
Abstract
A central part of singing includes learning new pieces of vocal music. Learning a new song is a complex task that involves several functions and modalities, such as memory functions, language and motor skills, and auditory and visual perception. Memory functions are a well-studied area, but it is unknown how memory theories apply to a multimodal activity such as singing. In this study, an attempt is made to translate the theories to the applied field of singing. This study aims to investigate the effectiveness of three types of learning formats for learning new song lyrics: auditory learning with image support (AI), auditory learning with text support (AT), and auditory learning only (A). Ninety-five participants were randomly assigned to one of the three experimental conditions. A univariate analysis of variance revealed a significant effect of condition on the lyric recall score and post-hoc tests showed that participants performed significantly better in the AI condition in comparison to both the AT and the A condition. No significant difference was found between AT and A. This study sheds light on how memory processes might work in learning song lyrics. Practical implications for practitioners such as music educators, conductors, and choir singers are discussed.
Keywords
Musical activities such as singing are an important source of enjoyment, learning, and well-being (Williams et al., 2018). A central part of singing includes learning new pieces and memorizing lyrics, and it is important to use proper learning methods that make the task easier (Ginsborg, 2002, 2004a, 2004b). This task is essential at all levels of mastery, and the aim of this study is to investigate the effectiveness of three learning formats when learning lyrics: auditory learning with image support (AI), auditory learning with text support (AT), and auditory learning only (A).
Images and texts as learning aids in a musical context
Paivio’s (1986) dual coding theory (DCT) describes how verbal information (symbolic coding) and non-verbal information (analogue coding) are processed separately and simultaneously, without necessarily increasing the cognitive load. This suggests that images can be processed simultaneously while listening to melody and lyrics. Furthermore, pictures can create effective cues for learning according to the picture superiority effect (Paivio & Csapo, 1973), suggesting that pictures in general are easier to remember than words (see also Paivio, 2014). Semantic meaning seems also to enhance memory performance: Craik and Lockhart (1972) propose in their levels of processing approach that learning is improved when information is processed more deeply rather than shallowly. Therefore, using images when learning lyrics should stimulate a deeper semantic understanding, given that they have an association (see also Craik, 2002).
Furthermore, encoding is not the only component of successful learning; retrieval has proven to be more important than previously thought. Karpicke and Roediger (2008) found in their study that participants who read a text and then were instructed to silently rehearse the content for themselves, scored better at retrieval than did those who instead re-read the text. We suggest that rehearsing lyrics or melody without looking at the lyrics simultaneously could be considered as one type of retrieval-based learning, as it forces the singer to retain the phrase in the working memory instead of re-reading (encoding) it. See also Roediger and Karpicke (2006) for the closely related concept of testing effect.
Aldalalah and Fong (2010) in one study presented computer-based music theory lessons in three different formats: audio and image (AI), text with image (TI), and audio with image and text (AIT). The results showed that participants using the AI mode performed significantly better than those in the TI mode, but no difference was found between the TI and the AIT mode. The authors suggested that the image and text may compete for limited cognitive resources in the visual channel, interfering with learning rather than facilitating.
Lyrics memorization
When it comes to memorizing lyrics, there are several identified strategies (see Ginsborg, 2002; Ginsborg & Sloboda, 2007; Stramkale, 2020). Among others, the strategies of putting down the notes and trying to sing from memory as well as (less frequently used) creating mental images or imagined a story, were identified. However, the above-mentioned studies do not assess or draw any conclusions about the effectiveness of the strategies.
Using images as a mnemonic aid can be beneficial provided that the learner constructs a meaningful connection between the image and the lyrics. See for example, Paivio and Yuille’s (1969) findings on how concreteness and meaningfulness of words affect learning when paired with images.
In an experimental study, Han (2018) showed that no main effect was found when using visually presented text (VPL) for memorizing a new difficult song, compared with not using any text. However, a significant interaction effect was found between the participants’ level of music training (music majors vs non-music majors) and the presentation condition, suggesting that music majors learn lyrics better when not seeing the text. In another study, Han (2021) found an indirect learning effect of using VPL, as a result of reduced the cognitive load. Still, no significant effect of recall accuracy was found between the groups who used VPL and those who did not.
