
Abstract
As a nascent field within the academy, the contours, attributes, and bounties of data science are still indeterminate and contested. We studied how participants in an initiative to establish data science at a large American research university defined data science and articulated their relationships to the field. We discuss two contrasting visions for data science among our research participants. One vision is a transdisciplinary view portraying data science as a phenomenon with transcendent, appropriative, and impositional qualities that sits apart from academic domains. Another view of data science—one that was far more prevalent among our research subjects—casts data science as grounded, relational, and adaptive, emerging from crosspollination of numerous academic domains. We argue that this latter formulation represents a more quotidian reality of data science and positions the field as an extradiscipline, defined as a field that exists to facilitate the exchange of knowledge, skills, tools, and methods from an indeterminate and fluctuating set of disciplinary perspectives while conserving the boundaries of those disciplines. We argue that the dueling transdisciplinary and extradisciplinary visions for data science have important implications for how the field will mature, and that the extradiscipline concept opens novel directions for studying academic knowledge production in STS, contributing additional precision to the literature on disciplinarity and its permutations.
A statistician, a computer scientist, and an astrophysicist walk into a panel discussion about data science. The moderator asks the panelists, what does data science mean to you?
This isn’t the setup for a joke, but it plays out like one. After the other panelists at the National Science Foundation-sponsored Data Science Workshop provide their answers, the astrophysicist offers his own interpretation of their responses: ‘It’s interesting that data science, to a computer scientist, is computer science. And data science, to a statistician, is statistics.’ The astrophysicist then delivers the punchline: ‘Data science, to a scientist, is just science.’ As the audience chuckles, he continues, ‘It’s what we’ve been doing for many years and it’s what we will be doing for many years, but it’s with larger data sets.’
The lighthearted exchange above belies the high stakes of data science’s institutionalization within the academy. Significant public and private resources are being garnered to rapidly proliferate data science programs and initiatives. All the while, data-intensive technologies lie at the heart of numerous controversies and ethical transgressions, and big data research methods raise important epistemological questions about reliability, interpretability, and reproducibility. Even as this drama plays out, there is little agreement on what data science is or should be. Examining this moment of nascence, ferment, and contention has implications not only for how we understand what the field of data science is or will become, but also for how we understand the organization and evolution of knowledge production within the disciplinary structure of American academia.
We explore situated views of data science as articulated by research participants during a long-term ethnographic study of data science practice and culture at a major U.S.-based research university. We argue that the multifarious perspectives of our research participants represent two distinct formulations of data science. One formulation portrays data science as transcendent, appropriative, and impositional—qualities that, we argue, situate data science as a transdiscipline, or a discipline whose methods and tools are applied in other fields (Scriven, 2008). A contrasting formulation portrays data science as grounded, relational, and adaptive—qualities that render the field of data science as something more amorphous that we call an extradiscipline. Rather than standing apart and developing its own approaches that transgress disciplinary boundaries, an extradiscipline facilitates the exchange of knowledge, skills, tools, and methods from an indeterminate and fluctuating set of disciplinary perspectives while conserving the boundaries of those disciplines. We argue that the extradiscipline concept opens novel directions for theorizing and studying academic knowledge production in STS, contributing additional precision to the literature on disciplinarity and its permutations. In the context of data science, the extradisciplinary vision is one in which data science is simultaneously both a driver of innovation on a technical level and an agent of conservatism on the disciplinary level. We argue that the dueling transdisciplinary and extradisciplinary visions for data science imply different futures for the immature field and will influence how it congeals, as they understand data science as very different practices with divergent possibilities for its institutionalization, commercialization, and relations to other fields of knowledge production.
Fieldwork and positionality
The vignette from the panel discussion that opened this paper took place in August of 2015 on the campus of the University of Washington. The timing is notable for being in the early days of two closely coupled experiments. The first experiment was the Moore-Sloan Data Science Environments—an effort privately funded through a $38 million grant by the Gordon and Betty Moore Foundation and the Alfred P. Sloan Foundation that spanned the University of Washington, New York University, and the University of California Berkeley. This concerted effort to support the advancement of data science within the academy launched at the height of perception that the world was newly awash in a flood of data (Strasser & Edwards, 2017) and on the heels of several historical trend lines (Aronova et al., 2017): private industry’s ability to exploit ever more granular views of their customers through the collection and analysis of digital traces (Bouk, 2017), decades of advances in data storage and retrieval (Aronova, 2017), and the celebration of ‘Big Science’ projects involving thousands of collaborators and distributed computational infrastructure (Aronova et al., 2017). The Moore-Sloan Data Science Environments were tasked with creating enabling conditions and opportunities for data-intensive science within each academic institution. This included establishing classroom education offerings, creating extracurricular training programs, hiring faculty with expertise in data-intensive computational methods, creating collaborative workspaces, developing open-source scientific software, and much more.
The universities coordinated their efforts to some degree, but each campus had its own emphases and priorities for instantiating data science. At the University of Washington, data science activities were spearheaded by an organization called the eScience Institute. The organization of data science at the University of Washington diverged from its sister institutions in the Moore-Sloan Data Science Environments in certain ways that are salient to the topic of this paper. At both New York University and University of California Berkeley, data science was advanced by degree-granting units that quickly spun up undergraduate majors (and in the case of New York University, a doctoral program as well). At the University of Washington, meanwhile, the data science banner has been carried by a non-degree granting research center that coordinated with other degree-granting units to create specializations in data science within existing undergraduate majors and doctoral programs rather than establishing stand-alone degree programs (only recently has an undergraduate degree in data science been offered, in the form of a minor rather than a major). While the focus of this paper is not on formal educational offerings, we describe these arrangements to illustrate that compared to peer institutions, data science at the University of Washington has been a diffuse enterprise by design. Indeed, a recent visualization of disciplinary participation in data science initiatives suggests that data science at the University of Washington is less concentrated in math, statistics, physics, computer science, and engineering, with a larger proportion of eScience Institute affiliates having backgrounds in the natural, social, and human sciences than many peer institutions, including the other Moore-Sloan Data Science Environment institutions (Norén et al., 2019).
The second, related, experiment—our experiment—involved embedding ethnographers within the Moore-Sloan Data Science Environments to study their unfolding development and simultaneously provide a social scientific perspective that could influence the trajectory of data science practice. From 2014 to 2019, a team of ethnographers at the University of Washington, one of whom (Tanweer) is an author on this paper, engaged in long-term participant-observation within the Data Science Environments initiative and conducted more than 100 interviews with people involved in activities supported through that initiative and run by the eScience Institute. Some of these interviews were conducted within the setting of data science training programs in which interviewees represented program participants with various roles—from students and mentees, to trainers and mentors, to administrative organizers. These programs included a Data Science Incubator program that paired a researcher with a data science mentor for intensive collaboration over the course of an academic quarter and a Data Science for Social Good program that assembled teams of students, data science mentors, and project partners to work together over the summer on projects intended to produce societal benefit. Outside the training programs, we also interviewed Data Science Postdoctoral Fellows, leaders of the campus-wide data science initiative, and a handful of others doing work related to data-intensive research both within and beyond the University of Washington campus. Tanweer conducted participant-observation and interviews as a doctoral student from 2015 to 2018, then went on to work as a research scientist at the eScience Institute following the completion of graduate studies and was employed there while developing this manuscript. Steinhoff, a postdoctoral fellow at the eScience Institute from 2020–2021, joined the research team after data generation was complete.
Grounded theory development process
In most of our interviews, we opened by asking subjects the very same question posed in the panel described above: What does data science mean to you? We followed this question by asking people if they saw themselves as a data scientist, and why or why not. In this way, the very same questions the actors in our field site asked themselves to make sense of their own practices also became important sites of inquiry for us as ethnographers.
We followed a constructivist grounded theory approach (Charmaz, 2000) while engaging in constant comparison of fieldnotes from participant-observation and coding the responses to interview questions. We completed a round of open coding in which we tagged excerpts of interview transcripts with initial descriptors that captured the sentiment of each excerpt. We then conducted a round of selective theoretical coding, in which we grouped our open codes according to connections, similarities, and contrasts among them, and consulted extant literature to develop and refine a reduced set of conceptual categories that captured our dataset as exhaustively as possible. We made separate decisions about coding applications, and then discussed those decisions until we achieved interpretive convergence (Brinkmann & Kvale, 2018). We focus here on providing detailed evidence in the form of interview extracts while presenting observational data as succinct generalizations rather than ‘thick description’ (Geertz, 1973).
