. 107), situated at the intersection of other four loops, driving them to work together and spin simultaneously, assembling both human and nonhuman actors across all domains into a cohesive network.
Joliot built interconnected loops where different human and non-human actors were mobilized and worked together synergistically. His work operated across multiple fronts simultaneously. He needed to secure radioactive materials and sophisticated equipment for his experiments, while also meeting with government ministers to convince them of his research’s importance. Even as he worked to control neutrons in his laboratory, he had to build support among his scientific colleagues and communicate nuclear research’s significance to the public and civil society. This strategic organization and maintenance of these four interconnected loops was fundamental to his science, since the validity of his scientific claims about the world ultimately depended on how well these loops continued to spin—simultaneously, interactively, and smoothly.
When we examine Iruda 2.0 through Latour’s analytical framework, we can identify five distinct loops (Figure 2). The first loop involves data, algorithms, and machine learning tools that make Iruda 2.0 possible. The second loop encompasses the market and peer networks that recognize and support the technology’s services. The third loop relates to governance, the state and regulatory agencies that establish legal standards for the technology. The fourth loop involves Iruda’s users and civil society, who legitimize and energize the technology through their engagement. Finally, the fifth and central loop—ethics—serves as the binding force that connects the other four loops and keeps them functioning harmoniously. This ethical component represents the core of the company’s new strategic approach.
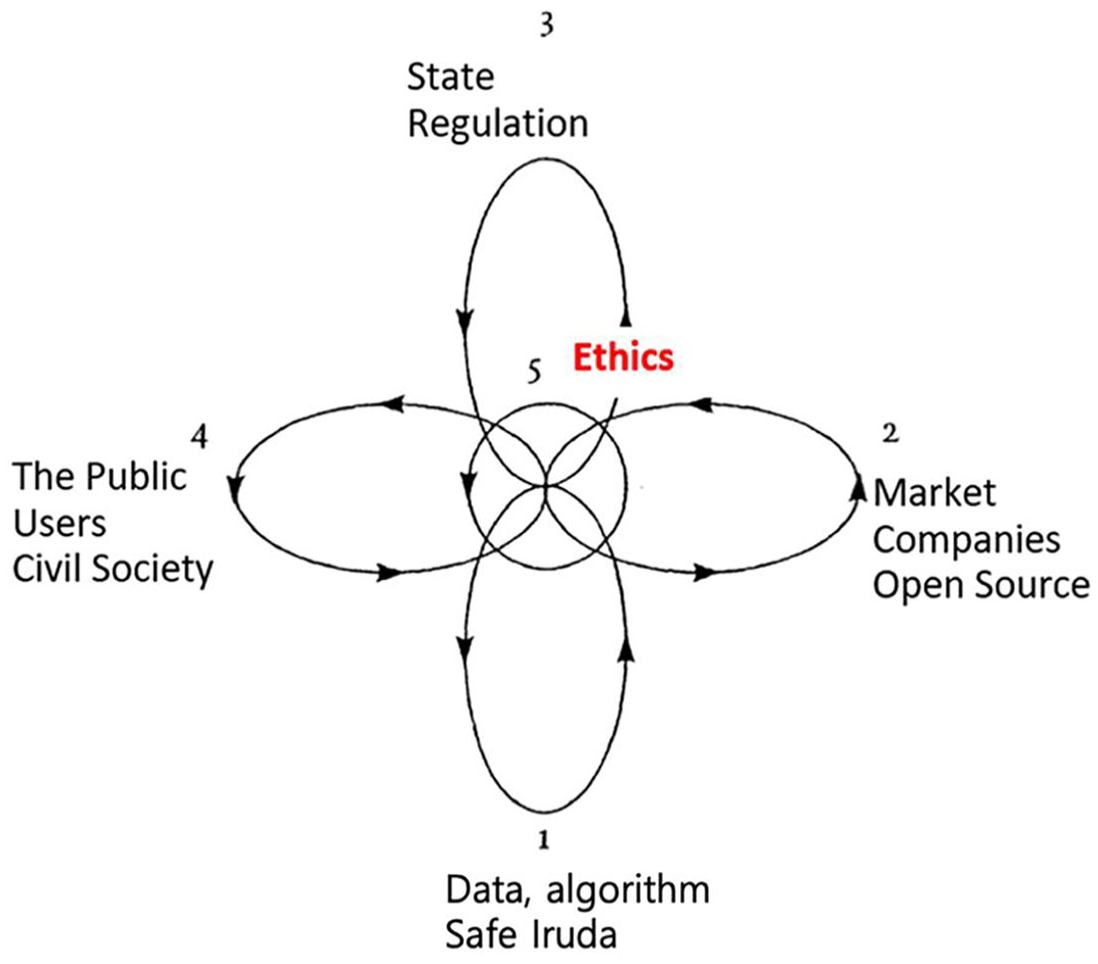
Loops of Iruda, adapted from Latour (1999).