The present study
The current study aimed to investigate the effectiveness of three types of learning formats for learning lyrics: AI, AT, and A. The participants were instructed to learn a new song by heart and afterwards lyric recall was measured. We instructed the participants to learn melody and lyrics integrated, just like they would in a real situation (Ginsborg & Sloboda, 2007). The first hypothesis of the study is that AI condition may enhance lyric recall compared with the other two learning formats (AT, A), considering this is the only condition that benefits from the picture superiority effect and levels of processing. The second hypothesis is that condition A and AI may enhance lyric recall compared with AT, due to benefits of retrieval-based learning.
These three conditions were chosen with the aim of reflecting three common ways of rehearsing lyrics, whether doing so alone or in a group (e.g., in a choir). The A condition corresponds to auditory learning (also called learning by ear), which is used as a default method unless musical notation is provided. AI and AT correspond to auditory learning with images and text as mnemonic aids respectively; for example, a teacher might show pictures on a projector or hand out a piece of paper. Thus, we did not include an AIT condition because of the possibility of auditory and text information competing for limited resources (Aldalalah & Fong, 2010).
A working memory task was also included and we hypothesized that higher working memory capacity (WMC) would positively correlate with lyric recall, and thus would need to be controlled for. The WMC task also served the purpose of being a distraction task.
Other measures were included for exploratory and descriptive reasons, such as gender, age, years of choir singing experience, years of music education, and number of instruments played.
Method
Participants
One hundred and sixteen participants were recruited for this study and after exclusion, 95 participants (age: M = 39.89, SD = 16.89, 59 women) remained in the total sample. Participants were recruited through a link shared in social media or by e-mail. Before starting the experiment, participants were informed about the inclusion criteria: (1) having at least 1 year of choir experience, (2) being fluent in Swedish, and (3) being over 18 years old. The sampling was purposive, addressing Swedish choristers through convenience sampling. The choristers, some of whom were professional musicians and others non-professionals had varying musical backgrounds (see Table 2).
The experiment was conducted digitally, remotely, and unsupervised, and the participants were asked the question, “Did anything occur during the experiment that might have affected the validity of your answers (e.g., interruptions or technical issues)?” with a forced choice response with the alternatives “No, all worked well,” or “Yes, a problem occurred with the . . .,” followed by a text box. Participants who either (1) reported a problem (e.g., technical issue and / or interruption), (2) restarted the experiment, (3) in an obvious manner misinterpreted the task (e.g., typing lyrics instead of numbers), or (4) did not type at least one digit on any of the WMC task levels, were excluded. Participants who only reported a problem regarding the self-perceived ability to focus were still included.
Experimental procedure and material
A four-phrase, 31-word song in Swedish (see Supplementary Appendix 1) was composed and recorded by the first author. In total, the song consisted of eight measures, each phrase being two measures long.
The study consisted of three parts: (1) the song learning task, (2) the working memory (distraction) task, and (3) a short questionnaire. The song learning task was a randomized controlled trial and the participants were assigned to one of the three experimental conditions. The remaining parts of the study were identical for all conditions.
The participants joined the study by clicking a link to a webpage. Following their consent, participants were instructed they would try to learn a song by heart. The participants were asked to conduct the experiment on either a computer or a tablet (not a mobile phone), in an environment where they would not be disturbed or interrupted, using either headphones or speakers.
In all conditions, an audio file with a duration of 3 min 27 s was played. The audio file consisted of four practice blocks, each with spoken instructions between blocks. All four blocks were automatically played in one go when the participant started the audio file (no possibility to initiate the next block), and the participant could neither pause it nor replay it.
In the first block, the song was played in its entirety with vocals and the participants were instructed to just listen and memorize.