Disciplinarity and its others
Our research participants were actively engaged in establishing a field, building an institution, developing a practice, and forging a community—processes that lent themselves to introspection and deliberation. As demonstrated by our opening vignette, they frequently contemplated the identity of their field and its connections to others. These questions are also taken up in scholarship about academic disciplines and their interrelations.
A history of disciplines and interdisciplinarity is well beyond the scope of this paper. Suffice to say that disciplines have been around in some form for centuries, and that the modern structure of the American university, organized primarily around discipline-based departments, has been more or less stable since the early 20th century (Klein, 2021). Nonetheless, as Klein (2021) has observed, disciplines themselves ‘are neither static nor monolithic’ (p. 20). While the disciplinary structure is something of a constant, within it there has been constant flux in the relationships between disciplines and frequent additions of new ones. In this shifting landscape, interdisciplinarity is not some newfangled idea, but a consistent factor in the shaping and reshaping of the American university’s disciplinary landscape (Graff, 2015). Indeed, Abbott (2001) argues that ‘the emphasis on interdisciplinarity emerged contemporaneously with, not after, the disciplines…. The one bred the other almost immediately’ (p. 132). Be that as it may, it is impossible to ignore the upswell of interest in interdisciplinary work over the last several decades. This trend is reflected in funding initiatives from both private and public sources, patterns in faculty hiring, the development of new degree programs, the establishment of applied research centers, and scholarly publications related to interdisciplinarity (Graff, 2015; Jacobs & Frickel, 2009).
Despite increased attention to interdisciplinarity, it remains a difficult phenomenon to precisely define. As Callard and Fitzgerald (2015) have put it, ‘Interdisciplinarity is a term that everyone invokes and none understands’ (p. 4). Colloquially, the term is often used in a manner akin to how Jacobs and Frickel (2009) broadly define it, meaning simply ‘communication and collaboration across academic disciplines’ (p. 44). This covers expansive territory, capturing everything from the practice of citing work originating in multiple disciplines, to one-off partnerships between researchers with different disciplinary training, to the organization of whole new fields intended to synthesize knowledge from constituent disciplines. Using a single term to capture all this variation elides how differences in the scale, mode, and purpose of interdisciplinary activity may be consequential for the production of knowledge and organization of the academy. Indeed, Klein argues that interdisciplinarity ‘is no longer an adequate term to account for heterogeneity’ in the activities and relationships it is intended to capture (Klein, 2021, p. 5).
Klein (2021) favors using the term crossdisciplinary to generically describe activity that is not constrained to a single discipline—a convention that we adopt in this paper. This ‘composite term’ (Klein, 2021, p. xv) encompasses what Klein considers to be the most prevalent and salient types of crossdisciplinary work: interdisciplinarity, multidisciplinarity and transdisciplinarity. In this typology, interdisciplinarity is reserved for describing the ‘integration’ of knowledge from multiple disciplines to address a particular question or problem, while ‘multidisciplinarity’ refers simply to the simultaneous or serial juxtaposition of different disciplinary perspectives around a common question or problem. The term transdisciplinarity has been defined in divergent ways (Klein, 2017), but we consider the common thread among these to be the application of a particular intellectual approach across widely divergent disciplines and problems.
While the adoption of these distinctions may reduce ambiguity to some extent, each of these terms itself remains a baggy container into which phenomena of many shapes, sizes, and textures may fit. One may achieve more precision by specifying the scale at which crossdisciplinarity functions. Our analysis is concerned with the establishment of a crossdisciplinary field, as opposed to other loci and scales at which crossdisciplinarity may be enacted. This puts us in conversation with authors who have studied and theorized the constitution of other crossdisciplinary fields, which are frequently characterized as either ‘interdisciplines’ or ‘transdisciplines.’ Interdisciplines are conceptualized as ‘hybridized knowledge fields situated between and within existing disciplines’ (Frickel, 2004, p. 369) that share a ‘common object’ of study (Darbellay, 2015, p. 166). They are best thought of as compound approaches that blend two or more fields into a more or less stable union. A transdiscipline, in contrast, is not wholly different from a discipline, but rather a particular kind of discipline, for it ‘has standalone status as a discipline and it is also used as a methodological or analytical tool in several other disciplines’ (Scriven, 2008, p. 65, emphasis original).
Our empirical investigation of data science as a nascent field provides an opportunity to add greater nuance and dimensionality to theorizations of the various forms that crossdisciplinary relationships may take among fields. Our purpose in this paper, however, is not to advance an exhaustive framework for understanding all possible permutations. We began by trying to understand the perspectives of actors engaged in establishing, defining, and bounding an emergent field that explicitly purports to span disciplinary boundaries. During the theoretical coding stage of analysis, we realized that some of our participants described the field of data science in ways that resembled a transdiscipline. Yet we found that other participants had a different, and in some ways contrasting, way of describing this crossdisciplinary field—a formulation that did not fit neatly with prior conceptualizations of either a transdiscipline or an interdiscipline. This phenomenon is what we term an extradiscipline. After developing this concept, we discuss the implications that the case of data science and the concept of extradisciplinarity hold for theorizations of crossdisciplinary pursuits. Building on work about interdisciplinarity’s role in the formation and reconfiguration of disciplines (Graff, 2015), we argue that extradisciplinarity may instead play an important role in the preservation and continuity of disciplines.
Data science and the disciplines
Although the term ‘data science’ was coined by academic researchers decades ago, its use remained rather isolated (see Hayashi, 1998; Wu, 1997) until the early 2010’s when businesses were increasingly looking for people who had both the analytical and computational acumen needed to deal with newly available sources of unstructured and heterogeneous data in large volumes (T. H. Davenport & Patil, 2012). Unsurprisingly, then, a considerable portion of literature concerned with what distinguishes data science from other pursuits focuses on commercial contexts (e.g., Crisan et al., 2021; T. Davenport, 2020; Harris et al., 2013; Muller et al., 2019; Zhang et al., 2020). Much of the empirical work on commercial data scientists iterates on Harris et al.’s (2013) study that characterized them as ‘T-shaped’ people: individuals with a broad set of skills (the horizontal bar of the ‘T’) and greater depth in particular tools and methods for analyzing data (the vertical bar of the ‘T’).
The metaphor of the T-shaped person, meanwhile, has been invoked in academia in a way that throws into relief important differences between commercial and academic data science—what some, including many of our research subjects, would call ‘data science for science’ (Blei & Smyth, 2017, p. 8690). Among academics, data scientists are sometimes idealized as ‘Pi-shaped’ people, in explicit contrast to a T-shaped person. In this formulation, which is often attributed originally to the astrophysicist Alex Szalay (VanderPlas, 2014), one leg of the Greek symbol Pi (Π) represents computationally-intensive research methods, while the other leg represents ‘domain knowledge’—essentially, disciplinary or subject-matter expertise. Both legs are of equal length, signifying commensurate depth in both areas. The existence of this metaphorical ideal reflects concerns that are prevalent within academic data science. The two legs of the Pi metaphor imply a dependency between methodological tools and knowledge; suggest an entwinement of technological progress and scientific progress; and evoke questions about the relationship between data science and established academic disciplines or domains. So whereas literature focused on data science in business contexts tends to consider academic institutions only insofar as they are equipped to prepare students for careers as data scientists in private industry (Hardoon, 2021; Provost & Fawcett, 2013), literature concerned with data science for academic research is concerned with ‘intellectual trends’ rather than commercial ones (Donoho, 2017). It frequently takes up questions about epistemological foundations (Kitchin, 2014; Rieder & Simon, 2016; Wagner-Pacifici et al., 2015), academic lineage (Leslie, 2021; Meng, 2019), and institutional politics (Craiu, 2019; Lue, 2019; Lupton, 2016).