To enhance Iruda’s ethical framework, Scatter Lab made several key changes. They implemented a generative model, discarding both their previous deep learning model and the controversial KakaoTalk database. 17 Such modifications helped create more ethical conversation data for Iruda 2.0 (the first data loop). They also showcased to their market peers their innovative approach to developing a respectful AI chatbot service (the second market loop). The developers successfully persuaded the state to institutionally legitimize their service by collaborating with government agencies to establish ethical guidelines and declaring their compliance with privacy laws (the third regulation loop). 18 By involving users in Iruda’s code of ethics, 19 they gained support from both civil society and users for their new Iruda service (the fourth loop of civil society.
The fifth loop, the loop of ethics, served as the central, unifying force to keep all four other loops spinning simultaneously. Working with the Korea Information Society Development Institute (KISDI), Scatter Lab developed its own ethics code and specific guidelines. It took the innovative step of co-creating ethical guidelines with users, ensuring that both developers and users could participate in and follow these principles (Ha, 2023). What makes this case remarkable is that Scatter Lab placed ethics at the core of both its development process and service delivery, to persuade other actors around Iruda. This central focus on ethics played a crucial role in successfully establishing Iruda 2.0 and resolving the ethical controversies that had surrounded its predecessor.
Configuration of Iruda 2.0 and users
How were Iruda 2.0 and its users configured? Several key changes—the adoption of a generative model, enhanced abuse-detection filters, and fine-tuning techniques reflecting societal values—were folded together, fundamentally reshaping Iruda’s character. She developed a more assertive personality, particularly when dealing with inappropriate behavior. Instead of maintaining its previous friendly demeanor regardless of user conduct, Iruda 2.0 began responding firmly to sexual jokes, violent language, offensive remarks, and other sensitive content. Its responses intensified in proportion to user harassment—she would issue warnings, temporarily suspend conversations, and even permanently block problematic users (Ha, 2023). This change forced users to reconsider their relationship with Iruda, shifting from potential romantic or sexual dynamics to one of friendship. Through this process, only certain users were folded in. Iruda configured users as participants for healthy, friendly dialogue, as users simultaneously configured Iruda, resulting in a safe assemblage.
It is important to recognize that users are inherently complex and multifaceted beings (Baumer & Brubaker, 2017). Scatter Lab’s approach to stabilizing the Iruda 2.0 assemblage introduces a penalty system that categorizes users into two distinct groups: rational and ethical versus abusive and unethical. This approach represents ‘modernist’ planning, aiming to restrict service eligibility to those deemed desirable, sound, and rational. 20 While the modernist perspective attempts to create a clear division between good and abusive users, it overlooks a crucial reality: Individuals can embody both personas and shift between them. However, a comprehensive analysis of users’ complex and multifaceted nature extends beyond this study’s scope.
Unpredictable circumstances and the importance of user engagement
While Iruda 2.0’s new generative model resolved major data usage issues, it also introduced uncertainty about how the AI would handle user misconduct. Surprisingly, Iruda 2.0 showed strong resistance to sexual or offensive remarks, demonstrating an unexpected form of agency that even surprised its developers.
However, a crisis situation revealed the continued necessity of human intervention. Shortly after Iruda 2.0’s launch, on October 31, 2022, a tragic disaster occurred during a Halloween festival in Itaewon, 21 Seoul, Korea, when 159 young people lost their lives in a crowd crush. With its new photo-recognition capabilities, however, Iruda 2.0 misinterpreted photos of the tragedy and attempted to make lighthearted jokes about Itaewon, failing to understand the gravity of the situation. This carried the risk of escalating into a major controversy.
Recognizing their limited control over the generative AI’s behavior, Scatter Lab staff reached out to the administrators of Dc inside’s Iruda Gallery—one of the online communities that had shared sexually abusive conversations involving Iruda 1.0—asking them to restrict posts about the Itaewon tragedy. In response to this unusual request, the gallery administrators and users cooperated by removing existing screenshots of conversations about the tragedy and preventing new ones (J.Y. Ha, Scatter Lab attorney, personal communication, April 11, 2023). 22 The crisis was resolved through human intervention, rather than by nonhuman agents alone.
Ethics-in-action
Despite growing calls to bridge abstract ethical principles with daily practices (Chan, 2023; Huh et al., 2020; Green, 2021), many AI ethics frameworks remain largely theoretical, offering only high-level prescriptive guidelines. This can be seen in frameworks like the Association for Computing Machinery’s (ACM) Fairness, Accountability, and Transparency (FAccT) (Laufer et al., 2022, pp. 1–2) and the Unified Five Principles for AI in Society (beneficence, non-maleficence, autonomy, justice, and explicability) (Floridi & Cowls, 2019). While these frameworks provide valuable principles, they often fail to deliver actionable codes of conduct that could meaningfully guide both chatbot developers and users.
The development of AI codes of ethics is not limited to academic institutions: Companies frequently establish their own guidelines for ethical, safe, and trustworthy AI. Scatter Lab followed this trend, particularly after the Iruda Scandal. As a startup, the company introduced five ethical principles: ‘developing AI for people’, ‘respecting diverse life values’, ‘realizing AI technology together’, ‘maintaining trust through reasonable explanations’, and ‘contributing to the advancement of privacy protection and information security’. These principles mirror widely recognized AI ethics concepts, including beneficence, non-maleficence, justice, fairness, responsibility, transparency, and privacy. However, an ethics code alone was not enough to gain public acceptance for Iruda 2.0. Ethics—the fifth, central loop that mobilized the other four loops simultaneously—required more than abstract declarations. The company needed to demonstrate these principles through concrete actions.