The second and third blocks were identical and had an echoing structure; one phrase was played at a time with vocals, and in an immediate reprise, the participant was asked to echo the phrase accompanied by an instrumental background (only chords, no melody). After each instrumental echoing phrase was played, without any break and in tempo, the upcoming phrase would start, until all four phrases had been echoed. There was a short break along with instructions between the second and the third block, explaining that the same echoing procedure would now be repeated.
In the fourth and the final block, the participant was asked to sing the song in its entirety, accompanied by the instrumental background (without vocals).
In the first condition, AI (n = 31), four illustrations, one for each phrase, were shown (see Supplementary Appendix 2) along with the audio file. The illustrations were made for the purpose of the study and aimed to reflect the content of each phrase. Only one image was shown at a time, and simultaneously with the corresponding phrase plus during the echo reprise. In the second condition, A (n = 36), the audio file was played without any image or text support. Instead, a blank screen was displayed. In the third condition, AT (n = 28), one text phrase at a time was shown during the corresponding phrase plus during the echo reprise.
The second part of the study was a simplified digit span test with increasing difficulty (4–11 digits, 7 levels in total), in which the participants were asked to memorize digit sequences. Each digit was displayed for 0.9 s followed by an equal time of blank screen. After each sequence, the participants were asked to type their answer in a box. The scores were based on the highest correctly completed level of the digit span test.
After completion, the participants were asked to type on four lines (one for each phrase) what they remembered from the lyrics. The lyric recall score was based on the number of correctly remembered words (minimum = 0; maximum = 31), and the responses were scored using a scoring protocol. The order of the words was insignificant, but they had to be written on the correct phrase line. Misspelled words were scored as correct, and points were also given for words that were phonologically similar, while simultaneously semantically and grammatically possible.
The third and final part of the study consisted of a survey, in which participants were asked about age, gender, years of choral singing, proficiency in other musical instruments, years of post-high school music studies, and finally report any technical problems or distractions.
The independent variable’s (learning formats) effect on the dependent variable (lyric recall) was analyzed in a between-groups univariate analysis of variance (ANOVA), as well as a series of analyses of covariance (ANCOVAs) controlling for WMC, age, gender, years of choir experience, number of played instruments, and years of post-high school music education.
Ethical considerations
Participants were informed that their participation was anonymous and that they could cancel their participation at any time without giving any explanation. They were given a complete description of all tasks and had to give their consent by checking a box before proceeding. No manipulation or deception was implemented, and no personal or sensitive data were asked for nor generated. Debriefing was offered by providing contact information to the study’s first author. The study hence meets the requirements that, according to Swedish legislation (SFS 2003:460), allow research without ethical review.
Results
Initial analyses
In the initial analyses, descriptive data of the sample were examined (Tables 1 and 2), as well as correlations of the measures (Table 3).
Recalled Lyrics in Words (Maximum = 31). M (SD).

Note. AI: auditory learning with image support; AT: auditory learning with text support; A: auditory learning only.
Descriptive Data of All Control Variables.

Note. AI: auditory learning with image support; AT: auditory learning with text support; A: auditory learning only.
Correlation Matrix for the Relationships between the Covariates and the Dependent Measure.