Data science is known for approaches that eschew both the hypothetico-deductive model of science and the reliance on data specifically designed to answer particular research questions in favor of more abductive and inductive approaches that are suited to large, noisy, heterogeneous, and repurposed data sets (Goldberg, 2015; Thatcher, 2014). While data science is sometimes considered to be the ‘child’ of statistics and computer science (Blei & Smyth, 2017), its lineage is also frequently traced to developments in a host of scientific fields posing questions that require massive amounts of data (Aronova et al., 2017)—for example, studying subatomic particles, sequencing genomes, or surveying the night sky. In this telling, data science is portrayed as an evolution of the scientific method, a ‘fourth paradigm’ unifying theory, experimentation, and simulation under the guise of data-intensive science (Hey et al., 2009) that requires ‘a new set of methods, infrastructures and skills’ (Leonelli, 2014, p. 9).
Given this multi-pronged genealogy, data science does not fit neatly into disciplinary silos on university campuses, and its position and status are currently indeterminate, prompting a ‘gold rush’ and ‘disciplinary turf war’ over the control of data science and its spoils (Ribes, 2019, p. 515). How it ultimately ends up being situated within the academy remains to be seen. In this paper we ask, what is the field of academic data science, how does it relate to the disciplinary structure of the academy, and what can we learn from its indeterminate disciplinary status about the organization of academic knowledge production more broadly?
Of direct relevance to these questions is recent scholarship produced by Ribes, Slota, Hoffmann, and Bowker (Ribes, 2019; Ribes et al., 2019; Slota et al., 2020). These authors were among the first to study data science’s emergence in the academy, and the actors in their field sites overlapped with actors in ours to some extent. They explore data science’s role in what they call the ‘logic of domains,’ which ‘parses the world into domains of human action or expertise, along with something beyond or between the domains’ (Ribes et al., 2019, p. 283). According to these scholars, data science positions itself as that something. In the ‘logic of domains’ account, data science is premised on the notion that ‘the analytic tools developed for managing and reasoning about very large data sets are to some extent agnostic to their initial context of production and are applicable to a heterogeneous set of other domains’ (Slota et al., 2020, p. 4). Through an ‘absence of specificity’ (Ribes et al., 2019, p. 290), data science is framed as a universal science, ‘essential to all future sciences and beyond’ (Ribes, 2019, p. 516). Data science recognizes domains, such as biology or astronomy, but it does not consider itself one of them. Slota et al. (2020) argue that data science ‘has no data of its own’ and functions as a ‘parasite’ characterized by ‘emptiness and hunger’ that must always attach itself to domains to obtain data (pp. 1–3). Data science attaches to the domains via a procedure which Slota et al. (2020) call ‘prospecting’ or the ‘activities of discovering disordered or inaccessible data resources’ (p. 1). Importantly, prospecting is not a neutral phenomenon, for the process of ‘opening up domain resources, and of making them available to engagement by data scientific approaches’ is ‘a normative process of ordering… according to certain (data scientific) conventions’ (Slota et al., 2020, p. 5). Taken as a whole, we consider the trio of works led by Ribes and Slota to posit three distinct but mutually reinforcing characteristics of data science: It is transcendent in its ‘agnosticism’ for disciplinary context, appropriative in its ‘prospecting’ for data from other domains, and impositional in its ‘ordering’ of data and questions as they are submitted to and shaped by data science tools and methods.
We, too, found some evidence for this characterization of data science in our own field site and among some of our research participants. However, we found this perspective to be partial, equivocal, and at odds with a more prevalent formulation of data science. Rather than viewing data science as transcending disciplinary contexts, many of our research participants described it as grounded in specific applications and highly sensitive to context. Rather than viewing data science as appropriating domain knowledge, they described a relational arrangement in which data science does not exist separate and apart from scientific domains but rather emerges at their intersection through collaboration and interaction. And rather than characterizing data science imposing order on science through form-driven inquiry, they saw data science as an adaptive practice that entails improvisation, customization, and exploration. The existence of this second formulation in our field site challenges the characterization of academic data science developed in the work led by Ribes and Slota, indicating that the field’s emergence is marked by more plurality. Below, we explore these two divergent formulations and argue that each represents an alternative vision for the field. We argue that the transcendent, appropriative, and impositional perspectives taken together portray data science as a transdiscipline, and that this formulation is primarily associated with the sociotechnical vanguard vision (Hilgartner, 2015) of data science put forth by the field’s relatively powerful boosters engaged programmatically in the rollout of data science. Meanwhile, we found the grounded, relational, and adaptive perspectives to be associated more strongly with those who are engaged with learning, teaching, and practicing data science in their day-to-day research. We consider this more quotidian formulation to be envisioning data science as something that we call an extradiscipline. We argue that conceiving of data science as an extradiscipline more accurately represents the reality of academic data science ‘on the ground’. Efforts to develop and institutionalize the field should take account of this situated practice alongside the transdisciplinary view, if high-level, field-shaping plans and programs are to align with the needs of practitioners and traditional academic disciplines.
Transdisciplinary data science: Transcendent, appropriative, impositional
Data science as transcendent
A transcendent view of data science sees it as relevant to all domains of knowledge, irrespective of contextual specifics. Indeed, eScience data scientists come from a remarkably diverse range of disciplinary backgrounds. It is less common for the organization’s research staff to have degrees in methodological or technical fields such as statistics, computer science, or applied mathematics, and more common for them to hail from fields like astrophysics, geology, neuroscience, oceanography, or zoology. The transcendent perspective of data science informs the eScience Institute’s raison d’etre, as evidenced by its tagline, ‘advancing data-intensive discovery in all fields’. By positioning itself as relevant to ‘all fields’, the eScience Institute signals that data science is not constrained to ‘science’ at all; indeed, in recent years the organization has made concerted efforts—with varying degrees of success—to build relationships across the arts and humanities.
Although the organization’s original leadership had backgrounds in computer science, and its fiscal administration is handled by the Allen School of Computer Science and Engineering, the eScience Institute’s decision-making and accountability structures are independent from any academic department and none of the organization’s leaders, at the time of writing, are associated with the computer science department. Organizational leaders often emphasize the institute’s ‘neutrality’ on campus, implying that it rises above any competition for prestige or resources that may exist between traditional academic units. And by making itself available as a resource for training, consultation, and collaboration, the institute has cast itself as a ‘service’ organization available to the broader campus community. This line of argumentation helped the institute secure dedicated funding from the university to support its operations, including a core staff of non-faculty research scientists in the unusual position of having permanent salary lines rather than precarious soft-money positions. This unique status is at least in part premised on the organization’s success at portraying data science as transcending disciplinary boundaries.
These institutional arrangements explicitly informed the perceptions of some of our interviewees who emphasized the transcendent quality of data science. For example, the ‘service’ activities of eScience contributed to an oceanography postdoc’s view of data science as something that is categorically different from scientific domains, yet is universally applicable to them: I say this in a very non-pejorative way, but this idea that what eScience is providing is support services, right? I'm an oceanographer, and so 75% of my brain is oceanography, and 15% is [the programming language] R, and 10% is databases, right? And so I can go and find someone who 75% of their brain is cloud computing and databases. Or…. Python and PCA or some statistical method….I mean, obviously people here have interests, whether it's astronomy or whatever it might be, but you're also a little bit application agnostic. I can come to [Mariah] or [Anika] with an oceanography problem or a demographics problem or whatever it might be, and there's some capacity for them to engage with it because it is just math or it is just Python or it is just statistics, whatever it might be.
This person dismisses the fact that an eScience data scientist may have a PhD in a field like astronomy as entirely incidental to that person’s ability to answer an oceanographer’s hypothetical questions—their disciplinary identity is considered a mere ‘interest,’ even though data scientists at the eScience Institute typically continue to work and publish in their own domain areas. Data scientists are framed as an academic other, providing ‘service’ to domain researchers. They can ‘just’ collaborate on methods, obviating the need to engage with the domain particulars of the researcher they are helping.