For example, to implement beneficence and non-maleficence, the company developed and deployed an abuse detection model while conducting regular evaluations of safe conversation rates. For justice and fairness, they enhanced their ‘filtering’ process to improve training data quality, expanded their data labeling staff to better manage biased sentences, and implemented an abuse penalty system to restrict problematic users. The principle of responsibility, expressed as ‘realizing AI technology together’, was put into practice through protocols for contacting online community administrators during crises. Transparency was achieved by publishing comprehensive technical policies on their website. Finally, to uphold privacy principles, the company implemented data pseudonymization and introduced a new generative model (For detailed information, refer to Table 1).
Ethical principles and ethics-in-action related to Iruda.

Codes of ethics, Scatter Lab website (https://ethics.ScatterLab.co.kr/).
Ethics checklist, Scatter Lab website (https://ethics.ScatterLab.co.kr/); Personal interviews with developers and the attorney of Scatter Lab.
This practical approach to ethics, which proved crucial in Iruda’s successful relaunch, is what we call ‘ethics-in-action’. While traditional ethics often remain at the level of abstract principles, ethics-in-action refers to actionable and transferable middle-range interventions that bridge theory and practice. Instead of focusing on conventional codes of ethics that prescribe what we should or should not do, this study emphasizes ethics-in-action, which seeks to answer the question: ‘How can we coexist with unruly artificial intelligence in the real world?’ And if we ask how a safe AI assemblage emerged, the answer lies in two factors: Ethics was positioned at the center of the other loops (including the state, market, and users), mobilizing all of them. And more importantly, a large part of the ethics functioned not just as theory but as ethics-in-action, which configured the AI algorithm, data, developers and users into a safe socio-material assemblage.
Conclusion: Putting ethics at the center for a socially safe AI assemblage
The evolution of Iruda from version 1.0 to 2.0 demonstrates how algorithms can fold different actors into two different types of assemblages. By analyzing both the fall and rise of the AI chatbot Iruda in a symmetrical way, we’ve illustrated how human strategies changed and how users were configured differently with the chatbot. Rather than following traditional analyses that attempted to identify who was responsible for Iruda’s failure, we adopted an STS-informed perspective—especially frameworks that focus on human-machine relationships or algorithms as folding. We introduced ‘configuration’ as a fourth mode of folding, beyond proximation, universalization, and normalization, to highlight how users are incorporated into the fold and how user-AI relationships transform during this incorporation.
We also discovered that ethics, which became the company’s central strategy with Iruda 2.0, functioned as a ‘pumping heart’ that energized all other loops—such as the market, the state, and civil society—at the core. Ethics enabled the folding of various actors necessary for Iruda 2.0’s social acceptance and facilitated the emergence of a safe human-AI assemblage. Additionally, we introduced the concept of ‘ethics-in-action’, which refers to a transferable, actionable intervention in practice. In Iruda 2.0, the implementation of ‘ethics-in-action’ went beyond mere modifications to data and algorithms. It also mobilized users, regulatory agencies, and civil society members, guiding them to reassess and ultimately embrace Iruda, transforming it from a previously problematic technology into one viewed in a more positive light. A large part of ethics involved in Iruda 2.0 was indeed ethics-in-action.
This research offers broader insights into social experimentation with new technologies. While new technologies typically undergo various pre-release tests like beta testing, Iruda’s case shows how developers of failed technologies can learn from their mistakes. As van de Poel (2017) argues, the social failures of technology can serve as valuable experiments. In this light, the fall and rise of Iruda can be seen as an extended social experiment in the development of relationship-oriented AI chatbots. If this interpretation holds, it would be worthwhile to examine whether this understanding can be extrapolated to the introduction of future AI technologies or applied to other past cases. Looking back, we can reinterpret the case of Xiaoice, the Chinese chatbot with hundreds of millions of users, as a similar social experiment. Like Iruda, Xiaoice encountered numerous social controversies after launch, including sexual harassment issues, which led to multiple shutdowns and relaunches. Today, Xiaoice reportedly handles problematic situations skillfully and enjoys widespread user acceptance. 23 In 2023, Microsoft launched Bing AI, a new AI chatbot that appeared to incorporate lessons from their earlier Tay debacle. 24 This launch can be interpreted as another social experiment with AI chatbots. These cases highlight an important reality: It is virtually impossible to introduce perfectly calibrated technologies, especially AI chatbots designed for social interaction with diverse users. This observation isn’t meant to excuse corporate negligence or poor design choices for technology. Rather, it suggests that companies should expect and prepare for social experimentation involving uncontrollable users and unruly algorithms. Equally important, users and citizens have a responsibility to participate constructively in these experiments.
Footnotes
Acknowledgements
We thank the anonymous reviewers and the editor of this journal, Sergio Sismondo, for their very helpful comments and suggestions.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by AI Institute at Seoul National University (AIIS) in 2025.