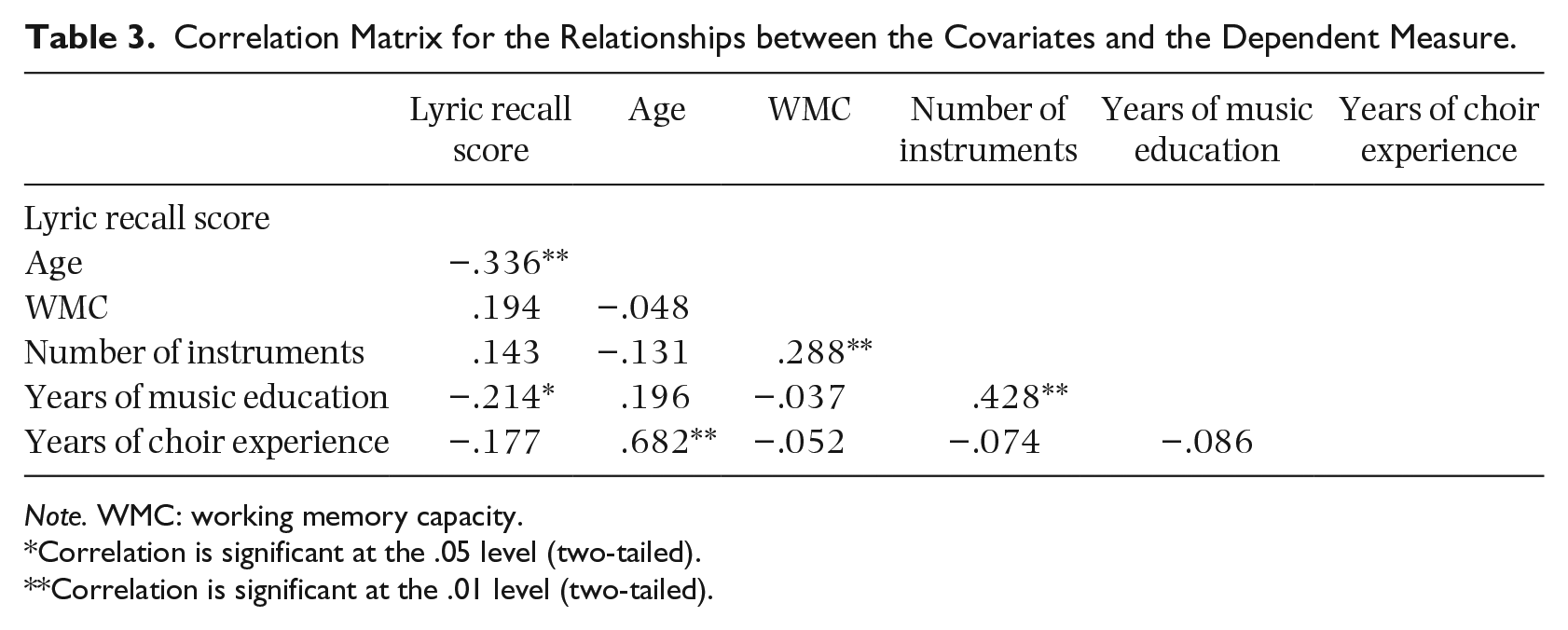
Note. WMC: working memory capacity.
Correlation is significant at the .05 level (two-tailed).
Correlation is significant at the .01 level (two-tailed).
There was a significant negative correlation between lyric recall score and age. A significant negative correlation was also found between lyric recall score and years of music education. A significant correlation was found between WMC and numbers of instruments, as well as between numbers of instruments and years of music education.
Main analyses
To test the two hypotheses of the study, a univariate ANOVA was performed and a planned pairwise comparison between the conditions. First, the ANOVA revealed a significant effect of condition on lyric recall score, F (2, 94) = 4.03, p = .021, η2 = 0.081. Second, the post hoc tests (least significant difference) revealed a significant difference in lyric recall score between the image support condition AI (M = 19.71, SD = 8.07) and the audio only condition A (M = 14.53, SD = 9.80), p = .023, d = .57, 95% CI = [0.08, 1.06]. Furthermore, the post hoc tests did also reveal a significant difference in lyric recall score between the AI and AT condition (M = 13.50, SD = 9.49), p = .011, d = .71, 95% CI = [0.18, 1.23]. No significant difference was found between the A and the AT condition. In sum, participants in the AI condition recalled significantly more words of the song than participants in both the A and the AT condition. However, participants in the AT condition did not significantly score better on lyric recall compared with the A condition.
When re-running the main analyses without excluding any participants (N = 116), or when excluding all of those who reported a problem regardless of reason (n = 93), the post-hoc comparisons remained significant.