Data science as appropriative
Recall that according to Slota et al. (2020), data science is evidenced by an ‘emptiness and hunger’ (p. 3) that necessitates a continual reaching outside of itself and into the domains to find new sources of data to advance itself. Among our research subjects, this appropriative perspective of data science was exceedingly rare. The only unequivocal articulation of it came from someone in a senior leadership position at the eScience Institute with an advanced degree in computer science. This person addressed the challenges of being a data scientist by comparing it to the experiences of people in the computer science community who work on the development of scientific software: There are a lot of people that spend a lot of time working with scientists … and we sort of trade war stories. The risk is that you can spend a lot of time working with scientists and find out that what they really need is an off-the-shelf, number three on the menu [solution], that doesn't really require any computer science research. So you will have just spent ten months determining that and you may get nothing out of it.
While this person was explicitly referring to the computer science community, it was with the intention of drawing an analogy to the situation between data scientists and ‘scientists.’ Data science and the domains have tidy and discrete roles to play in this framing, with different goals and rewards: the domains provide raw material in the form of data, while data science provides the tools to transform it; the domains need data science to provide technical advances for dealing with an unprecedented deluge of data, and data science uses the domains to stay relevant and innovative. When those expectations are not met, it is deemed a failure.
Data science as impositional
The transcendent and appropriative perspectives go hand-in-hand with a view that sees data science as imposing order upon domain content to render it available to data science (Slota et al., 2020). Put another way, knowledge within the domains is shaped by the predetermined formalism of data science tools and methods. This sentiment is implicitly expressed in the following interview extract from a geosciences researcher who had recently joined the eScience Institute: I'm coming into this field a bit new. I'll give you what I know so far, which is ways of learning about the world, purely by looking at the data. I come from a background of hypothesis driven science, whereas data science, the approach is to collect as much information as you can and use some of these newer technologies to actually let our knowledge of these systems fall out of the data themselves.… [using] machine learning and all the different statistical techniques that are enabling us to mine the data sets in new ways.… I see it in the framework of the Fourth Paradigm. That's really what actually got me excited about this path. I know that's the case for a lot of people.
Here, research is not driven first and foremost by the quest to answer particular questions. Instead, data are promiscuously collected and, upon the seamless application of data science tools and methods, knowledge simply appears. This interviewee explicitly ties the adoption of this perspective to their reading of the Fourth Paradigm, a collection of essays published by Microsoft Research that was frequently referenced among data science’s boosters and institutional players in the early days of the data science initiative at the University of Washington. This notion that data science produces tools to be seamlessly adopted by other domains can also be found in the following quote from one of the founders of the institute: Tools that are being developed in industry to solve problems that we would probably have too in science, are designed with the target audience being a pretty developed IT shop catching that technology and then applying it and deploying it and using it and so on. That developed IT shop doesn't really exist in science.
This interviewee is likening data science to an ‘IT shop’ for science, harvesting new tools from industry settings and transporting them into academia to be frictionlessly adopted across a wide range of fields.
Data science and transdisciplinarity
We consider the transcendent, appropriative, and impositional perspectives described above to comprise a vision of data science as a transdiscipline. A transdiscipline can be thought of as a ‘common system of axioms that transcends the scope of disciplinary worldviews through an overarching synthesis’ (Klein, 2017, p. 10). In their influential treatise on what they call ‘Mode 2’ knowledge production, Gibbons et al. (1994) write that transdisciplinarity begins within a particular application context, but ‘develops its own distinct theoretical structures, research methods and modes of practice’ that get diffused through ‘ever closer interaction of knowledge production with a succession of problem contexts’ (“Some attributes of knowledge production in mode 2” section). Despite the normative view advanced by boosters of transdisciplinarity that it represents a wholly transformative way of producing knowledge (Gibbons et al., 1994), extant transdisciplines do not escape the disciplinary structure of the academy. Transdisciplines tend to become a particular kind of discipline which ‘has standalone status as a discipline and it is also used as a methodological or analytical tool in several other disciplines’ (Scriven, 2008, p. 65, emphasis original).
For Scriven (2008), statistics is an exemplar transdiscipline (p. 65), with statistical methods being widely applied across a diverse range of disciplines even as statistics retains a strong disciplinary identity and structure (though this structure was unsettled in its nascence; see Porter, 2020). Similarly, the most likely fate for data science, if the transdisciplinary formulation of it prevails, is for the field to eventually establish a conventional disciplinary presence within the academy while developing methods that are then ‘applied’ in other fields.
Although to some observers ‘[t]he transdisciplinary aspect of data science is undisputed’ (Fayyad & Hamutcu, 2020), in our community of study there was little appetite for data science to evolve into a discipline or transdiscipline. Indeed, the architects of data science at the University of Washington have argued against that possibility and explicitly tried to design data science initiatives, programs, and educational offerings in such a way as to avoid that future. For example, all degrees and certificates in data science at the University of Washington are governed and executed by multiple disciplinary units on campus. Yet as we have shown, characterizations of data science as transcendent, appropriative, and impositional have strong transdisciplinary connotations—and transdisciplines typically are propagated through a disciplinary structure while being applied across disciplinary boundaries. And this is, indeed, the shape data science is starting to take elsewhere.
After several years of being propagated primarily through crossdisciplinary research centers, more universities in the U.S. are starting to establish schools, divisions, and departments for data science. At the time of writing, there are a growing number of newly established doctoral programs in data science qua data science at U.S.-based universities—trailblazing programs like those established circa 2015–17 at Indiana University–Purdue University Indianapolis, Kennesaw State University, New York University, and Yale University have recently been joined by a slate of data science PhD programs popping up circa 2021–22 at the University of California San Diego, the University of Texas El Paso, and the University of Virginia. This represents an important step on the path toward data science becoming a transdiscipline with disciplinary standing, for as Abbott (2001) convincingly argues, a discipline can essentially be defined as a job market for PhDs in a particular field.
However, a transdisciplinary evolution akin to statistics is not the only possible future for data science. And indeed, a more prevalent formulation of data science found among our research participants points to an alternative way of understanding the field. It is to this alternative vision that we now turn (Table 1).
Summary of the two alternative visions for data science found in our field site.
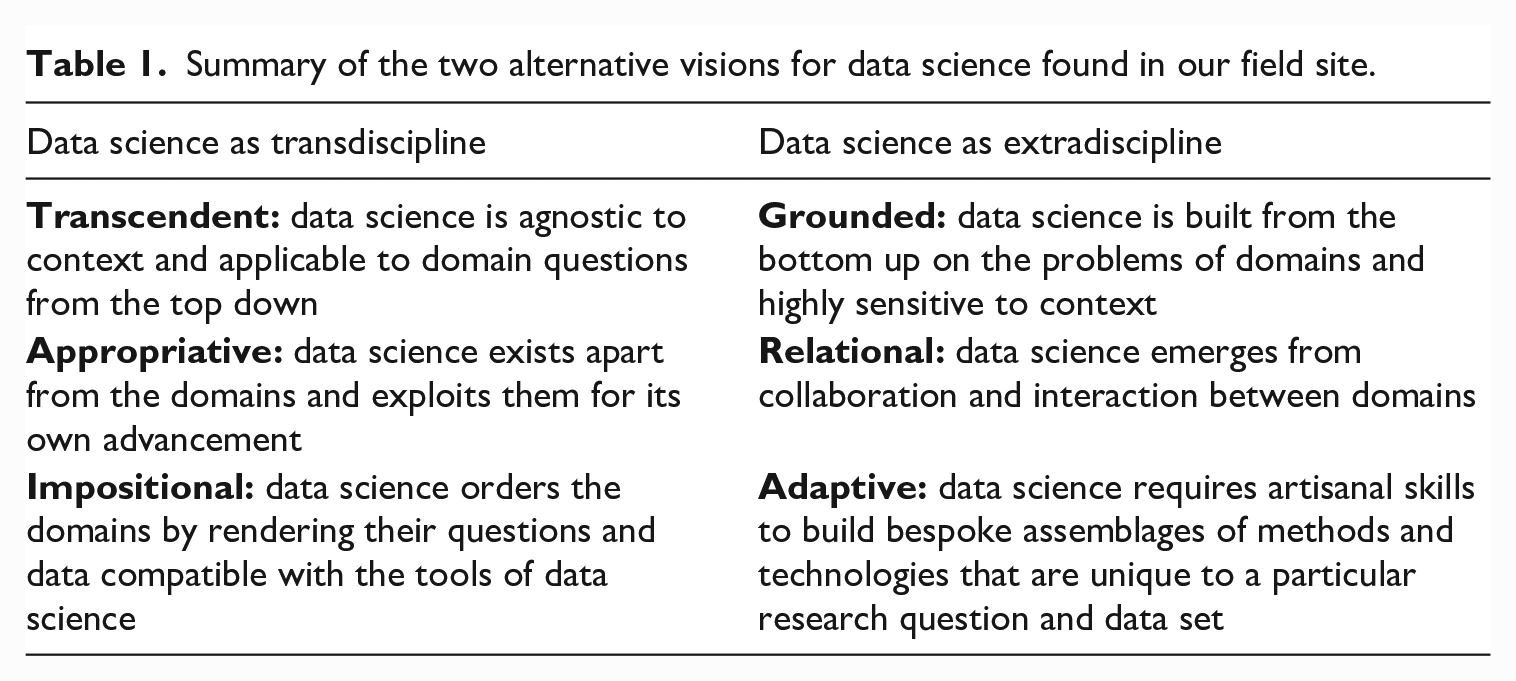
Extradisciplinary data science: Grounded, relational, and adaptive
We found articulations of data science among our research participants that stand in direct contrast to the transcendent, appropriative, and impositional perspectives that characterize a transdisciplinary view of the field. Rather than seeing data science as transcendent in its ‘agnosticism’ for context and applicability to domain questions from the top down, many of our subjects described data science as grounded in specific applications and highly sensitive to context. Instead of viewing data science as sitting apart from the domains and exploiting them for its own advancement in an appropriative way, they described data science as a relational field that emerges through collaboration and interaction between the domains. Further, as opposed to characterizing data science as an impositional phenomenon that orders domains by subjecting them to the preordained tools and methods of data science, they described data science as an adaptive practice that requires artisanal skills to build bespoke assemblages of methods and technologies.
Data science as grounded
The transcendent view of data science previously described coexists alongside a perspective that sees data science as necessarily attending to, and staying grounded in, the idiosyncrasies of specific data, problems, applications, and contexts. As a way of answering the question, ‘what does data science mean to you?’ one interviewee contrasted their experience in the Data Science Incubator program with a previous attempt at reaching out to computer scientists: I've been trying to figure that out for a while and I think the shortest explanation I could give is that when I have this big data problem, I first went to the computer science department and a couple different people there, and they weren't very interested in it. Then when I went to eScience, [Josh] was very interested in it. I think to me it's dealing with problems that have to do with big, messy data sets rather than computer science type topics.…All computers work with data. No matter what you're doing, it's working with data. It's just whether you're solving more theoretical problems that could have an application or whether you're solving real-world messy data problems.
To this person, data science is distinctive in its engagement with practical details and specific applications, rather than being concerned with engineering computational solutions that are more generally applicable, which is what they see as the mandate of computer science. This requires being intimately familiar with the particulars of data’s provenance, a sentiment articulated here by an eScience data scientist talking through their conception of data science: I think it's an interconnected set of things, but I personally am deeply interested in… understanding what your data actually is and caring about that from the beginning. I'm very turned off by people who go mess with data without understanding what it means, how it came to be. I just don't think it's a terribly useful thing to do. I think that’s it.
Data science’s groundedness means grappling not just with the material messiness and meaning of the data themselves, but also understanding the meaning and significance of the underlying question or problem being addressed—a perspective articulated in the following interview extract from a data scientist at the eScience Institute: If you're just doing machine learning, then you would be like, here's the result of my classifier. You don't really have to explain or justify. You just say this is what I got when I ran this thing. It's kind of like the hard evidence, but you don't have to do the extra step to ask, ‘what does it really mean?’ Somebody's going to ask you, like in health care, should we really do surgery or should we not do surgery? You don't just tell what the result of your classifier is. Dealing with these extra levels makes it more data science.
Such sentiments are sometimes captured by referencing the importance of understanding ‘context’ in data science, as explained by a participant in the Data Science for Social Good internship program: There’s a lot of context that goes into it … we’ve had a lot of workshops and had a lot of discussions about that, too, where the context of the problem really plays a huge role. Just looking at the data alone, you can make conclusions that aren’t relevant or mean nothing or aren’t necessarily true. Making into a science of actually looking at the context you are putting it in and thinking about what the problem really means, makes the data actually—gives it a purpose really and you can draw meaningful conclusions from it instead of just drawing conclusions that sound good.
In other words, to these individuals, the very thing that makes data science distinctive—indeed, the very thing that makes it ‘science’—is an interest in, and commitment to, a grounded understanding of the origins, processes, significance, and challenges of particular data, problems, and questions.
Data science as relational
As noted earlier, the neat bifurcation of ‘data science’ and ‘domain science' is commonly deployed rhetorically in our field site. For example, the eScience Institute often runs programs that pair ‘domain scientists’ from outside the eScience Institute with ‘data scientists’ employed by the institute. But as mentioned previously, eScience ‘data scientists’ often have advanced training in what are typically considered to be ‘domains’ and have not left their home disciplines to exclusively embrace the identity of a data scientist. They continue to identify with their own ‘domains’ by, for example, holding joint appointments in other departments, writing for disciplinary-specific publications, and organizing data science trainings within their own disciplinary communities. This situation complicates the narrative of data science as an appropriative entity that exists separate and apart from domains and feeds off their content.
It is perhaps unsurprising then, that many of our interviewees saw data science not as a distinct field appropriating data from the domains, but as a relational phenomenon that emerges from the intersection of domains and produces a space for cross-pollination between them. This sentiment was colorfully expressed by a biology postdoc: You let the astronomers come up with new image analysis techniques because that's what they do all the time and then you apply it to your data…. there’s no reason we shouldn't be going dumpster diving in their fields to take things that we can apply to biology and other domain sciences…. I see the things that you could do by combining multiple fields as the thing that's very exciting and we call it data science and that's cool.
While this interviewee uses language with appropriative undertones, the distinction we make here is that they are not claiming data science as a distinct methodological field whose success is dependent on its ability to prospect among the domains, but rather as the space where researchers from many different fields can learn, share, and transfer methods and tools. As this interviewee went on to explain: ‘I just need to be able to have a common language with which I can describe the problem to those people and then form collaborations with them and that's awesome.’
As an eScience data scientist with a background in oceanography explains in the following interview extract, computational and methodological advances that happen without this cross-pollination between domains are decidedly not data science: It's not simply computers and science. Because there are places in science where computers have been there from the very beginning. They don't need our help. When I did data science in my case with my research, it absolutely was because I pushed the field of bioinformatics forward by bringing knowledge that I had from a different domain. I consider that to be data science.
Importantly, many people do not talk about cross-disciplinary dialogue and collaboration in data science as a purely instrumental pursuit to advance research objectives, but as relationship-building that provides them with satisfaction and pleasure, as expressed by this eScience data scientist: I happen to be coming from an environmental science background, but the great thing about this job for me that I'm new to, is being able to talk to people in medicine and genomics, molecular biology, demographics, et cetera. I think I identify as a research fanboy or something like that.
A similar sentiment was sometimes expressed by the ‘domain scientists’ in eScience collaborations as well, as is the case with this graduate student who participated in the Data Science Incubator program: I can't separate data science out from the concept [of] social learning because to me, every experience I've had with data science has been about collaboration, so that's something I thrive on. I think of data science and I think of collaborating on projects. That's part of data science.
For those who emphasized cross-pollination, collaboration, and curiosity about other disciplines, data science was portrayed as emerging from interactions between domains of knowledge rather than as an expertise that first existed apart from domains and is then applied to them. And because data science is relational and emergent in this way, it is also relative—what counts as ‘data science’ in one situation may not count as data science in another.