Effect of covariates
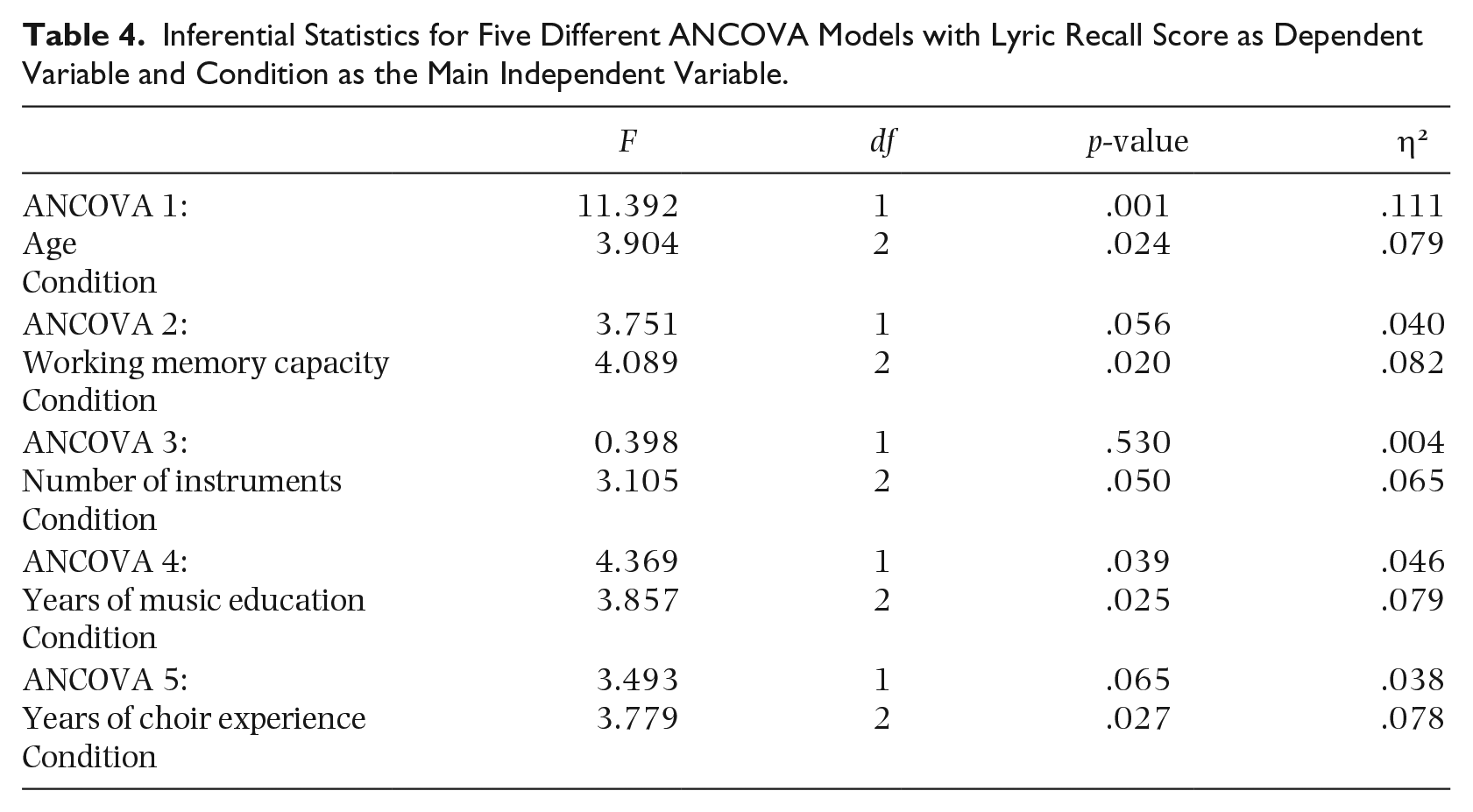
A series of ANCOVAs were performed to control for the effect of other variables on the lyric recall scores. The analyses revealed that none of the other variables influenced the effect of condition on the lyric recall scores. Age and years of music education were the only variables that significantly influenced lyric recall scores; however, they did so irrespective of the condition (Table 4). WMC was approaching significance, also irrespective of condition.
Inferential Statistics for Five Different ANCOVA Models with Lyric Recall Score as Dependent Variable and Condition as the Main Independent Variable.
Discussion
In accordance with the study’s first hypothesis, the results showed that audio learning with image support (AI) significantly enhanced lyric recall in comparison with audio learning only (A) and audio learning with text support (AT). There was no significant difference between the A and AT condition, and thus, the study’s second hypothesis was not supported.
The ANCOVAs showed that only age and years of music education were significant covariates for the outcome of the lyric recall scores, however neither of them altered the effect of the condition.
Results in relation to relevant theories of learning
The findings in this study are in accordance with Paivio and Csapo’s (1973) picture superiority effect, as the condition with image support (AI) resulted in significantly higher lyric recall score than the other two conditions (A, AT) without images. This is also consistent with Baddeley and Hitch’s (1974) working memory model, and Paivio’s (1986) DCT, suggesting that it should be possible to process verbal and visual information simultaneously. Judging by the results, images do not seem to increase the cognitive load, even though they increase the total amount of information. It is likely that the images contribute with a deeper processing of the lyrics’ content, and the findings thus agree with Craik and Lockhart’s (1972) levels of processing approach.
According to the results, displaying text does not improve nor impair learning. The second hypothesis suggested that condition A may enhance lyric recall compared with AT since it forces the listener to retain the phrase in the phonological loop and thus it cannot be re-read. In this study, the A and AI conditions were theorized to correspond to retrieval-based learning (Karpicke & Roediger, 2008; see also Roediger & Karpicke, 2006), however this assumption might be questioned. A more correct interpretation of retrieval-based learning in singing could perhaps be applied when the test–retest has a longer interval in combination with repeated rehearsal sessions (e.g., once a day for a week).
Results of covariates
The effect of WMC approached statistical significance and it was the only included covariate for which we had an a priori hypothesis. Lyric recall was also found to be negatively correlated with age, which is not surprising as memory function tends to decrease with age. Years of music education showed a significant negative correlation with lyric recall, and a negative correlation of years of choir singing experience and lyric recall was approaching significance. One could hypothesize that experience and education in the musical domain could be positively correlated with lyric recall. However, experience and education in music may increase with age but higher age is generally negatively correlated with memory function (Nilsson, 2003) and could thus be negatively associated with lyric recall. Since we did not know beforehand the exact levels of experience, education, or the mean age of our participants, we did not hypothesize how these variables would correlate with lyric recall. Inclusion criteria were that the participants had to be 18 years or over and have at least 1 year of choir singing experience. Surprisingly, the number of instruments played was positively correlated with WMC. The authors have no obvious explanation for this result; a far-fetched guess could perhaps be that individuals with high WMC tend to be more interested in learning new instruments. Less surprisingly, years of music education was found to be correlated with number of played instruments, which is possibly due to the increased exposure to musical education providing more opportunities to learn new instruments.
Our results according to previous findings
Han (2018) examined whether visually presented lyrics could facilitate learning when the song was difficult, as it was hypothesized that it would reduce cognitive load. However, no significant difference in recall accuracy was found between the group that was presented with lyrics and that which was not. In a later study, Han (2021) concluded that the cognitive load was reduced when visually presenting lyrics, thus indicating an indirect effect of improved learning, even though no difference in recall accuracy was found. Our results, even though not using a difficult song, are consistent with Han’s (2018) first finding since there was no significant difference between the A and AT condition. Regarding Han’s (2021) second finding, we believe it is theoretically important to investigate whether usage of printed text is beneficial. In our study, we are only interested in direct effects, namely, whether improved lyric recall is actually manifested during testing. Since singing is a performing art, it is essential to reproduce the lyrics correctly in a performance (which actually could be considered a type of test situation). However, indirect effects, such as cognitive load, can be interesting from other perspectives, considering that these might affect the performer’s experience or the artistic performance itself in other respects. One could argue that reduced cognitive load makes the learning task more enjoyable and less stressful, and thus plays an important role in the learning process. It is also possible that the use of visually presented lyrics could be more helpful during certain phases of learning a novel piece.