Data science as adaptive
According to the impositional perspective discussed earlier, tools are preeminent, prefiguring which questions and problems can be addressed through data science and disciplining data to become legible to data science approaches. The adaptive perspective, on the other hand, sees questions and data within the domains as requiring an artisanal engagement with the tools of data science. In this formulation, data science is a practice that entails creativity and adaptation rather than conformity to a preordained form. As this Data Science Incubator participant put it: I'm not trying to diminish a tool, the contribution of the data science part of the project. I personally don't think it's an important factor in the conceptual design of a question, or how you answer a question. I really think it's more about building the tool to implement the ideas and the questions that come out of the domain science….I can't generalize because what I had done for this is so specific, those working on a different project might be completely different depending on what the data is.
In other words, data science requires the creation of bespoke tool assemblages that are tailored to one’s data and question. Such a tool assemblage might require working in multiple programming languages, importing various libraries, designing a database structure, and developing a pipeline for working across local and distributed machines. While the constituent tools that make up an assemblage often exist already instead of being built from scratch, the researcher stitches all those things together into a unique, functional whole that meets the specific needs of their data and questions. Getting this right requires much tinkering and practice, as emphasized by this data science postdoc in biology who described their research process as ‘gropily walking around trying to figure out what to do next’ while they built out tools for image analysis: I think that's something I get better at over time, and my initial data sets get larger over time as I'm more and more comfortable working with them….I don't know any class I can take in that. It's some combination of code organization, and visualization scripting, and all this mixed together.
In this telling, the labor of data science resembles craftsmanship, requiring the researcher to develop skills that cannot be formally taught but instead must be acquired through iterative contact with their medium (data) and tools (software). This analogy between data science and craft was explicitly expressed by a participant in the Data Science for Social Good program: It's all just because you want to do it and you want to get good at your craft. It's like a craft. Honestly, it's a craft. You can do this thing. You can take data and mold it… When you think of craft, you think of woodworker—they apprentice, but a lot of it is self-taught. They just do it themselves out of their own vision of what they think woodworking should be like. That's what this is….So much of it is tool based. You have to keep up with tools, like Spark, Hadoop, AWS, R. You need to keep up with the times. There's this huge emphasis on staying current and doing it because you want to stay current.
Tools play a central role here, as they do in the universalizing formulation of data science. But their relationships with questions, data, and researchers are qualitatively different. Rather than data being ordered such that they become available to the seamless application of data science tools, tools are instead intimately learned, arranged, configured, and wielded by researchers to address their idiosyncratic needs and visions. Rather than wielding an array of domain-agnostic tools with universal applicability, the data scientist is here cast as a bricoleur, coming up with ad hoc solutions by combining heterogeneous tools in idiosyncratic ways. Data science is defined by its adaptation to the domains, rather than the domains’ subordination to data science. This suggests that data science’s function as a field could be not to subsume domains, but to exist interstitially between them. Not blurring their boundaries, but rather supplying them with the means to preserve and reinforce their boundaries by generating incremental innovation through bespoke technical apparatuses that can answer the particular research questions of the domains.
Data science and extradisciplinarity
Taken together, the grounded, relational, adaptive perspectives on data science paint a picture that is quite different from the transdisciplinary vision described earlier. In this telling, data science is a recombinant skillset that occurs at the interstices of distinct fields and emerges from the knowledge shared across them. Such a description bears similarity to vernacular understandings of interdisciplinarity, but we argue that, in important ways, the field of data science does not conform to theorizations of what constitutes an interdiscipline. Interdisciplines are understood to be ‘hybridized knowledge fields situated between and within existing disciplines’ (Frickel, 2004, p. 369). According to Scriven (2008), interdisciplines are best thought of as compound approaches that blend two or more fields into a more or less stable union. One well-studied example of an interdiscipline is bioinformatics (Bartlett et al., 2016), which is generally described as the marriage of biology and computer science. Such a mantle does not easily fit the grounded, relational, and adaptive conceptualization of data science in our fieldsite. Rather than being composed of nearly equal contributions from a stable set of participating fields, many of our research subjects described the field as a shifting landscape of temporary pairwise and groupwise collaborations and interactions involving a panoply of disciplines.
As such, the grounded, relational, and adaptive view of data science represents something more nebulous and harder to pin down than an interdiscipline—a phenomenon that we call an extradiscipline. While uses of the term ‘extradisciplinary’ are rare and tend to refer simply to stepping outside of a particular discipline (e.g., Tang, 2004), we draw inspiration from art and cultural critic Holmes’ (2009) concept of ‘extradisciplinary investigations,’ which involve a recursive relationship between what Holmes calls tropism and reflexivity: The word tropism conveys the desire or need to turn towards something else, towards an exterior field or discipline; while the notion of reflexivity…indicates a critical return to the departure point, an attempt to transform the initial discipline, to end its isolation, to open up new possibilities of expression, analysis, cooperation and commitment. This back-and-forth movement, or rather, this transformative spiral, is the operative principle of what I will be calling extradisciplinary investigations. (Holmes, 2009, p. 54)
This description aligns closely with the grounded, relational, and adaptive formulation of data science articulated by our research participants. What counted as data science was a moving target relative to their home disciplines, and the field was seen as an emergent space where researchers from any field collaborated to learn and develop knowledge, skills, tools, and methods that could be used and adapted within their own disciplinary-specific contexts to incrementally transform them and ‘keep up with the times,’ as one respondent put it. This, we suggest, is a vision of data science as an extradiscipline—a field that serves to facilitate the exchange of knowledge, skills, tools, and methods from an indeterminate and fluctuating set of disciplinary perspectives while conserving the boundaries of participating disciplines.
Distinguishing the extradiscipline
Our notion of an extradiscipline differs from conventional understandings of both transdisciplines and interdisciplines in several key ways: In a transdiscipline like statistics, a stable core of disciplinary participants produces an approach to knowledge production that can be broadly applied to any manner of question or problem, effectively transgressing multiple disciplinary boundaries. This means that the perpetuation of the transdiscipline is agnostic to the disciplinary questions with which it engages, and the field has an indeterminate periphery of disciplinary actors who apply the transdisciplinary approach but are not necessarily engaged in its development. An interdiscipline like biostatistics consists of a relatively stable core of participants from a set of defined disciplines, with a determinate periphery of actors from those constituent disciplines who are indirectly impacted by their fields’ interdisciplinary activities without directly engaging in interdisciplinary pursuits themselves. The interdiscipline is organized around a set of questions or problems that are shared across its constituent disciplines, and its participants advance the state of knowledge on these questions or problems by combining their disciplinary expertise, effectively blurring the boundaries of participating disciplines. An extradiscipline, meanwhile, has a shifting core of disciplinary participants, and by extension, an indeterminate periphery of affected-but-not-directly-involved disciplinary actors. It creates a space for exchange that allows participants to adapt approaches from a panoply of other fields while working on their own idiosyncratic questions and advancing their own disciplinary agendas, effectively conserving the boundaries of participating disciplines (Table 2).
Comparison of the transdiscipline, interdiscipline, and extradiscipline concepts.