Practical implications of the findings
First, the most obvious practical implication of this study is that the results can be applied by all those who are exposed to the task of learning or teaching others a new song. Since choral singing is a collective activity, the results are relevant not only to the individual singer, but also on for the choir’s joint improved performance.
Second, the study shows that we still do not fully understand the cognitive processes that take place in song learning, which is interesting from a theoretical point of view. Several memory functions are involved, and it is therefore important to test learning theories in this context to draw any conclusions.
Limitations and future studies
In this experiment, the participants reproduced the lyric recall in writing, but since singing is a performing art, it would be optimal in terms of internal and external validity if the modality of reproduction was also sung, real-time vocal production. We believe that despite this limitation, there are good arguments for why written responses still provide results that should be generalizable. First, in both the AI and A conditions, participants transformed auditory information into written text—there is no reason to believe that what they produced in text would not reflect learned content they could reproduce verbally. Although producing text and vocals are not the exact same process, we argue that there is enough overlap to infer how well the lyrics is remembered (see, for example, Patel, 2003; Peretz et al., 2004; Serafine et al., 1984). We therefore argue that in some cases, as in our study, it is justified to only measure lyric recall. It is unlikely that participants would remember better due to writing down the answers instead of singing them. However, it is possible that a loss of recall occurs upon transforming recall from one modality to another, which then would have favored AT over both the AI and A condition. In AI and A participants had to transform the modality from auditory to written text while in AT they were presented with both another modality (auditory) and the same modality (written text) which they then had to produce. That said, we still believe that these arguments need to be empirically tested, and we encourage future studies to replicate with sung responses. Such an approach would also allow the inclusion of melody recall, which arguably also would have been a relevant measure (see Besson et al., 1998). However, melody recall is a rather complex task.
Since the experiment was conducted digitally, there were a few potential problems that the researchers could not control. For example, the use of the wrong device (mobile phone), tiredness, cheating (writing down lyrics or numbers), or other intentional or unintentional deviation from the instructions. However, the randomization should have resolved these issues.
In this study, the associations (illustrations) were chosen by the authors, but previous studies have shown that participants’ own associations can lead to improved learning (Mäntylä, 1986; Mäntylä & Nilsson, 1988). A suggestion for future studies is to investigate the effectiveness of singers creating their own mental images for each phrase. The insights could be used for developing effective study techniques for song memorization. It is also possible that improved learning using images or imagery could be mediated by a higher level of engagement or increased motivation. For this reason, we suggest future studies also measure motivational or other relevant factors such as attentional focus using different learning methods.
In this experiment, the lyrics were fairly concrete, which might have helped the participants make meaningful connections to the images shown in the AI condition without much effort. In light of Paivio and Yuille’s (1969) findings, it is possible that lyrics that are more abstract are less likely to benefit learners who are presented with images that are intended as mnemonic aids.
Conclusion
In our study, the effectiveness of different learning formats was investigated, which was important as very little research has been done on learning formats for song lyrics before. In essence, the results showed that the learning of new song lyrics was improved when images were used (AI), in comparison with both text support (AT) and audio learning only (A). The results showed neither enhancement nor impairment of learning when text support was used in comparison with audio learning only. This result has important practical implications for those who are faced with the task of learning and teaching new songs—for example, professional singers, music educators, choir singers and students. The study is also important from a theoretical point of view to understand how memory processes work in singing and music.
Supplemental Material
sj-pdf-1-pom-10.1177_03057356231211810 – Supplemental material for Memorizing song lyrics: Comparing the effectiveness of three learning formats
Supplemental material, sj-pdf-1-pom-10.1177_03057356231211810 for Memorizing song lyrics: Comparing the effectiveness of three learning formats by Miriam Napadow and László Harmat in Psychology of Music
Footnotes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.