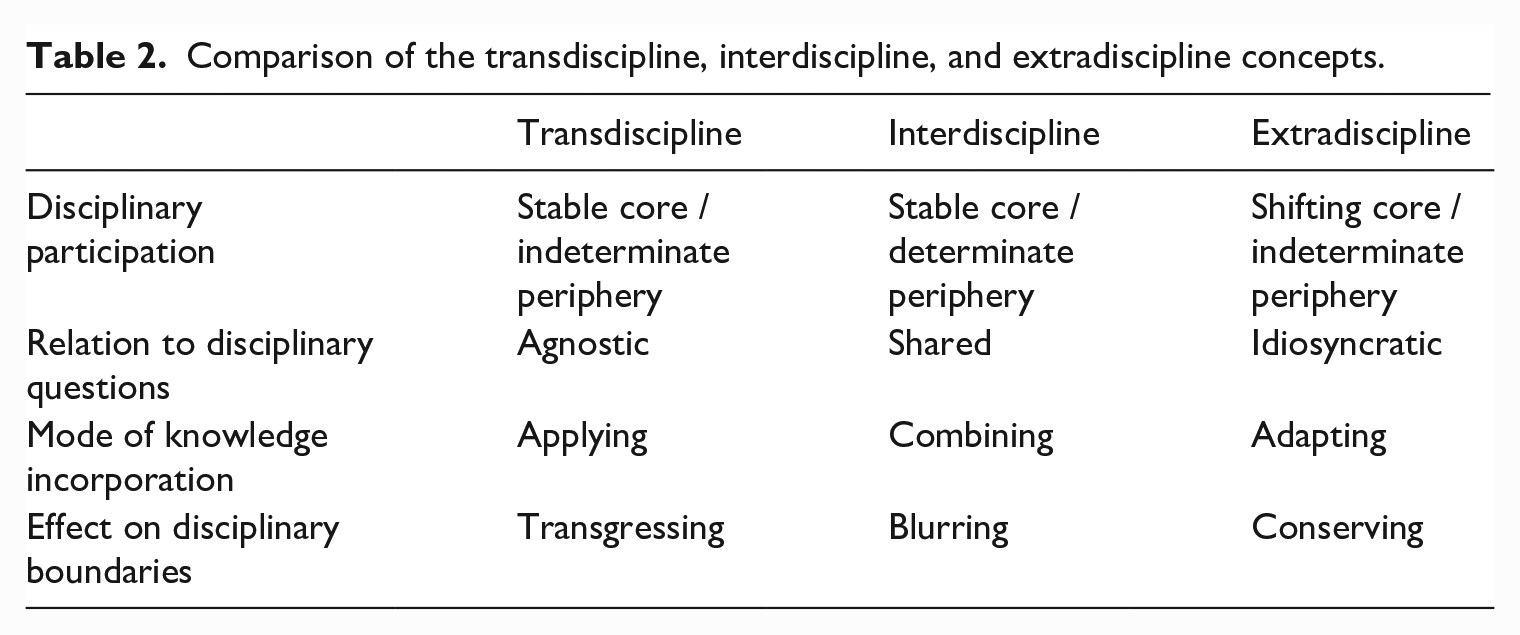
We introduce the idea of the extradiscipline with a dose of caution and humility. Graff (2015) notes that interdisciplines each follow their own unique trajectories and so parsing patterns among them is a fraught exercise that ‘may mislead more than clarify’ (p. 12). Similarly, Turner (2000) notes that ‘[i]nterdisciplinary efforts may have a great many different ends, and ends of different kinds. One may attempt to classify these ends, but this turns out to be a difficult matter’ (p. 57). Given the degree of variation noted by scholars of interdisciplinarity, it is perhaps unsurprising that we found formulations of data science to not fit well with common generalizations about the nature of interdisciplines and transdisciplines. However, we see the idea of extradisciplinarity to be adding nuance and dimensionality to conceptualizations of disciplinarity and its others, rather than further generalizing and flattening.
Interpreting data science’s distinctive formulations
We have thus far laid out two distinct formulations of data science: a transdisciplinary vision and an extradisciplinary vision. This raises the question of how exactly these two visions for data science are related. What does it mean that these two formulations of data science are simultaneously in circulation at this time when the boundaries, stakes, and spoils of academic data science are being defined and contested?
Comparing and contrasting distinctive versions of knowledge-producing practices is a familiar and illuminating approach in STS and beyond. Some of the seminal ideas to result from this approach include Snow’s (2013) ‘two cultures’ of the sciences and humanities, Deleuze and Guattari’s (1987) ‘royal and nomad sciences,’ and Knorr-Cetina’s (1999) work on ‘epistemic cultures’. All of these distinguish between actually-existing, contemporaneous knowledge cultures. However, rather than representing fully formed manifestations of data science, the two formulations expressed by our research participants represent two tenuous visions for what this inchoate field might become, at a moment in time when its future is very much up for grabs. The views expressed by our research subjects are helping to determine the shape of data science, form its relationships with other fields, and establish its place in the structure of the academy. As such, their views represent a form of boundary work.
Originally developed by Gieryn (1983) to describe ‘ideological efforts by scientists to distinguish their work and its products from non-scientific intellectual activities’ (p. 782), boundary work has been adapted for wider application wherever boundaries are of interest, and may thus be defined as ‘a composite label for claims, activities, and institutional structures that define, maintain, break down, and reformulate boundaries between knowledge units’ (Fisher, 1993, pp. 13–14). Kinchy and Kleinman (2003) argue that there are two types of boundary work: strategic and routine. While strategic boundary work involves ‘calculated efforts with explicit stakes’ (p. 870), actors perform routine boundary work as they enact the tacit norms of their field through quotidian practices. Building on this distinction, we argue that the transdisciplinary and extradisciplinary formulations of data science expressed by our research participants are two distinct boundary discourses (Klein, 2017, p. 27) that represent strategic boundary work and routine boundary work, respectively.
We consider the transdisciplinary formulation of data science to be an expression of strategic boundary work performed by relatively powerful or senior actors involved in the competition for and distribution of resources required for institutionalizing and legitimating the field of data science. In our study, the clearest and most plentiful expressions of this formulation were found among individuals involved in leading the rollout of data science at the University of Washington, in cases when people were describing or reflecting on the structure of the eScience Institute, and when respondents were drawing on comparisons to other fields, hypothetical situations, or broader discourses. Similar views are reflected in texts like The Fourth Paradigm (Hey et al., 2009) that served as an inspiration for this community and in materials produced by the National Science Foundation on its funding priority in the area of ‘Harnessing the Data Revolution’ (National Science Foundation, n.d.). In other words, these views tend to be associated with people and institutions that have the authority and platforms to articulate an idealized vision and an agenda for what gets included under the banner of data science, which is why we consider the transdisciplinary formulation to be strategic boundary work. It is a ‘vanguard vision’ put forth by data science’s ‘sociotechnical vanguards’—what Hilgartner (2015) has defined as ‘relatively small collectives that formulate and act intentionally to realize particular sociotechnical visions of the future that have yet to be accepted by wider collectives’ (p. 34).
In contrast, we consider the extradisciplinary formulation of data science to be an expression of routine boundary work performed by relatively junior actors engaged in data science as they carve out their own personal paths through a shifting disciplinary landscape. The grounded, relational, and adaptive vision of data science was the reflection of a quotidian reality for people engaging with data science tools and methods in the course of their day-to-day work. The interview extracts associated with the extradisciplinary perspective typically are not peddling in hypotheticals, comparisons to other fields, or generalities, as was the case with many of the quotes reflecting a transdisciplinary formulation of data science. Instead, they tended to describe specific personal experiences with research conducted under the banner of ‘data science’. This formulation of data science was also often most clearly articulated by individuals intimately involved in learning, practicing, and teaching the approaches of data science.
The disconnect between these two conceptions is captured in this quote from one of the architects of the Data Science Environments initiative at the University of Washington: We have a set of education programs that enable people to use the tools of data science. That is, to do data-intensive discovery. I don't consider those people to be data scientists. I consider them to be biologists. They just have a new way of doing things. At the same time, you can imagine somebody who is purely doing work in advancing methodology. I think that person is a statistician or a computer scientist, not a data scientist. I think of a data scientist as somebody who is driving both parts forward. That is, methodology coupled to applications, and trying to advance both.
The designation of data scientist here is reserved for a select few who fit the mold of the ‘Pi-shaped person’ discussed earlier; in the course of original scientific research, they create novel data science tools that are then seamlessly ‘used’ by non-data scientists, thereby advancing innovations in both scientific knowledge and computationally-intensive methods. In reality, it is anything but seamless for the vast majority of those researchers engaged with data science as a mode of research. These are the practitioners who described data science as extradisciplinary—tending to idiosyncrasies rather than generalities, collaborating with and learning from people in other fields, stitching together a bespoke assemblage of tools to suit their research goals. The quotidian reality is that data science in its day-to-day guise is more of a craft—it requires an abundance of creativity and improvisation, but is not primarily concerned with chasing novelty or generalizability of computational methods. Indeed, we found almost no one who identified unequivocally as being a data scientist, though some people noted that under certain circumstances they would refer to themselves as one. In the course of conducting fieldwork, we heard many conversations in which graduate students and postdocs who invested time and energy on methodological advancements fretted over their positioning in the academic job market, worried that they would not be seen as serious scientists. In private conversations and breakout discussions at annual meetings, faculty members hired through data science initiatives in joint positions shared between methods- and domain-based disciplines expressed feeling pulled in multiple directions and concerned that they would have difficulty making tenure cases. These observations align with reports that departments looking to hire faculty with data science specializations have difficulty finding the right fit (Craiu, 2019). All told, the academic data scientist who achieves the transdisciplinary ideal appears to be just as much of a ‘unicorn’ as its counterpart in industry (T. Davenport, 2020).
This paradox of data scientist identity is one expression of the distance between the transdisciplinary and extradisciplinary formulations of data science. To call the transdisciplinary formulation of data science a form of strategic boundary work and compare it with routine boundary work that reflects a more quotidian extradisciplinary reality is not to say that the transdisciplinary formulation of data science is not at all real, only that it has not achieved complete hegemony. Indeed, we suspect that Ribes, Slota and their coauthors (Ribes, 2019; Ribes et al., 2019; Slota et al., 2020) emphasize data science’s ‘universalizing’ character precisely because their field sites involved top-down efforts to build generalized tools and establish a nation-wide organizational infrastructure in support of data science. In other words, from our perspective, they were privy to the sociotechnical vanguard vision for data science. In our field site, on the other hand, early-career researchers, small-scale collaborations, and educational activities were all highly visible, giving us access to the articulation of data science in a different register. It would be a mistake to take the transdisciplinary vanguard vision for data science at face value without stopping to consider what data science looks like in its more mundane guise. It is, of course, always important to look under the surface to discover variation, friction, and inconsistency in social phenomena, but this is especially true when one’s object of study is nascent, unsettled, and contested—lest our scholarship end up contributing to the reification of dominant discourses. With that in mind, we turn to the question of what these two distinct formulations may mean for the future of data science and the academy.
Conclusion: The stakes of extradisciplinarity for data science and beyond
Interdisciplinarity and transdisciplinarity are sometimes portrayed as signaling ‘the obsolescence of university structures which see their development solely in the context of the disciplinary regime’ (Darbellay, 2015, p. 173). But, despite prognostications about the demise of disciplinary silos and the dawn of a ‘postdisciplinary’ age (Weingart & Stehr, 2000, p. xii), the disciplinary structure of the American academy endures, alongside interdisciplinarity. Historical and social studies of science show how interdisciplinarity is a ‘part of the disciplinary process itself’, involved in the ‘making and ongoing reshaping of modern disciplines’ (Graff, 2015, pp. 5–6). For example, biology emerged as the successful consolidation of fields through interdisciplinary activity, while sociology ‘spun off’ a number of new fields through interdisciplinary engagements (Graff, 2015, pp. 20–51).
Our concept of extradisciplinarity suggests yet another way in which crossdisciplinary pursuits and fields may be implicated in the disciplinary structure of the university: not by erasing or reconfiguring disciplinary boundaries but by conserving them via incremental change. In the extradisciplinary formulation of data science, our research participants talked about retaining their disciplinary identities, and viewed their participation in data science as a way to ‘stay current’ and address the problems of their own fields. In Panofsky’s (2011) terms, they exhibited a ‘heteronomous orientation’ toward the field of data science as opposed to an ‘autonomous’ one, making data science an ‘inside out field’ (p. 300). Rather than participating in data science primarily to obtain recognition within the field of data science, they sought recognition from fields outside of data science—namely, their home disciplines or the home disciplines of their collaborators. They described it as providing an opportunity for them to develop and practice the craft-like skills that are not promoted, supported, or rewarded within their own disciplines, by connecting and collaborating with people in other disciplines. As Callard and Fitzgerald (2015) argue, even as interdisciplinary research is widely regarded as a risky career move, staying in one’s disciplinary lane also does not ensure career security and success given the shifting realities of 21st century research. For many of our research participants, data science provided a space to learn and tinker with a set of methods and tools that are constantly and rapidly evolving, while figuring out how to adapt them to their own (and their fields’) idiosyncratic needs. In this way, when practiced as an extradiscipline, data science may help to preserve the viability of the disciplines by giving researchers an opportunity to learn what cannot be provided in their home disciplines; in essence, helping the disciplines to innovate incrementally without challenging their disciplinary core. Returning to the vignette that opened our paper, data science in the guise of an extradiscipline is not a wholly new form of knowledge production or a disruptive disciplinary upstart, it is ‘just science.’
This vision of data science—as an extradiscipline leading to incremental change within a stable disciplinary structure through the support of craft-like skills, collaborative practices, and idiosyncratic problems—is a conservative and relatively humble one. At least, compared to the vision of data science as a transdiscipline developing paradigmatically novel methods and tools that promise to be universally impactful. The latter is undoubtedly a more seductive, and therefore fundable, proposition. After all, academic data science, for all its antecedents in venerable academic traditions, gained traction while riding a wave of enthusiasm generated by the Big Data boom that is proving highly profitable for private industry (Van Dijck, 2014; Zuboff, 2019). Indeed, in the early days of the Data Science Environments initiative we studied, leaders of the initiative frequently quoted a lament by Silicon Valley executive Jeff Hammerbacher that ‘the greatest minds of my generation are thinking about how to get people to click on ads’ (Rosenberg, 2011). They positioned data science in the academy as a more noble alternative, but essentially an extension of the same phenomenon. And it is no coincidence that some of the largest investments in academic data science at American universities thus far have resulted from commercial data science’s largesse. The University of Virginia’s School of Data Science was established with the largest gift in UVA’s history, a $120 million donation from the philanthropic arm of a data science-driven hedge fund (Kelly, 2021), while the University of California San Diego’s Halicioğlu Data Science Institute was established with a $75 million gift from the person described as ‘Facebook’s first fulltime hire’ (UCSD, 2017).
Not surprisingly, given that data science has been entangled in the histories, resources, and discourses of for-profit Big Data and Silicon Valley startup culture, academic data science is not entirely immune to hype or hyperbole. It is one thing for the sociotechnical vanguards of data science to strategically indulge in a sweeping transdisciplinary vision while continuing to support a more modest extradisciplinary quotidian reality on the ground—which is how we interpret the dichotomous views we saw in our field site. It is quite another to organize institutions around a transdisciplinary ideal in which data science is distanced from academic disciplines in its transcendent, appropriative, and impositional guise. Such arrangements will likely only exacerbate known problems with data-intensive computational technologies and methods. Consider the oft-repeated epistemological critique that data science and related phenomena (such as big data analytics and machine learning) are prone to erroneous, biased, or uninterpretable results because they tend to ignore context and theory (Boyd & Crawford, 2012; Dalton et al., 2016; Selbst et al., 2019; Tanweer et al., 2021). Such concerns will only be amplified if data science congeals as a field that produces tools and methods at a distance from the contexts, theories, and questions developed within domains. On the other hand, it is possible that the extradisciplinary form of data science could serve as something of an antidote to techno-utopian hype because it is built from the bottom-up on disciplinary problems rather than applied to them from the top down, it emerges from interaction between disciplines rather than sitting apart from them, and it is adaptive to the unique needs of researchers rather than prescriptive of the kinds of questions that can be answered. But this more amorphous extradisciplinary vision may be harder to realize given the seductive appeal of the transdisciplinary vanguard vision for data science, and the current trend to centralize data science as a discipline. With the momentum clearly moving the field in that direction, it is worth investigating further the extradisciplinary aspects of data science, their epistemic and practical affordances and constraints—and asking whether and how a heterogeneous data science which encompasses both its transdisciplinary and extradisciplinary visions might be developed.
Footnotes
Acknowledgements
We thank Brittany Fiore-Gartland and Mar Drouhard for their contributions to the field observations and interviews on which our analysis is based. We are deeply grateful to our many research participants who openly shared their work and perspectives with us, and especially those who read and commented on drafts of this paper. This work was strengthened by early feedback we received from members of the Data Ecologies Lab led by David Ribes, constructive input from two anonymous reviewers, and insightful editorial guidance provided by Nicole Nelson. Remaining shortcomings are our own.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported through the Moore-Sloan Data Science Environments grant issued by the Gordon and Betty Moore Foundation (grant #3835) and the Alfred P. Sloan Foundation (grant #G-2016-7192).